
時系列分類問題における因果推論

記事の内容
- はじめに
- 因果推論の歴史
- 機械学習における因果推論の基本
- 因果推論におけるエビデンスラダー
- 因果推論における表記
- 偏り(バイアス)
- ランダム化実験
- マッチング
- 不確実性
- メタ学習器
- 取引システム構築の例
前回は、メタ学習器による訓練と交差検証、そしてONNX形式でのモデルの保存について徹底的に検証しました。また、機械学習モデルは、バラバラで矛盾したデータからいきなりパターンを見つけ出すことはできないと指摘しました。この場合、ニューラルネットワークやその他の機械学習アルゴリズムの入出力に何が送られるかが非常に重要になります。
その一方で、因果関係がすでに構造化されているような、必要な訓練データを常に用意することはできません。原則として、これは指標と売買シナリオの例のセットです。移動平均線の符号の増分、ジグザグ、または相対的な位置は、将来の取引の方向を設定するためによく使用されます。これらの印はすべて専門的ではなく、原則として真の因果関係を含んでいません。
データのタグ付けは、おそらく機械学習の世界で最もコストがかかり、時間とリソースを消費するプロセスです。研究対象分野の専門家(いわゆる注釈者)の関与が必要だからです。大量のデータで訓練されたGPTやその類型のような強力な言語ニューラルネットワークでさえ、意味文脈を形成する言語パターンしか分類できません。特定の声明が実際に真か偽かという問題には答えられません。アノテーター(注釈者)のチームがこれらのモデルを使用して作業をおこない、エンドユーザーにとって有用な答えになるように調整します。
この場合、トレーダーは、データにラベルを付ける方法がわかっているならなぜニューラルネットワークが必要なのかという、合理的な疑問を抱きます。結局のところ、自分の知識に基づいてロジックを書き、それを効果的に使用するだけでいいのです。この考えは正しいと同時に間違っています。間違っているのは、ニューラルネットワークは予測というタスクによく対応するので、わざわざ取引戦略のロジックを書かなくても、よくラベル付けされたデータで学習させ、新しいデータで予測を受け取れば十分で、さらに、組み込まれた機能により、新しいデータを使用して予測の信頼性を評価することができるという点です。そして、この考えが正しいのは、ニューラルネットワークの入力に何を送り込めばいいのかがわからなければ、あるいは間違ったラベル付けをしたデータを出力として供給しなければ、デフォルトでは収益性の高い取引戦略を作成することはできないという点でです。
上記のような機械学習の問題点は、すぐにトレーダーに理解されたわけではありません。当初、最初の単純な機械学習アルゴリズムの作成者でさえ、ニューロンの数学的アナログが脳神経細胞の働きをコピーすると固く信じていました。つまり、十分に大きなニューラルネットワークは脳の機能を完全に実行し、独立して情報を分析することを学ぶことができるということです。その後、脳には高度に専門化された多くの部門があることが理解されました。それぞれが特定の情報を処理し、他部門に伝達します。こうして多層ニューラルネットワークアーキテクチャが登場し、研究者たちは脳の働きの謎の解明に近づきました。このようなアーキテクチャは、視覚、テキスト、音声、表形式のデータなど、特定の情報を完璧に処理することを学んできました。
後に判明したことですが、このようなニューラルネットワークは、教師あり学習をおこなっている間は、真のパターンに関して独立した結論を出す能力を持っていないため、過剰訓練と主観に陥りやすくなります。
脳の構造と機能を理解するための次のステップは、自然のニューラルネットワークは強化学習に基づいており、既成のサンプルから学習するだけではないという発見でした。これは学習の一種であり、複雑なシステムは主観的に正しい判断には報酬を与え、誤った判断にはペナルティを与えます。そのような報酬を、目の前のタスクに応じて何度も受け取るうちに、経験が蓄積され、主観的に正しい答えの選択肢が学習されます。脳やニューラルネットワークは、ある特定のケースにおいて、すでにそのケースに遭遇したことがあれば、ミスを少なくするようになります。
このため、研究者自身が報酬関数(最適化アルゴリズムにおける適応度関数のようなもの)を設定し、正解と不正解に対してそれぞれニューラルネットワークに報酬を与えたり罰を与えたりする強化学習が登場しました。機械学習アルゴリズムは、もはや既製のラベル付けされたデータで学習されるのではなく、報酬関数を最大化しようと試行錯誤します。現在、さまざまなタスクに対応する強化学習アルゴリズムが数多く存在し、この分野は非常に活発に発展しています。
これは、金融時系列の分類の問題などに使用され始めるまでは、画期的なことのように思われました。このような学習は制御が非常に難しいことが明らかになりました。というのも、今やすべては正しい報酬関数を設定し、正しいネットワークアーキテクチャを選択することに帰結するからです。私たちは同じ些細な問題に直面します。システムの状態とその反応との間の真の因果関係を記述する真の目的関数を知らなければ、運が良くない限り、目的関数そのものと様々な強化学習アルゴリズムの両方を何度も検索しても、それを見つけることはできないでしょう。
同じようなことは、教師なしで条件付き学習する生成モデルでも起こりました。エンコーダデコーダ、あるいはジェネレーターディスクリミネーターの原理に基づき、情報を圧縮したり、重要な特徴量を強調したり、(敵対的ニューラルネットワークの場合)実際のサンプルと架空のサンプルを区別したりすることを学習し、画像などのもっともらしい例を生成します。画像の場合、すべてが多かれ少なかれ明確であり、ニューラルネットワークの一種のもっともらしい「ナンセンス」ですが、正確で一貫した回答を生成するとなると、すべてがはるかに複雑になります。特定の答えの生成に内在するランダム性の要素は、因果関係についての明確な結論を導き出すことを許しません。これは、アルゴリズムのランダムな行動が損失の代名詞となる取引のようなリスクの高い活動には適していません。
この記事の著者は、時系列の分類問題、特にFXの通貨ペアについて、これらのアルゴリズムをすべて試しましたが、その結果にはあまり満足していません。
最近、いわゆる「信頼できる」あるいは「信用できる」機械学習に関する論文を目にする機会が増えています。一般的に、一連のアプローチはまだ完全には形成されておらず、領域によって異なります。これが機械学習アルゴリズムによる因果推論の問題に取り組んでいることを理解することが重要です。研究者たちは機械学習を理解し、信頼するようになったため、データの因果関係を検索するタスクを機械学習に任せる準備が整いました。もちろん、これにより機械学習はまったく新しいレベルに引き上げられます。因果推論は、医学、計量経済学、マーケティングなどの分野で広く使用されています。
この記事では、アルゴリズム取引に関連するいくつかの因果推論を理解するための試みについて述べます。
因果推論の歴史
因果関係には長い歴史があり、私たちが知っている先進文化のすべてではないにしても、そのほとんどで考慮されてきました。
古代ギリシャで最も多作な哲学者の1人であったアリストテレスは、あるプロセスの因果構造を理解することは、そのプロセスについて知るために必要な要素であると主張しました。さらに彼は、「なぜ」という問いに答える能力こそが科学的説明の本質だと主張しました。アリストテレスは4種類の原因(物質的原因、形式的原因、効率的原因、最終的原因)を挙げています。この考えは、現代人にとっては直感に反するかもしれませんが、現実の興味深い側面を反映しているかもしれません。
18世紀の有名なスコットランドの哲学者デイヴィッド・ヒュームは、因果関係についてより統一的な枠組みを提案しました。ヒュームはまず、世界の因果関係が観察されることはないと主張しました。観察されているのは、いくつかの出来事が互いに関連しているということだけです。私たちは、どちらか一方がもう一方に続いていることに気づくだけです。1つのビリヤードの球の勢いは、2つ目の球の動きを伴います。これが外的感覚に現れる全体です。心は、この一連の物体から何の感情も内的印象も経験しません。したがって、それぞれの特定の現象には、力や必然的なつながりを示唆するものは何もありません。
ヒュームの因果論の解釈の1つは次のようなものです。
- 私たちは、物体Aの動きや出現が物体Bの動きや出現にどのように先行するかを観察するだけです。
- このシークエンスを何度も目にすれば、私たちは期待感を抱くようになります。
- この期待感こそが、私たちの因果関係の概念の本質なのです(それは世界についてではなく、私たちが抱く感情についてです)。
この理論は、少なくとも2つの観点から非常に興味深いものです。第一に、この理論の要素は、心理学における条件付けと呼ばれる考え方に非常によく似ています。条件付けは学習の一形態です。条件付けには多くの種類がありますが、それらはすべて、連想という共通の基盤に依存しています(それゆえ、この種の学習は連想学習と呼ばれます)。どのような条件付けにおいても、私たちは何らかの出来事や物体(通常は刺激と呼ばれる)を取り上げ、それを特定の行動や反応に結びつけます。連想学習はさまざまな動物種で機能します。ヒト、サル、イヌ、ネコだけでなく、カタツムリのようなもっと単純な生物にも見られます。
第二に、古典的な機械学習アルゴリズムの多くも、連想に基づいて動作します。教師あり学習の場合、入力と出力を対応付ける関数を見つけようとします。これを効率的におこなうには、入力のどの要素が出力の予測に役立つかを把握する必要があります。たいていの場合、この目的には関連付けだけで十分です。
因果関係を研究する可能性についての追加情報は、児童心理学から得られています。
アリソン・ゴプニックはアメリカの児童心理学者で、乳幼児がどのように世界のモデルを構築していくかを研究しています。また、コンピュータ科学者と協力し、人間の幼児がどのようにして外界について常識的な概念を構築するのかを理解する手助けもしています。子どもは大人以上に連想学習を使用しますが、同時に飽くなき実験者でもあります。おもちゃを投げつけるのをやめさせようとしている親を見たことがあるでしょうか。このような行動を無作法、破壊的、攻撃的と解釈する親もいますが、子供には別の動機があることが多いです。彼らは物理法則や社会的相互作用のルールを研究するための体系的な実験をおこなっているのです(Gopnik, 2009)。11ヶ月の乳児は、予測可能な行動をする物体よりも、予測不可能な特性を示す物体で実験することを好みます(Stahl & Feigenson, 2015)。この嗜好性により、彼らは世界のモデルを効果的に構築することができます。
赤ちゃんから学べることは、ヒュームが想定したように、私たちは世界を観察することに限定されないということです。交流することもできます。因果推論の文脈では、これらの相互作用は介入と呼ばれます。介入は、多くの人が科学的手法の聖杯と考えているもの、すなわちランダム化比較テスト(randomized controlled trial:RCT)の中心にあります。
しかし、本当の因果関係から関連性を見分けるにはどうすればいいのでしょうか。それを解明してみましょう。
機械学習における因果推論の基本
機械学習における因果推論の主な目的は、訓練された機械学習アルゴリズムに基づいて意思決定ができるかどうかを判断することです。ここでは、予測の正確さや頻度に常に関心があるわけではありませんが、それも重要です。ただし、私たちがもっと興味を持っているのは、その安定性と、それに対する信頼のレベルです。
因果推論の主要なテーゼは「相関関係は因果関係を意味しない」ということです。つまり、相関関係は、ある事象が別の事象に及ぼす影響を証明するものではなく、これら2つ以上の事象の線形関係を決定するだけです。
したがって因果関係は、ある変数が別の変数に影響を与えることによって決定されます。影響を与える変数は、第三者介入の場合は操作と呼ばれることが多く、また単に共変量(機械学習では特徴量)の1つと呼ばれることもあります。あるいは、ある行為を通じて別の行為につながります。一般的に、出来事Aの後には必ず出来事Bが起こるのでしょうか。それとも、Aという出来事がBという出来事を引き起こしているのでしょうか。これが、A/Bテストとも呼ばれる理由です。これについては、機械学習アルゴリズムを使用してさらに詳しく説明します。
因果関係の推論には、ランダム化実験を用いたもの、操作変数や機械学習を用いたものなど、さまざまなアプローチがあります。ここにすべての手法を列挙するのは意味がありません。他の研究がこのことに専念しているためです。私たちに興味があるのは、これを時系列分類問題にどのように応用できるかということです。
重要なことは、これらの手法のほとんどすべてが、ルービン因果モデルまたは潜在的な結果(成果)のモデルに基づいていることです。これは、ある事象が実際に別の事象の結果であるかどうかを判断するのに役立つ統計的アプローチです。
例えば、訓練された分類器は訓練サブサンプルと検証サブサンプルで利益を示しますが、そのシグナルはテストサブサンプルでは損失につながります。この分類器を使った新しいデータに対する因果効果を測定するには、実際に学習させた場合と学習させなかった場合の新しいデータに対する結果を比較する必要があります。未訓練の分類器は売買シグナルを生成しないため、その結果を見ることは不可能であり、この潜在的な結果は未知数です。私たちが持っているのは訓練後の実際の結果だけであり、訓練なしの未知の結果は反事実的です。言い換えれば、分類器を訓練することが、例えば無作為に取引を開始することに比べて、利益の増加につながるのか、あるいは新しいデータで利益を上げることにつながるのかを調べる必要があります。つまり、分類器を訓練することによって、何かプラスの効果があるのかということです。
このジレンマは「因果推論の根本的な問題」です。分類器が訓練されていなければ実際の結果がどうであったかはわからないが、訓練された後に初めて実際の結果がわかるというものです。
因果推論の基本的な問題により、ユニットレベル(単一の訓練例)の因果効果を直接観察することはできません。比較するものがないため、予測が改善されたかどうかを確実に言うことはできません。しかしランダム化実験では、集団レベルでの因果効果を評価することができます。ランダム化実験では、分類子は異なるサブサンプルでランダムに訓練されます。訓練例がこのようにランダムに分布するため、分類器の予測結果は(平均して)同等であり、特定の例に対する分類器の予測結果の違いは、テストセットの例が訓練例に含まれる場合と含まれない場合に起因します。そして、平均因果効果(平均処置効果とも呼ばれる)の推定値は、処置された(データに訓練された分類器を用いた)サンプルと制御(データに訓練されていない分類器を用いた)サンプルの平均結果の差を計算することで得ることができます。
あるいは、多元宇宙があり、それぞれの下位宇宙(subuniverse)で同じ人間が生きていて、その人間が異なる決断を下し、異なる結果(outcome)をもたらしたとします。各下位宇宙にいる人は、自分自身の未来のバージョンしか知らず、他の下位宇宙にいる他の自分自身の未来の選択肢を知りません。
多元宇宙の例では、すべての人が他の宇宙に対応する存在を持っていると仮定します。人は皆、平均すれば似たようなものです。つまり、彼らが下した決断の理由とその結果を比較することができるのです。したがって、この知識に基づいて、ある特定の人物が別の宇宙で、それまでそこで行動したことのないような行動をとったらどうなるか、という因果関係の結論を導き出すことが可能になります。もちろん、これらの宇宙が似たようなものであればの話です。
因果推論におけるエビデンスラダー
因果推論方法には体系化されており、その証拠能力に応じて方法の階層が表現されています。これは、私たちが選んだ手法がどのような証拠力を持つかを知るのに役立つでしょう。以下は、上記リンク先の記事からの引用です。

- 梯子の1段目には、典型的な科学実験が置かれています。
中学校や小学校で教わったことでしょう。科学実験のやり方を説明するために、私の生物学の先生は箱から種を取り出し、2つのグループに分けて2つの瓶に植えさせました。先生は、同じ数の種、同じ湿らせ方など。2つの瓶の中の条件を完全に同じにするよう主張しました。目的は、植物の成長に対する光の影響を測定することだったので、瓶の1つを窓際に置き、もう1つを押し入れに閉じ込めました。2週間後、窓際に置いていた瓶はすべて小さなつぼみをつけていましたが、押し入れに置いていた瓶はほとんど成長していませんでした。光への露出が2つの瓶の唯一の違いであると先生は説明し、光線遮断が植物を成長させないと結論づけることが許されました。
これは基本的に、原因を特定する際に最も厳格な方法です。悪い知らせは、この手法論が適用されるのは、処置群(光を受ける方)と対照群(押し入れの方)の両方を一定レベルで制御できる場合だけだということです。少なくとも、実験する1つのパラメータ(この場合は光)以外は、すべての条件が厳密に同一になるように十分に制御します。明らかに、これは社会科学やデータサイエンスには当てはまりません。
では、著者はなぜこの記事を書いたでしょうか。基本的にはこれが参照方法だからです。すべての因果推論手法は、中学校の先生が説明したルールに厳密に従えば結論が出せないはずの状況で、この単純な手法論を再現するために考案されたある意味ハックなのです。
- 統計的実験(別名A/Bテスト)
おそらく技術分野で最もよく知られた因果推論手法でしょう。A/Bテスト、別名ランダム化比較試験です。統計的実験の背後にある考え方は、無作為性とサンプルサイズに頼って、処置群と対照群を全く同じ条件に置くことができないことを緩和することです。大数の法則、中心極限定理、ベイズ推論などの基本的な統計定理は、これが機能することを保証し、収集したデータから推定値とその精度を推論する方法を与えてくれます。
- 準実験
準実験とは、処置群と対照群が、真の無作為ではないが、推定値を計算するのに十分近いと考えられる自然な過程によって分けられる状況をいいます。実際には、A/Bテストの状況にどの程度「近い」かについて、異なる仮定に対応する異なる手法があることを意味します。自然実験の有名な例として、ベトナム戦争の徴兵くじを使用して退役軍人であることが収入に与える影響を推定したり、ニュージャージー州とペンシルベニア州の境界を使って最低賃金が経済に与える影響を研究したりすることが挙げられます。
- 反実仮想法
ここでは、処置群と対照群という考え方を捨て(実際には、完全ではありませんが)、実際には、Xがすでに登場する将来のXの参加なしに、過去のデータから時系列Yをモデル化します。したがって、実験中に、(Xが参加した)Yの実際のデータとモデル(XなしのYの予測)を比較し、Yに対するモデルの精度を調整しながら、効果量を推測することができます。しかし、この仮定が真実に近いものであるためには、手法の安定性について最大限のテストをおこなう必要があります。その結果得られる効果は、モデルの質だけでなく、一般的に、選択した手法を正しく適用できるかどうかにも決定的に左右されます。
時系列分類モデルを構築する場合、反事実的な手法しか使用できません。言い換えれば、操作変数や処置法を自分たちで考え出し、それを観察に適用し、手法の安定性について適切なテストをおこなう必要があります。明らかに、これは最も複雑なアプローチであり、エビデンスラダーによれば最も証拠能力が低いです。
因果推論における表記
「処置」Tが、診療所の患者、広告キャンペーンの影響下にある人、あるいは訓練セットからのサンプルなど、対象への何らかの影響を意味することには同意しました。それなら、選択肢は2つあります。被験者が処置を受けたか受けなかったかです。

また、各対象(ユニット)は同時に処置されることも処置されないこともあり得ないこともすでに知っています。つまり、2つのうちのどちらかでしょう。
つまり
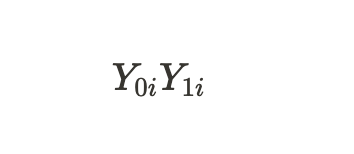
は、処置なしのユニットと処置ありのユニットの潜在的な結果を示しています。これらの潜在的な結果の差を通して、個々の処置効果を計算することができます。
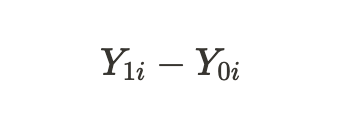
前述の因果推論の基本的な問題により、結果の1つしかわからないため、個別の処置効果を求めることはできませんが、処置を受けた被験者もいれば受けなかった被験者もいる、すべての類似した被験者にわたる平均処置効果を計算することはできます。
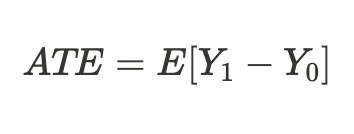
あるいは、処置を受けたユニットだけの平均処置効果を得ることもできます。
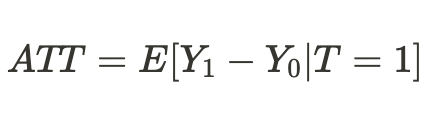
偏り(バイアス)
偏りとは、相関関係(関連性)と因果関係(原因と結果)を区別するものです。もし別の宇宙で、私たちの自分自身がまったく異なる存在条件に置かれ、彼らが下した決断の結果が、私たちがこの宇宙で慣れ親しんでいるものとはもはや一致しないとしたらどうでしょう。そうなると、起こりうる結果についての結論は誤りであることが判明し、仮定は連想的なものにとどまり、因果関係にはなりません。
これは訓練された分類器にも言えることで、今まで見たことのない新しいデータで利益を上げなくなったり、単に正しく予測しなくなったりします。
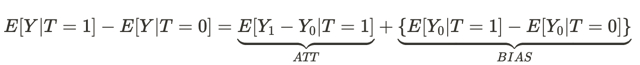
この式は、なぜ連想関係が因果関係ではないのかという疑問に答えます。ここでいう偏りとは、異なる宇宙に住む人々の生活条件が、両方の宇宙で影響を及ぼす前に、どれだけ異なっているかということです。なぜなら、彼らが下す決断の結果には、他にも多くの変数が影響するからです。その結果、ある宇宙と別の宇宙では、意思決定が異なるだけでなく、存在条件も異なります。
異なる宇宙における私たちの存在の条件が同等であることが判明した場合、別の宇宙における私たちの行動の結果(平均値)に関する私たちの結論は、因果関係があることが判明します。
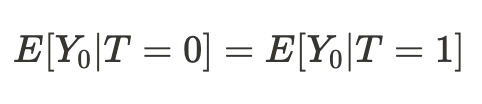
したがって、平均値の差が平均的な因果効果となります。
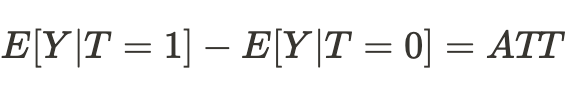
因果効果を推定するためには、ある宇宙からの標本は別の宇宙からの標本と比較可能でなければならないと結論づけることができます。もしそうであれば、真の関係を見極めることができ、別の宇宙での「自分自身」の行動の結果を高い確率で予測することができるでしょう。
言い換えれば、偏りがゼロに等しいとき、関連は因果関係になります。
上記を機械学習の用語に置き換えてみます。私たちは通常、訓練データと検証データ、そしてテストデータを扱います。機械学習モデルは、検証データの一部が加わった訓練データを使用して学習します。もしサブサンプルが同等であれば、訓練データと検証データの予測誤差はほぼ同じになります。サブサンプルが条件付き偏りによって異なる場合、検証データの予測誤差はより大きくなります。テスト用サブサンプルは言うまでもなく、そのデータ分布は最初の2つの分布とまったく似ていないかもしれません。
しかし、もしサブサンプルの分布が異なっていたら、どのように因果関係を推論することができるでしょうか。その答えはすでに前節で部分的に示されています。ランダム化実験によって因果関係を推論することができるということです。
ランダム化実験
すでに明らかになったように、ランダム化によってデータをランダムにグループに分け、一方は「処置」(この場合はモデル訓練)を受け、もう一方は受けませんでした。しかも、これを何度か繰り返し、多くのモデルを訓練する必要があります。これは推定値の偏りを排除するために必要なことです。複数の分類器をランダム化して訓練することで、潜在的な結果が1つの特定の機械学習モデルに依存することがなくなります。
最初は少し混乱するかもしれません。特定のモデルに対する結果(予測)の依存性がないため、そのモデルを訓練しても意味がないと考えるかもしれません。この特別なモデルの予測という観点から見れば、その通りです。しかし、私たちは潜在的な結果(予測)を扱っています。
潜在的な結果とは、モデルが訓練された場合とされなかった場合の結果のことです。ランダム化実験では、モデルの訓練が結果に直接影響するため、結果(予測)が訓練に依存しないことは望まれませんが、
私たちが望んでいるのは潜在的な結果が、偏った特定の分類器の訓練に依存しないことです。
これは、対照群とテスト群の結果が同じであることを意味します。推定値から偏りを取り除きたいため、訓練データとテストデータを比較する必要がありますが、個々の分類器は、たとえそれらが混在していたとしても、異なる訓練例に対して異なる重みを与えます。これにより、観察ごとに処置の量が異なります。これは因果推論を複雑にします。
訓練例のランダム化により、テストサンプルと訓練サンプルのモデル誤差の差を得ることで、処置(訓練)の効果を評価することができます。ただし、分類の場合は、機械学習アルゴリズムの特徴量を考慮する必要があります。この場合、個々の分類器は元の例の半分かそれ以上で訓練され、各例に異なる重み(処置)を与えるので、効果推定はまだ偏っています。複数の分類器(のアンサンブル)を使用することで、分類器のスコアを平均化することで偏りを最小化し、各ユニットの処置をより均等にします。これにより、すべての訓練例が同じ条件に置かれ、同じ値が与えられます。
このセクションでは、ランダム化実験がデータから偏りを取り除き、より信頼性の高い因果推論をおこなうのに役立つことを学びました。モデルアンサンブルは、訓練効果について同等の推定値を出すのに役立ちます。
マッチング
ランダム化された実験では、モデルのアンサンブルを訓練する平均的な効果を推定することができます。しかし、私たちは各訓練例の個別効果を得ることに興味があります。これは、取引戦略が平均してどのような状況で利益をもたらし、どのような状況を調整すべきか、あるいは取引から除外すべきかを理解するために必要です。言い換えれば、各対象の個々の特徴量に応じて、訓練の効果の条件付き推定値を得たいのです。
マッチングとは、サンプル全体から個々のサンプルを比較し、それらが訓練セットに含まれているか否かを除く他のすべての特徴量において類似していることを確認する方法です。これにより、各訓練例の個別のスコアを導き出すことができます。
マッチングには厳密なものと不正確なものがあります。
例えばラフマッチングでは、ユークリッド距離やミンコフスキー距離、マハラノビス距離などの近接基準に基づいてすべてのユニットを比較することができますが、私たちは時系列を扱っているので、ユニットを時間ごとに位置的に比較するオプションがあります。モデルのアンサンブルを訓練する場合、任意の時点における各モデルの予測は、タイムライン上のその時点に存在する特徴量のセットとすでに関連付けられています。私たちがすべきことは、特定の時点におけるすべてのモデルの予測を比較することです。このような比較の計算の複雑さは、他の手法と比較して最小であり、より多くの実験を可能にします。加えて、これは正確なマッチングとなります。
不確実性
アルゴリズム取引では、最終的な分類モデルを構築したいので、平均的な処置効果と個々の処置効果を決定するだけでは十分ではありません。データセットの不確実性を推定するために因果推論ツールを適用し、条件付き処置(分類器の訓練)に反応するユニットとそうでないユニットに分ける必要があります。言い換えれば、大半の場合、正しく分類されるものとそうでないものに分けられます。不確実性の程度によりますが、これはすべてのアンサンブルモデルの潜在的な結果の差の合計として計算されます。
分類器の観点からデータの不確実性を推定しているので、買い注文と売り注文は別々に評価されるべきです。なぜなら、それらの結合分布が最終的な推定値を混乱させるからです。
メタ学習器
因果推論におけるメタ学習器とは、因果効果の推定を助ける機械学習モデルのことです。
ATEとATTの概念にはすでに慣れ親しんできました。これらは母集団における平均的な因果効果に関する情報を与えてくれます。しかし、人間やその他の複雑な生物(例えば動物、社会集団、企業、国など)は、同じ処置を受けても異なる反応を示す可能性があることを忘れてはなりません。このような状況に対処するとき、ATEは重要な情報を隠してしまうことがあります。
この問題に対する1つの解決策は、HTEとしても知られるCATE(条件付き平均処置効果)を計算することです。CATEを計算する際には、処置だけでなく、処置が結果に与える影響を変化させうる、各ユニットの個々の特性を定義する一連の変数に注目します。
二者択一の処置の場合、CATEは次のように定義できます。
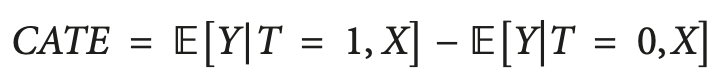
ここで、Xは個々の対象(ユニット)を記述する特性です。こうして、均質な処置効果から不均質な処置効果へと移行します。
同じ処置に対して、人や他のユニットが異なる反応を示すという考え方は、しばしば行列の形で表現され、アップリフト行列と呼ばれることもあります。
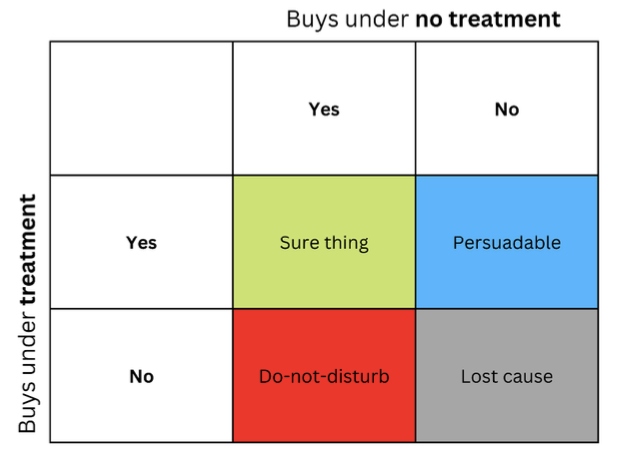
文字列は、メッセージ(広告など)が受信者に提示されたときのコンテンツに対する反応を表します。列は無処置の場合の回答をを表します。
4色のセルは処置効果のダイナミクスを表します。自信のある買い手(緑)は、処置に関係なく買います。赤(Do Not Disturb)は処置しなくても買うことがありますが、処置すると買わなくなります。興味を失った人(灰色)は処置の有無にかかわらず買わず、青色の人は処置を受けなければ買いませんが、声をかければ買う可能性があります。
予算に限りのあるマーケターは、青グループ(説得可能)へのマーケティングに集中し、可能であれば赤グループ(Do Not Disturb)へのマーケティングを避けるべきです。
「Sure thing」と「Lost cause」グループでのマーケティングが直接的な損害を与えることはありませんが、利益をもたらすこともありません。
同じように、医者は、その薬によって恩恵を受けそうな人には薬を処方し、害を受けそうな人には処方しないようにしたいものです。多くの実世界のシナリオでは、結果変数は確率的(例えば、購入の確率)または連続的(例えば、支出額)です。このような場合、個別のグループを識別することはできず、無処置条件と処置条件との間の結果変数の期待増加量が最も大きいユニットを見つけることに集中します。このように、処置をおこなった場合とおこなわなかった場合の結果の違いを、アップリフトと呼ぶことがあります。
これを時系列分類の言葉に置き換えると、訓練セットからどの例が処置(分類器の訓練)に最もよく反応するかを決定し、それらを別のグループに入れる必要があります。
異質な処置効果を推定する1つの簡単な方法は、使用する予測変数に基づいて処置変数を予測する代理モデルを構築することであり、形式的には次のように表現されます。
T〜X
このようなモデルのパフォーマンスは基本的にランダムであるべきです。もし非ランダムであれば、これは処置が特徴量に依存することを意味し、それは私たちが考慮しなかった何らかの欠落した変数が存在することを意味し、因果推論に影響を与え、混乱をもたらすことになります。これは、処置法が実際には無作為に代入られていない、不十分なランダム化比較テストデザインに起因することが多いです。
S-Learner
S-Learnerは、CATEモデリングへのシンプルなアプローチの名前です。S-Learnerは、いわゆるメタ学習器のカテゴリに属します。因果メタ学習器は、従来の機械学習で使用されていたメタ学習の概念とは直接関係がありません。1つ以上の基本的な(従来の)機械学習モデルを用いて、因果関係を計算します。一般的に、十分な複雑さを持つ機械学習モデル(ツリー、ニューラルネットワークなど)であれば、データに適合するものであれば基本学習器として使用することができます。
S-Learnerは最も単純なメタモデルで、基本的な学習器を1つしか使用しません。これが名前S(ingle)-Learnerの由来です。S-Learnerの背後にある考え方は驚くほど単純です。処置変数を特徴量として含む完全な訓練データセットで1つのモデルを訓練し、両方の潜在的な結果を予測し、CATEを得るために結果を差し引きます。
訓練後、S-Learnerのステップバイステップの予測手順は以下の通りです。
- 関心のある観測を選択する
- この観測の処置値を1 (true)に設定する
- 学習したモデルを用いて結果を予測する
- もう一度同じ観察をする
- 今回は処置値を0(False)に設定する
- 予想する
- 処置ありの予測値から処置なしの予測値を引く
T-Learner
T-Learnerの主な動機は、S-Learnerの主な制限を克服することです。S-Learnerが処置を無視することを学ぶことができるのなら、なぜ無視できないようにしないのでしょうか。
それこそがT-Learnerなのです。すべての観測(処置済みと未処置)に1つのモデルを適合させる代わりに、2つのモデル(1つは処置済みユニットのみ、もう1つは未処置ユニットのみ)を適合させます。
ある意味では、これはツリーベースモデルの最初の分割を強制的に処置変数による分割にすることと同じです。
T-Learnerの学習プロセスは以下の通りです。
- 処置変数でデータを2つのサブセットに分割する
- 2つのモデルを訓練する(各サブセットで1つずつ)
- 各観測について、両方のモデルを用いて結果を予測する
- 処置ありのモデルの結果から処置なしのモデルの結果を引く
処置分割を2つの別々のモデルとしてコード化したため、処置が無視される可能性がなくなっています。
T-Learnerは、S-Learnerが失敗する可能性のある(必ずしもではない)一面だけを改善することに重点を置いています。この改善にはコストがかかります。2つの異なるサブセットのデータに2つのアルゴリズムをフィットさせることは、それぞれのアルゴリズムがより少ないデータで訓練されることを意味し、フィットの質を低下させる可能性があります。
このため、T-Learnerのデータ使用効率も悪くなります(S-Learnerに匹敵する品質の表現を生成するために、各T-Learner 基本学習器を訓練するために2倍のデータが必要)。その結果、T-Learnerのスコアは、S-Learnerのスコアに比べてばらつきが大きくなります。特に、一方の処置群の観測が他方よりはるかに少ない場合、分散が非常に大きくなる可能性があります。
要約すると、T-Learnerは処置効果が小さいと予想される場合に有用であり、S-Learnerはそれを認識できない可能性があります。注意すべき点として、このメタ学習器は一般的にS-Learnerよりもデータ負荷が高いが、データセット全体のサイズが大きくなるにつれてその差は小さくなります。
X-Learner
X-Learnerは、データから得られる情報をより効率的に利用するために設計されたメタ学習器です。
X-LearnerはCATEを直接推定しようとしますが、その際、S-LearnerとT-Learnerが以前は捨てていた情報を使用します。これはどのようなデータなのでしょうか。S-LearnerとT-Learnerは、反応関数と呼ばれるもの、すなわちユニットがどのように処置に反応するかを研究しました(言い換えれば、反応関数とは、形質Xと処置Tと結果yとの対応付けである)。同時に、どのモデルもCATEのシミュレーションに実際の結果を使用していません。
- 最初のステップは簡単で、すでに分かっています。それこそがT-Learnerでやったことです。処置変数ごとにデータを分割し、2つの別々の部分集合を得ました。1つ目は処置を受けたユニットだけを含み、2つ目は処置を受けなかったユニットだけを含みます。次に、2つのモデルを訓練します。
- 傾向スコアモデル」(最も単純な場合はロジスティック回帰)と呼ばれる追加モデルを導入し、X形質に対する処置を予測するように訓練します。
- 次に、処置効果を計算し、特徴量とCATE値で2つのモデルを訓練します。
- 2つのモデルを使用した結果は、モデルの傾向スコアから得られた重みと加算されます。
一方、データセットが非常に小さい場合、X-Learnerは最適な選択ではないかもしれません。なぜなら、モデルを追加するごとに、フィッティング時にノイズが追加され、そのモデルを使用するのに十分なデータがない可能性があるからです。この場合、S-Learnerの方が適しています。
もっと上級のメタ学習器もあります。それらを使用するつもりはないので、この短い記事でそれらを論じる意味はほとんどありません。これらはバイアス除去(debiased)/直交機械学習とR-Learnerです。ご自分でご勉強ください。
既存のメタ学習器に関する結論
提案されたアルゴリズムは、かなり広範な理論的部分にもかかわらず、CATE効果の推定にすぎません。因果推論に関する文献は、処置効果の検出と評価の全サイクルにほとんど触れていません。ただし、これらが非常に明白なケースである場合、結果として得られるモデルをビジネス プロセスに実装する状況もかなり弱いものになります。実験を定式化し、これらの推定量を使用するのは研究者次第であると述べられています。私は、もう少し踏み込んで、これらの推計の要素を組み込んで、自動的に発生する取引システムを作ることにしました。アルゴリズムの入力と出力には、これまでと同じように符号とラベルが与えられ、アルゴリズムはデータのうち因果関係が特定可能な部分については因果関係を特定し、それ以外の部分については取引判断のロジックから除外しようとします。
取引アルゴリズム構築のためのメタ学習器機能の実装
必要最低限の知識で武装した上で、私自身のアルゴリズムを考えてみることにします。因果関係を分析するために、さまざまなメタ学習器やその利用方法を用いた多くの実験がおこなわれてきました。現時点では、提案されているアルゴリズムは、改良の余地はあるものの、最も優れたものの1つです。
潜在的な結果を評価するのに、偏った単一の分類器を使用するのは現実的ではないと判断したので、関数の最初の引数は、指定された数の分類器です。私はCatBoostアルゴリズムを使用しました。次に、反復回数やツリーの深さ、bad_samples_fraction(メタ学習器に特化した最初の記事から知られているパラメータ)などの学習者ハイパーパラメータがあります。これは、最終的な訓練セットから除外されるべき、分類が不十分な例の割合です。このような時には取引をしないようにすべきです。
BAD_BUYとBAD_SELLは、各反復で補充される悪い例のインデックスのコレクションです。
新しい反復のたびに、その数は指定された学習器数に等しく、データセットはランダムに訓練と検証のサブサンプルに分割されます(ここでは50/50)。これにより、各アルゴリズムが過剰訓練に陥らないようにしています。ランダム分割により、各分類器はユニークなサブサンプルで学習検証され、データセット全体が推定値を生成するために使用されます。これによって推定値の偏りがなくなり、どの例が実際に処置(分類器の訓練)に対して感受性が低いかをより正確に評価できるようになります。
各訓練の後、実際のクラスラベルが予測されたものと比較されます。誤って予測されたラベルは、悪い例のコレクションに加わります。分類器の数が増えるにつれて、本当に悪いサンプルの推定値の偏りが少なくなることを期待しています。
悪いサンプルのコレクションが形成された後、すべてのインデックスにまたがる悪いサンプルの平均数を計算します。この後、悪い例の数が平均を一定量上回るインデックスを選択します。これは、最終モデルの訓練に含まれる悪い例の数を変えることを可能にします。なぜなら、再訓練の回数が多いと、各インデックスが少なくとも一度は悪い例に入る確率があるからです。この場合、すべての例が最終的な訓練セットから除外されることがわかり、このアルゴリズムは機能しません。
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float): dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] BAD_BUY = pd.DatetimeIndex([]) BAD_SELL = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_b = coreset[coreset['labels']==0] coreset_s = coreset[coreset['labels']==1] diff_negatives_b = coreset_b['labels'] != coreset_b['labels_pred'] diff_negatives_s = coreset_s['labels'] != coreset_s['labels_pred'] BAD_BUY = BAD_BUY.append(diff_negatives_b[diff_negatives_b == True].index) BAD_SELL = BAD_SELL.append(diff_negatives_s[diff_negatives_s == True].index) to_mark_b = BAD_BUY.value_counts() to_mark_s = BAD_SELL.value_counts() marked_idx_b = to_mark_b[to_mark_b > to_mark_b.mean() * bad_samples_fraction].index marked_idx_s = to_mark_s[to_mark_s > to_mark_s.mean() * bad_samples_fraction].index data.loc[data.index.isin(marked_idx_b), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_s), 'meta_labels'] = 0.0 return data[data.columns[1:]]
残りの関数は変更されておらず、前回の記事で説明されています。そこからダウンロードして、メタ学習器関数を提案されたものに置き換えることができます。この記事の残りでは、実験に焦点を当て、最終的な結論を導き出そうとします。
因果推論アルゴリズムのテスト
ある基準(いわゆる適応度関数)に従って取引戦略を遺伝的に最適化すると仮定しましょう。私たちの興味は、最高の最適化結果だけでなく、すべてのパスの結果が平均的に良好であることを保証することでもあります。取引戦略が悪かったり、パラメータの広がりが大きすぎたりすると、満足のいく結果を得られない最適化パスが多数発生し、平均推定値に悪影響を及ぼします。これを避けたいので、アルゴリズムを何度も訓練し、その結果を平均し、最良の結果と平均を比較します。
そのために、私はカスタムテスターを改造して、リストからすべての訓練済みモデルを一度にテストするようにしました。
def test_all_models(result: list): pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] pr_tst['labels'] = 0.5 pr_tst['meta_labels'] = 0.5 for i in range(len(result)): pr_tst['labels'] += result[i][1].predict_proba(X)[:,1] pr_tst['meta_labels'] += result[i][2].predict_proba(X)[:,1] pr_tst['labels'] = pr_tst['labels'] / (len(result)+1) pr_tst['meta_labels'] = pr_tst['meta_labels'] / (len(result)+1) pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(pr_tst, plot=plt)
ここで因果推論を25回おこないます(25個の独立したモデルを訓練します。これらはランダムにサブサンプルに分割される点で非常にランダム化されています)。
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learners(15, 25, 2, 0.3)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
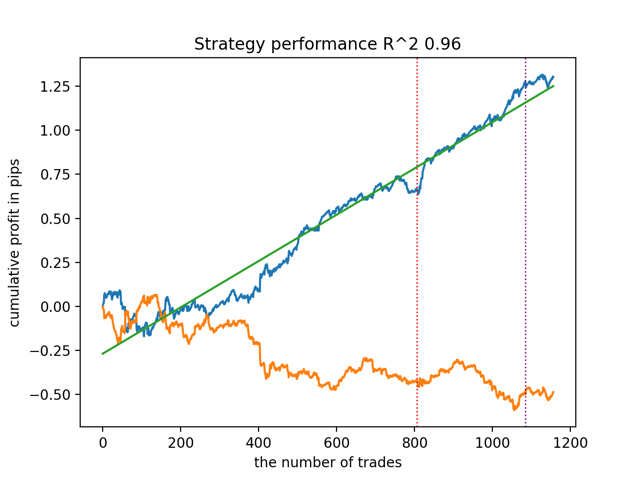
test_all_models(options) まず、決定係数バージョンに従って最良のモデルをテストしてみましょう。
そして、すべてのモデルを一度にテストします。
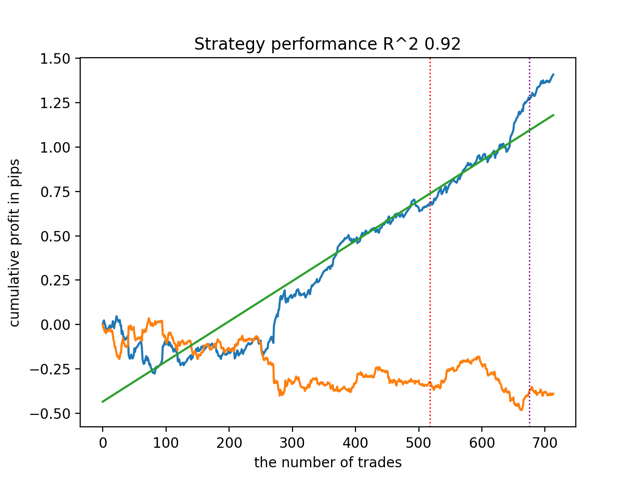
平均的な結果は最良なものと大差ありません。つまり、ランダム化対照実験の過程で、真の因果関係に近づくことが可能です。
他のメタ学習器入力パラメータを用いてアルゴリズムを訓練し、テストしてみましょう。
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learners(5, 10, 1, 0.4)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
test_all_models(options) 以下が結果です。
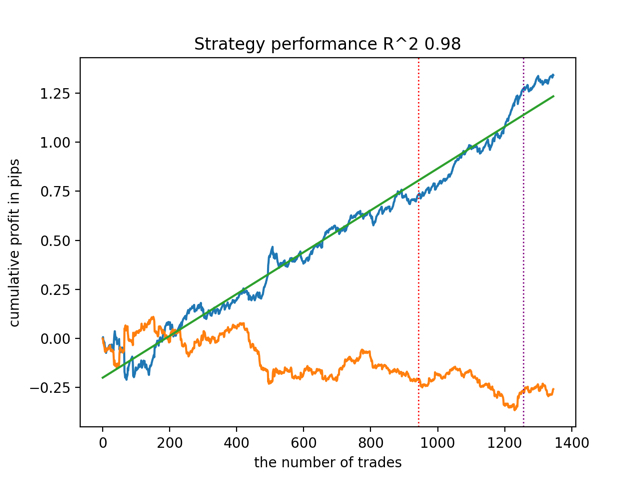
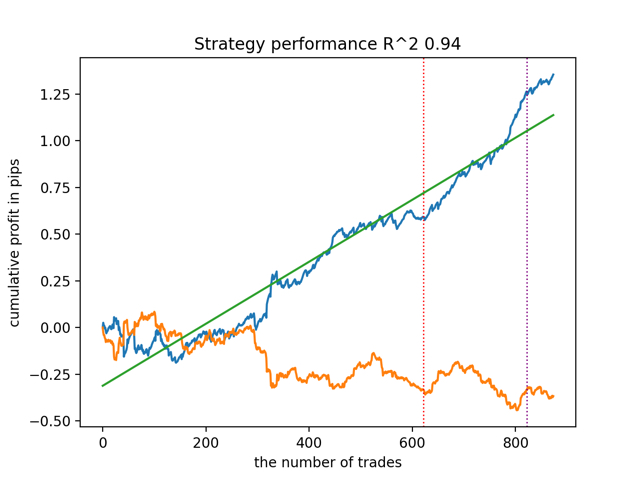
また、訓練履歴の深さ(グラフの縦線で強調)は、モデルの特徴量数やその他のハイパーパラメータと同様に、結果の品質に影響を与えますが(これは一般的に驚くべきことではない)、モデルの品質における広がりは小さいままであることが指摘されました。その結果得られる安定性は、提案されたアルゴリズムの重要な特性であり、その結果得られる取引戦略の品質にさらなる自信を持つことを可能にするものであると、私は信じています。
まとめ
この記事では、因果推論の基本的な概念について紹介しました。このトピックは、1つの記事ですべての側面を網羅するには、かなり広範で複雑です。因果推論と因果思考は哲学と心理学にルーツを持ち、現実を理解する上で重要な役割を果たしています。したがって、書かれていることの多くは、直感的なレベルでよく理解できます。しかし、やや不可知論的な立場から、私は時系列分類問題におけるいわゆる因果推論の威力を示すために、実際的で例示的な例を挙げようとしました。このアルゴリズムを使用して様々な実験をおこなうことができます。前回の記事で紹介したコードの中の関数をいくつか置き換えるだけです。実験はこれで終わりません。もしかしたら、新しい興味深い情報が得られるかもしれません。
参考文献
- Aleksander Molak 『Causal inference and discovery in Python』
- Matheus Facure 『Causal inference for the Brave and True』
- Miguel A. Hernan, James M. Robins 『Causal inference:What If』
- Gabriel Okasa『Meta-learners for estimation of causal effects: finite sample cross-fit performance』
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13957
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索