
Kausalschluss in den Problemen bei Zeitreihenklassifizierungen
Inhalt des Artikels:
- Einführung
- Geschichte des Kausalschlusses
- Grundlagen der Kausalschlusses beim maschinellen Lernen
- Evidenzleiter bei kausalen Schlussfolgerungen
- Notation bei kausalen Schlussfolgerungen
- Bias
- Randomisierte Experimente
- Passend dazu
- Ungewissheit
- Meta-Lernende
- Ein Beispiel für den Aufbau eines Handelssystems
Im vorangegangenen Artikel haben wir uns eingehend mit dem Training mittels Meta-Learner und Kreuzvalidierung sowie dem Speichern von Modellen im ONNX-Format beschäftigt. Ich habe auch festgestellt, dass Modelle des maschinellen Lernens nicht in der Lage sind, in disparaten und widersprüchlichen Daten von vornherein Muster zu erkennen. In diesem Fall ist es sehr wichtig, was genau an den Eingang und Ausgang eines neuronalen Netzes oder eines anderen Algorithmus für maschinelles Lernen gesendet wird.
Andererseits können wir nicht immer die notwendigen Trainingsdaten vorbereiten, deren Struktur bereits kausale Beziehungen enthält. In der Regel handelt es sich dabei um eine Reihe von Indikatoren und Beispielen für Kauf- und Verkaufsszenarien. Das inkrementelle Vorzeichen, der Zickzackkurs oder die Position der gleitenden Durchschnitte im Verhältnis zueinander wird häufig verwendet, um die Richtung eines zukünftigen Handels festzulegen. Alle diese Arten von Kennzeichnungen sind nicht fachmännisch und enthalten in der Regel keine echten Kausalbeziehungen.
Die Kennzeichnung von Daten ist vielleicht der teuerste und zeit- und ressourcenaufwändigste Prozess in der Welt des maschinellen Lernens, da es die Einbeziehung von Spezialisten auf dem untersuchten Gebiet (so genannte Annotatoren) erfordert. Selbst leistungsstarke neuronale Netze wie GPT und ihre Analoga, die auf großen Datenmengen trainiert wurden, sind nur in der Lage, Sprachmuster zu klassifizieren, die einen semantischen Kontext bilden. Sie geben jedoch keine Antwort auf die Frage, ob eine bestimmte Aussage tatsächlich wahr oder falsch ist. Teams von Kommentatoren arbeiten mit diesen Modellen und passen ihre Antworten so an, dass sie für den Endnutzer nützlich werden.
In diesem Fall hat der Händler eine berechtigte Frage: Wenn ich weiß, wie ich Daten kennzeichnen kann, warum brauche ich dann ein neuronales Netz? Schließlich kann ich einfach eine Logik schreiben, die auf meinem Wissen basiert, und diese effektiv nutzen. Diese Idee ist richtig und falsch zugleich. Das ist insofern falsch, als das neuronale Netz die Aufgabe der Vorhersage gut bewältigt, sodass es ausreicht, es auf gut beschrifteten Daten zu trainieren und dann Vorhersagen auf neuen Daten zu erhalten, ohne sich die Mühe zu machen, die Logik der Handelsstrategie zu schreiben. Darüber hinaus ermöglicht die integrierte Funktionsweise die Bewertung der Zuverlässigkeit von Vorhersagen anhand neuer Daten. Und es ist richtig, dass das neuronale Netz nicht in der Lage ist, eine profitable Handelsstrategie zu erstellen, wenn es nicht weiß, was es in den Input einspeisen soll, oder wenn es falsch beschriftete Daten als Output liefert.
Das Verständnis für die oben genannten Probleme des maschinellen Lernens ist den Händlern nicht sofort gekommen. Ursprünglich glaubten sogar die Entwickler der ersten einfachen Algorithmen für maschinelles Lernen fest daran, dass das mathematische Analogon eines Neurons die Arbeit der Neuronen des Gehirns kopiert, was bedeutet, dass ein ausreichend großes neuronales Netz in der Lage sein wird, die Funktionen des Gehirns vollständig zu übernehmen und zu lernen, Informationen unabhängig zu analysieren. Später erkannte man, dass das Gehirn über eine große Anzahl hochspezialisierter Abteilungen verfügt. Jede von ihnen verarbeitet bestimmte Informationen und leitet sie an andere Abteilungen weiter. Auf diese Weise entstanden mehrschichtige neuronale Netzarchitekturen, dank derer die Forscher den Rätseln der Funktionsweise des Gehirns näher kamen. Solche Architekturen haben gelernt, bestimmte Informationen, wie z. B. Bild-, Text-, Audio- oder Tabellendaten, perfekt zu verarbeiten.
Wie sich später herausstellte, sind solche neuronalen Netze auch beim überwachten Lernen nicht in der Lage, unabhängige Rückschlüsse auf wahre Muster zu ziehen. Sie sind anfällig für Übertraining und Subjektivität.
Der nächste Schritt auf dem Weg zum Verständnis der Struktur und Funktionsweise des Gehirns war die Entdeckung, dass natürliche neuronale Netze auf Verstärkungslernen beruhen und nicht nur auf dem Lernen aus vorgefertigten Mustern. Dies ist eine Art des Lernens, bei der ein komplexes System für subjektiv richtige Entscheidungen belohnt und für falsche bestraft wird. Nachdem man solche Belohnungen je nach Aufgabe mehrfach erhalten hat, sammelt man Erfahrungen und lernt subjektiv richtige Antwortmöglichkeiten. Das Gehirn bzw. das neuronale Netz beginnt, in bestimmten Fällen weniger Fehler zu machen, wenn es ihnen schon einmal begegnet ist.
Dies führte zur Entwicklung des Verstärkungslernens, bei dem die Forscher selbst die Belohnungsfunktion (eine Art Fitnessfunktion in Optimierungsalgorithmen) festlegen und das neuronale Netz für richtige oder falsche Antworten belohnen oder bestrafen. Jetzt wird der Algorithmus für maschinelles Lernen nicht mehr auf vorgefertigten, gut beschrifteten Daten trainiert, sondern versucht durch Versuch und Irrtum, die Belohnungsfunktion zu maximieren. Gegenwärtig gibt es eine große Anzahl von Algorithmen des verstärkten Lernens für verschiedene Aufgaben, und dieser Bereich entwickelt sich sehr aktiv.
Dies schien ein Durchbruch zu sein, bis man begann, es unter anderem für Probleme bei der Klassifizierung von Finanzzeitreihen zu verwenden. Es wurde deutlich, dass ein solches Lernen sehr schwer zu kontrollieren ist, da es nun darauf ankommt, die richtige Belohnungsfunktion einzustellen und die richtige Netzarchitektur zu wählen. Wir stehen vor dem gleichen trivialen Problem: Wenn wir die wahre Zielfunktion, die die tatsächlichen kausalen Beziehungen zwischen den Zuständen des Systems und seinen Reaktionen beschreibt, nicht kennen, dann ist es unwahrscheinlich, dass wir sie durch zahlreiche Suchvorgänge sowohl der Zielfunktion selbst als auch verschiedener Algorithmen des verstärkten Lernens finden, es sei denn, wir haben Glück.
Ähnlich verhält es sich mit generativen Modellen, die ohne einen Supervisor konditional lernen. Nach dem Prinzip eines Encoder-Decoders oder Generator-Diskriminators lernen sie, Informationen zu komprimieren, wichtige Merkmale hervorzuheben oder reale von fiktiven Mustern zu unterscheiden (im Fall von adversen neuronalen Netzen) und dann plausible Beispiele, wie z. B. Bilder, zu erzeugen. Während bei Bildern alles mehr oder weniger klar ist und sie eine Art plausibler „Unsinn“ eines neuronalen Netzes sind, ist es bei der Generierung von genauen, konsistenten Antworten viel komplizierter. Das Zufallselement, das der Generierung einer bestimmten Antwort innewohnt, lässt keine eindeutigen Rückschlüsse auf kausale Zusammenhänge zu, was für eine so riskante Tätigkeit wie den Handel, bei dem das zufällige Verhalten des Algorithmus ein Synonym für Verluste ist, nicht geeignet ist.
Der Autor des Artikels hat alle diese Algorithmen für die Klassifizierung von Zeitreihen, insbesondere von Forex-Währungspaaren, ausprobiert und war mit den Ergebnissen nicht sehr zufrieden.
In letzter Zeit stößt man immer häufiger auf Veröffentlichungen zum Thema des so genannten „zuverlässigen“ oder „vertrauenswürdigen“ (reliable oder trustworthy) maschinellen Lernens. Im Allgemeinen sind die Ansätze noch nicht vollständig ausgearbeitet und variieren von Bereich zu Bereich. Es ist wichtig zu verstehen, dass es das Problem des Kausalschlusses durch Algorithmen des maschinellen Lernens angeht. Die Forscher haben gelernt, das maschinelle Lernen zu verstehen und ihm so sehr zu vertrauen, dass sie bereit sind, es mit der Suche nach kausalen Zusammenhängen in Daten zu betrauen, was das maschinelle Lernen natürlich auf eine völlig neue Ebene hebt. Der Kausalschluss ist in Bereichen wie Medizin, Ökonometrie und Marketing weit verbreitet.
Dieser Artikel beschreibt einen Versuch, einige Techniken des Kausalschlusses in Bezug auf den algorithmischen Handel.
Geschichte des Kausalschlusses
Kausalität hat eine lange Geschichte und wurde in den meisten, wenn nicht allen uns bekannten Hochkulturen berücksichtigt.
Aristoteles, einer der produktivsten Philosophen der griechischen Antike, argumentierte, dass das Verständnis der kausalen Struktur eines Prozesses ein notwendiger Bestandteil des Wissens über diesen Prozess ist. Darüber hinaus vertrat er die Auffassung, dass die Fähigkeit, „Warum“-Fragen zu beantworten, das Wesen der wissenschaftlichen Erklärung ausmacht. Aristoteles unterscheidet vier Arten von Ursachen (materielle, formale, effiziente und endgültige). Dieser Gedanke mag einige interessante Aspekte der Realität widerspiegeln, auch wenn er für einen modernen Menschen kontraintuitiv klingen mag.
David Hume, der berühmte schottische Philosoph aus dem 18. Jahrhundert, schlug einen einheitlicheren Rahmen für kausale Beziehungen vor. Hume argumentierte zunächst, dass wir niemals kausale Beziehungen in der Welt beobachten. Das Einzige, was wir beobachten, ist, dass einige Ereignisse miteinander verbunden sind: Wir stellen nur fest, dass das eine auf das andere folgt. Der Schwung der einen Billardkugel wird von der Bewegung der zweiten begleitet. Dies ist das Ganze, das den äußeren Sinnen erscheint. Der Verstand erfährt durch diese Abfolge von Objekten keine Gefühle oder inneren Eindrücke: Es gibt also nichts in jedem einzelnen Phänomen, was auf eine Kraft oder einen notwendigen Zusammenhang schließen ließe.
Eine Interpretation der Humeschen Verursachungstheorie lautet wie folgt:
- Wir beobachten nur, wie die Bewegung oder das Erscheinen von Objekt A der Bewegung oder dem Erscheinen von Objekt B vorausgeht.
- Wenn wir diese Sequenz oft genug sehen, entwickeln wir ein Gefühl der Vorfreude.
- Dieses Gefühl der Erwartung ist die Essenz unseres Konzepts der Kausalität (es geht nicht um die Welt, sondern um das Gefühl, das wir entwickeln).
Diese Theorie ist unter mindestens zwei Gesichtspunkten sehr interessant. Erstens haben Elemente dieser Theorie große Ähnlichkeit mit einer Idee, die in der Psychologie als Konditionierung bezeichnet wird. Konditionierung ist eine Form des Lernens. Es gibt viele Arten der Konditionierung, aber sie alle beruhen auf einer gemeinsamen Grundlage - der Assoziation (daher der Name dieser Art des Lernens - assoziatives Lernen). Bei jeder Art von Konditionierung nehmen wir ein Ereignis oder ein Objekt (in der Regel einen Reiz) und verbinden es mit einem bestimmten Verhalten oder einer Reaktion. Assoziatives Lernen funktioniert bei verschiedenen Tierarten. Man findet es bei Menschen, Affen, Hunden und Katzen, aber auch bei viel einfacheren Organismen wie Schnecken.
Zweitens arbeiten die meisten klassischen Algorithmen für maschinelles Lernen ebenfalls auf der Grundlage von Assoziationen. Beim überwachten Lernen versuchen wir, eine Funktion zu finden, die Eingaben auf Ausgaben abbildet. Um dies effizient zu tun, müssen wir herausfinden, welche Elemente der Eingabe für die Vorhersage der Ausgabe nützlich sind. In den meisten Fällen reicht die Assoziation für diesen Zweck aus.
Weitere Informationen über die Möglichkeiten der Untersuchung kausaler Beziehungen stammen aus der Kinderpsychologie.
Alison Gopnik ist eine amerikanische Kinderpsychologin, die untersucht, wie Kleinkinder Modelle der Welt entwickeln. Sie arbeitet auch mit Informatikern zusammen, um zu verstehen, wie menschliche Kleinkinder Konzepte über die Außenwelt mit gesundem Menschenverstand konstruieren. Kinder nutzen assoziatives Lernen noch mehr als Erwachsene, aber sie sind auch unersättliche Experimentatoren. Haben Sie schon einmal ein Elternteil gesehen, das versucht, sein Kind davon zu überzeugen, nicht mehr mit Spielzeug um sich zu werfen? Manche Eltern neigen dazu, dieses Verhalten als unhöflich, destruktiv oder aggressiv zu interpretieren, aber Kinder haben oft andere Beweggründe. Sie führen systematische Experimente durch, mit denen sie die Gesetze der Physik und die Regeln der sozialen Interaktion untersuchen können (Gopnik, 2009). Kleinkinder im Alter von 11 Monaten experimentieren lieber mit Objekten, die unvorhersehbare Eigenschaften aufweisen, als mit Objekten, die sich vorhersehbar verhalten (Stahl & Feigenson, 2015). Diese Vorliebe ermöglicht es ihnen, effektiv Modelle von der Welt zu erstellen.
Was wir von Babys lernen können, ist, dass wir uns nicht darauf beschränken, die Welt zu beobachten, wie Hume annahm. Wir können auch mit ihr interagieren. Im Zusammenhang mit Kausalschlüssen werden diese Interaktionen als Interventionen bezeichnet. Interventionen sind das Herzstück dessen, was viele für den Heiligen Gral der wissenschaftlichen Methode halten: die randomisierte kontrollierte Studie (RCT).
Aber wie können wir eine Assoziation von einer echten kausalen Beziehung unterscheiden? Versuchen wir, es herauszufinden.
Grundlagen der Kausalschlusses beim maschinellen Lernen
Das Hauptziel der kausalen Inferenz beim maschinellen Lernen besteht darin, festzustellen, ob wir auf der Grundlage eines trainierten Algorithmus für maschinelles Lernen Entscheidungen treffen können. Dabei sind wir nicht immer an der Genauigkeit und Häufigkeit der Vorhersagen interessiert, obwohl dies auch wichtig ist, sondern eher an ihrer Stabilität und dem Grad des Vertrauens in sie.
Die Hauptthese des Kausalschlusses lautet: „Korrelation bedeutet nicht Kausalität“. Das bedeutet, dass die Korrelation nicht den Einfluss eines Ereignisses auf ein anderes beweist, sondern lediglich die lineare Beziehung zwischen diesen zwei oder mehr Ereignissen feststellt.
Ein kausaler Zusammenhang wird also durch den Einfluss einer Variable auf eine andere bestimmt. Die Einflussvariable wird oft als Instrumentalvariable bezeichnet, wenn es sich um eine Intervention Dritter handelt, oder einfach als eine der Kovariablen (Merkmale beim maschinellen Lernen). Oder durch eine Aktion zu einer anderen Aktion. Folgt auf das Ereignis A im Allgemeinen immer das Ereignis B? Oder verursacht das Ereignis A tatsächlich das Ereignis B? Aus diesem Grund wird es auch A/B-Testing genannt. Genau damit werden wir uns im Folgenden beschäftigen, allerdings unter Verwendung von Algorithmen des maschinellen Lernens.
Es gibt eine Reihe von Ansätzen, um den Kausalitätsnachweis zu erbringen, sowohl mit Hilfe von randomisierten Experimenten als auch mit Hilfe von Instrumentalvariablen und maschinellem Lernen. Es macht keinen Sinn, hier alle Methoden aufzulisten, da sich andere Werke damit befassen. Uns interessiert, wie wir dies auf ein Problem der Zeitreihenklassifizierung anwenden können.
Es ist wichtig zu beachten, dass fast alle diese Methoden auf dem Neumann-Rubin-Kausalmodell oder Modellen potenzieller Ergebnisse (Outcomes) basieren. Dies ist ein statistischer Ansatz, mit dessen Hilfe festgestellt werden kann, ob ein Ereignis tatsächlich eine Folge eines anderen ist.
Ein trainierter Klassifikator zeigt beispielsweise Gewinne in den Teilstichproben für Training und Validierung, während seine Signale zu Verlusten in der Teilstichprobe des Tests führen. Um den kausalen Effekt auf neue Daten mit diesem Klassifikator zu messen, müssen wir die Ergebnisse auf neue Daten vergleichen, wenn er tatsächlich trainiert wurde und wenn er nicht trainiert wurde. Da es unmöglich ist, die Ergebnisse eines untrainierten Klassifikators zu sehen, da er keine Kauf- oder Verkaufssignale erzeugt, ist dieses potenzielle Ergebnis unbekannt. Wir haben nur das tatsächliche Ergebnis, nachdem wir es trainiert haben, und das unbekannte Ergebnis ohne Training ist kontrafaktisch. Mit anderen Worten: Wir müssen herausfinden, ob das Trainieren eines Klassifikators zu höheren Gewinnen oder zu einem Gewinn bei neuen Daten führt im Vergleich zu von z. B. zufälligen Handelsgeschäften. Das heißt, hat das Training eines Klassifikators überhaupt einen positiven Effekt?
Bei diesem Dilemma handelt es sich um ein „grundlegendes Problem des Kausalschlusses“, wenn wir nicht wissen, wie das tatsächliche Ergebnis ausgesehen hätte, wenn der Klassifikator nicht trainiert worden wäre, wir aber das tatsächliche Ergebnis erst kennen, nachdem er trainiert worden ist.
Aufgrund des grundsätzlichen Problems des Kausalschlusses können kausale Effekte auf der Ebene einer Einheit (ein einzelnes Trainingsbeispiel) nicht direkt beobachtet werden. Wir können nicht mit Sicherheit sagen, ob sich unsere Vorhersagen verbessert haben, weil wir nichts haben, womit wir sie vergleichen könnten. Mit Hilfe von randomisierten Experimenten können wir jedoch kausale Effekte auf der Ebene von Populationen bewerten. In einem randomisierten Experiment werden die Klassifikatoren nach dem Zufallsprinzip auf verschiedenen Teilstichproben trainiert. Aufgrund dieser zufälligen Verteilung der Trainingsbeispiele sind die Vorhersageergebnisse der Klassifikatoren (im Durchschnitt) gleichwertig, und die Unterschiede in den Vorhersagen der Klassifikatoren für bestimmte Beispiele lassen sich darauf zurückführen, ob Beispiele aus dem Teseinstellungen in den Trainingsbeispielen enthalten sind oder nicht. Wir können dann eine Schätzung des durchschnittlichen kausalen Effekts (auch als durchschnittlicher Behandlungseffekt bezeichnet) erhalten, indem wir die Differenz der durchschnittlichen Ergebnisse zwischen den behandelten (mit einem trainierten Klassifikator auf den Daten) und den Kontrollproben (mit einem untrainierten Klassifikator auf den Daten) berechnen.
Oder stellen Sie sich vor, dass es ein Multiversum gibt und in jedem der Subuniversen dieselbe Person lebt, die unterschiedliche Entscheidungen trifft, die zu unterschiedlichen Ergebnissen führen. Die Person in jedem Subuniversum kennt nur ihre eigene Version der Zukunft und kennt nicht die Zukunftsoptionen ihrer anderen „Ichs“ in anderen Subuniversen.
Im Beispiel des Multiversums gehen wir davon aus, dass alle Menschen ein Pendant in anderen Universen haben. Alle Menschen sind sich im Durchschnitt ähnlich. Das bedeutet, dass wir die Gründe für die von ihnen getroffenen Entscheidungen mit den Ergebnissen dieser Entscheidungen vergleichen können. Auf der Grundlage dieses Wissens ist es also möglich, eine kausale Schlussfolgerung darüber zu ziehen, was mit einer bestimmten Person in einem anderen Universum geschehen würde, wenn sie sich auf eine Art und Weise verhalten würde, die sie dort noch nie getan hat. Natürlich nur, wenn diese Universen ähnlich sind.
Evidenzleiter bei kausalen Schlussfolgerungen
Es gibt ein System von Kausalschlussmethoden, die eine Hierarchie der Methoden nach ihrer Beweisfähigkeit darstellt. Auf diese Weise lässt sich herausfinden, welche Beweiskraft die von uns gewählte Methode haben wird. Nachfolgend finden Sie Zitate aus dem Artikel, zu dem Sie oben einen Link finden.

- Auf der ersten Sprosse der Leiter stehen typische wissenschaftliche Experimente.
Die Art, die Sie wahrscheinlich in der Mittelschule oder sogar in der Grundschule gelernt haben. Um zu erklären, wie ein wissenschaftliches Experiment durchgeführt werden sollte, ließ mein Biologielehrer uns Samen aus einer Schachtel nehmen, sie in zwei Gruppen aufteilen und in zwei Gläser einpflanzen. Die Lehrerin bestand darauf, dass die Bedingungen in den beiden Gläsern völlig identisch sein sollten: gleiche Anzahl von Samen, gleiche Bodenfeuchtigkeit usw. Ziel war es, die Auswirkungen des Lichts auf das Pflanzenwachstum zu messen. Deshalb stellten wir eines unserer Gefäße in die Nähe eines Fensters und schlossen das andere in einem Schrank ein. Zwei Wochen später hatten alle unsere Gläser in der Nähe des Fensters schöne kleine Knospen, während die, die wir im Schrank gelassen hatten, kaum gewachsen waren. Da die Lichtexposition der einzige Unterschied zwischen den beiden Gläsern sei, so die Lehrerin, dürfe man daraus schließen, dass Lichtmangel die Pflanzen nicht wachsen lasse.
Dies ist im Grunde die rigoroseste Methode, die man anwenden kann, wenn man Ursachen zuordnen will. Die schlechte Nachricht ist, dass diese Methode nur dann anwendbar ist, wenn Sie ein gewisses Maß an Kontrolle über Ihre Behandlungsgruppe (die Gruppe, die Licht erhält) und Ihre Kontrollgruppe (die Gruppe im Schrank) haben. Zumindest so viel, dass alle Bedingungen bis auf den einen Parameter, mit dem Sie experimentieren (in diesem Fall das Licht), absolut identisch sind. Das gilt natürlich weder für die Sozialwissenschaften noch für die Datenwissenschaft.
Warum hat der Autor sie dann in den Artikel aufgenommen, könnte man sich fragen? Nun, im Grunde, weil dies die Referenzmethode ist. Alle Kausalschlussmethoden sind in gewisser Weise Hacks, die darauf abzielen, diese einfache Methodik unter Bedingungen zu reproduzieren, unter denen man nicht in der Lage sein sollte, Schlussfolgerungen zu ziehen, wenn man sich strikt an die Regeln hält, die einem der Mittelschullehrer erklärt hat.
- Statistische Experimente (auch A/B-Tests genannt)
Wahrscheinlich die bekannteste Kausalschlussmethode in der Technik: A/B-Tests, auch bekannt als Randomized Controlled Trials (Randomisierte, kontrollierte Versuche). Die Idee hinter statistischen Experimenten ist es, sich auf den Zufall und die Stichprobengröße zu verlassen, um die Unmöglichkeit, die Behandlungs- und die Kontrollgruppe exakt denselben Bedingungen auszusetzen, abzumildern. Grundlegende statistische Theoreme wie das Gesetz der großen Zahlen, der zentrale Grenzwertsatz oder die Bayes'sche Inferenz bieten Garantien dafür, dass dies funktioniert, und eine Möglichkeit, Schätzungen und deren Genauigkeit aus den gesammelten Daten abzuleiten.
- Quasi-Experimente
Ein Quasi-Experiment liegt vor, wenn die Behandlungs- und die Kontrollgruppe durch einen natürlichen Prozess geteilt werden, der nicht wirklich zufällig ist, aber als nahe genug für die Berechnung von Schätzungen angesehen werden kann. In der Praxis bedeutet dies, dass Sie verschiedene Methoden haben werden, die verschiedenen Annahmen darüber entsprechen, wie „nah“ Sie an der A/B-Testsituation sind. Berühmte Beispiele für natürliche Experimente sind die Verwendung der Einberufungslotterie für den Vietnamkrieg, um die Auswirkungen des Veteranenstatus auf das Einkommen zu ermitteln, oder die Grenze zwischen New Jersey und Pennsylvania, um die Auswirkungen von Mindestlöhnen auf die Wirtschaft zu untersuchen.
- Kontrafaktische Methoden
Hier geben wir die Idee von Behandlungs- und Kontrollgruppen auf (eigentlich nicht ganz) und modellieren die Zeitreihe Y aus historischen Daten ohne die Beteiligung von X in der Zukunft, wo X bereits ins Spiel kommt. So können wir während des Experiments die tatsächlichen Daten von Y (an denen X teilgenommen hat) mit dem Modell (Vorhersage von Y ohne X) vergleichen und die Effektgröße schätzen, indem wir sie an die Genauigkeit des Modells für Y anpassen. Die daraus resultierende Wirkung hängt nicht nur entscheidend von der Qualität des Modells ab, sondern generell von der korrekten Anwendung der gewählten Methode.
Bei der Erstellung eines Zeitreihenklassifikationsmodells können wir nur kontrafaktische Methoden verwenden. Mit anderen Worten, wir müssen uns selbst eine Instrumentalvariable oder ein Treatment ausdenken, es auf unsere Beobachtungen anwenden und dann geeignete Tests zur Stabilität der Methode durchführen, was wir in Zukunft tun werden. Dies ist natürlich der komplexeste Ansatz und hat nach der Beweisleiter die geringste Beweiskraft.
Notation bei kausalen Schlussfolgerungen
Wir haben uns darauf geeinigt, dass sich der Begriff „treatment“ T (Behandlung) auf ein Objekt bezieht, sei es ein Klinikpatient, eine Person, die unter dem Einfluss einer Werbekampagne steht, oder eine Probe aus der Trainingsmenge. Dann gibt es zwei Möglichkeiten. Entweder wurde die Person behandelt oder nicht.

Wir wissen auch bereits, dass nicht jedes Objekt (jede Einheit) gleichzeitig behandelt und nicht behandelt werden kann. Das heißt, es könnte eines von zwei Dingen sein.
Ergo
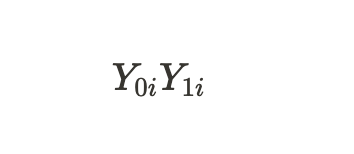
geben die möglichen Ergebnisse für eine Einheit ohne Behandlung und für eine Einheit mit Behandlung an. Wir können den individuellen Behandlungseffekt durch die Differenz dieser potenziellen Ergebnisse berechnen:
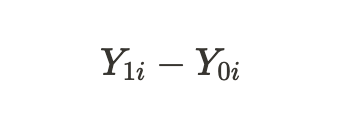
Aufgrund des oben erwähnten grundsätzlichen Problems der kausalen Schlussfolgerung können wir keinen individuellen Behandlungseffekt ermitteln, da nur eines der Ergebnisse bekannt ist, aber wir können den durchschnittlichen Behandlungseffekt für alle ähnlichen Probanden berechnen, von denen einige die Behandlung erhalten haben und andere nicht:
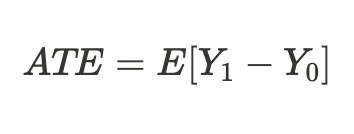
Oder wir können einen durchschnittlichen Behandlungseffekt nur für die Einheiten ermitteln, die behandelt wurden:
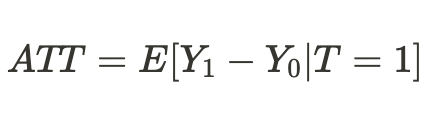
Bias
Voreingenommenheit ist der Unterschied zwischen Korrelation (Assoziation) und Kausalität (Ursache und Wirkung). Was wäre, wenn sich unsere „Ichs“ in einem anderen Universum in völlig anderen Existenzbedingungen befänden und die Ergebnisse ihrer Entscheidungen nicht mehr denen entsprächen, an die wir in diesem Universum gewöhnt sind? Dann werden sich die Schlussfolgerungen über mögliche Ergebnisse als falsch erweisen, und die Annahmen werden nur assoziative, aber keine kausalen Beziehungen sein.
Dies gilt auch für trainierte Klassifikatoren, wenn sie bei neuen Daten, die sie noch nicht gesehen haben, keinen Gewinn mehr erzielen oder einfach keine korrekten Vorhersagen mehr treffen.
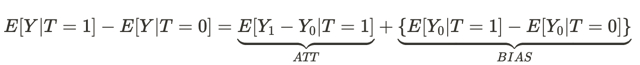
Diese Gleichung beantwortet die Frage, warum eine assoziative Beziehung keine kausale Beziehung ist. Die Verzerrung besteht darin, wie unterschiedlich die Lebensbedingungen der Menschen in verschiedenen Universen sind, bevor sie sich in beiden Universen auswirken. Das liegt daran, dass es viele andere Variablen gibt, die das Ergebnis der von ihnen getroffenen Entscheidung beeinflussen. Infolgedessen unterscheiden sich die Populationen von Menschen in einem Universum und in einem anderen nicht nur dadurch, dass unterschiedliche Entscheidungen getroffen werden, sondern auch durch unterschiedliche Existenzbedingungen.
Es stellt sich heraus, dass, wenn die Bedingungen unserer Existenz in verschiedenen Universen vergleichbar sind, unsere Schlussfolgerung in Bezug auf die Ergebnisse unserer Handlungen (im Durchschnitt) in einem anderen Universum kausal sein wird:
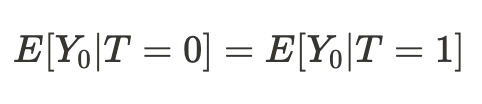
Dementsprechend wird die Differenz der Mittelwerte nun zum durchschnittlichen kausalen Effekt:
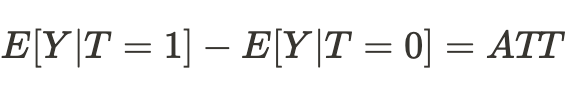
Wir können einfach schlussfolgern, dass zur Schätzung eines kausalen Effekts eine Stichprobe aus einer Grundgesamtheit mit einer Stichprobe aus einer anderen Grundgesamtheit vergleichbar sein sollte. Wenn dies der Fall ist, werden wir in der Lage sein, die wahre Beziehung zu bestimmen und mit hoher Wahrscheinlichkeit das Ergebnis der Handlungen unseres „Ichs“ in einem anderen Universum vorherzusagen.
Mit anderen Worten: Eine Assoziation wird zu einer kausalen Beziehung, wenn die Verzerrung gleich Null ist.
Übertragen auf das maschinelle Lernen bedeutet dies, dass wir es in der Regel mit Trainings- und Validierungsdaten sowie mit Testdaten zu tun haben. Das Maschinentrainingsmodell lernt anhand von Trainingsdaten unter teilweiser Einbeziehung von Validierungsdaten. Wenn die Teilstichproben vergleichbar sind, ergeben sich für die Trainings- und Validierungsdaten annähernd die gleichen Vorhersagefehler. Wenn sich die Teilstichproben durch eine bedingte Verzerrung unterscheiden, wird der Vorhersagefehler bei den Validierungsdaten größer sein. Ganz zu schweigen von der Testteilstichprobe, deren Datenverteilung möglicherweise überhaupt nicht mit den Verteilungen der beiden ersten Stichproben übereinstimmt.
Aber wie können wir dann eine kausale Schlussfolgerung ziehen, wenn die Verteilungen der Teilstichproben unterschiedlich sind? Die Antwort wurde teilweise bereits im vorherigen Abschnitt gegeben: Wir können durch ein randomisiertes Experiment kausale Schlüsse ziehen.
Randomisierte Experimente
Wie bereits deutlich wurde, ermöglicht die Randomisierung eine zufällige Aufteilung der Daten in Gruppen, von denen eine die „Behandlung“ (in unserem Fall das Modelltraining) erhält und die andere nicht. Außerdem sollten wir dies mehrmals tun und viele Modelle trainieren. Dies ist notwendig, um Verzerrungen bei unseren Schätzungen zu vermeiden. Durch das Randomisieren und Trainieren mehrerer Klassifikatoren wird die Abhängigkeit der potenziellen Ergebnisse von einem bestimmten Modell des maschinellen Lernens aufgehoben.
Dies mag anfangs etwas verwirrend sein. Man könnte meinen, dass die fehlende Abhängigkeit der Ergebnisse (Vorhersagen) von einem bestimmten Modell das Training dieses Modells nutzlos macht. Im Hinblick auf die Vorhersagen dieses speziellen Modells lautet die Antwort: Ja. Es handelt sich jedoch um mögliche Ergebnisse (Vorhersagen).
Das potenzielle Ergebnis ist das Ergebnis, das sich ergeben würde, wenn das Modell trainiert oder nicht trainiert wäre. Bei randomisierten Experimenten soll das Ergebnis (die Vorhersage) nicht unabhängig vom Training sein, da das Modelltraining das Ergebnis direkt beeinflusst.
Aber wir wollen, dass die potenziellen Ergebnisse unabhängig vom Training eines bestimmten Klassifikators sind, der voreingenommen ist!
Das bedeutet, dass die potenziellen Ergebnisse für die Kontroll- und die Testgruppe gleich sein sollen. Unsere Trainings- und Testdaten müssen vergleichbar sein, da wir Verzerrungen aus den Schätzungen entfernen wollen. Aber jeder einzelne Klassifikator gewichtet die verschiedenen Trainingsbeispiele unterschiedlich, selbst wenn sie gemischt sind, was dazu führt, dass jede Beobachtung in unterschiedlichem Maße behandelt wird. Dies erschwert den Kausalschluss.
Die Randomisierung der Trainingsbeispiele ermöglicht es uns, die Wirkung der Behandlung (des Trainings) zu bewerten, indem wir den Unterschied zwischen den Modellfehlern in den Test- und Trainingsstichproben ermitteln. Bei der Klassifizierung sollten jedoch die Merkmale von Algorithmen des maschinellen Lernens berücksichtigt werden. In diesem Fall ist die Effektschätzung immer noch verzerrt, weil jeder einzelne Klassifikator auf der Hälfte oder mehr der ursprünglichen Beispiele trainiert wird, wodurch jedes Beispiel unterschiedlich gewichtet wird (Behandlung). Durch die Verwendung mehrerer Klassifikatoren (eines Ensembles von Klassifikatoren) minimieren wir Verzerrungen, indem wir die Ergebnisse der Klassifikatoren mitteln, wodurch die Behandlung für jede Einheit gleichmäßiger wird. Dadurch werden alle Trainingsbeispiele unter die gleichen Bedingungen gestellt, wodurch sie den gleichen Wert erhalten.
In diesem Abschnitt haben wir gelernt, dass randomisierte Experimente dazu beitragen, Verzerrungen aus den Daten zu entfernen, um zuverlässigere Kausalschlüsse zu ziehen. Modell-Ensembles helfen uns, gleichwertige Schätzungen des Trainingseffekts abzugeben.
Passend dazu
Mit Hilfe von Zufallsexperimenten können wir die durchschnittliche Wirkung des Trainings eines Ensembles von Modellen abschätzen. Wir sind jedoch daran interessiert, individuelle Effekte für jedes Trainingsbeispiel zu erhalten. Dies ist notwendig, um zu verstehen, in welchen Situationen die Handelsstrategie im Durchschnitt Gewinn bringt und welche Situationen angepasst oder vom Handel ausgeschlossen werden sollten. Mit anderen Worten, wir wollen bedingte Schätzungen der Auswirkungen des Trainings erhalten, die von den individuellen Eigenschaften jedes Objekts abhängen.
Beim Matching werden einzelne Stichproben aus der Gesamtstichprobe verglichen, um sicherzustellen, dass sie sich in allen anderen Merkmalen ähneln, mit Ausnahme der Frage, ob sie in der Trainingsmenge enthalten waren oder nicht. Auf diese Weise können wir für jedes Trainingsbeispiel individuelle Bewertungen ableiten.
Es gibt eine genaue und eine ungenaue (ungefähre) Übereinstimmung.
Beim Grobabgleich können wir beispielsweise alle Einheiten anhand von Kriterien wie der Euklidischen Distanz, der Minkowski-Distanz oder der Mahalanobis-Distanz vergleichen. Da wir es aber mit Zeitreihen zu tun haben, haben wir die Möglichkeit, die Einheiten nach ihrer Position und Zeit zu vergleichen. Wenn wir ein Ensemble von Modellen trainieren, dann sind die Vorhersagen jedes Modells zu einem bestimmten Zeitpunkt bereits mit dem Satz von Merkmalen verknüpft, die zu diesem Zeitpunkt auf der Zeitachse vorhanden sind. Wir müssen nur die Vorhersagen aller Modelle für einen bestimmten Zeitpunkt vergleichen. Der Rechenaufwand für einen solchen Vergleich ist im Vergleich zu anderen Methoden minimal, sodass mehr Experimente möglich sind. Darüber hinaus wird dies eine genaue Abstimmung sein.
Ungewissheit
Beim algorithmischen Handel reicht es nicht aus, die durchschnittlichen und individuellen Behandlungseffekte zu ermitteln, da wir das endgültige Klassifizierungsmodell erstellen wollen. Wir müssen Instrumente zur kausalen Schlussfolgerung anwenden, um die Unsicherheit im Datensatz zu schätzen und die Einheiten in solche zu unterteilen, die auf die bedingte Behandlung reagieren (Training eines Klassifikators) und solche, die nicht reagieren. Mit anderen Worten: in solche, die in den allermeisten Fällen richtig und solche, die falsch eingestuft werden. Abhängig vom Grad der Unsicherheit, der als Summe der Unterschiede zwischen den möglichen Ergebnissen aller Ensemble-Modelle berechnet wird.
Da wir die Unsicherheit der Daten aus der Sicht des Klassifizierers schätzen, sollten Kauf- und Verkaufsaufträge getrennt bewertet werden, da ihre gemeinsame Verteilung die endgültige Schätzung verfälscht.
Meta-Lernende
Meta-Lernende (Meta learners) in der Kausalinferenz sind maschinelle Lernmodelle, die bei der Schätzung kausaler Effekte helfen.
Wir haben uns bereits mit den Konzepten ATE und ATT vertraut gemacht, die uns Informationen über die durchschnittliche kausale Wirkung in einer Population geben. Es ist jedoch zu bedenken, dass Menschen und andere komplexe Organismen (z. B. Tiere, soziale Gruppen, Unternehmen oder Länder) unterschiedlich auf dieselbe Behandlung reagieren können. In einer solchen Situation kann ATE wichtige Informationen vor uns verbergen.
Eine Lösung für dieses Problem ist die Berechnung des CATE (Conditional Average Treatment Effect, bedingter, durchschnittlicher Behandlungseffekt), auch bekannt als HTE. Bei der Berechnung von CATE betrachten wir nicht nur die Behandlung, sondern eine Reihe von Variablen, die die individuellen Merkmale jeder Einheit definieren, die den Einfluss der Behandlung auf das Ergebnis verändern können.
Im Falle einer binären Behandlung kann CATE wie folgt definiert werden:
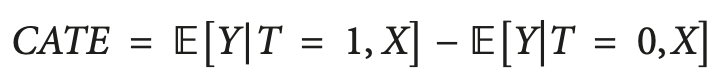
wobei X die Merkmale sind, die jedes einzelne Objekt (Einheit) beschreiben. Wir gehen also von einem homogenen Behandlungseffekt zu einem heterogenen Effekt über.
Der Gedanke, dass Menschen oder andere Einheiten unterschiedlich auf dieselbe Behandlung reagieren können, wird häufig in Form einer Matrix dargestellt, die manchmal auch als Uplift-Matrix bezeichnet wird und die Sie in der Abbildung sehen können.
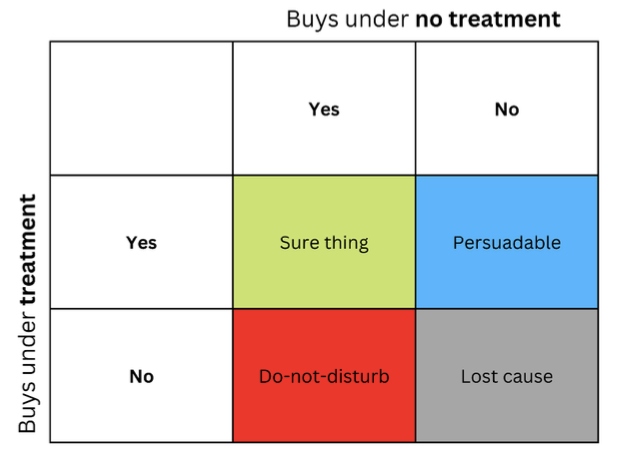
Die Zeichenfolgen stellen die Reaktion auf den Inhalt dar, wenn die Nachricht (z. B. eine Werbung) dem Empfänger präsentiert wird. Die Spalten stellen die Antworten dar, wenn keine Behandlung durchgeführt wird.
Die vier farbigen Zellen stellen die Dynamik des Behandlungseffekts dar. Zuversichtliche Käufer (grün) kaufen unabhängig von der Behandlung. Rote (Do Not Disturb) können ohne Behandlung kaufen, kaufen aber nicht, wenn sie behandelt werden. Diejenigen, die das Interesse verloren haben (grau), werden unabhängig vom Behandlungsstatus nicht kaufen, und die Blauen werden ohne Behandlung nicht kaufen, aber vielleicht kaufen, wenn sie angesprochen werden.
Wenn Sie ein Vermarkter mit kleinem Budget sind, sollten Sie sich auf das Marketing für die blaue Gruppe (überzeugbar) konzentrieren und das Marketing für die rote Gruppe (nicht stören) nach Möglichkeit vermeiden.
Marketing in den Gruppen „Sure thing“ und „Lost cause“ wird Ihnen nicht direkt schaden, aber es wird auch keinen Nutzen bringen.
Wenn Sie ein Arzt sind, möchten Sie ein Medikament denjenigen verschreiben, die davon profitieren können, und vermeiden, es denjenigen zu verschreiben, die dadurch geschädigt werden können. In vielen realen Szenarien kann die Ergebnisvariable probabilistisch (z. B. die Wahrscheinlichkeit eines Kaufs) oder kontinuierlich (z. B. der Betrag der Ausgaben) sein. In solchen Fällen sind wir nicht in der Lage, diskrete Gruppen zu identifizieren und konzentrieren uns darauf, die Einheiten mit dem größten erwarteten Anstieg der Ergebnisvariablen zwischen der Nicht-Behandlung und der Behandlung zu finden. Dieser Unterschied zwischen dem Ergebnis mit Behandlung und ohne Behandlung wird manchmal als Uplift bezeichnet.
Übertragen auf die Sprache der Zeitreihenklassifikation bedeutet dies, dass wir bestimmen müssen, welche Beispiele aus der Trainingsmenge am besten auf die Behandlung (Klassifikatortraining) ansprechen, und sie in eine separate Gruppe einordnen.
Eine einfache Möglichkeit zur Schätzung eines heterogenen Behandlungseffekts besteht darin, ein Surrogatmodell zu erstellen, das die Behandlungsvariable auf der Grundlage der verwendeten Prädiktoren vorhersagt und formal wie folgt dargestellt wird:
T ~ X
Die Leistung eines solchen Modells sollte im Wesentlichen zufällig sein. Wenn es auf den Zufall baut, würde das bedeuten, dass die Behandlung von den Merkmalen abhängt, was bedeutet, dass es eine fehlende Variable gibt, die wir nicht berücksichtigt haben, und die unsere kausalen Schlussfolgerungen beeinflusst und für Verwirrung sorgt. Dies ist häufig auf ein mangelhaftes Design randomisierter kontrollierter Studien zurückzuführen, bei denen die Behandlung nicht wirklich nach dem Zufallsprinzip zugewiesen wird.
S-Learner
S-Learner ist der Name eines einfachen Ansatzes zur CATE-Modellierung. S-Learner gehört zur Kategorie der sogenannten Meta-Lerner. Man beachte, dass kausale Meta-Lerner nicht direkt mit dem Konzept des Meta-Lernens verwandt sind, das im traditionellen maschinellen Lernen verwendet wird. Sie verwenden ein oder mehrere grundlegende (traditionelle) Modelle des maschinellen Lernens, um die kausale Wirkung zu berechnen. Im Allgemeinen können Sie jedes maschinelle Lernmodell von ausreichender Komplexität (Baum, neuronales Netz usw.) als Basis-Lernmodell verwenden, wenn es mit Ihren Daten kompatibel ist.
Der S-Learner ist das einfachste Metamodell, das nur einen Basis-Learner verwendet (daher der Name: S(ingle)-Learner). Die Idee, die hinter S-Learner steckt, ist überraschend einfach: Man trainiert ein Modell auf dem gesamten Trainingsdatensatz, einschließlich der Behandlungsvariable als Merkmal, sagt beide möglichen Ergebnisse voraus und subtrahiert die Ergebnisse, um CATE zu erhalten.
Nach dem Training läuft das schrittweise Prognoseverfahren für S-Learner wie folgt ab:
- Wählen Sie die Beobachtung aus, die Sie interessiert.
- Setzen Sie den Behandlungswert für diese Beobachtung auf 1 (oder Wahr).
- Vorhersage des Ergebnisses anhand des trainierten Modells.
- Wiederholen Sie die gleiche Beobachtung.
- Setzen Sie dieses Mal den Behandlungswert auf 0 (oder Falsch).
- Treffen Sie eine Vorhersage.
- Ziehen Sie den Vorhersagewert ohne Behandlung vom Vorhersagewert mit Behandlung ab.
T-Learner
Die Hauptmotivation von T-Learner ist die Überwindung der Hauptbeschränkung von S-Learner. Wenn der S-Learner lernen kann, die Behandlung zu ignorieren, warum sollte er es dann nicht unmöglich machen, sie zu ignorieren?
Das ist genau das, was T-Learner ist. Anstatt ein Modell auf alle Beobachtungen (behandelte und unbehandelte) anzuwenden, passen wir nun zwei Modelle an - eines nur für die behandelten Einheiten und eines nur für die unbehandelten Einheiten.
In gewisser Weise ist dies gleichbedeutend damit, dass der erste Split in einem baumbasierten Modell ein Split durch die Behandlungsvariable sein muss.
Der Lernprozess des T-Learner läuft folgendermaßen ab:
- Unterteile die Daten nach der Behandlungsvariable in zwei Teilmengen.
- Trainiere zwei Modelle - eines für jede Teilmenge.
- Sag für jede Beobachtung die Ergebnisse mit beiden Modellen voraus.
- Ziehe die Ergebnisse des Modells ohne Behandlung von den Ergebnissen des Modells mit Behandlung ab.
Es ist zu beachten, dass nun keine Möglichkeit mehr besteht, dass Behandlungen ignoriert werden, da wir den Behandlungssplit als zwei separate Modelle kodiert haben.
Der T-Learner konzentriert sich darauf, nur einen Aspekt zu verbessern, bei dem der S-Learner versagen kann (aber nicht muss). Diese Verbesserung ist mit Kosten verbunden. Die Anpassung von zwei Algorithmen an zwei verschiedene Teilmengen von Daten bedeutet, dass jeder Algorithmus auf weniger Daten trainiert wird, was die Qualität der Anpassung verringern kann.
Dadurch ist der T-Learner auch in Bezug auf die Datennutzung weniger effizient (wir benötigen doppelt so viele Daten, um jeden T-Learner-Basislerner zu trainieren und eine Darstellung zu erzeugen, die mit der Qualität des S-Learners vergleichbar ist). Dies führt in der Regel zu einer größeren Varianz der T-Learner-Punktzahl im Vergleich zur S-Learner-Punktzahl. Insbesondere kann die Varianz sehr groß werden, wenn eine Behandlungsgruppe viel weniger Beobachtungen hat als die andere.
Zusammenfassend lässt sich sagen, dass T-Learner nützlich sein kann, wenn man erwartet, dass der Behandlungseffekt gering ist, und S-Learner ihn möglicherweise nicht erkennt. Dabei ist zu beachten, dass dieser Meta-Learner im Allgemeinen datenintensiver ist als der S-Learner, aber der Unterschied nimmt mit zunehmender Gesamtgröße des Datensatzes ab.
X-Learner
X-Learner ist ein Meta-Learner, der die in den Daten vorhandenen Informationen effizienter nutzen soll.
X-Learner versucht, CATE direkt zu schätzen und verwendet dabei Informationen, die S-Learner und T-Learner zuvor verworfen haben. Um welche Art von Daten handelt es sich? S-Learner und T-Learner untersuchten die so genannte Response-Funktion, d. h. die Art und Weise, wie Einheiten auf eine Behandlung reagieren (mit anderen Worten: die Response-Funktion ist die Zuordnung von Merkmal X und Behandlung T zum Ergebnis y). Gleichzeitig wurde bei keinem der Modelle das tatsächliche Ergebnis zur Simulation von CATE verwendet.
- Der erste Schritt ist einfach, und Sie kennen ihn bereits. Das ist genau das, was wir mit T-Learner gemacht haben. Wir haben unsere Daten nach Behandlungsvariablen aufgeteilt, um zwei getrennte Teilmengen zu erhalten: die erste enthält nur die Einheiten, die die Behandlung erhalten haben, und die zweite nur die Einheiten, die die Behandlung nicht erhalten haben. Als Nächstes trainieren wir zwei Modelle: eines für jede Teilmenge.
- Wir führen ein zusätzliches Modell mit der Bezeichnung „Propensity-Score-Modell“ (Modell der Wahrscheinlichkeitsbewertung) ein - im einfachsten Fall handelt es sich um eine logistische Regression - und trainieren es, um die Behandlung für X Merkmale vorherzusagen.
- Anschließend berechnen wir den Behandlungseffekt und trainieren zwei Modelle auf den Merkmalen und CATE-Werten.
- Die Ergebnisse der beiden Modelle werden mit dem Gewicht addiert, das sich aus dem Propensity Score des Modells ergibt.
Wenn Ihr Datensatz jedoch sehr klein ist, ist X-Learner möglicherweise nicht die beste Wahl, da jedes zusätzliche Modell bei der Anpassung zusätzliches Rauschen mit sich bringt und wir möglicherweise nicht genügend Daten haben, um dieses Modell zu verwenden. In diesem Fall ist der S-Learner besser geeignet.
Es gibt auch fortgeschrittenere Meta-Lerner. Ich werde sie nicht verwenden, daher ist es wenig sinnvoll, sie in diesem kurzen Artikel zu erörtern. Dies sind „Debiased/orthogonal machine learning“ und „R-learner“, die Sie selbst studieren können.
Schlussfolgerung zu den vorhandenen Meta-Learner
Die vorgeschlagenen Algorithmen sind trotz eines recht umfangreichen theoretischen Teils nur Schätzer des CATE-Effekts. Die Literatur über Kausalschlüsse befasst sich kaum mit dem gesamten Zyklus der Entdeckung und Bewertung von Behandlungseffekten, es sei denn, es handelt sich um einige sehr offensichtliche Fälle, und auch die Umsetzung der daraus resultierenden Modelle in Geschäftsprozesse ist eher schwach. Es wird darauf hingewiesen, dass es dem Forscher obliegt, die Experimente zu formulieren und dann diese Schätzer zu verwenden. Ich beschloss, noch einen Schritt weiter zu gehen und Elemente dieser Schätzer in die Entwicklung eines Handelssystems einzubeziehen, das automatisch arbeitet. Der Algorithmus versucht dann, kausale Zusammenhänge in dem Teil der Daten zu erkennen, in dem dies möglich ist, und schließt den Rest aus der Logik der Handelsentscheidungen aus.
Implementierung der Meta-Lernfunktion zur Erstellung eines Handelsalgorithmus
Mit dem notwendigen Mindestmaß an Wissen ausgestattet, möchte ich nun meinen eigenen Algorithmus vorstellen. Es wurden viele Experimente mit verschiedenen Meta-Learner und Möglichkeiten, sie zur Analyse von kausalen Effekten zu nutzen, durchgeführt. Derzeit ist der vorgeschlagene Algorithmus einer der besten im Arsenal, obwohl er noch verbessert werden kann.
Da wir festgestellt haben, dass es nicht praktikabel ist, einen einzigen Klassifikator, der voreingenommen ist, zur Bewertung möglicher Ergebnisse zu verwenden, ist das erste Argument der Funktion eine bestimmte Anzahl von Klassifikatoren. Ich habe den CatBoost-Algorithmus verwendet. Als Nächstes folgen die Hyperparameter des Lerners, wie die Anzahl der Iterationen und die Baumtiefe, sowie der Anteil der schlechten Proben - ein Parameter, der bereits aus dem ersten Artikel über Meta-Learner bekannt ist. Dies ist der Prozentsatz der schlecht klassifizierten Beispiele, die aus der endgültigen Trainingsmenge ausgeschlossen werden sollten. Wir sollten versuchen, in diesen Momenten nicht zu handeln.
BAD_BUY und BAD_SELL sind Sammlungen von schlechten Beispielindizes, die bei jeder Iteration wieder aufgefüllt werden.
Bei jeder neuen Iteration, deren Anzahl gleich der angegebenen Anzahl der Lernenden ist, wird der Datensatz nach dem Zufallsprinzip in einem bestimmten Verhältnis (hier 50/50) in Trainings- und Validierungsteilstichproben aufgeteilt. Dadurch wird verhindert, dass jeder einzelne Algorithmus übertrainiert wird. Die zufällige Partitionierung ermöglicht es, jeden Klassifikator auf einzelnen Teilstichproben zu trainieren und zu validieren, während der gesamte Datensatz zur Erstellung von Schätzungen verwendet wird. Auf diese Weise werden Verzerrungen in den Schätzungen beseitigt, sodass wir genauer beurteilen können, welche Beispiele tatsächlich schlecht auf die Behandlung ansprechen (Klassifikatortraining).
Nach jedem Training werden die tatsächlichen Klassenbezeichnungen mit den vorhergesagten verglichen. Die falsch vorhergesagten Bezeichnungen werden in die Sammlung der schlechten Beispiele aufgenommen. Wir hoffen, dass mit zunehmender Anzahl von Klassifikatoren die Schätzungen der wirklich schlechten Proben weniger verzerrt werden.
Nachdem die Sammlungen von schlechten Beispielen gebildet wurden, berechnen wir die durchschnittliche Anzahl von schlechten Beispielen über alle Indizes hinweg. Danach wählen wir diejenigen Indizes aus, bei denen die Anzahl der schlechten Beispiele den Durchschnitt um einen bestimmten Betrag übersteigt. Auf diese Weise können wir die Anzahl der schlechten Beispiele, die in das Training des endgültigen Modells einfließen, variieren, da bei einer großen Anzahl von Retrainings die Wahrscheinlichkeit besteht, dass jeder Index mindestens einmal in schlechte Beispiele fällt. In diesem Fall stellt sich heraus, dass alle Beispiele aus der endgültigen Trainingsmenge ausgeschlossen werden, sodass dieser Algorithmus nicht funktionieren wird.
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float): dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] BAD_BUY = pd.DatetimeIndex([]) BAD_SELL = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_b = coreset[coreset['labels']==0] coreset_s = coreset[coreset['labels']==1] diff_negatives_b = coreset_b['labels'] != coreset_b['labels_pred'] diff_negatives_s = coreset_s['labels'] != coreset_s['labels_pred'] BAD_BUY = BAD_BUY.append(diff_negatives_b[diff_negatives_b == True].index) BAD_SELL = BAD_SELL.append(diff_negatives_s[diff_negatives_s == True].index) to_mark_b = BAD_BUY.value_counts() to_mark_s = BAD_SELL.value_counts() marked_idx_b = to_mark_b[to_mark_b > to_mark_b.mean() * bad_samples_fraction].index marked_idx_s = to_mark_s[to_mark_s > to_mark_s.mean() * bad_samples_fraction].index data.loc[data.index.isin(marked_idx_b), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_s), 'meta_labels'] = 0.0 return data[data.columns[1:]]
Die übrigen Funktionen wurden nicht geändert und sind im vorherigen Artikel beschrieben. Sie können sie dort herunterladen, wobei die Meta-Lernfunktion durch die vorgeschlagene ersetzt werden kann. Im weiteren Verlauf dieses Artikels werden wir uns auf die Experimente konzentrieren und versuchen, endgültige Schlussfolgerungen zu ziehen.
Testen des Algorithmus für kausale Schlussfolgerungen
Nehmen wir an, dass wir eine genetische Optimierung der Handelsstrategien nach einem Kriterium (der so genannten Fitnessfunktion) vornehmen. Wir sind nicht nur an dem besten Optimierungsergebnis interessiert, sondern auch daran, dass die Ergebnisse aller Durchgänge im Durchschnitt gut sind. Wenn die Handelsstrategie schlecht ist oder die Streuung der Parameter zu groß ist, wird es eine große Anzahl von Optimierungsdurchläufen mit unbefriedigenden Ergebnissen geben, was sich negativ auf die durchschnittliche Schätzung auswirkt. Um dies zu vermeiden, werden wir unseren Algorithmus mehrmals trainieren, dann den Durchschnitt der Ergebnisse ermitteln und das beste Ergebnis mit dem Durchschnitt vergleichen.
Zu diesem Zweck habe ich eine Modifikation eines nutzerdefinierten Testers geschrieben, der alle trainierten Modelle aus der Liste auf einmal testet:
def test_all_models(result: list): pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] pr_tst['labels'] = 0.5 pr_tst['meta_labels'] = 0.5 for i in range(len(result)): pr_tst['labels'] += result[i][1].predict_proba(X)[:,1] pr_tst['meta_labels'] += result[i][2].predict_proba(X)[:,1] pr_tst['labels'] = pr_tst['labels'] / (len(result)+1) pr_tst['meta_labels'] = pr_tst['meta_labels'] / (len(result)+1) pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(pr_tst, plot=plt)
Nun werden wir 25 Mal kausale Schlüsse ziehen (wir werden 25 unabhängige Modelle trainieren, die in Bezug auf die zufällige Aufteilung in Teilstichproben stark randomisiert sind):
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learners(15, 25, 2, 0.3)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
test_all_models(options) Testen wir zunächst das beste Modell nach der R^2-Version:
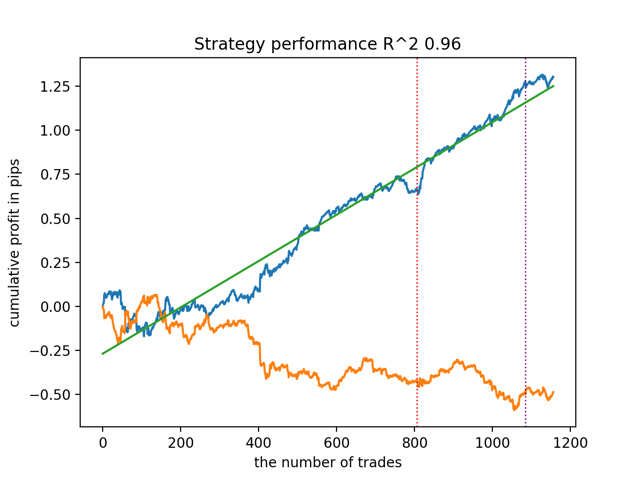
Dann testen wir alle Modelle auf einmal:
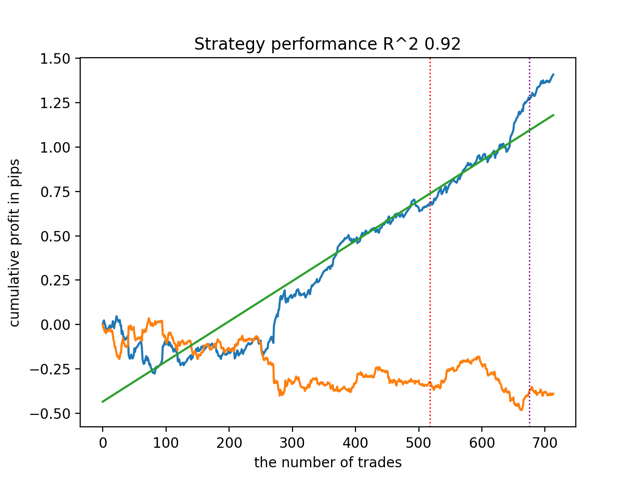
Das durchschnittliche Ergebnis unterscheidet sich nicht wesentlich von dem besten. Dies bedeutet, dass es im Rahmen eines kontrollierten, randomisierten Experiments möglich ist, sich wahren kausalen Beziehungen anzunähern.
Lassen Sie uns den Algorithmus mit anderen Eingabeparametern des Meta-Learners trainieren und testen.
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learners(5, 10, 1, 0.4)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
test_all_models(options) Die Ergebnisse sind wie folgt:
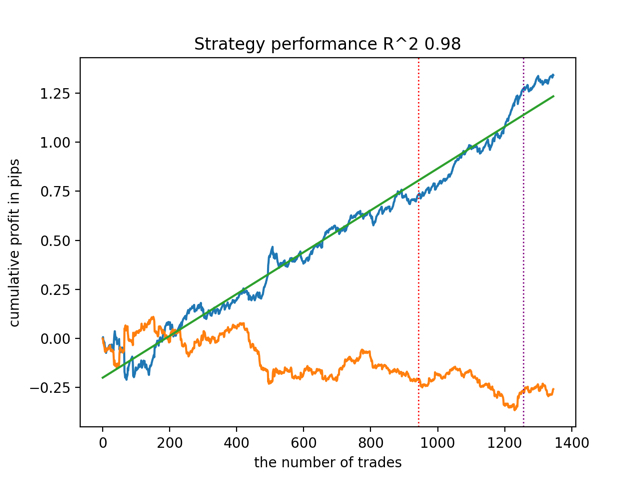
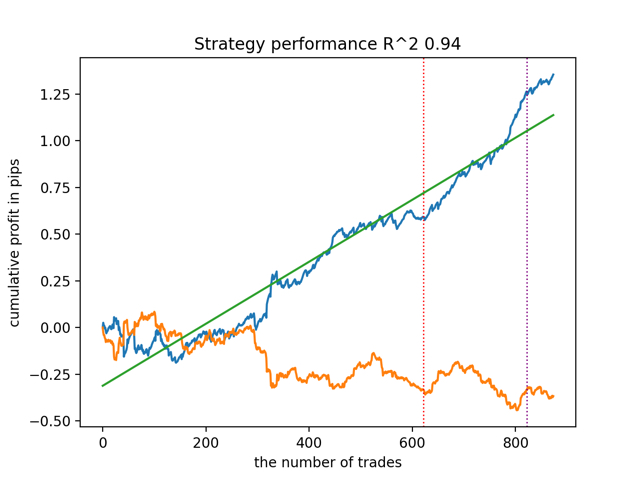
Es wurde auch festgestellt, dass die Tiefe der Trainingsgeschichte (hervorgehoben durch vertikale Linien in den Diagrammen) die Qualität der Ergebnisse beeinflusst, ebenso wie die Anzahl der Merkmale und andere Hyperparameter der Modelle (was im Allgemeinen nicht überraschend ist), während die Streuung der Qualität der Modelle gering bleibt. Ich glaube, dass die daraus resultierende Stabilität eine wichtige Eigenschaft oder ein wichtiges Merkmal des vorgeschlagenen Algorithmus ist, das uns zusätzliches Vertrauen in die Qualität der resultierenden Handelsstrategien gibt.
Zusammenfassung
In diesem Artikel wurden Sie mit den grundlegenden Konzepten des Kausalschlusses vertraut gemacht. Dies ist ein ziemlich umfangreiches und komplexes Thema, das in einem Artikel nicht in all seinen Aspekten behandelt werden kann. Kausalschlüsse und kausales Denken haben ihre Wurzeln in der Philosophie und Psychologie und spielen eine wichtige Rolle für unser Verständnis der Realität. Daher wird vieles von dem, was geschrieben wird, auf einer intuitiven Ebene gut wahrgenommen. Da ich jedoch nicht ganz unvoreingenommen bin, habe ich versucht, ein praktisches, anschauliches Beispiel zu geben, um die Leistungsfähigkeit der so genannten kausalen Inferenz bei Problemen der Zeitreihenklassifizierung zu demonstrieren. Mit diesem Algorithmus können Sie verschiedene Experimente durchführen. Ersetzen Sie einfach ein paar Funktionen in dem im vorherigen Artikel vorgestellten Code. Die Experimente sind damit noch nicht zu Ende. Vielleicht werden neue interessante Informationen auftauchen, die ich später mit Ihnen teilen werde.
Nützliche Hinweise
- Aleksander Molak "Causal inference and discovery in Python"
- Matheus Facure "Causal inference for the Brave and True"
- Miguel A. Hernan, James M. Robins "Causal inference: What If"
- Gabriel Okasa "Meta-learners for estimation of causal effects: finite sample cross-fit performance"
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13957
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich habe gemerkt, dass es nicht im Text des Artikels steht, es ist nur eine Abkürzung ohne Entschlüsselung).
Nun, oben über der Gleichung steht, dass es für die Behandelten ist. Im Allgemeinen wird der Schwerpunkt ein wenig auf die andere Seite verlagert, deshalb habe ich es nicht beschrieben) Konkret, wie man diese Wissenschaft mit seltsamen medizinischen Definitionen an die Blutdruckanalyse anpassen kann
Es ist schwer zu adaptieren. Reihen - Patienten ist schwer. Nur zum Teil, aber der Unterschied der Eigenschaften ist groß genug, um semantische Übertragungen ohne Erklärungen vorzunehmen)))))
Außerdem, wie ich schon schrieb, ist dies kein explizit verstandener Zusammenhang, sondern einer, der durch Experimente gefunden und nicht verstanden wurde. Ich würde quasi kausale Inferenz für Ehrlichkeit hinzufügen.Es ist schwierig, sich anzupassen. Zeilen - Patienten sind schwierig. Nur in Teilen, aber der Unterschied der Eigenschaften ist groß genug, um semantische Übertragungen ohne Erklärungen zu machen)))))
Außerdem handelt es sich, wie ich bereits schrieb, nicht um einen explizit verstandenen Zusammenhang, sondern um einen, der durch Experimente gefunden und nicht verstanden wurde. Ich würde quasi kausale Inferenz für Ehrlichkeit hinzufügen.Aus irgendeinem Grund ist die Datei nicht an den Artikel angehängt, wahrscheinlich wurde die falsche Version des Entwurfs veröffentlicht.
Ich habe die Quelle beigefügt.
Aus irgendeinem Grund wurde die Datei nicht an den Artikel angehängt, ich vermute, dass die falsche Version des Entwurfs veröffentlicht wurde.
Ich habe die Quelle beigefügt.
Er wurde am 30. Januar veröffentlicht. Hinzugefügt