
O escore de propensão na inferência causalidade

Introdução
Continuamos nossa imersão no mundo da inferência causal e suas ferramentas modernas. É claro que a tarefa é um pouco mais ampla - o uso de métodos de inferência causal na negociação. Já começamos estudando os fundamentos e até escrevemos nossos primeiros meta learners, que, a propósito, se mostraram bastante robustos. Ou melhor, os modelos que foram obtidos com a ajuda deles se mostraram robustos. Vale mencionar que eles foram os primeiros apenas para o leitor, já que são apenas mais um experimento para o escritor. Portanto, não há como voltar atrás e teremos que ir até o fim até que todo o tópico de inferência causal na negociação seja coberto. Afinal, as abordagens para a inferência causal podem ser diferentes, e eu gostaria de cobrir este tema interessante o mais amplamente possível.
Neste artigo, abordarei o tema de pareamento mencionado brevemente no artigo anterior, ou melhor, uma de suas variedades - pareamento por escore de propensão.
Isso é importante porque temos um determinado conjunto de dados rotulados que é heterogêneo. Por exemplo, no Forex, cada exemplo individual de treinamento pode pertencer à área de alta ou baixa volatilidade. Além disso, alguns exemplos podem aparecer mais frequentemente na amostra, enquanto outros aparecem com menos frequência. Ao tentar determinar o efeito causal médio (ATE) em uma amostra assim, inevitavelmente encontraremos estimativas enviesadas se assumirmos que todos os exemplos na amostra têm a mesma propensão para produzir tratamento. Ao tentar obter um efeito médio de tratamento condicional (CATE), podemos encontrar um problema chamado "maldição da dimensionalidade".
O pareamento é uma família de métodos para estimar efeitos causais ao parear observações (ou unidades) semelhantes nos grupos de tratamento e controle. O objetivo do pareamento é fazer comparações entre unidades semelhantes para obter uma estimativa o mais precisa possível do verdadeiro efeito causal.
Alguns autores da literatura de inferência causal sugerem que o pareamento deve ser considerado uma etapa de pré-processamento de dados sobre a qual qualquer estimador (por exemplo, meta learner) pode ser usado. Se tivermos dados suficientes para descartar potencialmente algumas observações, usar o pareamento como uma etapa de pré-processamento geralmente é útil.
Imagine que você tem um conjunto de dados para analisar. Esses dados contêm 1000 observações. Quais são as chances de você encontrar pelo menos uma correspondência exata para cada linha se você tiver 18 variáveis em seu conjunto de dados? A resposta obviamente depende de vários fatores. Quantas variáveis são binárias? Quantas delas são contínuas? Quantas delas são categóricas? Quantos níveis as variáveis categóricas têm? As variáveis são independentes ou correlacionadas entre si?
Aleksander Molak dá um bom exemplo visual em seu livro "Causal inference and discovery in Python".
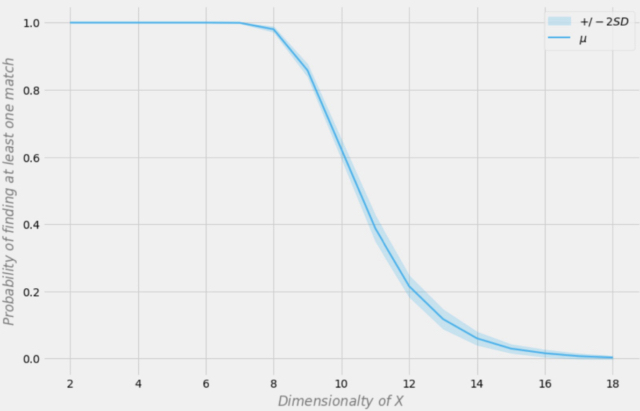
Probabilidade de encontrar uma correspondência exata dependendo da dimensão do conjunto de dados
Vamos supor que nossa amostra tenha 1000 observações. Na figura acima, o eixo X representa a dimensão do conjunto de dados (o número de variáveis no conjunto de dados), e o eixo Y representa a probabilidade de encontrar pelo menos uma correspondência exata em cada linha.
A linha azul é a probabilidade média e as áreas sombreadas representam +/- dois desvios padrão. O conjunto de dados foi gerado usando distribuições de Bernoulli independentes com p = 0,5. Portanto, cada variável é binária e independente.
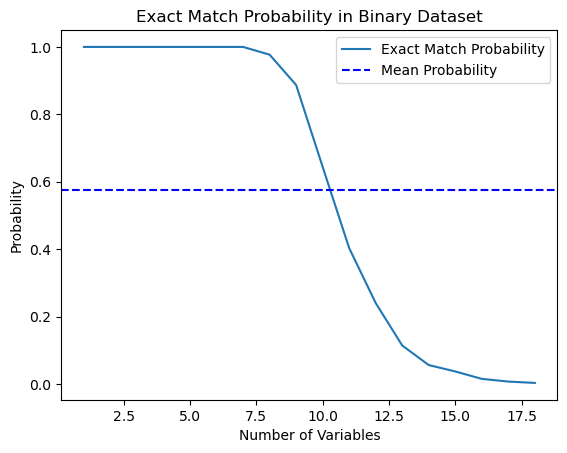
Eu decidi testar essa afirmação do livro e escrevi um script em Python que calcula essa probabilidade.
import numpy as np import matplotlib.pyplot as plt def calculate_exact_match_probability(dimensions): num_samples = 1000 num_trials = 1000 match_count = 0 for _ in range(num_trials): dataset = np.random.randint(2, size=(num_samples, dimensions)) row_sums = np.sum(dataset, axis=1) if any(row_sums == dimensions): match_count += 1 return match_count / num_trials def plot_probability_curve(max_dimensions): dimensions_range = list(range(1, max_dimensions + 1)) probabilities = [calculate_exact_match_probability(dim) for dim in dimensions_range] mean_probability = np.mean(probabilities) std_dev = np.std(probabilities) plt.plot(dimensions_range, probabilities, label='Exact Match Probability') plt.axhline(mean_probability, color='blue', linestyle='--', label='Mean Probability') plt.xlabel('Number of Variables') plt.ylabel('Probability') plt.title('Exact Match Probability in Binary Dataset') plt.legend() plt.show()
De fato, para 1000 observações, as probabilidades coincidiram. Como experimento, você pode calculá-las para as dimensões de seus próprios conjuntos de dados. Para nosso trabalho futuro, é suficiente entender que, se houver muitas características (covariáveis) nos dados em comparação com o número de exemplos de treinamento, então a capacidade de generalizar tais dados através do classificador será limitada. Quanto maior a quantidade de dados, mais precisas serão as estimativas estatísticas.
*Na prática real, isso nem sempre é o caso, pois a condição i.i.d (independentemente e identicamente distribuída) deve ser atendida.
Como você pode ver, a probabilidade de encontrar uma correspondência exata em um conjunto de dados binário aleatório de 18 dimensões é essencialmente zero. No mundo real, raramente trabalhamos com conjuntos de dados puramente binários, e para dados contínuos, o mapeamento multidimensional se torna ainda mais difícil. Isso apresenta um problema sério para a correspondência, mesmo no caso aproximado. Como podemos resolver esse problema?
Reduzindo a dimensionalidade dos dados usando a pontuação de propensão
Podemos resolver o problema da maldição da dimensionalidade usando a pontuação de propensão. As pontuações de propensão são estimativas da probabilidade de que uma determinada unidade seja atribuída ao grupo experimental com base em suas características. De acordo com o teorema da pontuação de propensão (Rosenbaum e Rubin, 1983), se tivermos dados não confundidos para a característica X, também teremos não confundimento dado a pontuação de propensão, assumindo positividade. Positividade significa que as distribuições tratadas e não tratadas devem se sobrepor. Esta é a suposição de positividade da inferência causal. Isso também faz sentido intuitivo. Se o grupo de teste e o grupo de controle não se sobrepõem, isso significa que eles são muito diferentes e não podemos extrapolar o efeito de um grupo para o outro. Essa extrapolação não é impossível (a regressão a faz), mas é muito perigosa. Isso é semelhante a testar um novo medicamento em um experimento onde apenas homens recebem o tratamento e, em seguida, assumir que as mulheres responderão igualmente bem a ele. Formalmente, a pontuação de propensão é escrita da seguinte forma:
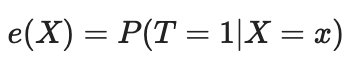
Em um mundo perfeito, teríamos uma pontuação de propensão verdadeira. No entanto, na prática, o mecanismo para atribuir o tratamento é desconhecido, e precisamos substituir a predisposição verdadeira por sua avaliação ou expectativa. Uma maneira comum de fazer isso é usar a regressão logística, mas outras técnicas de aprendizado de máquina, como o gradient boosting, podem ser usadas (embora isso exija alguns passos adicionais para evitar overfitting).
Podemos usar essa equação para resolver o problema da multidimensionalidade. As pontuações de propensão são univariadas, e assim agora podemos apenas combinar dois valores em vez de vetores multivariados.
Assim, se tivermos a independência condicional dos resultados potenciais do tratamento,
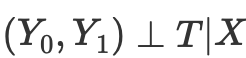
então podemos calcular o efeito causal médio para casos contínuos e discretos ao combinar sem pontuação de propensão:
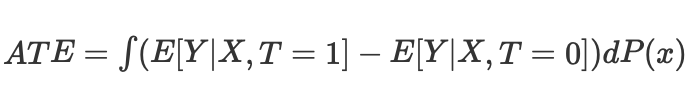
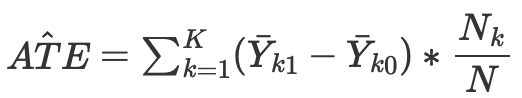
onde Nk é o número de observações em cada célula. Uma célula é um subgrupo de observações combinadas por alguma métrica de proximidade.
No entanto, a pontuação de propensão surge da realização de que não precisamos controlar diretamente os fatores de confusão X para alcançar a independência condicional.
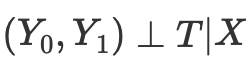
Em vez disso, é suficiente controlar o indicador de balanceamento
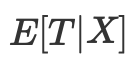
A pontuação de propensão permite que se seja independente de X como um todo para garantir que os resultados potenciais sejam independentes do tratamento. É suficiente condicionar nesta única variável, que é a pontuação de propensão:
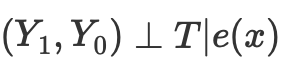
As fontes sobre inferência causal descrevem uma série de problemas com essa abordagem:
- Primeiro, as pontuações de propensão reduzem a dimensionalidade de nossos dados e, por definição, nos obrigam a descartar algumas informações.
- Segundo, duas observações que são muito diferentes no espaço de características original podem ter a mesma pontuação de propensão. Isso pode levar a correspondências de observações muito diferentes e, portanto, enviesar os resultados.
- Terceiro, o PSM (modelagem de pontuação de propensão) leva a um paradoxo. No caso binário, a pontuação de propensão ideal seria 0,5. O que acontece em um cenário perfeito onde todas as observações têm uma pontuação de propensão ideal de 0,5? A posição de cada observação no espaço de pontuação de propensão se torna idêntica a todas as outras observações. Isso às vezes é chamado de paradoxo do PSM.
Correspondência de pontuação de propensão e métodos relacionados
Existem vários métodos para corresponder unidades com base na pontuação de propensão. O principal método é considerado o método dos vizinhos mais próximos, que corresponde cada unidade i no grupo experimental com a unidade j no grupo de controle com a menor distância absoluta entre suas pontuações de propensão, expressa como
d(i, j) = minj{|e(Xi) – e(Xj)|}.
Alternativamente, a correspondência de limiar corresponde cada unidade i no grupo de tratamento com a unidade j no grupo de controle dentro de um limiar b pré-especificado, que é
d(i, j) = minj{|e(Xi) – e(Xj)| <b}.
Recomenda-se que o limiar b pré-especificado seja menor ou igual a 0,25 desvios padrão das pontuações de propensão. Outros pesquisadores argumentam que b = 0,20 do desvio padrão das pontuações de propensão é o ideal.
Outra opção de correspondência de limiar é a correspondência de raio, que é uma correspondência um-para-muitos e corresponde cada unidade i no grupo de tratamento com várias unidades no grupo de controle dentro do intervalo b predefinido; que é
d(i, j) = {|e(Xi) – e(Xj)| <b}.
Outros métodos de correspondência de pontuação de propensão incluem a métrica de Mahalanobis. Na correspondência usando a métrica de Mahalanobis, cada unidade i no grupo experimental é correspondida com a unidade j no grupo de controle, com a menor distância de Mahalanobis calculada com base na proximidade das variáveis.
Os métodos de correspondência de pontuação de propensão discutidos até agora podem ser implementados usando um algoritmo de correspondência ganancioso ou um algoritmo de correspondência ótima.
- Na correspondência gananciosa, uma vez que a correspondência é feita, as unidades correspondidas não podem ser alteradas. Cada par de unidades correspondidas é o melhor par atualmente disponível.
- Com a correspondência ótima, as unidades correspondidas anteriormente podem ser modificadas antes de realizar a correspondência atual para alcançar uma distância mínima ou ótima geral.
- Ambos os algoritmos de correspondência geralmente produzem os mesmos dados de correspondência quando o tamanho do grupo de controle é grande. No entanto, a correspondência ótima resulta em distâncias totais menores dentro das unidades correspondidas. Assim, se o objetivo for simplesmente encontrar grupos bem correspondidos, a correspondência gananciosa pode ser suficiente. Se o objetivo for, em vez disso, encontrar pares bem correspondidos, então a correspondência ótima pode ser preferível.
Existem métodos associados à correspondência de pontuação de propensão que não correspondem estritamente a unidades de amostragem individuais. Por exemplo, a subclassificação (ou estratificação) classifica todas as unidades na amostra inteira em várias estratificações com base no número correspondente de percentis de pontuação de propensão e corresponde as unidades por estratificação. Cinco estratificações foram observadas para eliminar até 90% do viés de seleção.
Um tipo especial de subclassificação é a correspondência completa, na qual subclasses são criadas de maneira ideal. Uma amostra completamente correspondida consiste em subconjuntos correspondidos, nos quais cada conjunto correspondido contém uma unidade experimental e uma ou mais unidades de controle, ou uma unidade de controle e uma ou mais unidades experimentais. A correspondência completa é ideal em termos de minimizar a média ponderada da medida de distância estimada entre cada sujeito de tratamento e cada sujeito de controle em cada subclasse.
Outro método associado à correspondência de pontuação de propensão é a correspondência de kernel (ou correspondência linear local), que combina correspondência e análise de resultados em um único procedimento com correspondência um-para-todos.
Apesar da variedade de métodos de comparação propostos, a eficiência de sua aplicação depende mais da formulação correta do problema do que de um método específico.
Forte suposição de negligência
"Negligência forte" é uma suposição crucial na construção da pontuação de propensão, que visa estimar efeitos causais em observações onde a atribuição de tratamento é aleatória. Essencialmente, isso significa que a atribuição de tratamento é independente dos resultados potenciais, dadas as covariáveis de linha de base observadas (características).
Vamos dar uma olhada mais de perto:
- Distribuição de tratamento: Isso é se uma unidade recebe tratamento ou não (como tomar um novo medicamento ou participar de um programa).
- Resultados potenciais: Estes são os resultados que uma unidade experimentaria nas condições de tratamento e controle, mas só podemos observar um para cada unidade.
- Covariáveis de linha de base: Estas são características da unidade medidas antes da alocação do tratamento que podem influenciar tanto a probabilidade de receber tratamento quanto o resultado.
A suposição "fortemente ignorável" afirma que:
- Não há fatores de confusão não medidos: Não existem variáveis não observadas que influenciem tanto a alocação do tratamento quanto o resultado. Isso é importante porque fatores de confusão não observados podem enviesar o efeito do tratamento estimado.
- Positividade: Cada unidade tem uma probabilidade diferente de zero de receber tanto o tratamento quanto o controle, dadas suas covariáveis observadas. Isso garante que haja unidades suficientes nos grupos sendo comparados para fazer comparações significativas.
Se essas condições forem atendidas, então condicionar na pontuação de propensão (a probabilidade estimada de receber tratamento dadas as covariáveis) produz estimativas não enviesadas do efeito médio do tratamento (ATE). O ATE representa a diferença média nos resultados entre os grupos de tratamento e controle como se o tratamento tivesse sido atribuído aleatoriamente.
Ponderação inversa da probabilidade
A ponderação inversa da probabilidade é uma das abordagens que implica a eliminação de ruído ou fatores de confusão, tentando reponderar observações em um conjunto de dados com base no inverso da probabilidade de atribuição de tratamento. A ideia é dar mais peso às observações que são consideradas menos propensas a serem tratadas, tornando-as mais representativas da população geral.
- Primeiro, uma pontuação de propensão é estimada, que é a probabilidade de receber tratamento dadas as covariáveis observadas.
- Uma pontuação de propensão inversa é calculada para cada observação.
- Cada observação é então multiplicada pelo seu peso correspondente. Isso significa que observações com menor probabilidade de receber o tratamento observado recebem mais peso.
- O conjunto de dados ponderado é então usado para análise. Pesos são aplicados tanto ao grupo de tratamento quanto ao grupo de controle, ajustando pela influência potencial das covariáveis observadas.
A ponderação inversa da probabilidade pode ajudar a equilibrar a distribuição das covariáveis entre os grupos de tratamento e controle, reduzindo o viés na estimativa dos efeitos causais. No entanto, baseia-se na suposição de que todas as variáveis de confusão relevantes são medidas e incluídas no modelo usado para estimar a pontuação de propensão. Além disso, como qualquer método estatístico, o sucesso do IPW depende da qualidade do modelo usado para estimar a pontuação de propensão.
A equação da pontuação de propensão inversa é a seguinte:
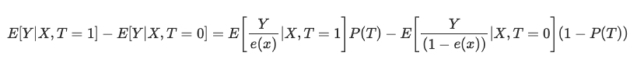
Sem entrar em detalhes, você pode comparar os dois termos da equação. O da esquerda é para o grupo de tratamento, enquanto o da direita é para o grupo de controle. A equação mostra que uma simples comparação de médias é equivalente a uma comparação de médias ponderadas inversamente. Isso cria uma população do mesmo tamanho que a original, mas na qual todos à esquerda recebem o tratamento. Pelos mesmos motivos, o lado direito considera os não tratados e dá um alto valor àqueles que se parecem com os tratados.
Avaliação dos resultados após a correspondência
Na inferência causal, a estimativa é construída como ATE ou CATE, ou seja, a diferença nas médias ponderadas (ajustadas pela pontuação de propensão) dos valores-alvo tratados e não tratados.
Uma vez que obtivemos a pontuação de propensão como e(x), podemos usar esses valores, por exemplo, para treinar outro classificador, em vez dos valores originais das características X. Também podemos comparar amostras pela sua pontuação de propensão para dividi-las em estratos. Outra opção é adicionar e(x) como uma característica separada ao treinar o avaliador final, o que ajudará a eliminar estimativas enviesadas devido à confusão, quando diferentes exemplos na amostra têm diferentes estimativas de acordo com a pontuação de propensão.
Estamos interessados em encontrar subgrupos que respondem bem ou mal ao tratamento (treinamento do modelo) e então treinar o classificador final apenas em dados que podem ser bem treinados (o erro de classificação é mínimo). Então, devemos colocar os dados mal classificados no segundo subgrupo e treinar o segundo classificador para distinguir entre esses dois subgrupos, ou seja, separar o trigo do joio, ou identificar subgrupos que são mais suscetíveis ao tratamento. Portanto, agora não adotaremos toda a metodologia de pontuação de propensão, mas corresponderemos as amostras de acordo com as probabilidades obtidas do classificador treinado, enquanto a avaliação geral do ATE (efeito médio do tratamento) nos interessa pouco.
Em outras palavras, basearemos nossa avaliação nos resultados do algoritmo rodando em novos dados que não participaram do treinamento. Além disso, ainda estamos interessados na velocidade média de um conjunto de modelos treinados em dados randomizados. Quanto maior a pontuação média dos modelos independentes, mais confiança teremos em cada modelo específico.
Avançando para os experimentos
Ao iniciar este artigo, estava ciente de que para muitos traders, especialmente aqueles que não estão familiarizados com aprendizado de máquina, este material aprofundado pode parecer muito contra-intuitivo. Lembrando-me do meu primeiro encontro com a inferência causal, essa falta de compreensão inicial feriu meu orgulho tanto que simplesmente não pude deixar de mergulhar nos detalhes. Além disso, eu nem podia imaginar que me daria a liberdade de adaptar técnicas de inferência causal para classificar séries temporais.
- propensity without matching.py file
Vamos começar com uma maneira de incorporar pontuações de propensão diretamente em nosso estimador, ou meta-aprendiz. Para fazer isso, precisamos treinar dois modelos. Primeiro, o próprio PSM (modelo de pontuação de propensão), que nos permitirá obter as probabilidades de atribuir exemplos de treinamento aos grupos de tratamento ou teste. Alimentaremos as probabilidades obtidas, juntamente com as características (covariáveis), como entrada para o segundo modelo, que preverá os resultados (comprar ou vender).
A intuição dessa abordagem é que o meta-aprendiz agora poderá distinguir subgrupos de amostras com base em sua tendência ao tratamento. Isso nos dará previsões ponderadas dos resultados que devem ser mais precisas. Depois disso, dividiremos o conjunto de dados em casos bem previsíveis e mal previsíveis, como foi o caso em artigos anteriores. Neste caso, não precisaremos de correspondência explícita de amostras porque o meta-aprendiz levará automaticamente em consideração a pontuação de propensão em suas estimativas. Essa abordagem parece bastante conveniente para mim, porque o aprendizado de máquina faz todo o trabalho para nós.
Primeiro, vamos criar subsamples 'train' e 'val' para treinar o meta-modelo. Como o meta-aprendiz será treinado na subsample de treinamento, criaremos um par de alvos y_T1, y_T0, e os preencheremos com uns e zeros. Isso corresponderá a se as unidades receberam tratamento (treinamento do modelo) ou não. Então, reorganizaremos a subseleção cujas variáveis-alvo são tratamentos.
X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # randomly assign treated and control y_T1 = pd.DataFrame(y_train) y_T1['T'] = 1 y_T1 = y_T1.drop(['labels'], axis=1) y_T0 = pd.DataFrame(y_val) y_T0['T'] = 0 y_T0 = y_T0.drop(['labels'], axis=1) y_TT = pd.concat([y_T1, y_T0]) y_TT = y_TT.sort_index() X_trainT, X_valT, y_trainT, y_valT = train_test_split( X, y_TT, train_size = 0.5, test_size = 0.5, shuffle = True)
O próximo passo é treinar o modelo PSM para prever se as amostras pertencem aos subgrupos de tratamento ou controle.
# fit propensity model PSM = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', use_best_model=True, early_stopping_rounds=15, verbose = False).fit(X_trainT, y_trainT, eval_set = (X_valT, y_valT), plot = False)
Em seguida, precisamos obter previsões de pertencimento aos grupos de tratamento e controle e adicioná-las às características do meta-aprendizado, e então treiná-lo.
# predict probabilities train_proba = PSM.predict_proba(X_train)[:, 1] val_proba = PSM.predict_proba(X_val)[:, 1] # fit meta-learner meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True, early_stopping_rounds=15).fit(X_train.assign(T=train_proba), y_train, eval_set = (X_val.assign(T=val_proba), y_val), plot = False)
Na etapa final, obteremos as previsões do meta-aprendizado, compararemos os rótulos previstos com os reais e preencheremos o livro de exemplos ruins.
# create daatset with predicted values predicted_PSM = PSM.predict_proba(X)[:,1] X_psm = X.assign(T=predicted_PSM) coreset = X.assign(T=predicted_PSM) coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X_psm)[:,1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_b = coreset[coreset['labels']==0] coreset_s = coreset[coreset['labels']==1] diff_negatives_b = coreset_b['labels'] != coreset_b['labels_pred'] diff_negatives_s = coreset_s['labels'] != coreset_s['labels_pred'] BAD_BUY = BAD_BUY.append(diff_negatives_b[diff_negatives_b == True].index) BAD_SELL = BAD_SELL.append(diff_negatives_s[diff_negatives_s == True].index)
Agora vamos tentar treinar 25 modelos e analisar os melhores resultados e os médios.
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res)) options.sort(key=lambda x: x[0]) test_model(options[-1][1:], plt=True) test_all_models(options)
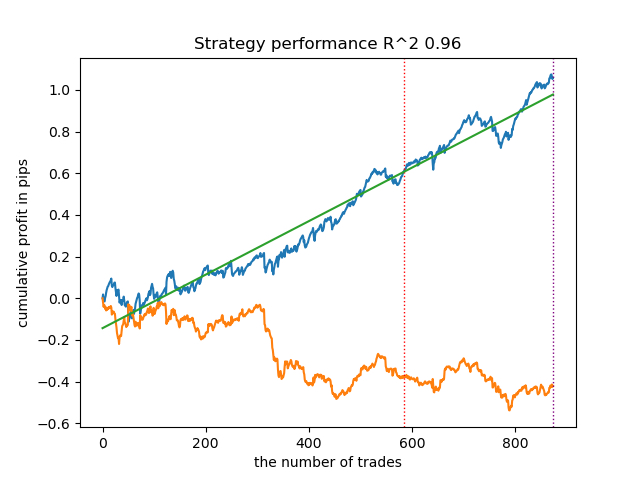
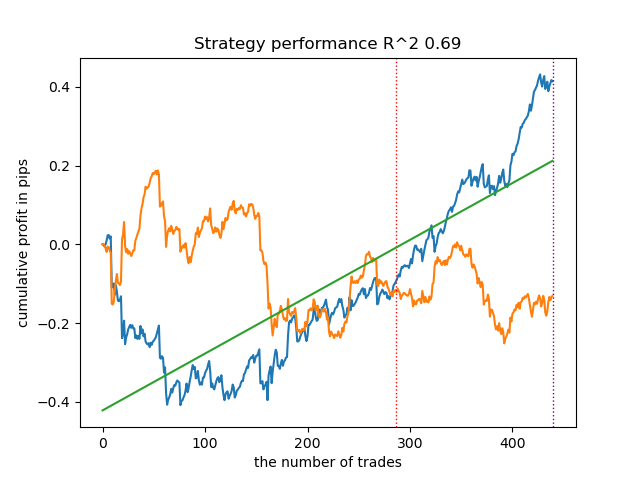
Conduzi uma série de tais treinamentos e concluí que essa abordagem não difere praticamente em nada na qualidade dos modelos da minha abordagem descrita no artigo anterior. Ambas as opções são capazes de gerar bons modelos que passam no OOS. Isso não deve nos surpreender, pois usamos e(x) como uma característica adicional, e o restante do algoritmo permaneceu inalterado.
- propensity matching naive.py file
Ao considerar métodos de implementação, nunca podemos saber de antemão qual método funcionará melhor. Como experimento, decidi fazer um pareamento não pela propensão a atribuir tratamento, mas pela propensão a prever rótulos-alvo. Isso deve parecer mais intuitivo para o leitor. A principal diferença aqui é que treinamos apenas um modelo PSM (convencionalmente nomeado). Em seguida, as probabilidades são previstas e uma lista de faixas é criada de acordo com o número de estratos em que queremos dividir as probabilidades obtidas. Para cada estrato, é contado o número de resultados corretamente/incorretamente previstos, após o qual, para estratos onde o número de exemplos incorretamente previstos (multiplicado por uma razão) excede o número de corretamente previstos, a condição para adicionar exemplos ruins ao livro de exemplos ruins é acionada.
bins = np.linspace(lower_bound, upper_bound, num=bins_number) coreset['bin'] = pd.cut(coreset['propensity'], bins) for val in range(len(coreset['bin'].unique())): values = coreset.loc[coreset['bin'] == coreset['bin'].unique()[val]] diff_negatives = values['labels'] != values['labels_pred'] if len(diff_negatives[diff_negatives == False]) < (len(diff_negatives[diff_negatives == True]) * coefficient): B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index)
Essa abordagem possui parâmetros adicionais:
- bins_number - número de faixas
- lower_bound - limite inferior de probabilidade a partir do qual os estratos são calculados
- upper_bound - limite superior de probabilidade até o qual os estratos são calculados
Como estamos usando um meta-aprendizado com pouca profundidade, as probabilidades geralmente se agrupam em torno de 0,5 e raramente atingem limites extremos. Portanto, podemos descartar valores extremos como não informativos definindo limites superior e inferior.
Vamos treinar 25 modelos e observar os resultados. Gostaria de observar que todos os modelos são treinados no mesmo conjunto de dados, portanto, sua comparação é bastante correta.
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5, bins_number=25, lower_bound=0.3, upper_bound=0.7, coefficient=1.0))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res)) options.sort(key=lambda x: x[0]) test_model(options[-1][1:], plt=True)
Surpreendentemente, essa implementação espontânea se saiu muito bem nos novos dados. Abaixo estão os gráficos de negociação para o melhor modelo e todos os 25 modelos de uma vez.
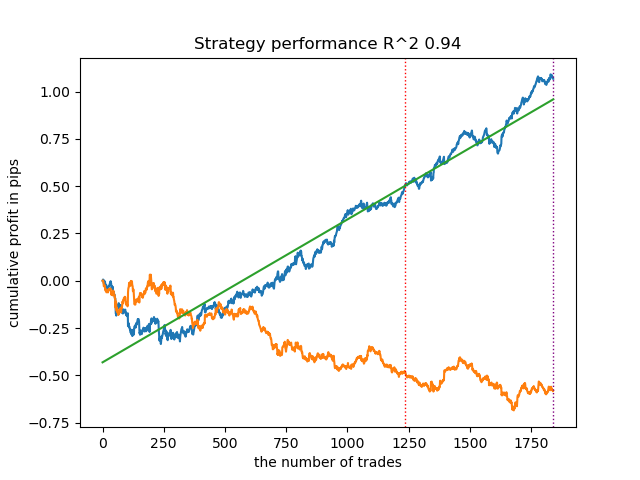
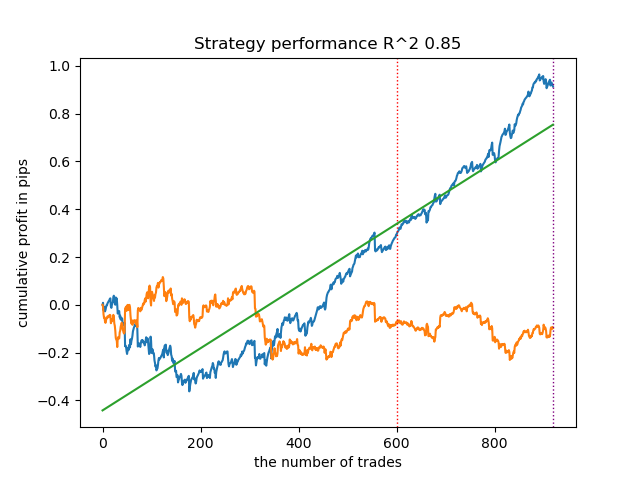
- propensity matching original.py file
Passamos para a implementação do exemplo mais próximo da teoria, em que a suposição de forte negligência (fortemente ignorável) é cumprida. Lembro que "fortemente ignorável" é quando a atribuição de tratamento não depende de maneira alguma dos resultados potenciais, o que significa que é completamente aleatória e não há variáveis não contabilizadas que influenciem o viés. Para isso, atribuímos aleatoriamente um tratamento e treinamos o modelo PSM. Em seguida, treinamos o meta-estimador para prever os resultados das negociações (rótulos de classe). Depois disso, estratificamos a amostra de acordo com o escore de propensão e adicionamos amostras ao livro de exemplos ruins apenas daqueles estratos em que o número de previsões mal-sucedidas excede o número de previsões bem-sucedidas, levando em conta a proporção.
Também adicionei a capacidade de usar IPW (ponderação inversa de probabilidade) descrita na parte teórica.
Após treinar dois classificadores, o seguinte código é executado.
# create daatset with predicted values coreset = X.copy() coreset['labels'] = y coreset['propensity'] = PSM.predict_proba(X)[:, 1] if Use_IPW: coreset['propensity'] = coreset['propensity'].apply(lambda x: 1 / x if x > 0.5 else 1 / (1 - x)) coreset['propensity'] = coreset['propensity'].round(3) coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) bins = np.linspace(lower_bound, upper_bound, num=bins_number) coreset['bin'] = pd.cut(coreset['propensity'], bins) for val in range(len(coreset['bin'].unique())): values = coreset.loc[coreset['bin'] == coreset['bin'].unique()[val]] diff_negatives = values['labels'] != values['labels_pred'] if len(diff_negatives[diff_negatives == False]) < (len(diff_negatives[diff_negatives == True]) * coefficient): B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index)
Vamos treinar 25 modelos sem usar IPW e observar o melhor gráfico de equilíbrio e o gráfico médio de todos os modelos, com as seguintes configurações:
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5, bins_number=25, lower_bound=0.3, upper_bound=0.7, coefficient=1.5, Use_IPW=False))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res))
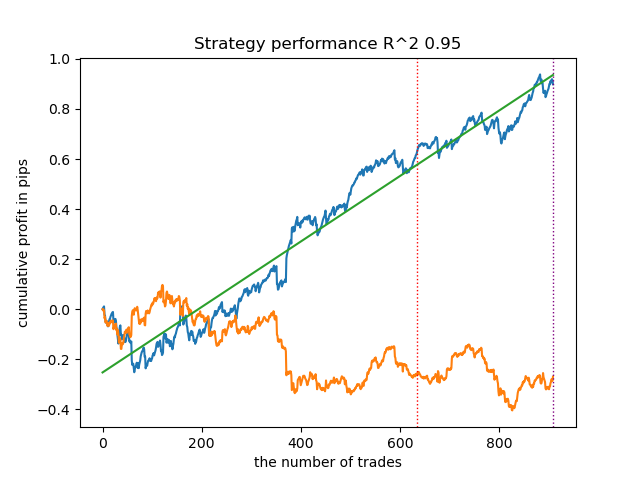
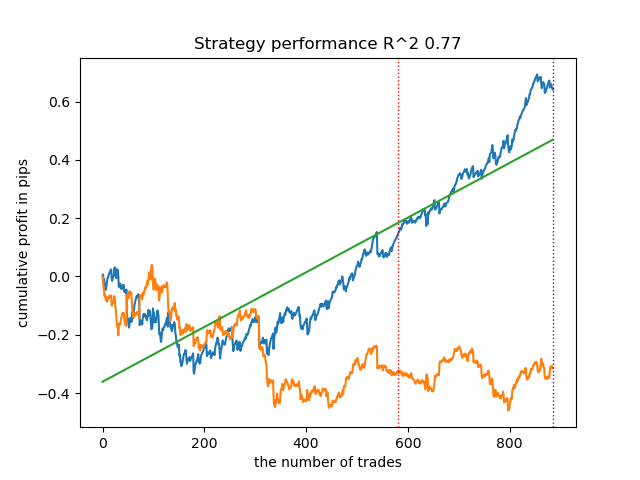
Em geral, os resultados são comparáveis aos resultados das implementações anteriores. Agora vamos fazer o mesmo com o IPW ativado.
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5, bins_number=25, lower_bound=0.1, upper_bound=10.0, coefficient=1.5, Use_IPW=True))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res))

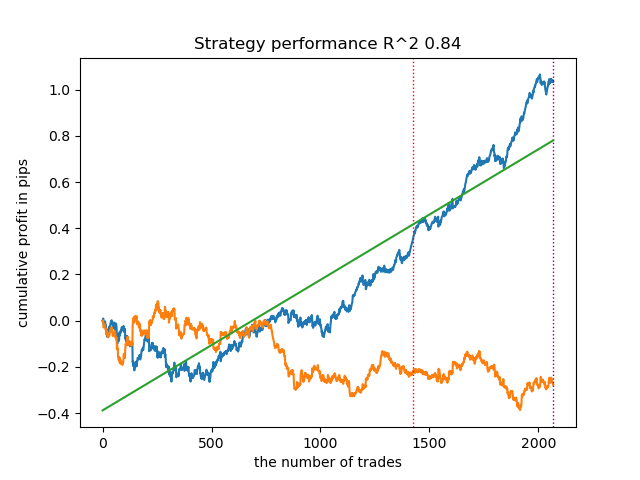
Os resultados se mostraram alguns dos melhores. Claro, para uma comparação mais detalhada, é necessário realizar múltiplos testes em diferentes símbolos, mas isso aumentaria o volume de um artigo já extenso. A tabela dos resultados obtidos é apresentada abaixo.
| Algoritmo | Melhor resultado | Resultado médio (25 modelos) |
|---|---|---|
| propensity without matching.py | 0.96 | 0.69 |
| propensity matching naive.py | 0.94 | 0.85 |
| propensity matching original.py | 0.95 | 0.77 |
| propensity matching original.py IPW | 0.97 | 0.84 |
Conclusão
Consideramos a possibilidade de usar o escore de propensão para o problema de classificar séries temporais financeiras. Essa abordagem tem uma boa justificativa teórica na área de inferência causal, mas também tem suas deficiências. Em geral, ela nos permitiu obter modelos que mantêm suas características em novos dados.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14360
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso