
Testador rápido de estratégias de trading em Python usando Numba

Por que um testador de estratégias próprio e rápido é importante
Ao desenvolver algoritmos de trading baseados em aprendizado de máquina, é importante avaliar corretamente e com rapidez os resultados históricos da estratégia. Se o testador for usado raramente, com intervalos de tempo grandes e com profundidade histórica limitada, o Python pode ser suficiente. No entanto, se a tarefa exige testes repetitivos, incluindo estratégias de alta frequência, a linguagem interpretada pode ser muito lenta.
Suponhamos que não estamos satisfeitos com a velocidade de execução de alguns scripts, mas não queremos abrir mão do ambiente de desenvolvimento familiar do Python. É aí que entra o Numba, que permite a tradução e a compilação instantânea de código Python nativo em código de máquina veloz, cuja velocidade de execução se aproxima à de linguagens como C e FORTRAN.
Descrição breve da biblioteca Numba
Numba é uma biblioteca para a linguagem Python, criada para acelerar a execução de código compilando funções no nível de bytecode para código de máquina usando compilação Just-In-Time (JIT). Essa tecnologia permite aumentar significativamente o desempenho dos cálculos, especialmente em aplicações científicas que envolvem o uso frequente de laços e operações matemáticas complexas. A biblioteca oferece suporte ao trabalho com arrays do NumPy e possibilita o uso eficiente de paralelismo e computação em GPU.
A forma mais comum de usar o Numba é aplicar seus decoradores em funções Python, para indicar à Numba que essas funções devem ser compiladas. Quando uma função decorada com Numba é chamada, ela é compilada em código de máquina “na hora”, permitindo que o código inteiro ou partes dele sejam executadas na velocidade de código de máquina nativo.
Atualmente, são suportadas as seguintes arquiteturas:
-
Sistemas operacionais: Windows (64 bits), OSX, Linux (64 bits).
-
Arquitetura: x86, x86_64, ppc64le, armv8l (aarch64), M1/Arm64.
-
GPUs: Nvidia CUDA.
-
CPython
-
NumPy 1.22 - 1.26
É importante observar que o pacote Pandas não é compatível com o Numba, e a manipulação de dataframes continuará com a mesma velocidade de execução.
Trabalhando com os códigos do artigo
Para que tudo funcione de imediato, faça as seguintes ações:
- instale todos os pacotes necessários;
pip install numpy pyp install pandas pip install catboost pip install scikit-learn pip install scipy
- baixe os dados EURGBP_H1.csv e coloque-os na pasta Files;
- baixe todos os scripts em Python e coloque-os em uma única pasta;
- ajuste a primeira linha do script Tester_ML.py para que fique assim: from tester_lib import test_model;
- indique o caminho do arquivo no script Tester_ML.py;
- p = pd.read_csv('C:/Program Files/MetaTrader 5/MQL5/Files/'EURGBP_H1'.csv', sep='\s+').
Como usar o pacote Numba?
No geral, o uso do pacote Numba se resume à sua instalação
pip install numba conda install numba
e à aplicação do decorador na função que desejamos acelerar, por exemplo:
@jit(nopython=True) def process_data(*args): ...
A chamada do decorador pode ser feita de duas formas diferentes.
- modo nopython
- modo object
A primeira forma compila a função decorada, de modo que ela funcione totalmente sem a participação do interpretador do Python. Essa é a forma mais rápida e recomendada para uso. No entanto, o Numba tem limitações: ele consegue compilar apenas operações internas do Python e operações sobre arrays do Numpy. Se a função usar objetos de outras bibliotecas, como o Pandas, o Numba não poderá compilar a função e o código será executado pelo interpretador.
Para contornar as limitações no uso de bibliotecas externas, o Numba pode usar o modo object. Nesse modo, o Numba compila a função assumindo que tudo é um objeto Python, e na prática executa o código pelo interpretador. A indicação
@jit(forceobj=true, looplift=True) pode melhorar o desempenho em comparação com o modo puramente baseado em objetos, já que o Numba tentará compilar os laços dentro da função para que sejam executados em código de máquina, enquanto o restante do código será executado pelo interpretador. Para obter melhor desempenho, evite usar o modo object sempre que possível!
Esse pacote também oferece suporte a cálculos paralelos, sempre que possível (Parallel=True). Observe que, na primeira chamada da função, ocorre a compilação para código de máquina, o que leva algum tempo. Depois disso, o código será armazenado em cache, e as chamadas subsequentes serão mais rápidas.
Exemplo de aceleração de uma função de anotação de negociações
Antes de começar a acelerar o testador, vamos tentar acelerar algo mais simples. Um ótimo candidato para isso é a função de anotação de negociações. Essa função recebe um dataframe com os preços e anota negociações de compra e venda (0 e 1). Funções desse tipo são frequentemente usadas para fazer a anotação preliminar dos dados, permitindo depois treinar um classificador.
def get_labels(dataset, min = 1, max = 15) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'].iloc[i] future_pr = dataset['close'].iloc[i + rand] if (future_pr + hyper_params['markup']) < curr_pr: labels.append(1.0) elif (future_pr - hyper_params['markup']) > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2.0].index) return dataset
Como dados, usamos os preços de fechamento minuto a minuto do par de moedas EURGBP ao longo de 15 anos:
>>> pr = get_prices() >>> pr close time 2010-01-04 00:00:00 0.88810 2010-01-04 00:01:00 0.88799 2010-01-04 00:02:00 0.88786 2010-01-04 00:03:00 0.88792 2010-01-04 00:04:00 0.88802 ... ... 2024-10-09 19:03:00 0.83723 2024-10-09 19:04:00 0.83720 2024-10-09 19:05:00 0.83704 2024-10-09 19:06:00 0.83702 2024-10-09 19:07:00 0.83703 [5480021 rows x 1 columns]
O dataset contém mais de cinco milhões de observações, o que é mais do que suficiente para testes.
Agora vamos medir a velocidade de execução dessa função com nossos dados:
# get labels test start_time = time.time() pr = get_labels(pr) pr['meta_labels'] = 1.0 end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
O tempo de execução foi de 74.1843 segundos.
Agora, vamos tentar acelerar essa função com o uso do pacote Numba. É visível que o pacote Pandas também está sendo utilizado na função original, e sabemos que esses dois pacotes não são compatíveis. Vamos separar tudo o que diz respeito ao Pandas em uma função distinta e acelerar o restante do código.
@jit(nopython=True) def get_labels_numba(close_prices, min_val, max_val, markup): labels = np.empty(len(close_prices) - max_val, dtype=np.float64) for i in range(len(close_prices) - max_val): rand = np.random.randint(min_val, max_val + 1) curr_pr = close_prices[i] future_pr = close_prices[i + rand] if (future_pr + markup) < curr_pr: labels[i] = 1.0 elif (future_pr - markup) > curr_pr: labels[i] = 0.0 else: labels[i] = 2.0 return labels def get_labels_fast(dataset, min_val=1, max_val=15): close_prices = dataset['close'].values markup = hyper_params['markup'] labels = get_labels_numba(close_prices, min_val, max_val, markup) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop(dataset[dataset.labels == 2.0].index) return dataset
Antes da primeira função, usamos o decorador @jit. Isso significa que essa função será compilada em bytecode. Também eliminamos o Pandas de seu escopo, utilizando apenas listas, laços e Numpy.
A segunda função faz a preparação. Ela converte o dataframe do Pandas em uma matriz Numpy e a envia para a primeira função. Em seguida, ela recupera o resultado e o converte de volta para um dataframe do Pandas. Assim, o cálculo principal da anotação será acelerado.
Agora medimos a velocidade. O tempo de cálculo caiu para 12 segundos! Para essa função, conseguimos uma aceleração superior a 5 vezes. Claro que esse não é um teste completamente limpo, pois o Pandas ainda é usado em cálculos intermediários, mas mesmo assim, conseguimos uma aceleração significativa na parte do cálculo das marcações.
Acelerando o testador de estratégias para tarefas de aprendizado de máquina
Separei o testador de estratégias em uma biblioteca própria, que pode ser encontrada no anexo do artigo. Lá existem duas funções, "tester" e "slow_tester", para fins de comparação.
O leitor pode levantar a objeção de que grande parte das acelerações em Python acontece por meio da vetorização. Isso é verdade, mas, às vezes, é necessário usar laços. Por exemplo, o testador possui um laço bastante complexo para percorrer todo o histórico e acumular o lucro total, considerando stop-loss e take-profit. Implementar isso por meio da vetorização não parece uma tarefa simples.O corpo do laço do testador (a parte que leva mais tempo para ser executada) é mostrado abaixo para fins de ilustração.
for i in range(dataset.shape[0]): line_f = len(report) if i <= forw else line_f line_b = len(report) if i <= backw else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 0 if pred < 0.5 else 1 continue if last_deal == 0: if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1: if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue
Vamos medir a velocidade de teste com os dados que utilizamos anteriormente. Primeiro, vejamos a velocidade do testador lento:
# native python tester test start_time = time.time() tester_slow(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['markup'], hyper_params['forward'], False) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Execution time: 6.8639 seconds Não parece tão lento, até dá para dizer que o interpretador executa o código de forma razoavelmente rápida.
Vamos novamente dividir a função do testador em duas partes. Uma será auxiliar, e a outra fará os cálculos principais.
O laço principal do testador está implementado na função process data e deve ser acelerado, pois os laços em Python são lentos. Ao mesmo tempo, a função tester prepara os dados para a função process data, recebe o resultado e realiza a plotagem do gráfico.
@jit(nopython=True) def process_data(close, labels, metalabels, stop, take, markup, forward, backward): last_deal = 2 last_price = 0.0 report = [0.0] chart = [0.0] line_f = 0 line_b = 0 for i in range(len(close)): line_f = len(report) if i <= forward else line_f line_b = len(report) if i <= backward else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 0 if pred < 0.5 else 1 continue if last_deal == 0: if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1: if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue return np.array(report), np.array(chart), line_f, line_b def tester(*args): ''' This is a fast strategy tester based on numba List of parameters: dataset: must contain first column as 'close' and last columns with "labels" and "meta_labels" stop: stop loss value take: take profit value forward: forward time interval backward: backward time interval markup: markup value plot: false/true ''' dataset, stop, take, forward, backward, markup, plot = args forw = dataset.index.get_indexer([forward], method='nearest')[0] backw = dataset.index.get_indexer([backward], method='nearest')[0] close = dataset['close'].to_numpy() labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() report, chart, line_f, line_b = process_data(close, labels, metalabels, stop, take, markup, forw, backw) y = report.reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = 1 if lr.coef_[0][0] >= 0 else -1 if plot: plt.plot(report) plt.plot(chart) plt.axvline(x=line_f, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x=line_b, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l, ".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
Agora vamos testar o testador de estratégias acelerado com o Numba:
start_time = time.time() tester(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], False) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
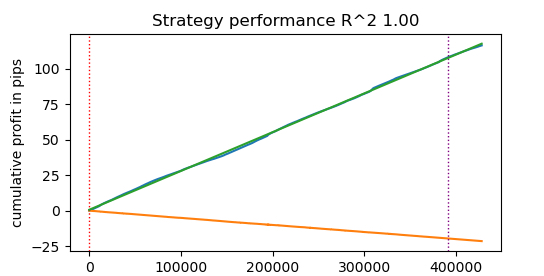
Execution time: 0.1470 seconds A velocidade aumentou quase 50 vezes! E mais de 400.000 negociações foram realizadas.
Imagine que, se você costumava gastar uma hora por dia testando seus algoritmos, com o testador rápido você levaria apenas um minuto.
Testando estratégias com dados de ticks
Vamos aumentar a complexidade e exportar do terminal o histórico de ticks dos últimos 3 anos em um arquivo .csv.
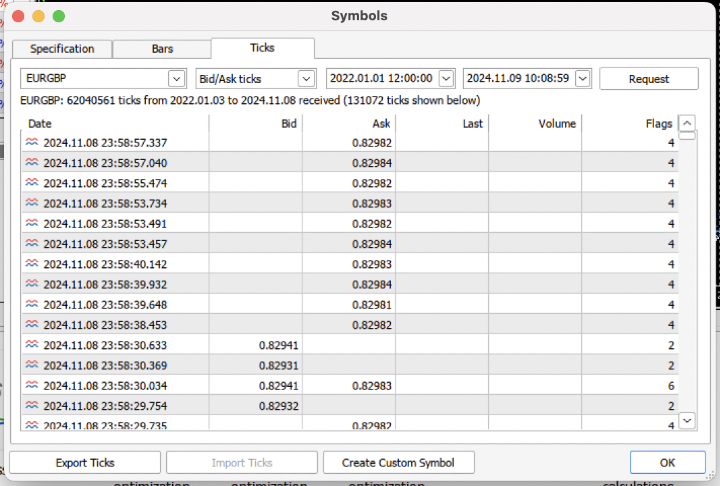
Para ler corretamente o arquivo, é necessário modificar um pouco a função de carregamento das cotações. Em vez dos preços de fechamento (Close), usaremos os preços de compra (Bid). Também é preciso remover os preços com índices duplicados.
def get_prices() -> pd.DataFrame: p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+') pFixed = pd.DataFrame(columns=['time', 'close']) pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>'] pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed') pFixed['close'] = p['<BID>'] pFixed.set_index('time', inplace=True) pFixed.index = pd.to_datetime(pFixed.index, unit='s') # Удаление повторяющихся строк по индексу 'time' pFixed = pFixed[~pFixed.index.duplicated(keep='first')] return pFixed.dropna()
Obtivemos quase 62 milhões de observações. Vale destacar que o testador espera preços na coluna chamada "close", por isso renomeamos os valores de Bid para Close.
>>> pr close time 2022-01-03 00:05:01.753 0.84000 2022-01-03 00:05:04.032 0.83892 2022-01-03 00:05:05.849 0.83918 2022-01-03 00:05:07.280 0.83977 2022-01-03 00:05:07.984 0.83939 ... ... 2024-11-08 23:58:53.491 0.82982 2024-11-08 23:58:53.734 0.82983 2024-11-08 23:58:55.474 0.82982 2024-11-08 23:58:57.040 0.82984 2024-11-08 23:58:57.337 0.82982 [61896607 rows x 1 columns]
Executamos a anotação rápida e medimos o tempo de execução.
# get labels test start_time = time.time() pr = get_labels_fast(pr) pr['meta_labels'] = 1.0 end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
O tempo de anotação foi de 9.5 segundos.
Agora executamos o testador rápido.
# numba tester test start_time = time.time() tester(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], True) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
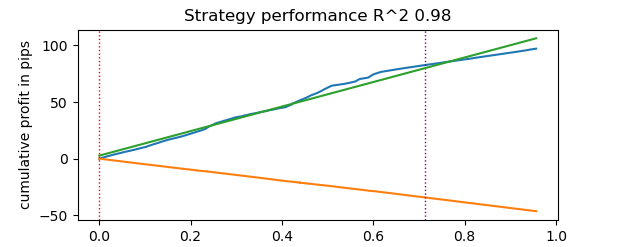
O tempo de teste foi de 0.16 segundos. Enquanto o testador lento levou 5.5 segundos.
O testador rápido com o Numba foi 35 vezes mais rápido do que o testador em Python puro. Na prática, para o observador, o teste com o testador rápido é instantâneo, enquanto com o testador lento há uma pausa perceptível. Ainda assim, o testador lento faz um bom trabalho e é perfeitamente utilizável para testar estratégias mesmo com dados de ticks.
No total, foram realizadas 1e6, ou um milhão de negociações.
Informações sobre o uso do testador rápido em tarefas de aprendizado de máquina
Se você realmente pretende usar o testador proposto, as informações a seguir podem ser úteis.
Vamos adicionar características ao nosso dataset para que possamos treinar um classificador.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC-pFixedC.rolling(i).mean() count += 1 return pFixed.dropna()
Essas são características simples, baseadas em diferenças de preços e médias móveis.
Depois, criamos um dicionário com hiperparâmetros do modelo, que serão utilizados durante o treinamento e o teste. E, com isso, geramos um novo dataset.
hyper_params = {
'symbol': 'EURGBP_H1',
'markup': 0.00010,
'stop_loss': 0.01000,
'take_profit': 0.01000,
'backward': datetime(2010, 1, 1),
'forward': datetime(2023, 1, 1),
'periods': [i for i in range(50, 300, 50)],
}
# catboost learning
dataset = get_labels_fast(get_features(get_prices()))
dataset['meta_labels'] = 1.0
data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() Aqui vale observar que o testador aceita não apenas os valores das marcações "labels", mas também os valores das "meta_labels". Para que servem elas? Elas são usadas se você quiser aplicar filtros ao seu sistema de trading baseado em aprendizado de máquina. Nesse caso, o valor 1 permite a negociação, e o valor 0 a proíbe. Como neste exemplo demonstrativo não usaremos filtros, vamos apenas criar uma coluna adicional preenchida com valores 1, permitindo sempre a negociação.
dataset['meta_labels'] = 1.0
Agora podemos treinar o modelo CatBoost com o dataset preparado, removendo previamente da história os dados de teste forward e backward, para que ele não aprenda com esses dados.
data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) model = CatBoostClassifier(iterations=500, thread_count=8, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False)
Após o treinamento, testamos o modelo em todo o dataset, incluindo os dados de teste. A função test_model está localizada no arquivo tester_lib.py junto com as funções do testador rápido e do testador lento. Ela serve como um invólucro para o testador rápido e realiza a tarefa de obter os valores previstos pelo modelo treinado de aprendizado de máquina (no nosso caso é o CatBoost, mas poderia ser qualquer outro).
def test_model(dataset: pd.DataFrame, result: list, stop: float, take: float, forward: float, backward: float, markup: float, plt = False): ext_dataset = dataset.copy() X = ext_dataset[dataset.columns[1:-2]] ext_dataset['labels'] = result[0].predict_proba(X)[:,1] # ext_dataset['meta_labels'] = result[1].predict_proba(X)[:,1] ext_dataset['labels'] = ext_dataset['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) # ext_dataset['meta_labels'] = ext_dataset['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(ext_dataset, stop, take, forward, backward, markup, plt)
No código acima, há linhas comentadas que permitem obter as meta_labels, responsáveis por indicar se deve ou não ser feita uma negociação. Ou seja, uma segunda modelo de aprendizado de máquina pode ser usada para esse fim. Neste artigo, esse uso não é adotado.
Vamos iniciar o teste propriamente dito.
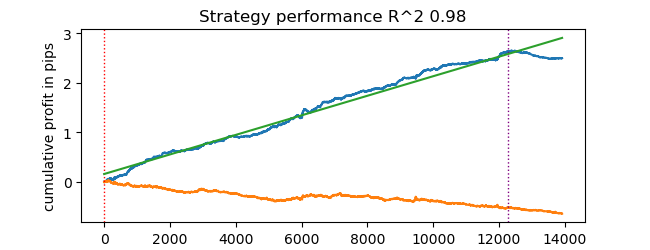
# test catboost model test_model(dataset, [model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], True)
E obter o resultado. O modelo está sobreajustado, isso é visível nos dados de teste à direita da linha vertical. Mas isso não é relevante para nós, pois o foco é testar o testador.
Como o testador permite o uso de stop-loss e take-profit, e você pode querer otimizá-los, então vamos usar otimização, já que nosso testador agora é muito rápido!
Otimização de parâmetros da estratégia de trading com aprendizado de máquina
Agora vamos considerar a possibilidade de otimizar os valores de stop-loss e take-profit. Na verdade, também seria possível otimizar outros parâmetros da estratégia, como as meta_labels, mas isso vai além do escopo deste artigo e pode ser explorado em uma próxima parte.
Vamos implementar dois tipos de otimização:
- Busca em grade (grid search)
- Otimização com o método L-BFGS-B
Vamos primeiro revisar rapidamente o código de cada método. Abaixo está apresentado o método GRID_SEARCH.
Como argumentos, ele recebe:
- o dataset de teste
- o modelo treinado
- um dicionário contendo os hiperparâmetros do algoritmo, descrito anteriormente
- o objeto do testador
# stop loss / take profit grid search def optimize_params_GRID_SEARCH(pr, model, hyper_params, test_model_func): best_r2 = -np.inf best_stop_loss = None best_take_profit = None # Диапазоны для stop_loss и take_profit stop_loss_range = np.arange(0.00100, 0.02001, 0.00100) take_profit_range = np.arange(0.00100, 0.02001, 0.00100) total_iterations = len(stop_loss_range) * len(take_profit_range) start_time = time.time() for stop_loss in stop_loss_range: for take_profit in take_profit_range: # Создаем копию hyper_params current_hyper_params = hyper_params.copy() current_hyper_params['stop_loss'] = stop_loss current_hyper_params['take_profit'] = take_profit r2 = test_model_func(pr, [model], current_hyper_params['stop_loss'], current_hyper_params['take_profit'], current_hyper_params['forward'], current_hyper_params['backward'], current_hyper_params['markup'], False) if r2 > best_r2: best_r2 = r2 best_stop_loss = stop_loss best_take_profit = take_profit end_time = time.time() total_time = end_time - start_time average_time_per_iteration = total_time / total_iterations print(f"Total iterations: {total_iterations}") print(f"Average time per iteration: {average_time_per_iteration:.6f} seconds") print(f"Total time: {total_time:.6f} seconds") return best_stop_loss, best_take_profit, best_r2
Agora vamos ver o código do método L-BFGS_B. Para conhecer melhor esse método, você pode acessar o link indicado.
Os argumentos da função permanecem os mesmos. Mas nela é criada uma função de fitness que chama o testador de estratégias. São definidas as fronteiras dos parâmetros de otimização e o número de inicializações (pontos aleatórios no espaço de parâmetros) para o algoritmo L-BFGS_B. As inicializações aleatórias são usadas para evitar que o algoritmo de otimização fique preso em mínimos locais. Depois disso, a função minimize é chamada e recebe os parâmetros do próprio otimizador.
def optimize_params_L_BFGS_B(pr, model, hyper_params, test_model_func): def objective(x): current_hyper_params = hyper_params.copy() current_hyper_params['stop_loss'] = x[0] current_hyper_params['take_profit'] = x[1] r2 = test_model_func(pr, [model], current_hyper_params['stop_loss'], current_hyper_params['take_profit'], current_hyper_params['forward'], current_hyper_params['backward'], current_hyper_params['markup'], False) return -r2 bounds = ((0.001, 0.02), (0.001, 0.02)) # Попробуем несколько случайных начальных точек n_attempts = 50 best_result = None best_fun = float('inf') start_time = time.time() for _ in range(n_attempts): # Случайная начальная точка x0 = np.random.uniform(0.001, 0.02, 2) result = minimize( objective, x0, method='L-BFGS-B', bounds=bounds, options={'ftol': 1e-5, 'disp': False, 'maxiter': 100} # Увеличиваем точность и число итераций ) if result.fun < best_fun: best_fun = result.fun best_result = result # Получаем время окончания и вычисляем общее время end_time = time.time() total_time = end_time - start_time print(f"Total time: {total_time:.6f} seconds") return best_result.x[0], best_result.x[1], -best_result.fun
Agora podemos executar ambos os algoritmos de otimização e observar o tempo de execução e a precisão.
# using
best_stop_loss, best_take_profit, best_r2 = optimize_params_GRID_SEARCH(dataset, model, hyper_params, test_model)
best_stop_loss, best_take_profit, best_r2 = optimize_params_L_BFGS_B(dataset, model, hyper_params, test_model) Algoritmo Grid search:
Total iterations: 400 Average time per iteration: 0.031341 seconds Total time: 12.536394 seconds Лучшие параметры: stop_loss=0.004, take_profit=0.002, R^2=0.9742298702323458
Algoritmo L-BFGS-B:
Total time: 4.733158 seconds Лучшие параметры: stop_loss=0.0030492548809269732, take_profit=0.0016816794762543421, R^2=0.9733045271274298
Com as configurações padrão, o L-BFGS-B foi mais de duas vezes mais rápido e apresentou um resultado comparável ao algoritmo de busca em grade.
Portanto, é possível usar ambos os algoritmos e escolher o melhor, dependendo da quantidade e da faixa dos parâmetros a serem otimizados.
Considerações finais
Este artigo demonstrou a possibilidade de acelerar um testador de estratégias, permitindo testar rapidamente estratégias baseadas em aprendizado de máquina. Mostrou-se que o Numba proporciona um ganho de velocidade de até 50 vezes. O teste se torna rápido, permitindo múltiplas execuções e até mesmo a otimização de parâmetros.
Estão anexados ao artigo:
- tester_lib.py – biblioteca do testador
- test tester.py – script para comparar o testador lento (Python) e o rápido (Numba)
- tester ticks.py – script para comparar os testadores com dados de ticks
- tester ML.py – script para treinar o classificador e otimizar hiperparâmetros
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14895
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso