
Análise volumétrica com redes neurais como chave para tendências futuras

Na era em que todo o trading está se tornando cada vez mais automatizado, vale lembrar dos antigos traders, muitos dos quais ensinavam que o volume é o rei. De fato, a análise técnica e volumétrica seria útil e muito interessante se usada como características para o aprendizado de máquina. Talvez, com a interpretação correta, isso nos traga resultados positivos. No artigo, avaliaremos a abordagem de análise de volume e características baseadas nele, utilizando a arquitetura LSTM.
Nosso sistema analisa anomalias nos volumes e prevê futuros movimentos de preço. Os principais destaques do sistema são a detecção de volume anômalo, a clusterização de volume e o treinamento do modelo por meio da integração Python + MetaTrader 5.
Também faremos um backtesting completo com visualização dos resultados. O modelo mostra uma eficiência especial no timeframe de uma hora do mercado de ações russo, o que é confirmado pelos resultados dos testes em dados históricos das ações do Sberbank no último ano. No artigo, vou analisar em detalhes a arquitetura do sistema, os princípios de funcionamento e os resultados práticos da aplicação.
Análise de código: dos dados às previsões
Vamos nos aprofundar e tentar criar um sistema que realmente entenda o que está acontecendo com os volumes. Começaremos com o básico: como obter e processar os dados. De certa forma, não é complicado, basta baixar os dados e trabalhar... Mas, como sempre, o diabo está nos detalhes.
Fonte de dados: indo mais fundo
Então, nossa função de carregamento de dados.
def get_mt5_data(self, symbol, timeframe, start_date, end_date): try: self.logger.info(f"Запрос данных MT5: {symbol}, {timeframe}, {start_date} - {end_date}") rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) df = pd.DataFrame(rates)
Parece ser a mais simples. Uso deliberadamente o copy_rates_range em vez do mais fácil copy_rates_from. Isso é necessário para não perder os períodos nulos ao trabalhar com instrumentos de baixa liquidez.
Depois, avançamos mais, começamos a trabalhar com características e indicadores.
Pré-processamento: a arte de preparar os dados
Não vamos nos torturar com a escolha das características, mas focar em algumas das mais óbvias.
def preprocess_data(self, df): # Базовые индикаторы объема df['vol_ma5'] = df['real_volume'].rolling(window=5).mean() df['vol_ma20'] = df['real_volume'].rolling(window=20).mean() df['vol_ratio'] = df['real_volume'] / df['vol_ma20'] # Индикаторы для ML df['price_momentum'] = df['close'].pct_change(24) df['volume_momentum'] = df['real_volume'].pct_change(24) df['volume_volatility'] = df['real_volume'].pct_change().rolling(24).std() df['price_volume_correlation'] = df['price_change'].rolling(24).corr( df['real_volume'].pct_change() )
Quando trabalhamos na escolha de características, é como se estivéssemos ajustando uma orquestra. Cada característica tem seu papel e seu som específico na sinfonia dos dados. Vamos observar nosso conjunto básico.
Primeiro, o mais simples: usamos a média móvel do volume. A média do volume com período 5 capta as menores oscilações, enquanto a de 20 reage a tendências de volume muito mais fortes.
Também é interessante a característica que representa a razão entre o volume e sua média. Quando há um salto brusco, frequentemente ocorre um forte impulso de preço em seguida.
Além disso, observamos o momentum do preço e o momentum do volume nos últimos 24 barras.
Existe ainda uma característica mais interessante, chamada de volatilidade do volume. Eu chamaria isso de um indicador dos nervos do mercado. Quando a volatilidade do volume aumenta, isso pode indicar grandes entradas no mercado por parte de players importantes.
A correlação entre preço e volume também é considerada pelo nosso modelo. No fim, vamos com certeza observar todas essas características em ação, visualizando nossos indicadores recém-criados.
Gargalo de desempenho
Para não sobrecarregar o sistema, podemos aplicar o batching dos dados e o processamento paralelo. Ou seja, dividimos os dados em pequenos blocos e os processamos em paralelo.
Essa técnica simples acelera o processamento dos dados várias vezes, além de ajudar a evitar problemas com vazamentos de memória em grandes volumes de dados.
Na próxima parte do artigo, falarei do mais interessante: como o sistema detecta volumes anômalos e o que acontece depois.
Em busca dos "cisnes negros": como reconhecer volumes anômalos
Todos nós, claro, já ouvimos falar sobre volumes anômalos e como identificá-los no gráfico. Qualquer trader experiente provavelmente é capaz de percebê-los. Mas aí vem o problema: como codificar isso? Como formalizar a lógica de identificação desses volumes?
Caça às anomalias
Depois de uma série de experimentos, minha pesquisa nessa área se firmou no método Isolation Forest. Você pode estar se perguntando por que esse método. Bem, métodos clássicos, como o z-score ou percentis, podem deixar passar uma anomalia local pequena. O que importa não são os valores absolutos ou percentuais, mas sim aqueles volumes que se destacam em relação ao restante, que saem do contexto geral.
def detect_volume_anomalies(self, df): scaler = StandardScaler() volume_normalized = scaler.fit_transform(df[['real_volume']]) iso_forest = IsolationForest(contamination=0.1, random_state=42) df['is_anomaly'] = iso_forest.fit_predict(volume_normalized)
Brincar com o parâmetro, claro, é sempre bom, mas uma solução ainda melhor seria ajustar todos os parâmetros do modelo com algoritmos como o BGA. Usei o valor recomendado em livros didáticos, 0.05, que corresponde a 5% de anomalias. Mas o mercado real é muito mais ruidoso do que se imagina. Por isso, esse limite foi levemente elevado, e ainda será útil ver as anomalias visualmente, agrupadas com os movimentos de preço (voltaremos a esse assunto mais adiante),
Clusterização: busca por padrões
As anomalias sozinhas não bastam para uma boa previsão. Também precisamos da clusterização dos volumes. Vamos focar nesta abordagem de clusterização:
def cluster_volumes(self, df, n_clusters=3): features = ['real_volume', 'vol_ratio', 'volatility'] X = StandardScaler().fit_transform(df[features]) kmeans = KMeans(n_clusters=n_clusters, random_state=42) df['volume_cluster'] = kmeans.fit_predict(X)
As características para a clusterização foram escolhidas de maneira bastante simples. Acredito que aplicar a clusterização apenas aos volumes reais seria estranho pois, afinal, por que teríamos criado nossas características e indicadores? Além disso, tanto o número de características quanto o de indicadores de volume poderiam ser ampliados de maneira significativa.
Três clusters foram escolhidos porque eu dividiria, de forma condicional, todos os volumes em: volumes de “fundo ou acumulação”, volumes de “movimento e ação” e volumes de “movimento extremo”.
Descobertas inesperadas
O trabalho com os dados revelou alguns padrões e sequências recorrentes, por exemplo, que após volumes anômalos, inicia-se o terceiro cluster de volumes, depois surge o volume ativo, e só então ocorre o movimento das cotações para algum dos lados.
Isso se manifesta de forma particularmente nítida nas primeiras horas após a abertura da sessão na bolsa. Aqui, seria útil montar um mapa de calor com os clusters e os movimentos de preços associados.
Rede neural: como ensinar a máquina a ler o mercado
Como já utilizo redes neurais há bastante tempo, foi natural concluir que seria adequado aplicar uma rede neural também à nossa análise de volumes. Até agora, eu nunca tinha experimentado a arquitetura LSTM, mas finalmente tomei a decisão, observando os casos de sucesso dessa arquitetura em outras áreas.
Vamos analisá-la com mais detalhes.
Arquitetura: menos é mais
Mais simples é melhor. Cheguei a uma arquitetura surpreendentemente simples:
class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size=64, num_layers=2, dropout=0.2): super(LSTMModel, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, dropout=dropout, batch_first=True ) self.dropout = nn.Dropout(dropout) self.linear = nn.Linear(hidden_size, 1)
À primeira vista, a arquitetura parece muito primitiva, com apenas duas camadas LSTM e uma camada linear. Contudo, toda a força está na simplicidade. Quando construímos uma rede mais elaborada, com um aprendizado mais profundo, o resultado é o overfitting. Inicialmente, criei uma rede muito mais complexa, com três camadas LSTM, camadas totalmente conectadas adicionais e um esquema de dropout complexo. Os resultados eram impressionantes... Nos dados de teste. Porém, assim que a rede foi exposta ao mercado real por um período mais longo, tudo desmoronou. Em outras palavras, observamos o fenômeno do sobreajuste.
A batalha contra o sobreajuste
O maior problema das redes neurais modernas é o sobreajuste. A rede neural aprende muito bem a encontrar relações nos trechos de dados de teste, mas se perde completamente nas condições reais do mercado. Aqui está como tento resolver esse problema especificamente com a arquitetura apresentada:
- Uma única camada não dá conta da complexidade das relações entre volumes e preços
- Três camadas acabam encontrando relações até onde elas na verdade não existem
O tamanho padrão da camada oculta é de 64 neurônios. Talvez seja melhor usar um número maior. No futuro, quando eu apresentar uma solução funcional para o problema do sobreajuste, poderemos usar uma arquitetura mais complexa com um número maior de neurônios.
Dados de entrada: a arte da seleção de características
Vamos analisar as características de entrada para o treinamento:
features = [ 'vol_ratio', 'vol_ma5', 'volatility', 'volume_cluster', 'is_anomaly', 'price_momentum', 'volume_momentum', 'volume_volatility', 'price_volume_correlation' ]
Com o conjunto de características, é possível fazer muitas experiências. Podemos adicionar indicadores técnicos, como derivadas de preços e volumes, por exemplo. Aqui vale tudo, conforme a criatividade de cada um. Mas lembre-se: mais características não significam necessariamente melhor qualidade de previsão. E, cada característica que parece perfeitamente lógica pode, na prática, ser apenas ruído nos dados.
Uma combinação interessante aqui é entre 'volume_cluster' e 'is_anomaly'. Separadamente, essas características são modestas, mas juntas, produzem uma sinergia muito interessante. Quando volumes anômalos surgem em determinados clusters, isso gera um efeito incomum na previsão.
Descoberta inesperada
O sistema mostrou-se mais eficaz nos períodos em que o movimento de preços é forte e marcante. Também se comporta bem em momentos que a maioria dos traders chamaria de ilegíveis, ou seja, em mercados laterais e fases de consolidação. É justamente nesses momentos que o sistema de análise de anomalias e clusters de volume enxerga o que está além da nossa visão.
Na próxima parte do artigo, falarei sobre como esse sistema se comportou em negociações reais e compartilharei exemplos concretos de sinais.
Dos prognósticos ao trading: transformando sinais em lucro
Todo algotrader sabe: um modelo apenas preditivo não basta, é necessário traduzi-lo em uma estratégia de negociação funcional. Mas como aplicar nosso modelo na prática? Vamos esclarecer esse ponto. Na próxima parte do artigo, não teremos apenas teoria seca, mas sim prática real, com testes reais de negociação, fortalecimento do algoritmo, melhoria no combate ao sobreajuste, mas por enquanto vamos nos manter na parte teórica do nosso estudo.
Anatomia de um sinal de negociação
Um dos pontos-chave no desenvolvimento de uma estratégia de trading é a geração de sinais de negociação. Na minha estratégia, os sinais são gerados com base nas previsões do modelo, que refletem a rentabilidade esperada para o período seguinte.
def backtest_prediction_strategy(self, df, lookback=24): # Генерация сигналов на основе предсказаний df['signal'] = 0 signal_threshold = 0.001 # Порог 0.1% df.loc[df['predicted_return'] > signal_threshold, 'signal'] = 1 df.loc[df['predicted_return'] < -signal_threshold, 'signal'] = -1
Escolha do limiar de sinal
Por um lado, poderíamos definir o limiar simplesmente acima de 0. Nesse caso, geraríamos muitos sinais, mas eles seriam poluídos pelo spread, pelas comissões e pelo ruído do mercado. Essa abordagem pode resultar em muitos sinais falsos, o que prejudica a eficácia da estratégia.
Por isso, a decisão mais sensata parece ser elevar o limiar da rentabilidade prevista para algo entre 0.1% e 0.2%. Isso ajuda a filtrar grande parte do ruído e a reduzir o impacto das comissões, já que os sinais serão gerados apenas quando houver mudanças de preço previstas mais significativas.
signal_threshold = 0.001 # Порог 0.1%
Aplicação dos sinais com defasagem
Após a geração dos sinais, eles são aplicados aos preços considerando uma defasagem de 24 períodos à frente. Isso permite levar em conta o atraso entre a tomada da decisão de negociação e sua execução.
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
A defasagem de 24 períodos significa que o sinal gerado no instante de tempo t , será aplicado ao preço no instante t + 24 . Isso é importante, pois, na realidade, as decisões de negociação não podem ser executadas de forma instantânea. Essa abordagem permite avaliar de maneira mais realista a eficácia da estratégia de negociação.
Cálculo da rentabilidade da estratégia
A rentabilidade da estratégia é calculada como o produto do sinal defasado e da variação de preço:
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Se o sinal for igual a 1, a rentabilidade da estratégia será igual à variação de preço (price_change). Se o sinal for igual a -1, a rentabilidade será igual à variação de preço negativa (-price_change). Se o sinal for igual a 0, a rentabilidade será nula.
Dessa forma, a defasagem dos sinais em 24 períodos permite considerar o atraso entre a decisão e a execução da operação, tornando a avaliação da estratégia mais realista.
Ponto de equilíbrio
Após semanas de testes, cheguei ao valor de 0.1% como limiar. E aqui está o porquê:
- Com esse limiar, o sistema gera sinais com frequência suficiente
- Cerca de 52-63% das operações resultam em lucro
- O lucro médio por operação é aproximadamente 2,5 vezes maior que a comissão
A descoberta mais incomum foi que a maior parte dos sinais falsos também pode se concentrar em determinados clusters temporais. Se desejar, pode-se considerar um filtro temporal desse tipo, que vamos explorar mais adiante, na próxima parte do artigo.
def apply_time_filter(self, df): # Торгуем только в активные часы trading_hours = df['time'].dt.hour df.loc[~trading_hours.between(10, 12), 'signal'] = 0
Gestão de riscos
Um tema à parte é a lógica de formação de posição e a lógica de gerenciamento das operações abertas (acompanhamento das operações durante o trading). Por um lado, a solução mais óbvia seria o uso de stops e targets fixos, mas o mercado é imprevisível e dinâmico demais para que limites de perdas e lucros sejam definidos por uma lógica formal comum.
Nossa solução é bem simples: utilizar a volatilidade prevista para definir stops de forma dinâmica.
def calculate_stop_levels(self, predicted_return, predicted_volatility): base_stop = abs(predicted_return) * 0.7 volatility_adjust = predicted_volatility * 1.5 return max(base_stop, volatility_adjust)
Essa abordagem também precisa ser testada separadamente. Pode-se ainda aplicar o modelo de análise de risco VaR para definir os stops e targets com base nesse sistema clássico, mas comprovadamente eficaz.
Descobertas inesperadas
Descobertas interessantes mostram que séries de sinais consecutivos podem prenunciar movimentos muito fortes. Também surgem problemas quando a volatilidade média do mercado dispara. Nesse caso, nosso limiar já não é suficiente para uma negociação eficaz. E se você reparar, os períodos de rebaixamento no gráfico coincidem justamente com momentos de alta volatilidade. Mas isso não é um problema para nós! Na próxima parte do artigo, vamos resolver e mitigar essa questão.
Visualização e registro: como não se afogar nos dados
Outro ponto muito importante é não esquecer o sistema de log. De forma geral, tudo o que envolve prints, logs, saídas e comentários do programa é vital na fase de depuração. Isso permite encontrar a origem de problemas no código de maneira rápida e eficaz.
Sistema de log: os detalhes fazem toda a diferença
No coração do sistema de log está um formato simples, mas eficiente:
log_format = '%(asctime)s [%(levelname)s] %(message)s'
date_format = '%Y-%m-%d %H:%M:%S'
logger = logging.getLogger('VolumeAnalyzer')
logger.setLevel(logging.DEBUG) Pode parecer que não há nada de especial nisso, mas cheguei a esse formato depois de passar por alguns momentos dolorosos em que eu simplesmente não conseguia entender por que o sistema havia aberto uma posição em um momento específico.
Agora, cada ação do sistema deixa um rastro claro nos logs. Em especial, faço log minucioso dos momentos ligados a volumes anômalos:
self.logger.info(f"Обнаружен аномальный объем: {volume:.2f}") self.logger.debug(f"Контекст: кластер {cluster}, волатильность {volatility:.4f}")
Também precisamos de visualização. A experiência com trading manual deixou um hábito forte: observar tudo visualmente, da mesma forma como se observa um gráfico comum. Aqui está nosso código de visualização:
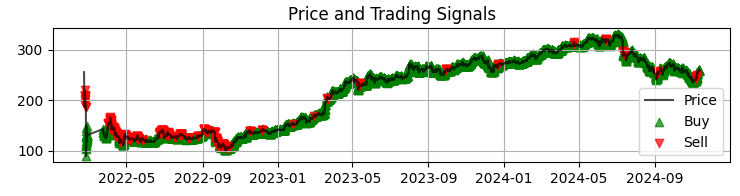
def visualize_results(self, df): plt.figure(figsize=(15, 12)) # График цены и сигналов plt.subplot(3, 1, 1) plt.plot(df['time'], df['close'], 'k-', label='Цена', alpha=0.7) plt.scatter(df[df['signal'] == 1]['time'], df[df['signal'] == 1]['close'], marker='^', color='g', label='Покупка')
O primeiro gráfico mostra o gráfico de preços da Sber com os sinais obtidos pelo modelo. Também adicionamos destaque nas velas onde há volumes anômalos. Isso nos ajuda a compreender os momentos em que o sistema lê o mercado como um livro aberto.
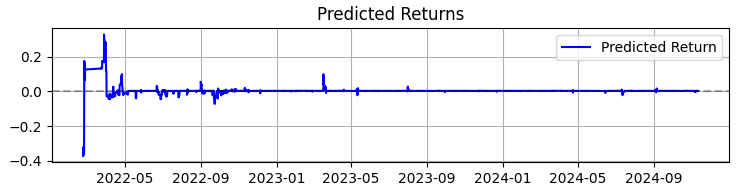
O segundo gráfico exibe a rentabilidade prevista. E ali fica bem claro que, antes de movimentos fortes nas cotações do ativo escolhido, frequentemente se inicia uma sequência muito intensa de previsões. Isso nos faz pensar na ideia de criar um sistema baseado apenas nessa observação específica. Naturalmente, o número de operações cairia. Mas não estamos buscando quantidade, e sim qualidade, certo?
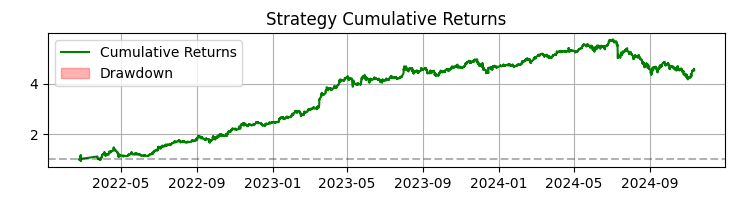
O terceiro gráfico mostra a rentabilidade acumulada com destaque para os períodos de rebaixamento.
Da teoria à prática: resultados e perspectivas
Vamos resumir o trabalho com este sistema, não com números frios, mas com descobertas que podem ajudar todos aqueles interessados em análise volumétrica no trading.
Primeiro: o mercado realmente se comunica conosco por meio do giro financeiro e do volume. Mas essa linguagem é muito mais complexa do que se pode imaginar. Na minha opinião pessoal, métodos clássicos como o VSA já estão se tornando rapidamente obsoletos, incapazes de acompanhar o ritmo igualmente acelerado da evolução do mercado. Os padrões estão ficando mais complexos, e o ponto central da realidade é que os volumes formam padrões extremamente sofisticados, quase invisíveis a olho nu.
De forma geral, após quase três anos de trabalho com aprendizado de máquina, posso resumir apenas o seguinte: o mercado está se tornando mais complexo a cada ano. Os algoritmos que operam nele, e que em parte formam os próprios fluxos de ordens (OrderFlow) que geram tendências e acumulações, também estão ficando mais sofisticados. À nossa frente está uma batalha de redes neurais, uma disputa entre máquinas pelo domínio do mercado, em que vence quem tiver o sistema mais eficaz.
Ao concluir o desenvolvimento deste sistema, quero compartilhar não apenas números, mas também as principais descobertas, que podem ser úteis para todos que trabalham com análise de volumes.
Em 365 dias operando ações da SBER, o sistema demonstrou resultados impressionantes:
- Rentabilidade total: 365,0% ao ano (sem alavancagem)
- Proporção de operações lucrativas: 50,73%
Mas esses números não são o mais importante. Muito mais relevante é o fato de que o sistema se mostrou resistente a diferentes condições de mercado. Ele funciona bem tanto em tendências quanto em mercados laterais, embora o comportamento dos sinais varie de forma perceptível.
Particularmente interessante foi o desempenho do sistema durante períodos de alta volatilidade. É justamente nesses momentos, quando a maioria dos traders prefere ficar fora do mercado, que a rede neural consegue identificar os padrões mais nítidos no fluxo de volumes. Talvez isso aconteça porque, nessas fases, os players institucionais deixam rastros mais evidentes de suas ações.
O que este projeto me ensinou- Aprendizado de máquina no trading não é uma solução mágica. O sucesso só vem com compreensão profunda do mercado e uma engenharia cuidadosa das características.
- Simplicidade é a chave da robustez. Todas as vezes que tentei complicar o modelo, adicionando novas camadas ou características, ele se tornava mais frágil.
- Volumes precisam ser analisados em contexto. Sozinhos, volumes anômalos ou clusters dizem pouco. A mágica acontece quando observamos como interagem com outros fatores.
E agora?
O sistema continua em evolução. Neste momento, estou trabalhando em algumas melhorias:
- Ajuste adaptativo dos parâmetros conforme a fase do mercado
- Integração com fluxo de ordens para uma análise mais precisa
- Expansão para outros ativos do mercado russo
O código-fonte do sistema está disponível nos anexos. Ficarei feliz em receber sugestões de melhoria. Será especialmente interessante ouvir a experiência de quem tentar adaptar o sistema a outros instrumentos.
Considerações finais
Para concluir, gostaria de destacar que a descoberta mais valiosa dos últimos meses foi a adaptação de abordagens clássicas, como a análise volumétrica que estudamos hoje, às novas tecnologias como aprendizado de máquina, redes neurais e big data.
A experiência das gerações passadas, caramba, está viva. Nossa tarefa é justamente essa: absorver esse conhecimento, extrair sua essência e aprimorá-lo a partir da perspectiva da nossa geração de traders, com o uso das tecnologias mais recentes. E claro, não podemos ficar para trás em relação ao presente. O que vem pela frente inclui aprendizado de máquina quântico, algoritmos quânticos para previsão de preços e volumes, e características multidimensionais para aprendizado de máquina. Já testei a análise de mercado em um supercomputador quântico da IBM com 20 qubits. Os resultados foram interessantes, e certamente falarei sobre eles em artigos futuros.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16062
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso