
Validação cruzada e noções básicas de inferência causal em modelos CatBoost, exportação para o formato ONNX

Introdução
Artigos anteriores descreveram diferentes maneiras originais de usar algoritmos de aprendizado de máquina para criar sistemas de negociação. Alguns se mostraram bastante bem-sucedidos, enquanto outros (principalmente das publicações mais antigas) sofreram de sobreajuste significativo. Assim, a sequência de meus artigos reflete a evolução do que, de fato, o aprendizado de máquina pode fazer e o que não pode. Claro, estamos falando sobre a classificação de séries temporais.
Por exemplo, no artigo anterior "Metamodelos em aprendizado de máquina e negociação", foi demonstrado um método de força bruta para encontrar padrões por meio da interação de dois classificadores. Esse método não trivial foi escolhido porque os algoritmos de aprendizado de máquina são bons em generalizar e prever, mas são "preguiçosos" quando se trata de buscar conexões causais. Ou seja, eles generalizam os exemplos de treinamento nos quais uma conexão causal pode já estar implícita, mantendo-se válida nos novos dados, mas essa conexão também pode ser associativa, ou seja, momentânea e não confiável.
O modelo não entende com que tipo de conexões está lidando; para ele, todos os dados de treinamento são apenas dados de treinamento. E isso é um grande problema para os iniciantes que tentam treiná-lo para negociar de forma lucrativa com novos dados. Assim sendo, no último artigo, foi feita uma tentativa de ensinar o algoritmo a analisar seus próprios erros, de modo a distinguir previsões estatisticamente significativas das aleatórias.
O presente artigo é uma continuação do tema anterior e o próximo passo na direção de criar um algoritmo autodidata, capaz de identificar padrões nos dados, minimizando o ajuste excessivo aos dados de treinamento. Afinal, queremos obter um efeito real da aplicação do aprendizado de máquina, para que ele não apenas generalize os exemplos de treinamento, mas também identifique por si mesmo a presença de conexões causais neles.
YIN (teoria)
Esta seção conterá algumas reflexões subjetivas baseadas em uma pitada de experiência obtida na tentativa de criar "Inteligência Artificial" para o Forex. Porque isso ainda não é amor, mas continua sendo uma experiência.
Assim como nossas conclusões muitas vezes são errôneas e precisam ser verificadas, os resultados das previsões dos modelos de aprendizado de máquina também precisam ser revalidados. Se o processo de revalidação for ciclizado em si mesmo, resulta em autocontrole. O autocontrole de um modelo de aprendizado de máquina envolve verificar se suas previsões têm erros muitas vezes em situações diferentes, mas semelhantes. Se o modelo erra pouco em média, significa que não está sobreajustado; se erra frequentemente, algo está errado com ele.
Se treinamos o modelo uma vez com dados selecionados, ele não pode exercer autocontrole. Se treinamos o modelo várias vezes com subamostras aleatórias e depois verificamos a qualidade das previsões em cada uma e somamos todos os erros, obtemos uma imagem relativamente confiável dos casos em que ele realmente erra frequentemente e dos casos que geralmente acerta. Esses casos podem ser divididos em dois grupos, separados um do outro. Isso é análogo à validação walk-forward ou à validação cruzada, mas com elementos adicionais. Somente dessa forma é possível alcançar o autocontrole e obter um modelo mais robusto.
Por isso, é necessário realizar a validação cruzada no conjunto de dados de treinamento, comparar as previsões do modelo com as etiquetas de treinamento e média dos resultados em todos os folds. Os exemplos que foram previstos incorretamente, em média, devem ser removidos do conjunto final de treinamento como errôneos. Também é necessário treinar um segundo modelo com todos os dados, modelo esse que distingue casos bem previstos dos mal previstos, permitindo cobrir mais completamente todos os resultados possíveis.
Quando os maus exemplos de treinamento são removidos, o modelo principal terá um pequeno erro de classificação, mas preverá mal nos casos que foram removidos como difíceis de prever. Ele terá alta precisão, mas pouca abrangência. Se agora adicionarmos um segundo classificador e o treinarmos para permitir que o primeiro modelo negocie apenas nos casos que o primeiro modelo aprendeu a classificar bem, ele deve melhorar os resultados de todo o sistema, pois tem menor precisão, mas maior abrangência.
Assim, os erros do primeiro modelo são transferidos para o segundo classificador, mas não desaparecem, portanto, agora ele preverá incorretamente com mais frequência. Mas, como ele não prevê diretamente a direção da operação e cobre mais dados, tais previsões ainda têm valor.
Vamos considerar que dois modelos são suficientes para compensar os erros de treinamento com seus resultados positivos.
Assim, pelo método de exclusão de maus exemplos de treinamento, buscaremos situações que, em média, sejam lucrativas. E tentaremos não negociar nos lugares que, em média, levam a perdas.
Núcleo do algoritmo
A função ‘meta aprendiz’ é o núcleo do algoritmo e faz tudo o que foi dito acima, portanto, deve ser mais detalhadamente examinada. As outras funções são auxiliares.
def meta_learner(folds_number: int, iter: int, depth: int, l_rate: float) -> pd.DataFrame: dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] B_S_B = pd.DatetimeIndex([]) # learn meta model with CV method meta_model = CatBoostClassifier(iterations = iter, max_depth = depth, learning_rate=l_rate, verbose = False) predicted = cross_val_predict(meta_model, X, y, method='predict_proba', cv=folds_number) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = [x[0] < 0.5 for x in predicted] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # select bad samples (bad labels indices) diff_negatives = coreset['labels'] != coreset['labels_pred'] B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index) to_mark = B_S_B.value_counts() marked_idx = to_mark.index data.loc[data.index.isin(marked_idx), 'meta_labels'] = 0.0 return data[data.columns[1:]]
Ela recebe:
- número de folds para a validação cruzada
- número de iterações de treinamento para o aprendiz básico
- profundidade da árvore do aprendiz básico
- passo do gradiente
Estes parâmetros influenciam o resultado final e devem ser ajustados empiricamente, ou por meio de uma grade.
A função cross_val_predict do pacote scikit-learn retorna as estimativas da validação cruzada para cada exemplo de treinamento, após o que essas estimativas são comparadas com as etiquetas originais. Se as previsões forem incorretas, elas são registradas no livro de maus exemplos, com base no qual são então formadas "meta etiquetas" para o segundo classificador.
A função retorna o dataframe fornecido, com "meta etiquetas" adicionadas. Este dataframe é então usado para treinar os modelos finais, como mostrado na listagem.
# features for model\meta models. We learn main model only on filtered labels X, X_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[:-2]] X = X[X.columns[:-2]] # labels for model\meta models y, y_meta = dataset[dataset['meta_labels']==1], dataset[dataset.columns[-1]] y = y[y.columns[-2]]
Acima no código, é observado que o primeiro modelo é treinado apenas nas linhas cujas meta etiquetas correspondem a um, ou seja, marcadas como bons exemplos de treinamento. Então, o segundo classificador é treinado em todo o conjunto de dados completamente.
Depois, simplesmente se treinam dois classificadores. Um prevê as probabilidades de compra e venda, e o outro decide se vale a pena negociar ou não.
Cada modelo também tem seus próprios parâmetros de treinamento, que não são externalizados como hiperparâmetros. Eles podem ser ajustados separadamente, mas eu conscientemente escolhi um pequeno número de iterações, igual a 100, para que os modelos não se sobreajustem mesmo nesta fase final. É possível alterar os tamanhos relativos dos conjuntos de treinamento e teste, o que também afetaria ligeiramente os resultados finais. Em geral, o primeiro modelo é relativamente simples de treinar, pois é treinado apenas em exemplos que são bem classificados, portanto, uma grande complexidade do modelo não é necessária. O segundo modelo tem uma tarefa mais complexa, portanto, pode-se aumentar a complexidade do mesmo.
# train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.5, test_size=0.5, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.5, test_size=0.5, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU') meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False)
Hiperparâmetros do algoritmo
Antes de começar o treinamento, é importante configurar corretamente todos os parâmetros de entrada, que também afetam o resultado final.
export_path = '/Users/dmitrievsky/Library/Application Support/MetaTrader 5/\ Bottles/metatrader5/drive_c/Program Files/MetaTrader 5/MQL5/Include/'
# GLOBALS SYMBOL = 'EURUSD' MARKUP = 0.00015 PERIODS = [i for i in range(10, 50, 10)] BACKWARD = datetime(2015, 1, 1) FORWARD = datetime(2022, 1, 1)
- Caminho para a pasta "Include" do terminal, para salvar os modelos treinados
- Ticker do símbolo
- Markup médio em pontos, incluindo spread, comissões e slippages
- Períodos das médias móveis, que são usados para calcular os incrementos de preço. Estes são os recursos para treinar o modelo.
- Intervalo de datas para treinamento. Histórico à esquerda e à direita deste intervalo permanece fora do treinamento (OOS), para testes em novos dados.
def get_labels(dataset, min= 3, max= 25) -> pd.DataFrame:
Esta função tem argumentos min e max, para amostragem aleatória de operações. Cada nova operação terá uma duração aleatória em barras. Se os mesmos valores forem definidos, todas as operações terão uma duração fixa.
Funções auxiliares e bibliotecas
Antes de começar, verifique se todos os pacotes necessários estão instalados e importados
import numpy as np import pandas as pd import random import math from datetime import datetime import matplotlib.pyplot as put from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.model_selection import cross_val_predict
Em seguida, exporte as cotações do terminal MetaTrader 5. Selecione o símbolo necessário, a escala de tempo e a profundidade do histórico. E salve-os no subdiretório /files do seu projeto Python.
def get_prices() -> pd.DataFrame: p = pd.read_csv('files/EURUSD_H1.csv', delim_whitespace=True) pFixed = pd.DataFrame(columns=['time', 'close']) pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>'] pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed') pFixed['close'] = p['<CLOSE>'] pFixed.set_index('time', inplace=True) pFixed.index = pd.to_datetime(pFixed.index, unit='s') pFixed = pFixed.dropna() pFixedC = pFixed.copy() count = 0 for i in PERIODS: pFixed[str(count)] = pFixedC.rolling(i).mean() - pFixedC count += 1 return pFixed.dropna()
É mostrado como o bot obtém as cotações e como cria recursos: subtraindo os preços de fechamento da média móvel, definida na lista PERIODS como hiperparâmetro.
Depois, o dataset formado é passado para a próxima função para anotação (ou metas).
def get_labels(dataset, min= 3, max= 25) -> pd.DataFrame: labels = [] meta_labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if future_pr < curr_pr: labels.append(1.0) if future_pr + MARKUP < curr_pr: meta_labels.append(1.0) else: meta_labels.append(0.0) elif future_pr > curr_pr: labels.append(0.0) if future_pr - MARKUP > curr_pr: meta_labels.append(1.0) else: meta_labels.append(0.0) else: labels.append(2.0) meta_labels.append(0.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset['meta_labels'] = meta_labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2.0].index) return dataset
Esta função retorna o mesmo dataframe, mas com colunas adicionais de "labels" e "meta labels".
A função de teste foi significativamente acelerada, agora é possível carregar grandes datasets sem se preocupar que o testador trabalhe muito lentamente:
def tester(dataset: pd.DataFrame, plot= False): last_deal = int(2) last_price = 0.0 report = [0.0] chart = [0.0] line = 0 line2 = 0 indexes = pd.DatetimeIndex(dataset.index) labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() close = dataset['close'].to_numpy() for i in range(dataset.shape[0]): if indexes[i] <= FORWARD: line = len(report) if indexes[i] <= BACKWARD: line2 = len(report) pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta==1: last_price = pr last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 report.append(report[-1] - MARKUP + (pr - last_price)) chart.append(chart[-1] + (pr - last_price)) continue if last_deal == 1 and pred < 0.5 and pred_meta==1: last_deal = 2 report.append(report[-1] - MARKUP + (last_price - pr)) chart.append(chart[-1] + (pr - last_price)) y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.plot(report) plt.plot(chart) plt.axvline(x = line, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x = line2, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l,".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
A função auxiliar de teste de modelos já treinados agora é mais concisa. Ela aceita uma lista de modelos, calcula as probabilidades de classes e as passa para o testador exatamente como se fosse um dataframe pronto com recursos e rótulos para testar. Assim, o testador funciona tanto com os dataframes de treinamento originais quanto com os formados como resultado de receber previsões de modelos já treinados.
def test_model(result: list, plt= False): pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] pr_tst['labels'] = result[0].predict_proba(X)[:,1] pr_tst['meta_labels'] = result[1].predict_proba(X)[:,1] pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(pr_tst, plot=plt)
YANG (prática)
Após a configuração dos hiperparâmetros, passamos diretamente para o treinamento dos modelos, que é realizado em um ciclo.
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learner(folds_number= 5, iter= 150, depth= 5, l_rate= 0.01)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
Aqui treinaremos 25 modelos, após o que testaremos e procederemos com a exportação para o terminal MetaTrader5.
Os parâmetros destacados, assim como a faixa de datas para treinamento e teste, e a duração das negociações têm um impacto significativo nos resultados do treinamento. Deve-se experimentar com esses parâmetros.
Vamos observar os top 5 melhores modelos segundo o R^2, considerando novos dados. Linhas horizontais nos gráficos mostram o OOS (Out-of-Sample) à esquerda e à direita.
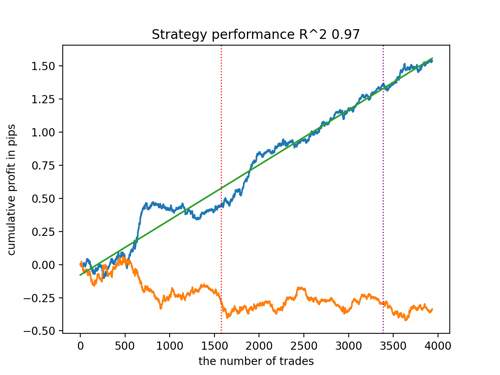
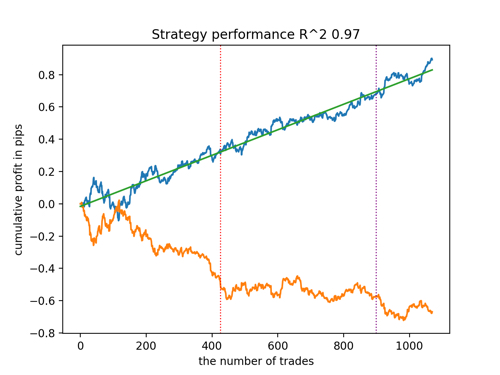
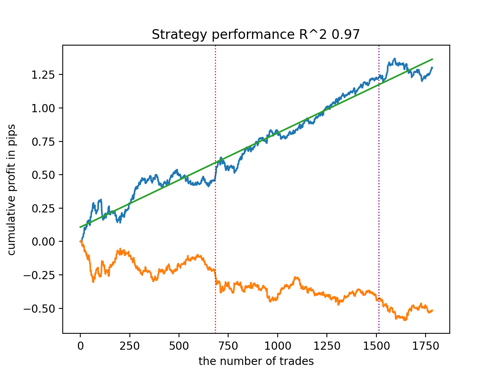
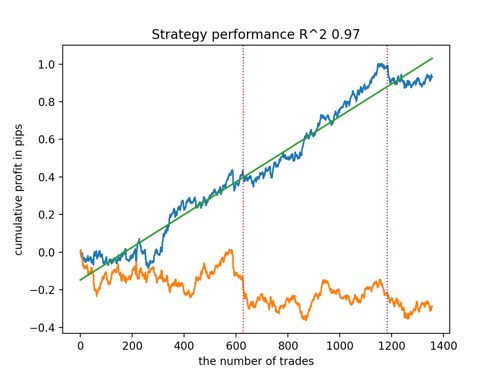
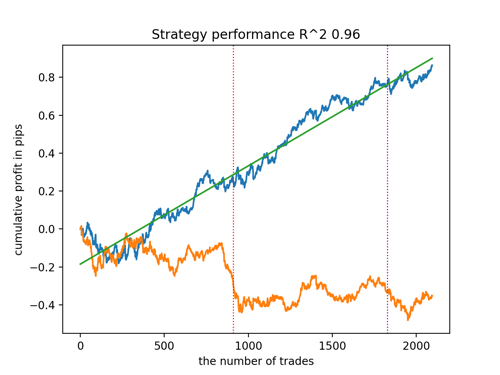
O gráfico do saldo é mostrado em azul e o gráfico das cotações em laranja. É evidente que todos os modelos são diferentes entre si. Isso se deve ao amostragem aleatória de negociações, bem como à randomização incorporada em cada modelo. No entanto, esses modelos já não parecem ser testes experimentais e operam com confiança no OOS. Além disso, pode-se comparar o número de negociações, lucro em pontos e a aparência geral das curvas. Claramente, o primeiro e segundo modelos se destacam favoravelmente, portanto, vamos exportá-los para o terminal.
Deve-se ter em mente que, alterando os parâmetros de treinamento e fazendo várias reinicializações, você obterá comportamentos únicos; os gráficos quase nunca serão idênticos, mas uma parte significativa deles (o que é importante) se sairá bem no OOS.
Exportação do modelo para o formato ONNX
Em artigos anteriores, usei a conversão de modelos do idioma C++ para MQL. Agora, o terminal MetaTrader 5 suporta a importação de modelos no formato ONNX. Isso é conveniente porque permite escrever menos código e transferir quase qualquer modelo treinado em Python.
O algoritmo CatBoost tem seu próprio método de exportação para o formato ONNX. Vamos examinar o processo de exportação mais detalhadamente.
Ao final, temos dois modelos CatBoost e uma função que forma características em forma de incrementos. Como a função é bastante simples, simplesmente a transferiremos para o código do bot, enquanto os modelos serão exportados para arquivos ONNX.
def export_model_to_ONNX(model, model_number): model[1].save_model( export_path +'catmodel' + str(model_number) +'.onnx', format="onnx", export_parameters={ 'onnx_domain': 'ai.catboost', 'onnx_model_version': 1, 'onnx_doc_string': 'test model for BinaryClassification', 'onnx_graph_name': 'CatBoostModel_for_BinaryClassification' }, pool=None) model[2].save_model( export_path + 'catmodel_m' + str(model_number) +'.onnx', format="onnx", export_parameters={ 'onnx_domain': 'ai.catboost', 'onnx_model_version': 1, 'onnx_doc_string': 'test model for BinaryClassification', 'onnx_graph_name': 'CatBoostModel_for_BinaryClassification' }, pool=None) code = '#include <Math\Stat\Math.mqh>' code += '\n' code += '#resource "catmodel'+str(model_number)+'.onnx" as uchar ExtModel[]' code += '\n' code += '#resource "catmodel_m'+str(model_number)+'.onnx" as uchar ExtModel2[]' code += '\n' code += 'int Periods' + '[' + str(len(PERIODS)) + \ '] = {' + ','.join(map(str, PERIODS)) + '};' code += '\n\n' # get features code += 'void fill_arays' + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods''[i],pr);\n' code += ' ret[0] = MathMean(pr) - pr[Periods[i]-1];\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' file = open(export_path + str(SYMBOL) + ' ONNX include' + str(model_number) + '.mqh', "w") file.write(code) file.close() print('The file ' + 'ONNX include' + '.mqh ' + 'has been written to disk')
A função de exportação recebe uma lista de modelos, cada um dos quais é salvo como ONNX, com parâmetros de exportação opcionais. Todo esse código salva os modelos na pasta Include do terminal, e também gera um arquivo .mqh, que se parece aproximadamente com o seguinte:
#resource "catmodel.onnx" as uchar ExtModel[] #resource "catmodel_m.onnx" as uchar ExtModel2[] #include <Math\Stat\Math.mqh> int Periods[4] = {10,20,30,40}; void fill_arays( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods[i],pr); ret[0] = MathMean(pr) - pr[Periods[i]-1]; ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Em seguida, é necessário conectá-lo ao bot. Cada arquivo tem um nome único, que é definido através do ticker do símbolo e do número de ordem do modelo no final. Por isso, você pode armazenar uma coleção desses modelos treinados no disco, ou conectar vários ao bot imediatamente. Limitarei a um arquivo para fins demonstrativos.
#include <EURUSD ONNX include1.mqh> Na função, é necessário inicializar corretamente os modelos, como mostrado abaixo. O mais importante é definir corretamente as dimensões dos dados de entrada e saída. Nossos modelos têm um vetor de características de comprimento variável, dependendo do número de características definidas na lista PERIODS ou no array exportado, assim, definimos a dimensão do vetor de entrada conforme mostrado abaixo. Ambos os modelos recebem a mesma quantidade de características.
A dimensão do vetor de saída pode causar alguma confusão.
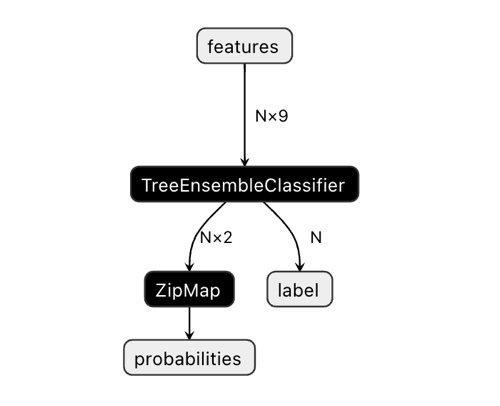

No aplicativo Netron, é visível que o modelo tem dois outputs. O primeiro é um tensor unitário com rótulos de classe, que é definido no código abaixo como o output zero ou output com índice zero. No entanto, não pode ser usado para obter previsões, já que existem problemas conhecidos descritos na documentação CatBoost:
"The label is inferred incorrectly for binary classification. This is a known bug in the onnxruntime implementation. Ignore the value of this parameter in case of binary classification."
Assim, devemos usar o segundo output "probabilities", mas não consegui definí-lo corretamente no código MQL, então simplesmente não o defini. No entanto, ele se configurou sozinho e tudo funciona. Não sei ao certo o motivo.
Por isso, para obter as probabilidades das classes no bot, usa-se o segundo output.
const long ExtInputShape [] = {1, ArraySize(Periods)};
int OnInit() { ExtHandle = OnnxCreateFromBuffer(ExtModel, ONNX_DEFAULT); ExtHandle2 = OnnxCreateFromBuffer(ExtModel2, ONNX_DEFAULT); if(ExtHandle == INVALID_HANDLE || ExtHandle2 == INVALID_HANDLE) { Print("OnnxCreateFromBuffer error ", GetLastError()); return(INIT_FAILED); } if(!OnnxSetInputShape(ExtHandle, 0, ExtInputShape)) { Print("OnnxSetInputShape failed, error ", GetLastError()); OnnxRelease(ExtHandle); return(-1); } if(!OnnxSetInputShape(ExtHandle2, 0, ExtInputShape)) { Print("OnnxSetInputShape failed, error ", GetLastError()); OnnxRelease(ExtHandle2); return(-1); } const long output_shape[] = {1}; if(!OnnxSetOutputShape(ExtHandle, 0, output_shape)) { Print("OnnxSetOutputShape error ", GetLastError()); return(INIT_FAILED); } if(!OnnxSetOutputShape(ExtHandle2, 0, output_shape)) { Print("OnnxSetOutputShape error ", GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); }
A obtenção de sinais dos modelos é realizada da seguinte maneira: Aqui, declaramos um array de características (features) e o preenchemos através da função fill_arrays(), que está no arquivo .mqh exportado.
Depois, declarei outro array f, para inverter a ordem dos valores do array features, e o passei para execução no Onnx Runtime. O primeiro output em forma de vetor é apenas passado, mas não usaremos. Como segundo output, é passado um array de estruturas.
Os modelos (principal e meta) são executados e retornam os valores previstos no array tensor. Eu pego dele as probabilidades da segunda classe.
void OnTick() { if(!isNewBar()) return; double features[]; fill_arays(features); double f[ArraySize(Periods)]; int k = ArraySize(Periods) - 1; for(int i = 0; i < ArraySize(Periods); i++) { f[i] = features[i]; k--; } static vector out(1), out_meta(1); struct output { long label[]; float tensor[]; }; output out2[], out2_meta[]; OnnxRun(ExtHandle, ONNX_DEBUG_LOGS, f, out, out2); OnnxRun(ExtHandle2, ONNX_DEBUG_LOGS, f, out_meta, out2_meta); double sig = out2[0].tensor[1]; double meta_sig = out2_meta[0].tensor[1];
O restante do código do bot deve ser familiar a partir do artigo anterior. Lá, verificamos o sinal de permissão meta_sig. Se for maior que 0.5, a permissão para abrir e fechar negociações é concedida, dependendo da direção indicada pelo sinal sig do primeiro modelo.
if(meta_sig > 0.5) if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(SymbolInfoInteger(_Symbol, SYMBOL_TRADE_FREEZE_LEVEL) < MathAbs(Bid - OrderOpenPrice())) { int res = -1; do { res = OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red); Sleep(50); } while (res == -1); } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(SymbolInfoInteger(_Symbol, SYMBOL_TRADE_FREEZE_LEVEL) < MathAbs(Bid - OrderOpenPrice())) { int res = -1; do { res = OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red); Sleep(50); } while (res == -1); } } if(meta_sig > 0.5) if(countOrders() < max_orders && CheckMoneyForTrade(_Symbol, LotsOptimized(meta_sig), ORDER_TYPE_BUY)) { double l = LotsOptimized(meta_sig); if(sig < 0.5) { int res = -1; do { double stop = Bid - stoploss * _Point; double take = Ask + takeprofit * _Point; res = OrderSend(Symbol(), OP_BUY, l, Ask, 0, stop, take, comment, OrderMagic); Sleep(50); } while (res == -1); } else { if(sig > 0.5) { int res = -1; do { double stop = Ask + stoploss * _Point; double take = Bid - takeprofit * _Point; res = OrderSend(Symbol(), OP_SELL, l, Bid, 0, stop, take, comment, OrderMagic); Sleep(50); } while (res == -1); } } }
Testes finais
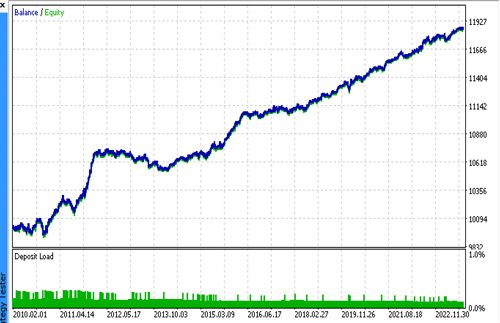
Vamos conectar sucessivamente 2 arquivos com os modelos de nossa preferência e garantir que os resultados do testador personalizado correspondam completamente aos resultados do testador do MetaTrader 5.
Adicionalmente, no otimizador do MetaTrader 5, pode-se testar os bots em ticks reais, otimizar stop loss e take profit, ajustar o tamanho do lote e adicionar mais negociações.
Palavra final
Não sei se há uma fundamentação científica para tal abordagem de classificação de séries temporais para tarefas de negociação. Foi desenvolvida por tentativa e erro e pareceu-me bastante interessante e promissora.
Com esse pequeno estudo, eu queria enfatizar que às vezes os modelos de aprendizado de máquina devem ser treinados de maneira diferente, não tão óbvia quanto parece. A escolha da arquitetura específica também é importante, mas a forma de aplicar esses modelos é fundamental. Ao mesmo tempo, a abordagem estatística para analisar os resultados do treinamento torna-se proeminente, seja em uma simulação completamente automática de "trader e pesquisador" apresentada neste artigo, ou em algoritmos mais simples que requerem intervenção de um "Mestre" especializado.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/11147
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso