
Inferencia causal en problemas de clasificación de series temporales

Contenido del artículo:
- Introducción
- Historia de la inferencia causal
- Fundamentos de la inferencia causal en el aprendizaje automático
- Escalera de pruebas en la inferencia causal
- Notación en la inferencia causal
- Sesgo
- Experimentos aleatorios
- Emparejamiento
- Incertidumbre
- Metaaprendizaje
- Ejemplo de creación de un sistema de negociación
En el artículo anterior, hemos examinado a fondo el entrenamiento mediante metaaprendizaje y validación cruzada, así como el guardado de modelos en formato ONNX. También he observado que los modelos de aprendizaje automático no son capaces de encontrar patrones a la primera en datos dispares y contradictorios. En este caso, es muy importante qué se envía exactamente a la entrada y a la salida de una red neuronal o de cualquier otro algoritmo de aprendizaje automático.
Por otra parte, no siempre podemos preparar los datos de entrenamiento necesarios, cuya estructura ya contiene relaciones causales. Por regla general, se trata de un conjunto de indicadores y ejemplos de escenarios de compra y venta. El signo incremental, el zigzag o la posición de las medias móviles entre sí suelen utilizarse para establecer la dirección de una futura operación. Todos estos tipos de marcas no son de expertos y, por regla general, no contienen verdaderas relaciones causales.
El etiquetado de datos es quizá el proceso más costoso y que más tiempo y recursos consume en el mundo del aprendizaje automático, ya que requiere la participación de especialistas en el campo estudiado (los llamados anotadores). Incluso las potentes redes neuronales lingüísticas como GPT y sus análogas, entrenadas con grandes cantidades de datos, sólo son capaces de clasificar patrones lingüísticos que forman un contexto semántico. Sin embargo, no responden a la pregunta de si una afirmación concreta es realmente verdadera o falsa. Equipos de anotadores trabajan con estos modelos, ajustando sus respuestas para que resulten útiles al usuario final.
En este caso, el comerciante tiene una pregunta razonable: si sé etiquetar datos, ¿para qué necesito una red neuronal? Después de todo, puedo simplemente escribir lógica basada en mis conocimientos y utilizarla de forma eficaz. Esta idea es correcta y errónea al mismo tiempo. Se equivoca en el sentido de que la red neuronal afronta bien la tarea de predicción, por lo que basta con entrenarla con datos bien etiquetados y luego recibir predicciones con datos nuevos, sin molestarse en escribir la lógica de la estrategia de negociación. Además, la funcionalidad incorporada permite evaluar la fiabilidad de las predicciones utilizando nuevos datos. Y tiene razón en que sin saber qué introducir en la entrada de la red neuronal o suministrando datos incorrectamente etiquetados como salida, ésta no podrá crear por defecto una estrategia de trading rentable.
La comprensión de los problemas anteriores del aprendizaje automático no llegó a los comerciantes inmediatamente. Al principio, incluso los creadores de los primeros algoritmos sencillos de aprendizaje automático creían firmemente que el análogo matemático de una neurona copia el trabajo de las neuronas cerebrales, lo que significa que una red neuronal suficientemente grande será capaz de realizar plenamente las funciones del cerebro y aprender a analizar la información de forma independiente. Más tarde se comprendió que el cerebro cuenta con un gran número de departamentos altamente especializados. Cada uno de ellos procesa determinada información y la transmite a otros departamentos. Así surgieron las arquitecturas de redes neuronales multicapa, gracias a las cuales los investigadores estuvieron más cerca de desentrañar los misterios del funcionamiento del cerebro. Estas arquitecturas han aprendido a procesar a la perfección información específica, como datos visuales, textuales, sonoros o tabulares.
Como se demostró más tarde, estas redes neuronales tampoco tienen la capacidad de sacar conclusiones independientes sobre patrones verdaderos, mientras se dedican al aprendizaje supervisado. Son propensos al sobreentrenamiento y a la subjetividad.
El siguiente paso en el camino hacia la comprensión de la estructura y el funcionamiento del cerebro fue el descubrimiento de que las redes neuronales naturales se basan en el aprendizaje por refuerzo, y no sólo en el aprendizaje a partir de muestras ya preparadas. Se trata de un tipo de aprendizaje en el que un sistema complejo es recompensado por las decisiones subjetivamente correctas y penalizado por las incorrectas. Tras recibir dichas recompensas varias veces, dependiendo de la tarea que se esté realizando, se acumula experiencia y se aprenden las opciones de respuesta subjetivamente correctas. El cerebro o la red neuronal empieza a cometer menos errores en determinados casos si ya se los ha encontrado antes.
Así surgió el aprendizaje por refuerzo, en el que los propios investigadores establecen la función de recompensa (una especie de función de adecuación en los algoritmos de optimización), premiando o castigando a la red neuronal por respuestas correctas o incorrectas. Ahora, el algoritmo de aprendizaje automático ya no se entrena con datos bien etiquetados ya preparados, sino que actúa por ensayo y error, tratando de maximizar la función de recompensa. En la actualidad, existe un gran número de algoritmos de aprendizaje por refuerzo para diferentes tareas, y este ámbito se está desarrollando de forma bastante activa.
Esto parecía un gran avance hasta que empezó a utilizarse, entre otras cosas, para problemas de clasificación de series temporales financieras. Quedó claro que este tipo de aprendizaje es muy difícil de controlar, ya que ahora todo se reduce a establecer la función de recompensa adecuada y elegir la arquitectura de red correcta. Nos enfrentamos al mismo problema trivial: si no conocemos la verdadera función objetivo, que describe las relaciones causales reales entre los estados del sistema y sus respuestas, es poco probable que la encontremos a través de numerosas búsquedas tanto de la propia función objetivo como de diversos algoritmos de aprendizaje por refuerzo, a menos que se tenga suerte.
Más o menos lo mismo ocurrió con los modelos generativos que aprenden condicionalmente sin un supervisor. Basadas en el principio codificador-decodificador o generador-discriminador, aprenden a comprimir la información, a resaltar los rasgos importantes o a distinguir las muestras reales de las ficticias (en el caso de las redes neuronales adversarias), para después generar ejemplos plausibles, como imágenes. Mientras que con las imágenes todo está más o menos claro y son una especie de "tonterías" plausibles de una red neuronal, todo es mucho más complicado con la generación de respuestas precisas y coherentes. El elemento de aleatoriedad inherente a la generación de una respuesta concreta no permite extraer conclusiones inequívocas sobre las relaciones causales, lo que no es adecuado para una actividad tan arriesgada como el trading, donde el comportamiento aleatorio del algoritmo es sinónimo de pérdidas.
El autor del artículo probó todos estos algoritmos para problemas de clasificación de series temporales, en particular pares de divisas Forex, y no quedó demasiado satisfecho con los resultados.
Últimamente, cada vez encontramos más publicaciones sobre el tema del llamado aprendizaje automático "fiable" o "digno de confianza". En general, el conjunto de planteamientos aún no está totalmente formado y varía de una zona a otra. Es importante entender que aborda el problema de la inferencia causal mediante algoritmos de aprendizaje automático. Los investigadores han aprendido a entender y confiar tanto en el aprendizaje automático que están dispuestos a confiarle la tarea de buscar relaciones causales en los datos, lo que, por supuesto, lleva el aprendizaje automático a un nivel completamente nuevo. La inferencia causal se utiliza ampliamente en campos como la medicina, la econometría y el marketing.
Este artículo describe un intento de comprender algunas técnicas de inferencia causal en relación con la negociación algorítmica.
Historia de la inferencia causal
La causalidad tiene una larga historia y se ha tenido en cuenta en la mayoría, si no en todas, las culturas avanzadas que conocemos.
Aristóteles, uno de los filósofos más prolíficos de la antigua Grecia, sostenía que comprender la estructura causal de un proceso es un componente necesario para conocer ese proceso. Además, sostenía que la capacidad de responder a las preguntas "por qué" es la esencia de la explicación científica. Aristóteles identifica cuatro tipos de causas (materiales, formales, eficientes y finales). Esta idea puede reflejar algunos aspectos interesantes de la realidad, aunque pueda sonar contraintuitiva para una persona moderna.
David Hume, el famoso filósofo escocés del siglo XVIII, propuso un marco más unificado para las relaciones causales. Hume comenzó argumentando que nunca observamos relaciones causales en el mundo. Lo único que observamos es que algunos acontecimientos están relacionados entre sí: Sólo descubrimos que uno de ellos sigue al otro. El impulso de una bola de billar va acompañado del movimiento de la segunda. Es el conjunto que aparece a los sentidos externos. La mente no experimenta sentimientos ni impresiones internas a partir de esta sucesión de objetos: por lo tanto, no hay nada en cada fenómeno particular que sugiera alguna fuerza o conexión necesaria.
Una interpretación de la teoría de la causalidad de Hume es la siguiente:
- Sólo observamos cómo el movimiento o aparición del objeto A precede al movimiento o aparición del objeto B.
- Si vemos esta secuencia suficientes veces, desarrollamos una sensación de anticipación.
- Este sentimiento de expectación es la esencia de nuestro concepto de causalidad (no se trata del mundo, sino del sentimiento que desarrollamos)
Esta teoría es muy interesante desde al menos dos puntos de vista. En primer lugar, los elementos de esta teoría son muy similares a una idea llamada condicionamiento en psicología. El condicionamiento es una forma de aprendizaje. Hay muchos tipos de condicionamiento, pero todos se basan en un principio común: la asociación (de ahí el nombre de este tipo de aprendizaje: aprendizaje asociativo). En cualquier tipo de condicionamiento, tomamos un acontecimiento u objeto (normalmente denominado estímulo) y lo asociamos a un comportamiento o respuesta específicos. El aprendizaje asociativo funciona en distintas especies animales. Puede encontrarse en humanos, monos, perros y gatos, así como en organismos mucho más simples, como los caracoles.
En segundo lugar, la mayoría de los algoritmos clásicos de aprendizaje automático también funcionan basándose en asociaciones. En el caso del aprendizaje supervisado, intentamos encontrar una función que asigne entradas a salidas. Para hacerlo con eficacia, tenemos que averiguar qué elementos de la entrada son útiles para predecir la salida. En la mayoría de los casos, la asociación es suficiente para este fin.
La psicología infantil aporta información adicional sobre las posibilidades de estudiar las relaciones causales.
Alison Gopnik es una psicóloga infantil estadounidense que estudia cómo los bebés desarrollan modelos del mundo. También colabora con informáticos para ayudarles a entender cómo los bebés construyen conceptos de sentido común sobre el mundo exterior. Los niños utilizan el aprendizaje asociativo incluso más que los adultos, pero también son experimentadores insaciables. ¿Has visto alguna vez a un padre intentando convencer a su hijo de que deje de tirar los juguetes? Algunos padres tienden a interpretar este comportamiento como grosero, destructivo o agresivo, pero los niños suelen tener otros motivos. Realizan experimentos sistemáticos que les permiten estudiar las leyes de la física y las reglas de la interacción social (Gopnik, 2009). Los bebés de tan solo 11 meses prefieren experimentar con objetos que presentan propiedades impredecibles antes que con objetos que se comportan de forma predecible (Stahl y Feigenson, 2015). Esta preferencia les permite construir eficazmente modelos del mundo.
Lo que podemos aprender de los bebés es que no nos limitamos a observar el mundo, como suponía Hume. También podemos interactuar con ella. En el contexto de la inferencia causal, estas interacciones se denominan intervenciones. Las intervenciones son el núcleo de lo que muchos consideran el Santo Grial del método científico: el ensayo controlado aleatorizado (ECA).
Pero, ¿cómo distinguir una asociación de una relación causal real? Intentemos averiguarlo.
Fundamentos de la inferencia causal en el aprendizaje automático
El principal objetivo de la inferencia causal en el aprendizaje automático es determinar si podemos tomar decisiones basadas en un algoritmo de aprendizaje automático entrenado. Aquí no siempre nos interesa la precisión y la frecuencia de las predicciones, aunque esto también es importante, sino que nos interesa más su estabilidad y nuestro nivel de confianza en ellas.
La tesis principal de la inferencia causal es: "La correlación no implica causalidad". Esto significa que la correlación no prueba la influencia de un acontecimiento sobre otro, sino que sólo determina la relación lineal de estos dos o más acontecimientos.
Por lo tanto, una relación causal se determina a través de la influencia de una variable sobre otra. La variable de influencia suele denominarse instrumental en el caso de la intervención de terceros, o simplemente una de las covariables (características en el aprendizaje automático). O a través de una acción a otra acción. En general, ¿al acontecimiento A siempre le sigue el acontecimiento B? ¿O el acontecimiento A es la causa del acontecimiento B? Por eso también se denomina prueba A/B. Esto es exactamente lo que trataremos más adelante, pero utilizando algoritmos de aprendizaje automático.
Existen varios enfoques para abordar la inferencia de causalidad, tanto mediante experimentos aleatorios como mediante variables instrumentales y aprendizaje automático. No tiene sentido enumerar aquí todos los métodos, ya que hay otras obras dedicadas a ello. Nos interesa saber cómo podemos aplicar esto a un problema de clasificación de series temporales.
Es importante señalar que casi todos estos métodos se basan en el modelo causal de Neumann-Rubin, o en modelos de resultados potenciales. Se trata de un enfoque estadístico que ayuda a determinar si un acontecimiento es realmente consecuencia de otro.
Por ejemplo, un clasificador entrenado muestra beneficios en las submuestras de entrenamiento y validación, mientras que sus señales provocan pérdidas en la submuestra de prueba. Para medir el efecto causal en los nuevos datos utilizando este clasificador, tenemos que comparar los resultados en los nuevos datos en caso de que se haya entrenado y en caso de que no se haya entrenado. Dado que es imposible ver los resultados de un clasificador no entrenado porque no genera ninguna señal de compra o venta, este resultado potencial es desconocido. Sólo tenemos el resultado actual después de entrenarlo, y el resultado desconocido sin entrenamiento es contrafactual. En otras palabras, tenemos que averiguar si el entrenamiento de un clasificador conduce a un aumento de los beneficios o a obtener beneficios con los nuevos datos en comparación con, por ejemplo, la apertura de operaciones al azar. Es decir, ¿tiene algún efecto positivo entrenar a un clasificador?
Este dilema es un "problema fundamental de la inferencia causal", cuando no sabemos cuál habría sido el resultado real si no se hubiera entrenado el clasificador, sino que sólo conocemos el resultado real después de haberlo entrenado.
Debido al problema fundamental de la inferencia causal, los efectos causales a nivel unitario (un único ejemplo de entrenamiento) no pueden observarse directamente. No podemos decir con certeza si nuestras predicciones han mejorado porque no tenemos con qué compararlas. Sin embargo, los experimentos aleatorios nos permiten evaluar los efectos causales a nivel de población. En un experimento aleatorio, los clasificadores se entrenan aleatoriamente en diferentes submuestras. Debido a esta distribución aleatoria de los ejemplos de entrenamiento, los resultados de predicción de los clasificadores son (de media) equivalentes, y la diferencia en las predicciones de los clasificadores para ejemplos específicos puede atribuirse al caso de ejemplos del conjunto de prueba que se incluyen o no en los ejemplos de entrenamiento. A continuación, podemos obtener una estimación del efecto causal medio (también denominado efecto medio del tratamiento) calculando la diferencia en los resultados medios entre las muestras tratadas (con un clasificador entrenado en los datos) y de control (con un clasificador no entrenado en los datos).
O imaginemos que existe un multiverso y en cada uno de los subuniversos vive la misma persona, que toma diferentes decisiones que conducen a diferentes resultados. La persona de cada subuniverso sólo conoce su propia versión del futuro y desconoce las opciones de futuro de sus otros "yoes" en otros subuniversos.
En el ejemplo del multiverso, suponemos que todas las personas tienen homólogos en otros universos. Todas las personas son, por término medio, similares. Esto significa que podemos comparar las razones de las decisiones que toman con los resultados de esas decisiones. Así, basándose en este conocimiento, será posible extraer una conclusión causal sobre lo que le ocurriría a una persona concreta en otro universo si actuara de una forma u otra que nunca antes había actuado allí. Si, por supuesto, estos universos son similares.
Escalera de pruebas en la inferencia causal
Existe una cierta sistematización de los métodos de inferencia causal, que representa una jerarquía de métodos según su capacidad probatoria. Esto ayudará a averiguar qué poder probatorio tendrá el método que hayamos elegido. A continuación figuran citas del artículo, cuyo enlace se facilita más arriba.

- En el primer peldaño de la escalera se sitúan los típicos experimentos científicos.
Del tipo que probablemente te enseñaron en secundaria o incluso en primaria. Para explicar cómo debe realizarse un experimento científico, mi profesor de biología nos hizo sacar semillas de una caja, dividirlas en dos grupos y plantarlas en dos tarros. El profesor insistió en que hiciéramos que las condiciones de los dos frascos fueran completamente idénticas: mismo número de semillas, misma humectación del suelo, etc. El objetivo era medir el efecto de la luz en el crecimiento de las plantas, así que pusimos uno de nuestros frascos cerca de una ventana y encerramos el otro en un armario. Dos semanas después, todos nuestros tarros cercanos a la ventana tenían bonitos cogollitos, mientras que los que dejamos en el armario apenas habían crecido. Al ser la exposición a la luz la única diferencia entre los dos frascos, explicó el profesor, podíamos concluir que la privación de luz provocaba que las plantas no crecieran.
Esto es básicamente lo más riguroso que se puede ser cuando se quiere atribuir una causa. La mala noticia es que esta metodología sólo se aplica cuando se tiene un cierto nivel de control tanto sobre el grupo de tratamiento (el que recibe la luz) como sobre el grupo de control (el que está en el armario). Suficiente control al menos para que todas las condiciones sean estrictamente idénticas excepto el único parámetro con el que estás experimentando (la luz en este caso). Obviamente, esto no se aplica ni a las ciencias sociales ni a la ciencia de datos.
Entonces, ¿por qué lo incluye el autor en el artículo? Bueno, básicamente porque este es el método de referencia. Todos los métodos de inferencia causal son, de alguna manera, trucos diseñados para reproducir esta metodología simple en condiciones donde no deberías ser capaz de sacar conclusiones si siguieras estrictamente las reglas explicadas por tu profesor de secundaria.
- Experimentos estadísticos (pruebas A/B)
Probablemente el método de inferencia causal más conocido en tecnología: Las pruebas A/B, también conocidas como ensayos controlados aleatorios. La idea que subyace a los experimentos estadísticos es confiar en la aleatoriedad y el tamaño de la muestra para mitigar la incapacidad de poner a los grupos de tratamiento y control exactamente en las mismas condiciones. Teoremas estadísticos fundamentales como la ley de los grandes números, el teorema del límite central o la inferencia bayesiana ofrecen garantías de que esto funcionará y una forma de deducir las estimaciones y su precisión a partir de los datos recopilados.
- Cuasiexperimentos
Un "cuasiexperimento" es la situación en la que el grupo de tratamiento y el de control se dividen mediante un proceso natural que no es verdaderamente aleatorio, pero que puede considerarse lo suficientemente cercano como para calcular estimaciones. En la práctica, esto significa que tendrá diferentes métodos que corresponderán a diferentes suposiciones sobre lo "cerca" que está de la situación de la prueba A/B. Entre los ejemplos famosos de experimentos naturales: utilizar la lotería del reclutamiento de la guerra de Vietnam para estimar el impacto de ser veterano en tus ingresos, o la frontera entre Nueva Jersey y Pensilvania para estudiar el efecto de los salarios mínimos en la economía.
- Métodos contrafactuales
Aquí abandonamos la idea de grupos de tratamiento y control (en realidad, no del todo) y, de hecho, modelamos la serie temporal "Y" a partir de datos históricos sin la participación de "X" en el futuro, donde "X" ya entra en juego. Así, durante el experimento, podemos comparar los datos reales de "Y" (en los que participó "X") con el modelo (predicción de "Y" sin "X") y adivinar el tamaño del efecto, ajustándolo a la precisión del modelo para "Y". Sin embargo, para que esta suposición se acerque a la verdad, necesitamos hacer el mayor número de pruebas de estabilidad del método. El efecto resultante dependerá críticamente no sólo de la calidad del modelo, sino también, en general, de la correcta aplicación del método elegido.
Al construir un modelo de clasificación de series temporales, sólo podemos utilizar métodos contrafactuales. En otras palabras, tenemos que idear nosotros mismos una variable instrumental o un tratamiento, aplicarlo a nuestras observaciones y, a continuación, realizar las pruebas oportunas para comprobar la estabilidad del método, que es lo que haremos en el futuro. Obviamente, este es el enfoque más complejo y el que tiene menos fuerza probatoria según la escalera de pruebas.
Notación en la inferencia causal
Acordamos que "tratamiento" T se refiere a algún impacto sobre un objeto, ya sea un paciente de una clínica, una persona bajo la influencia de una campaña publicitaria o alguna muestra del conjunto de entrenamiento. Entonces hay dos opciones. El sujeto recibía tratamiento o no.

También sabemos que cada objeto (unidad) no puede tratarse y no tratarse al mismo tiempo. Es decir, podría ser una de dos cosas.
Entonces,
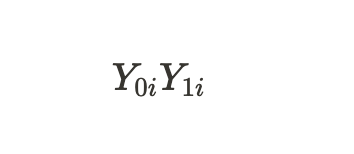
indican los resultados potenciales para una unidad sin tratamiento y para una unidad con tratamiento. Podemos calcular el efecto del tratamiento individual a través de la diferencia de estos resultados potenciales:
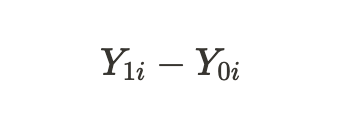
Debido al problema fundamental de la inferencia causal señalado anteriormente, no podemos obtener un efecto individual del tratamiento porque sólo se conoce uno de los resultados, pero podemos calcular el efecto medio del tratamiento en todos los sujetos similares, algunos de los cuales recibieron el tratamiento y otros no:
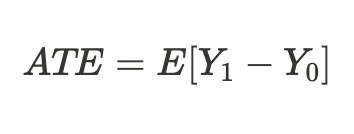
O podemos obtener un efecto medio del tratamiento sólo para las unidades que han sido tratadas:
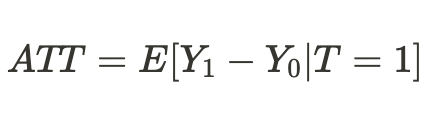
Sesgo
El sesgo es lo que distingue la correlación (asociación) de la causalidad (causa y efecto). ¿Y si, en otro universo, nuestros "yoes" se encontraran en condiciones de existencia completamente diferentes, y los resultados de las decisiones que tomaran ya no se correspondieran con los que estamos acostumbrados en este universo? Entonces, las conclusiones sobre los posibles resultados resultarán erróneas, y las suposiciones sólo serán relaciones asociativas, pero no causales.
Lo mismo ocurre con los clasificadores entrenados cuando dejan de obtener beneficios con nuevos datos que no han visto antes o simplemente dejan de predecir correctamente.
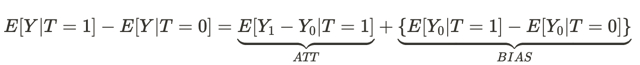
Esta ecuación responde a la pregunta de por qué una relación asociativa no es causal. El sesgo aquí es lo diferentes que son las condiciones de vida de las personas en universos diferentes antes de que tengan algún efecto en ambos universos. Esto se debe a que hay muchas otras variables que influyen en el resultado de la decisión que toman. Como resultado, las poblaciones de personas de un universo y de otro difieren no sólo en que se toman decisiones distintas, sino también en las condiciones de existencia.
Resulta que si las condiciones de nuestra existencia en diferentes universos resultan ser comparables, entonces nuestra conclusión sobre los resultados de nuestras acciones (en promedio) en otro universo resultará ser causal:
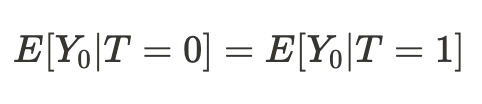
En consecuencia, la diferencia de medias se convierte ahora en el efecto causal medio:
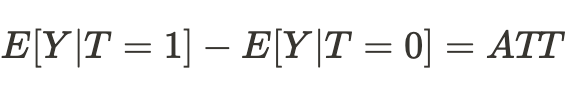
Simplemente podemos concluir que para estimar un efecto causal, una muestra de un universo debe ser comparable a una muestra de otro universo. Si esto es así, entonces podremos determinar la verdadera relación y con un alto grado de probabilidad podremos predecir el resultado de las acciones de nuestros "yoes" en otro universo.
En otras palabras, una asociación se convierte en una relación causal cuando el sesgo es igual a cero.
Traduciendo lo anterior a términos de aprendizaje automático, solemos tratar con datos de entrenamiento y validación, así como con datos de prueba. El modelo de entrenamiento de la máquina aprende utilizando datos de entrenamiento con participación parcial de datos de validación. Si las submuestras son comparables, entonces tendremos aproximadamente los mismos errores de predicción en los datos de entrenamiento y de validación. Si las submuestras difieren por un sesgo condicional, el error de predicción en los datos de validación será mayor. Por no hablar de la submuestra de prueba, cuya distribución de datos puede no parecerse en nada a las distribuciones de las dos primeras.
Pero, ¿cómo podemos entonces hacer una inferencia causal si las distribuciones de las submuestras son diferentes? La respuesta ya se ha dado parcialmente en la sección anterior: podemos hacer inferencias causales mediante experimentos aleatorios.
Experimentos aleatorios
Como ya ha quedado claro, la aleatorización nos permite dividir aleatoriamente los datos en grupos, uno de los cuales recibió el "tratamiento" (en nuestro caso, la formación del modelo), mientras que el otro no. Además, debemos hacerlo varias veces y entrenar muchos modelos. Esto es necesario para eliminar el sesgo de nuestras estimaciones. Aleatorizar y entrenar múltiples clasificadores elimina la dependencia de los resultados potenciales de un modelo específico de aprendizaje automático.
Esto puede resultar un poco confuso al principio. Podríamos pensar que la falta de dependencia de los resultados (predicciones) de un modelo concreto hace inútil el entrenamiento de ese modelo. Desde el punto de vista de las predicciones de este modelo concreto, la respuesta es sí. Sin embargo, se trata de potenciales resultados (predicciones).
Resultado potencial es cuál sería el resultado si el modelo estuviera entrenado o no. En los experimentos aleatorios, no queremos que el resultado (predicción) sea independiente del entrenamiento, ya que el entrenamiento del modelo afecta directamente al resultado.
Pero queremos que los resultados potenciales sean independientes del entrenamiento de cualquier clasificador en particular, ¡lo cual es tendencioso!
Con esto queremos decir que queremos que los resultados potenciales sean los mismos para los grupos de control y de prueba. Nuestros datos de entrenamiento y de prueba deben ser comparables porque queremos eliminar el sesgo de las estimaciones. Pero cada clasificador individual da pesos diferentes a los distintos ejemplos de entrenamiento, aunque estén mezclados, lo que hace que la cantidad de tratamiento sea diferente para cada observación. Esto complica la inferencia causal.
La aleatorización de los ejemplos de entrenamiento nos permite evaluar el efecto del tratamiento (entrenamiento) obteniendo la diferencia en los errores del modelo en las muestras de prueba y de entrenamiento. Sin embargo, en el caso de la clasificación, deben tenerse en cuenta las características de los algoritmos de aprendizaje automático. En este caso, la estimación del efecto sigue estando sesgada porque cada clasificador individual se entrena con la mitad o más de los ejemplos originales, dando a cada ejemplo pesos diferentes (tratamiento). Al utilizar varios clasificadores (un conjunto de ellos), minimizamos el sesgo promediando las puntuaciones de los clasificadores, lo que hace que el tratamiento sea más equitativo para cada unidad. Esto pone a todos los ejemplos de entrenamiento en las mismas condiciones, dándoles el mismo valor.
En esta sección hemos aprendido que los experimentos aleatorios ayudan a eliminar el sesgo de los datos para hacer inferencias causales más fiables. Los conjuntos de modelos nos ayudan a ofrecer estimaciones equivalentes del efecto del entrenamiento.
Emparejamiento
Los experimentos aleatorios permiten estimar el efecto medio del entrenamiento de un conjunto de modelos. Sin embargo, nos interesa obtener efectos individuales para cada ejemplo de entrenamiento. Esto es necesario para comprender en qué situaciones la estrategia de negociación, por término medio, aporta beneficios, y qué situaciones deben ajustarse o excluirse de la negociación. En otras palabras, queremos obtener estimaciones condicionales de los efectos del entrenamiento, en función de las características individuales de cada objeto.
El emparejamiento es una forma de comparar muestras individuales de toda la muestra para asegurarse de que son similares en todas las demás características, excepto en si se incluyeron o no en el conjunto de entrenamiento. Esto nos permite obtener puntuaciones individuales para cada ejemplo de formación.
Hay coincidencias exactas e imprecisas (aproximadas).
En el emparejamiento aproximado, por ejemplo, podemos comparar todas las unidades basándonos en criterios de proximidad como la distancia euclidiana, así como las distancias de Minkowski y Mahalanobis. Pero como se trata de series temporales, tenemos la opción de comparar unidades posicionalmente, por tiempo. Si entrenamos un conjunto de modelos, las predicciones de cada modelo en un momento dado ya están asociadas al conjunto de características presentes en ese punto de la línea temporal. Basta con comparar las predicciones de todos los modelos para un momento determinado. La complejidad computacional de tal comparación es mínima en comparación con otros métodos, lo que permitirá realizar más experimentos. Además, será una coincidencia exacta.
Incertidumbre
En el comercio algorítmico, no nos basta con determinar los efectos medios e individuales del tratamiento, porque queremos construir el modelo clasificador final. Necesitamos aplicar herramientas de inferencia causal para estimar la incertidumbre en el conjunto de datos y dividir las unidades en las que responden al tratamiento condicional (formación de un clasificador) y las que no. Es decir, en los que, en la inmensa mayoría de los casos, se clasifican correctamente y los que se clasifican incorrectamente. En función del grado de incertidumbre, que se calcula como la suma de las diferencias entre los resultados potenciales de todos los modelos ensemble.
Dado que estamos estimando la incertidumbre de los datos desde el punto de vista del clasificador, las órdenes de compra y venta deben evaluarse por separado porque su distribución conjunta confundirá la estimación final.
Metaaprendizaje
Los metaaprendices en la inferencia causal son modelos de aprendizaje automático que ayudan a estimar los efectos causales.
Ya nos hemos familiarizado con los conceptos ATE y ATT, que nos dan información sobre el efecto causal medio en una población. Sin embargo, es importante recordar que las personas y otros organismos complejos (por ejemplo, animales, grupos sociales, empresas o países) pueden responder de forma diferente al mismo tratamiento. Cuando nos enfrentamos a una situación así, ATE puede ocultarnos información importante.
Una solución a este problema es calcular el CATE (Conditional Average Treatment Effect / Efecto medio condicional del tratamiento), también conocido como HTE. Al calcular el CATE, no nos fijamos sólo en el tratamiento, sino en un conjunto de variables que definen las características individuales de cada unidad que pueden cambiar la forma en que el tratamiento afecta al resultado.
En el caso del tratamiento binario, el CATE puede definirse como:
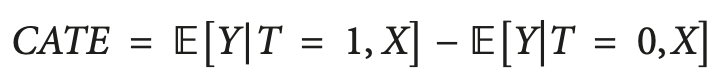
Donde "X" son las características que describen cada objeto individual (unidad). Así, pasamos de un efecto de tratamiento homogéneo a uno heterogéneo.
La idea de que las personas u otras unidades pueden reaccionar de forma diferente al mismo tratamiento suele representarse en forma de matriz, a veces llamada matriz de elevación, que puede ver en la figura.
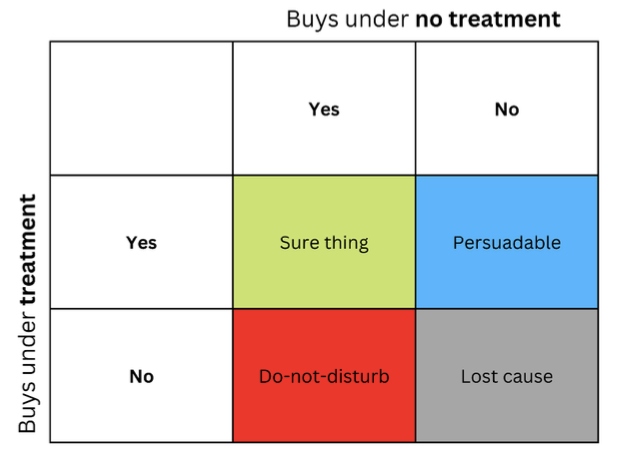
Las cadenas representan la respuesta al contenido cuando el mensaje (como un anuncio) se presenta al destinatario. Las columnas representan las respuestas cuando no se administra ningún tratamiento.
Las cuatro celdas coloreadas representan la dinámica del efecto del tratamiento. Compradores seguros (verdes) compran independientemente del tratamiento. Rojos (No molestar) pueden comprar sin tratamiento, pero no comprarán si se les trata. Los que han perdido el interés (grises) no comprarán independientemente del estado del tratamiento, y los azules no comprarán sin tratamiento, pero pueden comprar si se les aborda.
Si tiene un presupuesto limitado, debe centrarse en el grupo azul (Persuadible) y evitar, en la medida de lo posible, el grupo rojo (No molestar).
El marketing en los grupos "Seguro" y "Causa perdida" no le causará un perjuicio directo, pero tampoco le aportará ningún beneficio.
Del mismo modo, si usted es médico, querrá recetar un medicamento a las personas que puedan beneficiarse de él y evitar recetarlo a quienes pueda perjudicar. En muchos escenarios del mundo real, la variable de resultado puede ser probabilística (por ejemplo, la probabilidad de una compra) o continua (por ejemplo, el monto del gasto). En tales casos, no podemos identificar grupos discretos y nos centramos en encontrar las unidades con el mayor aumento esperado en la variable de resultado entre las condiciones de no tratamiento y tratamiento. Esta diferencia entre el resultado con tratamiento y sin tratamiento se denomina a veces elevación.
Traduciendo esto al lenguaje de la clasificación de series temporales, tenemos que determinar qué ejemplos del conjunto de entrenamiento responden mejor al tratamiento (entrenamiento del clasificador) y ponerlos en un grupo separado.
Una forma sencilla de estimar un efecto heterogéneo del tratamiento es construir un modelo sustitutivo que prediga la variable de tratamiento en función de los predictores que se utilicen, representado formalmente de la siguiente manera:
T ~ X
El rendimiento de un modelo de este tipo debería ser esencialmente aleatorio. Si no es aleatoria, significaría que el tratamiento depende de los rasgos, lo que significa que hay alguna variable omitida que no hemos tenido en cuenta y que afecta a nuestras inferencias causales, introduciendo confusión. Esto suele ocurrir debido a un mal diseño de los ensayos controlados aleatorios, en los que el tratamiento no se asigna realmente al azar.
S-Learner
S-Learner es el nombre de un enfoque sencillo para el modelado CATE. S-Learner pertenece a la categoría de los llamados metaaprendices. Nótese que los metaaprendices causales no están directamente relacionados con el concepto de metaaprendizaje utilizado en el aprendizaje automático tradicional. Toman uno o varios modelos básicos (tradicionales) de aprendizaje automático y los utilizan para calcular el efecto causal. En general, puede utilizar cualquier modelo de aprendizaje automático de complejidad suficiente (árbol, red neuronal, etc.) como aprendiz base si es compatible con sus datos.
S-Learner es el metamodelo más sencillo que sólo utiliza un aprendiz básico (de ahí su nombre: S(ingle)-Learner). La idea en la que se basa S-Learner es sorprendentemente sencilla: entrenar un modelo en el conjunto completo de datos de entrenamiento, incluyendo la variable de tratamiento como característica, predecir ambos resultados potenciales y restar los resultados para obtener CATE.
Tras el entrenamiento, el procedimiento de previsión paso a paso de S-Learner es el siguiente:
- Seleccione la observación de interés.
- Establezca el valor de tratamiento para esta observación en 1 (o True).
- Predecir el resultado utilizando el modelo entrenado.
- Vuelve a hacer la misma observación.
- Esta vez establezca el valor de tratamiento en 0 (o False).
- Haga una predicción.
- Reste el valor de predicción sin tratamiento del valor de predicción con tratamiento.
T-Learner
La principal motivación de T-Learner es superar la principal limitación de S-Learner. Si S-Learner puede aprender a ignorar el tratamiento, ¿por qué no hacer que sea imposible ignorarlo?
Eso es exactamente lo que es T-Learner. En lugar de ajustar un modelo a todas las observaciones (tratadas y no tratadas), ahora ajustamos dos modelos: uno sólo para las unidades tratadas y otro sólo para las no tratadas.
En cierto modo, esto equivale a forzar que la primera división en un modelo basado en árboles sea una división por la variable de tratamiento.
El proceso de aprendizaje de T-Learner es el siguiente:
- Divida los datos según la variable de tratamiento en dos subconjuntos.
- Entrene dos modelos, uno en cada subconjunto.
- Para cada observación, prediga los resultados utilizando ambos modelos.
- Reste los resultados del modelo sin tratamiento de los resultados del modelo con tratamiento.
Tenga en cuenta que ahora no hay posibilidad de que se ignoren los tratamientos porque hemos codificado la división de tratamientos como dos modelos separados.
T-Learner se centra en mejorar sólo un aspecto en el que S-Learner puede (pero no tiene por qué) fallar. Esta mejora tiene un coste. Ajustar dos algoritmos a dos subconjuntos diferentes de datos significa que cada algoritmo se entrena con menos datos, lo que puede reducir la calidad del ajuste.
Esto también hace que T-Learner sea menos eficiente en términos de uso de datos (necesitamos el doble de datos para entrenar a cada aprendiz base de T-Learner para producir una representación comparable en calidad a S-Learner). Esto suele dar lugar a una mayor varianza en la puntuación de T-Learner en comparación con la de S-Learner. En particular, la varianza puede llegar a ser muy grande en los casos en que un grupo de tratamiento tiene muchas menos observaciones que el otro.
En resumen, T-Learner puede ser útil cuando se espera que el efecto del tratamiento sea pequeño y S-Learner puede no reconocerlo. Hay que tener en cuenta que este metaaprendizaje suele requerir más datos que S-Learner, pero la diferencia disminuye a medida que aumenta el tamaño total del conjunto de datos.
X-Learner
X-Learner es un metaaprendizaje diseñado para hacer un uso más eficiente de la información disponible en los datos.
X-Learner trata de estimar directamente el CATE y, para ello, utiliza información que S-Learner y T-Learner descartaron previamente. ¿Qué tipo de datos son? S-Learner y T-Learner estudiaron lo que se denomina la función de respuesta, o cómo responden las unidades al tratamiento (en otras palabras, la función de respuesta es la correspondencia del rasgo "X" y el tratamiento "T" con el resultado "Y"). Al mismo tiempo, ninguno de los modelos utilizó el resultado real para simular el CATE.
- El primer paso es sencillo, y usted ya lo sabe. Eso es exactamente lo que hicimos con T-Learner. Dividimos nuestros datos por variable de tratamiento para obtener dos subconjuntos separados: el primero contiene sólo las unidades que recibieron el tratamiento, y el segundo contiene sólo las unidades que no recibieron el tratamiento. A continuación, entrenamos dos modelos: uno en cada subconjunto.
- Introducimos un modelo adicional denominado "modelo de puntuación de la propensión" (en el caso más sencillo se trata de una regresión logística) y lo entrenamos para predecir el tratamiento de los rasgos "X".
- A continuación, calculamos el efecto del tratamiento y entrenamos dos modelos con las características y los valores CATE.
- Los resultados de la utilización de los dos modelos se suman con la ponderación obtenida de la puntuación de propensión del modelo.
Por otro lado, si su conjunto de datos es muy pequeño, X-Learner puede no ser la mejor opción porque cada modelo adicional conlleva ruido adicional al ajustarlo, y puede que no tengamos suficientes datos para utilizar ese modelo. En este caso, S-Learner es más adecuado.
Hay metaaprendices más avanzados. No voy a utilizarlos, así que no tiene mucho sentido hablar de ellos en este breve artículo. Estos son el aprendizaje automático desviado/ortogonal y el R-Learner, los cuales puedes estudiar por tu cuenta.
Conclusión sobre los metaaprendices existentes
Los algoritmos propuestos, a pesar de una parte teórica bastante extensa, sólo son estimadores del efecto CATE. La bibliografía sobre inferencia causal apenas aborda el ciclo completo de detección y evaluación de los efectos del tratamiento, a menos que se trate de casos muy evidentes, y la situación de la aplicación de los modelos resultantes en los procesos empresariales también es bastante débil. Se afirma que corresponde al investigador formular los experimentos y luego utilizar estos estimadores. Decidí ir un poco más allá e incorporé elementos de estos estimadores en la creación de un sistema de negociación, que se produce automáticamente. Se suministran signos y etiquetas a la entrada y la salida del algoritmo, como antes, luego el algoritmo intenta identificar relaciones causales en la parte de los datos en que esto es posible, y excluye el resto de la lógica de la toma de decisiones comerciales.
Implementación de la función de metaaprendizaje para construir un algoritmo de trading
Armado con el mínimo necesario de conocimientos, me propongo considerar mi propio algoritmo. Se han realizado muchos experimentos con distintos metaaprendices y formas de utilizarlos para analizar los efectos causales. Por el momento, el algoritmo propuesto es uno de los mejores del arsenal, aunque puede mejorarse.
Dado que hemos determinado que no es práctico utilizar un único clasificador, que está sesgado, para evaluar los resultados potenciales, el primer argumento de la función es un número especificado de clasificadores. Usé el algoritmo CatBoost.< A continuación están los hiperparámetros del aprendiz, como el número de iteraciones y la profundidad del árbol, así como bad_samples_fraction, un parámetro conocido desde el primer artículo dedicado a los metaaprendices. Es el porcentaje de ejemplos mal clasificados que deben excluirse del conjunto de entrenamiento final. Deberíamos intentar no comerciar en estos momentos.
BAD_BUY y BAD_SELL son colecciones de índices de ejemplos malos que se reponen en cada iteración.
En cada nueva iteración, cuyo número es igual al número especificado de aprendices, el conjunto de datos se divide en submuestras de entrenamiento y validación de forma aleatoria en una proporción determinada (aquí es 50/50). Esto evita que cada algoritmo individual se sobreentrene. La partición aleatoria permite que cada clasificador se entrene y valide en submuestras únicas, mientras que todo el conjunto de datos se utiliza para producir estimaciones. Esto elimina el sesgo en las estimaciones, lo que nos permite evaluar con mayor precisión qué ejemplos son realmente poco susceptibles al tratamiento (entrenamiento del clasificador).
Después de cada entrenamiento, las etiquetas de clase reales se comparan con las predichas. Las etiquetas predichas incorrectamente se unen a las colecciones de malos ejemplos. Esperamos que, a medida que aumente el número de clasificadores, las estimaciones de las muestras realmente malas sean menos sesgadas.
Una vez formadas las colecciones de ejemplos malos, calculamos el número medio de muestras malas en todos los índices. A continuación, seleccionamos los índices en los que el número de ejemplos malos supera la media en una determinada cantidad. Esto nos permite variar el número de ejemplos malos incluidos en el entrenamiento del modelo final, ya que con un gran número de reentrenamientos existe la probabilidad de que cada índice caiga en ejemplos malos al menos una vez. En este caso, resulta que todos los ejemplos serán excluidos del conjunto de entrenamiento final, entonces este algoritmo no funcionará.
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float): dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] BAD_BUY = pd.DatetimeIndex([]) BAD_SELL = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_b = coreset[coreset['labels']==0] coreset_s = coreset[coreset['labels']==1] diff_negatives_b = coreset_b['labels'] != coreset_b['labels_pred'] diff_negatives_s = coreset_s['labels'] != coreset_s['labels_pred'] BAD_BUY = BAD_BUY.append(diff_negatives_b[diff_negatives_b == True].index) BAD_SELL = BAD_SELL.append(diff_negatives_s[diff_negatives_s == True].index) to_mark_b = BAD_BUY.value_counts() to_mark_s = BAD_SELL.value_counts() marked_idx_b = to_mark_b[to_mark_b > to_mark_b.mean() * bad_samples_fraction].index marked_idx_s = to_mark_s[to_mark_s > to_mark_s.mean() * bad_samples_fraction].index data.loc[data.index.isin(marked_idx_b), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_s), 'meta_labels'] = 0.0 return data[data.columns[1:]]
El resto de funciones no se han modificado y se describen en el artículo anterior. Puedes descargarlos allí, mientras que la función de metaaprendizaje puede ser reemplazada por la propuesta. En el resto de este artículo, nos centraremos en los experimentos e intentaremos sacar conclusiones finales.
Prueba del algoritmo de inferencia causal
Supongamos que utilizamos la optimización genética de las estrategias de negociación según algún criterio (la llamada función de adecuación). Nos interesa no sólo el mejor resultado de optimización, sino también que los resultados de todas las pasadas, por término medio, sean buenos. Si la estrategia comercial es mala o la dispersión de los parámetros es demasiado grande, habrá un gran número de pasadas de optimización con resultados insatisfactorios, lo que afectará negativamente a la estimación media. Nos gustaría evitarlo, así que entrenaremos nuestro algoritmo muchas veces, luego promediaremos los resultados y compararemos el mejor resultado con la media.
Para ello, he escrito una modificación de un comprobador personalizado que prueba todos los modelos entrenados de la lista a la vez:
def test_all_models(result: list): pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] pr_tst['labels'] = 0.5 pr_tst['meta_labels'] = 0.5 for i in range(len(result)): pr_tst['labels'] += result[i][1].predict_proba(X)[:,1] pr_tst['meta_labels'] += result[i][2].predict_proba(X)[:,1] pr_tst['labels'] = pr_tst['labels'] / (len(result)+1) pr_tst['meta_labels'] = pr_tst['meta_labels'] / (len(result)+1) pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(pr_tst, plot=plt)
Ahora haremos la inferencia causal 25 veces (entrenaremos 25 modelos independientes, que son altamente aleatorios en términos de división aleatoria en submuestras):
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learners(15, 25, 2, 0.3)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
test_all_models(options) Probemos primero el mejor modelo según la versión R^2:
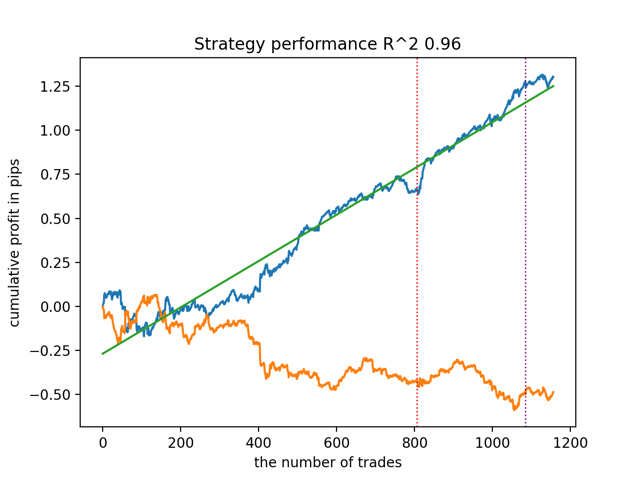
A continuación, prueba todos los modelos a la vez:
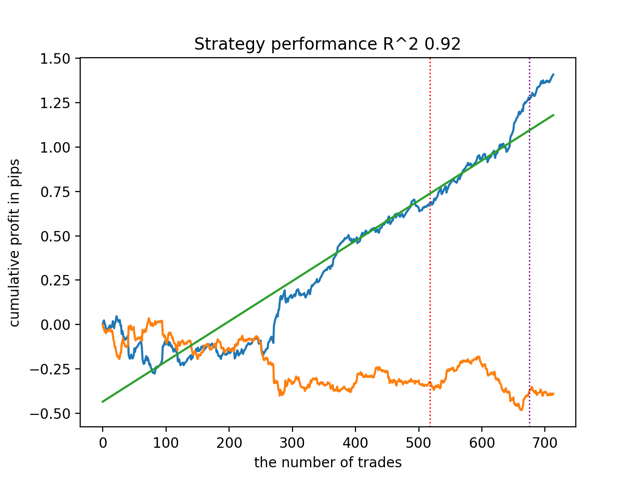
El resultado medio no difiere mucho del mejor. Esto significa que en el transcurso de un experimento aleatorio controlado es posible acercarse a las verdaderas relaciones causales.
Entrenemos y probemos el algoritmo con otros parámetros de entrada del metaaprendizaje.
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learners(5, 10, 1, 0.4)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
test_all_models(options) Los resultados son los siguientes:
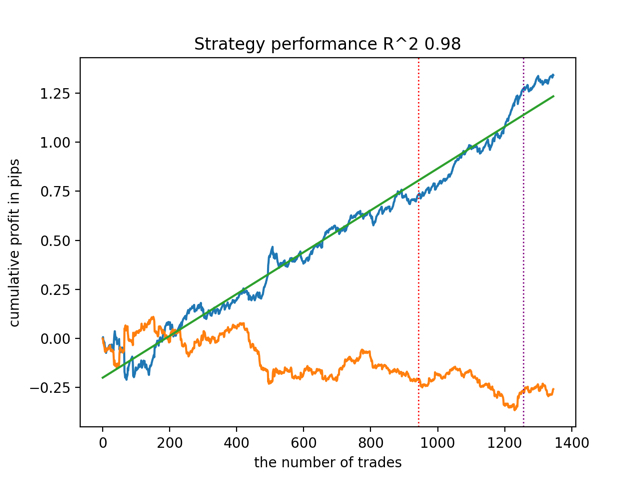
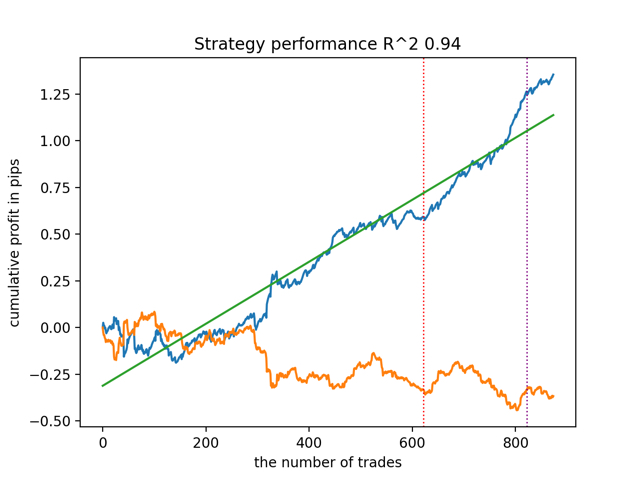
También se observó que la profundidad del historial de entrenamiento (resaltada por líneas verticales en los gráficos) afecta a la calidad de los resultados, así como al número de características y otros hiperparámetros de los modelos (lo que en general no es sorprendente), mientras que la dispersión en la calidad de los modelos sigue siendo pequeña. Creo que la estabilidad resultante es una propiedad o característica importante del algoritmo propuesto, que nos permite tener una confianza adicional en la calidad de las estrategias de negociación resultantes.
Resumen
Este artículo le ha presentado los conceptos básicos de la inferencia causal. Se trata de un tema bastante amplio y complejo para abarcar todos sus aspectos en un solo artículo. La inferencia causal y el pensamiento causal tienen sus raíces en la filosofía y la psicología y desempeñan un papel importante en nuestra comprensión de la realidad. Por lo tanto, gran parte de lo que se escribe se percibe bien a nivel intuitivo. Sin embargo, siendo algo agnóstico, intenté dar un ejemplo práctico e ilustrativo para demostrar el poder de la llamada inferencia causal en problemas de clasificación de series temporales. Puedes utilizar este algoritmo para realizar diversos experimentos. Basta con sustituir un par de funciones del código presentado en el artículo anterior. Los experimentos no acaban aquí. Tal vez aparezca nueva información interesante, que luego compartiré con ustedes.
Referencias útiles
- Aleksander Molak "Causal inference and discovery in Python / Inferencia y descubrimiento causal en Python"
- Matheus Facure "Causal inference for the Brave and True / Inferencia causal para los valientes y auténticos"
- Miguel A. Hernan, James M. Robins "Causal inference: What If / Inferencia causal: ¿Y si?"
- Gabriel Okasa "Meta-learners for estimation of causal effects: finite sample cross-fit performance / Metaaprendices para la estimación de efectos causales: rendimiento cruzado de muestras finitas"
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13957
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso