ニューラルネットワークが簡単に(第86回):U字型Transformer

はじめに
長期的な時系列の予測は、取引にとって特に重要です。2017年に紹介されたTransformerアーキテクチャは、自然言語処理(NLP)とコンピュータービジョン(CV)の分野で優れたパフォーマンスを発揮しました。使用されているSelf-Attentionメカニズムは、長期的な依存関係を効果的に捉え、コンテキストから重要な情報を抽出することが可能です。そのため、このメカニズムに基づいたさまざまな時系列予測アルゴリズムが次々と提案されています。
しかし、最近の研究では、単純な多層パーセプトロン(MLP)ネットワークが、従来のTransformerベースのモデルを上回る精度を示すことが報告されています。それにもかかわらず、Transformerアーキテクチャの有効性は依然として多くの分野で証明されており、実用化も進んでいます。したがって、その表現能力は非常に強いと考えられます。使用ためのメカニズムが必要です。バニラTransformerアルゴリズムを改善するための選択肢の1つに、論文「titlehttps://arxiv.org/abs/2307.09019titleU-shaped Transformer:Retain High Frequency Context in Time Series Analysis」があります。この論文では、U字型Transformerアルゴリズムが紹介されています。
1. アルゴリズム
U字型Transformer法の作者は包括的な研究をおこない、従来のTransformerのアーキテクチャを最適化する方法だけでなく、モデルを訓練するアプローチも提案しました。
Transformerアーキテクチャに基づくモデルの訓練には、多大な計算資源と大規模な訓練サンプルが必要であることは既に述べた通りです。そのため、NLPやCVの問題に対処する際には、事前に訓練されたモデルが広く使用されています。しかし、時系列データの多様な性質や構造を考慮する必要があるため、時系列データの問題にはこのような事前訓練されたモデルが存在しません。これを踏まえ、U字型Transformer法の著者は、モデル訓練プロセスを2段階に分けることを提案しています。
第一段階では、比較的大規模なデータセットを用いてU字型Transformerモデルを訓練し、ランダムにマスクされた入力データを復元します。この段階で、モデルはデータの構造や依存関係、時系列のコンテキストを学習するとともに、さまざまなノイズを効果的にフィルタリングできるようになります。さらに、この手法の著者は、異なる期間だけでなく、異なるソースから収集されたさまざまな時系列のデータで訓練データセットを補足しました。これにより、U字型Transformerは異なる問題にも対応できるようになります。
2番目の段階では、U字型Transformerの重みを凍結し、その上に「頭」と呼ばれる決断層を追加します。この決断層は、比較的小さな訓練データセットを用いて、特定の問題に対応するように微調整されます。
このプロセスにより、事前に訓練された1つのU字型Transformerモデルを使って、さまざまな時系列問題を効率的に解決することが可能になります。
ご覧のように、微調整は、完全なU字型Transformer全体を再訓練するよりも、はるかに迅速で、必要なリソースも少なくて済みます。
以下は、著者による一般的なプロセスの可視化です。
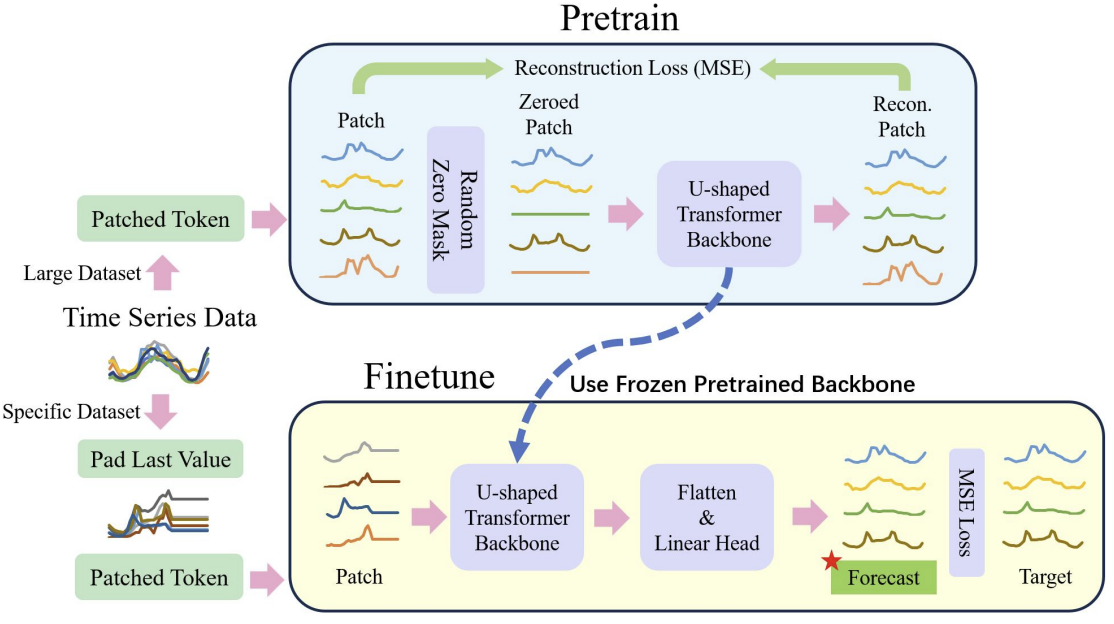
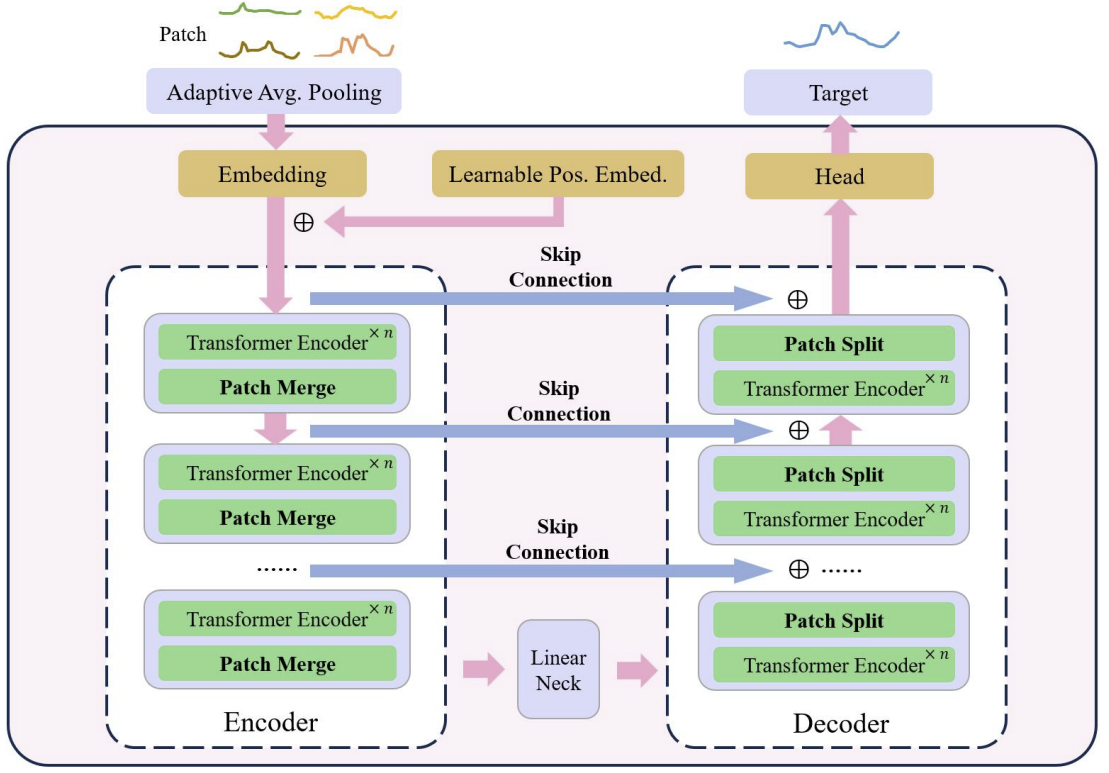
U字型Transformerの核心は、Transformer層の積み重ねにあります。複数のTransformer層がグループを形成します。グループを処理した後、異なるスケールの特徴量を統合するために、パッチを結合または分割する操作が実行されます。
エンコーダーからデコーダーへの高速データ転送には、複数の跳躍接続(skip connection)が使用されます。これにより、不必要な処理を省きながら、高頻度のデータを迅速にニューラルネットワークの出力に伝えることが可能です。Transformerグループの入力データは、同じ形状のデコーダー出力に供給されます。入力データの符号化プロセスでは、モデルが深くなるにつれて、高周波の特徴量が徐々にフィルタリングされ、共通の特徴量が抽出されます。デコーディングの段階では、一般的な特徴量が跳躍接続からの詳細な情報とともに再構成され、最終的に高周波数と低周波数の特徴量を組み合わせた時系列の表現が得られます。
パッチ演算は、異なるスケールの特徴量を得ることを可能にするため、U字型Transformerモデルにとって重要な要素です。選択された特徴量は、注意計算の基礎となる文脈に含まれる情報に直接影響します。従来のアプローチでは、時系列を2つの配列に分割し、それぞれを独立したチャンネルとして扱うことが多いです。U字型Transformer法の著者は、ある時間ステップにおける異なるチャンネルからのパッチに関する情報は、隣接する領域から発信されるものではないため、このアプローチは粗雑であると考えています。そこで、著者はパッチプーリングとして、ウィンドウサイズとストライドが2の畳み込みを使用することを提案しています。こうすることで、前のパッチが断片化されず、スケールがより良く融合されます。復号化処理中、この方法の著者は、パッチ分離操作として転置畳み込みを適宜使用しています。
U字型Transformer法は、埋め込み法として点カーネルとの畳み込みを用い、各パッチを高次元空間にマッピングします。次に、この手法の著者は、各パッチに対して訓練可能な相対位置エンコーダを用意し、これを埋め込みパッチに追加することで、パッチ間の事前知識の蓄積を強化します。
上述したように、U字型Transformer法の著者は、時系列データをより小さなブロックに分割するために、パッチ基本の埋め込みアプローチを使用しています。プレタスクとしてパッチリカバリーが使用されます。マスクされていないパッチを復元することで、値がゼロのノイズの多いデータに対するモデルのロバスト性が向上すると、この手法の著者は考えています。
事前訓練の後、モデルは特定のヘッドユニット上で微調整され、ターゲットタスクの生成を担当します。この段階で、ヘッドネットワーク以外のすべてのコンポーネントを凍結させます。
モデルの汎化能力を向上させ、より大きなデータセットでTransformerの潜在能力を引き出すために、より大きなデータセットを使用します。
データの不均衡をさらに緩和するために、著者は重み付きランダムサンプリングを使用し、訓練中の異なるデータセットからのサンプル数をバランスさせます。
Transformer基本のモデルにおける訓練の不安定性の問題を軽減するために、この手法の著者は、入力データを標準的な正規分布に近づけるために、各ミニバッチを正規化することを提案しています。
その結果、提案するデータ前処理法は、データセットの異なる部分からの効率的な特徴量抽出を達成し、複数のデータセットに対する共同訓練中のデータ不均衡の問題を効果的に克服します。
2. MQL5での実装
手法の理論的側面を考察した後は、本稿の実用的な部分に移ります。ここでは、提案されたアプローチをMQL5で実装します。
前述したように、U字型Transformerにはいくつかのアーキテクチャソリューションが採用されています。訓練可能な位置符号化のブロックから始めましょう。
2.1 位置符号化
位置符号化ブロックは、時系列の要素の位置に関する情報を時系列に入力するためのものです。ご存知のように、Self-Attentionアルゴリズムは、シリーズ内の位置に関係なく、要素間の依存関係を分析します。しかし、直列における要素の位置や、分析された要素間の距離に関する情報は、重要な役割を果たすことがあります。これは特に時系列データの場合に当てはまります。この情報を加えるために、従来のTransformerは、入力データに正弦波シーケンスを加えます。正弦波シーケンスの期間性は固定であり、解析されるシーケンスのサイズによって異なる実装で変化する可能性があります。
時系列は、期間性があることが特徴です。いくつかの周波数特性を持つこともあります。このような場合、位置符号化テンソルの周波数特性を、元のデータを歪ませたり余分な情報を加えたりしないように選択するための追加作業が必要になります。
原著論文には、訓練可能な位置符号化の方法についての詳細な記述はありません。この手法の作者は、モデルの訓練過程で、配列の各要素に対して位置符号化係数を選択したような印象を受けました。そのため、操作中はずっと固定されています。
実装では、もう少し踏み込んで、位置符号化係数を入力データに依存するようにします。位置符号化テンソルを生成するために、単純な全結合層を使用します。当然、訓練過程でこの層を訓練することになります。
提案されたメカニズムを実装するために、新しいクラスCNeuronLearnabledPEを作成します。ほとんどの場合と同様に、ニューラル層の基本クラスCNeuronBaseOCLから主な機能を継承します。
class CNeuronLearnabledPE : public CNeuronBaseOCL { protected: CNeuronBaseOCL cPositionEncoder; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronLearnabledPE(void) {}; ~CNeuronLearnabledPE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronLearnabledPE; } virtual void SetOpenCL(COpenCLMy *obj); };
このクラス構造には、ニューラルネットワークの基本層であるcPositionEncoderオブジェクトが1つ入れ子になっており、このオブジェクトには位置符号化テンソルの訓練可能なパラメータが含まれています。このオブジェクトは静的に指定されるので、クラスのコンストラクタとデストラクタは空にしておくことができます。
クラスのインスタンスはInitメソッドで初期化されます。メソッドのパラメータには、入れ子オブジェクトを正しく初期化するために必要な情報をすべて渡します。
bool CNeuronLearnabledPE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; if(!cPositionEncoder.Init(0, 1, OpenCL, numNeurons, optimization, iBatch)) return false; cPositionEncoder.SetActivationFunction(TANH); SetActivationFunction(None); //--- return true; }
このメソッドのアルゴリズムは非常にシンプルです。メソッド本体では、まず親クラスの同じメソッドを呼び出し、受け取った外部パラメータを確認し、継承したオブジェクトを初期化します。呼び出されたメソッドを実行した後に返される論理値によって、操作の結果を判断します。
次のステップは、cPositionEncoder入れ子オブジェクトを初期化することです。入れ子オブジェクトに対しては、活性化関数として双曲正接を設定します。この関数の値の範囲は-1から1で、これは正弦波シーケンスの値の範囲に相当します。
クラスの動的位置符号化では、活性化関数は存在しません。
すべての反復が正常に終了したら、trueの結果でメソッドを終了します。
CNeuronLearnabledPE::feedForwardメソッドで、このメソッドのフィードフォワードパスアルゴリズムを説明しましょう。親クラスの同じメソッドと同様に、このメソッドは入力データを含む前のニューラル層のオブジェクトへのポインタをパラメータとして受け取ります。
bool CNeuronLearnabledPE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cPositionEncoder.FeedForward(NeuronOCL)) return false; if(!SumAndNormilize(NeuronOCL.getOutput(), cPositionEncoder.getOutput(), Output, 1, false, 0, 0, 0, 1)) return false; //--- return true; }
得られた初期データに基づいて、まず位置符号化テンソルを生成します。そして、得られた値を入力データテンソルに加えます。
すべての操作の実行は、呼び出されたメソッドが返す値を使って制御されます。
誤差勾配分布法のCNeuronLearnabledPE::calcInputGradientsアルゴリズムは少し複雑に見えます。パラメータでは、前のニューラル層のオブジェクトへのポインタも受け取ります。これに誤差勾配を渡す必要があります。
bool CNeuronLearnabledPE::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!DeActivation(cPositionEncoder.getOutput(), cPositionEncoder.getGradient(), Gradient, cPositionEncoder.Activation())) return false; if(!DeActivation(NeuronOCL.getOutput(), NeuronOCL.getGradient(), Gradient, NeuronOCL.Activation())) return false; //--- return true; }
メソッド本体では、まずパラメータで受け取ったポインタの妥当性を確認します。
そして、後続層から得られる誤差勾配を内部オブジェクトの活性化関数に合わせます。初期化の過程で、内部オブジェクトには活性化関数を指定しましたが、CNeuronLearnabledPEオブジェクト自体には活性化関数を指定しなかったことを思い出してください。したがって、層バッファの誤差勾配は、活性化関数によって修正されませんでした。
次のステップは、誤差勾配の補正操作を繰り返すことです。しかし今回は、前の層の活性化関数に使用します。
位置符号化テンソルを生成する内部オブジェクトを通して誤差勾配を伝搬させないことに注意してください。この層のパラメータの更新を実行するには、その出力に誤差勾配があれば済みます。位置符号化テンソルを生成するブロックは、入力データやその埋め込みに影響を与えないはずなので、誤差勾配をオブジェクトを通して前の層に伝播させる必要はありません。
CNeuronLearnabledPEクラスのバックプロパゲーションパスアルゴリズムの実装を完了するために、学習パラメータを更新するメソッドupdateInputWeightsを作成しましょう。このメソッドは非常に単純で、同じ名前の入れ子オブジェクトのメソッドを呼び出します。
bool CNeuronLearnabledPE::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return cPositionEncoder.UpdateInputWeights(NeuronOCL); }
このクラスの完全なコードとすべてのメソッドは添付ファイルにあります。
2.2 U字型Transformerクラス
U字型Transformer法の著者たちが提案したアプローチの実装のバージョンを続けましょう。エンコーダーとデコーダーの間の跳躍接続の実装アーキテクチャの決定は、見かけの単純さとは裏腹に、それほど明白なものではなかったと言わざるを得ません。一方では、インナー層識別子への参照を使い、エンコーダーからデコーダーにデータを渡すこともできます。難しいことは何もありません。しかし、跳躍接続を介した誤差勾配の伝播について疑問が生じます。クラスのバックプロパゲーションアーキテクチャ全体は、後続のバックワードパスの間に誤差勾配を書き換えることで構築されています。したがって、跳躍接続を通して伝搬される誤差勾配は、跳躍接続オブジェクト間のニューラル層を通る勾配伝搬操作の間に取り除かれます。
解決策として、U字型Transformer全体のアーキテクチャを1つのクラスで作ることが考えられます。しかし、各ブロックのTransformer層の数が異なる、異なる数のエンコーダーデコーダーブロックを構築するメカニズムが必要です。その解決策は、オブジェクトを繰り返し作成することです。選択したメカニズムについては、実施プロセスで詳しく説明します。
U字型Transformerブロックを実装するために、CNeuronUShapeAttentionクラスを作成します。このクラスは、前のクラスと同様に、CNeuronBaseOCLニューラル層基底クラスから主な機能を継承します。
class CNeuronUShapeAttention : public CNeuronBaseOCL { protected: CNeuronMLMHAttentionOCL cAttention[2]; CNeuronConvOCL cMergeSplit[2]; CNeuronBaseOCL *cNeck; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); //--- public: CNeuronUShapeAttention(void) {}; ~CNeuronUShapeAttention(void) { delete cNeck; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronUShapeAttention; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *net, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
クラス本体には、多層多頭注意クラスCNeuronMLMHAttentionOCLの2要素の配列を作成します。これらは現在のブロックのエンコーダーとデコーダーになります。
また、2つの畳み込み層要素の配列を作成します。
現在のブロックのエンコーダーとデコーダーの間のすべての要素は、ニューラル層基本クラスのcNeckオブジェクトに配置されます。しかし、不特定多数のブロックを1つのブロックに加えることができるのでしょうか。この質問に答えるには、Initオブジェクト初期化メソッドの検討に移ることをお勧めします。
いつものように、メソッドのパラメータには、オブジェクトアーキテクチャの主要な定数を受け取ります:
- window:入力データウィンドウのサイズ(シーケンスの1要素の記述ベクトル).
- window_key:Self-Attention Query、Key、Valueエンティティのシーケンスの1要素を記述する内部ベクトルのサイズ
- head:Attention Headの数
- units_count:シーケンス内の要素数
- layers:1ブロック内のAttention層の数
- inside_bloks:U字型Transformer入れ子ブロックの数
パラメータwindow、window_key、heads、layersは、現在のU字型TransformerブロックとU字型Transformer入れ子ブロックで変更なく使用されます。
bool CNeuronUShapeAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッド本体では、まず親クラスの同じメソッドを呼び出し、受け取ったパラメータを制御し、継承したオブジェクトを初期化します。
次に、エンコーダーとパッチ分割オブジェクトを初期化します。
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2 * window, 4 * window, (units_count + 1) / 2, optimization, iBatch)) return false;
次に、初期化メソッドの最も興味深いブロックが登場します。まず、指定された入れ子ブロックの数を確認します。もし0以上であれば、現在のクラスと同様に、U字型Transformer入れ子ブロックを作成し、初期化します。しかし、配列の要素数は2倍になり、これはパッチ分割の結果に相当します。また、入れ子ブロックの数を1減らします。
if(inside_bloks > 0) { CNeuronUShapeAttention *temp = new CNeuronUShapeAttention(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, 2 * units_count, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
作成されたオブジェクトへのポインタをcNeck変数に保存します。そのために、ダイナミックオブジェクトを宣言しました。このように、初期化関数を繰り返し呼び出すことで、必要な数のU字型Transformer入れ子グループを作成します。
最後のブロックでは、エンコーダーとデコーダーの間に線形依存の畳み込み層を作ります。
{
CNeuronConvOCL *temp = new CNeuronConvOCL();
if(!temp)
return false;
if(!temp.Init(0, 2, OpenCL, window, window, window, 2 * units_count, optimization, iBatch))
{
delete temp;
return false;
}
cNeck = temp;
}
次に、デコーダーとパッチ融合オブジェクトを初期化します。
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, 2 * units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, 2 * window, 2 * window, window, units_count, optimization, iBatch)) return false;
不必要なコピー操作を排除するために、誤差勾配バッファを置き換えます。
if(Gradient != cMergeSplit[1].getGradient()) SetGradient(cMergeSplit[1].getGradient()); //--- return true; }
メソッドの実行を完了します。
次に登場するフィードフォワードメソッドは、もっとシンプルです。この中では、U字型Transformerアルゴリズムに従って、内部層の同名メソッドを1つずつ呼び出すだけです。まず、入力データはエンコーダーブロックを通過します。
bool CNeuronUShapeAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
その後、パッチを分割します。
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
そして、入れ子ブロックに対してはフィードフォワード方式と呼びます。
if(!cNeck.FeedForward(cMergeSplit[0].AsObject())) return false;
こうして処理されたデータはデコーダーに送られます。
if(!cAttention[1].FeedForward(cNeck)) return false;
続いてパッチ融合そうです。
if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
最後に、受信した入力データ(跳躍接続)と現在のU字型Transformerブロックの結果を合計し、高周波信号を保存します。
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), Output, 1, false)) return false; //--- return true; }
メソッドの実行を完了します。
フィードフォワードパスを実装した後、バックプロパゲーションメソッドの作成に移ります。まず、誤差勾配伝搬メソッドCNeuronUShapeAttention::calcInputGradientsを作成します。このメソッドのパラメータには、誤差勾配を伝搬しなければならない前の層のオブジェクトへのポインタを受け取ります。
bool CNeuronUShapeAttention::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
メソッド本体では、受け取ったポインタの妥当性を即座に確認します。
データバッファの置き換えを使用するため、誤差勾配は入れ子パッチ結合層のバッファにすでに格納されています。そこで、対応する誤差勾配分布法を呼び出すことができます。
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
次に、誤差勾配をデコーダーに伝搬させます。
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
次に、誤差勾配をU字型Transformer、パッチ分割層、エンコーダーの内部ブロックに順次通しまsす。
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject())) return false; if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
その後、現在のブロック(跳躍接続)の入力と出力の誤差勾配を合計します。
if(!SumAndNormilize(prevLayer.getGradient(), Gradient, prevLayer.getGradient(), 1, false)) return false; if(!DeActivation(prevLayer.getOutput(), prevLayer.getGradient(), prevLayer.getGradient(), prevLayer.Activation())) return false; //--- return true; }
誤差勾配を前の層の活性化関数に調整し、メソッドを完了します。
誤差勾配伝搬に続いて、モデルの訓練可能なパラメータが調整されます。この機能はCNeuronUShapeAttention::updateInputWeightsメソッドに実装されています。このメソッドのアルゴリズムは非常にシンプルです。入れ子オブジェクトの対応するメソッドを1つずつ呼び出すだけです。
bool CNeuronUShapeAttention::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cAttention[0].UpdateInputWeights(NeuronOCL)) return false; if(!cMergeSplit[0].UpdateInputWeights(cAttention[0].AsObject())) return false; if(!cNeck.UpdateInputWeights(cMergeSplit[0].AsObject())) return false; if(!cAttention[1].UpdateInputWeights(cNeck)) return false; if(!cMergeSplit[1].UpdateInputWeights(cAttention[1].AsObject())) return false; //--- return true; }
各ステップで結果を制御することを忘れないでください。
ファイル操作方法について、もう少し情報を提供すべきです。CNeuronUShapeAttention::Saveデータ保存メソッドでは、操作はいたって簡単です。親クラスとすべての入れ子オブジェクトの対応するメソッドを1つずつ呼び出します。
bool CNeuronUShapeAttention::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; for(int i = 0; i < 2; i++) { if(!cAttention[i].Save(file_handle)) return false; if(!cMergeSplit[i].Save(file_handle)) return false; } if(!cNeck.Save(file_handle)) return false; //--- return true; }
データロードメソッドCNeuronUShapeAttention::Loadに関しては、いくつかのニュアンスがあります。これらは、U字型Transformer入れ子ブロックの読み込みがどのように構成されるかに関連しています。まず、親クラスのメソッドを呼び出し、継承されたオブジェクトを読み込みます。
bool CNeuronUShapeAttention::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false;
その後、ループでエンコーダー、デコーダー、パッチ層のデータを読み込みます。
for(int i = 0; i < 2; i++) { if(!LoadInsideLayer(file_handle, cAttention[i].AsObject())) return false; if(!LoadInsideLayer(file_handle, cMergeSplit[i].AsObject())) return false; }
次に、入れ子ブロックを読み込む必要があります。覚えているように、ここではオブジェクトへのダイナミックポインタを使用します。したがって、いくつかの選択肢があります。変数内のポインタが無効であるか、別のクラスのオブジェクトを指している可能性があります。
必要なオブジェクトのタイプをファイルから読み取ります。また、cNeck変数が指すオブジェクトのタイプも確認します。タイプが異なる場合は、既存のオブジェクトを削除します。
int type = FileReadInteger(file_handle); if(!!cNeck) { if(cNeck.Type() != type) delete cNeck; }
次に、変数内のポインタの妥当性を確認し、必要であれば適切な型の新しいオブジェクトを作成します。
if(!cNeck) { switch(type) { case defNeuronUShapeAttention: cNeck = new CNeuronUShapeAttention(); if(!cNeck) return false; break; case defNeuronConvOCL: cNeck = new CNeuronConvOCL(); if(!cNeck) return false; break; default: return false; } }
準備作業を終えたら、ファイルからオブジェクトデータを読み込みます。
cNeck.SetOpenCL(OpenCL); if(!cNeck.Load(file_handle)) return false;
メソッドの最後に、誤差勾配バッファを置き換えます。
if(Gradient != cMergeSplit[1].getGradient()) SetGradient(cMergeSplit[1].getGradient()); //--- return true; }
メソッドの実行を完了します。
この記事の作成に使用したすべてのプログラムと同様に、すべてのクラスとそのメソッドの完全なコードは添付ファイルにあります。
2.3 モデルアーキテクチャ
モデルを構築するための新しいクラスを作成した後、訓練可能なモデルのアーキテクチャの説明に移ります。そのために「...\Experts\UShapeTransformer\Trajectory.mqh」というファイルを作成します。
前述したように、U字型Transformer法の著者は、2つのステップでモデルを訓練することを提案しています。最初のステップでは、マスクされたデータを復元するためにエンコーダーを訓練します。したがって、エンコーダーモデルのアーキテクチャの記述は、CreateEncoderDescriptionsという別のメソッドに移されます。メソッドのパラメータには、モデルアーキテクチャの記述を記録するための動的配列オブジェクトへのポインタを渡します。
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
メソッド本体では、受け取ったポインタの妥当性を確認し、必要であれば動的配列の新しいインスタンスを作成します。
次に、十分な大きさのソースデータ層を作成します。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
入力データは生の状態でモデルに投入されます。それをバッチ正規化層で前処理します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
バッチ正規化層番号を保存し、逆正規化層でそれを示します。
エンコーダーの訓練には、データマスキングを使用します。マスキングをおこなうために、ドロップアウト層を作成します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.4f; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
マスキング確率は入力データの40%に相当する0.4に設定されています。
元の入力データをマスキングしているのであって、埋め込みデータをマスキングしているのではないことに注意してください。
次のステップでは、2つの畳み込み層を使用して、マスクされた入力データの埋め込みを生成します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = descr.window; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
次に、入力データに位置符号化を加えます。この場合、学習可能な位置符号化を使用します。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count*prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
次に、U字型Transformerブロックを追加します。層では以下のパラメータが使用されます。
- descr.count:シーケンスのサイズ
- descr.window:1要素の説明のベクトルのサイズ
- descr.step:Attention Head数
- descr.window_out:Attention内部エンティティの要素のサイズ
- descr.layers:各Transformerブロックの層数
- descr.batch:U字型Transformer入れ子ブロックの数
ご覧の通り、ほとんどのパラメータはAttentionブロックから取られています。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronUShapeAttention; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 3; descr.batch = 2; if(!encoder.Add(descr)) { delete descr; return false; }
次に来るのは、3つの全結合層からなる意思決定ブロックです。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = BarDescr*(HistoryBars+NForecast); descr.activation=TANH; if(!encoder.Add(descr)) { delete descr; return false; }
エンコーダーの出力では、再構築された入力データといくつかの予測値を受け取ることに注意してください。このようにして、U字型Transformerを訓練し、入力データの依存関係を捉えるだけでなく、予測値を構築するための参照点を見つけたいと考えています。
エンコーダーを完成させるために、逆正規化層を追加し、再構成された予測値を元の入力データと同等にします。
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
エンコーダーのアーキテクチャを変更するには、モデルからデータを得るために隠れ層の定数を変更する必要があります。
#define LatentLayer 9
さらに、エンコーダーの結果層のサイズを変更するには、このデータを使用するActorモデルとCriticモデルのアーキテクチャも調整する必要があります。これらのモデルのアーキテクチャは、CreateDescriptionsメソッドで提供されます。パラメータとして、このメソッドは、対応するモデルのアーキテクチャを記録するための2つの動的配列へのポインタを受け取ります。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
メソッド本体では、受け取ったポインタを確認し、必要であれば新しい動的配列を作成します。
まず、Actorのアーキテクチャについて説明します。モデルには口座の状態記述ベクトルを与えます。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
得られたデータは全結合層で処理されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次に、5つのCross-Attention層を追加し、口座の状態とオープンポジションに関する情報を、エンコーダーによって生成された再構成値と予測値のデータと比較します。
for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, HistoryBars+NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
なお、Actor方策の訓練と運用の段階では、入力データをマスクしません。しかし、訓練されたエンコーダーは、その後の環境の状態を予測するだけでなく、過去の値からさまざまなノイズを取り除く、一種のフィルタとしても機能することが期待されています。
モデルの最後には、確率的な頭を持つ意思決定ブロックがあります。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
それに合わせてCriticのアーキテクチャも調整されました。これらの変更点については、ここでは説明しません。添付ファイルにあるコードを使って、これらのコードに慣れることをお勧めします。
2.4 訓練EAのエンコード
モデルアーキテクチャについて説明しました。では、エンコーダーモデルの訓練EAに移りましょう。本研究では、前回の記事で収集した訓練データセットを使用します。このデータセットでは、環境の状態を記述するために、あらゆる過去のデータを使用しました。このアプローチには長所と短所があります。長所としては、履歴データを蓄積するためのモデル内部のスタックが不要になることと、サンプリングされた状態をモデルの訓練に利用できることが挙げられます。しかし、その欠点は、何度も繰り返されるデータを含むため、訓練データセットファイルが大幅に増大することです。また、操作中、モデルは各ステップで、分析された履歴の深さ全体について、履歴データの再計算を繰り返します。しかし、この段階では、モデルに供給されたデータとマスキング後に復元されたデータを明確に比較することが重要です。そこで、提案されたアプローチをテストするために、このソリューションを使うことにしました。
新しいEA「...\Experts\UShapeTransformer\StudyEncoder.mq5」は、主に前回記事の該当EAを基本にしています。したがって、そのすべての方法について詳しく検討することはしません。モデルの訓練メソッドTrainについて検討しましょう。
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
メソッドの最初に、少し準備作業をします。リターンに基づいて軌道をサンプリングする確率を定義し、ローカル変数を宣言します。
次に、外部パラメータでユーザーが指定した反復回数でモデル訓練ループを編成します。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
ループの本体では、モデルを訓練するために、軌跡と1つの状態をサンプリングします。選択された状態に関する情報をデータバッファに読み込みます。
bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
次に、モデルのフィードフォワードパスメソッドを呼び出し、読み込まれたデータを渡します。
フィードフォワードパスが正常に実行されると、モデルの結果バッファには、過去の環境パラメータとその予測値の表現が格納されます。現時点では具体的な結果には興味がありません。
あとは、これから分析される環境状態の実データを準備する必要があります。前回と同様、まずは経験再生バッファから後続の環境状態を読み込みます。
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
フィードフォワードパスでモデルに入力されたデータを補足します。これまで見てきたように、バッファにはマスクされていないデータがあります。
if(!Result.AddArray(GetPointer(bState))) continue;
目標値のバッファが準備できたので、モデルのバックプロパゲーションパスを実行し、誤差が最小になるように重みを調整することができます。
if(!Encoder.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
モデルのパラメータを更新した後、訓練の進捗状況をユーザーに通知し、次の反復に移ります。
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
手術の実行結果は必ず確認すること。
モデル訓練ループのすべての反復が成功裏に完了したら、チャートのコメントフィールドを消去します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
モデルの訓練結果に関する情報をMetaTrader 5のログに出力し、EAの終了を開始します。
EAの全コードと全メソッドが添付ファイルにあります。
ActorおよびCriticの訓練EA「...\Experts\RevIN\Study.mq5」は、前の記事から実質的に変更せずにコピーされています。同じことが環境相互作用EAについても言えます。したがって、本稿ではそれらのアルゴリズムについて詳しく検討することはしません。この記事で使用したすべてのプログラムの完全なコードは添付ファイルにあります。
エンコーダー訓練EAを除くすべてのEAにおいて、エンコーダーモデルの訓練モードは無効にしなければならないことを、もう一度強調しておきたいとおもいます。
Encoder.TrainMode(false);
これは元の入力データのマスキングを無効にします。
3. テスト
U字型Transformer法の理論的側面について議論し、MQL5を使用して提案されたアプローチを実装するためにかなり多くの作業をおこないました。次に、実際の過去のデータを使って、仕事の結果をテストします。
前述したように、前回の記事で収集した訓練データセットを使ってモデルを訓練します。訓練データセットの収集方法については先に詳述したので、ここでは詳細な説明を割愛します。
モデルは2023年のEURUSDの履歴データ(H1)を使用して訓練されます。訓練されたActor方策は、同じ銘柄と時間枠で、2024年1月からの履歴データを使用して、MetaTrader5のストラテジーテスターでテストされます。
U字型Transformer法の著者が提案したアプローチに従い、2段階でモデルを訓練します。まず、事前に収集した訓練データでエンコーダーを訓練します。
ここで注意しなければならないのは、エンコーダーモデルは過去の銘柄データのみを分析するということです。したがって、エンコーダーの訓練プロセスで追加のパスを収集する必要はありません。すぐに十分な数のモデル訓練反復回数を設定し、訓練プロセスが完了するのを待つことができます。
この段階で、私は環境状態の予測の質がポジティブに変化していることに気づきました。
Actorの方策学習の2番目の段階は反復的です。この段階では、EA「...\Experts\UShapeTransformer\Research.mq5」と現在のActor方策を使って、訓練データセットに新しいパスを追加することで、Actor方策の訓練と環境に関する追加情報の収集を交互におこないます。
反復訓練によって、訓練データセットとテストデータセットの両方で利益を生み出せるモデルを得ることができました。
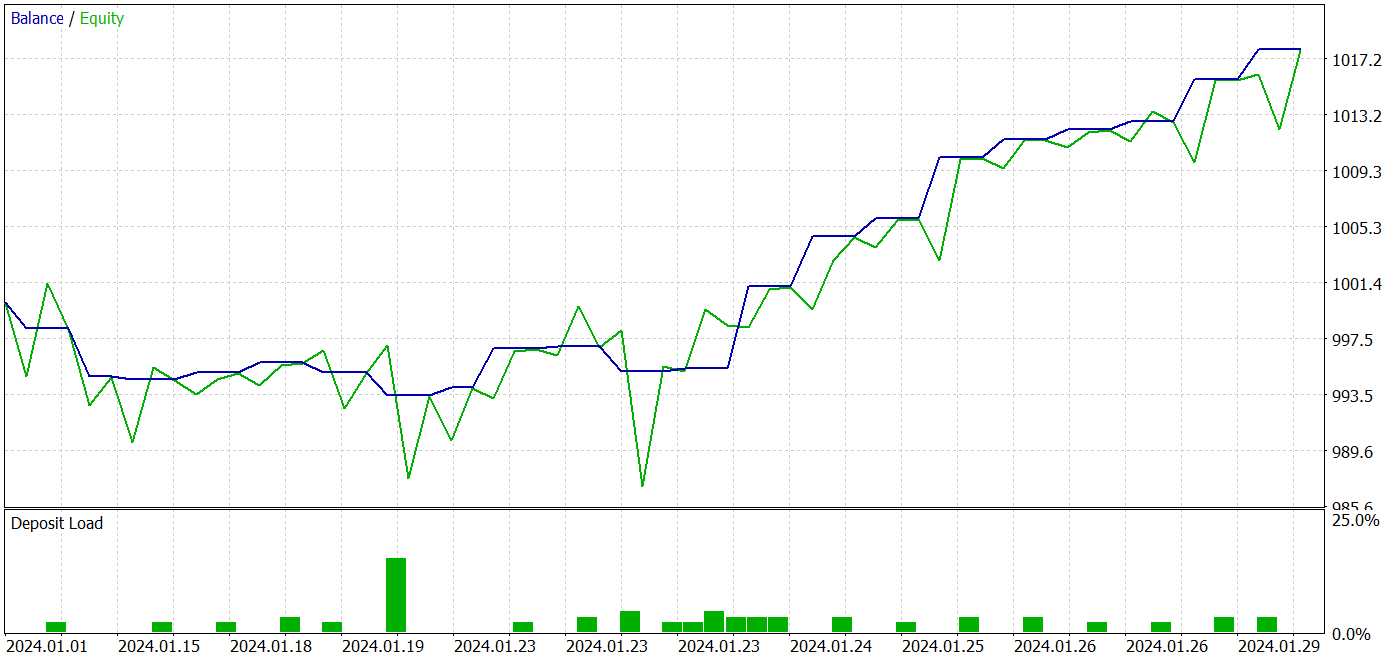
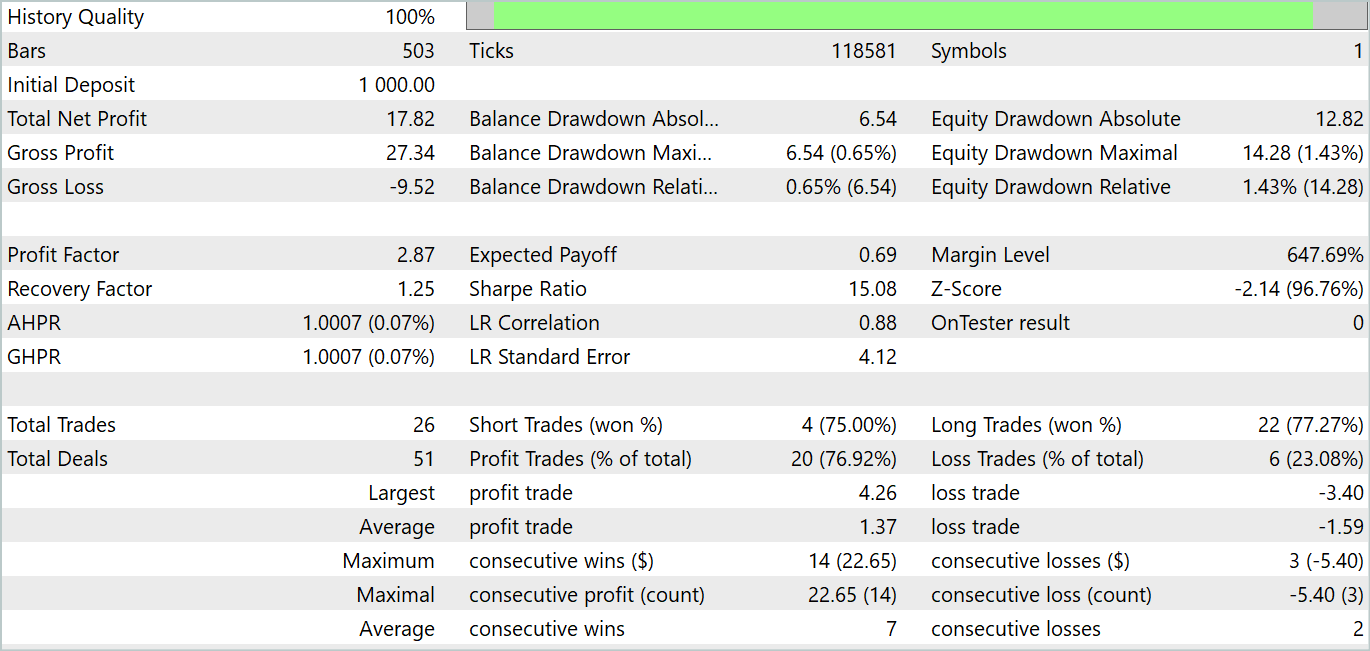
テスト期間中、このモデルは26回の取引をおこないました。そのうち20件が黒字で、76.92%の黒字となりました。プロフィットファクターは2.87でした。
得られた結果は有望ですが、モデルの安定性を確実に評価するにはテスト期間が1ヶ月と短すぎます。
結論
この記事では、時系列予測に特化したU字型Transformerアーキテクチャについて学びました。このアプローチは、Transformerと全結合パーセプトロンの利点を組み合わせたもので、時間データの長期的な依存関係を効果的に捉えつつ、高周波のコンテキストも処理できます。
U字型Transformerの大きな成果の1つは、跳躍接続と訓練可能なパッチの結合・分割操作を活用する点です。これにより、モデルは異なるスケールの特徴量を効率的に抽出し、情報をより正確に把握することができます。
実用的な部分では、MQL5を使用して提案されたアプローチを実装しました。実際の履歴データでモデルを訓練・テストしました。その結果、かなり良好なテスト結果が得られました。
ただし、もう一度強調しておきたいのは、この記事で紹介されているプログラムはあくまで技術デモンストレーションを目的としており、実際の市場で即座に使えるものではないという点です。1カ月間のテスト結果はモデルの能力を示すに過ぎず、長期的な安定動作を保証するものではありません。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | 訓練EAのエンコード |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14766

 エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索