Redes neurais de maneira fácil (Parte 86): Transformador em forma de U

Introdução
A previsão de séries temporais de longo prazo é de grande importância para o trading. A arquitetura Transformer, que foi apresentada em 2017, demonstrou um desempenho impressionante nas áreas de processamento de linguagem natural (NLP) e visão computacional (CV). O uso de mecanismos de Self-Attention permite capturar de maneira eficaz dependências em longos intervalos temporais, extraindo informações-chave do contexto. E é natural que um grande número de algoritmos diferentes tenha sido proposto rapidamente para resolver problemas na área de séries temporais usando esse mecanismo.
No entanto, pesquisas recentes mostraram que redes simples de perceptron multicamadas (MLP) podem superar a precisão dos modelos baseados em Transformer em vários conjuntos de dados de séries temporais. Ainda assim, a arquitetura Transformer provou sua eficácia em várias áreas e até encontrou aplicação prática. Portanto, sua capacidade representativa deve ser relativamente forte. E devem existir mecanismos para o seu uso. Uma das opções para aprimorar o algoritmo do Transformer vanilla é o trabalho "U-shaped Transformer: Retain High Frequency Context in Time Series Analysis", no qual o algoritmo U-shaped Transformer é apresentado.
1. Algoritmo
Provavelmente, é importante dizer de imediato que os autores do método U-shaped Transformer realizaram um trabalho abrangente e propuseram não apenas maneiras de otimizar a arquitetura clássica do Transformer, mas também uma abordagem para o treinamento do modelo.
Como é sabido, o treinamento de modelos baseados na arquitetura Transformer requer recursos computacionais significativos e um conjunto de dados de treinamento extenso. Portanto, na resolução de problemas de NLP e CV, são amplamente utilizadas diversas modelos pré-treinados. Infelizmente, somos privados dessa possibilidade ao resolver problemas de séries temporais. Isso se deve ao fato de que a natureza e a estrutura das séries temporais são bastante diversas. Entendendo isso, os autores do método U-shaped Transformer propõem dividir o processo de treinamento dos modelos em 2 etapas.
Primeiro, propõe-se treinar o modelo U-shaped Transformer em um conjunto de dados comparativamente grande para restaurar os dados brutos mascarados aleatoriamente. Isso permitirá que o modelo aprenda a estrutura dos dados brutos, dependências e o contexto das sequências. Bem como filtrar de maneira eficaz vários ruídos. Além disso, em seu trabalho, os autores do método incluíram no conjunto de dados de treinamento séries temporais de diferentes fontes e coletadas em diferentes intervalos de tempo. Assim, eles queriam treinar o U-shaped Transformer para resolver tarefas completamente diferentes.
Na segunda etapa, os pesos do U-shaped Transformer são congelados. A isso é adicionada uma "cabeça" de tomada de decisão. E realiza-se o ajuste fino para resolver tarefas específicas em um conjunto de dados de treinamento relativamente pequeno.
Assim, resolve-se a tarefa de usar um U-shaped Transformer previamente treinado para resolver várias tarefas.
É fácil notar que o ajuste fino é consideravelmente mais rápido e requer menos recursos em comparação com o processo de treinamento completo do U-shaped Transformer.
O processo geral é apresentado abaixo na visualização dos autores.
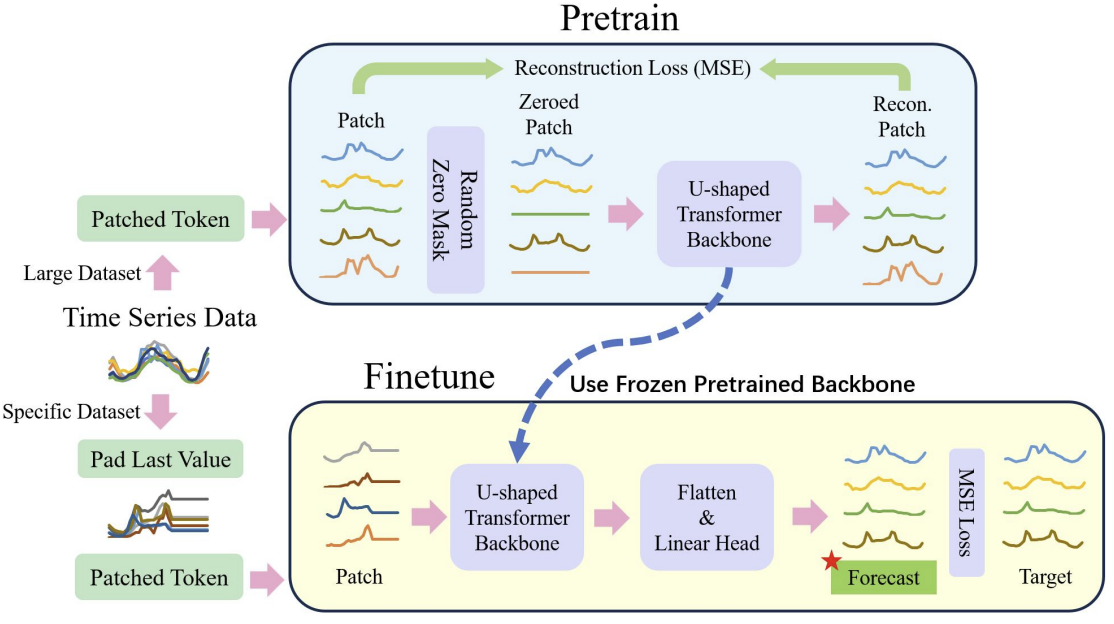
No núcleo do U-shaped Transformer está o empilhamento de camadas do Transformer. Várias camadas de Transformer formam um grupo. E após o processamento do grupo, são realizadas operações de junção ou separação de patches para integrar características de diferentes escalas.
Vários skip-connection servem para a rápida transferência de dados do codificador para o decodificador. Isso permite que dados de alta frequência cheguem rapidamente à saída da rede neural sem processamento excessivo. Os dados brutos do grupo Transformer são enviados à saída do decodificador com a mesma forma. Durante o processo de codificação dos dados brutos, à medida que a descida no modelo avança, as características de alta frequência são continuamente filtradas, enquanto as características gerais são extraídas. No processo de decodificação, as características gerais são continuamente restauradas com informações detalhadas do skip-connection, o que, no final, resulta em uma representação temporal da série que combina tanto características de alta frequência quanto de baixa frequência.
As operações com patches são componentes críticos para o modelo U-shaped Transformer. São elas que permitem obter características em diferentes escalas. As características selecionadas alteram diretamente quais informações serão incluídas no contexto principal do cálculo da atenção. Os métodos tradicionais frequentemente dividem séries temporais em matrizes duplas e as tratam como canais independentes. Os autores do U-shaped Transformer consideram essa abordagem grosseira, pois as informações sobre os patches de diferentes canais em um mesmo passo temporal não provêm de regiões vizinhas. Por isso, eles propõem usar convolução com tamanho de janela e passo iguais a 2 como forma de combinar patches, o que dobra o número de canais. Isso garante que o patch anterior não seja fragmentado e leva a uma melhor fusão de escalas. Durante o processo de decodificação, os autores do método utilizam convoluções transpostas como operação de separação de patches.
No método U-shaped Transformer, utiliza-se convolução com kernel pontual como método de embedding, para mapear cada patch em um espaço de maior dimensionalidade. Depois, os autores preparam um codificador posicional relativo treinável para cada patch, que é diretamente adicionado aos patches incorporados, para reforçar o acúmulo de conhecimento prévio entre os patches.
Como já foi mencionado anteriormente, os autores do método U-shaped Transformer utilizam a abordagem de embedding baseada em patches para dividir os dados de séries temporais em blocos menores. Eles utilizam a tarefa de restauração de patches como nossa tarefa prévia. Os autores do método acreditam que a restauração de patches não mascarados pode aumentar a resistência do modelo a dados ruidosos com valor zero.
Após o pré-treinamento, realiza-se o ajuste fino na parte específica da "cabeça", responsável pela geração das tarefas-alvo. Neste estágio, congelamos todos os componentes, exceto as redes da cabeça.
Para melhorar a capacidade de generalização do modelo e aproveitar o potencial do transformador em grandes conjuntos de dados, utiliza-se um conjunto de dados maior.
Para mitigar ainda mais o desequilíbrio dos dados, utiliza-se uma amostragem aleatória ponderada, onde a quantidade de amostras de diferentes conjuntos de dados durante o treinamento é balanceada.
E, para facilitar o problema da instabilidade de treinamento em modelos baseados no Transformer, os autores do método propõem normalizar cada mini-batch para trazer os dados brutos à distribuição normal padrão.
No final, o método de pré-processamento de dados proposto garante uma extração eficiente de características de diferentes partes do conjunto de dados e elimina de maneira eficaz o problema do desequilíbrio dos dados durante o treinamento conjunto em vários conjuntos de dados.
2. Implementação com MQL5
Após discutir os aspectos teóricos do método, passamos à parte prática de nosso artigo, onde implementamos uma das abordagens propostas usando MQL5.
Como já mencionado anteriormente, o U-shaped Transformer utiliza várias soluções arquitetônicas que precisaremos implementar. E começaremos com o bloco de codificação posicional treinável.
2.1 Codificação posicional
O bloco de codificação posicional é projetado para introduzir informações na série temporal sobre a posição dos elementos na sequência. Como você sabe, o algoritmo Self-Attention analisa as dependências entre elementos independentemente de sua posição na sequência. No entanto, as informações sobre a posição de um elemento na sequência e a distância entre os elementos analisados da sequência às vezes desempenham um papel importante. Isso é especialmente relevante para sequências temporais. Para adicionar essas informações, no Transformer clássico, utiliza-se a adição de uma sequência senoidal aos dados brutos. A periodicidade das sequências senoidais é fixa e pode variar em diferentes implementações, dependendo do tamanho da sequência analisada.
As séries temporais costumam ter alguma periodicidade. E, às vezes, possuem múltiplas características de frequência. Nesses casos, é necessário realizar um trabalho adicional para selecionar as características de frequência do tensor de codificação posicional, de modo que ele não distorça os dados brutos e acrescente informações adicionais.
No artigo dos autores, não há uma descrição detalhada do método de codificação posicional treinável utilizado. Minha impressão é que os autores ajustaram o coeficiente de codificação posicional para cada elemento da sequência durante o treinamento do modelo. E ele será fixo durante o uso.
Em nossa implementação, iremos um pouco além e faremos os coeficientes de codificação posicional dependentes dos dados brutos. Nós utilizaremos uma camada totalmente conectada simples para gerar o tensor de codificação posicional. Naturalmente, iremos treinar essa camada durante o processo de aprendizado.
Para implementar o mecanismo proposto, criaremos uma nova classe CNeuronLearnabledPE. E, como na maioria dos casos, a funcionalidade principal será herdada da classe base de camada neural CNeuronBaseOCL.
class CNeuronLearnabledPE : public CNeuronBaseOCL { protected: CNeuronBaseOCL cPositionEncoder; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronLearnabledPE(void) {}; ~CNeuronLearnabledPE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronLearnabledPE; } virtual void SetOpenCL(COpenCLMy *obj); };
Na estrutura da classe, vemos um objeto aninhado da camada neural base cPositionEncoder, que contém os parâmetros treináveis do nosso tensor de codificação posicional. Este objeto é especificado como estático, o que nos permite deixar o construtor e o destrutor da classe vazios.
A inicialização da instância da classe é realizada no método Init, cujos parâmetros irão passar todas as informações necessárias para a correta inicialização dos objetos aninhados.
bool CNeuronLearnabledPE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; if(!cPositionEncoder.Init(0, 1, OpenCL, numNeurons, optimization, iBatch)) return false; cPositionEncoder.SetActivationFunction(TANH); SetActivationFunction(None); //--- return true; }
O algoritmo do método é bastante simples. No corpo do método, primeiro chamamos o método homônimo da classe pai, onde ocorre a verificação dos parâmetros externos recebidos e a inicialização dos objetos herdados. O resultado das operações é determinado pelo valor lógico retornado após a execução do método chamado.
Na próxima etapa, ocorre a inicialização do objeto aninhado cPositionEncoder. Para o objeto aninhado, definimos a tangente hiperbólica como a função de ativação. Como se sabe, o intervalo de valores dessa função é de "-1" a "1", o que corresponde ao intervalo de valores das sequências de onda senoidais.
Para a nossa classe de codificação posicional dinâmica, a função de ativação está ausente.
Após a conclusão bem-sucedida de todas as iterações, encerramos o método com o resultado true.
O algoritmo de passagem direta do nosso método será descrito no método CNeuronLearnabledPE::feedForward. Semelhante ao método homônimo da classe pai, o método recebe como parâmetro um ponteiro para o objeto da camada neural anterior, que contém os dados de entrada.
bool CNeuronLearnabledPE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cPositionEncoder.FeedForward(NeuronOCL)) return false; if(!SumAndNormilize(NeuronOCL.getOutput(), cPositionEncoder.getOutput(), Output, 1, false, 0, 0, 0, 1)) return false; //--- return true; }
Com base nos dados de entrada recebidos, primeiro geramos o tensor de codificação posicional. Em seguida, somamos os valores obtidos ao tensor dos dados de entrada.
A execução de todas as operações é controlada pelos valores retornados pelos métodos chamados.
O algoritmo do método de retropropagação do gradiente de erro CNeuronLearnabledPE::calcInputGradients é um pouco mais complexo. Nos parâmetros, ele também recebe um ponteiro para o objeto da camada neural anterior, ao qual devemos passar o gradiente de erro.
bool CNeuronLearnabledPE::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!DeActivation(cPositionEncoder.getOutput(), cPositionEncoder.getGradient(), Gradient, cPositionEncoder.Activation())) return false; if(!DeActivation(NeuronOCL.getOutput(), NeuronOCL.getGradient(), Gradient, NeuronOCL.Activation())) return false; //--- return true; }
No corpo do método, primeiro verificamos a validade do ponteiro recebido nos parâmetros.
Em seguida, ajustamos o gradiente de erro recebido da camada subsequente com base na função de ativação do objeto interno. Lembro que, no processo de inicialização, especificamos a função de ativação para o objeto interno, mas deixamos a própria classe CNeuronLearnabledPE sem função de ativação. Consequentemente, o gradiente de erro no buffer da nossa camada não foi ajustado com base na função de ativação.
Na próxima etapa, repetimos a operação de ajuste do gradiente de erro, mas desta vez com base na função de ativação da camada anterior.
Observe que não realizamos a chamada do método de retropropagação do gradiente de erro através do objeto interno de geração do tensor de codificação posicional. O fato é que, para executar a operação de atualização dos parâmetros desta camada, é suficiente termos o gradiente de erro na sua saída. A propagação do gradiente de erro através do objeto para a camada anterior não é necessária, pois o bloco de geração do tensor de codificação posicional não deve influenciar os dados originais ou seu embedding.
Para finalizar a implementação do algoritmo de propagação reversa da classe CNeuronLearnabledPE, criaremos o método de atualização dos parâmetros treináveis updateInputWeights. Esse método é bastante simplificado e consiste em chamar o método homônimo do objeto aninhado.
bool CNeuronLearnabledPE::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return cPositionEncoder.UpdateInputWeights(NeuronOCL); }
Você pode consultar o código completo desta classe e de todos os seus métodos no anexo.
2.2 Classe U-shaped Transformer
Agora continuaremos com nossa versão da implementação das abordagens propostas pelos autores do método U-shaped Transformer. Devo dizer que a solução para a arquitetura de implementação da scip-connection entre o Codificador e o Decodificador, apesar da simplicidade aparente, não foi tão trivial. Por um lado, poderíamos usar um link para o identificador da camada interna e passar os dados do Codificador para o Decodificador. Isso não seria problemático. Mas surge a questão da propagação do gradiente de erro através da scip-connection. Afinal, toda a arquitetura de retropropagação das nossas classes é construída sobre a sobrescrita do gradiente de erro durante a retropropagação subsequente. Portanto, qualquer gradiente de erro que passarmos pela scip-connection será descartado nas operações de propagação do gradiente através das camadas neurais entre os objetos da scip-connection.
E isso levanta a ideia de criar toda a arquitetura do U-shaped Transformer dentro de uma única classe. Mas precisamos de um mecanismo para construir diferentes quantidades de blocos Codificador-Decodificador com quantidades variáveis de camadas Transformer em cada bloco. A solução foi encontrada na criação recorrente de objetos. Exploraremos o mecanismo escolhido em mais detalhes durante a implementação.
Para implementar nosso bloco U-shaped Transformer, criaremos a classe CNeuronUShapeAttention, que, como a anterior, herdará a funcionalidade principal da classe base de camada neural CNeuronBaseOCL.
class CNeuronUShapeAttention : public CNeuronBaseOCL { protected: CNeuronMLMHAttentionOCL cAttention[2]; CNeuronConvOCL cMergeSplit[2]; CNeuronBaseOCL *cNeck; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); //--- public: CNeuronUShapeAttention(void) {}; ~CNeuronUShapeAttention(void) { delete cNeck; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronUShapeAttention; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *net, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
No corpo da classe, criaremos um array de 2 elementos da classe de atenção multi-cabeça de múltiplas camadas CNeuronMLMHAttentionOCL. Estes serão o Codificador e o Decodificador do bloco atual.
Também criaremos um array de 2 elementos da camada convolucional, que usaremos para trabalhar com patches.
E todos os elementos entre o Codificador e o Decodificador do bloco atual serão colocados no objeto da classe base de camada neural cNeck, que, neste caso, será dinâmico. Há uma certa dúvida sobre como colocar uma quantidade indefinida de blocos dentro de um único bloco. Para responder a essa pergunta, sugiro que avancemos para a análise do método de inicialização do objeto Init.
Como de costume, nos parâmetros do método recebemos as principais constantes da arquitetura do objeto:
- window — o tamanho da janela dos dados de entrada (vetor de descrição de 1 elemento da sequência);
- window_key — o tamanho do vetor interno de descrição de 1 elemento da sequência nas entidades Self-Attention Query, Key, Value;
- heads — o número de cabeças de atenção;
- units_count — o número de elementos na sequência;
- layers — o número de camadas de atenção em um bloco;
- inside_bloks — o número de blocos aninhados do U-shaped Transformer.
Os parâmetros window, window_key, heads e layers são usados sem alterações para o bloco atual e os blocos aninhados do U-shaped Transformer.
bool CNeuronUShapeAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
No corpo do método, primeiro chamamos o método homônimo da classe base, que controla os parâmetros recebidos e inicializa os objetos herdados.
Em seguida, inicializamos os objetos do Codificador e da separação de patches.
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2 * window, 4 * window, (units_count + 1) / 2, optimization, iBatch)) return false;
E então vem a parte mais interessante do método de inicialização. Primeiro, verificamos o número de blocos aninhados especificados. Se for maior que "0", criamos e inicializamos um bloco aninhado do U-shaped Transformer, semelhante à classe atual. A única diferença é que o número de elementos na sequência é dobrado, o que corresponde ao resultado da separação de patches. E o número de blocos aninhados é diminuído em "1".
if(inside_bloks > 0) { CNeuronUShapeAttention *temp = new CNeuronUShapeAttention(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, 2 * units_count, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
O ponteiro para o objeto criado será armazenado na variável cNeck. É para isso que declaramos o objeto dinâmico. Assim, através de chamadas recursivas da função de inicialização, criaremos o número necessário de grupos aninhados do U-shaped Transformer.
No último bloco, criaremos uma camada convolucional de dependência linear entre o Codificador e o Decodificador.
{
CNeuronConvOCL *temp = new CNeuronConvOCL();
if(!temp)
return false;
if(!temp.Init(0, 2, OpenCL, window, window, window, 2 * units_count, optimization, iBatch))
{
delete temp;
return false;
}
cNeck = temp;
}
Em seguida, inicializamos os objetos do Decodificador e da fusão de patches.
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, 2 * units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, 2 * window, 2 * window, window, units_count, optimization, iBatch)) return false;
Para evitar operações de cópia excessivas, substituímos o buffer de gradientes de erro.
if(Gradient != cMergeSplit[1].getGradient()) SetGradient(cMergeSplit[1].getGradient()); //--- return true; }
E então encerramos o método.
O método de propagação para frente parece simples em comparação. Nele, chamamos sequencialmente os métodos homônimos das camadas internas de acordo com o algoritmo do U-shaped Transformer. Primeiro, os dados de entrada passam pelo bloco do Codificador.
bool CNeuronUShapeAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
Depois disso, fazemos a separação de patches.
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
E chamamos o método de propagação para os blocos aninhados.
if(!cNeck.FeedForward(cMergeSplit[0].AsObject())) return false;
Os dados processados dessa forma são enviados para o Decodificador.
if(!cAttention[1].FeedForward(cNeck)) return false;
E para a camada de fusão de patches.
if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
Por fim, somamos os resultados do trabalho do bloco atual U-shaped Transformer com os dados de entrada recebidos (scip-connection) para preservar o sinal de alta frequência.
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), Output, 1, false)) return false; //--- return true; }
E então encerramos o método.
Após organizar a propagação para frente, passamos à criação dos métodos de propagação reversa. Primeiro, criaremos o método de distribuição do gradiente de erro CNeuronUShapeAttention::calcInputGradients, nos parâmetros dos quais recebemos um ponteiro para o objeto da camada anterior, para o qual devemos passar o gradiente de erro.
bool CNeuronUShapeAttention::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
No corpo do método, verificamos imediatamente a validade do ponteiro recebido.
Graças à substituição dos buffers de dados, o gradiente de erro já está salvo no buffer da camada de fusão de patches aninhada. E imediatamente chamamos o método correspondente de distribuição do gradiente de erro.
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
Em seguida, propagamos o gradiente de erro através do Decodificador.
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
E, em seguida, passamos o gradiente de erro sequencialmente pelos blocos internos do U-shaped Transformer, pela camada de separação de patches e pelo Codificador.
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject())) return false; if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
Depois disso, somamos os gradientes de erro na entrada e na saída do bloco atual (scip-connection).
if(!SumAndNormilize(prevLayer.getGradient(), Gradient, prevLayer.getGradient(), 1, false)) return false; if(!DeActivation(prevLayer.getOutput(), prevLayer.getGradient(), prevLayer.getGradient(), prevLayer.Activation())) return false; //--- return true; }
Ajustamos o gradiente de erro com base na função de ativação da camada anterior e finalizamos o método.
Após a propagação do gradiente de erro, segue-se a correção dos parâmetros treináveis do modelo. Essa funcionalidade é realizada no método CNeuronUShapeAttention::updateInputWeights. O algoritmo do método é bastante simples. Apenas chamamos os métodos correspondentes dos objetos aninhados um por um.
bool CNeuronUShapeAttention::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cAttention[0].UpdateInputWeights(NeuronOCL)) return false; if(!cMergeSplit[0].UpdateInputWeights(cAttention[0].AsObject())) return false; if(!cNeck.UpdateInputWeights(cMergeSplit[0].AsObject())) return false; if(!cAttention[1].UpdateInputWeights(cNeck)) return false; if(!cMergeSplit[1].UpdateInputWeights(cAttention[1].AsObject())) return false; //--- return true; }
E, claro, não esquecemos de monitorar a execução das operações em cada etapa.
Também é necessário parar um pouco nos métodos de manipulação de arquivos. Se no método de salvamento de dados CNeuronUShapeAttention::Save tudo é bastante simples, apenas chamamos os métodos correspondentes da classe pai e de todos os objetos aninhados,
bool CNeuronUShapeAttention::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; for(int i = 0; i < 2; i++) { if(!cAttention[i].Save(file_handle)) return false; if(!cMergeSplit[i].Save(file_handle)) return false; } if(!cNeck.Save(file_handle)) return false; //--- return true; }
no entanto, no método de carregamento de dados CNeuronUShapeAttention::Load, existem alguns detalhes. E eles estão relacionados à organização do carregamento dos blocos aninhados U-shaped Transformer. Primeiro, como de costume, chamamos o método da classe pai para carregar os objetos herdados.
bool CNeuronUShapeAttention::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false;
Em seguida, em um loop, carregamos os dados do Codificador, Decodificador e das camadas de processamento de patches.
for(int i = 0; i < 2; i++) { if(!LoadInsideLayer(file_handle, cAttention[i].AsObject())) return false; if(!LoadInsideLayer(file_handle, cMergeSplit[i].AsObject())) return false; }
Depois, chega a etapa de carregamento dos blocos aninhados. Mas aqui, como você lembra, utilizamos um ponteiro dinâmico para o objeto. Portanto, há possibilidades variadas. A variável de ponteiro pode estar desatualizada ou apontando para um objeto de outra classe.
Lemos do arquivo o tipo do objeto necessário. E verificamos o tipo do objeto para o qual a variável cNeck aponta. Se os tipos forem diferentes, removemos o objeto existente.
int type = FileReadInteger(file_handle); if(!!cNeck) { if(cNeck.Type() != type) delete cNeck; }
Em seguida, verificamos a validade do ponteiro na variável e, se necessário, criamos um novo objeto do tipo correspondente.
if(!cNeck) { switch(type) { case defNeuronUShapeAttention: cNeck = new CNeuronUShapeAttention(); if(!cNeck) return false; break; case defNeuronConvOCL: cNeck = new CNeuronConvOCL(); if(!cNeck) return false; break; default: return false; } }
Após a conclusão do trabalho preparatório, carregamos os dados do objeto a partir do arquivo.
cNeck.SetOpenCL(OpenCL); if(!cNeck.Load(file_handle)) return false;
Ao final do método, substituímos os buffers do gradiente de erro.
if(Gradient != cMergeSplit[1].getGradient()) SetGradient(cMergeSplit[1].getGradient()); //--- return true; }
E então encerramos o método.
Você pode consultar o código completo de todos os métodos desta classe e de todos os outros programas utilizados na preparação deste artigo no anexo.
2.3 Arquitetura dos modelos
Após criar novas classes para a construção de nossos modelos, passamos para a descrição da arquitetura dos modelos treináveis, que, como sempre, registraremos no arquivo "...\Experts\UShapeTransformer\Trajectory.mqh".
Já foi mencionado anteriormente que os autores do método U-shaped Transformer propõem treinar os modelos em 2 etapas. Na primeira etapa, treinaremos o Codificador para restaurar os dados mascarados. Portanto, a descrição da arquitetura do modelo do Codificador será apresentada em um método separado CreateEncoderDescriptions. Nos parâmetros do método, é passado um ponteiro para o objeto de array dinâmico para gravar a descrição da arquitetura do modelo.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
No corpo do método, verificamos a validade do ponteiro recebido e, se necessário, criamos uma nova instância do array dinâmico.
Em seguida, criamos a camada de dados de entrada com tamanho suficiente.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados de entrada são fornecidos ao modelo "em bruto". E realizamos seu pré-processamento na camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Vamos memorizar o número da camada de normalização em lote para especificá-lo na camada de normalização reversa.
Para o treinamento do Codificador, utilizaremos a técnica de mascaramento de dados. E, para realizar o mascaramento, criaremos a camada Dropout.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.4f; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Definimos a probabilidade de mascaramento em 0,4, o que corresponde a 40% dos dados de entrada.
Aqui é importante observar que estamos mascarando os dados de entrada propriamente ditos, e não seus embeddings.
Na próxima etapa, utilizamos 2 camadas convolucionais para gerar embeddings dos dados de entrada mascarados.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = descr.window; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, adicionamos a codificação posicional aos dados de entrada. Neste caso, utilizamos uma codificação posicional treinável.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count*prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Agora, adicionamos o bloco U-shaped Transformer. Vamos dedicar um momento para descrever a camada e analisar as variáveis usadas:
- descr.count — tamanho da sequência;
- descr.window — tamanho do vetor de descrição de 1 elemento da sequência;
- descr.step — número de cabeças de atenção;
- descr.window_out — tamanho do elemento das entidades internas de atenção;
- descr.layers — número de camadas em cada bloco Transformer;
- descr.batch — número de blocos aninhados do U-shaped Transformer.
Como pode ser observado, a maioria dos parâmetros é herdada dos blocos de atenção.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronUShapeAttention; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 3; descr.batch = 2; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, temos um bloco de tomada de decisão composto por 3 camadas totalmente conectadas.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = BarDescr*(HistoryBars+NForecast); descr.activation=TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Observe que, na saída do Codificador, pretendemos obter os dados de entrada restaurados mais algumas previsões. Dessa forma, buscamos treinar o U-shaped Transformer para captar dependências não apenas nos dados de entrada, mas também para encontrar pontos de referência para gerar valores de previsão.
Ao final do Codificador, adicionaremos uma camada de normalização reversa para ajustar os valores restaurados e previstos ao formato comparável aos dados de entrada.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
A alteração na arquitetura do Codificador exige uma modificação na constante da camada oculta para a obtenção de dados do modelo.
#define LatentLayer 9
Além disso, a mudança no tamanho da camada de resultados do Codificador também exige ajustes na arquitetura dos modelos Ator e Crítico, que utilizam esses dados. A arquitetura dos modelos mencionados é apresentada no método CreateDescriptions. Nos parâmetros, o método recebe ponteiros para 2 arrays dinâmicos destinados ao registro das arquiteturas dos modelos correspondentes.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
No corpo do método, verificamos os ponteiros recebidos e, se necessário, criamos novos arrays dinâmicos.
Primeiro, descrevemos a arquitetura do Ator. Na entrada do modelo, passamos um vetor de descrição do estado da conta.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Os dados recebidos são processados por uma camada totalmente conectada.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, adicionamos 5 camadas de cross-attention, nas quais a informação sobre o estado da conta e as posições abertas será correlacionada com os dados restaurados e previstos gerados pelo Codificador.
for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, HistoryBars+NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
Vale destacar que, durante o treinamento da política do Ator e sua execução em produção, não mascaramos os dados de entrada. No entanto, espera-se que o Codificador treinado não apenas preveja os estados futuros do ambiente, mas também atue como um filtro de valores históricos, removendo diversos ruídos.
Ao final do modelo, temos um bloco de tomada de decisões com uma "cabeça" estocástica.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A arquitetura do Crítico recebeu correções semelhantes. E não vamos nos deter detalhadamente em sua descrição agora. Eu sugiro que você mesmo se familiarize com elas no anexo.
2.4 EA de treinamento do codificador
Após a descrição da arquitetura dos modelos, vamos focar no EA de treinamento do modelo do Codificador. Deve-se dizer que neste trabalho utilizamos o conjunto de dados de treinamento coletado para o artigo anterior. Como você deve se lembrar, nele utilizamos o conjunto completo de dados históricos para descrever o estado do ambiente. Essa abordagem tem tanto vantagens quanto desvantagens. Entre as vantagens, podemos destacar a ausência da necessidade de uma pilha dentro do modelo para acumular dados históricos, além da possibilidade de usar estados amostrados para o treinamento dos modelos. Entre as desvantagens, está o aumento significativo do arquivo de treinamento, que armazena repetidamente os mesmos dados. Além disso, durante a execução, o modelo recalcula os dados históricos em toda a profundidade da história analisada a cada etapa. Mas, neste estágio, o mais importante para nós é a correspondência clara entre os dados fornecidos à entrada do modelo e os restaurados após a aplicação da máscara. Portanto, para fins de teste das abordagens propostas, foi decidido manter essa solução.
No geral, o EA "...\Experts\UShapeTransformer\StudyEncoder.mq5" foi construído com base em um EA semelhante do artigo anterior. E não vamos nos aprofundar na análise de todos os seus métodos. Vamos apenas examinar o método de treinamento do modelo Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
No início do método, faremos uma pequena preparação. Determinaremos as probabilidades de amostragem das trajetórias com base em sua rentabilidade e declararemos as variáveis locais.
Em seguida, organizamos o ciclo de treinamento do modelo com o número de iterações que foi especificado pelo usuário nos parâmetros externos.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
No corpo do ciclo, amostramos uma trajetória e 1 estado nela para treinar o modelo. Carregamos as informações sobre o estado selecionado no buffer de dados.
bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E chamamos o método de propagação para frente da nossa modelo, passando os dados carregados para ele.
Após a conclusão bem-sucedida da propagação para frente, o buffer de resultados do modelo armazenará uma certa representação dos indicadores históricos do ambiente e de seus valores previstos. O resultado específico não nos interessa neste momento.
Agora, precisamos preparar os dados reais sobre os estados futuros e analisados do ambiente. Como no artigo anterior, primeiro carregaremos os estados subsequentes do ambiente a partir do buffer de reprodução de experiência.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
E os complementaremos com os dados fornecidos à entrada do modelo durante a propagação para frente. Lembro que no buffer temos dados não mascarados.
if(!Result.AddArray(GetPointer(bState))) continue;
Agora, com o buffer de valores-alvo preparado, podemos realizar a propagação reversa do modelo e ajustar os coeficientes de peso para minimizar o erro.
if(!Encoder.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Após a atualização dos parâmetros do modelo, informamos o usuário sobre o progresso do treinamento e passamos para a próxima iteração.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
É obrigatório verificar os resultados da execução de todas as operações.
Se todas as iterações do ciclo de treinamento forem executadas com sucesso, limpamos o campo de comentários no gráfico do ativo.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Registramos no diário do MetaTrader 5 as informações sobre os resultados do treinamento e iniciamos o processo de encerramento do EA.
O código completo do EA pode ser consultado no anexo.
O EA de treinamento da política do Ator e Crítico "...\Experts\RevIN\Study.mq5" foi transferido do artigo anterior praticamente sem alterações. O mesmo pode ser dito sobre os EAs de interação com o ambiente. Por isso, não vamos nos aprofundar na análise de seus algoritmos neste artigo. Você pode consultar o código completo de todos os programas usados na preparação deste artigo no anexo.
No entanto, gostaria de chamar a atenção mais uma vez para que, em todos os EAs, exceto no EA de treinamento do Codificador, o modo de treinamento para o modelo do Codificador deve ser desativado.
Encoder.TrainMode(false);
Isso ajudará a desativar o mascaramento dos dados originais.
3. Testes
Acima, discutimos os aspectos teóricos do método U-shaped Transformer e realizamos um grande trabalho de implementação das abordagens propostas usando MQL5. Agora é hora de verificar os resultados do nosso trabalho em dados históricos reais.
Como já mencionado, treinaremos os modelos usando o conjunto de dados de treinamento coletado para o artigo anterior. Não vamos detalhar os métodos de coleta do conjunto de treinamento, que foram discutidos anteriormente.
O treinamento do modelo é realizado em dados históricos de 2023 do ativo EURUSD no time frame H1. O teste da política do Ator treinada é realizado no testador de estratégias do MetaTrader 5 com dados históricos de janeiro de 2024, mantendo o ativo e o time frame do treinamento dos modelos.
Conforme a abordagem proposta pelos autores do método U-shaped Transformer, o treinamento dos modelos é realizado em 2 etapas. Primeiro, treinamos o Codificador com os dados de treinamento previamente coletados.
Deve-se dizer que o modelo Codificador analisa apenas os dados históricos do ativo. Portanto, não há necessidade de coletar passagens adicionais durante o treinamento do Codificador. Podemos simplesmente definir um número relativamente grande de iterações de treinamento do modelo e aguardar a conclusão do processo de treinamento.
Nesta fase, percebi um avanço positivo na qualidade da previsão dos estados do ambiente.
A segunda etapa do treinamento da política do Ator é iterativa. Nesta fase, alternamos o treinamento da política do Ator com a coleta de informações adicionais sobre o ambiente, adicionando novos passagens à amostra de treinamento usando o EA "...\Experts\UShapeTransformer\Research.mq5" e a política atualizada do Ator.
Durante o treinamento iterativo, consegui obter um modelo capaz de gerar lucro tanto na amostra de treinamento quanto na amostra de teste.
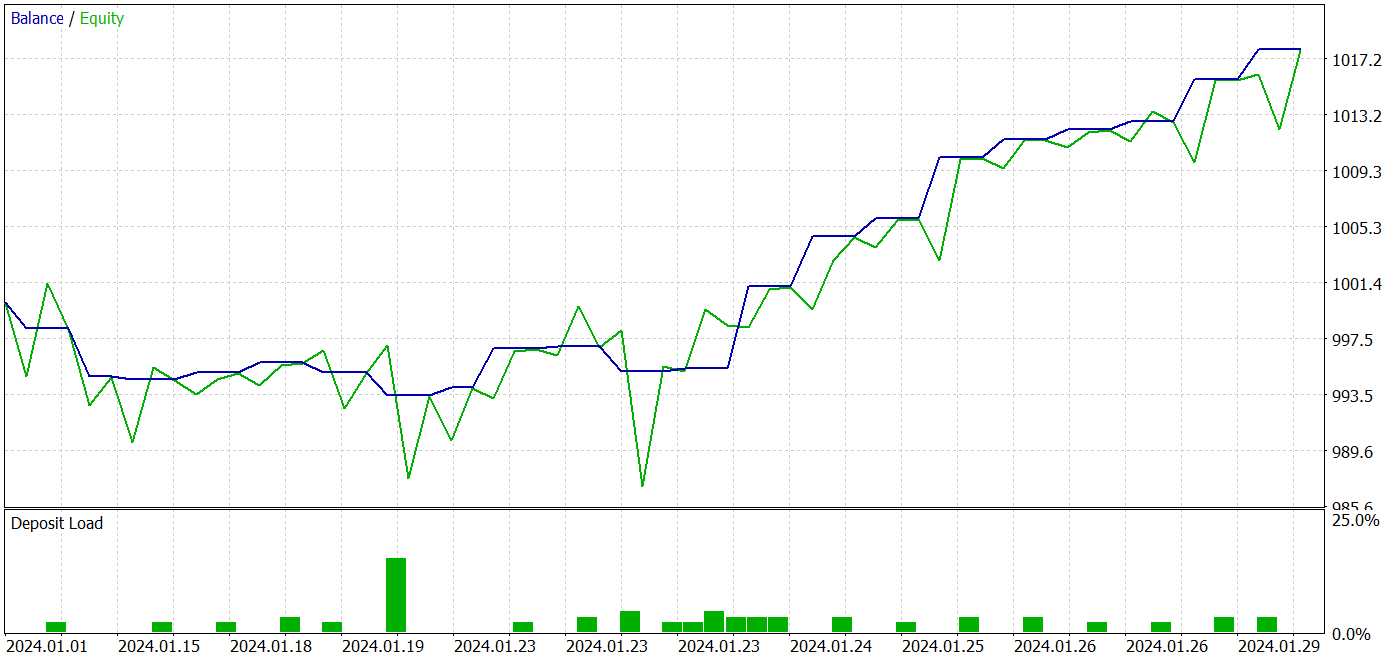
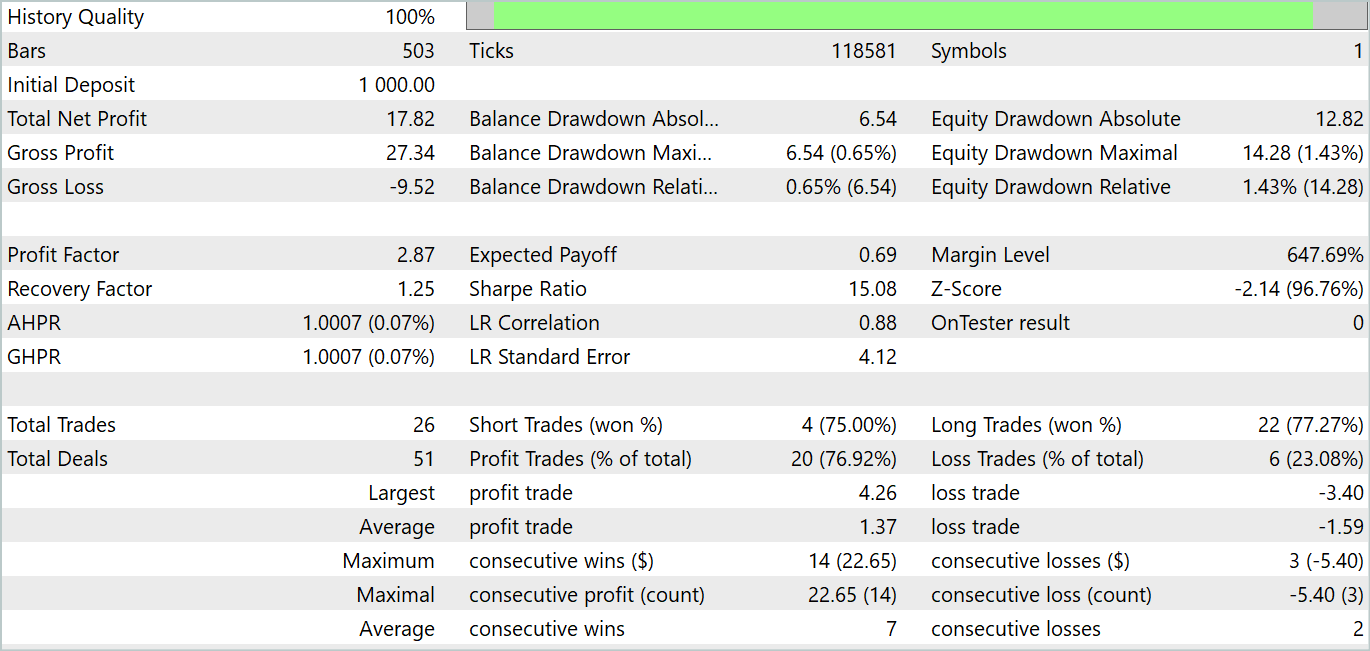
Durante o período de teste, o modelo realizou 26 negociações. E 20 delas foram fechadas com lucro, representando 76,92%. O fator de lucro foi de 2,87.
Os resultados obtidos são promissores, mas o período de teste de 1 mês é muito curto para avaliar a estabilidade do modelo.
Considerações finais
Neste artigo, conhecemos a arquitetura U-shaped Transformer, que foi especialmente desenvolvida para a previsão de séries temporais. A abordagem proposta combina as vantagens dos transformadores e dos perceptrons totalmente conectados, permitindo capturar de forma eficaz as dependências de longo prazo em dados temporais e processar o contexto de alta frequência.
Um dos principais avanços do U-shaped Transformer é o uso de skip-connection e operações treináveis de junção e divisão de patches. Isso permite que o modelo extraia eficientemente características em diferentes escalas e capture melhor as informações.
Na parte prática do artigo, implementamos as abordagens propostas utilizando MQL5. Treinamos e testamos o modelo obtido em dados históricos reais. Os resultados dos testes mostraram resultados bastante promissores.
No entanto, gostaria de enfatizar mais uma vez que todos os programas usados na preparação deste artigo são apenas para demonstração das abordagens propostas e não estão prontos para uso real em mercados reais. Os resultados dos testes em um intervalo de 1 mês podem apenas demonstrar as capacidades do modelo, mas não garantem seu desempenho estável em períodos mais longos.
Referências
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento de Modelos |
| 4 | StudyEncoder.mq5 | Expert Advisor | EA para treinamento do Codificador |
| 5 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criar uma rede neural |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código para o programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14766
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso