Нейросети — это просто (Часть 86): U-образный Трансформер

Введение
Прогнозирование долгосрочных временных рядов имеет большое значение для трейдинга. Архитектура Transformer, которая была представленные в 2017 году, продемонстрировала впечатляющую производительность в областях обработка естественного языка (NLP) и компьютерное зрение (CV). Использование механизмов Self-Attention позволяет эффективно захватывать зависимости на длинных временных интервалах, извлекая ключевую информацию из контекста. И вполне естественно, что довольно быстро было предложено большое количество различных алгоритмов для решения задач в области временных рядов с использованием этого механизма.
Однако недавние исследования показали, что простые сети многослойного персептрона (MLP) могут превзойти точность моделей на основе Transformer на различных наборах данных временных рядов. Тем не менее архитектура Transformer доказала свою эффективность в нескольких областях и даже нашла практическое применение. Следовательно, её репрезентативная способность должна быть относительно сильной. И должны быть механизмы её использования. Одним из вариантов совершенствования алгоритма ванильного Transformer является работа "U-shaped Transformer: Retain High Frequency Context in Time Series Analysis", в которой представлен алгоритм U-shaped Transformer.
1. Алгоритм
Наверное, сразу надо сказать, что авторы метода U-shaped Transformer провели комплексную работу и предложили не только пути оптимизации классической архитектуры Transformer, но и подход к обучению модели.
Как известно, обучение моделей на основе архитектуры Transformer требует значительных вычислительных ресурсов и обширной обучающей выборки. Поэтому, при решении задач NLP и CV широко используются различные предварительно обученные модели. К сожалению, мы лишены такой возможности при решении задач временных рядов. Это связано с тем, что природа и структура временных рядов довольно разнообразна. Понимая это, авторы метода U-shaped Transformer предлагают разделить процесс обучения моделей на 2 этапа.
Вначале предлагается на сравнительно большом наборе данных обучить модель U-shaped Transformer восстанавливать замаскированные случайным образом исходные данные. Это позволит модель изучить структуру исходных данных, зависимости и контекст последовательностей. А также эффективно фильтровать различные шумы. Кроме того, в своей работе авторы метода включили в обучающую выборку данные различных тайм-серий, которые были собраны не только в различные временные интервалы, но из различных источников. Таким образом они хотели обучить U-shaped Transformer для решения абсолютно различных задач.
На втором этапе замораживаются веса U-shaped Transformer. К нему добавляется "голова" принятия решений. И осуществляется тонкая настройка для решения конкретных задач на относительно малой обучающей выборке.
Таким образом решается задача использования 1 предварительно обученного U-shaped Transformer для решения нескольких задач.
Легко заметить, что тонкая настройка проходит значительно быстрее и требует меньше ресурсов по сравнению с процессом полного обучения U-shaped Transformer.
Общий процесс представлен ниже на авторской визуализации.
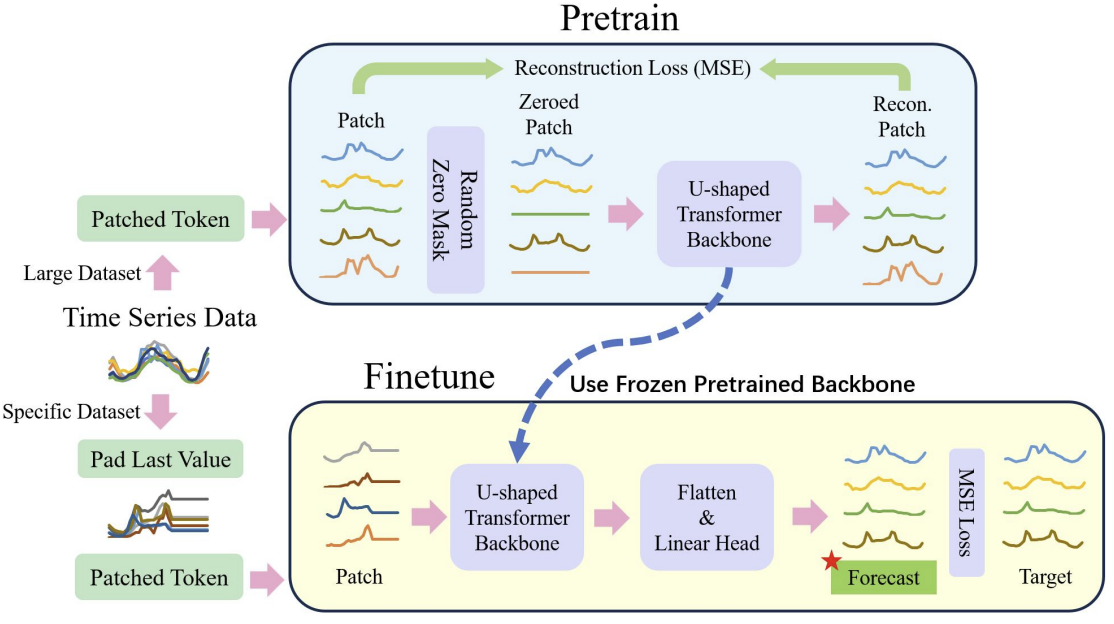
В основе U-shaped Transformer лежит стекирование слоев Transformer. Несколько слоев Transformer формируют группу. И после обработки группы выполняются операции объединения или разделения патчей для интеграции признаков различных масштабов.
Несколько skip-connection служат для быстрой передачи данных от энкодера к декодеру. Это позволяет высокочастотным данным быстро подходить к выходу нейронной сети без излишней обработки. Исходные данные группы Transformer, подаются на выход декодера с такой же формой. Во время процесса кодирования исходных данных, по мере продвижения вниз модели, высокочастотные признаки непрерывно фильтруются, тогда как общие признаки извлекаются. В процессе декодирования общие признаки непрерывно восстанавливаются с детализированной информацией от skip-connection, что в конечном итоге приводит к временному представлению ряда, сочетающего как высокочастотные, так и низкочастотные признаки.
Операции с патчами являются критическими компонентами для модели U-shaped Transformer. Именно они позволяют получать признаки на разных масштабах. Отобранные признаки непосредственно изменяют, какая информация будет включена в основной контекст вычисления внимания. Традиционные подходы часто разбивают временные ряды на двойные массивы и рассматривают их как независимые каналы. Авторы метода U-shaped Transformer считают этот подход грубым, поскольку информация о патчах из разных каналов на одном временном шаге не происходит из соседних регионов. Поэтому они предлагают использовать свертку с размером окна и шага равным 2 в качестве объединения патчей, что удваивает количество каналов. Это гарантирует, что предыдущий патч не будет фрагментирован и приводит к лучшему слиянию масштабов. Во время процесса декодирования авторы метода соответственно используют транспонированные свертки в качестве операции разделения патчей.
В методе U-shaped Transformer используется свертка с точечным ядром в качестве метода встраивания, чтобы сопоставить каждый патч с пространством более высокой размерности. Затем авторы метода подготавливают обучаемый относительный позиционный кодировщик для каждого патча, который непосредственно добавляется к встраиваемым патчам, чтобы усилить накопление предварительных знаний между патчами.
Как уже было упомянуто выше, авторы метода U-shaped Transformer используют подход встраивания на основе патчей для разделения данных временных рядов на более мелкие блоки. Они используют предварительную задачу восстановления патчей в качестве нашей предварительной задачи. Авторы метода считают, что восстановление немаскированных патчей может повысить устойчивость модели к шумным данным со значением ноль.
После предварительного обучения выполняется донастройка на специфичной головной части, которая отвечает за генерацию целевых задач. При этом замораживаем все компоненты, кроме головных сетей, на этом этапе.
Для улучшения обобщающей способности модели и использования потенциала трансформатора на больших наборах данных используется больший набор данных.
С целью дальнейшего смягчения дисбаланса данных используется взвешенная случайная выборка, где количество выборок из различных наборов данных во время обучения сбалансировано.
А для облегчения проблемы нестабильности обучения в моделях на основе Transformer авторы метода предлагают нормализовать каждую мини-партию, чтобы привести исходные данные к стандартному нормальному распределению.
В итоге предложенный метод предварительной обработки данных обеспечивает эффективное извлечение признаков из разных частей набора данных и эффективно устраняет проблему дисбаланса данных во время совместного обучения на нескольких наборах данных.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода мы переходим к практической части нашей статьи, в которой мы реализуем один из вариантов предложенных подходов средствами MQL5.
Как уже было сказано выше, U-shaped Transformer использует несколько архитектурных решений, которые нам предстоит реализовать. И начнем мы с блока обучаемого позиционного кодирования.
2.1 Позиционное кодирование
Блок позиционного кодирование предназначен для внесение информации в тайм-серию об положении элементов в последовательности. Как Вы знаете, алгоритм Self-Attention анализирует зависимости между элементами вне зависимости от их места в последовательности. Но информация о месте элемента в последовательности и о расстоянии между анализируемыми элементами последовательности порой играет важную роль. Особенно это актуально для временных последовательностей. Для добавления этой информации в классическом Transformer используется добавление синусоидальной последовательности к исходным данным. Периодичность синусоидальных последовательностей фиксирована и может меняться в различных реализациях в зависимости от размера анализируемой последовательности.
Временным рядам свойственно наличие некой периодичности. А парой они обладают несколькими частотными характеристиками. В подобных случаях необходимо проведение дополнительной работы по подбору частотных характеристик тензора позиционного кодирования таким образом, чтобы он не искажал исходные данные и вносили в них дополнительную информацию.
В авторской статье нет детального описания используемого метода обучаемого позиционного кодирования. У меня сложилось впечатление, что авторы метода в процессе обучения модели подбирали коэффициент позиционного кодирования для каждого элемента последовательности. И он будет фиксирован в процессе эксплуатации.
В своей реализации мы пойдем немного дальше и сделаем коэффициенты позиционного кодирования зависимыми от исходных данных. Мы воспользуемся простым полносвязным слоем для генерации тензора позиционного кодирования. Естественно, мы будем обучать данный слой в процессе обучения.
Для реализации предложенного механизма мы создадим новый класс CNeuronLearnabledPE. И как в большинстве случаев, основной функционал мы будем наследовать от базового класса нейронного слоя CNeuronBaseOCL.
class CNeuronLearnabledPE : public CNeuronBaseOCL { protected: CNeuronBaseOCL cPositionEncoder; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronLearnabledPE(void) {}; ~CNeuronLearnabledPE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronLearnabledPE; } virtual void SetOpenCL(COpenCLMy *obj); };
В структуре класса мы видим 1 вложенный объект базового слоя нейронной сети cPositionEncoder, который и содержит обучаемые параметры нашего тензора позиционного кодирования. Данный объект указан статично, что позволяет нам оставить пустыми конструктор и деструктор класса.
Инициализация экземпляра класса осуществляется в методе Init, в параметрах которого мы будем передавать всю необходимую информацию для корректной инициализации вложенных объектов.
bool CNeuronLearnabledPE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; if(!cPositionEncoder.Init(0, 1, OpenCL, numNeurons, optimization, iBatch)) return false; cPositionEncoder.SetActivationFunction(TANH); SetActivationFunction(None); //--- return true; }
Алгоритм метода довольно прост. В теле метода мы сначала вызываем одноименный метод родительского класса, в котором осуществляется проверка полученных внешних параметров и инициализация унаследованных объектов. Результат выполнения операций мы определяем по логическому значению, возвращаемому после выполнения вызванного метода.
Следующим этапом осуществляется инициализация вложенного объекта cPositionEncoder. Для вложенного объекта мы устанавливаем гиперболический тангенс в качестве функции активации. Как известно, диапазон значений данной функции от "-1" до "1", что соответствует диапазону значений синусоидальных волновых последовательностей.
Для нашего же класса динамического позиционного кодирования функция активации отсутствует.
После успешного завершения всех итераций мы завершаем работу метода с результатом true.
Алгоритм прямого прохода нашего метода мы опишем в методе CNeuronLearnabledPE::feedForward. По аналогии с одноименным методом родительского класса, в параметрах метод получает указатель на объект предшествующего нейронного слоя, который содержит исходные данные.
bool CNeuronLearnabledPE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cPositionEncoder.FeedForward(NeuronOCL)) return false; if(!SumAndNormilize(NeuronOCL.getOutput(), cPositionEncoder.getOutput(), Output, 1, false, 0, 0, 0, 1)) return false; //--- return true; }
На основании полученных исходных данных мы сначала генерируем тензор позиционного кодирования. А затем прибавим полученные значения к тензору исходных данных.
Выполнение всех операций контролируется по значениям, которые возвращаются вызванными методами.
Немного сложнее выглядит алгоритм метода распределения градиента ошибки CNeuronLearnabledPE::calcInputGradients. В параметрах от также получает указатель на объект предшествующего нейронного слоя, в который нам предстоит передать градиент ошибки.
bool CNeuronLearnabledPE::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!DeActivation(cPositionEncoder.getOutput(), cPositionEncoder.getGradient(), Gradient, cPositionEncoder.Activation())) return false; if(!DeActivation(NeuronOCL.getOutput(), NeuronOCL.getGradient(), Gradient, NeuronOCL.Activation())) return false; //--- return true; }
В теле метода мы сначала проверяем актуальность полученного в параметрах указателя.
Затем корректируем градиент ошибки, полученный от последующего слоя, на функцию активации внутреннего объекта. Напомню, что в процессе инициализации мы указали функцию активации для внутреннего объекта, но оставили без функции активации сам объект CNeuronLearnabledPE. Следовательно, градиент ошибки в буфере нашего слоя не корректировался на функцию активации.
Следующим этапом мы повторим операцию корректирования градиента ошибки, но на этот раз на функцию активации предшествующего слоя.
Обратите внимание, что мы не осуществляем вызов метода распределения градиента ошибки через внутренний объект генерации тензора позиционного кодирования. Дело в том, что для выполнения операции обновления параметров данного слоя нам достаточно наличия градиента ошибки на его выходе. А передача градиента ошибки через объект до предшествующего слоя нам не нужна, так как блок генерации тензора позиционного кодирования не должен оказывать влияния на исходные данные или их эмбединг.
Для завершения реализации алгоритма обратного прохода класса CNeuronLearnabledPE мы создадим метод обновления обучаемых параметров updateInputWeights. Данный метод максимально упрощен и заключается в вызове одноименного метода вложенного объекта.
bool CNeuronLearnabledPE::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return cPositionEncoder.UpdateInputWeights(NeuronOCL); }
С полным кодом данного класса и всех его методов Вы можете самостоятельно ознакомиться во вложении.
2.2 Класс U-shaped Transformer
А мы продолжим нашу версию реализации подходов, предложенных авторами метода U-shaped Transformer. Должен сказать, что решение по архитектуре реализации scip-connection между Энкодером и Декодером, несмотря на видимую простоту, оказалось не столь однозначным. С одной стороны, мы могли бы воспользоваться ссылкой на идентификатор внутреннего слоя и передать данные от Энкодера к Декодеру. И в этом нет затруднений. Но возникает вопрос по передаче градиента ошибки через scip-connection. Ведь вся архитектура обратного прохода наших классов построена на перезаписывании градиента ошибки при последующем обратном проходе. Следовательно, любой градиент ошибки, который мы передадим по scip-connection будет удален при операциях передачи градиента через нейронные слои между объектами scip-connection.
И здесь напрашивается идея создания всей архитектуры U-shaped Transformer в рамках одного класса. Но нам нужен механизм построения различного количества блоков Энкодер-Декодер с различным количеством слоев Transformer в каждом блоке. Выход был найден в рекуррентном создании объектов. Подробнее с выбранным механизмом мы познакомимся в процессе реализации.
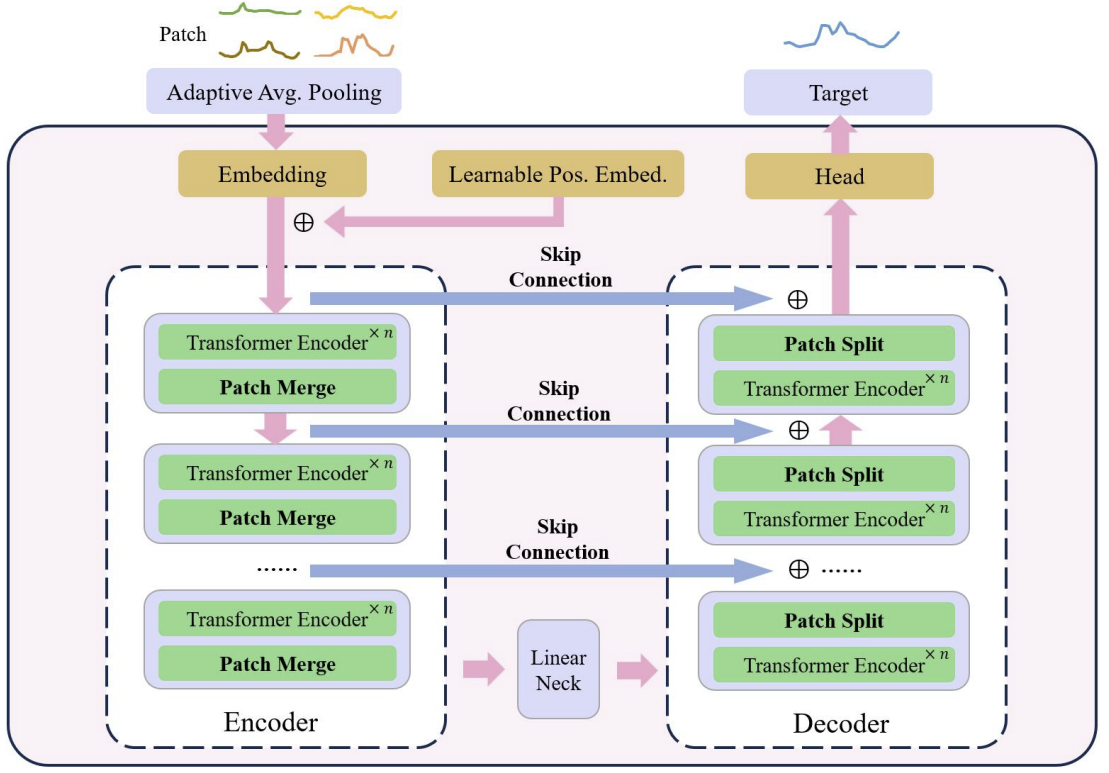
Для реализации нашего блока U-shaped Transformer мы создадим класс CNeuronUShapeAttention, который, как и предыдущий, будет наследовать основной функционал от базового класса нейронного слоя CNeuronBaseOCL.
class CNeuronUShapeAttention : public CNeuronBaseOCL { protected: CNeuronMLMHAttentionOCL cAttention[2]; CNeuronConvOCL cMergeSplit[2]; CNeuronBaseOCL *cNeck; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); //--- public: CNeuronUShapeAttention(void) {}; ~CNeuronUShapeAttention(void) { delete cNeck; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronUShapeAttention; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *net, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
В теле класса мы создаем массив из 2 элементов класса многослойного много-голового внимания CNeuronMLMHAttentionOCL. Это будут Энкодер и Декодер текущего блока.
Тут же мы создаем массив из 2 элементов сверточного слоя, которые мы будем использовать для работы с патчами.
А все элементы между Энкодером и Декодеров текущего блока мы разместим в объекте базового класса нейронного слоя cNeck, который в данном случае будет динамическим. Немного вызывает вопросы, каким образом неопределенное количество блоков "запихнуть" в один блок? Для ответа на этот вопрос предлагаю перейти к рассмотрению метода инициализации объекта Init.
Как всегда, в параметрах метода мы получаем основные константы архитектуры объекта:
- window — размер окна исходных данных (вектор описания 1 элемента последовательности);
- window_key — размер внутреннего вектора описания 1 элемента последовательности в сущностях Self-Attention Query, Key, Value;
- heads — количество голов внимания;
- units_count — количество элементов в последовательности;
- layers — количество слоев внимания в одном блоке;
- inside_bloks — количество вложенных блоков U-shaped Transformer.
Параметры window, window_key, heads и layers используются без изменений для текущего и вложенных блоков U-shaped Transformer.
bool CNeuronUShapeAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, uint inside_bloks, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В теле метода мы сначала вызываем одноименный метод родительского класса, в котором осуществляется контроль полученных параметров и инициализация унаследованных объектов.
Далее мы инициализируем объекты Энкодера и разделения патчей.
if(!cAttention[0].Init(0, 0, OpenCL, window, window_key, heads, units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[0].Init(0, 1, OpenCL, 2 * window, 2 * window, 4 * window, (units_count + 1) / 2, optimization, iBatch)) return false;
А вот затем идет наиболее интересный блок метода инициализации. Мы сначала проверяем количество указанных вложенных блоков. И если их больше "0", то создаем и инициализируем вложенный блок U-shaped Transformer, аналогичный текущему классу. Только количество элементов в последовательности увеличиваем в 2 раза, что соответствует результату разделения патчей. И количество вложенных блоков уменьшаем на "1".
if(inside_bloks > 0) { CNeuronUShapeAttention *temp = new CNeuronUShapeAttention(); if(!temp) return false; if(!temp.Init(0, 2, OpenCL, window, window_key, heads, 2 * units_count, layers, inside_bloks - 1, optimization, iBatch)) { delete temp; return false; } cNeck = temp; }
Указатель на созданный объект мы сохраним в переменную cNeck. Именно для этого мы объявили динамический объект. Таким образом, путем рекуррентного вызова функции инициализации мы создадим необходимое количество вложенных групп U-shaped Transformer.
В последнем блоке мы создадим сверточный слой линейной зависимости между Энкодером и Декодером.
{
CNeuronConvOCL *temp = new CNeuronConvOCL();
if(!temp)
return false;
if(!temp.Init(0, 2, OpenCL, window, window, window, 2 * units_count, optimization, iBatch))
{
delete temp;
return false;
}
cNeck = temp;
}
Далее мы инициализируем объекты Декодера и слияния патчей.
if(!cAttention[1].Init(0, 3, OpenCL, window, window_key, heads, 2 * units_count, layers, optimization, iBatch)) return false; if(!cMergeSplit[1].Init(0, 4, OpenCL, 2 * window, 2 * window, window, units_count, optimization, iBatch)) return false;
А для исключения операций излишнего копирования мы осуществим подмену буфера градиентов ошибки.
if(Gradient != cMergeSplit[1].getGradient()) SetGradient(cMergeSplit[1].getGradient()); //--- return true; }
И завершаем работу метода.
Метод прямого прохода на данном фоне выглядит просто. В нем мы лишь поочередно вызываем одноименные методы внутренних слоев в соответствии с алгоритмом U-shaped Transformer. Сначала исходные данные проходят через блок Энкодера.
bool CNeuronUShapeAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cAttention[0].FeedForward(NeuronOCL)) return false;
После чего мы осуществляем разделение патчей.
if(!cMergeSplit[0].FeedForward(cAttention[0].AsObject())) return false;
И вызываем метод прямого прохода для вложенных блоков.
if(!cNeck.FeedForward(cMergeSplit[0].AsObject())) return false;
Обработанные таким образом данные подаются на вход Декодеру.
if(!cAttention[1].FeedForward(cNeck)) return false;
И слой слияния патчей.
if(!cMergeSplit[1].FeedForward(cAttention[1].AsObject())) return false;
В завершении мы суммируем результаты работы текущего блока U-shaped Transformer с полученными исходными данными (scip-connection) для сохранения высокочастотного сигнала.
if(!SumAndNormilize(NeuronOCL.getOutput(), cMergeSplit[1].getOutput(), Output, 1, false)) return false; //--- return true; }
И завершаем работу метода.
После организации прямого прохода мы переходим к созданию методов обратного прохода. Вначале мы создадим метод распределения градиента ошибки CNeuronUShapeAttention::calcInputGradients, в параметрах которого мы получаем указатель на объект предыдущего слоя, в который нам и предстоит передать градиент ошибки.
bool CNeuronUShapeAttention::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
И в теле метода мы сразу проверяем актуальность полученного указателя.
Благодаря подмене буферов данных градиент ошибки уже сохранен в буфере вложенного слоя слияния патчей. И мы сразу вызываем соответствующий метод распределения градиента ошибки.
if(!cAttention[1].calcHiddenGradients(cMergeSplit[1].AsObject())) return false;
Далее мы проводим градиент ошибки через Декодер.
if(!cNeck.calcHiddenGradients(cAttention[1].AsObject())) return false;
И далее последовательно пропускаем градиент ошибки через внутренние блоки U-shaped Transformer, слой разделения патчей и Энкодер.
if(!cMergeSplit[0].calcHiddenGradients(cNeck.AsObject())) return false; if(!cAttention[0].calcHiddenGradients(cMergeSplit[0].AsObject())) return false; if(!prevLayer.calcHiddenGradients(cAttention[0].AsObject())) return false;
После чего мы суммируем градиенты ошибки на входе и выходе текущего блока (scip-connection).
if(!SumAndNormilize(prevLayer.getGradient(), Gradient, prevLayer.getGradient(), 1, false)) return false; if(!DeActivation(prevLayer.getOutput(), prevLayer.getGradient(), prevLayer.getGradient(), prevLayer.Activation())) return false; //--- return true; }
Скорректируем градиент ошибки на функцию активации предшествующего слоя и завершим работу метода.
За распределением градиента ошибки следует корректировка обучаемых параметров модели. Этот функционал выполняется в методе CNeuronUShapeAttention::updateInputWeights. Алгоритм метода довольно прост. Мы лишь поочередно вызываем соответствующие методы вложенных объектов.
bool CNeuronUShapeAttention::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cAttention[0].UpdateInputWeights(NeuronOCL)) return false; if(!cMergeSplit[0].UpdateInputWeights(cAttention[0].AsObject())) return false; if(!cNeck.UpdateInputWeights(cMergeSplit[0].AsObject())) return false; if(!cAttention[1].UpdateInputWeights(cNeck)) return false; if(!cMergeSplit[1].UpdateInputWeights(cAttention[1].AsObject())) return false; //--- return true; }
И, конечно, не забываем контролировать ход выполнения операций на каждом шаге.
Ещё надо немного остановиться на методах работы с файлами. Если в методе сохранения данных CNeuronUShapeAttention::Save все довольно просто. Мы лишь поочередно вызываем соответствующие методы родительского класса и всех вложенных объектов.
bool CNeuronUShapeAttention::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; for(int i = 0; i < 2; i++) { if(!cAttention[i].Save(file_handle)) return false; if(!cMergeSplit[i].Save(file_handle)) return false; } if(!cNeck.Save(file_handle)) return false; //--- return true; }
То в методе загрузки данных CNeuronUShapeAttention::Load есть свои нюансы. И они связаны с организацией загрузки вложенных блоков U-shaped Transformer. Вначале мы как обычно вызываем метод родительского класса для загрузки унаследованных объектов.
bool CNeuronUShapeAttention::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false;
Затем в цикле мы загружаем данные Энкодера, Декодера и слоев работы с патчами.
for(int i = 0; i < 2; i++) { if(!LoadInsideLayer(file_handle, cAttention[i].AsObject())) return false; if(!LoadInsideLayer(file_handle, cMergeSplit[i].AsObject())) return false; }
После чего наступает этап загрузки вложенных блоков. Но тут, как вы помните, мы используем динамический указатель на объект. Следовательно, возможны варианты. В переменной указатель может быть неактуальным или указывать на объект другого класса.
Мы считываем из файла тип нужного объекта. И проверяем тип объекта, на который указывает переменная cNeck. При отличии типов мы удаляем существующий объект.
int type = FileReadInteger(file_handle); if(!!cNeck) { if(cNeck.Type() != type) delete cNeck; }
Далее мы проверяем актуальность указателя в переменной и, при необходимости, создаем новый объект соответствующего типа.
if(!cNeck) { switch(type) { case defNeuronUShapeAttention: cNeck = new CNeuronUShapeAttention(); if(!cNeck) return false; break; case defNeuronConvOCL: cNeck = new CNeuronConvOCL(); if(!cNeck) return false; break; default: return false; } }
После завершения подготовительной работы загружаем данные объекта из файла.
cNeck.SetOpenCL(OpenCL); if(!cNeck.Load(file_handle)) return false;
В завершении метода осуществляем подмену буферов градиента ошибки.
if(Gradient != cMergeSplit[1].getGradient()) SetGradient(cMergeSplit[1].getGradient()); //--- return true; }
И завершаем работу метода.
С полным кодом всех методов данного класса и всех других программ, используемых при подготовке статьи, Вы можете познакомиться во вложении.
2.3 Архитектура моделей
После создания новых классов для построения наших моделей мы переходим к описанию архитектуры обучаемых моделей, которые мы, как всегда, запишем в файле "...\Experts\UShapeTransformer\Trajectory.mqh".
Ранее уже было сказано, что авторы метода U-shaped Transformer предлагают обучать модели в 2 этапа. На первом этапе мы будем обучать Энкодер восстанавливать замаскированные данные. Следовательно, описание архитектуры модели Энкодера будет вынесена в отдельный метод CreateEncoderDescriptions. В параметрах метода передается указатель на объект динамического массива для записи описания архитектуры модели.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы проверяем актуальность полученного указателя и, при необходимости, создаем новый экземпляр динамического массива.
Далее мы создаем слой исходный данных достаточного размера.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Исходные данные в модель подаются "в сыром" виде. И мы осуществляем из предварительную обработку в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Запомним номер слоя пакетной нормализации для указания в слое обратной нормализации.
Для обучения Энкодера мы будем использовать маскирование данных. И для осуществления маскирования мы создадим слой Dropout.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.4f; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Вероятность маскирования мы установим 0.4, что соответствует 40% исходных данных.
Здесь следует обратить внимание, мы маскируем именно исходные данные, а не их эмбединги.
На следующем этапе мы используем 2 сверточных слоя для генерации эмбедингов маскированных исходных.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = descr.window; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Затем добавим позиционное кодирование к исходным данным. В данном случае мы используем обучаемое позиционное кодирование.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count*prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
И теперь мы добавим блок U-shaped Transformer. Уделим немного внимания описанию слоя и рассмотрим используемые переменные:
- descr.count — размер последовательности;
- descr.window — размер вектора описания 1 элемента последовательности;
- descr.step — количество голов внимания;
- descr.window_out — размер элемента внутренних сущностей внимания;
- descr.layers — количество слое в каждом блоке Transformer;
- descr.batch — количество вложенных блоков U-shaped Transformer.
Как можно заметить, большинство параметров заимствовано из блоков внимания.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronUShapeAttention; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 3; descr.batch = 2; if(!encoder.Add(descr)) { delete descr; return false; }
Далее идет блок принятия решения из 3 полносвязных слоев.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation=LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count=descr.count = BarDescr*(HistoryBars+NForecast); descr.activation=TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Обратите внимание, что на выходе Энкодера мы планируем получить восстановленные исходные данные плюс прогнозных несколько значений. Таким образом мы ходим обучить U-shaped Transformer улавливать зависимости не только в исходных данных, но и найти реперные точки для построения прогнозных значений.
В завершении Энкодера мы добавим слой обратной нормализации для приведения восстановленных и прогнозных значений в вид, сопоставимый с исходными данными.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; prev_count = descr.count = prev_count; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Изменение архитектуры Энкодера требует изменения константы скрытого слоя для получения данных с модели.
#define LatentLayer 9
Кроме того, изменение размера слоя результатов Энкодера требует и корректировки архитектуры моделей Актера и Критика, которые используют эти данные. Архитектура указанных моделей представлена в методе CreateDescriptions. В параметрах метод получает указатели на 2 динамических массива для записи архитектур соответствующих моделей.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
В теле метода мы проверяем полученные указатели и, при необходимости, создаем новые динамические массивы.
Первой мы опишем архитектуру Актера. На вход модели мы будем подавать вектор описания состояния счета.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полученные данные обрабатываются полносвязным слоем.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Далее мы добавляем 5 слоев кросс-внимания, в которых будет сопоставляться информация о состоянии счета и открытых позиций с данными восстановленных и прогнозных значений, сгенерированных Энкодером.
for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, HistoryBars+NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
Здесь стоит обратить внимание, что на стадии обучения политики Актера и промышленной эксплуатации мы не будем маскировать исходные данные. Однако ожидается, что обученный Энкодер будет не только прогнозировать последующие состояния окружающей среды, но и выступать своеобразным фильтром исторических значений, удаляя в них различные шумы.
В завершении модели идет блок принятия решений со стохастической "головой".
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Архитектура Критика получила аналогичные корректировки. И мы не будем сейчас подробно останавливаться на их описании. Я предлагаю Вам самостоятельно ознакомиться с ними во вложении.
2.4 Советник обучения Энкодера
После описания архитектуры моделей мы обратим свое внимание на советник обучения модели Энкодера. Надо сказать, что в данной работе мы использовали обучающую выборку, собранную для предыдущей статьи. Как Вы помните, в ней мы использовали полный массив исторических данных для описания состояния окружающей среды. Такой подход имеет как плюсы, так и минусы. К плюсам можно отнести отказ от стека внутри модели для накопления исторических данных, возможность использования сэмплированных состояний для обучения моделей. К минусам же значительный рост файла обучающей выборки, который многократно хранит повторные данные. Да и в процессе эксплуатации модель на каждом шаге повторяет пересчет исторических данных на всю глубину анализируемой истории. Но на данном этапе нам важно четкое сопоставление данных, поданных на вход модели и восстановленных её после маскирования. Поэтому для целей тестирования предложенных подходов было принято решение остановиться на данном решении.
В целом советник "...\Experts\UShapeTransformer\StudyEncoder.mq5" был построен на базе аналогичного советника из предыдущей статьи. И мы не будем подробно останавливаться на рассмотрении всех его методов. Посмотрим лишь метод обучения модели Train.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Вначале метода мы проведем небольшую подготовительную работу. Определим вероятности сэмплирования траекторий на основании их доходности и объявим локальные переменные.
Затем организуем цикл обучения модели с числом итераций, которое было указано пользователем во внешних параметрах.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
В теле цикла мы сэмплируем траекторию и 1 состояние на ней для обучения модели. Информацию о выбранном состоянии загрузим в буфер данных.
bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
И вызовем метод прямого прохода наше модели, передав в него загруженные данные.
После успешного завершения прямого прохода в буфере результатов модели хранится некое представление об исторических показателях окружающей среды и их прогнозных значений. Конкретный результат нас в данный момент не интересует.
Сейчас нам необходимо подготовить реальные данные о предстоящих и проанализированных состояниях окружающей среды. Как и в прошлой статье, мы сначала загрузим последующие состояния окружающей среды из буфера воспроизведения опыта.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
И дополним их данными, поданными на вход модели при прямом проходе. Напомню, что в буфере у нас не маскированные данные.
if(!Result.AddArray(GetPointer(bState))) continue;
Теперь, когда мы подготовили буфер целевых значений мы можем осуществить обратный проход модели и скорректировать весовые коэффициенты в сторону минимизации ошибки.
if(!Encoder.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
После обновления параметров модели мы информируем пользователя о ходе обучения и переходим к следующей итерации.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
В обязательном порядке проверяем результаты выполнения всех операций.
При успешном выполнении всех итераций цикла обучения модели мы очищаем поле комментариев на графике инструмента.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Выводим в журнал MetaTrader 5 информацию о результатах обучения и инициализируем процесс завершения работы советника.
С полным кодом советника Вы можете самостоятельно ознакомиться во вложении.
Советник обучения политики Актера и Критика "...\Experts\RevIN\Study.mq5" был перенесен из предыдущей статьи практически без изменений. То же самое можно сказать и о советниках взаимодействия со средой. Поэтому мы не будем детально останавливаться на рассмотрении их алгоритмов в рамках данной статьи. Вы можете самостоятельно ознакомиться с полным кодом всех программ, используемых при подготовке данной статьи во вложении.
Однако хочется ещё раз акцентировать внимание, что во всех советниках, кроме советника обучения Энкодера, для модели Энкодера должен быть выключен режим обучения.
Encoder.TrainMode(false);
Это поможет отключить маскирования исходных данных.
3. Тестирование
Выше мы познакомились с теоретическими аспектами метода U-shaped Transformer и провели довольно большую работу по имплементации предложенных подходов средствами MQL5. Теперь пришло время проверить результаты нашего труда на реальных исторических данных.
Как уже было сказано выше, обучать модели мы будем на обучающей выборке, собранной для предыдущей статьи. И мы не будем сейчас останавливаться на подробном описании методов сбора обучающей выборки, которые были подробно описаны ранее.
Обучение модели осуществляется на исторических данных 2023 года инструмента EURUSD тайм-фрейм H1. Тестирование обученной политики Актера осуществляется в тестере стратегий MetaTrader 5 на исторических данных Января 2024 года с сохранением инструмента и тайм-фрейма обучения моделей.
В соответствии с предложенным авторами метода U-shaped Transformer подходом мы осуществляем обучение моделей в 2 этапа. Вначале мы обучаем Энкодер на предварительно собранных обучающих данных.
Здесь надо сказать, что модель Энкодера анализирует только исторические данные по инструменту. Поэтому нам нет необходимости в сборе дополнительных проходов в процессе обучения Энкодера. И мы можем сразу установить достаточно большое количество итераций обучения модели и дождаться завершения процесса обучения.
На этом этапе я заметил позитивный сдвиг в качестве прогноза состояний окружающей среды.
Второй этап обучения политики Актера является итерационным. На данном этапе мы чередуем обучение политики Актера со сбором дополнительной информации об окружающей среде путем добавления в обучающую выборку новых проходов с использованием советника "...\Experts\UShapeTransformer\Research.mq5" и актуальной политики Актера.
В процессе итерационного обучения мне удалось получить модель, способную генерировать прибыль как на обучающей, так и на тестовой выборке.
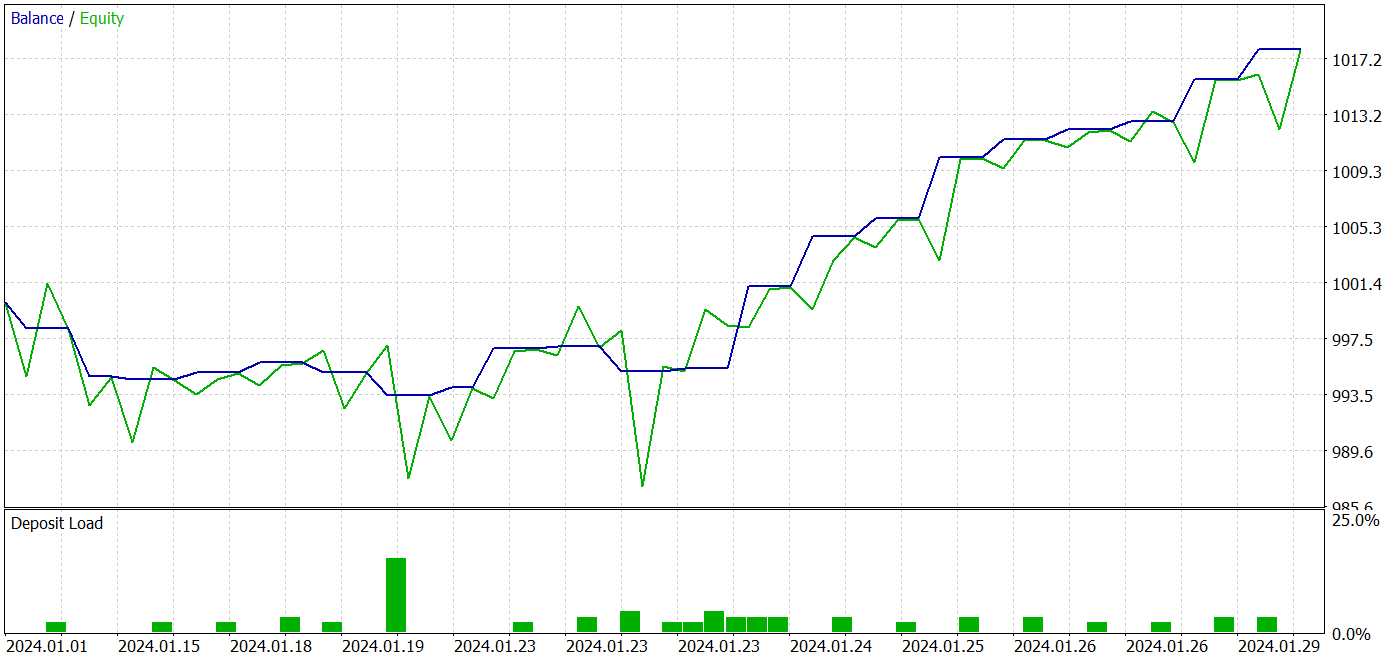
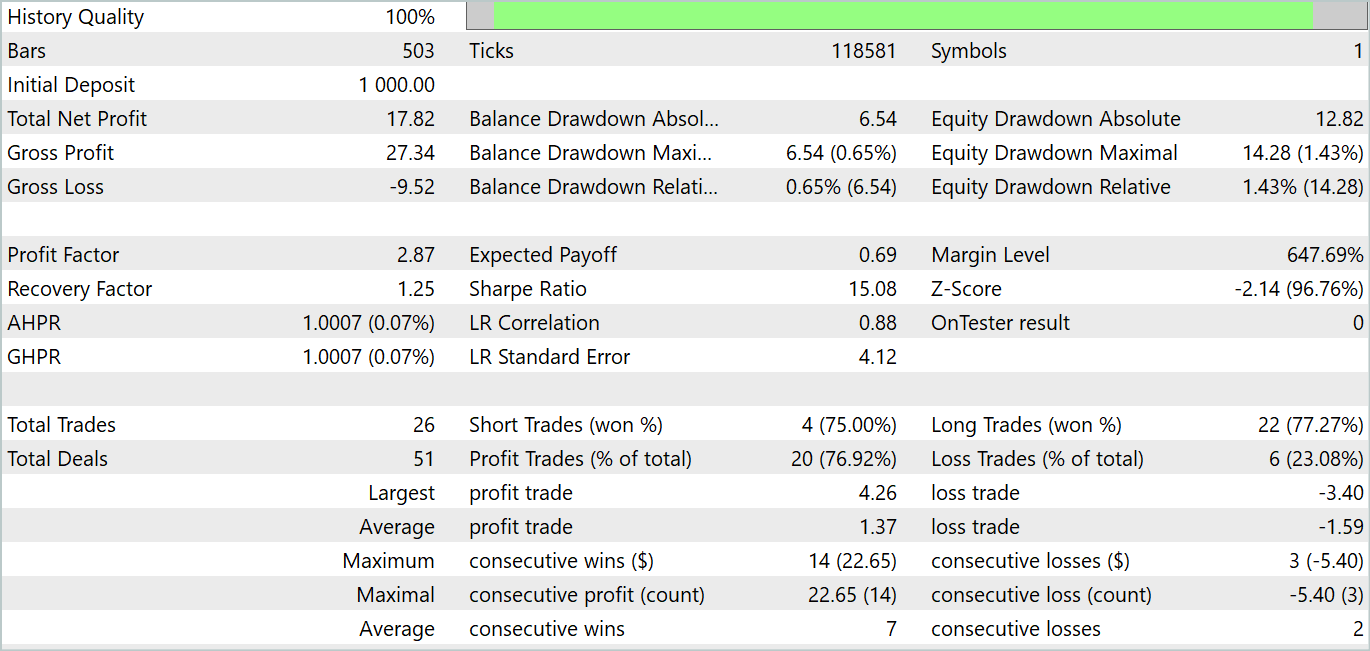
За период тестирования модель совершила 26 сделок. И 20 из них были закрыты с прибылью, что составило 76.92%. При этом профит-фактор составил 2.87.
Полученные результаты многообещающие, но период тестирования в 1 месяц довольно мал для оценки стабильности работы модели.
Заключение
В данной статье мы познакомились архитектуру U-shaped Transformer, которая была специально разработана для прогнозирования временных рядов. Предложенный подход объединяет преимущества трансформеров и полносвязных перцептронов, что позволяет эффективно улавливать долгосрочные зависимости во временных данных и обрабатывать высокочастотный контекст.
Одним из ключевых достижений U-shaped Transformer является использование scip-connection и обучаемых операций объединения и разделения патчей. Это позволяет модели эффективно извлекать признаки разных масштабов и лучше улавливать информацию.
В практической части статьи мы реализовали предложенные подходы средствами MQL5. Обучили и протестировали полученную модель на реальных исторических данных. Результаты тестирования продемонстрировали довольно хорошие результаты.
Однако хочу еще раз акцентировать внимание, что все программы, используемые при подготовке статьи, предназначены только для демонстрации предложенных подходов и не готовы для реального использования на реальных рынках. Результаты тестирования на интервале в 1 месяц могут только продемонстрировать возможности модели, но не подтверждают её стабильную работу на длительном временном отрезке.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования