
Aprendizaje automático y Data Science (Parte 23): ¿Por qué LightGBM y XGBoost superan a muchos modelos de IA?

¿Qué son los árboles potenciados por gradiente?
Los árboles de decisión potenciados por gradiente (GBDT, Gradient Boosted Decision Trees) son una poderosa técnica de aprendizaje automático utilizada principalmente para tareas de regresión y clasificación. Combinan las predicciones de múltiples estudiantes débiles, normalmente árboles de decisión, para crear un modelo predictivo fuerte.
La idea central es construir modelos secuencialmente, intentando cada nuevo modelo corregir los errores cometidos por los anteriores.
Estos árboles potenciados son:
- Extreme Gradient Boosting (XGBoost): Que es una implementación popular y eficiente del refuerzo de gradiente.
- Light Gradient Boosting Machnine (LightGBM): Que fue diseñado para un alto rendimiento y eficiencia, especialmente con grandes conjuntos de datos.
- CatBoost: Que maneja automáticamente las características categóricas y es robusto frente al sobreajuste.
Han ganado mucha popularidad en la comunidad de aprendizaje automático como los algoritmos elegidos por muchos equipos ganadores en competiciones de aprendizaje automático. En este artículo, descubriremos cómo podemos utilizar estos modelos precisos en nuestras aplicaciones comerciales.
Conceptos clave
Boosting
- Boosting es una técnica de aprendizaje en conjunto que combina múltiples estudiantes débiles (modelos que se desempeñan ligeramente mejor que la suposición aleatoria) para formar un estudiante fuerte.
- Cada nuevo modelo se centra en los errores de los modelos anteriores, mejorando gradualmente el rendimiento general.
Descenso de gradiente
- El aumento de gradiente utiliza el descenso de gradiente para minimizar una función de pérdida, que es la diferencia entre los valores previstos y los reales.
- Al agregar iterativamente nuevos modelos que apuntan en la dirección del gradiente de la función de pérdida, se refina el modelo de conjunto.
Con solo unas pocas líneas de código, estos árboles mejorados no solo pueden brindarle una precisión razonable, sino que también pueden llevar su proyecto de ciencia de datos al siguiente nivel.
import lightgbm as lgb train_data = lgb.Dataset(X_train, label=y_train) # preparing data the lightgbm way val_data = lgb.Dataset(X_test, label=y_test, reference=train_data) params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 10, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } # Train the model with evaluation results stored num_round = 100 bst = lgb.train(params, train_data, num_round, valid_sets=[train_data, val_data]) y_pred = bst.predict(X_test, num_iteration=bst.best_iteration) # For binary classification, you might want to threshold the predictions y_pred_binary = np.round(y_pred) print("Classification Report\n", classification_report(y_test, y_pred_binary))
Resultados:
Classification Report precision recall f1-score support 0.0 0.70 0.75 0.73 104 1.0 0.71 0.66 0.68 96 accuracy 0.70 200 macro avg 0.71 0.70 0.70 200 weighted avg 0.71 0.70 0.70 200
Apliqué los mismos datos a otros clasificadores populares.
| Clasificador | Informe de clasificación |
|---|---|
| Regresión logística | precision recall f1-score support 0.0 0.69 0.76 0.72 104 1.0 0.71 0.62 0.66 96 accuracy 0.69 200 macro avg 0.70 0.69 0.69 200 weighted avg 0.70 0.69 0.69 200 |
| Árbol de decisión | precision recall f1-score support 0.0 0.62 0.61 0.61 104 1.0 0.59 0.60 0.59 96 accuracy 0.60 200 macro avg 0.60 0.60 0.60 200 weighted avg 0.61 0.60 0.61 200 |
| Bayes ingenuo | precision recall f1-score support 0.0 0.64 0.84 0.73 104 1.0 0.73 0.49 0.59 96 accuracy 0.67 200 macro avg 0.69 0.67 0.66 200 weighted avg 0.68 0.67 0.66 200 |
| K-Vecinos más cercanos | precision recall f1-score support 0.0 0.68 0.73 0.71 104 1.0 0.69 0.64 0.66 96 accuracy 0.69 200 macro avg 0.69 0.68 0.68 200 weighted avg 0.69 0.69 0.68 200 |
| Máquina de vectores de soporte | precision recall f1-score support 0.0 0.69 0.69 0.69 104 1.0 0.66 0.66 0.66 96 accuracy 0.68 200 macro avg 0.67 0.67 0.67 200 weighted avg 0.67 0.68 0.67 200 |
El modelo LightGBM fue el que presentó mayor precisión general que los otros clasificadores para el mismo problema. Quizás hayas notado que ni siquiera me molesté en...normalizar los datos de entrada. Pero el modelo todavía fue capaz de superar a otros. Como sabemos, la normalización es crucial para el funcionamiento de los modelos de aprendizaje automático, pero LightGBM parece desafiar esta idea. Esta es una de las cosas que hacen que estos modelos sean interesantes.
Veamos la diferencia entre GBDT (LightGBM y XGBoost) y otros clasificadores de aprendizaje automático.
Árboles de decisión potenciados por gradiente (LighGBM y XGBoost) frente a otros clasificadores
| LightGBM y XGBoost | Otros clasificadores |
|---|---|
| No requieren el escalado de las características, ya que se basan en árboles de decisión que son insensibles a la escala de las características de entrada. | Los algoritmos como K-Nearest Neighbors (K-NN) y Máquinas de Vectores de Soporte (SVM), que se basan en la distancia entre puntos de datos, no pueden funcionar bien en un conjunto de datos con características en diferentes escalas. La escala es muy importante para la mayoría de los clasificadores. |
Tanto XGBoost como LightGBM tienen mecanismos integrados que puede manejar valores faltantes. Pueden aprender cómo manejar datos faltantes asignando valores faltantes a cada lado de una división durante el entrenamiento o simplemente pueden crear una rama para ese valor faltante en un árbol y comprender su patrón por separado. | En su mayoría no pueden manejar valores faltantes. Estos valores faltantes pueden reducir la precisión. |
Ajuste de parámetros es importante pero No requerido; Estos modelos funcionan razonablemente bien con los parámetros predeterminados. El ajuste de hiperparámetros sigue siendo crucial para lograr un rendimiento óptimo. | Los modelos clasificadores, como las redes neuronales, son muy sensibles a los hiperparámetros. Los parámetros predeterminados no ayudarán. |
Ahora que hemos visto cómo se comportan LightGBM y XGBoost en comparación con otros clasificadores de aprendizaje automático, analicemos un modelo tras otro, comenzando con XGBoost.
¿Qué es Extreme Gradient Boosting (XGBoost)?
XGBoost es una biblioteca optimizada de aumento de gradiente distribuido diseñada para el entrenamiento eficiente y escalable de modelos de aprendizaje automático. Contiene un método de aprendizaje conjunto que combina las predicciones de múltiples modelos débiles para producir una predicción más fuerte.
¿Cómo funciona XGBoost?
Para entender cómo funciona XGBoost, entendamos su teoría.
Inicialización
Comienza con una predicción inicial, generalmente la media de los valores objetivo para la regresión o el logaritmo de las probabilidades para la clasificación.
Impulso iterativo
- Cálculo residual:Para cada iteración
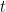 , calcular los residuos (errores) de las predicciones realizadas por el conjunto actual de modelos.
, calcular los residuos (errores) de las predicciones realizadas por el conjunto actual de modelos.
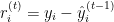
Donde:
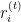 es el residual para la
es el residual para la 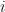 ésima observación en la iteración
ésima observación en la iteración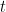 .
. es el valor objetivo real.
es el valor objetivo real.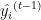 es el valor predicho en la iteración
es el valor predicho en la iteración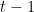 .
.
- Adaptación de un árbol nuevo:Ajustar un nuevo árbol de decisión a los residuos. El árbol está construido para predecir los residuos del modelo actual.
Las hojas del árbol representan los ajustes previstos para las predicciones del modelo actual.
- Actualizar el modelo:Agregue las predicciones del nuevo árbol a las predicciones del modelo actual, generalmente escaladas por una tasa de aprendizaje
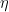 .
.
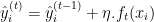
Donde: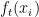 es la predicción del nuevo árbol en la iteración
es la predicción del nuevo árbol en la iteración 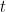 para la entrada
para la entrada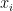 .
.
Función objetivo
La función objetivo en XGBoost consta de dos partes:
- La función de pérdida, que mide lo bien que el modelo se ajusta a los datos de entrenamiento. Las funciones de pérdida comunes incluyen el error cuadrático medio para la regresión y la pérdida logarítmica para la clasificación.
- El término de regularización, que se encarga de penalizar la complejidad del modelo para evitar el sobreajuste. XGBoost utiliza regularización L1 (Lasso) y L2 (Ridge).
La función objetivo a minimizar es:
![]()
Donde:
![]() es el término de pérdida.
es el término de pérdida.
![]() Es el término de regularización para el
Es el término de regularización para el ![]() -ésimo árbol.
-ésimo árbol.
![]() es el número de observaciones.
es el número de observaciones.
![]() es el número de árboles.
es el número de árboles.
Gradiente y hessiano
XGBoost utiliza la expansión de Taylor de segundo orden (gradiente y hessiano) para aproximar la función de pérdida y lograr un cálculo eficaz de las divisiones óptimas. El gradiente es la primera derivada de la función de pérdida con respecto a la predicción, mientras que el Hessiano es la segunda derivada de la función de pérdida con respecto a la predicción.
Poda de árboles
Los árboles se cultivan iterativamente y se podan para optimizar la función objetivo. La poda ayuda a prevenir el sobreajuste al eliminar los nodos que no proporcionan una mejora significativa en la función objetivo.
La tasa de aprendizaje η escala la contribución de cada árbol para controlar el tamaño del paso en el proceso de impulso. Las tasas de aprendizaje más pequeñas generalmente requieren más árboles.
Implementación de XGBoost en Python
Se necesitan unas pocas líneas de código para implementar el modelo XGBoost en Python. Dado que es una biblioteca independiente, debes instalarla primero si aún no lo has hecho.
pip install xgboost
Necesitamos importar la función Pipeline de Scikit-learn.Esto nos ayudará a crear un objeto de aprendizaje automático con preprocesamiento y otros pasos necesarios.
from sklearn.pipeline import Pipeline
Como se dijo anteriormente, los árboles potenciados pueden funcionar bien incluso sin normalizar los datos; sin embargo, agregarlos no hará daño, sin mencionar que nos brinda varias ventajas, como ayudarnos a mitigar problemas de inestabilidad numérica causados por números grandes que podrían ser el resultado de multiplicaciones de matrices en nuestros modelos. Agreguemos la normalización como una buena práctica mientras creamos una canalización para el modelo y la ajustamos a los datos de entrenamiento.
Python:
# Create a pipeline with a scaler and the XGBoost classifier pipe = Pipeline([ ("scaler", StandardScaler()), ("xgb", xgb.XGBClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
El modelo XGBoost viene con algunos parámetros que son cruciales para comprender no solo cómo funcionan sino también cómo ajustarlos para mejorarlos.
Python:
params = {
'objective': 'binary:logistic',
'learning_rate': 0.05,
'max_depth': 5,
'n_estimators': 100,
'colsample_bytree': 0.9,
'subsample': 0.9,
'eval_metric': ['auc', 'logloss']
} | Parámetro | Descripción | Afinación |
|---|---|---|
| Objective | Este parámetro especifica la tarea de aprendizaje y el objetivo de aprendizaje correspondiente; el binary:logistic utilizado anteriormente se utiliza para la clasificación binaria con regresión logística. Proporciona salidas de probabilidad. | Los objetivos comunes incluyen reg:squarederror' para la regresión, 'binary:logistic' para la clasificación binaria y 'multi:softmax' para la clasificación multiclase. Elija siempre el objetivo en función de la naturaleza de su problema. |
| learning_rate | También conocido como eta ( Una tasa de aprendizaje más baja hace que el modelo sea más robusto al evitar el sobreajuste, pero requiere más rondas de refuerzo y viceversa. | Las tasas de aprendizaje más bajas (por ejemplo, 0,01-0,1) tienden a requerir más árboles (n_estimadores más altos) pero pueden mejorar la estabilidad y el rendimiento del modelo. Es una buena idea empezar con un valor moderado (por ejemplo, 0,1) y ajustarlo en función del rendimiento de la validación cruzada. |
| max_depth | Esta es la profundidad máxima del árbol. Aumentar este valor hace que el modelo sea más complejo y tenga más probabilidades de sobreajustarse. Controla la complejidad del modelo. Los árboles más profundos capturan más patrones entre las características, lo que aumenta el riesgo de sobreajuste. | Los valores habituales oscilan entre 3 y 10. Utilice la validación cruzada para encontrar la profundidad óptima. |
| n_estimators | Este es el número de rondas o árboles de refuerzo que hay que construir. Más árboles incrementan el tiempo de cálculo y son propensos al sobreajuste. | La detención temprana se puede utilizar en la validación cruzada para encontrar una cantidad adecuada de árboles. |
| colsample_bytree | Es la relación de submuestras de columnas al construir cada árbol. Un valor de 0,9 (utilizado en el código anterior) significa que se utilizará el 90% de las características para construir cada árbol. Ayuda a reducir el sobreajuste al introducir aleatoriedad a nivel de columna. También puede acelerar el entrenamiento y hacer que el modelo sea más robusto. | Los valores suelen oscilar entre 0,3 y 1,0. Los valores más altos utilizan más funciones, mientras que los valores más bajos introducen más aleatoriedad. |
| subsample | La proporción de submuestras de las instancias de entrenamiento. Un valor de 0,9 significa que se utilizará el 90% de los datos de entrenamiento para construir cada árbol. Similar a colsample_bytree, este parámetro reduce el sobreajuste al agregar aleatoriedad a nivel de datos y puede mejorar la generalización. | Los valores suelen oscilar entre 0,5 y 1,0. Los valores más altos utilizan más datos, mientras que los valores más bajos introducen más aleatoriedad. |
| eval_metric | La métricas de evaluación para ser utilizado durante el entrenamiento. Múltiples métricas de evaluación pueden proporcionar una visión más completa del rendimiento del modelo. | Entre las métricas comunes se incluyen 'rmse' para la regresión, 'logloss' para la clasificación y error para la clasificación binaria. Elija siempre métricas que se alineen con la naturaleza de su problema y sus objetivos. |
Dado que ya hemos entrenado el modelo. Vamos a probarlo y observar su rendimiento.
Python:
y_pred = pipe.predict(X_test)
# For binary classification, you might want to threshold the predictions since these are probabilities
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix xgboost") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.71 0.73 0.72 104 1.0 0.70 0.68 0.69 96 accuracy 0.70 200 macro avg 0.70 0.70 0.70 200 weighted avg 0.70 0.70 0.70 200
El modelo hizo un gran trabajo en las predicciones fuera de la muestra: tuvo una precisión del 71% y del 70% para las señales bajistas (clase 0) y alcistas (clase 1) respectivamente.
Ahora que hemos analizado XGBoost, analicemos LightGBM y veamos de qué se trata.
¿Qué es la máquina potenciadora de gradiente ligera (LightGBM)?
Este es un marco de aprendizaje automático de código abierto diseñado específicamente para lograr eficiencia, escalabilidad y precisión. Fue desarrollado por Microsoft como parte de un kit de herramientas de aprendizaje automático distribuido y se lanzó el 24 de abril de 2017.
LightGBM se construyó con base en árboles de decisiones potenciados por gradiente existentes, como XGBoost, y ofrece varias mejoras clave que se describen a continuación.
Mejoras en LightGBM
Exactitud. Si bien prioriza la velocidad y la eficiencia de la memoria, LightGBM no compromete la precisión. Las técnicas empleadas están diseñadas para lograr un rendimiento similar o incluso mejor en comparación con los modelos GBDT anteriores.
¿Cómo funciona LightGBM?
GBM ligero funciona igual que XGBoost cuando se trata de teoría matemática con un ligero cambio en cómo se cultivan los árboles, veamos los conceptos centrales detrás de LightGBM.
Boosting. Al igual que XGBoost, en el aumento de gradiente, cada nuevo modelo tiene como objetivo corregir los errores cometidos por los modelos anteriores ajustándose a los residuos (errores).
Árboles de decisión. Mientras XGBoost utiliza el crecimiento de árboles por niveles, lo que significa que hace crecer el árbol en profundidad y lo equilibra de manera más uniforme. LightGBM dispone de crecimiento de árboles por hojas, lo que permite crear árboles más profundos y más complejos.

Dado que estos dos modelos son muy similares en su funcionamiento, veamos su tabla de diferencias para ayudarnos a entenderlos bien mediante la comparación.
Las diferencias entre XGBoost y LightGBM.
| Aspecto | XGBoost | LightGBM |
|---|---|---|
| Estrategia de crecimiento de los árboles | Crecimiento por niveles (los árboles crecen en profundidad, árboles más equilibrados) | Crecimiento por hojas (hace crecer primero la hoja con la mayor reducción de pérdida, árboles potencialmente más profundos) |
| Manejo de valores faltantes | Aprende la dirección óptima para manejar los valores faltantes durante el entrenamiento | Puede manejar valores faltantes directamente, divide los datos en categorías faltantes y no faltantes |
| Regularización | Utiliza la regularización L1 (Lasso) y L2 (Ridge) para penalizar la complejidad del modelo | Utiliza regularización L2, centrándose más en prevenir el sobreajuste. |
| Técnica de muestreo | Utiliza el aumento de gradiente tradicional con todos los datos. | Muestreo unilateral basado en gradientes (GOSS) para centrarse en puntos de datos importantes con grandes gradientes |
| Manejo de funciones | Requiere codificación one-hot u otro preprocesamiento para variables categóricas | Admite funciones categóricas de forma nativa mediante la agrupación de funciones exclusivas (EFB) |
| Conciencia de la escasez | Optimizado para datos dispersos, utiliza un algoritmo que tiene en cuenta la escasez para lograr eficiencia de memoria y cálculo. | Maneja datos dispersos de manera eficiente, tiene técnicas de optimización similares a XGBoost |
| Algoritmo de búsqueda de divisiones | Utiliza algoritmos aproximados y bosquejos cuantiles para encontrar divisiones eficientes de manera predeterminada | Utiliza algoritmos basados en histogramas para una búsqueda más rápida de divisiones y eficiencia de memoria. |
| Procesamiento paralelo | Admite computación paralela y distribuida para el procesamiento de datos a gran escala. | También admite computación paralela y distribuida, optimizada para grandes conjuntos de datos. |
| Velocidad de entrenamiento | Generalmente más lento en comparación con LightGBM debido al crecimiento por niveles. | Generalmente más rápido debido al crecimiento de las hojas y a las técnicas de muestreo eficientes. |
| Flexibilidad y personalización | Altamente flexible, admite funciones de pérdida personalizadas y métricas de evaluación. | También es muy flexible y cuenta con amplias opciones de personalización para el proceso de refuerzo. |
Implementación de LightGBM en Python
Como se vio anteriormente, se necesitan unas pocas líneas de código para implementar un modelo LightGBM. Implementémoslo esta vez dentro de una canalización. De la misma forma que hicimos con XGBoost.
Tenemos que instalarlo primero.
pip install lightgbm
El LightGBM también tiene algunos parámetros que es importante comprender.
| Parámetro | Descripción | Ajuste |
|---|---|---|
| boosting_type | Tipo de algoritmo de impulso a utilizar. El valor predeterminado es 'gbdt' (árbol de decisión con refuerzo de gradiente). | Los valores típicos son 'gbdt','dart','goss'. 'gbdt' Es el más común. Elija según su conjunto de datos y experimentación. |
| Objective | Especifica la tarea de aprendizaje y el objetivo de aprendizaje correspondiente. 'binary' se utiliza para clasificación binaria. | Los objetivos comunes incluyen «regression» para tareas de regresión, «binary» para clasificación binaria. Elija siempre en función de la naturaleza de su problema. |
| Métrica | Métrica(s) de evaluación que se utilizarán durante la capacitación. 'auc' y 'binary_logloss' son comunes para la clasificación binaria. | Los valores típicos oscilan entre 20 y 50. Aumentar el número de hojas puede capturar patrones más complejos, pero puede provocar un sobreajuste. Utilice la validación cruzada para encontrar el valor óptimo. |
| num_leaves | Número máximo de hojas en un árbol. Un valor más alto aumenta la complejidad del modelo y viceversa. | Los valores típicos oscilan entre 20 y 50. Aumentar este valor puede capturar patrones más complejos, pero puede provocar sobreajuste. |
| n_estimators | Número de rondas de refuerzo (árboles). Generalmente, más árboles aumentan el tiempo de cálculo y el riesgo de sobreajuste. | Utilice la detención temprana en la validación cruzada para determinar la cantidad adecuada de árboles. Comience con un valor moderado (por ejemplo, 100) y ajústelo según el rendimiento. |
| max_depth | Profundidad máxima de un árbol. Aumentar este valor hace que el modelo sea más complejo y tenga más probabilidades de sobreajustarse. | Los valores habituales oscilan entre 3 y 10. Los árboles más profundos capturan más patrones pero aumentan el riesgo de sobreajuste. Utilice la validación cruzada para encontrar la profundidad óptima. |
| learning_rate | Tamaño del paso en cada iteración mientras se avanza hacia el mínimo de la función de pérdida. Los valores más bajos hacen que el modelo sea más robusto pero requieren más rondas de refuerzo. | Las tasas de aprendizaje más bajas (por ejemplo, 0,01-0,1) requieren más árboles (n_estimators más altos) pero pueden mejorar la estabilidad y el rendimiento del modelo. Comience con un valor moderado (por ejemplo, 0,1) y ajústelo según el rendimiento de la validación cruzada. |
| feature_fraction | Fracción de características que se utilizarán en cada ronda de refuerzo. Un valor de 0,9 significa que se utilizarán el 90% de las características para construir cada árbol. | Los valores suelen oscilar entre 0,3 y 1,0. Los valores más altos utilizan más funciones, mientras que los valores más bajos introducen más aleatoriedad. Ayuda a reducir el sobreajuste al introducir aleatoriedad en el nivel de características. |
Para obtener más información sobre estos hiperparámetros, consulte la documentación vinculada al final del artículo. Ahora, entrenemos el modelo LightGBM.
Python:
params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 25, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } pipe = Pipeline([ ("scaler", StandardScaler()), ("lgbm", lgb.LGBMClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
Consola de salidas:
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Info] Number of positive: 398, number of negative: 402 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000177 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 1594 [LightGBM] [Info] Number of data points in the train set: 800, number of used features: 8 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.497500 -> initscore=-0.010000 [LightGBM] [Info] Start training from score -0.010000 [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf
No podemos comprender su rendimiento por ahora, proporcionemos nuevos datos al modelo entrenado y observemos el rendimiento.
y_pred = pipe.predict(X_test) # Changes from bst to pipe
# For binary classification, you might want to threshold the predictions
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix lightgbm") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.69 0.72 0.70 104 1.0 0.68 0.65 0.66 96 accuracy 0.69 200 macro avg 0.68 0.68 0.68 200 weighted avg 0.68 0.69 0.68 200
Genial, el modelo tiene una precisión del 69% en la muestra de prueba. Ahora que tenemos estos dos modelos bien entrenados, guardémoslos en formato ONNX que podemos implementar en MQL5.
Guardando XGBoost y LightGBM en ONNX.
Guardar estos dos modelos puede ser complicado, ya que ambos vienen por separado en sus bibliotecas personalizadas. Su proceso de guardado no es tan sencillo como guardar modelos de Scikit-learn, TensorFlow o Keras. Para obtener más información, consulte la documentación de ONNX sobre cómo guardarLightGBM y XGBoost.
Comencemos guardando el modelo GBM Light. El proceso es exactamente el mismo para ambos modelos..
Guardando el modelo LightGBM | Código Python:
from skl2onnx.common.data_types import FloatTensorType from skl2onnx import convert_sklearn, to_onnx, update_registered_converter from skl2onnx.common.shape_calculator import calculate_linear_classifier_output_shapes from onnxmltools.convert.xgboost.operator_converters.XGBoost import convert_xgboost from onnxmltools.convert import convert_xgboost as convert_xgboost_booster update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_lightgbm", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Guardando el modelo XGBoost | Código Python:
update_registered_converter( xgb.XGBClassifier, "XGBClassifier", calculate_linear_classifier_output_shapes, convert_xgboost, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_xgboost", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("xgboost.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Cargando el modelo ONNX en MQL5
La carga de árboles de decisión potenciados por gradiente (GBDT) puede ser complicada, a diferencia de la carga de otros modelos, a pesar de que el proceso es el mismo.
MQL5 | LightGBM.mqh
bool CLightGBM::OnnxLoad(long &handle) { //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",output_count," output(s)"); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"output",type_info); ArrayCopy(outputs, type_info.tensor.dimensions); } } //--- replace(inputs); replace(outputs); //--- Setting the input size for (long i=0; i<input_count; i++) if (!OnnxSetInputShape(handle, i, inputs)) //Giving the Onnx handle the input shape { printf("Failed to set the input shape Err=%d",GetLastError()); DebugBreak(); return false; } //--- Setting the output size for(long i=0; i<output_count; i++) { if(!OnnxSetOutputShape(handle,i,outputs)) { printf("Failed to set the Output[%d] shape Err=%d",i,GetLastError()); //DebugBreak(); //return false; } } initialized = true; Print("ONNX model Initialized"); return true; }
Pestaña Resultados | Expertos:
JM 0 10:49:34.197 LightGBM EA (EURUSD,H1) model has 1 input(s)
MG 0 10:49:34.197 LightGBM EA (EURUSD,H1) 0 input name is input
KM 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
CF 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
HP 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1, 8]
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 input shape must be defined explicitly before model inference
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape of input data can be reduced to [8] if undefined dimension set to 1
EM 0 10:49:34.198 LightGBM EA (EURUSD,H1) model has 2 output(s)
MJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output name is output_label
MR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
RK 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1]
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output shape must be defined explicitly before model inference
GJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 1 output name is output_probability
OR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_SEQUENCE
KN 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_SEQUENCE
OF 0 10:49:34.198 LightGBM EA (EURUSD,H1) no dimensions defined for 1 output
HM 0 10:49:34.198 LightGBM EA (EURUSD,H1) Failed to set the Output[1] shape Err=5802
IH 0 10:49:34.198 LightGBM EA (EURUSD,H1) ONNX model Initialized
Si observamos más de cerca el modelo enNetron:

La primera capa de salida es de tipo tensor con una matriz de enteros 1D de tamaño desconocido. Cambiar el tamaño de esta capa a la forma de 1 debería funcionar bien. Cuando se trata de la segunda capa de salida, hay una secuencia con un mapa (se parece a un diccionario en Python) con dos matrices unidimensionales de tamaños desconocidos, una para etiquetas y la otra para probabilidades. Así lo indica ZipMap, por si se lo está preguntando.
Establecer el tamaño de esta segunda capa de salida utilizando OnnxSetOutputShape para este tipo de objeto complejo es difícil y puede arrojar errores extraños no fui capaz de averiguarlo sin embargo, redimensionarlo a 1 funciona bien ya que lanzará una advertencia pero sigue funcionando bien. Cuando ejecute el modelo ONNX de la forma adecuada. Lea más.
float output_data[]; struct Map { ulong key[]; float value[]; } output_data_map[]; //--- ArrayResize(output_data, outputs.Size()); if (!OnnxRun(onnx_handle, ONNX_DATA_TYPE_FLOAT, x_float, output_data, output_data_map)) { printf("Failed to get predictions from Onnx err %d",GetLastError()); return proba; }
Dentro de la clase LightGBM y XGBoost tenemos los siguientes métodos:
MQL5 | LightGBM.mqh
class CLightGBM { bool initialized; long onnx_handle; void PrintTypeInfo(const long num,const string layer,const OnnxTypeInfo& type_info); long inputs[], outputs[]; void replace(long &arr[]) { for (uint i=0; i<arr.Size(); i++) if (arr[i] < 0) arr[i] = UNDEFINED_REPLACE; } bool OnnxLoad(long &handle); public: CLightGBM(void); ~CLightGBM(void); virtual bool Init(const uchar &onnx_buff[], ulong flags=ONNX_DEFAULT); //Initilaized ONNX model from a resource uchar array with default flag virtual bool Init(string onnx_filename, uint flags=ONNX_DEFAULT); //Initializes the ONNX model from a .onnx filename given virtual long predict_bin(const vector &x); //REturns the predictions for the current given matrix | useful in real-time prediction virtual vector predict_proba(const vector &x); //Returns the predictions in probability terms | useful in real-time prediction virtual matrix predict_proba(const matrix &x); //Returns the predicted probability for the whole matrix | useful for testing virtual vector predict_bin(const matrix &x); //gives out the vector for all the predictions | useful for testing };
Uso de LightGBM y XGBoost en el trading
Después de que el modelo se inicializa en la función OnInit.
MQL5 | LightGBM EA.mq5
int OnInit() { if (!lgbm.Init(lightgbm_onnx)) return INIT_FAILED; }
Los modelos ONNX cargados pueden desplegarse con datos recogidos de la misma forma que los datos de entrenamiento.
void OnTick() { int size = CopyRates(Symbol(), PERIOD_CURRENT, 1, 1, rates_x); //We copy only one recent-closed bar //--- if (NewBar()) { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); }
Hagamos una estrategia comercial sencilla basada en las señales obtenidas.
if (NewBar()) //Trade at the opening of a new candle { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions m_trade.Buy(lotsize, Symbol(), ticks.ask, ticks.bid-stoploss*Point(), ticks.ask+takeprofit*Point()); //Open a buy trade } else //Bearish signal { if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions m_trade.Sell(lotsize, Symbol(), ticks.bid, ticks.ask+stoploss*Point(), ticks.bid-takeprofit*Point()); //open a sell trade } }
Realicé una prueba en el Probador de estrategias, en un marco temporal de 1 hora en EURUSD desde el 01.01.2023 hasta el 23.05.2024.
LightGBM:

XGBoost:

Ambos modelos tuvieron pérdidas. XGBoost tuvo -8 $ menos de pérdidas que LightGBM. Ambos tenían un gráfico de balance casi igual.

El informe del probador de estrategia no puede decirnos si los modelos están haciendo el buen trabajo para el cual fueron entrenados, es decir, predecir el próximo movimiento de la barra. Como sabemos, hay muchas cosas que deben tenerse en cuenta para que un Asesor Experto sea rentable.
Para comprender cómo se desempeñaban los modelos, creemos un script para recopilar datos de la misma manera que recopilamos los datos de entrenamiento. Al hacerlo, creamos una variable de destino.
void OnStart() { //--- if (!lgb.Init(lightgbm_onnx)) return; //--- custom out-of-sample testing int bars = 9000; int start = 1000; MqlRates rates_x[]; ArraySetAsSeries(rates_x, true); int size = CopyRates(Symbol(), PERIOD_CURRENT, start, bars, rates_x); //We start at the bar 1000 and collect 9000 candles backward MqlRates rates_y[]; ArraySetAsSeries(rates_y, true); CopyRates(Symbol(), PERIOD_CURRENT, start-1, bars, rates_y); //We do the same thing here but we only collect one bar forward making sure we get the prediction for the next candle //--- vector actual(size), predictions(size); for (int i=0; i<size; i++) { vector x = { rates_x[i].open, rates_x[i].high, rates_x[i].low, rates_x[i].close, rates_x[i].close-rates_x[i].open, rates_x[i].high-rates_x[i].low, rates_x[i].close-rates_x[i].low, rates_x[i].close-rates_x[i].high }; actual[i] = rates_y[i].close > rates_x[i].open ? 1 : 0; //making the target variable predictions[i] = (double)lgb.predict_bin(x); } Metrics::classification_report(actual, predictions); }
Pestaña Resultados | Expertos:
EG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Confusion Matrix
PO 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [[2857,1503]
CI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [926,3714]]
FM 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NF 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Classification Report
HJ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
KP 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [CLS] precision recall specificity f1 score support
QQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [0.0] 0.76 0.66 0.80 0.70 4360
CQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [1.0] 0.71 0.80 0.66 0.75 4640
HS 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NK 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) accuracy 0.73 9000
RG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) average 0.73 0.73 0.73 0.73 9000
LI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Weighed avg 0.73 0.73 0.73 0.73 9000
El modelo tuvo una precisión del 73% en datos fuera de la muestra. Esto nos indica que nuestro modelo está funcionando bien a pesar de no poder producir una curva ascendente en el probador de estrategias. Este debería ser un buen punto de partida para crear sus propios Asesores Expertos rentables realizados con GBDT en MQL5.
Ventajas de los árboles de decisión potenciados por gradientes
1. Alta precisión predictiva
Los GBDT a menudo superan a muchos otros algoritmos de aprendizaje automático en términos de precisión predictiva. Esto se debe a que combinan las fortalezas de los árboles de decisión con el aumento de gradiente, que mejora iterativamente el rendimiento del modelo al centrarse en los errores de los árboles anteriores.
2. Robustez frente al sobreajuste
El proceso de refuerzo implica agregar nuevos árboles que corrigen los errores del conjunto existente, lo que ayuda a reducir el sobreajuste. Técnicas como el ajuste de la tasa de aprendizaje, la regularización y la detención temprana pueden mejorar aún más esta robustez.
3. No es necesario un preprocesamiento extenso
Los GBDT no requieren pasos de preprocesamiento extensos, como escalamiento de características, manejo de valores faltantes o codificación de variables categóricas, que normalmente son necesarios para otros algoritmos como la regresión lineal o las máquinas de vectores de soporte.
4. Flexibilidad y personalización
Los GBDT ofrecen una amplia gama de hiperparámetros que se pueden ajustar para optimizar el rendimiento de tareas específicas. Estos incluyen el número de árboles, la tasa de aprendizaje, la profundidad máxima de los árboles y el número mínimo de muestras necesarias para dividir un nodo, entre otros.
5. Maneja relaciones complejas
Los GBDT pueden modelar relaciones no lineales complejas entre las características y la variable objetivo. Esto los hace adecuados para capturar patrones complejos en los datos que los modelos más simples podrían pasar por alto.
6. Técnicas de regularización
Los GBDT incluyen parámetros de regularización que ayudan a controlar la complejidad del modelo y evitar el sobreajuste. Parámetros comoprofundidad máxima,división de muestras mínimas, ymin_muestras_hoja desempeñan un papel crucial en la regularización.
7. Escalabilidad
Implementaciones como XGBoost, LightGBM y CatBoost están optimizadas para la velocidad y la escalabilidad. Pueden manejar grandes conjuntos de datos de manera eficiente y aprovechar las capacidades del hardware como la computación paralela y distribuida.Como ocurre con cualquier modelo de aprendizaje automático, estos modelos también tienen desventajas que deben reconocerse, no para disuadir a nadie de utilizarlos, sino para consolidar su comprensión.
Desventajas de los árboles de decisión potenciados por gradiente
1. Complejidad computacional. El entrenamiento de GBDT puede resultar costoso desde el punto de vista computacional, especialmente con una gran cantidad de árboles y árboles profundos. En conjuntos de datos grandes, el proceso de entrenamiento puede consumir una cantidad significativa de memoria en conjuntos de datos grandes y profundos.
2. Ajuste de hiperparámetros. A pesar de poder trabajar con parámetros predeterminados para ambos modelos analizados, aún tienen muchos hiperparámetros que deben ajustarse cuidadosamente para lograr un rendimiento óptimo. Parámetros como el número de árboles, la tasa de aprendizaje, la profundidad máxima y el mínimo de muestras por hoja.
Como todos sabemos, ajustar estos parámetros puede llevar mucho tiempo y requerir un gran esfuerzo computacional.
3. Sensibilidad constante a datos ruidosos. Dado que cada árbol intenta corregir los errores de los árboles anteriores, cualquier ruido en los datos puede amplificarse mediante el proceso de refuerzo.
4. A menudo requiere grandes conjuntos de datos. Los GBDT a menudo requieren una gran cantidad de datos para lograr un buen rendimiento. Es posible que los conjuntos de datos pequeños no proporcionen suficiente información para que el proceso de refuerzo funcione de manera eficaz.
El resultado final
Los árboles potenciados por gradiente son herramientas valiosas para los operadores de Forex, ya que hemos visto que superan a muchos modelos de aprendizaje automático desde el principio. La gente solía creer que los modelos basados en redes neuronales complejas como GRU, RNN y LSTM eran los modelos ideales para superar al mercado, pero ese ya no es el caso ya que los árboles potenciados por gradiente están creciendo en popularidad en la comunidad de aprendizaje automático debido a su simplicidad y su capacidad para realizar la tarea predictiva en cuestión.
Saludos cordiales.
Realice un seguimiento del desarrollo de los modelos de aprendizaje automático y mucho más en esta serie de artículos sobre este tema. Repositorio de GitHub.
El código Python analizado en esta publicación está vinculado aquí.
Tablas de anexos:
Asesores expertos | Carpeta 'Experts':
| Nombre del archivo | Descripción y uso |
|---|---|
| LightGBM EA.mq5 | Un asesor experto para probar Light Gradient Boosted Machine (LightGBM) |
| XGBoost EA.mq5 | Un asesor experto para probar Extreme Gradient Boosting (XGBoost) |
Bibliotecas | Carpeta 'Include':
| Nombre del archivo | Descripción y uso |
|---|---|
| LightGBM.mqh | Una biblioteca para cargar, inicializar e implementar modelos ONNX de Light Gradient Boosted Machine (LightGBM) |
| XGBoost.mqh | Una biblioteca para cargar, inicializar y desplegar modelos Extreme Gradient Boosting (XGBoost) ONNX |
Scripts | Carpeta 'Scripts':
| Nombre del archivo | Descripción y uso |
|---|---|
| LightGBM Performance TestScript.mq5 | Un script para probar el modelo LightGBM en tiempo real |
Archivos | Carpeta 'Files':
| Nombre del archivo | Descripción y uso |
|---|---|
| EURUSD.PERIOD_H1.csv | Un archivo CSV que contiene el conjunto de datos de entrenamiento |
| lightgbm.eurusd.h1.onnx xgboost.eurusd.h1.onnx | Modelos LightGBM y XGBoost en formato ONNX |
Código Python:
| Nombre del archivo | Descripción y uso |
|---|---|
| lightgbm-xgboost.ipynb | Cuaderno Jupyter que contiene todo el código Python analizado en esta publicación. |
Fuentes y referencias:
- ¿Puede alguien hacerlo mejor que XGBoost? - Mateusz Susik (https://www.youtube.com/watch?v=5CWwwtEM2TA).
- Desbloqueo del poder de los árboles potenciados por gradientes (usando LightGBM) | PyData London 2022: (https://www.youtube.com/watch?v=qGsHlvE8KZM).
- Documentación de LightGBM: (https://lightgbm.readthedocs.io/en/latest/Parameters.html).
- Documentación de XGBoost: (https://xgboost.readthedocs.io/en/stable/tutorials/model.html).
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/14926
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso