
データサイエンスと機械学習(第23回):LightGBMとXGBoostが多くのAIモデルを凌駕する理由

勾配ブースティング決定木とは?
勾配ブースティング決定木(GBDT)は、主に回帰と分類タスクに使用される強力な機械学習手法です。複数の弱い学習機(通常は決定木)の予測を組み合わせて、強力な予測モデルを作成します。
核となる考え方は、モデルを順次構築していき、それぞれの新しいモデルで前のモデルの誤差を修正しようとすることです。
次はブースト決定木の例です。
- Extreme Gradient Boosting (XGBoost): 勾配ブースティングの一般的で効率的な実装です。
- Light Gradient Boosting Machnine (LightGBM): 特に大規模なデータセットで高いパフォーマンスと効率を発揮するように設計されています。
- CatBoost: カテゴリ特徴量を自動的に処理し、過剰適合に対して頑健です。
機械学習コンテストで多くの優勝チームが選択するアルゴリズムとして、機械学習コミュニティで人気を博しています。この記事では、取引アプリケーションでこれらの正確なモデルをどのように使用することができるかを紹介します。
主な概念
ブースティング
- ブースティングは、複数の弱い学習機(ランダムな推測よりもわずかに良い結果を出すモデル)を組み合わせて強い学習機を形成するアンサンブル学習手法です。
- 各新モデルは、前モデルの失敗に焦点を当て、全体的なパフォーマンスを徐々に向上させています。
勾配降下法
- 勾配ブースティングは、予測値と実際の値の差である損失関数を最小化するために勾配降下を使用します。
- 損失関数の勾配の方向を指す新しいモデルを繰り返し追加することで、アンサンブルモデルは洗練されていきます。
わずか数行のコードで、これらのブーストされた木は、合理的な精度を与えるだけでなく、データサイエンスプロジェクトを次のレベルに引き上げることができます。
import lightgbm as lgb train_data = lgb.Dataset(X_train, label=y_train) # preparing data the lightgbm way val_data = lgb.Dataset(X_test, label=y_test, reference=train_data) params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 10, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } # Train the model with evaluation results stored num_round = 100 bst = lgb.train(params, train_data, num_round, valid_sets=[train_data, val_data]) y_pred = bst.predict(X_test, num_iteration=bst.best_iteration) # For binary classification, you might want to threshold the predictions y_pred_binary = np.round(y_pred) print("Classification Report\n", classification_report(y_test, y_pred_binary))
結果
Classification Report precision recall f1-score support 0.0 0.70 0.75 0.73 104 1.0 0.71 0.66 0.68 96 accuracy 0.70 200 macro avg 0.71 0.70 0.70 200 weighted avg 0.71 0.70 0.70 200
同じデータを他の一般的な分類器にも適用してみました。
| 分類機 | 分類レポート |
|---|---|
| ロジスティック回帰 | precision recall f1-score support 0.0 0.69 0.76 0.72 104 1.0 0.71 0.62 0.66 96 accuracy 0.69 200 macro avg 0.70 0.69 0.69 200 weighted avg 0.70 0.69 0.69 200 |
| 決定木 | precision recall f1-score support 0.0 0.62 0.61 0.61 104 1.0 0.59 0.60 0.59 96 accuracy 0.60 200 macro avg 0.60 0.60 0.60 200 weighted avg 0.61 0.60 0.61 200 |
| ナイーブベイズ | precision recall f1-score support 0.0 0.64 0.84 0.73 104 1.0 0.73 0.49 0.59 96 accuracy 0.67 200 macro avg 0.69 0.67 0.66 200 weighted avg 0.68 0.67 0.66 200 |
| K-最近傍 | precision recall f1-score support 0.0 0.68 0.73 0.71 104 1.0 0.69 0.64 0.66 96 accuracy 0.69 200 macro avg 0.69 0.68 0.68 200 weighted avg 0.69 0.69 0.68 200 |
| サポートベクターマシン | precision recall f1-score support 0.0 0.69 0.69 0.69 104 1.0 0.66 0.66 0.66 96 accuracy 0.68 200 macro avg 0.67 0.67 0.67 200 weighted avg 0.67 0.68 0.67 200 |
LightGBMモデルは、同じ問題に対して他の分類器よりも総合的な精度が高くなりました。お気づきかもしれませんが、入力データを正規化しませんでした。それでも、モデルは他を凌駕することができました。正規化が機械学習モデルのパフォーマンスにとって極めて重要であることはご存知の通りですが、lightGBMはこの考えに反しているようです。これが、このモデルの面白さのひとつです。
GBDT(LightGBMとXGBoost)と他の機械学習分類器の違いを見てみましょう。
勾配ブースティング決定木(LighGBMとXGBoost)と他の分類器との比較
| LightGBMとXGBoost | その他の分類器 |
|---|---|
| 入力特徴のスケールに影響されない決定木に基づいているため、特徴のスケーリングを必要としません。 | K-最近傍(K-NN)やサポートベクターマシン(SVM)のようなデータ点間の距離に依存するアルゴリズムは、異なるスケールの特徴を持つデータセットではうまく機能しません。 スケーリングはほとんどの分類器にとって非常に重要です。 |
XGBoostもLightGBMにも、欠損値を処理できるメカニズムが組み込まれています。訓練中に欠損値を分割のどちらか一方に割り当てることで、欠損データへの対処法を学ぶこともできるし、単純に木内に欠損値用のブランチを作成し、そのパターンを個別に理解することもできます。 | 欠損値を扱えないことがほとんどです。これらの欠損値は精度を低下させる可能性があります。 |
パラメータチューニングは重要ですが、必須ではありません。これらのモデルは、デフォルトのパラメータでそれなりにうまく機能します。最適なパフォーマンスを達成するためには、ハイパーパラメータのチューニングが依然として重要です。 | ニューラルネットワークのような分類モデルは、ハイパーパラメータに非常に敏感です。 デフォルトのパラメータでは役に立ちません。 |
さて、LightGBMとXGBoostが他の機械学習分類器に対してどのような結果を出すかを見てきたところで、XGBoostから順にモデルを解剖していきましょう。
Extreme Gradient Boosting (XGBoost)とは?
XGBoostは、機械学習モデルの効率的かつスケーラブルな訓練のために設計された、最適化された分散勾配ブースティングライブラリです。その中には、複数の弱いモデルの予測を組み合わせて、より強い予測を作り出すアンサンブル学習法があります。
XGBoostはどのように機能するのか?
XGBoostがどのように機能するかを理解するために、その理論を理解しましょう。
初期化
これは初期予測(通常は回帰の目標値の平均、または分類のオッズの対数)から始まります。
反復ブースティング
- 残差計算: 各反復
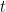 について、現在のモデルのアンサンブルによる予測の残差(誤差)を計算します。
について、現在のモデルのアンサンブルによる予測の残差(誤差)を計算します。
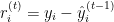
ここで
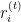 は、
は、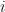 番目の観測値(反復
番目の観測値(反復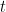 )に対する残差です。
)に対する残差です。 は実際の目標値です。
は実際の目標値です。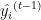 は反復
は反復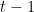 における予測値です。
における予測値です。
- 新しい木のフィッティング: 残差に新しい決定木をフィッティングします。木は、現在のモデルの残差を予測するために構築されます。
木の葉は、現在のモデルの予測に対する予測された調整を表しています。
- モデルを更新: 新しい木の予測値を現在のモデルの予測値に追加します。通常、学習率
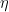 でスケーリングします。
でスケーリングします。
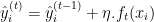
ここで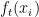 は入力
は入力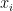 に対する反復
に対する反復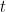 における新しい木の予測値です。
における新しい木の予測値です。
目的関数
XGBoostの目的関数は2つの部分からなります。
- 損失関数:モデルがどれだけ訓練データに適合しているかを測定します。一般的な損失関数には、回帰の平均二乗誤差や分類の対数損失などがあります。
- 正則化項:過剰適合を防ぐために、モデルの複雑さにペナルティを与えます。XGBoostはL1 (Lasso)とL2 (Ridge)の両方の正則化を使用します。
最小化する目的関数は次の通りです。
![]()
ここで
![]() は損失項
は損失項
![]() は
は![]() 番目の木の正則化項。
番目の木の正則化項。
![]() は観測数
は観測数
![]() は木の本数
は木の本数
勾配とヘッセ行列
XGBoostは2次のテイラー展開(勾配とヘッセ行列)を使用して損失関数を近似し、最適分割の計算を効率化します。勾配は予測に対する損失関数の一次導関数であり、ヘシアンは予測に対する損失関数の二次導関数です。
木の剪定
木は反復的に成長し、目的関数を最適化するために剪定されます。剪定は、目的関数の有意な改善をもたらさないノードを削除することで、過剰適合を防ぐのに役立ちます。
学習率ηは、ブースティングプロセスのステップサイズを制御するために、それぞれの木の寄与をスケーリングします。学習率が小さいほど、通常、より多くの木が必要になります。
PythonでXGBoostを実装する
PythonでXGBoostモデルを実装するには、数行のコードで済みます。これは別のライブラリなので、まだインストールしていない場合は先にインストールしておく必要があります。
pip install xgboost
Scikit-learnからPipeline関数をインポートする必要があります。 これは、前処理やその他の必要なステップで機械学習オブジェクトを作るのに役立ちます。
from sklearn.pipeline import Pipeline
先に述べたように、ブースティングされた木は、データを正規化しなくても十分な性能を発揮しますが、正規化を加えても損はありません。もちろん、正規化を加えることで、モデルの行列乗算の結果生じるかもしれない、大きな数値による数値的不安定性の問題を軽減できるなど、いくつかの利点が得られます。モデルのパイプラインを作成し、訓練データにフィットさせる間に、グッドプラクティスとして正規化を追加しましょう。
Python
# Create a pipeline with a scaler and the XGBoost classifier pipe = Pipeline([ ("scaler", StandardScaler()), ("xgb", xgb.XGBClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
XGBoostモデルにはいくつかのパラメータがあり、それがどのように機能するかだけでなく、どのようにチューニングすればより良くなるかを理解することが重要です。
Python
params = {
'objective': 'binary:logistic',
'learning_rate': 0.05,
'max_depth': 5,
'n_estimators': 100,
'colsample_bytree': 0.9,
'subsample': 0.9,
'eval_metric': ['auc', 'logloss']
} | パラメータ | 詳細 | チューニング |
|---|---|---|
| objective | 学習タスクと対応する学習目的を指定します。上記で使用したbinary:logisticは、ロジスティック回帰による2値分類に使用されます。確率を出力します。 | 一般的な目的には、回帰には'reg:squarederror'、バイナリ分類には'binary:logistic'、マルチクラス分類には'multi:softmax'があります。 常に問題の性質に基づいて目的を選択します。 |
| learning_rate | eta( 学習率が低ければ低いほど、過剰適合を防いで頑健なモデルになりますが、ブースティングの回数は多くなります。 | より低い学習率(例えば0.01~0.1)は、より多くの木(より高いn_estimators)を必要とする傾向がありますが、モデルの安定性とパフォーマンスを向上させることができます。 適度な値(たとえば0.1)から始めて、交差検証のパフォーマンスに基づいて調整するのがよいです。 |
| max_depth | この値を大きくすると、モデルがより複雑になり、過剰適合の可能性が高くなります。 モデルの複雑さを制御するもので、深い木は特徴間のパターンをより多く捉え、過剰適合のリスクを高めます。 | 一般的な値は3~10です。交差検証を使用して最適な深さを見つけてください。 |
| n_estimators | ブースティングラウンドや木を構築する数です。 木の本数が多いと計算時間が長くなり、過剰適合になりやすいです。 | 早期停止は、適切な木の数を見つけるために交差検証で使用することができます。 |
| colsample_bytree | それぞれの木を構成する際の列のサブサンプル比率です。0.9(上記コードで使用)は、それぞれの木の構築に90%の特徴が使用されることを意味します。 列レベルでランダム性を導入することで、過剰適合を減らすのに役立ちます。また、訓練を高速化し、モデルをより頑健にすることもできます。 | 数値は通常0.3~1.0です。より高い値ではより多くの特徴を使用し、より低い値ではより多くのランダム性を導入します。 |
| subsample | 訓練インスタンスのサブサンプル比率。0.9という値は、訓練データの90%がそれぞれの木の構築に使用されることを意味します。 colsample_bytreeと同様に、このパラメータはデータレベルにランダム性を加えることで過剰適合を減らし、汎化を改善することができます。 | 値は通常0.5から1.0の範囲です。値が大きいほど多くのデータを使用し、値が小さいほどランダム性が高まります。 |
| eval_metric | 訓練中に使用する評価メトリクス。 複数の評価指標により、モデルの性能をより包括的に見ることができます。 | 一般的なメトリクスには、回帰のrmse、分類のlogloss、バイナリ分類のerrorなどがあります。 常に、問題の性質と目標に沿った指標を選択します。 |
モデルはすでに訓練済みです。テストして、そのパフォーマンスを観察してみましょう。
Python
y_pred = pipe.predict(X_test)
# For binary classification, you might want to threshold the predictions since these are probabilities
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix xgboost") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.71 0.73 0.72 104 1.0 0.70 0.68 0.69 96 accuracy 0.70 200 macro avg 0.70 0.70 0.70 200 weighted avg 0.70 0.70 0.70 200
弱気シグナル(クラス0)では71%、強気シグナル(クラス1)では70%の精度を示しました。
さて、XGBoostについて説明したところで、LightGBMを解剖し、その全貌を見てみましょう。
Light Gradient Boosting Machine (LightGBM)とは?
LightGBMはオープンソースの機械学習フレームワークで、効率性、拡張性、正確性を特に重視して設計されています。分散型機械学習ツールキットの一部としてマイクロソフトによって開発され、2017年4月24日にリリースされました。
LightGBMは、XGBoostのような既存の勾配ブースティング決定木をベースに構築されました。以下に概説するいくつかの重要な改善点が提供されます。
LightGBMの改善
正確さ:スピードとメモリ効率を優先しながらも、LightGBMは精度に妥協しません。採用された技術は、従来のGBDTモデルと同等か、それ以上の性能を達成するように設計されています。
LightGBMの仕組み
LightGBMは、数学的理論に関してはXGBoostと同じ働きをしますが、木の成長方法が少し変わっています。LightGBMの背後にある中核概念を見てみましょう。
ブースティング:XGBoostと同じ勾配ブースティングでは、それぞれの新しいモデルは、残差(誤差)にフィッティングすることで、前のモデルによる誤差を修正することを目指します。
決定木:一方、XGBoostはレベルごとの木成長を使用します。つまり、木を深さ方向に成長させ、木のバランスをより均一にします。LightGBMは葉ごとに木を成長させるので、より深くより複雑な木を作ることができます。

この2つのモデルは、どのように機能するかという点では非常によく似ています。比較して理解を深めるために、それらの相違点の表を見てみましょう。
XGBoostとLightGBMの違い
| 側面 | XGBoost | LightGBM |
|---|---|---|
| 木の成長戦略 | レベル単位の成長(木の深さ方向に成長し、よりバランスの取れた木になる) | 葉単位の成長(損失削減が最も高い葉を最初に成長させ、潜在的に深い木になる) |
| 欠損値の処理 | 訓練中に欠損値を処理する最適な方向を学習する | 欠損値を直接扱うことができ、データを欠損のないカテゴリと欠損のカテゴリに分割する |
| 正則化 | L1 (Lasso)とL2 (Ridge)正則化を用いてモデルの複雑性にペナルティを与える | L2正則化を使用し、過剰適合を防ぐことに重点を置く |
| サンプリング手法 | すべてのデータで従来の勾配ブースティングを使用 | Gradient-based One-Side Sampling (GOSS)により、大きな勾配を持つ重要なデータ点に焦点を当てる |
| 特徴の処理 | カテゴリ変数に対するone-hotエンコーディングまたはその他の前処理が必要 | Exclusive Feature Bundling (EFB)を使用し、カテゴリ特徴量をネイティブでサポートする |
| スパースアウェアネス | スパースデータ用に最適化され、スパース性を考慮したアルゴリズムを使用してメモリと計算を効率化 | スパースデータを効率的に処理し、XGBoostと同様の最適化技術を持つ |
| 分割探索アルゴリズム | 効率的な分割探索のために、デフォルトで近似アルゴリズムと分位スケッチを使用 | ヒストグラムベースのアルゴリズムを使用し、分割探索の高速化とメモリ効率を実現 |
| 並列処理 | 大規模データ処理のための並列分散コンピューティングをサポート | 大規模データセットに最適化された並列分散コンピューティングもサポート |
| 訓練スピード | レベルごとの成長のため、LightGBMより一般的に遅い | 葉ごとの生長と効率的なサンプリング技術により、一般に速い |
| 柔軟性とカスタマイズ | 柔軟性が高く、カスタム損失関数と評価メトリクスをサポート | また、柔軟性も高く、ブーストプロセスには幅広いカスタマイズオプションが用意されている |
PythonによるLightGBMの実装
先に見たように、LightGBMモデルを実装するには数行のコードで済みます。今回はパイプラインの中に実装してみましょう。 XGBoostと同じようにです。
まずはそれをインストールしなければなりません。
pip install lightgbm
LightGBMには、理解することが重要なパラメータもあります。
| パラメータ | 詳細 | チューニング |
|---|---|---|
| boosting_type | 使用するブースティングアルゴリズムの種類。デフォルトはgbdt (Gradient Boosting Decision Tree)。 | 代表的な値はgbdt、dart、goss、gbdtです。データセットと実験に基づいて選択します。 |
| objective | 学習タスクとそれに対応する学習目的を指定します。binaryは二値分類に使用されます。 | 一般的な目的には、回帰タスクのregression、バイナリ分類のbinaryなどがあります。常に問題の性質に基づいて選択します。 |
| metric | aucとbinary_loglossはバイナリ分類によく使用されます。 | 標準的な値は20から50の範囲です。num_leavesを増やすと、より複雑なパターンを捉えることができますが、過剰適合につながる可能性があります。交差検証を用いて最適値を見つけます。 |
| num_leaves | 1本の木の葉の最大数。値が高いほどモデルの複雑さが増し、その逆も同様です。 | 標準的な値は20から50の範囲です。この値を大きくすると、より複雑なパターンを捉えることができますが、過剰適合につながる可能性があります。 |
| n_estimators | ブースティングラウンド(木)の数。一般に、木の本数が増えると計算時間が長くなり、過剰適合のリスクが高まります。 | 適切な木の数を決定するために、交差検証で早期停止を使用します。適度な値(例えば100)から始め、パフォーマンスに応じて調整します。 |
| max_depth | 木の最大深度。この値を大きくするとモデルが複雑になり、過剰適合の可能性が高くなります。 | 一般的な値は3~10です。より深い木はより多くのパターンを捉えるが、過剰適合のリスクが高まります。 交差検証を使用して最適な深さを見つけます。 |
| learning_rate | 損失関数の最小値に向かって移動しながら、各反復におけるステップサイズ。値が低いほどモデルはより頑健になりますが、より多くのブーストラウンドを必要とします。 | より低い学習率(例えば0.01~0.1)は、より多くの木(より高いn_estimators)を必要としますが、モデルの安定性とパフォーマンスを向上させることができます。適度な値(例えば0.1)から始め、交差検証のパフォーマンスに基づいて調整します。 |
| feature_fraction | ブースティングラウンドで使用される特徴量の数。0.9という値は、それぞれの木を構築するために90%の特徴量が使用されることを意味します。 | 数値は通常0.3~1.0です。高い値ではより多くの特徴を使用し、低い値ではより多くのランダム性を導入します。特徴量レベルにランダム性を導入することで、過剰適合を抑えることができます。 |
これらのハイパーパラメータに関する詳細は、記事の最後にリンクされているドキュメントを参照してください。では、LightGBMモデルを訓練してみましょう。
Python
params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 25, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } pipe = Pipeline([ ("scaler", StandardScaler()), ("lgbm", lgb.LGBMClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
コンソール出力は次のようになります。
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Info] Number of positive: 398, number of negative: 402 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000177 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 1594 [LightGBM] [Info] Number of data points in the train set: 800, number of used features: 8 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.497500 -> initscore=-0.010000 [LightGBM] [Info] Start training from score -0.010000 [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf
訓練したモデルに新しいデータを与え、そのパフォーマンスを観察してみましょう。
y_pred = pipe.predict(X_test) # Changes from bst to pipe
# For binary classification, you might want to threshold the predictions
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix lightgbm") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.69 0.72 0.70 104 1.0 0.68 0.65 0.66 96 accuracy 0.69 200 macro avg 0.68 0.68 0.68 200 weighted avg 0.68 0.69 0.68 200
素晴らしいですね。このモデルはテストサンプルで69%の精度です。この2つのよく訓練されたモデルをONNX形式に保存し、MQL5に展開してみましょう。
XGBoostとLightGBMをONNXに保存すつ
この2つのモデルはどちらもカスタムライブラリで別々に提供されているため、保存するのが厄介です。保存プロセスは、Scikit-learn、TensorFlow、Kerasのモデルの保存のように簡単ではありません。詳しくは、Light GBMとXGBoostの保存方法に関するONNXのドキュメントを参照してください。
まず、LightGBMモデルを保存するところから始めましょう。プロセスはどちらのモデルでも全く同じです。
LightGBMモデルの保存 | Pythonコード
from skl2onnx.common.data_types import FloatTensorType from skl2onnx import convert_sklearn, to_onnx, update_registered_converter from skl2onnx.common.shape_calculator import calculate_linear_classifier_output_shapes from onnxmltools.convert.xgboost.operator_converters.XGBoost import convert_xgboost from onnxmltools.convert import convert_xgboost as convert_xgboost_booster update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_lightgbm", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
XGBoostモデルの保存|Pythonコード
update_registered_converter( xgb.XGBClassifier, "XGBClassifier", calculate_linear_classifier_output_shapes, convert_xgboost, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_xgboost", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("xgboost.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
MQL5でONNXモデルを読み込む
勾配ブースティング決定木(GBDT)の読み込みは、他のモデルの読み込みとは異なり、プロセスは同じであるにもかかわらず、厄介な場合があります。
MQL5|LightGBM.mqh
bool CLightGBM::OnnxLoad(long &handle) { //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",output_count," output(s)"); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"output",type_info); ArrayCopy(outputs, type_info.tensor.dimensions); } } //--- replace(inputs); replace(outputs); //--- Setting the input size for (long i=0; i<input_count; i++) if (!OnnxSetInputShape(handle, i, inputs)) //Giving the Onnx handle the input shape { printf("Failed to set the input shape Err=%d",GetLastError()); DebugBreak(); return false; } //--- Setting the output size for(long i=0; i<output_count; i++) { if(!OnnxSetOutputShape(handle,i,outputs)) { printf("Failed to set the Output[%d] shape Err=%d",i,GetLastError()); //DebugBreak(); //return false; } } initialized = true; Print("ONNX model Initialized"); return true; }
出力|[エキスパート]タブ:
JM 0 10:49:34.197 LightGBM EA (EURUSD,H1) model has 1 input(s)
MG 0 10:49:34.197 LightGBM EA (EURUSD,H1) 0 input name is input
KM 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
CF 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
HP 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1, 8]
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 input shape must be defined explicitly before model inference
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape of input data can be reduced to [8] if undefined dimension set to 1
EM 0 10:49:34.198 LightGBM EA (EURUSD,H1) model has 2 output(s)
MJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output name is output_label
MR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
RK 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1]
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output shape must be defined explicitly before model inference
GJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 1 output name is output_probability
OR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_SEQUENCE
KN 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_SEQUENCE
OF 0 10:49:34.198 LightGBM EA (EURUSD,H1) no dimensions defined for 1 output
HM 0 10:49:34.198 LightGBM EA (EURUSD,H1) Failed to set the Output[1] shape Err=5802
IH 0 10:49:34.198 LightGBM EA (EURUSD,H1) ONNX model Initialized
 のモデルを詳しく見てみましょう。
のモデルを詳しく見てみましょう。
最初の出力層は、未知のサイズの1次元整数配列を持つテンソル型です。この層を1の形にサイズ変更すればうまくいくはずです。2つ目の出力層には、未知のサイズの2つの1次元配列(1つはラベル、もう1つは確率)を持つマップ(Pythonの辞書に似ている)を持つシーケンスがあります。念のため言っておきますが、これはZipMapで説明されています。
この複雑なオブジェクトタイプに対してOnnxSetOutputShapeを使用してこの2番目の出力層のサイズを設定するのは難しく、奇妙なエラーが発生する可能性があります。原因はわかりませんでしたが、サイズを1に変更すると警告が表示されますが、それでも正常に動作します。ONNXモデルを適切な方法で実行した場合。 詳細...
float output_data[]; struct Map { ulong key[]; float value[]; } output_data_map[]; //--- ArrayResize(output_data, outputs.Size()); if (!OnnxRun(onnx_handle, ONNX_DATA_TYPE_FLOAT, x_float, output_data, output_data_map)) { printf("Failed to get predictions from Onnx err %d",GetLastError()); return proba; }
LightGBMクラスとXGBoostの内部には、以下のメソッドがあります。
MQL5|LightGBM.mqh
class CLightGBM { bool initialized; long onnx_handle; void PrintTypeInfo(const long num,const string layer,const OnnxTypeInfo& type_info); long inputs[], outputs[]; void replace(long &arr[]) { for (uint i=0; i<arr.Size(); i++) if (arr[i] < 0) arr[i] = UNDEFINED_REPLACE; } bool OnnxLoad(long &handle); public: CLightGBM(void); ~CLightGBM(void); virtual bool Init(const uchar &onnx_buff[], ulong flags=ONNX_DEFAULT); //Initilaized ONNX model from a resource uchar array with default flag virtual bool Init(string onnx_filename, uint flags=ONNX_DEFAULT); //Initializes the ONNX model from a .onnx filename given virtual long predict_bin(const vector &x); //REturns the predictions for the current given matrix | useful in real-time prediction virtual vector predict_proba(const vector &x); //Returns the predictions in probability terms | useful in real-time prediction virtual matrix predict_proba(const matrix &x); //Returns the predicted probability for the whole matrix | useful for testing virtual vector predict_bin(const matrix &x); //gives out the vector for all the predictions | useful for testing };
取引におけるLightGBMとXGBoostの使用
OnInit関数でモデルが初期化された後。
MQL5|LightGBM EA.mq5
int OnInit() { if (!lgbm.Init(lightgbm_onnx)) return INIT_FAILED; }
読み込まれたONNXモデルは、訓練データと同じ方法で収集されたデータで展開できます。
void OnTick() { int size = CopyRates(Symbol(), PERIOD_CURRENT, 1, 1, rates_x); //We copy only one recent-closed bar //--- if (NewBar()) { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); }
得られたシグナルをもとに、簡単な取引戦略を立ててみましょう。
if (NewBar()) //Trade at the opening of a new candle { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions m_trade.Buy(lotsize, Symbol(), ticks.ask, ticks.bid-stoploss*Point(), ticks.ask+takeprofit*Point()); //Open a buy trade } else //Bearish signal { if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions m_trade.Sell(lotsize, Symbol(), ticks.bid, ticks.ask+stoploss*Point(), ticks.bid-takeprofit*Point()); //open a sell trade } }
ストラテジーテスターで、EURUSDの1時間足で2023年1月1日から2024年5月23日までテストしてみました。
LightGBM

XGBoost

両モデルとも赤字でした。XGBoostの損失はLightGBMより8ドル少なくなりました。どちらもほとんど同じような残高チャートでした。

ストラテジーテスターのレポートでは、モデルが次のバーの動きを予測するという、訓練された仕事をきちんとこなしているかどうかを知ることはできません。エキスパートアドバイザーを収益性の高いものにするためには、多くのことを考慮しなければならないことはご存知の通りです。
モデルのパフォーマンスを理解するために、訓練データを収集したのと同じ方法でデータを収集するスクリプトを作ってみましょう。
void OnStart() { //--- if (!lgb.Init(lightgbm_onnx)) return; //--- custom out-of-sample testing int bars = 9000; int start = 1000; MqlRates rates_x[]; ArraySetAsSeries(rates_x, true); int size = CopyRates(Symbol(), PERIOD_CURRENT, start, bars, rates_x); //We start at the bar 1000 and collect 9000 candles backward MqlRates rates_y[]; ArraySetAsSeries(rates_y, true); CopyRates(Symbol(), PERIOD_CURRENT, start-1, bars, rates_y); //We do the same thing here but we only collect one bar forward making sure we get the prediction for the next candle //--- vector actual(size), predictions(size); for (int i=0; i<size; i++) { vector x = { rates_x[i].open, rates_x[i].high, rates_x[i].low, rates_x[i].close, rates_x[i].close-rates_x[i].open, rates_x[i].high-rates_x[i].low, rates_x[i].close-rates_x[i].low, rates_x[i].close-rates_x[i].high }; actual[i] = rates_y[i].close > rates_x[i].open ? 1 : 0; //making the target variable predictions[i] = (double)lgb.predict_bin(x); } Metrics::classification_report(actual, predictions); }
結果|[エキスパート]タブ
EG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Confusion Matrix
PO 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [[2857,1503]
CI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [926,3714]]
FM 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NF 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Classification Report
HJ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
KP 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [CLS] precision recall specificity f1 score support
QQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [0.0] 0.76 0.66 0.80 0.70 4360
CQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [1.0] 0.71 0.80 0.66 0.75 4640
HS 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NK 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) accuracy 0.73 9000
RG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) average 0.73 0.73 0.73 0.73 9000
LI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Weighed avg 0.73 0.73 0.73 0.73 9000
このモデルは、サンプル外のデータでは73%の精度を示しました。ストラテジーテスターで上向きのカーブを描くことができなかったにもかかわらず、これは、私たちのモデルがうまくいっていることを物語っています。MQL5でGBDTを使用して独自の収益性の高いEAを作成するための良い出発点になるはずです。
勾配ブースティング決定木の利点
1.高い予測精度
GBDTは、予測精度の点で他の多くの機械学習アルゴリズムを上回ることが多いです。これは、決定木と勾配ブースティングの長所を組み合わせたもので、前の木の誤差に注目することでモデルの性能を反復的に向上させます。
2.過剰適合に対する頑健性
ブースティングプロセスは、既存のアンサンブルの誤差を修正する新しい木を追加することで、過剰適合を減らすのに役立ちます。学習率の調整、正則化、早期停止などのテクニックは、この頑健性をさらに高めることができます。
3. 大規模な前処理は不要
GBDTは、線形回帰やサポートベクトルマシンのような他のアルゴリズムで一般的に必要とされる、特徴のスケーリング、欠損値の処理、カテゴリ変数のエンコーディングのような大規模な前処理ステップを必要としません。
4.柔軟性とカスタマイズ
GBDTは、特定のタスクのパフォーマンスを最適化するために調整可能な、幅広いハイパーパラメータを提供します。これには、木の本数、学習率、木の最大深さ、ノードを分割するのに必要な最小サンプル数などが含まれます。
5.複雑な関係を扱う
GBDTは、特徴量とターゲット変数の間の複雑な非線形関係をモデル化することができます。そのため、単純なモデルでは見逃してしまうような、データ内の複雑なパターンを捉えるのに適しています。
6.正則化のテクニック
GBDTには、モデルの複雑さを制御し、過剰適合を防ぐための正則化パラメータが含まれています。max_depth、min_samples_split、min_samples_leafなどのパラメータは、正則化において重要な役割を果たします。
7.スケーラビリティ
XGBoost、LightGBM、CatBoostなどの実装は、スピードとスケーラビリティのために最適化されています。大規模なデータセットを効率的に処理し、並列コンピューティングや分散コンピューティングなどのハードウェア機能を活用することができます。どの機械学習モデルにも言えることですが、これらのモデルにも欠点があり、それを認めなければなりません。それらを使用することをやめさせるためではなく、理解を固めるためです。
勾配ブースティング決定木の欠点
1.計算の複雑さ:GBDTは、特に木の数が多く、深い木の場合、訓練に計算コストがかかることがあります。大規模なデータセットや深いデータセットでは、訓練プロセスにかなりのメモリを消費する可能性があります。
2.ハイパーパラメータの調整:両モデルともデフォルトのパラメータで動作可能であるにもかかわらず、最適なパフォーマンスを達成するために注意深く調整する必要がある多くのハイパーパラメータを持っています。木の本数、学習率、最大深度、葉ごとの最小サンプル数などのパラメータです。
これらのパラメータを調整するのは、時間と計算量がかかることは周知の通りです。
3. ノイジーなデータに対する感度はまだ高い:それぞれの木は前の木の誤差を修正しようとするため、データ中のノイズはブースティング処理によって増幅される可能性があります。
4.多くの場合、大規模なデータセットを必要とします。 GBDTは優れたパフォーマンスを達成するために、しばしば大量のデータを必要とします。小さなデータセットでは、ブースティング処理を効果的におこなうための十分な情報が得られない可能性があります。
結論
勾配ブースティング木はFXトレーダーにとって貴重なツールです。これらのモデルは多くの機械学習モデルよりも優れたパフォーマンスを発揮することが分かっているからです。以前は、GRU、RNN、LSTMのような複雑なニューラルネットワークベースのモデルが、市場を打ち負かすのに最適なモデルだと信じられていましたが、もはやそうではありません。勾配ブースティング決定木は、そのシンプルさと予測タスクを達成できる能力により、機械学習コミュニティで人気が高まっています。
ご精読ありがとうございました。
機械学習モデルの開発を追跡し、本連載で説明されている多くのことは、このGitHubレポに掲載されています。
この投稿で取り上げているPythonコードは、こちらです。
添付表
EA|Expertsフォルダ:
| ファイル名 | 説明と使用法 |
|---|---|
| LightGBM EA.mq5 | Light Gradient Boosted Machine (LightGBM)をテストするEA |
| XGBoost EA.mq5 | Extreme Gradient Boosting (XGBoost)をテストするEA |
ライブラリ|インクルードフォルダ:
| ファイル名 | 説明と使用法 |
|---|---|
| LightGBM.mqh | Light Gradient Boosted Machine (LightGBM) ONNXモデルのロード、初期化、配置用ライブラリ |
| XGBoost.mqh | Extreme Gradient Boosting (XGBoost) ONNXモデルの読み込み、初期化、展開のためのライブラリ |
スクリプト|スクリプトフォルダ:
| ファイル名 | 説明と使用法 |
|---|---|
| LightGBM Performance TestScript.mq5 | LightGBMモデルをリアルタイムでテストするスクリプト |
Files | Filesフォルダ:
| ファイル名 | 説明と使用法 |
|---|---|
| EURUSD.PERIOD_H1.csv | 訓練データセットを含むcsvファイル |
| lightgbm.eurusd.h1.onnx xgboost.eurusd.h1.onnx | ONNX形式のLightGBMとXGBoostモデル |
Pythonのコード:
| ファイル名 | 説明と使用法 |
|---|---|
| lightgbm-xgboost.ipynb | Jupyterノートブックには、この投稿で説明したすべてのpythonコードが含まれています。 |
情報源と参考文献
- Can one do better than XGBoost? - Mateusz Susik (https://www.youtube.com/watch?v=5CWwwtEM2TA)
- Unlocking the Power of Gradient-Boosted Trees (using LightGBM) | PyData London 2022(https://www.youtube.com/watch?v=qGsHlvE8KZM)
- LightGBMのドキュメント(https://lightgbm.readthedocs.io/ja/latest/Parameters.html)
- XGBoostのドキュメント(https://xgboost.readthedocs.io/ja/stable/tutorials/model.html)
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/14926
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
コンパイル時にエラーが出る