
Машинное обучение и Data Science (Часть 23): Почему LightGBM и XGBoost лучше многих ИИ-моделей?

Что такое деревья с градиентным бустингом?
Деревья решений с градиентным бустингом (Gradient Boosted Decision Trees, GBDT) — это эффективный метод машинного обучения, используемый в основном для задач регрессии и классификации. Они объединяют прогнозы нескольких слабых учеников, обычно деревьев решений, для создания сильной прогностической модели.
Основная идея заключается в последовательном построении моделей, при этом каждая новая модель пытается исправить ошибки, допущенные предыдущими.
Примеры деревьев с бустингом:
- XGBoost (Extreme Gradient Boosting) — экстремальный градиентный бустинг, популярная и эффективная реализация;
- LightGBM (Light Gradient Boosting Machnine) — эффективный метод градиентного усиления, особенно при работе с большими наборами данных.
- CatBoost — автоматически обрабатывает категориальные признаки и устойчив к переобучению.
Эти алгоритмы приобрели большую популярность в сообществе машинного обучения — многие победители в командных соревнованиях по машинному обучению используют именно их. В этой статье мы узнаем, как эти точные модели можно использовать в торговых приложениях.
Основные понятия
Бустинг (Boosting)
- Бустинг — это метод ансамблевого обучения, который объединяет несколько слабых учеников (моделей, которые работают немного лучше, чем случайное угадывание) для формирования сильного ученика.
- Каждая новая модель фокусируется на ошибках предыдущих моделей, постепенно улучшая общие характеристики.
Градиентный спуск
- Градиентный бустинг использует градиентный спуск для минимизации функции потерь, которая представляет собой разницу между прогнозируемыми и фактическими значениями.
- Путем итеративного добавления новых моделей, указывающих направление градиента функции потерь, ансамблевая модель совершенствуется.
С помощью всего лишь нескольких строк кода эти улучшенные деревья не только обеспечивают приемлемую точность, но и могут вывести целый проект на новый уровень.
import lightgbm as lgb train_data = lgb.Dataset(X_train, label=y_train) # preparing data the lightgbm way val_data = lgb.Dataset(X_test, label=y_test, reference=train_data) params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 10, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } # Train the model with evaluation results stored num_round = 100 bst = lgb.train(params, train_data, num_round, valid_sets=[train_data, val_data]) y_pred = bst.predict(X_test, num_iteration=bst.best_iteration) # For binary classification, you might want to threshold the predictions y_pred_binary = np.round(y_pred) print("Classification Report\n", classification_report(y_test, y_pred_binary))
Результат:
Classification Report precision recall f1-score support 0.0 0.70 0.75 0.73 104 1.0 0.71 0.66 0.68 96 accuracy 0.70 200 macro avg 0.71 0.70 0.70 200 weighted avg 0.71 0.70 0.70 200
Я применил те же данные в других популярных классификаторах.
| Классификатор | Отчет о классификации |
|---|---|
| Логистическая регрессия | precision recall f1-score support 0.0 0.69 0.76 0.72 104 1.0 0.71 0.62 0.66 96 accuracy 0.69 200 macro avg 0.70 0.69 0.69 200 weighted avg 0.70 0.69 0.69 200 |
| Древо решений | precision recall f1-score support 0.0 0.62 0.61 0.61 104 1.0 0.59 0.60 0.59 96 accuracy 0.60 200 macro avg 0.60 0.60 0.60 200 weighted avg 0.61 0.60 0.61 200 |
| Наивный Байес | precision recall f1-score support 0.0 0.64 0.84 0.73 104 1.0 0.73 0.49 0.59 96 accuracy 0.67 200 macro avg 0.69 0.67 0.66 200 weighted avg 0.68 0.67 0.66 200 |
| К-ближайших соседи | precision recall f1-score support 0.0 0.68 0.73 0.71 104 1.0 0.69 0.64 0.66 96 accuracy 0.69 200 macro avg 0.69 0.68 0.68 200 weighted avg 0.69 0.69 0.68 200 |
| Машина опорных векторов | precision recall f1-score support 0.0 0.69 0.69 0.69 104 1.0 0.66 0.66 0.66 96 accuracy 0.68 200 macro avg 0.67 0.67 0.67 200 weighted avg 0.67 0.68 0.67 200 |
Модель Light GBM оказалась наиболее точной среди других классификаторов при решении одной и той же задачи. Как видите, мы даже не нормализовали входные данные, но модель все равно смогла превзойти другие. Часто нормализация имеет решающее значение для эффективности моделей машинного обучения, но в случае с lightGBM это не так. Это одна из причин, по которой эти модели нам интересны.
Давайте рассмотрим разницу между GBDT (LightGBM и XGBoost) и другими классификаторами машинного обучения.
Деревья решений с градиентным бустом (LighGBM и XGBoost) в сравнении с другими классификаторами
| LightGBM & XGBoost | Другие классификаторы |
|---|---|
| Yе требуют масштабирования функций, поскольку основаны на деревьях решений, которые нечувствительны к масштабу входных признаков. | Такие алгоритмы, как метод K-ближайших соседей (K-NN) и метод опорных векторов (SVM), которые полагаются на расстояние между точками данных, не могут эффективно работать с наборами данных с признаками в разных масштабах. Масштабирование очень важно для большинства классификаторов. |
И XGBoost, и LightGBM имеют встроенные механизмы, которые могут обрабатывать недостающие данные. Они могут научиться справляться с отсутствующими данными, присваивая отсутствующие значения какой-либо стороне во время обучения, или могут просто создать ветвь для отсутствующего значения в дереве и изучить ее закономерности отдельно. | В большинстве случаев не могут обрабатывать отсутствующие данные. Отсутствие данных может снизить точность. |
Настройка параметров важна, но не обязательна; эти модели работают достаточно хорошо с параметрами по умолчанию. Настройка гиперпараметров по-прежнему имеет решающее значение для достижения оптимальной производительности. | Модели классификаторов, такие как нейронные сети, очень чувствительны к гиперпараметрам. Параметры по умолчанию не подходят. |
В таблице показаны преимущества моделей LightGBM и XGBoost над другими классификаторами машинного обучения. Давайте теперь рассмотрим их по-отдельности, начнем с XGBoost.
Что такое экстремальный градиентный бустинг (XGBoost)?
XGBoost — оптимизированная распределенная библиотека градиентного бустинга, предназначенная для эффективного и масштабируемого обучения моделей. В его основе лежит метод ансамблевого обучения, который объединяет прогнозы нескольких слабых моделей для получения более сильного прогноза.
Как работает метод XGBoost?
Чтобы понять, как работает XGBoost, давайте для начала разберемся с теорией.
Инициализация
Все начинается с начального прогноза, обычно среднего значения целевых значений для регрессии или логарифма шансов для классификации.
Итеративный бустинг
- Расчет остатков — на каждой итерации
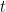 вычисляется остаток (ошибки) прогнозов, сделанных текущим ансамблем моделей.
вычисляется остаток (ошибки) прогнозов, сделанных текущим ансамблем моделей.
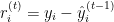
Где:
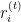 — остаток в
— остаток в 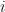 -ом наблюдении на итерации
-ом наблюдении на итерации 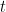 .
. — фактическое целевое значение.
— фактическое целевое значение.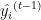 — прогнозное значение на итерации
— прогнозное значение на итерации 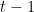 .
.
- Обучение нового дерева — обучаем дерево на остатках. Дерево строится для прогнозирования остатков текущей модели.
Листья дерева представляют собой прогнозируемые корректировки прогнозов текущей модели.
- Обновление модели — добавляем прогнозы нового дерева к прогнозам текущей модели, обычно масштабируемым по скорости обучения.
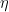 .
.
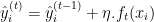
Где: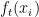 — прогноз нового дерева на итерации
— прогноз нового дерева на итерации 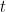 для входа
для входа 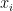 .
.
Целевая функция
Целевая функция в XGBoost состоит из двух частей:
- Функция потерь, которая измеряет, насколько хорошо модель соответствует обучающим данным. Наиболее распространенные функции потерь — среднеквадратичная ошибка для регрессии и логарифм потерь для классификации.
- Регуляризация накладывает штраф за сложность модели для предотвращения переобучения. XGBoost использует регуляризацию L1 (Lasso) и L2 (Ridge).
Целевая функция, которую необходимо минимизировать, имеет вид:
![]()
Где:
![]() — функция потерь.
— функция потерь.
![]() — регуляризация
— регуляризация ![]() -го дерева.
-го дерева.
![]() — количество наблюдений.
— количество наблюдений.
![]() — количество деревьев.
— количество деревьев.
Градиент и гессиан
XGBoost использует разложение Тейлора второго порядка (градиент и гессиан) для аппроксимации функции потерь для эффективного вычисления оптимальных разбиений. Градиент — это первая производная функции потерь относительно прогноза, а гессиан — вторая.
Усечение деревьев (Pruning)
Для оптимизации целевой функции мы итеративно растим и обрезаем деревья. Такая обрезка помогает предотвратить переобучение — мы просто удаляем узлы, которые не обеспечивают существенного улучшения целевой функции.
Скорость обучения η масштабирует вклад каждого дерева и тем самым влияет на размер шага в процессе бустинга. Меньшие скорости обучения обычно требуют большего количества деревьев.
Реализация XGBoost на Python
Для реализации модели XGBoost на Python нужно всего несколько строк кода. Это отдельная библиотека, поэтому перед началом работу нужно ее установить.
pip install xgboost
Нужно импортировать функцию Pipeline из Scikit-learn. Это позволит создать объект машинного обучения с предварительной обработкой и другими необходимыми этапами.
from sklearn.pipeline import Pipeline
Как мы говорили, усиленные деревья могут хорошо работать даже без нормализации данных. Однако добавление нормализации не повредит. Более того, Вы получите ряд преимуществ, таких как помощь в смягчении проблем числовой нестабильности, вызванных большими числами, которые могут появиться в результате умножения матриц в наших моделях. Давайте добавим нормализацию при создании конвейера для модели и прогоне под обучающие данные.
Python:
# Create a pipeline with a scaler and the XGBoost classifier pipe = Pipeline([ ("scaler", StandardScaler()), ("xgb", xgb.XGBClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
Давайте посмотрим на параметры модели XGBoost, как они работают и как их настроить.
Python:
params = {
'objective': 'binary:logistic',
'learning_rate': 0.05,
'max_depth': 5,
'n_estimators': 100,
'colsample_bytree': 0.9,
'subsample': 0.9,
'eval_metric': ['auc', 'logloss']
} | Параметр | Описание | Настройка |
|---|---|---|
| objective | Этот параметр определяет задачу обучения и соответствующую цель обучения, binary:logistic выше используется для бинарной классификации с логистической регрессией. Он выдает вероятностные результаты. | Варианты значений: 'reg:squarederror' для задач регрессии, 'binary:logistic' для бинарной классификации, 'multi:softmax' для многоклассовой классификации. Всегда выбирайте задачу, исходя из характера вашей проблемы. |
| learning_rate | Также обозначается как Более низкая скорость обучения делает модель более надежной и борется с переобучением, но требует при этом большего количества раундов бустинга. | И наоборот, низкая скорость обучения (например, 0,01–0,1), как правило, требует большего количества деревьев (более высоких значений n_estimators), но может улучшить стабильность и производительность модели. Рекомендуется начинать со среднего значения (например, 0,1) и корректировать его на основе результатов кросс-валидации. |
| max_depth | Максимальная глубина дерева. Увеличение этого значения делает модель более сложной и повышает вероятность ее переобучения. Отвечает за сложность модели. Более глубокие деревья улавливают больше закономерностей между признаками, но это увеличивает риск переобучения. | Часто значения варьируются от 3 до 10. Оптимальную глубину можно найти с помощью кросс-валидации. |
| n_estimators | Это количество раундов бустинга или деревьев, которые нужно построить. Чем больше деревьев, тем больше время вычислений и подверженность переобучению. | Раннюю остановку можно использовать при кросс-валидации для поиска подходящего количества деревьев. |
| colsample_bytree | Это отношение подвыборки столбцов при построении каждого дерева. Значение 0.9 ( используется в коде выше) означает, что для построения каждого дерева будут использованы 90% признаков. Помогает снизить переобучение за счет введения случайности на уровне столбцов. Это также может ускорить обучение и сделать модель более надежной. | Обычно используются значения в диапазоне от 0.3 до 1.0. Более высокие значения используют больше признаков, тогда как более низкие значения вносят больше случайности. |
| subsample | Коэффициент подвыборки обучающих экземпляров. Значение 0.9 означает, что для построения каждого дерева будет использовано 90% обучающих данных. Как и colsample_bytree, этот параметр уменьшает переобучение за счет добавления случайности на уровне данных и может улучшить обобщение. | Обычно используются значения в диапазоне от 0.5 до 1.0. Более высокие значения используют больше данных, тогда как более низкие значения вносят больше случайности. |
| eval_metric | Метрики оценки, которые будут использоваться во время обучения. Множественные метрики оценки могут дать более полное представление об эффективности модели. | Часто используются 'rmse' для оценки регрессии,'logloss' для классификации и 'error' для бинарной классификации. Метрики нужно выбирать в зависимости от характера задачи и целей. |
Мы уже обучили модель. Давайте теперь протестируем его и посмотрим на ее работу.
Python:
y_pred = pipe.predict(X_test)
# For binary classification, you might want to threshold the predictions since these are probabilities
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix xgboost") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.71 0.73 0.72 104 1.0 0.70 0.68 0.69 96 accuracy 0.70 200 macro avg 0.70 0.70 0.70 200 weighted avg 0.70 0.70 0.70 200
Модель отлично справилась с прогнозами за пределами выборки. Ее точность составила 71% и 70% для медвежьих (класс 0) и бычьих (класс 1) сигналов соответственно.
Мы с вами рассмотрели XGBoost, теперь давайте разберем метод LightGBM и посмотрим, что он из себя представляет.
Что такое LightGBM?
Это фреймворк машинного обучения с открытым исходным кодом, разработанный для обеспечения эффективности, масштабируемости и точности. Метод разработан корпорацией Microsoft как часть инструментария распределенного машинного обучения. Он был выпущен 24 апреля 2017 года.
LightGBM был создан на основе существующих деревьев решений с градиентным бустингом, таких как XGBoost. Метод предлагает несколько ключевых улучшений, рассмотрим их.
Преимущества LightGBM
Точность. С одной стороны, метод старается поддерживать высокую скорость обучения и эффективно потреблять память, он довольно точен. Используются определенные техники, чтобы обеспечить аналогичную или даже лучшую производительность по сравнению с предыдущими моделями GBDT.
Как работает LightGBM?
LightGBM работает как XGBoost с точки зрения математической теории. Есть небольшая разница в способах выращивания деревьев. Давайте рассмотрим основные концепции, лежащие в основе метода LightGBM.
Бустинг. Как и при XGBoost, в градиентном бустинге каждая новая модель стремится исправить ошибки, допущенные предыдущими моделями, путем подгонки под остатки (ошибки).
Деревья решений. Мы видели ранее, что XGBoost использует поуровневый рост деревьев, то есть он увеличивает глубину дерева и делает его более равномерным. В LightGBM рост деревьев происходит по листьям, такое способ позволяет создавать более глубокие и более сложные деревья.

Поскольку эти две модели очень похожи по принципу работы, давайте рассмотрим их различия в таблице.
Различия между XGBoost и LightGBM
| Характеристики | XGBoost | LightGBM |
|---|---|---|
| Стратегия роста деревьев | Рост по уровням (деревья растут в глубину, более сбалансированные деревья) | Рост по листьям (сначала растет лист с наибольшим сокращением потерь, потенциально более глубокие деревья) |
| Обработка недостающих значений | Изучает оптимальное направление обработки недостающих значений во время обучения | Может напрямую обрабатывать отсутствующие значения, разделяет данные на категории с отсутствующими и неотсутствующими значениями |
| Регуляризация | Использует регуляризацию L1 (Лассо) и L2 (Ридж) для наложения штрафа за сложность модели | Использует регуляризацию L2, пытаясь избежать переобучение. |
| Метод составления выборок | Использует традиционный градиентный бустинг со всеми данными | Односторонняя выборка на основе градиента (GOSS) для выбора важных точек данных с большими градиентами |
| Обработка признаков | Требуется прямой энкодинг или другая предварительная обработка для категориальных переменных. | Поддержка категориальных функций изначально с использованием эксклюзивного объединения функций (EFB) |
| Разреженность данных | Оптимизирован для работы разреженными данных, использует алгоритм, учитывающий разреженность, для повышения эффективности памяти и вычислений. | Эффективно обрабатывает разреженные данные, имеет схожие методы оптимизации с XGBoost. |
| Алгоритм поиска разделения | Использует приближенные алгоритмы и квантильные критерии для поиска разбиений | Использует алгоритмы на основе гистограмм для более быстрого поиска разделений и эффективного использования памяти. |
| Параллельная обработка | Поддерживает параллельные и распределенные вычисления для обработки данных | Также поддерживает параллельные и распределенные вычисления, оптимизирован для больших наборов данных. |
| Скорость обучения | В целом медленнее по сравнению с LightGBM из-за уровневого роста дерева | Быстрее благодаря росту по листьям и эффективным методам составления выборок |
| Гибкость и настройка | Высокая гибкость, поддержка настраиваемых функций потерь и показателей оценки | Также очень гибкий, с широкими возможностями настройки процесса бустинга |
Реализация метода LightGBM в Python
Как было сказано в начале раздела, для реализации модели LightGBM требуется всего несколько строк кода. Реализуем в пайплайне, как и в случае с XGBoost ранее.
Сначала нужно установить.
pip install lightgbm
Рассмотрим параметры Light GBM.
| Параметр | Описание | Настройка |
|---|---|---|
| boosting_type | Тип используемого алгоритма бустинга. По умолчанию используется 'gbdt' (Gradient Boosting Decision Tree). | Часто используются алгоритмы 'gbdt', 'dart', 'goss'. Из них наиболее популярный 'gbdt'. Следует выбирать в соответствии с типом данных. |
| objective | Определяет задачу и соответствующую цель обучения. 'binary' используется для бинарной классификации. | Это могут быть 'regression' для задач регрессии, 'binary' для классификации. Выбор зависит от природы решаемой задачи. |
| metric | Метрики оценки, которые будут использоваться во время обучения. 'auc' и 'binary_logloss' используются для задач бинарной классификации. | Обычно значения варьируются от 20 до 50. Увеличение num_leaves позволяет улавливать более сложные закономерности, но может привести к переобучению. Используйте кросс-валидацию, чтобы найти оптимальное значение. |
| num_leaves | Максимальное количество листьев на одном дереве. Более высокое значение увеличивает сложность модели и наоборот. | Обычно значения варьируются от 20 до 50. Увеличение параметра позволяет улавливать более сложные закономерности, но может привести к переобучению. |
| n_estimators | Количество раундов бустинга (деревьев). Большее количество деревьев, как правило, увеличивает время вычислений и риск переобучения. | Можно использовать раннюю остановку при кросс-валидации для поиска подходящего количества деревьев. Начните с какого-то среднего значения (например, 100) и корректируйте его в зависимости от результата. |
| max_depth | Максимальная глубина дерева. Увеличение параметра делает модель более сложной и повышает вероятность ее переобучения. | Часто значения варьируются от 3 до 10. Более глубокие деревья охватывают больше закономерностей, но увеличивают риск переобучения. Оптимальную глубину можно найти с помощью кросс-валидации. |
| learning_rate | Размер шага на каждой итерации в направлении к минимизации функции потерь. Более низкие значения делают модель более надежной, но требуют большего количества раундов бустинга. | И наоборот, низкая скорость обучения (0.01–0.1), как правило, требует большего количества деревьев (более высоких значений n_estimators), но может улучшить стабильность и производительность модели. Начните с какого-то среднего значения (например, 0,1) и корректируйте его на основе результатов кросс-валидации. |
| feature_fraction | Доля признаков, которые будут использоваться для каждого раунда бустинга. Значение 0.9 означает, что для построения каждого дерева будет использовано 90% признаков. | Обычно используются значения в диапазоне от 0.3 до 1.0. Более высокие значения используют больше признаков, тогда как более низкие значения вносят больше случайности. Позволяют снизить переобучение за счет введения случайности на уровне признаков. |
Более подробную информацию об этих гиперпараметрах можно найти в документации, ссылка на которую приведена в конце статьи. Теперь давайте обучим модель LightGBM.
Python:
params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 25, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } pipe = Pipeline([ ("scaler", StandardScaler()), ("lgbm", lgb.LGBMClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
Вывод в консоль:
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Info] Number of positive: 398, number of negative: 402 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000177 seconds. Можно установить `force_col_wise=true`, чтобы убрать накладные расходы. [LightGBM] [Info] Total Bins 1594 [LightGBM] [Info] Number of data points in the train set: 800, number of used features: 8 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.497500 -> initscore=-0.010000 [LightGBM] [Info] Start training from score -0.010000 [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf
На данный момент мы не можем оценить ее эффективность, давайте дадим обученной модели новые данные и посмотрим на ее работу.
y_pred = pipe.predict(X_test) # Changes from bst to pipe
# For binary classification, you might want to threshold the predictions
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix lightgbm") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.69 0.72 0.70 104 1.0 0.68 0.65 0.66 96 accuracy 0.69 200 macro avg 0.68 0.68 0.68 200 weighted avg 0.68 0.69 0.68 200
Модель показала точность 69% на тестовой выборке. Теперь, когда у нас есть две хорошо обученные модели, давайте сохраним их обе в формате ONNX, который мы сможем развернуть в MQL5.
Сохраняем XGBoost и LightGBM в ONNX.
Сохранение этих двух моделей может показаться сложным, поскольку они поставляются отдельно в своих собственных библиотеках; процесс сохранения сложнее, чем сохранение моделей Scikit-learn, TensorFlow или Keras. Для более подробной информации о том, как сохранить LightGBM и XGBoost, обратитесь к документации ONNX.
Начнем с сохранения модели LightGBM, процесс абсолютно одинаков для обеих моделей.
Сохранение модели LightGBM | Код Python:
from skl2onnx.common.data_types import FloatTensorType from skl2onnx import convert_sklearn, to_onnx, update_registered_converter from skl2onnx.common.shape_calculator import calculate_linear_classifier_output_shapes from onnxmltools.convert.xgboost.operator_converters.XGBoost import convert_xgboost from onnxmltools.convert import convert_xgboost as convert_xgboost_booster update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_lightgbm", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Сохранение модели XGBoost | Код Python:
update_registered_converter( xgb.XGBClassifier, "XGBClassifier", calculate_linear_classifier_output_shapes, convert_xgboost, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_xgboost", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("xgboost.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Загрузка модели ONNX в MQL5
Загрузка деревьев решений с градиентным усилением (GBDT) немного сложнее, чем других моделей, хотя в целом процессы одинаковые.
MQL5 | LightGBM.mqh
bool CLightGBM::OnnxLoad(long &handle) { //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",output_count," output(s)"); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"output",type_info); ArrayCopy(outputs, type_info.tensor.dimensions); } } //--- replace(inputs); replace(outputs); //--- Setting the input size for (long i=0; i<input_count; i++) if (!OnnxSetInputShape(handle, i, inputs)) //Giving the Onnx handle the input shape { printf("Failed to set the input shape Err=%d",GetLastError()); DebugBreak(); return false; } //--- Setting the output size for(long i=0; i<output_count; i++) { if(!OnnxSetOutputShape(handle,i,outputs)) { printf("Failed to set the Output[%d] shape Err=%d",i,GetLastError()); //DebugBreak(); //return false; } } initialized = true; Print("ONNX model Initialized"); return true; }
Результат на вкладке Эксперты:
JM 0 10:49:34.197 LightGBM EA (EURUSD,H1) model has 1 input(s)
MG 0 10:49:34.197 LightGBM EA (EURUSD,H1) 0 input name is input
KM 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
CF 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
HP 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1, 8]
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 input shape must be defined explicitly before model inference
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape of input data can be reduced to [8] if undefined dimension set to 1
EM 0 10:49:34.198 LightGBM EA (EURUSD,H1) model has 2 output(s)
MJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output name is output_label
MR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
RK 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1]
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output shape must be defined explicitly before model inference
GJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 1 output name is output_probability
OR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_SEQUENCE
KN 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_SEQUENCE
OF 0 10:49:34.198 LightGBM EA (EURUSD,H1) no dimensions defined for 1 output
HM 0 10:49:34.198 LightGBM EA (EURUSD,H1) Failed to set the Output[1] shape Err=5802
IH 0 10:49:34.198 LightGBM EA (EURUSD,H1) ONNX model Initialized
Давайте посмотрим на модель в Netron:

Первый выходной слой имеет тип тензора с одномерным целочисленным массивом неизвестного размера. Можно спокойно изменить размер этого слоя до формы 1. Что касается второго выходного слоя, то есть последовательность, которая напоминает словарь в Python, с двумя одномерными массивами неизвестных размеров: один для меток, а другой для вероятностей. Если вам интересно, это вывод от ZipMap.
Для этого второго выходного слоя установить размер с помощью OnnxSetOutputShape с учетом сложного типа объекта сложно и может приводить к странным ошибкам. Я не смог разобраться, однако изменение его размера до 1 работает нормально. Да, мы получаем предупреждение, но все же изменение работает нормально. Главное правильно запустить модель ONNX. Читать далее...
float output_data[]; struct Map { ulong key[]; float value[]; } output_data_map[]; //--- ArrayResize(output_data, outputs.Size()); if (!OnnxRun(onnx_handle, ONNX_DATA_TYPE_FLOAT, x_float, output_data, output_data_map)) { printf("Failed to get predictions from Onnx err %d",GetLastError()); return proba; }
Внутри классов LightGBM и XGBoost находятся следующие методы:
MQL5 | LightGBM.mqh
class CLightGBM { bool initialized; long onnx_handle; void PrintTypeInfo(const long num,const string layer,const OnnxTypeInfo& type_info); long inputs[], outputs[]; void replace(long &arr[]) { for (uint i=0; i<arr.Size(); i++) if (arr[i] < 0) arr[i] = UNDEFINED_REPLACE; } bool OnnxLoad(long &handle); public: CLightGBM(void); ~CLightGBM(void); virtual bool Init(const uchar &onnx_buff[], ulong flags=ONNX_DEFAULT); //Initilaized ONNX model from a resource uchar array with default flag virtual bool Init(string onnx_filename, uint flags=ONNX_DEFAULT); //Initializes the ONNX model from a .onnx filename given virtual long predict_bin(const vector &x); //REturns the predictions for the current given matrix | useful in real-time prediction virtual vector predict_proba(const vector &x); //Returns the predictions in probability terms | useful in real-time prediction virtual matrix predict_proba(const matrix &x); //Returns the predicted probability for the whole matrix | useful for testing virtual vector predict_bin(const matrix &x); //gives out the vector for all the predictions | useful for testing };
Использование LightGBM и XGBoost в торговле
Инициализируем модель в функции OnInit.
MQL5 | LightGBM EA.mq5
int OnInit() { if (!lgbm.Init(lightgbm_onnx)) return INIT_FAILED; }
Загруженные модели ONNX разворачиваем с данными, собранными так же, как данные обучения.
void OnTick() { int size = CopyRates(Symbol(), PERIOD_CURRENT, 1, 1, rates_x); //We copy only one recent-closed bar //--- if (NewBar()) { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); }
Давайте создадим простую торговую стратегию на основе полученных сигналов.
if (NewBar()) //Trade at the opening of a new candle { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions m_trade.Buy(lotsize, Symbol(), ticks.ask, ticks.bid-stoploss*Point(), ticks.ask+takeprofit*Point()); //Open a buy trade } else //Bearish signal { if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions m_trade.Sell(lotsize, Symbol(), ticks.bid, ticks.ask+stoploss*Point(), ticks.bid-takeprofit*Point()); //open a sell trade } }
Я провел тестирование в тестере стратегий на таймфрейме H1 по данным EURUSD с 01.01.2023 по 23.05.2024
LightGBM:

XGBoost:

Обе модели оказались убыточными. У XGBoost было на 8$ меньше потерь, чем у LightGBM. Их графики баланса очень схожи.

Судя по отчету тестера стратегий, нельзя судить о том, как модели справляются с задачей, для которой они были обучены, а именно с прогнозированием движения следующего бара. Как мы знаем, чтобы сделать советник прибыльным, необходимо учесть множество факторов.
Чтобы понять, как работают модели, давайте создадим скрипт для сбора данных таким же образом, как мы собирали обучающие данные. При этом мы создадим целевую переменную.
void OnStart() { //--- if (!lgb.Init(lightgbm_onnx)) return; //--- custom out-of-sample testing int bars = 9000; int start = 1000; MqlRates rates_x[]; ArraySetAsSeries(rates_x, true); int size = CopyRates(Symbol(), PERIOD_CURRENT, start, bars, rates_x); //We start at the bar 1000 and collect 9000 candles backward MqlRates rates_y[]; ArraySetAsSeries(rates_y, true); CopyRates(Symbol(), PERIOD_CURRENT, start-1, bars, rates_y); //We do the same thing here but we only collect one bar forward making sure we get the prediction for the next candle //--- vector actual(size), predictions(size); for (int i=0; i<size; i++) { vector x = { rates_x[i].open, rates_x[i].high, rates_x[i].low, rates_x[i].close, rates_x[i].close-rates_x[i].open, rates_x[i].high-rates_x[i].low, rates_x[i].close-rates_x[i].low, rates_x[i].close-rates_x[i].high }; actual[i] = rates_y[i].close > rates_x[i].open ? 1 : 0; //making the target variable predictions[i] = (double)lgb.predict_bin(x); } Metrics::classification_report(actual, predictions); }
Results | Experts tab:
EG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Confusion Matrix
PO 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [[2857,1503]
CI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [926,3714]]
FM 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NF 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Classification Report
HJ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
KP 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [CLS] precision recall specificity f1 score support
QQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [0.0] 0.76 0.66 0.80 0.70 4360
CQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [1.0] 0.71 0.80 0.66 0.75 4640
HS 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NK 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) accuracy 0.73 9000
RG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) average 0.73 0.73 0.73 0.73 9000
LI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Weighed avg 0.73 0.73 0.73 0.73 9000
Точность модели на вневыборочных данных составила 73%. Это говорит о том, что модель работает хорошо, несмотря на то, что она не может создать восходящую кривую в тестере стратегий. Это может стать хорошей отправной точкой для создания собственных прибыльных советников с использованием GBDT на языке MQL5.
Преимущества деревьев решений с градиентным бустингом
1. Высокая точность прогнозирования
Модели GBDT часто превосходят многие другие алгоритмы машинного обучения с точки зрения точности прогнозирования. Это объясняется тем, что они сочетают в себе преимущества деревьев решений с градиентным бустингом, который итеративно улучшает производительность модели, исходя из ошибок предыдущих деревьев.
2. Устойчивость к переобучению
Процесс бустинга подразумевает добавление новых деревьев, которые исправляют ошибки существующего ансамбля, что помогает снизить переобучение. Такие методы, как корректировка скорости обучения, регуляризация и ранняя остановка, могут еще больше повысить эту надежность.
3. Нет необходимости в затратной предварительной обработке
Модели GBDT не требуют крупных этапов предварительной обработки, таких как масштабирование признаков, обработка пропущенных значений или кодирование категориальных переменных, которые обычно необходимы для других алгоритмов, таких как линейная регрессия или машины опорных векторов.
4. Гибкость и настройка
Модели GBDT предлагают широкий спектр гиперпараметров, которые можно настраивать для оптимизации производительности для конкретных задач. К ним относятся, среди прочего, количество деревьев, скорость обучения, максимальная глубина деревьев и минимальное количество выборок, необходимых для разделения узла.
5. Обработка сложных отношений
Модели GBDT могут моделировать сложные нелинейные связи между признаками и целевой переменной. Это делает их подходящими для выявления сложных закономерностей в данных, которые более простые модели могут упустить.
6. Методы регуляризации
Алгоритмы GBDT включают параметры регуляризации, которые помогают контролировать сложность модели и предотвращать переобучение. Для регуляризации используются параметры max_depth, min_samples_split и min_samples_leaf.
7. Масштабируемость
Реализации алгоритмы, например XGBoost, LightGBM и CatBoost, оптимизированы для скорости и масштабируемости. Они могут эффективно обрабатывать большие наборы данных и использовать возможности оборудования, такие как параллельные и распределенные вычисления.Как и любая модель машинного обучения, эти модели также имеют недостатки, которые следует понимать и учитывать.
Недостатки деревьев решений с градиентным бустингом
1. Вычислительная сложность. Обучение моделей GBDT может быть затратным с точки зрения вычислений, особенно при большом количестве деревьев и при наличии глубоких деревьев. В больших наборах данных процесс обучения может потреблять значительный объем памяти в больших и глубоких наборах данных.
2. Настройка гиперпараметров. Несмотря на то, что обе обсуждаемые модели могут работать с параметрами по умолчанию, в них по-прежнему имеется множество гиперпараметров, которые необходимо тщательно настраивать для достижения оптимальной производительности. Это количество деревьев, скорость обучения, максимальная глубина и минимальное количество выборок на лист.
А настройка всех этих параметров может потребовать много времени и вычислений.
3. Чувствительность к зашумленным данным Поскольку каждое дерево пытается исправить ошибки предыдущих деревьев, любой шум в данных может быть усилен посредством процесса бустинга.
4. Часто требуются большие наборы данных. Для достижения хорошей производительности алгоритм GBDT часто требует большой объем данных. В небольших наборах данных может быть недостаточно информации для эффективного бустинга.
Заключение
Деревья с градиентным бустингом являются ценными инструментами для трейдеров на рынке Форекс и превосходят многие другие модели машинного обучения. Раньше люди считали, что сложные модели на основе нейронных сетей, такие как GRU, RNN и LSTM, являются лучшими моделями, которые позволят победить рынок. Но в настоящее время деревья с градиентным бустингом становятся все более популярными в сообществе машинного обучения благодаря своей простоте и способности выполнять поставленные предиктивные задачи.
Всем удачи!
За развитием этой модели машинного обучения и многого другого из этой серии статей можно следить в моем репозиторий на GitHub.
Код на Python, показанный в статье, можно найти здесь.
Приложенные файлы:
Торговые Советники | Папка Experts:
| Наименование файла | Описание и использование |
|---|---|
| LightGBM EA.mq5 | Советник для тестирования алгоритма Light Gradient Boosted Machine (LightGBM) |
| XGBoost EA.mq5 | Советник для тестирования алгоритма Extreme Gradient Boosting (XGBoost) |
Библиотеки | Папка Include:
| Наименование файла | Описание и использование |
|---|---|
| LightGBM.mqh | Библиотека для загрузки, инициализации и развертывания моделей ONNX Light Gradient Boosted Machine (LightGBM) |
| XGBoost.mqh | Библиотека для загрузки, инициализации и развертывания ONNX-модели Extreme Gradient Boosting (XGBoost) |
Скрипты | Папка Scripts:
| Наименование файла | Описание и использование |
|---|---|
| LightGBM Performance TestScript.mq5 | Скрипт для тестирования модели LightGBM в реальном времени |
Файлы | Папка Files:
| Наименование файла | Описание и использование |
|---|---|
| EURUSD.PERIOD_H1.csv | CSV-файл, содержащий обучающий набор данных. |
| lightgbm.eurusd.h1.onnx xgboost.eurusd.h1.onnx | Модели LightGBM и XGBoost в формате ONNX |
Код Python:
| Наименование файла | Описание и использование |
|---|---|
| lightgbm-xgboost.ipynb | Блокнот Jupyter, содержащий весь код Python, обсуждаемый в статье. |
Источники:
- Can one do better than XGBoost? - Mateusz Susik (https://www.youtube.com/watch?v=5CWwwtEM2TA).
- Unlocking the Power of Gradient-Boosted Trees (using LightGBM) | PyData London 2022 (https://www.youtube.com/watch?v=qGsHlvE8KZM).
- Документация по LightGBM (https://lightgbm.readthedocs.io/en/latest/Parameters.html).
- Документация по XGBoost (https://xgboost.readthedocs.io/en/stable/tutorials/model.html).
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/14926


- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования