
数据科学与机器学习(第23部分):为什么LightGBM和XGBoost能超越许多AI模型?

什么是梯度提升树?
梯度提升决策树(GBDT)是一种强大的机器学习技术,主要用于回归和分类任务。它们将多个弱学习器(通常是决策树)的预测结果结合起来,以创建一个强大的预测模型。
核心思想是顺序构建模型,每个新模型都试图纠正前一个模型所犯的错误。
这些提升树,如:
- 极限梯度提升(XGBoost):这是一种流行且高效的梯度提升实现,
- 轻量级梯度提升机(LightGBM):这是为了高性能和效率而设计的,尤其适用于大型数据集。
- CatBoost:它会自动处理分类特征,并且对过拟合具有鲁棒性。
这些算法在机器学习社区中广受欢迎,成为许多机器学习竞赛获胜队伍的首选算法。在本文中,我们将探讨如何在交易应用中使用这些精确模型。
核心概念
提升(Boosting)
- 提升是一种集成学习技术,它将多个弱学习器(表现略好于随机猜测的模型)组合成一个强学习器。
- 每个新模型都专注于前一个模型的错误,逐渐提高整体性能。
梯度下降
- 梯度提升使用梯度下降来最小化损失函数,即预测值与实际值之间的差异。
- 通过迭代添加指向损失函数梯度方向的新模型,可以对集成模型进行细化。
只需几行代码,这些提升树不仅能提供合理的准确性,还能将您的数据科学项目提升到新的水平。
import lightgbm as lgb train_data = lgb.Dataset(X_train, label=y_train) # preparing data the lightgbm way val_data = lgb.Dataset(X_test, label=y_test, reference=train_data) params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 10, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } # Train the model with evaluation results stored num_round = 100 bst = lgb.train(params, train_data, num_round, valid_sets=[train_data, val_data]) y_pred = bst.predict(X_test, num_iteration=bst.best_iteration) # For binary classification, you might want to threshold the predictions y_pred_binary = np.round(y_pred) print("Classification Report\n", classification_report(y_test, y_pred_binary))
结果:
Classification Report precision recall f1-score support 0.0 0.70 0.75 0.73 104 1.0 0.71 0.66 0.68 96 accuracy 0.70 200 macro avg 0.71 0.70 0.70 200 weighted avg 0.71 0.70 0.70 200
我将相同的数据应用到了其他流行的分类器中。
| 分类器 | 分类报告 |
|---|---|
| 逻辑回归 | precision recall f1-score support 0.0 0.69 0.76 0.72 104 1.0 0.71 0.62 0.66 96 accuracy 0.69 200 macro avg 0.70 0.69 0.69 200 weighted avg 0.70 0.69 0.69 200 |
| 决策树 | precision recall f1-score support 0.0 0.62 0.61 0.61 104 1.0 0.59 0.60 0.59 96 accuracy 0.60 200 macro avg 0.60 0.60 0.60 200 weighted avg 0.61 0.60 0.61 200 |
| 朴素贝叶斯 | precision recall f1-score support 0.0 0.64 0.84 0.73 104 1.0 0.73 0.49 0.59 96 accuracy 0.67 200 macro avg 0.69 0.67 0.66 200 weighted avg 0.68 0.67 0.66 200 |
| K-最近邻算法 | precision recall f1-score support 0.0 0.68 0.73 0.71 104 1.0 0.69 0.64 0.66 96 accuracy 0.69 200 macro avg 0.69 0.68 0.68 200 weighted avg 0.69 0.69 0.68 200 |
| 支持向量机 | precision recall f1-score support 0.0 0.69 0.69 0.69 104 1.0 0.66 0.66 0.66 96 accuracy 0.68 200 macro avg 0.67 0.67 0.67 200 weighted avg 0.67 0.68 0.67 200 |
对于同一个问题,Light GBM模型的总体准确率超过了其他分类器。你可能已经注意到,我甚至没有费心去归一化输入数据,但模型仍然能够超越其他模型。众所周知,归一化对于机器学习模型的性能至关重要,但LightGBM似乎违背了这一观念。这正是使这些模型变得有趣的原因之一。
让我们看看GBDT(包括LightGBM和XGBoost)与其他机器学习分类器之间的区别。
梯度提升决策树(LightGBM与XGBoost)与其他分类器的对比
| LightGBM & XGBoost | 其他分类器 |
|---|---|
| 它们不需要特征缩放,因为它们是基于决策树的,而决策树对输入特征的尺度不敏感。 | 像K-最近邻算法(K-NN)和支持向量机(SVM)这样依赖于数据点之间距离的算法,在特征尺度不同的数据集上无法表现出色。对于大多数分类器而言,缩放非常重要。 |
XGBoost和LightGBM都内置了可以处理缺失值的机制。它们可以通过在训练期间将缺失值分配给分裂的任一侧来学习如何处理缺失数据,或者它们可以简单地在树中为该缺失值创建一个分支,并单独理解其模式。 | 它们大多数情况下不能处理缺失值。这些缺失值可能会降低准确性。 |
参数调优很重要,但并非必需;这些模型使用默认参数也能表现出相当不错的性能。然而,为了获得最佳性能,超参数调优仍然至关重要。 | 像神经网络这样的分类器模型对超参数非常敏感。默认参数不会带来帮助。 |
既然我们已经了解了LightGBM和XGBoost与其他机器学习分类器的对比情况,接下来让我们逐一剖析这些模型,首先从XGBoost开始。
什么是极端梯度提升(XGBoost)?
XGBoost是一个经过优化的分布式梯度提升库,旨在高效且可扩展地训练机器学习模型。在其内部,它采用集成学习方法,将多个弱模型的预测结果结合起来,从而产生一个更强的预测结果。
XGBoost是如何工作的?
为了理解XGBoost的工作原理,我们先来了解其理论基础。
初始化
它从一个初始预测开始,对于回归问题,这个初始预测通常是目标值的均值;对于分类问题,则是几率的对数。
迭代提升(Iterative Boosting)
- 残差计算: 对于每次迭代
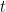 ,计算当前模型集合所做预测的残差(误差)。
,计算当前模型集合所做预测的残差(误差)。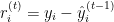
其中:
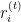 是迭代
是迭代 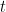 中第
中第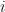 个观测值的残差。
个观测值的残差。 是实际目标值。
是实际目标值。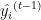 是迭代得的预测值
是迭代得的预测值 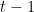 。
。
- 拟合新树:将一棵新的决策树拟合到残差上。这棵树是为了预测当前模型的残差而构建的。
树的叶子节点代表对当前模型预测的调整预测值。
- 更新模型: 将新树的预测值加到当前模型的预测值上,通常会通过一个学习率
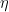 进行缩放。
进行缩放。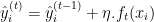
其中: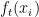 在迭代
在迭代 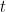 中,对于输入
中,对于输入 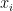 ,新树的预测。
,新树的预测。
目标函数
在XGBoost中,目标函数由两部分组成:
- 损失函数(loss function):衡量模型对训练数据的拟合程度。常见的损失函数包括用于回归的均方误差(Mean Squared Error, MSE)和用于分类的对数损失(Log Loss)。
- 正则化项(regularization term):负责惩罚模型的复杂度,以防止过拟合。XGBoost同时使用L1(Lasso)和L2(Ridge)正则化。
需要最小化的目标函数是:
![]()
其中:
![]() 是损失。
是损失。
![]() 是第
是第![]() 棵树的正则化项。
棵树的正则化项。
![]() 是观测值的数量。
是观测值的数量。
![]() 是树的数量。
是树的数量。
梯度(Gradient)和海森矩阵(Hessian)
XGBoost使用二阶泰勒展开(梯度和海森矩阵)来近似损失函数,以便高效地计算最佳分割点。梯度是损失函数关于预测的一阶导数,而海森矩阵是损失函数关于预测的二阶导数。
树剪枝(Trees Prunin)
树是通过迭代生长并进行剪枝来优化目标函数的。剪枝有助于通过移除对目标函数没有显著改善的节点来防止过拟合。
学习率η用于缩放每棵树对提升过程中步长的贡献。较小的学习率通常需要更多的树。
在Python中实现XGBoost
在Python中实现XGBoost模型只需要几行代码。由于它是一个独立的库,如果你还没有安装它,你需要先安装。
pip install xgboost
我们需要从Scikit-learn导入Pipeline函数。这将帮助我们创建一个包含预处理和其他必要步骤的机器学习对象。
from sklearn.pipeline import Pipeline
如前所述,即使不对数据进行归一化处理,增强树也能表现良好。然而,添加归一化处理并无害处,更不用说它还能带给我们诸多优势,比如帮助我们解决模型中矩阵乘法可能产生的大数所导致的数值不稳定问题。在创建模型管道并将其拟合到训练数据时,我们将归一化作为一个良好的实践添加进去。
Python:
# Create a pipeline with a scaler and the XGBoost classifier pipe = Pipeline([ ("scaler", StandardScaler()), ("xgb", xgb.XGBClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
XGBoost模型带有一些参数,这些参数对于理解模型的工作机制以及如何进行调优至关重要。
Python:
params = {
'objective': 'binary:logistic',
'learning_rate': 0.05,
'max_depth': 5,
'n_estimators': 100,
'colsample_bytree': 0.9,
'subsample': 0.9,
'eval_metric': ['auc', 'logloss']
} | 参数 | 说明 | 调优 |
|---|---|---|
| objective | 此参数指定了学习任务和相应的学习目标。上面使用的binary:logistic是用于逻辑回归的二分类任务。它输出概率结果。 | 常见的目标函数包括用于回归'reg:squarederror',用于二分类的'binary:logistic',以及用于多分类的'multi:softmax'。 始终要根据问题的性质来选择合适的目标函数。 |
| learning_rate | 也称为eta( 较低的学习率通过防止过拟合来增强模型的鲁棒性,但需要更多的提升轮次,反之亦然。 | 较低的学习率(例如0.01-0.1)往往需要更多的树(即更高的n_estimators值),但可以改善模型的稳定性和性能。 最好从一个适中的值(例如0.1)开始,然后根据交叉验证的性能进行调整。 |
| max_depth | 这是树的最大深度。增加此值会使模型变得更复杂,并增加过拟合的风险。 它控制着模型的复杂性。更深的树能够捕获特征之间的更多模式,从而增加了过拟合的风险。 | 常见值的范围在3到10之间。请使用交叉验证来找到最佳深度。 |
| n_estimators | 这是需要构建的提升轮次或树的数量。 更多的树会增加计算时间,并且容易导致过拟合。 | 在交叉验证中可以使用早停法(early stopping)来找到合适数量的树。 |
| colsample_bytree | 这是在构建每棵树时列的抽样比例。上述代码中使用的值0.9( 如上所示) 意味着将使用90%的特征来构建每棵树。 通过在列级别引入随机性,有助于减少过拟合。它还可以加快训练速度并使模型更加稳健。 | 值通常介于0.3到1.0之间。较高的值会使用更多的特征,而较低的值会引入更多的随机性。 |
| subsample | 训练样本的抽样比例。值为0.9意味着将使用90%的训练数据来构建每棵树。 与colsample_bytree类似,此参数通过在数据级别增加随机性来减少过拟合,并可以提高模型的泛化能力。 | 值通常介于0.5到1.0之间。较高的值会使用更多的数据,而较低的值会引入更多的随机性。 |
| eval_metric | 训练期间要使用的评估指标。 多个评估指标可以提供更全面的模型性能视图。 | 常见的指标包括用于回归的'rmse'(均方根误差),用于分类的'logloss'(对数损失),以及用于二分类的'error'(错误率)。 始终选择与您的问题性质和目标相一致的评估指标。 |
由于我们已经训练了模型。让我们对其进行测试并观察其性能。
Python:
y_pred = pipe.predict(X_test)
# For binary classification, you might want to threshold the predictions since these are probabilities
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix xgboost") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.71 0.73 0.72 104 1.0 0.70 0.68 0.69 96 accuracy 0.70 200 macro avg 0.70 0.70 0.70 200 weighted avg 0.70 0.70 0.70 200
该模型在样本外预测方面表现出色,对于看跌信号(类别0)和看涨信号(类别1)的准确率分别为71%和70%。
既然我们已经讨论了XGBoost,现在让我们来剖析一下LightGBM,看看它到底是什么。
什么是轻量级梯度提升机(LightGBM)?
这是一个专为效率、可扩展性和准确性而设计的开源机器学习框架。它是由微软开发的一款分布式机器学习工具包的一部分,并于2017年4月24日发布。
LightGBM是在现有的梯度提升决策树(如XGBoost)的基础上构建的,它提供了以下概述的几个关键改进。
轻量GBM改进
准确性。在优先考虑速度和内存效率的同时,LightGBM并没有在准确性上妥协。所采用的技术旨在实现与以前的GBDT模型相似甚至更好的性能。
LightGBM是如何运作的?
Light GBM与XGBoost 在数学理论层面相似,但在决策树的生长方式上略有不同。接下来,让我们深入了解Light GBM的核心概念。
提升(Boosting)。与XGBoost一样,在梯度提升中,每个新模型都旨在通过拟合残差(误差)来纠正前一个模型所犯的错误。
决策树XGBoost采用层级式树生长方式,即按深度逐层生长树,使树的结构更加均衡。而LightGBM则采用叶节点式树生长方式,这种方式可以生成更深且更复杂的树。

由于这两个模型的工作原理非常相似,让我们通过对比它们的差异表来更好地理解它们。
XGBoost与Light GBM的差异
| Aspect | XGBoost | LightGBM |
|---|---|---|
| 树的生长策略 | 层级式生长(按深度逐层生长,树的结构更加均衡) | 叶节点式生长(首先生长损失减少最大的叶节点,可能生成更深的树) |
| 处理缺失值 | 在训练过程中学习处理缺失值的最佳方向 | 可以直接处理缺失值,将数据分为非缺失和缺失类别 |
| 正则化 | 使用L1(Lasso)和L2(Ridge)正则化来惩罚模型复杂度 | 它使用L2正则化,更注重防止过拟合 |
| 采样技术 | 使用包含所有数据的传统梯度提升 | 基于梯度的单侧采样(GOSS)以关注具有大梯度的重要数据点 |
| 特征处理 | 需要对分类变量进行独热编码或其他预处理 | 原生支持分类特征,使用独家特征捆绑(EFB) |
| 稀疏性感知 | 针对稀疏数据进行了优化,使用稀疏性感知算法来提高内存和计算效率 | 高效处理稀疏数据,具有与XGBoost类似的优化技术 |
| 分裂查找算法 | 默认使用近似算法和分位数草图来进行高效的分裂查找 | 使用基于直方图的算法来更快地进行分裂查找并提高内存效率 |
| 并行处理 | 支持并行和分布式计算,用于大规模数据处理 | 同样支持并行和分布式计算,针对大数据集进行了优化 |
| 训练速度 | 由于采用层级式生长,通常比LightGBM慢 | 由于采用叶节点式生长和高效的采样技术,通常更快 |
| 灵活性和自定义 | 高度灵活,支持自定义损失函数和评估指标 | 同时,它还具有高度灵活性,针对提升过程提供了广泛的自定义选项。 |
在Python中实现LightGBM
如前所述,实现一个LightGBM模型只需几行代码。这次我们将在管道中实现它。就像我们之前对XGBoost所做的那样。
首先我们需要安装它。
pip install lightgbm
LightGBM也有一些重要的参数需要了解。
| 参数 | 说明 | 调优 |
|---|---|---|
| boosting_type | 提升算法的类型。默认值是'gbdt'(梯度提升决策树)。 | 典型值有'gbdt'、'dart'、'goss'。'gbdt'是最常见的。根据数据集和实验结果进行选择。 |
| objective | 指定学习任务和相应的学习目标。'binary' 用于二分类任务。 | 常见的目标包括用于回归任务的 'regression' 和用于二分类的 'binary'。始终根据问题的性质进行选择。 |
| metric | 训练期间使用的评估指标。对于二分类任务,'auc' 和 'binary_logloss' 是常见的评估指标。 | 典型值范围在20到50之间。增加num_leaves(每棵树的最大叶子数)可以捕获更复杂的模式,但可能导致过拟合。使用交叉验证来找到最优值。 |
| num_leaves | 每棵树的最大叶子数。值越高,模型越复杂,反之亦然。 | 典型值范围在20到50之间。增加此值可以捕获更复杂的模式,但可能导致过拟合。 |
| n_estimators | 提升轮次(树)的数量。更多的树通常会增加计算时间并增加过拟合的风险。 | 在交叉验证中使用早停法来确定适当的树的数量。从一个适中的值(例如100)开始,并根据性能进行调整。 |
| max_depth | 树的最大深度。增加此值会使模型更复杂,并可能导致过拟合。 | 常见值的范围在3到10之间。更深的树能捕获更多模式但增加了过拟合的风险 使用交叉验证来找到最优的树深度。 |
| learning_rate | 在向损失函数最小值移动的过程中,每次迭代的步长。较低的值使模型更稳健,但需要更多的提升轮次。 | 较低的学习率(例如0.01-0.1)需要更多的树(更高的n_estimators),但可以提高模型的稳定性和性能。从一个适中的值(例如0.1)开始,并根据交叉验证的性能进行调整。 |
| feature_fraction | 每轮提升中使用的特征比例。值为0.9意味着将使用90%的特征来构建每棵树。 | 值通常介于0.3到1.0之间。较高的值使用更多的特征,而较低的值引入更多的随机性。通过在特征层面引入随机性来帮助减少过拟合。 |
有关这些超参数的更多信息,请参阅文章末尾提供的文档链接。现在,让我们来训练LightGBM模型。
Python:
params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 25, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } pipe = Pipeline([ ("scaler", StandardScaler()), ("lgbm", lgb.LGBMClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
输出控制台:
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Info] Number of positive: 398, number of negative: 402 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000177 seconds. 你可以将"force_col_wise设置为true"来减少额外的开销。 [LightGBM] [Info] Total Bins 1594 [LightGBM] [Info] Number of data points in the train set: 800, number of used features: 8 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.497500 -> initscore=-0.010000 [LightGBM] [Info] Start training from score -0.010000 [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf
我们目前不知道它的性能如何,让我们给训练好的模型提供新的数据,并观察其表现。
y_pred = pipe.predict(X_test) # Changes from bst to pipe
# For binary classification, you might want to threshold the predictions
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix lightgbm") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.69 0.72 0.70 104 1.0 0.68 0.65 0.66 96 accuracy 0.69 200 macro avg 0.68 0.68 0.68 200 weighted avg 0.68 0.69 0.68 200
非常好,该模型在测试样本上的准确率为69%。既然我们已经有了这两个训练良好的模型,让我们将它们都保存为ONNX格式,这样我们就可以在MQL5中部署它们了。
将XGBoost和LightGBM保存为ONNX格式。
保存这两个模型可能会有些棘手,因为它们分别来自各自的自定义库,保存过程并不像保存Scikit-learn、TensorFlow或Keras模型那样直接简单。有关如何保存LightGBM和XGBoost模型的更多信息,请参阅ONNX文档。
让我们先从保存LightGBM模型开始,两个模型的保存过程是完全相同的。
保存LightGBM模型的Python代码:
from skl2onnx.common.data_types import FloatTensorType from skl2onnx import convert_sklearn, to_onnx, update_registered_converter from skl2onnx.common.shape_calculator import calculate_linear_classifier_output_shapes from onnxmltools.convert.xgboost.operator_converters.XGBoost import convert_xgboost from onnxmltools.convert import convert_xgboost as convert_xgboost_booster update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_lightgbm", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
保存XGBoost模型的Python代码:
update_registered_converter( xgb.XGBClassifier, "XGBClassifier", calculate_linear_classifier_output_shapes, convert_xgboost, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_xgboost", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("xgboost.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
在MQL5中加载ONNX模型
尽管加载过程与其他模型相似,但加载梯度提升决策树(GBDT)可能会有些棘手。
MQL5 | LightGBM.mqh
bool CLightGBM::OnnxLoad(long &handle) { //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",output_count," output(s)"); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"output",type_info); ArrayCopy(outputs, type_info.tensor.dimensions); } } //--- replace(inputs); replace(outputs); //--- Setting the input size for (long i=0; i<input_count; i++) if (!OnnxSetInputShape(handle, i, inputs)) //Giving the Onnx handle the input shape { printf("Failed to set the input shape Err=%d",GetLastError()); DebugBreak(); return false; } //--- Setting the output size for(long i=0; i<output_count; i++) { if(!OnnxSetOutputShape(handle,i,outputs)) { printf("Failed to set the Output[%d] shape Err=%d",i,GetLastError()); //DebugBreak(); //return false; } } initialized = true; Print("ONNX model Initialized"); return true; }
输出 | Experts标签页:
JM 0 10:49:34.197 LightGBM EA (EURUSD,H1) model has 1 input(s)
MG 0 10:49:34.197 LightGBM EA (EURUSD,H1) 0 input name is input
KM 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
CF 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
HP 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1, 8]
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 input shape must be defined explicitly before model inference
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape of input data can be reduced to [8] if undefined dimension set to 1
EM 0 10:49:34.198 LightGBM EA (EURUSD,H1) model has 2 output(s)
MJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output name is output_label
MR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
RK 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1]
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output shape must be defined explicitly before model inference
GJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 1 output name is output_probability
OR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_SEQUENCE
KN 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_SEQUENCE
OF 0 10:49:34.198 LightGBM EA (EURUSD,H1) no dimensions defined for 1 output
HM 0 10:49:34.198 LightGBM EA (EURUSD,H1) Failed to set the Output[1] shape Err=5802
IH 0 10:49:34.198 LightGBM EA (EURUSD,H1) ONNX model Initialized
如果你仔细查看Netron模型:

第一输出层是张量类型,包含一个未知大小的一维整型数组。将该层的形状调整为1应该可以正常工作。至于第二输出层,它包含一个序列,该序列有一个映射(类似于Python中的字典),映射中包含两个未知大小的一维数组,一个用于标签,另一个用于概率。如果你好奇的话,这就是ZipMap的表述方式。
设置这个复杂对象类型的第二个输出层的大小使用OnnxSetOutputShape是很困难的,并且可能会引发一些我无法理解的奇怪错误。然而,将其大小调整为1是可行的,因为虽然它会抛出一个警告,但模型仍然可以正常工作。当你以正确的方式运行ONNX模型时。阅读更多。..
float output_data[]; struct Map { ulong key[]; float value[]; } output_data_map[]; //--- ArrayResize(output_data, outputs.Size()); if (!OnnxRun(onnx_handle, ONNX_DATA_TYPE_FLOAT, x_float, output_data, output_data_map)) { printf("Failed to get predictions from Onnx err %d",GetLastError()); return proba; }
在LightGBM类和XGBoost中,我们都有以下方法:
MQL5 | LightGBM.mqh
class CLightGBM { bool initialized; long onnx_handle; void PrintTypeInfo(const long num,const string layer,const OnnxTypeInfo& type_info); long inputs[], outputs[]; void replace(long &arr[]) { for (uint i=0; i<arr.Size(); i++) if (arr[i] < 0) arr[i] = UNDEFINED_REPLACE; } bool OnnxLoad(long &handle); public: CLightGBM(void); ~CLightGBM(void); virtual bool Init(const uchar &onnx_buff[], ulong flags=ONNX_DEFAULT); //Initilaized ONNX model from a resource uchar array with default flag virtual bool Init(string onnx_filename, uint flags=ONNX_DEFAULT); //Initializes the ONNX model from a .onnx filename given virtual long predict_bin(const vector &x); //REturns the predictions for the current given matrix | useful in real-time prediction virtual vector predict_proba(const vector &x); //Returns the predictions in probability terms | useful in real-time prediction virtual matrix predict_proba(const matrix &x); //Returns the predicted probability for the whole matrix | useful for testing virtual vector predict_bin(const matrix &x); //gives out the vector for all the predictions | useful for testing };
在交易中使用LightGBM和XGBoost
在OnInit函数中初始化模型之后。
MQL5 | LightGBM EA.mq5
int OnInit() { if (!lgbm.Init(lightgbm_onnx)) return INIT_FAILED; }
加载的ONNX模型可以使用与训练数据相同的方式收集的数据进行部署。
void OnTick() { int size = CopyRates(Symbol(), PERIOD_CURRENT, 1, 1, rates_x); //We copy only one recent-closed bar //--- if (NewBar()) { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); }
让我们根据获得的信号来制定一个简单的交易策略。
if (NewBar()) //Trade at the opening of a new candle { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions m_trade.Buy(lotsize, Symbol(), ticks.ask, ticks.bid-stoploss*Point(), ticks.ask+takeprofit*Point()); //Open a buy trade } else //Bearish signal { if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions m_trade.Sell(lotsize, Symbol(), ticks.bid, ticks.ask+stoploss*Point(), ticks.bid-takeprofit*Point()); //open a sell trade } }
我在策略测试器上进行了测试,测试对象是2023年1月1日至2024年5月23日期间,欧元对美元(EURUSD)的1小时时间框架。
LightGBM:

XGBoost:

两个模型都产生了亏损。XGBoost的亏损比LightGBM少了8美元。它们的资金曲线图看起来几乎一样。

策略测试器报告无法告诉我们模型是否在其训练的预测下一根K线走势的任务上做得很好。我们知道,要使一个智能交易系统(EA)盈利,必须考虑很多事情。
为了了解模型的表现,我们编写一个脚本来收集与训练数据收集方式相同的数据,并在此过程中创建一个目标变量。
void OnStart() { //--- if (!lgb.Init(lightgbm_onnx)) return; //--- custom out-of-sample testing int bars = 9000; int start = 1000; MqlRates rates_x[]; ArraySetAsSeries(rates_x, true); int size = CopyRates(Symbol(), PERIOD_CURRENT, start, bars, rates_x); //We start at the bar 1000 and collect 9000 candles backward MqlRates rates_y[]; ArraySetAsSeries(rates_y, true); CopyRates(Symbol(), PERIOD_CURRENT, start-1, bars, rates_y); //We do the same thing here but we only collect one bar forward making sure we get the prediction for the next candle //--- vector actual(size), predictions(size); for (int i=0; i<size; i++) { vector x = { rates_x[i].open, rates_x[i].high, rates_x[i].low, rates_x[i].close, rates_x[i].close-rates_x[i].open, rates_x[i].high-rates_x[i].low, rates_x[i].close-rates_x[i].low, rates_x[i].close-rates_x[i].high }; actual[i] = rates_y[i].close > rates_x[i].open ? 1 : 0; //making the target variable predictions[i] = (double)lgb.predict_bin(x); } Metrics::classification_report(actual, predictions); }
结果 | Experts标签:
EG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Confusion Matrix
PO 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [[2857,1503]
CI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [926,3714]]
FM 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NF 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Classification Report
HJ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
KP 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [CLS] precision recall specificity f1 score support
QQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [0.0] 0.76 0.66 0.80 0.70 4360
CQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [1.0] 0.71 0.80 0.66 0.75 4640
HS 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NK 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) accuracy 0.73 9000
RG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) average 0.73 0.73 0.73 0.73 9000
LI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Weighed avg 0.73 0.73 0.73 0.73 9000
模型在样本外数据上的准确率为73%。这告诉我们,尽管模型在策略测试器中无法产生向上的曲线,但它的表现还是不错的。这应该是在MQL5中使用梯度提升决策树(GBDTs)制作自己的盈利智能交易系统的一个良好的起点。
梯度提升决策树的优势
1. 高预测准确性
梯度提升决策树在预测准确性方面通常优于许多其他机器学习算法。这是因为它们结合了决策树的优点和梯度提升,后者通过专注于前一棵树的误差来迭代地提高模型性能。
2. 对过拟合的鲁棒性
提升过程涉及添加新的树来纠正现有集成树的误差,这有助于减少过拟合。学习率调整、正则化和早停等技术可以进一步增强这种鲁棒性。
3. 无需大量预处理
梯度提升决策树不需要像线性回归或支持向量机等其他算法通常需要的特征缩放、缺失值处理或分类变量编码等大量预处理步骤。
4. 灵活性和可定制性
梯度提升决策树提供了广泛的超参数,这些超参数可以根据特定任务进行优化以调整性能。这些超参数包括树的数量、学习率、树的最大深度以及拆分节点所需的最小样本数等。
5. 处理复杂关系
梯度提升决策树可以模拟特征和目标变量之间的复杂非线性关系。这使得它们能够捕捉到数据中简单模型可能会遗漏的复杂模式。
6. 正则化技术
梯度提升决策树包含有助于控制模型复杂性和防止过拟合的正则化参数。诸如max_depth、min_samples_split和min_samples_leaf等参数在正则化中起着至关重要的作用。
7. 可扩展性
像XGBoost、LightGBM和CatBoost这样的实现针对速度和可扩展性进行了优化。它们可以高效地处理大型数据集,并利用并行计算和分布式计算等硬件功能。与任何机器学习模型一样,这些模型也有必须承认的缺点,这不是为了劝阻人们使用它们,而是为了巩固人们对它们的理解。
梯度提升决策树的缺点
1. 计算复杂性。梯度提升决策树的训练在计算上可能很昂贵,尤其是在树的数量和深度都很大的情况下。在大型和深度数据集中,训练过程可能会消耗大量内存。
2. 超参数优调。尽管这两个讨论的模型都可以使用默认参数工作,但它们仍然有许多超参数需要仔细调整才能实现最佳性能。这些参数包括树的数量、学习率、最大深度和每个叶子的最小样本数。
众所周知,调整这些参数可能既耗时又耗费计算资源。
3. 仍然对噪声数据敏感。由于每棵树都试图纠正前一棵树的误差,因此数据中的任何噪声都可能通过提升过程被放大。
4. 通常需要大数据集。梯度提升决策树通常需要大量数据才能获得良好的性能。小型数据集可能无法为提升过程提供足够的信息以有效工作。
总结
对于外汇交易者来说,梯度提升树是有价值的工具,因为我们已经看到它们在初始阶段就优于许多机器学习模型。人们过去认为基于复杂神经网络的模型(如门控循环单元(GRU)、循环神经网络(RNN)和长短期记忆网络(LSTM))是击败市场的首选模型,但情况已不再如此,因为梯度提升树在机器学习社区中越来越受欢迎,这得益于它们的简单性和完成预测任务的能力。
此致敬礼。
在GitHub的这个仓库中,本系列文章将追踪机器学习模型的发展情况,并深入讨论更多内容。
本文中讨论的Python代码可在此链接中找到。
附件表格:
EA | Experts文件夹:
| 文件名 | 说明和用法 |
|---|---|
| LightGBM EA.mq5 | 用于测试轻量梯度提升机(LightGBM)的EA |
| XGBoost EA.mq5 | 用于测试极限梯度提升 (XGBoost)的EA |
库 | 包含文件夹:
| 文件名 | 说明和用法 |
|---|---|
| LightGBM.mqh | 一个用于加载、初始化和部署轻量级梯度提升机(LightGBM)ONNX模型的库 |
| XGBoost.mqh | 一个用于加载、初始化和部署极限梯度提升(XGBoost)ONNX模型的库 |
脚本 | 脚本文件夹:
| 文件名 | 说明和用法 |
|---|---|
| LightGBM Performance TestScript.mq5 | 一个用于实时测试LightGBM模型的脚本 |
文件 | 文件夹:
| 文件名 | 说明和用法 |
|---|---|
| EURUSD.PERIOD_H1.csv | 一个包含训练数据集的CSV文件 |
| lightgbm.eurusd.h1.onnx xgboost.eurusd.h1.onnx | ONNX格式的LightGBM和XGBoost模型 |
Python代码:
| 文件名 | 说明和用法 |
|---|---|
| lightgbm-xgboost.ipynb | 包含本文中讨论的所有Python代码的Jupyter笔记本 |
资料来源与参考文献:
- 有没有比XGBoost更好的选择?- Mateusz Susik (https://www.youtube.com/watch?v=5CWwwtEM2TA).
- 解锁梯度提升树的力量(使用LightGBM)| PyData 伦敦 2022(https://www.youtube.com/watch?v=qGsHlvE8KZM)
- LightGBM文档:(https://lightgbm.readthedocs.io/en/latest/Parameters.html)。
- XGBoost文档 (https://xgboost.readthedocs.io/en/stable/tutorials/model.html)。
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/14926
 MQL5 简介(第 7 部分):在 MQL5 中构建 EA 交易和使用 AI 生成代码的初级指南
MQL5 简介(第 7 部分):在 MQL5 中构建 EA 交易和使用 AI 生成代码的初级指南