
Datenwissenschaft und maschinelles Lernen (Teil 23): Warum schneiden LightGBM und XGBoost besser ab als viele KI-Modelle?

Was sind Gradient Boosted Trees?
Gradient Boosted Decision Trees (GBDT, gradientenverstärkte Entscheidungsbäume) sind eine leistungsstarke Technik des maschinellen Lernens, die hauptsächlich für Regressions- und Klassifizierungsaufgaben verwendet wird. Sie kombinieren die Vorhersagen mehrerer schwacher Lerner, normalerweise Entscheidungsbäume, um ein starkes Vorhersagemodell zu erstellen.
Der Kerngedanke besteht darin, Modelle nacheinander zu erstellen, wobei mit jedem neuen Modell versucht wird, die Fehler der vorangegangenen Modelle zu korrigieren.
Diese förderten Bäume wie zum Beispiel:
- Extreme Gradient Boosting (XGBoost): Dies ist eine beliebte und effiziente Implementierung des Gradient Boosting,
- Light Gradient Boosting Machnine (LightGBM): Es wurde für hohe Leistung und Effizienz, insbesondere bei großen Datenmengen, entwickelt.
- CatBoost: Die kategorischen Merkmale werden automatisch verarbeitet und sind robust gegen Überanpassung.
Sie haben in der Gemeinschaft des maschinellen Lernens große Popularität erlangt, da sie die bevorzugten Algorithmen für viele Siegerteams in Wettbewerben des maschinellen Lernens sind. In diesem Artikel werden wir herausfinden, wie wir diese präzisen Modelle in unseren Handelsanwendungen nutzen können.
Wichtige Konzepte
Boosting
- Boosting (verstärkend) ist ein Ensemble-Lernverfahren, bei dem mehrere schwache Lerner (Modelle, die etwas besser abschneiden als zufälliges Raten) zu einem starken Lerner kombiniert werden.
- Mit jedem neuen Modell werden die Fehler der Vorgängermodelle behoben und die Gesamtleistung schrittweise verbessert.
Gradient Descent
- Beim Gradient Boosting wird ein „gradient descent“ (Gradientenabstieg) verwendet, um eine Verlustfunktion zu minimieren, die die Differenz zwischen den vorhergesagten und den tatsächlichen Werten darstellt.
- Durch das iterative Hinzufügen neuer Modelle, die in die Richtung des Gradienten der Verlustfunktion zeigen, wird das Ensemblemodell verfeinert.
Mit nur wenigen Zeilen Code können Sie mit diesen verstärkten Bäumen nicht nur eine angemessene Genauigkeit erzielen, sondern auch Ihr Data-Science-Projekt auf die nächste Stufe bringen.
import lightgbm as lgb train_data = lgb.Dataset(X_train, label=y_train) # preparing data the lightgbm way val_data = lgb.Dataset(X_test, label=y_test, reference=train_data) params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 10, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } # Train the model with evaluation results stored num_round = 100 bst = lgb.train(params, train_data, num_round, valid_sets=[train_data, val_data]) y_pred = bst.predict(X_test, num_iteration=bst.best_iteration) # For binary classification, you might want to threshold the predictions y_pred_binary = np.round(y_pred) print("Classification Report\n", classification_report(y_test, y_pred_binary))
Results:
Classification Report precision recall f1-score support 0.0 0.70 0.75 0.73 104 1.0 0.71 0.66 0.68 96 accuracy 0.70 200 macro avg 0.71 0.70 0.70 200 weighted avg 0.71 0.70 0.70 200
Ich habe die gleichen Daten auf andere gängige Klassifikatoren angewandt.
| Klassifikator | Klassifizierungsbericht |
|---|---|
| Logistische Regression | precision recall f1-score support 0.0 0.69 0.76 0.72 104 1.0 0.71 0.62 0.66 96 accuracy 0.69 200 macro avg 0.70 0.69 0.69 200 weighted avg 0.70 0.69 0.69 200 |
| Entscheidungsbaum | precision recall f1-score support 0.0 0.62 0.61 0.61 104 1.0 0.59 0.60 0.59 96 accuracy 0.60 200 macro avg 0.60 0.60 0.60 200 weighted avg 0.61 0.60 0.61 200 |
| Naive Bayes | precision recall f1-score support 0.0 0.64 0.84 0.73 104 1.0 0.73 0.49 0.59 96 accuracy 0.67 200 macro avg 0.69 0.67 0.66 200 weighted avg 0.68 0.67 0.66 200 |
| K-Nächste Nachbarn | precision recall f1-score support 0.0 0.68 0.73 0.71 104 1.0 0.69 0.64 0.66 96 accuracy 0.69 200 macro avg 0.69 0.68 0.68 200 weighted avg 0.69 0.69 0.68 200 |
| Support-Vektor-Maschine | precision recall f1-score support 0.0 0.69 0.69 0.69 104 1.0 0.66 0.66 0.66 96 accuracy 0.68 200 macro avg 0.67 0.67 0.67 200 weighted avg 0.67 0.68 0.67 200 |
Das Light-GBM-Modell war dasjenige mit einer höheren Gesamtgenauigkeit als die anderen Klassifikatoren für dasselbe Problem. Sie haben vielleicht bemerkt, dass ich mir nicht einmal die Mühe gemacht habe, die Eingabedaten zu normalisieren, aber das Modell konnte trotzdem andere übertreffen. Wie wir wissen, ist die Normalisierung von entscheidender Bedeutung für die Leistungsfähigkeit von Modellen des maschinellen Lernens, aber lightGBM scheint sich dieser Idee zu widersetzen. Das ist einer der Punkte, die diese Modelle interessant machen.
Betrachten wir den Unterschied zwischen GBDT (LightGBM und XGBoost) und anderen maschinellen Lernklassifizierern.
Gradient Boosted Decision Trees (LighGBM & XGBoost) im Vergleich zu anderen Klassifikatoren
| LightGBM & XGBoost | Andere Klassifikatoren |
|---|---|
| Sie erfordern keine Skalierung der Merkmale, da sie auf Entscheidungsbäumen beruhen, die für eine Skalierung der Eingangsmerkmale unempfindlich sind. | Algorithmen wie K-Nearest Neighbors (K-NN) und Support Vector Machine (SVM), die sich auf den Abstand zwischen Datenpunkten stützen, können bei einem Datensatz mit Merkmalen in unterschiedlichen Größenordnungen nicht gut funktionieren. Die Skalierung ist für die meisten Klassifikatoren sehr wichtig. |
Sowohl XGBoost als auch LightGBM verfügen über integrierte Mechanismen, die fehlende Werte verarbeiten können. Sie können lernen, mit fehlenden Daten umzugehen, indem sie während des Trainings fehlende Werte auf beiden Seiten eines Splits zuordnen, oder sie können einfach einen Zweig für diesen fehlenden Wert in einem Baum erstellen und sein Muster separat verstehen. | Mit fehlenden Werten können sie meist nicht umgehen. Diese fehlenden Werte können die Genauigkeit verringern. |
Die Einstellung der Parameter ist wichtig, aber nicht erforderlich; diese Modelle funktionieren bereits mit den Standardparametern recht gut. Die Einstellung der Hyperparameter ist nach wie vor entscheidend, um eine optimale Leistung zu erzielen. | Klassifizierungsmodelle wie neuronale Netze sind sehr empfindlich gegenüber Hyperparametern. Standardparameter sind nicht hilfreich. |
Nachdem wir nun gesehen haben, wie LightGBM und XGBoost im Vergleich zu anderen maschinellen Lernklassifizierern abschneiden, wollen wir ein Modell nach dem anderen analysieren, beginnend mit XGBoost.
Was ist Extreme Gradient Boosting (XGBoost)?
XGBoost ist eine optimierte verteilte Gradient-Boosting-Bibliothek, die für effizientes und skalierbares Training von Machine-Learning-Modellen entwickelt wurde. Dabei handelt es sich um eine Ensemble-Lernmethode, die die Vorhersagen mehrerer schwacher Modelle kombiniert, um eine bessere Vorhersage zu erhalten.
Wie funktioniert XGBoost?
Um zu verstehen, wie XGBoost funktioniert, müssen wir seine Theorie verstehen.
Initialisierung
Sie beginnt mit einer anfänglichen Vorhersage, in der Regel dem Mittelwert der Zielwerte bei der Regression oder dem Logarithmus der Quoten bei der Klassifizierung.
Iterative Verstärkung
- Berechnung der Residuen: Berechne für jede Iteration
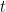 die Residuen (Fehler) der Vorhersagen, die von der aktuellen Gruppe von Modellen gemacht werden.
die Residuen (Fehler) der Vorhersagen, die von der aktuellen Gruppe von Modellen gemacht werden.
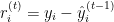
Wobei:
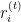 ist das Residuum für die
ist das Residuum für die 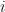 -te Beobachtung bei der Iteration
-te Beobachtung bei der Iteration 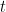 .
. ist der tatsächliche Zielwert.
ist der tatsächliche Zielwert.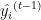 ist der vorhergesagte Wert bei der Iteration
ist der vorhergesagte Wert bei der Iteration 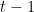 .
.
- Einen neuen Baum aufstellen: Anpassung eines neuen Entscheidungsbaums an die Residuen. Der Baum wird erstellt, um die Residuen des aktuellen Modells vorherzusagen.
Die Blätter des Baums stellen die voraussichtlichen Anpassungen an die aktuellen Modellvorhersagen dar.
- Aktualisieren Sie das Modell: Addieren Sie die Vorhersagen des neuen Baums zu den Vorhersagen des aktuellen Modells, in der Regel skaliert mit einer Lernrate
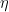 .
.
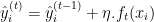
Wobei: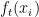 ist die Vorhersage des neuen Baums bei der Iteration
ist die Vorhersage des neuen Baums bei der Iteration 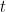 für die Eingabe
für die Eingabe 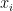 .
.
Zielfunktion
Die Zielfunktion von XGBoost besteht aus zwei Teilen:
- Die Verlustfunktion, die misst, wie gut das Modell zu den Trainingsdaten passt. Gängige Verlustfunktionen sind der mittlere quadratische Fehler für die Regression und der logarithmische Verlust für die Klassifikation.
- Der Regularisierungsterm, der für die Bestrafung der Komplexität des Modells verantwortlich ist, um eine Überanpassung zu verhindern. XGBoost verwendet sowohl L1 (Lasso) als auch L2 (Ridge) Regularisierung.
Die zu minimierende Zielfunktion lautet:
![]()
wobei:
![]() ist der Verlustterm.
ist der Verlustterm.
![]() ist der Regularisierungsterm für den
ist der Regularisierungsterm für den ![]() -ten Baum.
-ten Baum.
![]() ist die Anzahl der Beobachtungen.
ist die Anzahl der Beobachtungen.
![]() ist die Anzahl der Bäume.
ist die Anzahl der Bäume.
Gradient und Hessian
XGBoost verwendet eine Taylor-Erweiterung zweiter Ordnung (Gradient und Hessian), um die Verlustfunktion für eine effiziente Berechnung der optimalen Splits zu approximieren. Der Gradient ist die erste Ableitung der Verlustfunktion in Bezug auf die Vorhersage, während der Hessian die zweite Ableitung der Verlustfunktion in Bezug auf die Vorhersage ist.
Trees Pruning
Die Bäume wachsen iterativ und werden beschnitten, um die Zielfunktion zu optimieren. Das Pruning (Beschneiden) hilft, eine Überanpassung zu verhindern, indem Knoten entfernt werden, die keine signifikante Verbesserung der Zielfunktion bewirken.
Die Lernrate η skaliert den Beitrag jedes Baums, um die Schrittgröße im Boosting-Prozess zu steuern. Kleinere Lernraten erfordern in der Regel mehr Bäume.
Implementierung von XGBoost in Python
Zur Implementierung des XGBoost-Modells in Python sind nur wenige Zeilen Code erforderlich. Da es sich um eine separate Bibliothek handelt, müssen Sie sie zuerst installieren, falls Sie dies nicht bereits getan haben.
pip install xgboost
Wir müssen die Funktion Pipeline aus Scikit-learn importieren. Dies wird uns helfen, ein maschinelles Lernobjekt mit Vorverarbeitung und anderen notwendigen Schritten zu erstellen.
from sklearn.pipeline import Pipeline
Wie bereits erwähnt, können Boosted Trees auch ohne Normalisierung der Daten gute Leistungen erbringen, aber das Hinzufügen von Boosted Trees kann nicht schaden, ganz zu schweigen davon, dass es uns mehrere Vorteile bietet, wie z. B. die Abschwächung numerischer Instabilitätsprobleme, die durch große Zahlen verursacht werden, die ein Ergebnis von Matrixmultiplikationen in unseren Modellen sein könnten. Fügen wir die Normalisierung als gute Praxis hinzu, während wir eine Pipeline für das Modell erstellen und es an die Trainingsdaten anpassen.
Python:
# Create a pipeline with a scaler and the XGBoost classifier pipe = Pipeline([ ("scaler", StandardScaler()), ("xgb", xgb.XGBClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
Das XGBoost-Modell verfügt über einige Parameter, bei denen es wichtig ist, nicht nur zu verstehen, wie sie funktionieren, sondern auch, wie man sie optimal einstellen kann.
Python:
params = {
'objective': 'binary:logistic',
'learning_rate': 0.05,
'max_depth': 5,
'n_estimators': 100,
'colsample_bytree': 0.9,
'subsample': 0.9,
'eval_metric': ['auc', 'logloss']
} | Parameter | Beschreibung | Einstellungen |
|---|---|---|
| objective | Dieser Parameter gibt die Lernaufgabe und das entsprechende Lernziel an. binary:logistic wird für die binäre Klassifikation mit logistischer Regression verwendet. Es gibt Wahrscheinlichkeitsausgaben aus. | Zu den üblichen Zielen gehören „reg:squarederror“ für Regression, „binary:logistic“ für binäre Klassifikation und „multi:softmax“ für Mehrklassen-Klassifikation. Wählen Sie das Ziel immer nach der Art Ihres Problems aus. |
| learning_rate | Auch bekannt als eta( Eine niedrigere Lernrate macht das Modell robust, indem sie eine Überanpassung verhindert, erfordert aber mehr Boosting-Runden und umgekehrt. | Niedrigere Lernraten (z. B. 0,01-0,1) erfordern in der Regel mehr Bäume (höhere n_estimators), können aber die Stabilität und Leistung des Modells verbessern. Es empfiehlt sich, mit einem moderaten Wert (z. B. 0,1) zu beginnen und diesen anhand der Ergebnisse der Kreuzvalidierung anzupassen. |
| max_depth | Dies ist die maximale Tiefe des Baums. Eine Erhöhung dieses Werts macht das Modell komplexer und erhöht die Wahrscheinlichkeit einer Überanpassung. Er steuert die Komplexität des Modells. Tiefere Bäume erfassen mehr Muster zwischen den Merkmalen, was das Risiko einer Überanpassung erhöht. | Übliche Werte reichen von 3 bis 10. Bitte verwenden Sie eine Kreuzvalidierung, um die optimale Tiefe zu finden. |
| n_estimators | Dies ist die Anzahl der zu bauenden Verstärkungsrunden oder Bäume. Mehr Bäume erhöhen die Berechnungszeit und neigen zur Überanpassung. | Bei der Kreuzvalidierung kann ein frühes Stoppen verwendet werden, um eine angemessene Anzahl von Bäumen zu finden. |
| colsample_bytree | Es ist das Verhältnis der Unterstichproben (subsample) der Spalten bei der Konstruktion jedes Baumes. Ein Wert von 0,9 (im obigen Code verwendet) bedeutet, dass 90 % der Merkmale zur Erstellung jedes Baums verwendet werden. Das hilft, die Überanpassung durch Einführung von Zufälligkeiten auf Spaltenebene zu reduzieren. Sie kann auch das Training beschleunigen und das Modell robuster machen. | Die Werte liegen in der Regel zwischen 0,3 und 1,0. Höhere Werte verwenden mehr Merkmale, während niedrigere Werte mehr Zufälligkeit einführen. |
| subsample | Das Unterstichprobenverhältnis der Trainingsinstanzen. Ein Wert von 0,9 bedeutet, dass 90 % der Trainingsdaten für die Erstellung jedes Baums verwendet werden. Ähnlich wie colsample_bytree verringert dieser Parameter die Überanpassung durch Hinzufügen von Zufälligkeiten auf der Datenebene und kann die Verallgemeinerung verbessern. | Die Werte liegen in der Regel zwischen 0,5 und 1,0. Bei höheren Werten werden mehr Daten verwendet, während bei niedrigeren Werten mehr Zufälligkeiten auftreten. |
| eval_metric | Die Auswertungs-Metriken, die während des Trainings verwendet werden sollen. Mehrere Bewertungsmetriken können einen umfassenderen Überblick über die Modellleistung geben. | Übliche Metriken sind „rmse“ für Regression, „logloss“ für Klassifizierung und „error“ für binäre Klassifizierung. Wählen Sie immer Messgrößen, die mit der Art Ihres Problems und Ihren Zielen übereinstimmen. |
Da wir das Modell bereits trainiert haben. Testen wir es und beobachten seine Leistung.
Python:
y_pred = pipe.predict(X_test)
# For binary classification, you might want to threshold the predictions since these are probabilities
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix xgboost") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.71 0.73 0.72 104 1.0 0.70 0.68 0.69 96 accuracy 0.70 200 macro avg 0.70 0.70 0.70 200 weighted avg 0.70 0.70 0.70 200
Das Modell leistete hervorragende Arbeit bei den Vorhersagen außerhalb der Stichprobe. Es lag zu 71 % bzw. 70 % richtig für Verkäufe (Klasse 0) und Käufe (Klasse 1).
Nachdem wir nun über XGBoost gesprochen haben, wollen wir LightGBM genauer unter die Lupe nehmen und sehen, worum es dabei geht.
Was ist die Light Gradient Boosting Machine (LightGBM)?
Dies ist ein Open-Source-Framework für maschinelles Lernen, das speziell für Effizienz, Skalierbarkeit und Genauigkeit entwickelt wurde. Es wurde von Microsoft als Teil eines verteilten Toolkits für maschinelles Lernen entwickelt und am 24. April 2017 veröffentlicht.
Der LightGBM wurde auf der Grundlage bestehender Gradient Boosted Decision Trees wie XGBoost entwickelt. Er bietet mehrere wichtige Verbesserungen, die im Folgenden beschrieben werden.
Leichte GBM-Verbesserungen
Genauigkeit. Bei LightGBM stehen Geschwindigkeit und Speichereffizienz im Vordergrund, ohne dass die Genauigkeit darunter leidet. Die angewandten Techniken sind so konzipiert, dass sie im Vergleich zu früheren GBDT-Modellen ähnliche oder sogar bessere Leistungen erzielen.
Wie funktioniert LightGBM?
Light GBM funktioniert genauso wie XGBoost, wenn es um die mathematische Theorie geht, mit einer kleinen Änderung in der Art und Weise, wie Bäume wachsen. Lassen Sie uns einen Blick auf die Kernkonzepte hinter Light GBM werfen.
Boosting. Wie XGBoost Beim Gradient Boosting zielt jedes neue Modell darauf ab, die von den vorherigen Modellen gemachten Fehler zu korrigieren, indem es an die Residuen (Fehler) angepasst wird.
Decision Trees. XGBoost hingegen verwendet ein ebenenweises Baumwachstum, d. h. der Baum wächst schrittweise und ist gleichmäßiger. LightGBM verfügt über ein blattweises Baumwachstum, das tiefere und komplexere Bäume erzeugen kann.

Da sich diese beiden Modelle in ihrer Funktionsweise sehr ähneln, wollen wir uns die Unterschiede in einer Tabelle ansehen, um sie im Vergleich besser verstehen zu können.
Die Unterschiede zwischen XGBoost und Light GBM
| Aspekt | XGBoost | LichtGBM |
|---|---|---|
| Strategie zum Baumwachstum | Wachstum der Ebenen (Bäume wachsen in die Tiefe, sie sind ausgewogener) | Blattweises Wachstum (das Blatt mit der höchsten Verlustreduzierung wächst zuerst, potenziell tiefere Bäume) |
| Umgang mit fehlenden Werten | Lernt die optimale Richtung für den Umgang mit fehlenden Werten während des Trainings | Kann fehlende Werte direkt verarbeiten, teilt die Daten in nicht fehlende und fehlende Kategorien auf |
| Regularisierung | Verwendet L1 (Lasso) und L2 (Ridge) Regularisierung, um die Modellkomplexität zu bestrafen | Verwendet L2-Regularisierung und konzentriert sich mehr auf die Vermeidung von Überanpassung |
| Technik der Probenahme | Verwendet traditionelles Gradient Boosting mit allen Daten | Gradientenbasiertes einseitiges Sampling (GOSS) zur Konzentration auf wichtige Datenpunkte mit großen Gradienten |
| Handhabung von Merkmalen | Erfordert One-Hot-Codierung oder andere Vorverarbeitung für kategoriale Variablen | Unterstützt kategorische Merkmale nativ mit Exclusive Feature Bundling (EFB) |
| Bewusstsein für Sparsamkeit | Optimiert für spärliche (sparse) Daten, verwendet einen spartenspezifischen Algorithmus für Speicher- und Berechnungseffizienz | Behandelt spärliche Daten effizient und verfügt über ähnliche Optimierungstechniken wie XGBoost |
| Algorithmen zur Aufteilung | Verwendet standardmäßig Näherungsalgorithmen und Quantilskizzen für standardmäßiges Finden einer effizienten Aufteilung. | Verwendet histogrammbasierte Algorithmen für eine schnellere Aufteilung und effizienteren Speicherbedarf. |
| Parallele Verarbeitung | Unterstützt paralleles und verteiltes Rechnen für die Verarbeitung großer Datenmengen | Unterstützt auch parallele und verteilte Datenverarbeitung, optimiert für große Datenmengen. |
| Trainingsgeschwindigkeit | Generell langsamer im Vergleich zu LightGBM aufgrund des ebenenweises Wachstums. | Im Allgemeinen ist das blattweise Wachstum schneller und bietet effiziente Probenahmetechniken. |
| Flexibilität und Anpassungsfähigkeit | Äußerst flexibel, unterstützt nutzerdefinierte Verlustfunktionen und Bewertungsmetriken. | Auch sehr flexibel, mit umfangreichen Anpassungsmöglichkeiten für den Boosting-Prozess. |
Implementierung von Light GBM in Python
Wie bereits erwähnt, sind nur wenige Zeilen Code erforderlich, um ein Light GBM-Modell zu implementieren. Diesmal wollen wir sie in einer Pipeline implementieren. Genauso haben wir es mit XGBoost gemacht.
Wir müssen es zuerst installieren.
pip install lightgbm
Light GBM hat auch einige Parameter, die wichtig zu verstehen sind.
| Parameter | Beschreibung | Abstimmung |
|---|---|---|
| boosting_type | Typ des zu verwendenden Boosting-Algorithmus. Die Standardeinstellung ist „gbdt“ (Gradient Boosting Decision Tree). | Typische Werte sind „gbdt“, „dart“, „goss“, „gbdt“ ist der häufigste. Wählen Sie auf der Grundlage Ihres Datensatzes und Ihrer Experimente. |
| objective | Gibt die Lernaufgabe und das entsprechende Lernziel an. „binary“ wird für binäre Klassifikation verwendet. | Übliche Ziele umfassen „Regression“ für Regressionsaufgaben, „binär“ für binäre Klassifikation. Wählen Sie immer nach der Art Ihres Problems. |
| metric | Bewertungsmetrik(en), die beim Training verwendet werden soll(en). „auc“ und „binary_logloss“ sind für die binäre Klassifikation üblich. | Typische Werte liegen zwischen 20 und 50. Eine Erhöhung von num_leaves kann komplexere Muster erfassen, kann aber zu einer Überanpassung führen. Verwenden Sie eine Kreuzvalidierung, um den optimalen Wert zu finden. |
| num_leaves | Maximale Anzahl von Blättern in einem Baum. Ein höherer Wert erhöht die Modellkomplexität und umgekehrt. | Typische Werte liegen zwischen 20 und 50. Ein höherer Wert kann komplexere Muster erfassen, kann aber zu einer Überanpassung führen. |
| n_estimators | Anzahl der Verstärkungsrunden (Bäume). Mehr Bäume erhöhen im Allgemeinen die Rechenzeit und das Risiko einer Überanpassung. | Verwenden Sie das frühe Stoppen bei der Kreuzvalidierung, um die geeignete Anzahl von Bäumen zu bestimmen. Beginnen Sie mit einem moderaten Wert (z. B. 100) und passen Sie ihn je nach Leistung an. |
| max_depth | Maximale Tiefe eines Baumes. Ein höherer Wert macht das Modell komplexer und führt wahrscheinlich zu einer Überanpassung. | Übliche Werte reichen von 3 bis 10. Tiefere Bäume erfassen mehr Muster, erhöhen aber das Risiko einer Überanpassung. Verwenden Sie die Kreuzvalidierung, um die optimale Tiefe zu finden. |
| learning_rate | Schrittweite bei jeder Iteration auf dem Weg zum Minimum der Verlustfunktion. Niedrigere Werte machen das Modell robuster, erfordern aber mehr Verstärkungsrunden. | Niedrigere Lernraten (z. B. 0,01-0,1) erfordern mehr Bäume (höhere n_estimators), können aber die Stabilität und Leistung des Modells verbessern. Beginnen Sie mit einem moderaten Wert (z. B. 0,1) und passen Sie ihn anhand der Ergebnisse der Kreuzvalidierung an. |
| feature_fraction | Anteil der Merkmale, die für jede Boosting-Runde verwendet werden. Ein Wert von 0,9 bedeutet, dass 90 % der Merkmale zur Erstellung jedes Baums verwendet werden. | Die Werte liegen in der Regel zwischen 0,3 und 1,0. Höhere Werte verwenden mehr Merkmale, während niedrigere Werte mehr Zufälligkeit einführen. Hilft bei der Verringerung der Überanpassung durch Einführung von Zufälligkeiten auf der Merkmalsebene. |
Weitere Informationen zu diesen Hyperparametern finden Sie in der am Ende des Artikels verlinkten Dokumentation. Nun wollen wir das Light-GBM-Modell trainieren.
Python:
params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 25, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } pipe = Pipeline([ ("scaler", StandardScaler()), ("lgbm", lgb.LGBMClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
Gibt die Konsole aus:
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Info] Number of positive: 398, number of negative: 402 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000177 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 1594 [LightGBM] [Info] Number of data points in the train set: 800, number of used features: 8 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.497500 -> initscore=-0.010000 [LightGBM] [Info] Start training from score -0.010000 [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf
Wir können die Leistung des Modells im Moment noch nicht verstehen. Geben wir dem trainierten Modell neue Daten und beobachten wir die Leistung.
y_pred = pipe.predict(X_test) # Changes from bst to pipe
# For binary classification, you might want to threshold the predictions
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix lightgbm") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.69 0.72 0.70 104 1.0 0.68 0.65 0.66 96 accuracy 0.69 200 macro avg 0.68 0.68 0.68 200 weighted avg 0.68 0.69 0.68 200
Großartig, das Modell ist bei der Testprobe zu 69 % genau. Da wir nun diese beiden gut trainierten Modelle haben, sollten wir beide im ONNX-Format speichern, das wir in MQL5 einsetzen können.
Speichern von XGBoost und LightGBM in ONNX.
Das Speichern dieser beiden Modelle kann schwierig sein, da beide Modelle separat in ihren eigenen Bibliotheken enthalten sind. Ihr Speichervorgang ist nicht so einfach wie das Speichern der Modelle von Scikit-learn, TensorFlow oder Keras. Weitere Informationen finden Sie in der ONNX-Dokumentation, wie Sie Light GBM und XGBoost speichern können.
Beginnen wir mit dem Speichern des Light-GBM-Modells. Der Vorgang ist für beide Modelle identisch.
Speichern des LightGBM-Modells | Python-Code:
from skl2onnx.common.data_types import FloatTensorType from skl2onnx import convert_sklearn, to_onnx, update_registered_converter from skl2onnx.common.shape_calculator import calculate_linear_classifier_output_shapes from onnxmltools.convert.xgboost.operator_converters.XGBoost import convert_xgboost from onnxmltools.convert import convert_xgboost as convert_xgboost_booster update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_lightgbm", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Speichern des XGBoost-Modells | Python-Code:
update_registered_converter( xgb.XGBClassifier, "XGBClassifier", calculate_linear_classifier_output_shapes, convert_xgboost, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_xgboost", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("xgboost.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
ONNX-Modell in MQL5 laden
Das Laden von Gradient Boosted Decision Trees (GBDT) kann im Gegensatz zum Laden anderer Modelle schwierig sein, obwohl der Prozess derselbe ist.
MQL5 | LightGBM.mqh
bool CLightGBM::OnnxLoad(long &handle) { //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",output_count," output(s)"); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"output",type_info); ArrayCopy(outputs, type_info.tensor.dimensions); } } //--- replace(inputs); replace(outputs); //--- Setting the input size for (long i=0; i<input_count; i++) if (!OnnxSetInputShape(handle, i, inputs)) //Giving the Onnx handle the input shape { printf("Failed to set the input shape Err=%d",GetLastError()); DebugBreak(); return false; } //--- Setting the output size for(long i=0; i<output_count; i++) { if(!OnnxSetOutputShape(handle,i,outputs)) { printf("Failed to set the Output[%d] shape Err=%d",i,GetLastError()); //DebugBreak(); //return false; } } initialized = true; Print("ONNX model Initialized"); return true; }
Registerkarte Ausgaben | Experten:
JM 0 10:49:34.197 LightGBM EA (EURUSD,H1) model has 1 input(s)
MG 0 10:49:34.197 LightGBM EA (EURUSD,H1) 0 input name is input
KM 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
CF 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
HP 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1, 8]
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 input shape must be defined explicitly before model inference
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape of input data can be reduced to [8] if undefined dimension set to 1
EM 0 10:49:34.198 LightGBM EA (EURUSD,H1) model has 2 output(s)
MJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output name is output_label
MR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
RK 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1]
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output shape must be defined explicitly before model inference
GJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 1 output name is output_probability
OR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_SEQUENCE
KN 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_SEQUENCE
OF 0 10:49:34.198 LightGBM EA (EURUSD,H1) no dimensions defined for 1 output
HM 0 10:49:34.198 LightGBM EA (EURUSD,H1) Failed to set the Output[1] shape Err=5802
IH 0 10:49:34.198 LightGBM EA (EURUSD,H1) ONNX model Initialized
Wenn Sie sich das Modell mit Netron genauer ansehen, werden Sie feststellen, dass es sich um ein Modell handelt:

Die erste Ausgabeschicht ist vom Tensortyp mit einem 1D-Ganzzahlfeld unbekannter Größe. Diese Ebene auf die Form 1 zu verkleinern, sollte gut funktionieren. In der zweiten Ausgabeschicht gibt es eine Sequenz mit einer Karte (ähnlich einem Wörterbuch in Python) mit zwei 1D dimensionalen Feldern unbekannter Größe, eines für Bezeichnungen und das andere für Wahrscheinlichkeiten. So macht es auch ZipMap, falls Sie sich das fragen.
Die Einstellung der Größe dieser zweiten Ausgabeschicht mit OnnxSetOutputShape für diesen komplexen Objekttyp ist schwierig und kann seltsame Fehler auslösen, die mir unerklärlich waren, aber die Größenänderung auf 1 funktioniert gut, zwar wird eine Warnung ausgegeben, aber es funktioniert immer noch gut. Wenn Sie das ONNX-Modell auf die richtige Weise ausführen. Lesen Sie mehr ...
float output_data[]; struct Map { ulong key[]; float value[]; } output_data_map[]; //--- ArrayResize(output_data, outputs.Size()); if (!OnnxRun(onnx_handle, ONNX_DATA_TYPE_FLOAT, x_float, output_data, output_data_map)) { printf("Failed to get predictions from Onnx err %d",GetLastError()); return proba; }
Sowohl in der Klasse Light GBM als auch in XGBoost gibt es die folgenden Methoden:
MQL5 | LightGBM.mqh
class CLightGBM { bool initialized; long onnx_handle; void PrintTypeInfo(const long num,const string layer,const OnnxTypeInfo& type_info); long inputs[], outputs[]; void replace(long &arr[]) { for (uint i=0; i<arr.Size(); i++) if (arr[i] < 0) arr[i] = UNDEFINED_REPLACE; } bool OnnxLoad(long &handle); public: CLightGBM(void); ~CLightGBM(void); virtual bool Init(const uchar &onnx_buff[], ulong flags=ONNX_DEFAULT); //Initilaized ONNX model from a resource uchar array with default flag virtual bool Init(string onnx_filename, uint flags=ONNX_DEFAULT); //Initializes the ONNX model from a .onnx filename given virtual long predict_bin(const vector &x); //REturns the predictions for the current given matrix | useful in real-time prediction virtual vector predict_proba(const vector &x); //Returns the predictions in probability terms | useful in real-time prediction virtual matrix predict_proba(const matrix &x); //Returns the predicted probability for the whole matrix | useful for testing virtual vector predict_bin(const matrix &x); //gives out the vector for all the predictions | useful for testing };
Verwendung von LightGBM und XGBoost im Handel
Nachdem das Modell in der Funktion OnInit initialisiert wurde.
MQL5 | LightGBM EA.mq5
int OnInit() { if (!lgbm.Init(lightgbm_onnx)) return INIT_FAILED; }
Die geladenen ONNX-Modelle können mit Daten verwendet werden, die auf die gleiche Weise gesammelt wurden wie die Trainingsdaten.
void OnTick() { int size = CopyRates(Symbol(), PERIOD_CURRENT, 1, 1, rates_x); //We copy only one recent-closed bar //--- if (NewBar()) { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); }
Lassen Sie uns eine einfache Handelsstrategie auf der Grundlage der erhaltenen Signale entwickeln.
if (NewBar()) //Trade at the opening of a new candle { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions m_trade.Buy(lotsize, Symbol(), ticks.ask, ticks.bid-stoploss*Point(), ticks.ask+takeprofit*Point()); //Open a buy trade } else //Bearish signal { if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions m_trade.Sell(lotsize, Symbol(), ticks.bid, ticks.ask+stoploss*Point(), ticks.bid-takeprofit*Point()); //open a sell trade } }
Ich habe einen Test mit dem Strategy-Tester auf einem 1-Stunden-Zeitrahmen für EURUSD vom 01.01.2023 bis 23.05.2024 durchgeführt.
LichtGBM:

XGBoost:

Beide Modelle haben Verluste gemacht. XGBoost machte -8$ weniger Verluste als LightGBM. Beide erzeugten eine Saldenkurve, die fast gleich ausieht.

Der Bericht des Strategietesters kann uns nicht sagen, ob die Modelle eine gute Arbeit leisten, für die sie trainiert wurden, nämlich die Vorhersage der nächsten Balkenbewegung. Wie wir wissen, müssen viele Dinge berücksichtigt werden, um einen Expert Advisor profitabel zu machen.
Um zu verstehen, wie die Modelle abschneiden, erstellen wir ein Skript, um Daten auf die gleiche Weise zu sammeln, wie wir die Trainingsdaten gesammelt haben, und erstellen eine Zielvariable.
void OnStart() { //--- if (!lgb.Init(lightgbm_onnx)) return; //--- custom out-of-sample testing int bars = 9000; int start = 1000; MqlRates rates_x[]; ArraySetAsSeries(rates_x, true); int size = CopyRates(Symbol(), PERIOD_CURRENT, start, bars, rates_x); //We start at the bar 1000 and collect 9000 candles backward MqlRates rates_y[]; ArraySetAsSeries(rates_y, true); CopyRates(Symbol(), PERIOD_CURRENT, start-1, bars, rates_y); //We do the same thing here but we only collect one bar forward making sure we get the prediction for the next candle //--- vector actual(size), predictions(size); for (int i=0; i<size; i++) { vector x = { rates_x[i].open, rates_x[i].high, rates_x[i].low, rates_x[i].close, rates_x[i].close-rates_x[i].open, rates_x[i].high-rates_x[i].low, rates_x[i].close-rates_x[i].low, rates_x[i].close-rates_x[i].high }; actual[i] = rates_y[i].close > rates_x[i].open ? 1 : 0; //making the target variable predictions[i] = (double)lgb.predict_bin(x); } Metrics::classification_report(actual, predictions); }
Registerkarte Ergebnisse | Experten:
EG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Confusion Matrix
PO 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [[2857,1503]
CI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [926,3714]]
FM 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NF 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Classification Report
HJ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
KP 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [CLS] precision recall specificity f1 score support
QQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [0.0] 0.76 0.66 0.80 0.70 4360
CQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [1.0] 0.71 0.80 0.66 0.75 4640
HS 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NK 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) accuracy 0.73 9000
RG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) average 0.73 0.73 0.73 0.73 9000
LI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Weighed avg 0.73 0.73 0.73 0.73 9000
Das Modell war bei Daten, die nicht in der Stichprobe enthalten waren, zu 73 % genau. Dies zeigt uns, dass unser Modell gut funktioniert, obwohl es nicht in der Lage ist, eine aufwärts gerichtete Kurve im Strategietester zu erzeugen. Dies sollte ein guter Ausgangspunkt für die Erstellung Ihrer eigenen profitablen Expert Advisors mit GBDTs in MQL5 sein.
Vorteile der Gradient-Boosted Entscheidungsbäumen
1. Hohe Vorhersagegenauigkeit
GBDTs übertreffen oft viele andere Algorithmen des maschinellen Lernens in Bezug auf die Vorhersagegenauigkeit. Dies liegt daran, dass sie die Stärken von Entscheidungsbäumen mit Gradient Boosting kombinieren, das die Modellleistung iterativ verbessert, indem es sich auf die Fehler der vorherigen Bäume konzentriert.
2. Robustheit gegenüber Überanpassung
Der Boosting-Prozess beinhaltet das Hinzufügen neuer Bäume, die die Fehler des bestehenden Ensembles korrigieren, wodurch die Überanpassung reduziert wird. Techniken wie die Anpassung der Lernrate, die Regularisierung und das frühe Stoppen können diese Robustheit weiter verbessern.
3. Keine aufwendige Vorverarbeitung erforderlich
GBDTs erfordern keine umfangreichen Vorverarbeitungsschritte wie die Skalierung von Merkmalen, die Behandlung fehlender Werte oder die Kodierung kategorialer Variablen, die bei anderen Algorithmen wie der linearen Regression oder Support Vector Machines in der Regel erforderlich sind.
4. Flexibilität und Anpassungsfähigkeit
GBDTs bieten eine breite Palette von Hyperparametern, die zur Optimierung der Leistung für bestimmte Aufgaben eingestellt werden können. Dazu gehören u. a. die Anzahl der Bäume, die Lernrate, die maximale Tiefe der Bäume und die Mindestanzahl von Stichproben, die zur Aufteilung eines Knotens erforderlich sind.
5. Handhabung komplexer Beziehungen
GBDTs können komplexe nichtlineare Beziehungen zwischen Merkmalen und der Zielvariablen modellieren. Dadurch sind sie geeignet, komplizierte Muster in den Daten zu erfassen, die einfacheren Modellen entgehen könnten.
6. Regularisierungstechniken
GBDTs enthalten Regularisierungsparameter, die helfen, die Komplexität des Modells zu kontrollieren und eine Überanpassung zu verhindern. Parameter wie max_depth, min_samples_split und min_samples_leaf spielen eine entscheidende Rolle bei der Regularisierung.
7. Skalierbarkeit
Implementierungen wie XGBoost, LightGBM und CatBoost sind für Geschwindigkeit und Skalierbarkeit optimiert. Sie können große Datenmengen effizient verarbeiten und Hardwarekapazitäten wie paralleles und verteiltes Rechnen nutzen.Wie jedes Modell des maschinellen Lernens haben auch diese Modelle Nachteile, die anerkannt werden müssen, nicht um von ihrer Verwendung abzuschrecken, sondern um das eigene Verständnis zu festigen.
Nachteile von Gradient Boosted Decision Trees
1. Berechnungskomplexität: Das Training von GBDTs kann sehr rechenintensiv sein, insbesondere bei einer großen Anzahl von Bäumen und tiefen Bäumen. Bei großen Datensätzen kann der Trainingsprozess einen beträchtlichen Speicherplatz in großen und tiefen Datensätzen verbrauchen
2. Abstimmung der Hyperparameter. Obwohl die beiden besprochenen Modelle mit Standardparametern arbeiten können, haben sie dennoch viele Hyperparameter, die sorgfältig abgestimmt werden müssen, um eine optimale Leistung zu erzielen. Parameter wie die Anzahl der Bäume, die Lernrate, die maximale Tiefe und die Mindestproben pro Blatt.
Wie wir alle wissen, kann die Abstimmung dieser Parameter zeitaufwändig und rechenintensiv sein.
3. Immer noch empfindlich gegenüber verrauschten Daten. Da jeder Baum versucht, die Fehler der vorherigen Bäume zu korrigieren, kann jegliches Rauschen in den Daten durch den Boosting-Prozess verstärkt werden.
4. Erfordert oft große Datensätze. GBDTs benötigen oft eine große Menge an Daten, um eine gute Leistung zu erzielen. Kleine Datensätze liefern möglicherweise nicht genügend Informationen, damit das Boosting-Verfahren effektiv arbeiten kann.
Die Quintessenz
Gradient Boosted Trees sind wertvolle Werkzeuge für Devisenhändler, denn wir haben gesehen, dass sie viele maschinelle Lernmodelle auf Anhieb übertreffen. Früher glaubte man, dass komplexe, auf neuronalen Netzen basierende Modelle wie GRU, RNN und LSTM die besten Modelle sind, um den Markt zu schlagen, aber das ist nicht mehr der Fall, da Gradient Boosted Trees in der Gemeinschaft des maschinellen Lernens aufgrund ihrer Einfachheit und ihrer Fähigkeit, die jeweilige Vorhersageaufgabe zu bewältigen, immer beliebter werden.
Mit freundlichen Grüßen.
Verfolgen Sie die Entwicklung von Modellen für maschinelles Lernen und vieles mehr in dieser Artikelserie auf diesem GitHub repo.
Der in diesem Beitrag behandelte Python-Code ist hier zu finden.
Tabellen der Anhänge:
Expert Advisors | Experten-Verzeichnis
| Dateiname | Beschreibung und Verwendung |
|---|---|
| LightGBM EA.mq5 | Ein Experten Advisor zum Testen von Light Gradient Boosted Machine (LightGBM) |
| XGBoost EA.mq5 | Ein Experten Advisor zum Testen von Extreme Gradient Boosting (XGBoost) |
Bibliotheken | Ordner Include:
| Dateiname | Beschreibung und Verwendung |
|---|---|
| LightGBM.mqh | Eine Bibliothek zum Laden, Initialisieren und Einsetzen von Light Gradient Boosted Machine (LightGBM) ONNX-Modellen |
| XGBoost.mqh | Eine Bibliothek zum Laden, Initialisieren und Einsetzen von Extreme Gradient Boosting (XGBoost) ONNX-Modelle |
Skripte | Verzeichnis der Skripte:
| Dateiname | Beschreibung und Verwendung |
|---|---|
| LightGBM Performance TestScript.mq5 | Ein Skript zum Testen des LightGBM-Modells in Echtzeit |
Dateien | Verzeichnis der Dateien:
| Dateiname | Beschreibung und Verwendung |
|---|---|
| EURUSD.PERIOD_H1.csv | Eine csv-Datei mit dem Trainingsdatensatz |
| lightgbm.eurusd.h1.onnx xgboost.eurusd.h1.onnx | LightGBM- und XGBoost-Modelle im ONNX-Format |
Python-Code:
| Dateiname | Beschreibung und Verwendung |
|---|---|
| lightgbm-xgboost.ipynb | Jupyter-Notebook mit dem gesamten Python-Code, der in diesem Beitrag besprochen wurde. |
Quellen und Referenzen:
- Can one do better than XGBoost? - Mateusz Susik (https://www.youtube.com/watch?v=5CWwwtEM2TA).
- Unlocking the Power of Gradient-Boosted Trees (using LightGBM) | PyData London 2022 (https://www.youtube.com/watch?v=qGsHlvE8KZM).
- LightGBM Dokumentation: (https://lightgbm.readthedocs.io/en/latest/Parameters.html).
- XGBoost Dokumentation (https://xgboost.readthedocs.io/en/stable/tutorials/model.html).
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/14926
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.