
Aprendizaje automático y Data Science (Parte 28): Predicción de múltiples futuros para el EURUSD mediante IA

Contenido
- Introducción
- Previsión directa de varios pasos
- Fortaleza de la previsión directa de múltiples pasos
- Debilidades de la previsión directa de múltiples pasos
- Pronóstico recursivo de varios pasos
- Ventajas de la previsión recursiva de múltiples pasos
- Debilidades de la previsión recursiva de múltiples pasos
- Pronóstico de múltiples pasos utilizando modelos de múltiples resultados
- Ventajas de la previsión en varios pasos utilizando modelos de múltiples resultados
- Desventajas de la previsión de múltiples pasos utilizando modelos de múltiples resultados
- Cuándo y dónde utilizar la previsión de múltiples pasos
- Conclusión
Introducción
En el mundo del análisis de datos financieros mediante aprendizaje automático, el objetivo a menudo es predecir valores futuros basándose en datos históricos. Si bien predecir el próximo valor inmediato es muy útil como hemos comentado en muchos artículos de esta serie. Hay muchas situaciones en aplicaciones del mundo real en las que podríamos necesitar predecir múltiples valores futuros en lugar de uno. El intento de predecir varios valores consecutivos se conoce como pronóstico multipaso o multihorizonte.
La previsión de varios pasos es crucial en diversos ámbitos, como las finanzas, la predicción meteorológica, la gestión de la cadena de suministro y la atención sanitaria. Por ejemplo, en los mercados financieros, los inversores necesitan prever los precios de las acciones o los tipos de cambio con varios días, semanas o incluso meses de antelación. En la predicción del tiempo, los pronósticos precisos para los próximos días o semanas pueden ayudar en la planificación y la gestión de desastres.

Este artículo asume que usted tiene un conocimiento básico de aprendizaje automático e IA, ONNX, cómo utilizar modelos ONNX en MQL5, regresión lineal, LightGBM, y redes neuronales.
El proceso de pronóstico de múltiples pasos involucra varias metodologías, cada una con sus fortalezas y debilidades. Estos métodos incluyen:
- Previsión directa de varios pasos
- Pronóstico recursivo de múltiples pasos
- Modelos de múltiples salidas
- Autorregresión vectorial (Vector Auto-regression, VAR) (se tratará en los próximos artículos)
En este artículo, exploraremos estas metodologías, sus aplicaciones y cómo se pueden implementar utilizando diversas técnicas estadísticas y de aprendizaje automático. Al comprender y aplicar pronósticos de múltiples pasos, podemos tomar decisiones más informadas sobre el futuro del EURUSD.
# Create target variables for multiple future steps def create_target(df, future_steps=10): target = pd.concat([df['Close'].shift(-i) for i in range(1, future_steps + 1)], axis=1) # using close prices for the next i bar target.columns = [f'target_close_{i}' for i in range(1, future_steps + 1)] # naming the columns return target # Combine features and targets new_df = pd.DataFrame({ 'Open': df['Open'], 'High': df['High'], 'Low': df['Low'], 'Close': df['Close'] }) future_steps = 5 target_columns = create_target(new_df, future_steps).dropna() combined_df = pd.concat([new_df, target_columns], axis=1) #concatenating the new pandas dataframe with the target columns combined_df = combined_df.dropna() #droping rows with NaN values caused by shifting values target_cols_names = [f'target_close_{i}' for i in range(1, future_steps + 1)] X = combined_df.drop(columns=target_cols_names).values #dropping all target columns from the x array y = combined_df[target_cols_names].values # creating the target variables print(f"x={X.shape} y={y.shape}") combined_df.head(10)
Pronóstico directo de varios pasos
La previsión directa de múltiples pasos es un método en el que se entrenan modelos predictivos separados para cada paso de tiempo futuro que desea predecir. Por ejemplo, si queremos predecir los valores para los próximos 5 pasos de tiempo, entrenaríamos 5 modelos diferentes. Uno para predecir el primer paso, otro para predecir el segundo paso, y así sucesivamente.
En la previsión directa de varios pasos, cada modelo está diseñado para predecir un horizonte específico. Este enfoque permite que cada modelo se centre en los patrones y relaciones específicos que son relevantes para su paso de tiempo futuro correspondiente, mejorando potencialmente la precisión de cada predicción. Sin embargo, también significa que es necesario entrenar y mantener múltiples modelos, lo que puede consumir muchos recursos.
Intentemos realizar previsiones en varios pasos utilizando el modelo de aprendizaje automático LightGBM.
En primer lugar, creamos una función para manejar datos de múltiples pasos.
Preparando los datos
Código Python
def multi_steps_data_process(data, step, train_size=0.7, random_state=42): # Since we are using the OHLC values only data["next signal"] = data["Signal"].shift(-step) # The target variable from next n future values data = data.dropna() y = data["next signal"] X = data.drop(columns=["Signal", "next signal"]) return train_test_split(X, y, train_size=train_size, random_state=random_state)
Esta función crea la nueva variable de destino utilizando la columna "Signal" del conjunto de datos. La variable objetivo se toma del valor del índice paso+1 de la columna señal.
Supongamos que tienes.
| Señales |
|---|
1 |
2 |
3 |
4 |
5 |
En el paso 1, la siguiente señal será 2, en el paso 2, la siguiente señal será 3, y así sucesivamente.
En este artículo, vamos a utilizar datos tomados del marco temporal horario del EURUSD para 1000 barras.
Código Python
df = pd.read_csv("/kaggle/input/eurusd-period-h1/EURUSD.PERIOD_H1.csv") print(df.shape) df.head(10)
Salidas:
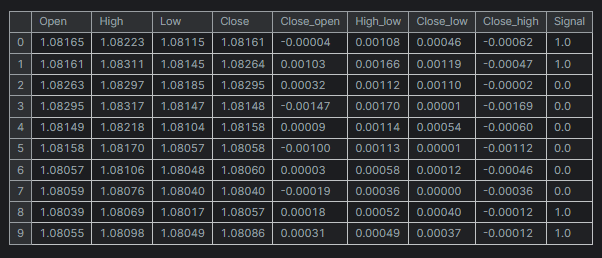
Para simplificar, creé un mini conjunto de datos para solo cinco (5) variables.

La columna "Signal" representa señales de velas alcistas o bajistas, fue creada por la lógica, de que siempre que el precio de cierre fuera mayor que el precio de apertura a la señal se le asignaba un valor de 1 y un valor de 0 para lo opuesto.
Ahora que tenemos una función para crear datos de varios pasos, declaremos nuestros modelos para manejar cada paso.
Entrenamiento de múltiples modelos para realizar pronósticos
Codificar manualmente los modelos para cada paso de tiempo puede llevar mucho tiempo y resultar ineficaz. Codificar dentro de un bucle será más fácil y más efectivo. Dentro del bucle, hacemos todas las cosas necesarias, como entrenar, validar y guardar el modelo para uso externo en MetaTrader 5.
Código Python
for pred_step in range(1, 6): # We want to 5 future values lgbm_model = lgbm.LGBMClassifier(**params) X_train, X_test, y_train, y_test = multi_steps_data_process(new_df, pred_step) # preparing data for the current step lgbm_model.fit(X_train, y_train) # training the model for this step # Testing the trained mdoel test_pred = lgbm_model.predict(X_test) # Changes from bst to pipe # Ensuring the lengths are consistent if len(y_test) != len(test_pred): test_pred = test_pred[:len(y_test)] print(f"model for next_signal[{pred_step} accuracy={accuracy_score(y_test, test_pred)}") # Saving the model in ONNX format, Registering ONNX converter update_registered_converter( lgbm.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) # Final LightGBM conversion to ONNX model_onnx = convert_sklearn( lgbm_model, "lightgbm_model", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open(f"lightgbm.EURUSD.h1.pred_close.step.{pred_step}.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Salidas:
model for next_signal[1 accuracy=0.5033333333333333 model for next_signal[2 accuracy=0.5566666666666666 model for next_signal[3 accuracy=0.4866666666666667 model for next_signal[4 accuracy=0.4816053511705686 model for next_signal[5 accuracy=0.5317725752508361
Sorprendentemente, el modelo para predecir la siguiente segunda barra fue el modelo más preciso, con una precisión del 55%, seguido por el modelo para predecir la siguiente quinta barra, que proporcionó una precisión del 53%.
Carga de modelos para realizar previsiones en MetaTrader 5
Comenzamos integrando todos los modelos de IA de LightGBM guardados en formato ONNX dentro de nuestro Asesor Experto como archivos de recursos.
Código MQL5
#resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.1.onnx" as uchar model_step_1[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.2.onnx" as uchar model_step_2[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.3.onnx" as uchar model_step_3[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.4.onnx" as uchar model_step_4[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.5.onnx" as uchar model_step_5[] #include <MALE5\Gradient Boosted Decision Trees(GBDTs)\LightGBM\LightGBM.mqh> CLightGBM *light_gbm[5]; //for storing 5 different models MqlRates rates[];
Luego inicializamos nuestros 5 modelos diferentes.
Código MQL5
int OnInit() { //--- for (int i=0; i<5; i++) light_gbm[i] = new CLightGBM(); //Creating LightGBM objects //--- if (!light_gbm[0].Init(model_step_1)) { Print("Failed to initialize model for step=1 predictions"); return INIT_FAILED; } if (!light_gbm[1].Init(model_step_2)) { Print("Failed to initialize model for step=2 predictions"); return INIT_FAILED; } if (!light_gbm[2].Init(model_step_3)) { Print("Failed to initialize model for step=3 predictions"); return INIT_FAILED; } if (!light_gbm[3].Init(model_step_4)) { Print("Failed to initialize model for step=4 predictions"); return INIT_FAILED; } if (!light_gbm[4].Init(model_step_5)) { Print("Failed to initialize model for step=5 predictions"); return INIT_FAILED; } return(INIT_SUCCEEDED); }
Finalmente, podemos recopilar valores de apertura, máximo, mínimo y cierre de la barra anterior y usarlos para obtener predicciones de los cinco modelos diferentes.
Código MQL5
void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close}; string comment_string = ""; int signal = -1; for (int i=0; i<5; i++) { signal = (int)light_gbm[i].predict_bin(input_x); comment_string += StringFormat("\n Next[%d] bar predicted signal=%s",i+1, signal==1?"Buy":"Sell"); } Comment(comment_string); }
Resultado:

Ventajas de la previsión directa de múltiples pasos
- Cada modelo está especializado para un horizonte de pronóstico particular, lo que potencialmente conduce a predicciones más precisas para cada paso.
- Entrenar modelos separados puede ser sencillo, especialmente si está utilizando algoritmos simples de aprendizaje automático.
- Puede elegir diferentes modelos o algoritmos para cada paso, lo que permite una mayor flexibilidad para manejar diferentes desafíos de pronóstico.
Debilidades de la previsión directa de múltiples pasos
- Requiere entrenamiento y mantenimiento de múltiples modelos, lo que puede ser computacionalmente costoso y consumir mucho tiempo.
- A diferencia de los métodos recursivos, los errores de un paso no se propagan directamente al siguiente, lo que puede ser tanto una fortaleza como una debilidad. Puede generar inconsistencias entre los pasos.
- Cada modelo es independiente y puede que no capture las dependencias entre los horizontes de pronóstico tan eficazmente como un enfoque unificado.
Pronóstico recursivo de varios pasos
La previsión recursiva de múltiples pasos, también conocida como previsión iterativa, es un método en el que se utiliza un solo modelo para realizar una predicción un paso por delante. Luego, esta predicción se retroalimenta al modelo para realizar la siguiente predicción. Este proceso se repite hasta que se realicen predicciones para el número deseado de pasos de tiempo futuros.
En la previsión recursiva de varios pasos, el modelo se entrena para predecir el siguiente valor inmediato. Una vez que se predice este valor, se agrega a los datos de entrada y se utiliza para predecir el siguiente valor. Este método aprovecha el mismo modelo de forma iterativa.
Para lograr esto, vamos a utilizar el modelo de regresión lineal para predecir el próximo precio de cierre utilizando el cierre anterior. De esta manera, el precio de cierre previsto se puede utilizar como entrada para la siguiente iteración y así sucesivamente. Este enfoque parece funcionar bien y fácilmente con una única variable (característica) independiente.
Código Python
new_df = pd.DataFrame({
'Close': df['Close'],
'target close': df['Close'].shift(-1) # next bar closing price
})
Entonces:
new_df = new_df.dropna() # after shifting we want to drop all NaN values X = new_df[["Close"]].values # Assigning close values into a 2D x array y = new_df["target close"].values print(new_df.shape) new_df.head(10)
Salidas:
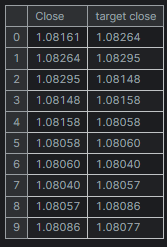
Entrenamiento y prueba de un modelo de regresión lineal
Antes de entrenar el modelo, dividimos los datos sin aleatorizar. Esto podría ayudar al modelo a capturar dependencias temporales entre los valores, ya que sabemos que el próximo cierre se ve afectado por el precio de cierre anterior.
model = Pipeline([ ("scaler", StandardScaler()), ("linear_regression", LinearRegression()) ]) # Split the data into training and test sets train_size = int(len(new_df) * 0.7) X_train, X_test = X[:train_size], X[train_size:] y_train, y_test = y[:train_size], y[train_size:] # Train the model model.fit(X_train, y_train)
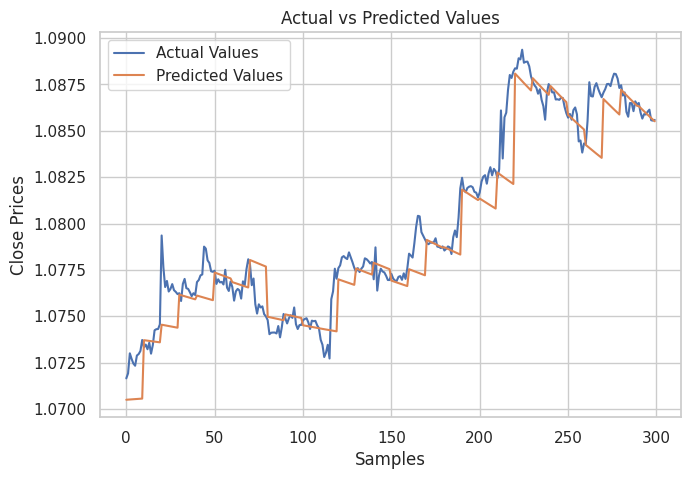
Luego creé un gráfico para mostrar los valores reales de la muestra de prueba y sus valores previstos, para analizar la eficacia del modelo al realizar predicciones.
# Testing the Model
test_pred = model.predict(X_test) # Make predictions on the test set
# Plot the actual vs predicted values
plt.figure(figsize=(7.5, 5))
plt.plot(y_test, label='Actual Values')
plt.plot(test_pred, label='Predicted Values')
plt.xlabel('Samples')
plt.ylabel('Close Prices')
plt.title('Actual vs Predicted Values')
plt.legend()
plt.show()
Resultado:

Como se puede ver en la imagen de arriba. El modelo hizo predicciones decentes, de hecho fue 98% preciso en la muestra de prueba, sin embargo, las predicciones del gráfico muestran cómo se desempeñó el modelo lineal en el conjunto de datos históricos, haciendo predicciones de manera normal, no en un formato recursivo. Para que el modelo realice predicciones recursivas, necesitamos crear una función personalizada para el trabajo.
Código Python
# Function for recursive forecasting def recursive_forecast(model, initial_value, steps): predictions = [] current_input = np.array([[initial_value]]) for _ in range(steps): prediction = model.predict(current_input)[0] predictions.append(prediction) # Update the input for the next prediction current_input = np.array([[prediction]]) return predictions
Podemos entonces obtener predicciones futuras para 10 barras.
current_close = X[-1][0] # Use the last value in the array # Number of future steps to forecast steps = 10 # Forecast future values forecasted_values = recursive_forecast(model, current_close, steps) print("Forecasted Values:") print(forecasted_values)
Salidas:
Forecasted Values: [1.0854623040804965, 1.0853751608200348, 1.0852885667357617, 1.0852025183667728, 1.0851170122739744, 1.085032045039946, 1.0849476132688034, 1.0848637135860637, 1.0847803426385094, 1.0846974970940555]
Para probar la precisión de un modelo recursivo, podemos utilizar la función recursive_forecast anterior, para realizar predicciones para los 10 próximos pasos temporales a lo largo de la historia a partir del índice actual tras 10 pasos temporales en un bucle.
predicted = [] for i in range(0, X_test.shape[0], steps): current_close = X_test[i][0] # Use the last value in the test array forecasted_values = recursive_forecast(model, current_close, steps) predicted.extend(forecasted_values) print(len(predicted))
Salidas:
La precisión del modelo recursivo fue del 91%.
Finalmente, podemos guardar el modelo de regresión lineal en formato ONNX que es compatible con MQL5.
# Convert the trained pipeline to ONNX
initial_type = [('float_input', FloatTensorType([None, 1]))]
onnx_model = convert_sklearn(model, initial_types=initial_type)
# Save the ONNX model to a file
with open("Lr.EURUSD.h1.pred_close.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
print("Model saved to Lr.EURUSD.h1.pred_close.onnx") Realizar predicciones recursivas en MQL5.
Comenzamos agregando el modelo de regresión lineal ONNX en nuestro Asesor Experto.
#resource "\\Files\\Lr.EURUSD.h1.pred_close.onnx" as uchar lr_model[]
Luego importamos la clase controladora del modelo de regresión lineal.
#include <MALE5\Linear Models\Linear Regression.mqh>
CLinearRegression lr; Después de inicializar el modelo dentro de la función OnInit, podemos obtener el precio de cierre de la barra cerrada anterior y luego hacer predicciones para las siguientes 10 barras.
int OnInit() { //--- if (!lr.Init(lr_model)) return INIT_FAILED; //--- ArraySetAsSeries(rates, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].close}; //get the previous closed bar close price vector predicted_close(10); //predicted values for the next 10 timestepps for (int i=0; i<10; i++) { predicted_close[i] = lr.predict(input_x); input_x[0] = predicted_close[i]; //The current predicted value is the next input } Print(predicted_close); }
Salidas:
OR 0 16:39:37.018 Recursive-Multi step forecasting (EURUSD,H4) [1.084011435508728,1.083933353424072,1.083855748176575,1.083778619766235,1.083701968193054,1.083625793457031,1.083550095558167,1.08347487449646,1.083400130271912,1.083325862884521]
Para hacer las cosas más interesantes, decidí crear objetos de línea de tendencia para mostrar estos valores predichos para 10 pasos de tiempo en el gráfico principal.
if (NewBar()) { for (int i=0; i<10; i++) { predicted_close[i] = lr.predict(input_x); input_x[0] = predicted_close[i]; //The current predicted value is the next input //--- ObjectDelete(0, "step"+string(i+1)+"-prediction"); //delete an object if it exists TrendCreate("step"+string(i+1)+"-prediction",rates[0].time, predicted_close[i], rates[0].time+(10*60*60), predicted_close[i], clrBlack); //draw a line starting from the previous candle to 10 hours forward } }
La función TrendCreate crea una línea de tendencia horizontal corta que comienza desde la barra cerrada anterior hasta 10 barras hacia adelante.
Resultado:
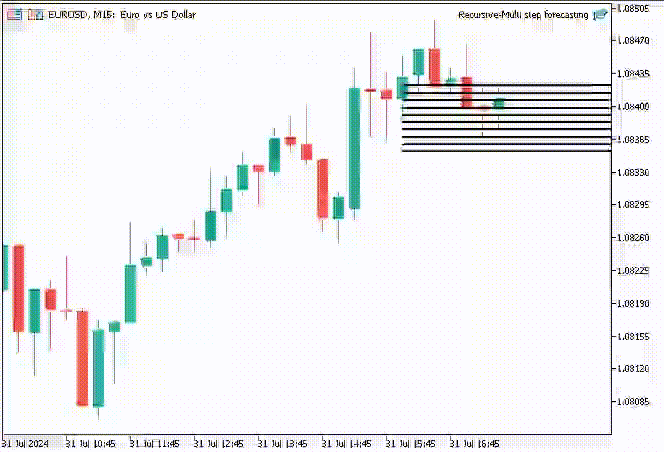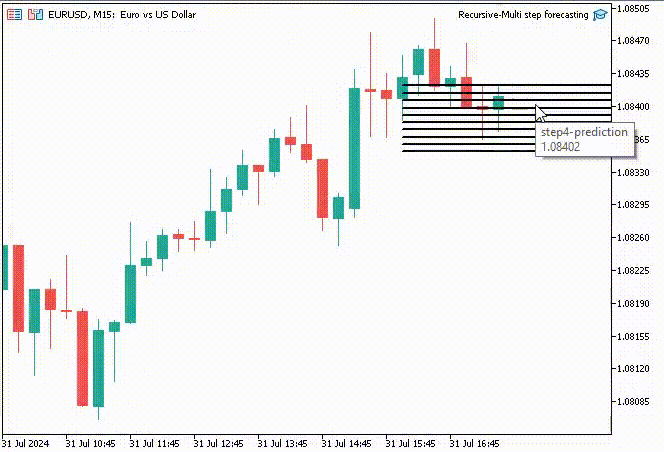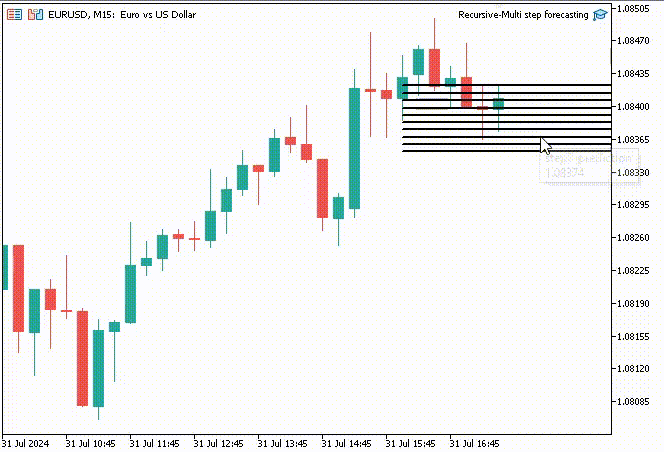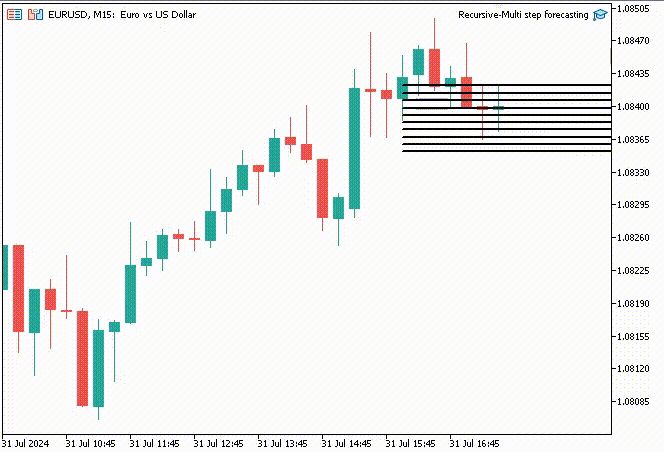
Ventajas de la previsión recursiva de múltiples pasos
- Dado que solo se entrena y mantiene un modelo, esto simplifica la implementación y reduce los recursos computacionales.
- Dado que el mismo modelo se utiliza iterativamente, mantiene la consistencia a lo largo del horizonte de predicción.
Debilidades de la predicción recursiva de múltiples pasos
- Los errores en las predicciones tempranas pueden propagarse y magnificarse en predicciones posteriores, reduciendo potencialmente la precisión general.
- Este enfoque supone que las relaciones capturadas por el modelo permanecen estables durante el horizonte de pronóstico, lo que puede no ser siempre el caso.
Pronóstico de varios pasos mediante modelos de múltiples salidas
Los modelos de múltiples salidas están diseñados para predecir múltiples valores a la vez; podemos usar esto a nuestro favor haciendo que los modelos predigan pasos de tiempo futuros simultáneamente. En lugar de entrenar modelos separados para cada horizonte de pronóstico o usar un solo modelo de forma recursiva, un modelo de múltiples salidas tiene múltiples salidas, cada una correspondiente a un paso de tiempo futuro.
En un modelo de múltiples salidas, el modelo se entrena para producir un vector de predicciones en una sola pasada. Esto significa que el modelo aprende a comprender directamente las relaciones y dependencias entre diferentes pasos de tiempo futuros. Este enfoque se puede implementar bien utilizando redes neuronales, ya que son capaces de producir múltiples resultados.
Preparación de un conjunto de datos para un modelo de red neuronal de múltiples salidas
Tenemos que preparar las variables de destino para todos los pasos de tiempo que queremos que nuestro modelo de red neuronal entrenado pueda predecir.
Código Python
# Create target variables for multiple future steps def create_target(df, future_steps=10): target = pd.concat([df['Close'].shift(-i) for i in range(1, future_steps + 1)], axis=1) # using close prices for the next i bar target.columns = [f'target_close_{i}' for i in range(1, future_steps + 1)] # naming the columns return target # Combine features and targets new_df = pd.DataFrame({ 'Open': df['Open'], 'High': df['High'], 'Low': df['Low'], 'Close': df['Close'] }) future_steps = 5 target_columns = create_target(new_df, future_steps).dropna() combined_df = pd.concat([new_df, target_columns], axis=1) #concatenating the new pandas dataframe with the target columns combined_df = combined_df.dropna() #droping rows with NaN values caused by shifting values target_cols_names = [f'target_close_{i}' for i in range(1, future_steps + 1)] X = combined_df.drop(columns=target_cols_names).values #dropping all target columns from the x array y = combined_df[target_cols_names].values # creating the target variables print(f"x={X.shape} y={y.shape}") combined_df.head(10)
Salidas:
x=(995, 4) y=(995, 5)
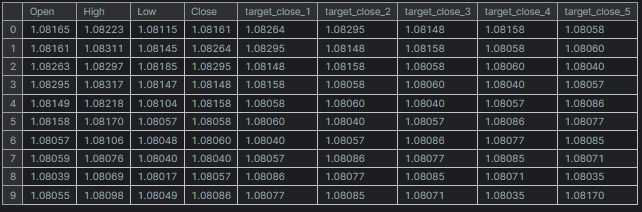
Entrenamiento y prueba de redes neuronales de múltiples salidas
Comenzamos definiendo un modelo de red neuronal secuencial.
Código Python
# Defining the neural network model model = Sequential([ Input(shape=(X.shape[1],)), Dense(units = 256, activation='relu'), Dense(units = 128, activation='relu'), Dense(units = future_steps) ]) # Compiling the model adam = Adam(learning_rate=0.01) model.compile(optimizer=adam, loss='mse') # Mmodel summary model.summary()
Salidas:
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense (Dense) │ (None, 256) │ 1,280 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 128) │ 32,896 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_2 (Dense) │ (None, 5) │ 645 │ └─────────────────────────────────┴────────────────────────┴───────────────┘ Total params: 34,821 (136.02 KB) Trainable params: 34,821 (136.02 KB) Non-trainable params: 0 (0.00 B)
Luego dividimos los datos en muestras de entrenamiento y prueba respectivamente, a diferencia de lo que hicimos en el pronóstico recursivo de múltiples pasos. Esta vez dividimos los datos después de aleatorizarlos con una semilla aleatoria de 42 ya que no queremos que el modelo comprenda patrones secuenciales pues creemos que la red neuronal rendirá aún mejor al comprender relaciones no lineales a partir de estos datos.
Finalmente, entrenamos el modelo NN utilizando los datos de entrenamiento.
# Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) scaler = MinMaxScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) # Training the model early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True) # stop training when 5 epochs doesn't improve history = model.fit(X_train, y_train, epochs=20, validation_split=0.2, batch_size=32, callbacks=[early_stopping])
Después de probar el modelo en un conjunto de datos de prueba.
# Testing the Model test_pred = model.predict(X_test) # Make predictions on the test set # Plotting the actual vs predicted values for each future step plt.figure(figsize=(7.5, 10)) for i in range(future_steps): plt.subplot((future_steps + 1) // 2, 2, i + 1) # subplots grid plt.plot(y_test[:, i], label='Actual Values') plt.plot(test_pred[:, i], label='Predicted Values') plt.xlabel('Samples') plt.ylabel(f'Close Price +{i+1}') plt.title(f'Actual vs Predicted Values (Step {i+1})') plt.legend() plt.tight_layout() plt.show() # Evaluating the model for each future step for i in range(future_steps): accuracy = r2_score(y_test[:, i], test_pred[:, i]) print(f"Step {i+1} - R^2 Score: {accuracy}")
A continuación el resultado.

Step 1 - R^2 Score: 0.8664635514027637 Step 2 - R^2 Score: 0.9375671150885528 Step 3 - R^2 Score: 0.9040736780305894 Step 4 - R^2 Score: 0.8491904738263638 Step 5 - R^2 Score: 0.8458062142647863
La red neuronal produjo resultados impresionantes para este problema de regresión. El código siguiente muestra cómo obtener las predicciones en Python.
# Predicting multiple future values current_input = X_test[0].reshape(1, -1) # use the first row of the test set, reshape the data also predicted_values = model.predict(current_input)[0] # adding[0] ensures we get a 1D array instead of 2D print("Predicted Future Values:") print(predicted_values)
Salidas:
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step Predicted Future Values: [1.0892788 1.0895394 1.0892794 1.0883198 1.0884078]
Luego podemos guardar este modelo de red neuronal en formato ONNX y los archivos del escalador en archivos con formato binario.
import tf2onnx
# Convert the Keras model to ONNX
spec = (tf.TensorSpec((None, X_train.shape[1]), tf.float16, name="input"),)
model.output_names=['output']
onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=13)
# Save the ONNX model to a file
with open("NN.EURUSD.h1.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
# Save the used scaler parameters to binary files
scaler.data_min_.tofile("NN.EURUSD.h1.min_max.min.bin")
scaler.data_max_.tofile("NN.EURUSD.h1.min_max.max.bin") Finalmente, podemos utilizar el modelo guardado y sus parámetros de escalador de datos en MQL5.
Obtención de predicciones de múltiples pasos de redes neuronales en MQL5
Comenzamos agregando el modelo y los parámetros del escalador Min-max a nuestro Asesor Experto (EA).
#resource "\\Files\\NN.EURUSD.h1.onnx" as uchar onnx_model[]; //rnn model in onnx format #resource "\\Files\\NN.EURUSD.h1.min_max.max.bin" as double min_max_max[]; #resource "\\Files\\NN.EURUSD.h1.min_max.min.bin" as double min_max_min[];
Luego importamos la clase de red neuronal de regresión ONNX y el controlador de la biblioteca del escalador Min-Max.
#include <MALE5\Neural Networks\Regressor Neural Nets.mqh> #include <MALE5\preprocessing.mqh> CNeuralNets nn; MinMaxScaler *scaler;
Luego podemos inicializar el modelo NN y el escalador, y luego obtener las predicciones finales del modelo.
MqlRates rates[]; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!nn.Init(onnx_model)) return INIT_FAILED; scaler = new MinMaxScaler(min_max_min, min_max_max); //Initializing the scaler, populating it with trained values //--- ArraySetAsSeries(rates, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(scaler)!=POINTER_INVALID) delete (scaler); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close}; input_x = scaler.transform(input_x); // We normalize the input data vector preds = nn.predict(input_x); Print("predictions = ",preds); }
Salidas:
2024.07.31 19:13:20.785 Multi-step forecasting using Multi-outputs model (EURUSD,H4) predictions = [1.080284595489502,1.082370758056641,1.083482265472412,1.081504583358765,1.079929828643799]
Para hacer las cosas más interesantes, agregué líneas de tendencia en el gráfico para marcar todas las predicciones futuras de la red neuronal.
void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close}; if (NewBar()) { input_x = scaler.transform(input_x); // We normalize the input data vector preds = nn.predict(input_x); for (int i=0; i<(int)preds.Size(); i++) { //--- ObjectDelete(0, "step"+string(i+1)+"-prediction"); //delete an object if it exists TrendCreate("step"+string(i+1)+"-prediction",rates[0].time, preds[i], rates[0].time+(5*60*60), preds[i], clrBlack); //draw a line starting from the previous candle to 5 hours forward } } }
Esta vez obtuvimos líneas de predicción de mejor aspecto que las que obtuvimos utilizando el modelo de regresión lineal recursiva.

Descripción general de la previsión en varios pasos mediante modelos de múltiples resultados
Ventajas- Al predecir múltiples pasos a la vez, el modelo puede capturar las relaciones y dependencias entre pasos de tiempo futuros.
- Sólo se necesita un modelo, esto simplifica la implementación y el mantenimiento.
- El modelo aprende a producir predicciones consistentes a lo largo de todo el horizonte de pronóstico.
Desventajas
- Entrenar un modelo para generar múltiples valores futuros puede ser más complejo y puede requerir arquitecturas más sofisticadas, especialmente para redes neuronales.
- Dependiendo de la complejidad del modelo, puede requerir más recursos computacionales para el entrenamiento y la inferencia.
- Existe el riesgo de sobreajuste, especialmente si el horizonte de pronóstico es largo y el modelo se vuelve demasiado especializado para los datos de entrenamiento.
Utilización de pronósticos de múltiples pasos en estrategias comerciales
La previsión de varios pasos, especialmente mediante modelos como redes neuronales y LightGBM, puede mejorar significativamente diversas estrategias comerciales al permitir ajustes dinámicos basados en movimientos previstos del mercado. En el comercio en red, en lugar de establecer órdenes fijas, los pronósticos de múltiples pasos permiten entradas dinámicas que se ajustan a los cambios de precios anticipados, mejorando la capacidad de respuesta del sistema a las condiciones del mercado.
Las estrategias de cobertura también se benefician ya que los pronósticos brindan orientación sobre cuándo abrir o cerrar posiciones para protegerse contra posibles pérdidas, como tomar posiciones cortas o comprar opciones de venta si se predice una tendencia a la baja. Además, en la detección de tendencias, comprender las direcciones futuras del mercado a través de pronósticos ayuda a los operadores a alinear sus estrategias en consecuencia, ya sea favoreciendo posiciones cortas o saliendo de posiciones largas para evitar pérdidas.
Por último, en el trading de alta frecuencia (High-Frequency Trading, HFT), los pronósticos rápidos de varios pasos pueden guiar a los algoritmos para capitalizar los movimientos de precios a corto plazo, mejorando así la rentabilidad al ejecutar órdenes de compra y venta oportunas en función de los cambios de precios previstos en los próximos segundos o minutos.
El resultado final
En el análisis financiero y el comercio de divisas, tener la capacidad de predecir múltiples valores en el futuro es muy útil, como se analiza en la sección anterior de este artículo. Esta publicación tiene como objetivo brindarle diferentes enfoques sobre cómo afrontar este desafío. En los próximos artículos exploraremos la autorregresión vectorial, que es una técnica creada para la tarea de analizar múltiples valores y también puede predecir múltiples valores.
Paz.
Realiza un seguimiento del desarrollo de modelos de aprendizaje automático y mucho más, detallado en esta serie de artículos en este repositorio de GitHub.
Tabla de archivos adjuntos
| Nombre del archivo | Tipo de archivo | Descripciones y uso |
|---|---|---|
Direct Muilti step Forecasting.mq5 Multi-step forecasting using multi-outputs model.mq5 Recursive-Multi step forecasting.mq5 | Asesores expertos | Este EA tiene el código que utiliza múltiples modelos LightGBM para pronósticos de múltiples pasos. Este EA tiene el modelo de red neuronal que predice múltiples pasos utilizando una estructura de múltiples salidas. Este EA tiene la regresión lineal prediciendo iterativamente pasos de tiempo futuros. |
| LightGBM.mqh | Archivo de biblioteca MQL5 | Tiene el código para cargar el modelo LightGBM en formato ONNX y usarlo para hacer predicciones. |
| Linear Regression.mqh | Archivo de biblioteca MQL5 | Tiene el código para cargar el modelo de regresión lineal en formato ONNX y usarlo para predicciones. |
| preprocessing.mqh | Archivo de biblioteca MQL5 | Este archivo consta del escalador Min-max, una técnica de escala utilizada para normalizar los datos de entrada. |
| Regressor Neural Nets.mqh | Archivo de biblioteca MQL5 | Tiene el código para cargar e implementar el modelo de red neuronal del formato ONNX a MQL5. |
lightgbm.EURUSD.h1.pred_close.step.1.onnx lightgbm.EURUSD.h1.pred_close.step.2.onnx lightgbm.EURUSD.h1.pred_close.step.3.onnx lightgbm.EURUSD.h1.pred_close.step.4.onnx lightgbm.EURUSD.h1.pred_close.step.5.onnx Lr.EURUSD.h1.pred_close.onnx NN.EURUSD.h1.onnx | Modelos de IA en formato ONNX | Modelos LightGBM para predecir los valores de los próximos pasos futuros Un modelo de regresión lineal simple en formato ONNX Red neuronal de avance en formato ONNX |
| NN.EURUSD.h1.min_max.max.bin NN.EURUSD.h1.min_max.min.bin | Archivos binarios | Contiene valores máximos y mínimos respectivamente para el escalador Min-max |
| predicting-multiple-future-tutorials.ipynb | Jupyter Notebook | Todo el código de Python que se muestra en este artículo se puede encontrar en este archivo |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/15465
 MetaTrader 5 en macOS
MetaTrader 5 en macOS
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso