
Aprendizaje automático y Data Science (Parte 26): La batalla definitiva en la previsión de series temporales: redes neuronales LSTM frente a GRU

Contenido
- ¿Qué es una red neuronal de memoria a largo plazo (LSTM)?
- Matemáticas de la red de memoria a largo plazo (LSTM)
- ¿Qué es una red neuronal de unidades recurrentes controladas (GRU)?
- Matemáticas de la red de unidades recurrentes controladas (GRU)
- Construcción de la clase principal para redes LSTM y GRU
- Clases de hijos de redes neuronales LSTM y GRU
- Entrenamiento de ambos modelos
- Comprobación de la importancia de las características en ambos modelos
- Clasificadores LSTM frente a GRU en el probador de estrategias
- Diferencias entre los modelos de redes neuronales LSTM y GRU
- Conclusión
¿Qué es una red neuronal de memoria a largo plazo y a corto plazo (LSTM)?
La memoria a largo plazo y a corto plazo (MLAP) es un tipo de red neuronal recurrente diseñada para tareas de secuencia, destacando en la captura y utilización de dependencias a largo plazo en datos. A diferencia de las redes neuronales recurrentes tradicionales (RNN simples) analizadas en el artículo anterior de esta serie (de lectura obligada). Que no puede capturar dependencias a largo plazo en los datos.
Los LSTM se introdujeron para corregir la memoria a corto plazo que prevalece en las RNN simples.
El problema de las redes neuronales recurrentes simples
Las redes neuronales recurrentes (RNN) simples están diseñadas para manejar datos secuenciales utilizando su estado oculto interno (memoria) para capturar información sobre entradas anteriores en la secuencia. A pesar de su simplicidad conceptual y su éxito inicial en el modelado de datos secuenciales, tienen varias limitaciones.
Una cuestión importante es el problema del gradiente evanescente. Durante la retropropagación, los gradientes se utilizan para actualizar los pesos de la red. En las RNN simples, estos gradientes pueden disminuir exponencialmente a medida que se propagan hacia atrás en el tiempo, especialmente para secuencias largas. El resultado es que la red es incapaz de aprender dependencias a largo plazo, ya que los gradientes son demasiado pequeños para realizar actualizaciones efectivas de los pesos, lo que dificulta que las RNN simples capturen patrones que abarcan muchos pasos temporales.
Otro reto es el problema del gradiente explosivo, que es lo contrario del problema del gradiente evanescente. En este caso, los gradientes crecen exponencialmente durante la retropropagación. Esto puede causar inestabilidad numérica y hacer que el proceso de formación sea muy difícil. Aunque es menos común que los gradientes desvanecientes, los gradientes explosivos pueden provocar actualizaciones excesivamente grandes de los pesos de la red, haciendo que el proceso de aprendizaje fracase.
Las RNN simples también son difíciles de entrenar debido a su susceptibilidad tanto a los problemas de gradiente evanescente como a los de gradiente explosivo, que pueden hacer que el proceso de entrenamiento sea ineficiente y lento. Entrenar RNN simples puede ser más costoso desde el punto de vista informático y puede requerir un ajuste cuidadoso de los hiperparámetros.
Además, las RNN simples son incapaces de manejar dependencias temporales complejas en los datos. Debido a su limitada capacidad de memoria, a menudo tienen dificultades para comprender y captar patrones secuenciales complejos.
Para las tareas que implican una comprensión de las dependencias de largo alcance en los datos, las RNN simples pueden no captar el contexto necesario, lo que conduce a un rendimiento subóptimo.
Matemáticas de la red de memoria a largo plazo (LSTM)
Para entender los entresijos de la LSTM, veamos primero la célula LSTM.

01: Puerta del olvido
Dada por la ecuación.
![]()
Una función sigmoidea ![]() toma como entrada el estado oculto anterior
toma como entrada el estado oculto anterior![]() y la entrada actual
y la entrada actual![]() . La salida
. La salida ![]() es un valor entre 0 y 1, que indica qué cantidad de cada componente en
es un valor entre 0 y 1, que indica qué cantidad de cada componente en ![]() (estado anterior de la celda) debe conservarse.
(estado anterior de la celda) debe conservarse.
![]() - peso de la puerta del olvido.
- peso de la puerta del olvido.
![]() - sesgo de la puerta de olvido.
- sesgo de la puerta de olvido.
La puerta de olvido determina qué información del estado anterior de la celda debe transferirse. Emite un número entre 0 y 1 para cada número del estado de la celda ![]() , donde 0 significa olvido completo y 1 significa retención completa.
, donde 0 significa olvido completo y 1 significa retención completa.
02: Puerta de entrada
Dado por la fórmula.
![]()
Una función sigmoidea ![]() determina qué valores actualizar. Esta puerta controla la entrada de nuevos datos en la celda de memoria.
determina qué valores actualizar. Esta puerta controla la entrada de nuevos datos en la celda de memoria.
![]() - puerta de entrada de peso.
- puerta de entrada de peso.
![]() - puerta de entrada de polarización.
- puerta de entrada de polarización.
Esta puerta decide qué valores de la nueva entrada ![]() se utilizan para actualizar el estado de la celda. Regula el flujo de nueva información hacia la célula.
se utilizan para actualizar el estado de la celda. Regula el flujo de nueva información hacia la célula.
03: Célula de memoria candidata
Dada por la ecuación.
![]()
Una función tanh genera nueva información potencial que podría almacenarse en el estado de la celda.
![]() - Peso de la celda de memoria candidata.
- Peso de la celda de memoria candidata.
![]() - Sesgo de la célula de memoria candidata.
- Sesgo de la célula de memoria candidata.
Este componente genera los nuevos valores candidatos que se pueden agregar al estado de la celda. Utiliza la función de activación tanh para garantizar que los valores estén entre -1 y 1.
04: Actualización del estado de la celda
Dada por la ecuación.
![]()
El estado anterior de la celda ![]() se multiplica por
se multiplica por ![]() (salida de la compuerta de olvido) para descartar información sin importancia. A continuación,
(salida de la compuerta de olvido) para descartar información sin importancia. A continuación, ![]() (salida de la puerta de entrada) se multiplica por
(salida de la puerta de entrada) se multiplica por ![]() (estado de la celda candidata), y los resultados se suman para formar el nuevo estado de la celda
(estado de la celda candidata), y los resultados se suman para formar el nuevo estado de la celda ![]() .
.
El estado de la celda se actualiza combinando el estado de la celda anterior y los valores candidatos. La salida de la puerta de olvido controla la contribución del estado de la celda anterior, y la salida de la puerta de entrada controla la contribución de los nuevos valores candidatos.
05: Puerta de salida
Dada por la ecuación.
![]()
Una función sigmoidea determina qué partes del estado celular mostrar. Esta puerta controla la salida de información de la celda de memoria.
![]() - Peso de la capa de salida
- Peso de la capa de salida
![]() - Sesgo de la capa de salida
- Sesgo de la capa de salida
Esta puerta determina la salida final para el estado actual de la celda. Decide qué partes del estado de la celda deben salir en función de la entrada ![]() y el estado oculto anterior
y el estado oculto anterior ![]() .
.
06: Actualización del estado oculto
Dada por la ecuación.
![]()
El nuevo estado oculto ![]() se obtiene multiplicando la puerta de salida
se obtiene multiplicando la puerta de salida ![]() por el tanh del estado actualizado de la celda
por el tanh del estado actualizado de la celda ![]() .
.
El estado oculto se actualiza según el estado de la celda y la decisión de la puerta de salida. Se utiliza como salida para el paso de tiempo actual y como entrada para el siguiente paso de tiempo.
¿Qué es una red neuronal de unidades recurrentes controladas (GRU)?
La unidad recurrente cerrada (GRU) es un tipo de red neuronal recurrente (RNN) que, en ciertos casos, tiene ventajas sobre la memoria a corto plazo (LSTM). GRU utiliza menos memoria y es más rápido que LSTM, sin embargo, LSTM es más preciso cuando se utilizan conjuntos de datos con secuencias más largas.
Se introdujeron los LSTM y los GRU para mitigar la memoria a corto plazo prevaleciente en las redes neuronales recurrentes simples. Ambos tienen memoria a largo plazo habilitada mediante el uso de puertas en sus células.
A pesar de funcionar de manera similar a las RNN simples en muchos aspectos, las LSTM y las GRU abordan el problema del gradiente evanescente que padecen las redes neuronales recurrentes simples.
Matemáticas detrás de la red de unidades recurrentes cerradas (GRU)
La imagen a continuación ilustra cómo se ve la célula GRU cuando se diseca.

01: La puerta de actualización
Dado por la fórmula.
![]()
Esta puerta determina cuánto del estado oculto anterior ![]() debe conservarse y cuánto del estado oculto candidato
debe conservarse y cuánto del estado oculto candidato ![]() debe utilizarse para actualizar el estado oculto.
debe utilizarse para actualizar el estado oculto.
La puerta de actualización controla qué parte del estado oculto anterior ![]() debe trasladarse al siguiente paso temporal. Decide efectivamente el equilibrio entre mantener la información antigua e incorporar información nueva.
debe trasladarse al siguiente paso temporal. Decide efectivamente el equilibrio entre mantener la información antigua e incorporar información nueva.
02: Puerta de reinicio
Dado por la fórmula.
![]()
La función sigmoidea ![]() en esta puerta, determina qué partes del estado oculto anterior deben reiniciarse antes de combinarse con la entrada actual para crear la activación candidata.
en esta puerta, determina qué partes del estado oculto anterior deben reiniciarse antes de combinarse con la entrada actual para crear la activación candidata.
03: Activación de candidatos
Dado por la fórmula.
![]()
La activación candidata se calcula utilizando la entrada actual ![]() y el estado oculto restablecido
y el estado oculto restablecido ![]() .
.
Este componente genera nuevos valores potenciales para el estado oculto que pueden incorporarse en función de la decisión de la puerta de actualización.
04: Actualización del estado oculto
Dado por la fórmula.
![]()
La salida de la puerta de actualización ![]() controla cuánto del estado oculto candidato
controla cuánto del estado oculto candidato ![]() se utiliza para formar el nuevo estado oculto
se utiliza para formar el nuevo estado oculto ![]() .
.
El estado oculto se actualiza combinando el estado oculto anterior y el estado oculto candidato. La puerta de actualización ![]() controla esta combinación, asegurando que se retiene la información relevante del pasado a la vez que se incorpora nueva información.
controla esta combinación, asegurando que se retiene la información relevante del pasado a la vez que se incorpora nueva información.
Creación de la clase principal para redes LSTM y GRU
Dado que LSTM y GRU funcionan de forma similar en muchos aspectos y toman los mismos parámetros, podría ser una buena idea tener una clase base(padre) para las funciones necesarias para construir, compilar, optimizar, comprobar la importancia de las características y guardar los modelos. Esta clase se heredará en las clases secundarias LSTM y GRU posteriores.
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, GRU, Dense, Input, Dropout from keras.callbacks import EarlyStopping from keras.optimizers import Adam import tf2onnx import optuna import shap from sklearn.metrics import accuracy_score class RNNClassifier(): def __init__(self, time_step, x_train, y_train, x_test, y_test): self.model = None self.time_step = time_step self.x_train = x_train self.y_train = y_train self.x_test = x_test self.y_test = y_test # a crucial function that all the subclasses must implement def build_compile_and_train(self, params, verbose=0): raise NotImplementedError("Subclasses should implement this method") # a function for saving the RNN model to onnx & the Standard scaler parameters def save_onnx_model(self, onnx_file_name): # optuna objective function to oprtimize def optimize_objective(self, trial): # optimize for 50 trials by default def optimize(self, n_trials=50): def _rnn_predict(self, data): def check_feature_importance(self, feature_names):
Optimización de LSTM y GRU con Optuna
Como dije una vez, las redes neuronales son muy sensibles a los hiperparámetros. Sin la sintonización adecuada y sin disponer de los parámetros óptimos, las redes neuronales podrían resultar ineficaces.
Python
def optimize_objective(self, trial): params = { "neurons": trial.suggest_int('neurons', 10, 100), "n_hidden_layers": trial.suggest_int('n_hidden_layers', 1, 5), "dropout_rate": trial.suggest_float('dropout_rate', 0.1, 0.5), "learning_rate": trial.suggest_float('learning_rate', 1e-5, 1e-2, log=True), "hidden_activation_function": trial.suggest_categorical('hidden_activation_function', ['relu', 'tanh', 'sigmoid']), "loss_function": trial.suggest_categorical('loss_function', ['categorical_crossentropy', 'binary_crossentropy', 'mean_squared_error', 'mean_absolute_error']) } val_accuracy = self.build_compile_and_train(params, verbose=0) # we build a model with different parameters and train it, just to return a validation accuracy value return val_accuracy # optimize for 50 trials by default def optimize(self, n_trials=50): study = optuna.create_study(direction='maximize') # we want to find the model with the highest validation accuracy value study.optimize(self.optimize_objective, n_trials=n_trials) return study.best_params # returns the parameters that produced the best performing model
El método optimize_objective define la función objetivo para la optimización de hiperparámetros utilizando el marco Optuna. Guía el proceso de optimización para encontrar el mejor conjunto de hiperparámetros que maximicen el rendimiento del modelo.
El método Optimize utiliza Optuna para realizar la optimización de hiperparámetros llamando repetidamente al método optimize_objective.
Comprobación de la importancia de las características mediante SHAP
Medir el impacto que tienen las características en las predicciones del modelo es importante para un científico de datos. No solo podría ayudarnos a comprender las áreas que requieren mejoras clave, sino también agudizar nuestra comprensión de un conjunto de datos particular sobre un modelo.
def check_feature_importance(self, feature_names): # Sample a subset of training data for SHAP explainer sampled_idx = np.random.choice(len(self.x_train), size=100, replace=False) explainer = shap.KernelExplainer(self._rnn_predict, self.x_train[sampled_idx].reshape(100, -1)) # Get SHAP values for the test set shap_values = explainer.shap_values(self.x_test[:100].reshape(100, -1), nsamples=100) # Update feature names for SHAP feature_names = [f'{feature}_t{t}' for t in range(self.time_step) for feature in feature_names] # Plot the SHAP values shap.summary_plot(shap_values, self.x_test[:100].reshape(100, -1), feature_names=feature_names, max_display=len(feature_names), show=False) # Adjust layout and set figure size plt.subplots_adjust(left=0.12, bottom=0.1, right=0.9, top=0.9) plt.gcf().set_size_inches(7.5, 14) plt.tight_layout() # Get the class name of the current instance class_name = self.__class__.__name__ # Create the file name using the class name file_name = f"{class_name.lower()}_feature_importance.png" plt.savefig(file_name) plt.show()
Cómo guardar los clasificadores LSTM y GRU en formatos de modelos ONNX
Por último, después de haber construido los modelos, tenemos que guardarlos en formato ONNX que es compatible con MQL5.
def save_onnx_model(self, onnx_file_name):
# Convert the Keras model to ONNX
spec = (tf.TensorSpec((None, self.time_step, self.x_train.shape[2]), tf.float16, name="input"),)
self.model.output_names = ['outputs']
onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13)
# Save the ONNX model to a file
with open(onnx_file_name, "wb") as f:
f.write(onnx_model.SerializeToString())
# Save the mean and scale parameters to binary files
scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin")
scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
Clases secundarias de redes neuronales LSTM y GRU
Las redes neuronales recurrentes funcionan de forma similar en muchos aspectos, incluso su implementación mediante Keras sigue un enfoque y parámetros similares. Su principal diferencia es el tipo de modelo, todo lo demás permanece igual.
Clasificador LSTM
Python
class LSTMClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(LSTM(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
Clasificador GRU
Python
class GRUClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(GRU(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
Como se puede ver en los clasificadores de clases secundarias, la única diferencia es el tipo de modelo, tanto los LSTM como los GRU adoptan un enfoque similar.
Entrenando ambos modelos
En primer lugar, tenemos que inicializar las instancias de clase para ambos modelos. Comenzando con el modelo LSTM.
lstm_clf = LSTMClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
Luego inicializamos el modelo GRU.
gru_clf = GRUClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
Después de optimizar ambos modelos durante 20 pruebas;
best_params = lstm_clf.optimize(n_trials=20)
best_params = gru_clf.optimize(n_trials=20) El modelo de clasificador LSTM en la prueba 19 fue el mejor.
[I 2024-07-01 11:14:40,588] Trial 19 finished with value: 0.5597269535064697 and parameters: {'neurons': 79, 'n_hidden_layers': 4, 'dropout_rate': 0.335909076638275, 'learning_rate': 3.0704319088493336e-05, 'hidden_activation_function': 'relu', 'loss_function': 'categorical_crossentropy'}. Best is trial 19 with value: 0.5597269535064697.
Con una precisión de aproximadamente el 55,97% en los datos de validación, el modelo clasificador GRU encontrado en la prueba 3 fue el mejor de todos los modelos.
[I 2024-07-01 11:18:52,190] Trial 3 finished with value: 0.532423198223114 and parameters: {'neurons': 55, 'n_hidden_layers': 5, 'dropout_rate': 0.2729838602302831, 'learning_rate': 0.009626688728041802, 'hidden_activation_function': 'sigmoid', 'loss_function': 'mean_squared_error'}. Best is trial 3 with value: 0.532423198223114.
Proporcionó una precisión de aproximadamente el 53,24% en los datos de validación.
Comprobación de la importancia de las características en ambos modelos
| Clasificador LSTM | Clasificador GRU |
|---|---|
feature_importance = lstm_clf.check_feature_importance(X.columns) Resultado. 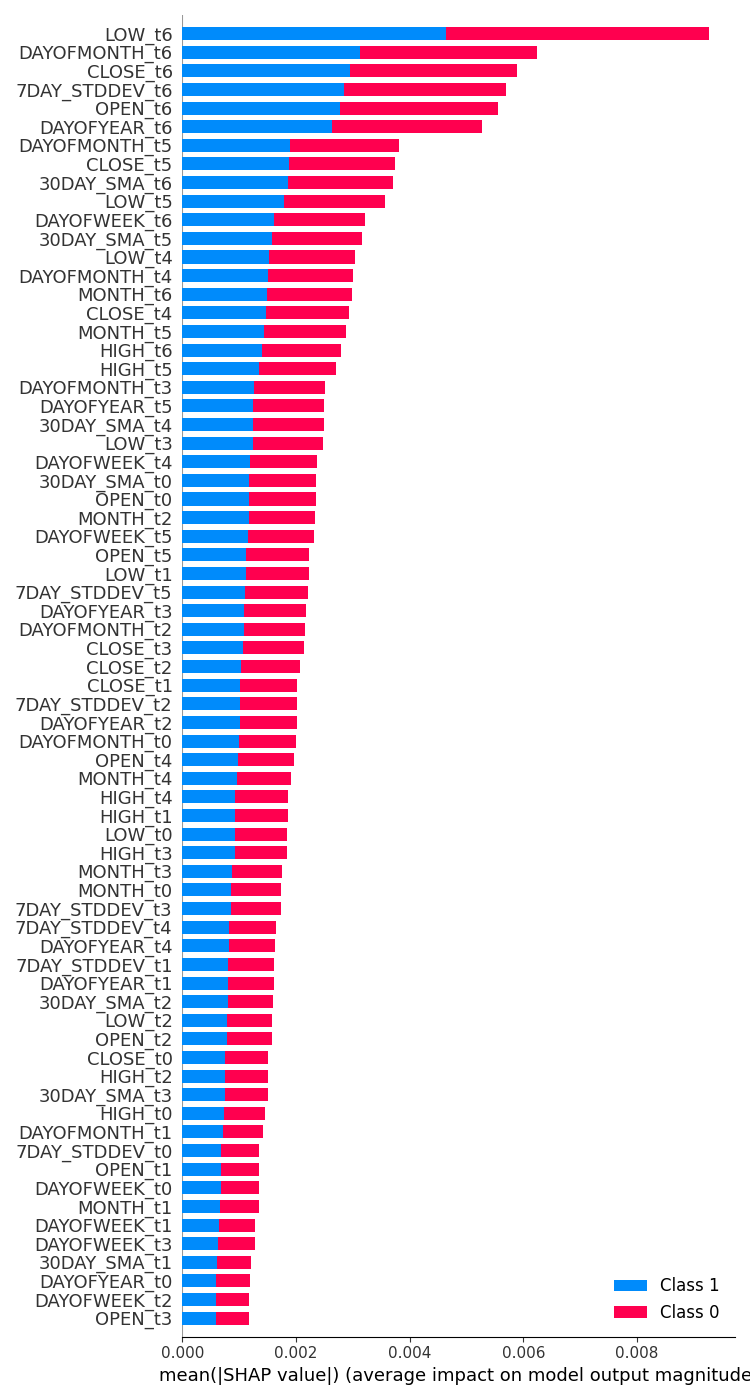 | feature_importance = gru_clf.check_feature_importance(X.columns) Resultado.  |
La importancia de la característica del clasificador LSTM se parece en cierto modo a la que obtuvimos con el modelo RNN simple. Las variables menos importantes proceden de pasos temporales lejanos, mientras que las más importantes proceden de pasos temporales más cercanos.
Esto es como decir, que las variables que más contribuyen a lo que ocurre con la barra actual son la información de las barras cerradas recientemente.
El clasificador del GRU tuvo una opinión diversa que no parece tener mucho sentido. Esto podría deberse a que su modelo tenía una precisión menor.
Decía que la variable más impactante era el día de la semana 7 días antes. Elementos como Apertura, Máximo, Mínimo y Cierre del paso temporal 6, que es la información más reciente, se situaron en el centro, lo que indica que su contribución al resultado final de la predicción fue media.
Clasificadores LSTM frente a GRU en el Probador de Estrategias
Poco después del entrenamiento, los modelos de clasificación LSTM y GRU se guardaron en formato ONNX.
LSTM | Python
lstm_clf.build_compile_and_train(best_params, verbose=1) # best_params = best parameters obtained after optimization lstm_clf.save_onnx_model("lstm.EURUSD.D1.onnx")
GRU | Python
gru_clf.build_compile_and_train(best_params, verbose=1) gru_clf.save_onnx_model("gru.EURUSD.D1.onnx") # best_params = best parameters obtained after optimization
Después de guardar el modelo ONNX y sus archivos de escalado en el directorio MQL5\Files, podemos añadir los archivos a ambos Asesores Expertos como archivos de recursos.
| LSTM | GRU |
|---|---|
#resource "\\Files\\lstm.EURUSD.D1.onnx" as uchar onnx_model[]; //lstm model in onnx format #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\LSTM.mqh> CLSTM lstm; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique | #resource "\\Files\\gru.EURUSD.D1.onnx" as uchar onnx_model[]; //gru model in onnx format #resource "\\Files\\gru.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\gru.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\GRU.mqh> CGRU gru; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique |
El código para el resto de Asesores Expertos sigue siendo el mismo como ya comentamos.
Utilizando la configuración por defecto que hemos utilizado desde la Parte 24 de esta serie de artículos, donde comenzamos con la previsión de series temporales.
Stop loss: 500, Take profit: 700, Slippage: 50.
De nuevo, dado que los datos se recogieron en un marco temporal diario, podría ser una buena idea probarlo en un marco temporal inferior para evitar errores cuando «errores de cierre de mercado», ya que estamos buscando señales de trading en la apertura de una nueva barra. También podemos establecer el tipo de modelización en precios abiertos para realizar pruebas más rápidas.

Resultados del Asesor Experto LSTM


Resultados del Asesor Experto de GRU


¿Qué podemos aprender de los resultados del Probador de Estrategias?
A pesar de ser el modelo menos preciso con un 44,98%, el Asesor Experto basado en LSTM fue el más rentable con un beneficio neto de 138 $, seguido del Asesor Experto basado en GRU que fue rentable el 45,25% de las veces, a pesar de dar un beneficio neto total de 120 $.
LSTM es un claro ganador en este caso en cuanto a beneficios. A pesar de que LSTM es técnicamente más inteligente que otras RNNs de su clase, puede haber muchos factores que lleven a esto todos los modelos recurrentes son buenos y pueden superar a otros en ciertas situaciones, siéntete libre de usar cualquiera de los modelos discutidos en este artículo y en el anterior.
Diferencias entre los modelos de redes neuronales LSTM y GRU
Comprender estos modelos en comparación ayuda a la hora de decidir qué ofrece cada modelo en contraste con el otro. Cuándo se debe usar uno y cuándo no. A continuación se presentan sus diferencias tabuladas.
| Aspecto | LSTM | GRU |
|---|---|---|
Complejidad de la arquitectura | Las LSTM tienen un diseño más complejo con tres puertas (entrada, salida, olvido) y un estado de celda, lo que proporciona un control detallado sobre qué información se guarda o se descarta en cada paso temporal. | Las GRUs tienen un diseño más sencillo con sólo dos puertas (reset y update). Esta arquitectura sencilla facilita su aplicación. |
Velocidad de entrenamiento | Tener puertas adicionales y un estado de celda en los LSTM significa que hay más procesos que realizar y parámetros que optimizar. Son más lentos durante el entrenamiento. | Al tener menos puertas y operaciones más sencillas, se suelen entrenar más rápido que las LSTM. |
Rendimiento | En problemas complejos en los que es crucial captar las dependencias a largo plazo, los LSTM tienden a funcionar ligeramente mejor que sus homólogos. | Las GRU suelen ofrecer un rendimiento comparable al de las LSTM en muchas tareas. |
Gestión de las dependencias a largo plazo | Las LSTM están diseñadas explícitamente para retener dependencias a largo plazo en los datos, gracias al estado de las celdas y a los mecanismos de compuerta que controlan el flujo de información a lo largo del tiempo. | Aunque las GRU también manejan bien las dependencias a largo plazo, puede que no sean tan eficaces como las LSTM a la hora de capturar dependencias a muy largo plazo debido a su estructura más simple. |
| Uso de memoria | Debido a su estructura compleja y parámetros adicionales, los LSTM consumen más memoria, lo que puede ser una limitación en entornos con recursos limitados. | Los GRU, por otro lado, son más simples, tienen menos parámetros y utilizan menos memoria. Haciéndolos más adecuados para aplicaciones con recursos computacionales limitados. |
Reflexiones finales
Las redes neuronales LSTM (Long Short-Term Memory) y GRU (Gated Recurrent Unit) son herramientas poderosas para los traders que buscan aprovechar modelos avanzados de pronóstico de series de tiempo. Si bien los LSTM proporcionan una arquitectura más compleja que se destaca en la captura de dependencias a largo plazo en datos de mercado, los GRU ofrecen una alternativa más simple y eficiente que a menudo puede igualar el rendimiento de los LSTM con menores costos computacionales.
Estos modelos de aprendizaje profundo de series temporales (LSTM y GRU) se han utilizado en varios dominios fuera del comercio de divisas, como el pronóstico del tiempo, el modelado del consumo de energía, la detección de anomalías y el reconocimiento de voz, con gran éxito, como suele promocionarse; sin embargo, en el mercado de divisas en constante cambio, no puedo garantizar tales promesas.
Este artículo tiene como único objetivo ofrecer una comprensión profunda de estos modelos y de cómo se pueden implementar en MQL5 para el trading. No dude en explorar y jugar con los modelos y conjuntos de datos que se analizan en este artículo y compartir sus resultados en la sección de debate.
¡Saludos!
Siga el desarrollo de modelos de aprendizaje automático y mucho más discutido en esta serie de artículos en este repositorio de GitHub.
Tabla de archivos adjuntos
| Nombre del archivo | Tipo de archivo | Descripción y uso |
|---|---|---|
| GRU EA.mq5 LSTM EA.mq5 | Expert Advisors | Asesor experto basado en GRU. Asesor experto basado en LSTM. |
| gru.EURUSD.D1.onnx lstm.EURUSD.D1.onnx | Archivos ONNX | Modelo GRU en formato ONNX. Modelo LSTM en formato ONNX. |
| lstm.EURUSD.D1.standard_scaler_mean.bin lstm.EURUSD.D1.standard_scaler_scale.bin | Archivos binarios | Archivos binarios para el escalador de estandarización utilizado para el modelo LSTM. |
| gru.EURUSD.D1.standard_scaler_mean.bin gru.EURUSD.D1.standard_scaler_scale.bin | Archivos binarios | Archivos binarios para el escalador de estandarización utilizado para el modelo GRU. |
| preprocessing.mqh | Archivo de inclusión | Una biblioteca que consta del escalador de estandarización. |
| lstm-gru-for-forex-trading-tutorial.ipynb | Python Script/Jupyter Notebook | Contiene todo el código Python analizado en este artículo. |
- Guía ilustrada de LSTM y GRU: explicación paso a paso
- Diseño de decodificadores basados en redes neuronales para códigos de superficie
- Una red neuronal adaptativa antirruido para el diagnóstico de fallos de rodamientos en condiciones de ruido y carga variable.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/15182
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso