
ニューラルネットワークが簡単に(第78回):Transformerを用いたデコーダなしの物体検出器(DFFT)

はじめに
これまでの記事では、主に今後の値動きの予測や過去のデータの分析に焦点を当てました。この分析に基づき、今後の値動きをさまざまな方法で予測してみました。いくつかの戦略では、予測される動きをすべて構築し、それぞれの予測の確率を推定しようとしました。当然ながら、このようなモデルの訓練や運用には、多大なコンピューティングリソースが必要となります。
しかし、本当に今後の値動きを予測する必要があるのでしょうか。しかも、得られる予測の精度は望むべくもありません。
私たちの究極の目標は利益を生み出すことです。エージェントの取引が成功することで利益が得られると期待しているのです。エージェントは、得られた予測価格軌道に基づいて最適な行動を選択します。
その結果、予測軌道の構築における誤差は、エージェントによる行動選択においてさらに大きな誤差を引き起こす可能性があります。「引き起こす可能性がある」と言ったのは、学習過程でActorが予測誤差に適応し、誤差をわずかに平準化することができるからです。しかし、予測誤差が比較的一定であれば、このような状況もあり得ます。確率的予測誤差の場合、エージェントの行動の誤差は大きくなるばかりです。
そのような状況では、誤差を最小限に抑える方法を探します。今後の値動きの軌跡を予測する中間段階を省いたらどうでしょう。古典的な強化学習のアプローチに戻りましょう。過去のデータの分析に基づいて、Actorに行動を選択させます。しかし、これは1歩下がるという意味ではなく、むしろ1歩横に行くという意味です。
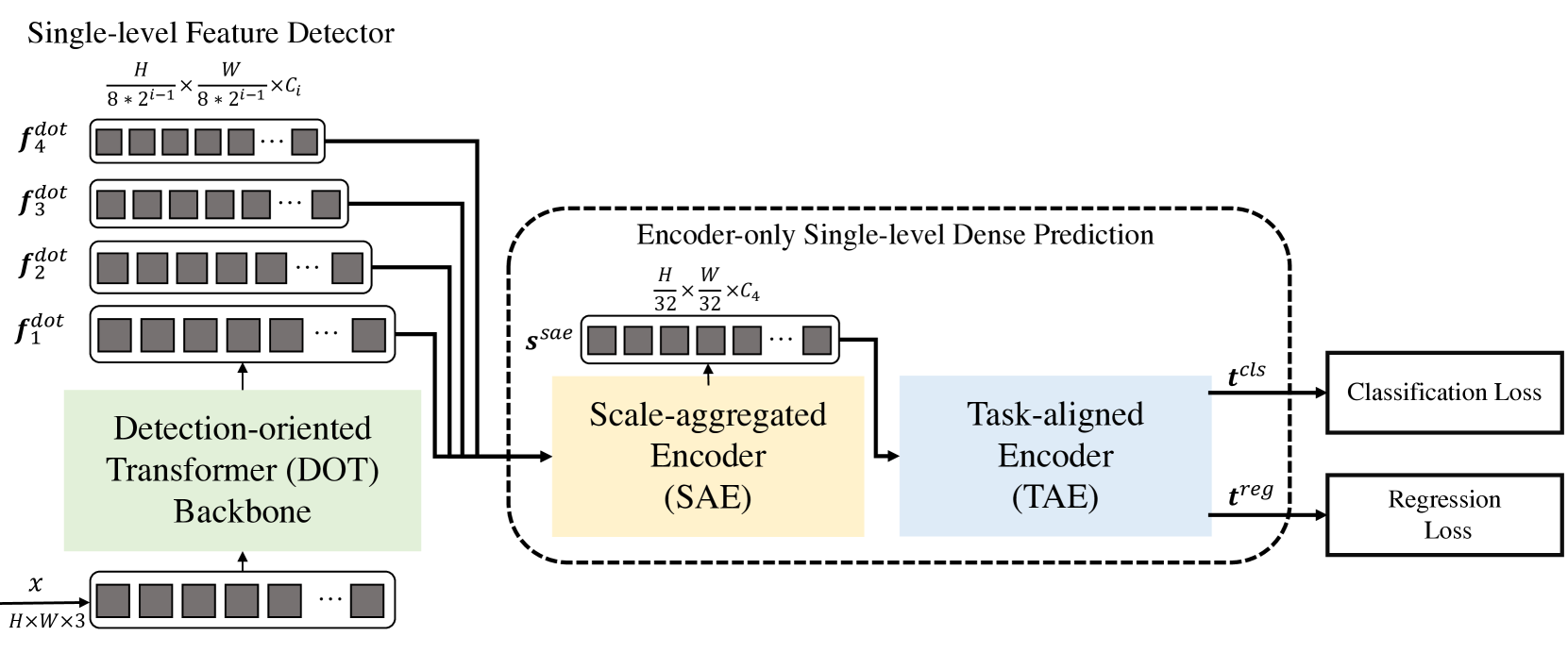
コンピュータビジョンの分野で問題を解決するために発表された興味深い方法を知っておくことをお勧めします。「Efficient Decoder-free Object Detection with Transformers」稿で紹介されている、Transformerを用いたデコーダなしの物体検出器 (Decoder-Free Fully Transformer-based: DFFT)法です。
本稿で提案するDFFT法は、訓練段階と動作段階の両方で高い効率を保証します。この手法の著者は、エンコーダのみを用いて、物体検出を単一レベルの密な予測タスクに単純化しています。2つの問題の解決に焦点が当てられています。
- 非効率なデコーダを排除し、2つの強力なエンコーダを使用することで、単一レベルの特徴量マップ予測精度を維持する
- 計算量に制約のある検出タスクのために低レベルのsemantic feature(セマンティック特徴)を学習する
特に、この手法の著者は、豊富な意味情報を持つ低レベルの特徴量を効果的に捉える、新しい軽量検出指向の変換バックボーンを提案しています。この論文で紹介されている実験では、計算コストの削減と訓練エポックの削減が実証されています。
1.DFFTアルゴリズム
Decoder-Free Fully Transformer-based (DFFT)法は、デコーダなしのTransformerのみに基づく効率的なオブジェクト検出器です。Transformerのバックボーンは、オブジェクトの検出に重点を置いています。それを4つのスケールで抽出し、次のシングルレベルエンコーダのみの密度予測モジュールに送ります。予測モジュールはまず、Scale-Aggregated Encoderを使用して、マルチスケール特徴を単一の特徴量マップに集約します。
そして、この手法の著者は、分類と回帰問題の同時特徴量マッチングにTask-Aligned Encoderを使用することを提案しています。
Detection-Oriented Transformer (DOT)バックボーンは、厳密な意味情報を持つマルチスケール特徴量を抽出するために設計されています。1つのEmbeddingモジュールと4つのDOT段階が階層的に積み重ねられています。意味的に強化された新しいAttentionモジュールは、DOTの2つの連続する各段階の低レベルの意味情報を集約します。
高解像度の特徴量マップを高密度に予測処理する場合、従来の変換ブロックは、Multi-Head Self-Attention (MSA)を局所空間Attentionとウィンドウ型Multi-Head Self-Attention (SW-MSA)の層に置き換えることで計算コストを削減します。しかし、この構造では、限られた低レベルの意味情報を持つマルチスケールオブジェクトしか抽出できないため、検出性能が低下します。
この欠点を軽減するために、DFFT法の著者はDOTブロックに複数のSW-MSAブロックとチャンネルをまたぐ1つの大域的Attentionブロックを追加しています。各Attentionブロックは、Attention層とFFN層を含みます。
この手法の著者は、連続する局所的な空間的Attention層の後に、チャンネル上に軽いAttention層を配置することで、各スケールにおける物体の意味情報を推測するのに役立つことを発見しました。
DOTブロックは、チャンネルを横断する大域的Attentionによって低レベル特徴量の意味情報を改善しますが、検出タスクを改善するために意味情報をさらに改善することができます。この目的のために、この手法の著者は、2つの連続したDOT層の間で意味情報を交換し、その特徴量を補完するSemantic-Augmented Attention (SAA)という新しいモジュールを提案しています。SAAは、アップサンプリング層と、チャンネルをまたぐ大域的Attentionブロックで構成されます。連続する2つのDOTブロックごとにSAAが加えられます。正式には、SAAは現在のDOTブロックと前段階のDOTの結果を受け入れ、セマンティックで補強された関数を返します。これが、次のDOT段階に送られ、最終的なマルチスケール特徴にも寄与します。
一般に、検出指向の段階は4つのDOT層で構成され、各段階には1つのDOTブロックと1つのSAAモジュールが含まれます(第1段階を除く)。特に、SAAモジュールの入力は2つの連続するDOT段階から来るため、第1段階は1つのDOTブロックを含み、SAAモジュールを含みません。次に、入力次元を再構成するダウンサンプリング層が来ます。
次のモジュールは、推論とモデル学習の効率DFFTの両方を改善するために設計されています。まず、Scale-Aggregated Encoder (SAE)を使用して、DOTバックボーンからのマルチスケールオブジェクトを1つのSsaeオブジェクトマップに集約します。
次に、Task-Aligned Encoder (TAE)を使用して、1つのヘッドで、整列した分類関数 𝒕clsと回帰関数𝒕regを同時に作成します。
Scale-Aggregated Encoder (SAE) は、3つのSAEブロックから構成されます。各SAEブロックは、2つのオブジェクトを入力データとして受け取り、すべてのSAEブロックにわたって段階的に集約します。検出精度と計算コストのバランスをとるために、オブジェクトの有限集合体のスケールが利用されています。
通常、検出器は、2つの別々の分岐(接続されていないヘッド)を使用して、互いに独立してオブジェクトの分類と局地化を実行します。この2分岐構造では、2つのタスク間の相互作用が考慮されておらず、予測に一貫性がありません。一方、2つのタスクの特徴量を学習する場合、通常、共役ヘッドの衝突が発生します。DFFT法の著者は、タスクに特化したエンコーダを使用することを提案しています。このエンコーダは、連結されたヘッド内のチャンネルにまたがるグループAttentionユニットを組み合わせることで、インタラクティブな学習とタスクに特化した特徴量の学習との間のより良いバランスを提供します。
このエンコーダは2種類のチャンネルAttentionブロックから構成されています。まず、チャンネルをまたいだマルチレベルのグループAttentionブロックが整列し、Ssaeに集約されたオブジェクトを2つの部分に分離します。第2に、チャンネルをまたがる大域的Attentionブロックは、分離された2つの物体のうち1つを、その後の回帰課題のためにエンコードします。
特に、チャンネルAttentionのグループブロックとチャンネルAttentionの大域的ブロックの違いは、チャンネルをまたぐグループ注意ブロックにおけるQuery/Key/Valueの埋め込みに対する投影を除いて、すべての線形投影が2つのグループで実行されることです。このように、特徴量は注意操作では相互作用しながら、出力投影では別々に出力されます。
論文の著者が提示した、この手法のオリジナルの視覚化を以下に示します。
2.MQL5を使用した実装
Decoder-Free Fully Transformer-based (DFFT)法の理論的側面を検討した後で、MQL5を使用して提案されたアプローチの実装に移りましょう。ただし、私たちのモデルはオリジナルの方法とは若干異なります。モデルを構築する際には、この手法が提案されたコンピュータビジョンの問題と、私たちがモデルを構築しようとしている金融市場における操作の特殊性の違いを考慮に入れています。
2.1 DOTブロックの構造
始める前に、提案されているアプローチは、私たちが以前に構築したモデルとはかなり異なることに注意してください。DOTブロックは、先に検討したAttentionブロックとも異なります。そこで、新しいニューラル層CNeuronDOTOCLを構築することから始めます。ニューラル層の基本クラスであるCNeuronBaseOCLの子孫として、新しい層を作成します。
他のAttentionブロックと同様に、主要なパラメータを格納する変数を追加します。
- iWindowSize:シーケンス要素1個のウィンドウサイズ
- iPrevWindowSize:直前の層シーケンスの1要素のウィンドウサイズ
- iDimension:内部エンティティQuery、Key、Valueのベクトルサイズ
- iUnits:シーケンス内の要素数
- iHeads:Attentionヘッドの数
iPrevWindowSizeという変数にお気づきだと思います。この変数を追加することで、DFFT法が提供するように、層から層へとデータを圧縮する機能を実装することができます。
また、新しいクラスで直接おこなう作業を最小限に抑え、以前に作成した開発を最大限に利用するために、私たちのライブラリからネストされたニューラル層を使用して機能の一部を実装しています。フィードフォワードとバックプロパゲーションのメソッドを実装しながら、その機能を詳しく考えていきます。
class CNeuronDOTOCL : public CNeuronBaseOCL { protected: uint iWindowSize; uint iPrevWindowSize; uint iDimension; uint iUnits; uint iHeads; //--- CNeuronConvOCL cProjInput; CNeuronConvOCL cQKV; int iScoreBuffer; CNeuronBaseOCL cRelativePositionsBias; CNeuronBaseOCL MHAttentionOut; CNeuronConvOCL cProj; CNeuronBaseOCL AttentionOut; CNeuronConvOCL cFF1; CNeuronConvOCL cFF2; CNeuronBaseOCL SAttenOut; CNeuronXCiTOCL cCAtten; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool DOT(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool updateRelativePositionsBias(void); virtual bool DOTInsideGradients(void); public: CNeuronDOTOCL(void) {}; ~CNeuronDOTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint dimension, uint heads, uint units_count, uint prev_window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronDOTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
一般的に、オーバーライドされるメソッドのリストは標準的なものです。
クラス本体では、静的オブジェクトを使用しています。これにより、クラスのコンストラクタとデストラクタを空にしておくことができます。
クラスはInitメソッドで初期化されます。必要なデータはパラメータとしてメソッドに渡されます。情報の必要最小限の制御は、親クラスの関連メソッドに実装されています。ここでは、継承されたオブジェクトも初期化します。
bool CNeuronDOTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint dimension, uint heads, uint units_count, uint prev_window, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
次に、ソースデータのサイズが現在の層のパラメータと一致するかどうかを確認します。必要に応じて、データスケーリング層を初期化します。
if(prev_window != window) { if(!cProjInput.Init(0, 0, OpenCL, prev_window, prev_window, window, units_count, optimization_type, batch)) return false; }
次に、層のアーキテクチャを定義する、呼び出し元から受け取った基本定数を内部クラス変数に保存します。
iWindowSize = window; iPrevWindowSize = prev_window; iDimension = dimension; iHeads = heads; iUnits = units_count;
次に、すべての内部オブジェクトを順次初期化します。まず、Query、Key、Value層を生成する層を初期化します。1つのニューラル層「cQKV」の本体で、3つのエンティティをすべて並行して生成します。
if(!cQKV.Init(0, 1, OpenCL, window, window, dimension * heads, units_count, optimization_type, batch)) return false;
次に、オブジェクト依存係数を記録するためのiScoreBufferバッファを作成します。ここで注目すべきは、DOTブロックではまず局地的な意味情報を分析するということです。これをおこなうには、オブジェクトとその2つの最近傍との間の依存関係を確認します。したがって、ScoreバッファのサイズをiUnits * iHeads * 3に定義します。
さらに、バッファに保存された係数は、フィードフォワードパスごとに再計算されます。これらは次のバックプロパゲーションパスにのみ使用されます。したがって、バッファデータはモデル保存ファイルには保存しません。さらに、メインプログラムのメモリにバッファを作成することもしません。OpenCLのコンテキストメモリにバッファを作成するだけです。メインプログラム側では、バッファへのポインタを格納するだけです。
//--- iScoreBuffer = OpenCL.AddBuffer(sizeof(float) * iUnits * iHeads * 3, CL_MEM_READ_WRITE); if(iScoreBuffer < 0) return false;
ウィンドウ型Self-Attentionメカニズムでは、古典的なTransformerとは異なり、各トークンは特定のウィンドウ内のトークンのみと相互作用します。これにより、計算の複雑さが大幅に軽減されます。しかし、この制限はまた、モデルがウィンドウ内のトークンの相対的な位置を考慮しなければならないことを意味します。この機能を実装するために、訓練可能なパラメータcRelativePositionsBiasを導入します。iWindowSizeウィンドウ内の各トークンのペア(i, j)に対して、cRelativePositionsBiasは、相対的な位置に基づいてこれらのトークン間の相互作用の重要性を決定する重みを含みます。
このバッファのサイズはScore係数バッファのサイズと等しいです。しかし、パラメータを訓練するためには、値そのもののバッファに加えて、さらにバッファが必要になります。内部オブジェクトの数を減らし、コードを読みやすくするため、cRelativePositionsBiasについては、すべての追加バッファを含むニューラル層オブジェクトを宣言します。
if(!cRelativePositionsBias.Init(1, 2, OpenCL, iUnits * iHeads * 3, optimization_type, batch)) return false;
同様に、Self-Attentionメカニズムの残りの要素も加えます。
if(!MHAttentionOut.Init(0, 3, OpenCL, iUnits * iHeads * iDimension, optimization_type, batch)) return false; if(!cProj.Init(0, 4, OpenCL, iHeads * iDimension, iHeads * iDimension, window, iUnits, optimization_type, batch)) return false; if(!AttentionOut.Init(0, 5, OpenCL, iUnits * window, optimization_type, batch)) return false; if(!cFF1.Init(0, 6, OpenCL, window, window, 4 * window, units_count, optimization_type,batch)) return false; if(!cFF2.Init(0, 7, OpenCL, window * 4, window * 4, window, units_count, optimization_type, batch)) return false; if(!SAttenOut.Init(0, 8, OpenCL, iUnits * window, optimization_type, batch)) return false;
大域的AttentionブロックとしてCNeuronXCiTOCL層を使用します。
if(!cCAtten.Init(0, 9, OpenCL, window, MathMax(window / 2, 3), 8, iUnits, 1, optimization_type, batch)) return false;
バッファ間のデータコピー操作を最小限にするため、オブジェクトとバッファを置き換えます。
if(!!Output) delete Output; Output = cCAtten.getOutput(); if(!!Gradient) delete Gradient; Gradient = cCAtten.getGradient(); SAttenOut.SetGradientIndex(cFF2.getGradientIndex()); //--- return true; }
メソッドの実行を完了します。
クラスを初期化した後、フィードフォワードアルゴリズムの構築に移ります。次に、OpenCLプログラム側のウィンドウ型Self-Attentionメカニズムの整理に移ります。そのためにDOTFeedForwardカーネルを作ります。カーネルパラメータには、4つのデータバッファへのポインタを渡します。
- qkv:Query、Key、Valueエンティティバッファ
- score:依存係数バッファ
- rpb:位置オフセットバッファ
- out:マルチヘッドウィンドウ型Self-Attentionの結果バッファ
__kernel void DOTFeedForward(__global float *qkv, __global float *score, __global float *rpb, __global float *out) { const size_t d = get_local_id(0); const size_t dimension = get_local_size(0); const size_t u = get_global_id(1); const size_t units = get_global_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
3次元のタスク空間でカーネルを立ち上げるつもりです。カーネル本体では、3次元すべてでスレッドを識別します。ここで、Query、Key、Valueのエンティティの最初の次元では、ローカルメモリでバッファ共有するワークグループを作成することに注意すべきです。
次に、分析対象の前のデータバッファのオフセットを決定します。
uint step = 3 * dimension * heads; uint start = max((int)u - 1, 0); uint stop = min((int)u + 1, (int)units - 1); uint shift_q = u * step + h * dimension; uint shift_k = start * step + dimension * (heads + h); uint shift_score = u * 3 * heads;
また、同じワークグループのスレッド間でデータを交換するためのローカルバッファもここで作成します。
const uint ls_d = min((uint)dimension, (uint)LOCAL_ARRAY_SIZE); __local float temp[LOCAL_ARRAY_SIZE][3];
前述したように、オブジェクトの2つの最近傍によって局所的な意味情報を決定します。まず、分析されるオブジェクトに対する近隣オブジェクトの影響を判断します。ワーキンググループ内での依存係数を計算します。まず、QueryとKeyエンティティの要素を対にして、並列ストリームで掛け合わせます。
//--- Score if(d < ls_d) { for(uint pos = start; pos <= stop; pos++) { temp[d][pos - start] = 0; } for(uint dim = d; dim < dimension; dim += ls_d) { float q = qkv[shift_q + dim]; for(uint pos = start; pos <= stop; pos++) { uint i = pos - start; temp[d][i] = temp[d][i] + q * qkv[shift_k + i * step + dim]; } } barrier(CLK_LOCAL_MEM_FENCE);
そして、出来上がった積を総和します。
int count = ls_d; do { count = (count + 1) / 2; if(d < count && (d + count) < dimension) for(uint i = 0; i <= (stop - start); i++) { temp[d][i] += temp[d + count][i]; temp[d + count][i] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); }
得られた値にオフセットパラメータを加え、SoftMax関数で正規化します。
if(d == 0) { float sum = 0; for(uint i = 0; i <= (stop - start); i++) { temp[0][i] = exp(temp[0][i] + rpb[shift_score + i]); sum += temp[0][i]; } for(uint i = 0; i <= (stop - start); i++) { temp[0][i] = temp[0][i] / sum; score[shift_score + i] = temp[0][i]; } } barrier(CLK_LOCAL_MEM_FENCE);
結果は従属係数バッファに保存されます。
ここで、得られた係数にValueエンティティの対応する要素を掛け合わせることで、ウィンドウ型Multi-Head Self-Attentionブロックの結果を決定することができます。
int shift_out = dimension * (u * heads + h) + d; int shift_v = dimension * (heads * (u * 3 + 2) + h); float sum = 0; for(uint i = 0; i <= (stop - start); i++) sum += qkv[shift_v + i] * temp[0][i]; out[shift_out] = sum; }
結果の値を結果バッファの対応する要素に保存し、カーネルを終了します。
カーネルを作成した後、メインプログラムに戻り、新しいCNeuronDOTOCLクラスのメソッドを作成します。まず、DOTメソッドを作成し、その中で上記で作成したカーネルを実行キューに入れます。
このメソッドのアルゴリズムは非常にシンプルです。単に外部パラメータをカーネルに渡すだけです。
bool CNeuronDOTOCL::DOT(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iUnits, iHeads}; uint local_work_size[3] = {iDimension, 1, 1}; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_qkv, cQKV.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_score, iScoreBuffer)) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTFeedForward, def_k_dot_out, MHAttentionOut.getOutputIndex())) return false;
そしてカーネルを実行キューに送ります。
ResetLastError(); if(!OpenCL.Execute(def_k_DOTFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
各ステップで結果を制御することを忘れないでください。
準備作業を終えたら、CNeuronDOTOCL::feedForwardメソッドの作成に移ります。このメソッドでは、層のフィードフォワードアルゴリズムを定義します。
メソッドのパラメータで、直前のニューラル層へのポインタを受け取ります。使いやすいように、結果のポインタをローカル変数に保存しておきましょう。
bool CNeuronDOTOCL::feedForward(CNeuronBaseOCL *NeuronOCL)
{
CNeuronBaseOCL* inputs = NeuronOCL;
次に、ソースデータのサイズが現在の層のパラメータと異なるかどうかを確認します。必要に応じて、ソースデータをスケーリングし、Query、Key、Valueエンティティを計算します。
データバッファが等しい場合、スケーリングステップは省略され、Query、Key、Valueエンティティが即座に生成されます。
if(iPrevWindowSize != iWindowSize) { if(!cProjInput.FeedForward(inputs) || !cQKV.FeedForward(GetPointer(cProjInput))) return false; inputs = GetPointer(cProjInput); } else if(!cQKV.FeedForward(inputs)) return false;
次のステップは、上記で作成したウィンドウのSelf-Attentionメソッドを呼び出すことです。
if(!DOT()) return false;
データの次元を下げます。
if(!cProj.FeedForward(GetPointer(MHAttentionOut))) return false;
結果をソースデータバッファに追加します。
if(!SumAndNormilize(inputs.getOutput(), cProj.getOutput(), AttentionOut.getOutput(), iWindowSize, true)) return false;
FeedForwardブロックを通して結果を伝播します。
if(!cFF1.FeedForward(GetPointer(AttentionOut))) return false; if(!cFF2.FeedForward(GetPointer(cFF1))) return false;
再びバッファの結果を追加します。今回は、ウインドウ型Self-Attentionブロックの出力と結果を加えます。
if(!SumAndNormilize(AttentionOut.getOutput(), cFF2.getOutput(), SAttenOut.getOutput(), iWindowSize, true)) return false;
ブロックの最後には大域的Self-Attentionがあります。この段階では、CNeuronXCiTOCL層を使用します。
if(!cCAtten.FeedForward(GetPointer(SAttenOut))) return false; //--- return true; }
操作の結果を確認し、メソッドを終了します。
これで、クラスでのフィードフォワードパスの実装についての考察を終えます。次に、バックプロパゲーションの実装に移ります。ここでは、ウィンドウ型Self-Attentionブロックのバックプロパゲーションカーネル(DOTInsideGradients)を作成する作業も開始します。フィードフォワードカーネルと同様に、新しいカーネルを3次元のタスク空間で起動します。ただし、今回はローカルグループは作成しません。
カーネルはパラメータで、必要なすべてのデータバッファへのポインタを受け取ります。
__kernel void DOTInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *rpb, __global float *rpb_g, __global float *gradient) { //--- init const uint u = get_global_id(0); const uint d = get_global_id(1); const uint h = get_global_id(2); const uint units = get_global_size(0); const uint dimension = get_global_size(1); const uint heads = get_global_size(2);
カーネル本体では、3次元すべてでスレッドを識別します。また、タスク空間も決定します。これは、結果として得られるバッファのサイズを示すことになります。
ここで、データバッファのオフセットも決定します。
uint step = 3 * dimension * heads; uint start = max((int)u - 1, 0); uint stop = min((int)u + 1, (int)units - 1); const uint shift_q = u * step + dimension * h + d; const uint shift_k = u * step + dimension * (heads + h) + d; const uint shift_v = u * step + dimension * (2 * heads + h) + d;
次に、直接勾配分布に移ります。まず、Value要素の誤差勾配を定義します。そのために、得られた勾配に対応する影響係数を掛けます。
//--- Calculating Value's gradients float sum = 0; for(uint i = start; i <= stop; i ++) { int shift_score = i * 3 * heads; if(u == i) { shift_score += (uint)(u > 0); } else { if(u > i) shift_score += (uint)(start > 0) + 1; } uint shift_g = dimension * (i * heads + h) + d; sum += gradient[shift_g] * scores[shift_score]; } qkv_g[shift_v] = sum;
次のステップは、Queryエンティティの誤差勾配を定義することです。ここでのアルゴリズムはもう少し複雑です。まず、依存係数の対応するベクトルの誤差勾配を決定し、得られた勾配をSoftMax関数の微分に合わせる必要があります。この後初めて、得られた依存係数の誤差勾配に、Keyエンティティテンソルの対応する要素を掛けることができます。
依存係数を正規化する前に、位置Attenitionのバイアス要素を加えていることに注意してください。ご存知のように、足し算をする場合、勾配は両方向に完全に移動します。誤差のダブルカウントは、小さな学習係数によって簡単に相殺されます。したがって、依存係数行列のレベルの誤差勾配を位置シフト誤差勾配バッファに転送します。
//--- Calculating Query's gradients float grad = 0; uint shift_score = u * heads * 3; for(int k = start; k <= stop; k++) { float sc_g = 0; float sc = scores[shift_score + k - start]; for(int v = start; v <= stop; v++) for(int dim=0;dim<dimension;dim++) sc_g += scores[shift_score + v - start] * qkv[v * step + dimension * (2 * heads + h) + dim] * gradient[dimension * (u * heads + h) + dim] * ((float)(k == v) - sc); grad += sc_g * qkv[k * step + dimension * (heads + h) + d]; if(d == 0) rpb_g[shift_score + k - start] = sc_g; } qkv_g[shift_q] = grad;
次に、Keyエンティティの誤差勾配を同様に定義する必要があります。アルゴリズムはQueryと似ていますが、係数行列の次元が異なります。
//--- Calculating Key's gradients grad = 0; for(int q = start; q <= stop; q++) { float sc_g = 0; shift_score = q * heads * 3; if(u == q) { shift_score += (uint)(u > 0); } else { if(u > q) shift_score += (uint)(start > 0) + 1; } float sc = scores[shift_score]; for(int v = start; v <= stop; v++) { shift_score = v * heads * 3; if(u == v) { shift_score += (uint)(u > 0); } else { if(u > v) shift_score += (uint)(start > 0) + 1; } for(int dim=0;dim<dimension;dim++) sc_g += scores[shift_score] * qkv[shift_v-d+dim] * gradient[dimension * (v * heads + h) + d] * ((float)(d == v) - sc); } grad += sc_g * qkv[q * step + dimension * h + d]; } qkv_g[shift_k] = grad; }
これでカーネルでの作業を終了し、CNeuronDOTOCLクラスでの作業に戻ります。このクラスでは、上記で作成したカーネルを呼び出すDOTInsideGradientsメソッドを作成します。アルゴリズムは変わりません。
- タスク空間を定義します。
bool CNeuronDOTOCL::DOTInsideGradients(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iUnits, iDimension, iHeads};
- パラメータを渡します。
if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_qkv, cQKV.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_qkv_g, cQKV.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_scores, iScoreBuffer)) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_rpb_g, cRelativePositionsBias.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_DOTInsideGradients, def_k_dotg_gradient, MHAttentionOut.getGradientIndex())) return false;
- 実行キューに入れます。
ResetLastError(); if(!OpenCL.Execute(def_k_DOTInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
- その後、操作の結果を確認し、メソッドを終了します。
calcInputGradientsメソッドでは、バックプロパゲーションのアルゴリズムを直接記述します。このメソッドはパラメータで、誤差が伝播されるべき前の層のオブジェクトへのポインタを受け取ります。メソッド本体では、受け取ったポインタの妥当性を即座に確認します。ポインタが無効であれば、誤差勾配を渡す場所がなくなってしまうからです。そうなると、すべての演算の論理的意味は「0」に近くなります。
bool CNeuronDOTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer) return false;
次に、フィードフォワードパスの操作を逆の順序で繰り返します。CNeuronDOTOCLクラスを初期化する際、慎重にバッファを置き換えました。さて、後続のニューラル層から誤差勾配を受け取るとき、それを大域的Attention層に直接受け取りました。その結果、すでに不要なデータコピー操作を省略し、大域的Attentionの内部層で関連するメソッドを即座に呼び出します。
if(!cCAtten.calcInputGradients(GetPointer(SAttenOut))) return false;
ここでもバッファ置換技術を使用し、FeedForwardブロックを介して直ちに誤差勾配を伝播させました。
if(!cFF2.calcInputGradients(GetPointer(cFF1))) return false; if(!cFF1.calcInputGradients(GetPointer(AttentionOut))) return false;
次に、2つのスレッドの誤差勾配を合計します。
if(!SumAndNormilize(AttentionOut.getGradient(), SAttenOut.getGradient(), cProj.getGradient(), iWindowSize, false)) return false;
そして、それをAttentionヘッドの間で分配します。
if(!cProj.calcInputGradients(GetPointer(MHAttentionOut))) return false;
ウィンドウ型Self-Attentionブロックを通して誤差勾配を分配するメソッドを呼び出します。
if(!DOTInsideGradients()) return false;
次に、前の層と現在の層のサイズを確認します。データをスケーリングする必要がある場合は、まず誤差勾配をスケーリング層に伝搬させます。2つのスレッドからの誤差勾配を合計します。ここで始めて、誤差勾配を前の層にスケーリングします。
if(iPrevWindowSize != iWindowSize) { if(!cQKV.calcInputGradients(GetPointer(cProjInput))) return false; if(!SumAndNormilize(cProjInput.getGradient(), cProj.getGradient(), cProjInput.getGradient(), iWindowSize, false)) return false; if(!cProjInput.calcInputGradients(prevLayer)) return false; }
ニューラル層が等しい場合は、直ちに誤差勾配を前の層に移します。次に、2つ目のスレッドからの誤差勾配を補足します。
else { if(!cQKV.calcInputGradients(prevLayer)) return false; if(!SumAndNormilize(prevLayer.getGradient(), cProj.getGradient(), prevLayer.getGradient(), iWindowSize, false)) return false; } //--- return true; }
すべてのニューラル層に誤差勾配を伝搬させた後、誤差を最小化するようにモデルのパラメータを更新する必要があります。あることがなければ、ここではすべてがシンプルです。要素の位置影響パラメータバッファについて覚えていらっしゃるでしょうか。そのパラメータを更新する必要があります。この機能を実行するために、RPBUpdateAdamカーネルを作成します。カーネルパラメータには、現在のパラメータのバッファと誤差勾配へのポインタを渡します。Adam法の補助テンソルや定数も渡します。
__kernel void RPBUpdateAdam(__global float *target, __global const float *gradient, __global float *matrix_m, ///<[in,out] Matrix of first momentum __global float *matrix_v, ///<[in,out] Matrix of seconfd momentum const float b1, ///< First momentum multiplier const float b2 ///< Second momentum multiplier ) { const int i = get_global_id(0);
カーネル本体では、データバッファ内のオフセットを示すスレッドを識別します。
次に、ローカル変数を宣言し、グローバルバッファに必要な値を保存します。
float m, v, weight; m = matrix_m[i]; v = matrix_v[i]; weight = target[i]; float g = gradient[i];
Adam法に従い、まずモーメンタムを決定します。
m = b1 * m + (1 - b1) * g; v = b2 * v + (1 - b2) * pow(g, 2);
得られたモーメンタムに基づいて、必要なパラメータの調整を計算します。
float delta = m / (v != 0.0f ? sqrt(v) : 1.0f);
すべてのデータをグローバルバッファの対応する要素に保存します。
target[i] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[i] = m; matrix_v[i] = v; }
CNeuronDOTOCLクラスに戻り、カーネルを呼び出すupdateRelativePositionsBiasメソッドを作成しましょう。ここでは1次元のタスク空間を使用します。
bool CNeuronDOTOCL::updateRelativePositionsBias(void) { if(!OpenCL) return false; //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {cRelativePositionsBias.Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_rpb, cRelativePositionsBias.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_gradient, cRelativePositionsBias.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_matrix_m, cRelativePositionsBias.getFirstMomentumIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_RPBUpdateAdam, def_k_rpbw_matrix_v, cRelativePositionsBias.getSecondMomentumIndex())) return false; if(!OpenCL.SetArgument(def_k_RPBUpdateAdam, def_k_rpbw_b1, b1)) return false; if(!OpenCL.SetArgument(def_k_RPBUpdateAdam, def_k_rpbw_b2, b2)) return false; ResetLastError(); if(!OpenCL.Execute(def_k_RPBUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
準備作業は完了しました。次に、ブロックパラメータを更新するためのトップレベルメソッドupdateInputWeightsの作成に移ります。このメソッドはパラメータで、前の層のオブジェクトへのポインタを受け取ります。この場合、受信したポインタの確認は内部層のメソッドでおこなわれるので省略します。
まず、スケーリング層のパラメータを更新する必要があるかどうかを確認します。更新が必要な場合は、指定された層の関連メソッドを呼び出します。
if(iWindowSize != iPrevWindowSize) { if(!cProjInput.UpdateInputWeights(NeuronOCL)) return false; if(!cQKV.UpdateInputWeights(GetPointer(cProjInput))) return false; } else { if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; }
次に、Query、Key、Valueの各エンティティ生成層のパラメータを更新します。
同様に、すべての内部層のパラメータを更新します。
if(!cProj.UpdateInputWeights(GetPointer(MHAttentionOut))) return false; if(!cFF1.UpdateInputWeights(GetPointer(AttentionOut))) return false; if(!cFF2.UpdateInputWeights(GetPointer(cFF1))) return false; if(!cCAtten.UpdateInputWeights(GetPointer(SAttenOut))) return false;
そしてメソッドの最後に、位置オフセットのパラメータを更新します。
if(!updateRelativePositionsBias()) return false; //--- return true; }
繰り返しになりますが、各段階で結果をコントロールすることを忘れてはなりません。
これで、新しいニューラル層CNeuronDOTOCLのメソッドについての考察は終わりです。この記事で説明していないものも含め、このクラスとメソッドの完全なコードは添付ファイルにあります。
次に進み、新しいモデルのアーキテクチャを構築していきます。
2.2 モデルアーキテクチャ
いつものように、CreateDescriptionsメソッドでモデルのアーキテクチャを記述します。このメソッドはパラメータで、モデル記述を格納するための3つの動的配列へのポインタを受け取ります。メソッド本体では、受け取ったポインタの関連性を即座に確認し、必要であれば新しい配列のインスタンスを作成します。
bool CreateDescriptions(CArrayObj *dot, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!dot) { dot = new CArrayObj(); if(!dot) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
3つのモデルを作成する必要があります。
- DOT
- Actor
- Critic
DOTブロックはDFFTアーキテクチャによって提供されますが、ActorやCriticについては何もありません。DFFT法は、分類と回帰の出力を持つTAEブロックの作成を提案していることを思い出してください。ActorとCriticの連続使用はTAEブロックを発するべきです。Actorは行動分類器であり、Criticは報酬回帰です。
DOTモデルには、環境の現在の状態を記述します。
//--- DOT dot.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
バッチ正規化層で「生」データを処理します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
そして、最新データの埋め込みを作成し、スタックに追加します。
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!dot.Add(descr)) { delete descr; return false; }
次に、データの位置符号化を追加します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!dot.Add(descr)) { delete descr; return false; }
ここまでは、これまでの研究による埋め込みアーキテクチャを繰り返してきましたが、変更があります。最初のDOTブロックを追加し、個々の状態のコンテキストで分析を実行します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
次のブロックでは、データを2倍に圧縮しますが、個々の状態の文脈で分析を続けます。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; prev_wout = descr.window = prev_wout / 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
次に、分析用のデータを2つの連続した状態にグループ分けします。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; prev_count = descr.count = prev_count / 2; prev_wout = descr.window = prev_wout * 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
もう一度、データを圧縮します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDOTOCL; descr.count = prev_count; prev_wout = descr.window = prev_wout / 2; descr.step = 4; descr.window_out = prev_wout / descr.step; if(!dot.Add(descr)) { delete descr; return false; }
DOTモデルの最後の層は、DFFT法を超えます。ここではCross-Attention層を追加しました。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMH2AttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = prev_wout / descr.step; descr.optimization = ADAM; if(!dot.Add(descr)) { delete descr; return false; }
Actorモデルは、環境状態のDOTモデルで処理された入力を受け取ります。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = prev_count*prev_wout; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
受信したデータは、現在の口座ステータスと組み合わされます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
データは2つの全結合層で処理されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
出力では、確率的Actorポリシーを生成します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Criticもまた、処理された環境状態を入力として使用します。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); if(!critic.Add(descr)) { delete descr; return false; }
環境状態の記述をエージェントの行動で補足します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; }
データは、出力に報酬ベクトルを持つ2つの全結合層によって処理されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.3 環境との相互作用EA
モデルのアーキテクチャを作成した後は、環境とのインタラクションのためのEA「...\Experts\DFFT\Research.mq5」の作成に移ります。このEAは、最初の訓練サンプルを収集し、その後、経験再生バッファを更新するように設計されています。EAは訓練済みモデルのテストにも使用できますが、この機能を実行するためには、別のEA「...\Experts\DFFT\Test.mq5」が提供されています。どちらのEAもアルゴリズムは似ていますが、後者は、その後の訓練のためにデータを経験再生バッファに保存しません。これは、訓練されたモデルの「公正」な テストのためにおこなわれます。
どちらのEAも主に過去の作業からコピーしたものです。本稿の枠内では、モデルの仕様に関連する変更にのみ焦点を当てます。
データ収集中は、Criticモデルは使用しません。
CNet DOT; CNet Actor;
EAの初期化メソッドでは、まず必要な指標を接続します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- load models float temp;
次に、事前訓練されたモデルを読み込んでみます。
if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *dot = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, actor, critic)) { delete dot; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Actor.Create(actor)) { delete dot; delete actor; delete critic; return INIT_FAILED; } delete dot; delete actor; delete critic; }
モデルを読み込めなかった場合は、ランダムなパラメータで新しいモデルを初期化します。その後、両方のモデルを1つのOpenCLコンテキストに転送します。
Actor.SetOpenCL(DOT.GetOpenCL());
また、モデルアーキテクチャの最小限の確認もおこないます。
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- DOT.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
残高の状態をローカル変数に保存します。
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
環境とのインタラクションとデータ収集はOnTickメソッドで実装されます。メソッド本体では、まず新しいバーの開始イベントの発生を確認します。いかなる分析も、新しいローソク足に対してのみ実行されます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
次に、履歴データを更新します。
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
環境の状態を記述するためのバッファを埋めます。
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
次のステップは、現在の口座ステータスに関するデータを収集することです。
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
収集されたデータは、口座ステータスを示すバッファに統合されます。
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
ここでは、現在の状態のタイムスタンプを追加します。
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); //--- if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return;
初期データを収集した後、エンコーダのフィードフォワードパスを実行します。
if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
即座にActorのフィードフォワードパスを実行します。
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(DOT), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
モデル結果を受け取ります。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions);
それを解読しながら取引をおこないます。
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
環境から受け取ったデータを経験再生バッファに保存します。
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
EAの残りのメソッドは変更なく移管されました。添付ファイルをご覧ください。
2.4 モデル訓練EA
訓練用データセットを収集した後、モデル訓練用EA「...\Experts\DFFT\Study.mq5」の構築に進みます。環境相互作用EAと同様、そのアルゴリズムは過去の記事からほぼコピーされました。したがって、本稿の枠組みでは、Trainモデルの訓練メソッドのみを検討することを提案します。
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
メソッドの本体では、まず、訓練データセットから軌道を選択するための確率ベクトルを、その収益性に応じて生成します。最も収益性の高いパスは、モデルの訓練に頻繁に使用されます。
次に、必要なローカル変数を宣言します。
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
準備作業を終えたら、モデルの訓練ループのシステムを構築します。エンコーダのモデルでは、履歴データを積み重ねて使用したことを思い出してください。このようなモデルは、使用されるデータの過去のシーケンスに非常に敏感です。そのため、外側のループでは、経験再生バッファから軌跡をサンプリングし、この軌跡で学習するための初期状態をサンプリングします。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
その後、モデルの内部スタックをクリアします。
DOT.Clear();
モデルを訓練するために、経験再生バッファから連続した履歴状態を抽出するネストされたサイクルを作成します。モデルの訓練バッチは、モデル内部のトラックの深さより2日浅く設定しました。
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
ネストされたループの本体では、経験再生バッファから1つの環境状態を抽出し、それをエンコーダのフィードフォワードパスに使用します。
//--- Trajectory if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Actorの方策を訓練するためには、環境相互作用アドバイザーでおこなったように、まず口座状態記述バッファを埋める必要があります。しかし今は、環境をポーリングするのではなく、経験再生バッファからデータを抽出しています。
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
また、タイムスタンプも追加します。
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
その後、ActorとCriticのフィードフォワードパスを実行します。
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(DOT), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Critic if(!Critic.feedForward((CNet *)GetPointer(DOT), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
次に、経験再生バッファから行動をおこすようにActorを訓練し、その勾配をエンコーダモデルに転送します。オブジェクトはDFFT法で提案されたようにTAEブロックで分類されます。
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, (CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
次に、環境の新しい状態への遷移に対する報酬を決定します。
result.Assign(Buffer[tr].States[i+1].rewards); target.Assign(Buffer[tr].States[i+2].rewards); result=result-target*DiscFactor;
誤差勾配を両モデルに転送することで、Criticモデルを訓練します。
Result.AssignArray(result); if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !DOT.backPropGradient((CBufferFloat*)NULL) || !Actor.backPropGradient((CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
多くのアルゴリズムで、モデルの相互適応を避けようとしてきたことに注意してください。そのため、望ましくない結果を避けるように努めました。これに対してDFFT法の著者は、この手法によってエンコーダのパラメータをより適切に設定し、最大限の情報を引き出すことができると述べています。
モデルを訓練した後、訓練の進捗状況をユーザーに通知し、ループの次の反復に移ります。
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
訓練プロセスのすべての反復が成功したら、チャートのコメント欄を消去します。学習結果は操作ログに出力されます。次に、EAの完成を初期化します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
これで、モデル訓練EAのメソッドについての確認は終わりです。EAの全コードと全メソッドが添付ファイルにあります。添付ファイルには、この記事で使用したすべてのプログラムも含まれています。
3.テスト
MQL5を使用してDecoder-Free Fully Transformer-based (DFFT)法を実装するために、かなり多くの作業をおこないました。さて、いよいよ記事のパート3です。前回と同様に、新しいモデルはEURUSD H1のヒストリカルデータを使用して訓練およびテストされます。指標はデフォルトのパラメータで使用されます。
モデルを訓練するために、2023年の最初の7ヶ月間にわたって500のランダムな軌跡を収集しました。訓練済みモデルは、2023年8月の過去データでテストされました。したがって、テスト区間は訓練セットに含まれていません。これにより、新しいデータでのパフォーマンス評価が可能になります。
このモデルは、訓練の過程でも、テスト中の動作モードでも、消費される計算資源がかなり「軽い」ことがわかりました。
学習プロセスは非常に安定しており、ActorとCriticの両者とも、誤差はスムーズに減少しました。訓練の過程で、訓練データとテストデータの両方で小さな利益を生み出すことができるモデルが得られました。しかし、より高いレベルの収益性と、より均等なバランスラインを得ることができれば、それに越したことはありません。
結論
本稿では、コンピュータビジョンの問題を解決するために発表された、デコーダなしのTransmitterベースの効果的な物体検出器であるDFFT法について学びました。このアプローチの主な特徴は、特徴量抽出のためのTransmitterの使用と、単一の特徴量マップ上での高密度予測です。この手法は、モデルの訓練と運用の効率を向上させる新しいモジュールを提供しています。
この手法の著者らは、DFFTが比較的低い計算コストで高精度の物体検出を実現することを実証しました。
本稿の実践編では、MQL5を用いて提案されたアプローチを実装しました。構築したモデルを実際の履歴データで訓練し、テストしました。得られた結果は、提案アルゴリズムの有効性を確認するものであり、より詳細な実用的研究に値します。
この記事で紹介されているプログラムはすべて、情報提供のみを目的としていることをお断りしておきます。これらは、提案されたアプローチとその能力を実証するためだけに作られました。実際の金融市場でプログラムを使用する前に、必ず最終的な結論を出し、徹底的にテストしてください。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14338
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索