
Redes neuronales: así de sencillo (Parte 72): Predicción de trayectorias en entornos ruidosos

Introducción
Predecir el movimiento futuro de un activo analizando sus trayectorias históricas es importante en el contexto de la negociación en los mercados financieros, donde el análisis de las tendencias pasadas puede ser un factor clave para el éxito de una estrategia. Las trayectorias futuras de los activos suelen contener incertidumbre debido a los cambios en los factores subyacentes y a la reacción del mercado ante ellos, lo que determina muchos posibles movimientos futuros de los activos. Por lo tanto, un método eficaz para predecir los movimientos del mercado debe ser capaz de generar una distribución de posibles trayectorias futuras, o al menos varios escenarios plausibles.
A pesar de la considerable variedad de arquitecturas existentes para las predicciones más probables, los modelos pueden enfrentarse al problema de las previsiones demasiado simplistas a la hora de predecir las trayectorias futuras de los activos financieros. El problema persiste porque el modelo interpreta de forma restrictiva los datos del conjunto de entrenamiento. En ausencia de patrones claros de las trayectorias de los activos, el modelo de predicción acaba generando escenarios de movimientos simples u homogéneos que son incapaces de captar la diversidad de cambios en el movimiento de los instrumentos financieros. Esto puede provocar una disminución de la precisión de las previsiones.
Los autores del artículo "Enhancing Trajectory Prediction through Self-Supervised Waypoint Noise Prediction" ofrecen un nuevo enfoque para resolver estos problemas, Self-Supervised Waypoint Noise Prediction (SSWNP), que consta de dos módulos:
- Módulo de coherencia espacial
- Módulo de predicción de ruido
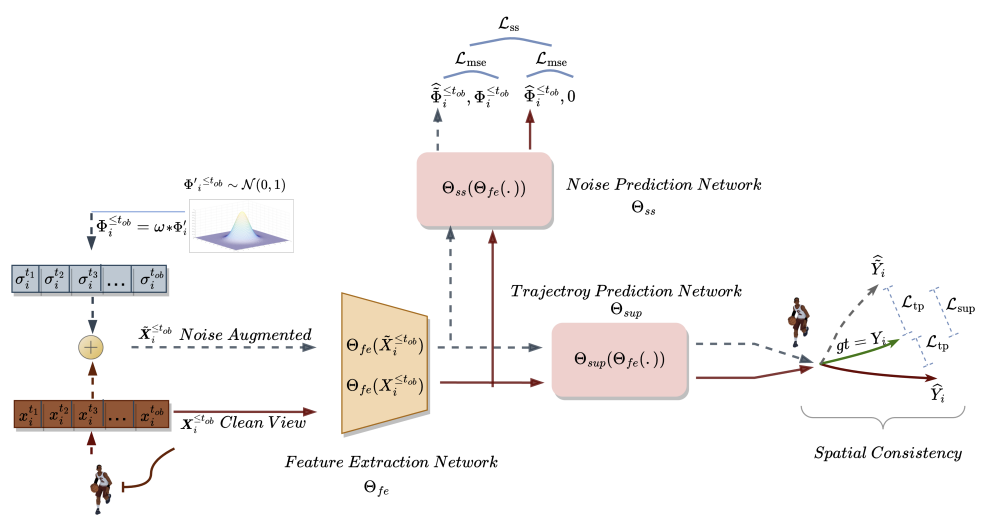
El primero crea dos vistas diferentes de trayectorias observadas históricamente: vistas limpias y vistas aumentadas por ruido del dominio espacial de los puntos clave. Como su nombre indica, la versión limpia representa las trayectorias originales, mientras que la versión aumentada con ruido representa las trayectorias pasadas que se han movido en el espacio de características original con ruido añadido. Este enfoque aprovecha el hecho de que la versión ruidosa de las trayectorias pasadas no corresponde a una interpretación estricta de los datos del conjunto de entrenamiento. El modelo utiliza esta información adicional para superar el problema de las predicciones demasiado simplistas y explorar escenarios más diversos. Tras generar dos trayectorias pasadas diferentes, entrenamos un modelo de predicción de trayectorias futuras para mantener la coherencia espacial entre las predicciones de ambas y aprender características espaciotemporales más allá de la tarea de predicción del movimiento.
El módulo de predicción de ruido resuelve el problema auxiliar de identificar el ruido en las trayectorias analizadas. Esto ayuda al modelo de predicción de movimientos a modelizar mejor la diversidad espacial potencial y mejora la comprensión de la representación subyacente en la predicción de movimientos, mejorando así las predicciones futuras.
Los autores del método realizaron experimentos adicionales para demostrar empíricamente la importancia crítica de los módulos de coherencia espacial y predicción de ruido para SSWNP. Cuando se utiliza únicamente el módulo de coherencia espacial para resolver el problema de predicción del movimiento, se observa un rendimiento subóptimo del modelo entrenado. Por ello, integran ambos módulos en su trabajo.
1. Algoritmo SSWNP
El objetivo de la predicción de trayectorias es determinar la trayectoria futura más probable de un agente en un entorno dinámico a partir de sus trayectorias observadas previamente. Una trayectoria se representa mediante una serie temporal de puntos espaciales denominados waypoints. La trayectoria observada abarca un período comprendido entre t1 y tob y puede denotarse como
![]()
donde Xi* corresponde a las coordenadas de i en un paso de tiempo t*. Del mismo modo, la trayectoria futura prevista para el agente i durante el periodo [tob+1,tfu] puede describirse como Ŷtob+1≤t≤tfu. La trayectoria verdadera correspondiente para el movimiento futuro del agente i puede describirse como Ytob+1≤t≤tfu.
En el método SSWNP, primero se crean dos vistas diferentes de las trayectorias: una se caracteriza como vista limpia (X≤tob), y la otra como vista aumentada por ruido (Ẍ≤tob). La vista limpia corresponde a la trayectoria original del conjunto de datos de entrenamiento, mientras que la vista aumentada por ruido corresponde a una trayectoria que se ha desplazado en el espacio de características añadiendo ruido.
Se utiliza ruido de la distribución normal estándar N(0, 1) para distorsionar la trayectoria limpia. Los autores del método introducen un parámetro denominado factor de ruido (ω), que controla el movimiento espacial de los waypoints.
![]()
Tras crear las vistas de trayectoria limpia y aumentada por ruido, las introducimos en el modelo de extracción de características (Θfe), que genera características correspondientes tanto a la vista limpia como a la vista aumentada por ruido. Las características resultantes se introducen en un modelo de predicción de trayectorias (Θsup) para predecir las trayectorias Ŷtob+1≤t≤tfu y Ÿtob+1≤t≤tfu, como se muestra en las ecuaciones siguientes:
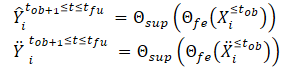
Entrenamos el modelo para minimizar la diferencia entre las trayectorias predichas y la trayectoria real del conjunto de datos de entrenamiento. Como puede verse, al minimizar el error en la predicción de trayectorias a partir de datos iniciales limpios y aumentados por ruido (Ŷ y Ÿ) con respecto a la trayectoria real del conjunto de datos de entrenamiento (Y), estamos reduciendo indirectamente la diferencia entre las 2 trayectorias pronosticadas. De este modo se mantiene la coherencia espacial entre las predicciones de trayectorias futuras basadas en trayectorias observadas limpias y en trayectorias aumentadas por el ruido.
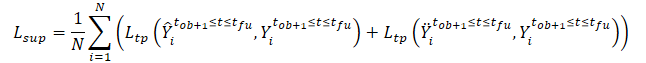
Además, el método SSWNP resuelve el problema de la predicción autosupervisada del ruido, que incluye la predicción del ruido presente en su forma limpia, la trayectoria pasada observada X≤tob, así como en la forma aumentada por el ruido Ẍ≤tob. El objetivo aquí es estimar el valor de ruido asociado a un waypoint observado dado.
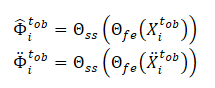
Nótese que las características extraídas por el modelo Θfe se utilizan como datos de entrada para el modelo de predicción de ruido (Θss), que determina el nivel de ruido en las trayectorias observadas (vistas limpias y aumentadas). Como función de pérdida para el aprendizaje autosupervisado del modelo de predicción de ruido, los autores del método proponen utilizar el error cuadrático medio (MSE, Mean Square Error).
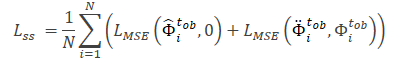
El valor 0 denota aquí la ausencia de ruido en la trayectoria de forma limpia.
La función de pérdida general del método SSWNP se representa como:
![]()
Donde λ denota la contribución del error de predicción del ruido al error total cuando se entrena el modelo utilizando el enfoque propuesto.
A continuación se presenta la visualización original del método Self-Supervised Waypoint Noise Prediction.
2. Implementación usando MQL5
Hemos visto los aspectos teóricos del método Self-Supervised Waypoint Noise Prediction. Como puede verse, los enfoques propuestos no imponen ninguna restricción ni a la arquitectura de los modelos utilizados ni a la estructura de los datos de origen. Esto nos permite integrar los enfoques propuestos con un gran número de algoritmos que hemos considerado anteriormente. En concreto, en este artículo añadiremos los enfoques propuestos al algoritmo de entrenamiento del autoencoder TrajNet, el método que analizamos en el reciente artículo sobre Goal-Conditioned Predictive Coding (GCPC).
Como ya hemos comentado, el algoritmo GCPC ofrece 2 etapas de entrenamiento del modelo:
El método SSWNP analizado en este artículo pretende mejorar la eficacia de la predicción de trayectorias futuras. Por lo tanto, sólo cubre la etapa de "Entrenamiento de la función de trayectoria". Haremos los ajustes necesarios en esta etapa. La segunda fase, "Formación en política de comportamiento", se utilizará en su forma actual.
2.1 Problemas de integración de métodos
Al integrar nuevos enfoques en una estructura ya creada, debemos asegurarnos de que los cambios que introduzcamos no perturben el proceso ya construido. Por lo tanto, antes de comenzar nuestro trabajo, debemos analizar el impacto de los nuevos enfoques en el proceso de aprendizaje previamente creado y el posterior funcionamiento del modelo.
El aumento de ruido en las trayectorias del conjunto de datos de entrenamiento cambiará obviamente la distribución de los datos originales. En consecuencia, esto afectará a los parámetros de la capa de normalización por lotes, en la que preprocesamos los datos de origen. Por un lado, esto es lo que intentamos conseguir. Queremos entrenar un modelo para que funcione en condiciones cercanas a las reales en un entorno con alta estocasticidad. Por otra parte, la adición de ruido aleatorio puede llevar los datos originales más allá de los valores reales de los parámetros analizados. Para minimizar el impacto negativo de este factor, los autores del algoritmo añadieron un factor de ruido (ω), que regula la cantidad de desplazamiento de datos. Si disponemos de datos "brutos" no normalizados, necesitaremos un factor de ruido distinto para cada métrica de los datos de origen. Así, llegamos a utilizar un vector de factores de ruido. A continuación, la selección de un vector de hiperparámetros se convierte en una tarea bastante compleja, cuya complejidad aumenta con el incremento del número de parámetros analizados.
Resulta que la solución a este problema es bastante sencilla. Multiplicar el ruido de una distribución normal por un cierto factor es en realidad bastante similar al truco de reparametrización, que utilizamos en la capa del autoencoder variacional.
![]()
Por lo tanto, utilizando los parámetros de la distribución del conjunto de datos de entrenamiento, podemos mantener el modelo dentro de la distribución original. Al mismo tiempo, añadimos la estocasticidad inherente al entorno analizado.
Sin embargo, hay que tener en cuenta un punto más. Añadimos ruido a las trayectorias reales del conjunto de datos de entrenamiento en lugar de sustituir sus datos por valores aleatorios. Al resolver el problema directamente, obtenemos los parámetros de distribución de los datos iniciales.
Volvamos a la idea de utilizar el ruido. En un momento determinado, disponemos de datos reales de cada uno de los parámetros analizados. En el siguiente paso temporal, los parámetros cambian en una determinada cantidad. La magnitud del cambio de cada parámetro depende de un gran número de factores diferentes, lo que la aproxima a una variable aleatoria. Al mismo tiempo, este cambio tiene sus límites. Por lo tanto, para preservar la distribución natural de los datos originales, podemos determinar los parámetros de distribución de dichas desviaciones entre 2 valores posteriores de cada parámetro analizado. Estos serán los parámetros para reparametrizar nuestro ruido.
Aquí hay que tener en cuenta que un cambio significativo en los valores de los parámetros suele indicar un cambio en la situación del mercado. Según el método SSWNP, el modelo se entrena para minimizar la diferencia entre las predicciones de trayectorias a partir de datos limpios y de datos ruidosos. Por lo tanto, utilizaremos el factor de ruido propuesto por los autores del método para limitar el sesgo de las trayectorias reales del conjunto de entrenamiento.
El segundo punto es el uso de la capa DropOut en el método GCPC, que también sirve como una especie de regularización y está diseñada para entrenar al modelo a ignorar algunos "valores atípicos" y restaurar los parámetros que faltan. En el caso de los métodos combinados, tenemos la ignorancia del ruido añadido a los parámetros enmascarados por la capa DropOut. Por otro lado, el enmascaramiento de parámetros dificulta mucho más el problema resuelto por el modelo en comparación con la adición de ruido.
Como ya se ha dicho, no debemos violar el proceso previamente construido. Por lo tanto, no excluiremos la capa DropOut de la arquitectura del codificador. Será interesante observar los resultados del entrenamiento del modelo.
Veamos ahora cómo se construye el método Self-Supervised Waypoint Noise Prediction. Según el algoritmo, entrenaremos 3 modelos:
- modelo de extracción de características
- modelo de predicción de trayectoria
- modelo de predicción del ruido
Tenemos previsto integrar el algoritmo SSWNP en el proceso GCPC construido previamente. Intentemos comparar los modelos de ambos métodos. El modelo de extracción de características SSWNP corresponde al codificador GCPC. A su vez, el decodificador GCPC puede representarse como un modelo de predicción de trayectoria SSWNP. Por lo tanto, tenemos que añadir un modelo de predicción de ruido.
2.2 Arquitectura modelo
Las arquitecturas de los modelos se describirán en el método CreateTrajNetDescriptions, al que añadiremos una descripción del tercer modelo. En los parámetros, el método recibe punteros a tres matrices dinámicas para describir la arquitectura de estos tres modelos. En el cuerpo del método, comprobamos la pertinencia de los punteros recibidos y, si es necesario, creamos nuevas instancias de objetos.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *decoder, CArrayObj *noise) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; } if(!noise) { noise = new CArrayObj(); if(!noise) return false; }
Copiamos la descripción de las arquitecturas del codificador y el decodificador sin cambios. Como hemos visto en artículos anteriores, introducimos en el codificador datos iniciales sin procesar, entre los que indicamos únicamente las variaciones históricas de los precios y los indicadores analizados.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Se someten a un tratamiento primario en la capa de normalización por lotes.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos normalizados se enmascaran aleatoriamente en la capa DropOut.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.8f; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Después buscamos patrones estables utilizando un bloque de capas convolucionales.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 2; descr.window = 3; descr.step = 1; int prev_wout = descr.window_out = 3; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, procesamos los datos en un bloque de capas totalmente conectado.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Añadimos de forma recurrente los resultados de las pasadas anteriores del codificador.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * EmbeddingSize; descr.window = prev_count; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación, transferimos los datos a la pila interna del historial que estamos analizando.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = GPTBars; { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
El conjunto de datos históricos resultante se analiza en el bloque de atención.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count * 2; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 4; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los resultados del análisis se comprimen mediante una capa totalmente conectada.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = 1; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
A la salida del codificador, normalizamos los datos utilizando la función SoftMax.
Los resultados del paso hacia delante del codificador se introducen en el decodificador.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
En este caso, se trata de datos obtenidos a partir del modelo anterior, que ya han sido normalizados. Por lo tanto, no es necesario preprocesar los datos. Inmediatamente los ampliamos utilizando una capa totalmente conectada.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars + PrecoderBars) * EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Los datos recibidos se analizan en el bloque de atención.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 2; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
A la salida del bloque de atención, tenemos una incrustación de cada vela predicha. Para descodificar las incrustaciones resultantes, utilizaremos una capa multimodelo totalmente conectada.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiModels; descr.count = 3; descr.window = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Tras describir la arquitectura del codificador y el decodificador, tenemos que añadir una descripción de la arquitectura del modelo de predicción de ruido. Este modelo, al igual que el decodificador, utiliza los resultados del codificador como datos de entrada. Por lo tanto, nos limitamos a copiar la capa de datos del decodificador original.
//--- Noise Prediction noise.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(decoder.At(0)); if(!noise.Add(descr)) { delete descr; return false; }
A continuación, utilizando una capa totalmente conectada, ampliamos los datos recibidos al tamaño de los datos originales en la entrada del codificador.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = HistoryBars * EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; }
Ahora atención. En el siguiente paso, probablemente por primera vez en toda la serie de artículos, creé ramificaciones para la arquitectura del modelo en función de los hiperparámetros seleccionados. La clave aquí es el número de velas analizadas en la entrada del codificador. Al analizar más de una vela, la arquitectura del modelo se parecerá a la del decodificador. Utilizamos un bloque de atención y una capa multimodelo para descodificar las incrustaciones. Sólo que aquí no estamos hablando de velas de pronóstico, sino de velas analizadas.
//--- if(HistoryBars > 1) { //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 2; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiModels; descr.count = BarDescr; descr.window = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; } }
Cuando se analiza una sola vela en la entrada del codificador, no tiene sentido utilizar una capa de atención que analice las relaciones entre diferentes velas. Por lo tanto, utilizaremos un perceptrón simple.
else { //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!noise.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr; descr.activation = None; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; } } //--- return true; }
La descripción anterior sólo se ofrece para las arquitecturas de los modelos que participan en el entrenamiento del modelo de función de trayectoria. La arquitectura de los modelos de formación de políticas de comportamiento de los agentes se utiliza sin cambios. Los encontrará en el archivo adjunto. En el anterior artículo se ofrecía una descripción detallada.
2.3 Programas de entrenamiento de modelos
Tras describir la arquitectura de los modelos utilizados, podemos pasar a considerar los algoritmos de los programas. Téngase en cuenta que los autores del método SSWNP no presentan requisitos para la selección de datos fuente y la recogida de trayectorias observadas para el entrenamiento. Por lo tanto, los programas que interactúan con el entorno se utilizan tal cual, sin ningún ajuste. El código completo de todos los programas utilizados en el artículo está disponible en el archivo adjunto, por lo que puede estudiarlos. Si necesita aclaraciones, consulte el artículo anterior o formule una pregunta en la discusión en el foro.
Pasamos al entrenamiento de la función de trayectoria del EA ...\_Experts\SSWNP\StudyEncoder.mq5, en el que entrenaremos simultáneamente 3 modelos:
- modelo de extracción de características (Encoder)
- modelo de predicción de trayectoria (Decodificador)
- modelo de predicción de ruido (Ruido).
CNet Encoder; CNet Decoder; CNet Noise;
Como se mencionó en la parte teórica, para implementar el algoritmo SSWNP, necesitamos definir 2 hiperparámetros. Las implementaremos como constantes en nuestro programa.
#define STE_Noise_Multiplier 1.0f/10 // λ determined the impact of noise prediction error #define STD_Delta_Multiplier 1.0f/10 // noise factor ω
En el método de inicialización del EA, primero cargamos el conjunto de entrenamiento.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
A continuación, intentamos abrir modelos previamente entrenados. Si se produce un error al cargar los modelos, creamos otros nuevos y los inicializamos con parámetros aleatorios.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Decoder.Load(FileName + "Dec.nnw", temp, temp, temp, dtStudied, true) || !Noise.Load(FileName + "NP.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *encoder = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *noise = new CArrayObj(); if(!CreateTrajNetDescriptions(encoder, decoder, noise)) { delete encoder; delete decoder; delete noise; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Decoder.Create(decoder) || !Noise.Create(noise)) { delete encoder; delete decoder; delete noise; return INIT_FAILED; } delete encoder; delete decoder; delete noise; //--- }
Transfiere todos los modelos a un único contexto OpenCL.
//---
OpenCL = Encoder.GetOpenCL();
Decoder.SetOpenCL(OpenCL);
Noise.SetOpenCL(OpenCL);
A continuación, añadimos un control de los parámetros clave de la arquitectura de los modelos utilizados.
//--- Encoder.getResults(Result); if(Result.Total() != EmbeddingSize) { PrintFormat("The scope of the Encoder does not match the embedding size count (%d <> %d)", EmbeddingSize, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Decoder.GetLayerOutput(0, Result); if(Result.Total() != EmbeddingSize) { PrintFormat("Input size of Decoder doesn't match Encoder output (%d <> %d)", Result.Total(), EmbeddingSize); return INIT_FAILED; } //--- Noise.GetLayerOutput(0, Result); if(Result.Total() != EmbeddingSize) { PrintFormat("Input size of Noise Prediction model doesn't match Encoder output (%d <> %d)", Result.Total(), EmbeddingSize); return INIT_FAILED; } //--- Noise.getResults(Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Output size of Noise Prediction model doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Después de pasar con éxito todos los controles, creamos el búfer de datos auxiliar.
//--- if(!LastEncoder.BufferInit(EmbeddingSize, 0) || !Gradient.BufferInit(EmbeddingSize, 0) || !LastEncoder.BufferCreate(OpenCL) || !Gradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
Generar un evento personalizado para el inicio del proceso de aprendizaje.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
En el método de desinicialización del EA, guardamos los modelos entrenados y borramos de la memoria los objetos dinámicos creados previamente.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Encoder.Save(FileName + "Enc.nnw", 0, 0, 0, TimeCurrent(), true); Decoder.Save(FileName + "Dec.nnw", Decoder.getRecentAverageError(), 0, 0, TimeCurrent(), true); Noise.Save(FileName + "NP.nnw", Noise.getRecentAverageError(), 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
El proceso real de entrenamiento de los modelos se implementa en el método Train. Como antes, en el cuerpo del método, primero calculamos las probabilidades de elegir trayectorias del búfer de repetición de experiencias.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
A continuación, creamos e inicializamos las variables locales necesarias.
//--- vector<float> result, target, inp; matrix<float> targets; matrix<float> delta; STE = vector<float>::Zeros((HistoryBars + PrecoderBars) * 3); STE_Noise = vector<float>::Zeros(HistoryBars * BarDescr); int std_count = 0; int batch = GPTBars + 50; bool Stop = false; uint ticks = GetTickCount();
Con esto se completa el trabajo preparatorio. A continuación, creamos un sistema de ciclos de formación de modelos. Como recordarás, la arquitectura GPT utilizada en el codificador establece requisitos estrictos para la secuencia de datos de entrada. Por lo tanto, creamos un sistema de bucles anidados. En el cuerpo del bucle externo, muestreamos una trayectoria y el estado en ella para iniciar el lote de entrenamiento. En el bucle anidado, entrenamos el modelo en un lote de estados secuenciales de una trayectoria.
Aquí viene otro reto. No podemos utilizar datos limpios y con ruido en la misma secuencia. Según el método SSWNP, el ruido se añade a las trayectorias en lugar de a los estados individuales.
Al mismo tiempo, no podemos introducir alternativamente en el modelo un estado limpio y otro con ruido añadido en una iteración. En la pila interna, los modelos de estado se mezclarán y el modelo los percibirá como una única trayectoria. Esto distorsiona enormemente la secuencia analizada.
Una solución aceptable es alternar trayectorias. El modelo se entrena primero con una trayectoria limpia y luego con una trayectoria aumentada por el ruido. Este enfoque nos permite resolver simultáneamente otra cuestión que concierne al vector de coeficientes de reparametrización del ruido. Al entrenar un modelo con datos limpios, recogemos información sobre la distribución de los cambios de los parámetros. Utilizamos los valores de la distribución recogida para reparametrizar el ruido añadido al entrenar el modelo con datos aumentados por el ruido.
Como ya se ha mencionado, creamos un bucle externo en el que muestreamos la trayectoria y el estado inicial.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
A continuación, borramos las pilas de modelos y el búfer auxiliar.
Encoder.Clear();
Decoder.Clear();
Noise.Clear();
LastEncoder.BufferInit(EmbeddingSize, 0);
Determinamos el estado final del paquete de entrenamiento en la trayectoria y despejamos la matriz para recoger información sobre los cambios en los parámetros analizados.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); delta = matrix<float>::Zeros(end - state - 1, Buffer[tr].States[state].state.Size());
Observe que el tamaño de la matriz de varianza es 1 fila menor que el lote de entrenamiento. Esto se debe a que en esta matriz guardaremos el delta del cambio entre 2 estados posteriores.
En esta fase, todo está listo para empezar a entrenar el modelo sobre una trayectoria limpia. Así, creamos el primer bucle de entrenamiento anidado.
for(int i = state; i < end; i++) { inp.Assign(Buffer[tr].States[i].state); State.AssignArray(inp); int row = i - state; if(i < (end - 1)) delta.Row(inp, row);
En el cuerpo del bucle, extraemos el estado analizado de la muestra de entrenamiento y lo transferimos al búfer de datos de origen.
Utilizamos el mismo estado para calcular las desviaciones. En primer lugar, comprobamos si el estado actual es el último del lote de datos de entrenamiento y añadimos el estado analizado a la fila correspondiente de la matriz de desviación (el último estado no se añade).
¿Por qué añadimos los estados tal cual, cuando se trata de una matriz de desviación? La respuesta está en el siguiente paso. En cada iteración posterior del bucle, restamos la acción que se está analizando de la fila anterior de la matriz de desviación, que contiene el estado previo guardado en el paso anterior. Por supuesto, nos saltamos este paso para el primer estado cuando no hay paso previo.
if(row > 0) delta.Row(delta.Row(row - 1) - inp, row - 1);
A continuación, llamamos secuencialmente a los métodos de paso feed-forward de los modelos entrenados. Primero viene el codificador (Encoder).
if(!LastEncoder.BufferWrite() || !Encoder.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(LastEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Le sigue el descodificador (Decoder).
if(!Decoder.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
El bloque forward-forward termina con un modelo de predicción de ruido.
if(!Noise.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Como de costumbre, después del bloque de avance (feed-forward), ejecutamos una pasada de retropropagación de los modelos entrenados, en la cual ajustamos sus parámetros para minimizar el error. En primer lugar, ejecutamos un paso de retropropagación del decodificador, pasando el gradiente de error al codificador. Antes de llamar al pase de retropropagación del modelo, necesitamos preparar los valores objetivo.
A la salida del decodificador, esperamos recibir los parámetros del estado inicial que se introducen en el codificador más una predicción para un horizonte de planificación determinado. En el artículo anterior, analizamos la composición de los parámetros predichos para cada vela. Seguiré manteniendo la misma opinión. Por tanto, no han cambiado ni la arquitectura del descodificador ni el algoritmo de preparación de los valores objetivo. Primero rellenamos la matriz de valores objetivo con los datos introducidos en la entrada del codificador.
target.Assign(Buffer[tr].States[i].state); ulong size = target.Size(); targets = matrix<float>::Zeros(1, size); targets.Row(target, 0); if(size > BarDescr) targets.Reshape(size / BarDescr, BarDescr); ulong shift = targets.Rows();
A continuación, la completamos con los datos del búfer de repetición de experiencias para un horizonte de planificación determinado.
targets.Resize(shift + PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, shift + t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
Transferimos la información recibida a un vector y la comparamos con los resultados del decodificador feed-forward.
Decoder.getResults(result); vector<float> error = target - result;
Como antes, durante el proceso de formación nos centramos en las desviaciones más altas. Por lo tanto, primero calculamos el error cuadrático medio móvil.
std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1));
A continuación, comparamos el error actual con un valor umbral basado en la desviación estándar. El paso de retropropagación se ejecuta sólo cuando el error actual supera el valor umbral en al menos un parámetro.
vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Decoder.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
La idea de hacer hincapié en las desviaciones máximas está tomada del método CFPI.
Utilizamos un algoritmo de retropropagación similar para el modelo de predicción del ruido. Pero aquí el enfoque para organizar el vector de valores objetivo es mucho más sencillo: cuando trabajamos con trayectorias limpias, simplemente utilizamos un vector de valores cero.
target = vector<float>::Zeros(delta.Cols()); Noise.getResults(result); error = (target - result) * STE_Noise_Multiplier;
Tenga en cuenta que al calcular el error, multiplicamos la desviación resultante por la constante STE_Noise_Multiplier, que determina el impacto del error de predicción del ruido en el error global del modelo.
También nos centramos en las desviaciones máximas y realizamos un pase de retropropagación sólo si hay un error por encima de un valor umbral para al menos un parámetro.
STE_Noise = MathSqrt((MathPow(STE_Noise, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; check = MathAbs(error) - STE_Noise; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Noise.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Pasamos el gradiente de error del modelo de predicción de ruido al codificador y, si es necesario, llamamos a su método de retropropagación.
Después de actualizar los parámetros de todos los modelos entrenados, guardamos los últimos resultados del paso feed-forward del codificador en un buffer auxiliar.
Encoder.getResults(result); LastEncoder.AssignArray(result);
Informamos al usuario del progreso del proceso de aprendizaje y pasamos a la siguiente iteración del bucle anidado.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); str += StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Noise Prediction", percent, Noise.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Aquí solemos completar la descripción de las iteraciones en el sistema de bucles de entrenamiento del modelo. Pero esta vez el caso es diferente. Hemos procesado un lote de modelos de entrenamiento en una trayectoria limpia. Ahora tenemos que repetir las operaciones para la trayectoria aumentada por el ruido. Así pues, aquí definimos primero los parámetros estadísticos de la distribución del ruido.
//--- With noise vector<float> std_delta = delta.Std(0) * STD_Delta_Multiplier; vector<float> mean_delta = delta.Mean(0);
Obsérvese que la desviación típica se multiplica por el factor de ruido para reducir al máximo el posible sesgo en los valores de las características analizadas.
Creamos un vector y un array para generar ruido.
ulong inp_total = std_delta.Size(); vector<float> noise = vector<float>::Zeros(inp_total); double ar_noise[];
Después, muestreamos la nueva trayectoria y el estado inicial en ella.
tr = SampleTrajectory(probability); state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
Vaciamos las pilas de modelos y el buffer auxiliar.
Encoder.Clear();
Decoder.Clear();
Noise.Clear();
LastEncoder.BufferInit(EmbeddingSize, 0);
A continuación, creamos otro bucle anidado para trabajar con una trayectoria aumentada por el ruido.
end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); for(int i = state; i < end; i++) { if(!Math::MathRandomNormal(0, 1, (int)inp_total, ar_noise)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } noise.Assign(ar_noise);
En el cuerpo del bucle, primero generamos ruido a partir de una distribución normal y lo transferimos a un vector. Después, lo reparametrizamos.
noise = mean_delta + std_delta * noise;
En esta fase, hemos preparado el ruido para la iteración de entrenamiento actual. Cargamos el estado limpio desde el búfer de repetición de la experiencia y le añadimos el ruido generado.
inp.Assign(Buffer[tr].States[i].state); inp = inp + noise;
El estado aumentado por el ruido resultante se carga en el búfer de datos de origen.
State.AssignArray(inp);
A continuación, ejecutamos un bloque feed-forward, similar al trabajo con trayectorias limpias.
if(!LastEncoder.BufferWrite() || !Encoder.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(LastEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!Decoder.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!Noise.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Según el método SSWNP, debemos crear una coherencia espacial entre las trayectorias previstas para las trayectorias limpias y las trayectorias aumentadas por el ruido. Como hemos visto en la parte teórica, ambas trayectorias convergen hacia el mismo objetivo. En consecuencia, construiremos el bloque de retropropagación del decodificador de la misma forma que hicimos anteriormente para las trayectorias limpias.
target.Assign(Buffer[tr].States[i].state); ulong size = target.Size(); targets = matrix<float>::Zeros(1, size); targets.Row(target, 0); if(size > BarDescr) targets.Reshape(size / BarDescr, BarDescr); ulong shift = targets.Rows(); targets.Resize(shift + PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, shift + t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
Decoder.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Decoder.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Para el modelo de predicción del ruido, la diferencia está en los valores objetivo. Para trayectorias limpias usamos un vector lleno de valores cero, ahora usamos el ruido añadido al estado limpio antes de alimentarlo a la entrada del codificador como valores objetivo.
target = noise; Noise.getResults(result); error = (target - result) * STE_Noise_Multiplier;
STE_Noise = MathSqrt((MathPow(STE_Noise, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; check = MathAbs(error) - STE_Noise; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Noise.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Tras actualizar los parámetros del modelo, guardamos los resultados de la última pasada del codificador en un búfer auxiliar.
Encoder.getResults(result); LastEncoder.AssignArray(result);
Informamos al usuario sobre el progreso del proceso de aprendizaje y pasamos a la siguiente iteración del ciclo.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter + 0.5) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); str += StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Noise Prediction", percent, Noise.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Con esto concluye la descripción de las iteraciones en el sistema de ciclos de formación de modelos. Una vez completadas con éxito todas las iteraciones, borramos el campo de comentarios del gráfico del instrumento financiero.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Decoder", Decoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Noise Prediction", Noise.getRecentAverageError()); ExpertRemove(); //--- }
Imprime los resultados del proceso de formación en el registro e inicia la finalización del EA.
El código completo de todos los programas utilizados en el artículo está disponible en el archivo adjunto.
Arriba se muestra el algoritmo actualizado del EA de entrenamiento de la función de trayectoria. El algoritmo de formación de políticas no ha cambiado. Su descripción detallada figuraba en el anterior artículo. El código completo del EA "...\Experts\SSWNP\Study.mq5" se adjunta a continuación.
3. Prueba
En la parte práctica de este artículo, integramos los enfoques del método Self-Supervised Waypoint Noise Prediction en el EA de entrenamiento de funciones de trayectoria previamente construido con el método Goal-Conditioned Predictive Coding. Ahora esperamos una mejora en la calidad de la predicción del movimiento de los precios. Ahora es el momento de probar los resultados en datos reales en el probador de estrategias de MetaTrader 5.
Al igual que antes, los modelos se entrenan y prueban utilizando datos históricos para EURUSD H1. El modelo se entrena utilizando datos de los 7 primeros meses de 2023. Para probar el modelo entrenado, utilizamos datos históricos de agosto de 2023. Como puede ver, el periodo de prueba sigue directamente al periodo de formación.
Antes de entrenar los modelos, necesitamos recopilar un conjunto de datos de entrenamiento primario. Dado que implementamos nuevos enfoques en un EA construido previamente sin cambiar la arquitectura del modelo ni la estructura de los datos, podemos omitir este paso y utilizar la base de datos de ejemplos existente que se creó al entrenar los modelos con el método GCPC. Creamos una copia del archivo del búfer de repetición de la experiencia llamado "SSWNP.bd". A continuación, pasamos directamente al proceso de entrenamiento del modelo.
Según el algoritmo del método GCPC, los modelos se entrenan en 2 etapas. En la primera etapa, entrenamos la función de trayectoria. Esta etapa contiene los planteamientos del nuevo método SSWNP. En la entrada del codificador sólo se introducen datos históricos de movimientos de precios e indicadores. Esto hace que todas las trayectorias en el búfer de repetición de experiencias sean idénticas, porque los valores de estado de cuenta y posición abierta que marcan diferencias en las trayectorias no se analizan en esta fase. Por lo tanto, podemos utilizar la base de datos de ejemplos existente y entrenar la función de trayectoria hasta obtener un resultado aceptable sin necesidad de recopilar ejemplos adicionales.
La segunda etapa del entrenamiento del modelo, el entrenamiento de la política de comportamiento, implica la búsqueda de las acciones óptimas del Agente en condiciones históricas de mercado con cambios en el estado de la cuenta y las posiciones abiertas, que dependen de las condiciones del mercado y de las acciones realizadas por el Agente. En esta fase, utilizamos el entrenamiento iterativo de modelos, alternando entre el entrenamiento de modelos y la recopilación de ejemplos adicionales que nos permitan evaluar con mayor precisión la política de comportamiento actualizada del Agente.
Nuestro proceso de formación ha dado algunos resultados. Conseguimos entrenar un modelo capaz de generar beneficios tanto en los datos históricos del conjunto de datos de entrenamiento como en el periodo de prueba.


Conclusión
En este artículo presentamos el método Self-Supervised Waypoint Noise Prediction. Este enfoque permite mejorar la eficacia de los modelos en entornos estocásticos complejos, en los que las trayectorias futuras de los Agentes están sujetas a incertidumbres debidas a condiciones cambiantes y limitaciones físicas. Este objetivo se consigue aumentando el ruido en las trayectorias pasadas, lo que contribuye a predecir con mayor precisión y diversidad las trayectorias futuras. La innovadora metodología presentada consta de dos módulos: un módulo de coherencia espacial y un módulo de predicción del ruido, que juntos proporcionan apoyo para una previsión precisa y fiable en escenarios estocásticos.
La construcción propuesta por los autores del método es bastante universal, lo que permite integrarla en una amplia gama de diferentes algoritmos de entrenamiento de modelos. Esto se aplica no sólo a los métodos de aprendizaje por refuerzo. En su artículo, los autores del método muestran ejemplos de cómo la aplicación de los planteamientos propuestos aumenta la eficacia de los métodos básicos.
En la parte práctica de este artículo, integramos los enfoques propuestos por el método SSWNP en la estructura del algoritmo GCPC. Los resultados de nuestras pruebas confirman la eficacia del método propuesto.
Sin embargo, una vez más, me gustaría recordarle que todos los programas presentados en el artículo están destinados únicamente a demostrar la tecnología y no están listos para su uso en el comercio financiero del mundo real.
Referencias
- Enhancing Trajectory Prediction through Self-Supervised Waypoint Noise Prediction
- Redes neuronales: así de sencillo (Parte 71): Previsión de estados futuros basada en objetivos (GCPC)
Programas utilizados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de recopilación de ejemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para la recopilación de ejemplos utilizando el método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA de entrenamiento de políticas |
| 4 | StudyEncoder.mq5 | Expert Advisor | EA de entrenamiento de autoencoders utilizando enfoques SSWNP |
| 5 | Test.mq5 | Expert Advisor | EA de prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema |
| 7 | NeuroNet.mqh | Biblioteca de clases | Una biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Código base | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14044
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso