
Neuronale Netze leicht gemacht (Teil 75): Verbesserung der Leistung von Modellen zur Vorhersage einer Trajektorie

Einführung
Die Vorhersage des Verlaufs der bevorstehenden Preisbewegung spielt wahrscheinlich eine der wichtigsten Rollen im Prozess der Erstellung von Handelsplänen für den gewünschten Planungshorizont. Die Genauigkeit solcher Prognosen ist entscheidend. Um die Qualität der Vorhersage einer Trajektorie zu verbessern, komplizieren wir unsere Modelle für die Flugbahnvorhersage.
Dieser Prozess hat jedoch auch eine Kehrseite der Medaille. Komplexere Modelle erfordern mehr Rechenressourcen. Dies bedeutet, dass der Aufwand sowohl für das Training der Modelle als auch für deren Betrieb steigen. Der Aufwand des Modelltrainings muss berücksichtigt werden. Was den Betriebsaufwand betrifft, so können diese jedoch noch kritischer sein. Vor allem, wenn es um den Echtzeithandel mit Marktaufträgen in einem hochvolatilen Markt geht. In solchen Fällen suchen wir nach Methoden, um die Leistung unserer Modelle zu verbessern. Im Idealfall sollte eine solche Optimierung die Qualität zukünftiger Vorhersagen von Trajektorien nicht beeinträchtigen.
Die Methoden zur Vorhersage einer Trajektorie, die wir in den letzten Artikeln behandelt haben, stammen aus der Branche der autonomen Fahrzeuge. Die Forscher auf diesem Gebiet stehen vor demselben Problem. Die Geschwindigkeit der Fahrzeuge stellt erhöhte Anforderungen an die Entscheidungszeit. Die Verwendung teurer Modelle zur Vorhersage von Trajektorien und zur Entscheidungsfindung führt nicht nur zu einem höheren Zeitaufwand für die Entscheidungsfindung, sondern auch zu einem Anstieg der Kosten für die verwendete Ausrüstung, da dies die Installation teurerer Hardware erfordert. In diesem Zusammenhang schlage ich vor, die in dem Artikel „Efficient Baselines for Motion Prediction in Autonomous Driving“ vorgestellten Ideen zu berücksichtigen. Die Autoren haben sich die Aufgabe gestellt, ein schlankes („lightweight“) Modell für die Vorhersage von Trajektorien zu entwickeln, und heben die folgenden Ergebnisse hervor:
- Identifizierung einer Schlüsselherausforderung bei der Größe von Bewegungsvorhersagemodellen mit Auswirkungen auf die Echtzeit-Inferenz und den Einsatz auf ressourcenbeschränkten Geräten.
- Es werden mehrere wirksame Grundlagen für die Vorhersage des Fahrzeugverkehrs vorgeschlagen, die sich nicht explizit auf die erschöpfende Analyse einer hochwertigen Kontextkarte stützen, sondern auf vorherige Karteninformationen, die in einem einfachen Vorverarbeitungsschritt gewonnen werden und als Leitfaden für die Vorhersage dienen.
- Verwendung weniger Parameter und Operationen, um eine wettbewerbsfähige Leistung bei geringeren Rechenkosten zu erzielen.
1. Techniken zur Leistungssteigerung
Unter Berücksichtigung des Gleichgewichts zwischen den analysierten Quelldaten und der Komplexität des Modells bemühen sich die Autoren der Methode, wettbewerbsfähige Ergebnisse zu erzielen, indem sie leistungsstarke Deep-Learning-Techniken, einschließlich Aufmerksamkeitsmechanismen und graphische neuronale Netze (GNN), einsetzen. Dies reduziert die Anzahl der Parameter und Operationen im Vergleich zu anderen Methoden. Die Autoren des Papiers verwenden insbesondere die folgenden Daten als Eingangsdaten für ihre Modelle:
- Vergangene Trajektorien von Agenten und ihre entsprechenden Interaktionen als einziger Input für den Block der sozialen Basisebene und
- Erweiterung, die der kartografischen Datenbank eine vereinfachte Darstellung des Toleranzbereichs des Agenten als zusätzliche Eingabe hinzufügt.
Daher benötigen die vorgeschlagenen Modelle keine qualitativ hochwertigen, vollständig kommentierten Karten oder gerasterten Szenendarstellungen, um den physischen Kontext zu berechnen.
Die Autoren der Methode schlagen vor, einen einfachen, aber leistungsfähigen Algorithmus zur Vorverarbeitung des Plans zu verwenden, bei dem die Trajektorie des Zielagenten zunächst gefiltert wird. Dann berechnen sie den möglichen Bereich, in dem der Zielagent interagieren kann, wobei nur die geometrischen Informationen der Karte berücksichtigt werden.
Die soziale Basislinie verwendet als Input die vergangenen Trajektorien der wichtigsten Hindernisse als relative Verschiebungen, um das Encoder-Modul zu speisen. Die sozialen Informationen werden dann mit Hilfe eines Graph Neural Network (GNN) berechnet. In ihrer Arbeit verwenden die Autoren der Methode Convolutional Network (Crystal-GCN) und Multi-Head Self Attention (MHSA) Schichten, um die wichtigsten Interaktionen zwischen Agenten zu ermitteln. Danach wird diese latente Information im Decoder-Modul mit Hilfe einer autoregressiven Strategie dekodiert, bei der die Ausgabe im i-ten Schritt von der vorherigen abhängt.
Eines der Merkmale der vorgeschlagenen Methode ist die Analyse der Interaktion mit Agenten, die Informationen über den gesamten Zeithorizont Th = Tobs + Tlen. Gleichzeitig wird die Anzahl der Agenten, die in komplexen Verkehrsszenarien berücksichtigt werden müssen, reduziert. Anstatt absolute 2D-Ansichten von oben zu verwenden, besteht die Eingabe für den Agenten i aus einer Reihe von relativen Verschiebungen:
![]()
Die Autoren der Methode haben die Anzahl der Agenten in der Sequenz nicht begrenzt oder festgelegt. Um die relativen Verschiebungen aller Agenten zu berücksichtigen, wird ein LSTM-Block verwendet, in dem die zeitliche Information jedes Agenten in der Sequenz berechnet wird.
Nach der Codierung der analysierten Geschichte jedes Fahrzeugs werden die Interaktionen zwischen den Agenten berechnet, um die wichtigsten sozialen Informationen zu erhalten. Zu diesem Zweck wird ein Interaktionsdiagramm erstellt. Die Schicht Crystal-GCN wird zur Erstellung eines Graphen verwendet. Dann wird MHSA angewendet, um das Lernen von Agenten-Agenten-Interaktionen zu verbessern.
Bevor ein Interaktionsmechanismus geschaffen wird, zerlegen die Autoren der Methode temporäre Informationen in geeignete Szenen. Dabei wird berücksichtigt, dass jedes Bewegungsszenario eine unterschiedliche Anzahl von Bearbeitern haben kann. Der Interaktionsmechanismus ist als bidirektionaler, vollständig verbundener Graph definiert, bei dem die anfänglichen Knotenmerkmale v0i durch latente zeitliche Informationen für jedes Fahrzeug hi,out dargestellt werden, die durch den Bewegungsverlaufs-Encoder berechnet werden. Andererseits werden die Kanten vom Knoten k zum Knoten l durch den Abstandsvektor ek,l zwischen den entsprechenden Agenten zu einem Zeitpunkt tobs,len in absoluten Koordinaten dargestellt:
![]()
Bei einem Graphen von Interaktionen (Knoten und Kanten) ist Crystal-GCN wie folgt definiert:
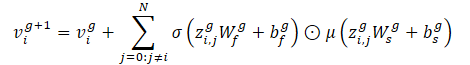
Mit diesem Operator können wir Kantenmerkmale einbetten, um die Knotenmerkmale auf der Grundlage der Entfernung zwischen den Fahrzeugen zu aktualisieren. Die Autoren der Methode verwenden 2 Schichten von Crystal-GCN mit ReLU und Batch-Normalisierung als Nichtlinearitäten zwischen den Schichten.
σ und μ sind die Aktivierungsfunktionen von Sigmoid bzw. Softplus. Außerdem ist zi,j=(vi‖vj‖ei,j) eine Verkettung von Merkmalen zweier Knoten in der GNN-Schicht und der entsprechenden Kante, N steht für die Gesamtzahl der Agenten in der Szene, und W und b sind Gewichte und Verschiebungen der entsprechenden Schichten.
Nach dem Durchlaufen des Interaktionsgraphen enthält jedes aktualisierte Knotenmerkmal vi Informationen über den zeitlichen und sozialen Kontext des Agenten i. Abhängig von der aktuellen Position und dem bisherigen Verlauf muss der Agent jedoch unter Umständen auf bestimmte soziale Informationen achten. Um diese Methode zu modellieren, verwenden die Autoren der Methode den mehrköpfigen Self-Attention-Mechanismus mit 4 Köpfen, der auf die aktualisierte Knotenmerkmalmatrix V angewendet wird, die die Merkmale des Knotens vi als Strings enthält.
Jede Zeile der endgültigen sozialen Aufmerksamkeitsmatrix SATT (Ausgabe des sozialen Aufmerksamkeitsmoduls, nach den Mechanismen von GNN und MHSA) stellt ein Interaktionsmerkmal für den Agenten i mit den umliegenden Agenten dar, wobei die Zeitinformationen unter der Haube berücksichtigt werden.
Als Nächstes erweitern die Autoren der Methode das soziale Basismodell unter Verwendung minimaler Informationen über die Karte, aus der sie das Gebiet P des Zielagenten als eine Teilmenge von r zufällig ausgewählten Punkten {p0, p1...pr} um die plausiblen Mittellinien (hochrangige und strukturierte Merkmale) diskretisieren, wobei sie die Geschwindigkeit und Beschleunigung des Zielagenten im letzten Beobachtungsrahmen berücksichtigen. Dies ist ein Schritt der Kartenvorverarbeitung, sodass das Modell die hochauflösende Karte nie zu Gesicht bekommt.
Basierend auf den Gesetzen der Physik behandeln die Autoren der Methode das Fahrzeug als starre Struktur ohne plötzliche Bewegungsänderungen zwischen aufeinanderfolgenden Zeitstempeln. Dementsprechend liegen bei der Beschreibung der Aufgabe, eine Straße zu befahren, die wichtigsten Merkmale meist in einer bestimmten Richtung (in Fahrtrichtung). Auf diese Weise kann eine vereinfachte Version der Karte erstellt werden.
Informationen über Trajektorien enthalten oft Rauschen, das mit dem Prozess der realen Datenerfassung zusammenhängt. Um die dynamischen Variablen des Zielagenten im letzten Beobachtungsrahmen tobs,len zu schätzen, schlagen die Autoren der Methode vor, zunächst vergangene Beobachtungen des Zielagenten mithilfe eines Algorithmus der kleinsten Quadrate entlang jeder der Achsen zu filtern. Sie gehen davon aus, dass sich der Agent mit konstanter Beschleunigung bewegt und können die dynamischen Eigenschaften (Geschwindigkeit und Beschleunigung) des Zielagenten berechnen. Dann berechnen sie den Vektor der geschätzten Geschwindigkeit und Beschleunigung. Zusätzlich werden diese Vektoren als Skalare summiert, um eine geglättete Schätzung zu erhalten, wobei den ersten Beobachtungen weniger Gewicht (höherer Vergessensfaktor λ) zugewiesen wird. Auf diese Weise spielen die jüngsten Beobachtungen eine Schlüsselrolle bei der Bestimmung des aktuellen kinematischen Zustands des Agenten:
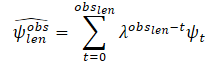
wobei
obslen die Anzahl der beobachteten Bilder ist, ψt die geschätzte Geschwindigkeit/Beschleunigung im Rahmen t und λ ∈ (0, 1) der Vergessensfaktor.
Nach der Berechnung des kinematischen Zustands wird die zurückgelegte Strecke geschätzt, wobei von einem physikalischen Modell ausgegangen wird, das auf der Beschleunigung mit einer konstanten Drehgeschwindigkeit zu jedem Zeitpunkt t basiert.
Diese plausiblen Trajektorien werden dann verarbeitet, um als plausible physikalische Informationen verwendet zu werden. Zunächst suchen sie den Punkt, der der letzten Beobachtung des Zielagenten am nächsten liegt und den Ausgangspunkt einer plausiblen Mittellinie darstellt. Dann schätzen sie die zurückgelegte Strecke entlang der ursprünglichen Mittellinien. Sie bestimmen den Endpunktindex p der Mittellinie m als den Punkt, an dem der kumulierte Abstand (unter Berücksichtigung des euklidischen Abstands zwischen den einzelnen Punkten) größer oder gleich der vorberechneten Abweichung ist.
Dann führen sie eine kubische Interpolation zwischen dem Anfangs- und dem Endpunkt der entsprechenden Mittellinie m durch, um Schritte auf dem Planungshorizont zu erhalten. Die von den Autoren der Methode durchgeführten Experimente zeigen, dass die beste a priori Information unter Berücksichtigung des mittleren und des medianen Abstands L2 über den gesamten Validierungssatz zwischen dem Endpunkt der wahren Trajektorie des Zielagenten und den Endpunkten der gefilterten Mittellinien durch die Berücksichtigung der Geschwindigkeit und der Beschleunigung im kinematischen Zustand und die Filterung der Eingabe mit der Methode der kleinsten Quadrate erreicht wird.
Zusätzlich zu diesen übergeordneten und strukturierten Mittellinien schlagen die Autoren der Methode vor, auf alle plausiblen Mittellinien Punktverzerrungen gemäß der Normalverteilung N(0, 0,2) anzuwenden. Dadurch wird die plausible Region P als eine Teilmenge von r zufällig ausgewählten Punkten {p0, p1...pr} um plausible Mittellinien diskretisiert. So können sie sich einen Überblick über den plausiblen Bereich verschaffen, der als Low-Level-Merkmal identifiziert wurde. Die Autoren der Methode verwenden die Normalverteilung N als zusätzlichen Regularisierungsterm, anstatt die Fahrbahngrenzen zu verwenden. Dadurch wird eine Überanpassung im Kodierungsmodul verhindert, ähnlich wie bei der Datenerweiterung für frühere Trajektorien.
Flächen- und Mittelliniengeber werden zur Berechnung latenter Karteninformationen verwendet. Sie verarbeiten höher- und niedergradige Kartenmerkmale. Jeder dieser Encoder wird durch ein mehrschichtiges Perzeptron (MLP) dargestellt. Zunächst glätten sie die Informationen entlang der Dimension der Punkte, wobei sie die Informationen entlang der Koordinatenachsen abwechseln. Dann wird der entsprechende MLP (3 Schichten, mit Batch-Normalisierung, ReLU und DropOut in der ersten Schicht) die interpretierten absoluten Koordinaten um den Ursprung in repräsentative latente physikalische Informationen um. Der statische physische Kontext (Ausgabe des Codierers der Region) dient als gemeinsame latente Darstellung für die verschiedenen Modi, während der spezifische physische Kontext spezifische Karteninformationen für jeden Modus veranschaulicht.
Der Decoder für die zukünftige Flugbahn stellt die dritte Komponente der vorgeschlagenen Basismodelle dar. Das Modul besteht aus einem LSTM-Block, der Relativbewegungen für zukünftige Zeitschritte rekursiv schätzt, so wie die vergangenen Relativbewegungen im Motion History Encoder gelernt wurden. Für den sozialen Basisfall verwendet das Modell den vom Modul für soziale Interaktion berechneten sozialen Kontext, wobei nur die Daten des Zielagenten berücksichtigt werden. Der soziale Kontext allein repräsentiert den gesamten Verkehr im Szenario und stellt den latenten Eingangsvektor des autoregressiven LSTM-Prädiktors dar.
Aus der Sicht des kartographischen Basisfalls für den Modus m schlagen die Autoren der Methode vor, den latenten Verkehrskontext als eine Verkettung von sozialem Kontext, statischem physischem Kontext und spezifischem physischem Kontext zu identifizieren, der als versteckter Eingangsvektor des LSTM-Decoders dienen wird.
Bezogen auf die Originaldaten eines LSTM-Blocks im sozialen Fall wird dieser durch die kodierten vergangenen n relativen Bewegungen des Zielagenten nach der räumlichen Einbettung dargestellt, während die kartografische Basislinie den kodierten Distanzvektor zwischen der aktuellen absoluten Position des Zielagenten und der aktuellen Mittellinie sowie den aktuellen skalaren Zeitstempel t hinzufügt. In beiden Fällen (sozial und Karte) werden die Ergebnisse des LSTM-Blocks mit einer standardmäßigen voll verbundenen Schicht verarbeitet.
Nachdem wir eine relative Vorhersage zu einem Zeitpunkt t erhalten haben, verschieben wir die Anfangsdaten der vergangenen Beobachtung so, dass unsere letzte berechnete relative Bewegung an das Ende des Vektors kommt und die ersten Daten entfernt werden.
Nachdem die multimodalen Vorhersagen berechnet wurden, werden sie verkettet und von einem MLP-Residuum verarbeitet, um Vertrauen zu gewinnen (je höher das Vertrauen, desto wahrscheinlicher ist das Regelwerk und desto näher an der Wahrheit).
Die originale Visualisierung der von den Verfassern des Artikels vorgestellten Methode ist nachfolgend zu finden. Hier repräsentieren blaue Linien die sozialen Informationen, und rote Linien zeigen die Übertragung von Informationen über die Karte.

2. Implementierung mit MQL5
Wir haben die theoretischen Aspekte des vorgeschlagenen Ansatzes betrachtet. Nun wollen wir sie mit MQL5 implementieren. Wie Sie sehen können, haben die Autoren der Methode das Modell in Blöcke unterteilt. Jeder Block verwendet eine Mindestanzahl von Schichten. Gleichzeitig wird die Vereinfachung der Architektur der einzelnen Blöcke von einer zusätzlichen Datenanalyse begleitet, die a priori Information über die analysierte Umgebung nutzt. Insbesondere wird die Karte vorverarbeitet und die übergebenen Trajektorien werden gefiltert. Auf diese Weise kann das Rauschen und die Menge der Ausgangsdaten reduziert werden, ohne dass die Qualität der Vorhersagetrajektorien beeinträchtigt wird.
2.1 Erstellen einer CrystalGraph-Faltungsnetzschicht
Darüber hinaus stoßen wir bei den vorgeschlagenen Ansätzen auf graphische neuronale Schichten, die wir bisher noch nicht kannten. Bevor wir mit der Entwicklung des vorgeschlagenen Algorithmus fortfahren, werden wir daher eine neue Ebene in unserer Bibliothek erstellen.
Die von den Autoren der Methode vorgeschlagene CrystalGraph-Faltungsnetzschicht kann durch die folgende Formel dargestellt werden:
Im Wesentlichen handelt es sich hier um eine elementweise Multiplikation der Ergebnisse der Arbeit von 2 vollständig verbundenen Schichten. Eine davon wird durch den Sigmoid aktiviert und stellt eine trainierbare, binäre Matrix für das Vorhandensein von Verbindungen zwischen den Knoten des Graphen dar. Die zweite Schicht wird durch die SoftPlus-Funktion aktiviert, die ein weiches Analogon von ReLU ist.
Um das CrystalGraph Convolutional Network zu implementieren, erstellen wir eine neue Klasse CNeuronCGConvOCL, die die grundlegende Funktionalität von CNeuronBaseOCL erbt.
class CNeuronCGConvOCL : public CNeuronBaseOCL { protected: CNeuronBaseOCL cInputF; CNeuronBaseOCL cInputS; CNeuronBaseOCL cF; CNeuronBaseOCL cS; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronCGConvOCL(void) {}; ~CNeuronCGConvOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronCGConvOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Unsere neue Klasse erhält von der übergeordneten Klasse einen Standardsatz von Methoden zum Überschreiben und grundlegende Funktionen. Um den Faltungsalgorithmus des Graphen zu implementieren, werden wir 4 interne, vollständig verbundene Schichten erstellen:
- 2 zum Schreiben der Originaldaten und der Fehlergradienten während des Backpropagation-Durchgangs(cInputF und cInputS)
- 2, um die Funktion zu erfüllen(cF und cS).
Wir werden alle internen Objekte statisch erstellen, sodass der Konstruktor und der Destruktor der Klasse „leer“ bleiben.
In der Initialisierungsmethode unserer Init-Klasse rufen wir zunächst die entsprechende Methode der Elternklasse auf, die alle notwendigen Kontrollen für die vom externen Programm empfangenen Daten implementiert und die geerbten Objekte und Variablen initialisiert.
bool CNeuronCGConvOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; activation = None;
Danach werden die hinzugefügten internen Objekte durch den Aufruf ihrer Initialisierungsmethoden nacheinander initialisiert.
if(!cInputF.Init(numNeurons, 0, OpenCL, window, optimization, batch)) return false; if(!cInputS.Init(numNeurons, 1, OpenCL, window, optimization, batch)) return false; cInputF.SetActivationFunction(None); cInputS.SetActivationFunction(None); //--- if(!cF.Init(0, 2, OpenCL, numNeurons, optimization, batch)) return false; cF.SetActivationFunction(SIGMOID); if(!cS.Init(0, 3, OpenCL, numNeurons, optimization, batch)) return false; cS.SetActivationFunction(LReLU); //--- return true; }
Bitte beachten Sie, dass wir für die internen Schichten der Quelldatenerfassung das Fehlen einer Aktivierungsfunktion festgelegt haben. Bei den funktionalen Schichten wurden die Aktivierungsfunktionen berücksichtigt, die der Algorithmus der erstellten Schicht vorsieht. Die Schicht CNeuronCGConvOCL selbst hat keine Aktivierungsfunktion.
Nach der Initialisierung des Objekts wird eine Vorwärts-Durchgangs-Methode feedForward erstellt. In den Parametern erhält die Methode einen Zeiger auf das Objekt der vorhergehenden neuronalen Schicht, deren Ausgabe die Ausgangsdaten enthält.
bool CNeuronCGConvOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !NeuronOCL.getOutput() || NeuronOCL.getOutputIndex() < 0) return false;
Im Hauptteil der Methode wird sofort die Relevanz des empfangenen Zeigers geprüft.
Nach erfolgreicher Übergabe des Kontrollblocks müssen wir die Quelldaten aus dem Puffer der vorherigen Schicht in die Puffer unserer beiden internen Quelldatenschichten übertragen. Vergessen Sie nicht, dass wir alle Operationen mit unseren neuronalen Schichten auf der OpenCL-Kontextseite durchführen. Daher müssen wir auch Daten in den Speicher des OpenCL-Kontexts kopieren. Wir gehen aber noch einen Schritt weiter und führen ein „Kopieren“ durch, ohne die Daten physisch zu übertragen. Wir werden einfach den Zeiger auf den Ergebnispuffer in den inneren Schichten ersetzen und ihnen einen Zeiger auf den Ergebnispuffer der vorherigen Schicht übergeben. Hier geben wir auch die Aktivierungsfunktion der vorherigen Schicht an.
if(cInputF.getOutputIndex() != NeuronOCL.getOutputIndex()) { if(!cInputF.getOutput().BufferSet(NeuronOCL.getOutputIndex())) return false; cInputF.SetActivationFunction((ENUM_ACTIVATION)NeuronOCL.Activation()); } if(cInputS.getOutputIndex() != NeuronOCL.getOutputIndex()) { if(!cInputS.getOutput().BufferSet(NeuronOCL.getOutputIndex())) return false; cInputS.SetActivationFunction((ENUM_ACTIVATION)NeuronOCL.Activation()); }
So erhalten wir bei der Arbeit mit internen Schichten direkten Zugriff auf den Ergebnispuffer der vorherigen Schicht, ohne die Daten physisch zu kopieren. Wir haben die Aufgabe der Datenübertragung mit minimalen Ressourcen umgesetzt. Darüber hinaus entfällt die Erstellung von zwei zusätzlichen Puffern im Kontext von OpenCL, wodurch die Speichernutzung optimiert wird.
Dann rufen wir einfach Vorwärts-Durchgangs-Methoden für die internen Funktionsschichten auf.
if(!cF.FeedForward(GetPointer(cInputF))) return false; if(!cS.FeedForward(GetPointer(cInputS))) return false;
Als Ergebnis dieser Operationen erhalten wir Matrizen von Kontext- und Graphverbindungen. Dann führen wir ihre elementweise Multiplikation durch. Zur Durchführung dieser Operation verwenden wir den Dropout-Kernel, den wir für die elementweise Multiplikation der Originaldaten mit einer Maske entwickelt haben. In unserem Fall haben wir einen anderen Hintergrund für dieselbe mathematische Operation.
Übergeben wir dem Kernel die erforderlichen Parameter und Anfangsdaten.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = int(Neurons() + 3) / 4; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_input, cF.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_map, cS.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_out, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_Dropout, def_k_dout_dimension, Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_Dropout, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Danach stellen wir sie in die Ausführungswarteschlange.
Der nächste Schritt ist die Implementierung von Funktionen für Rückwärts-Durchgänge (Backpropagation). Hier beginnen wir mit der Erstellung eines Kernels auf der OpenCL-Seite des Programms. Der Punkt ist, dass die Verteilung des Fehlergradienten aus der vorhergehenden Schicht mit seiner Übertragung auf die internen Schichten entsprechend ihrem Einfluss auf das Endergebnis beginnt. Dazu müssen wir den resultierenden Fehlergradienten mit den Ergebnissen des Vorwärtsdurchgang der zweiten Funktionsschicht multiplizieren. Um zu vermeiden, dass der oben verwendete elementweise Multiplikationskernel zweimal aufgerufen wird, erstellen wir einen neuen Kernel, mit dem wir Fehlergradienten für beide Schichten in einem Durchgang erhalten.
In den Kernelparametern von CGConv_HiddenGradient übergeben wir Zeiger auf 5 Datenpuffer und die Typen der Aktivierungsfunktionen beider Schichten.
__kernel void CGConv_HiddenGradient(__global float *matrix_g,///<[in] Tensor of gradients at current layer __global float *matrix_f,///<[in] Previous layer Output tensor __global float *matrix_s,///<[in] Previous layer Output tensor __global float *matrix_fg,///<[out] Tensor of gradients at previous layer __global float *matrix_sg,///<[out] Tensor of gradients at previous layer int activationf,///< Activation type (#ENUM_ACTIVATION) int activations///< Activation type (#ENUM_ACTIVATION) ) { int i = get_global_id(0);
Wir werden den Kernel in einem eindimensionalen Aufgabenraum starten, der auf der Anzahl der Neuronen in unseren Schichten basiert. Im Hauptteil des Kernels wird anhand der Thread-Kennung sofort der Offset in den Datenpuffern zu dem zu analysierenden Element bestimmt.
Um die „intensiven“ Operationen für den Zugriff auf den globalen GPU-Speicher zu reduzieren, werden wir die Daten des analysierten Elements in lokalen Variablen speichern, auf die um ein Vielfaches schneller zugegriffen werden kann.
float grad = matrix_g[i]; float f = matrix_f[i]; float s = matrix_s[i];
Zu diesem Zeitpunkt haben wir alle Daten, die wir zur Berechnung der Fehlergradienten auf beiden Ebenen benötigen, und wir berechnen sie.
float sg = grad * f; float fg = grad * s;
Bevor wir jedoch die erhaltenen Werte in die Elemente der globalen Datenpuffer schreiben, müssen wir die gefundenen Fehlergradienten an die entsprechenden Aktivierungsfunktionen anpassen.
switch(activationf) { case 0: f = clamp(f, -1.0f, 1.0f); fg = clamp(fg + f, -1.0f, 1.0f) - f; fg = fg * max(1 - pow(f, 2), 1.0e-4f); break; case 1: f = clamp(f, 0.0f, 1.0f); fg = clamp(fg + f, 0.0f, 1.0f) - f; fg = fg * max(f * (1 - f), 1.0e-4f); break; case 2: if(f < 0) fg *= 0.01f; break; default: break; }
switch(activations) { case 0: s = clamp(s, -1.0f, 1.0f); sg = clamp(sg + s, -1.0f, 1.0f) - s; sg = sg * max(1 - pow(s, 2), 1.0e-4f); break; case 1: s = clamp(s, 0.0f, 1.0f); sg = clamp(sg + s, 0.0f, 1.0f) - s; sg = sg * max(s * (1 - s), 1.0e-4f); break; case 2: if(s < 0) sg *= 0.01f; break; default: break; }
Am Ende der Kernel-Operation speichern wir die Ergebnisse der Operationen in den entsprechenden Elementen der globalen Datenpuffer.
matrix_fg[i] = fg; matrix_sg[i] = sg; }
Nachdem wir den Kernel erstellt haben, arbeiten wir wieder an den Methoden unserer Klasse. Die Fehlergradientenverteilung wird in der Methode calcInputGradients implementiert, in deren Parametern wir einen Zeiger auf das Objekt der vorherigen Schicht übergeben. Im Hauptteil der Methode wird sofort die Relevanz des empfangenen Zeigers geprüft.
bool CNeuronCGConvOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer || !prevLayer.getGradient() || prevLayer.getGradientIndex() < 0) return false;
Als Nächstes müssen wir den oben beschriebenen Kernel für die Verteilung des Gradienten auf die internen Ebenen CGConv_HiddenGradient aufrufen. Hier definieren wir zunächst den Aufgabenraum.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = Neurons();
Dann übergeben wir die notwendigen Parameter an den Kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_f, cF.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_fg, cF.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_s, cS.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_sg, cS.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_g, getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CGConv_HiddenGradient, def_k_cgc_activationf, cF.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CGConv_HiddenGradient, def_k_cgc_activations, cS.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Den Kernel stellen wir in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_CGConv_HiddenGradient, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Als Nächstes müssen wir den Fehlergradienten durch die internen vollverknüpften Schichten propagieren. Zu diesem Zweck rufen wir die entsprechenden Methoden auf.
if(!cInputF.calcHiddenGradients(GetPointer(cF))) return false; if(!cInputS.calcHiddenGradients(GetPointer(cS))) return false;
In diesem Stadium haben wir die Ergebnisse von 2 Strömen von Fehlergradienten auf 2 internen Schichten der Originaldaten. Wir addieren sie einfach und übertragen das Ergebnis auf die Ebene der vorherigen Schicht.
if(!SumAndNormilize(cF.getOutput(), cS.getOutput(), prevLayer.getOutput(), 1, false)) return false; //--- return true; }
Bitte beachten Sie, dass wir in diesem Fall die Aktivierungsfunktion der vorherigen Schicht nirgends explizit berücksichtigen. Dies ist wichtig für die korrekte Übertragung des Fehlergradienten. Aber es gibt hier eine Nuance. Alle unsere Klassen neuronaler Schichten sind so aufgebaut, dass die Anpassung an die Ableitung der Aktivierungsfunktion erfolgt, bevor der Gradient an den Puffer der vorherigen Schicht weitergegeben wird. Zu diesem Zweck haben wir während des Feed-Forward-Durchgangs die Aktivierungsfunktion der vorherigen Schicht für unsere internen Schichten der Quelldaten festgelegt. Wenn also der Fehlergradient durch unsere internen Funktionsschichten propagiert wurde, haben wir den Fehlergradienten sofort an die Ableitung der Aktivierungsfunktion angepasst, die für die Gradienten beider Ströme gleich ist. Am Ausgang summieren wir die bereits um die Ableitung der Aktivierungsfunktion bereinigten Fehlergradienten.
Der Algorithmus der zweiten Backpropagation-Methode (Aktualisierung der Gewichtsmatrix updateInputWeights) ist recht einfach. Hier rufen wir einfach die entsprechenden Methoden der funktionalen internen Schichten auf.
bool CNeuronCGConvOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cF.UpdateInputWeights(cInputF.AsObject())) return false; if(!cS.UpdateInputWeights(cInputS.AsObject())) return false; //--- return true; }
Die Implementierung der übrigen Methoden unserer Klasse CNeuronCGConvOCL ist meiner Meinung nach nicht von besonderem Interesse. Ich habe dabei die üblichen Algorithmen für die entsprechenden Methoden verwendet, die bereits mehrfach in dieser Artikelserie beschrieben wurden. Sie finden sie in der Anlage. Dort finden Sie auch den vollständigen Code aller Programme, die beim Schreiben des Artikels verwendet wurden. Kommen wir nun zur Umsetzung der vorgeschlagenen Ansätze beim Aufbau der Modellarchitektur und beim Training der Modelle.
2.2 Modellarchitektur
Um die Architektur der Modelle zu erstellen, werden wir Modelle aus den vorangegangenen Artikeln verwenden, wobei die Struktur der ursprünglichen Daten beibehalten wird. Dies geschieht absichtlich. In der ADAPT-Struktur können Sie auch ein Encoder-Modul auswählen, das als Feature Encoding dargestellt wird. Sie umfasst auch einen Block sozialer Aufmerksamkeit aus aufeinanderfolgenden Schichten der mehrköpfigen Aufmerksamkeit. Der Endpunktvorhersageblock kann mit den vorgeschlagenen Mittellinien verglichen werden. Der Konfidenzblock ähnelt der Vorhersage von Trajektorie-Wahrscheinlichkeiten. Das macht die Arbeit mit den neuen Modellen noch interessanter.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Beginnen wir mit dem Encoder-Modell. Wir füttern das Modell mit Rohdaten über den Zustand der Umwelt.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die rohen Quelldaten werden in der Batch-Daten-Normalisierungseinheit vorverarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Als Nächstes habe ich anstelle des von den Autoren vorgeschlagenen LSTM-Blocks die Einbettungsschicht mit Positionskodierung belassen, da dieser Ansatz es uns ermöglicht, eine tiefere Geschichte zu speichern und zu analysieren.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Ich habe auch einen Block für soziale Aufmerksamkeit in das Encoder-Modell aufgenommen. In Übereinstimmung mit der ursprünglichen Methode besteht sie aus 2 aufeinanderfolgenden Graphfaltungsschichten, die durch eine Schicht zur Stapelnormalisierung getrennt sind.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
Die Ausgabe des sozialen Aufmerksamkeitsblocks erfolgt über eine Mehrkopf-Aufmerksamkeitsschicht.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
In unserem Fall gibt es keine Karte der Umgebung, aus der wir analytisch einige der wahrscheinlichsten Optionen für die bevorstehende Kursbewegung ableiten könnten. Deshalb belassen wir anstelle der zentralen Linien den Endpunktvorhersageblock. Die Ergebnisse des Blocks Soziale Aufmerksamkeit werden als Quelldaten verwendet.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (prev_count * prev_wout); descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Doch zunächst müssen wir die Daten in einer vollständig verknüpften Schicht vorverarbeiten.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Dann werden wir den LSTM-Block verwenden, wie er von den Autoren der Methode für den Trajektorendecodierungsblock vorgeschlagen wurde.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 3 * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Am Ausgang des Blocks erzeugen wir eine multimodale Darstellung der Endpunkte für eine bestimmte Anzahl von Optionen.
Das Modell zur Vorhersage der Wahrscheinlichkeiten für die Wahl der Bahnen blieb unverändert. Wir füttern das Modell mit den Ergebnissen der 2 vorherigen Modelle.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false; //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; }
Wir verarbeiten sie mit einem Block aus vollständig verbundenen Schichten.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Die Ergebnisse übersetzen wir mit Hilfe der SoftMax-Ebene in den Bereich der Wahrscheinlichkeiten.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Wie in der vorangegangenen Arbeit werden wir nicht versuchen, den genauen Verlauf der Preisbewegungen vorherzusagen. Unser Hauptziel ist es, auf den Finanzmärkten Gewinne zu erzielen. Daher werden wir ein Akteursmodell trainieren, das in der Lage ist, auf der Grundlage der vorhergesagten Endpunkte der Preisbewegung optimale Verhaltensstrategien zu entwickeln.
Die Modellarchitektur ist vollständig aus dem vorherigen Artikel übernommen und wird im Anhang in der Methode CreateDescriptions in der Datei „...\Experts\BaseLines\Trajectory.mqh“ dargestellt. Eine ausführliche Beschreibung findet sich in dem vorangegangenen Artikel.
2.3 Modelltraining
Wie aus der vorgestellten Architektur der Modelle hervorgeht, ist die Reihenfolge ihrer Verwendung in EAs, die mit der Umwelt interagieren, unverändert geblieben. Daher werden wir uns in diesem Artikel nicht mit der Betrachtung von Algorithmen von Programmen zur Sammlung von Trainingsdaten und zum Testen trainierter Modelle befassen. Wir gehen gleich zum EA für das Modelltrainingen. Wie im vorherigen Artikel werden alle Modelle in einem EA „...\Experts\BaseLines\Study.mq5“ trainiert.
Bei der EA-Initialisierungsmethode laden wir zunächst eine Datenbank mit Beispielen für das Training von Modellen.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Dann laden wir bereits trainierte Modelle und erstellen bei Bedarf neue.
//--- load models float temp; if(!BLEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !BLEndpoints.Load(FileName + "Endp.nnw", temp, temp, temp, dtStudied, true) || !BLProbability.Load(FileName + "Prob.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *encoder = new CArrayObj(); CArrayObj *endpoint = new CArrayObj(); CArrayObj *prob = new CArrayObj(); if(!CreateTrajNetDescriptions(encoder, endpoint, prob)) { delete endpoint; delete prob; delete encoder; return INIT_FAILED; } if(!BLEncoder.Create(encoder) || !BLEndpoints.Create(endpoint) || !BLProbability.Create(prob)) { delete endpoint; delete prob; delete encoder; return INIT_FAILED; } delete endpoint; delete prob; delete encoder; }
if(!StateEncoder.Load(FileName + "StEnc.nnw", temp, temp, temp, dtStudied, true) || !EndpointEncoder.Load(FileName + "EndEnc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *endpoint = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); if(!CreateDescriptions(actor, endpoint, encoder)) { delete actor; delete endpoint; delete encoder; return INIT_FAILED; } if(!Actor.Create(actor) || !StateEncoder.Create(encoder) || !EndpointEncoder.Create(endpoint)) { delete actor; delete endpoint; delete encoder; return INIT_FAILED; } delete actor; delete endpoint; delete encoder; //--- }
Dann übertragen wir alle Modelle in einen einzigen OpenCL-Kontext.
OpenCL = Actor.GetOpenCL(); StateEncoder.SetOpenCL(OpenCL); EndpointEncoder.SetOpenCL(OpenCL); BLEncoder.SetOpenCL(OpenCL); BLEndpoints.SetOpenCL(OpenCL); BLProbability.SetOpenCL(OpenCL);
Und kontrollieren die Architektur der Modelle.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
BLEndpoints.getResults(Result); if(Result.Total() != 3 * NForecast) { PrintFormat("The scope of the Endpoints does not match forecast endpoints (%d <> %d)", 3 * NForecast, Result.Total()); return INIT_FAILED; }
BLEncoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Am Ende der Methode werden Hilfsdatenpuffer erstellt und ein nutzerdefiniertes Ereignis für den Beginn des Modelltrainings erzeugt.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Bei der Deinitialisierungsmethode werden die trainierten Modelle gespeichert und der Speicher der dynamischen Objekte gelöscht.
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); StateEncoder.Save(FileName + "StEnc.nnw", 0, 0, 0, TimeCurrent(), true); EndpointEncoder.Save(FileName + "EndEnc.nnw", 0, 0, 0, TimeCurrent(), true); BLEncoder.Save(FileName + "Enc.nnw", 0, 0, 0, TimeCurrent(), true); BLEndpoints.Save(FileName + "Endp.nnw", 0, 0, 0, TimeCurrent(), true); BLProbability.Save(FileName + "Prob.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
Das Modelltraining wird mit der Methode Train durchgeführt. Im Hauptteil der Methode wird zunächst ein Vektor von Wahrscheinlichkeiten für die Auswahl der Trajektorien erstellt.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Danach erstellen wir lokale Variablen.
vector<float> result, target; matrix<float> targets, temp_m; bool Stop = false; //--- uint ticks = GetTickCount();
Wir erstellen ein System von Modell-Trainingsschleifen.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Im Hauptteil der äußeren Schleife werden die Trajektorie aus dem Erfahrungswiedergabepuffer und der Status des Lernbeginns abgerufen.
Hier wird der letzte Zustand des Trainingspakets auf der ausgewählten Trajektorie bestimmt und die Puffer für die rekurrenten Daten gelöscht.
BLEncoder.Clear(); BLEndpoints.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
Im Hauptteil der verschachtelten Schleife wird ein Umgebungszustand aus dem Erfahrungswiedergabepuffer entnommen und die Endpunktvorhersagemodelle und ihre Wahrscheinlichkeiten vorwärts durchlaufen.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- Trajectory if(!BLEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!BLEndpoints.feedForward((CNet*)GetPointer(BLEncoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!BLProbability.feedForward((CNet*)GetPointer(BLEncoder), -1, (CNet*)GetPointer(BLEndpoints))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Wie Sie sehen können, unterscheiden sich die oben beschriebenen Vorgänge nicht wesentlich von denen im vorherigen Artikel. Aber es wird Veränderungen geben. Sie betreffen insbesondere die Übertragung von a priori Wissen auf das Modell während des Trainingsprozesses. Denn durch die Nutzung von a priori Wissen über die Umwelt versuchen die Autoren der Methode, die Genauigkeit der Vorhersagen zu erhöhen und gleichzeitig die Architektur der Modelle selbst zu vereinfachen.
In der Tat gibt es mehrere Ansätze zur Übertragung von a priori Wissen auf ein Modell. Wir können die Rohdaten vorverarbeiten, um sie zu komprimieren und informativer zu machen. Dies wurde von den Autoren der Methode mit Mittellinien vorgeschlagen.
Auch bei der Generierung von Zielwerten im Rahmen des Modelltrainings können wir a priori Wissen nutzen. Dadurch kann das Modell den wichtigsten Objekten in den Quelldaten mehr Aufmerksamkeit schenken. Natürlich ist es möglich, beide Ansätze gleichzeitig anzuwenden.
Für die Zwecke dieses Artikels werden wir den zweiten Ansatz wählen. Um die Zielwerte für das Training des Endpunkt-Vorhersagemodells vorzubereiten, werden wir zunächst Daten über bevorstehende Kursbewegungen aus dem Replay-Puffer sammeln.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(target.Size() > BarDescr) { matrix<float> temp(1, target.Size()); temp.Row(target, 0); temp.Reshape(target.Size() / BarDescr, BarDescr); temp.Resize(temp.Rows(), 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } target = targets.Col(0).CumSum(); targets.Col(target, 0); targets.Col(target + targets.Col(1), 1); targets.Col(target + targets.Col(2), 2);
Als Beispiel für a priori Wissen werden wir die Signale des MACD-Indikators verwenden. Die Daten unserer Hauptlinie werden in Element 7 des Arrays gespeichert, das den Zustand der Umgebung beschreibt. Der Wert der Signallinie steht in Element 8 desselben Arrays. Wenn die Signallinie über der Hauptlinie liegt, betrachten wir den aktuellen Trend als Aufwärtstrend. Ansonsten als Abwärtstrend.
int direct = (Buffer[tr].States[i].state[8] >= Buffer[tr].States[i].state[7] ? 1 : -1);
Ich stimme zu, dass dieser Ansatz ziemlich vereinfacht ist und wir mehr Signale und Indikatoren verwenden könnten, um Trends zu erkennen. Aber gerade diese Einfachheit wird ein klares Beispiel für die Umsetzung im Rahmen des Artikels liefern und uns ermöglichen, die Auswirkungen des Ansatzes zu bewerten. Ich schlage vor, dass Sie bei Ihren Projekten umfassendere Ansätze verwenden, um optimale Ergebnisse zu erzielen.
Nachdem wir die Richtung des Trends bestimmt haben, bestimmen wir das Extremum in dieser Richtung. Wir beschränken auch die Matrix der bevorstehenden Kursbewegung auf das gefundene Extremum.
ulong extr=(direct>0 ? target.ArgMax() : target.ArgMin()); if(extr==0) { direct=-direct; extr=(direct>0 ? target.ArgMax() : target.ArgMin()); } targets.Resize(extr+1, 3);
Hier ist zu beachten, dass das MACD-Signal den Trendänderungen hinterherhinkt. Wenn wir also bei der Bestimmung des Extremwerts diesen in der ersten Zeile der Matrix finden, ändern wir die Richtung des Trends in die entgegengesetzte Richtung und definieren den Extremwert neu.
Durch die Verwendung von Trends, die auf der Grundlage von a priori Wissen über die Umgebung ermittelt werden, wird die Stochastizität der Zielwerte etwas reduziert, die zuvor bei der Verwendung der Richtung der ersten kommenden Kerze beobachtet wurde. Im Allgemeinen sollte dies dazu beitragen, dass unser Modell Trends und künftige Richtungen der Preisbewegung besser bestimmen kann.
Aus der verkürzten Matrix der bevorstehenden Kursbewegung bestimmen wir die Zielwerte durch das Extremum der bevorstehenden Kursbewegung.
if(direct >= 0) { target = targets.Max(AXIS_HORZ); target[2] = targets.Col(2).Min(); } else { target = targets.Min(AXIS_HORZ); target[1] = targets.Col(1).Max(); }
Wie zuvor ermitteln wir die genaueste Modellvorhersage aus dem gesamten multimodalen Endpunktraum und passen in einem Rückwärtsdurchgang nur die ausgewählte Vorhersage an.
BLEndpoints.getResults(result); targets.Reshape(1, result.Size()); targets.Row(result, 0); targets.Reshape(NForecast, 3); temp_m = targets; for(int i = 0; i < 3; i++) temp_m.Col(temp_m.Col(i) - target[i], i); temp_m = MathPow(temp_m, 2.0f); ulong pos = temp_m.Sum(AXIS_VERT).ArgMin(); targets.Row(target, pos); Result.AssignArray(targets);
Die so vorbereiteten Zielwerte ermöglichen die Aktualisierung der Parameter des Endpunktvorhersagemodells und des anfänglichen Umweltzustands Encoder.
if(!BLEndpoints.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!BLEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Hier passen wir die Wahrscheinlichkeitsvorhersagemodelle an. Aber der Fehlergradient dieses Modells wird an das Endpunkt-Vorhersagemodell oder den Encodernicht übermittelt.
bProbs.AssignArray(vector<float>::Zeros(NForecast)); bProbs.Update((int)pos, 1); bProbs.BufferWrite(); if(!BLProbability.backProp(GetPointer(bProbs), GetPointer(BLEndpoints))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Der nächste Schritt besteht darin, die Politik des Akteurs zu trainieren. Hier bereiten wir zunächst Informationen über den Kontostand und die offenen Positionen auf.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Dann erstellen wir Einbettungen von Zuständen und vorhergesagten Endpunkten.
//--- State embedding if(!StateEncoder.feedForward((CNet *)GetPointer(BLEncoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Endpoint embedding if(!EndpointEncoder.feedForward((CNet *)GetPointer(BLEndpoints), -1, (CNet*)GetPointer(BLProbability))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Beachten Sie, dass wir im Gegensatz zu früheren Arbeiten die Ergebnisse des Vorwärtsdurchgangs über den trainierten Modellen verwenden, um die Einbettung der prädiktiven Endpunkte zu erzeugen, und nicht die Zielwerte. So können wir die Leistung des Akteurs an die Ergebnisse des Endpunktvorhersagemodells anpassen.
Nach der Vorbereitung der Einbettungen führen wir einen Vorwärtsdurchgang durch das Akteursmodell durch.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(StateEncoder), -1, (CNet*)GetPointer(EndpointEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Nach erfolgreicher Ausführung des Vorwärtsdurchgangs folgt ein Rückwärtsdurchgang, der die Modellparameter aktualisiert. Hier werden wir bei der Vorbereitung der Zielwerte für das Training des Akteursmodells auch etwas a priori Wissen hinzufügen. Insbesondere werden vor der Eröffnung eines Handels in die eine oder andere Richtung die Werte des RSI- und des CCI-Indikators überprüft, die im vierten bzw. fünften Element des Arrays zur Beschreibung des Umweltzustands gespeichert sind.
if(direct > 0) { if(Buffer[tr].States[i].state[4] > 30 && Buffer[tr].States[i].state[5] > -100 ) { float tp = float(target[1] / _Point / MaxTP); result[1] = tp; int sl = int(MathMax(MathMax(target[1] / 3, -target[2]) / _Point, MaxSL / 10)); result[2] = float(sl) / MaxSL; result[0] = float(MathMax(risk / (value * sl), 0.01)) + FLT_EPSILON; } }
else { if(Buffer[tr].States[i].state[4] < 70 && Buffer[tr].States[i].state[5] < 100 ) { float tp = float((-target[2]) / _Point / MaxTP); result[4] = tp; int sl = int(MathMax(MathMax((-target[2]) / 3, target[1]) / _Point, MaxSL / 10)); result[5] = float(sl) / MaxSL; result[3] = float(MathMax(risk / (value * sl), 0.01)) + FLT_EPSILON; } }
Bitte beachten Sie, dass wir in diesem Fall die Signale des MACD-Indikators nicht explizit überprüfen, da diese bereits bei der direkten Bestimmung der Richtung der kommenden Bewegung berücksichtigt wurden.
Mit diesen vorbereiteten Zielwerten können wir einen Rückwärtsdurchgang durch das zusammengesetzte Actor-Modell durchführen.
Result.AssignArray(result); if(!Actor.backProp(Result, (CNet *)GetPointer(EndpointEncoder)) || !StateEncoder.backPropGradient(GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !EndpointEncoder.backPropGradient((CNet*)GetPointer(BLProbability)) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Wir verwenden den Fehlergradienten des Akteurs, um die Encoder-Parameter zu aktualisieren, aber wir aktualisieren nicht das Endpunkt-Vorhersagemodell.
if(!BLEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Am Ende der Operationen innerhalb des Schleifensystems müssen wir den Nutzer lediglich über den Fortschritt des Trainingsprozesses informieren.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Endpoints", percent, BLEndpoints.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Probability", percent, BLProbability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Nach Abschluss des Modelltrainings wird das Kommentarfeld im Diagramm gelöscht. Wir geben die Ergebnisse des Modelltrainings im Protokoll aus und leiten den Beendigungsprozess des EAs ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Endpoints", BLEndpoints.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", BLProbability.getRecentAverageError()); ExpertRemove(); //--- }
Damit sind unsere Überlegungen zu Algorithmen für die Umsetzung der vorgeschlagenen grundlegenden Ansätze zur Optimierung der Vorhersagemodelle von Trajektorien abgeschlossen. Und im Anhang finden Sie den vollständigen Code aller hier verwendeten Programme.
3. Tests
Wir haben grundlegende Ansätze zur Optimierung von Prognosemodellen von Trajektorien mit MQL5 umgesetzt. Insbesondere haben wir eine Graphenfaltungsschicht entwickelt und Ansätze angewandt, um bei der Festlegung von Zielen während des Modelltrainings a priori Wissen über die Umgebung zu nutzen. Dadurch hat sich die Anzahl der Schichten in den Modellen verringert, was die Komplexität der Modelle verringern und ihre Arbeitsgeschwindigkeit erhöhen dürfte. Wir bewerteten die Auswirkungen der vorgeschlagenen Ansätze beim Training und Testen der trainierten Modelle auf realen Daten im MetaTrader 5 Strategietester.
Wie zuvor werden Training und Test der Modelle für die ersten 7 Monate des Jahres 2023 von EURUSD H1 durchgeführt.
Beim Aufbau der Modellarchitektur haben wir bereits erwähnt, dass die Struktur der Ausgangsdaten erhalten bleiben muss. So konnten wir beim Training den in früheren Artikeln gesammelten Erfahrungswiedergabepuffer nutzen. Wir benennen einfach die zuvor gesammelte Datendatei in BaseLines.bd um. Wenn Sie einen neuen Trainingsdatensatz erstellen möchten, können Sie eine der zuvor beschriebenen Methoden unter Verwendung von Umweltinteraktions-EAs verwenden.
Der Prozess der Generierung von Zielwerten während des Modelltrainings ermöglichte es uns, den Trainingsdatensatz so lange zu verwenden, bis wir optimale Ergebnisse erzielen, ohne ihn aktualisieren und ergänzen zu müssen.
Die Ergebnisse des Trainings waren jedoch nicht so vielversprechend wie erwartet. Beim Testen der trainierten Modelle haben wir den Testzeitraum von 1 auf 3 Monate verlängert.


Nun, es ist uns gelungen, ein Modell zu erhalten, das sowohl bei den Trainings- als auch bei den Teststichproben Gewinne erzielen kann. Darüber hinaus zeigte das resultierende Modell eine gute Stabilität mit einem Gewinnfaktor von 1,4. Nach einem 7-monatigen Training mit historischen Daten ist das Modell in der Lage, mindestens 3 Monate lang Gewinne zu erzielen. Dies könnte darauf hindeuten, dass das Modell in der Lage war, relativ stabile Prädiktoren zu ermitteln.
Allerdings war das Modell in Bezug auf die Anzahl der Abschlüsse ziemlich schlecht. 11 abgeschlossene Handelsgeschäfte in 3 Monaten sind sehr wenig. Das ist nicht das Ergebnis, das wir erreichen wollten.
Schlussfolgerung
In diesem Artikel haben wir grundlegende Ansätze zur Optimierung der Leistung von Modellen zur Trajektorie-Prognose untersucht. Die Umsetzung der vorgeschlagenen Ansätze ermöglicht es, Modelle zu trainieren, die in der Lage sind, wirklich signifikante Prädiktoren in den Quelldaten zu identifizieren. Dies ermöglicht einen stabilen Betrieb über einen längeren Zeitraum nach dem Training.
Unsere Ergebnisse deuten jedoch auf einen starken Konservatismus bei den von den Modellen getroffenen Entscheidungen hin. Dies spiegelt sich in einer sehr geringen Zahl von Abschlüssen wider. Das ist also die Richtung, in der wir weiter forschen müssen.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modelltraining EA |
| 4 | Test.mq5 | Expert Advisor | Modelltraining EA |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14187
 Einführung in MQL5 (Teil 7): Anleitung für Anfänger zur Erstellung von Expert Advisors und zur Verwendung von AI-generiertem Code in MQL5
Einführung in MQL5 (Teil 7): Anleitung für Anfänger zur Erstellung von Expert Advisors und zur Verwendung von AI-generiertem Code in MQL5
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.