
Neuronale Netze leicht gemacht (Teil 72): Entwicklungsvorhersage in verrauschten Umgebungen

Einführung
Die Vorhersage der künftigen Entwicklung eines Vermögenswerts durch die Analyse seiner historischen Entwicklung ist im Zusammenhang mit dem Finanzmarkthandel von Bedeutung, wo die Analyse der vergangenen Trends ein Schlüsselfaktor für eine erfolgreiche Strategie sein kann. Die künftige Entwicklung von Vermögenswerten ist häufig mit Unsicherheiten behaftet, die auf Veränderungen der zugrunde liegenden Faktoren und der Reaktion des Marktes auf diese Faktoren zurückzuführen sind, was viele potenzielle künftige Vermögensbewegungen bestimmt. Daher muss eine wirksame Methode zur Vorhersage von Marktbewegungen in der Lage sein, eine Verteilung möglicher zukünftiger Verläufe oder zumindest mehrere plausible Szenarien zu erstellen.
Trotz der beträchtlichen Vielfalt der bestehenden Architekturen für die wahrscheinlichsten Vorhersagen können die Modelle bei der Vorhersage der künftigen Entwicklung von Finanzanlagen mit dem Problem allzu einfacher Prognosen konfrontiert sein. Das Problem bleibt bestehen, weil das Modell die Daten aus dem Trainingssatz zu eng interpretiert. In Ermangelung klarer Muster bei der Entwicklung von Vermögenswerten führt das Prognosemodell zu einfachen oder homogenen Bewegungsszenarien, die nicht in der Lage sind, die Vielfalt der Veränderungen bei den Bewegungen von Finanzinstrumenten zu erfassen. Dies kann zu einer Verschlechterung der Prognosegenauigkeit führen.
Die Autoren des Artikels „Enhancing Trajectory Prediction through Self-Supervised Waypoint Noise Prediction“ haben einen neuen Ansatz zur Lösung dieser Probleme entwickelt: Self-Supervised Waypoint Noise Prediction (SSWNP), der aus zwei Modulen besteht:
- Modul für räumliche Konsistenz
- Modul der Vorhersagen von Rauschen
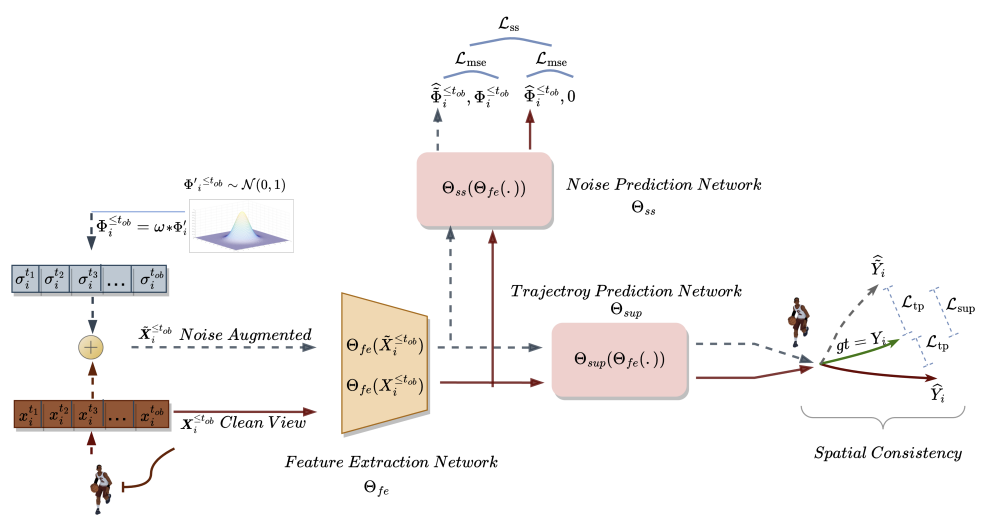
Bei der ersten Methode werden zwei verschiedene Ansichten von historisch beobachteten Trajektorien erstellt: reine und verrauschte Ansichten des räumlichen Bereichs von Schlüsselpunkten. Wie der Name schon sagt, stellt die saubere Version die ursprünglichen Trajektorien dar, während die verrauschte Version vergangene Trajektorien darstellt, die im ursprünglichen Merkmalsraum mit hinzugefügtem Rauschen bewegt wurden. Dieser Ansatz macht sich die Tatsache zunutze, dass die verrauschte Version der vergangenen Trajektorien nicht einer engen Interpretation der Daten aus dem Trainingssatz entspricht. Das Modell nutzt diese zusätzlichen Informationen, um das Problem allzu simpler Vorhersagen zu überwinden und vielfältigere Szenarien zu untersuchen. Nach der Generierung von zwei verschiedenen vergangenen Trajektorien trainieren wir ein Modell zur Vorhersage zukünftiger Trajektorien, um die räumliche Konsistenz zwischen den beiden Vorhersagen aufrechtzuerhalten und raum-zeitliche Merkmale zu erlernen, die über die Aufgabe der Bewegungsvorhersage hinausgehen.
Das Modul zur Rauschvorhersage löst das Zusatzproblem der Identifizierung von Rauschen in den analysierten Trajektorien. Dies hilft dem Modell zur Bewegungsvorhersage, die potenzielle räumliche Vielfalt besser zu modellieren, und verbessert das Verständnis der zugrunde liegenden Darstellung bei der Bewegungsvorhersage, wodurch künftige Vorhersagen verbessert werden.
Die Autoren der Methode führten zusätzliche Experimente durch, um die entscheidende Bedeutung der Module für räumliche Konsistenz und Rauschvorhersage für SSWNP empirisch nachzuweisen. Wenn nur das Modul für räumliche Konsistenz zur Lösung des Problems der Bewegungsvorhersage verwendet wird, wird eine suboptimale Leistung des trainierten Modells beobachtet. Deshalb integrieren sie beide Module in ihre Arbeit.
1. SSWNP-Algorithmus
Das Ziel der Trajektorievorhersage ist es, die wahrscheinlichste zukünftige Trajektorie eines Agenten in einer dynamischen Umgebung auf der Grundlage seiner zuvor beobachteten Trajektorien zu bestimmen. Eine Trajektorie wird durch eine Zeitreihe von räumlichen Punkten, den so genannten Wegpunkten, dargestellt. Die beobachtete Trajektorie erstreckt sich über einen Zeitraum von t1 to tob und kann wie folgt bezeichnet werden
![]()
wobei Xi* den Koordinaten von i in einem Zeitschritt t* entspricht. In ähnlicher Weise kann die vorhergesagte, zukünftige Trajektorie für den Agenten i während der Periode [tob+1,tfu] als Ŷtob+1≤t≤tfu beschrieben werden. Die entsprechende wahre Trajektorie für die zukünftige Bewegung des Agenten i kann als Ytob+1≤t≤tfu. beschrieben werden.
Bei der SSWNP-Methode werden zunächst zwei verschiedene Ansichten der Trajektorien erstellt: eine wird als saubere Ansicht (X≤tob) und die andere als rauschverstärkte Ansicht (Ẍ≤tob). Die saubere Ansicht entspricht der ursprünglichen Trajektorie aus dem Trainingsdatensatz, während die verrauschte Ansicht einer Trajektorie entspricht, die durch Hinzufügen von Rauschen im Merkmalsraum verschoben wurde.
Rauschen aus der Standardnormalverteilung N(0, 1) wird verwendet, um die saubere Trajektorie zu verzerren. Die Autoren der Methode führen einen Parameter namens Rauschfaktor (ω) ein, der die räumliche Bewegung der Wegpunkte steuert.
![]()
Nach der Erstellung der sauberen und verrauschten Trajektorienansichten werden diese in das Modell zur Merkmalsextraktion (Θfe) eingespeist, das Merkmale sowohl für die saubere als auch für die verrauschte Ansicht erzeugt. Die sich daraus ergebenden Merkmale werden dann in ein Bahnvorhersagemodell (Θsup) eingegeben, um die Trajektorien Ŷtob+1≤t≤tfu und Ÿtob+1≤t≤tfu vorherzusagen, wie in den folgenden Gleichungen dargestellt:
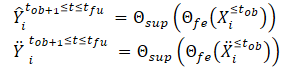
Wir trainieren das Modell so, dass die Lücke zwischen den vorhergesagten Trajektorien und der wahren Trajektorie aus dem Trainingsdatensatz minimiert wird. Wie man sieht, wird durch die Minimierung des Fehlers bei der Vorhersage von Trajektorien aus sauberen und verrauschten Ausgangsdaten (Ŷ and Ÿ) gegenüber der wahren Trajektorie aus dem Trainingsdatensatz (Y) indirekt der Abstand zwischen den beiden vorhergesagten Trajektorien verringert. Dadurch wird die räumliche Konsistenz zwischen zukünftigen Trajektorievorhersagen, die auf sauberen beobachteten Trajektorien basieren, und rauschverstärkten Trajektorien aufrechterhalten.
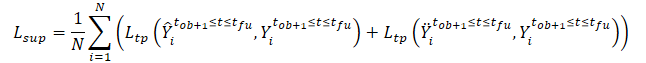
Darüber hinaus löst die SSWNP-Methode das Problem der selbstüberwachten Rauschvorhersage, die die Vorhersage des vorhandenen Rauschens in seiner reinen Form, der beobachteten vergangenen Trajektorie X≤tob, sowie in der mit Rauschen angereicherten Form umfasst Ẍ≤tob. Ziel ist es, den mit einem bestimmten beobachteten Wegpunkt verbundenen Rauschwert zu schätzen.
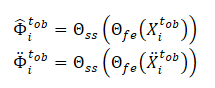
Beachten Sie, dass die vom Modell Θfe extrahierten Merkmale als Eingabedaten für das Rauschvorhersagemodell (Θss) verwendet werden, das den Rauschpegel in den beobachteten Trajektorien (saubere und erweiterte Ansichten) bestimmt. Als Verlustfunktion für das selbstüberwachte Lernen des Rauschvorhersagemodells schlagen die Autoren der Methode die Verwendung des mittleren quadratischen Fehlers (MSE) vor.
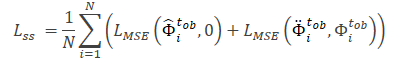
Der Wert 0 bedeutet hier das Fehlen von Rauschen in der Trajektorie der reinen Form.
Die allgemeine Verlustfunktion der SSWNP-Methode wird wie folgt dargestellt:
![]()
Dabei bezeichnet λ den Beitrag des Rauschvorhersagefehlers zum Gesamtfehler beim Training des Modells mit dem vorgeschlagenen Ansatz.
Die ursprüngliche Visualizierung der selbstüberwachten Wegpunkt-Rauschvorhersagemethode wird im Folgenden vorgestellt.
2. Implementierung mit MQL5
Wir haben die theoretischen Aspekte der selbstüberwachten Methode zur Vorhersage von Wegpunkten des Rauschens kennen gelernt. Wie Sie sehen, gibt es bei den vorgeschlagenen Ansätzen keine Einschränkungen hinsichtlich der Architektur der verwendeten Modelle oder der Struktur der Quelldaten. Dies ermöglicht es uns, die vorgeschlagenen Ansätze mit einer großen Anzahl von Algorithmen zu integrieren, die wir zuvor betrachtet haben. Insbesondere werden wir in diesem Artikel die vorgeschlagenen Ansätze dem Autoencoder-Trainingsalgorithmus TrajNet hinzufügen, der Methode, die wir in dem kürzlich erschienenen Artikel über Goal-Conditioned Predictive Coding diskutiert haben.
Wie bereits erwähnt, sieht der GCPC-Algorithmus 2 Stufen der Modellbildung vor:
Die in diesem Artikel vorgestellte SSWNP-Methode zielt darauf ab, die Effizienz der Vorhersage künftiger Trajektorien zu verbessern. Daher deckt sie nur die Phase „Training der Trajektionsfunktion“ ab. Wir werden die notwendigen Anpassungen in dieser Phase vornehmen. Die zweite Stufe, das „Verhaltenstraining“, wird in der bestehenden Form weitergeführt.
2.1 Fragen der Methodenintegration
Wenn wir neue Ansätze in eine fertige Struktur integrieren, müssen wir sicherstellen, dass die Änderungen, die wir vornehmen, den bereits bestehenden Prozess nicht stören. Bevor wir mit unserer Arbeit beginnen, müssen wir daher die Auswirkungen der neuen Ansätze auf den zuvor geschaffenen Lernprozess und die anschließende Funktionsweise des Modells analysieren.
Durch das Hinzufügen von Rauschen zu den Trajektorien aus dem Trainingsdatensatz wird die Verteilung der ursprünglichen Daten natürlich verändert. Dies wirkt sich folglich auf die Parameter der Batch-Normalisierungsschicht aus, in der wir die Quelldaten vorverarbeiten. Einerseits versuchen wir, genau das zu erreichen. Wir wollen ein Modell trainieren, das unter realitätsnahen Bedingungen in einer Umgebung mit hoher Stochastizität funktioniert. Andererseits kann die Hinzufügung von Zufallsrauschen die ursprünglichen Daten über die tatsächlichen Werte der analysierten Parameter hinausschieben. Um die negativen Auswirkungen dieses Faktors zu minimieren, haben die Autoren des Algorithmus einen Rauschfaktor (ω) hinzugefügt, der den Umfang der Datenverschiebung reguliert. In den Fällen, in denen wir „rohe“, nicht normalisierte Daten haben, benötigen wir einen separaten Rauschfaktor für jede Metrik der Quelldaten. So kommen wir zur Verwendung eines Vektors von Rauschfaktoren. Dann wird die Auswahl eines Vektors von Hyperparametern zu einer recht komplexen Aufgabe, deren Komplexität mit der Zunahme der Zahl der analysierten Parameter zunimmt.
Die Lösung für dieses Problem ist, wie sich herausstellt, recht einfach. Die Multiplikation des Rauschens aus einer Normalverteilung mit einem bestimmten Faktor ähnelt dem Trick der Reparametrisierung, den wir in der Variations-Autoencoder-Schicht verwendet haben.
![]()
Durch die Verwendung der Parameter der Verteilung des Trainingsdatensatzes können wir daher das Modell innerhalb der ursprünglichen Verteilung halten. Gleichzeitig fügen wir die Stochastizität hinzu, die dem analysierten Umfeld innewohnt.
Allerdings muss hier noch ein weiterer Punkt berücksichtigt werden. Wir fügen den realen Trajektorien aus dem Trainingsdatensatz Rauschen hinzu, anstatt ihre Daten durch Zufallswerte zu ersetzen. Wenn wir das Problem direkt lösen, erhalten wir die Verteilungsparameter der Ausgangsdaten.
Werfen wir noch einen Blick auf die Idee, Rauschen zu verwenden. Zu einem bestimmten Zeitpunkt liegen uns aktuelle Daten für jeden der analysierten Parameter vor. Beim nächsten Zeitschritt ändern sich die Parameter um einen bestimmten Betrag. Das Ausmaß der Veränderung jedes Parameters hängt von einer großen Anzahl verschiedener Faktoren ab, was einer Zufallsvariablen gleichkommt. Gleichzeitig hat ein solcher Wandel aber auch seine Grenzen. Um die natürliche Verteilung der ursprünglichen Daten zu erhalten, können wir daher die Verteilungsparameter solcher Abweichungen zwischen zwei aufeinander folgenden Werten jedes analysierten Parameters bestimmen. Dies sind die Parameter für die Reparametrisierung unseres Rauschens.
Dabei ist zu berücksichtigen, dass eine signifikante Veränderung der Parameterwerte häufig auf eine Veränderung der Marktsituation hinweist. Nach der SSWNP-Methode wird das Modell so trainiert, dass die Lücke zwischen den Bahnvorhersagen aus sauberen und verrauschten Daten minimiert wird. Daher werden wir den von den Autoren der Methode vorgeschlagenen Rauschfaktor verwenden, um die Verzerrung durch die realen Trajektorien aus dem Trainingssatz zu begrenzen.
Der zweite Punkt ist die Verwendung der DropOut-Schicht in der GCPC-Methode, die ebenfalls als eine Art Regularisierung dient und das Modell darauf trainieren soll, einige „Ausreißer“ zu ignorieren und fehlende Parameter wiederherzustellen. Bei der Kombination von Methoden wird das Rauschen ignoriert, das zu den durch die DropOut-Ebene maskierten Parametern hinzugefügt wird. Andererseits erschwert die Maskierung von Parametern die Lösung des Problems durch das Modell im Vergleich zur Hinzufügung von Rauschen erheblich.
Wie bereits erwähnt, sollten wir den zuvor erstellten Prozess nicht verletzen. Daher werden wir die DropOut-Schicht nicht aus der Encoder-Architektur ausschließen. Es wird interessant sein, die Ergebnisse das Modelltraining zu beobachten.
Betrachten wir nun den Aufbau der selbstüberwachten Methode zur Vorhersage von Wegpunktrauschen. Je nach Algorithmus werden wir 3 Modelle trainieren:
- Modell zur Merkmalsextraktion
- Trajektorievorhersagemodell
- Rauschvorhersagemodell
Wir planen, den SSWNP-Algorithmus in den bereits entwickelten GCPC-Prozess zu integrieren. Versuchen wir, die Modelle der beiden Methoden zu vergleichen. Das SSWNP-Merkmalsextraktionsmodell entspricht dem GCPC-Encoder. Der GCPC-Decoder kann wiederum als SSWNP-Trajektorienvorhersagemodell dargestellt werden. Wir müssen also ein Modell zur Vorhersage von Rauschen hinzufügen.
2.2 Modellarchitektur
Die Modellarchitekturen werden in der Methode CreateTrajNetDescriptions beschrieben, zu der wir eine Beschreibung des dritten Modells hinzufügen werden. In den Parametern erhält die Methode Zeiger auf drei dynamische Arrays zur Beschreibung der Architektur dieser drei Modelle. Im Hauptteil der Methode prüfen wir die Relevanz der erhaltenen Zeiger und erstellen gegebenenfalls neue Instanzen von Objekten.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *decoder, CArrayObj *noise) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; } if(!noise) { noise = new CArrayObj(); if(!noise) return false; }
Wir übernehmen die Beschreibung der Encoder- und Decoder-Architekturen ohne Änderungen. Wie wir in früheren Artikeln gesehen haben, geben wir Rohdaten in den Encoder ein, unter denen wir nur historische Kursveränderungen und analysierte Indikatoren angeben.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Sie werden in der Batch-Normalisierungsschicht primär verarbeitet.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die normalisierten Daten werden in der DropOut-Ebene zufällig maskiert.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.8f; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Danach suchen wir mit Hilfe eines Blocks von Faltungsschichten nach stabilen Mustern.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 2; descr.window = 3; descr.step = 1; int prev_wout = descr.window_out = 3; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Dann verarbeiten wir die Daten in einem Block mit vollständig verbundenen Schichten.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Wir fügen die Ergebnisse früherer Durchläufe des Encoders immer wieder hinzu.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * EmbeddingSize; descr.window = prev_count; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Dann übertragen wir die Daten in den internen Stapel des zu analysierenden Verlaufs.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = GPTBars; { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Der daraus resultierende Satz an historischen Daten wird im Aufmerksamkeitsblock analysiert.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count * 2; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 4; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die Analyseergebnisse werden durch eine vollständig verbundene Schicht komprimiert.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = 1; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Am Ausgang des Encoders werden die Daten mit der Funktion SoftMax normalisiert.
Die Ergebnisse des Feedforward-Durchgangs des Encoders werden in den Decoder eingespeist.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
In diesem Fall handelt es sich um Daten aus dem vorherigen Modell, die bereits normalisiert wurden. Eine Vorverarbeitung der Daten ist daher nicht erforderlich. Wir erweitern sie sofort mit einer vollständig verbundenen Schicht.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars + PrecoderBars) * EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Die empfangenen Daten werden im Aufmerksamkeitsblock ausgewertet.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 2; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Am Ausgang des Aufmerksamkeitsblocks liegt eine Einbettung von jeder vorhergesagten Kerze vor. Um die resultierenden Einbettungen zu dekodieren, verwenden wir eine voll verbundene Schicht mit mehreren Modellen.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiModels; descr.count = 3; descr.window = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Nach der Beschreibung der Architektur des Encoders und des Decoders müssen wir eine Beschreibung der Architektur des Rauschvorhersagemodells hinzufügen. Dieses Modell verwendet wie der Decoder die Ergebnisse des Encoders als Eingangsdaten. Daher kopieren wir einfach die ursprüngliche Decoder-Datenschicht.
//--- Noise Prediction noise.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(decoder.At(0)); if(!noise.Add(descr)) { delete descr; return false; }
Als Nächstes expandieren wir die empfangenen Daten mit Hilfe einer voll verknüpften Schicht auf die Größe der ursprünglichen Daten am Eingang des Encoders.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = HistoryBars * EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; }
Jetzt, Achtung. Im nächsten Schritt habe ich, wahrscheinlich zum ersten Mal in der gesamten Artikelserie, eine Verzweigung für die Modellarchitektur in Abhängigkeit von den gewählten Hyperparametern erstellt. Der Schlüssel dazu ist die Anzahl der analysierten Kerzen am Eingang des Encoders. Wenn mehr als eine Kerze analysiert wird, ähnelt die Modellarchitektur dem Decoder. Wir verwenden einen Aufmerksamkeitsblock und eine Multimodell-Schicht zur Dekodierung von Einbettungen. Nur sprechen wir hier nicht von prognostizierten, sondern von analysierten Kerzen.
//--- if(HistoryBars > 1) { //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 2; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiModels; descr.count = BarDescr; descr.window = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; } }
Wenn nur eine Kerze am Encoder-Eingang analysiert wird, ist es nicht sinnvoll, eine Aufmerksamkeitsschicht zu verwenden, die die Beziehungen zwischen verschiedenen Kerzen analysiert. Daher werden wir ein einfaches Perceptron verwenden.
else { //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!noise.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr; descr.activation = None; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; } } //--- return true; }
Die obige Beschreibung bezieht sich nur auf die Architekturen der Modelle, die am Training des Trajektorienfunktionsmodells teilnehmen. Die Architektur der Agentenverhaltensrichtlinien-Trainingsmodelle wird ohne Änderungen übernommen. Sie finden sie in der Anlage. Eine ausführliche Beschreibung wurde in dem vorangegangenen Artikel gegeben.
2.3 Trainingsprogramme der Modelle
Nachdem wir die Architektur der verwendeten Modelle beschrieben haben, können wir uns nun den Algorithmen der Programme zuwenden. Bitte beachten Sie, dass die Autoren der SSWNP-Methode keine Anforderungen an die Auswahl der Quelldaten und die Erfassung der beobachteten Trajektorien für das Training stellen. Daher werden die Programme, die mit der Umgebung interagieren, so verwendet, wie sie sind, ohne irgendwelche Anpassungen. Der vollständige Code aller Programme, die in diesem Artikel verwendet werden, ist im Anhang verfügbar, sodass Sie sie studieren können. Bei Klärungsbedarf lesen Sie bitte den vorherigen Artikel oder stellen Sie eine Frage im Diskussionsteil.
Wir fahren mit dem Training der Trajektorienfunktion EA ...\Experts\SSWNP\StudyEncoder.mq5 fort, in dem wir gleichzeitig 3 Modelle trainieren werden:
- Modell zur Merkmalsextraktion (Encoder)
- Modell der Trajektorievorhersage (Decoder)
- Rauschvorhersagemodell (Noise).
CNet Encoder; CNet Decoder; CNet Noise;
Wie im Theorieteil erwähnt, müssen wir zur Implementierung des SSWNP-Algorithmus 2 Hyperparameter definieren. Wir werden sie als Konstanten in unserem Programm implementieren.
#define STE_Noise_Multiplier 1.0f/10 // λ determined the impact of noise prediction error #define STD_Delta_Multiplier 1.0f/10 // noise factor ω
Bei der EA-Initialisierungsmethode laden wir zunächst die Trainingsmenge hoch.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Dann versuchen wir, die zuvor trainierten Modelle zu öffnen. Wenn ein Fehler beim Laden der Modelle auftritt, erstellen wir neue Modelle und initialisieren sie mit zufälligen Parametern.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Decoder.Load(FileName + "Dec.nnw", temp, temp, temp, dtStudied, true) || !Noise.Load(FileName + "NP.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *encoder = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *noise = new CArrayObj(); if(!CreateTrajNetDescriptions(encoder, decoder, noise)) { delete encoder; delete decoder; delete noise; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Decoder.Create(decoder) || !Noise.Create(noise)) { delete encoder; delete decoder; delete noise; return INIT_FAILED; } delete encoder; delete decoder; delete noise; //--- }
Wir übertragen alle Modelle in einen einzigen OpenCL-Kontext.
//---
OpenCL = Encoder.GetOpenCL();
Decoder.SetOpenCL(OpenCL);
Noise.SetOpenCL(OpenCL);
Dann fügen wir eine Kontrolle für die wichtigsten Parameter der Architektur der verwendeten Modelle hinzu.
//--- Encoder.getResults(Result); if(Result.Total() != EmbeddingSize) { PrintFormat("The scope of the Encoder does not match the embedding size count (%d <> %d)", EmbeddingSize, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Decoder.GetLayerOutput(0, Result); if(Result.Total() != EmbeddingSize) { PrintFormat("Input size of Decoder doesn't match Encoder output (%d <> %d)", Result.Total(), EmbeddingSize); return INIT_FAILED; } //--- Noise.GetLayerOutput(0, Result); if(Result.Total() != EmbeddingSize) { PrintFormat("Input size of Noise Prediction model doesn't match Encoder output (%d <> %d)", Result.Total(), EmbeddingSize); return INIT_FAILED; } //--- Noise.getResults(Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Output size of Noise Prediction model doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Nach erfolgreicher Übergabe aller Kontrollen erstellen wir den Hilfsdatenpuffer.
//--- if(!LastEncoder.BufferInit(EmbeddingSize, 0) || !Gradient.BufferInit(EmbeddingSize, 0) || !LastEncoder.BufferCreate(OpenCL) || !Gradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
Für den Beginn des Lernprozesses erzeugen wir ein nutzerdefiniertes Ereignis.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Bei der EA-Deinitialisierungsmethode speichern wir die trainierten Modelle und löschen den Speicher der zuvor erstellten dynamischen Objekte.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Encoder.Save(FileName + "Enc.nnw", 0, 0, 0, TimeCurrent(), true); Decoder.Save(FileName + "Dec.nnw", Decoder.getRecentAverageError(), 0, 0, TimeCurrent(), true); Noise.Save(FileName + "NP.nnw", Noise.getRecentAverageError(), 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
Der eigentliche Prozess des Trainings von Modellen ist in der Methode Train implementiert. Wie zuvor haben wir im Hauptteil der Methode zunächst die Wahrscheinlichkeiten für die Auswahl von Trajektorien aus dem Erfahrungswiedergabepuffer berechnet.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Dann erstellen und initialisieren wir die erforderlichen lokalen Variablen.
//--- vector<float> result, target, inp; matrix<float> targets; matrix<float> delta; STE = vector<float>::Zeros((HistoryBars + PrecoderBars) * 3); STE_Noise = vector<float>::Zeros(HistoryBars * BarDescr); int std_count = 0; int batch = GPTBars + 50; bool Stop = false; uint ticks = GetTickCount();
Damit ist die Vorbereitungsphase abgeschlossen. Als Nächstes erstellen wir ein System von Modelltrainingszyklen. Wie Sie sich erinnern, stellt die im Encoder verwendete GPT-Architektur strenge Anforderungen an die Reihenfolge der Eingabedaten. Daher erstellen wir ein System von verschachtelten Schleifen. Im Hauptteil der äußeren Schleife werden eine Trajektorie und der Zustand auf dieser Trajektorie abgetastet, um den Trainingslauf zu starten. In der verschachtelten Schleife trainieren wir das Modell anhand einer Reihe von aufeinanderfolgenden Zuständen aus einer Trajektorie.
Hier kommt eine weitere Herausforderung. Wir können keine sauberen und verrauschten Daten in derselben Sequenz verwenden. Bei der SSWNP-Methode wird das Rauschen den Trajektorien und nicht den einzelnen Zuständen hinzugefügt.
Gleichzeitig können wir dem Modell nicht in einer Iteration abwechselnd einen sauberen Zustand und einen Zustand mit hinzugefügtem Rauschen zuführen. Im internen Stapel werden die Zustandsmodelle gemischt und das Modell nimmt sie als eine einzige Trajektorie wahr. Dadurch wird die analysierte Sequenz stark verzerrt.
Eine akzeptable Lösung besteht darin, die Trajektorien zu wechseln. Das Modell wird zunächst auf einer sauberen Trajektorie und dann auf einer mit Rauschen angereicherten Trajektorie trainiert. Dieser Ansatz ermöglicht es uns, gleichzeitig ein weiteres Problem zu lösen, das den Vektor der Koeffizienten für die Neuparametrisierung des Rauschens betrifft. Beim Training eines Modells auf sauberen Daten sammeln wir Informationen über die Verteilung der Parameteränderungen. Wir verwenden die Werte der gesammelten Verteilung, um das Rauschen zu reparametrisieren, das beim Training des Modells auf verrauschten Daten hinzugefügt wurde.
Wie bereits erwähnt, erstellen wir eine äußere Schleife, in der wir die Trajektorie und den Anfangszustand abfragen.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
Dann leeren wir die Modellstapel und den Hilfspuffer.
Encoder.Clear();
Decoder.Clear();
Noise.Clear();
LastEncoder.BufferInit(EmbeddingSize, 0);
Wir bestimmen den Endzustand des Trainingspakets auf der Trajektorie und löschen die Matrix, um Informationen über Änderungen der analysierten Parameter zu sammeln.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); delta = matrix<float>::Zeros(end - state - 1, Buffer[tr].States[state].state.Size());
Beachten Sie, dass die Größe der Varianzmatrix um 1 Zeile kleiner ist als die der Trainingsmenge. Der Grund dafür ist, dass wir in dieser Matrix das Delta der Veränderung zwischen 2 aufeinanderfolgenden Zuständen speichern.
In diesem Stadium ist alles bereit, um mit dem Training des Modells auf einer sauberen Trajektorie zu beginnen. Wir erstellen also die erste verschachtelte Trainingsschleife.
for(int i = state; i < end; i++) { inp.Assign(Buffer[tr].States[i].state); State.AssignArray(inp); int row = i - state; if(i < (end - 1)) delta.Row(inp, row);
Im Hauptteil der Schleife extrahieren wir den analysierten Zustand aus der Trainingsstichprobe und übertragen ihn in den Quelldatenpuffer.
Wir verwenden denselben Zustand, um die Abweichungen zu berechnen. Zunächst wird geprüft, ob der aktuelle Zustand der letzte im Trainingsdatenstapel ist, und der analysierte Zustand wird der entsprechenden Zeile der Abweichungsmatrix hinzugefügt (der letzte Zustand wird nicht hinzugefügt).
Warum fügen wir die Zustände so hinzu, wie sie sind, während dies eine Abweichungsmatrix ist? Die Antwort liegt im nächsten Schritt. Bei jeder weiteren Iteration der Schleife subtrahieren wir die zu analysierende Aktion von der vorherigen Zeile der Abweichungsmatrix, die den im vorherigen Schritt gespeicherten Zustand enthält. Natürlich überspringen wir diesen Schritt für den ersten Zustand, wenn es keinen vorherigen Schritt gibt.
if(row > 0) delta.Row(delta.Row(row - 1) - inp, row - 1);
Als Nächstes rufen wir nacheinander die Vorwärtsdurchgangs-Methoden der trainierten Modelle auf. Zuerst kommt der Encoder.
if(!LastEncoder.BufferWrite() || !Encoder.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(LastEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Es folgt der Decoder.
if(!Decoder.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Der Vorwärts-Vorwärts-Block endet mit einem Rauschvorhersagemodell.
if(!Noise.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Wie üblich führen wir nach dem Feedforward-Block einen Backpropagation-Durchlauf der trainierten Modelle durch, bei dem wir ihre Parameter anpassen, um den Fehler zu minimieren. Zunächst führen wir einen Backpropagation-Durchlauf des Decoders durch und geben den Fehlergradienten an den Encoder weiter. Bevor wir den Backpropagation-Durchgang des Modells aufrufen, müssen wir die Zielwerte vorbereiten.
Am Ausgang des Decoders erwarten wir die Parameter des Ausgangszustands, der in den Encoder eingespeist wird, sowie eine Vorhersage für einen bestimmten Planungshorizont. Im vorherigen Artikel haben wir die Zusammensetzung der vorhergesagten Parameter für jede Kerze besprochen. Ich bleibe bei meiner Meinung. Daher hat sich weder die Architektur des Decoders noch der Algorithmus zur Erstellung der Zielwerte geändert. Zunächst füllen wir die Zielwertmatrix mit den Daten, die dem Encoder-Eingang zugeführt werden.
target.Assign(Buffer[tr].States[i].state); ulong size = target.Size(); targets = matrix<float>::Zeros(1, size); targets.Row(target, 0); if(size > BarDescr) targets.Reshape(size / BarDescr, BarDescr); ulong shift = targets.Rows();
Dann ergänzen wir sie mit Daten aus dem Erfahrungswiedergabepuffer für einen bestimmten Planungshorizont.
targets.Resize(shift + PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, shift + t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
Wir übertragen die empfangenen Informationen in einen Vektor und vergleichen sie mit den Ergebnissen des Decoders.
Decoder.getResults(result); vector<float> error = target - result;
Wie zuvor konzentrieren wir uns beim Training auf die höchsten Abweichungen. Wir berechnen also zunächst den gleitenden, mittleren, quadratischen Fehler.
std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1));
Dann vergleichen wir den aktuellen Fehler mit einem Schwellenwert, der auf der Standardabweichung basiert. Der Backpropagation-Durchgang wird nur ausgeführt, wenn der aktuelle Fehler in mindestens einem Parameter den Schwellenwert überschreitet.
vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Decoder.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Die Idee, die maximalen Abweichungen hervorzuheben, ist der Methode CFPI entlehnt.
Wir verwenden einen ähnlichen Backpropagation-Algorithmus für das Geräuschvorhersagemodell. Aber hier ist der Ansatz, den Vektor der Zielwerte zu organisieren, viel einfacher: Wenn wir mit sauberen Trajektorien arbeiten, verwenden wir einfach einen Vektor von Nullwerten.
target = vector<float>::Zeros(delta.Cols()); Noise.getResults(result); error = (target - result) * STE_Noise_Multiplier;
Beachten Sie, dass wir bei der Berechnung des Fehlers die resultierende Abweichung mit der Konstante STE_Noise_Multiplier multiplizieren, die den Einfluss des Rauschvorhersagefehlers auf den Gesamtmodellfehler bestimmt.
Wir konzentrieren uns auch auf maximale Abweichungen und führen nur dann einen Backpropagation-Durchgang durch, wenn bei mindestens einem Parameter ein Fehler über einem Schwellenwert liegt.
STE_Noise = MathSqrt((MathPow(STE_Noise, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; check = MathAbs(error) - STE_Noise; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Noise.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Wir geben den Fehlergradienten des Rauschvorhersagemodells an den Encoder weiter und rufen, falls erforderlich, dessen Backpropagation-Methode auf.
Nach der Aktualisierung der Parameter aller trainierten Modelle werden die letzten Ergebnisse des Vorwärtsdurchgangs des Encoders in einem Hilfspuffer gespeichert.
Encoder.getResults(result); LastEncoder.AssignArray(result);
Wir informieren den Nutzer über den Fortschritt des Lernprozesses und fahren mit der nächsten Iteration der verschachtelten Schleife fort.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); str += StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Noise Prediction", percent, Noise.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Hier vervollständigen wir in der Regel die Beschreibung der Iterationen im System der Modelltrainingsschleifen. Doch dieses Mal ist der Fall anders. Wir haben einen Stapel von Trainingsmodellen auf einer sauberen Trajektorie verarbeitet. Nun müssen wir die Vorgänge für die rauscherhöhte Trajektorie wiederholen. Wir definieren also zunächst die statistischen Parameter der Rauschverteilung.
//--- With noise vector<float> std_delta = delta.Std(0) * STD_Delta_Multiplier; vector<float> mean_delta = delta.Mean(0);
Beachten Sie, dass die Standardabweichung mit dem Rauschfaktor multipliziert wird, um die maximal mögliche Verzerrung der Werte der analysierten Merkmale zu reduzieren.
Wir erstellen einen Vektor und ein Array, um Rauschen zu erzeugen.
ulong inp_total = std_delta.Size(); vector<float> noise = vector<float>::Zeros(inp_total); double ar_noise[];
Danach werden die neue Trajektorie und der Anfangszustand abgetastet.
tr = SampleTrajectory(probability); state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
Wir löschen die Stapel der Modelle und den Hilfspuffer.
Encoder.Clear();
Decoder.Clear();
Noise.Clear();
LastEncoder.BufferInit(EmbeddingSize, 0);
Dann erstellen wir eine weitere verschachtelte Schleife, um mit einer rauscherhöhten Trajektorie zu arbeiten.
end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); for(int i = state; i < end; i++) { if(!Math::MathRandomNormal(0, 1, (int)inp_total, ar_noise)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } noise.Assign(ar_noise);
Im Hauptteil der Schleife erzeugen wir zunächst Rauschen aus einer Normalverteilung und übertragen es in einen Vektor. Danach wird es neu parametrisiert.
noise = mean_delta + std_delta * noise;
In diesem Stadium haben wir das Rauschen für die aktuelle Trainingsiteration vorbereitet. Wir laden den sauberen Zustand aus dem Erfahrungswiedergabepuffer und fügen das erzeugte Rauschen hinzu.
inp.Assign(Buffer[tr].States[i].state); inp = inp + noise;
Der resultierende verrauschte Zustand wird in den Quelldatenpuffer geladen.
State.AssignArray(inp);
Als Nächstes führen wir einen Feed-Forward-Block aus, ähnlich wie bei der Arbeit mit sauberen Trajektorien.
if(!LastEncoder.BufferWrite() || !Encoder.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(LastEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!Decoder.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!Noise.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Nach der SSWNP-Methode sollte eine räumliche Übereinstimmung zwischen den vorhergesagten Trajektorien für saubere und rauschbelastete Trajektorien hergestellt werden. Wie wir im theoretischen Teil gesehen haben, laufen beide Wege auf das gleiche Ziel zu. Folglich werden wir den Backpropagation-Block des Decoders auf die gleiche Weise konstruieren, wie wir es oben für saubere Trajektorien getan haben.
target.Assign(Buffer[tr].States[i].state); ulong size = target.Size(); targets = matrix<float>::Zeros(1, size); targets.Row(target, 0); if(size > BarDescr) targets.Reshape(size / BarDescr, BarDescr); ulong shift = targets.Rows(); targets.Resize(shift + PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, shift + t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
Decoder.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Decoder.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Bei dem Modell zur Rauschvorhersage liegt der Unterschied in den Zielwerten. Für saubere Trajektorien haben wir einen mit Nullwerten gefüllten Vektor verwendet. Jetzt verwenden wir das Rauschen, das dem sauberen Zustand hinzugefügt wird, bevor wir ihn in den Encoder-Eingang einspeisen, als Zielwerte.
target = noise; Noise.getResults(result); error = (target - result) * STE_Noise_Multiplier;
STE_Noise = MathSqrt((MathPow(STE_Noise, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; check = MathAbs(error) - STE_Noise; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Noise.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Nach der Aktualisierung der Modellparameter speichern wir die Ergebnisse des letzten Encoder-Durchgangs in einem Hilfspuffer.
Encoder.getResults(result); LastEncoder.AssignArray(result);
Wir informieren den Nutzer über den Fortschritt des Lernprozesses und fahren mit der nächsten Iteration des Zyklus fort.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter + 0.5) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); str += StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Noise Prediction", percent, Noise.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Damit ist die Beschreibung der Iterationen im System der Modellbildungszyklen abgeschlossen. Nachdem alle Iterationen erfolgreich abgeschlossen wurden, wird das Kommentarfeld im Diagramm des Finanzinstruments gelöscht.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Decoder", Decoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Noise Prediction", Noise.getRecentAverageError()); ExpertRemove(); //--- }
Drucken Sie die Ergebnisse des Trainingsprozesses in das Protokoll und leiten Sie die Beendigung des EA ein.
Der vollständige Code aller in diesem Artikel verwendeten Programme ist im Anhang verfügbar.
Oben ist der aktualisierte Algorithmus für das Training der Trajektorienfunktion EA dargestellt. Der Algorithmus für das Training der Richtlinien blieb unverändert. Eine ausführliche Beschreibung wurde im vorigen Artikel gegeben. Der vollständige Code des EA „...\Experts\SSWNP\Study.mq5“ ist unten angefügt.
3. Test
Im praktischen Teil dieses Artikels haben wir die Ansätze der Self-Supervised Waypoint Noise Prediction-Methode mit der Goal-Conditioned Predictive Coding-Methode in den zuvor erstellten EA mit dem Trajektorienfunktionstraining integriert. Jetzt erwarten wir eine Verbesserung der Qualität der Preisbewegungsprognosen. Nun ist es an der Zeit, die Ergebnisse mit realen Daten im MetaTrader 5 Strategietester zu testen.
Wie zuvor werden die Modelle anhand historischer Daten für EURUSD H1 trainiert und getestet. Das Modell wird mit den Daten der ersten 7 Monate des Jahres 2023 trainiert. Um das trainierte Modell zu testen, verwenden wir historische Daten vom August 2023. Wie Sie sehen, schließt sich die Testphase direkt an die Trainingsphase an.
Bevor wir die Modelle trainieren, müssen wir einen primären Trainingsdatensatz sammeln. Da wir neue Ansätze in einen bereits erstellten EA implementiert haben, ohne die Modellarchitektur und die Datenstruktur zu ändern, können wir diesen Schritt überspringen und die bestehende Beispieldatenbank verwenden, die beim Training der Modelle mit der GCPC-Methode erstellt wurde. Wir erstellen eine Kopie der Erfahrungswiedergabe-Pufferdatei mit dem Namen „SSWNP.bd“. Dann gehen wir direkt zum Modelltraining über.
Nach dem Algorithmus der GCPC-Methode werden die Modelle in 2 Stufen trainiert. In der ersten Phase trainieren wir die Trajektorfunktion. Diese Phase beinhaltet die Ansätze der neuen SSWNP-Methode. Nur historische Kursbewegungen und Indikatordaten werden in den Encoder-Eingang eingespeist. Dadurch sind alle Trajektorien im Erfahrungswiedergabepuffer identisch, da der Kontostatus und die offenen Positionswerte, die Unterschiede in den Trajektorien verursachen, in diesem Stadium nicht analysiert werden. Daher können wir die vorhandene Beispieldatenbank verwenden und die Trajektorienfunktion so lange trainieren, bis wir ein akzeptables Ergebnis erhalten, ohne zusätzliche Beispiele zu sammeln.
In der zweiten Phase des Modelltrainings, dem Training der Verhaltenspolitik, wird nach den optimalen Handlungen des Agenten unter historischen Marktbedingungen gesucht, wobei sich der Kontostatus und die offenen Positionen ändern, die von den Marktbedingungen und den vom Agenten durchgeführten Aktionen abhängen. In dieser Phase verwenden wir ein iteratives Modelltraining, bei dem wir abwechselnd Modelle trainieren und zusätzliche Beispiele sammeln, die es uns ermöglichen, die aktualisierte Verhaltenspolitik des Agenten genauer zu bewerten.
Unser Trainingsprozess hat einige Ergebnisse gezeigt. Es ist uns gelungen, ein Modell zu trainieren, das in der Lage ist, sowohl auf den historischen Daten des Trainingsdatensatzes als auch auf dem Testzeitraum Gewinne zu erzielen.


Schlussfolgerung
In diesem Artikel stellen wir die Methode der selbstüberwachten Wegpunkt-Rauschvorhersage vor. Dieser Ansatz ermöglicht die Verbesserung der Modelleffizienz in komplexen stochastischen Umgebungen, in denen die zukünftigen Trajektorien der Agenten aufgrund von sich ändernden Bedingungen und physikalischen Beschränkungen mit Unsicherheit behaftet sind. Dieses Ziel wird erreicht, indem vergangene Trajektorien mit Rauschen angereichert werden, was zu genaueren und vielfältigeren Vorhersagen zukünftiger Pfade beiträgt. Die vorgestellte innovative Methodik besteht aus zwei Modulen: einem Modul für räumliche Konsistenz und einem Modul für Rauschvorhersage, die zusammen eine genaue und zuverlässige Vorhersage in stochastischen Szenarien ermöglichen.
Die von den Autoren der Methode vorgeschlagene Konstruktion ist recht universell, sodass sie in ein breites Spektrum verschiedener Modelltrainingsalgorithmen integriert werden kann. Dies gilt nicht nur für Methoden des Verstärkungslernens. In ihrem Papier zeigen die Autoren der Methode anhand von Beispielen, wie die Umsetzung der vorgeschlagenen Ansätze die Effizienz der grundlegenden Methoden erhöht.
Im praktischen Teil dieses Artikels haben wir die von der SSWNP-Methode vorgeschlagenen Ansätze in die Struktur des GCPC-Algorithmus integriert. Die Ergebnisse unserer Tests bestätigen die Wirksamkeit der vorgeschlagenen Methode.
Ich möchte Sie jedoch noch einmal daran erinnern, dass alle in diesem Artikel vorgestellten Programme nur der Demonstration der Technologie dienen und nicht für den Einsatz im realen Finanzhandel geeignet sind.
Referenzen
- Enhancing Trajectory Prediction through Self-Supervised Waypoint Noise Prediction
- Neuronale Netze leicht gemacht (Teil 71): Zielgerichtete prädiktive Kodierung (GCPC)
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Trainings-EA der Politik |
| 4 | StudyEncoder.mq5 | Expert Advisor | Autoencoder-Training EA mit SSWNP-Ansätzen |
| 5 | Test.mq5 | Expert Advisor | Trainings-EA für das Model |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14044
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.