
Redes neurais de maneira fácil (Parte 72): previsão de trajetórias em condições de ruído

Introdução
Prever o movimento futuro de um ativo analisando suas trajetórias históricas é de grande importância no contexto do trading em mercados financeiros, onde a análise de tendências passadas pode ser um fator chave para uma estratégia bem-sucedida. As trajetórias futuras dos ativos frequentemente apresentam incerteza devido à mudança de fatores fundamentais e à reação do mercado a esses fatores, o que determina múltiplos movimentos futuros potenciais para os ativos. Com isso em mente, um método eficaz de previsão de movimentos nos mercados deve ser capaz de gerar uma distribuição de trajetórias futuras potenciais ou, pelo menos, alguns cenários prováveis.
Apesar da diversidade significativa de soluções arquitetônicas existentes para previsões mais prováveis, no processo de previsão de trajetórias futuras de ativos financeiros, os modelos podem enfrentar o problema de previsões excessivamente simplificadas. Esse problema persiste devido à interpretação restrita dos dados da amostra de treinamento pelo modelo. Na ausência de padrões claros de trajetórias dos ativos, o modelo de previsão gera cenários simples ou homogêneos de movimento, incapazes de capturar a diversidade das mudanças nos movimentos dos instrumentos financeiros, o que pode diminuir a precisão das previsões.
Para resolver esses problemas, no artigo "Enhancing Trajectory Prediction through Self-Supervised Waypoint Noise Prediction" foi proposta uma nova abordagem, Self-Supervised Waypoint Noise Prediction (SSWNP), que consiste em dois módulos:
- módulo de consistência espacial
- módulo de previsão de ruído
No primeiro, são criados dois tipos diferentes de trajetórias observadas no passado: limpas e ruidosas na área espacial dos pontos-chave. Como o nome sugere, a variante limpa representa a trajetória original percorrida, enquanto a variante ruidosa representa trajetórias passadas deslocadas no espaço original dos recursos analisados com adição de ruído. Essa abordagem utiliza o fato de que a variante ruidosa das trajetórias passadas não corresponde à interpretação restrita dos dados da amostra de treinamento. O modelo usa essa informação adicional para superar o problema das previsões excessivamente simplificadas e aprender cenários de movimento mais diversificados. Após a criação das duas variantes diferentes das trajetórias percorridas, treinamos o modelo de previsão de trajetórias futuras para manter a consistência espacial entre as previsões dessas duas variantes e estudar as características espaço-temporais, além da tarefa de previsão de movimento.
No módulo de previsão de ruído, é resolvida uma tarefa auxiliar de destacar o ruído nas trajetórias analisadas. Isso ajuda o modelo de previsão de movimento a modelar melhor a diversidade espacial potencial e melhora a compreensão da representação subjacente na previsão de movimento, melhorando assim as previsões futuras.
Os autores do método realizam experimentos adicionais para demonstrar empiricamente a importância crítica dos módulos de consistência espacial e de previsão de ruído para o SSWNP. Ao usar apenas o módulo de consistência espacial para a tarefa de previsão de movimento, observa-se um desempenho subótimo do modelo treinado. Portanto, em seu trabalho, eles integram ambos os módulos.
1. Algoritmo SSWNP
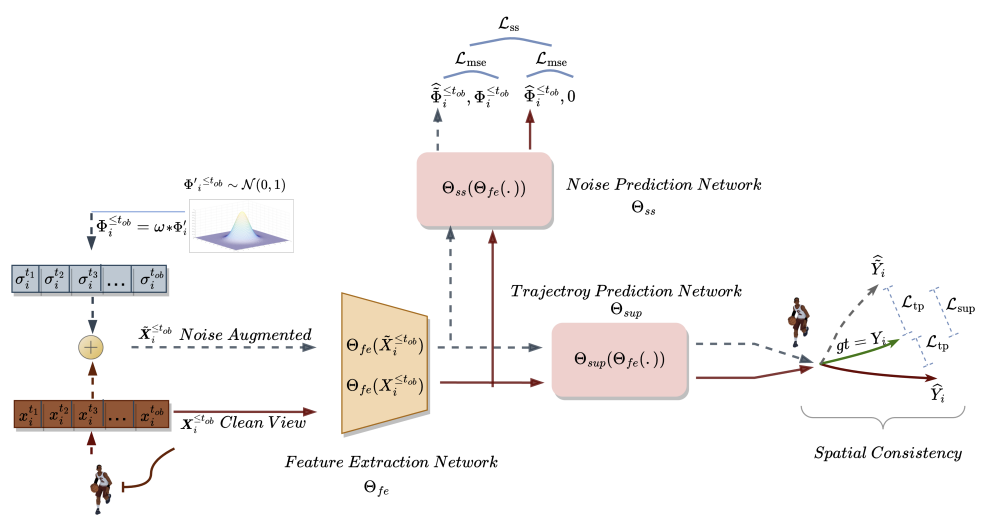
O objetivo da previsão de trajetórias é determinar a trajetória futura mais provável do agente em um ambiente dinâmico com base em suas trajetórias percorridas anteriormente. A trajetória é representada por uma série temporal de pontos espaciais, chamados de pontos de rota. A trajetória observada cobre o período de t1 a tob e pode ser designada como
![]()
onde Xi* corresponde às coordenadas do agente i no instante de tempo t*. Da mesma forma, a trajetória futura prevista para o agente i durante o período [tob+1,tfu] pode ser descrita como Ŷtob+1≤t≤tfu. A trajetória real correspondente para o movimento futuro do agente i pode ser descrita como Ytob+1≤t≤tfu.
No método SSWNP, inicialmente são criados dois tipos diferentes de trajetórias percorridas: uma caracterizada como limpa (X≤tob), e outra como com adição de ruído (Ẍ≤tob). A variante limpa corresponde à trajetória original da amostra de treinamento, enquanto a variante com adição de ruído corresponde à trajetória que foi deslocada no espaço dos recursos analisados com adição de ruído.
Para distorcer a trajetória limpa, utiliza-se ruído de uma distribuição normal padrão N(0, 1). Os autores do método introduzem um parâmetro chamado coeficiente de ruído (ω), que controla o deslocamento espacial dos pontos de rota.
![]()
Após criar as variantes limpa e aumentada da trajetória, passamos essas variantes para o modelo de extração de recursos (Θfe), que gera recursos correspondentes tanto para a variante limpa quanto para a variante com adição de ruído. Os recursos obtidos são então passados para o modelo de previsão de trajetórias (Θsup) para prever as trajetórias Ŷtob+1≤t≤tfu e Ÿtob+1≤t≤tfu, como mostrado nas equações abaixo:
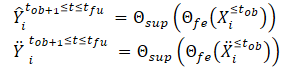
Treinamos o modelo para minimizar a diferença entre as trajetórias previstas e a trajetória real da amostra de treinamento. Como se pode perceber, ao minimizar o erro de previsão das trajetórias dos dados limpos e ruidosos (Ŷ e Ÿ) para a trajetória real da amostra de treinamento (Y), reduzimos indiretamente a diferença entre as duas trajetórias previstas. Assim, mantém-se a consistência espacial entre as previsões da trajetória futura com base nas trajetórias limpas.
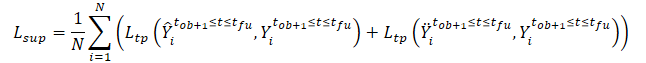
Além disso, no método SSWNP, resolve-se a tarefa de previsão de ruído autossupervisionada, que envolve a previsão do ruído presente tanto na variante limpa da trajetória passada observada X≤tob quanto na variante com adição de ruído Ẍ≤tob. Aqui, o objetivo é avaliar o valor do ruído associado a um ponto de rota observado específico.
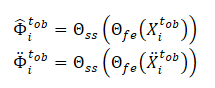
Observe que os recursos extraídos pelo modelo Θfe são usados como dados brutos para o modelo de previsão de ruído (Θss), que determina o nível de ruído nas trajetórias observadas (variantes limpa e aumentada). Como função de perda para o aprendizado autossupervisionado do modelo de previsão de ruído, os autores do método propõem usar o erro quadrático médio (MSE).
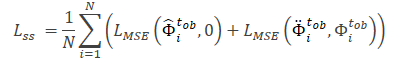
Aqui, o valor "0" indica a ausência de ruído na trajetória da variante limpa.
A função de perda geral do método SSWNP é representada como:
![]()
Onde λ denota a contribuição do erro de previsão de ruído para o erro total ao treinar o modelo usando a abordagem proposta.
A visualização do método Self-Supervised Waypoint Noise Prediction pelos autores é apresentada abaixo.
2. Implementação usando MQL5
Acima, nos familiarizamos com os aspectos teóricos do método Self-Supervised Waypoint Noise Prediction. Como pode ser observado, as abordagens propostas não impõem quaisquer restrições à arquitetura dos modelos utilizados ou à estrutura dos dados brutos. Isso permite integrar as abordagens propostas com muitos dos algoritmos que discutimos anteriormente. Em particular, neste artigo, adicionaremos as abordagens propostas ao algoritmo de treinamento do autocodificador TrajNet, discutido no método Goal-Conditioned Predictive Coding no artigo anterior.
Lembro que o algoritmo GCPC prevê 2 etapas de treinamento do modelo:
O método SSWNP discutido neste artigo visa melhorar a eficácia da previsão de trajetórias futuras. Consequentemente, afeta apenas a primeira etapa, "treinamento da função de trajetória". Faremos as correções necessárias nessa etapa. A segunda etapa, "treinamento da política de comportamento", será transferida sem alterações.
2.1 Questões de integração de métodos
É necessário observar que, ao integrar novas abordagens em uma estrutura já existente, devemos garantir que as mudanças introduzidas não interrompam o processo já estabelecido. Por isso, antes de iniciar o trabalho, devemos analisar o impacto das novas abordagens no processo de treinamento criado anteriormente e no funcionamento subsequente do modelo durante a utilização prática.
Primeiro, é preciso entender que adicionar ruído às trajetórias do conjunto de dados de treinamento obviamente alterará a distribuição dos dados brutos. Consequentemente, isso afetará os parâmetros da camada de normalização em lote, onde processamos inicialmente os dados brutos. Por um lado, é isso que buscamos. Queremos treinar o modelo para operar em condições próximas às reais, em um ambiente com alta estocasticidade. Por outro lado, adicionar ruído aleatório pode levar os dados brutos além dos valores reais dos parâmetros analisados. Para minimizar o impacto negativo deste fator, os autores do algoritmo adicionaram um coeficiente de ruído (ω), que regula a magnitude do viés dos dados. Em nossas condições de dados "brutos" não normalizados, precisaremos de um coeficiente de ruído separado para cada indicador dos dados brutos. Ou seja, utilizamos um vetor de coeficientes de ruído. E ajustar o vetor de hiperparâmetros se torna uma tarefa bastante complexa, cuja dificuldade aumenta com o número de parâmetros analisados.
A solução para essa questão, como se verificou, está na superfície. Se pensarmos bem, multiplicar o ruído da distribuição normal por um coeficiente lembra muito o truque de reparametrização, que usamos na camada do autocodificador variacional..
![]()
Portanto, utilizando os parâmetros da distribuição do conjunto de treinamento, podemos manter o modelo dentro da distribuição original, adicionando a estocasticidade inerente ao ambiente analisado.
No entanto, deve-se considerar outro ponto. Adicionamos ruído às trajetórias reais do conjunto de dados de treinamento, e não substituímos seus dados por valores aleatórios. Enquanto ao resolver o problema de forma direta obtemos os parâmetros da distribuição dos dados brutos.
Vamos revisar a ideia de usar ruído. Em um momento específico, temos os dados reais de cada um dos parâmetros analisados. No próximo passo temporal, os parâmetros mudam em uma certa magnitude. O tamanho da mudança para cada parâmetro depende de muitos fatores diferentes, o que o aproxima de uma variável aleatória. Ao mesmo tempo, essa mudança não é ilimitada e tem seus limites. Assim sendo, para preservar a distribuição natural dos dados brutos, podemos determinar os parâmetros da distribuição dessas variações entre dois valores subsequentes de cada parâmetro analisado. Esses serão os parâmetros para a reparametrização do nosso ruído.
É importante observar que mudanças significativas nos parâmetros geralmente indicam uma mudança na situação do mercado. E o método SSWNP prevê treinar o modelo para minimizar a diferença entre as previsões das trajetórias de dados limpos e com ruído. Portanto, usaremos o coeficiente de ruído proposto pelos autores do método para limitar o desvio das trajetórias reais do conjunto de dados de treinamento.
Outro ponto que quero destacar é o uso da camada DropOut no método GCPC, que também serve como uma espécie de regularização e é projetada para treinar o modelo a ignorar alguns valores "atípicos" e recuperar parâmetros ausentes. Ao combinar os métodos, ignoramos o ruído adicionado aos parâmetros mascarados pela camada DropOut. Por outro lado, mascarar o parâmetro torna a tarefa resolvida pelo modelo significativamente mais difícil do que adicionar ruído.
Como mencionado anteriormente, não violamos o processo construído anteriormente. Daí que não vamos excluir a camada DropOut da arquitetura do Codificador. E será interessante observar os resultados do treinamento do modelo.
Agora vamos ver a construção do método Self-Supervised Waypoint Noise Prediction. Seu algoritmo inclui o treinamento de três modelos:
- modelo de extração de características
- modelo de previsão de trajetória
- modelo de previsão de ruído.
Planejamos integrar o algoritmo SSWNP no processo GCPC construído anteriormente. Vamos tentar comparar os modelos de ambos os métodos. O modelo de extração de características do SSWNP corresponde ao Codificador do GCPC. Por sua vez, o Decodificador do GCPC pode ser representado como o modelo de previsão de trajetória do SSWNP. Já o modelo de previsão de ruído precisa ser adicionado.
2.2 Arquitetura dos modelos
As arquiteturas dos modelos serão descritas no método CreateTrajNetDescriptions, no qual adicionaremos a descrição do terceiro modelo. Nos parâmetros, o método recebe ponteiros para três matrizes dinâmicas para descrever a arquitetura dos três modelos. No corpo do método, verificamos a validade dos ponteiros recebidos e, se necessário, criamos novas instâncias dos objetos.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *decoder, CArrayObj *noise) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; } if(!noise) { noise = new CArrayObj(); if(!noise) return false; }
Como já foi dito, transferimos a descrição da arquitetura do Codificador e do Decodificador sem alterações. Lembro que na entrada do Codificador fornecemos dados brutos, entre os quais indicamos apenas dados históricos de variação de preços e indicadores analisados.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Esses dados passam por um processamento inicial na camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados normalizados são submetidos a mascaramento aleatório na camada DropOut.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.probability = 0.8f; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Depois, buscamos padrões estáveis usando um bloco de camadas convolucionais.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 2; descr.window = 3; descr.step = 1; int prev_wout = descr.window_out = 3; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, processamos os dados em um bloco de camada totalmente conectada.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Adicionamos recorrente os resultados das passagens anteriores do Codificador.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * EmbeddingSize; descr.window = prev_count; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
E transferimos os dados para a pilha interna do histórico analisado.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = GPTBars; { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
O conjunto de dados históricos obtido é analisado no bloco de atenção.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count * 2; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 4; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os resultados da análise são compactados em uma camada totalmente conectada.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = 1; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
E na saída do Codificador, normalizamos os dados com a função SoftMax.
Os resultados da propagação do Codificador são fornecidos na entrada do Decodificador.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Neste caso, lidamos com dados obtidos do modelo anterior, que já estão normalizados. Portanto, não precisamos realizar o processamento inicial dos dados. E os expandimos imediatamente usando uma camada totalmente conectada.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars + PrecoderBars) * EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Os dados obtidos são analisados no bloco de atenção.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 2; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Na saída do bloco de atenção, temos a incorporação de cada vela prevista. E para decodificar as incorporações obtidas, utilizamos uma camada totalmente conectada multimodal.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiModels; descr.count = 3; descr.window = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Depois de descrever a arquitetura do Codificador e do Decodificador, precisamos adicionar a descrição da arquitetura do modelo de previsão de ruído. Este modelo, assim como o Decodificador, usa como dados brutos os resultados do trabalho do Codificador. E simplesmente copiaremos a camada de dados brutos do Decodificador.
//--- Noise Prediction noise.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(decoder.At(0)); if(!noise.Add(descr)) { delete descr; return false; }
Em seguida, com uma camada totalmente conectada, expandimos os dados obtidos até o tamanho dos dados brutos na entrada do Codificador.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = HistoryBars * EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; }
E, no próximo passo, provavelmente pela primeira vez em toda a série de artigos, fiz uma ramificação para a arquitetura do modelo dependendo dos hiperparâmetros selecionados. Aqui, o ponto chave é a quantidade de velas analisadas na entrada do Codificador. Ao analisar mais de uma vela, a arquitetura do modelo lembrará o Decodificador. Usamos um bloco de atenção e uma camada multimodal para decodificar as incorporações. Apenas aqui, estamos falando não de velas previstas, mas de velas analisadas.
//--- if(HistoryBars > 1) { //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 2; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiModels; descr.count = BarDescr; descr.window = prev_wout; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; } }
No entanto, ao analisar apenas uma vela na entrada do Codificador, todo o sentido de usar a camada de atenção, que analisa as inter-relações entre diferentes velas, é perdido. Portanto, usaremos um perceptron simples.
else { //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!noise.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr; descr.activation = None; descr.optimization = ADAM; if(!noise.Add(descr)) { delete descr; return false; } } //--- return true; }
Gostaria de lembrar que as arquiteturas dos modelos descritas acima participam apenas da etapa de treinamento do modelo de função de trajetórias. As arquiteturas dos modelos de treinamento da política de comportamento do Agente foram transferidas sem alterações. Você pode analisá-las no anexo. Uma descrição detalhada foi fornecida no artigo anterior.
2.3 Programas de treinamento dos modelos
Após descrever a arquitetura dos modelos utilizados, passamos a considerar os algoritmos dos programas utilizados. De antemão, digo que os autores do método SSWNP não especificaram requisitos para a escolha dos dados brutos e coleta de trajetórias passadas para treinamento. Portanto, os programas de interação com o ambiente foram transferidos sem quaisquer alterações em seus algoritmos. Você pode consultar o código completo desses programas no anexo. Se precisar de esclarecimentos, consulte o artigo anterior ou faça uma pergunta no fórum.
Agora, vamos ao Expert Advisor de treinamento da função de trajetória «...\Experts\SSWNP\StudyEncoder.mq5», onde treinaremos simultaneamente 3 modelos:
- modelo de extração de características (Encoder)
- modelo de previsão de trajetória (Decoder)
- modelo de previsão de ruído (Noise).
CNet Encoder; CNet Decoder; CNet Noise;
Como indicado na parte teórica, para implementar o algoritmo SSWNP, precisamos definir 2 hiperparâmetros. Vamos declará-los como constantes em nosso programa.
#define STE_Noise_Multiplier 1.0f/10 // λ определяет влияние ошибки прогнозирования шума #define STD_Delta_Multiplier 1.0f/10 // коэффициент шума ω
No método de inicialização do Expert Advisor, assim como antes, carregamos primeiro o conjunto de dados de treinamento.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Em seguida, tentamos abrir os modelos previamente treinados. Em caso de erro ao carregar os modelos, criamos novos e os inicializamos com parâmetros aleatórios.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Decoder.Load(FileName + "Dec.nnw", temp, temp, temp, dtStudied, true) || !Noise.Load(FileName + "NP.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *encoder = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *noise = new CArrayObj(); if(!CreateTrajNetDescriptions(encoder, decoder, noise)) { delete encoder; delete decoder; delete noise; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Decoder.Create(decoder) || !Noise.Create(noise)) { delete encoder; delete decoder; delete noise; return INIT_FAILED; } delete encoder; delete decoder; delete noise; //--- }
Transferimos todos os modelos para um único contexto OpenCL.
//---
OpenCL = Encoder.GetOpenCL();
Decoder.SetOpenCL(OpenCL);
Noise.SetOpenCL(OpenCL);
Depois, controlamos os principais parâmetros da arquitetura dos modelos utilizados.
//--- Encoder.getResults(Result); if(Result.Total() != EmbeddingSize) { PrintFormat("The scope of the Encoder does not match the embedding size count (%d <> %d)", EmbeddingSize, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Decoder.GetLayerOutput(0, Result); if(Result.Total() != EmbeddingSize) { PrintFormat("Input size of Decoder doesn't match Encoder output (%d <> %d)", Result.Total(), EmbeddingSize); return INIT_FAILED; } //--- Noise.GetLayerOutput(0, Result); if(Result.Total() != EmbeddingSize) { PrintFormat("Input size of Noise Prediction model doesn't match Encoder output (%d <> %d)", Result.Total(), EmbeddingSize); return INIT_FAILED; } //--- Noise.getResults(Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Output size of Noise Prediction model doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Após passar com sucesso por todos os controles, criamos buffers auxiliares.
//--- if(!LastEncoder.BufferInit(EmbeddingSize, 0) || !Gradient.BufferInit(EmbeddingSize, 0) || !LastEncoder.BufferCreate(OpenCL) || !Gradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
E geramos um evento de usuário para iniciar o processo de treinamento.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
No método de desinicialização do Expert Advisor, salvamos os modelos treinados e liberamos a memória dos objetos dinâmicos criados anteriormente.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Encoder.Save(FileName + "Enc.nnw", 0, 0, 0, TimeCurrent(), true); Decoder.Save(FileName + "Dec.nnw", Decoder.getRecentAverageError(), 0, 0, TimeCurrent(), true); Noise.Save(FileName + "NP.nnw", Noise.getRecentAverageError(), 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
O processo de treinamento dos modelos é realizado no método Train. Como antes, no corpo do método, primeiro determinamos as probabilidades de seleção de trajetórias do buffer de reprodução de experiência.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Depois, criamos e inicializamos as variáveis locais necessárias.
//--- vector<float> result, target, inp; matrix<float> targets; matrix<float> delta; STE = vector<float>::Zeros((HistoryBars + PrecoderBars) * 3); STE_Noise = vector<float>::Zeros(HistoryBars * BarDescr); int std_count = 0; int batch = GPTBars + 50; bool Stop = false; uint ticks = GetTickCount();
Com isso, concluímos o trabalho preparatório e criamos o sistema de ciclos de treinamento dos modelos. Como você lembra, a arquitetura GPT usada no Codificador é exigente quanto à sequência dos dados brutos. Portanto, criamos um sistema de ciclos aninhados. No corpo do ciclo externo, amostramos a trajetória e o estado nela para iniciar o pacote de treinamento. No ciclo aninhado, treinamos o modelo em um pacote de estados sequenciais de uma única trajetória.
E aqui enfrentamos outro desafio. Dentro de uma única sequência, não podemos usar dados limpos e com ruído. O método SSWNP prevê a adição de ruído às trajetórias, e não a estados isolados.
Ao mesmo tempo, não podemos, em uma iteração, fornecer à modelo um estado limpo seguido de um com ruído. Na pilha interna do modelo, os estados se misturam e o modelo os perceberá como uma única trajetória, o que distorce consideravelmente a sequência analisada.
A solução encontrada foi alternar trajetórias. Primeiro, o modelo é treinado em uma trajetória limpa e, em seguida, em uma trajetória com ruído adicionado. Essa abordagem nos permite resolver paralelamente outra questão — o vetor de coeficientes de reparametrização do ruído. Ao treinar o modelo com dados limpos, coletamos informações sobre a distribuição das mudanças nos parâmetros. E os indicadores da distribuição coletada são usados para reparametrizar o ruído adicionado ao treinar o modelo com dados ruidosos.
Como mencionado anteriormente, criamos um ciclo externo no qual amostramos a trajetória e o estado inicial.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
Em seguida, limpamos as pilhas dos modelos e o buffer auxiliar.
Encoder.Clear();
Decoder.Clear();
Noise.Clear();
LastEncoder.BufferInit(EmbeddingSize, 0);
Determinamos o estado final do pacote de treinamento na trajetória e limpamos a matriz de coleta de informações sobre as mudanças dos parâmetros analisados.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); delta = matrix<float>::Zeros(end - state - 1, Buffer[tr].States[state].state.Size());
Observe que o tamanho da matriz de desvios é uma linha menor que o pacote de treinamento. Isso ocorre porque nela salvaremos a variação entre dois estados subsequentes.
Neste ponto, tudo está pronto para iniciar o treinamento do modelo em uma trajetória limpa e criamos o primeiro ciclo de treinamento aninhado.
for(int i = state; i < end; i++) { inp.Assign(Buffer[tr].States[i].state); State.AssignArray(inp); int row = i - state; if(i < (end - 1)) delta.Row(inp, row);
No corpo do ciclo, extraímos da amostra de treinamento o estado analisado e o transferimos para o buffer de dados brutos.
Esse mesmo estado usamos para calcular os desvios. Primeiro, verificamos se o estado atual não é o último no pacote de dados de treinamento e adicionamos o estado analisado à linha correspondente da matriz de desvios (o último estado não é adicionado).
Uma questão lógica é: por que adicionamos os estados como estão, se esta é uma matriz de desvios? A resposta está na próxima ação. Em cada iteração subsequente do ciclo, subtraímos o estado analisado da linha anterior da matriz de desvios, que contém o estado anterior salvo no passo anterior. Naturalmente, esse passo é pulado para o primeiro estado, quando não há estado anterior.
if(row > 0) delta.Row(delta.Row(row - 1) - inp, row - 1);
Depois, chamamos sequencialmente os métodos de propagação dos modelos em treinamento. Primeiro, o Codificador.
if(!LastEncoder.BufferWrite() || !Encoder.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(LastEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Depois, o Decodificador.
if(!Decoder.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E finaliza o bloco de propagação o modelo de previsão de ruído.
if(!Noise.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Como de costume, após o bloco de propagação, organizamos o retropropagação dos modelos em treinamento, no qual ajustamos seus parâmetros para minimizar o erro. Primeiro, organizamos o retropropagação do Decodificador, passando o gradiente de erro para o Codificador. E, antes de chamar o retropropagação dos modelos, precisamos preparar os valores alvo.
Na saída do Decodificador, esperamos obter os parâmetros do estado inicial, fornecidos na entrada do Codificador, mais a previsão para um determinado horizonte de planejamento. No artigo anterior, discutimos a composição dos parâmetros previstos para cada vela. Eu mantenho a mesma opinião. Portanto, nem a arquitetura do Decodificador, nem o algoritmo de preparação dos valores-alvo mudaram. Primeiro, preenchemos a matriz de valores-alvo com os dados fornecidos na entrada do Codificador.
target.Assign(Buffer[tr].States[i].state); ulong size = target.Size(); targets = matrix<float>::Zeros(1, size); targets.Row(target, 0); if(size > BarDescr) targets.Reshape(size / BarDescr, BarDescr); ulong shift = targets.Rows();
Em seguida, complementamos com dados do buffer de reprodução de experiência para o horizonte de planejamento definido.
targets.Resize(shift + PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, shift + t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
Transferimos as informações obtidas para um vetor e comparamos com os resultados da propagação do Decodificador.
Decoder.getResults(result); vector<float> error = target - result;
Como antes, durante o treinamento, focamos nas máximas discrepâncias. Para isso, primeiro calculamos o erro quadrático médio móvel.
std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1));
Em seguida, comparamos o erro atual com o valor limite baseado no desvio quadrático médio. A retropropagação é realizada apenas quando o erro atual excede o valor limite em pelo menos um parâmetro.
vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Decoder.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Lembro que a ideia de focar nas máximas discrepâncias foi emprestada do método CFPI.
Usamos um algoritmo semelhante de retropropagação para o modelo de previsão de ruído. No entanto, aqui a abordagem para organizar o vetor de valores-alvo é muito mais simples - ao trabalhar com trajetórias limpas, usamos apenas um vetor de valores zero.
target = vector<float>::Zeros(delta.Cols()); Noise.getResults(result); error = (target - result) * STE_Noise_Multiplier;
Observe que, ao calcular o erro, multiplicamos a discrepância obtida por uma constante STE_Noise_Multiplier, que determina a influência do erro de previsão de ruído no erro total do modelo.
Também focamos nas máximas discrepâncias e realizamos a retropropagação apenas se houver um erro acima do valor limite em pelo menos um parâmetro.
STE_Noise = MathSqrt((MathPow(STE_Noise, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; check = MathAbs(error) - STE_Noise; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Noise.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Transmitimos o gradiente do erro do modelo de previsão de ruído para o Codificador e, se necessário, chamamos seu método de retropropagação.
Após atualizar os parâmetros de todos os modelos treináveis, salvamos os últimos resultados da propagação do Codificador no buffer auxiliar.
Encoder.getResults(result); LastEncoder.AssignArray(result);
Informamos o usuário sobre o progresso do processo de treinamento e passamos para a próxima iteração do ciclo aninhado.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); str += StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Noise Prediction", percent, Noise.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Geralmente, terminamos a descrição das iterações no sistema de ciclos de treinamento do modelo aqui, mas não hoje. Acima, processamos o pacote de treinamento dos modelos na trajetória limpa. A seguir, repetiremos as operações para a trajetória com adição de ruído. Primeiro, determinamos os parâmetros estatísticos da distribuição de ruído.
//--- With noise vector<float> std_delta = delta.Std(0) * STD_Delta_Multiplier; vector<float> mean_delta = delta.Mean(0);
Observe que o desvio quadrático médio é multiplicado pelo coeficiente de ruído para reduzir o viés máximo possível dos valores dos sinais analisados.
Criamos um vetor e uma matriz para gerar ruído.
ulong inp_total = std_delta.Size(); vector<float> noise = vector<float>::Zeros(inp_total); double ar_noise[];
Depois, amostramos uma nova trajetória e o estado inicial nela.
tr = SampleTrajectory(probability); state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
Limpamos as pilhas de modelos e o buffer auxiliar.
Encoder.Clear();
Decoder.Clear();
Noise.Clear();
LastEncoder.BufferInit(EmbeddingSize, 0);
E organizamos outro ciclo aninhado para trabalhar com a trajetória com ruído.
end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); for(int i = state; i < end; i++) { if(!Math::MathRandomNormal(0, 1, (int)inp_total, ar_noise)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } noise.Assign(ar_noise);
No corpo do ciclo, primeiro geramos ruído a partir de uma distribuição normal e o transferimos para um vetor. Em seguida, realizamos sua reparametrização.
noise = mean_delta + std_delta * noise;
Neste estágio, preparamos o ruído para a iteração de treinamento atual. Carregamos o estado limpo do buffer de reprodução de experiência e adicionamos o ruído gerado a ele.
inp.Assign(Buffer[tr].States[i].state); inp = inp + noise;
Carregamos o estado obtido com a adição de ruído no buffer de dados brutos.
State.AssignArray(inp);
Em seguida, realizamos o bloco de propagação, semelhante ao trabalho com trajetórias limpas.
if(!LastEncoder.BufferWrite() || !Encoder.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(LastEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!Decoder.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!Noise.feedForward(GetPointer(Encoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
O método SSWNP prevê a criação de consistência espacial entre as trajetórias previstas para trajetórias limpas e com adição de ruído. Como mostrado na parte teórica, ambas as trajetórias convergem para um único objetivo. Portanto, construímos o bloco de retropropagação do Decodificador da mesma forma que fizemos acima para trajetórias limpas.
target.Assign(Buffer[tr].States[i].state); ulong size = target.Size(); targets = matrix<float>::Zeros(1, size); targets.Row(target, 0); if(size > BarDescr) targets.Reshape(size / BarDescr, BarDescr); ulong shift = targets.Rows(); targets.Resize(shift + PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, shift + t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
Decoder.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Decoder.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Para o modelo de previsão de ruído, a diferença está nos valores-alvo. Se para trajetórias limpas usávamos um vetor preenchido com valores zero, agora usamos o ruído adicionado ao estado limpo antes de ser fornecido na entrada do Codificador como valores-alvo.
target = noise; Noise.getResults(result); error = (target - result) * STE_Noise_Multiplier;
STE_Noise = MathSqrt((MathPow(STE_Noise, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; check = MathAbs(error) - STE_Noise; if(check.Max() > 0) { //--- Result.AssignArray(CAGrad(error) + result); if(!Noise.backProp(Result, (CNet *)NULL) || !Encoder.backPropGradient(GetPointer(LastEncoder), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Após atualizar os parâmetros dos modelos, salvamos os resultados da última passagem do Codificador no buffer auxiliar.
Encoder.getResults(result); LastEncoder.AssignArray(result);
Informamos o usuário sobre o progresso do processo de treinamento e passamos para a próxima iteração do ciclo.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter + 0.5) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Decoder", percent, Decoder.getRecentAverageError()); str += StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Noise Prediction", percent, Noise.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Neste ponto, terminamos a descrição das iterações no sistema de ciclos de treinamento dos modelos. E após a conclusão bem-sucedida de todas as iterações, limpamos o campo de comentários no gráfico da ferramenta.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Decoder", Decoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Noise Prediction", Noise.getRecentAverageError()); ExpertRemove(); //--- }
Registramos os resultados do processo de treinamento no diário e inicializamos o encerramento do programa.
Você pode encontrar o código completo do EA e de todos os programas usados no artigo no anexo.
Acima foi apresentado o algoritmo atualizado do EA de treinamento da função de trajetória. O algoritmo de treinamento da política permaneceu inalterado. Sua descrição detalhada é fornecida no artigo anterior. E o código completo do EA pode ser encontrado no anexo «...\Experts\SSWNP\Study.mq5».
3. Teste
Na parte prática deste artigo, integramos as abordagens do método Self-Supervised Waypoint Noise Prediction no EA de treinamento da função de trajetória do método Goal-Conditioned Predictive Coding e esperamos uma melhoria na qualidade da previsão do movimento dos preços. Agora é hora de verificar os resultados do nosso trabalho em dados reais no testador de estratégias MetaTrader 5.
Como antes, o treinamento e teste dos modelos são realizados em dados históricos do instrumento EURUSD no time frame H1. Para o treinamento dos modelos, usamos o intervalo histórico dos primeiros 7 meses de 2023. O teste dos modelos treinados é realizado em dados históricos de agosto de 2023. Como pode ser observado, o período de teste é imediatamente após o período de treinamento.
Antes de treinar os modelos, precisamos coletar a amostra de treinamento inicial. Como implementamos novas abordagens no EA anteriormente construído sem alterar a arquitetura dos modelos e a estrutura dos dados, podemos pular essa etapa e usar a base de exemplos pronta criada durante o treinamento dos modelos pelo método GCPC. Vamos criar uma cópia do arquivo de buffer de reprodução de experiência com o nome «SSWNP.bd». Em seguida, passamos diretamente ao processo de treinamento dos modelos.
Como previsto pelo método GCPC, o treinamento dos modelos é realizado em duas etapas. Na primeira etapa, treinamos a função de trajetória. É nesta fase que implementamos as abordagens do método SSWNP. Na entrada do Codificador, fornecemos apenas dados históricos de movimento de preços e indicadores analisados. Isso torna todas as trajetórias no buffer de reprodução de experiência idênticas, pois os parâmetros de estado da conta e posições abertas, que introduzem variações nas trajetórias, não são analisados nesta etapa. Consequentemente, podemos utilizar a base de exemplos existente e treinar a função de trajetória até obter um resultado aceitável sem coletar exemplos adicionais.
A segunda etapa do treinamento do modelo, o treinamento da política de comportamento, envolve a busca das ações ótimas do Agente em condições de estados de mercado históricos, com variações no estado da conta e posições abertas, que dependem das condições do mercado e das ações realizadas pelo Agente. Nesta etapa, utilizamos o treinamento iterativo dos modelos, alternando entre processos de treinamento dos modelos e a coleta de exemplos adicionais, permitindo uma avaliação mais precisa da política de comportamento atualizada do Agente.
O processo de treinamento que realizamos produziu resultados. Conseguimos treinar um modelo capaz de gerar lucro tanto em dados históricos da amostra de treinamento quanto no período de teste.


Considerações finais
Neste artigo, nos familiarizamos com o método Self-Supervised Waypoint Noise Prediction. Esta abordagem aumenta a eficácia dos modelos em ambientes estocásticos complexos, onde as trajetórias futuras dos Agentes são sujeitas a incertezas devido a condições variáveis e limitações físicas. O objetivo é alcançado através da introdução de ruído nas trajetórias passadas, o que favorece uma previsão mais precisa e diversificada dos caminhos futuros. A metodologia inovadora apresentada consiste em dois módulos: o módulo de consistência espacial e o módulo de previsão de ruído, que juntos suportam a previsão precisa e confiável em cenários estocásticos.
A estrutura proposta pelos autores do método é bastante versátil, permitindo sua integração em uma ampla gama de algoritmos de treinamento de modelos. Isso inclui não apenas métodos de aprendizado por reforço. Em seu trabalho, os autores do método demonstram exemplos de como a implementação das abordagens propostas melhora a eficácia dos métodos básicos.
Na parte prática deste artigo, integramos as abordagens propostas pelo método SSWNP na estrutura do algoritmo GCPC. E os resultados dos testes realizados confirmam a eficácia do método proposto.
No entanto, todos os programas apresentados no artigo são destinados apenas à demonstração das capacidades dos algoritmos e não estão prontos para uso em mercados financeiros reais.
Referências
- Enhancing Trajectory Prediction through Self-Supervised Waypoint Noise Prediction
- Redes neurais de maneira fácil (Parte 71): Previsão de estados futuros com base em objetivos (GCPC)
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | EA | EA de treinamento de Política |
| 4 | StudyEncoder.mq5 | EA | EA de treinamento do Autocodificador utilizando abordagens SSWNP |
| 5 | Test.mq5 | EA | EA para testar o modelo |
| 6 | Trajectory.mqh | Biblioteca de classes | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classes | Biblioteca de classes para criar redes neurais |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14044
 Previsão baseada em aprendizado profundo e abertura de ordens com o pacote MetaTrader 5 python e arquivo de modelo ONNX
Previsão baseada em aprendizado profundo e abertura de ordens com o pacote MetaTrader 5 python e arquivo de modelo ONNX
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso