
Neuronale Netze leicht gemacht (Teil 70): Operatoren der Closed-Form Policy Improvement (CFPI)

Einführung
Der Ansatz zur Optimierung der Agentenpolitik mit Verhaltensrestriktionen hat sich als vielversprechend für die Lösung von Offline-Verstärkungslernproblemen erwiesen. Unter Ausnutzung historischer Übergänge wird die Agentenpolitik so trainiert, dass sie eine gelernte Wertfunktion maximiert.
Eine verhaltensorientierte Politik kann dazu beitragen, eine signifikante Verteilungsverschiebung in Bezug auf die Aktionen des Agenten zu vermeiden, was ausreichend Vertrauen in die Bewertung der Aktionskosten schafft. Im vorigen Artikel haben wir die Methode SPOT kennengelernt, die sich diesen Ansatz zunutze macht. Als Fortsetzung des Themas schlage ich vor, sich mit dem Algorithmus Closed-Form Policy Improvement (CFPI) vertraut zu machen, der in dem Artikel „Offline Reinforcement Learning with Closed-Form Policy Improvement Operators“ vorgestellt wurde.
1. Der CFPI-Algorithmus (Closed-Form Policy Improvement)
Ein geschlossener Ausdruck ist eine mathematische Funktion, die mit einer begrenzten Anzahl von Standardoperationen ausgedrückt wird. Sie kann Konstanten, Variablen, Standardoperatoren und Funktionen enthalten, enthält aber in der Regel keine Grenzwerte, Differential- oder Integrationsausdrücke. Die CFPI-Methode, die wir in besprechen, führt also einige analytische Körner in den Algorithmus des Agenten zum Erlernen von Strategien ein.
Die meisten existierenden Offline Reinforcement Learning Modelle verwenden Stochastic Gradient Descent (SGD), um ihre Strategien zu optimieren, was zu Instabilität im Trainingsprozess führen kann und eine sorgfältige Abstimmung der Lernrate erfordert. Außerdem kann die Leistung von offline trainierten Strategien vom jeweiligen Bewertungspunkt abhängen. Dies führt häufig zu erheblichen Abweichungen in der Endphase des Lernens. Diese Instabilität stellt eine große Herausforderung beim Offline-Verstärkungslernen dar, da der begrenzte Zugang zur Interaktion mit der Umgebung die Abstimmung der Hyperparameter erschwert. Zusätzlich zu den Abweichungen zwischen den verschiedenen Bewertungspunkten kann die Verwendung von SGD zur Verbesserung einer Strategie zu erheblichen Leistungsabweichungen unter verschiedenen zufälligen Ausgangsbedingungen führen.
Die Autoren der CFPI-Methode zielen in ihrer Arbeit darauf ab, die erwähnte Instabilität des Offline-RL-Lernens zu reduzieren. Sie entwickeln stabile Betreiber zur Verbesserung der Strategie. Insbesondere weisen sie darauf hin, dass die Notwendigkeit, die Verteilungsverschiebung zu begrenzen, die Verwendung einer Taylor-Näherung erster Ordnung motiviert, die zu einer linearen Annäherung an die politische Zielfunktion des Agenten führt, die innerhalb einer ausreichend kleinen Nachbarschaft der Verhaltensstrategie genau ist. Auf der Grundlage dieser wichtigen Beobachtung konstruieren die Autoren der Methode Operatoren zur Strategieverbesserung, die Lösungen in geschlossener Form liefern.
Durch die Modellierung von Verhaltensstrategien als eine einzige Gauß-Verteilung verschiebt der von den Autoren von CFPI vorgeschlagene Strategieverbesserungsoperator die Verhaltenspolitik deterministisch in Richtung einer Wertverbesserung. Infolgedessen vermeidet die vorgeschlagene Closed-Form Policy Improvement-Methode die Lerninstabilität der Strategieverbesserung, da sie nur das Lernen der grundlegenden Verhaltensstrategien eines gegebenen Datensatzes verwendet.
Die Autoren der CFPI-Methode weisen auch darauf hin, dass in der Praxis häufig mit heterogenen Strategien Daten erhoben werden. Dies kann zu einer multimodalen Verteilung von Agentenaktionen führen. Eine einfache Gauß-Verteilung ist nicht in der Lage, viele der Modi der zugrundeliegenden Verteilung zu erfassen, wodurch das Verbesserungspotenzial der Strategie eingeschränkt wird. Die Modellierung der Verhaltenspolitik als eine Mischung von Gaußschen Verteilungen bietet eine bessere Aussagekraft, bringt aber zusätzliche Optimierungsprobleme mit sich. Die Autoren der Methode lösen dieses Problem, indem sie eine untere Schranke für LogSumExp und die Jensen'sche Ungleichung verwenden, die auch zu einem geschlossenen Strategieverbesserungsoperator führt, der auf multimodale Verhaltensstrategien anwendbar ist.
Die Autoren heben die folgenden Beiträge der Closed-Form Policy Improvement Methode hervor:
- CFPI-Operatoren, die mit Single-Mode- und Multi-Mode-Verhaltensstrategien kompatibel sind und die von anderen Algorithmen erlernten Strategien verbessern können.
- Empirische Belege für die Vorteile der Modellierung von Verhaltensstrategien als eine Mischung von Gauß-Verteilungen.
- Einzelschrittweise und iterative Varianten des vorgeschlagenen Algorithmus übertreffen die bestehenden Algorithmen bei einem Standard-Benchmark.
Die Autoren von CFPI entwickeln einen Operator zur Verbesserung der analytischen Strategie ohne Training, um Instabilität in Offline-Szenarien zu vermeiden. Sie stellen fest, dass die Optimierung in Bezug auf die Zielfunktion eine Strategie erzeugt, die eine eingeschränkte Abweichung von der Verhaltensstrategie in der Offline-Stichprobe erlaubt. Daher wird beim Training nur der Q-Wert in der Nähe des Verhaltens abgefragt. Dies motiviert natürlich die Verwendung einer linearen Approximation erster Ordnung.
Gleichzeitig liefert die Bewertung der Aktionen in der aktualisierten Strategie eine genaue lineare Annäherung an die gelernte Wertfunktion nur in einer ausreichend kleinen Nachbarschaft der Verteilung der Trainingsstichprobe. Daher ist die Auswahl des Zustands-Aktions-Paares aus dem Trainingsdatensatz entscheidend für das endgültige Lernergebnis.
Um das Problem zu lösen, schlagen die Autoren vor, das folgende Näherungsproblem für einen beliebigen Zustand S zu lösen:
![]()
Es ist zu beachten, dass D(•,•) keine mathematisch definierte Divergenzfunktion sein muss. Wir können jedes allgemeine D(•,•) in Betracht ziehen, das die Abweichung der Verhaltenspolitik des Agenten von der Verteilung des Trainingsdatensatzes einschränken kann.
Im Allgemeinen gibt es für das obige Problem nicht immer eine geschlossene Form der Lösung. Die Autoren der CFPI-Methode analysieren einen speziellen Fall:
- Sie verwenden eine Gauß-Strategie, um den Trainingsdatensatz zu sammeln.
- Dann trainieren sie die deterministische Verhaltenspolitik des Agenten.
- D(•,•) ist die negative Likelihood-Funktion.
In einem solchen Szenario ist es sinnvoll, sich bei der Schulung von Richtlinien auf die Verteilung des Schulungsdatensatzes zu konzentrieren. Dann kann das vorgeschlagene Optimierungsproblem als geschlossene Form dargestellt werden:
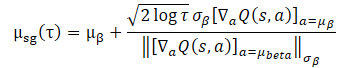
Die Verwendung dieses geschlossenen Ausdrucks zur Verbesserung der Agentenpolitik bringt eine vorteilhafte Berechnungseffizienz mit sich und vermeidet die durch SGD verursachte potenzielle Instabilität. Ihre Anwendbarkeit hängt jedoch von der Annahme eines einzelnen Gauß für die Erfassungsstrategie der Trainingsdaten ab. In der Praxis werden historische Datensätze in der Regel durch heterogene Strategien mit unterschiedlichem Fachwissen gesammelt. Da ein eindimensionaler Gauß nicht unbedingt das gesamte Verteilungsbild abbildet, erscheint es sinnvoll, eine Gauß-Mischung zur Darstellung der Datenerhebungspolitik zu verwenden.
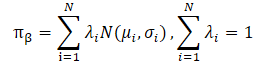
Die direkte Substitution einer Gauß'schen Mischung für die Trainingsdatenerfassung verletzt jedoch die Anwendbarkeit des oben dargestellten Problems, da sie zu einer nicht-konvexen Zielfunktion führt. Hier stehen wir bei der Lösung des Optimierungsproblems vor zwei großen Herausforderungen.
Erstens ist unklar, wie die geeignete Aktion aus dem Trainingsdatensatz ausgewählt werden kann. Auch hier muss sichergestellt werden, dass die Lösung der Zielpolitik in einer kleinen Nachbarschaft der gewählten Aktion liegt.
Zweitens lässt die Verwendung einer Gauß'schen Mischung keine konvexe Form zu, was zu Optimierungsproblemen führt.
Durch die Verwendung von LogSumExp können wir das Optimierungsproblem umformen.
![]()
Dies kann als geschlossener Ausdruck dargestellt werden.
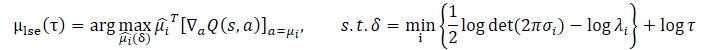
Die Anwendung der Jensen‘schen Ungleichung ermöglicht es uns, das folgende Optimierungsproblem zu erhalten:
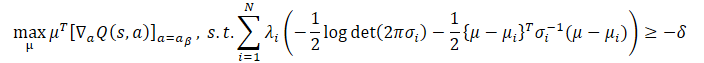
Die geschlossene Lösung für dieses Problem sieht wie folgt aus:
![]()
Verglichen mit dem ursprünglichen Optimierungsproblem sind beide vorgeschlagenen Erweiterungen mit strengeren Konfidenzintervallbeschränkungen verbunden. Dies wird erreicht, indem eine untere Schranke für die Log-Wahrscheinlichkeiten der Gauß-Mischung oberhalb eines bestimmten Schwellenwerts festgelegt wird. Gleichzeitig steuert der Parameter τ die Größe des Konfidenzintervalls.
Beide Optimierungsprobleme haben ihre Vor- und Nachteile. Wenn die Verteilung des Trainingsdatensatzes eine offensichtliche Multimodalität aufweist, kann die untere Schranke des Logarithmus der Datenerfassungspolitik, die durch die Jensen‘sche Ungleichung konstruiert wurde, aufgrund ihrer Konkavität keine unterschiedlichen Modi erfassen, wodurch der Vorteil der Modellierung der Datenerfassungspolitik als Gaußsches Gemisch verloren geht. In diesem Fall kann das LogSumExp-Optimierungsproblem als angemessener Ersatz für das ursprüngliche Optimierungsproblem dienen, da die untere Schranke von LogSumExp die Multimodalität des Logarithmus der Datenerhebungspolitik bewahrt.
Wenn die Verteilung des Trainingsdatensatzes auf Single Gaussian reduziert wird, wird die Annäherung durch die Jensen‘sche Ungleichung zu einer Gleichung. Somit löst µjensen das gegebene Optimierungsproblem genau. In diesem Fall hängt der Grad der Genauigkeit der unteren Schranke von LogSumExp jedoch weitgehend von den Gewichten λi=1 λi=1...N ab.
Glücklicherweise können wir die besten Eigenschaften beider Ansätze kombinieren und einen CFPI-Operator erhalten, der alle oben genannten Szenarien berücksichtigt und eine Verhaltenspolitik liefert, die die höherrangige Aktion aus µlse und µjensen auswählt:
![]()
In der Originalarbeit finden Sie detaillierte Berechnungen und Beweise für die Anwendbarkeit aller vorgestellten Ausdrücke.
Die Autoren der CFPI-Methode weisen darauf hin, dass die vorgeschlagene Methode auch auf nicht-gaußsche Verteilungen des Trainingsdatensatzes anwendbar ist. Gleichzeitig ermöglichen die vorgestellten CFPI-Operatoren die Erstellung einer allgemeinen Vorlage für das Offline-Lernen mit der Möglichkeit, einstufige, mehrstufige und iterative Methoden zu erhalten.
Ein vorab trainiertes Kritiker-Modell wird zur Bewertung von Aktionen verwendet. Es kann auf dem Trainingsdatensatz auf jede bekannte Weise trainiert werden. Dies ist die erste Stufe des Algorithmus für das Training des Modells.
Als Nächstes wird ein bestimmtes Paket von Zuständen aus dem Trainingsdatensatz entnommen. Für dieses Paket werden Aktionen unter Berücksichtigung der aktuellen Agentenpolitik erstellt. Anschließend werden die daraus resultierenden Maßnahmen unter Berücksichtigung der oben vorgeschlagenen CFPI-Operatoren bewertet.
Auf der Grundlage der Ergebnisse dieser Bewertung werden optimale Zustände ausgewählt, bei denen die Agentenpolitik aktualisiert wird.
Bei der Entwicklung von mehrstufigen und iterativen Methoden wird der Prozess wiederholt.
Obwohl das Design der CFPI-Operatoren durch das Paradigma der verhaltensorientierten Agentenpolitik inspiriert ist, sind die vorgeschlagenen Ansätze mit den üblichen grundlegenden Methoden des Reinforcement Learning kompatibel. Die Autoren zeigten in ihrem Beitrag Beispiele, in denen CFPI-Operatoren die Effizienz von Strategien, die mit anderen Algorithmen gelernt wurden, erhöhten.
2. Implementierung mit MQL5
Die obigen Ausführungen sind eine theoretische Beschreibung der Methode zur Verbesserung der Politik in geschlossener Form. Ich stimme zu, dass die vorgestellten mathematischen Gleichungen recht kompliziert erscheinen mögen. Versuchen wir also, sie im Zuge der Umsetzung der vorgeschlagenen Ansätze genauer zu verstehen.
Es sei gleich darauf hingewiesen, dass der von den Autoren des Artikels vorgeschlagene Algorithmus für das Modelltraining ein sequentielles Training des Kritikers und des Akteur vorsieht. Das Kritiker-Modell wird zuerst trainiert. Erst danach können wir damit beginnen, die Politik des Akteurs zu trainieren.
Mit diesem Ansatz wird unsere Technik, bei der der Kritiker das Akteursmodell zur Vorverarbeitung der Quelldaten verwendet, irrelevant. Denn in der Phase des Trainings des Kritikers hat sich das Akteursmodell noch nicht herausgebildet. Natürlich können wir auch ein Akteursmodell erstellen und es wie bisher verwenden. In diesem Fall ergibt sich jedoch folgendes Problem: In der Phase des Politik-Trainings sieht der CFPI-Algorithmus keine Aktualisierung des Kritiker-Modells vor. Eine Änderung der Parameter des Akteurs führt zwangsläufig zu einer Änderung der Parameter der Vorverarbeitung der Quelldaten. In diesem Fall ändert sich die Verteilung am Kritiker-Eingang. Dies führt im Allgemeinen zu einer Verzerrung bei der Bewertung der Maßnahmen des Akteurs.
Um die beschriebene Situation zu korrigieren, können wir die Verwendung des gemeinsamen Initial State Encoders vermeiden oder ihn in ein separates Modell verschieben.
Wir können den Encoder nicht auf das Kritiker-Modell übertragen, da der Vorwärts-Durchgang (feed-forward pass) des Kritikers Aktionen erfordert, die vom Akteur generiert werden. Der Vorwärts-Durchgang des Akteurs benötigt auch die Ergebnisse des Encoders. Der Kreis schließt sich.
2.1 Modellarchitektur
In meiner Implementierung habe ich beschlossen, den Environmental State Encoder als separates Modell zu erstellen. Dies wirkte sich wiederum auf die Architektur der Modelle aus. Die Beschreibung der Modellarchitektur wird in der Methode CreateDescriptions gegeben. Trotz des einheitlichen Trainings der Akteur- und Kritiker-Modelle habe ich die Beschreibung der Modellarchitektur nicht in 2 Methoden aufgeteilt. Daher erhält die Methode in den Parametern Zeiger auf 3 dynamische Arrays von Objekten zur Erfassung der Modellarchitektur.
Im Hauptteil der Methode prüfen wir die Relevanz der empfangenen Zeiger und erstellen gegebenenfalls neue Array-Objektinstanzen.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Der erste Teil ist eine Beschreibung der Architektur des Current State Encoders. Die Architektur des Modells beginnt mit einer Schicht von Quelldaten, deren Umfang ausreichen muss, um Informationen über Kursbewegungen und Indikatorwerte für die gesamte Tiefe der analysierten Historie zu erfassen.
//--- State Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die resultierenden „Rohdaten“ werden in der Batch-Normalisierungsschicht vorverarbeitet.
Als Nächstes kommt der Faltungsblock, der es uns ermöglicht, die Dimensionalität der Daten zu reduzieren und gleichzeitig stabile Muster in den Daten zu erkennen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Die Ergebnisse des Faltungsblocks werden von 2 vollständig verbundenen neuronalen Schichten verarbeitet.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Die auf diese Weise verarbeiteten Daten werden durch Informationen über den Kontostand ergänzt, zu denen auch die Zeitstempel-Welleneigenschaften (timestamp harmonics) gehören.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; }
Wir erzeugen Stochastizität am Ausgang des Encoders. Dadurch können wir sowohl die Möglichkeit einer Überanpassung des Modells verringern als auch die Stabilität unseres Modells in einem stochastischen externen Umfeld erhöhen.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Es folgt eine Beschreibung der Architektur des Akteurs. Er erhält als Eingabe die Ergebnisse des oben beschriebenen Umwelt-Encoders.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wie man sehen kann, werden alle vorbereitenden Arbeiten zur Aufbereitung der Ausgangsdaten im Encoder durchgeführt. Dies ermöglicht es uns, das Akteursmodell so einfach wie möglich zu gestalten. Hier erstellen wir 3 vollständig verbundene Schichten.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Am Ausgang des Modells bilden wir eine stochastische Politik in einem kontinuierlichen Handlungsraum.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Das Kritiker-Modell verwendet ebenfalls die Ergebnisse des Encoders als Input. Im Gegensatz zum Akteursmodell werden die Ergebnisse jedoch durch einen Vektor der bewerteten Handlungen ergänzt. Daher verwenden wir nach der Quelldatenschicht eine Verkettungsschicht, die 2 Quelldatentensoren kombiniert.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; }
Als Nächstes folgt der Entscheidungsfindungsblock aus vollständig verbundenen neuronalen Schichten.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Damit ist die Beschreibung der Modellarchitektur abgeschlossen, und wir können mit der Konstruktion eines Modelllernalgorithmus fortfahren.
Bevor wir mit dem Training der Modelle beginnen, müssen wir natürlich einen Trainingsdatensatz sammeln. Bitte beachten Sie nun Folgendes. Dieses Mal kann ich die Expert Advisors für Umweltinteraktion aus früheren Arbeiten nicht in unveränderter Form verwenden. Die Modellarchitektur hat sich geändert, und der Umgebungszustandscodierer wurde in ein externes Modell ausgelagert. Dies hat sich auf die Algorithmen unserer Expert Advisors ausgewirkt. Diese Änderungen wurden jedoch nur an bestimmten Punkten vorgenommen, mit denen Sie sich in den Dateien „...\Experts\CFPI\Research.mq5“ und „...\Experts\CFPI\Test.mq5“ vertraut machen können. Diese Dateien sind in der Anlage enthalten. Wir gehen nun dazu über, einen Lernalgorithmus für den Kritiker zu entwickeln.
2.2 Training der Kritiker
Der Trainingsalgorithmus des Kritiker-Modells ist in dem EA „...\Experts\CFPI\StudyCritic.mq5“ implementiert. In diesem EA haben wir zwei Kritiker-Modelle parallel trainiert. Wie Sie wissen, können wir durch den Einsatz von zwei Kritikern die Stabilität und Effizienz des späteren Trainings der Verhaltenspolitik des Akteurs erhöhen. Zusammen mit den Kritikern-Modellen trainieren wir einen allgemeinen Encoder für den Zustand der Umgebung.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 1e6; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ STrajectory Buffer[]; CNet StateEncoder; CNet Critic1; CNet Critic2;
Bei der EA-Initialisierungsmethode versuchen wir zunächst, den Trainingsdatensatz zu laden.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Dann laden wir die erforderlichen Modelle. Wenn es nicht möglich ist, bereits trainierte Modelle zu laden, generieren wir neue Modelle mit zufälligen Parametern.
//--- load models float temp; if(!StateEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); if(!CreateDescriptions(actor, critic, encoder)) { delete actor; delete critic; delete encoder; return INIT_FAILED; } if(!Critic1.Create(critic) || !Critic2.Create(critic) || !StateEncoder.Create(encoder)) { delete actor; delete critic; delete encoder; return INIT_FAILED; } delete actor; delete critic; delete encoder; //--- }
Wir übertragen alle Modelle in einen einzigen OpenCL-Kontext, der den Datenaustausch zwischen den Modellen ohne unnötige Übertragung von Informationen in den Hauptspeicher des Programms und zurück ermöglicht.
//---
OpenCL = Critic1.GetOpenCL();
Critic2.SetOpenCL(OpenCL);
StateEncoder.SetOpenCL(OpenCL);
Um mögliche Fehler bei der Datenübertragung zwischen den Modellen auszuschließen, überprüfen wir deren Übereinstimmung mit dem einheitlichen Layout der verwendeten Daten.
//--- StateEncoder.getResults(Result); if(Result.Total() != LatentCount) { PrintFormat("The scope of the State Encoder does not match the latent size count (%d <> %d)", LatentCount, Result.Total()); return INIT_FAILED; } //--- StateEncoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Critic1.GetLayerOutput(0, Result); if(Result.Total() != LatentCount) { PrintFormat("Input size of Critic1 doesn't match State Encoder output (%d <> %d)", Result.Total(), LatentCount); return INIT_FAILED; } //--- Critic2.GetLayerOutput(0, Result); if(Result.Total() != LatentCount) { PrintFormat("Input size of Critic2 doesn't match State Encoder output (%d <> %d)", Result.Total(), LatentCount); return INIT_FAILED; }
Nachdem alle Kontrollen erfolgreich durchgeführt wurden, wird der Hilfsdatenpuffer initialisiert.
//--- Gradient.BufferInit(AccountDescr, 0);
Wir initialisieren auch ein nutzerdefiniertes Ereignis, um den Modellbildungsprozess zu starten.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Danach schließen wir den Vorgang der EA-Initialisierungsmethode ab.
Bei der EA-Deinitialisierungsmethode speichern wir die trainierten Modelle und löschen den Speicher.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { StateEncoder.Save(FileName + "Enc.nnw", 0, 0, 0, TimeCurrent(), true); Critic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
Der eigentliche Prozess des Trainings von Modellen ist in der Train-Methode implementiert. Im Hauptteil der Methode berechnen wir zunächst die gewichteten Wahrscheinlichkeiten für die Auswahl von Trajektorien aus dem Erfahrungswiedergabepuffer.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Dann deklarieren wir lokale Variablen und erstellen eine Trainingsschleife mit einer Anzahl von Iterationen, die dem vom Nutzer in den externen Parameterndes EAs angegebenen Wert entspricht.
vector<float> rewards, rewards1, rewards2, target_reward; uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) {
Im Körper der Trainingsschleife werden eine Trajektorie und der Zustand auf dieser Trajektorie gesampelt.
int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3)); if(i < 0) { iter--; continue; }
Danach füllen wir die Quelldatenpuffer. Zunächst füllen wir den Puffer für die Beschreibung des Zustands der Umgebung mit Daten über die Preisbewegung und die Werte der analysierten Indikatoren aus dem Erfahrungswiedergabepuffer.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
Dann füllen wir den Puffer mit der Beschreibung des Kontostands und der offenen Positionen.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Ergänzen wir den Puffer mit Zeitstempel-Welleneigenschaften.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Die gesammelten Daten reichen für einen Vorwärts-Durchlauf des Environment State Encoders aus.
//--- if(!StateEncoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wie bereits erwähnt, verwenden wir in diesem Stadium nicht das Akteursmodell. Die Kritiker werden durch überwachte Lernmethoden trainiert, wobei die Auswertung der tatsächlichen Handlungen und der von der Umgebung erhaltenen Belohnungen verwendet wird, die zuvor im Trainingsdatensatz gespeichert wurden. Daher verwenden wir für einen Vorwärts-Durchlauf der beiden Kritiker die Ergebnisse des Umgebungszustands-Encoders und den Aktionsvektor aus dem Trainingsdatensatz.
//--- Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wir überprüfen die Korrektheit der Operationen und laden die Ergebnisse des Vorwärts-Durchlaufs der beiden Kritiker.
//---
Critic1.getResults(rewards1);
Critic2.getResults(rewards2);
Der nächste Schritt ist die Erstellung von Zielwerten für das Training der Modelle. Wie bereits erwähnt, werden wir die tatsächlichen Werte aus dem Trainingsdatensatz trainieren. In diesem Stadium verwenden wir eine Belohnung für einen Übergang in einen neuen Zustand. Um die Konvergenz zu verbessern, passen wir die Richtung des Fehlergradientenvektors mit der Methode CAGrad an.
Die Parameter der Modelle werden nach und nach angepasst. Zunächst passen wir die Parameter des ersten Kritiker an und rufen dann die Methode des Rückwärts-Durchgangs (backpropagation) des Environment State Encoders auf.
rewards.Assign(Buffer[tr].States[i + 1].rewards); target_reward.Assign(Buffer[tr].States[i + 2].rewards); rewards = rewards - target_reward * DiscFactor; Result.AssignArray(CAGrad(rewards - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !StateEncoder.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Dann wiederholen wir die Vorgänge für den zweiten Kritiker.
Result.AssignArray(CAGrad(rewards - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !StateEncoder.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Bitte beachten Sie, dass nach dem Aktualisieren jedes Kritikers die Encoder-Parameter angepasst werden. Wir versuchen daher, die Einbettung der Umwelt so informativ und genau wie möglich zu gestalten.
Nach erfolgreicher Aktualisierung der Modellparameter müssen wir den Nutzer nur noch über den Trainingsfortschritt informieren und zur nächsten Iteration der Schleife übergehen.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nachdem alle Iterationen des Lernschleifensystems abgeschlossen sind, löschen wir das Kommentarfeld im Chart. Außerdem geben wir Informationen über die Trainingsergebnisse in das Protokoll ein und leiten die Beendigungdes EAs ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Den vollständigen Code des Expert Advisors finden Sie im Anhang.
2.3 Schulungen zur Verhaltenspolitik
Nachdem wir die Kritiker trainiert haben, gehen wir zur nächsten Stufe über - dem Training der Verhaltensregeln für Akteur. Wir implementieren diese Funktionalität in dem EA „...\Experts\CFPI\Study.mq5“. Zunächst fügen wir zu den externen Parametern die Größe des Pakets hinzu, in dem wir den optimalen Punkt für das Training auswählen werden.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 10000; input int BatchSize = 256;
In diesem EA werden wir 4 Modelle verwenden, aber wir werden nur den Akteur trainieren.
CNet Actor; CNet Critic1; CNet Critic2; CNet StateEncoder;
Bei der EA-Initialisierungsmethode laden wir zunächst die Trainingsmenge hoch.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Danach laden wir die Modelle. Zunächst laden wir die vortrainierten Umgebungszustandsmodelle Encoder und Kritiker. Wenn diese Modelle nicht verfügbar sind, können wir den Lernprozess nicht weiterführen. Wenn also beim Laden von Modellen ein Fehler auftritt, brechen wir den EA-Vorgang ab.
//--- load models float temp; if(!StateEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("Can't load Critic models"); return INIT_FAILED; }
Wenn es keinen vortrainierten Akteur gibt, wird ein neues Modell mit zufälligen Parametern initialisiert.
if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
Wir übertragen alle Modelle in einen OpenCL-Kontext und deaktivieren den Trainingsmodus für den Encoder und die Kritiker.
OpenCL = Actor.GetOpenCL(); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); StateEncoder.SetOpenCL(OpenCL); //--- StateEncoder.TrainMode(false); Critic1.TrainMode(false); Critic2.TrainMode(false);
Danach prüfen wir die Kompatibilität der Modellarchitekturen.
//--- Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
StateEncoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
StateEncoder.getResults(Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic1 doesn't match output State Encoder (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Critic2.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic2 doesn't match output State Encoder (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Actor.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Actor doesn't match output State Encoder (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Wenn der Prüfblock erfolgreich abgeschlossen wurde, können wir mit dem nächsten Schritt fortfahren. Wir initialisieren den Hilfspuffer und erzeugen ein nutzerdefiniertes Ereignis, um den Lernprozess zu starten.
Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Damit sind die Operationen der EA-Initialisierungsmethode abgeschlossen. Bei der EA-Deinitialisierungsmethode speichern wir die trainierten Modelle und löschen den Speicher.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; delete OpenCL; }
Der Trainingsprozess für das Akteur-Modell wird mit der Train-Methode durchgeführt. Im Hauptteil der Methode bestimmen wir zunächst die Wahrscheinlichkeiten für die Auswahl von Trajektorien aus dem Trainingsdatensatz.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Danach werden wir die notwendigen lokalen Variablen erstellen.
//--- vector<float> rewards, rewards1, rewards2, target_reward; vector<float> action, action_beta; float Improve = 0; int bar = (HistoryBars - 1) * BarDescr; uint ticks = GetTickCount();
Als Nächstes erstellen wir eine Modell-Trainingsschleife mit der in den externen Parameterndes EAs angegebenen Anzahl von Iterationen.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) {
Im Hauptteil der Schleife zum Trainieren der Verhaltenspolitik des Akteurs werden wir die Ansätze der CFPI-Methode verwenden. Zunächst müssen wir eine Stichprobe von Daten aus dem Trainingsdatensatz bilden. Wir müssen die Maßnahmen der aktuellen Akteurspolitik in ausgewählten Staaten erstellen und bewerten. Um diese Operationen durchzuführen, erstellen wir eine verschachtelte Schleife mit einer Anzahl von Iterationen, die der Größe des zu analysierenden Pakets entspricht. Wir werden die Ergebnisse der Operationen in der lokalen mBatch-Matrix speichern.
matrix<float> mBatch = matrix<float>::Zeros(BatchSize, 4); for(int b = 0; b < BatchSize; b++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { b--; continue; }
Die Stichprobenverfahren ähneln denen, die wir zuvor durchgeführt haben.
Wir füllen die Puffer, die den Zustand der Umgebung beschreiben, mit Daten aus jedem ausgewählten Zustand.
//--- State
State.AssignArray(Buffer[tr].States[i].state);
Hinzufügen von Puffern des Kontostands.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Hinzufügen von Zeitstempel-Welleneigenschaften.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Ausführen des Vorwärts-Durchgangs des Encoder States.
//--- State embedding if(!StateEncoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Nach der Generierung der Einbettung des Umweltzustands werden die Aktionen des Agenten unter Berücksichtigung der aktuellen Politik generiert.
//--- Action if(!Actor.feedForward(GetPointer(StateEncoder), -1, NULL, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Die erzeugten Aktionen werden von beiden Kritikern bewertet.
//--- Cost if(!Critic1.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Nach erfolgreichem Abschluss aller Operationen laden wir die Ergebnisse in lokale Vektoren hoch. Dann bilden wir ähnliche Datenvektoren aus dem Trainingsdatensatz.
Critic1.getResults(rewards1); Critic2.getResults(rewards2); Actor.getResults(action); action_beta.Assign(Buffer[tr].States[i].action); rewards.Assign(Buffer[tr].States[i + 1].rewards); target_reward.Assign(Buffer[tr].States[i + 2].rewards);
Die Koordinaten des analysierten Zustands werden in der Ergebnismatrix in Form von Indizes der Trajektorie und des Zustands in ihr gespeichert. Wir speichern auch die Abweichung des Aktionsvektors und ihre Auswirkungen auf das Ergebnis.
//--- Collect mBatch[b, 0] = float(tr); mBatch[b, 1] = float(i); mBatch[b, 2] = MathMin(rewards1.Sum(), rewards2.Sum()) - (rewards - target_reward * DiscFactor).Sum(); mBatch[b, 3] = MathSqrt(MathPow(action - action_beta, 2).Sum()); }
Danach gehen wir zur Probenahme und Bewertung des nächsten Zustands über.
Nachdem wir die Daten des gesamten Pakets verarbeitet und gesammelt haben, müssen wir den optimalen Zustand auswählen, um die Verhaltenspolitik des Akteurs zu optimieren. In diesem Stadium müssen wir einen Zustand auswählen, der eine zuverlässige kritische Bewertung und einen maximalen Einfluss auf das Modellergebnis hat.
Was die Zuverlässigkeit der Handlungsbewertung angeht, so haben wir bereits gesagt, dass die Bewertung der Handlungen durch den Kritiker genauer ist, wenn die Abweichungen von der Verteilung des Trainingsdatensatzes minimal sind. Mit zunehmender Abweichung nimmt die Genauigkeit der Beurteilung durch den Kritiker ab. Dieser Logik folgend, kann das Kriterium für die Genauigkeit der Handlungsbewertung der Abstand zwischen den Handlungen sein, den wir in der Spalte mit dem Index 3 unserer analytischen Matrix gespeichert haben.
Nun müssen wir ein Konfidenzintervall wählen. In der Originalarbeit verwendeten die Autoren der CFPI-Methode die Varianz der Verteilung. Wir können jedoch nicht die Varianz für den Vektor der Handlungsabweichungen nehmen. Die Varianz wird nämlich als Standardabweichung von der Mitte der Verteilung betrachtet. In unserem Fall haben wir die absoluten Werte der Abweichungen beibehalten. Die Nullabweichung, bei der die Schätzung des Kritikers am genauesten ist, kann also nur ein Extremwert sein. Der Durchschnittswert der Verteilung ist weit von diesem Punkt entfernt. Folglich garantiert die Verwendung der Varianz in diesem Fall nicht die gewünschte Genauigkeit der Aktionsschätzungen.
Aber hier können wir die „3-Sigma“-Regel anwenden: Bei einer Normalverteilung weichen 68 % der Daten um nicht mehr als eine Standardabweichung von der mathematischen Erwartung ab. Dies bedeutet, dass wir die Quantilfunktion verwenden können, um den Vertrauensbereich zu bestimmen. Mithilfe einfacher mathematischer Operationen erstellen wir den Gewichtungsvektor mit Null für Aktionen, deren Abweichungen größer als das Konfidenzintervall sind, und „1“ für die übrigen.
action = mBatch.Col(3); float quant = action.Quantile(0.68); vector<float> weights = action - quant - FLT_EPSILON; weights.Clip(weights.Min(), 0); weights = weights / weights; weights.ReplaceNan(0);
Wir haben uns für ein Konfidenzintervall entschieden. Jetzt können wir eine Reihe von Zuständen mit einer angemessenen Bewertung der Maßnahmen auswählen. Wir müssen den optimalen Zustand wählen, um die Verhaltenspolitik des Akteurs zu optimieren. Um den gesamten Algorithmus zu vereinfachen und den Modellbildungsprozess zu beschleunigen, habe ich beschlossen, die von den Autoren des CFPI-Algorithmus vorgeschlagenen analytischen Methoden nicht zu verwenden und stattdessen eine einfachere Methode einzusetzen.
Es liegt auf der Hand, dass in unserem Fall die optimale Optimierungsrichtung diejenige ist, bei der sich die Rentabilität der Verhaltenspolitik des Agenten mit einer minimalen Verschiebung im Aktionsunterraum ändert. Denn wir wollen die Rentabilität unserer Politik maximieren, und minimale Abweichungen deuten auf eine genauere Bewertung der Aktionen durch den Kritiker hin. Natürlich gibt es in unserer Analysematrix sowohl positive als auch negative Abweichungen bei der Bewertung von Maßnahmen. Die Steigerung der Gesamtrentabilität wird gleichermaßen durch einen Anstieg der Gewinne und einen Rückgang der Verluste beeinflusst. Daher verwenden wir zur Berechnung des optimalen Auswahlkriteriums den absoluten Wert der Abweichung der Übergangsbelohnung.
rewards = mBatch.Col(2); weights = MathAbs(rewards) * weights / action;
Aus dem resultierenden Vektor wird das Element mit dem höchsten Wert ausgewählt. Sein Index verweist auf den optimalen Zustand, der im Modelloptimierungsalgorithmus verwendet wird.
ulong pos = weights.ArgMax(); int sign = (rewards[pos] >= 0 ? 1 : -1);
Hier wird das Vorzeichen der Belohnungsabweichung in einer lokalen Variablen gespeichert.
Ein wenig vorausschauend muss ich sagen, dass wir die Verhaltenspolitik des Akteurs mit Hilfe von Fehlergradienten, die durch das Kritiker-Modell weitergegeben werden, aktualisieren werden. In diesem Lernmodus können wir den Fehler in den Akteur-Vorhersagen nicht berechnen. Um den Lernprozess zu kontrollieren, habe ich einen Koeffizienten für die durchschnittliche Verbesserung der verwendeten Zustände eingeführt.
Improve = (Improve * iter + weights[pos]) / (iter + 1);
Danach folgt der bekannte Algorithmus zur Optimierung des Politikmodells. Diesmal verwenden wir jedoch keinen zufälligen Zustand, sondern einen, in dem wir die Leistung des Modells maximieren können.
int tr = int(mBatch[pos, 0]); int i = int(mBatch[pos, 1]);
Wie zuvor füllen wir die Puffer für die Beschreibung des Zustands der Umgebung und des Zustands des Kontos.
//--- Policy study State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Zeitstempel-Status hinzufügen.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Generieren wir die Einbettung des Umweltzustands.
//--- State if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!StateEncoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Agentenaktion unter Berücksichtigung der aktuellen Politik.
//--- Action if(!Actor.feedForward(GetPointer(StateEncoder), -1, NULL, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Schätzen wir die Kosten für die Aktionen des Agenten.
//--- Cost if(!Critic1.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Zur Optimierung des Agentenverhaltens verwenden wir den Kritiker mit einer Mindestpunktzahl. Um die Konvergenz zu erhöhen, wird der Richtungsvektor des Gradienten mit Hilfe der CAGrad-Methode angepasst.
Critic1.getResults(rewards1); Critic2.getResults(rewards2); //--- rewards.Assign(Buffer[tr].States[i + 1].rewards); target_reward.Assign(Buffer[tr].States[i + 2].rewards); rewards = rewards - target_reward * DiscFactor; CNet *critic = NULL; if(rewards1.Sum() <= rewards2.Sum()) { Result.AssignArray(CAGrad((rewards1 - rewards)*sign) + rewards1); critic = GetPointer(Critic1); } else { Result.AssignArray(CAGrad((rewards2 - rewards)*sign) + rewards2); critic = GetPointer(Critic2); }
Wir führen den Rückwärts-Durchlauf von Kritiker und Akteur nacheinander durch.
if(!critic.backProp(Result, GetPointer(Actor), -1) || !Actor.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Bitte beachten Sie, dass wir in diesem Stadium das Kritiker-Modell nicht optimieren. Daher ist ein Rückwärts-Durchlauf durch den Environment State Encoder nicht erforderlich.
Damit sind die Operationen einer Iteration zur Aktualisierung der Verhaltensrichtlinie des Agenten abgeschlossen. Wir informieren den Nutzer über den Fortschritt des Lernprozesses und fahren mit der nächsten Iteration des Zyklus fort.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> %15.8f\n", "Mean Improvement", iter * 100.0 / (double)(Iterations), Improve); Comment(str); ticks = GetTickCount(); } }
Nach Abschluss aller Iterationen des Trainingszyklus löschen wir das Kommentarfeld auf dem Diagramm, zeigen Informationen über die Trainingsergebnisse im Protokoll an und leiten die Abschaltungdes EAs ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Mean Improvement", Improve); ExpertRemove(); //--- }
Hier schließen wir die Betrachtung der in diesem Artikel verwendeten Algorithmen ab. Der vollständige Code aller Programme ist unten beigefügt. Wir gehen nun zur Überprüfung der Ergebnisse der durchgeführten Arbeiten über.
3. Test
Oben haben wir die Methode zur Verbesserung der geschlossenen Form gesehen und uns ausführlich mit der Umsetzung ihrer Ansätze mit MQL5 befasst. Wir haben die von den Autoren der Methode vorgeschlagenen Ideen verwendet. Die analytische Methode, die für die Auswahl des optimalen Zustands verwendet wurde, unterscheidet sich jedoch von der in diesem Papier vorgeschlagenen. Darüber hinaus haben wir bei unserer Arbeit Entwicklungen aus unseren früheren Erfahrungen genutzt. Daher können die erzielten Ergebnisse erheblich von den Ergebnissen abweichen, die die Autoren der Methode in ihrem Papier präsentieren. Natürlich unterscheidet sich unsere Testumgebung von den in der Originalarbeit beschriebenen Experimenten.
Wie immer werden die Modelle anhand historischer Daten für EURUSD H1 trainiert und getestet. Das Modell wird mit den Daten der ersten 7 Monate des Jahres 2023 trainiert. Um das trainierte Modell zu testen, verwenden wir historische Daten vom August 2023. Alle Indikatoren werden mit Standardparametern verwendet.
Die Implementierung der CFPI-Methode erforderte einige Änderungen in der Modellarchitektur, hatte aber keine Auswirkungen auf die Struktur der Quelldaten. Daher können wir in der ersten Phase des Trainings den zuvor erstellten Trainingsdatensatz verwenden, wenn wir einen der zuvor diskutierten Lernalgorithmen testen. Ich habe den Trainingsdatensatz aus den vorherigen Artikeln verwendet. Für diesen Artikel habe ich eine Kopie einer Datei mit dem Namen „CFPI.bd“ erstellt. Sie können aber auch einen völlig neuen Trainingsdatensatz mit einer der zuvor beschriebenen Methoden erstellen. In diesem Teil unterliegt die CFPI-Methode keinen Einschränkungen.
Die Änderungen an der Architektur erlaubten es uns jedoch nicht, bereits trainierte Modelle zu verwenden. Daher wurde der gesamte Lernprozess „von Grund auf“ neu eingeführt.
Zunächst haben wir die State Encoder- und Kritiker-Modelle mit dem EA „...\Experts\CFPI\StudyCritic.mq5“ trainiert.
Der Trainingsdatensatz umfasst 500 Trajektorien mit jeweils 3591 Umweltzuständen. Insgesamt handelt es sich um fast 1,8 Millionen „State-Action-Reward“-Sets. Das primäre Training der Kritiker-Modelle wurde für 1 Million Iterationen durchgeführt, was uns theoretisch erlaubt, fast jeden zweiten Zustand zu analysieren. Für kontinuierliche Verläufe, bei denen nicht jeder neue Zustand des Umfelds zu grundlegenden Veränderungen der Marktsituation führt, ist dies ein ziemlich gutes Ergebnis. Da der Schwerpunkt auf Strecken mit maximaler Rentabilität liegt, können die Kritiker solche Strecken fast vollständig untersuchen und ihren „Horizont“ auf weniger rentable Strecken erweitern.
Der nächste Schritt ist das Trainieren der Akteur-Verhaltenspolitik in dem EA „...\Experts\CFPI\Study.mq5“. Hier führen wir 10 Tausend Trainingsiterationen mit einem Paket von 256 Zuständen durch. Insgesamt können wir so mehr als 2,5 Millionen Zustände analysieren, was größer ist als unser Trainingsdatensatz.
Ich muss sagen, dass man nach der ersten Trainingsiteration im Test einige Voraussetzungen für die Erstellung profitabler Strategien feststellen kann. Die Bilanztabellen weisen einige gewinnbringende Intervalle auf. Bei der zusätzlichen Sammlung von Trainingstrajektorien wurden von 200 Durchgängen 3 mit Gewinn abgeschlossen. Natürlich kann dies entweder meine subjektive Meinung sein oder das Ergebnis des Zusammenwirkens bestimmter Faktoren, die unabhängig von der Methode sind. Wir hatten zum Beispiel Glück, und die zufällige Initialisierung der Modelle führte zu recht guten Ergebnissen. Auf jeden Fall können wir mit Sicherheit sagen, dass als Ergebnis der nachfolgenden Iterationen des Modelltrainings und der Sammlung zusätzlicher Pässe eine klare Tendenz zu einer Erhöhung der durchschnittlichen Rentabilität und des Gewinnfaktors der Pässe besteht.
Nach mehreren Iterationen des Modelltrainings erhielten wir eine Strategie für das Verhalten des Akteurs, die in der Lage war, sowohl auf den historischen Daten des Trainingsdatensatzes als auch auf Testdaten, die nicht im Trainingsdatensatz enthalten waren, Gewinne zu erzielen. Die Ergebnisse der Modellversuche sind nachstehend aufgeführt.


Die Saldenkurve zeigt zu Beginn des Testzeitraums einen gewissen Drawdown. Aber dann zeigt das Modell eine ziemlich gleichmäßige Tendenz eines ausgeglichenen Wachstums. Auf diese Weise können wir sowohl das, was wir verloren haben, zurückgewinnen als auch die Gewinne steigern. Insgesamt tätigte das Modell während des Testzeitraums 125 Transaktionen, von denen 45,6 % mit Gewinn abgeschlossen wurden. Der höchstprofitable und der durchschnittlich profitable Handel liegen 50 % über den entsprechenden Verlustmetriken. Daraus ergibt sich ein Gewinnfaktor von 1,23.
Schlussfolgerung
In diesem Artikel haben wir einen weiteren Algorithmus für das Modelltraining kennengelernt: Closed-Form Policy Improvement. Der wahrscheinlich wichtigste Beitrag dieser Methode ist die Hinzufügung von analytischen Ansätzen für die Wahl der Optimierungsrichtung des trainierten Modells. Nun, dieser Prozess erfordert zusätzliche Berechnungskosten. Seltsamerweise reduziert dieser Ansatz jedoch die Kosten für die Modellschulung insgesamt. Das liegt daran, dass wir nicht versuchen, die besten der vorgestellten Bahnen vollständig zu wiederholen. Stattdessen konzentrieren wir uns auf Bereiche mit maximaler Effizienz und verschwenden keine Zeit mit der Suche nach optimalen Lärmphänomenen.
Im praktischen Teil unseres Artikels haben wir die von den Autoren der CFPI-Methode vorgeschlagenen Ideen umgesetzt, allerdings mit einigen Änderungen im Vergleich zu den ursprünglichen mathematischen Berechnungen der Autoren. Dennoch haben wir positive Erfahrungen gemacht und gute Testergebnisse erhalten.
Ich persönlich bin der Meinung, dass die Methode zur Verbesserung der Politik in geschlossener Form eine Überlegung wert ist. Man kann seine Ansätze nutzen, um eigene Handelsstrategien zu entwickeln.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA-Beispielsammlung |
| 2 | ResearchRealORL.mq5 | EA | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | EA | Trainings-EA des Akteurs |
| 4 | StudyCritic.mq5 | EA | Trainings EA des Kritikers |
| 5 | Test.mq5 | EA | Modeltest-EA |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13982
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.