
Neuronale Netze leicht gemacht (Teil 73): AutoBots zur Vorhersage von Kursbewegungen

Einführung
Die effektive Vorhersage der Entwicklung von Währungspaaren ist ein wichtiger Aspekt eines sicheren Handelsmanagements. In diesem Zusammenhang wird besonderes Augenmerk auf die Entwicklung effizienter Modelle gelegt, die die gemeinsame Verteilung von kontextuellen und zeitlichen Informationen, die für Handelsentscheidungen erforderlich sind, genau approximieren können. Als eine mögliche Lösung für solche Aufgaben wird eine neue Methode namens „Latent Variable Sequential Set Transformers“ (AutoBots) diskutiert, die in dem Artikel „Latent Variable Sequential Set Transformers For Joint Multi-Agent Motion Prediction“ vorgestellt wird. Die vorgeschlagene Methode basiert auf der Encoder-Decoder-Architektur. Es wurde entwickelt, um Probleme der sicheren Steuerung von Robotersystemen zu lösen. Es ermöglicht die Erzeugung von Trajektorienfolgen für mehrere Agenten, die mit der Szene übereinstimmen. AutoBots können die Trajektorie eines Ego-Agenten oder die Verteilung der zukünftigen Trajektorien aller Agenten in der Szene vorhersagen. In unserem Fall werden wir versuchen, das vorgeschlagene Modell anzuwenden, um Sequenzen von Preisbewegungen von Währungspaaren zu erzeugen, die mit der Marktdynamik übereinstimmen.
1. Algorithmen für AutoBots
„Latent Variable Sequential Set Transformers“ (AutoBots) ist eine Methode, die auf der Encoder-Decoder-Architektur basiert. Es verarbeitet Folgen von Einstellungen (sets). AutoBot wird mit einer Folge von Einstellungen X1:t = (X1, …, Xt) gefüttert, die im Problem der Bewegungsvorhersage als der Zustand der Umgebung für t Zeitschritte betrachtet werden kann. Jedes Einstellung enthält M Elemente (Agenten, Finanzinstrumente und/oder Indikatoren) mit K Attributen (Vorzeichen). Um soziale und zeitliche Informationen im Encoder zu verarbeiten, werden die folgenden zwei Transformationen verwendet.
Zunächst fügt der AutoBots Encoder zeitliche Informationen in eine Folge von Einstellungen ein, indem er eine Sinus-Positionskodierungsfunktion PE(.) verwendet. In diesem Stadium werden die Daten als eine Sammlung von Matrizen {X0, …, XM} analysiert, die die Entwicklung der Agenten im Laufe der Zeit beschreiben. Der Encoder verarbeitet die zeitlichen Beziehungen zwischen den Einstellungen mit Hilfe eines mehrköpfigen Aufmerksamkeitsblocks.
Darauf folgt die Verarbeitung von Slices S durch Extraktion von Einstellungen von Agenten-Zuständen Sꚍ zu einem bestimmten Zeitpunkt ꚍ. Sie werden erneut im mehrköpfigen Aufmerksamkeitsblock verarbeitet.
Diese beiden Operationen werden Lenc Mal wiederholt, um einen Kontexttensor C der Dimension {dK, M, t} zu erhalten, der die gesamte Szenendarstellung der Originaldaten zusammenfasst, wobei t die Anzahl der Zeitschritte in der Quelldatenszene ist.
Das Ziel des Decoders ist es, Vorhersagen zu generieren, die im Kontext multimodaler Datenverteilungen zeitlich und sozial konsistent sind. Um c verschiedene Vorhersagen oder die gleiche Szene der Originaldaten zu erzeugen, verwendet der AutoBot-Decoder c Matrizen trainierbarer Anfangsparameter Qi mit der Dimension {dK, T}, wobei T der Planungshorizont ist.
Intuitiv entspricht jede Matrix von trainierbaren Anfangsparametern der Einstellung einer diskreten latenten Variable in AutoBot. Jede trainierbare Matrix Qi wird dann M-mal entlang der Agenten-Dimension wiederholt, um den Eingabe-Tensor Q0i mit der Dimension {dK, M, T} zu erhalten.
Der Algorithmus bietet die Möglichkeit, zusätzliche kontextbezogene Informationen zu verwenden, die mit Hilfe eines neuronalen Faltungsnetzwerks kodiert werden, um einen Merkmalsvektor mi zu erstellen. Um Kontextinformationen für alle zukünftigen Zeitschritte und alle Elemente der Einstellung bereitzustellen, wird vorgeschlagen, diesen Vektor entlang der Dimensionen M und T zu kopieren, wodurch ein Tensor Mi mit der Dimension {dK, M, T} entsteht. Jeder Tensor Q0i wird dann mit Mi in der Dimension dK kombiniert. Dieser Tensor erhält dann mit Hilfe der vollständig verbundenen Schicht (rFFN) den Tensor H mit der Diemsion {dK, M, T}.
Die Dekodierung beginnt mit der Verarbeitung der am Ausgang des Encoders ermittelten Zeitdimension (C) sowie der kodierten Anfangsparameter und Informationen über die Umgebung (H). Der Decoder verarbeitet jeden Agenten in H separat und verwendet einen mehrköpfigen Aufmerksamkeitsblock. Auf diese Weise erhalten wir einen Tensor, der die zukünftige zeitliche Entwicklung jedes Elements der Menge unabhängig kodiert.
Um die soziale Konsistenz der zukünftigen Szene zwischen den Elementen der Menge zu gewährleisten, verarbeiten wir jede Zeitscheibe H0 und extrahieren Mengen von Agentenzuständen H0ꚍ zu einem zukünftigen Zeitpunkt ꚍ. Jedes Element der Sequenz wird von einer mehrköpfigen Aufmerksamkeitseinheit verarbeitet. In diesem Block wird bei jedem Zeitschritt zwischen allen Elementen der Menge unterschieden.
Diese beiden Operationen werden Ldec-mal wiederholt, um den endgültigen Ausgabentensor für den Agenten i zu erstellen. Der Dekodierungsprozess wird c-mal mit verschiedenen trainierten Anfangsparametern Qi und zusätzlichen Kontextinformationen mi wiederholt. Die Ausgabe des Decoders ist ein Tensor O mit der Dimension {dK, M, T, c}, der dann mit einem neuronalen Netz ф(.) verarbeitet werden kann, um die gewünschte Ausgabedarstellung zu erhalten.
Einer der wichtigsten Beiträge, die das Ergebnis und die Trainingszeit von AutoBot im Vergleich zu anderen Methoden beschleunigen, ist die Verwendung von anfänglichen Decoderparametern Qr. Diese Optionen haben einen doppelten Zweck. Erstens berücksichtigen sie die Vielfalt bei der Vorhersage der Zukunft, wobei jede Matrix Qi einer Einstellung einer diskreten latenten Variable entspricht. Zweitens tragen sie zur Beschleunigung von AutoBot bei, indem sie es ihm ermöglichen, eine gesamte Szene mit einem einzigen Durchlauf durch den Decoder ohne sequenzielle Auswahl zu inferieren.
Das Original der von den Verfassern des Papiers vorgestellten Methode ist unter „visualization“ zu finden.
 Methode, die von den Autoren der Arbeit zur Verfügung gestellt wurde")
2. Implementierung mit MQL5
Wir haben die theoretischen Aspekte der Latent Variable Sequential Set Transformers (AutoBots) Methode diskutiert. Kommen wir nun zum praktischen Teil des Artikels, in dem wir unsere Vision der vorgestellten Methode mit MQL5 umsetzen werden.
Zunächst einmal sollten Sie die folgenden 2 Punkte beachten.
Erstens bietet die Methode eine positionsbezogene Kodierung. Wir haben jedoch bereits gesehen, dass eine ähnliche Positionskodierung im Rahmen der grundlegenden Methode der Selbstaufmerksamkeit gibt. Tatsache ist jedoch, dass früher bei der Untersuchung von Aufmerksamkeitsmethoden die positionsbezogene Kodierung der Quelldaten auf der Seite des Hauptprogramms implementiert wurde. In AutoBot wird die Positionskodierung jedoch erst nach der Vorverarbeitung und Erstellung der Einbettung der Quelldaten in das Modell implementiert. Natürlich könnten wir die Datenvorverarbeitung in ein separates Modell verlagern und die Positionskodierung auf der Seite des Hauptprogramms implementieren, bevor die Daten an den Encoder übertragen werden. Diese Option würde jedoch zusätzliche Datenübertragungsoperationen zwischen dem Speicher des OpenCL-Kontexts und dem Hauptprogramm erfordern. Darüber hinaus würde eine solche Implementierung unsere Flexibilität bei der Verwendung verschiedener Modellarchitekturen innerhalb eines einzigen Programms einschränken, ohne dass zusätzliche Anpassungen am Code vorgenommen werden müssten. Daher ist es besser, den gesamten Prozess in einem Modell zu organisieren.
Zweitens erfordert die Methode der Latent Variable Sequential Set Transformers (AutoBots) sowohl im Encoder als auch im Decoder einen alternativen Einsatz von Aufmerksamkeitsblöcken im Rahmen der verschiedenen Dimensionen der analysierten Tensoren (Analyse der zeitlichen und sozialen Abhängigkeiten). Um die Dimension des Aufmerksamkeitsfokus zu ändern, müssen wir die mehrköpfige Aufmerksamkeitsschicht CNeuronMLMHAttentionOCL ändern oder Tensoren transponieren. Das Transponieren von Tensoren scheint hier eine einfachere Aufgabe zu sein. Dies erfordert bestimmte Schritte, die bereits für die Positionskodierung erörtert wurden. Wir werden sie hier nicht wiederholen. Es ist nur so, dass wir eine Tensor-Transpositionsschicht auf der OpenCL-Kontextseite erstellen müssen.
2.1 Positionelle Kodierungsschicht
Wir beginnen mit der Ebene der Positionskodierung. Wir erben die Klasse der Positionskodierungsschicht CNeuronPositionEncoder von der Basisklasse der neuronalen Schicht unserer Bibliothek CNeuronBaseOCL und überschreiben die grundlegenden Methoden:
- Init — Initialisierung
- feedForward — Vorwärtsdurchlauf
- calcInputGradients — Weitergabe von Fehlergradienten an die vorherige Schicht
- updateInputWeights — Aktualisierung der Gewichte
- Speichern und Laden — Dateioperationen
class CNeuronPositionEncoder : public CNeuronBaseOCL { protected: CBufferFloat PositionEncoder; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronPositionEncoder(void) {}; ~CNeuronPositionEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) { return true; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronPEOCL; } virtual void SetOpenCL(COpenCLMy *obj); };
Wir lassen den Konstruktor und den Destruktor der Klasse leer.
Bevor wir zu den anderen Methoden übergehen, wollen wir die Funktionalität und die Konstruktionslogik der Klasse ein wenig diskutieren. Im Transformer-Algorithmus wird die Positionskodierung durch Hinzufügen von sinusförmigen Schwingungen zu den Quelldaten mit Hilfe der folgenden Funktionen realisiert:
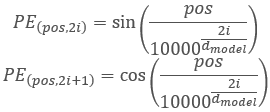
Bitte beachten Sie, dass wir in diesem Fall eine Positionskodierung für die Elemente in der analysierten Sequenz durchführen. Sie ist nicht mit den zuvor verwendeten Zeitstempel-Schwingungen verbunden, die wir neben dem Hauptprogramm erstellen. Das Verfahren ist ähnlich, aber die Bedeutung ist anders.
Die Größe der analysierten Sequenz im Modell wird natürlich immer konstant sein. Daher können wir einfach einen harmonischen Puffer PositionEncoder in der Klasseninitialisierungsmethode Init erstellen und füllen. Während des Vorwärtsdurchgangs werden in der feedForward-Methode lediglich die harmonischen Werte zu den Originaldaten hinzugefügt.
Dies betrifft den Vorwärtsdurchgang. Was ist mit dem Rückwärtsdurchgang? Im Vorwärtsdurchgang haben wir die Addition von zwei Tensoren durchgeführt. Folglich wird der Fehlergradient während des Rückwärtsdurchgangs gleichmäßig verteilt oder vollständig auf beide Terme übertragen. Der harmonische Tensor der Positionskodierung ist in unserem Fall eine Konstante. Daher wird der gesamte Fehlergradient auf die vorherige Schicht übertragen.
Was die trainierbaren Gewichte betrifft, so gibt es sie in der Positionskodierungsschicht einfach nicht. Daher wird die Methode updateInputWeights nur aus Gründen der Klassenkompatibilität außer Kraft gesetzt und gibt immer true zurück.
Das ist die Logik. Schauen wir uns nun die Umsetzung an. Die Klasse wird in der Methode Init initialisiert. Die Methode wird mit Parametern versehen:
- numOutputs — Anzahl der Verbindungen zur nächsten Schicht
- open_cl — Zeiger auf OpenCL-Kontext
- count — Anzahl der Elemente in der Sequenz
- window — Anzahl der Parameter für jedes Element der Sequenz
- optimization_type — Parameter Optimierungsmethode.
bool CNeuronPositionEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window, optimization_type, batch)) return false;
Im Hauptteil der Methode rufen wir die Initialisierungsmethode der übergeordneten Klasse auf, die die grundlegende Funktionalität implementiert. Wir überprüfen auch das Ergebnis der Operationen.
Als Nächstes müssen wir positionskodierende Schwingung (harmonic) erstellen. Hierfür werden wir Matrixoperationen verwenden. Bereiten wir zunächst die Matrix vor.
matrix<float> pe = matrix<float>::Zeros(count, window);
Wir erstellen einen Vektor zur Nummerierung der Positionen der Elemente im Tensor und einen konstanten Faktor, der für alle Elemente verwendet wird.
vector<float> position = vector<float>::Ones(count); position = position.CumSum() - 1; float multipl = -MathLog(10000.0f) / window;
Da wir gemäß der Positionskodierung abwechselnd die Formeln Sinus und Kosinus für Schwingungen verwenden müssen, füllen wir die Matrix in einer Schleife mit einem Schritt von 2. Im Hauptteil der Schleife berechnen wir zunächst einen Vektor von Positionswerten. Dann addieren wir in den geraden Spalten den Sinus des Vektors der Positionswerte. In die ungeraden Spalten schreiben wir den Kosinus desselben Vektors.
for(uint i = 0; i < window; i += 2) { vector<float> temp = position * MathExp(i * multipl); pe.Col(MathSin(temp), i); if((i + 1) < window) pe.Col(MathCos(temp), i + 1); }
Wir kopieren die resultierenden Positionsschwingungen in den Datenpuffer und übertragen sie in den OpenCL-Kontext.
if(!PositionEncoder.AssignArray(pe)) return false; //--- return PositionEncoder.BufferCreate(open_cl); }
Nach CNeuronPositionEncoder gehen wir dazu über, einen Feedforward-Durchgang in der MethodefeedForward zu organisieren. Wie Sie vielleicht bemerkt haben, haben wir keinen Prozessorganisationskern auf der OpenCL-Kontextseite erstellt. Wir gehen direkt zur Implementierung der Methode über. Das liegt daran, dass der Kernel für die Addition von 2 Matrizen SumMatrix bereits früher erstellt wurde, als wir die Selbstaufmerksamkeit Methode implementiert haben.
Wie üblich erhält die Methode feedForward in den Parametern einen Zeiger auf die vorherige neuronale Schicht, die als Quelldaten dient. Im Hauptteil der Methode prüfen wir den erhaltenen Zeiger.
bool CNeuronPositionEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!Gradient || Gradient != NeuronOCL.getGradient()) { if(!!Gradient) delete Gradient; Gradient = NeuronOCL.getGradient(); }
Wir ersetzen auch sofort den Zeiger auf den Fehlergradientenpuffer. Diese einfache Methode ermöglicht es uns, den Fehlergradienten während des Rückwärtsdurchgangs direkt von der nächsten Schicht auf die vorherige zu übertragen, wodurch unnötiges Kopieren von Daten in unserer Positionskodierungsschicht vermieden wird.
Als Nächstes übergeben wir die erforderlichen Daten an die Parameter des Vektoradditionskerns.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = Neurons(); if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix1, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix2, PositionEncoder.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix_out, Output.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_dimension, (int)1)) return false; if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_multiplyer, 1.0f)) return false;
Den Kernel stellen wir in die Ausführungswarteschlange.
if(!OpenCL.Execute(def_k_MatrixSum, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel MatrixSum: %d", GetLastError()); return false; } //--- return true; }
Überprüfen Sie die Ergebnisse der Operationen. Damit kann die Implementierung des Feedforward-Prozesses als abgeschlossen betrachtet werden.
Wie bereits erwähnt, enthält die Schicht für die Positionskodierung keine trainierbaren Parameter. Daher ist die Methode updateInputWeights „leer“ und gibt immer true zurück. Durch das Ersetzen des Pufferzeigers für den Fehlergradienten haben wir die Positionskodierungsschicht vollständig aus dem Prozess der Ausbreitung des Fehlergradienten entfernt. Daher bleibt die Methode calcInputGradients ebenso wie die Parameteraktualisierungsmethode „leer“ und wird nur zu Kompatibilitätszwecken überschrieben.
Damit ist die Diskussion über die Methoden der Positionskodierungsebene abgeschlossen. Der vollständige Code der Klasse ist im Anhang „...\Experts\NeuroNet_DNG\NeuroNet.mqh“ verfügbar, der alle Klassen unserer Bibliothek enthält.
2.2 Transponieren von Tensoren
Die nächste Schicht, die wir erstellen wollen, ist die Tensortranspositionsschicht CNeuronTransposeOCL. Wie bei der Positionskodierungsschicht erben wir bei der Erstellung einer Klasse von der Basisklasse der neuronalen Schicht CNeuronBaseOCL. Die Liste der außer Kraft gesetzten Klassen bleibt standardmäßig. Wir werden jedoch auch 2 Variablen der Klasse hinzufügen, um die Dimensionen der transponierten Matrix zu speichern.
class CNeuronTransposeOCL : public CNeuronBaseOCL { protected: uint iWindow; uint iCount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronTransposeOCL(void) {}; ~CNeuronTransposeOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronTransposeOCL; } };
Der Konstruktor und der Destruktor der Klasse bleiben leer. Die Initialisierungsmethode der Klasse Init ist sehr vereinfacht. Im Hauptteil der Methode rufen wir nur die entsprechende Methode der übergeordneten Klasse auf und speichern die Dimensionen der erhaltenen transponierten Matrix in den Parametern. Vergessen wir nicht, die Ergebnisse der Ausführung der Operation zu überprüfen.
bool CNeuronTransposeOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window, optimization_type, batch)) return false; //--- iWindow = window; iCount = count; //--- return true; }
Für die Feedforward-Methode müssen wir zunächst einen Matrix-Transpositionstensor Transpose erstellen. In den Kernel-Parametern werden nur Zeiger auf die Puffer der Quelldaten und Ergebnismatrizen übergeben. Wir erhalten die Größen der Matrizen aus dem 2-dimensionalen Problemraum.
__kernel void Transpose(__global float *matrix_in, ///<[in] Input matrix __global float *matrix_out ///<[out] Output matrix ) { const int r = get_global_id(0); const int c = get_global_id(1); const int rows = get_global_size(0); const int cols = get_global_size(1); //--- matrix_out[c * rows + r] = matrix_in[r * cols + c]; }
Der Kernel-Algorithmus ist recht einfach. Wir bestimmen nur die Position des Elements in der Quelldatenmatrix und der Ergebnismatrix. Danach übertragen wir den Wert.
Der Kernel wird von der Feed-Forward-Pass-Methode feedForward aufgerufen. Der Algorithmus für den Kernelaufruf ist ähnlich wie oben beschrieben. Wir definieren zunächst den Problemraum, aber diesmal im 2-dimensionalen Raum (Anzahl der Elemente in der Sequenz * Anzahl der Merkmale in jedem Element der Sequenz). Dann übergeben wir Zeiger auf die Datenpuffer an die Kernel-Parameter und stellen sie in die Ausführungswarteschlange. Vergessen wir nicht, die Ergebnisse der Ausführung der Operation zu überprüfen.
bool CNeuronTransposeOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {iCount, iWindow}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, Output.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel Transpose: %d -> %s", GetLastError(), error); return false; } //--- return true; }
Während des Backpropagation-Durchgangs muss der Fehlergradient in die entgegengesetzte Richtung propagiert werden. Außerdem müssen wir die Matrix des Fehlergradienten transponieren. Daher werden wir denselben Kernel verwenden. Wir müssen lediglich die Dimension des Problemraums umkehren und Zeiger auf die Puffer für die Fehlergradienten angeben.
bool CNeuronTransposeOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {iWindow, iCount}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, NeuronOCL.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, Gradient.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel Transpose: %d -> %s", GetLastError(), error); return false; } //--- return true; }
Wie Sie sehen können, enthält die Klasse CNeuronTransposeOCL keine trainierbaren Parameter, daher gibt die Methode updateInputWeights immer true zurück.
2.3 Architektur des AutoBot
Oben haben wir 2 neue, sehr vielseitige Ebenen erstellt. Nun können wir direkt mit der Implementierung der Methode „Latent Variable Sequential Set Transformers“ (AutoBots) fortfahren. Zunächst wird in der Methode CreateTrajNetDescriptions die Architektur des Prognosemodells für die Preisbewegung erstellt. Um die Operationen auf der Seite des Hauptprogramms zu reduzieren, habe ich beschlossen, die AutoBot-Operationen im Rahmen eines Modells zu organisieren. Zur Beschreibung wird ein Zeiger auf ein dynamisches Array an die Methode übergeben. Im Hauptteil der Methode wird der empfangene Zeiger überprüft und gegebenenfalls eine neue Instanz des dynamischen Array-Objekts erstellt.
bool CreateTrajNetDescriptions(CArrayObj *autobot) { //--- CLayerDescription *descr; //--- if(!autobot) { autobot = new CArrayObj(); if(!autobot) return false; }
Das Modell wird mit dem Tensor der Originaldaten gefüttert. Um die Berechnungen während des Betriebs und des Trainings des Modells zu optimieren, werden wir wie bisher nur die Beschreibung des letzten Balkens als Ausgangsdaten verwenden. Der gesamte Verlauf wird im Puffer der Einbettungsebene gespeichert.
//--- Encoder autobot.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Die primäre Verarbeitung der Quelldaten wird in der Batch-Normalisierungsschicht durchgeführt.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000,GPTBars); descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Danach erzeugen wir eine Zustandseinbettung und fügen sie dem historischen Datenpuffer hinzu.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!autobot.Add(descr)) { delete descr; return false; }
Bitte beachten Sie, dass wir in diesem Fall nur eine Entität einbetten, die den aktuellen Zustand der Umgebung beschreibt. Die Funktionsweise dieser Schicht ist ähnlich wie die der vollverknüpften Schicht. Wir verwenden jedoch die Schicht CNeuronEmbeddingOCL, da wir einen Puffer für die historische Abfolge der Einbettungen erstellen müssen. Der Algorithmus legt jedoch keine Einschränkungen für die Analyse von Instrumentenbalken fest. Wir können sowohl mehrere Kerzen als auch mehrere Handelsinstrumente analysieren. In diesem Fall müssen Sie jedoch die Anordnung der Einbettungen anpassen.
Als Nächstes fügen wir der gesamten historischen Einbettungssequenz einen Positionskodierungstensor hinzu.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; }
Wir führen den ersten Aufmerksamkeitsblock aus, um die Abhängigkeiten zwischen den Szenen in der Zeit zu bewerten.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Dann müssen wir die Abhängigkeiten zwischen den einzelnen Merkmalen analysieren. Dazu transponieren wir den Tensor und wenden einen Aufmerksamkeitsblock auf den transponierten Tensor an.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Bitte beachten Sie, dass wir nach der Transposition auch die Dimensionen im Aufmerksamkeitsblock ändern, damit sie dem transponierten Tensor entsprechen.
Wir transponieren den Tensor erneut, um ihn in seine ursprüngliche Dimension zurückzuführen. Dann wiederholen wir die Aufmerksamkeitsblöcke des Encoders noch einmal.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_wout; descr.window = prev_count; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Am Ausgang des Encoders erhalten wir einen Kontext, der den aktuellen Zustand der Umgebung beschreibt. Wir müssen sie an den Decoder weitergeben, um die zukünftigen Parameter der Preisbewegung in der erforderlichen Planungstiefe vorherzusagen. Nach dem Algorithmus „Latent Variable Sequential Set Transformers“ müssen wir jedoch in dieser Phase trainierbare Anfangsparameter Q hinzufügen. In der derzeitigen Implementierung unserer Bibliothek umfassen die trainierbaren Parameter jedoch nur die Gewichte der neuronalen Schichten. Um das bestehende Verfahren nicht zu verkomplizieren, habe ich eine Lösung gewählt, die zwar nicht dem Standard entspricht, aber effektiv ist. In diesem Fall wird die Tensorkonkatenationsschicht СNeuronConcatenate verwendet. Der erste Teil der Schicht ersetzt die vollständig verbundene Schicht, um die vom Encoder erhaltene Kontextdarstellung des aktuellen Umgebungszustands zu ändern. Die Gewichte des zweiten Blocks dienen als erste, trainierbare Parameter Q. Um die Werte der Parameter Q nicht zu verfälschen, wird ein mit Einsen gefüllter Vektor in den zweiten Eingang eingespeist.
Am Ausgang der Schicht erwarten wir einen Zustandseinbettungstensor für eine bestimmte Planungstiefe.
//--- Decoder //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = PrecoderBars * EmbeddingSize; descr.window = prev_count * prev_wout; descr.step = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Wie bei Encoder betrachten wir zunächst die Abhängigkeiten zwischen den Zuständen im Zeitverlauf.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = PrecoderBars; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Dann transponieren wir den Tensor und analysieren die Kontextabhängigkeit zwischen den einzelnen Merkmalen.
//--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Danach wiederholen wir die Decoderoperationen erneut.
//--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = prev_count * prev_wout; descr.window = descr.count; descr.step = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 16 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Beachten Sie, dass die Verwendung eines konstanten Vektors von Einsen als zweite Eingabe des Modells es uns ermöglicht, die Verkettungsschicht im Decoder viele Male zu iterieren. In diesem Fall spielen die trainierbaren Gewichtsparameter die Rolle der Parameter Q, die für jede Schicht einzigartig sind.
Um den Decoder zu vervollständigen, verwenden wir eine vollständig verknüpfte Schicht, die es uns ermöglicht, die Daten in dem gewünschten Format darzustellen.
//--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = PrecoderBars * 3; descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 Training des AutoBot
Wir haben die Architektur des AutoBot-Modells zur Vorhersage der Parameter der bevorstehenden Kursbewegung bei einer bestimmten Planungstiefe erörtert. Die Verwendung der Ergebnisse des trainierten Modells ist nur durch Ihre Phantasie begrenzt. Wenn Sie eine Vorhersage der nachfolgenden Preisbewegung haben, können Sie einen klassischen algorithmischen EA erstellen, der Operationen in Übereinstimmung mit der erhaltenen Vorhersage durchführt. Optional können Sie es an das Akteursmodell übergeben, um direkt Handlungsempfehlungen zu generieren. Ich habe die zweite Option gewählt. In diesem Fall wurden die Architektur der Akteursmodelle und die Zielsetzung aus den vorherigen Artikeln übernommen. Die Änderungen betrafen nur die Quelldatenebene, um die Ergebnisse des obigen AutoBot-Modells zu erreichen. Wir werden uns jetzt nicht mit ihnen befassen. Sie sind unten angefügt (Methode CreateDescriptions), damit Sie sie selbst studieren können. Dort können Sie sich auch mit den spezifischen Einstellungen im EA für die Interaktion mit der Umgebung „...\Experts\AutoBots\Research.mq5“ vertraut machen. Wir fahren fort mit der Organisation des Modelltrainings für die Vorhersage der kommenden Kursbewegung. Der Trainingsprozess ist in dem EA „...\Experts\AutoBots\StudyTraj.mq5“ implementiert.
In diesem EA trainieren wir nur ein Modell.
CNet Autobot;
In der EA-Initialisierungsmethode OnInit laden wir zunächst den Trainingsdatensatz.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Dann versuchen wir, das vortrainierte AutoBot-Modell zu laden, und wenn ein Fehler auftritt, erstellen wir ein neues Modell, das mit zufälligen Parametern initialisiert wird.
//--- load models float temp; if(!Autobot.Load(FileName + "Traj.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *autobot = new CArrayObj(); if(!CreateTrajNetDescriptions(autobot)) { delete autobot; return INIT_FAILED; } if(!Autobot.Create(autobot)) { delete autobot; return INIT_FAILED; } delete autobot; //--- }
Danach überprüfen wir die Modellarchitektur auf die Einhaltung der Hauptkriterien.
Autobot.getResults(Result); if(Result.Total() != PrecoderBars * 3) { PrintFormat("The scope of the Autobot does not match the precoder bars (%d <> %d)", PrecoderBars * 3, Result.Total()); return INIT_FAILED; } //--- Autobot.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Autobot doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Wir erstellen die erforderlichen Datenpuffer.
OpenCL = Autobot.GetOpenCL(); if(!Ones.BufferInit(EmbeddingSize, 1) || !Gradient.BufferInit(EmbeddingSize, 0) || !Ones.BufferCreate(OpenCL) || !Gradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; } State.BufferInit(HistoryBars * BarDescr, 0);
Wir erzeugen ein nutzerdefiniertes Ereignis für den Beginn des Modelltrainings.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Bei der EA-Deinitialisierungsmethode speichern wir das trainierte Modell und löschen dynamische Objekte aus dem Speicher.
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) Autobot.Save(FileName + "Traj.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; delete OpenCL; }
Wie üblich wird das Modelltraining mit der Methode Train durchgeführt. Im Hauptteil der Methode bestimmen wir zunächst die Wahrscheinlichkeiten für die Auswahl von Trajektorien auf der Grundlage ihrer Rentabilität.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Dann deklarieren und initialisieren wir lokale Änderungen.
vector<float> result, target, inp; matrix<float> targets; matrix<float> delta; STE = vector<float>::Zeros(PrecoderBars * 3); int std_count = 0; int batch = GPTBars + 50; bool Stop = false; uint ticks = GetTickCount(); ulong size = HistoryBars * BarDescr;
Wie immer beschränken wir uns beim Training eines Trajektorienmodells auf die von den Autoren der Methode Latent Variable Sequential Set Transformers vorgeschlagenen Ansätze. Insbesondere werden wir das Training auf maximale Abweichungen konzentrieren, wie bei der Methode CFPI. Um die Stabilität des Modells in einem stochastischen Markt zu gewährleisten, werden wir den Raum der Trainingsstichprobe erweitern, indem wir den ursprünglichen Daten Rauschen hinzufügen, wie es in der Methode SSWNP vorgeschlagen wird. Zur Umsetzung dieser Ansätze werden wir in einer lokalen Variablen eine Matrix der Parameteränderungen delta und einen Vektor der mittleren quadratischen Fehler STE deklarieren.
Aber kommen wir zurück zum Algorithmus unserer Methode. In der Architektur unseres AutoBot zur Vorhersage von Trajektorien haben wir eine Einbettungsschicht mit einem eingebauten Puffer für die Akkumulation historischer Daten verwendet, die es uns ermöglicht, Darstellungen von sich wiederholenden Daten während des Betriebs des Modells nicht neu zu berechnen. Dieser Ansatz erfordert jedoch auch die Einhaltung der historischen Konsistenz bei der Übermittlung der ersten Daten während des Lernprozesses. Daher werden wir ein verschachteltes Schleifensystem verwenden, um das Modell zu trainieren. Die äußere Schleife bestimmt die Anzahl der Trainingsiterationen.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
Im Schleifenkörper wird die Trajektorie unter Berücksichtigung der zuvor berechneten Wahrscheinlichkeiten aus dem Puffer entnommen. Dann wird der Anfangszustand des Lernens auf der ausgewählten Bahn zufällig bestimmt.
Wir bestimmen auch den Endzustand des Ausbildungspakets. Löschen wir die Historienpuffer unseres Autobot. und bereiten wir eine Matrix für die Aufzeichnung von Parameteränderungen vor.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); Autobot.Clear(); delta = matrix<float>::Zeros(end - state - 1, Buffer[tr].States[state].state.Size());
Als Nächstes erstellen wir eine verschachtelte Schleife für die Arbeit mit sauberen Trajektorien, in deren Hauptteil wir den Quelldatenpuffer füllen.
for(int i = state; i < end; i++) { inp.Assign(Buffer[tr].States[i].state); State.AssignArray(inp);
Wir berechnen die Abweichung der Parameterwerte zwischen 2 aufeinander folgenden Umweltzuständen.
if(i < (end - 1)) delta.Row(inp, row); if(row > 0) delta.Row(delta.Row(row - 1) - inp, row - 1);
Nach den vorbereitenden Arbeiten führen wir einen Vorwärtsdurchlauf unseres Modells durch.
if(!Autobot.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(Ones))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Bitte beachten Sie, dass wir als zweiten Quelldatenstrom einen Puffer verwenden, der mit konstanten Einsen gefüllt ist, wie bei der Beschreibung der Modellarchitektur erläutert. Dieser Puffer wurde während der EA-Initialisierung vorbereitet und ändert sich während des gesamten Trainings des Modells nicht.
Auf den Vorwärtsdurchgang folgt ein Rückwärtsdurchgang zur Aktualisierung der Modellparameter. Bevor wir diese Funktion aufrufen, müssen wir jedoch zunächst die Zielwerte vorbereiten. Lassen Sie uns dazu „in die Zukunft schauen“. Während des Trainingsprozesses wird diese Fähigkeit durch den Trainingsdatensatz bereitgestellt. Aus dem Erfahrungswiedergabepuffer extrahieren wir eine Beschreibung der nachfolgenden Umweltzustände bei einer bestimmten Planungstiefe. Wir kopieren die erforderlichen Daten in den Vektor der Zielwerte target.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
Anschließend laden wir die Ergebnisse von Autobots Vorwärtsdurchgang und bestimmen anhand der Größe des Vorhersagefehlers im aktuellen Zustand, ob ein Rückwärtsdurchgang erforderlich ist.
Autobot.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; vector<float> check = MathAbs(error) - STE * STE_Multiplier;
Der Rückwärtsdurchgang wird durchgeführt, wenn der Vorhersagefehler bei mindestens einem der Parameter über dem Schwellenwert liegt, der durch einen Koeffizienten mit dem mittleren quadratischen Vorhersagefehler des Modells verbunden ist.
if(check.Max() > 0) { //--- Result.AssignArray(target); if(!Autobot.backProp(Result, GetPointer(Ones), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Anschließend informieren wir den Nutzer über den Fortschritt des Trainingsprozesses und fahren mit der nächsten Iteration fort, bei der der Stapel sauberer Trajektorien verarbeitet wird.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Autobot", percent, Autobot.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nach Abschluss des Trainings für saubere Trajektorien gehen wir zum zweiten Block über - ein Trajektorienmodell für verrauschte Daten. Hier definieren wir zunächst die Parameter für die Neuparametrisierung des Rauschens
//--- With noise vector<float> std_delta = delta.Std(0) * STD_Delta_Multiplier; vector<float> mean_delta = delta.Mean(0);
und bereiten ein Array und einen Vektor für die Arbeit mit Lärm vor.
ulong inp_total = std_delta.Size(); vector<float> noise = vector<float>::Zeros(inp_total); double ar_noise[];
Außerdem entnehmen wir die Trajektorie aus dem Trainingsdatensatz, bestimmen den Anfangs- und Endzustand des Trainingsstapels und löschen die historischen Puffer unseres Modells.
tr = SampleTrajectory(probability); state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; } end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); Autobot.Clear();
Dann erstellen wir eine zweite, verschachtelte Schleife.
for(int i = state; i < end; i++) { if(!Math::MathRandomNormal(0, 1, (int)inp_total, ar_noise)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } noise.Assign(ar_noise); noise = mean_delta + std_delta * noise;
Im Hauptteil der Schleife erzeugen wir Rauschen und parametrisieren es mit den oben berechneten Verteilungsparametern.
Wir fügen das resultierende Rauschen zu den Originaldaten hinzu und führen den Vorwärtsdurchgang des Modells durch.
inp.Assign(Buffer[tr].States[i].state); inp = inp + noise; State.AssignArray(inp); //--- if(!Autobot.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(Ones))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Wir kopieren den Algorithmus für die Durchführung eines Rückwärtsdurchgangs, einschließlich der Vorbereitung der Zieldaten und der Ermittlung des Bedarfs, vollständig aus dem Block der Operationen mit einer sauberen Trajektorie.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0); Autobot.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(target); if(!Autobot.backProp(Result, GetPointer(Ones), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Am Ende müssen wir den Nutzer nur über den Trainingsfortschritt informieren und zur nächsten Trainingsiteration übergehen.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter + 0.5) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Autobot", percent, Autobot.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Nach Abschluss aller Iterationen des Modelltrainingskreislaufs wird das Kommentarfeld in der Tabelle gelöscht. Ausdruck der Trainingsergebnisse in das Protokoll und Abschluss des EAs.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Autobot", Autobot.getRecentAverageError()); ExpertRemove(); //--- }
Wir haben die Prüfung der Expert Advisor-Methoden für das Trajektorientrainingsmodell „...\Experts\AutoBots\StudyTraj.mq5“ abgeschlossen. Der vollständige Code dieses EA ist unten angefügt. Die Anhänge enthalten auch das Training der Akteurspolitik „...\Experts\AutoBots\Study.mq5“ und den Test des trainierten Modells mit historischen Daten „...\Experts\AutoBots\Test.mq5“. In diesen EAs haben wir nur bestimmte Änderungen berücksichtigt, die die Funktionsweise des AutoBot-Modells betreffen. Wir gehen nun in die Testphase über.
3. Test
Wir haben recht umfangreiche Arbeit geleistet, um die Ansätze der Methode Latent Variable Sequential Set Transformers (AutoBots) in MQL5 zu implementieren. Nun ist es an der Zeit, die Ergebnisse zu bewerten. Wie in allen vorherigen Fällen wird unser Modell anhand der EURUSD-H1-Daten für die ersten 7 Monate des Jahres 2023 trainiert. Um das trainierte Modell der Actor-Politik zu testen, verwenden wir historische Daten vom August 2023. Wie Sie sehen, schließt sich der Testzeitraum unmittelbar an den Trainingszeitraum an, was eine maximale Kompatibilität zwischen den Daten der Trainings- und Testdatensätze gewährleistet.
Die Parameter aller Indikatoren, die zur Analyse der Marktsituation verwendet werden, wurden während des Trainings- und Testprozesses nicht optimiert. Sie wurden mit Standardparametern verwendet.
Wie Sie vielleicht bemerkt haben, wurden die Zusammensetzung und Struktur der Ausgangsdaten und die Ergebnisse unseres Modells zur Vorhersage der Trajektorie unverändert aus der früheren Arbeit übernommen. Daher können wir zum Trainieren des Modells die zuvor erstellte Datenbank mit Beispielen verwenden. Auf diese Weise können wir die Phase der primären Sammlung von Trainingsdaten vermeiden und direkt mit dem Trainingsprozess des Modells beginnen.
Wir werden die Modelle in 2 Stufen trainieren:
- Training eines Modells zur Trajektorievorhersage
- Ausbildung der Akteurspolitik
Das Modell zur Vorhersage von Kursverläufen betrachtet nur die Marktdynamik und die analysierten Indikatoren, ohne Bezugnahme auf den Kontostatus und die offenen Positionen, die den Kursverläufen der Trainingsstichprobe zusätzliche Vielfalt verleihen. Da wir alle Trajektorien von einem Instrument und über denselben historischen Zeitraum gesammelt haben, sind nach dem Verständnis von AutoBot alle Trajektorien identisch. Daher können wir das Modell zur Vorhersage von Preisbewegungen mit einem einzigen Trainingsdatensatz trainieren, ohne die Trajektorien zu aktualisieren, bis akzeptable Ergebnisse erzielt werden.
Der Trainingsprozess erwies sich als recht stabil und zeigte eine gute Dynamik mit nahezu konstanter Fehlerreduktion. Hier muss ich den Autoren der Methode zustimmen, wenn sie von der Lerngeschwindigkeit des Modells sprechen. So geben die Autoren der Methode an, dass bei ihrer Arbeit alle Modelle 48 Stunden lang auf einem 1080 Ti Desktop-Grafikbeschleuniger trainiert wurden.
Inspiriert durch das Training eines Modells zur Vorhersage von Preisbewegungen dachte ich, dass es nicht ganz korrekt ist, einen Algorithmus zur Vorhersage von Kursverläufen auf der Grundlage der Leistung einer trainierten Akteurspolitik zu bewerten. Obwohl die Politik des Akteurs auf den Daten der erhaltenen Vorhersage basiert, passt sie sich an mögliche Fehler in den erstellten Vorhersagen an. Die Qualität einer solchen Anpassung ist eine andere Sache und hängt mit der Architektur des Akteurs und dem Prozess seiner Ausbildung zusammen. Eine solche Anpassung hat jedoch sicherlich Auswirkungen. Daher habe ich einen kleinen EA für den klassischen algorithmischen Handel „...\Experts\AutoBots\Alternate.mq5“ erstellt.
Der EA wurde nur erstellt, um die Qualität der Vorhersage von Kursbewegungen im Strategy Tester zu testen, und sein Code weckt meiner Meinung nach kein großes Interesse. Deshalb werden wir in diesem Artikel nicht näher darauf eingehen. Sie können den Code im Anhang selbst studieren.
Dieser EA wertet die prognostizierte Bewegung aus und eröffnet Transaktionen mit einem minimalen Lot in Richtung eines ausgeprägten Trends am Planungshorizont. Die EA-Parameter wurden nicht optimiert. Interessant ist das Ergebnis, das beim Testen des EA im Strategietester bis Ende 2023 erzielt wurde.
Nach dem Training eines Prognosemodells für die Preisentwicklung auf der Grundlage historischer Daten von 7 Monaten erhielten wir eine stabile Tendenz, dass der Saldo über 2 Monate wächst.

Alle Handelsgeschäfte wurden mit dem Mindestvolumen durchgeführt. Das bedeutet, dass das erzielte Ergebnis nur von der Qualität der Trajektorieplanung abhängt.
Schlussfolgerung
In diesem Artikel haben wir uns mit der Methode „Latent Variable Sequential Set Transformers“ (AutoBots) vertraut gemacht. Die von den Autoren der Methode vorgeschlagenen Ansätze beruhen auf der Modellierung der gemeinsamen Verteilung von kontextuellen und zeitlichen Informationen, die zuverlässige Instrumente für die genaue (möglichst genaue) Vorhersage der künftigen Preisentwicklung bieten.
AutoBots nutzt die Encoder-Decoder-Architektur und demonstriert einen effizienten Betrieb durch den Einsatz von multifunktionalen Aufmerksamkeitsblöcken sowie durch die Einführung einer diskreten latenten Variable zur Modellierung multimodaler Verteilungen.
Im praktischen Teil des Artikels haben wir die vorgeschlagenen Ansätze mit MQL5 implementiert und vielversprechende Ergebnisse in Bezug auf die Geschwindigkeit des Modelllernens und die Prognosequalität erzielt.
Der vorgeschlagene AutoBots-Algorithmus stellt somit ein vielversprechendes Instrument zur Lösung von Prognoseproblemen auf dem Devisenmarkt dar, das Genauigkeit, Robustheit gegenüber Veränderungen und die Fähigkeit zur Modellierung multimodaler Verteilungen für ein tieferes Verständnis der Dynamik der Marktbewegungen bietet.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Trainings-EA der Politik |
| 4 | StudyTraj.mq5 | Expert Advisor | Training des Trajektorievorhersagemodells EA |
| 5 | Test.mq5 | Expert Advisor | Trainings-EA für das Model |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek |
| 9 | Alternate.mq5 | Expert Advisor | Prüfung der Qualität der Trajektorievorhersage EA |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14095
 Neuronale Netze leicht gemacht (Teil 76): Erforschung verschiedener Interaktionsmuster mit Multi-Future Transformer
Neuronale Netze leicht gemacht (Teil 76): Erforschung verschiedener Interaktionsmuster mit Multi-Future Transformer
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.