Neuronale Netze leicht gemacht (Teil 56): Nuklearnorm als Antrieb für die Erkundung nutzen

Einführung
Das Verstärkungslernen basiert auf dem Paradigma der unabhängigen Erkundung der Umgebung durch den Agenten. Der Agent wirkt auf die Umgebung ein, was zu deren Veränderung führt. Im Gegenzug erhält der Agent eine Art Belohnung.
Hier werden die beiden Hauptprobleme des Verstärkungslernens hervorgehoben: die Erkundung der Umgebung und die Belohnungsfunktion. Eine richtig strukturierte Belohnungsfunktion ermutigt den Agenten, die Umgebung zu erkunden und nach den optimalsten Verhaltensstrategien zu suchen.
Bei der Lösung der meisten praktischen Probleme sind wir jedoch mit sparsamen externen Belohnungen konfrontiert. Um dieses Hindernis zu überwinden, wurde der Einsatz von so genannten internen Belohnungen vorgeschlagen. Sie ermöglichen es dem Agenten, sich neue Fähigkeiten anzueignen, die ihm in Zukunft bei der Erlangung externer Belohnungen von Nutzen sein können. Interne Belohnungen können jedoch aufgrund der Stochastik der Umgebung verrauscht sein. Die direkte Anwendung verrauschter Prognosewerte auf Beobachtungen kann sich negativ auf die Effizienz des Trainings der Agentenpolitik auswirken. Außerdem verwenden viele Methoden die L2-Norm oder die Varianz, um die Neuheit einer Studie zu messen, was das Rauschen aufgrund der Quadrierung erhöht.
Um dieses Problem zu lösen, schlägt der Artikel „Nuclear Norm Maximization Based Curiosity-Driven Learning“ einen neuen Algorithmus zur Stimulierung der Neugier des Agenten auf der Grundlage der Nuklearnorm-Maximierung (NNM) vor. Eine solche interne Belohnung ist in der Lage, die Neuartigkeit der Umgebungserkundung genauer zu bewerten. Gleichzeitig bietet es eine hohe Störfestigkeit gegenüber Rauschen und Spannungsspitzen.
1. Die Nuklearnorm und ihre Anwendung
Matrixnormen, einschließlich der Nuklearnorm, werden in der Analyse und den Berechnungsmethoden der linearen Algebra häufig verwendet. Die Nuklearnorm spielt eine wichtige Rolle bei der Untersuchung der Eigenschaften von Matrizen, bei Optimierungsproblemen, bei der Bewertung der Konditionalität und in vielen anderen Bereichen der Mathematik und der angewandten Wissenschaften.
Die Nuklearnorm einer Matrix ist ein numerisches Merkmal, das die „Größe“ einer Matrix bestimmt. Sie ist ein Spezialfall der Schatten-Norm und entspricht der Summe der Matrixsingulärwerte.
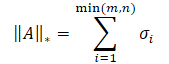
wobei σi die Elemente des Singulärwertvektors der Matrix A darstellt.
Im Kern ist die Nuklearnorm die konvexe Hülle der Rangfunktion für eine Menge von Matrizen mit der gleichen Spektralnorm. Dadurch kann es für die Lösung verschiedener Optimierungsprobleme eingesetzt werden.
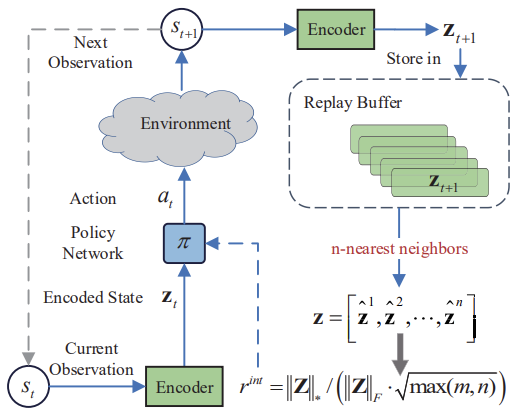
Die Hauptidee der Methode der Nuklearnorm-Maximierung (NNM) besteht darin, die Neuheit anhand der Nuklearnorm einer Matrix beim Besuch eines Zustands genau abzuschätzen und gleichzeitig die Auswirkungen von Rauschen und verschiedenen Spikes zu mildern. Die Matrix der Größe n*m umfasst n kodierte Zustände der Umgebung. Jeder Zustand hat die Dimension m. Die Matrix kombiniert den aktuellen Zustand von s und seine (n - 1) nächstgelegenen Nachbarzustände. Hier stellt s einen abstrakten Zustand dar, indem die ursprüngliche hochdimensionale Beobachtung in einen niedrigdimensionalen abstrakten Raum abgebildet wird. Da jede Zeile der Matix S den kodierten Zustand darstellt, kann rang(S) zur Darstellung der Vielfalt innerhalb einer Matrix verwendet werden. Ein höherer Rang der Matrix S bedeutet einen größeren linearen Abstand zwischen den kodierten Zuständen. Die Autoren der Methode verfolgen einen kreativen Ansatz zur Lösung des Problems und nutzen die Matrix-Rang-Maximierung, um die Forschungsvielfalt zu erhöhen. Dies ermutigt den Agenten unseres Modells, mehr verschiedene Zustände mit großer Vielfalt zu besuchen.
Es gibt zwei Möglichkeiten, den maximalen Rang einer Matrix zu ermitteln. Wir können sie als Verlustfunktion oder als Belohnung verwenden. Die direkte Maximierung des Matrix-Rangs ist ein ziemlich schwieriges Problem mit einer nicht-konvexen Funktion. Daher werden wir sie nicht als Verlustfunktion verwenden. Der Rang der Matrix ist jedoch diskret und kann die Neuartigkeit der Zustände nicht genau wiedergeben. Daher ist es auch ineffizient, den rohen Matrix-Rang als Belohnung für die Modellschulung zu verwenden.
Mathematisch gesehen wird die Berechnung des Rangs einer Matrix gewöhnlich durch ihre Nuklearnorm ersetzt. Daher kann die Neuartigkeit durch eine annähernde Maximierung der Nuklearnorm erhalten werden. Im Vergleich zum Rang hat die Nuklearnorm mehrere gute Eigenschaften. Erstens ermöglicht die Konvexität der Nuklearnorm die Entwicklung von schnellen und konvergenten Optimierungsalgorithmen. Zweitens ist die Nuklearnorm eine kontinuierliche Funktion, was für viele Ausbildungsaufgaben wichtig ist.
Die Autoren der NNM-Methode schlagen vor, die interne Belohnung anhand der folgenden Gleichung zu bestimmen
![]()
wobei:
λ ist ein Gewicht zur Festlegung des Bereichs der Nuklearnormwerte;
‖S‖⋆ ist eine Nuklearnorm der Zustandsmatrix;
‖S‖F ist eine Frobenius-Norm der Zustandsmatrix.
Wir haben uns bereits mit der Nuklearnorm einer Matrix vertraut gemacht, während die Frobenius-Norm als Quadratwurzel aus der Summe der Quadrate aller Matrixelemente berechnet wird.
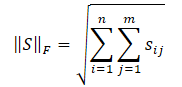
Die Cauchy-Bunyakovsky-Ungleichung erlaubt es uns, die folgenden Umformungen vorzunehmen.
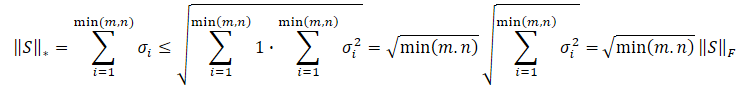
Es liegt auf der Hand, dass die Quadratwurzel der Summe der quadrierten Werte immer kleiner oder gleich der Summe der Werte selbst ist. Daher wird die Nuklearnorm der Matrix immer größer oder gleich der Frobenius-Norm derselben Matrix sein. Daraus lassen sich die folgenden Ungleichungen ableiten.
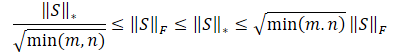
Diese Ungleichung zeigt, dass die Nuklearnorm und die Frobenius-Norm sich gegenseitig einschränken. Wenn die Nuklearnorm zunimmt, dann nimmt auch die Frobenius-Norm tendenziell zu.
Darüber hinaus hat die Frobenius-Norm eine weitere für uns nützliche Eigenschaft - sie ist der Entropie in der Monotonie streng entgegengesetzt. Ihre Zunahme ist gleichbedeutend mit einer Abnahme der Entropie. Die Auswirkungen der Nuklearnorm lassen sich daher in zwei Bereiche unterteilen:
- Große Vielfalt.
- Niedrige Entropie.
Wir müssen den Agenten ermutigen, neuere Zustände zu besuchen, und unser Ziel ist Vielfalt. Eine Abnahme der Entropie bedeutet jedoch eine Zunahme der Aggregation von Zuständen. Das bedeutet eine große Ähnlichkeit der Zustände. Daher wollen wir den ersten Effekt fördern und den Einfluss des zweiten verringern. Dazu wird die Nuklearnorm einer Matrix durch ihre Frobenius-Norm geteilt.
Dividiert man die obigen Ungleichungen durch die Frobenius-Norm, so ergibt sich folgendes:
![]()
Es liegt auf der Hand, dass die direkte Verwendung einer solchen Belohnungsskala für das Modelltraining nachteilig sein kann. Darüber hinaus kann die Wurzel der minimalen Dimension der Zustandsmatrix in verschiedenen Umgebungen oder bei verschiedenen Architekturen trainierter Modelle variieren. Daher ist es wünschenswert, unsere Belohnungsskala neu zu normieren. Da min(m, n) ≤ max(m, n) ist, erhalten wir:
![]()
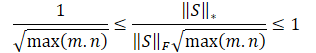
Anhand der obigen mathematischen Berechnungen lässt sich der Anpassungsfaktor für den Wertebereich der Nuklearnorm der Matrix λ automatisch wie folgt bestimmen:
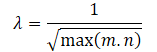
Die interne Belohnungsgleichung hat also folgende Form:
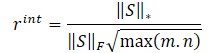
Unten sehen Sie die Visualisierung der Methode der Nuklearnorm-Maximierung durch den Autor.
Die in dem Artikel des Autors vorgestellten Testergebnisse zeigen die Überlegenheit der vorgeschlagenen Methode gegenüber anderen Algorithmen der Umgebungserkundung, darunter das zuvor überprüfte Intrinsic Curiosity Module und Self-Supervised Exploration via Disagreement. Darüber hinaus ist es bemerkenswert, dass die Methode bessere Ergebnisse liefert, wenn den Originaldaten Rauschen hinzugefügt wird. Kommen wir nun zum praktischen Teil unseres Artikels und bewerten die Fähigkeiten der Methode bei der Lösung unserer Probleme.
2. Implementierung mit MQL5
Bevor wir mit der Umsetzung der Methode der Nuklearnorm-Maximierung (NNM) beginnen, wollen wir ihre wichtigste Neuerung hervorheben - die neue interne Belohnungsgleichung. Daher kann dieser Ansatz als Ergänzung zu fast allen bisher betrachteten Algorithmen des Reinforcement Learning eingesetzt werden.
Es ist auch zu beachten, dass der Algorithmus einen Kodierer verwendet, um Umgebungszustände in eine Art komprimierte Darstellung zu übersetzen. Der Algorithmus der k-nächsten Nachbarn wird auch angewandt, um eine Matrix komprimierter Darstellungen des Umgebungszustands zu bilden.
Meiner Meinung nach scheint die einfachste Lösung die Einführung der vorgeschlagenen internen Belohnung in den RE3-Algorithmus zu sein. Außerdem wird ein Encoder verwendet, um Umgebungszustände in eine komprimierte Darstellung zu übersetzen. Wir verwenden für diese Zwecke einen zufälligen Faltungscodierer in RE3. Dadurch können wir die Kosten für das Training des Encoders reduzieren.
Darüber hinaus wendet RE3 auch k-nächste Umgebungsbedingungen für die Bildung einer internen Belohnung an. Diese Belohnung wird jedoch anders gestaltet.
Die Richtung unseres Handelns ist klar, es ist also an der Zeit, sich an die Arbeit zu machen. Zuerst kopieren wir alle Dateien aus dem Verzeichnis „...\Experts\RE3\“ und „...\Experts\NNM\“. Wie Sie sich vielleicht erinnern, enthält sie vier Dateien:
- Trajectory.mqh — die Bibliothek der allgemeinen Konstanten, Strukturen und Methoden.
- Research.mq5 — der EA für die Interaktion mit der Umgebung und das Sammeln einer Ausbildungsprobe.
- Study.mq5 — der EA für das direkte Modelltraining.
- Test.mq5 — der EA zum Testen trainierter Modelle.
Wir werden auch aufgeteilte (decomposed) Belohnungen verwenden. Die Struktur des Belohnungsvektors sieht wie folgt aus.
//+------------------------------------------------------------------+ //| Rewards structure | //| 0 - Delta Balance | //| 1 - Delta Equity ( "-" Drawdown / "+" Profit) | //| 2 - Penalty for no open positions | //| 3 - NNM | //+------------------------------------------------------------------+
In der Datei „...\NNM\Trajectory.mqh“ erhöhen wir die Größe der komprimierten Darstellung des Umgebungszustands und der internen vollverknüpften Schicht unserer Modelle.
#define EmbeddingSize 16 #define LatentCount 512
Die Datei enthält auch die Methode CreateDescriptions zur Beschreibung der Architektur der verwendeten Modelle. Hier werden wir drei neuronale Netzmodelle verwenden: Akteur (Actor), Kritiker (Critic) und Codierer (Encoder). Wir werden einen zufälligen Faltungscodierer als letzteren verwenden.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; }
Im Hauptteil der Methode erstellen wir eine lokale Variable, die einen Zeiger auf ein Objekt speichert, das eine neuronale Schicht CLayerDescription beschreibt, und initialisieren gegebenenfalls dynamische Arrays, die die Architekturlösungen der verwendeten Modelle beschreiben.
Zunächst wird die Architektur des Akteurs beschrieben, die aus zwei Blöcken besteht: Vorverarbeitung der Quelldaten und Entscheidungsfindung.
Wir übermitteln historische Daten über die Preisbewegung des analysierten Instruments und Indikatorwerte an den Eingang des Blocks für die vorläufige Datenverarbeitung. Wie Sie sehen können, haben die verschiedenen Indikatoren unterschiedliche Parameterbereiche. Dies wirkt sich negativ auf die Effizienz der Modellbildung aus. Deshalb normalisieren wir die empfangenen Daten mit der Batch-Normalisierungsschicht CNeuronBatchNormOCL.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wir lassen die normalisierten Daten durch zwei Faltungsschichten laufen, um nach individuellen Indikatormustern zu suchen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = BarDescr; descr.window = HistoryBars; descr.step = HistoryBars; int prev_wout=descr.window_out = HistoryBars/2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die gewonnenen Daten werden von vollständig verbundenen, neuronalen Schichten verarbeitet.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
In dieser Phase des ersten Datenvorverarbeitungsblocks erwarten wir eine Art latente Darstellung der historischen Daten für das analysierte Instrument. Dies kann ausreichen, um die Richtung der Eröffnung oder des Haltens einer Position zu bestimmen, aber nicht genug, um Geldmanagementfunktionen zu implementieren. Ergänzen wir die Daten mit Informationen über den Kontostatus.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
Darauf folgt ein Entscheidungsfindungsblock aus vollständig verknüpften Schichten, der mit einer stochastischen Schicht einer latenten Repräsentation eines Variations-Autocodierers endet. Wie zuvor verwenden wir diese Art von Schicht am Ausgang des Modells, um die stochastische Akteurspolitik umzusetzen.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Wir haben die Architektur des Akteurs vollständig beschrieben. Gleichzeitig haben wir ein Modell für die Umsetzung einer stochastischen Politik entwickelt, um die Möglichkeit der Anwendung der Methode der Nuklearnorm-Maximierung für solche Entscheidungen aufzuzeigen. Darüber hinaus wird unser Akteur in einem kontinuierlichen Handlungsraum arbeiten. Dies schränkt jedoch den Anwendungsbereich der NNM-Methode nicht ein.
Der nächste Schritt besteht darin, eine Beschreibung der Architektur des Kritikers zu erstellen. Hier werden wir eine bereits bewährte Technik verwenden und den Datenvorverarbeitungsblock ausklammern. Wir werden eine latente Repräsentation des Zustands der historischen Daten des Instruments und den Zustand des Kontos aus den internen neuronalen Schichten des Akteurs als Ausgangsdaten verwenden. Gleichzeitig kombinieren wir die interne Repräsentation des Umgebungszustands und den vom Akteur generierten Aktionstensor.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; }
Die gewonnenen Daten werden von den vollständig verknüpften Schichten unseres Kritikers verarbeitet. Der Vektor der vorhergesagten Werte wird im Zusammenhang mit der Zerlegung unserer Belohnungsfunktion erstellt.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
Wir haben bereits die Architektur von zwei Modellen beschrieben. Nun müssen wir die Encoder-Architektur erstellen. Hier kehren wir zum theoretischen Teil zurück und stellen fest, dass die NNM-Methode einen Vergleich der Umgebungszustände nach dem Übergang St+1 ermöglicht. Offensichtlich wurde die Methode für die Online-Training entwickelt. Aber darüber werden wir etwas später sprechen. In der Phase der Ausarbeitung der Modellarchitektur ist es wichtig zu verstehen, dass der Encoder die historischen Daten des analysierten Instruments und die Kontostandswerte verarbeiten wird. Erstellen wir jetzt eine ausreichend große Quelldatenschicht erstellen.
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
Beachten Sie, dass wir weder eine Daten-Normalisierungsschicht noch eine Vereinigung von zwei Datentensoren verwenden. Dies ist darauf zurückzuführen, dass wir nicht vorhaben, dieses Modell zu trainieren. Es soll lediglich eine mehrdimensionale Darstellung der Umgebung in einen zufällig komprimierten Raum zu übersetzen, in dem wir den Abstand zwischen den Zuständen messen werden. Wir werden jedoch eine vollständig verknüpfte Schicht verwenden, die es uns ermöglicht, die Daten in einer vergleichbaren Form darzustellen.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 1024; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!convolution.Add(descr)) { delete descr; return false; }
Als Nächstes folgt der Block der Faltungsschichten, um die Dimensionalität der Daten zu reduzieren.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = 1024 / 16; descr.window = 16; descr.step = 16; prev_wout = descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 8; descr.window = 8; descr.step = 8; prev_wout = descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
Schließlich reduzieren wir die Dimensionalität der Daten für eine bestimmte Größe mit Hilfe einer vollständig verbundenen Schicht.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- return true; }
Die Verwendung von vollständig verbundenen Schichten am Eingang und Ausgang des Encoders ermöglicht es uns, die Architektur der Faltungsschichten anzupassen, ohne an die Dimensionen der Quelldaten und die komprimierte Repräsentationseinbettung gebunden zu sein.
Damit ist unsere Arbeit mit der Modellarchitektur abgeschlossen. Kommen wir zurück zur Beschreibung des zukünftigen Zustands. Im Falle einer Online-Schulung würden wir in dieser Hinsicht keine Schwierigkeiten haben. Doch die Online-Ausbildung hat auch ihre Nachteile. Bei der Verwendung des Erfahrungswiedergabepuffers haben wir keine Fragen zu den historischen Daten der Preisbewegung des analysierten Instruments und der Indikatoren. Die Auswirkungen des Handelns des Akteurs auf sie sind vernachlässigbar gering. Der Kontostand ist eine andere Sache. Sie hängt direkt von der Richtung und dem Volumen der offenen Position ab. Wir müssen den Kontostatus in Abhängigkeit vom Vektor der Aktionen vorhersagen, die der Akteur auf der Grundlage der Ergebnisse der Analyse des aktuellen Status generiert. Wir implementieren diese Funktionalität in der Funktion ForecastAccount.
In den Methodenparametern werden wir übergeben:
- prev_account — das Array der Beschreibungen des aktuellen Kontostands (vor den Aktionen des Agenten);
- actions — Vektor der Aktionen des Akteurs;
- prof_1l — Gewinn pro ein Lot einer Kaufposition;
- time_label — Zeitstempel des prognostizierten Balkens.
Sie können die große Vielfalt der Parametertypen erkennen. Dies hängt mit der Datenquelle zusammen. Eine Beschreibung des aktuellen Kontostands und den Zeitstempel des Prognosebalkens erhalten wir aus dem Erfahrungswiedergabepuffer, in dem die Daten in dynamischen Arrays vom Typ float gespeichert sind.
Die Aktionen des Akteurs ergeben sich aus den Ergebnissen eines direkten Durchlaufs durch das Modell in Form eines Vektors.
vector<float> ForecastAccount(float &prev_account[], vector<float> &actions, double prof_1l, float time_label ) { vector<float> account; double min_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); double step_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); double stops = MathMax(SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL), 1) * Point(); double margin_buy,margin_sell; if(!OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_ASK),margin_buy) || !OrderCalcMargin(ORDER_TYPE_SELL,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_BID),margin_sell)) return vector<float>::Zeros(prev_account.Size());
Wir leisten ein wenig Vorbereitungsarbeit im Funktionskörper. Wir bestimmen die Mindestlosgröße des Instruments und den Schrittweite der Veränderung des Positionsvolumens. Rufen die aktuellen Stop-Level und die Höhe der Marge pro Handelsgeschäft ab. Beachten Sie, dass wir keinen zusätzlichen Parameter einführen, um das analysierte Instrument zu identifizieren. Wir verwenden das Instrument des Charts, auf dem das Programm gestartet wird. Daher ist es beim Training von Modellen sehr wichtig, sich an das Instrument zur Erhebung der Ausgangsdaten der Trainingsstichprobe sowie an die Tabelle zu halten, an die das Modelltrainingsprogramm angehängt ist.
Als Nächstes passen wir den Aktionsvektor des Akteurs so an, dass er ein Handelsgeschäft in nur einer Richtung anhand der Volumendifferenz auswählt. Ähnliche Operationen führen wir in den EAs für die Interaktion mit der Umgebung durch. Die Einhaltung einheitlicher Regeln in allen Programmen des Modellbildungsprozesses ist sehr wichtig, um das gewünschte Ergebnis zu erzielen.
Wir prüfen auch sofort, ob auf dem Konto genügend Geld vorhanden ist, um eine Position zu eröffnen.
account.Assign(prev_account); //--- if(actions[0] >= actions[3]) { actions[0] -= actions[3]; actions[3] = 0; if(actions[0]*margin_buy >= MathMin(account[0],account[1])) actions[0] = 0; } else { actions[3] -= actions[0]; actions[0] = 0; if(actions[3]*margin_sell >= MathMin(account[0],account[1])) actions[3] = 0; }
Der Kontostatus wird auf der Grundlage des angepassten Vektors von Aktionen vorhergesagt. Zunächst prüfen wir Kaufpositionen. Wenn es notwendig ist, eine Position zu schließen, übertragen wir den aufgelaufenen Gewinn auf das Konto. Dann setzen wir das Volumen der offenen Position und den aufgelaufenen Gewinn zurück.
Wenn wir eine offene Position halten, prüfen wir die Notwendigkeit, die Position teilweise zu schließen oder aufzustocken. Bei der teilweisen Schließung einer Position wird der kumulierte Gewinn im Verhältnis zwischen dem geschlossenen und dem verbleibenden Teil aufgeteilt. Der Anteil der geschlossenen Position wird aus dem Gewinnvortrag in den Kontosaldo übertragen.
Falls erforderlich, passen wir das Volumen der offenen Position an und ändern den Betrag der kumulierten Gewinne/Verluste im Verhältnis zum Volumen der gehaltenen Position.
//--- buy control if(actions[0] < min_lot || (actions[1] * MaxTP * Point()) <= stops || (actions[2] * MaxSL * Point()) <= stops) { account[0] += account[4]; account[2] = 0; account[4] = 0; } else { double buy_lot = min_lot + MathRound((double)(actions[0] - min_lot) / step_lot) * step_lot; if(account[2] > buy_lot) { float koef = (float)buy_lot / account[2]; account[0] += account[4] * (1 - koef); account[4] *= koef; } account[2] = (float)buy_lot; account[4] += float(buy_lot * prof_1l); }
Wie wiederholen ähnliche Vorgänge für Verkaufspositionen.
//--- sell control if(actions[3] < min_lot || (actions[4] * MaxTP * Point()) <= stops || (actions[5] * MaxSL * Point()) <= stops) { account[0] += account[5]; account[3] = 0; account[5] = 0; } else { double sell_lot = min_lot + MathRound((double)(actions[3] - min_lot) / step_lot) * step_lot; if(account[3] > sell_lot) { float koef = float(sell_lot / account[3]); account[0] += account[5] * (1 - koef); account[5] *= koef; } account[3] = float(sell_lot); account[5] -= float(sell_lot * prof_1l); }
Als Nächstes wird das Gesamtvolumen der kumulierten Gewinne/Verluste in beide Richtungen und das Eigenkapital des Kontos angepasst.
account[6] = account[4] + account[5]; account[1] = account[0] + account[6];
Auf der Grundlage der erhaltenen Prognosewerte wird ein Vektor erstellt, der den Kontostand im Format der Datenbereitstellung für das Modell beschreibt. Das Ergebnis der Operationen wird an das aufrufende Programm zurückgegeben.
vector<float> result = vector<float>::Zeros(AccountDescr); result[0] = (account[0] - prev_account[0]) / prev_account[0]; result[1] = account[1] / prev_account[0]; result[2] = (account[1] - prev_account[1]) / prev_account[1]; result[3] = account[2]; result[4] = account[3]; result[5] = account[4] / prev_account[0]; result[6] = account[5] / prev_account[0]; result[7] = account[6] / prev_account[0]; double x = (double)time_label / (double)(D'2024.01.01' - D'2023.01.01'); result[8] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_MN1); result[9] = (float)MathCos(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_W1); result[10] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_D1); result[11] = (float)MathSin(2.0 * M_PI * x); //--- return result return result; }
Alle vorbereitenden Arbeiten sind bereits erledigt. Kommen wir nun zur Aktualisierung der Programme für die Interaktion mit der Umgebung und die Ausbildung von Modellen. Ich möchte Sie daran erinnern, dass die NNM-Methode Änderungen an der internen Belohnungsfunktion vornimmt. Diese Funktion hat keinen Einfluss auf die Interaktion mit der Umgebung. Daher bleiben die EAs „...\NNM\Research.mq5“ und „...\NNM\Test.mq5“ unverändert. Der Code ist unten beigefügt. Die Algorithmen selbst wurden in den vorangegangenen Artikeln beschrieben.
Richten wir unsere Aufmerksamkeit auf das EA-Modell „...\NNM\Study.mq5“. Zunächst einmal muss gesagt werden, dass die NNM-Methode in erster Linie für das Online-Training entwickelt wurde. Dies wird durch einen Vergleich der nachfolgenden Zustände deutlich. Natürlich können wir für eine ziemlich lange Zeit Vorhersagezustände erzeugen. Ihr Fehlen in der Vergleichsdatenbank der Zustände kann sich jedoch negativ auf das gesamte Training auswirken. In ihrer Abwesenheit wird das Modell die Zustände als neu wahrnehmen und ihre wiederholten Besuche fördern, ohne zu wissen, dass sie bereits während der Ausbildung besucht wurden.
Theoretisch gibt es zwei Möglichkeiten, dieses Problem zu lösen:
- Hinzufügen von Vorhersagezuständen zur Beispieldatenbank.
- Reduzierung der Iterationen des Ausbildungszyklus.
Beide Ansätze haben ihre Nachteile. Wenn wir der Beispieldatenbank prädiktive Zustände hinzufügen, füllen wir sie mit unzuverlässigen und unvollständigen Daten. Natürlich haben wir eine mathematische Berechnung durchgeführt, die auf unserem A-priori-Wissen und einer Reihe von Annahmen beruht. Und doch geben wir zu, dass sie eine gewisse Anzahl von Fehlern enthalten. Außerdem haben wir keine tatsächlichen Belohnungswerte für diese Aktionen, um das Modell zu trainieren. Daher haben wir uns für die zweite Methode entschieden, obwohl sie einen höheren manuellen Arbeitsaufwand in Form einer größeren Anzahl von Durchläufen für die Sammlung von Trainingsdaten und das Training von Modellen mit sich bringt.
Wir reduzieren die Anzahl der Iterationen in der Trainingsschleife.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 10000; input float Tau = 0.001f;
Während des Trainings verwenden wir einen Akteur, 2 Kritiker und deren Zielmodelle sowie einen zufälligen Convolutional Encoder. Alle Kritiker-Modelle haben die gleiche Architektur, aber unterschiedliche Parameter, die beim Training gebildet werden.
CNet Actor; CNet Critic1; CNet Critic2; CNet TargetCritic1; CNet TargetCritic2; CNet Convolution;
Wir werden einen Akteur und zwei Kritiker trainieren. Wir werden die kritischen Zielmodelle anhand der Parameter des entsprechenden kritischen Modells mit dem Tau-Parameter sanft aktualisieren. Der Encoder ist nicht trainiert.
In der Initialisierungsmethode OnInit des EAs laden wir vorab gesammelte Anfangsdaten. Wenn es nicht möglich ist, bereits trainierte Modelle zu laden, werden neue Modelle entsprechend der vorgegebenen Architektur initialisiert. Dieses Verfahren ist unverändert geblieben und Sie können sich in der Anlage mit ihm vertraut machen. Wir gehen direkt zur Trainingsmethode des Models Train über.
Bei dieser Methode wird zunächst die Anzahl der im Erfahrungswiedergabepuffer gespeicherten Trajektorien ermittelt und die Gesamtzahl der darin enthaltenen Zustände gezählt.
Bereiten Sie die Matrizen für die Aufzeichnung der Zustandseinbettung und der entsprechenden externen Belohnungen vor.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards);
Als Nächstes ordnen wir ein System von verschachtelten Schleifen an. Im Schleifenkörper ordnen wir die Kodierung aller Zustände aus dem Erfahrungswiedergabepuffer an. Die gewonnenen Daten werden zum Ausfüllen der Einbettungsmatrizen der Zustände und der entsprechenden Belohnungen verwendet. Bitte beachten Sie, dass wir die Belohnungen für einen einzelnen Übergang in einen neuen Zustand speichern, ohne die kumulierten Werte bis zum Ende des Durchgangs zu berücksichtigen. Wir wollen also Zustände in eine vergleichbare Form bringen, die in ihrer Grundidee ähnlich sind, aber zeitlich voneinander getrennt sind.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); next.Assign(Buffer[tr].States[st + 1].rewards); rewards.Row(temp - next * DiscFactor,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { rewards.Resize(state,NRewards); state_embedding.Reshape(state,state_embedding.Cols()); total_states = state; }
Nachdem wir die Einbettung der Zustände vorbereitet haben, gehen wir direkt dazu über, den Trainingszyklus des Modells zu organisieren. Wie üblich wird die Anzahl der Zyklusiterationen durch einen externen Parameter festgelegt, und wir fügen eine Prüfung auf das Ereignis der Beendigung durch den Nutzer hinzu.
Im Schleifenkörper wählen wir zufällig eine Trajektorie und einen separaten Zustand aus dem Erfahrungswiedergabepuffer aus.
vector<float> rewards1, rewards2; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; } vector<float> reward, target_reward = vector<float>::Zeros(NRewards); reward.Assign(Buffer[tr].States[i].rewards);
Bereiten Sie Vektoren für die Aufzeichnung von Belohnungen vor.
Als Nächstes bereiten wir eine Beschreibung des nächsten Zustands vor. Bitte beachten Sie, dass wir sie unabhängig von der Notwendigkeit der Verwendung von Zielmodellen vorbereiten. Schließlich brauchen wir sie auf jeden Fall, um mit der NNM-Methode interne Belohnungen zu erzeugen.
//--- Target TargetState.AssignArray(Buffer[tr].States[i + 1].state);
Im Gegenteil, der nachfolgende Kontostand-Beschreibungsvektor und die direkte Passage der Zielmodelle werden nur bei Bedarf durchgeführt.
if(iter >= StartTargetIter) { float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(TargetState), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; for(ulong r = 0; r < target_reward.Size(); r++) target_reward -= Buffer[tr].States[i + 1].rewards[r]; target_reward *= DiscFactor; }
Als Nächstes trainieren wir die Kritiker. In diesem Block bereiten wir zunächst Daten für den aktuellen Zustand der Umgebung vor.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Als Nächstes führen wir einen Vorwärtsdurchlauf des Akteurs durch.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Hier sollten wir darauf achten, dass wir für das Training der Kritiker die tatsächlichen Handlungen des Akteurs bei der Interaktion mit der Umgebung und die tatsächlich erhaltene Belohnung verwenden. Wir haben jedoch noch einen Vorwärtsdurchlauf des Akteurs durchgeführt, um seine von der Architektur des Kritikers ausgeschlossene Quelldaten-Vorverarbeitungseinheit zu verwenden.
Wir bereiten den Aktionspuffer des Akteurs aus dem Erfahrungswiedergabepuffer vor und führen einen direkten Durchlauf der beiden Kritiker durch.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Nach dem Vorwärtsdurchlauf müssen wir einen Rückwärtsdurchlauf durchführen und die Modellparameter aktualisieren. Wie Sie sich vielleicht erinnern, verwenden wir eine aufgeteilte (decomposed) Belohnungsfunktion. Die Methode CAGrad wird zur Optimierung der Gradienten verwendet. Trotz desselben Ziels sind die Fehlergradienten für jeden Kritiker natürlich unterschiedlich. Wir aktualisieren die Modelle sequentiell. Zunächst korrigieren wir die Fehlergradienten und führen einen umgekehrten Durchlauf von Kritiker 1 durch.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(reward + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Dann wiederholen wir die Vorgänge für Kritiker 2. Natürlich kontrollieren wir die Vorgänge bei jedem Schritt.
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(reward + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Kritische Modelle werden darauf trainiert, die Aktionen des Akteurs in einem bestimmten Umgebungszustand korrekt zu bewerten. Wir erwarten, dass wir als Ergebnis der Arbeit des Modells des Kritikers die korrekte vorhergesagte Belohnung erhalten. Dies ist nur die Spitze des Eisbergs. Aber es gibt auch den Unterwasserteil. Während des Trainings nähert sich der Kritiker der Q-Funktion an und stellt bestimmte Beziehungen zwischen den Handlungen des Akteurs und der Belohnung her.
Unser Ziel ist die Maximierung der externen Belohnungen. Sie hängt jedoch nicht direkt von der Qualität der Ausbildung des Kritikers ab. Im Gegenteil, die Belohnung wird durch die Handlungen des Akteurs erreicht. Um die Aktionen des Akteurs anzupassen, werden wir die approximierte Q-Funktion verwenden. Der Fehlergradient zwischen der Bewertung der Handlungen des Akteurs durch den Kritiker und der erhaltenen Belohnung zeigt die Richtung der Anpassung der Handlungen des Akteurs an. Die Wahrscheinlichkeit von überschätzten Aktionen wird abnehmen, während die Wahrscheinlichkeit von unterschätzten Aktionen zunehmen wird.
Um den Akteur zu trainieren, werden wir einen Kritiker mit einem minimalen durchschnittlichen gleitenden Vorhersagefehler verwenden, der uns möglicherweise eine genauere Bewertung der Handlungen des Akteurs ermöglicht.
CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
Wir haben bereits einen direkten Durchlauf des Akteurs durchgeführt. Um die ausgewählten Aktionen zu bewerten, müssen wir einen direkten Durchlauf des ausgewählten Kritiker durchführen. Doch zunächst wollen wir einen Vektor der Zielbelohnungswerte vorbereiten. Die Aufgabe ist nicht trivial. Wir müssen irgendwie externe Belohnungen aus der Umgebungvorhersagen und sie mit intrinsischen Belohnungen ergänzen, um das Erkundungspotenzial des Akteurs zu stimulieren.
So seltsam es auch klingen mag, wir beginnen mit der internen Belohnung, die wir mit der NNM-Methode ermitteln werden. Wie bereits erwähnt, müssen wir, um die interne Belohnung zu bestimmen, eine kodierte Darstellung des nachfolgenden Zustands erhalten. Die historischen Daten des Folgezustands wurden bereits dem TargetState-Puffer hinzugefügt. Den Status des Prognosekontos erhalten wir mit der zuvor beschriebenen Funktion ForecastAccount.
Actor.getResults(rewards1); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,rewards1, prof_1l,Buffer[tr].States[i + 1].account[7]); TargetState.AddArray(forecast);
Wir verketten 2 Tensoren und führen einen direkten Durchlauf durch 2 Critics-Modelle durch, um die Aktionen des Actors und des Encoders zu bewerten und eine komprimierte Darstellung des vorhergesagten Zustands zu erhalten.
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Convolution.feedForward(GetPointer(TargetState))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Als Nächstes gehen wir zur Bildung des Belohnungsvektors über. Zur Erinnerung: Der Vektor target_reward enthält die Abweichung der Bewertung der Handlungen des Akteurs durch den Ziel-Kritiker von der tatsächlichen kumulativen Belohnung, die er bei der Interaktion mit der Umgebung erhalten hat. Im Wesentlichen stellt dieser Vektor die Auswirkungen politischer Veränderungen auf das Gesamtergebnis dar.
Wir verwenden die tatsächlichen Belohnungen der k-nächsten Nachbarn, bereinigt um den Abstand zwischen den Vektoren, als externe Zielbelohnung für die aktuelle Aktion des Akteurs. Dabei gehen wir davon aus, dass die Belohnung für eine Aktion umgekehrt proportional zur Entfernung zum entsprechenden Nachbarn ist.
Die Auswahl der k-nächsten Nachbarn und die Bildung der internen Belohnungen erfolgt in der Funktion KNNReward. Ich werde sie später noch ein wenig beschreiben.
Aber hier müssen wir noch auf einen weiteren Punkt achten. Wir haben die externe Belohnung in der Belohnungsmatrix der kodierten Zustände nur für den letzten Übergang ohne kumulative Summe gespeichert. Um vergleichbare Ziele zu erhalten, müssen wir daher zu target_reward die kumulativen Belohnungen addieren, die wir vor Abschluss des aktuellen Durchgangs aus dem Erfahrungswiedergabepuffer erhalten haben.
next.Assign(Buffer[tr].States[i + 1].rewards); target_reward+=next; Convolution.getResults(rewards1); target_reward=KNNReward(7,rewards1,state_embedding,rewards) + next * DiscFactor; if(forecast[3] == 0.0f && forecast[4] == 0.0f) target_reward[2] -= (Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance) / DiscFactor; critic.getResults(reward); reward += CAGrad(target_reward - reward);
Wir passen die Abweichung der Zielbelohnungswerte von der Einschätzung des Kritikers mit der Methode Conflict-Averse Gradient Descent an und addieren die resultierenden Werte zu den vom Kritiker vorhergesagten Werten. Auf diese Weise erhalten wir einen Vektor von Zielwerten, der unter Berücksichtigung der Belohnungszerlegung angepasst wird. Damit können wir zurückgehen und die Parameter des Akteurs aktualisieren. Zunächst deaktivieren wir den Trainingsmodus des Kritikers, um seine Parameter nicht an die angepassten Ziele anzupassen.
Result.AssignArray(reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
Nach erfolgreicher Aktualisierung der Parameter des Akteurs schalten wir das Kritiker-Modell wieder in den Trainingsmodus und aktualisieren die Zielmodelle der beiden Kritiker.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau);
Damit sind die Iterationen des Modelltrainingszyklus abgeschlossen. Alles, was wir tun müssen, ist, den Nutzer über durchgeführte Operationen zu informieren.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nachdem alle Iterationen der Trainingsschleife erfolgreich abgeschlossen wurden, wird der Kommentarbereich des Charts gelöscht. Senden Sie die Ergebnisse des Modelltrainings an das Protokoll und leiten Sie die Beendigung des EA ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Um die Funktionsweise des Algorithmus für das Modelltraining vollständig zu verstehen, werden wir uns nun die Funktion zur Erzeugung der Belohnung von KNNReward ansehen. Diese Funktion enthält die wichtigsten Merkmale der Methode der Nuklearnorm-Maximierung.
In ihren Parametern erhält die Funktion die Anzahl der analysierten nächsten Nachbarn, die Einbettung des analysierten Zustands, die Zustandseinbettungsmatrizen und die entsprechenden Belohnungen aus dem Erfahrungswiedergabepuffer.
vector<float> KNNReward(ulong k, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards ) { if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return vector<float>::Zeros(0); }
Im Hauptteil der Methode wird die Einbettungsdimension des aktuellen Zustands und der Zustände aus dem Erfahrungswiedergabepuffer überprüft. In der derzeitigen Implementierung mag diese Prüfung überflüssig erscheinen. Schließlich erhalten wir in diesem EA alle Einbettungen über einen Encoder. Aber es kann sehr nützlich sein, wenn Sie sich entscheiden, die Zustandseinbettung zu generieren, während Sie mit der Umgebung interagieren, und sie im Erfahrungswiedergabepuffer zu speichern, wie die Methode RE3 des ursprünglichen Artikel empfiehlt.
Als Nächstes werden wir ein wenig Vorarbeit leisten, indem wir einige Konstanten als lokale Variablen definieren. Falls erforderlich, reduzieren wir die Anzahl der nächsten Nachbarn auf die Anzahl der Zustände im Erfahrungswiedergabepuffer. Die Wahrscheinlichkeit, dass ein solcher Bedarf besteht, ist recht gering. Aber diese Funktion macht unseren Code vielseitiger und schützt ihn vor Laufzeitfehlern.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); k = MathMin(k,states); ulong rew_size = rewards.Cols(); matrix<float> temp = matrix<float>::Zeros(states,size);
Der nächste Schritt besteht darin, den Abstand zwischen dem Vektor des analysierten Zustands und den Zuständen im Erfahrungswiedergabepuffer zu bestimmen. Die ermittelten Werte werden im Abstandsvektor distance gespeichert.
for(ulong i = 0; i < size; i++) temp.Col(MathPow(state_embedding.Col(i) - embedding[i],2.0f),i); vector<float> distance = MathSqrt(temp.Sum(1));
Nun müssen wir die k-nächsten Nachbarn bestimmen. Wir werden ihre Parameter in den Matrizen k_embeding und k_rewards speichern. Beachten Sie, dass wir eine weitere Zeile in der Matrix k_embeding erstellen. Wir werden die Einbettung des analysierten Zustands in diesen schreiben.
Die Daten werden in einer Schleife entsprechend der Anzahl der gesuchten Vektoren in Matrizen übertragen. Im Schleifenkörper verwenden wir die Vektor-Operation ArgMin, um die Position des Minimalwertes im Abstandsvektor zu bestimmen. Das wird unser nächster Nachbar sein. Wir übertragen seine Daten in die entsprechenden Zeilen unserer Matrizen, während wir im Abstandsvektor die maximal mögliche Konstante an diese Position setzen. Wir haben also nach dem Kopieren der Daten den Mindestabstand in den Maximalwert geändert. Bei der nächsten Schleifeniteration liefert uns die Operation ArgMin die Position des nächsten Nachbarn.
Beachten Sie, dass wir bei der Übertragung des Belohnungsvektors seine Werte um einen Faktor anpassen, der umgekehrt zum Abstand zwischen den Zustandsvektoren ist.
matrix<float> k_rewards = matrix<float>::Zeros(k,rew_size); matrix<float> k_embeding = matrix<float>::Zeros(k + 1,size); for(ulong i = 0; i < k; i++) { ulong pos = distance.ArgMin(); k_rewards.Row(rewards.Row(pos) * (1 - MathLog(distance[pos] + 1)),i); k_embeding.Row(state_embedding.Row(pos),i); distance[pos] = FLT_MAX; } k_embeding.Row(embedding,k);
Dieser Algorithmus hat eine Reihe von Vorteilen:
- Die Anzahl der Iterationen hängt nicht von der Größe des Erfahrungswiedergabepuffers ab, was bei der Verwendung großer Datenbanken praktisch ist;
- Es besteht keine Notwendigkeit, Daten zu sortieren, was oft sehr viele Ressourcen erfordert;
- wir kopieren die Daten jedes Nachbarn nur einmal, wir kopieren keine anderen Daten.
Nach der Übertragung der Daten aller notwendigen Nachbarn fügen wir den aktuellen Zustand mit der letzten Zeile der Matrix k_embedding zusammen.
Als Nächstes müssen wir die Singulärwerte der Matrix finden, um die Nuklearnorm der Matrix k_embedingten zu bestimmen und die NNM-Methode zu implementieren. Zu diesem Zweck verwenden wir die Matrix-Operation SVD.
matrix<float> U,V; vector<float> S; k_embeding.SVD(U,V,S);
Nun werden die Singulärwerte der Matrix im S-Vektor gespeichert. Um die Nuklearnorm zu bestimmen, müssen wir nur ihre Werte zusammenfassen. Zunächst wird jedoch ein Vektor der externen Belohnungen als Vektor der Durchschnittswerte der Spalten der Matrix k_rewards der ausgewählten Belohnungen erstellt.
Wir definieren die interne Belohnung mit der NNM-Methode als das Verhältnis der Nuklearnorm der Zustandseinbettungsmatrix zu ihrer Frobenius-Norm und passen sie durch den Skalierungsfaktor der Nuklearnorm an. Wir schreiben den resultierenden Wert in das entsprechende Element des Belohnungs-Vektors und geben den Belohnungs-Vektor an das aufrufende Programm zurück.
vector<float> result = k_rewards.Mean(0); result[rew_size - 1] = S.Sum() / (MathSqrt(MathPow(k_embeding,2.0f).Sum() * MathMax(k + 1,size))); //--- return (result); }
Damit ist unsere Arbeit zur Implementierung der Methode der Nuklearnorm-Maximierung mit MQL5 abgeschlossen. Der vollständige Code aller in diesem Artikel verwendeten Programme ist im Anhang verfügbar.
3. Test
Wir haben viel Arbeit investiert, um die Integration der Methode der Nuklearnorm-Maximierung in den RE3-Algorithmus zu implementieren. Jetzt ist es Zeit für einen Test. Wie immer werden die Modelle auf EURUSD H1 für 1-5 Monate des Jahres 2023 trainiert und getestet. Die Parameter aller Indikatoren werden standardmäßig verwendet.
Ich habe bereits die Eigenschaften der Methode und das Fehlen von generierten Zuständen im Erfahrungswiedergabepuffer bei der Erstellung des „...\NNM\Study.mq5“ Trainings-EA erwähnt. Dann beschlossen wir, die Anzahl der Iterationen eines Trainingszyklus zu reduzieren. Das hinterlässt natürlich Spuren in der gesamten Ausbildung.
Wir haben den Puffer für die Wiederholung des Erlebnisses als Ganzes nicht verringert. Gleichzeitig besteht jedoch keine Notwendigkeit, eine Datenbank mit 1,3 Mio. Zuständen zu verwenden, um 10.000 Iterationen zur Aktualisierung der Modellparameter durchzuführen. Mit einer größeren Datenbank können wir das Modell natürlich besser abstimmen. Aber wenn es mehr als 100 Zustände pro Aktualisierungsiteration gibt, sind wir nicht in der Lage, sie alle durchzuarbeiten. Daher werden wir den Erfahrungswiedergabepuffer nach und nach füllen. In der ersten Iteration starten wir die Trainingsdatenerfassung EA für nur 50 Durchgänge. Damit haben wir bereits etwa 120K Zustände für das Training von Modellen für den angegebenen historischen Zeitraum.
Nach der ersten Iteration des Modelltrainings ergänzen wir die Beispieldatenbank um weitere 50 Durchläufe. So füllen wir den Erfahrungswiedergabepuffer nach und nach mit neuen Zuständen, die den Handlungen des Akteurs im Rahmen der trainierten Politik entsprechen.
Dieser Ansatz erhöht den manuellen Arbeitsaufwand für den Start von EAs erheblich. Dies ermöglicht es uns jedoch, die Datenbank mit den Beispielen relativ aktuell zu halten. Die erzeugte interne Belohnung wird den Akteur dazu veranlassen, neue Umgebungszustände zu erkunden.
Beim Training der Modelle ist es uns gelungen, ein Modell zu erhalten, das in der Lage ist, aus der Trainingsstichprobe einen Gewinn zu erzielen und das erworbene Wissen für nachfolgende Umgebungszustände zu generalisieren. Im Strategietester konnte das von uns trainierte Modell beispielsweise innerhalb eines Monats nach der Trainingsstichprobe einen Gewinn von 1 % erzielen. Während des Testzeitraums führte das Modell 133 Handelsgeschäfte durch, von denen 42 % mit Gewinn abgeschlossen wurden. Der maximale Gewinn pro Handel ist fast 2-mal höher als der maximale Verlust pro Handel. Der durchschnittliche Gewinn pro Handel ist 40 % höher als der durchschnittliche Verlust. All dies zusammen ermöglichte es uns, einen Gewinnfaktor von 1,02 zu erhalten.


Schlussfolgerung
In diesem Artikel habe ich einen neuen Ansatz zur Förderung der Exploration beim Verstärkungslernen vorgestellt, der auf der Maximierung von Nuklearnormen basiert. Mit dieser Methode können wir die Neuartigkeit der Umgebungsforschung effektiv bewerten, wobei historische Informationen berücksichtigt werden und eine hohe Toleranz gegenüber Lärm und Emissionen gewährleistet ist.
Im praktischen Teil des Artikels haben wir die Methode der Nuklearnorm-Maximierung in den RE3-Algorithmus integriert. Wir haben das Modell trainiert und mit dem MetaTrader 5 Strategie-Tester getestet. Anhand der Testergebnisse können wir sagen, dass die vorgeschlagene Methode das Verhalten des Akteurs im Vergleich zu den Ergebnissen des Trainings des Modells mit der reinen Methode RE3 erheblich diversifiziert hat. Am Ende war der Handel jedoch eher chaotisch. Dies könnte auf die Notwendigkeit hinweisen, das Gleichgewicht zwischen Erkundung und Ausbeutung durch die Einführung zusätzlicher Einflussfaktoren in die Belohnungsfunktion zu verbessern.
Links
- Nuclear Norm Maximization Based Curiosity-Driven Learning
- Neuronale Netze leicht gemacht (Teil 53): Aufteilung der Belohnung
- Neuronale Netze leicht gemacht (Teil 54): Einsatz von Random Encoder für eine effiziente Forschung (RE3)
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mq5 | Expert Advisor | Trainings-EA des Agenten |
| 3 | Test.mq5 | Expert Advisor | Test-EA des Modells |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 6 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13242
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.