
Redes neurais de maneira fácil (Parte 73): AutoBots para previsão de movimentos de preço

Introdução
A previsão eficaz do movimento dos pares de moedas é um aspecto fundamental da gestão segura das operações de trading. Neste contexto, o foco está no o desenvolvimento de modelos eficientes capazes de aproximar com precisão a distribuição conjunta das informações contextuais e temporais necessárias para a tomada de decisões de trading. Para resolver tais tarefas, proponho que você conheça o método "Latent Variable Sequential Set Transformers" (AutoBots), apresentado no artigo "Latent Variable Sequential Set Transformers For Joint Multi-Agent Motion Prediction". O método proposto é baseado na arquitetura Encoder-Decoder, ou codificador-decodificador, e foi desenvolvido para resolver problemas de gestão segura de sistemas robóticos. Ele permite gerar sequências de trajetórias para múltiplos agentes, concordantes com o cenário. Os "AutoBots" podem prever a trajetória de um único agente ego ou a distribuição de trajetórias futuras para todos os agentes no cenário. No nosso caso, tentaremos aplicar o modelo proposto para gerar sequências de movimentos de preços de pares de moedas, concordantes com a dinâmica do mercado.
1. Algoritmos “AutoBots”
"Latent Variable Sequential Set Transformers" (AutoBots) é um método baseado na arquitetura Encoder-Decoder que processa sequências de conjuntos. O AutoBot recebe como entrada uma sequência de conjuntos X1:t = (X1, …, Xt), que na tarefa de previsão de movimento pode ser considerada como o estado do ambiente durante t passos de tempo. Cada conjunto contém M elementos (agentes, instrumentos financeiros e/ou indicadores) com K atributos (características). Para processar a informação social e temporal no Encoder, são aplicadas duas transformações.
Primeiramente, o Encoder AutoBots introduz a informação temporal na sequência de conjuntos utilizando a função de codificação posicional senoidal PE(.). Nesta etapa, os dados são analisados como uma coleção de matrizes, {X0, …, XM}, que descrevem a evolução dos agentes ao longo do tempo. O Encoder processa as relações temporais entre os conjuntos utilizando um bloco de atenção multi-cabeças.
Em seguida, são processadas fatias temporais S, extraindo conjuntos de estados dos agentes Sꚍ em algum momento ꚍ e processando-os novamente no bloco de atenção multi-cabeças.
Estas duas operações se repetem Lenc vezes para obter o tensor contextual C de dimensão {dK, M, t}, que resume a representação final de todo o cenário dos dados brutos, onde t é o número de passos de tempo no cenário dos dados brutos.
O objetivo do Decoder é gerar previsões concordantes no tempo e socialmente no contexto das distribuições multimodais dos dados. Para gerar c diferentes previsões para o mesmo cenário dos dados brutos, o Decoder AutoBot usa c matrizes de parâmetros iniciais treináveis Qi de dimensão {dK, T}, onde T é o horizonte de planejamento.
Intuitivamente, cada matriz de parâmetros iniciais treináveis corresponde à configuração de uma variável latente discreta no AutoBot. Cada matriz treinável Qi é então repetida M vezes ao longo da dimensão do agente para obter o tensor de entrada Q0i de dimensão {dK, M, T}.
O algoritmo prevê a possibilidade de usar informações contextuais adicionais, que são codificadas usando uma rede neural convolucional para criar um vetor de características mi. Para fornecer informações contextuais a todos os passos de tempo futuros e a todos os elementos do conjunto, propõe-se copiar esse vetor nas dimensões M e T, criando o tensor Mi de dimensão {dK, M, T}. Cada tensor Q0i é então combinado com Mi ao longo da dimensão dK. Esse tensor é então processado usando uma camada densamente conectada por linha (rFFN) para obter o tensor H de dimensão {dK, M, T}.
A decodificação começa processando a dimensão temporal, condicionada à saída do Encoder (C), assim como os parâmetros iniciais codificados e as informações do ambiente (H). O Decoder processa cada agente em H separadamente, usando um bloco de atenção multi-cabeças. Dessa forma, obtemos um tensor que codifica a evolução temporal futura de cada elemento do conjunto de forma independente.
Para garantir a consistência social do cenário futuro entre os elementos do conjunto, processamos cada fatia temporal H0, extraindo conjuntos de estados dos agentes H0ꚍ em algum momento futuro ꚍ. Cada elemento da sequência é processado por um bloco de atenção multi-cabeças. Essencialmente, esse bloco realiza a atenção em cada passo de tempo entre todos os elementos do conjunto.
Essas duas operações se repetem Ldec vezes para criar o tensor de saída final para o agente i. O processo de decodificação se repete c vezes com diferentes parâmetros iniciais treináveis Qi e informações contextuais adicionais mi. A saída do decodificador é um tensor O de dimensão {dK, M, T, c}, que pode ser processado usando uma rede neural ф(.), para obter a representação de saída desejada.
Uma das principais contribuições que tornam o resultado e o tempo de treinamento do AutoBot mais rápidos em comparação com outros métodos é o uso dos parâmetros iniciais Q do decodificador. Esses parâmetros servem a dois propósitos. Primeiro, eles consideram a diversidade na previsão do futuro, onde cada matriz Qi corresponde a uma configuração de uma variável latente discreta. Segundo, eles aceleram o AutoBot, permitindo que ele realize a inferência em todo o cenário com uma única passagem pelo Decoder, sem seleção sequencial.
A visualização autoral do método é apresentada abaixo.

2. Implementação usando MQL5
Acima, conhecemos os aspectos teóricos do método "Latent Variable Sequential Set Transformers" (AutoBots). E agora passamos para a parte prática do nosso artigo, onde implementamos nossa visão do método proposto usando MQL5.
Primeiro, devemos prestar atenção aos seguintes 2 pontos.
Primeiro, o método prevê a codificação posicional. No entanto, isso não é algo novo e uma codificação posicional semelhante é prevista no método básico Self-Attention. Mas a questão é que, anteriormente, ao estudar métodos de atenção, a codificação posicional dos dados brutos era realizada do lado do programa principal. No entanto, no AutoBot, a codificação posicional é realizada dentro do modelo após o pré-processamento e a criação do embedding dos dados brutos. Claro, poderíamos ter externalizado o pré-processamento dos dados em um modelo separado. E realizar a codificação posicional do lado do programa principal antes de passar os dados para o Encoder. Mas tal opção de implementação exigiria operações adicionais de transferência de dados entre a memória de contexto OpenCL e o programa principal. Além disso, essa implementação limita o grau de liberdade com variações no uso de diferentes arquiteturas de modelos dentro de um programa sem fazer ajustes adicionais no código. Desse modo, é preferível para nós organizar todo o processo dentro de um único modelo.
O segundo ponto, tanto no Encoder quanto no Decoder pelo método "Latent Variable Sequential Set Transformers" (AutoBots), prevê o uso alternado de blocos de atenção no contexto de diferentes dimensões dos tensores analisados (análise das dependências temporais e sociais). Para mudar a dimensão do foco de atenção, precisamos fazer alterações na camada de atenção multi-cabeças CNeuronMLMHAttentionOCL ou realizar a transposição dos tensores. A transposição dos tensores aqui parece uma tarefa mais simples. E novamente, paramos nos mesmos pontos discutidos para a codificação posicional. Não vamos repeti-los, mas chegamos à necessidade de criar uma camada de transposição de tensores do lado do contexto OpenCL.
2.1 Camada de codificação posicional
Vamos começar o trabalho com a camada de codificação posicional. A classe da camada de codificação posicional CNeuronPositionEncoder será herdada da classe base de camadas neurais em nossa biblioteca CNeuronBaseOCL e vamos redefinir o conjunto básico de métodos:
- Init — inicialização
- feedForward — propagação para frente
- calcInputGradients — distribuição do gradiente de erro para a camada anterior
- updateInputWeights — atualização dos coeficientes de peso
- Save e Load — operações com arquivos.
class CNeuronPositionEncoder : public CNeuronBaseOCL { protected: CBufferFloat PositionEncoder; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronPositionEncoder(void) {}; ~CNeuronPositionEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) { return true; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronPEOCL; } virtual void SetOpenCL(COpenCLMy *obj); };
O construtor e o destrutor da classe serão deixados vazios.
E antes de prosseguirmos para discutir os métodos, vamos discutir um pouco sobre a funcionalidade e a lógica de construção da classe. No algoritmo Transformador, é prevista a codificação posicional adicionando harmônicas senoidais aos dados brutos usando funções:
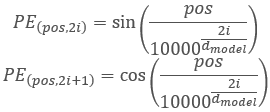
Aqui, é importante notar que a codificação posicional dos elementos na sequência analisada não está relacionada com as harmônicas de marcas temporais que criamos no lado do programa principal. O processo é semelhante, mas carrega um significado diferente.
É evidente que o tamanho da sequência analisada no modelo será sempre constante. Portanto, podemos simplesmente criar e preencher o buffer de harmônicas PositionEncoder no método de inicialização da classe Init. E durante a propagação para frente no método feedForward, apenas adicionaremos os valores das harmônicas aos dados brutos.
Entendemos a propagação para frente. E quanto à propagação reversa? Na propagação para frente, somamos dois tensores. Portanto, o gradiente de erro na propagação reversa é distribuído uniformemente ou completamente transferido para ambos os termos. O tensor de harmônicas de codificação posicional, neste caso, é uma constante. Então, todo o gradiente de erro será transferido para a camada anterior.
Quanto aos coeficientes de peso treináveis, simplesmente não existem na camada de codificação posicional. Consequentemente, o método updateInputWeights é redefinido apenas para compatibilidade de classes e sempre retorna true.
Com a lógica entendida, vamos olhar para a implementação. Como mencionado acima, a inicialização da classe é realizada no método Init. Nos parâmetros, o método recebe:
- numOutputs — número de conexões com a camada subsequente
- open_cl — ponteiro para o contexto OpenCL
- count — número de elementos na sequência
- window — número de parâmetros para cada elemento da sequência
- optimization_type — método de otimização dos parâmetros.
bool CNeuronPositionEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window, optimization_type, batch)) return false;
No corpo do método, chamamos imediatamente o método de inicialização da classe pai, no qual a funcionalidade básica é implementada. E verificamos o resultado das operações.
Em seguida, criaremos as harmônicas de codificação posicional. Para isso, utilizaremos operações matriciais. Primeiro, preparamos a matriz.
matrix<float> pe = matrix<float>::Zeros(count, window);
Criamos um vetor de numeração das posições dos elementos no tensor e um multiplicador constante, que é usado para todos os elementos.
vector<float> position = vector<float>::Ones(count); position = position.CumSum() - 1; float multipl = -MathLog(10000.0f) / window;
E como as fórmulas de codificação posicional preveem a alternância de seno e cosseno para as harmônicas, preencheremos a matriz em um loop com passo 2. No corpo do loop, primeiro calculamos o vetor de valores posicionais. Depois, nas colunas pares, adicionamos o seno do vetor de valores posicionais. Nas colunas ímpares, escrevemos o cosseno do mesmo vetor.
for(uint i = 0; i < window; i += 2) { vector<float> temp = position * MathExp(i * multipl); pe.Col(MathSin(temp), i); if((i + 1) < window) pe.Col(MathCos(temp), i + 1); }
As harmônicas posicionais obtidas são copiadas para o buffer de dados e transferidas para o contexto OpenCL.
if(!PositionEncoder.AssignArray(pe)) return false; //--- return PositionEncoder.BufferCreate(open_cl); }
Após a inicialização da classe CNeuronPositionEncoder, passamos para a propagação para frente no método feedForward. Como você pode notar, não criamos o kernel de criação do processo no lado do contexto OpenCL e passamos diretamente para a implementação do método. O fato é que o kernel de soma de duas matrizes SumMatrix já foi criado anteriormente durante a implementação do método Self-Attention.
Como de costume, o método de propagação para frente feedForward recebe como parâmetros um ponteiro para a camada neural anterior, que para nós são os dados brutos. No corpo do método, verificamos o ponteiro recebido.
bool CNeuronPositionEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!Gradient || Gradient != NeuronOCL.getGradient()) { if(!!Gradient) delete Gradient; Gradient = NeuronOCL.getGradient(); }
E imediatamente substituímos o ponteiro pelo buffer de gradientes de erro. Este método simples nos permitirá, na propagação reversa, transferir diretamente o gradiente de erro da camada subsequente para a anterior, evitando a cópia excessiva de dados em nossa camada de codificação posicional.
Em seguida, passamos os dados necessários para os parâmetros do kernel de soma dos vetores.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = Neurons(); if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix1, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix2, PositionEncoder.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix_out, Output.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_dimension, (int)1)) return false; if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_multiplyer, 1.0f)) return false;
E colocamos o kernel na fila de execução.
if(!OpenCL.Execute(def_k_MatrixSum, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel MatrixSum: %d", GetLastError()); return false; } //--- return true; }
Verificamos os resultados das operações. E assim podemos considerar concluída a configuração do processo de propagação para frente.
Como mencionado anteriormente, a camada de codificação posicional não contém parâmetros treináveis. Portanto, o método updateInputWeights é "vazio" e sempre retorna true. Substituindo o ponteiro do buffer de gradiente de erro, excluímos a camada de codificação posicional completamente do processo de distribuição do gradiente de erro. Consequentemente, o método calcInputGradients, assim como o método de atualização de parâmetros, permanece "vazio" e é redefinido apenas para fins de compatibilidade.
Com isso, terminamos a revisão dos métodos da camada de codificação posicional. O código completo da classe pode ser encontrado no anexo do arquivo "...\Experts\NeuroNet_DNG\NeuroNet.mqh", que contém todas as classes da nossa biblioteca.
2.2 Transposição de tensores
A próxima camada que concordamos em criar é a camada de transposição de tensores CNeuronTransposeOCL. Assim como na camada de codificação posicional, ao criar a classe, herdamos da classe base de camadas neurais CNeuronBaseOCL. A lista de classes redefinidas permanece padrão. No entanto, adicionaremos 2 variáveis na classe para armazenar os tamanhos da matriz a ser transposta.
class CNeuronTransposeOCL : public CNeuronBaseOCL { protected: uint iWindow; uint iCount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronTransposeOCL(void) {}; ~CNeuronTransposeOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronTransposeOCL; } };
O construtor e o destrutor da classe permanecem vazios. E o método de inicialização da classe Init é o mais simplificado possível. No corpo do método, chamamos apenas o método de mesmo nome da classe pai e salvamos, nos parâmetros, os tamanhos da matriz a ser transposta. No entanto, não esquecemos de verificar o resultado das operações.
bool CNeuronTransposeOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window, optimization_type, batch)) return false; //--- iWindow = window; iCount = count; //--- return true; }
Para o método de propagação para frente, primeiro precisamos criar o tensor de transposição das matrizes Transpose. Nos parâmetros do kernel, passaremos apenas ponteiros para os buffers das matrizes de dados brutos e dos resultados. Os tamanhos das matrizes são obtidos do espaço bidimensional das tarefas.
__kernel void Transpose(__global float *matrix_in, ///<[in] Input matrix __global float *matrix_out ///<[out] Output matrix ) { const int r = get_global_id(0); const int c = get_global_id(1); const int rows = get_global_size(0); const int cols = get_global_size(1); //--- matrix_out[c * rows + r] = matrix_in[r * cols + c]; }
O algoritmo do kernel é bastante simples. Apenas determinamos as posições dos elementos nas matrizes de dados brutos e resultados. Depois, realizamos a transferência dos valores.
A chamada do kernel é realizada a partir do método de propagação para frente feedForward. O algoritmo de chamada do kernel é semelhante ao mencionado anteriormente. Primeiro, determinamos o espaço das tarefas, desta vez no espaço bidimensional (número de elementos na sequência * número de características em cada elemento da sequência). Em seguida, passamos os ponteiros para os buffers de dados nos parâmetros do kernel e o colocamos na fila de execução. Ao mesmo tempo, não devemos esquecer de verificar o resultado das operações.
bool CNeuronTransposeOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {iCount, iWindow}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, Output.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel Transpose: %d -> %s", GetLastError(), error); return false; } //--- return true; }
No processo de propagação reversa, precisaremos passar o gradiente de erro na direção inversa. E, curiosamente, teremos que transpor a matriz de gradientes de erro. Portanto, usaremos o mesmo kernel. Apenas inverteremos a dimensão do espaço de tarefas e apontaremos os ponteiros para os buffers dos gradientes de erro.
bool CNeuronTransposeOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {iWindow, iCount}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, NeuronOCL.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, Gradient.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel Transpose: %d -> %s", GetLastError(), error); return false; } //--- return true; }
Como pode ser observado, a classe CNeuronTransposeOCL não contém parâmetros treináveis, portanto, o método updateInputWeights sempre retorna true.
2.3 Arquitetura do "AutoBot"
Acima, criamos duas novas camadas bastante universais. E agora podemos passar diretamente para a implementação do método "Latent Variable Sequential Set Transformers" (AutoBots). Primeiro, criaremos a arquitetura do modelo de previsão de movimento de preços no método CreateTrajNetDescriptions. Para reduzir operações do lado do programa principal, foi decidido realizar o trabalho do AutoBot dentro de um único modelo. Para sua descrição, um ponteiro para um array dinâmico é passado como parâmetro para o método. No corpo do método, verificamos o ponteiro recebido e, se necessário, criamos uma nova instância do objeto array dinâmico.
bool CreateTrajNetDescriptions(CArrayObj *autobot) { //--- CLayerDescription *descr; //--- if(!autobot) { autobot = new CArrayObj(); if(!autobot) return false; }
O tensor de dados brutos é alimentado no modelo. Como antes, para otimizar cálculos no processo de execução e treinamento do modelo, apenas a descrição da última barra é usada como dados brutos. Todo o histórico é acumulado dentro do buffer da camada de Embedding.
//--- Encoder autobot.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
O pré-processamento inicial dos dados brutos é realizado na camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000,GPTBars); descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Depois, geramos o embedding do estado e o adicionamos ao buffer de dados históricos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!autobot.Add(descr)) { delete descr; return false; }
Observe que, neste caso, criamos o embedding de apenas uma entidade que descreve o estado atual do ambiente. E a funcionalidade dessa camada é semelhante à de uma camada totalmente conectada. No entanto, o uso da camada CNeuronEmbeddingOCL é devido à necessidade de criar um buffer de sequência histórica de embeddings. No entanto, o algoritmo não nos limita a analisar apenas uma barra de um instrumento. Podemos analisar várias velas, bem como vários instrumentos. Mas, nesse caso, precisamos ajustar o array de embeddings.
Em seguida, ao longo de toda a sequência histórica de embeddings, adicionamos o tensor de codificação posicional.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; }
E realizamos o primeiro bloco de atenção, para avaliar as dependências entre os cenários ao longo do tempo.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Depois, precisamos analisar as dependências entre as características individuais. Para isso, trans o tensor e aplicamos o bloco de atenção ao tensor transposto.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Observe que, após a transposição, também alteramos as dimensões no bloco de atenção de modo que correspondam ao tensor transposto.
Transpomos o tensor novamente para retornar às dimensões originais. E repetimos os blocos de atenção do Encoder novamente.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_wout; descr.window = prev_count; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Na saída do Encoder, obtemos o contexto que descreve o estado atual do ambiente. E precisamos passá-lo para o Decoder, para prever os parâmetros futuros do movimento de preços na profundidade de planejamento necessária. No entanto, o algoritmo "Latent Variable Sequential Set Transformers" prevê a adição de parâmetros iniciais treináveis Q neste estágio. Mas, na implementação atual de nossa biblioteca, apenas os coeficientes de peso das camadas neurais são treinados. Para não complicar o processo existente, foi tomada uma decisão talvez não padrão, mas muito eficaz. Nesse caso, usaremos a camada de concatenação de tensores CNeuronConcatenate. A primeira parte da camada substituirá a camada totalmente conectada para alterar a representação do contexto do estado atual do ambiente, obtido do Encoder. E os coeficientes de peso do segundo bloco atuarão como parâmetros iniciais treináveis Q. Para não distorcer os valores dos parâmetros Q, na segunda entrada, passaremos um vetor preenchido com "1".
Na saída da camada, esperamos obter um tensor de embedding dos estados na profundidade de planejamento definida.
//--- Decoder //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = PrecoderBars * EmbeddingSize; descr.window = prev_count * prev_wout; descr.step = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Como no Encoder, primeiro analisamos as dependências entre os estados ao longo do tempo.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = PrecoderBars; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Depois, transpomos o tensor e analisamos a dependência contextual entre os diferentes atributos.
//--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Em seguida, repetimos as operações do Decoder.
//--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = prev_count * prev_wout; descr.window = descr.count; descr.step = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 16 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
Observe que o uso de um vetor constante de "1" como segunda entrada do modelo nos permite repetir a camada de concatenação várias vezes no Decoder. Nesse ponto, os parâmetros de peso treináveis atuam como parâmetros Q, únicos para cada camada.
No final do Decoder, usamos uma camada totalmente conectada, que nos permite apresentar os dados no formato necessário.
//--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = PrecoderBars * 3; descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 Treinamento do "AutoBot"
Acima está apresentada a arquitetura do modelo AutoBot para prever os parâmetros do movimento de preços futuro na profundidade de planejamento definida. O uso dos resultados do trabalho do modelo treinado é limitado apenas pela sua imaginação. Tendo a previsão do movimento de preços subsequente, você pode construir um EA clássico para realizar operações de acordo com a previsão obtida. Ou você pode passá-la para um modelo de Ator para gerar diretamente recomendações de ação. No meu trabalho, usei a segunda opção. A arquitetura dos modelos de Ator e de definição de objetivos foi tomada de um artigo anterior artigo. As alterações afetaram apenas a camada de dados brutos para corresponder aos resultados do modelo AutoBot apresentado acima. Mas não vamos nos deter sobre elas agora. Você pode consultá-las no anexo (método CreateDescriptions). Lá, você também pode ver as correções pontuais no EA de interação com o ambiente "...\Experts\AutoBots\Research.mq5". Agora, passamos ao processo de treinamento do modelo de previsão de movimento de preços futuro, que está elaborado no EA "...\Experts\AutoBots\StudyTraj.mq5".
Neste EA, treinamos apenas um modelo.
CNet Autobot;
No método de inicialização do EA OnInit, primeiro carregamos o conjunto de dados de treinamento.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Depois, tentamos carregar o modelo pré-treinado do AutoBot e, em caso de erro, criamos um novo modelo, inicializado com parâmetros aleatórios.
//--- load models float temp; if(!Autobot.Load(FileName + "Traj.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *autobot = new CArrayObj(); if(!CreateTrajNetDescriptions(autobot)) { delete autobot; return INIT_FAILED; } if(!Autobot.Create(autobot)) { delete autobot; return INIT_FAILED; } delete autobot; //--- }
Em seguida, verificamos a arquitetura do modelo para garantir que atenda aos critérios principais.
Autobot.getResults(Result); if(Result.Total() != PrecoderBars * 3) { PrintFormat("The scope of the Autobot does not match the precoder bars (%d <> %d)", PrecoderBars * 3, Result.Total()); return INIT_FAILED; } //--- Autobot.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Autobot doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Criamos os buffers de dados necessários.
OpenCL = Autobot.GetOpenCL(); if(!Ones.BufferInit(EmbeddingSize, 1) || !Gradient.BufferInit(EmbeddingSize, 0) || !Ones.BufferCreate(OpenCL) || !Gradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; } State.BufferInit(HistoryBars * BarDescr, 0);
E geramos um evento de usuário para iniciar o treinamento do modelo.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
No método de desinicialização do EA, salvamos o modelo treinado e removemos os objetos dinâmicos da memória.
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) Autobot.Save(FileName + "Traj.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; delete OpenCL; }
O treinamento do modelo, como de costume, é realizado no método Train. No corpo do método, primeiro determinamos as probabilidades de escolha das trajetórias, com base em sua rentabilidade.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Depois, declaramos e inicializamos variáveis locais.
vector<float> result, target, inp; matrix<float> targets; matrix<float> delta; STE = vector<float>::Zeros(PrecoderBars * 3); int std_count = 0; int batch = GPTBars + 50; bool Stop = false; uint ticks = GetTickCount(); ulong size = HistoryBars * BarDescr;
Como sempre, ao treinar o modelo de trajetórias, limitamo-nos apenas às abordagens propostas pelos autores do método Latent Variable Sequential Set Transformers. Em particular, focamos o treinamento nas máximas divergências, como no método CFPI. Além disso, para a estabilidade do modelo em um mercado estocástico, "expandimos" o espaço da amostra de treinamento adicionando ruído aos dados brutos, conforme sugerido no método SSWNP. Para implementar essas abordagens, entre as variáveis locais, declaramos uma matriz de mudanças de parâmetros delta e um vetor de erros quadráticos médios STE.
Mas voltemos ao algoritmo do nosso método. Na arquitetura do nosso "AutoBot" de previsão de trajetória, usamos uma camada de Embedding com um buffer embutido para acumulação de dados históricos, o que nos permite não recalcular representações de dados repetidos durante a execução do modelo. No entanto, essa abordagem também exige a manutenção da sequência histórica ao fornecer dados brutos durante o treinamento. Portanto, para treinar o modelo, utilizamos um sistema de loops aninhados. O loop externo define o número de iterações de treinamento.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
No corpo do loop, amostramos uma trajetória do buffer de reprodução de experiência considerando as probabilidades calculadas anteriormente. Depois, determinamos aleatoriamente o estado inicial do treinamento na trajetória selecionada.
Neste ponto, também determinamos o estado final do pacote de treinamento. Limpamos os buffers de acumulação de histórico do nosso AutoBot. E preparamos a matriz para registrar as mudanças de parâmetros.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); Autobot.Clear(); delta = matrix<float>::Zeros(end - state - 1, Buffer[tr].States[state].state.Size());
Em seguida, criamos um loop interno para trabalhar com trajetórias limpas, no qual preenchemos o buffer de dados brutos.
for(int i = state; i < end; i++) { inp.Assign(Buffer[tr].States[i].state); State.AssignArray(inp);
E calculamos a divergência nos valores dos parâmetros entre dois estados subsequentes do ambiente.
if(i < (end - 1)) delta.Row(inp, row); if(row > 0) delta.Row(delta.Row(row - 1) - inp, row - 1);
Após realizar o trabalho preparatório, executamos a propagação para frente do nosso modelo.
if(!Autobot.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(Ones))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Observe que, como o segundo fluxo de dados brutos, usamos um buffer preenchido com valores constantes Ones, conforme discutido na descrição da arquitetura do modelo. Esse buffer foi preparado durante a inicialização do EA e não é alterado durante todo o processo de treinamento do modelo.
Após a propagação para frente, segue-se a propagação reversa com a atualização dos parâmetros do modelo. Mas, antes de chamá-la, precisamos preparar os valores-alvo. Para isso, "olhamos um pouco para o futuro", o que a amostra de treinamento nos permite fazer durante o processo de treinamento. Do buffer de reprodução de experiência, extraímos a descrição dos estados futuros do ambiente na profundidade de planejamento definida. E copiamos os dados necessários para o vetor de valores-alvo target.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
Em seguida, carregamos os resultados da propagação para frente do AutoBot e determinamos a necessidade de realizar a propagação reversa com base na magnitude do erro de previsão no estado atual.
Autobot.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; vector<float> check = MathAbs(error) - STE * STE_Multiplier;
A propagação reversa é realizada se houver um erro de previsão de pelo menos um dos parâmetros acima do valor limite, que está relacionado ao coeficiente do erro quadrático médio da previsão do modelo.
if(check.Max() > 0) { //--- Result.AssignArray(target); if(!Autobot.backProp(Result, GetPointer(Ones), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Em seguida, informamos o usuário sobre o progresso do processo de treinamento e passamos para a próxima iteração do processamento do pacote de trajetória limpa.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Autobot", percent, Autobot.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Após a conclusão do pacote de treinamento da trajetória limpa, passamos para o segundo bloco — o modelo de trajetória com dados adicionados com ruído. Aqui, primeiro determinamos os parâmetros de reparametrização do ruído.
//--- With noise vector<float> std_delta = delta.Std(0) * STD_Delta_Multiplier; vector<float> mean_delta = delta.Mean(0);
E preparamos uma matriz e um vetor para trabalhar com o ruído.
ulong inp_total = std_delta.Size(); vector<float> noise = vector<float>::Zeros(inp_total); double ar_noise[];
Também amostramos uma trajetória da amostra de treinamento. Determinamos os estados inicial e final do pacote de treinamento nela. E limpamos os buffers históricos do nosso modelo.
tr = SampleTrajectory(probability); state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; } end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); Autobot.Clear();
Depois, criamos o segundo loop aninhado.
for(int i = state; i < end; i++) { if(!Math::MathRandomNormal(0, 1, (int)inp_total, ar_noise)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } noise.Assign(ar_noise); noise = mean_delta + std_delta * noise;
No corpo do loop, geramos ruído e realizamos sua reparametrização usando os parâmetros de distribuição calculados anteriormente.
O ruído gerado é adicionado aos dados brutos e realizamos a propagação para frente do nosso modelo.
inp.Assign(Buffer[tr].States[i].state); inp = inp + noise; State.AssignArray(inp); //--- if(!Autobot.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(Ones))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
O algoritmo de realização da propagação reversa, incluindo a preparação dos dados-alvo e a determinação da necessidade de sua execução, copiamos integralmente do bloco de trabalho com a trajetória limpa.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0); Autobot.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(target); if(!Autobot.backProp(Result, GetPointer(Ones), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Por fim, apenas informamos o usuário sobre o progresso do processo de treinamento e passamos para a próxima iteração do loop.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter + 0.5) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Autobot", percent, Autobot.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após a conclusão de todas as iterações do sistema de loops de treinamento do modelo, limpamos o campo de comentários no gráfico. Registramos os resultados do treinamento no log e encerramos o EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Autobot", Autobot.getRecentAverageError()); ExpertRemove(); //--- }
Com isso, concluímos a revisão dos métodos do EA de treinamento do modelo de trajetória "...\Experts\AutoBots\StudyTraj.mq5". Você pode conferir o código completo no anexo. Lá você também encontrará os EAs de treinamento da política do Ator "...\Experts\AutoBots\Study.mq5" e de teste do modelo treinado em dados históricos "...\Experts\AutoBots\Test.mq5". Nos EAs mencionados, limitamo-nos a ajustes pontuais na exploração do modelo AutoBot, que você pode revisar por conta própria. Agora passamos para o teste do trabalho realizado.
3. Teste
Acima, realizamos um trabalho meticuloso na implementação das abordagens do método "Latent Variable Sequential Set Transformers" (AutoBots) usando MQL5. E chegou a hora de avaliar os resultados práticos do nosso esforço. Como sempre, para treinar nosso modelo, utilizamos dados históricos dos primeiros 7 meses de 2023 do instrumento EURUSD, no time frame H1. O teste da política do Ator treinado é realizado em dados históricos de agosto de 2023. Como pode ser observado, o período de teste segue imediatamente o período de treinamento, garantindo a máxima compatibilidade entre os dados da amostra de treinamento e da amostra de teste.
Os parâmetros de todos os indicadores usados para analisar a situação do mercado durante o treinamento e teste não foram otimizados. Valores padrão foram estabelecidos para eles.
Como você pôde perceber, a composição e a estrutura dos dados brutos e dos resultados do nosso modelo de previsão de trajetória foram transferidas sem alterações da nossa trabalho anterior. Consequentemente, para o treinamento do modelo, podemos utilizar a base de exemplos criada anteriormente. Isso nos permite excluir a etapa de coleta inicial de dados de treinamento e passar diretamente ao processo de treinamento dos modelos.
Treinaremos os modelos em 2 etapas:
- Treinamento do modelo de previsão de trajetória.
- Treinamento da política do Ator.
O modelo de previsão de trajetória analisa apenas a dinâmica do mercado e os indicadores sem considerar o estado da conta e as posições abertas, que introduzem diversidade nas trajetórias da amostra de treinamento. E como todas as trajetórias foram coletadas de um único instrumento e em um único período histórico, para o "AutoBot", todas as trajetórias são idênticas. Portanto, podemos treinar o modelo de previsão de movimento de preços em uma única amostra de treinamento até obter resultados aceitáveis.
Devo dizer que o processo de treinamento do modelo foi bastante estável e com uma boa dinâmica de redução quase constante do erro. Aqui devo concordar com os autores do método quando falam sobre a velocidade de treinamento do modelo. Por exemplo, os autores do método afirmam que, durante o trabalho deles, todos os modelos foram treinados em 48 horas em um acelerador gráfico de desktop 1080 Ti.
Inspirado pelo processo de treinamento do modelo de previsão de movimento de preços, pensei que não seria totalmente correto avaliar o algoritmo de previsão de trajetória pelos resultados da política do Ator treinado. Sim, a política do Ator é baseada nos dados da previsão obtida. Mas, ao mesmo tempo, ela se adapta às possíveis imprecisões das previsões fornecidas. A qualidade dessa adaptação é outra questão e está relacionada à arquitetura do Ator e ao seu processo de treinamento. No entanto, a influência dessa adaptação é inegável. Portanto, foi criado um pequeno EA de trading algorítmico clássico "...\Experts\AutoBots\Alternate.mq5".
O EA foi criado apenas para verificar a qualidade da previsão de movimento de preços nas condições do Testador de Estratégias, e seu código, na minha opinião, não é de grande interesse. Por isso, não vamos nos aprofundar nele neste artigo. Aqueles que estiverem interessados podem revisá-lo no anexo.
O referido EA avalia o movimento previsto e abre negociações com o lote mínimo na direção da tendência identificada no horizonte de planejamento. Os parâmetros do EA não foram otimizados. E o resultado obtido ao rodar o EA no testador de estratégias até o final de 2023 é ainda mais interessante.
Após treinar o modelo de previsão de movimento de preços em dados históricos de 7 meses, obtivemos uma tendência consistente de aumento do saldo ao longo de 2 meses.

Lembro que todas as negociações foram realizadas com o lote mínimo. O que significa que o resultado obtido depende apenas da qualidade do planejamento da trajetória.
Considerações finais
Neste artigo, conhecemos o método "Latent Variable Sequential Set Transformers" (AutoBots). As abordagens propostas pelos autores do método são baseadas na modelagem da distribuição conjunta de informações contextuais e temporais, o que fornece ferramentas confiáveis para a previsão precisa (na medida do possível) do movimento futuro dos preços.
Os AutoBots exploram a arquitetura Encoder-Decoder e demonstram sua eficácia devido ao uso de blocos de atenção multifuncionais e à introdução de uma variável latente discreta para modelar distribuições multimodais.
Na parte prática do artigo, implementamos as abordagens propostas utilizando MQL5 e obtivemos resultados promissores em termos de velocidade de treinamento do modelo e qualidade das previsões.
Assim, o algoritmo AutoBots representa uma ferramenta promissora para resolver tarefas de previsão no mercado FOREX, proporcionando precisão, resistência a mudanças e capacidade de modelar distribuições multimodais para uma compreensão mais profunda da dinâmica dos movimentos de mercado.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | EA | EA de treinamento de Política |
| 4 | StudyTraj.mq5 | EA | EA de treinamento do modelo de previsão de trajetória |
| 5 | Test.mq5 | EA | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
| 9 | Alternate.mq5 | EA | EA de teste de qualidade de previsão de trajetória |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14095
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso