
Redes neurais de maneira fácil (Parte 75): aumentando a produtividade dos modelos de previsão de trajetórias

Introdução
A previsão da trajetória do movimento futuro dos preços desempenha, provavelmente, um dos papéis principais na construção de planos de negociação para o horizonte de planejamento considerado. A precisão dessas previsões é fundamental. Para melhorar a qualidade da previsão de trajetórias, complicamos nossos modelos de previsão de trajetórias.
No entanto, esse processo tem um "lado negativo". Modelos mais complexos exigem mais recursos computacionais. O que significa que aumentam os custos tanto para o treinamento quanto para a operação dos modelos. Sim, os custos de treinamento dos modelos precisam ser considerados. Mas, às vezes, os custos operacionais podem ser críticos. Especialmente quando se trata de negociar ordens de mercado em tempo real em um mercado altamente volátil. Nesses casos, focamos em métodos para aumentar o desempenho de nossos modelos. E, de preferência, sem reduzir a qualidade da previsão das trajetórias futuras.
Os métodos de previsão de trajetórias que discutimos nos artigos anteriores foram emprestados da indústria de construção de modelos de condução autônoma. E, curiosamente, os pesquisadores dessa área enfrentam o mesmo problema. A velocidade dos veículos impõe maiores exigências ao tempo de tomada de decisão. E o uso de modelos de previsão de trajetórias e tomada de decisões onerosos leva não apenas a um aumento no tempo de tomada de decisão, mas também a um aumento nos custos do meio utilizado. Pois é necessário instalar hardware mais caro. Nesse contexto, merece destaque o artigo "Efficient Baselines for Motion Prediction in Autonomous Driving". Seus autores propõem a tarefa de construir um modelo de previsão de trajetória "leve" e destacam as seguintes realizações:
- Identificação do problema chave no tamanho dos modelos de previsão de movimento com implicações para a inferência em tempo real e a implantação em dispositivos com recursos limitados.
- Proposta de várias opções de base eficientes para a previsão do movimento dos veículos, que não se baseiam explicitamente em uma análise exaustiva de um mapa de alta qualidade, mas em informações preliminares do mapa obtidas em uma simples etapa de pré-processamento, servindo como guia para a previsão.
- Uso de um menor número de parâmetros e operações para alcançar um desempenho competitivo com menor custo computacional.
1. Métodos para aumentar o desempenho
Ao considerar o equilíbrio entre os dados brutos analisados e a complexidade do modelo, os autores do método buscam alcançar resultados competitivos utilizando técnicas poderosas de aprendizado profundo, incluindo mecanismos de atenção e redes neurais gráficas (GNN). Ao mesmo tempo, o número de parâmetros e operações é reduzido em comparação com outros métodos. Em particular, como dados brutos para seus modelos, eles utilizam:
- trajetórias passadas dos agentes e suas interações correspondentes, como única entrada para o bloco de nível básico social;
- expansão, onde uma representação simplificada da área de admissibilidade do agente é adicionada como entrada adicional para a base cartográfica.
Assim, os modelos propostos não exigem mapas completamente anotados de alta qualidade ou representações rasterizadas da cena para calcular o contexto físico.
Os autores do método propõem usar um algoritmo de pré-processamento de mapa simples, mas poderoso, onde a trajetória do agente alvo é inicialmente filtrada. E então, a área de admissibilidade onde o agente alvo pode interagir é calculada, considerando apenas informações geométricas do mapa.
O nível básico social utiliza como dados brutos as trajetórias passadas dos obstáculos mais significativos em forma de deslocamentos relativos para alimentar o módulo Codificador. Em seguida, a informação social é calculada usando uma rede neural gráfica. Em seu trabalho, os autores do método utilizam camadas CrystalGraph Convolutional Network (Crystal-GCN) e Multi-Head Self Attention (MHSA) para destacar as interações mais significativas entre os agentes. Após isso, no módulo Decodificador, essa informação latente é decodificada usando uma estratégia autorregressiva, na qual a saída no i-ésimo passo depende do anterior.
Uma das características do método proposto é a análise da interação com os agentes, sobre os quais há informações em todo o horizonte temporal Th = Tobs + Tlen.. Ao mesmo tempo, reduz-se o número de agentes a serem considerados em cenários de movimento complexos. Em vez de usar representações absolutas 2D de cima, a entrada para o agente i é uma série de deslocamentos relativos:
![]()
Os autores do método não limitam nem fixam o número de agentes na sequência. Para considerar os deslocamentos relativos de todos os agentes, é utilizado um único LSTM-bloco, no qual a informação temporal de cada agente na sequência é calculada.
Após a codificação do histórico analisado de cada veículo na sequência, as interações entre os agentes são calculadas, com o objetivo de obter a informação social mais significativa. Para isso, é construído um grafo de interações. Na prática, para construir o grafo, é usada a camada Crystal-GCN. Em seguida, é aplicado o MHSA para melhorar o aprendizado das interações agente-agente.
Antes de criar o mecanismo de interação, os autores do método dividem a informação temporal em cenas correspondentes. Considerando que cada cenário de movimento pode ter um número diferente de agentes. O mecanismo de interação é definido como um grafo totalmente conectado e bidirecional, onde as características iniciais do nó v0i são representadas pela informação temporal latente para cada veículo hi,out, calculada pelo codificador do histórico de movimento. Por outro lado, as arestas do nó k ao nó l são representadas pelo vetor de distância ek,l entre os respectivos agentes no momento tobs,len em coordenadas absolutas:
![]()
Dado o grafo de interações (nós e arestas), Crystal-GCN é definido como:
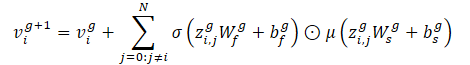
Este operador permite incorporar as características da aresta para atualizar as características do nó com base na distância entre os veículos. Os autores do método utilizam 2 camadas de Crystal-GCN com ReLU e normalização em lote como não-linearidades entre as camadas.
σ e μ são funções de ativação sigmoide e softplus, respectivamente. Além disso, zi,j=(vi‖vj‖ei,j) representa a concatenação das características de dois nós na camada GNN e a aresta correspondente, N representa o número total de agentes na cena, e W e b são os pesos e desvios das respectivas camadas.
Após passar pelo grafo de interação, cada característica de nó atualizada vi contém informações sobre o contexto temporal e social do agente i. No entanto, dependendo da posição atual e da trajetória passada, o agente pode precisar prestar atenção a informações sociais específicas. Para modelar isso, os autores do método utilizam um mecanismo de autoatenção multi-cabeça Self-Attention com 4 cabeças, aplicado à matriz de características do nó atualizada V, contendo as características do nó vi como linhas.
Cada linha da matriz final de atenção social SATT (saída do módulo de atenção social, após os mecanismos GNN e MHSA) representa uma característica de interação para o agente i com os agentes circundantes, considerando informações temporais internamente.
Os autores do método expandem o modelo básico social, utilizando informações mínimas do mapa, onde a área P do agente alvo é discretizada como um subconjunto r de pontos aleatoriamente selecionados {p0, p1...pr} ao redor das linhas centrais prováveis (características de alto nível e estruturadas), considerando a velocidade e a aceleração do agente alvo no último quadro de observação. Este é um passo de pré-processamento do mapa, de modo que o modelo nunca vê o mapa em alta resolução.
Com base nas leis da física, os autores do método consideram o veículo como uma estrutura rígida sem mudanças bruscas de movimento entre marcas de tempo consecutivas. Assim, ao descrever a tarefa de movimento na estrada, as características mais importantes geralmente estão em uma direção específica (à frente no curso do movimento). Isso permite obter uma versão simplificada do mapa.
As informações sobre as trajetórias percorridas muitas vezes contêm ruído, relacionado ao processo de coleta de dados no mundo real. Para avaliar as variáveis dinâmicas do agente alvo no último quadro de observação tobs,len, os autores do método propõem primeiro filtrar as observações passadas do agente alvo, utilizando um algoritmo de mínimos quadrados para cada um dos eixos. Assume-se que o agente se move com aceleração constante e podemos calcular as características dinâmicas (velocidade e aceleração) do agente alvo. Então, calcula-se o vetor de estimativa de velocidade e aceleração. Além disso, esses vetores são somados como escalares para obter uma estimativa suave, atribuindo menor peso (maior coeficiente de esquecimento λ) às primeiras observações. Assim, as últimas observações desempenham um papel crucial na determinação do estado cinemático atual do agente:
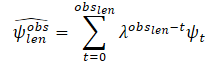
onde
obslen é o número de quadros observados, ψt é a velocidade/aceleração estimada no quadro t, λ ∈ (0, 1) é o coeficiente de esquecimento.
Após calcular o estado cinemático, estima-se a distância percorrida, assumindo um modelo físico baseado em aceleração com velocidade constante de rotação a qualquer momento t.
Em seguida, esses candidatos a trajetórias plausíveis são processados para serem usados como informações físicas plausíveis. Primeiro, encontramos o ponto mais próximo dos últimos dados de observação do agente alvo, que representará o ponto inicial da linha central plausível. Depois, estimamos a distância percorrida ao longo das linhas centrais originais. Determinamos o índice do ponto final p da linha central m como o ponto onde a distância acumulada (considerando a distância euclidiana entre cada ponto) é maior ou igual ao desvio previamente calculado.
E então é realizada uma interpolação cúbica entre os pontos inicial e final da linha central correspondente m, para obter os passos no horizonte de planejamento. Os experimentos realizados pelos autores do método demonstram que a melhor informação prévia, considerando a distância média e mediana L2 em todo o conjunto de validação entre o ponto final da trajetória verdadeira do agente alvo e os pontos finais das linhas centrais filtradas, é alcançada ao considerar a velocidade e aceleração no estado cinemático e a filtragem da entrada pelo método dos mínimos quadrados.
Além dessas linhas centrais estruturadas e de alto nível, os autores do método propõem aplicar distorções na posição dos pontos a todas as linhas centrais plausíveis de acordo com a distribuição normal N(0, 0.2). Isso permitirá discretizar a área plausível P como um subconjunto r de pontos aleatoriamente selecionados {p0, p1...pr} ao redor das linhas centrais plausíveis. E assim obter uma representação geral da área plausível, definida como características de baixo nível. Os autores do método utilizam a distribuição normal N como um termo de regularização adicional, em vez de usar os limites das faixas. Isso ajudará a evitar o sobreajuste no módulo de codificação, similar ao uso de aumento de dados nas trajetórias anteriores.
Para calcular as informações cartográficas latentes, utilizam-se codificadores de área e de linha central. Eles processam características do mapa de baixo e alto nível, respectivamente. Cada um desses codificadores é representado por um perceptron multicamada (MLP). Primeiro, suavizamos a informação ao longo da dimensão dos pontos, alternando a informação nos eixos das coordenadas. Em seguida, o correspondente MLP (3 camadas, com normalização em lote, ReLU e DropOut na primeira camada) transforma as coordenadas absolutas interpretáveis ao redor da origem em informações físicas latentes representativas. O contexto físico estático (saída do codificador de área) servirá como uma representação latente geral para vários modos, enquanto o contexto físico específico ilustrará informações cartográficas específicas para cada modo.
O decodificador da trajetória futura é o terceiro componente dos modelos base propostos. O módulo consiste em um bloco LSTM, que avalia recursivamente os deslocamentos relativos para futuros passos temporais, assim como foram estudados os deslocamentos relativos passados no Codificador de história de movimento. No que diz respeito à variante social básica, o modelo utiliza o contexto social calculado pelo módulo de interação social, prestando atenção apenas aos dados do agente alvo. Somente o contexto social representa todo o tráfego no cenário, representando o vetor oculto de entrada do preditor autorregressivo LSTM.
Do ponto de vista da variante cartográfica básica para o modo m, os autores do método propõem identificar o contexto latente de tráfego como a concatenação do contexto social, do contexto físico estático e do contexto físico específico, que servirá como vetor oculto de entrada do decodificador LSTM.
Em relação aos dados brutos do bloco LSTM no caso social, ele é representado pelos deslocamentos relativos passados n do agente alvo após a incorporação espacial, enquanto a variante cartográfica básica adiciona o vetor de distância codificado entre a posição absoluta atual do agente alvo e a linha central atual, bem como o carimbo temporal escalar atual t. Em ambos os casos (social e cartográfico), os resultados do bloco LSTM são processados usando uma camada totalmente conectada padrão.
Após obter a previsão relativa no passo temporal t, deslocamos os dados iniciais da observação passada para incluir nosso último deslocamento relativo calculado no final do vetor, removendo os primeiros dados.
Após calcular as previsões multimodais, elas são concatenadas e processadas usando um MLP residual para obter a confiança (quanto maior a confiança, mais provável é o modo, e mais próximo da verdade).
A visualização do método pelos autores é apresentada abaixo. Nela, linhas azuis representam o fluxo de informações sociais, enquanto linhas vermelhas mostram a transmissão de informações cartográficas.

2. Implementação usando MQL5
Após considerar os aspectos teóricos das abordagens propostas, passamos para a implementação prática usando MQL5. Como se pode notar, os autores do método dividiram o modelo em blocos. Cada bloco usa um número mínimo de camadas. Além disso, a simplificação da arquitetura dos blocos individuais é acompanhada por uma análise adicional de dados, utilizando informações prévias sobre o ambiente analisado. Em particular, realiza-se o pré-processamento do mapa e a filtragem das trajetórias percorridas. Isso permite reduzir o ruído e o volume dos dados brutos, sem perder a qualidade na construção das trajetórias previstas.
2.1 Criação da camada CrystalGraph Convolutional Network
Além disso, entre as abordagens propostas, encontramos camadas de redes neurais gráficas, com as quais não tínhamos trabalhado antes. Portanto, antes de avançar na construção do algoritmo proposto, precisamos criar uma nova camada em nossa biblioteca.
A camada CrystalGraph Convolutional Network proposta pelos autores pode ser representada pela fórmula:
Essencialmente, aqui vemos a multiplicação elemento a elemento dos resultados de 2 camadas totalmente conectadas. Uma delas é ativada pela função sigmoide e representa uma matriz binária treinável de presença de conexões entre os vértices do grafo. A outra camada é ativada pela função SoftPlus, que é uma versão suavizada do ReLU.
Para implementar a CrystalGraph Convolutional Network, criaremos uma nova classe CNeuronCGConvOCL, herdando a funcionalidade básica de CNeuronBaseOCL.
class CNeuronCGConvOCL : public CNeuronBaseOCL { protected: CNeuronBaseOCL cInputF; CNeuronBaseOCL cInputS; CNeuronBaseOCL cF; CNeuronBaseOCL cS; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronCGConvOCL(void) {}; ~CNeuronCGConvOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronCGConvOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Nossa nova classe recebe um conjunto padrão de métodos para sobrescrever e a funcionalidade básica da classe pai. Para implementar o algoritmo de convolução gráfica, criaremos 4 camadas totalmente conectadas internas:
- 2 para registrar os dados brutos e os gradientes de erro na propagação reversa (cInputF e cInputS)
- 2 para executar a funcionalidade (cF e cS).
Todos os objetos internos serão criados como estáticos, de modo que o construtor e o destrutor da classe permanecerão "vazios".
No método de inicialização da nossa classe Init, primeiro chamaremos o método semelhante da classe pai, no qual todos os controles necessários dos dados recebidos do programa externo são realizados e os objetos e variáveis herdados são inicializados.
bool CNeuronCGConvOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; activation = None;
Depois disso, inicializamos sequencialmente os objetos internos adicionados chamando seus métodos de inicialização.
if(!cInputF.Init(numNeurons, 0, OpenCL, window, optimization, batch)) return false; if(!cInputS.Init(numNeurons, 1, OpenCL, window, optimization, batch)) return false; cInputF.SetActivationFunction(None); cInputS.SetActivationFunction(None); //--- if(!cF.Init(0, 2, OpenCL, numNeurons, optimization, batch)) return false; cF.SetActivationFunction(SIGMOID); if(!cS.Init(0, 3, OpenCL, numNeurons, optimization, batch)) return false; cS.SetActivationFunction(LReLU); //--- return true; }
Observe que para as camadas internas de registro dos dados brutos, não especificamos uma função de ativação. E para as camadas funcionais, especificamos as funções de ativação previstas pelo algoritmo da camada criada. Ao mesmo tempo, a própria camada CNeuronCGConvOCL não possui função de ativação.
Após a inicialização do objeto, passamos à criação do método de propagação para frente feedForward. Nos parâmetros, o método recebe um ponteiro para o objeto da camada neural anterior, cuja saída contém os dados brutos para nós.
bool CNeuronCGConvOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL || !NeuronOCL.getOutput() || NeuronOCL.getOutputIndex() < 0) return false;
No corpo do método, verificamos imediatamente a atualidade do ponteiro recebido.
Após passar com sucesso pelo bloco de controles, transferimos os dados brutos do buffer da camada anterior para os buffers de nossas 2 camadas internas de dados brutos. Lembrando que todas as operações com nossas camadas neurais são realizadas no contexto do OpenCL. Portanto, a cópia de dados também deve ser realizada na memória do contexto OpenCL. Mas iremos um pouco além e realizaremos a "cópia" sem transferência física de dados. Vamos simplesmente substituir o ponteiro para o buffer de resultados nas camadas internas e passaremos para elas o ponteiro para o buffer de resultados da camada anterior. Simultaneamente, especificaremos a função de ativação da camada anterior.
if(cInputF.getOutputIndex() != NeuronOCL.getOutputIndex()) { if(!cInputF.getOutput().BufferSet(NeuronOCL.getOutputIndex())) return false; cInputF.SetActivationFunction((ENUM_ACTIVATION)NeuronOCL.Activation()); } if(cInputS.getOutputIndex() != NeuronOCL.getOutputIndex()) { if(!cInputS.getOutput().BufferSet(NeuronOCL.getOutputIndex())) return false; cInputS.SetActivationFunction((ENUM_ACTIVATION)NeuronOCL.Activation()); }
Dessa forma, ao trabalhar com as camadas internas, teremos acesso direto ao buffer de resultados da camada anterior sem a necessidade de cópia física dos dados. Essa tarefa de transferência de dados é realizada com recursos mínimos. Além disso, evitamos a criação de dois buffers adicionais no contexto OpenCL, otimizando assim o uso da memória.
Em seguida, simplesmente chamamos os métodos de propagação para frente das camadas funcionais internas.
if(!cF.FeedForward(GetPointer(cInputF))) return false; if(!cS.FeedForward(GetPointer(cInputS))) return false;
Como resultado dessas operações, obtivemos matrizes de contexto e de conexões do grafo. E então precisamos realizar a multiplicação elemento a elemento. Para executar essa operação, utilizaremos o kernel Dropout, que criamos para a multiplicação elemento a elemento dos dados brutos com a máscara. No nosso caso, a operação matemática é a mesma, mas com uma finalidade diferente.
Passamos os parâmetros necessários e os dados brutos para o kernel.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = int(Neurons() + 3) / 4; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_input, cF.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_map, cS.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_Dropout, def_k_dout_out, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_Dropout, def_k_dout_dimension, Neurons())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_Dropout, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Depois, colocamos o kernel na fila de execução.
A próxima etapa é implementar a funcionalidade da propagação reversa. Aqui, começamos com a criação do kernel no programa OpenCL. A questão é que a distribuição do gradiente de erro da camada anterior começa com a transmissão para as camadas internas de acordo com sua influência no resultado final. Para isso, precisamos multiplicar o gradiente de erro recebido pelos resultados da propagação para frente da segunda camada funcional. E, para não chamar o kernel de multiplicação elemento a elemento duas vezes, criaremos um novo kernel, onde obteremos os gradientes de erro para ambas as camadas em uma única execução.
Nos parâmetros do kernel CGConv_HiddenGradient, passaremos ponteiros para 5 buffers de dados e os tipos de funções de ativação de ambas as camadas.
__kernel void CGConv_HiddenGradient(__global float *matrix_g,///<[in] Tensor of gradients at current layer __global float *matrix_f,///<[in] Previous layer Output tensor __global float *matrix_s,///<[in] Previous layer Output tensor __global float *matrix_fg,///<[out] Tensor of gradients at previous layer __global float *matrix_sg,///<[out] Tensor of gradients at previous layer int activationf,///< Activation type (#ENUM_ACTIVATION) int activations///< Activation type (#ENUM_ACTIVATION) ) { int i = get_global_id(0);
Executaremos o kernel em um espaço unidimensional de tarefas, conforme o número de neurônios em nossas camadas. No corpo do kernel, definimos imediatamente o deslocamento nos buffers de dados até o elemento analisado pelo identificador do fluxo.
Em seguida, para reduzir as operações "custosas" de acesso à memória global da GPU, salvaremos os dados do elemento analisado em variáveis locais, cujo acesso é significativamente mais rápido.
float grad = matrix_g[i]; float f = matrix_f[i]; float s = matrix_s[i];
Nesta etapa, temos todos os dados necessários para calcular os gradientes de erro nas duas camadas, e os calculamos.
float sg = grad * f; float fg = grad * s;
Mas antes de gravar os valores obtidos nos elementos dos buffers de dados globais, precisamos ajustar os gradientes de erro encontrados para as funções de ativação correspondentes.
switch(activationf) { case 0: f = clamp(f, -1.0f, 1.0f); fg = clamp(fg + f, -1.0f, 1.0f) - f; fg = fg * max(1 - pow(f, 2), 1.0e-4f); break; case 1: f = clamp(f, 0.0f, 1.0f); fg = clamp(fg + f, 0.0f, 1.0f) - f; fg = fg * max(f * (1 - f), 1.0e-4f); break; case 2: if(f < 0) fg *= 0.01f; break; default: break; }
switch(activations) { case 0: s = clamp(s, -1.0f, 1.0f); sg = clamp(sg + s, -1.0f, 1.0f) - s; sg = sg * max(1 - pow(s, 2), 1.0e-4f); break; case 1: s = clamp(s, 0.0f, 1.0f); sg = clamp(sg + s, 0.0f, 1.0f) - s; sg = sg * max(s * (1 - s), 1.0e-4f); break; case 2: if(s < 0) sg *= 0.01f; break; default: break; }
Ao finalizar o kernel, salvamos os resultados das operações nos elementos correspondentes dos buffers de dados globais.
matrix_fg[i] = fg; matrix_sg[i] = sg; }
Após criar o kernel, voltamos a trabalhar nos métodos da nossa classe. A funcionalidade de distribuição do gradiente de erro é implementada no método calcInputGradients, cujos parâmetros incluem um ponteiro para o objeto da camada anterior. No corpo do método, verificamos imediatamente a atualidade do ponteiro recebido.
bool CNeuronCGConvOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!prevLayer || !prevLayer.getGradient() || prevLayer.getGradientIndex() < 0) return false;
Em seguida, chamaremos o kernel de distribuição de gradiente descrito anteriormente para os camadas internas CGConv_HiddenGradient. Primeiro, definimos o espaço de tarefas.
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = Neurons();
Depois, passamos os parâmetros necessários para o kernel.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_f, cF.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_fg, cF.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_s, cS.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_sg, cS.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CGConv_HiddenGradient, def_k_cgc_matrix_g, getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CGConv_HiddenGradient, def_k_cgc_activationf, cF.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CGConv_HiddenGradient, def_k_cgc_activations, cS.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
E colocamos o kernel na fila de execução.
if(!OpenCL.Execute(def_k_CGConv_HiddenGradient, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
A seguir, precisamos passar o gradiente de erro pelas camadas totalmente conectadas internas. Para isso, simplesmente chamamos seus métodos correspondentes.
if(!cInputF.calcHiddenGradients(GetPointer(cF))) return false; if(!cInputS.calcHiddenGradients(GetPointer(cS))) return false;
Neste ponto, temos os resultados de 2 fluxos de gradientes de erro nas 2 camadas internas de dados brutos. Nós simplesmente os somamos e passamos o resultado para o nível da camada anterior.
if(!SumAndNormilize(cF.getOutput(), cS.getOutput(), prevLayer.getOutput(), 1, false)) return false; //--- return true; }
Observe que, neste caso, não consideramos explicitamente a função de ativação da camada anterior. E isso é importante para a transmissão correta do gradiente de erro. Mas há um detalhe. Todas as nossas classes de camadas neurais são construídas de forma que o ajuste pela derivada da função de ativação seja feito antes da transmissão do gradiente para o buffer da camada anterior. É precisamente para esses fins que, na propagação, especificamos a função de ativação da camada anterior para nossas camadas internas de dados brutos. Assim, ao passar o gradiente de erro pelas nossas camadas funcionais internas, já ajustamos o gradiente pela derivada da função de ativação, que é a mesma para os gradientes de ambos os fluxos. E na saída, somamos os gradientes de erro já ajustados pela derivada da função de ativação.
O algoritmo do segundo método de propagação reversa (atualização da matriz de coeficientes de peso updateInputWeights) é bastante simples. Aqui, apenas chamamos os métodos correspondentes das camadas funcionais internas.
bool CNeuronCGConvOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cF.UpdateInputWeights(cInputF.AsObject())) return false; if(!cS.UpdateInputWeights(cInputS.AsObject())) return false; //--- return true; }
A implementação dos outros métodos da nossa classe CNeuronCGConvOCL, a meu ver, não representa um grande interesse. Neles, usei algoritmos comuns para os métodos correspondentes, que já foram descritos várias vezes nesta série de artigos. E sugiro que você os consulte no anexo. Lá você encontrará o código completo de todos os programas usados na preparação deste artigo. Agora passamos à implementação das abordagens propostas na construção da arquitetura dos modelos e seu treinamento.
2.2 Arquitetura dos modelos
Ao começar a trabalhar na arquitetura dos modelos, digo de antemão que tomamos como base os modelos do artigo anterior e mantivemos a estrutura dos dados brutos. Isso não é por acaso. Na estrutura ADAPT, também pode-se destacar o módulo codificador, que é apresentado como Feature Encoding. Ele inclui o bloco de atenção social de camadas sequenciais de atenção multi-cabeça. O bloco de previsão de pontos finais pode ser comparado às linhas centrais propostas. E o bloco de confiança é semelhante à previsão de probabilidades de trajetórias. E será ainda mais interessante ver os resultados do trabalho dos modelos.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Começamos pelo modelo do codificador. No modelo de entrada, fornecemos dados brutos sobre o estado do ambiente.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados brutos passam por um pré-processamento no bloco de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, em vez do bloco LSTM proposto pelos autores, deixei a camada de Embedding com codificação posicional, pois essa abordagem permite preservar e analisar um histórico mais profundo.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
No modelo Codificador, também incluí o bloco de atenção social. Este bloco, conforme as sugestões dos autores do método, consiste em 2 camadas sequenciais de convolução gráfica, separadas por uma camada de normalização em lote.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
Na saída do bloco de atenção social, é utilizada 1 camada de atenção multi-cabeça.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
No nosso caso, não há um mapa do ambiente a partir do qual poderíamos deduzir analiticamente as prováveis opções de movimento futuro dos preços. Dessa forma, em vez de linhas centrais, deixamos o bloco de previsão de pontos finais. Como dados brutos, ele usará os resultados do bloco de atenção social.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (prev_count * prev_wout); descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Estes resultados são primeiramente processados por uma camada totalmente conectada.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Em seguida, utilizamos um bloco LSTM, conforme proposto pelos autores do método para o bloco de decodificação de trajetórias.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 3 * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Na saída do bloco, geramos uma representação multimodal dos pontos finais para um número determinado de opções.
O modelo de previsão de probabilidades de escolha de trajetórias permaneceu inalterado. No modelo de entrada, fornecemos os resultados dos dois modelos anteriores.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false; //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; }
Processamos esses resultados com um bloco de camadas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
E os resultados são convertidos para a área de probabilidades usando a camada SoftMax.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Como no trabalho anterior, não tentaremos prever a trajetória detalhada do movimento dos preços. Nosso objetivo principal é obter lucro nos mercados financeiros. Assim, treinaremos o modelo Ator, capaz de gerar a política de comportamento ótima com base nas previsões dos pontos finais do movimento dos preços.
A arquitetura do modelo foi completamente transferida do trabalho anterior e está apresentada no método CreateDescriptions do arquivo «...\Experts\BaseLines\Trajectory.mqh». Uma descrição detalhada está apresentada no artigo anterior.
2.3 Treinamento dos modelos
Como pode ser observado na arquitetura dos modelos apresentada, a sequência de uso dos modelos em conselheiros de interação com o ambiente permaneceu inalterada. Portanto, neste artigo, não abordaremos os algoritmos de coleta de dados de treinamento e teste dos modelos treinados. Passamos diretamente ao EA de treinamento dos modelos. Como no trabalho anterior, todos os modelos são treinados em um único EA «...\Experts\BaseLines\Study.mq5»
No método de inicialização do EA, carregamos primeiro a base de exemplos para o treinamento dos modelos.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Depois, carregamos os modelos previamente treinados e, se necessário, criamos novos.
//--- load models float temp; if(!BLEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !BLEndpoints.Load(FileName + "Endp.nnw", temp, temp, temp, dtStudied, true) || !BLProbability.Load(FileName + "Prob.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *encoder = new CArrayObj(); CArrayObj *endpoint = new CArrayObj(); CArrayObj *prob = new CArrayObj(); if(!CreateTrajNetDescriptions(encoder, endpoint, prob)) { delete endpoint; delete prob; delete encoder; return INIT_FAILED; } if(!BLEncoder.Create(encoder) || !BLEndpoints.Create(endpoint) || !BLProbability.Create(prob)) { delete endpoint; delete prob; delete encoder; return INIT_FAILED; } delete endpoint; delete prob; delete encoder; }
if(!StateEncoder.Load(FileName + "StEnc.nnw", temp, temp, temp, dtStudied, true) || !EndpointEncoder.Load(FileName + "EndEnc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *endpoint = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); if(!CreateDescriptions(actor, endpoint, encoder)) { delete actor; delete endpoint; delete encoder; return INIT_FAILED; } if(!Actor.Create(actor) || !StateEncoder.Create(encoder) || !EndpointEncoder.Create(endpoint)) { delete actor; delete endpoint; delete encoder; return INIT_FAILED; } delete actor; delete endpoint; delete encoder; //--- }
Em seguida, transferimos todos os modelos para um único contexto OpenCL.
OpenCL = Actor.GetOpenCL(); StateEncoder.SetOpenCL(OpenCL); EndpointEncoder.SetOpenCL(OpenCL); BLEncoder.SetOpenCL(OpenCL); BLEndpoints.SetOpenCL(OpenCL); BLProbability.SetOpenCL(OpenCL);
E realizamos o controle da arquitetura dos modelos.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
BLEndpoints.getResults(Result); if(Result.Total() != 3 * NForecast) { PrintFormat("The scope of the Endpoints does not match forecast endpoints (%d <> %d)", 3 * NForecast, Result.Total()); return INIT_FAILED; }
BLEncoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Ao finalizar o método, criamos buffers de dados auxiliares e geramos um evento de usuário para iniciar o treinamento dos modelos.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
No método de desinicialização, não esquecemos de salvar os modelos treinados e limpar a memória dos objetos dinâmicos.
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); StateEncoder.Save(FileName + "StEnc.nnw", 0, 0, 0, TimeCurrent(), true); EndpointEncoder.Save(FileName + "EndEnc.nnw", 0, 0, 0, TimeCurrent(), true); BLEncoder.Save(FileName + "Enc.nnw", 0, 0, 0, TimeCurrent(), true); BLEndpoints.Save(FileName + "Endp.nnw", 0, 0, 0, TimeCurrent(), true); BLProbability.Save(FileName + "Prob.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
O treinamento dos modelos é realizado diretamente no método Train. No corpo do método, primeiro geramos um vetor de probabilidades de escolha de trajetórias.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Depois, criamos variáveis locais.
vector<float> result, target; matrix<float> targets, temp_m; bool Stop = false; //--- uint ticks = GetTickCount();
E criamos um sistema de ciclos de treinamento dos modelos.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
No corpo do ciclo externo, amostramos a trajetória do buffer de reprodução de experiência e o estado inicial do treinamento nela.
Aqui também definimos o último estado do lote de treinamento na trajetória escolhida e limpamos os buffers de dados recorrentes.
BLEncoder.Clear(); BLEndpoints.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
No corpo do ciclo aninhado, pegamos um estado do ambiente do buffer de reprodução de experiência e realizamos propagações dos modelos de previsão dos pontos finais e suas probabilidades.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- Trajectory if(!BLEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!BLEndpoints.feedForward((CNet*)GetPointer(BLEncoder), -1, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
if(!BLProbability.feedForward((CNet*)GetPointer(BLEncoder), -1, (CNet*)GetPointer(BLEndpoints))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Como pode ser notado, as operações descritas acima pouco diferem das similares no artigo anterior. Mas ainda, haverá mudanças. E elas se referem à transmissão de conhecimento apriorístico para o modelo durante o treinamento. Pois é justamente utilizando conhecimento prévio sobre o ambiente que os autores do método buscam aumentar a precisão das previsões simplificando a arquitetura dos próprios modelos.
Na verdade, existem várias abordagens para transmitir conhecimento apriorístico para o modelo. Podemos realizar o pré-processamento dos dados brutos para comprimi-los e torná-los mais informativos. Como sugerido pelos autores do método com o uso de linhas centrais.
Podemos também usar conhecimento apriorístico na geração de valores-alvo durante o treinamento dos modelos. Isso ajudará o modelo a prestar mais atenção aos objetos mais significativos dos dados brutos. E, claro, é possível usar ambas as abordagens simultaneamente.
Neste artigo, usaremos a segunda abordagem. Para preparar os valores-alvo para o treinamento do modelo de previsão dos pontos finais, primeiro coletamos dados sobre o movimento de preços futuro do buffer de reprodução.
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(target.Size() > BarDescr) { matrix<float> temp(1, target.Size()); temp.Row(target, 0); temp.Reshape(target.Size() / BarDescr, BarDescr); temp.Resize(temp.Rows(), 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } target = targets.Col(0).CumSum(); targets.Col(target, 0); targets.Col(target + targets.Col(1), 1); targets.Col(target + targets.Col(2), 2);
Como exemplo de conhecimento apriorístico, utilizaremos os sinais do indicador MACD. Os dados da linha principal são armazenados no elemento 7 da matriz de descrição do estado do ambiente. E o valor da linha de sinal no elemento 8 da mesma matriz. Se a linha de sinal estiver acima da principal, consideramos a tendência atual como altista. Caso contrário, baixista.
int direct = (Buffer[tr].States[i].state[8] >= Buffer[tr].States[i].state[7] ? 1 : -1);
Concordo que essa abordagem é bastante simplificada e poderíamos usar mais sinais e indicadores para determinar tendências. Mas essa simplicidade fornecerá um exemplo claro de implementação no artigo e permitirá avaliar o impacto da abordagem no resultado. Em seus trabalhos, sugiro que você utilize abordagens mais complexas para obter resultados ótimos.
Após determinar a direção da tendência, identificamos o extremo nessa direção. E limitamos a matriz de movimento de preços futuros ao extremo encontrado.
ulong extr=(direct>0 ? target.ArgMax() : target.ArgMin()); if(extr==0) { direct=-direct; extr=(direct>0 ? target.ArgMax() : target.ArgMin()); } targets.Resize(extr+1, 3);
Vale destacar que o sinal MACD é um pouco atrasado em relação às mudanças de tendência. Portanto, se ao identificar o extremo, o encontramos na primeira linha da matriz, mudamos a direção da tendência para a oposta e redefinimos o extremo.
Ao utilizar tendências determinadas com conhecimento apriorístico sobre o ambiente, reduzimos a estocasticidade dos valores-alvo, que era observada anteriormente ao usar a direção da primeira vela futura. E, em geral, isso deve ajudar nosso modelo a determinar tendências e futuras direções de movimento de preços de forma mais precisa.
Da matriz truncada de movimento de preços futuros, determinamos os valores-alvo pelo extremo do movimento de preços futuros.
if(direct >= 0) { target = targets.Max(AXIS_HORZ); target[2] = targets.Col(2).Min(); } else { target = targets.Min(AXIS_HORZ); target[1] = targets.Col(1).Max(); }
Como antes, identificamos a previsão mais precisa do modelo de todo o espaço de pontos finais multimodais e ajustamos apenas a previsão escolhida na propagação reversa.
BLEndpoints.getResults(result); targets.Reshape(1, result.Size()); targets.Row(result, 0); targets.Reshape(NForecast, 3); temp_m = targets; for(int i = 0; i < 3; i++) temp_m.Col(temp_m.Col(i) - target[i], i); temp_m = MathPow(temp_m, 2.0f); ulong pos = temp_m.Sum(AXIS_VERT).ArgMin(); targets.Row(target, pos); Result.AssignArray(targets);
Os valores-alvo preparados dessa forma nos permitem atualizar os parâmetros do modelo de previsão de pontos finais e do Codificador do estado inicial do ambiente.
if(!BLEndpoints.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!BLEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Aqui, também corrigimos os modelos de previsão de probabilidades. Somente o gradiente de erro deste modelo não é passado nem para o modelo de previsão de pontos finais, nem para o Codificador.
bProbs.AssignArray(vector<float>::Zeros(NForecast)); bProbs.Update((int)pos, 1); bProbs.BufferWrite(); if(!BLProbability.backProp(GetPointer(bProbs), GetPointer(BLEndpoints))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A próxima etapa é o treinamento da política do Ator. Primeiro, preparamos a informação sobre o estado da conta e as posições abertas.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Em seguida, criaremos embeddings dos estados e dos pontos finais previstos.
//--- State embedding if(!StateEncoder.feedForward((CNet *)GetPointer(BLEncoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Endpoint embedding if(!EndpointEncoder.feedForward((CNet *)GetPointer(BLEndpoints), -1, (CNet*)GetPointer(BLProbability))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Observe que, ao contrário do trabalho anterior, para gerar o embedding dos pontos finais previstos, usamos os resultados da propagação para frente dos modelos treinados acima, e não os valores-alvo. Isso permitirá adaptar o Ator aos resultados do modelo de previsão de pontos finais.
Após preparar os embeddings, realizamos a propagação para frente do modelo do Ator.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(StateEncoder), -1, (CNet*)GetPointer(EndpointEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Após a execução bem-sucedida da propagação, segue-se a etapa de propagação reversa com atualização dos parâmetros dos modelos. Aqui, ao preparar os valores-alvo para o treinamento do modelo do Ator, também adicionamos alguns conhecimentos apriorísticos. Em particular, antes de abrir uma negociação em uma determinada direção, verificamos os valores dos indicadores RSI e CCI, que são armazenados no 4º e 5º elemento da matriz de descrição do estado do ambiente, respectivamente.
if(direct > 0) { if(Buffer[tr].States[i].state[4] > 30 && Buffer[tr].States[i].state[5] > -100 ) { float tp = float(target[1] / _Point / MaxTP); result[1] = tp; int sl = int(MathMax(MathMax(target[1] / 3, -target[2]) / _Point, MaxSL / 10)); result[2] = float(sl) / MaxSL; result[0] = float(MathMax(risk / (value * sl), 0.01)) + FLT_EPSILON; } }
else { if(Buffer[tr].States[i].state[4] < 70 && Buffer[tr].States[i].state[5] < 100 ) { float tp = float((-target[2]) / _Point / MaxTP); result[4] = tp; int sl = int(MathMax(MathMax((-target[2]) / 3, target[1]) / _Point, MaxSL / 10)); result[5] = float(sl) / MaxSL; result[3] = float(MathMax(risk / (value * sl), 0.01)) + FLT_EPSILON; } }
Observe que, neste caso, não verificamos explicitamente os sinais do indicador MACD, pois eles já foram considerados ao determinar a direção do movimento futuro direct anteriormente.
Os valores-alvo preparados dessa forma nos permitem realizar a propagação reversa do modelo composto do Ator.
Result.AssignArray(result); if(!Actor.backProp(Result, (CNet *)GetPointer(EndpointEncoder)) || !StateEncoder.backPropGradient(GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) || !EndpointEncoder.backPropGradient((CNet*)GetPointer(BLProbability)) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Usamos o gradiente de erro do Ator para atualizar os parâmetros do Codificador, mas não atualizamos o modelo de previsão de pontos finais.
if(!BLEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Ao concluir as operações dentro do sistema de ciclos, resta apenas informar o usuário sobre o progresso do processo de treinamento.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Endpoints", percent, BLEndpoints.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Probability", percent, BLProbability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após a conclusão do processo de treinamento dos modelos, limpamos o campo de comentários no gráfico. Registramos no log os resultados do treinamento dos modelos e iniciamos o processo de encerramento do programa.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Endpoints", BLEndpoints.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", BLProbability.getRecentAverageError()); ExpertRemove(); //--- }
Com isso, concluímos a consideração dos algoritmos de implementação das abordagens básicas propostas para otimização dos modelos de previsão de trajetórias. Você pode encontrar o código completo de todos os programas usados na preparação deste artigo no anexo.
3. Testes
Acima, foi realizado o trabalho de implementação de abordagens básicas para a otimização dos modelos de previsão de trajetórias usando MQL5. Em particular, foi criada uma camada de convolução gráfica e aplicadas abordagens para usar conhecimentos apriorísticos sobre o ambiente ao definir metas no processo de treinamento dos modelos. Ao mesmo tempo, o número de camadas nos modelos foi reduzido, o que potencialmente deve diminuir a complexidade dos modelos e aumentar sua velocidade de operação. Avaliamos o impacto das abordagens propostas durante o treinamento e teste dos modelos treinados em dados reais no testador de estratégias do MetaTrader 5.
Como sempre, o treinamento dos modelos foi realizado com dados históricos dos primeiros 7 meses de 2023 para o instrumento EURUSD no timeframe H1.
Acima, na construção da arquitetura dos modelos, já foi mencionada a manutenção da estrutura dos dados brutos. Isso nos permitiu utilizar o buffer de reprodução de experiência coletado durante a preparação dos artigos anteriores no processo de treinamento. Para isso, basta renomear o arquivo de dados coletados anteriormente para "BaseLines.bd". Se desejar criar uma nova amostra de treinamento, você pode usar qualquer um dos métodos discutidos anteriormente com o uso de conselheiros de interação com o ambiente.
A geração de valores-alvo durante o treinamento dos modelos permitiu utilizar a amostra de treinamento até obter resultados ótimos sem a necessidade de atualização e complementação.
No entanto, os resultados do treinamento não foram tão promissores quanto esperávamos. Durante o teste dos modelos treinados, aumentamos o período de teste de 1 para 3 meses.


Sim, conseguimos obter um modelo capaz de gerar lucro tanto na amostra de treinamento quanto na amostra de teste. Além disso, o modelo demonstrou boa estabilidade com um fator de lucro de 1.4. Após treinar com dados históricos de 7 meses, ele conseguiu gerar lucro por pelo menos 3 meses. Isso pode indicar que o modelo conseguiu identificar preditores bastante estáveis.
Entretanto, o número de negociações foi muito baixo. Foram realizadas apenas 11 negociações em 3 meses — muito pouco. E este não é o resultado que esperávamos alcançar.
Conclusão
Neste artigo, abordamos as abordagens básicas para otimização do funcionamento dos modelos de previsão de trajetórias. A implementação das abordagens propostas permite treinar modelos capazes de identificar preditores realmente significativos nos dados brutos. Isso permite que eles funcionem de forma estável por um período de tempo razoavelmente longo após o treinamento.
Porém, os resultados obtidos indicam um conservadorismo excessivo nas decisões tomadas pelos modelos. Isso se reflete no número muito baixo de negociações realizadas. E esse é o ponto em que precisamos continuar nossas pesquisas.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | EA | EA de treinamento de Modelos |
| 4 | Test.mq5 | EA | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14187
 Redes neurais de maneira fácil (Parte 76): explorando diversos modos de interação (Multi-future Transformer)
Redes neurais de maneira fácil (Parte 76): explorando diversos modos de interação (Multi-future Transformer)
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso