
Redes neurais de maneira fácil (Parte 79): consultas agregadas de características (FAQ)

Introdução
A maioria dos métodos que discutimos anteriormente analisa o estado do ambiente como algo estático, o que é consistente com a definição de um processo de Markov. Naturalmente, preenchemos a descrição do estado do ambiente com dados históricos para fornecer ao modelo o máximo de informações necessárias. Mas o modelo não avalia a dinâmica das mudanças nos estados. Isso também se aplica ao método apresentado no artigo anterior: DFFT foi desenvolvido para detectar objetos em imagens estáticas.
No entanto, observações dos movimentos dos preços indicam que a dinâmica das mudanças pode, às vezes, indicar a força e a direção do movimento futuro com probabilidade suficiente. Logicamente, agora voltamos nossa atenção para métodos de detecção de objetos em vídeo.
A detecção de objetos em vídeo tem uma série de características específicas e deve resolver o problema das mudanças nas características dos objetos causadas pelo movimento, que não são encontradas no domínio da imagem. Uma das soluções é usar informações temporais e combinar características de quadros adjacentes. O artigo "FAQ: Feature Aggregated Queries for Transformer-based Video Object Detectors" propõe uma nova abordagem para a detecção de objetos em vídeo. Os autores do artigo melhoram a qualidade das consultas para modelos baseados em Transformer, agregando-as. Para alcançar esse objetivo, é proposto um método prático para gerar e agregar consultas segundo as características dos quadros de entrada. Os resultados dos experimentos realizados no artigo demonstram claramente a eficácia do método proposto. As abordagens propostas podem ser estendidas a uma ampla gama de métodos para detectar objetos em imagens e vídeos para melhorar sua eficiência.
1. Algoritmo de consultas agregadas de características
O método FAQ não é o primeiro a usar a arquitetura Transformer para detectar objetos em vídeo. No entanto, os detectores de objetos em vídeo existentes que usam Transformer melhoram a representação das características dos objetos, agregando Query. A ideia inicial e básica é fazer a média das Query dos quadros vizinhos. As Query são inicializadas aleatoriamente e usadas durante o processo de treinamento. As consultas vizinhas são agregadas em Δ𝑸 para o quadro atual 𝑰 e são representadas como:
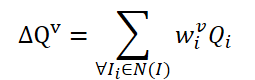
onde w são pesos de treinamento para a agregação.
A ideia simples de criar pesos treinados é baseada na similaridade cosseno das características do quadro de entrada. Seguindo os detectores de objetos em vídeo existentes, os autores do método FAQ geram pesos de agregação usando a fórmula:
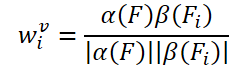
onde α, β são funções de mapeamento, e |⋅| denota normalização.
As características relevantes do quadro atual 𝑰 e seus vizinhos 𝑰i são denotadas como 𝑭 e 𝑭i. Como resultado, a probabilidade de identificar um objeto pode ser expressa como:
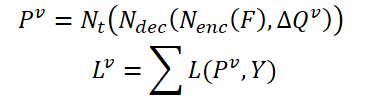
onde 𝑷v é a probabilidade prevista usando consultas agregadas Δ𝑸v.
Há um problema no módulo de agregação de consultas básico: essas consultas vizinhas 𝑸i são inicializadas aleatoriamente e não estão associadas aos seus quadros correspondentes 𝑰i. Portanto, as consultas vizinhas 𝑸i não fornecem informações temporais ou semânticas suficientes para superar problemas de degradação de desempenho causados por movimento rápido. Embora os pesos wi, usados para a agregação, estejam relacionados às funções 𝑭 e 𝑭i, não há restrições suficientes no número dessas consultas iniciadas aleatoriamente. Portanto, os autores do método FAQ sugerem atualizar o módulo de agregação Query para uma versão dinâmica que adicione restrições às consultas e ajuste os pesos segundo os quadros vizinhos. A ideia de implementação simples é gerar consultas 𝑸i diretamente das características 𝑭i do quadro de entrada. No entanto, experimentos conduzidos pelos autores do método mostram que esse método é difícil de treinar e sempre gera resultados piores. Em contraste com a ideia ingênua mencionada acima, os autores do método propõem gerar novas consultas, adaptáveis aos dados originais, a partir das Query inicializadas aleatoriamente. Primeiro, definimos dois tipos de vetores de Consulta: básicos e dinâmicos. Durante os processos de aprendizado e operação, consultas dinâmicas são geradas a partir de consultas básicas conforme as características 𝑭i e 𝑭 dos quadros de entrada como:
![]()
onde M é uma função de mapeamento para construir uma relação da consulta básica Qb com a consulta dinâmica Qd segundo as características 𝑭 e 𝑭i.
Primeiro, dividimos as consultas básicas em grupos de acordo com r consultas. Então, para cada grupo, usamos os mesmos pesos 𝑽 para determinar a consulta média ponderada no grupo atual:
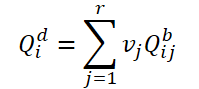
Para construir uma relação entre consultas dinâmicas 𝑸d e o quadro correspondente 𝑰i, os autores do método propõem gerar pesos 𝑽 usando características globais:
![]()
onde A é uma operação de pooling global para mudar a dimensão do tensor de características e criar características ao nível global,
G é uma função de mapeamento que permite projetar características globais na dimensão da Consulta dinâmica do tensor.
Assim, o processo de agregação de consultas dinâmicas baseado nas características dos dados de origem pode ser atualizado da seguinte forma:
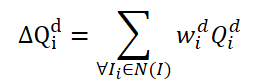
Durante o treinamento, os autores do método propõem agregar tanto consultas dinâmicas quanto básicas. Ambos os tipos de consultas são agregados com os mesmos pesos e as previsões correspondentes 𝑷d e 𝑷b são geradas. Aqui também calculamos o erro de concordância bidirecional para ambas as previsões. O hiperparâmetro γ é usado para equilibrar o efeito dos erros.
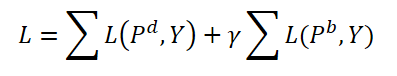
Durante a operação, usamos apenas consultas dinâmicas 𝑸d e suas previsões correspondentes 𝑷d como resultados que complicam apenas ligeiramente os modelos originais.
Abaixo está a visualização dos autores do método.

2. Implementação usando MQL5
Consideramos os aspectos teóricos dos algoritmos. Agora, passemos para a parte prática do nosso artigo, na qual implementaremos as abordagens propostas usando MQL5.
Como pode ser visto na descrição acima do método FAQ, sua principal contribuição é a criação de um módulo para gerar e agregar o tensor de consultas dinâmicas no Decodificador Transformer. Gostaria de lembrar que os autores do método DFFT excluíram o decodificador devido à sua ineficácia. Bem, no trabalho atual, adicionaremos um Decodificador e avaliaremos sua eficácia no contexto do uso de consultas dinâmicas propostas pelos autores do método FAQ.
2.1 Classe de consultas dinâmicas
Para gerar consultas dinâmicas, criaremos uma nova classe CNeuronFAQOCL. O novo objeto herdará da classe base de camadas neurais da nossa biblioteca CNeuronBaseOCL.
class CNeuronFAQOCL : public CNeuronBaseOCL { protected: //--- CNeuronConvOCL cF; CNeuronBaseOCL cWv; CNeuronBatchNormOCL cNormV; CNeuronBaseOCL cQd; CNeuronXCiTOCL cDQd; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronFAQOCL(void) {}; ~CNeuronFAQOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronFAQOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
No novo método, além do conjunto básico de métodos sobrescritos, adicionaremos 5 camadas neurais internas. Explicaremos seus propósitos durante a implementação. Declaramos todos os objetos internos como estáticos, o que nos permite deixar o construtor e o destrutor da classe vazios.
Um objeto de classe é inicializado no método CNeuronFAQOCL::Init. Nos parâmetros do método, obtemos todos os parâmetros chave para inicializar os objetos internos. No corpo do método, chamamos o respectivo método da classe pai. Como você já sabe, esse método implementa o controle mínimo necessário dos parâmetros recebidos e a inicialização dos objetos herdados.
bool CNeuronFAQOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint heads, uint units_count, uint input_units, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Não há função de ativação especificada para nossa classe.
activation = None;
Em seguida, inicializamos os objetos internos. Aqui nos voltamos para as abordagens de geração de consultas dinâmicas propostas pelos autores do método FAQ. Para gerar pesos de agregação para as consultas básicas com base nas características dos dados de origem, criamos 3 camadas. Primeiro, passamos as características dos dados de origem por uma camada convolucional, na qual analisamos os padrões dos estados ambientais vizinhos.
if(!cF.Init(0, 0, OpenCL, 3 * window, window, 8, fmax((int)input_units - 2, 1), optimization_type, batch)) return false; cF.SetActivationFunction(None);
Para aumentar a estabilidade do processo de treinamento e operação do modelo, normalizamos os dados recebidos.
if(!cNormV.Init(8, 1, OpenCL, fmax((int)input_units - 2, 1) * 8, batch, optimization_type)) return false; cNormV.SetActivationFunction(None);
Em seguida, comprimimos os dados para o tamanho do tensor de pesos de agregação das consultas básicas. Para garantir que os pesos resultantes estejam no intervalo [0,1], usamos uma função de ativação sigmoid.
if(!cWv.Init(units_count * window_out, 2, OpenCL, 8, optimization_type, batch)) return false; cWv.SetActivationFunction(SIGMOID);
Segundo o algoritmo FAQ, temos que multiplicar o vetor resultante de coeficientes de agregação pela matriz de consultas básicas, geradas aleatoriamente no início do treinamento. Na minha implementação, decidi ir um pouco além e treinar consultas básicas. Bem, não pensei em nada melhor do que usar uma camada neural totalmente conectada. Alimentamos a camada com um vetor de coeficientes de agregação, enquanto a matriz de pesos da camada totalmente conectada é um tensor de consultas básicas sendo treinadas.
if(!cQd.Init(0, 4, OpenCL, units_count * window_out, optimization_type, batch)) return false; cQd.SetActivationFunction(None);
A seguir, vem a agregação de consultas dinâmicas. Os autores do método FAQ em seu artigo apresentam os resultados de experimentos com vários métodos de agregação. O mais eficaz foi a agregação dinâmica de consultas usando a arquitetura Transformer. Seguindo os resultados acima, usamos o objeto da classe CNeuronXCiTOCL para agregar consultas dinâmicas.
if(!cDQd.Init(0, 5, OpenCL, window_out, 3, heads, units_count, 3, optimization_type, batch)) return false; cDQd.SetActivationFunction(None);
E para eliminar operações desnecessárias de cópia de dados, substituímos os buffers de resultados do nosso classe e os gradientes de erro.
if(Output != cDQd.getOutput()) { Output.BufferFree(); delete Output; Output = cDQd.getOutput(); } if(Gradient != cDQd.getGradient()) { Gradient.BufferFree(); delete Gradient; Gradient = cDQd.getGradient(); } //--- return true; }
Após inicializar o objeto, passamos a organizar o processo de propagação para frente no método CNeuronFAQOCL::feedForward. Tudo aqui é bastante simples e direto. Nos parâmetros do método, recebemos um ponteiro para a camada de dados de origem com parâmetros para descrever o estado do ambiente. No corpo do método, chamamos alternadamente métodos de propagação para frente dos objetos internos.
bool CNeuronFAQOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- if(!cF.FeedForward(NeuronOCL)) return false;
Primeiro, transferimos a descrição do ambiente por uma camada convolucional e normalizamos os dados resultantes.
if(!cNormV.FeedForward(GetPointer(cF))) return false;
Em seguida, geramos coeficientes de agregação das consultas básicas.
if(!cWv.FeedForward(GetPointer(cNormV))) return false;
Criamos consultas dinâmicas.
if(!cQd.FeedForward(GetPointer(cWv))) return false;
E as agregamos no objeto da classe CNeuronXCiTOCL.
if(!cDQd.FeedForward(GetPointer(cQd))) return false; //--- return true; }
Como temos a substituição de buffers de dados, os resultados da camada interna cDQd são refletidos no buffer de resultados da nossa classe CNeuronFAQOCL sem operações desnecessárias de cópia. Portanto, podemos concluir o método.
A seguir, criamos os métodos de retropropagação CNeuronFAQOCL::calcInputGradients e CNeuronFAQOCL::updateInputWeights. Semelhante ao método de propagação para frente, aqui chamamos os métodos relevantes dos objetos internos, mas em ordem inversa. Portanto, não consideraremos o algoritmo em detalhes neste artigo. O código completo de todos os métodos da classe de geração de consultas dinâmicas CNeuronFAQOCL pode ser encontrado nos anexos do artigo.
2.2 Classe de Cross-Attention
O próximo passo é criar uma classe de Cross-Attention. Anteriormente, no contexto da implementação do método ADAPT, já criamos uma camada de cross-attention CNeuronMH2AttentionOCL. No entanto, naquela ocasião, analisamos as relações entre diferentes dimensões de um tensor. Agora a tarefa é um pouco diferente. Precisamos avaliar as dependências das consultas dinâmicas geradas da classe CNeuronFAQOCL para o estado comprimido do ambiente do Codificador do nosso modelo. Em outras palavras, precisamos avaliar a relação entre 2 tensores diferentes.
Para implementar essa funcionalidade, criaremos uma classe CNeuronCrossAttention, que herdará parte da funcionalidade necessária da classe CNeuronMH2AttentionOCL mencionada acima.
class CNeuronCrossAttention : public CNeuronMH2AttentionOCL { protected: uint iWindow_K; uint iUnits_K; CNeuronBaseOCL *cContext; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); virtual bool attentionOut(void); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context); virtual bool AttentionInsideGradients(void); public: CNeuronCrossAttention(void) {}; ~CNeuronCrossAttention(void) { delete cContext; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context); //--- virtual int Type(void) const { return defNeuronCrossAttenOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); };
Além do conjunto padrão de métodos sobrescritos, você pode notar 2 novas variáveis aqui:
- iWindow_K — o tamanho do vetor de descrição para um elemento do 2º tensor;
- iUnits_K — o número de elementos na sequência do 2º tensor.
Além disso, adicionaremos um ponteiro dinâmico para a camada neural auxiliar cContext, que será inicializada como um objeto-fonte, se necessário. Como este objeto desempenha um papel auxiliar opcional, o construtor da nossa classe permanece vazio. No entanto, no destrutor da classe, precisamos deletar o objeto dinâmico.
~CNeuronCrossAttention(void) { delete cContext; }
A inicialização do objeto, como de costume, é realizada no método CNeuronCrossAttention::Init. Nos parâmetros do método, obtemos os dados necessários sobre a arquitetura da camada criada. No corpo do método, chamamos o respectivo método da classe base de camadas neurais CNeuronBaseOCL::Init.
bool CNeuronCrossAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint window_k, uint units_k, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
Observe que estamos chamando o método de inicialização não da classe pai direta CNeuronMH2AttentionOCL, mas da classe base CNeuronBaseOCL. Isso se deve às diferenças nas arquiteturas das classes CNeuronCrossAttention e CNeuronMH2AttentionOCL. Portanto, mais adiante no corpo do método inicializamos não apenas objetos novos, mas também herdados.
Primeiro, salvamos as configurações da nossa camada.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iWindow_K = fmax(window_k, 1); iUnits_K = fmax(units_k, 1); iHeads = fmax(heads, 1); activation = None;
Em seguida, inicializamos a camada de geração de entidades Query.
if(!Q_Embedding.Init(0, 0, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, optimization_type, batch)) return false; Q_Embedding.SetActivationFunction(None);
Fazemos o mesmo para as entidades Key e Value.
if(!KV_Embedding.Init(0, 0, OpenCL, iWindow_K, iWindow_K, 2 * iWindowKey * iHeads, iUnits_K, optimization_type, batch)) return false; KV_Embedding.SetActivationFunction(None);
Por favor, não confunda as entidades Query geradas aqui com as Queries dinâmicas geradas na classe CNeuronFAQOCL.
Como parte da implementação do método FAQ, inseriremos as Queries dinâmicas geradas nesta classe como dados iniciais. Aqui podemos dizer que a camada Q_Embedding as distribui entre as cabeças de atenção. E a camada KV_Embedding gerará entidades a partir de uma representação comprimida do estado ambiental recebido do Codificador.
Mas voltemos ao nosso método de inicialização da classe. Após inicializar as camadas de geração de entidades, criaremos um buffer de matriz de coeficientes de dependência Score.
ScoreIndex = OpenCL.AddBuffer(sizeof(float) * iUnits * iUnits_K * iHeads, CL_MEM_READ_WRITE); if(ScoreIndex == INVALID_HANDLE) return false;
Aqui também criamos uma camada de resultados da atenção multihead.
if(!MHAttentionOut.Init(0, 0, OpenCL, iWindowKey * iUnits * iHeads, optimization_type, batch)) return false; MHAttentionOut.SetActivationFunction(None);
E uma camada de agregação das cabeças de atenção.
if(!W0.Init(0, 0, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, optimization_type, batch)) return false; W0.SetActivationFunction(None); if(!AttentionOut.Init(0, 0, OpenCL, iWindow * iUnits, optimization_type, batch)) return false; AttentionOut.SetActivationFunction(None);
Em seguida, vem o bloco FeedForward.
if(!FF[0].Init(0, 0, OpenCL, iWindow, iWindow, 4 * iWindow, iUnits, optimization_type, batch)) return false; if(!FF[1].Init(0, 0, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, optimization_type, batch)) return false; for(int i = 0; i < 2; i++) FF[i].SetActivationFunction(None);
No final do método de inicialização, organizamos a substituição de buffers.
Gradient.BufferFree(); delete Gradient; Gradient = FF[1].getGradient(); //--- return true; }
Após inicializar a classe, como de costume, prosseguimos para organizar a propagação para frente. Dentro desta classe, não criaremos novos kernels no lado do programa OpenCL. Neste caso, usaremos kernels criados para implementar processos da classe pai. No entanto, precisamos fazer alguns pequenos ajustes nos métodos de chamada dos kernels. Por exemplo, no método CNeuronCrossAttention::attentionOut, mudaremos apenas os arrays que indicam o espaço da tarefa e os grupos locais em termos do tamanho da sequência da entidade Key (destacado no código em vermelho).
bool CNeuronCrossAttention::attentionOut(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits/*Q units*/, iUnits_K/*K units*/, iHeads}; uint local_work_size[3] = {1, iUnits_K, 1}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, MHAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Todo o algoritmo de propagação para frente é descrito no nível superior, no método CNeuronCrossAttention::feedForward. Ao contrário do método relevante da classe pai, este método recebe ponteiros para 2 objetos de camadas neurais em seus parâmetros. Eles contêm os dados de 2 tensores para análise de dependência.
bool CNeuronCrossAttention::feedForward(CNeuronBaseOCL *NeuronOCL, CNeuronBaseOCL *Context) { //--- if(!Q_Embedding.FeedForward(NeuronOCL)) return false; //--- if(!KV_Embedding.FeedForward(Context)) return false;
No corpo do método, primeiro geramos entidades a partir dos dados recebidos. Em seguida, chamamos o método de atenção multihead.
if(!attentionOut()) return false;
Agregamos os resultados da atenção.
if(!W0.FeedForward(GetPointer(MHAttentionOut))) return false;
E somamos com os dados de origem. Após isso, normalizamos o resultado nos elementos da sequência. No contexto da implementação do método FAQ, a normalização será realizada no contexto de queries dinâmicas individuais.
if(!SumAndNormilize(W0.getOutput(), NeuronOCL.getOutput(), AttentionOut.getOutput(), iWindow)) return false;
Os dados então passam pelo bloco FeedForward.
if(!FF[0].FeedForward(GetPointer(AttentionOut))) return false; if(!FF[1].FeedForward(GetPointer(FF[0]))) return false;
Depois, somamos e normalizamos os dados novamente.
if(!SumAndNormilize(FF[1].getOutput(), AttentionOut.getOutput(), Output, iWindow)) return false; //--- return true; }
Após completar com sucesso todas as operações acima, encerramos o método.
Com isso, completamos a descrição do método de propagação para frente e passamos a organizar a propagação reversa. Aqui também usamos o kernel criado como parte da implementação da classe pai e fazemos mudanças específicas no método de chamada do kernel CNeuronCrossAttention::AttentionInsideGradients.
bool CNeuronCrossAttention::AttentionInsideGradients(void) { if(!OpenCL) return false; //--- uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindowKey, iHeads}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_q, Q_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_qg, Q_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kv, KV_Embedding.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kvg, KV_Embedding.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_score, ScoreIndex)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionInsideGradients, def_k_mh2aig_outg, MHAttentionOut.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionInsideGradients, def_k_mh2aig_kunits, (int)iUnits_K)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MH2AttentionInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
O processo de propagação do gradiente de erro através da nossa camada de cross-attention é implementado no método CNeuronCrossAttention::calcInputGradients. Assim como no método de propagação para frente, nos parâmetros deste método passamos ponteiros para 2 camadas com 2 fluxos de dados.
bool CNeuronCrossAttention::calcInputGradients(CNeuronBaseOCL *prevLayer, CNeuronBaseOCL *Context) { if(!FF[1].calcInputGradients(GetPointer(FF[0]))) return false; if(!FF[0].calcInputGradients(GetPointer(AttentionOut))) return false;
Graças à substituição dos buffers de dados, o gradiente de erro obtido da camada subsequente é imediatamente propagado para o buffer de gradiente de erro da 2ª camada do bloco FeedForward. Portanto, não precisamos copiar os dados. Em seguida, chamamos imediatamente os métodos para distribuir o gradiente de erro das camadas internas do bloco FeedForward.
Nesta etapa, precisamos adicionar o gradiente de erro recebido do bloco FeedForward e da camada neural subsequente.
if(!SumAndNormilize(FF[1].getGradient(), AttentionOut.getGradient(), W0.getGradient(), iWindow, false)) return false;
Em seguida, distribuímos o gradiente de erro pelas cabeças de atenção.
if(!W0.calcInputGradients(GetPointer(MHAttentionOut))) return false;
Chamamos o método para propagar o gradiente de erro para as entidades Query, Key e Value.
if(!AttentionInsideGradients()) return false;
O gradiente das entidades Key e Value é transferido para a camada Context (Codificador).
if(!KV_Embedding.calcInputGradients(Context)) return false;
O gradiente de Query é transferido para a camada anterior.
if(!Q_Embedding.calcInputGradients(prevLayer)) return false;
Não se esqueça de somar os gradientes de erro.
if(!SumAndNormilize(prevLayer.getGradient(), W0.getGradient(), prevLayer.getGradient(), iWindow, false)) return false; //--- return true; }
Então, completamos o método.
O método de atualização dos parâmetros internos dos objetos CNeuronCrossAttention::updateInputWeights é bastante simples. Ele apenas chama os métodos relevantes nos objetos internos um por um. Você pode encontrá-los no anexo. Além disso, o anexo contém os métodos de operação de arquivo necessários. E contém, também, o código completo de todos os programas e classes usados neste artigo.
Com isso, completamos criar novas classes e passamos a descrever a arquitetura do modelo.
2.3 Arquitetura do Modelo
A arquitetura dos modelos é apresentada no método CreateDescriptions. A arquitetura atual dos modelos é amplamente copiada da implementação do método DFFT. No entanto, adicionamos um Decodificador. Portanto, o Ator e o Crítico recebem dados do Decodificador. Assim, para criar uma descrição dos modelos, precisamos de 4 arrays dinâmicos.
bool CreateDescriptions(CArrayObj *dot, CArrayObj *decoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!dot) { dot = new CArrayObj(); if(!dot) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
O modelo Codificador (dot) foi copiado do artigo anterior sem alterações. Você pode encontrar sua descrição detalhada aqui.
O Decodificador usa os dados latentes do Codificador no nível da camada de codificação posicional como dados de entrada.
//--- Decoder decoder.Clear(); //--- Input layer CLayerDescription *po = dot.At(LatentLayer); if(!po || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = po.count * po.window; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Lembre-se de que, neste nível, removemos embeddings de vários estados ambientais armazenados na pilha local com rótulos de codificação posicional adicionados. По essência, esses dados contêm uma sequência de características que descrevem o estado do ambiente para as velas GPTBars. Isso pode ser comparado aos quadros de uma série de vídeos. Com base nesses dados, geramos Queries dinâmicas.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFAQOCL; { int temp[] = {QueryCount, po.count}; ArrayCopy(descr.units, temp); } descr.window = po.window; descr.window_out = 16; descr.optimization = ADAM; descr.step = 4; descr.activation = None; if(!decoder.Add(descr)) { delete descr; return false; }
E implementamos Cross-Attention.
//--- layer 2 CLayerDescription *encoder = dot.At(dot.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {QueryCount, encoder.count}; ArrayCopy(descr.units, temp); } { int temp[] = {16, encoder.window}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
O Ator recebe dados do Decodificador.
//--- Actor actor.Clear(); //--- Input layer encoder = decoder.At(decoder.Total() - 1); if(!encoder || !(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = encoder.units[0] * encoder.windows[0]; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
E os combina com a descrição do estado da conta.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
Depois disso, os dados passam por 2 camadas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Na saída, adicionamos estocasticidade à política do Ator.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O modelo Crítico foi copiado quase como está. A única mudança é que a fonte dos dados iniciais foi alterada de Codificador para Decodificador.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(0)); if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.Copy(actor.At(1)); descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 EAs de Interação com o Ambiente
Ao preparar este artigo, usei 3 EAs de interação com o ambiente:
- Research.mq5
- ResearchRealORL.mq5
- Test.mq5
O EA "...\Experts\FAQ\ResearchRealORL.mq5" não está vinculado à arquitetura dos modelos. Como todos os EAs são treinados e testados analisando os mesmos dados iniciais que descrevem o ambiente, este EA é utilizado em diferentes artigos sem alterações. Você pode encontrar uma descrição completa do seu código e abordagens de uso aqui.
No código do EA "...\Experts\FAQ\Research.mq5", adicionamos um modelo Decodificador.
CNet DOT; CNet Decoder; CNet Actor;
Conforme necessário, no método de inicialização, adicionamos o carregamento deste modelo e, se necessário, a inicialização com parâmetros aleatórios.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; //--- if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; } //--- Decoder.SetOpenCL(DOT.GetOpenCL()); Actor.SetOpenCL(DOT.GetOpenCL()); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Observe que, neste caso, não estamos usando o modelo Crítico. Sua funcionalidade não está envolvida no processo de interação com o ambiente e coleta de dados para treinamento.
O processo real de interação com o ambiente é organizado no método OnTick. No corpo do método, primeiro verificamos a ocorrência de um novo evento de abertura de barra.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Todo o processo é baseado na análise de velas fechadas.
Quando o evento necessário ocorre, primeiro carregamos os dados históricos.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Transferimos os dados para o buffer que descreve o estado atual do ambiente.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Depois, coletamos dados sobre o estado da conta e posições abertas.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Os dados recebidos são agrupados no buffer de estado da conta.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
Também adicionamos as harmônicas de timestamp aqui.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Os dados coletados são alimentados primeiro na entrada do Codificador.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Os resultados da operação do Codificador são transferidos para o Decodificador.
if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer,(CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; }
Depois, são transferidos para o Ator.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } //--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Carregamos as ações previstas pelo Ator e excluímos operações contrárias.
vector<float> temp; Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Depois, decodificamos as ações previstas e executamos as ações de trading necessárias. Primeiro, implementamos posições longas.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Depois, posições curtas.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
No final do método, salvamos os resultados da interação com o ambiente no buffer de reprodução de experiência.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
Os outros métodos do EA não sofreram alterações.
Mudanças semelhantes foram feitas no EA "...\Experts\FAQ\Test.mq5". Você pode estudar o código completo de ambos os EAs no anexo.
2.5 Treinamento do modelo EA
Os modelos são treinados no EA "...\Experts\FAQ\Study.mq5". Assim como nos EAs desenvolvidos anteriormente, a estrutura do EA é copiada de trabalhos anteriores. Conforme as mudanças na arquitetura do modelo, adicionamos um Decodificador.
CNet DOT; CNet Decoder; CNet Actor; CNet Critic;
Como pode ver, o Crítico também participa do processo de treinamento do modelo.
No método de inicialização do EA, primeiro carregamos os dados de treinamento.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
A seguir, tentamos carregar os modelos pré-treinados. Se não conseguirmos carregar os modelos, criamos novos modelos e os inicializamos com parâmetros aleatórios.
//--- load models float temp; if(!DOT.Load(FileName + "DOT.nnw", temp, temp, temp, dtStudied, true) || !Decoder.Load(FileName + "Dec.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic.Load(FileName + "Crt.nnw", temp, temp, temp, dtStudied, true) ) { CArrayObj *dot = new CArrayObj(); CArrayObj *decoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(dot, decoder, actor, critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } if(!DOT.Create(dot) || !Decoder.Create(decoder) || !Actor.Create(actor) || !Critic.Create(critic)) { delete dot; delete decoder; delete actor; delete critic; return INIT_FAILED; } delete dot; delete decoder; delete actor; delete critic; }
Transferimos todos os modelos para um contexto OpenCL.
OpenCL = DOT.GetOpenCL(); Decoder.SetOpenCL(OpenCL); Actor.SetOpenCL(OpenCL); Critic.SetOpenCL(OpenCL);
Implementamos um controle mínimo sobre a conformidade da arquitetura dos modelos.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- DOT.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Criamos buffers de dados auxiliares.
if(!bGradient.BufferInit(MathMax(AccountDescr, NForecast), 0) || !bGradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; }
E geramos um evento personalizado para o início do processo de aprendizado.
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
No método de desinicialização do EA, salvamos os modelos treinados e limpamos a memória dos objetos dinâmicos.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); DOT.Save(FileName + "DOT.nnw", 0, 0, 0, TimeCurrent(), true); Decoder.Save(FileName + "Dec.nnw", 0, 0, 0, TimeCurrent(), true); Critic.Save(FileName + "Crt.nnw", 0, 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
O processo de treinamento dos modelos é implementado no método Train. No corpo do método, primeiro determinamos a probabilidade de escolher trajetórias de acordo com sua rentabilidade.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Depois, declaramos variáveis locais.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Então, criamos um sistema de loops aninhados para o processo de aprendizado.
A arquitetura do Codificador fornece uma camada de Embedding com um buffer interno para acumular dados históricos. Esse tipo de solução arquitetônica é muito sensível à sequência histórica dos dados recebidos. Portanto, para treinar os modelos, organizamos um sistema de loops aninhados. O loop externo conta o número de lotes de treinamento. Em um loop aninhado dentro do lote de treinamento, os dados iniciais são fornecidos em cronologia histórica.
No corpo do loop externo, amostramos uma trajetória e o estado para iniciar o lote de treinamento.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
Limpamos o buffer interno usado para a acumulação de dados históricos.
DOT.Clear();
Determinamos o estado do fim do pacote de treinamento.
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
Então, organizamos um loop de aprendizado aninhado. No seu corpo, primeiro carregamos uma descrição histórica do estado do ambiente do buffer de reprodução de experiência.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state);
Com os dados disponíveis, executamos uma propagação para frente pelo Codificador e Decodificador.
//--- Trajectory if(!DOT.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(!Decoder.feedForward((CNet*)GetPointer(DOT), LatentLayer, (CNet*)GetPointer(DOT))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Também carregamos a descrição correspondente do estado da conta do buffer de reprodução de experiência e transferimos os dados para o buffer apropriado.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Adicionamos as harmônicas de timestamp.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
O processo repete completamente o dos EAs de interação com o ambiente. No entanto, não consultamos o terminal, mas carregamos todos os dados do buffer de reprodução de experiência.
Após receber os dados, podemos realizar uma propagação para frente sequencial para o Ator e Crítico.
//--- Actor if(!Actor.feedForward((CNet *)GetPointer(Decoder), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } //--- Critic if(!Critic.feedForward((CNet *)GetPointer(Decoder), -1, (CNet*)GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A propagação para frente é seguida por uma propagação reversa, durante a qual os parâmetros do modelo são otimizados. Primeiro, realizamos uma propagação reversa do Ator para minimizar o erro nas ações do buffer de reprodução de experiência.
Result.AssignArray(Buffer[tr].States[i].action); if(!Actor.backProp(Result, (CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient)) ||
O gradiente de erro do Ator é transferido para o Decodificador.
!Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) ||
O Decodificador, por sua vez, transmite o gradiente de erro para o Codificador. Note que o Decodificador recebe os dados iniciais de 2 camadas do Codificador e transmite o gradiente de erro para 2 camadas correspondentes. Para atualizar corretamente os parâmetros do modelo, primeiro propagamos o gradiente da camada latente.
!DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) ||
E só então por toda a modelagem do Codificador.
!DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Em seguida, determinamos a recompensa para a próxima transição.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result);
E otimizamos os parâmetros do Crítico com subsequente transmissão do gradiente de erro para todos os modelos participantes.
if(!Critic.backProp(Result, (CNet *)GetPointer(Actor)) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) || !Actor.backPropGradient((CBufferFloat *)GetPointer(bAccount), (CBufferFloat *)GetPointer(bGradient), -1, false) || !Decoder.backPropGradient((CNet *)GetPointer(DOT), -1, -1, false) || !DOT.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer) || !DOT.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
No final das operações no sistema de loops, informamos ao usuário sobre o progresso do treinamento e passamos para a próxima iteração.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após concluir com sucesso todas as iterações do sistema de loops de treinamento do modelo, limpamos o campo de comentários no gráfico.
Comment("");
Também imprimimos os resultados do treinamento no log do terminal e iniciamos a terminação do EA.
PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Isso conclui a descrição dos algoritmos dos programas utilizados. Você pode revisar o código completo deles no anexo. Agora passamos para a parte final do artigo: testar o trabalho realizado.
3. Testes
Neste artigo, nos familiarizamos com o método Feature Aggregated Queries e implementamos suas abordagens usando MQL5. Chegou o momento de avaliar os resultados do nosso trabalho. Como sempre, treinei e testei meu modelo em dados históricos do instrumento EURUSD com o timeframe H1. Os modelos são treinados em um período histórico dos primeiros 7 meses de 2023. Para testar os modelos treinados, usamos dados históricos de agosto de 2023.
O modelo discutido neste artigo analisa dados de entrada de forma semelhante aos modelos dos artigos anteriores. Os vetores de ações do Ator e as recompensas para as transições para um novo estado também são idênticos aos artigos anteriores. Portanto, para treinar os modelos, podemos usar o buffer de reprodução de experiência coletado durante o treinamento dos modelos dos artigos anteriores. Para isso, basta renomear o arquivo para "FAQ.bd".
No entanto, se você não tiver um arquivo dos trabalhos anteriores ou quiser criar um novo, recomendo primeiro salvar algumas passagens usando o histórico de negociações de sinais reais. Isso foi descrito no artigo sobre o método RealORL.
Depois, você pode complementar o buffer de reprodução de experiência com passagens aleatórias usando o EA "...\\Experts\\FAQ\\Research.mq5". Para isso, execute a otimização lenta deste EA no MetaTrader 5 Strategy Tester com dados históricos do período de treinamento.
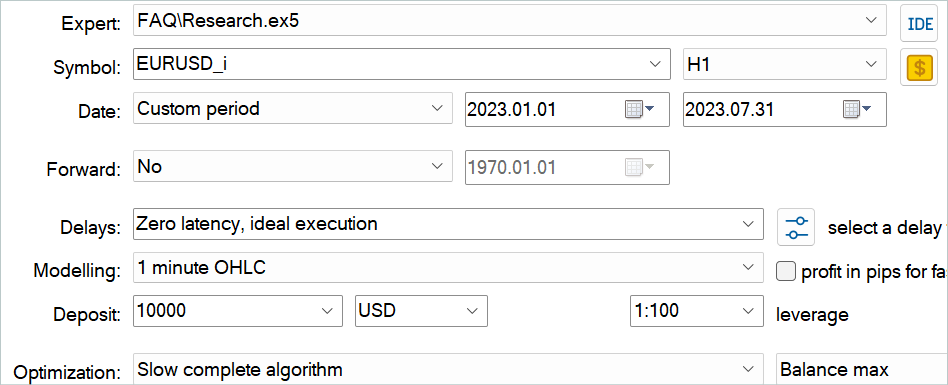
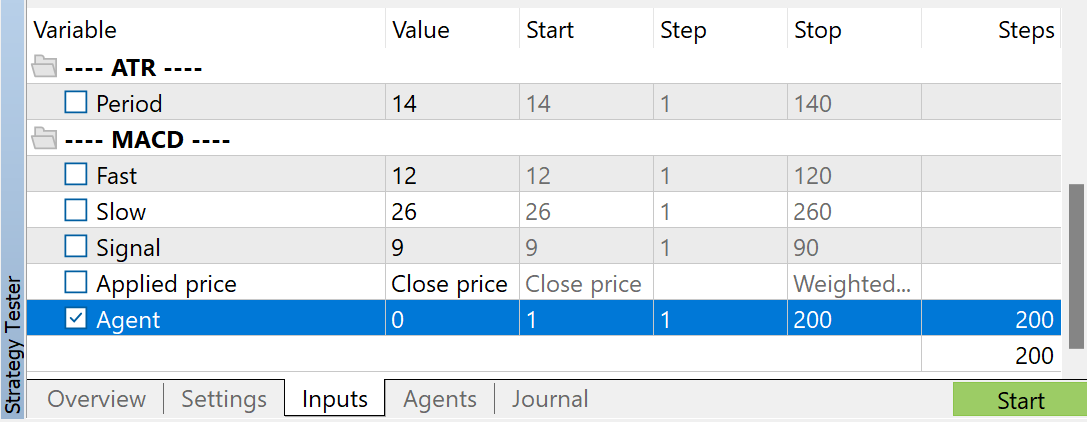
Você pode usar quaisquer parâmetros de indicadores. Mas é muito importante usar os mesmos parâmetros ao coletar a amostra de treinamento e ao testar o modelo treinado. Esses parâmetros também precisam ser salvos para a operação do modelo. Ao preparar o artigo, usei as configurações padrão para todos os indicadores.
Para regular o número de passagens coletadas, uso a otimização para o parâmetro Agent. Este parâmetro foi adicionado ao EA apenas para regular as passagens de otimização e não é utilizado no código do EA.
Após coletar os dados de treinamento, executamos o EA "...\\Experts\\FAQ\\Study.mq5" no gráfico em tempo real. O código do EA treina os modelos usando a amostra de treinamento coletada sem realizar operações de negociação. Portanto, a operação do EA em um gráfico real não afetará o saldo da sua conta.
Normalmente, utilizo uma abordagem iterativa para treinar modelos. Durante esse processo, alterno o treinamento dos modelos com a coleta de dados adicionais para a amostra de treinamento. Com essa abordagem, o tamanho do nosso conjunto de dados de treinamento é limitado e não consegue cobrir toda a variedade de comportamentos do Agente no ambiente. Durante os próximos lançamentos do EA "...\\Experts\\FAQ\\Research.mq5", no processo de interação com o ambiente, ele se guiará pela nossa política treinada em vez de uma política aleatória. Assim, reabastecemos o buffer de reprodução de experiência com estados e ações próximos à nossa política. Dessa forma, exploramos o ambiente ao redor da nossa política, similarmente ao processo de aprendizado online. Isso significa que, durante os treinamentos subsequentes, recebemos recompensas reais por ações em vez de interpoladas. Isso ajudará nosso Ator a ajustar a política na direção correta.
Ao mesmo tempo, monitoramos periodicamente os resultados do treinamento em dados não incluídos no conjunto de treinamento.
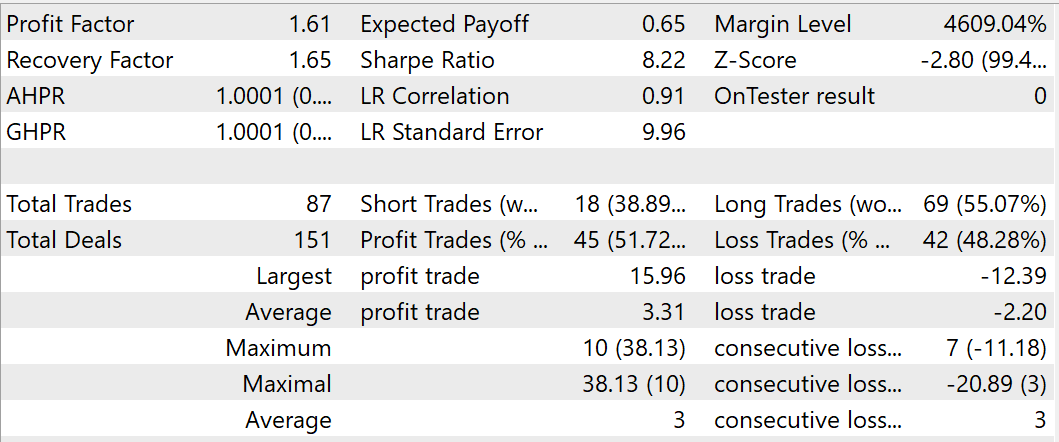
Durante o processo de treinamento, consegui obter um modelo capaz de gerar lucro nos conjuntos de dados de treinamento e teste. Durante o teste do modelo treinado, em agosto de 2023, o EA realizou 87 negociações, das quais 45 foram fechadas com lucro. Isso equivale a 51,72%. Os lucros da negociação mais lucrativa e da média das negociações lucrativas superam os valores correspondentes das negociações perdedoras. Durante o período de teste, o EA alcançou um fator de lucro de 1,61 e um fator de recuperação de 1,65.
Conclusão
Neste artigo, nos familiarizamos com o método de detecção de objetos em vídeo Feature Aggregated Queries. Os autores deste método focaram na inicialização de queries e na agregação das mesmas com base nos dados de entrada para detectores baseados na arquitetura Transformer, a fim de equilibrar a eficiência e o desempenho do modelo. Eles desenvolveram um módulo de agregação de queries que amplia a representação dos detectores de objetos. Isso melhora seu desempenho em tarefas de vídeo.
Além disso, os autores do método FAQ estenderam o módulo de agregação de queries para uma versão dinâmica, que pode gerar inicializações de queries adaptativamente e ajustar os pesos de agregação de queries conforme os dados de origem.
O método proposto é um módulo plug-and-play que pode ser integrado à maioria dos detectores de objetos modernos baseados em Transformer para resolver problemas em vídeo e outras sequências temporais.
Na parte prática deste artigo, implementamos as abordagens propostas utilizando MQL5. Treinamos o modelo em dados históricos reais e o testamos em um período fora do conjunto de treinamento. Nossos resultados de teste confirmam a eficácia das abordagens propostas. No entanto, o período de treinamento e teste é bastante curto para tirar conclusões específicas. Todos os programas apresentados neste artigo são destinados apenas para demonstrar e testar as abordagens propostas.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA para coleta de exemplos usando o método Real-ORL |
| 3 | Study.mq5 | EA | EA para treinamento de modelos |
| 4 | Test.mq5 | EA | EA para testar o modelo |
| 5 | Trajectory.mqh | Biblioteca de classes | Estrutura para descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classes | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código para o programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14394
 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso