
Redes neurais de maneira fácil (Parte 70): melhorando a política usando operadores de forma fechada (CFPI)

Introdução
A abordagem de otimização da política do Agente, considerando restrições em seu comportamento, tem se mostrado promissora na resolução de problemas de aprendizado por reforço off-line. Mediante transições históricas, treina-se uma política de comportamento do Agente voltada para maximizar o valor da função de valor.
As restrições no comportamento ajudam a evitar mudanças significativas na distribuição das ações do Agente, proporcionando confiança suficiente na avaliação do custo das ações. No artigo anterior, discutimos o método SPOT, que explora essa abordagem. Como continuidade do tema, propomos conhecer o algoritmo Closed-Form Policy Improvement (CFPI), apresentado no artigo "Offline Reinforcement Learning with Closed-Form Policy Improvement Operators".
1. Algoritmo Closed-Form Policy Improvement (CFPI)
Uma expressão de forma fechada é uma função matemática expressa por meio de um número finito de operações padrão. Ela pode conter constantes, variáveis, operações padrão e funções, mas geralmente não contém limites, expressões diferenciais ou integrais. Assim, o método CFPI que estamos analisando introduz alguns elementos analíticos no algoritmo de aprendizado da política do Agente.
A maioria dos modelos existentes para aprendizado por reforço off-line utiliza descida de gradiente estocástico (SGD) para otimizar suas estratégias, o que pode levar a instabilidade no processo de treinamento e exige um ajuste cuidadoso da taxa de aprendizado. Além disso, o desempenho das estratégias treinadas off-line pode depender do ponto específico de avaliação. Isso frequentemente resulta em variações significativas na fase final do treinamento. Essa instabilidade representa uma grande dificuldade no aprendizado por reforço off-line, pois o acesso limitado à interação com o ambiente dificulta o ajuste dos hiperparâmetros. Além das variações em diferentes pontos de avaliação, o uso de SGD para melhorar a estratégia pode levar a variações significativas no desempenho sob diferentes condições iniciais aleatórias.
Em seu trabalho, os autores do método CFPI procuram reduzir a instabilidade mencionada no aprendizado por reforço off-line. Eles desenvolvem operadores de melhoria de estratégia estáveis. Em particular, eles observam que a necessidade de limitar a mudança distributiva motiva o uso da aproximação de Taylor de primeira ordem, que leva a uma aproximação linear da função objetiva da política do Agente, que é precisa em uma vizinhança suficientemente pequena da ação da política de comportamento. Com base nessa observação chave, os autores constroem operadores de melhoria de estratégia que retornam soluções de forma fechada.
Modelando as políticas de comportamento como uma distribuição gaussiana unitária, o operador de melhoria de estratégia proposto pelos autores do CFPI desloca deterministicamente a política de comportamento na direção de melhoria do valor. Como resultado, o método proposto Closed-Form Policy Improvement evita a instabilidade no treinamento ao melhorar a estratégia, pois utiliza apenas o treinamento de políticas de comportamento básicas em um determinado conjunto de dados.
Os autores do método CFPI também observam que conjuntos de dados práticos geralmente são coletados por estratégias heterogêneas. Isso pode levar a uma distribuição multimodal das ações do Agente. Nesse caso, uma distribuição gaussiana unitária não conseguiria capturar muitas das modas da distribuição subjacente, limitando o potencial de melhoria da estratégia. Modelar a política de comportamento como uma mistura de distribuições gaussianas oferece melhor expressividade, mas acarreta complexidades adicionais na otimização. Os autores resolvem esse problema utilizando a fronteira inferior LogSumExp e a desigualdade de Jensen, o que também leva a um operador de melhoria de estratégia de forma fechada, aplicável a políticas de comportamento multimodais.
Os autores destacam as seguintes contribuições do método Closed-Form Policy Improvement:
- Operadores CFPI, compatíveis com políticas de comportamento unimodais e multimodais, e capazes de melhorar políticas aprendidas por outros algoritmos.
- Evidências empíricas dos benefícios de modelar a política de comportamento como uma mistura de distribuições gaussianas.
- Variações de um passo e iterativas do algoritmo proposto superam algoritmos anteriores em benchmarks padrão.
Os autores do CFPI criam um operador de melhoria de estratégia analítico sem necessidade de treinamento, visando evitar a instabilidade em cenários off-line. Eles observam que a otimização em relação à função objetivo gera uma política que permite um desvio limitado da política de comportamento no conjunto de dados off-line. Consequentemente, ela solicitará o valor Q apenas na vizinhança da ação de comportamento durante o treinamento. Isso motiva naturalmente o uso de uma aproximação linear de primeira ordem.
A avaliação das ações na política atualizada fornece uma aproximação linear precisa da função de valor aprendida apenas em uma vizinhança suficientemente pequena da distribuição do conjunto de dados de treinamento. Por isso, a escolha do par "Estado-Ação" do conjunto de dados de treinamento é fundamental para o resultado final do treinamento.
Para resolver a tarefa proposta, os autores sugerem resolver a seguinte tarefa aproximada para qualquer estado S:
![]()
É importante notar que D(•,•) não precisa ser uma função de divergência matematicamente definida. Qualquer D(•,•) geral que possa restringir o desvio da ação da política de comportamento do Agente da distribuição do conjunto de dados de treinamento pode ser considerada.
No caso geral, a tarefa acima nem sempre tem uma solução de forma fechada. Os autores do método CFPI analisam um caso especial:
- Uma política gaussiana é usada para coletar o conjunto de dados de treinamento.
- Uma política de comportamento determinística do Agente é treinada.
- D(•,•) é uma função de verossimilhança negativa.
Nesse cenário, uma escolha razoável para treinar a política é concentrar-se em torno da distribuição do conjunto de dados de treinamento. Então, a tarefa de otimização proposta pode ser representada em uma expressão de forma fechada:
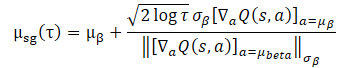
O uso desta expressão de forma fechada para melhorar a política do Agente traz uma melhor desempenho computacional e evita a potencial instabilidade causada pelo SGD. No entanto, sua aplicabilidade depende da suposição de uma única gaussiana para a estratégia de coleta do conjunto de treinamento. Na prática, os conjuntos de dados históricos geralmente são coletados por estratégias heterogêneas com diferentes níveis de expertise. Uma gaussiana unidimensional pode não captar toda a distribuição, então parece razoável usar uma mistura de gaussianas para representar a política de coleta de dados.
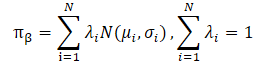
No entanto, a substituição direta de uma mistura de gaussianas para políticas de coleta de dados de treinamento compromete a aplicabilidade da tarefa apresentada, pois resulta em uma função objetivo não convexa. Aqui enfrentamos dois principais problemas ao resolver a tarefa de otimização.
Primeiro, não está claro como escolher a ação adequada do conjunto de treinamento. Além disso, é necessário garantir que a solução da política objetivo esteja em uma vizinhança próxima da ação escolhida.
Em segundo lugar, o uso de uma mistura de gaussianas não permite uma forma convexa, o que representa um desafio na otimização.
A aplicação do LogSumExp permite transformar a tarefa de otimização.
![]()
O que pode ser representado como uma expressão de forma fechada.
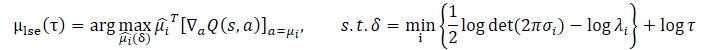
O uso da desigualdade de Jensen permite obter a seguinte tarefa de otimização:
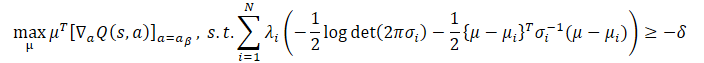
A forma fechada da solução para esta tarefa é:
![]()
Em comparação com a tarefa de otimização original, ambas as adições propostas impõem restrições mais rigorosas ao intervalo de confiança. Isso é alcançado garantindo que o limite inferior das probabilidades logarítmicas da mistura de gaussianas esteja acima de um certo valor limiar. Simultaneamente, o parâmetro τ controla o tamanho do intervalo de confiança.
Ambas as tarefas de otimização têm seus prós e contras. Quando a distribuição do conjunto de treinamento apresenta multimodalidade evidente, o limite inferior do logaritmo da política de coleta de dados, construído usando a desigualdade de Jensen, não pode capturar os diversos modos devido à sua concavidade, perdendo a vantagem de modelar a política de coleta de dados como uma mistura de gaussianas. Nesse caso, a tarefa de otimização LogSumExp pode servir como uma substituição razoável para a tarefa de otimização original, pois o limite inferior do LogSumExp preserva a multimodalidade do logaritmo da política de coleta de dados.
Quando a distribuição do conjunto de treinamento se reduz a uma única gaussiana, a aproximação usando a desigualdade de Jensen se torna uma igualdade. Assim, µjensen resolve exatamente a tarefa de otimização proposta. No entanto, neste caso, o grau de precisão do limite inferior do LogSumExp depende significativamente dos pesos λi=1...N.
Felizmente, podemos combinar as melhores qualidades de ambas as abordagens e obter um operador CFPI que leva em conta todos os cenários mencionados acima, retornando uma política de comportamento que escolhe a ação mais bem avaliada de µlse e µjensen:
![]()
No artigo original, você pode encontrar derivações detalhadas e provas da aplicabilidade de todas as expressões apresentadas.
Os autores do método CFPI destacam que o método proposto também é aplicável a distribuições de conjuntos de treinamento não-gaussianos. Além disso, os operadores CFPI apresentados permitem criar um modelo geral de aprendizado off-line com a possibilidade de obtenção de métodos unipasso, multipasso e iterativos.
Para a avaliação das ações, é utilizada uma modelo Crítico previamente treinado. O treinamento desse modelo pode ser realizado no conjunto de treinamento por qualquer método conhecido. Isso, essencialmente, constitui a primeira etapa do algoritmo de treinamento do modelo.
Em seguida, é amostrado um certo lote de Estados do conjunto de treinamento. Para esse lote, são geradas Ações com base na política atual do Agente. Depois disso, é realizada a avaliação das ações obtidas usando os operadores CFPI propostos anteriormente.
Com base nos resultados dessa avaliação, são escolhidos os estados ótimos, nos quais se realiza a atualização da política do Agente.
Na construção de métodos multipasso e iterativos, o processo se repete.
Embora o desenvolvimento dos operadores CFPI tenha sido inspirado pelo paradigma de restrição da política do Agente pelo comportamento, as abordagens propostas são compatíveis com os métodos básicos gerais de aprendizado por reforço. No artigo original, são demonstrados exemplos em que os operadores CFPI aumentaram a eficiência das estratégias aprendidas utilizando outros algoritmos.
2. Implementação com MQL5
A descrição acima é uma descrição teórica do método Closed-Form Policy Improvement. Concordo que as fórmulas matemáticas apresentadas podem parecer bastante complexas. Mas tentaremos entendê-las mais detalhadamente durante a implementação das abordagens propostas.
Imediatamente, deve-se notar que no algoritmo de treinamento de modelos proposto pelos autores do artigo, está previsto o treinamento sequencial do Crítico e do Ator. Primeiro, o modelo Crítico é treinado. E só então começamos a treinar a política do Ator.
Com essa abordagem, nosso método, no qual o Crítico usa o modelo do Ator para pré-processamento dos dados de entrada, se torna irrelevante. Pois na fase de treinamento do Crítico, o modelo do Ator ainda não está formado. Claro, poderíamos gerar o modelo do Ator e usá-lo como antes. Mas nesse caso, enfrentamos o seguinte problema: na fase de treinamento da política, o algoritmo CFPI não prevê a atualização do modelo do Crítico. E a mudança nos parâmetros do Ator levará necessariamente à mudança nos parâmetros do pré-processamento dos dados de entrada. E, nesse caso, a distribuição na entrada do Crítico muda. O que, no geral, leva à distorção da avaliação das ações do Ator.
Para corrigir a situação descrita, podemos deixar de usar o Codificador geral do estado inicial ou movê-lo para um modelo separado.
Não podemos transferir o Codificador para o modelo do Crítico, pois para a propagação do Crítico são necessárias ações geradas pelo Ator. E para a propagação do Ator são necessários os resultados do Codificador. O ciclo se fechou.
2.1 Arquitetura dos modelos
Na minha implementação, decidi mover o Codificador do estado do ambiente para um modelo separado, o que se refletiu na arquitetura dos modelos. A descrição da arquitetura dos modelos é dada no método CreateDescriptions. Apesar do treinamento sequencial dos modelos Ator e Crítico, eu não separei a descrição da arquitetura dos modelos em dois métodos. Nos parâmetros, o método recebe ponteiros para três arrays dinâmicos de objetos para registrar a arquitetura dos modelos.
No corpo do método, verificamos a validade dos ponteiros recebidos e, se necessário, criamos novas instâncias dos objetos dos arrays.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
Primeiro vem a descrição da arquitetura do Codificador do estado atual. A arquitetura do modelo começa com a camada de dados de entrada, cujo tamanho deve ser suficiente para registrar informações sobre o movimento dos preços e os indicadores em toda a profundidade do histórico analisado.
//--- State Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os "dados brutos" recebidos passam por um processamento inicial na camada de normalização em lote.
Em seguida, vem um bloco convolucional, que permite reduzir a dimensionalidade dos dados enquanto identifica padrões consistentes.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Os resultados do bloco convolucional são processados por dois camadas totalmente conectadas.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os dados processados dessa maneira são complementados com informações sobre o estado da conta, que incluem as harmônicas da marca de tempo.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!encoder.Add(descr)) { delete descr; return false; }
Na saída do Codificador, criamos estocasticidade. Isso nos permite tanto reduzir a possibilidade de overfitting do modelo quanto aumentar a estabilidade do modelo em um ambiente externo estocástico.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A seguir, vem a descrição da arquitetura do Ator. Na entrada, ele recebe os resultados do codificador do ambiente descrito acima.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Como pode ser observado, no codificador foi realizado todo o trabalho preparatório de processamento dos dados de entrada. Isso permite tornar o modelo do Ator o mais simples possível. Aqui, criamos três camadas totalmente conectadas.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
E na saída do modelo, formamos uma política estocástica em um espaço contínuo de ações.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O modelo Crítico também usa os resultados do Codificador como dados de entrada. Mas, ao contrário do modelo do Ator, ele complementa esses dados com um vetor das Ações avaliadas. Por isso, após a camada de dados de entrada, utilizamos uma camada de concatenação, que une dois tensores de dados de entrada.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; }
Em seguida, vem o bloco de tomada de decisão, composto por camadas totalmente conectadas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Com isso, concluímos a descrição da arquitetura dos modelos e passamos à construção do algoritmo de treinamento dos modelos.
Claro, antes de iniciar o treinamento dos modelos, precisamos coletar o conjunto de treinamento. E desta vez, não posso dizer que os advisors de interação com o ambiente foram transferidos de trabalhos anteriores sem alterações. A alteração na arquitetura dos modelos, destacando o codificador do ambiente em um modelo externo, impactou também os algoritmos desses advisors. Mas essas mudanças são tão pontuais que sugiro que você se familiarize com elas nos arquivos "...\Experts\CFPI\Research.mq5" e "...\Experts\CFPI\Test.mq5". Os programas mencionados podem ser encontrados no anexo. E agora passamos à construção do algoritmo de treinamento do Crítico.
2.2 Treinamento do crítico
O algoritmo de treinamento do modelo Crítico é implementado no advisor "...\Experts\CFPI\StudyCritic.mq5". Deve-se dizer que, neste advisor, é realizado o treinamento paralelo de dois modelos Críticos. Como você sabe, o uso de dois Críticos permite aumentar a estabilidade e a eficiência do treinamento subsequente da política de comportamento do Ator. E junto com os modelos de Críticos, vamos treinar o codificador geral do estado do ambiente.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 1e6; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ STrajectory Buffer[]; CNet StateEncoder; CNet Critic1; CNet Critic2;
No método de inicialização do EA, tentamos primeiro carregar o conjunto de treinamento.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
E então carregamos os modelos necessários. Se não for possível carregar os modelos previamente treinados, geramos novos, preenchidos com parâmetros aleatórios.
//--- load models float temp; if(!StateEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); if(!CreateDescriptions(actor, critic, encoder)) { delete actor; delete critic; delete encoder; return INIT_FAILED; } if(!Critic1.Create(critic) || !Critic2.Create(critic) || !StateEncoder.Create(encoder)) { delete actor; delete critic; delete encoder; return INIT_FAILED; } delete actor; delete critic; delete encoder; //--- }
Transferimos todos os modelos para um único contexto OpenCL, o que permite trocar dados entre os modelos sem a transferência excessiva de informações para a memória do programa principal e de volta.
//---
OpenCL = Critic1.GetOpenCL();
Critic2.SetOpenCL(OpenCL);
StateEncoder.SetOpenCL(OpenCL);
Para evitar possíveis erros na transferência de dados entre os modelos, verificamos sua conformidade com o layout único dos dados utilizados.
//--- StateEncoder.getResults(Result); if(Result.Total() != LatentCount) { PrintFormat("The scope of the State Encoder does not match the latent size count (%d <> %d)", LatentCount, Result.Total()); return INIT_FAILED; } //--- StateEncoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Critic1.GetLayerOutput(0, Result); if(Result.Total() != LatentCount) { PrintFormat("Input size of Critic1 doesn't match State Encoder output (%d <> %d)", Result.Total(), LatentCount); return INIT_FAILED; } //--- Critic2.GetLayerOutput(0, Result); if(Result.Total() != LatentCount) { PrintFormat("Input size of Critic2 doesn't match State Encoder output (%d <> %d)", Result.Total(), LatentCount); return INIT_FAILED; }
Após a conclusão bem-sucedida de todas as verificações, inicializamos o buffer auxiliar de dados.
//--- Gradient.BufferInit(AccountDescr, 0);
E inicializamos o evento do usuário para iniciar o processo de treinamento dos modelos.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Após isso, concluímos o método de inicialização do EA.
No método de desinicialização do EA, salvamos os modelos treinados e realizamos a limpeza da memória.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) { StateEncoder.Save(FileName + "Enc.nnw", 0, 0, 0, TimeCurrent(), true); Critic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); } delete Result; delete OpenCL; }
O processo de treinamento dos modelos é realizado diretamente no método Train. No corpo do método, primeiro calculamos as probabilidades ponderadas de seleção de trajetórias a partir do buffer de reprodução de experiências.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Depois declaramos variáveis locais e executamos o ciclo de treinamento com o número de iterações especificado pelo usuário nos parâmetros externos do EA.
vector<float> rewards, rewards1, rewards2, target_reward; uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) {
No corpo do ciclo de treinamento, amostramos a trajetória e o estado nela.
int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3)); if(i < 0) { iter--; continue; }
Depois disso, preenchemos os buffers de dados de entrada. Primeiro, preenchemos o buffer de descrição do estado do ambiente com dados sobre o movimento de preços e indicadores analisados a partir do buffer de reprodução de experiências.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
Depois, preenchemos o buffer de descrição do estado da conta e das posições abertas.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Complementamos o buffer com as harmônicas do marca temporal.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Os dados coletados são suficientes para a propagação do codificador do estado do ambiente.
//--- if(!StateEncoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Como já foi mencionado acima, nesta etapa não utilizamos o modelo do Ator. Os Críticos são treinados usando métodos de aprendizado supervisionado na avaliação das ações reais e recompensas recebidas do ambiente, que foram previamente armazenadas no conjunto de treinamento. Portanto, para a propagação de ambos os Críticos, usamos os resultados do codificador do ambiente e o vetor de ações do conjunto de treinamento.
//--- Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Verificamos as operações e carregamos os resultados da propagação de ambos os Críticos.
//---
Critic1.getResults(rewards1);
Critic2.getResults(rewards2);
A próxima etapa é formar os valores-alvo para o treinamento dos modelos. Como já foi mencionado acima, treinaremos com os valores reais do conjunto de treinamento. Nesta etapa, utilizamos a recompensa por uma transição para um novo estado. E para aumentar a convergência, ajustamos a direção do vetor do gradiente do erro com o método CAGrad.
Ajustamos os parâmetros dos modelos alternadamente. Primeiro ajustamos os parâmetros do primeiro Crítico e, em seguida, chamamos o método de retropropagação do codificador do estado do ambiente.
rewards.Assign(Buffer[tr].States[i + 1].rewards); target_reward.Assign(Buffer[tr].States[i + 2].rewards); rewards = rewards - target_reward * DiscFactor; Result.AssignArray(CAGrad(rewards - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !StateEncoder.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Depois repetimos as operações para o segundo Crítico.
Result.AssignArray(CAGrad(rewards - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !StateEncoder.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Note que após a atualização de cada Crítico, os parâmetros do codificador são ajustados. Assim, tentamos tornar a incorporação do estado do ambiente o mais informativa e precisa possível.
Após a atualização bem-sucedida dos parâmetros dos modelos, informamos o usuário sobre o progresso do treinamento e passamos para a próxima iteração do ciclo.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Ao concluir todas as iterações do nosso ciclo de treinamento, limpamos o campo de comentários no gráfico. Registramos no log informações sobre os resultados do treinamento e iniciamos o encerramento do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
O código completo do programa está disponível no anexo.
2.3 Treinamento da política de comportamento
Após treinar os Críticos, passamos para a próxima etapa — o treinamento da política de comportamento do Ator. Implementamos essa funcionalidade no Expert Advisor "...\Experts\CFPI\Study.mq5". Primeiro, adicionamos nos parâmetros externos o tamanho do lote, no qual selecionaremos o ponto ideal para treinamento.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input int Iterations = 10000; input int BatchSize = 256;
Neste EA, usaremos 4 modelos, mas treinaremos apenas o Ator.
CNet Actor; CNet Critic1; CNet Critic2; CNet StateEncoder;
No método de inicialização do EA, como antes, primeiro carregamos o conjunto de treinamento.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Depois, carregamos os modelos. Primeiro, carregamos os modelos pré-treinados do codificador do estado do ambiente e do Crítico. A ausência dos modelos mencionados impede a continuidade do processo de treinamento. Se ocorrer um erro ao carregar os modelos, encerramos o EA.
//--- load models float temp; if(!StateEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("Cann't load Critic models"); return INIT_FAILED; }
Caso o Ator pré-treinado esteja ausente, inicializamos um novo modelo com parâmetros aleatórios.
if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; }
Transferimos todos os modelos para um único contexto OpenCL e desativamos o modo de treinamento do codificador e dos Críticos.
OpenCL = Actor.GetOpenCL(); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); StateEncoder.SetOpenCL(OpenCL); //--- StateEncoder.TrainMode(false); Critic1.TrainMode(false); Critic2.TrainMode(false);
Em seguida, verificamos se a arquitetura dos modelos é adequada e compatível.
//--- Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
StateEncoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
StateEncoder.getResults(Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic1 doesn't match output State Encoder (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Critic2.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic2 doesn't match output State Encoder (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
Actor.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Actor doesn't match output State Encoder (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
A passagem bem-sucedida pelo bloco de verificações nos permite avançar. Inicializamos o buffer auxiliar e geramos o evento do usuário para iniciar o processo de treinamento.
Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Neste ponto, concluímos as operações do método de inicialização do EA. No método de desinicialização, como de costume, salvamos o modelo treinado e limpamos a memória.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; delete OpenCL; }
O processo de treinamento do modelo do Ator é implementado no método Train. No corpo do método, primeiro determinamos as probabilidades de seleção de trajetórias a partir do conjunto de treinamento.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Depois, criamos as variáveis locais necessárias.
//--- vector<float> rewards, rewards1, rewards2, target_reward; vector<float> action, action_beta; float Improve = 0; int bar = (HistoryBars - 1) * BarDescr; uint ticks = GetTickCount();
E criamos o ciclo de treinamento do modelo com o número de iterações definido nos parâmetros externos do EA.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) {
No corpo do ciclo, para treinar a política de comportamento do Ator, utilizaremos as abordagens do método CFPI. Primeiro, precisamos amostrar um lote de dados do conjunto de treinamento. Geramos e avaliamos ações da política atual do Ator nos estados selecionados. Para realizar essas operações, criamos um ciclo aninhado com o número de iterações igual ao tamanho do lote analisado. Os resultados das operações são salvos na matriz local mBatch.
matrix<float> mBatch = matrix<float>::Zeros(BatchSize, 4); for(int b = 0; b < BatchSize; b++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { b--; continue; }
As operações de amostragem são semelhantes às realizadas anteriormente.
Com os dados de cada estado selecionado, preenchemos os buffers de descrição do estado do ambiente.
//--- State
State.AssignArray(Buffer[tr].States[i].state);
E o buffer de descrição do estado da conta.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Adicionamos as harmônicas do marca temporal.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
E realizamos o método de propagação do codificador do estado.
//--- State embedding if(!StateEncoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Após formar a incorporação do estado do ambiente, geramos ações do Agente considerando a política atual.
//--- Action if(!Actor.feedForward(GetPointer(StateEncoder), -1, NULL, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
As ações geradas são avaliadas por ambos os Críticos.
//--- Cost if(!Critic1.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Após a conclusão bem-sucedida de todas as operações, carregamos os resultados em vetores locais. E imediatamente formamos vetores de dados semelhantes a partir do conjunto de treinamento.
Critic1.getResults(rewards1); Critic2.getResults(rewards2); Actor.getResults(action); action_beta.Assign(Buffer[tr].States[i].action); rewards.Assign(Buffer[tr].States[i + 1].rewards); target_reward.Assign(Buffer[tr].States[i + 2].rewards);
Na nossa matriz de resultados, armazenamos as coordenadas do estado analisado como índices de trajetória e estado. Também salvamos a variação do vetor de ações e sua influência no resultado.
//--- Collect mBatch[b, 0] = float(tr); mBatch[b, 1] = float(i); mBatch[b, 2] = MathMin(rewards1.Sum(), rewards2.Sum()) - (rewards - target_reward * DiscFactor).Sum(); mBatch[b, 3] = MathSqrt(MathPow(action - action_beta, 2).Sum()); }
Depois, passamos para a amostragem e avaliação do próximo estado.
Após processar e coletar os dados de todo o lote, precisamos escolher o estado ideal para otimizar a política de comportamento do Ator. Nesta etapa, devemos escolher o estado com uma avaliação confiável do Crítico e com o maior impacto no resultado do modelo.
Quanto à confiabilidade da avaliação das ações, já mencionamos que a avaliação do Crítico é mais precisa com mínimas variações em relação à distribuição do conjunto de treinamento. À medida que a variação aumenta, a precisão da avaliação dos Críticos diminui. Seguindo essa lógica, o critério de precisão da avaliação das ações pode ser a distância entre as ações, que salvamos na coluna com índice 3 da nossa matriz analítica.
Agora precisamos definir o intervalo de confiança. No trabalho dos autores do método CFPI, eles usaram a variância da distribuição. Não podemos usar a variância para o vetor de variações das ações. Isso porque a variância é calculada como o desvio quadrático médio em relação ao centro da distribuição. No nosso caso, salvamos valores absolutos das variações. Assim, a variação zero, onde a avaliação do Crítico é mais precisa, pode ser apenas um extremo. O valor médio da distribuição está longe desse ponto. Portanto, o uso da variância nesse caso não garante a precisão desejada das avaliações das ações.
Mas aqui podemos usar a regra das "3 sigmas": em uma distribuição normal, 68% dos dados não se afastam da expectativa matemática mais do que um desvio padrão. Portanto, para determinar o intervalo de confiança, podemos usar a função quantílica. Com operações matemáticas simples, criamos um vetor weights com valores zero para ações com variações fora do intervalo de confiança e "1" para as demais.
action = mBatch.Col(3); float quant = action.Quantile(0.68); vector<float> weights = action - quant - FLT_EPSILON; weights.Clip(weights.Min(), 0); weights = weights / weights; weights.ReplaceNan(0);
Definido o intervalo de confiança, podemos escolher um conjunto de estados com avaliações de ações adequadas. E agora precisamos escolher o estado mais ideal para otimizar a política de comportamento do Ator. Para simplificar todo o algoritmo e acelerar o processo de treinamento do modelo, abandonei o uso de métodos analíticos propostos pelos autores do CFPI e utilizei um mais simples.
Acho que é óbvio que, no nosso caso, a direção mais ideal de otimização é aquela na qual a rentabilidade da política de comportamento do Agente é maximamente alterada com o mínimo desvio no subespaço das ações. Afinal, buscamos maximizar a rentabilidade da nossa política, e variações mínimas permitem uma avaliação mais precisa das ações pelo Crítico. Claro, em nossa matriz analítica existem variações positivas e negativas na avaliação das ações. Além disso, aumentar a rentabilidade geral é igualmente influenciado tanto pelo aumento dos lucros quanto pela redução das perdas. Assim, para calcular o critério de escolha do ótimo, usamos o valor absoluto da variação da recompensa pela transição.
rewards = mBatch.Col(2); weights = MathAbs(rewards) * weights / action;
No vetor obtido, escolhemos o elemento com o valor máximo. Seu índice nos indicará o estado ótimo para uso no algoritmo de otimização do modelo.
ulong pos = weights.ArgMax(); int sign = (rewards[pos] >= 0 ? 1 : -1);
Aqui, armazenamos na variável local o sinal da variação da recompensa.
Adiantando um pouco, devemos mencionar que atualizaremos a política de comportamento do Ator usando gradientes de erro, passados através do modelo do Crítico. Nesse modo de treinamento, não podemos calcular o erro das previsões do Ator. E para controlar o processo de treinamento, introduzi um coeficiente de média de melhoria dos estados utilizados.
Improve = (Improve * iter + weights[pos]) / (iter + 1);
Em seguida, segue o já familiar algoritmo de otimização do modelo de política. Desta vez, usamos não um estado aleatório, mas aquele onde podemos maximizar a performance do modelo.
int tr = int(mBatch[pos, 0]); int i = int(mBatch[pos, 1]);
Como anteriormente, preenchemos os buffers com a descrição do estado do ambiente e do estado da conta.
//--- Policy study State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Adicionamos as harmônicas da marca temporal.
double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Geramos a incorporação do estado do ambiente.
//--- State if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!StateEncoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Ação do Agente considerando a política atual.
//--- Action if(!Actor.feedForward(GetPointer(StateEncoder), -1, NULL, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
E avaliamos o custo das ações do Agente.
//--- Cost if(!Critic1.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(StateEncoder), -1, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Para otimizar a política de comportamento do Agente, usamos o Crítico com a avaliação mínima. E para melhorar a convergência, ajustamos o vetor da direção do gradiente usando o método CAGrad.
Critic1.getResults(rewards1); Critic2.getResults(rewards2); //--- rewards.Assign(Buffer[tr].States[i + 1].rewards); target_reward.Assign(Buffer[tr].States[i + 2].rewards); rewards = rewards - target_reward * DiscFactor; CNet *critic = NULL; if(rewards1.Sum() <= rewards2.Sum()) { Result.AssignArray(CAGrad((rewards1 - rewards)*sign) + rewards1); critic = GetPointer(Critic1); } else { Result.AssignArray(CAGrad((rewards2 - rewards)*sign) + rewards2); critic = GetPointer(Critic2); }
Executamos sucessivamente a retropropagação do Crítico e do Ator.
if(!critic.backProp(Result, GetPointer(Actor), -1) || !Actor.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Aqui, quero lembrar que nesta etapa não otimizamos o modelo do Crítico. Não há necessidade de retropropagação do Codificador dos estados do ambiente.
Com isso, concluímos as operações de uma iteração de atualização da política de comportamento do Agente. Informamos o usuário sobre o progresso do treinamento e passamos para a próxima iteração do nosso ciclo.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> %15.8f\n", "Mean Improvement", iter * 100.0 / (double)(Iterations), Improve); Comment(str); ticks = GetTickCount(); } }
Após a conclusão de todas as iterações do ciclo de treinamento, limpamos o campo de comentários no gráfico, registramos no diário as informações sobre os resultados do treinamento e iniciamos o encerramento do Expert Advisor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Mean Improvement", Improve); ExpertRemove(); //--- }
Aqui, encerramos a análise dos algoritmos usados nos programas do artigo. Você pode consultar o código completo nos anexos. Agora, passamos à verificação dos resultados do trabalho realizado.
3. Teste
Acima, familiarizamos-nos com o método Closed-Form Policy Improvement e realizamos um trabalho considerável para implementar suas abordagens usando MQL5. Gostaria de lembrar que utilizamos as ideias propostas. Mas aplicamos um método analítico de escolha do estado ótimo diferente do proposto no artigo. Além disso, em nosso trabalho, utilizamos conhecimentos de experiências anteriores. Portanto, os resultados obtidos podem diferir significativamente dos apresentados pelos autores do método em seu trabalho. Bem, é claro que nosso ambiente de teste é diferente dos experimentos mencionados no artigo do autor.
Como sempre, o treinamento e teste dos modelos foram realizados com dados históricos do instrumento EURUSD no timeframe H1. Para o treinamento dos modelos, usamos dados dos primeiros 7 meses de 2023. O teste dos modelos treinados é realizado com dados históricos de agosto de 2023. Os parâmetros de todos os indicadores analisados são usados por padrão.
A implementação do método CFPI exigiu algumas mudanças na arquitetura dos modelos, mas não afetou a estrutura dos dados de entrada. Por isso, na primeira etapa de treinamento, podemos usar o conjunto de treinamento criado anteriormente ao testar um dos algoritmos de aprendizado discutidos. Em meu trabalho, utilizei o conjunto de treinamento da artigo anterior. Para isso, criei uma cópia do arquivo chamado "CFPI.bd". Mas você também pode criar um novo conjunto de treinamento completo usando um dos métodos discutidos anteriormente. Nesta parte, o método CFPI não impõe restrições.
No entanto, as mudanças na arquitetura não nos permitiram usar os modelos previamente treinados. Assim, todo o processo de treinamento foi realizado do zero.
Primeiramente, treinamos os modelos do Codificador de estados e dos Críticos usando o Expert Advisor "...\Experts\CFPI\StudyCritic.mq5".
O conjunto de treinamento utilizado por nós contava com 500 trajetórias de 3591 estados cada. No total, isso nos dá cerca de 1,8 milhões de conjuntos "Estado-Ação-Recompensa". O treinamento inicial dos modelos dos Críticos foi realizado em 1 milhão de iterações, o que teoricamente permite analisar praticamente todo segundo estado. Convenhamos, para trajetórias contínuas, onde nem todo novo estado do ambiente introduz mudanças radicais na situação do mercado, este é um resultado bastante bom. E com foco nas trajetórias com maior rentabilidade, isso permitirá que os Críticos estudem praticamente todas essas trajetórias e ampliem a compreensão sobre as trajetórias menos lucrativas.
Na próxima etapa, treinamos a política de comportamento do Ator no Expert Advisor "...\Experts\CFPI\Study.mq5". Nesta etapa, realizamos 10 mil iterações de treinamento com um lote de 256 estados. No total, isso permite analisar mais de 2,5 milhões de estados, o que já excede nosso conjunto de treinamento.
Devo dizer que, já após a primeira iteração de treinamento nos testes, é possível observar alguns indícios da criação de estratégias lucrativas. Nos gráficos de saldo, é possível destacar seções lucrativas. No processo de coleta adicional de trajetórias de treinamento, de 200 passagens, 3 terminaram com lucro. Claro, isso pode ser minha opinião subjetiva ou resultado de alguns fatores independentes do método. Por exemplo, tivemos sorte, e a inicialização aleatória dos modelos resultou em um bom desempenho. Mas é possível afirmar que, como resultado das iterações subsequentes de treinamento dos modelos e da coleta de passagens adicionais, observa-se uma tendência clara de aumento da rentabilidade média e do fator de lucro das passagens.
Após várias iterações de treinamento do modelo, foi obtida uma política de comportamento do Ator capaz de gerar lucro tanto nos dados históricos do conjunto de treinamento quanto nos dados de teste subsequentes que não fazem parte do conjunto de treinamento. Os resultados do teste do modelo são apresentados abaixo.


No gráfico de saldo, é possível observar uma certa retração no início do período de teste. Mas depois, o modelo demonstra uma tendência bastante estável de crescimento do saldo. Isso permite recuperar as perdas e aumentar o lucro. No total, durante o período de teste, o modelo realizou 125 operações, das quais 45,6% foram fechadas com lucro. Aqui vale destacar que a maior operação lucrativa e a média das operações lucrativas superam em 50% os indicadores similares das operações com prejuízo. E isso nos permite obter um fator de lucro de 1,23.
Considerações finais
Neste artigo, nos familiarizamos com mais um algoritmo de aprendizado de modelos, o Closed-Form Policy Improvement. Provavelmente, a principal contribuição deste método é a adição de abordagens analíticas para a escolha da direção de otimização do modelo em treinamento. Sim, esse processo requer custos computacionais adicionais. Mas, curiosamente, essa abordagem reduz os custos de treinamento do modelo como um todo. A questão é que não tentamos reproduzir completamente a melhor das trajetórias apresentadas. Em vez disso, concentramos os esforços nos pontos de máxima eficiência e não perdemos tempo buscando a otimalidade em eventos ruidosos.
Na parte prática do nosso trabalho, implementamos as ideias propostas pelos autores do método CFPI, embora com algumas adaptações em relação às formulações matemáticas dos autores. No entanto, obtivemos uma experiência positiva e bons resultados nos testes realizados.
Minha opinião pessoal é que o método Closed-Form Policy Improvement merece atenção. E podemos usar suas abordagens para construir nossas estratégias de negociação.
Referências
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | Expert Advisor para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | Expert Advisor para coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | EA | Expert Advisor para treinamento do Ator |
| 4 | StudyCritic.mq5 | EA | Expert Advisor para treinamento dos Críticos |
| 5 | Test.mq5 | EA | Expert Advisor para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13982
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso