
ニューラルネットワークが簡単に(第73回):値動きを予測するAutoBot

はじめに
通貨ペアの動きを効果的に予測することは、安全な取引管理の重要な側面です。この文脈では、取引の意思決定に必要な文脈情報と時間情報の共同分布を正確に近似できる効率的なモデルの開発に特別な注意が払われています。このような課題に対する可能な解決策として、論文「Variable Sequential Set Transformers For Joint Multi-Agent Motion Prediction」で発表されたLatent Variable Sequential Set Transformers(AutoBots)と呼ばれる新しい手法について説明しましょう。提案された方法は、エンコーダーデコーダーアーキテクチャーに基づいています。ロボットシステムの安全制御の問題を解決するために開発されました。これにより、シーンに合致した複数のエージェントの軌道シーケンスを生成することができます。AutoBotは、1つのエゴエージェントの軌道、またはシーン内のすべてのエージェントの将来の軌道の分布を予測することができます。今回のケースでは、提案されたモデルを適用して、市場ダイナミクスに合致した通貨ペアの一連の値動きの生成を試みます。
1.AutoBotのアルゴリズム
「Latent Variable Sequential Set Transformers (AutoBots)」(潜在変数順次セットトランスフォーマー)は、エンコーダーデコーダーアーキテクチャに基づく手法です。セットのシーケンスが処理されます。AutoBotには、X1:t = (X1, …, Xt)の一連の集合が供給されます。この集合は、移動予測の問題では、t時間ステップの環境状態とみなすことができます。各集合は、K個の属性(符号)を持つM個の要素(エージェント、金融商品、指標)を含みます。エンコーダーで社会情報と時間情報を処理するために、以下の2つの変換が使用されます。
まず、AutoBotsエンコーダーは、正弦位置符号化関数PE(.)を使って、一連の集合に時間情報を導入します。この段階で、データは、エージェントの経時的な進化を記述する行列{X0, …, XM}の集まりとして分析されます。エンコーダーは、マルチヘッドアテンションブロックを使ってセット間の時間的関係を処理します。
続いて、ある時点ꚍにおけるエージェントの状態Sꚍのセットを抽出することによって、スライスSを処理します。それらは再びマルチヘッドアテンションブロックで処理されます。
これら2つの操作をLenc回繰り返して、次元{dK, M, t}のコンテキストテンソルCを取得します。これは、元のデータのシーンの表現全体を要約したものです。ここで、tはソースデータシーン内の時間ステップの数です。
デコーダーの目標は、マルチモーダルなデータ分布の中で、時間的社会的に一貫性のある予測を生成することです。c個の異なる予測、または元データの同じシーンを生成するために、AutoBotデコーダは{dK, T}次元を持つ学習可能な初期パラメータQiのc個の行列を使用します。
直感的には、訓練可能な初期パラメータの各行列は、AutoBotの離散潜在変数の設定に対応します。次に、各訓練可能行列Qiをエージェント次元に沿ってM回繰り返し、{dK, M, T}次元を持つ入力テンソルQ0iを得ます。
このアルゴリズムは、特徴ベクトルmiを作成するために畳み込みニューラルネットワークを使用して符号化される追加のコンテキスト情報を使用する機能を提供します。将来のすべての時間ステップと集合のすべての要素に文脈情報を提供するために、このベクトルを次元MとTに沿ってコピーし、次元{dK, M, T}のテンソルMiを作成することが提案されています。次に、各テンソルQ0iは、次元dKに沿ってMiと結合されます。このテンソルを 全結合層 (rFFN)で処理し、次元{dK, M, T}のテンソルHを得ます。
デコーディングは、エンコーダーの出力で決定された時間次元(C)と、エンコードされた初期パラメータ、環境に関する情報(H)を処理することから始まります。デコーダーは、マルチヘッドアテンションブロックを使って、Hの各エージェントを個別に処理します。こうして、集合の各要素の将来の時間発展を独立に符号化したテンソルが得られます。
集合の要素間の未来の場面の社会的一貫性を確保するために、各タイムスライスH0を処理し、ある未来の時点ꚍにおけるエージェントの状態H0ꚍの集合を抽出します。 シーケンスの各要素は、マルチヘッドアテンションユニットによって処理されます。このブロックは、各時間ステップで、集合の全要素間の注意を実行します。
この2つの操作をLdec回繰り返すことで、エージェントiの最終的な出力テンソルを作成します。異なる学習済み初期パラメータQiと追加的な文脈情報miを用いて、復号化処理をc回繰り返します。デコーダーの出力は{dK, M, T, c}次元のテンソルOであり、これをニューラルネットワークф(.)を用いて処理することで、目的の出力表現を得ることができます。
AutoBotの結果と学習時間を他の方法よりも早くする主な貢献の1つは、初期デコーダパラメータQrの使用です。 これらのオプションには2つの目的があります。第一に、将来予測における多様性を考慮しており、各行列Qiは離散潜在変数の1つの設定に対応します。第二に、順次選択することなく、デコーダーを1回通過するだけで、シーン全体を推論できるようにすることで、AutoBotのスピードアップに貢献します。
論文の著者によって発表された可視化方法の原文を以下に示します。
法のオリジナルの視覚化")
2.MQL5を使用した実装
ここまで、Latent Variable Sequential Set Transformers (AutoBots)法の理論的側面について述べてきました。では、記事の実践編に移りましょう。MQL5を使って、今回紹介する方法のビジョンを実践してみましょう。
まず、以下の2点に注意してください。
第一に、この方法は位置符号化を提供します。しかし、同じような位置符号化は、基本的なセルフアテンションメソッドですでに利用されています。それ以前は、アテンションメソッドを研究する際、ソースデータの位置符号化はメインプログラムの側で実施されていたのが事実です。しかし、AutoBotでは、位置符号化は、ソースデータの予備処理と埋め込みの作成後にモデル内に実装されます。もちろん、データの前処理を別のモデルに移し、エンコーダーにデータを転送する前に、メインプログラムの側で位置符号化を実装することもできます。しかし、このオプションでは、OpenCLコンテキストのメモリとメインプログラムの間で追加のデータ転送操作が必要になります。さらに、このような実装では、コードを追加調整することなく、1つのプログラム内でさまざまなモデルアーキテクチャを使用する柔軟性が制限されてしまいます。したがって、望ましい方法は、全プロセスを1つのモデル内にまとめることです。
第二に、エンコーダーとデコーダーの両方において、Latent Variable Sequential Set Transformers (AutoBots)法は、分析されたテンソルの様々な次元(時間と社会的依存性の分析)の枠組みの中で、アテンションブロックの代替的な使用を必要とします。アテンションの焦点の次元を変えるには、マルチヘッドアテンション層CNeuronMLMHAttentionOCLを修正するか、テンソルを転置する必要があります。テンソルの転置は、こちらの方が単純な作業に見えます。これには、以前に位置符号化について説明した特定のステップが必要です。ここでは繰り返しません。ただ、OpenCLコンテキスト側でテンソルの転置層を作る必要があるだけです。
2.1 位置符号化層
まずは位置符号化層から。位置符号化層クラスCNeuronPositionEncoderをCNeuronBaseOCLライブラリのニューラル層基本クラスから継承し、基本的なメソッド群をオーバーライドします。
- Init:初期化
- feedForward:フィードフォワードパス
- calcInputGradients:前の層への誤差勾配伝搬
- updateInputWeights:重みの更新
- SaveとLoad:ファイル操作
class CNeuronPositionEncoder : public CNeuronBaseOCL { protected: CBufferFloat PositionEncoder; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronPositionEncoder(void) {}; ~CNeuronPositionEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) { return true; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronPEOCL; } virtual void SetOpenCL(COpenCLMy *obj); };
クラスのコンストラクタとデストラクタは空にしておきます。
他のメソッドに移る前に、クラスの機能と構築ロジックについて少し説明しましょう。Transformerアルゴリズムでは、位置符号化は、以下の関数を使用してソースデータに正弦波高調波を追加することで実装されます。
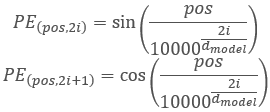
この場合、解析された配列の要素に対して位置符号化をおこなうことに注意してください。これは、メインプログラムの側で作成する、先に使用したタイムスタンプ高調波とは関係ありません。プロセスは似ていますが、意味は異なります。
当然ながら、モデル内の分析された配列のサイズは常に一定です。したがって、クラスの初期化メソッドInitで高調波バッファPositionEncoderを作成し、入力するだけです。フィードフォワードパスの間、feedForwardメソッドでは、元のデータに高調波値を加えるだけです。
これはフィードフォワードパスに関するものです。バックプロパゲーションパスは?フィードフォワードパスでは、2つのテンソルの加算をおこないました。その結果、バックプロパゲーションパスの間の誤差勾配は、両項へ均等に分配されるか、完全に移行します。この場合の位置符号化の高調波テンソルは定数です。したがって、誤差勾配をすべて前の層に移します。
訓練可能な重みに関しては、位置符号化層には存在しません。したがって、updateInputWeightsメソッドはクラスの互換性のためだけにオーバーライドされ、常にtrueを返します。
これが論理です。それでは実装を見てみましょう。クラスはInitメソッドで初期化されます。メソッドは次のパラメータを受け取ります。
- numOutputs:次の層への接続数
- open_cl:OpenCL コンテキストへのポインタ
- count:シーケンス内の要素数
- window:シーケンスの各要素に対するパラメータの数
- optimization_type:パラメータの最適化手法
bool CNeuronPositionEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window, optimization_type, batch)) return false;
メソッド本体では、基本的な機能を実装した親クラスの初期化メソッドを呼び出しています。操作の結果も確認します。
次に、位置を符号化する高調波を作る必要があります。これには行列演算を使用します。まず、行列を用意しましょう。
matrix<float> pe = matrix<float>::Zeros(count, window);
テンソルの要素の位置を番号付けするためのベクトルと、すべての要素に使用される定数係数を作成します。
vector<float> position = vector<float>::Ones(count); position = position.CumSum() - 1; float multipl = -MathLog(10000.0f) / window;
位置符号化によれば、高調波の正弦と余弦を交互に計算する必要があるので、ステップ2のループで行列を埋めます。ループの本体では、まず位置値のベクトルを計算します。次に、偶数列に位置値のベクトルの正弦を加えます。奇数列には同じベクトルの余弦を書き込みます。
for(uint i = 0; i < window; i += 2) { vector<float> temp = position * MathExp(i * multipl); pe.Col(MathSin(temp), i); if((i + 1) < window) pe.Col(MathCos(temp), i + 1); }
得られた位置高調波をデータバッファにコピーし、OpenCLコンテキストに転送します。
if(!PositionEncoder.AssignArray(pe)) return false; //--- return PositionEncoder.BufferCreate(open_cl); }
CNeuronPositionEncoderの後は、メソッドfeedForwardでフィードフォワードパスの構成に移ります。お気づきかもしれませんが、OpenCLコンテキスト側ではプロセス編成カーネルを作成していません。メソッドの実装に直行します。これは、2つの行列SumMatrixを加算するためのカーネルが、以前にSelf-Attentionメソッドを実装したときにすでに作成されているからです。
いつものように、feedForwardメソッドは、パラメータでソースデータとなる前のニューラル層へのポインタを受け取ります。メソッド本体では、受け取ったポインタを確認します。
bool CNeuronPositionEncoder::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!Gradient || Gradient != NeuronOCL.getGradient()) { if(!!Gradient) delete Gradient; Gradient = NeuronOCL.getGradient(); }
これを誤差勾配バッファへのポインタも即座に置き換えます。このシンプルな方法によって、バックプロパゲーションパスの間に、次の層から前の層へ誤差勾配を直接転送することができるようになり、位置符号化層の不必要なデータコピーをなくすことができます。
次に、ベクトル加算カーネルのパラメータに必要なデータを渡します。
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = Neurons(); if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix1, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix2, PositionEncoder.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix_out, Output.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_dimension, (int)1)) return false; if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_multiplyer, 1.0f)) return false;
カーネルを実行キューに入れます。
if(!OpenCL.Execute(def_k_MatrixSum, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel MatrixSum: %d", GetLastError()); return false; } //--- return true; }
操作の結果を確認します。これで、フィードフォワードプロセスの実装は完了したとみなすことができます。
前述したように、位置符号化層には学習可能なパラメータは含まれていません。したがって、updateInputWeightsメソッドは「空」であり、常にtrueを返します。誤差勾配バッファのポインタを置き換えることで、誤差勾配伝播プロセスから位置符号化層を完全に排除しました。したがって、calcInputGradientsメソッドは、パラメータ更新メソッドと同様、「空」のままで、互換性のためだけにオーバーライドされます。
これで、位置符号化層の方法についての説明は終わりです。クラスの完全なコードは、当ライブラリの全クラスを含む添付ファイル「...\Experts\NeuroNet_DNG\NeuroNet.mqh」にあります。
2.2 転置テンソル
次に作成することに合意したのは、CNeuronTransposeOCL転置テンソル層です。位置符号化層と同様、クラスを作成する際にはニューラル層基本クラスCNeuronBaseOCLを継承します。オーバーライドされるクラスのリストは標準のままです。ただし、転置行列の次元を格納するために2つの変数クラスも追加します。
class CNeuronTransposeOCL : public CNeuronBaseOCL { protected: uint iWindow; uint iCount; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronTransposeOCL(void) {}; ~CNeuronTransposeOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronTransposeOCL; } };
クラスのコンストラクタとデストラクタは空のままです。Initクラスの初期化メソッドは非常に単純化されています。メソッド本体では、親クラスの関連するメソッドだけを呼び出し、得られた転置行列の次元をパラメータに保存します。操作実行結果の確認も忘れてはいけません。
bool CNeuronTransposeOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window, optimization_type, batch)) return false; //--- iWindow = window; iCount = count; //--- return true; }
フィードフォワードメソッドでは、まず行列の転置テンソルTransposeを作らなければなりません。カーネルパラメータには、ソースデータと結果行列のバッファへのポインタだけを渡します。2次元の問題空間から行列のサイズを求めます。
__kernel void Transpose(__global float *matrix_in, ///<[in] Input matrix __global float *matrix_out ///<[out] Output matrix ) { const int r = get_global_id(0); const int c = get_global_id(1); const int rows = get_global_size(0); const int cols = get_global_size(1); //--- matrix_out[c * rows + r] = matrix_in[r * cols + c]; }
カーネルのアルゴリズムは非常にシンプルです。ソースデータ行列と結果行列における要素の位置を決定するだけです。その後、値を移動します。
カーネルはフィードフォワードパスのメソッドfeedForwardから呼び出されます。カーネルの呼び出しアルゴリズムは、上に示したものと同様です。まず問題空間を定義しますが、今回は2次元空間とします(シーケンスの要素数 * シーケンスの各要素の特徴量数)。そして、データバッファへのポインタをカーネルパラメータに渡し、実行キューに入れます。操作結果の確認も忘れてはいけません。
bool CNeuronTransposeOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {iCount, iWindow}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, Output.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel Transpose: %d -> %s", GetLastError(), error); return false; } //--- return true; }
バックプロパゲーションパスの間、誤差勾配を逆方向に伝播させる必要があります。また、誤差勾配行列を転置する必要があります。したがって、同じカーネルを使用します。問題空間の次元を逆にし、誤差勾配バッファへのポインタを指定するだけです。
bool CNeuronTransposeOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {iWindow, iCount}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, NeuronOCL.getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, Gradient.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel Transpose: %d -> %s", GetLastError(), error); return false; } //--- return true; }
ご覧のように、CNeuronTransposeOCLクラスは訓練可能なパラメータを含んでいないため、updateInputWeightsメソッドは常にtrueを返します。
2.3 AutoBotのアーキテクチャ
以上、非常に汎用性の高い2つの新しい層を作成しました。これで、「Latent Variable Sequential Set Transformers」(AutoBots)法の実装に直接進むことができます。まず、CreateTrajNetDescriptionsメソッドで値動き予測モデルのアーキテクチャを作成します。メインプログラム側の操作を減らすために、AutoBotの操作を1つのモデルの枠内で整理することにしました。これを説明すると、動的配列へのポインタがメソッドに渡されます。メソッド本体では、受け取ったポインタを確認し、必要であれば動的配列オブジェクトの新しいインスタンスを生成します。
bool CreateTrajNetDescriptions(CArrayObj *autobot) { //--- CLayerDescription *descr; //--- if(!autobot) { autobot = new CArrayObj(); if(!autobot) return false; }
モデルには元データのテンソルが入力されます。前回同様、モデルの運用と訓練時の計算を最適化するため、初期データとして最後の小節の記述のみを使用します。全履歴は埋め込み層のバッファに蓄積されます。
//--- Encoder autobot.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
ソースデータの一次処理は、バッチ正規化層で実行されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000,GPTBars); descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
その後、状態の埋め込みを生成し、履歴データバッファに追加します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!autobot.Add(descr)) { delete descr; return false; }
この場合、環境の現在の状態を記述する1つのエンティティだけを埋め込んでいることに注意してください。この層の機能は 全結合層に近くなります。ただし、過去の埋め込みシーケンスのバッファを作成する必要があるため、CNeuronEmbeddingOCL層を使用します。このアルゴリズムでは、商品バーの分析には何の制限も設けていません。複数のローソク足と複数の取引商品の両方を分析することができます。ただし、この場合、埋め込み配列を調整する必要があります。
次に、位置符号化テンソルを履歴埋め込みシーケンス全体に加えます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; }
シーン間の時間的な依存関係を評価するために、最初のアテンションブロックを実行します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
次に、個々の特徴量間の依存関係を分析する必要があります。そのために、テンソルを転置し、転置されたテンソルにアテンションブロックを適用します。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
転置した後、アテンションブロックの次元も転置されたテンソルに対応するように変更することに注意してください。
テンソルを元の次元に戻すために、もう一度転置します。そして、エンコーダーのアテンションブロックをもう一度繰り返します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_wout; descr.window = prev_count; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
エンコーダーの出力では、環境の現在の状態を表すコンテキストを受け取ります。それをデコーダーに転送して、将来の値動きのパラメータを必要な計画深度まで予測する必要があります。ただし、Latent Variable Sequential Set Transformersアルゴリズムによれば、この段階で、訓練可能な初期パラメータQを追加する必要があります。ライブラリの現在の実装では、学習可能なパラメータはニューラル層の重みだけです。既存のプロセスを複雑にしないために、標準的ではないかもしれないが効果的な解決策を採用しました。この場合、СNeuronConcatenateテンソル連結層を使用します。層の最初の部分は、エンコーダーから受け取った現在の環境状態のコンテキスト表現を変更するために、 全結合層に取って代わります。2つ目のブロックの重みは、初期の訓練可能パラメータQとして機能します。Qパラメータの値を歪めないようにするため、2番目の入力に1で埋め尽くされたベクトルを送り込みます。
層の出力では、与えられた計画深度に対する状態埋め込みテンソルを受け取ることが期待されます。
//--- Decoder //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = PrecoderBars * EmbeddingSize; descr.window = prev_count * prev_wout; descr.step = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
エンコーダーの場合と同様に、まず時間経過に伴う状態間の依存関係を見ます。
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = PrecoderBars; prev_wout = descr.window = EmbeddingSize; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
次に、テンソルを転置し、個々の特徴量間の文脈依存性を分析します。
//--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
その後、再びデコーダーの操作を繰り返します。
//--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = prev_count * prev_wout; descr.window = descr.count; descr.step = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 16 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout; if(!autobot.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_wout; descr.window = prev_count; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; }
1sの定数ベクトルをモデルの2番目の入力として使用することで、デコーダーの連結層を何度も繰り返すことができることに注意してください。この場合、学習可能な重みパラメータは、各層に固有のQパラメータの役割を果たします。
デコーダーを完成させるために、必要な形式でデータを表示できる 全結合層を使用します。
//--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = PrecoderBars * 3; descr.activation = None; descr.optimization = ADAM; if(!autobot.Add(descr)) { delete descr; return false; } //--- return true; }
2.4 AutoBotの訓練
ここまで、与えられた計画深度における今後の値動きのパラメータを予測するAutoBotモデルのアーキテクチャについて述べてきました。訓練されたモデルの結果の使用は、読者の想像力によってのみ制限されます。その後の値動きの予測があれば、古典的なアルゴリズムEAを構築して、受け取った予測に従って操作を実行することができます。オプションで、それをActorモデルに渡して、アクションのための推奨事項を直接生成することもできます。私は2番目のオプションを使いました。この場合、Actorモデルとゴール設定のアーキテクチャは以前の記事から拝借しました。この変更は、上記のAutoBotモデルの結果と一致させるために、ソースデータ層にのみ影響を与えました。今はそのことにこだわるつもりはありません。以下に添付する(CreateDescriptionsメソッド)ので、ご自分で勉強してください。また、EAで環境と連動させるための具体的な調整も「...\Experts\AutoBots\Research.mq5」でおこなうことができます。次に、今後の値動きを予測するためのモデル訓練プロセスを整理します。EA「..\Experts\AutoBots\StudyTraj.mq5」に訓練プロセスを実装します。
このEAでは、1つのモデルだけを訓練します。
CNet Autobot;
EAの初期化メソッドOnInitでは、まず訓練データセットを読み込みます。
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
次に、事前に訓練されたAutoBotモデルの読み込みを試み、エラーが発生した場合は、ランダムなパラメータで初期化された新しいモデルを作成します。
//--- load models float temp; if(!Autobot.Load(FileName + "Traj.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new models"); CArrayObj *autobot = new CArrayObj(); if(!CreateTrajNetDescriptions(autobot)) { delete autobot; return INIT_FAILED; } if(!Autobot.Create(autobot)) { delete autobot; return INIT_FAILED; } delete autobot; //--- }
その後、モデルアーキテクチャが主な基準に適合しているかを確認します。
Autobot.getResults(Result); if(Result.Total() != PrecoderBars * 3) { PrintFormat("The scope of the Autobot does not match the precoder bars (%d <> %d)", PrecoderBars * 3, Result.Total()); return INIT_FAILED; } //--- Autobot.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Autobot doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
必要なデータバッファを作成します。
OpenCL = Autobot.GetOpenCL(); if(!Ones.BufferInit(EmbeddingSize, 1) || !Gradient.BufferInit(EmbeddingSize, 0) || !Ones.BufferCreate(OpenCL) || !Gradient.BufferCreate(OpenCL)) { PrintFormat("Error of create buffers: %d", GetLastError()); return INIT_FAILED; } State.BufferInit(HistoryBars * BarDescr, 0);
モデル訓練開始のカスタムイベントを生成します。
if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
EAの非初期化メソッドでは、訓練済みモデルを保存し、動的オブジェクトをメモリから削除します。
void OnDeinit(const int reason) { //--- if(!(reason == REASON_INITFAILED || reason == REASON_RECOMPILE)) Autobot.Save(FileName + "Traj.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; delete OpenCL; }
通常通り、モデルの訓練プロセスはTrainメソッドで実行されます。メソッドの本体では、まず収益性に基づいて軌道を選択する確率を決定します。
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
次に、ローカル変更の宣言と初期化をおこないます。
vector<float> result, target, inp; matrix<float> targets; matrix<float> delta; STE = vector<float>::Zeros(PrecoderBars * 3); int std_count = 0; int batch = GPTBars + 50; bool Stop = false; uint ticks = GetTickCount(); ulong size = HistoryBars * BarDescr;
いつものように、軌跡モデルを訓練する際には、Latent Variable Sequential Set Transformers法の著者が提案したアプローチのみに限定します。特に、CFPI法のように、最大偏差に焦点を当てた訓練をおこないます。さらに、確率市場におけるモデルの安定性を確保するため、SSWNP法で提案されているように、元データにノイズを加えることで学習サンプル空間を「拡張」します。これらのアプローチを実装するために、ローカル変数にパラメータ変化量deltaの行列と平均二乗誤差STEベクトルを宣言します。
私たちのメソッドのアルゴリズムに戻りましょう。私たちの軌跡予測AutoBotのアーキテクチャでは、過去のデータを蓄積するためのバッファを内蔵した埋め込み層を使用しており、モデルの動作中に繰り返しデータの表現を再計算する必要がありません。ただし、このアプローチでは、学習過程で初期データを提出する際に、過去の一貫性を守る必要もあります。そのため、モデルの訓練には入れ子のループシステムを使用します。外側のループは訓練の反復回数を決定します。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; }
ループ本体では、先に計算した確率を考慮して、バッファから軌跡をサンプリングします。そして、選択された軌道上での学習の初期状態をランダムに決定します。
また、訓練パッケージの最終状態も決定します。AutoBotの履歴バッファをクリアし、パラメータ変更を記録するための行列を準備しましょう。
int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); Autobot.Clear(); delta = matrix<float>::Zeros(end - state - 1, Buffer[tr].States[state].state.Size());
次に、クリーンな軌跡を処理するための入れ子になったループを作成し、その中でソースデータバッファを埋めます。
for(int i = state; i < end; i++) { inp.Assign(Buffer[tr].States[i].state); State.AssignArray(inp);
2つの環境状態間のパラメータ値の偏差を計算します。
if(i < (end - 1)) delta.Row(inp, row); if(row > 0) delta.Row(delta.Row(row - 1) - inp, row - 1);
準備作業の後、モデルのフォワードパスをおこないます。
if(!Autobot.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(Ones))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
モデルアーキテクチャの説明の際に述べたように、Ones定数値で満たされたバッファを第2のソースデータストリームとして使用していることに注意してください。このバッファはEAの初期化時に用意されたもので、モデルの訓練全体を通して変化することはありません。
フィードフォワードパスに続いて、バックプロパゲーションパスがモデルパラメータを更新します。しかし、これを呼び出す前に、まず目標値を準備する必要があります。そのために「未来に目を向けましょう」。訓練プロセスでは、この能力は訓練データセットによって提供されます。経験再生バッファから、与えられた計画深度における、その後の環境状態の記述を抽出します。必要なデータを目標値のベクトルtargetにコピーします。
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0);
次に、AutoBotのフィードフォワードパスの結果を読み込み、現在の状態における予測誤差の大きさに基づいて、バックプロパゲーションパスが必要かどうかを判断します。
Autobot.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; vector<float> check = MathAbs(error) - STE * STE_Multiplier;
バックプロパゲーションパスは、パラメータの少なくとも1つに閾値以上の予測誤差がある場合に実行されます。この予測誤差は、モデルの二乗平均平方根予測誤差に係数で関連付けられます。
if(check.Max() > 0) { //--- Result.AssignArray(target); if(!Autobot.backProp(Result, GetPointer(Ones), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
次に、学習プロセスの進捗状況をユーザーに通知し、クリーンな軌跡バッチを処理する次の反復処理に移ります。
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Autobot", percent, Autobot.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
クリーンな軌跡の訓練バッチが完了したら、2番目のブロックに移ります。ノイズ拡張データ上の軌跡モデルです。ここではまず、ノイズの再パラメータ化パラメータを定義します。
//--- With noise vector<float> std_delta = delta.Std(0) * STD_Delta_Multiplier; vector<float> mean_delta = delta.Mean(0);
そして、ノイズを扱うための配列とベクトルを用意します。
ulong inp_total = std_delta.Size(); vector<float> noise = vector<float>::Zeros(inp_total); double ar_noise[];
また、訓練データセットから軌道をサンプリングし、その上で訓練バッチの初期状態と最終状態を決定し、モデルの履歴バッファをクリアします。
tr = SampleTrajectory(probability); state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 3 - PrecoderBars - batch)); if(state < 0) { iter--; continue; } end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars); Autobot.Clear();
次に、2つ目の入れ子ループを作ります。
for(int i = state; i < end; i++) { if(!Math::MathRandomNormal(0, 1, (int)inp_total, ar_noise)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } noise.Assign(ar_noise); noise = mean_delta + std_delta * noise;
ループの本体では、ノイズを発生させ、上で計算した分布パラメータを使って再パラメータ化します。
得られたノイズを元のデータに加え、モデルのフィードフォワードパスを実行します。
inp.Assign(Buffer[tr].States[i].state); inp = inp + noise; State.AssignArray(inp); //--- if(!Autobot.feedForward((CBufferFloat*)GetPointer(State), 1, false, (CBufferFloat*)GetPointer(Ones))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
目標データの準備や必要性の判断など、バックプロパゲーションパスを実行するアルゴリズムを、クリーンな軌道を持つ演算ブロックから完全にコピーします。
targets = matrix<float>::Zeros(PrecoderBars, 3); for(int t = 0; t < PrecoderBars; t++) { target.Assign(Buffer[tr].States[i + 1 + t].state); if(size > BarDescr) { matrix<float> temp(1, size); temp.Row(target, 0); temp.Reshape(size / BarDescr, BarDescr); temp.Resize(size / BarDescr, 3); target = temp.Row(temp.Rows() - 1); } targets.Row(target, t); } targets.Reshape(1, targets.Rows()*targets.Cols()); target = targets.Row(0); Autobot.getResults(result); vector<float> error = target - result; std_count = MathMin(std_count, 999); STE = MathSqrt((MathPow(STE, 2) * std_count + MathPow(error, 2)) / (std_count + 1)); std_count++; vector<float> check = MathAbs(error) - STE * STE_Multiplier; if(check.Max() > 0) { //--- Result.AssignArray(target); if(!Autobot.backProp(Result, GetPointer(Ones), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
最後に、訓練の進捗状況をユーザーに知らせ、次の訓練反復に移ります。
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / (2 * (end - state)) + iter + 0.5) * 100.0 / (Iterations); string str = StringFormat("%-20s %6.2f%% -> Error %15.8f\n", "Autobot", percent, Autobot.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
モデル訓練ループシステムのすべての反復が完了したら、チャートのコメントフィールドをクリアします。訓練結果をログに出力し、EA操作を完了します。
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Autobot", Autobot.getRecentAverageError()); ExpertRemove(); //--- }
軌跡学習モデル「...\Experts\AutoBots\StudyTraj.mq5」の EAメソッドの検討が完了しました。このEAの全コードは以下に添付されています。また、Actorr方策の学習用「...\Experts\AutoBots\Study.mq5」と、過去のデータを使った学習済みモデルのテスト用「...\Experts\AutoBots\Test.mq5」も添付されています。これらのEAでは、AutoBotモデルの動作に関わる特定の変更のみを考慮しました。次にテスト段階に移ります。
3.検証
MQL5にLatent Variable Sequential Set Transformers (AutoBots)法のアプローチを実装するために、かなり大規模な作業をおこないました。結果を評価する時です。これまでのすべてのケースと同様に、私たちのモデルは2023年の最初の7ヶ月間のEURUSD H1データを使用して訓練されています。Actor政策の学習済みモデルをテストするために、2023年8月からの履歴データを使用します。ご覧のように、テスト期間は訓練期間の直後にあり、訓練データセットとテストデータセットのデータ間の互換性を最大限に確保しています。
市場の状況を分析するために使用されるすべての指標のパラメータは、訓練とテストの過程で最適化されませんでした。これらはデフォルトのパラメータで使用されました。
お気づきかもしれませんが、初期データの構成と構造、そして軌道予測モデルの結果は、前作から変更なくコピーされています。したがって、モデルを訓練するには、以前に作成した例のデータベースを使用することができます。これにより、訓練データの一次収集の段階を回避し、そのままモデルの訓練プロセスに移行することができます。
モデルの訓練は2段階に分けておこないます。
- 軌道予測モデルの訓練
- Actor方策の訓練
軌跡予測モデルは、学習サンプルの軌跡に多様性を加える口座ステータスやポジションを参照することなく、市場ダイナミクスと分析指標のみを参照します。1つの商品から、同じ履歴期間にわたってすべての軌跡を収集したので、AutoBotの理解では、すべての軌跡は同一です。したがって、許容できる結果が得られるまで、軌道を更新することなく、1つの訓練データセットで値動き予測モデルを訓練することができます。
訓練プロセスは非常に安定しており、ほぼ一定の誤差を減少させる良好なダイナミクスを示しました。モデルの学習スピードについて語るとき、私はこの手法の著者に同意せざるを得ません。例えば、この手法の著者は、彼らの作業中、すべてのモデルを1台の1080 Tiデスクトップグラフィックスアクセラレーターで48時間訓練したと主張しています。
私は、値動き予測モデルを訓練する過程からヒントを得て、訓練されたActor方策のパフォーマンスに基づいて軌道予測アルゴリズムを評価するのは完全には正しくないと考えました。Actorの方針は受信した予測のデータに基づいていますが、生成された予測に起こりうる誤差に適応します。このような適応の質はまた別の問題で、Actorのアーキテクチャとその訓練の過程に関係してきます。しかし、そのような適応がもたらす影響は確かにあります。そこで、古典的なアルゴリズム取引用の小型EA「...\Experts\AutoBots\Alternate.mq5」を作成しました。
このEAは、ストラテジーテスターで値動きの予測の質をテストするためだけに作成されたもので、そのコードはあまり興味をそそるものではないと思います。従って、この記事ではそれについては触れないことにします。添付ファイルにあるコードをご自身で勉強してください。
このEAは、予測される動きを評価し、計画期間上の顕著なトレンドの方向に最小ロットで取引を開始します。EAのパラメータは最適化されていません。興味深いのは、ストラテジーテスターで2023年末までEAをテストしたときの結果です。
値動き予測モデルを7ヶ月間の過去データで訓練した結果、2ヶ月間で安定的に残高が増加する傾向が得られました。

すべての取引は最小ロットでおこなわれました。つまり、得られる結果は軌道計画の質のみに依存します。
結論
この記事では、Latent Variable Sequential Set Transformers (AutoBots)という手法を紹介しました。この手法の著者が提案するアプローチは、文脈情報と時間情報の共同分布のモデル化に基づいており、将来の値動きを正確に(可能な限り正確に)予測するための信頼できるツールを提供します。
AutoBotsはEncoder-Decoderアーキテクチャを利用し、多機能アテンションブロックの使用や、マルチモーダル分布をモデル化するための離散潜在変数の導入により、効率的な動作を示します。
本稿の実用的な部分では、MQL5を使用して提案されたアプローチを実装し、モデルの学習スピードと予測品質の点で有望な結果を得ました。
このように、提案されたAutoBotsアルゴリズムは、FOREX市場における予測問題を解決するための有望なツールを提供し、精度、変化に対する頑健性、市場の動きのダイナミクスをより深く理解するためのマルチモーダル分布のモデル化能力を提供します。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | 方策訓練EA |
| 4 | StudyTraj.mq5 | EA | 軌道予測モデルの訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
| 9 | Alternate.mq5 | EA | 軌道予測品質テストEA |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14095

 エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
エラー 146 (「トレードコンテキスト ビジー」) と、その対処方法
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索