
データサイエンスと機械学習(第28回):AIを使ってEURUSDの複数の先物を予測する

内容
- はじめに
- 直接多段階予測
- 直接多段階予測の強み
- 直接多段階予測の弱点
- 再帰的多段階予測
- 再帰的多段階予測の利点
- 再帰的多段階予測の弱点
- 多出力モデルを用いた多段階予測
- 多出力モデルを用いた多段階予測の利点
- 多出力モデルを用いた多段階予測の欠点
- いつ、どこで多段階予測を使うか
- 結論
はじめに
機械学習を用いた金融データ分析の世界では、過去のデータに基づいて将来の価値を予測することがしばしば目標とされています。本連載で取り上げてきた多くの記事でも、直後の値を予測することの有用性について触れています。実世界のアプリケーションでは、将来の値を1つではなく複数予測する必要がある場合が多々あります。様々な連続値を予測する試みは、「多段階予測」または「複数期間予測」として知られています。
多段階予測は、金融、気象予測、サプライチェーン管理、ヘルスケアなど様々な領域で極めて重要です。例えば金融市場では、投資家は数日、数週間、あるいは数ヶ月先の株価や為替レートを予測する必要があります。気象予測では、今後数日あるいは数週間の正確な予測が、計画や災害管理に役立ちます。

この記事では、読者に機械学習とAI、ONNX、MQL5でONNXモデルを使用する方法、線形回帰、LightGBM、ニューラルネットワークの基本的な理解があることを前提としています。
多段階予測のプロセスにはいくつかの方法論があり、それぞれに長所と短所があります。これらには以下が含まれます。
- 直接多段階予測
- 再帰的多段階予測
- 多出力モデル
- ベクトル自己回帰(VAR: Vector Auto-regression)(次回の記事で説明)
この記事では、これらの方法論とその応用例、そして様々な機械学習や統計技術を用いてどのように実装できるかを探ります。多段階予測を理解し適用することで、EURUSDの将来についてより多くの情報に基づいた意思決定をおこなうことができます。
# Create target variables for multiple future steps def create_target(df, future_steps=10): target = pd.concat([df['Close'].shift(-i) for i in range(1, future_steps + 1)], axis=1) # using close prices for the next i bar target.columns = [f'target_close_{i}' for i in range(1, future_steps + 1)] # naming the columns return target # Combine features and targets new_df = pd.DataFrame({ 'Open': df['Open'], 'High': df['High'], 'Low': df['Low'], 'Close': df['Close'] }) future_steps = 5 target_columns = create_target(new_df, future_steps).dropna() combined_df = pd.concat([new_df, target_columns], axis=1) #concatenating the new pandas dataframe with the target columns combined_df = combined_df.dropna() #droping rows with NaN values caused by shifting values target_cols_names = [f'target_close_{i}' for i in range(1, future_steps + 1)] X = combined_df.drop(columns=target_cols_names).values #dropping all target columns from the x array y = combined_df[target_cols_names].values # creating the target variables print(f"x={X.shape} y={y.shape}") combined_df.head(10)
直接多段階予測
直接多段階予測とは、将来のタイムステップごとに別々の予測モデルを訓練する方法です。例えば、次の5つのタイムステップの値を予測する場合、5つの異なるモデルを訓練することになります。第1段階を予測するもの、第2段階を予測するもの......といった具合です。
このアプローチでは、各モデルが特定のタイムステップに対する予測をおこなうように設計されています。これにより、各モデルは対応する将来のタイムステップに関連する特定のパターンや関係に焦点を当てることができ、その結果、各予測の精度を向上させる可能性があります。しかし、同時に複数のモデルを訓練し、維持する必要があるため、リソースを多く消費する可能性もあります。
LightGBM機械学習モデルを使って多段階予測を試みてみましょう。
まず、複数のステップからのデータを処理する関数を作成します。
データの準備
Pythonコード
def multi_steps_data_process(data, step, train_size=0.7, random_state=42): # Since we are using the OHLC values only data["next signal"] = data["Signal"].shift(-step) # The target variable from next n future values data = data.dropna() y = data["next signal"] X = data.drop(columns=["Signal", "next signal"]) return train_test_split(X, y, train_size=train_size, random_state=random_state)
この関数は、データセットから列 Signal を使用して新しい目的変数を作成します。目的変数は、シグナル列のインデックスstep+1の値から取られます。
次があるとします。
| シグナル |
|---|
1 |
2 |
3 |
4 |
5 |
ステップ1では次のシグナルは2、ステップ2では次のシグナルは3、といった具合です。
この記事では、EURUSDの1時間足時間枠から取得した1000バーのデータを使用します。
Pythonコード
df = pd.read_csv("/kaggle/input/eurusd-period-h1/EURUSD.PERIOD_H1.csv") print(df.shape) df.head(10)
出力
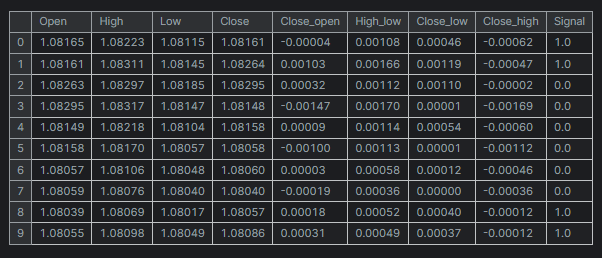
簡単にするために、5つの変数だけのミニデータセットを作成しました。

「シグナル」列は、強気または弱気のローソク足のシグナルを表し、終値が始値より大きい場合はシグナルに1が割り当てられ、反対の場合は0が割り当てられるというロジックで作成されています。
多段階データを作成する関数ができたので、各段階を処理するモデルを宣言しましょう。
予測のための複数モデルの訓練
各タイムステップのモデルを手作業でハードコーディングするのは時間がかかり、効果的ではありません。ループ内でのコーディングがより簡単で効果的になります。ループ内では、訓練、検証、MetaTrader 5での外部使用のためのモデルの保存など、必要なすべてのことをおこないます。
Pythonコード
for pred_step in range(1, 6): # We want to 5 future values lgbm_model = lgbm.LGBMClassifier(**params) X_train, X_test, y_train, y_test = multi_steps_data_process(new_df, pred_step) # preparing data for the current step lgbm_model.fit(X_train, y_train) # training the model for this step # Testing the trained mdoel test_pred = lgbm_model.predict(X_test) # Changes from bst to pipe # Ensuring the lengths are consistent if len(y_test) != len(test_pred): test_pred = test_pred[:len(y_test)] print(f"model for next_signal[{pred_step} accuracy={accuracy_score(y_test, test_pred)}") # Saving the model in ONNX format, Registering ONNX converter update_registered_converter( lgbm.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) # Final LightGBM conversion to ONNX model_onnx = convert_sklearn( lgbm_model, "lightgbm_model", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open(f"lightgbm.EURUSD.h1.pred_close.step.{pred_step}.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
出力
model for next_signal[1 accuracy=0.5033333333333333 model for next_signal[2 accuracy=0.5566666666666666 model for next_signal[3 accuracy=0.4866666666666667 model for next_signal[4 accuracy=0.4816053511705686 model for next_signal[5 accuracy=0.5317725752508361
意外なことに、次の2本目のバーを予測するモデルが最も正確で、55%の精度を示し、次の5本目のバーを予測するモデルは53%の精度を示しました。
MetaTrader 5で予測用モデルをロードする
まず、ONNX形式で保存されたすべてのLightGBM AIモデルをリソースファイルとしてEAに統合します。
MQL5コード
#resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.1.onnx" as uchar model_step_1[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.2.onnx" as uchar model_step_2[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.3.onnx" as uchar model_step_3[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.4.onnx" as uchar model_step_4[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.5.onnx" as uchar model_step_5[] #include <MALE5\Gradient Boosted Decision Trees(GBDTs)\LightGBM\LightGBM.mqh> CLightGBM *light_gbm[5]; //for storing 5 different models MqlRates rates[];
そして、5つの異なるモデルを初期化します。
MQL5コード
int OnInit() { //--- for (int i=0; i<5; i++) light_gbm[i] = new CLightGBM(); //Creating LightGBM objects //--- if (!light_gbm[0].Init(model_step_1)) { Print("Failed to initialize model for step=1 predictions"); return INIT_FAILED; } if (!light_gbm[1].Init(model_step_2)) { Print("Failed to initialize model for step=2 predictions"); return INIT_FAILED; } if (!light_gbm[2].Init(model_step_3)) { Print("Failed to initialize model for step=3 predictions"); return INIT_FAILED; } if (!light_gbm[3].Init(model_step_4)) { Print("Failed to initialize model for step=4 predictions"); return INIT_FAILED; } if (!light_gbm[4].Init(model_step_5)) { Print("Failed to initialize model for step=5 predictions"); return INIT_FAILED; } return(INIT_SUCCEEDED); }
最後に、前のバーのOpen、High、Low、Closeの値を収集し、それらを使って5つの異なるモデルすべてから予測を得ることができます。
MQL5コード
void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close}; string comment_string = ""; int signal = -1; for (int i=0; i<5; i++) { signal = (int)light_gbm[i].predict_bin(input_x); comment_string += StringFormat("\n Next[%d] bar predicted signal=%s",i+1, signal==1?"Buy":"Sell"); } Comment(comment_string); }
結果

直接多段階予測の強み
- 直接多段階予測の強みは、各モデルが特定の予測水平線に特化しているため、各ステップにおいてより正確な予測が可能になる点です。
- 特に、単純な機械学習アルゴリズムを使用する場合、別々のモデルを訓練するのが容易です。
- また、各ステップごとに異なるモデルやアルゴリズムを選択できるため、さまざまな予測課題に柔軟に対応することができます。
直接多段階予測の弱み
- まず、複数のモデルを訓練し維持する必要があるため、計算コストや時間がかかることがあります。
- また、再帰的手法とは異なり、あるステップでの誤差が次のステップに直接伝搬しないため、ステップ間に矛盾が生じる可能性があります。
- さらに、それぞれのモデルが独立しているため、統一されたアプローチに比べて予測期間の依存関係を効果的に捉えることが難しい場合があります。
再帰的多段階予測
再帰的多段階予測は、反復予測とも呼ばれ、1つのモデルを用いて1段階先の予測をおこなう方法です。この予測結果は、次の予測を行う際にモデルにフィードバックされ、希望する数の将来のタイムステップについての予測が得られるまでこのプロセスが繰り返されます。
このアプローチでは、モデルは直近の値を予測するように訓練されます。予測された値は、次の予測の際に入力データに加えられ、次の値の予測に使用されます。つまり、同じモデルを繰り返し活用することになります。
具体的には、線形回帰モデルを使用して前回の終値から次の終値を予測することができます。こうすることで、予測された終値を次の反復の入力として利用できます。このアプローチは、単一の独立変数(特徴量)でも効果的に機能することが示されています。
Pythonコード
new_df = pd.DataFrame({
'Close': df['Close'],
'target close': df['Close'].shift(-1) # next bar closing price
})
その後、次が続きます。
new_df = new_df.dropna() # after shifting we want to drop all NaN values X = new_df[["Close"]].values # Assigning close values into a 2D x array y = new_df["target close"].values print(new_df.shape) new_df.head(10)
出力
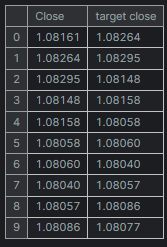
線形回帰モデルの訓練とテスト
モデルを訓練する前に、データをランダム化せずに分割しました。この方法は、モデルが値間の時間的依存関係を把握するのに役立つ可能性があります。次の終値が前の終値に影響を受けることが知られているためです。
model = Pipeline([ ("scaler", StandardScaler()), ("linear_regression", LinearRegression()) ]) # Split the data into training and test sets train_size = int(len(new_df) * 0.7) X_train, X_test = X[:train_size], X[train_size:] y_train, y_test = y[:train_size], y[train_size:] # Train the model model.fit(X_train, y_train)
そして、テストサンプルの実際の値と予測値を示すプロットを作成し、モデルが予測にどれだけ効果的であったかを分析しました。
# Testing the Model
test_pred = model.predict(X_test) # Make predictions on the test set
# Plot the actual vs predicted values
plt.figure(figsize=(7.5, 5))
plt.plot(y_test, label='Actual Values')
plt.plot(test_pred, label='Predicted Values')
plt.xlabel('Samples')
plt.ylabel('Close Prices')
plt.title('Actual vs Predicted Values')
plt.legend()
plt.show()
結果

上の画像からわかるように、このモデルは非常に高い予測精度を示し、テストサンプルでは98%の精度を達成しました。ただし、このチャートにおける予測は、線形モデルが過去のデータセットに基づいてどのような結果を出したかを示しており、再帰的な形式ではなく通常の方法での予測です。モデルに再帰的予測をおこなわせるためには、カスタム関数を作成する必要があります。
Pythonコード
# Function for recursive forecasting def recursive_forecast(model, initial_value, steps): predictions = [] current_input = np.array([[initial_value]]) for _ in range(steps): prediction = model.predict(current_input)[0] predictions.append(prediction) # Update the input for the next prediction current_input = np.array([[prediction]]) return predictions
すると、10バー分の将来予測を得ることができます。
current_close = X[-1][0] # Use the last value in the array # Number of future steps to forecast steps = 10 # Forecast future values forecasted_values = recursive_forecast(model, current_close, steps) print("Forecasted Values:") print(forecasted_values)
出力
Forecasted Values: [1.0854623040804965, 1.0853751608200348, 1.0852885667357617, 1.0852025183667728, 1.0851170122739744, 1.085032045039946, 1.0849476132688034, 1.0848637135860637, 1.0847803426385094, 1.0846974970940555]
再帰的モデルの精度をテストするために、上記の関数recursive_forecastを使って、ループで10タイムステップ後の現在のインデックスから、履歴を通して次の10タイムステップの予測をおこなうことができます。
predicted = [] for i in range(0, X_test.shape[0], steps): current_close = X_test[i][0] # Use the last value in the test array forecasted_values = recursive_forecast(model, current_close, steps) predicted.extend(forecasted_values) print(len(predicted))
出力
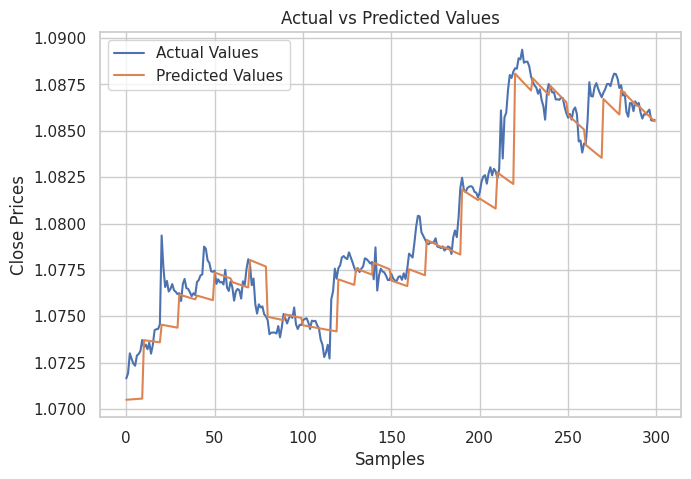
再帰的モデルの精度は91%でした。
最後に、線形回帰モデルをMQL5と互換性のあるONNX形式に保存します。
# Convert the trained pipeline to ONNX
initial_type = [('float_input', FloatTensorType([None, 1]))]
onnx_model = convert_sklearn(model, initial_types=initial_type)
# Save the ONNX model to a file
with open("Lr.EURUSD.h1.pred_close.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
print("Model saved to Lr.EURUSD.h1.pred_close.onnx") MQL5で再帰的予測をおこなう
まず、EAに線形回帰ONNXモデルを追加します。
#resource "\\Files\\Lr.EURUSD.h1.pred_close.onnx" as uchar lr_model[]
線形回帰モデルハンドラクラスをインポートします。
#include <MALE5\Linear Models\Linear Regression.mqh>
CLinearRegression lr; OnInit関数内でモデルを初期化した後、前のバーの終値を取得し、次の10バーの予測をおこないます。
int OnInit() { //--- if (!lr.Init(lr_model)) return INIT_FAILED; //--- ArraySetAsSeries(rates, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].close}; //get the previous closed bar close price vector predicted_close(10); //predicted values for the next 10 timestepps for (int i=0; i<10; i++) { predicted_close[i] = lr.predict(input_x); input_x[0] = predicted_close[i]; //The current predicted value is the next input } Print(predicted_close); }
出力
OR 0 16:39:37.018 Recursive-Multi step forecasting (EURUSD,H4) [1.084011435508728,1.083933353424072,1.083855748176575,1.083778619766235,1.083701968193054,1.083625793457031,1.083550095558167,1.08347487449646,1.083400130271912,1.083325862884521]
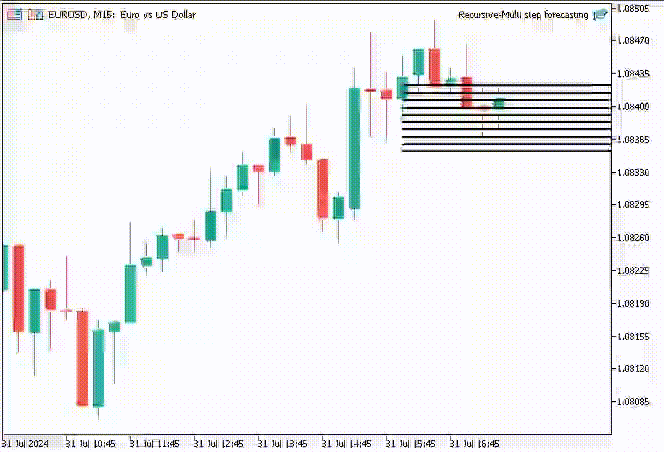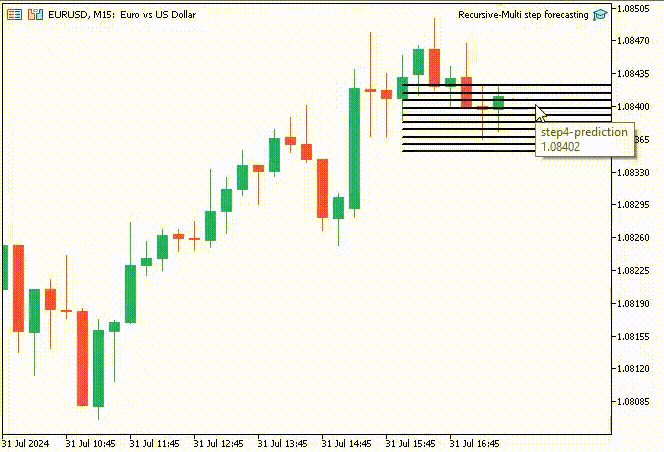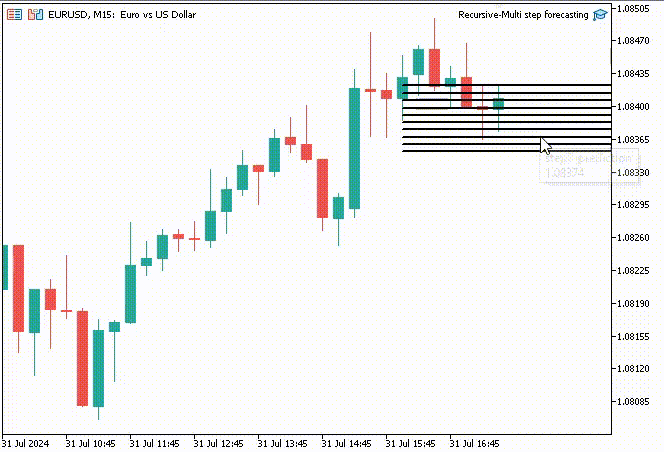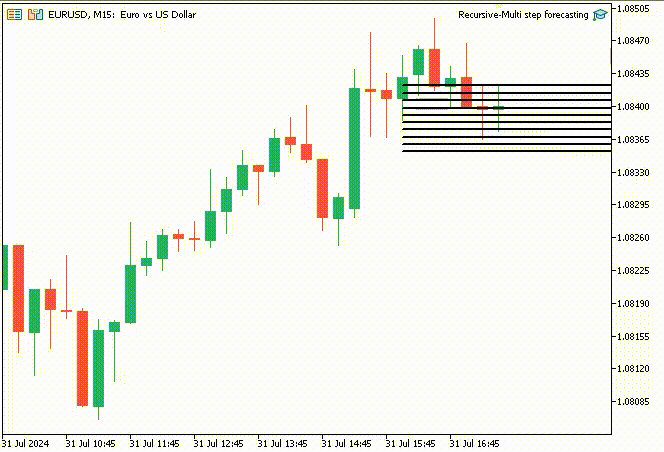
面白くするために、トレンドラインオブジェクトを作り、メインチャート上に10タイムステップの予測値を表示することにしました。
if (NewBar()) { for (int i=0; i<10; i++) { predicted_close[i] = lr.predict(input_x); input_x[0] = predicted_close[i]; //The current predicted value is the next input //--- ObjectDelete(0, "step"+string(i+1)+"-prediction"); //delete an object if it exists TrendCreate("step"+string(i+1)+"-prediction",rates[0].time, predicted_close[i], rates[0].time+(10*60*60), predicted_close[i], clrBlack); //draw a line starting from the previous candle to 10 hours forward } }
TrendCreate関数は、直前のクローズバーから10本先までの短い水平トレンドラインを作成します。
結果
再帰的多段階予測の利点
- 訓練されて維持されるモデルは1つだけなので、実装が単純化され、計算リソースが削減されます。
- 同じモデルが繰り返し使用されるため、予測期間にわたって一貫性が保たれます。
再帰的多段階予測の弱点
- 初期の予測におけるエラーは、その後の予測に伝播し拡大する可能性があり、全体的な精度を低下させる可能性があります。
- このアプローチは、モデルによって把握された関係が予測期間中も安定していることを前提としているが、必ずしもそうとは限りません。
多出力モデルによる多段階予測
多出力モデルは、一度に複数の値を予測するように設計されているため、将来のタイムステップを同時に予測させることで、これを有利に利用することができます。各予測期間ごとに別々のモデルを訓練したり、単一のモデルを再帰的に使用したりする代わりに、多出力モデルは複数の出力を持ち、それぞれが将来のタイムステップに対応します。
多出力モデルでは、モデルは1回のパスで予測ベクトルを生成するように訓練されます。つまりモデルは、異なる将来のタイムステップ間の関係と依存関係を直接理解するように学習します。ニューラルネットワークは複数の出力を生成することができるため、このアプローチはニューラルネットワークをうまく利用することができます。
多出力ニューラルネットワークモデル用のデータセットの準備
訓練済みニューラルネットワークモデルに予測させたいすべてのタイムステップの目的変数を準備しなければなりません。
Pythonコード
# Create target variables for multiple future steps def create_target(df, future_steps=10): target = pd.concat([df['Close'].shift(-i) for i in range(1, future_steps + 1)], axis=1) # using close prices for the next i bar target.columns = [f'target_close_{i}' for i in range(1, future_steps + 1)] # naming the columns return target # Combine features and targets new_df = pd.DataFrame({ 'Open': df['Open'], 'High': df['High'], 'Low': df['Low'], 'Close': df['Close'] }) future_steps = 5 target_columns = create_target(new_df, future_steps).dropna() combined_df = pd.concat([new_df, target_columns], axis=1) #concatenating the new pandas dataframe with the target columns combined_df = combined_df.dropna() #droping rows with NaN values caused by shifting values target_cols_names = [f'target_close_{i}' for i in range(1, future_steps + 1)] X = combined_df.drop(columns=target_cols_names).values #dropping all target columns from the x array y = combined_df[target_cols_names].values # creating the target variables print(f"x={X.shape} y={y.shape}") combined_df.head(10)
出力
x=(995, 4) y=(995, 5)
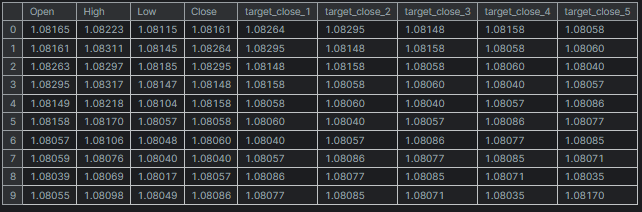
多出力ニューラルネットワークの訓練とテスト
まず、逐次ニューラルネットワークモデルを定義します。
Pythonコード
# Defining the neural network model model = Sequential([ Input(shape=(X.shape[1],)), Dense(units = 256, activation='relu'), Dense(units = 128, activation='relu'), Dense(units = future_steps) ]) # Compiling the model adam = Adam(learning_rate=0.01) model.compile(optimizer=adam, loss='mse') # Mmodel summary model.summary()
出力
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense (Dense) │ (None, 256) │ 1,280 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 128) │ 32,896 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_2 (Dense) │ (None, 5) │ 645 │ └─────────────────────────────────┴────────────────────────┴───────────────┘ Total params: 34,821 (136.02 KB) Trainable params: 34,821 (136.02 KB) Non-trainable params: 0 (0.00 B)
そして、再帰的多段階予測でおこなったのとは異なり、データをそれぞれ訓練サンプルとテストサンプルに分割します。今回は、ニューラルネットワークがこのデータから非線形関係を理解する際にさらに優れたパフォーマンスを発揮すると考えられるため、モデルに連続パターンを理解させたくないため、42のランダム シードでランダム化してからデータを分割します。
最後に、訓練データを使ってNNモデルを訓練します。
# Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) scaler = MinMaxScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) # Training the model early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True) # stop training when 5 epochs doesn't improve history = model.fit(X_train, y_train, epochs=20, validation_split=0.2, batch_size=32, callbacks=[early_stopping])
テストデータセットでモデルをテストした後。
# Testing the Model test_pred = model.predict(X_test) # Make predictions on the test set # Plotting the actual vs predicted values for each future step plt.figure(figsize=(7.5, 10)) for i in range(future_steps): plt.subplot((future_steps + 1) // 2, 2, i + 1) # subplots grid plt.plot(y_test[:, i], label='Actual Values') plt.plot(test_pred[:, i], label='Predicted Values') plt.xlabel('Samples') plt.ylabel(f'Close Price +{i+1}') plt.title(f'Actual vs Predicted Values (Step {i+1})') plt.legend() plt.tight_layout() plt.show() # Evaluating the model for each future step for i in range(future_steps): accuracy = r2_score(y_test[:, i], test_pred[:, i]) print(f"Step {i+1} - R^2 Score: {accuracy}")
以下はその結果です。

Step 1 - R^2 Score: 0.8664635514027637 Step 2 - R^2 Score: 0.9375671150885528 Step 3 - R^2 Score: 0.9040736780305894 Step 4 - R^2 Score: 0.8491904738263638 Step 5 - R^2 Score: 0.8458062142647863
ニューラルネットワークはこの回帰問題で素晴らしい結果を出しました。以下のコードは、Pythonで予測値を得る方法を示しています。
# Predicting multiple future values current_input = X_test[0].reshape(1, -1) # use the first row of the test set, reshape the data also predicted_values = model.predict(current_input)[0] # adding[0] ensures we get a 1D array instead of 2D print("Predicted Future Values:") print(predicted_values)
出力
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step Predicted Future Values: [1.0892788 1.0895394 1.0892794 1.0883198 1.0884078]
そして、このニューラルネットワークモデルをONNX形式で、スケーラーファイルをバイナリ形式で保存することができます。
import tf2onnx
# Convert the Keras model to ONNX
spec = (tf.TensorSpec((None, X_train.shape[1]), tf.float16, name="input"),)
model.output_names=['output']
onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=13)
# Save the ONNX model to a file
with open("NN.EURUSD.h1.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
# Save the used scaler parameters to binary files
scaler.data_min_.tofile("NN.EURUSD.h1.min_max.min.bin")
scaler.data_max_.tofile("NN.EURUSD.h1.min_max.max.bin") 最後に、保存したモデルとそのデータスケーラーパラメータをMQL5で使用することができます。
MQL5でニューラルネットワークの多段階予測を得る
まず、モデルとMin-maxスケーラーパラメータをEAに追加します。
#resource "\\Files\\NN.EURUSD.h1.onnx" as uchar onnx_model[]; //rnn model in onnx format #resource "\\Files\\NN.EURUSD.h1.min_max.max.bin" as double min_max_max[]; #resource "\\Files\\NN.EURUSD.h1.min_max.min.bin" as double min_max_min[];
次に、回帰ニューラルネットワークONNXクラスとMinMaxスケーラーライブラリハンドラをインポートします。
#include <MALE5\Neural Networks\Regressor Neural Nets.mqh> #include <MALE5\preprocessing.mqh> CNeuralNets nn; MinMaxScaler *scaler;
次に、NNモデルとスケーラーを初期化し、モデルから最終的な予測値を得ることができます。
MqlRates rates[]; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!nn.Init(onnx_model)) return INIT_FAILED; scaler = new MinMaxScaler(min_max_min, min_max_max); //Initializing the scaler, populating it with trained values //--- ArraySetAsSeries(rates, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(scaler)!=POINTER_INVALID) delete (scaler); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close}; input_x = scaler.transform(input_x); // We normalize the input data vector preds = nn.predict(input_x); Print("predictions = ",preds); }
出力
2024.07.31 19:13:20.785 Multi-step forecasting using Multi-outputs model (EURUSD,H4) predictions = [1.080284595489502,1.082370758056641,1.083482265472412,1.081504583358765,1.079929828643799]
面白くするために、チャートにトレンドラインを追加し、すべてのニューラルネットワークの将来予測をマークしました。
void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close}; if (NewBar()) { input_x = scaler.transform(input_x); // We normalize the input data vector preds = nn.predict(input_x); for (int i=0; i<(int)preds.Size(); i++) { //--- ObjectDelete(0, "step"+string(i+1)+"-prediction"); //delete an object if it exists TrendCreate("step"+string(i+1)+"-prediction",rates[0].time, preds[i], rates[0].time+(5*60*60), preds[i], clrBlack); //draw a line starting from the previous candle to 5 hours forward } } }
この時、再帰的線形回帰モデルを使った時よりも見栄えのする予測線が得られました。

多出力モデルを用いた多段階予測の概要
メリット- 一度に複数のステップを予測することで、モデルは将来のタイムステップ間の関係や依存関係を捉えることができます。
- 必要なモデルは1つだけなので、実装とメンテナンスが簡素化されます。
- このモデルは、予測期間全体にわたって一貫した予測をおこなうように学習します。
デメリット
- 複数の将来値を出力するモデルの訓練はより複雑になり、特にニューラルネットワークの場合、より洗練されたアーキテクチャが必要になることがあります。
- モデルの複雑さによっては、学習と推論に多くの計算リソースが必要になります。
- 特に予測期間が長く、モデルが訓練データに特化しすぎた場合、過剰適合のリスクがあります。
取引戦略における多段階予測の活用
特にニューラルネットワークやLightGBMなどのモデルを活用した多段階予測は、予測された市場の動きに基づいたダイナミックな調整を可能にし、さまざまな取引戦略を大幅に強化することができます。たとえば、グリッド取引においては、固定注文を設定するのではなく、多段階予測を用いることで予想される価格変動に応じたダイナミックなエントリが可能となり、市況に対するシステムの応答性が向上します。
また、下落トレンドが予測される場合には、ショートポジションを取ったりプットオプションを購入したりするなど、潜在的な損失から守るためにポジションをいつ建てたり閉じたりすべきかという指針を得ることができ、ヘッジ戦略も恩恵を受けます。さらに、トレンド検出においては、予測を通じて将来の市場の方向性を理解することで、トレーダーはショートポジションを優先するか、損失を回避するためにロングポジションを終了するかのいずれかの戦略をそれに応じて調整することができます。
最後に、高頻度取引(HFT)では、迅速な多段階予測により、アルゴリズムが短期的な値動きを利用できるようになり、数秒から数分後に予測される価格変動に基づいてタイムリーに売買注文を執行することで、収益性を高めることができます。
結論
この記事の前のセクションで説明したように、金融分析や外国為替取引において、将来の複数の値を予測する能力は非常に有用です。この投稿では、この挑戦に取り組むためのさまざまなアプローチを提供することを目的としています。次回は、複数の値を分析し予測するために特に構築された技術であるベクトル自己回帰について説明します。
では、また。
機械学習モデルの開発を追跡し、本連載で議論されている多くのことを、このレポに掲載しています。
添付ファイルの表
| ファイル名 | ファイルの種類 | 説明と使用法 |
|---|---|---|
Direct Muilti step Forecasting.mq5 Multi-step forecasting using multi-outputs model.mq5 Recursive-Multi step forecasting.mq5 | EA | 多段階予測のために複数のLightGBMモデルを使用するコード 多出力構造を用いて多段階を予測するニューラルネットワークモデル 線形回帰で将来のタイムステップを繰り返し予測 |
| LightGBM.mqh | MQL5ライブラリファイル | ONNXフォーマットでLightGBMモデルをロードし、予測に使用するコード |
| Linear Regression.mqh | MQL5ライブラリファイル | 線形回帰モデルをONNXフォーマットでロードし、予測に使用するためのコード |
| preprocessing.mqh | MQL5ライブラリファイル | MInMaxスケーラーで構成されており、入力データを正規化するために使用されるスケーリング技術 |
| Regressor Neural Nets.mqh | MQL5ライブラリファイル | ONNXフォーマットからMQL5にニューラルネットワークモデルをロードし、デプロイするためのコード |
lightgbm.EURUSD.h1.pred_close.step.1.onnx lightgbm.EURUSD.h1.pred_close.step.2.onnx lightgbm.EURUSD.h1.pred_close.step.3.onnx lightgbm.EURUSD.h1.pred_close.step.4.onnx lightgbm.EURUSD.h1.pred_close.step.5.onnx Lr.EURUSD.h1.pred_close.onnx NN.EURUSD.h1.onnx | ONNXフォーマットのAIモデル | 次のステップ値を予測するLightGBMモデル ONNX形式の単純な線形回帰モデル ONNX形式のフィードフォワードニューラルネットワーク |
| NN.EURUSD.h1.min_max.max.bin NN.EURUSD.h1.min_max.min.bin | バイナリファイル | MIn-maxスケーラーの最大値と最小値をそれぞれ含む |
| predicting-multiple-future-tutorials.ipynb | Jupyter Notebook | この記事で示したすべてのpythonコード |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/15465
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索