
Машинное обучение и Data Science (Часть 28): Прогнозирование множества будущих значений для EURUSD

Содержание
- Введение
- Прямое многошаговое прогнозирование
- Преимущества прямого многошагового прогнозирования
- Недостатки прямого многошагового прогнозирования
- Рекурсивное многошаговое прогнозирование
- Преимущества рекурсивного многошагового прогнозирования
- Недостатки рекурсивного многошагового прогнозирования
- Многошаговое прогнозирование с использованием моделей с множественными выходами
- Преимущества многошагового прогнозирования с использованием моделей с множественными выходами
- Недостатки многошагового прогнозирования с использованием моделей с множественными выходами
- Когда и где использовать многошаговое прогнозирование
- Заключение
Введение
В мире финансовой аналитики с использованием машинного обучения целью часто является прогнозирование будущих значений на основе исторических данных. В разных статьях в этой серии мы уже обсуждали возможности прогнозирования следующего непосредственного значения. Однако в реальных приложениях существует множество ситуаций, когда может потребоваться предсказать несколько будущих значений вместо одного. Попытка предсказать различные последовательные значения известна как многошаговое прогнозирование.
Многошаговое прогнозирование межет применяться в различных областях, таких как финансы, прогнозирование погоды, управление цепочками поставок и здравоохранение. Например, на финансовых рынках инвесторам необходимо прогнозировать цены акций или курсы валют на несколько дней, недель или даже месяцев вперед. Более точные прогнозы погоды на предстоящие дни или недели могут помочь в планировании и управлении чрезвычайными ситуациями.

В этой статье предполагается, что у вас есть базовые знания о машинном обучении и ИИ, ONNX, о том, как использовать модели ONNX в MQL5, о линейной регрессии, LightGBM и нейронных сетях.
Процесс многошагового прогнозирования включает в себя несколько методологий, каждая из которых имеет свои сильные и слабые стороны. Сюда относятся:
- Прямое многошаговое прогнозирование
- Рекурсивное многошаговое прогнозирование
- Модели с множеством выходов
- Векторная авторегрессия (VAR) (о ней будем говорить в следующей статье(ях))
В этой статье мы рассмотрим основы этих методов и узнаем, как их применять и как реализовать с использованием различных методов машинного обучения и статистики. Цель применения многошагового прогнозирования в этой статье — помощь в принятии решений о будущем движении пары EURUSD.
# Create target variables for multiple future steps def create_target(df, future_steps=10): target = pd.concat([df['Close'].shift(-i) for i in range(1, future_steps + 1)], axis=1) # using close prices for the next i bar target.columns = [f'target_close_{i}' for i in range(1, future_steps + 1)] # naming the columns return target # Combine features and targets new_df = pd.DataFrame({ 'Open': df['Open'], 'High': df['High'], 'Low': df['Low'], 'Close': df['Close'] }) future_steps = 5 target_columns = create_target(new_df, future_steps).dropna() combined_df = pd.concat([new_df, target_columns], axis=1) #concatenating the new pandas dataframe with the target columns combined_df = combined_df.dropna() #droping rows with NaN values caused by shifting values target_cols_names = [f'target_close_{i}' for i in range(1, future_steps + 1)] X = combined_df.drop(columns=target_cols_names).values #dropping all target columns from the x array y = combined_df[target_cols_names].values # creating the target variables print(f"x={X.shape} y={y.shape}") combined_df.head(10)
Прямое многошаговое прогнозирование
Прямое многошаговое прогнозирование — это метод, при котором отдельные прогностические модели обучаются для каждого будущего временного шага, который нужно спрогнозировать. Например, если мы хотим предсказать значения для следующих 5 временных шагов, нам нужно обучить 5 различных моделей. Одну — для прогнозирования первого шага, вторую — для прогнозирования второго шага и так далее.
При прямом многошаговом прогнозировании каждая модель предназначена для прогнозирования определенного горизонта. Такой подход позволяет каждой модели сосредоточиться на конкретных закономерностях и связях, которые имеют отношение к соответствующему будущему временному шагу, что потенциально повышает точность каждого прогноза. Однако это также означает, что придется обучать и поддерживать несколько моделей, что может потребовать значительных ресурсов.
Попытаемся спрогнозировать несколько шагов вперед с помощью модели машинного обучения LightGBM.
Сначала создадим функцию для обработки данных из множества шагов.
Подготовка данных
Код Python
def multi_steps_data_process(data, step, train_size=0.7, random_state=42): # Since we are using the OHLC values only data["next signal"] = data["Signal"].shift(-step) # The target variable from next n future values data = data.dropna() y = data["next signal"] X = data.drop(columns=["Signal", "next signal"]) return train_test_split(X, y, train_size=train_size, random_state=random_state)
Эта функция создает новую целевую переменную, используя столбец «Сигнал» из набора данных. Целевая переменная берется из значения индекса step+1 в столбце сигнала.
Предположим, что у нас есть такие данные:
| Сигналы |
|---|
1 |
2 |
3 |
4 |
5 |
На шаге 1 следующим сигналом будет 2, на шаге 2 следующим сигналом будет 3 и т. д.
В этой статье мы будем использовать данные с часового таймфрейма EURUSD на 1000 баров.
Код Python
df = pd.read_csv("/kaggle/input/eurusd-period-h1/EURUSD.PERIOD_H1.csv") print(df.shape) df.head(10)
Результаты
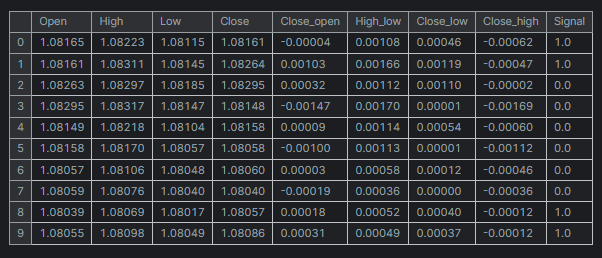
Для простоты я создал мини-набор данных только для пяти переменных.

Столбец «Сигнал» отображает сигналы бычьей или медвежьей свечи. Он был создан по такой логике: всякий раз, когда цена закрытия была больше цены открытия, сигналу присваивалось значение 1, а в противоположном случае — значение 0.
Теперь, когда у нас есть функция для создания многошаговых данных, объявим наши модели для обработки каждого шага.
Обучение нескольких моделей для прогнозирования
Писать код модели для каждого временного шага вручную может будет неэффективным, так как займет много времени. Программирование в цикле будет проще и эффективнее. В цикле мы выполняем все необходимые действия, такие как обучение, проверка и сохранение модели для внешнего использования в MetaTrader 5.
Код Python
for pred_step in range(1, 6): # We want to 5 future values lgbm_model = lgbm.LGBMClassifier(**params) X_train, X_test, y_train, y_test = multi_steps_data_process(new_df, pred_step) # preparing data for the current step lgbm_model.fit(X_train, y_train) # training the model for this step # Testing the trained mdoel test_pred = lgbm_model.predict(X_test) # Changes from bst to pipe # Ensuring the lengths are consistent if len(y_test) != len(test_pred): test_pred = test_pred[:len(y_test)] print(f"model for next_signal[{pred_step} accuracy={accuracy_score(y_test, test_pred)}") # Saving the model in ONNX format, Registering ONNX converter update_registered_converter( lgbm.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) # Final LightGBM conversion to ONNX model_onnx = convert_sklearn( lgbm_model, "lightgbm_model", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open(f"lightgbm.EURUSD.h1.pred_close.step.{pred_step}.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Результаты
model for next_signal[1 accuracy=0.5033333333333333 model for next_signal[2 accuracy=0.5566666666666666 model for next_signal[3 accuracy=0.4866666666666667 model for next_signal[4 accuracy=0.4816053511705686 model for next_signal[5 accuracy=0.5317725752508361
Удивительно, но модель для прогнозирования следующего второго бара оказалась самой точной, ее точность 55%, за ней следует модель для прогнозирования следующего пятого бара, которая показала точность 53%.
Загрузка моделей для прогнозирования в MetaTrader 5
Начнем с интеграции всех моделей LightGBM, сохраненных в формате ONNX, в наш советник в виде файлов ресурсов.
Код MQL5
#resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.1.onnx" as uchar model_step_1[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.2.onnx" as uchar model_step_2[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.3.onnx" as uchar model_step_3[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.4.onnx" as uchar model_step_4[] #resource "\\Files\\lightgbm.EURUSD.h1.pred_close.step.5.onnx" as uchar model_step_5[] #include <MALE5\Gradient Boosted Decision Trees(GBDTs)\LightGBM\LightGBM.mqh> CLightGBM *light_gbm[5]; //for storing 5 different models MqlRates rates[];
Затем инициализируем наши 5 различных моделей.
Код MQL5
int OnInit() { //--- for (int i=0; i<5; i++) light_gbm[i] = new CLightGBM(); //Creating LightGBM objects //--- if (!light_gbm[0].Init(model_step_1)) { Print("Failed to initialize model for step=1 predictions"); return INIT_FAILED; } if (!light_gbm[1].Init(model_step_2)) { Print("Failed to initialize model for step=2 predictions"); return INIT_FAILED; } if (!light_gbm[2].Init(model_step_3)) { Print("Failed to initialize model for step=3 predictions"); return INIT_FAILED; } if (!light_gbm[3].Init(model_step_4)) { Print("Failed to initialize model for step=4 predictions"); return INIT_FAILED; } if (!light_gbm[4].Init(model_step_5)) { Print("Failed to initialize model for step=5 predictions"); return INIT_FAILED; } return(INIT_SUCCEEDED); }
Наконец, мы можем собрать значения цен открытия, максимума, минимума и закрытия (Open, High, Low и Close) предыдущего бара и использовать их для получения прогнозов по всем 5 различным моделям.
Код MQL5
void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close}; string comment_string = ""; int signal = -1; for (int i=0; i<5; i++) { signal = (int)light_gbm[i].predict_bin(input_x); comment_string += StringFormat("\n Next[%d] bar predicted signal=%s",i+1, signal==1?"Buy":"Sell"); } Comment(comment_string); }
Результат

Преимущества прямого многошагового прогнозирования
- Каждая модель специализируется на определенном горизонте прогнозирования, что потенциально приводит к более точным прогнозам на каждом этапе.
- Обучать отдельные модели проще, особенно если вы используете простые алгоритмы машинного обучения.
- Вы можете выбрать различные модели или алгоритмы для каждого шага, что дает большую гибкость в решении различных задач прогнозирования.
Недостатки прямого многошагового прогнозирования
- Этот метод требует обучения и обслуживания нескольких моделей, что может быть затратным с точки зрения вычислений и времени.
- В отличие от рекурсивных методов, ошибки одного шага не распространяются напрямую на следующий, что может быть как достоинством, так и недостатком. Это может привести к несоответствию между шагами.
- Каждая модель независима и может отражать зависимости между горизонтами прогнозирования менее эффективно, чем единый подход.
Рекурсивное многошаговое прогнозирование
Рекурсивное многошаговое прогнозирование, также называемое итеративным прогнозированием, представляет собой метод, при котором для прогнозирования на один шаг вперед используется одна модель. Затем этот прогноз возвращается в модель для создания следующего прогноза. Этот процесс повторяется до тех пор, пока не будут сделаны прогнозы для желаемого количества будущих временных шагов.
При рекурсивном многошаговом прогнозировании модель обучается предсказывать значение, идущее сразу за текущим. После предсказания этого значения оно добавляется к входным данным и используется для прогнозирования следующего значения. Этот метод использует одну и ту же модель итеративно.
Мы воспользуемся моделью линейной регрессии, чтобы спрогнозировать следующую цену закрытия, используя предыдущую цену закрытия. Таким образом, спрогнозированная цена закрытия может быть использована в качестве входных данных для следующей итерации и так далее. Этот подход, по-видимому, также хорошо работает с одной независимой переменной (признаком).
Код Python
new_df = pd.DataFrame({
'Close': df['Close'],
'target close': df['Close'].shift(-1) # next bar closing price
})
Then.
new_df = new_df.dropna() # after shifting we want to drop all NaN values X = new_df[["Close"]].values # Assigning close values into a 2D x array y = new_df["target close"].values print(new_df.shape) new_df.head(10)
Результаты
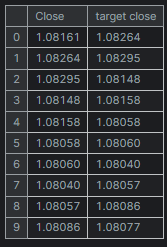
Обучение и тестирование модели линейной регрессии
Перед обучением модели разделим данные без рандомизации. Это может помочь модели уловить временные зависимости между значениями, поскольку мы знаем, что на следующее закрытие влияет предыдущая цена закрытия.
model = Pipeline([ ("scaler", StandardScaler()), ("linear_regression", LinearRegression()) ]) # Split the data into training and test sets train_size = int(len(new_df) * 0.7) X_train, X_test = X[:train_size], X[train_size:] y_train, y_test = y[:train_size], y[train_size:] # Train the model model.fit(X_train, y_train)
Затем я создал график, показывающий фактические значения из тестовой выборки и их прогнозируемые значения, чтобы проанализировать, насколько эффективна модель в составлении прогнозов.
# Testing the Model
test_pred = model.predict(X_test) # Make predictions on the test set
# Plot the actual vs predicted values
plt.figure(figsize=(7.5, 5))
plt.plot(y_test, label='Actual Values')
plt.plot(test_pred, label='Predicted Values')
plt.xlabel('Samples')
plt.ylabel('Close Prices')
plt.title('Actual vs Predicted Values')
plt.legend()
plt.show()
Результат

Yа изображении выше видно, что модель действительно давала приличные прогнозы, на тестовой выборке ее точность составила 98%, однако прогнозы на диаграмме показывают, как линейная модель функционирует на историческом наборе данных, делая прогнозы обычным способом, а не в рекурсивном формате. Чтобы модель могла делать рекурсивные прогнозы, нужно создать пользовательскую функцию.
Код Python
# Function for recursive forecasting def recursive_forecast(model, initial_value, steps): predictions = [] current_input = np.array([[initial_value]]) for _ in range(steps): prediction = model.predict(current_input)[0] predictions.append(prediction) # Update the input for the next prediction current_input = np.array([[prediction]]) return predictions
Далее мы можем получить будущие прогнозы для 10 баров.
current_close = X[-1][0] # Use the last value in the array # Number of future steps to forecast steps = 10 # Forecast future values forecasted_values = recursive_forecast(model, current_close, steps) print("Forecasted Values:") print(forecasted_values)
Результаты
Forecasted Values: [1.0854623040804965, 1.0853751608200348, 1.0852885667357617, 1.0852025183667728, 1.0851170122739744, 1.085032045039946, 1.0849476132688034, 1.0848637135860637, 1.0847803426385094, 1.0846974970940555]
Чтобы проверить точность рекурсивной модели, используем функцию recursive_forecast, которая показана в коде выше, чтобы сделать прогнозы на 10 следующих шагов на протяжении всей истории начиная с текущего индекса в цикле.
predicted = [] for i in range(0, X_test.shape[0], steps): current_close = X_test[i][0] # Use the last value in the test array forecasted_values = recursive_forecast(model, current_close, steps) predicted.extend(forecasted_values) print(len(predicted))
Результаты

Точность рекурсивной модели составила 91%.
Наконец, можем сохранить модель линейной регрессии в формате ONNX, совместимом с MQL5.
# Convert the trained pipeline to ONNX
initial_type = [('float_input', FloatTensorType([None, 1]))]
onnx_model = convert_sklearn(model, initial_types=initial_type)
# Save the ONNX model to a file
with open("Lr.EURUSD.h1.pred_close.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
print("Model saved to Lr.EURUSD.h1.pred_close.onnx") Рекурсивные прогнозы в MQL5.
Начнем с добавления модели линейной регрессии ONNX в наш советник.
#resource "\\Files\\Lr.EURUSD.h1.pred_close.onnx" as uchar lr_model[]
Затем импортируем класс обработчика модели линейной регрессии.
#include <MALE5\Linear Models\Linear Regression.mqh>
CLinearRegression lr; После инициализации модели внутри функции OnInit мы можем получить цену закрытия предыдущего закрытого бара, а затем сделать прогнозы на следующие 10 баров.
int OnInit() { //--- if (!lr.Init(lr_model)) return INIT_FAILED; //--- ArraySetAsSeries(rates, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].close}; //get the previous closed bar close price vector predicted_close(10); //predicted values for the next 10 timestepps for (int i=0; i<10; i++) { predicted_close[i] = lr.predict(input_x); input_x[0] = predicted_close[i]; //The current predicted value is the next input } Print(predicted_close); }
Результаты
OR 0 16:39:37.018 Recursive-Multi step forecasting (EURUSD,H4) [1.084011435508728,1.083933353424072,1.083855748176575,1.083778619766235,1.083701968193054,1.083625793457031,1.083550095558167,1.08347487449646,1.083400130271912,1.083325862884521]
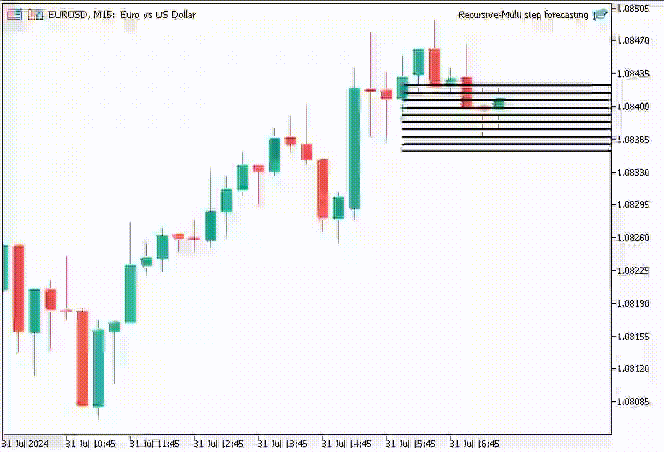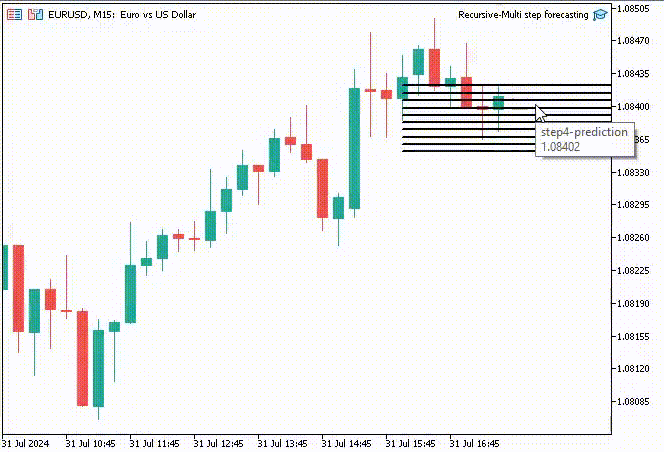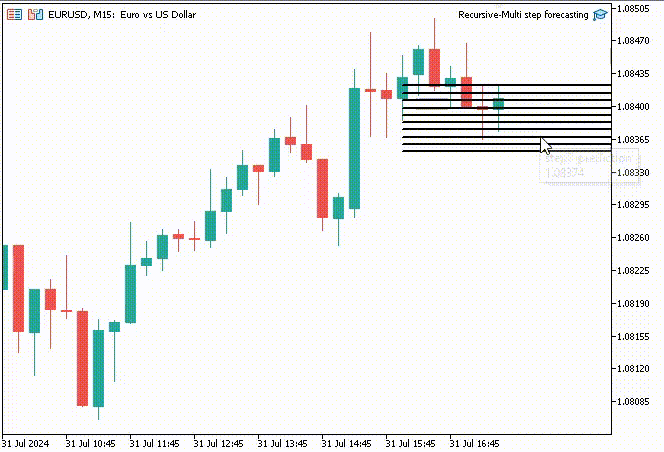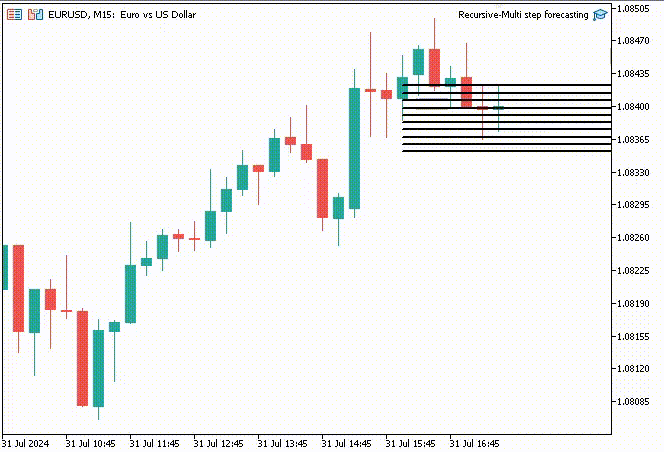
Для интереса я решил создать объекты линий тренда, чтобы показать эти прогнозируемые значения для 10 временных интервалов на основном графике.
if (NewBar()) { for (int i=0; i<10; i++) { predicted_close[i] = lr.predict(input_x); input_x[0] = predicted_close[i]; //The current predicted value is the next input //--- ObjectDelete(0, "step"+string(i+1)+"-prediction"); //delete an object if it exists TrendCreate("step"+string(i+1)+"-prediction",rates[0].time, predicted_close[i], rates[0].time+(10*60*60), predicted_close[i], clrBlack); //draw a line starting from the previous candle to 10 hours forward } }
Функция TrendCreate создает короткую горизонтальную линию тренда, начиная с предыдущего закрытого бара на 10 баров вперед.
Результат
Преимущества рекурсивного многошагового прогнозирования
- Поскольку обучается и поддерживается только одна модель, это упрощает реализацию и сокращает вычислительные ресурсы.
- Одна и та же модель используется итеративно, что обеспечивает согласованность прогнозов на протяжении всего горизонта предсказания.
Недостатки рекурсивного многошагового прогнозирования
- Ошибки в ранних прогнозах могут распространяться и усиливаться в последующих прогнозах, потенциально снижая общую точность.
- Данный подход предполагает, что взаимосвязи, зафиксированные моделью, остаются стабильными в течение всего периода прогнозирования, что не всегда соответствует действительности.
Многошаговое прогнозирование с использованием моделей с множественными выходами
Модели с множественными выходами предназначены для прогнозирования нескольких значений одновременно. Таким образом, мы можем заставить модели одновременно прогнозировать будущие шаги. Вместо обучения отдельных моделей для каждого горизонта прогнозирования или рекурсивного использования одной модели, такая модель генерирует несколько выходов, каждый из которых соответствует будущему шагу.
В модели с несколькими выходами модель обучается создавать вектор прогнозов за один проход. Это означает, что модель учится понимать взаимосвязи и зависимости между различными будущими временными шагами напрямую. Этот подход можно успешно реализовать с использованием нейронных сетей, поскольку они способны генерировать несколько выходов.
Подготовка набора данных для модели нейронной сети с несколькими выходами
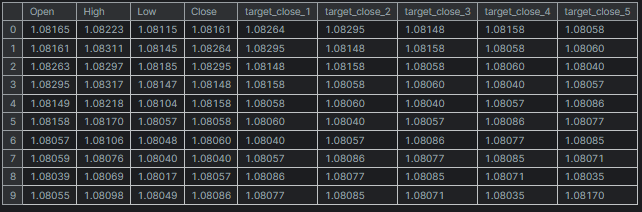
Нам необходимо подготовить целевые переменные для всех временных шагов, которые должна уметь прогнозировать наша обученная модель нейронной сети.
Код Python
# Create target variables for multiple future steps def create_target(df, future_steps=10): target = pd.concat([df['Close'].shift(-i) for i in range(1, future_steps + 1)], axis=1) # using close prices for the next i bar target.columns = [f'target_close_{i}' for i in range(1, future_steps + 1)] # naming the columns return target # Combine features and targets new_df = pd.DataFrame({ 'Open': df['Open'], 'High': df['High'], 'Low': df['Low'], 'Close': df['Close'] }) future_steps = 5 target_columns = create_target(new_df, future_steps).dropna() combined_df = pd.concat([new_df, target_columns], axis=1) #concatenating the new pandas dataframe with the target columns combined_df = combined_df.dropna() #droping rows with NaN values caused by shifting values target_cols_names = [f'target_close_{i}' for i in range(1, future_steps + 1)] X = combined_df.drop(columns=target_cols_names).values #dropping all target columns from the x array y = combined_df[target_cols_names].values # creating the target variables print(f"x={X.shape} y={y.shape}") combined_df.head(10)
Результаты
x=(995, 4) y=(995, 5)
Обучение и тестирование нейронной сети с множественными выходами
Начнем с определения последовательной модели нейронной сети.
Код Python
# Defining the neural network model model = Sequential([ Input(shape=(X.shape[1],)), Dense(units = 256, activation='relu'), Dense(units = 128, activation='relu'), Dense(units = future_steps) ]) # Compiling the model adam = Adam(learning_rate=0.01) model.compile(optimizer=adam, loss='mse') # Mmodel summary model.summary()
Результаты
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense (Dense) │ (None, 256) │ 1,280 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 128) │ 32,896 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_2 (Dense) │ (None, 5) │ 645 │ └─────────────────────────────────┴────────────────────────┴───────────────┘ Total params: 34,821 (136.02 KB) Trainable params: 34,821 (136.02 KB) Non-trainable params: 0 (0.00 B)
Затем разделим данные на обучающую и тестовую выборки соответственно — этот шаг отличается от рекурсивного многошагового прогнозирования. На этот раз мы делим данные после рандомизации с помощью 42 случайных начальных чисел, чтобы модель не понимала последовательные закономерности, поскольку мы предполагаем, что нейронная сеть будет работать лучше при понимании нелинейных взаимосвязей на основе этих данных.
Наконец, обучаем модель, используя обучающую выборку.
# Split the data into training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42) scaler = MinMaxScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) # Training the model early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True) # stop training when 5 epochs doesn't improve history = model.fit(X_train, y_train, epochs=20, validation_split=0.2, batch_size=32, callbacks=[early_stopping])
Затем тестируем модель на тестовом наборе данных.
# Testing the Model test_pred = model.predict(X_test) # Make predictions on the test set # Plotting the actual vs predicted values for each future step plt.figure(figsize=(7.5, 10)) for i in range(future_steps): plt.subplot((future_steps + 1) // 2, 2, i + 1) # subplots grid plt.plot(y_test[:, i], label='Actual Values') plt.plot(test_pred[:, i], label='Predicted Values') plt.xlabel('Samples') plt.ylabel(f'Close Price +{i+1}') plt.title(f'Actual vs Predicted Values (Step {i+1})') plt.legend() plt.tight_layout() plt.show() # Evaluating the model for each future step for i in range(future_steps): accuracy = r2_score(y_test[:, i], test_pred[:, i]) print(f"Step {i+1} - R^2 Score: {accuracy}")
Ниже представлен результат.

Step 1 - R^2 Score: 0.8664635514027637 Step 2 - R^2 Score: 0.9375671150885528 Step 3 - R^2 Score: 0.9040736780305894 Step 4 - R^2 Score: 0.8491904738263638 Step 5 - R^2 Score: 0.8458062142647863
Нейронная сеть показала впечатляющие результаты при решении этой задачи регрессии. Код ниже позволяет получить прогнозы в Python.
# Predicting multiple future values current_input = X_test[0].reshape(1, -1) # use the first row of the test set, reshape the data also predicted_values = model.predict(current_input)[0] # adding[0] ensures we get a 1D array instead of 2D print("Predicted Future Values:") print(predicted_values)
Результаты
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step Predicted Future Values: [1.0892788 1.0895394 1.0892794 1.0883198 1.0884078]
Затем можем сохранить эту модель в формате ONNX, а файлы масштабирования — в бинарных файлах.
import tf2onnx
# Convert the Keras model to ONNX
spec = (tf.TensorSpec((None, X_train.shape[1]), tf.float16, name="input"),)
model.output_names=['output']
onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=13)
# Save the ONNX model to a file
with open("NN.EURUSD.h1.onnx", "wb") as f:
f.write(onnx_model.SerializeToString())
# Save the used scaler parameters to binary files
scaler.data_min_.tofile("NN.EURUSD.h1.min_max.min.bin")
scaler.data_max_.tofile("NN.EURUSD.h1.min_max.max.bin") Наконец, можем использовать сохраненную модель и ее параметры масштабирования данных в MQL5.
Получение многошаговых предсказаний нейронной сети в MQL5
Начнем с добавления модели и параметров масштабирования Min-Max в советник.
#resource "\\Files\\NN.EURUSD.h1.onnx" as uchar onnx_model[]; //rnn model in onnx format #resource "\\Files\\NN.EURUSD.h1.min_max.max.bin" as double min_max_max[]; #resource "\\Files\\NN.EURUSD.h1.min_max.min.bin" as double min_max_min[];
Затем импортируем класс регрессионной нейронной сети ONNX и обработчик библиотеки масштабирования MinMax.
#include <MALE5\Neural Networks\Regressor Neural Nets.mqh> #include <MALE5\preprocessing.mqh> CNeuralNets nn; MinMaxScaler *scaler;
Далее мы можем инициализировать модель и масштабатор, а затем получить окончательные прогнозы из модели.
MqlRates rates[]; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!nn.Init(onnx_model)) return INIT_FAILED; scaler = new MinMaxScaler(min_max_min, min_max_max); //Initializing the scaler, populating it with trained values //--- ArraySetAsSeries(rates, true); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- if (CheckPointer(scaler)!=POINTER_INVALID) delete (scaler); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close}; input_x = scaler.transform(input_x); // We normalize the input data vector preds = nn.predict(input_x); Print("predictions = ",preds); }
Результаты
2024.07.31 19:13:20.785 Multi-step forecasting using Multi-outputs model (EURUSD,H4) predictions = [1.080284595489502,1.082370758056641,1.083482265472412,1.081504583358765,1.079929828643799]
Также я добавил на график линии тренда, чтобы отметить все будущие прогнозы нейронной сети.
void OnTick() { //--- CopyRates(Symbol(), PERIOD_H1, 1, 1, rates); vector input_x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close}; if (NewBar()) { input_x = scaler.transform(input_x); // We normalize the input data vector preds = nn.predict(input_x); for (int i=0; i<(int)preds.Size(); i++) { //--- ObjectDelete(0, "step"+string(i+1)+"-prediction"); //delete an object if it exists TrendCreate("step"+string(i+1)+"-prediction",rates[0].time, preds[i], rates[0].time+(5*60*60), preds[i], clrBlack); //draw a line starting from the previous candle to 5 hours forward } } }
На этот раз мы получили более качественные линии прогноза, чем те, которые мы получили с помощью рекурсивной линейной регрессионной модели.

Обзор многошагового прогнозирования с использованием моделей с множественными выходами
Преимущества- Прогнозируя несколько шагов одновременно, модель может улавливать взаимосвязи и зависимости между будущими временными шагами.
- Нужна только одна модель, что упрощает внедрение и обслуживание.
- Модель учится делать последовательные прогнозы на всем горизонте прогнозирования.
Недостатки
- Обучение модели для вывода нескольких будущих значений может оказаться более сложным и потребовать более сложной архитектуры, особенно для нейронных сетей.
- В зависимости от сложности модели для обучения и вывода могут потребоваться дополнительные вычислительные ресурсы.
- Существует риск переобучения, особенно если горизонт прогнозирования велик и модель становится слишком специализированной для обучающих данных.
Использование многошагового прогнозирования в торговых стратегиях
Многошаговое прогнозирование может значительно улучшить различные торговые стратегии, поскольку позволяет осуществлять динамические корректировки на основе прогнозируемых движений рынка. В сеточной торговле многошаговые прогнозы позволяют не устанавливать фиксированные ордера, а совершать динамические входы, которые подстраиваются под ожидаемые изменения цен, что повышает скорость реагирования системы на рыночные условия.
Также они могут быть полезны в хеджинговых стратегиях, поскольку такие прогнозы помогают определять, когда открывать или закрывать позиции для защиты от потенциальных убытков, например, открывать короткие позиции или покупать опционы пут, если прогнозируется нисходящая тенденция. Кроме того, при выявлении трендов понимание будущих направлений рынка помогает трейдерам корректировать свои стратегии, либо отдавая предпочтение коротким позициям, либо закрывая длинные позиции, чтобы избежать убытков.
Наконец, в высокочастотной торговле (HFT) быстрые многошаговые прогнозы могут направлять алгоритмы, пытающиеся заработать на краткосрочных движениях цен. Они могут помочь быстрее реагировать на изменения цен, ожидаемые в ближайшие секунды или минуты.
Заключение
В финансовом анализе и форекс-трейдинге полезно иметь возможность прогнозировать несколько будущих значений. В данной статье представлены несколько подходов для получения таких прогнозов. В следующей статье(ях) мы рассмотрим векторную авторегрессию — метод, который также может предсказывать множественные значения.
Всем добра.
За развитием этой модели машинного обучения и многого другого из этой серии статей можно следить в моем репозитории на GitHub.
Таблица вложений
| Наименование файла | Тип файла | Описание и использование |
|---|---|---|
Direct Muilti step Forecasting.mq5 Multi-step forecasting using multi-outputs model.mq5 Recursive-Multi step forecasting.mq5 | Советники | Советник использует несколько моделей LightGBM для многошагового прогнозирования. Советник на основе модели нейронной сети, прогнозирующей несколько шагов с использованием структуры с несколькими выходами. В этом советнике линейная регрессия итеративно предсказывает будущие временные шаги. |
| LightGBM.mqh | Файл библиотеки MQL5 | Содержит код для загрузки модели LightGBM в формате ONNX и использования ее для прогнозирования. |
| Linear Regression.mqh | Файл библиотеки MQL5 | Содержит код для загрузки модели линейной регрессии в формате ONNX и использования ее для прогнозирования. |
| preprocessing.mqh | Файл библиотеки MQL5 | Этот файл содержит масштабатор MInMax, используемый для нормализации входных данных. |
| Regressor Neural Nets.mqh | Файл библиотеки MQL5 | Содержит код для загрузки и развертывания модели нейронной сети из формата ONNX в MQL5. |
lightgbm.EURUSD.h1.pred_close.step.1.onnx lightgbm.EURUSD.h1.pred_close.step.2.onnx lightgbm.EURUSD.h1.pred_close.step.3.onnx lightgbm.EURUSD.h1.pred_close.step.4.onnx lightgbm.EURUSD.h1.pred_close.step.5.onnx Lr.EURUSD.h1.pred_close.onnx NN.EURUSD.h1.onnx | Модели ИИ в формате ONNX | Модели LightGBM для прогнозирования значений следующего будущего шага Простая модель линейной регрессии в формате ONNX Нейронная сеть с прямой связью в формате ONNX |
| NN.EURUSD.h1.min_max.max.bin NN.EURUSD.h1.min_max.min.bin | Двоичные файлы | Содержит максимальные и минимальные значения соответственно для масштабатора MinMax |
| predicting-multiple-future-tutorials.ipynb | Jupyter Notebook | Весь код Python, показанный в этой статье, можно найти в этом файле. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15465
 Автооптимизация тейк-профитов и параметров индикатора с помощью SMA и EMA
Автооптимизация тейк-профитов и параметров индикатора с помощью SMA и EMA
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования