
データサイエンスと機械学習(第26回):時系列予測における究極の戦い - LSTM対GRUニューラルネットワーク

内容
- 長短期記憶(LSTM: Long Short-Term Memory)ニューラルネットワークとは?
- 長期記憶(LSTM)ネットワークを支える数学
- ゲート型リカレントユニット(GRU: Gated Recurrent Unit)ニューラルネットワークとは?
- ゲート型リカレントユニット(GRU)ネットワークの背後にある数学
- LSTMとGRUネットワークの親クラスの構築
- LSTMとGRUニューラルネットワークの子クラス
- 両モデルの訓練
- 両モデルの特徴量の重要度を確認する
- ストラテジーテスターにおけるLSTMとGRU分類器の比較
- LSTMとGRUニューラルネットワークモデルの違い
- 結論
長短期記憶(LSTM: Long Short-Term Memory)ニューラルネットワークとは?
長短期記憶(LSTM)は、シーケンスタスク用に設計された再帰型ニューラルネットワークの一種であり、データの長期的な依存関係を捉えて活用するのに優れています。本連載の前回記事(必読)で取り上げたバニラ再帰型ニューラルネットワーク(単純RNN)とは異なります。単純RNNはデータの長期的な依存関係を捉えることはできません。
LSTMは、単純RNNにありがちな短期記憶を修正するために紹介されました。
単純再帰型ネットワークの問題点
単純再帰型ネットワーク(RNN: Recurrent Neural Network)は、内部の隠れ状態(メモリ)を利用して、シーケンスの過去の入力情報を保持しながら、逐次データを処理するように設計されています。概念的には単純で、逐次データのモデル化には当初成功したものの、いくつかの限界があります。
重要な問題の1つは消失勾配です。バックプロパゲーション中にネットワークの重みを更新するために勾配が使用されますが、単純RNNではこれらの勾配が特に長いシーケンスにおいて時間と共に指数関数的に減少する可能性があります。その結果、勾配が極端に小さくなり、効果的な重みの更新が困難になるため、長期的な依存関係を学習できず、多くの時間ステップにわたるパターンを捉えるのが難しくなります。
もう1つの課題は、消失勾配問題の反対である爆発勾配問題です。この場合、勾配がバックプロパゲーションの過程で指数関数的に増大し、数値的な不安定さを引き起こします。これにより訓練プロセスが非常に困難になります。勾配消失よりも一般的ではありませんが、勾配爆発はネットワークの重みに非常に大きな更新をもたらし、事実上学習プロセスの失敗を引き起こす可能性があります。
また、消失勾配問題や爆発勾配問題の影響を受けやすいため、単純RNNの訓練は困難で、効率が悪く、低速で、計算コストが高くなります。ハイパーパラメータの調整も慎重に行う必要があります。
さらに、単純RNNではデータの複雑な時間依存性を扱うのが難しく、記憶容量が限られているため、複雑な連続パターンの理解や捉え方に苦労します。
データの長距離依存関係を理解する必要があるタスクでは、単純RNNでは必要なコンテキストを捉えることができず、パフォーマンスが最適化されない可能性があります。
長短期記憶(LSTM)ネットワークを支える数学
LSTMを理解するために、まずLSTMセルを見てみましょう。

01:忘却ゲート(Forget Gate)
次の式で与えられます。
![]()
シグモイド関数![]() は、前の隠れ状態
は、前の隠れ状態![]() と現在の入力
と現在の入力![]() を入力とします。出力
を入力とします。出力![]() は0から1の間の値で、
は0から1の間の値で、![]() (前のセル状態)の各成分をどれだけ保持すべきかを示します。
(前のセル状態)の各成分をどれだけ保持すべきかを示します。
![]() :忘却ゲートの重み
:忘却ゲートの重み
![]() :忘却ゲートのバイアス
:忘却ゲートのバイアス
忘却ゲートは、前のセル状態からどの情報を繰り越すべきかを決定します。セル状態![]() の各数値について、0から1の間の数値を出力します。ここで、0は完全に忘れることを意味し、1は完全に保持することを意味します。
の各数値について、0から1の間の数値を出力します。ここで、0は完全に忘れることを意味し、1は完全に保持することを意味します。
02:入力ゲート(Input Gate)
次の式で与えられます。
![]()
シグモイド関数![]() は更新する値を決定します。このゲートは、メモリセルへの新しいデータの入力を制御します。
は更新する値を決定します。このゲートは、メモリセルへの新しいデータの入力を制御します。
![]() :入力ゲートの重み
:入力ゲートの重み
![]() :入力ゲートのバイアス
:入力ゲートのバイアス
このゲートは、新しい入力![]() のどの値をセル状態の更新に使うかを決定します。細胞内に新しい情報が流れ込むのを制御しています。
のどの値をセル状態の更新に使うかを決定します。細胞内に新しい情報が流れ込むのを制御しています。
03:メモリセル候補
次の式で与えられます。
![]()
tanh関数は、セルの状態に保存される可能性のある新しい情報を生成します。
![]() :メモリセル候補の重み
:メモリセル候補の重み
![]() :メモリセル候補のバイアス
:メモリセル候補のバイアス
このコンポーネントはセル状態に追加できる新しい候補値を生成します。tanh活性化関数を使用し、値が-1から1の間になるようにします。
04:セル状態の更新
次の式で与えられます。
![]()
前のセル状態![]() に
に![]() (忘却ゲート出力)を掛けて、重要でない情報を破棄します。そして、
(忘却ゲート出力)を掛けて、重要でない情報を破棄します。そして、![]() (入力ゲートの出力)に
(入力ゲートの出力)に ![]() (セル状態の候補)を掛け、その結果を合計して新しいセル状態
(セル状態の候補)を掛け、その結果を合計して新しいセル状態![]() を形成します。
を形成します。
セル状態は、古いセル状態と候補値を組み合わせて更新されます。忘却ゲート出力は前のセル状態の寄与を制御し、入力ゲート出力は新しい候補値の寄与を制御します。
05:出力ゲート(Output Gate)
次の式で与えられます。
![]()
シグモイド関数は、セル状態のどの部分を出力するかを決定します。このゲートはメモリセルからの情報の出力を制御します。
![]() :出力層の重み
:出力層の重み
![]() :出力層のバイアス
:出力層のバイアス
このゲートは現在のセル状態の最終出力を決定します。入力![]() と直前の隠れ状態
と直前の隠れ状態![]() に基づいて、セル状態のどの部分を出力すべきかを決定します。
に基づいて、セル状態のどの部分を出力すべきかを決定します。
06:隠し状態の更新
次の式で与えられます。
![]()
新しい隠れ状態![]() は出力ゲート
は出力ゲート![]() と更新されたセル状態
と更新されたセル状態![]() のtanhを掛け合わせることで得られます。
のtanhを掛け合わせることで得られます。
隠れ状態はセルの状態と出力ゲートの決定に基づいて更新されます。現在の時間ステップの出力として、また次の時間ステップの入力として使用されます。
ゲート型リカレントユニット(GRU: Gated Recurrent Unit)ニューラルネットワークとは?
ゲート型リカレントユニット(GRU)は、再帰型ニューラルネットワーク(RNN)の一種であり、場合によっては長短期記憶(LSTM)よりも優れています。GRUはLSTMよりも少ないメモリで高速に処理できますが、より長いシーケンスのデータセットを使用する場合はLSTMの方がより正確です。
LSTMとGRUは、単純再帰型ニューラルネットワークにありがちな短期記憶を緩和するために紹介されました。どちらもセル内のゲートを使うことで長期記憶を可能にしています。
LSTMとGRUは、多くの点で単純RNNと同様に動作するにもかかわらず、単純再帰型ニューラルネットワークが苦しむ勾配の消失問題に対処しています。
ゲート型リカレントユニット(GRU)ネットワークの背後にある数学
下の画像は、GRUセルを解剖したときの様子を示しています。

01:更新ゲート(Update Gate)
次の式で与えられます。
![]()
このゲートは、以前の隠れ状態![]() をどれだけ保持し、隠れ状態候補
をどれだけ保持し、隠れ状態候補![]() をどれだけ使用して隠れ状態を更新するかを決定します。
をどれだけ使用して隠れ状態を更新するかを決定します。
更新ゲートは、前の隠された状態(![]() )をどれだけ次の時間ステップに持ち越すかを制御します。古い情報を残すことと、新しい情報を取り入れることのバランスを効果的に決定します。
)をどれだけ次の時間ステップに持ち越すかを制御します。古い情報を残すことと、新しい情報を取り入れることのバランスを効果的に決定します。
02:リセットゲート(Reset Gate)
次の式で与えられます。
![]()
このゲートのシグモイド関数![]() は 、現在の入力と組み合わせて活性化候補を作る前に、前の隠れ状態のどの部分をリセットすべきかを決定します。
は 、現在の入力と組み合わせて活性化候補を作る前に、前の隠れ状態のどの部分をリセットすべきかを決定します。
03:活性化候補(candidate activation)
次の式で与えられます。
![]()
活性化候補は、現在の入力![]() とリセットされた隠れ状態を用いて計算されます。
とリセットされた隠れ状態を用いて計算されます。 ![]() .
.
このコンポーネントは、更新ゲートの決定に基づいて取り込むことができる、隠れた状態の新しい潜在的な値を生成します。
04:隠し状態の更新
次の式で与えられます。
![]()
更新ゲート出力![]() は、新しい隠れ状態
は、新しい隠れ状態![]() を形成するために、候補の隠れ状態
を形成するために、候補の隠れ状態![]() をどれだけ使うかを制御します。
をどれだけ使うかを制御します。
隠れ状態は、前の隠れ状態と候補の隠れ状態を組み合わせて更新されます。更新ゲート![]() はこの組み合わせを制御し、過去の関連情報を確実に保持しつつ、新しい情報を取り込みます。
はこの組み合わせを制御し、過去の関連情報を確実に保持しつつ、新しい情報を取り込みます。
LSTMとGRUネットワークの親クラスの構築
LSTMとGRUは多くの点で同じように動作し、同じパラメータを取るので、モデルのビルド、コンパイル、最適化、特徴量の重要性の確認、保存に必要な関数のための基本(親)クラスを持つのが良いアイデアかもしれません。このクラスは、後続のLSTMとGRUの子クラスに継承されます。
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, GRU, Dense, Input, Dropout from keras.callbacks import EarlyStopping from keras.optimizers import Adam import tf2onnx import optuna import shap from sklearn.metrics import accuracy_score class RNNClassifier(): def __init__(self, time_step, x_train, y_train, x_test, y_test): self.model = None self.time_step = time_step self.x_train = x_train self.y_train = y_train self.x_test = x_test self.y_test = y_test # a crucial function that all the subclasses must implement def build_compile_and_train(self, params, verbose=0): raise NotImplementedError("Subclasses should implement this method") # a function for saving the RNN model to onnx & the Standard scaler parameters def save_onnx_model(self, onnx_file_name): # optuna objective function to oprtimize def optimize_objective(self, trial): # optimize for 50 trials by default def optimize(self, n_trials=50): def _rnn_predict(self, data): def check_feature_importance(self, feature_names):
Optunaを用いたLSTMとGRUの最適化
以前も言ったように、ニューラルネットワークはハイパーパラメータに非常に敏感です。適切なチューニングや最適なパラメータがなければ、ニューラルネットワークは効果を発揮しない可能性があります。
Python
def optimize_objective(self, trial): params = { "neurons": trial.suggest_int('neurons', 10, 100), "n_hidden_layers": trial.suggest_int('n_hidden_layers', 1, 5), "dropout_rate": trial.suggest_float('dropout_rate', 0.1, 0.5), "learning_rate": trial.suggest_float('learning_rate', 1e-5, 1e-2, log=True), "hidden_activation_function": trial.suggest_categorical('hidden_activation_function', ['relu', 'tanh', 'sigmoid']), "loss_function": trial.suggest_categorical('loss_function', ['categorical_crossentropy', 'binary_crossentropy', 'mean_squared_error', 'mean_absolute_error']) } val_accuracy = self.build_compile_and_train(params, verbose=0) # we build a model with different parameters and train it, just to return a validation accuracy value return val_accuracy # optimize for 50 trials by default def optimize(self, n_trials=50): study = optuna.create_study(direction='maximize') # we want to find the model with the highest validation accuracy value study.optimize(self.optimize_objective, n_trials=n_trials) return study.best_params # returns the parameters that produced the best performing model
optimize_objectiveメソッドは、Optunaフレームワークを使ったハイパーパラメータ最適化の目的関数を定義します。これは、モデルのパフォーマンスを最大化する最適なハイパーパラメータのセットを見つけるための最適化プロセスをガイドします。
Optimizeメソッドは、Optunaを使用してoptimize_objectiveメソッドを繰り返し呼び出し、ハイパーパラメータの最適化をおこないます。
SHAPを使った特徴量重要度の確認
データサイエンティストにとって、特徴量がモデルの予測にどの程度影響するかを測定することは重要です。これは、重要な改善点を理解するだけでなく、特定のデータセットに対するモデルの理解をより深めるのにも役立ちます。
def check_feature_importance(self, feature_names): # Sample a subset of training data for SHAP explainer sampled_idx = np.random.choice(len(self.x_train), size=100, replace=False) explainer = shap.KernelExplainer(self._rnn_predict, self.x_train[sampled_idx].reshape(100, -1)) # Get SHAP values for the test set shap_values = explainer.shap_values(self.x_test[:100].reshape(100, -1), nsamples=100) # Update feature names for SHAP feature_names = [f'{feature}_t{t}' for t in range(self.time_step) for feature in feature_names] # Plot the SHAP values shap.summary_plot(shap_values, self.x_test[:100].reshape(100, -1), feature_names=feature_names, max_display=len(feature_names), show=False) # Adjust layout and set figure size plt.subplots_adjust(left=0.12, bottom=0.1, right=0.9, top=0.9) plt.gcf().set_size_inches(7.5, 14) plt.tight_layout() # Get the class name of the current instance class_name = self.__class__.__name__ # Create the file name using the class name file_name = f"{class_name.lower()}_feature_importance.png" plt.savefig(file_name) plt.show()
LSTMとGRU分類器をONNXモデル形式に保存する
最後に、モデルを構築したら、MQL5と互換性のあるONNX形式で保存しなければなりません。
def save_onnx_model(self, onnx_file_name):
# Convert the Keras model to ONNX
spec = (tf.TensorSpec((None, self.time_step, self.x_train.shape[2]), tf.float16, name="input"),)
self.model.output_names = ['outputs']
onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13)
# Save the ONNX model to a file
with open(onnx_file_name, "wb") as f:
f.write(onnx_model.SerializeToString())
# Save the mean and scale parameters to binary files
scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin")
scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
LSTMとGRUニューラルネットワークの子クラス
再帰型ニューラルネットワークは多くの点で同様の働きをし、Kerasを使用した実装でさえ、同様のアプローチとパラメータに従っています。大きな違いはモデルの種類で、それ以外はすべて同じです。
LSTM分類器
Python
class LSTMClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(LSTM(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
GRU分類器
Python
class GRUClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(GRU(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
子クラス分類器に見られるように、唯一の違いはモデルのタイプで、LSTMもGRUも同様のアプローチをとります。
両モデルの訓練
まず、両方のモデルのクラスインスタンスを初期化しなければなりません。まずはLSTMモデルからです。
lstm_clf = LSTMClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
次にGRUモデルを初期化します。
gru_clf = GRUClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
両モデルを20回の試行で最適化した後
best_params = lstm_clf.optimize(n_trials=20)
best_params = gru_clf.optimize(n_trials=20) 試行19のLSTM分類器モデルが最も優れていました。
[I 2024-07-01 11:14:40,588] Trial 19 finished with value: 0.5597269535064697 and parameters: {'neurons': 79, 'n_hidden_layers': 4, 'dropout_rate': 0.335909076638275, 'learning_rate': 3.0704319088493336e-05, 'hidden_activation_function': 'relu', 'loss_function': 'categorical_crossentropy'}. Best is trial 19 with value: 0.5597269535064697.
一方、検証データでは約55.97%の精度が得られ、トライアル3で発見されたGRU分類器モデルは、すべてのモデルの中で最も優れていました。
[I 2024-07-01 11:18:52,190] Trial 3 finished with value: 0.532423198223114 and parameters: {'neurons': 55, 'n_hidden_layers': 5, 'dropout_rate': 0.2729838602302831, 'learning_rate': 0.009626688728041802, 'hidden_activation_function': 'sigmoid', 'loss_function': 'mean_squared_error'}. Best is trial 3 with value: 0.532423198223114.
検証データでは約53.24%の精度を示しました。
両モデルの特徴量の重要度の確認
| LSTM分類器 | GRUクラシファイア |
|---|---|
feature_importance = lstm_clf.check_feature_importance(X.columns) 成果だ。 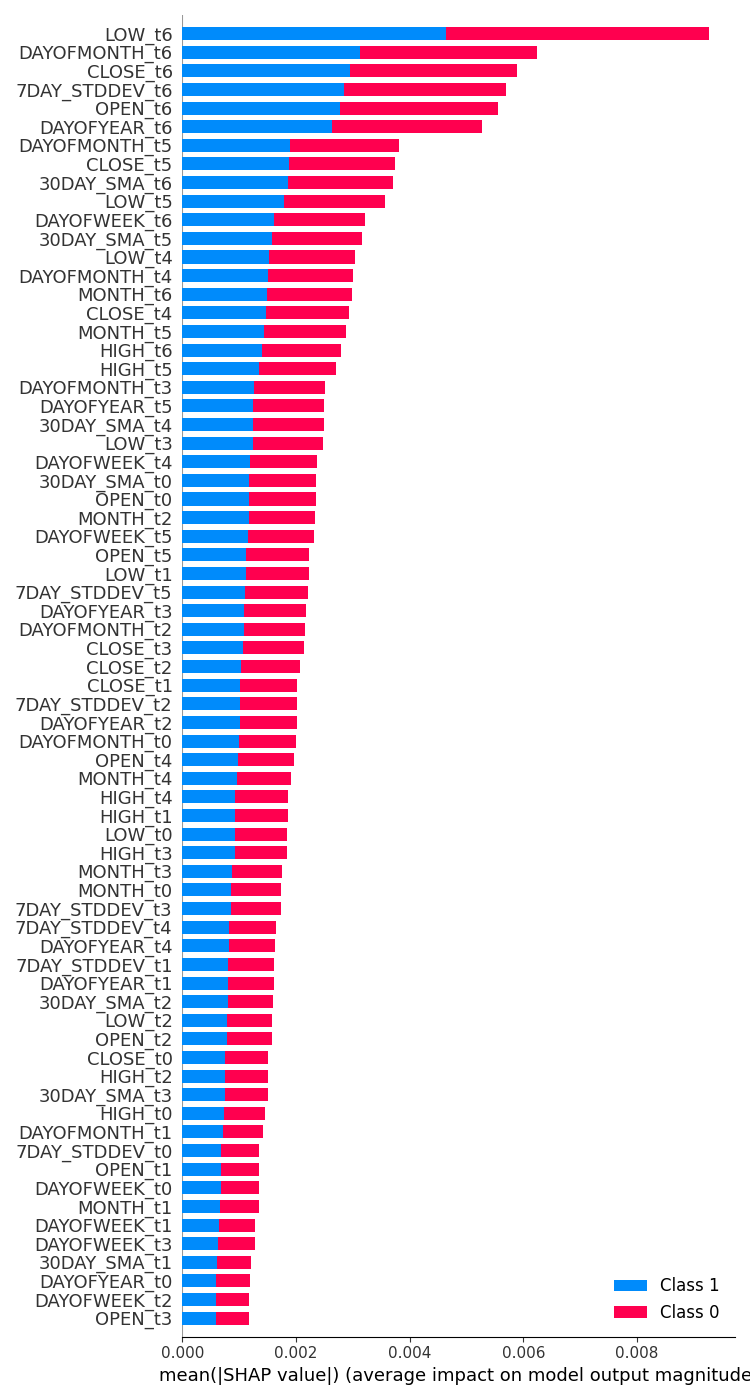 | feature_importance = gru_clf.check_feature_importance(X.columns) 成果だ。  |
LSTM分類器の特徴量の重要度は、単純RNNモデルで得られたものと似ています。最も重要でない変数は遠い時間ステップのものであり、最も重要な特徴量は近い時間ステップのものです。
これは、現在のバーに何が起こるかに最も貢献する変数は、最近閉じたバーの情報である、と言っているようなものです。
GRU分類器は、あまり意味をなさないような多様な意見を持っていました。これは、そのモデルの精度が低かったからかもしれません。
最も影響力のある変数は7日前の曜日だったと言いました。直近の情報である時間ステップ値6からのOpen、High、Low、Closeのような特徴量は、最終的な予測結果に対して平均的な寄与があることを示す真ん中に配置されました。
ストラテジーテスターにおけるLSTMとGRU分類器の比較
学習後すぐに、LSTMとGRUの分類器モデルをONNX形式に保存しました。
LSTM | Python
lstm_clf.build_compile_and_train(best_params, verbose=1) # best_params = best parameters obtained after optimization lstm_clf.save_onnx_model("lstm.EURUSD.D1.onnx")
GRU | Python
gru_clf.build_compile_and_train(best_params, verbose=1) gru_clf.save_onnx_model("gru.EURUSD.D1.onnx") # best_params = best parameters obtained after optimization
ONNXモデルとそのスケーラーファイルをMQL5Filesディレクトリに保存した後、リソースファイルとして両方のEAにファイルを追加することができます。
| LSTM | GRU |
|---|---|
#resource "\\Files\\lstm.EURUSD.D1.onnx" as uchar onnx_model[]; //lstm model in onnx format #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\LSTM.mqh> CLSTM lstm; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique | #resource "\\Files\\gru.EURUSD.D1.onnx" as uchar onnx_model[]; //gru model in onnx format #resource "\\Files\\gru.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\gru.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\GRU.mqh> CGRU gru; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique |
残りのEAのコードは説明したものと同じです。
時系列予測を始めた本連載の第24回以来使用しているデフォルト設定を使用します。
ストップロス:500、テイクプロフィット:700、スリッページ:50
繰り返しますが、データは日足で収集されています。新しいバーのオープンで売買シグナルを探しているため、「market closed errors」エラーを避けるために、より下位の時間枠でテストすることをお勧めします。また、より迅速なテストのために、モデリングタイプを始値に設定することもできます。

LSTM EAの結果


GRU EAの結果


ストラテジーテスターの成果から学ぶこと
44.98%と最も精度の低いモデルであるにもかかわらず、LSTMベースのEAは138ドルの純利益を上げ、最も収益性が高い結果を示しました。一方、GRUベースのEAは120ドルの純利益を達成しつつも、利益を上げたのは時間の45.25%に過ぎませんでした。
ここの結果から、LSTMが利益面で明らかに優れていることがわかります。LSTMは技術的には同種の他のRNNよりも優れていますが、これにはさまざまな要因が考えられます。すべての再帰型モデルは優れており、特定の状況では他のモデルよりも優れたパフォーマンスを発揮します。この記事や前回の記事で説明したモデルを自由に使用してください。
LSTMとGRUニューラルネットワークモデルの違い
これらのモデルを比較して理解することは、各モデルが他のモデルと比較して何を提供するかを決定する際に役立ちます。どのモデルを使うべきか、または使うべきではないかを見極める際に参考になります。以下にその違いを示します。
| 側面 | LSTM | GRU |
|---|---|---|
アーキテクチャの複雑さ | 3つのゲート(入力、出力、忘却)とセルの状態を持つより複雑な設計で、各時間ステップでどの情報を保持するか、あるいは破棄するかを詳細に制御できる | 2つのゲート(リセットと更新)だけのシンプルな設計。このシンプルなアーキテクチャーが、実装を容易にしている |
訓練スピード | 追加のゲートとセルの状態があるということは、やるべき処理と最適化すべきパラメータが増えるということで、 訓練中はもっと遅い | ゲートの数が少なく、動作が単純なため、通常LSTMよりも高速に学習する |
パフォーマンス | 長期的な依存関係をとらえることが重要な複雑な問題では、GRUよりわずかに良い結果を出す傾向がある | 通常、多くのタスクでLSTMに匹敵する性能を発揮する |
長期的な依存関係への対応 | セル状態と、時間の経過とともに情報の流れを制御するゲーティング機構によって、データの長期的な依存関係を保持するように明示的に設計されている | 長期的な依存関係もうまく扱うが、構造が単純なため、超長期的な依存関係を捉えるにはLSTMほど効果的ではないかもしれない |
| メモリ使用量 | その複雑な構造と追加パラメータによりより多くのメモリを消費するため、リソースに制約のある環境では制限となりうる | シンプルで、パラメータが少なくメモリ使用量も少ないため、計算資源が限られているアプリケーションに適している |
最後に
LSTM (Long Short-Term Memory) とGRU (Gated Recurrent Unit)の両ニューラルネットワークは、高度な時系列予測モデルを活用するトレーダーにとって非常に強力なツールです。LSTMは市場データの長期的な依存関係を捉えるのに優れた、より複雑なアーキテクチャを提供します。一方、GRUはLSTMに匹敵する性能を、よりシンプルで効率的な構造で実現し、計算コストが少ないという利点があります。
これらの時系列ディープラーニングモデル(LSTMとGRU)は、天気予報、エネルギー消費モデリング、異常検知、音声認識など、FX取引以外の様々な領域で活用され、通常宣伝されているような大きな成功を収めています。しかし、常に変動するFX市場においては、同様の成功を保証することは難しいでしょう。
この記事は、これらのモデルを深く理解し、MQL5でどのように取引に導入できるかを提供することだけを目的としています。 この記事で紹介したモデルやデータセットを自由に探求し、試してみてください。ぜひ、ディスカッションセクションで結果を共有してください。
ご精読ありがとうございました。
機械学習モデルの開発を追跡し、本連載で説明されている多くのことは、このGitHubレポに掲載されています。
添付ファイルの表
| ファイル名 | ファイルタイプ | 説明と使用法 |
|---|---|---|
| GRU EA.mq5 LSTM EA.mq5 | EA | GRUベースのEA LSTMベースのEA |
| gru.EURUSD.D1.onnx lstm.EURUSD.D1.onnx | ONNXファイル | ONNX形式のGRUモデル ONNX形式のLSTMモデル |
| lstm.EURUSD.D1.standard_scaler_mean.bin lstm.EURUSD.D1.standard_scaler_scale.bin | バイナリファイル | LSTMモデルに使用される標準化スケーラー用のバイナリファイル |
| gru.EURUSD.D1.standard_scaler_mean.bin gru.EURUSD.D1.standard_scaler_scale.bin | バイナリファイル | GRUモデルで使用される標準化スケーラー用のバイナリファイル |
| preprocessing.mqh | インクルードファイル | 標準化スケーラーで構成されるライブラリ |
| lstm-gru-for-forex-trading-tutorial.ipynb | Pythonスクリプト/Jupyterノートブック | この記事で取り上げたすべてのpythonコードで構成される |
- Illustrated Guide to LSTM's and GRU's:A step by step explanation
- Designing neural network based decoders for surface codes
- An Adaptive Anti-Noise Neural Network for Bearing Fault Diagnosis Under Noise and Varying Load Conditions
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/15182
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索