
Datenwissenschaft und ML (Teil 26): Der ultimative Kampf der Zeitreihenprognosen — LSTM vs. GRU Neuronale Netze

Inhalt
- Was ist das neuronale Netz Long Short-Term Memory (LSTM)?
- Die Mathematik hinter Long-Short-Term Memory (LSTM)
- Was ist das neuronale Netz Gated Recurrent Unit (GRU)?
- Die Mathematik hinter Gated Recurrent Unit (GRU)
- Aufbau der übergeordneten Klasse für LSTM- und GRU-Netze
- Die neuronalen Netzunterklassen für LSTM und GRU
- Training beider Modelle
- Überprüfung der Bedeutung von Merkmalen für beide Modelle
- LSTM- und GRU-Klassifikatoren auf dem Strategietestgerät
- Die Unterschiede zwischen den neuronalen Netzmodellen LSTM und GRU
- Schlussfolgerung
Was ist das neuronale Netz Long Short-Term Memory (LSTM)?
Das Long Short-Term Memory (LSTM) ist eine Art rekurrentes neuronales Netz, das für Sequenzaufgaben entwickelt wurde und sich durch die Erfassung und Nutzung langfristiger Abhängigkeiten in Daten auszeichnet. Im Gegensatz zu den einfachen rekurrenten neuronalen Netzen (RNNs), die im vorigen Artikel dieser Serie besprochen wurden (ein Lese-Muss). Dadurch können langfristige Abhängigkeiten in den Daten nicht erfasst werden.
LSTMs wurden eingeführt, um das Kurzzeitgedächtnis zu verbessern, das in einfachen RNNs vorherrscht.
Das Problem mit einfachen rekurrenten neuronalen Netzen
Einfache rekurrente neuronale Netze (RNNs) sind für die Verarbeitung sequentieller Daten konzipiert, indem sie ihren internen verborgenen Zustand (Speicher) nutzen, um Informationen über frühere Eingaben in der Sequenz zu erfassen. Trotz ihrer konzeptionellen Einfachheit und ihres anfänglichen Erfolgs bei der Modellierung sequenzieller Daten weisen sie mehrere Einschränkungen auf.
Ein wichtiges Problem ist das Problem des verschwindenden Gradienten. Bei der Backpropagation werden Gradienten verwendet, um die Gewichte des Netzes zu aktualisieren. In einfachen RNNs können diese Gradienten exponentiell abnehmen, wenn sie rückwärts durch die Zeit propagiert werden, insbesondere bei langen Sequenzen. Dies führt dazu, dass das Netz keine langfristigen Abhängigkeiten erlernen kann, da die Gradienten zu klein werden, um die Gewichte effektiv zu aktualisieren, was es für einfache RNNs schwierig macht, Muster zu erfassen, die sich über viele Zeitschritte erstrecken.
Eine weitere Herausforderung ist das Problem des explodierenden Gradienten, das das Gegenteil des Problems des verschwindenden Gradienten ist. In diesem Fall wachsen die Gradienten während der Backpropagation exponentiell. Dies kann zu numerischer Instabilität führen und den Trainingsprozess sehr schwierig machen. Obwohl sie weniger häufig vorkommen als verschwindende Gradienten, können explodierende Gradienten zu sehr großen Aktualisierungen der Gewichte des Netzes führen, was den Lernprozess zum Scheitern bringt.
Einfache RNNs sind auch schwierig zu trainieren, da sie anfällig für Probleme mit verschwindenden und explodierenden Gradienten sind, was den Trainingsprozess ineffizient und langsam machen kann. Das Training einfacher RNNs kann rechenaufwändiger sein und erfordert möglicherweise eine sorgfältige Abstimmung der Hyperparameter.
Außerdem sind einfache RNNs nicht in der Lage, komplexe zeitliche Abhängigkeiten in Daten zu verarbeiten. Aufgrund ihrer begrenzten Speicherkapazität haben sie oft Schwierigkeiten, komplexe sequenzielle Muster zu verstehen und zu erfassen.
Bei Aufgaben, die ein Verständnis für weitreichende Abhängigkeiten in den Daten erfordern, können einfache RNNs den notwendigen Kontext nicht erfassen, was zu suboptimalen Leistungen führt.
Die Mathematik hinter dem Langzeitgedächtnis(LSTM)-Netzwerk
Um die Feinheiten des LSTM zu verstehen, sollten wir uns zunächst die LSTM-Zelle ansehen.

01: Forget Gate
Gegeben durch die Gleichung:
![]()
Eine sigmoidale Funktion ![]() nimmt als Eingabe den vorherigen versteckten Zustand
nimmt als Eingabe den vorherigen versteckten Zustand ![]() und die aktuelle Eingabe
und die aktuelle Eingabe ![]() . Die Ausgabe
. Die Ausgabe ![]() ist ein Wert zwischen 0 und 1, der angibt, wie viel von jeder Komponente in
ist ein Wert zwischen 0 und 1, der angibt, wie viel von jeder Komponente in ![]() (vorheriger Zellzustand) beibehalten werden soll.
(vorheriger Zellzustand) beibehalten werden soll.
![]() - das Gewicht von forget gate.
- das Gewicht von forget gate.
![]() - das Bias von forget gate.
- das Bias von forget gate.
forget gate bestimmt, welche Informationen aus dem vorherigen Zellzustand übernommen werden sollen. Es gibt für jede Zahl im Zustand der Zelle ![]() eine Zahl zwischen 0 und 1 aus, wobei 0 bedeutet, dass sie vollständig vergessen wurde, und 1, dass sie vollständig behalten wurde.
eine Zahl zwischen 0 und 1 aus, wobei 0 bedeutet, dass sie vollständig vergessen wurde, und 1, dass sie vollständig behalten wurde.
02: Input Gate
Gegeben durch die Formel.
![]()
Eine Sigmoidfunktion ![]() bestimmt, welche Werte zu aktualisieren sind. Dieses Gate steuert die Eingabe neuer Daten in die Speicherzelle.
bestimmt, welche Werte zu aktualisieren sind. Dieses Gate steuert die Eingabe neuer Daten in die Speicherzelle.
![]() - das Gewicht von input gate.
- das Gewicht von input gate.
![]() - das Bias von input gate.
- das Bias von input gate.
Dieses Gate entscheidet, welche Werte aus dem neuen Eingang ![]() zur Aktualisierung des Zellzustands verwendet werden. Es regelt den Fluss neuer Informationen in die Zelle.
zur Aktualisierung des Zellzustands verwendet werden. Es regelt den Fluss neuer Informationen in die Zelle.
03: Candidate Memory Cell
Gegeben durch die Gleichung:
![]()
Eine Funktion tanh erzeugt potenzielle neue Informationen, die im Zellstatus gespeichert werden könnten.
![]() - das Gewicht von Candidate Memory Cell.
- das Gewicht von Candidate Memory Cell.
![]() - das Bias von Candidate Memory Cell.
- das Bias von Candidate Memory Cell.
Diese Komponente erzeugt die neuen Kandidatenwerte, die dem Zellstatus hinzugefügt werden können. Sie verwendet die Aktivierungsfunktion tanh, um sicherzustellen, dass die Werte zwischen -1 und 1 liegen.
04: Cell State Update
Gegeben durch die Gleichung:
![]()
Der vorherige Zustand der Zelle ![]() wird mit
wird mit ![]() (Ausgang von forget gate) multipliziert, um unwichtige Informationen zu verwerfen. Dann wird
(Ausgang von forget gate) multipliziert, um unwichtige Informationen zu verwerfen. Dann wird ![]() (Ausgang von input gates) multipliziert mit
(Ausgang von input gates) multipliziert mit ![]() (Kandidatenzustand), und die Ergebnisse werden addiert, um den neuen Zellzustand
(Kandidatenzustand), und die Ergebnisse werden addiert, um den neuen Zellzustand ![]() zu bilden.
zu bilden.
Der Zellstatus wird durch Kombination des alten Zellstatus und der Kandidatenwerte aktualisiert. Der Ausgang von forget gate steuert den Beitrag des vorherigen Zellzustands und der Ausgang des Eingangs-Gates den Beitrag der neuen Kandidatenwerte.
05: Output Gate
Gegeben durch die Gleichung:
![]()
Eine Sigmoidfunktion bestimmt, welche Teile des Zellzustands ausgegeben werden sollen. Dieses Gate steuert die Ausgabe von Informationen aus der Speicherzelle.
![]() - Gewicht der Ausgabeschicht
- Gewicht der Ausgabeschicht
![]() - Bias der Ausgabeschicht
- Bias der Ausgabeschicht
Dieses Gate bestimmt die endgültige Ausgabe für den aktuellen Zellzustand. Es entscheidet, welche Teile des Zellzustands auf der Grundlage der Eingabe ![]() und des vorherigen verborgenen Zustands
und des vorherigen verborgenen Zustands ![]() ausgegeben werden sollen.
ausgegeben werden sollen.
06: Verborgener Zustands-Update
Gegeben durch die Gleichung:
![]()
Der neue verborgene Zustand ![]() ergibt sich durch Multiplikation des Ausgangs-Gates
ergibt sich durch Multiplikation des Ausgangs-Gates ![]() mit tanh des aktualisierten Zellzustands
mit tanh des aktualisierten Zellzustands ![]() .
.
Der verborgene Zustand wird auf der Grundlage des Zellzustands und der Entscheidung des Ausgangs-Gates aktualisiert. Er wird als Ausgabe für den aktuellen Zeitschritt und als Eingabe für den nächsten Zeitschritt verwendet.
Was ist ein neuronales Netzwerk mit Gated Recurrent Unit (GRU)?
Die Gated Recurrent Unit (GRU) ist eine Art rekurrentes neuronales Netzwerk (RNN), das in bestimmten Fällen Vorteile gegenüber dem Langzeitgedächtnis (LSTM) hat. GRU benötigt weniger Speicherplatz und ist schneller als LSTM, allerdings ist LSTM bei Datensätzen mit längeren Sequenzen genauer.
LSTMs und GRUs wurden eingeführt, um das in einfachen rekurrenten neuronalen Netzen vorherrschende Kurzzeitgedächtnis abzuschwächen. Beide verfügen über ein Langzeitgedächtnis, das durch die Verwendung der Gates in ihren Zellen aktiviert wird.
Obwohl sie in vielerlei Hinsicht ähnlich wie einfache RNNs funktionieren, haben LSTMs und GRUs das Problem des verschwindenden Gradienten, unter dem einfache rekurrente neuronale Netze leiden.
Mathematik hinter dem Gated Recurrent Unit (GRU) Netzwerk
Die folgende Abbildung zeigt, wie die GRU-Zelle aussieht, wenn sie zerlegt wird.

01: Das Aktualisierungstor
Gegeben durch die Formel.
![]()
Dieses Gate bestimmt, wie viel des vorherigen verborgenen Zustands ![]() beibehalten werden soll und wie viel des Kandidaten für den verborgenen Zustand
beibehalten werden soll und wie viel des Kandidaten für den verborgenen Zustand ![]() zur Aktualisierung des verborgenen Zustands verwendet werden soll.
zur Aktualisierung des verborgenen Zustands verwendet werden soll.
Das Aktualisierungs-Gate steuert, wie viel des vorherigen verborgenen Zustands ![]() auf den nächsten Zeitschritt übertragen werden soll. Sie entscheidet effektiv über das Gleichgewicht zwischen der Beibehaltung der alten und der Aufnahme neuer Informationen.
auf den nächsten Zeitschritt übertragen werden soll. Sie entscheidet effektiv über das Gleichgewicht zwischen der Beibehaltung der alten und der Aufnahme neuer Informationen.
02: Reset Gate
Gegeben durch die Formel.
![]()
Die Sigmoidfunktion ![]() in diesem Gate bestimmt, welche Teile des vorherigen verborgenen Zustands zurückgesetzt werden sollten, bevor sie mit der aktuellen Eingabe kombiniert werden, um die Kandidatenaktivierung zu erstellen.
in diesem Gate bestimmt, welche Teile des vorherigen verborgenen Zustands zurückgesetzt werden sollten, bevor sie mit der aktuellen Eingabe kombiniert werden, um die Kandidatenaktivierung zu erstellen.
03: Kandidaten-Aktivierung
Gegeben durch die Formel.
![]()
Die Kandidatenaktivierung wird anhand der aktuellen Eingabe ![]() und des zurückgesetzten versteckten Zustands berechnet
und des zurückgesetzten versteckten Zustands berechnet ![]() .
.
Diese Komponente erzeugt neue potenzielle Werte für den verborgenen Zustand, die auf der Grundlage der Entscheidung des Aktualisierungs-Gates aufgenommen werden können.
04: Verborgener Zustands-Update
Gegeben durch die Formel.
![]()
Der Ausgang des Aktualisierungs-Gates ![]() steuert, wie viel von dem versteckten Kandidatenzustand
steuert, wie viel von dem versteckten Kandidatenzustand ![]() verwendet wird, um den neuen versteckten Zustand
verwendet wird, um den neuen versteckten Zustand ![]() zu bilden.
zu bilden.
Der verborgene Zustand wird durch die Kombination des vorherigen verborgenen Zustands und des verborgenen Kandidatenzustands aktualisiert. Das Update-Gate ![]() steuert diese Kombination und stellt sicher, dass die relevanten Informationen aus der Vergangenheit beibehalten werden, während neue Informationen integriert werden.
steuert diese Kombination und stellt sicher, dass die relevanten Informationen aus der Vergangenheit beibehalten werden, während neue Informationen integriert werden.
Aufbau der Elternklasse für LSTM- und GRU-Netze
Da LSTM und GRU in vielerlei Hinsicht ähnlich arbeiten und die gleichen Parameter verwenden, könnte es eine gute Idee sein, eine Klasse base(parent) für die Funktionen zu haben, die zum Erstellen, Kompilieren, Optimieren, Überprüfen der Merkmalsbedeutung und Speichern der Modelle erforderlich sind. Diese Klasse wird an die nachfolgenden LSTM- und GRU-Unterklassen vererbt.
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, GRU, Dense, Input, Dropout from keras.callbacks import EarlyStopping from keras.optimizers import Adam import tf2onnx import optuna import shap from sklearn.metrics import accuracy_score class RNNClassifier(): def __init__(self, time_step, x_train, y_train, x_test, y_test): self.model = None self.time_step = time_step self.x_train = x_train self.y_train = y_train self.x_test = x_test self.y_test = y_test # a crucial function that all the subclasses must implement def build_compile_and_train(self, params, verbose=0): raise NotImplementedError("Subclasses should implement this method") # a function for saving the RNN model to onnx & the Standard scaler parameters def save_onnx_model(self, onnx_file_name): # optuna objective function to oprtimize def optimize_objective(self, trial): # optimize for 50 trials by default def optimize(self, n_trials=50): def _rnn_predict(self, data): def check_feature_importance(self, feature_names):
Optimierung von LSTM und GRU mit /Optuna
Wie bereits gesagt, sind neuronale Netze sehr empfindlich gegenüber Hyperparametern. Ohne die richtige Einstellung und ohne die optimalen Parameter könnten neuronale Netze unwirksam sein.
Python
def optimize_objective(self, trial): params = { "neurons": trial.suggest_int('neurons', 10, 100), "n_hidden_layers": trial.suggest_int('n_hidden_layers', 1, 5), "dropout_rate": trial.suggest_float('dropout_rate', 0.1, 0.5), "learning_rate": trial.suggest_float('learning_rate', 1e-5, 1e-2, log=True), "hidden_activation_function": trial.suggest_categorical('hidden_activation_function', ['relu', 'tanh', 'sigmoid']), "loss_function": trial.suggest_categorical('loss_function', ['categorical_crossentropy', 'binary_crossentropy', 'mean_squared_error', 'mean_absolute_error']) } val_accuracy = self.build_compile_and_train(params, verbose=0) # we build a model with different parameters and train it, just to return a validation accuracy value return val_accuracy # optimize for 50 trials by default def optimize(self, n_trials=50): study = optuna.create_study(direction='maximize') # we want to find the model with the highest validation accuracy value study.optimize(self.optimize_objective, n_trials=n_trials) return study.best_params # returns the parameters that produced the best performing model
Die Methode optimize_objective definiert die Zielfunktion für die Hyperparameter-Optimierung unter Verwendung des Optuna-Rahmens. Sie leitet den Optimierungsprozess, um den besten Satz von Hyperparametern zu finden, der die Leistung des Modells maximiert.
Die Methode Optimize verwendet Optuna, um die Optimierung der Hyperparameter durch wiederholten Aufruf der Methode optimize_objective durchzuführen.
Prüfen der Merkmalsbedeutung mit SHAP
Für Datenwissenschaftler ist es wichtig zu messen, wie stark sich die Merkmale auf die Vorhersagen des Modells auswirken. Dies kann uns nicht nur dabei helfen, die Bereiche für wichtige Verbesserungen zu verstehen, sondern auch unser Verständnis eines bestimmten Datensatzes über ein Modell zu verbessern.
def check_feature_importance(self, feature_names): # Sample a subset of training data for SHAP explainer sampled_idx = np.random.choice(len(self.x_train), size=100, replace=False) explainer = shap.KernelExplainer(self._rnn_predict, self.x_train[sampled_idx].reshape(100, -1)) # Get SHAP values for the test set shap_values = explainer.shap_values(self.x_test[:100].reshape(100, -1), nsamples=100) # Update feature names for SHAP feature_names = [f'{feature}_t{t}' for t in range(self.time_step) for feature in feature_names] # Plot the SHAP values shap.summary_plot(shap_values, self.x_test[:100].reshape(100, -1), feature_names=feature_names, max_display=len(feature_names), show=False) # Adjust layout and set figure size plt.subplots_adjust(left=0.12, bottom=0.1, right=0.9, top=0.9) plt.gcf().set_size_inches(7.5, 14) plt.tight_layout() # Get the class name of the current instance class_name = self.__class__.__name__ # Create the file name using the class name file_name = f"{class_name.lower()}_feature_importance.png" plt.savefig(file_name) plt.show()
Speichern der LSTM- und GRU-Klassifikatoren in ONNX-Modellformaten
Nachdem wir die Modelle erstellt haben, müssen wir sie schließlich im ONNX-Format speichern, das mit MQL5 kompatibel ist.
def save_onnx_model(self, onnx_file_name):
# Convert the Keras model to ONNX
spec = (tf.TensorSpec((None, self.time_step, self.x_train.shape[2]), tf.float16, name="input"),)
self.model.output_names = ['outputs']
onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13)
# Save the ONNX model to a file
with open(onnx_file_name, "wb") as f:
f.write(onnx_model.SerializeToString())
# Save the mean and scale parameters to binary files
scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin")
scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
Die abgeleiteten Klassen des Neuronalen Netzwerks für LSTM und GRU
Rekurrente neuronale Netze funktionieren in vielerlei Hinsicht ähnlich, sogar ihre Implementierung mit Keras folgt einem ähnlichen Ansatz und ähnlichen Parametern. Ihr Hauptunterschied ist die Art des Modells, alles andere bleibt gleich.
LSTM-Klassifikator:
Python
class LSTMClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(LSTM(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
GRU-Klassifikator:
Python
class GRUClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(GRU(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
Wie bei den Klassifikatoren für untergeordnete Klassen zu sehen ist, besteht der einzige Unterschied in der Art des Modells; sowohl LSTMs als auch GRUs verfolgen einen ähnlichen Ansatz.
Ausbildung beider Modelle:
Zunächst müssen wir die Klasseninstanzen für beide Modelle initialisieren: Wir beginnen mit dem LSTM-Modell:
lstm_clf = LSTMClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
Dann initialisieren wir das GRU-Modell:
gru_clf = GRUClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
Nachdem beide Modelle für 20 Versuche optimiert wurden:
best_params = lstm_clf.optimize(n_trials=20)
best_params = gru_clf.optimize(n_trials=20) Das LSTM-Klassifikatormodell bei Versuch 19 war das beste:
[I 2024-07-01 11:14:40,588] Trial 19 finished with value: 0.5597269535064697 and parameters: {'neurons': 79, 'n_hidden_layers': 4, 'dropout_rate': 0.335909076638275, 'learning_rate': 3.0704319088493336e-05, 'hidden_activation_function': 'relu', 'loss_function': 'categorical_crossentropy'}. Best is trial 19 with value: 0.5597269535064697.
Mit einer Genauigkeit von etwa 55,97 % bei den Validierungsdaten war das GRU-Klassifikatormodell bei Versuch 3 das beste aller Modelle:
[I 2024-07-01 11:18:52,190] Trial 3 finished with value: 0.532423198223114 and parameters: {'neurons': 55, 'n_hidden_layers': 5, 'dropout_rate': 0.2729838602302831, 'learning_rate': 0.009626688728041802, 'hidden_activation_function': 'sigmoid', 'loss_function': 'mean_squared_error'}. Best is trial 3 with value: 0.532423198223114.
Sie lieferte eine Genauigkeit von etwa 53,24 % bei den Validierungsdaten.
Prüfen der Merkmalswichtigkeit für beide Modelle
| LSTM-Klassifikator | GRU-Klassifikator |
|---|---|
feature_importance = lstm_clf.check_feature_importance(X.columns) Das Ergebnis. 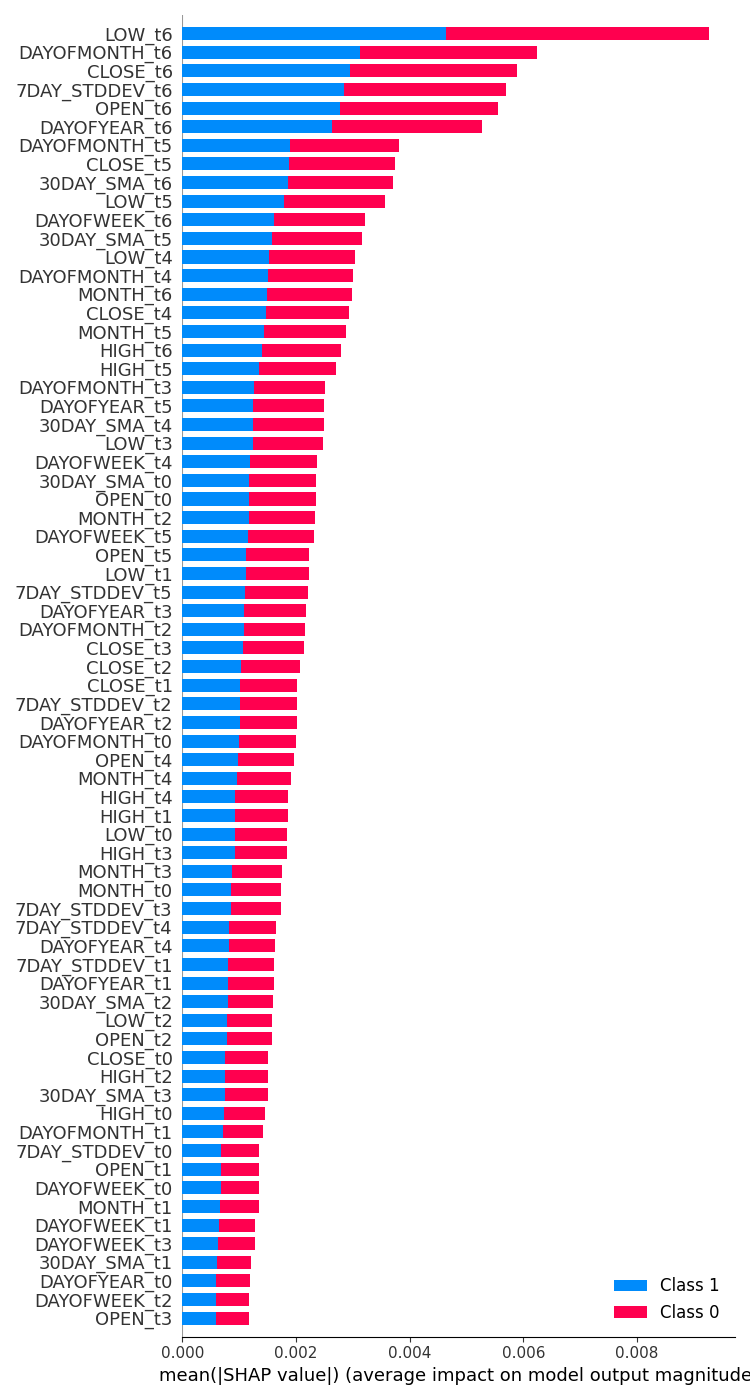 | feature_importance = gru_clf.check_feature_importance(X.columns) Das Ergebnis.  |
Die Bedeutung des LSTM-Klassifikators ähnelt in gewisser Weise derjenigen, die wir mit dem einfachen RNN-Modell erhalten haben. Die am wenigsten wichtigen Variablen stammen aus weit entfernten Zeitschritten, während die wichtigsten Merkmale aus näheren Zeitschritten stammen.
Das ist so, als würde man sagen, dass die Variablen, die am meisten dazu beitragen, was mit dem aktuellen Balken passiert, die Informationen über die letzten geschlossenen Balken sind.
Der GRU-Klassifizierer vertrat eine abweichende Meinung, die nicht viel Sinn zu ergeben scheint. Dies könnte daran liegen, dass sein Modell eine geringere Genauigkeit aufweist.
Die einflussreichste Variable war der Wochentag 7 Tage zuvor. Merkmale wie „Open“, „High“, „Low“ und „Close“ aus dem Zeitschrittwert von 6, also den jüngsten Informationen, wurden in der Mitte platziert, was bedeutet, dass sie einen durchschnittlichen Beitrag zum endgültigen Vorhersageergebnis leisten.
Die Klassifikatoren für LSTM versus GRU auf dem Strategy Tester
Kurz nach dem Training wurden sowohl die LSTM- als auch die GRU-Klassifikatormodelle im ONNX-Format gespeichert.
LSTM | Python
lstm_clf.build_compile_and_train(best_params, verbose=1) # best_params = best parameters obtained after optimization lstm_clf.save_onnx_model("lstm.EURUSD.D1.onnx")
GRU | Python
gru_clf.build_compile_and_train(best_params, verbose=1) gru_clf.save_onnx_model("gru.EURUSD.D1.onnx") # best_params = best parameters obtained after optimization
Nach dem Speichern des ONNX-Modells und seiner Skalierungsdateien im Verzeichnis MQL5\Files können wir die Dateien zu beiden Expert Advisors als Ressourcendateien hinzufügen.
| LSTM | GRU |
|---|---|
#resource "\\Files\\lstm.EURUSD.D1.onnx" as uchar onnx_model[]; //lstm model in onnx format #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\LSTM.mqh> CLSTM lstm; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique | #resource "\\Files\\gru.EURUSD.D1.onnx" as uchar onnx_model[]; //gru model in onnx format #resource "\\Files\\gru.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\gru.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\GRU.mqh> CGRU gru; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique |
Der Code für den Rest der Expert Advisors bleibt derselbe , wie wir ihn besprochen haben.
Mit den Standardeinstellungen, die wir seit Teil 24 dieser Artikelserie verwendet haben, wo wir mit der Zeitreihenprognose begonnen haben.
Stop loss: 500, Take profit: 700, Slippage: 50.
Da die Daten auf einem täglichen Zeitrahmen gesammelt wurden, könnte es eine gute Idee sein, sie auf einem niedrigeren Zeitrahmen zu testen, um den Fehler „Markt geschlossen“ zu vermeiden, da wir für Handelssignale für die Eröffnung einen neuen Balkenn suchen. Wir können auch die Modellierungsart auf Eröffnungspreis einstellen, um schneller zu testen.

LSTM Expert Advisor Ergebnisse


GRU Expert Advisor Ergebnisse


Was können wir von den Ergebnissen der Strategietester lernen?
Obwohl der LSTM-basierte Expert Advisor mit 44,98 % das am wenigsten genaue Modell war, war er mit einem Nettogewinn von 138 $ am profitabelsten, gefolgt vom GRU-basierten Expert Advisor, der in 45,25 % der Fälle profitabel war, obwohl er einen Nettogewinn von insgesamt 120 $ erzielte.
LSTM ist in diesem Fall ein klarer Gewinner , was die Gewinne angeht. Obwohl das LSTM technisch gesehen intelligenter ist als andere RNNs seiner Art, kann es viele Faktoren geben, die dazu führen, dass alle rekurrenten Modelle gut sind und andere in bestimmten Situationen übertreffen können. Sie können jedes der in diesem und dem vorherigen Artikel besprochenen Modelle verwenden.
Die Unterschiede zwischen den neuronalen Netzmodellen LSTM und GRU
Das Verständnis dieser Modelle im Vergleich hilft bei der Entscheidung, was jedes Modell im Gegensatz zu den anderen bietet. Wann eine solche verwendet werden sollte und wann nicht. Nachstehend sind die Unterschiede tabellarisch dargestellt.
| Aspekt | LSTM | GRU |
|---|---|---|
Komplexität der Architektur | LSTMs haben ein komplexeres Design mit drei Gates (Eingang, Ausgang, Vergessen) und einem Zellstatus, der eine detaillierte Kontrolle darüber ermöglicht, welche Informationen bei jedem Zeitschritt behalten oder verworfen werden. | GRUs haben einen einfacheren Aufbau mit nur zwei Gates (Reset und Update). Durch diese einfache Architektur sind sie leichter zu implementieren. |
Trainingsgeschwindigkeit | Zusätzliche Gates und ein Zellstatus in LSTMs bedeuten, dass mehr Prozesse durchgeführt und Parameter optimiert werden müssen. Im Training sind sie langsamer. | Da sie mit weniger Gates und einfacheren Operationen auskommen, trainieren sie in der Regel schneller als LSTMs. |
Leistung | Bei komplexen Problemen, bei denen die Erfassung langfristiger Abhängigkeiten von entscheidender Bedeutung ist, schneiden LSTMs tendenziell etwas besser ab als ihre Gegenspieler. | GRUs liefern in der Regel bei vielen Aufgaben eine vergleichbare Leistung wie LSTMs. |
Umgang mit langfristigen Abhängigkeiten | LSTMs sind explizit darauf ausgelegt, langfristige Abhängigkeiten in den Daten zu erhalten, und zwar dank des Zellzustands und der Gating-Mechanismen, die den Informationsfluss über die Zeit steuern. | Während GRUs auch langfristige Abhängigkeiten gut handhaben, sind sie aufgrund ihrer einfacheren Struktur bei der Erfassung sehr langfristiger Abhängigkeiten möglicherweise nicht so effektiv wie LSTMs. |
| Speicherverbrauch | Aufgrund ihrer komplexen Struktur und zusätzlicher Parameter verbrauchen LSTMs mehr Speicher, was in ressourcenbeschränkten Umgebungen eine Einschränkung darstellen kann. | GRUs hingegen sind einfacher, haben weniger Parameter und benötigen weniger Speicherplatz. Dadurch eignen sie sich besser für Anwendungen mit begrenzten Rechenressourcen. |
Abschließende Überlegungen
Die neuronale Netze sowohl von LSTM (Long Short-Term Memory) als auch von GRU (Gated Recurrent Unit) sind leistungsstarke Werkzeuge für Händler, die fortschrittliche Zeitreihenprognosemodelle nutzen wollen. Während LSTMs eine kompliziertere Architektur bieten, die sich durch die Erfassung langfristiger Abhängigkeiten in Marktdaten auszeichnet, bieten GRUs eine einfachere und effizientere Alternative, die oft die Leistung von LSTMs mit geringeren Rechenkosten erreichen kann.
Diese Deep Learning-Modelle von Zeitreihen (LSTM und GRU) wurden in verschiedenen Bereichen außerhalb des Forex-Handels eingesetzt, z. B. bei der Wettervorhersage, bei der Modellierung des Energieverbrauchs, bei der Erkennung von Anomalien und bei der Spracherkennung, und zwar mit großem Erfolg, wie in der Regel behauptet wird.
Dieser Artikel soll lediglich ein tieferes Verständnis für diese Modelle vermitteln und zeigen, wie sie in MQL5 für den Handel eingesetzt werden können. Sie können gerne mit den in diesem Artikel besprochenen Modellen und Datensätzen spielen und Ihre Ergebnisse im Diskussionsbereich mitteilen.
Mit freundlichen Grüßen.
Verfolgen Sie die Entwicklung von Modellen für maschinelles Lernen und vieles mehr in dieser Artikelserie auf diesem GitHub repo.
Tabelle der Anhänge
| Dateiname | Dateityp | Beschreibung und Verwendung |
|---|---|---|
| GRU EA.mq5 LSTM EA.mq5 | Expert Advisors | GRU-basierter Expertenratgeber. LSTM-basierter Expertenratgeber. |
| gru.EURUSD.D1.onnx lstm.EURUSD.D1.onnx | ONNX-Dateien | GRU-Modell im ONNX-Format. LSTM-Modell im ONNX-Format. |
| lstm.EURUSD.D1.standard_scaler_mean.bin lstm.EURUSD.D1.standard_scaler_scale.bin | Binäre Dateien | Binärdateien für den Standardisierungs-Skalierer, der für das LSTM-Modell verwendet wird. |
| gru.EURUSD.D1.standard_scaler_mean.bin gru.EURUSD.D1.standard_scaler_scale.bin | Binäre Dateien | Binärdateien für den Standardisierungs-Skalierer, der für das GRU-Modell verwendet wird. |
| preprocessing.mqh | Eine Include-Datei | Eine Bibliothek, die aus dem Standardization Scaler besteht. |
| lstm-gru-for-forex-trading-tutorial.ipynb | Python-Skript/Jupyter-Notizbuch | Besteht aus dem gesamten Python-Code, der in diesem Artikel besprochen wird |
- Leitfaden für LSTMs und GRUs: Eine schrittweise Erklärung
- Neuronales Netzwerk für die Dekodierung von Oberflächencodes
- Ein Adaptives neuronales Anti-Rausch-Netz für die Diagnose von Lagerfehlern unter Rauschen und wechselnden Lastbedingungen
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/15182
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.