Artikel über die Automatisierung von Handelssystemen in MQL5
Lesen Sie Artikel über Handelssysteme, in denen unterschiedlichste Ideen vorgestellt sind. Sie erfahren, wie man statistische Methoden und Muster auf japanischen Kerzen verwendet, wie man Signale filtern kann und wofür man Semaphor-Indikatoren braucht.
Mit dem Meister MQL5 lernen Sie, wie man einen Roboter ohne Programmieren zur schnellen Überprüfung von Handelsideen erstellen kann sowie was genetische Algorithmen sind.
Neuer Artikel

Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich

Entwicklung eines Replay System (Teil 32): Auftragssystem (I)
Von allen Dingen, die wir bisher entwickelt haben, ist dieses System, wie Sie wahrscheinlich bemerken und letztendlich zustimmen werden, das komplexeste. Nun müssen wir etwas sehr Einfaches tun: unser System soll den Betrieb eines Handelsservers simulieren. Die Notwendigkeit, die Funktionsweise des Handelsservers genau zu implementieren, scheint eine Selbstverständlichkeit zu sein. Zumindest in Worten. Aber wir müssen dies so tun, dass alles nahtlos und transparent für den Nutzer des Wiedergabe-/Simulationssystems ist.

Neuronale Netze leicht gemacht (Teil 46): Goal-conditioned reinforcement learning (GCRL, zielgerichtetes Verstärkungslernen)
In diesem Artikel werfen wir einen Blick auf einen weiteren Ansatz des Reinforcement Learning. Es wird als Goal-conditioned reinforcement learning (GCRL, zielgerichtetes Verstärkungslernen) bezeichnet. Bei diesem Ansatz wird ein Agent darauf trainiert, verschiedene Ziele in bestimmten Szenarien zu erreichen.

Advanced Variables and Data Types in MQL5
Variables and data types are very important topics not only in MQL5 programming but also in any programming language. MQL5 variables and data types can be categorized as simple and advanced ones. In this article, we will identify and learn about advanced ones because we already mentioned simple ones in a previous article.

Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 11): System von Kreuzaufträgen
In diesem Artikel werden wir ein System von Kreuzaufträgen (cross order system) erstellen. Es gibt eine Art von Vermögenswerten, die den Händlern das Leben sehr schwer macht - Terminkontrakte. Aber warum machen sie einem das Leben schwer?

Experimente mit neuronalen Netzen (Teil 6): Das Perzeptron als autarkes Instrument zur Preisprognose
Der Artikel liefert ein Beispiel für die Verwendung eines Perzeptrons als autarkes Preisprognoseinstrument, indem er allgemeine Konzepte und den einfachsten vorgefertigten Expert Advisor vorstellt und anschließend die Ergebnisse seiner Optimierung zeigt.

Neuronale Netze leicht gemacht (Teil 72): Entwicklungsvorhersage in verrauschten Umgebungen
Die Qualität der Vorhersage zukünftiger Zustände spielt eine wichtige Rolle bei der Methode des Goal-Conditioned Predictive Coding, die wir im vorherigen Artikel besprochen haben. In diesem Artikel möchte ich Ihnen einen Algorithmus vorstellen, der die Vorhersagequalität in stochastischen Umgebungen, wie z. B. den Finanzmärkten, erheblich verbessern kann.

Entwicklung eines Roboters in Python und MQL5 (Teil 1): Vorverarbeitung der Daten
Entwicklung eines auf maschinellem Lernen basierenden Handelsroboters: Ein detaillierter Leitfaden. Der erste Artikel in dieser Reihe befasst sich mit der Erfassung und Aufbereitung von Daten und Merkmalen. Das Projekt wird unter Verwendung der Programmiersprache Python und der Bibliotheken sowie der Plattform MetaTrader 5 umgesetzt.

MQL5-Assistenten-Techniken, die Sie kennen sollten (Teil 27): Gleitende Durchschnitte und der Anstellwinkel (Angle of Attack)
Der Anstellwinkel oder engl. „Angle of Attack“ ist eine oft zitierte Kennzahl, deren Steilheit stark mit der Stärke eines vorherrschenden Trends korreliert. Wir sehen uns an, wie es allgemein verwendet und verstanden wird, und untersuchen, ob es Änderungen gibt, die in der Art und Weise, wie es gemessen wird, zum Nutzen eines Handelssystems, das es verwendet, eingeführt werden könnten.
Lernen Sie, wie man ein Handelssystem mit dem OBV entwickelt
Dies ist ein neuer Artikel, der unsere Serie für Anfänger fortsetzt, in der es darum geht, wie man ein Handelssystem basierend auf einigen der beliebten Indikatoren entwirft. Wir werden einen neuen Indikator kennenlernen, nämlich das On Balance Volume (OBV), und wir werden lernen, wie wir ihn verwenden und ein darauf basierendes Handelssystem entwerfen können.

Die Kreuzvalidierung und die Grundlagen der kausalen Inferenz in CatBoost-Modellen, Export ins ONNX-Format
In dem Artikel wird eine Methode zur Erstellung von Bots durch maschinelles Lernen vorgeschlagen.

Neuinterpretation klassischer Strategien in Python: Das Kreuzen von MAs
In diesem Artikel wird die klassische Kreuzungsstrategie von gleitenden Durchschnitten erneut untersucht, um ihre aktuelle Wirksamkeit zu bewerten. Angesichts der langen Zeit, die seit ihrer Einführung vergangen ist, untersuchen wir die potenziellen Verbesserungen, die KI für diese traditionelle Handelsstrategie bringen kann. Durch den Einsatz von KI-Techniken wollen wir fortschrittliche Vorhersagefähigkeiten nutzen, um Einstiegs- und Ausstiegspunkte für den Handel zu optimieren, sich an unterschiedliche Marktbedingungen anzupassen und die Gesamtperformance im Vergleich zu herkömmlichen Ansätzen zu verbessern.

Entwicklung eines Replay Systems — Marktsimulation (Teil 14): Die Geburt des SIMULATORS (IV)
In diesem Artikel werden wir die Entwicklungsphase des Simulators fortsetzen. Diesmal werden wir sehen, wie wir eine Bewegung vom Typ RANDOM WALK effektiv erstellen können. Diese Art von Bewegung ist sehr interessant, denn sie bildet die Grundlage für alles, was auf dem Kapitalmarkt geschieht. Darüber hinaus werden wir beginnen, einige Konzepte zu verstehen, die für die Durchführung von Marktanalysen grundlegend sind.

Kombinatorisch symmetrische Kreuzvalidierung in MQL5
In diesem Artikel stellen wir die Implementierung der kombinatorisch symmetrischen Kreuzvalidierung in reinem MQL5 vor, um den Grad der Überanpassung nach der Optimierung einer Strategie unter Verwendung des langsamen vollständigen Algorithmus des Strategietesters zu messen.

Datenwissenschaft und maschinelles Lernen (Teil 19): Überladen Sie Ihre AI-Modelle mit AdaBoost
AdaBoost, ein leistungsstarker Boosting-Algorithmus, der die Leistung Ihrer KI-Modelle steigert. AdaBoost, die Abkürzung für Adaptive Boosting, ist ein ausgeklügeltes Ensemble-Lernverfahren, das schwache Lerner nahtlos integriert und ihre kollektive Vorhersagestärke erhöht.
MQL5-Assistent-Techniken, die Sie kennen sollten (Teil 26): Gleitende Durchschnitte und der Hurst-Exponent
Der Hurst-Exponent ist ein Maß dafür, wie stark eine Zeitreihe auf lange Sicht autokorreliert. Es wird davon ausgegangen, dass sie die langfristigen Eigenschaften einer Zeitreihe erfasst und daher in der Zeitreihenanalyse auch außerhalb von wirtschaftlichen/finanziellen Zeitreihen eine gewisse Bedeutung hat. Wir konzentrieren uns jedoch auf den potenziellen Nutzen für Händler, indem wir untersuchen, wie diese Metrik mit gleitenden Durchschnitten gepaart werden kann, um ein potenziell robustes Signal zu bilden.

Entwicklung eines Replay-Systems — Marktsimulation (Teil 11): Die Geburt des SIMULATORS (I)
Um die Daten, die die Balken bilden, nutzen zu können, müssen wir auf das Replay verzichten und einen Simulator entwickeln. Wir werden 1-Minuten-Balken verwenden, weil sie den geringsten Schwierigkeitsgrad aufweisen.

Rebuy-Algorithmus: Handelssimulation mit mehreren Währungen
In diesem Artikel werden wir ein mathematisches Modell zur Simulation der Preisbildung in mehreren Währungen erstellen und die Untersuchung des Diversifizierungsprinzips als Teil der Suche nach Mechanismen zur Steigerung der Handelseffizienz abschließen, die ich im vorherigen Artikel mit theoretischen Berechnungen begonnen habe.

Neuronale Netze leicht gemacht (Teil 42): Modell der Prokrastination, Ursachen und Lösungen
Im Kontext des Verstärkungslernens kann die Prokrastination (Zögern) eines Modells mehrere Ursachen haben. Der Artikel befasst sich mit einigen der möglichen Ursachen für Prokrastination bei Modellen und mit Methoden zu deren Überwindung.

Neuronale Netze leicht gemacht (Teil 44): Erlernen von Fertigkeiten mit Blick auf die Dynamik
Im vorangegangenen Artikel haben wir die DIAYN-Methode vorgestellt, die einen Algorithmus zum Erlernen einer Vielzahl von Fertigkeiten (skills) bietet. Die erworbenen Fertigkeiten können für verschiedene Aufgaben genutzt werden. Aber solche Fertigkeiten können ziemlich unberechenbar sein, was ihre Anwendung schwierig machen kann. In diesem Artikel wird ein Algorithmus zum Erlernen vorhersehbarer Fertigkeiten vorgestellt.
Neuronale Netze leicht gemacht (Teil 55): Contrastive Intrinsic Control (CIC)
Das kontrastive Training ist eine unüberwachte Methode zum Training der Repräsentation. Ziel ist es, ein Modell zu trainieren, das Ähnlichkeiten und Unterschiede in Datensätzen aufzeigt. In diesem Artikel geht es um die Verwendung kontrastiver Trainingsansätze zur Erkundung verschiedener Fähigkeiten des Akteurs (Actor skills).

Neuronale Netze leicht gemacht (Teil 61): Optimismusproblem beim Offline-Verstärkungslernen
Während des Offline-Lernens optimieren wir die Strategie des Agenten auf der Grundlage der Trainingsdaten. Die daraus resultierende Strategie gibt dem Agenten Vertrauen in sein Handeln. Ein solcher Optimismus ist jedoch nicht immer gerechtfertigt und kann zu erhöhten Risiken während des Modellbetriebs führen. Heute werden wir uns mit einer der Methoden zur Verringerung dieser Risiken befassen.

Entwicklung eines Expertenberaters für mehrere Währungen (Teil 6): Automatisieren der Auswahl einer Instanzgruppe
Nach der Optimierung der Handelsstrategie erhalten wir eine Reihe von Parametern. Wir können sie verwenden, um mehrere Instanzen von Handelsstrategien zu erstellen, die in einem EA kombiniert werden. Früher haben wir das manuell gemacht. Hier werden wir versuchen, diesen Prozess zu automatisieren.
Zeitreihen in der Bibliothek DoEasy (Teil 56): Nutzerdefiniertes Indikatorobjekt, das die Daten von Indikatorobjekten aus der Kollektion holt
In dem Artikel wird das Erstellen des nutzerdefinierten Indikatorobjekts für die Verwendung in EAs erklärt. Lassen Sie uns die Bibliotheksklassen leicht verbessern und Methoden hinzufügen, um Daten von Indikatorobjekten in EAs zu erhalten.
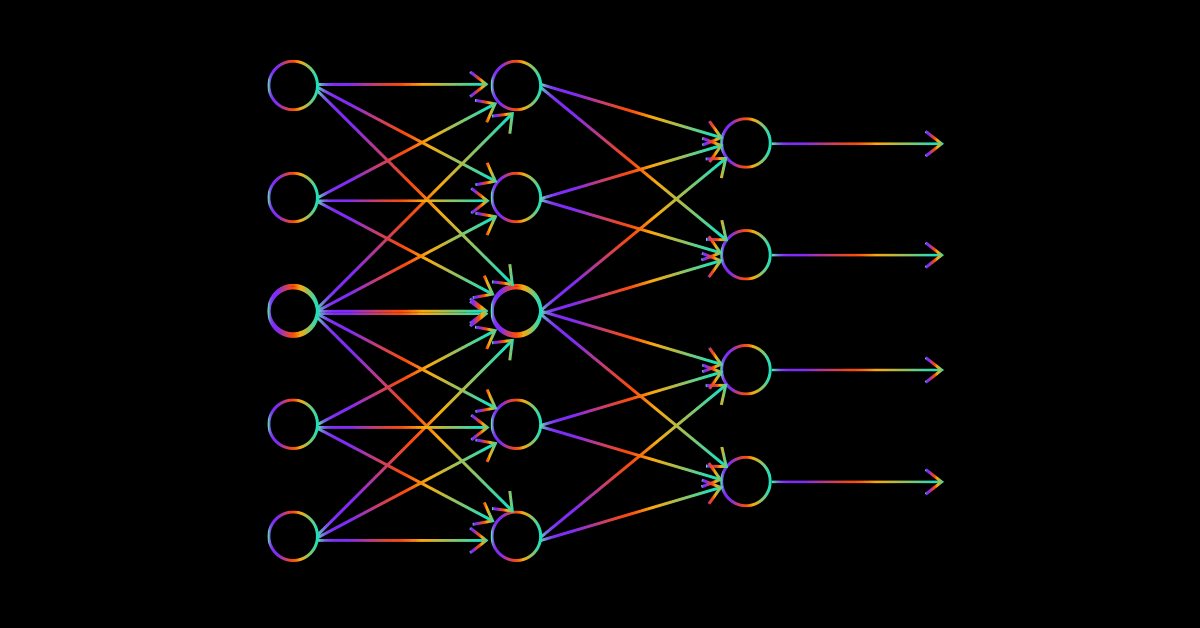
Datenwissenschaft und maschinelles Lernen — Neuronales Netzwerk (Teil 02): Entwurf von Feed Forward NN-Architekturen
Bevor wir fertig sind, müssen wir noch einige kleinere Dinge im Zusammenhang mit dem neuronalen Feed-Forward-Netz behandeln, unter anderem den Entwurf. Sehen wir uns an, wie wir ein flexibles neuronales Netz für unsere Eingaben, die Anzahl der verborgenen Schichten und die Knoten für jedes Netz aufbauen und gestalten können.

Neuronale Netze leicht gemacht (Teil 64): Die Methode konservativ gewichtetes Klonen von Verhaltensweisen (CWBC)
Aufgrund von Tests, die in früheren Artikeln durchgeführt wurden, kamen wir zu dem Schluss, dass die Optimalität der trainierten Strategie weitgehend von der verwendeten Trainingsmenge abhängt. In diesem Artikel werden wir uns mit einer relativ einfachen, aber effektiven Methode zur Auswahl von Trajektorien für das Training von Modellen vertraut machen.

Entwicklung eines Replay Systems — Marktsimulation (Teil 19): Erforderliche Anpassungen
Hier werden wir den Boden bereiten, damit wir, wenn wir neue Funktionen zum Code hinzufügen müssen, dies reibungslos und einfach tun können. Der derzeitige Kodex kann einige der Dinge, die notwendig sind, um sinnvolle Fortschritte zu erzielen, noch nicht abdecken oder behandeln. Wir müssen alles strukturieren, damit wir bestimmte Dinge mit minimalem Aufwand umsetzen können. Wenn wir alles richtig machen, erhalten wir ein wirklich universelles System, das sich sehr leicht an jede Situation anpassen lässt, die es zu bewältigen gilt.

Neuronale Netze leicht gemacht (Teil 60): Online Decision Transformer (ODT)
Die letzten beiden Artikel waren der Decision-Transformer-Methode gewidmet, die Handlungssequenzen im Rahmen eines autoregressiven Modells der gewünschten Belohnungen modelliert. In diesem Artikel werden wir uns einen weiteren Optimierungsalgorithmus für diese Methode ansehen.

Neuronale Netze leicht gemacht (Teil 52): Forschung mit Optimismus und Verteilungskorrektur
Da das Modell auf der Grundlage des Erfahrungswiedergabepuffers trainiert wird, entfernt sich die aktuelle Strategie oder Politik des Akteurs immer weiter von den gespeicherten Beispielen, was die Effizienz des Trainings des Modells insgesamt verringert. In diesem Artikel befassen wir uns mit einem Algorithmus zur Verbesserung der Effizienz bei der Verwendung von Stichproben in Algorithmen des verstärkten Lernens.

Neuronale Netze leicht gemacht (Teil 36): Relationales Verstärkungslernen
In den Verstärkungslernmodellen, die wir im vorherigen Artikel besprochen haben, haben wir verschiedene Varianten von Faltungsnetzwerken verwendet, die in der Lage sind, verschiedene Objekte in den Originaldaten zu identifizieren. Der Hauptvorteil von Faltungsnetzen ist die Fähigkeit, Objekte unabhängig von ihrer Position zu erkennen. Gleichzeitig sind Faltungsnetzwerke nicht immer leistungsfähig, wenn es zu verschiedenen Verformungen von Objekten und Rauschen kommt. Dies sind die Probleme, die das relationale Modell lösen kann.
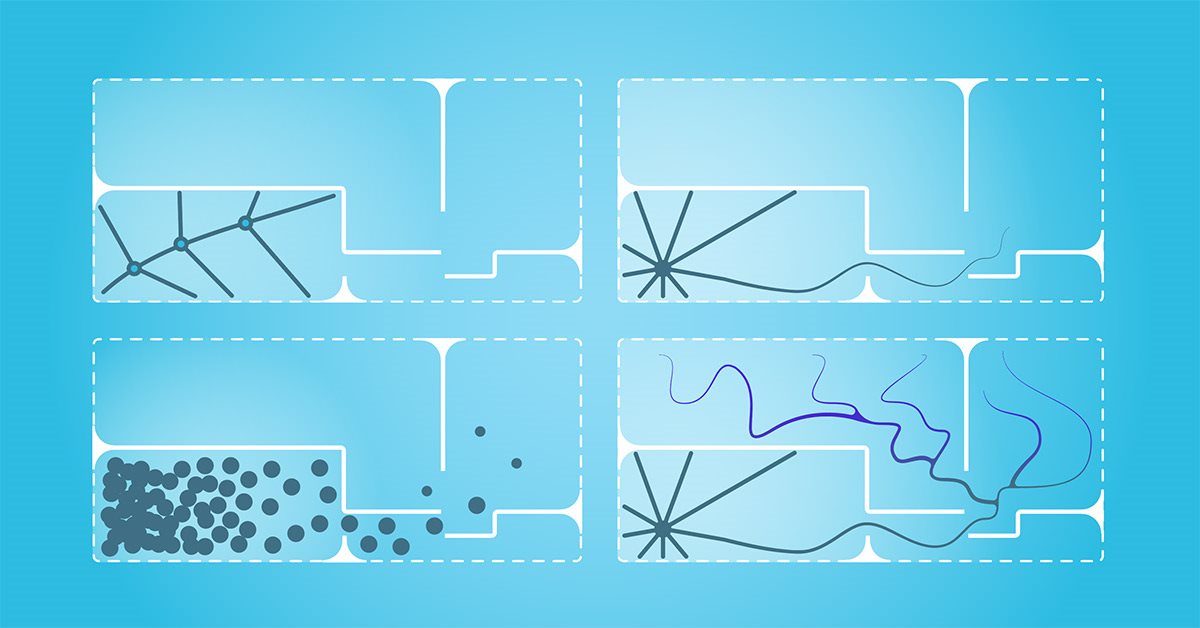
Neuronale Netze leicht gemacht (Teil 45): Training von Fertigkeiten zur Erkundung des Zustands
Das Training nützlicher Fertigkeiten ohne explizite Belohnungsfunktion ist eine der größten Herausforderungen beim hierarchischen Verstärkungslernen. Zuvor haben wir bereits zwei Algorithmen zur Lösung dieses Problems kennengelernt. Die Frage nach der Vollständigkeit der Umweltforschung bleibt jedoch offen. In diesem Artikel wird ein anderer Ansatz für das Training von Fertigkeiten vorgestellt, dessen Anwendung direkt vom aktuellen Zustand des Systems abhängt.

Entwicklung eines Wiedergabesystems — Marktsimulation (Teil 04): Anpassung der Einstellungen (II)
Lassen Sie uns mit der Entwicklung des Systems und der Kontrollen fortfahren. Ohne die Möglichkeit, den Dienst zu kontrollieren, ist es schwierig, Fortschritte zu machen und das System zu verbessern.

Entwurfsmuster in der Softwareentwicklung und MQL5 (Teil 2): Strukturelle Muster
In diesem Artikel werden wir unsere Artikel über Entwurfsmuster fortsetzen, nachdem wir gelernt haben, wie wichtig dieses Thema für uns als Entwickler ist, um erweiterbare, zuverlässige Anwendungen nicht nur mit der Programmiersprache MQL5, sondern auch mit anderen zu entwickeln. Wir werden eine andere Art von Entwurfsmustern kennenlernen, nämlich die strukturellen, um zu lernen, wie man Systeme entwirft, indem man das, was wir als Klassen haben, zur Bildung größerer Strukturen verwendet.

Trianguläre Arbitrage mit Vorhersagen
Dieser Artikel vereinfacht die Dreiecksarbitrage und zeigt Ihnen, wie Sie mit Hilfe von Prognosen und spezieller Software intelligenter mit Währungen handeln können, selbst wenn Sie neu auf dem Markt sind. Sind Sie bereit, mit Expertise zu handeln?

Neuronale Netze leicht gemacht (Teil 23): Aufbau eines Tools für Transfer Learning
In dieser Artikelserie haben wir bereits mehr als einmal über Transfer Learning berichtet. In diesem Artikel schlage ich vor, diese Lücke zu schließen und einen genaueren Blick auf Transfer Learning zu werfen.
Datenwissenschaft und maschinelles Lernen (Teil 07): Polynome Regression
Im Gegensatz zur linearen Regression ist die polynome Regression ein flexibles Modell, das darauf abzielt, Aufgaben besser zu erfüllen, die das lineare Regressionsmodell nicht bewältigen kann. Lassen Sie uns herausfinden, wie man polynome Modelle in MQL5 erstellt und etwas Positives daraus macht.
Modified Grid-Hedge EA in MQL5 (Part III): Optimizing Simple Hedge Strategy (I)
In this third part, we revisit the Simple Hedge and Simple Grid Expert Advisors (EAs) developed earlier. Our focus shifts to refining the Simple Hedge EA through mathematical analysis and a brute force approach, aiming for optimal strategy usage. This article delves deep into the mathematical optimization of the strategy, setting the stage for future exploration of coding-based optimization in later installments.

Neuronale Netze leicht gemacht (Teil 18): Assoziationsregeln
Als Fortsetzung dieser Artikelserie betrachten wir eine andere Art von Problemen innerhalb der Methoden des unüberwachten Lernens: die Ermittlung von Assoziationsregeln. Dieser Problemtyp wurde zuerst im Einzelhandel, insbesondere in Supermärkten, zur Analyse von Warenkörben eingesetzt. In diesem Artikel werden wir über die Anwendbarkeit solcher Algorithmen im Handel sprechen.

Neuronale Netze leicht gemacht (Teil 47): Kontinuierlicher Aktionsraum
In diesem Artikel erweitern wir das Aufgabenspektrum unseres Agenten. Der Ausbildungsprozess wird einige Aspekte des Geld- und Risikomanagements umfassen, die ein wesentlicher Bestandteil jeder Handelsstrategie sind.

Lernen Sie, wie man ein Handelssystem mit Bears Power entwirft
Willkommen zu einem neuen Artikel in unserer Serie über das Lernen, wie man ein Handelssystem durch die beliebtesten technischen Indikator hier ist ein neuer Artikel über das Lernen, wie man ein Handelssystem von Bears Power technischen Indikator zu entwerfen.

Erfahren Sie, wie Sie ein Handelssystem anhand des Relative Vigor Index entwickeln können
Ein neuer Artikel in unserer Serie darüber, wie man ein Handelssystem anhand eines beliebten technischen Indikators entwickelt. In diesem Artikel werden wir lernen, wie man das mit Hilfe des Relativen Vigot-Index-Indikators tun kann.