
Entwicklung eines Expertenberaters für mehrere Währungen (Teil 6): Automatisieren der Auswahl einer Instanzgruppe
Einführung
Im vorigen Artikel haben wir die Möglichkeit eingeführt, die Strategieoption zu wählen - mit einer konstanten Positionsgröße und mit einer variablen Positionsgröße. Auf diese Weise konnten wir eine Normalisierung der Arbeitsergebnisse der Strategien in Bezug auf den maximalen Drawdown einführen und die Möglichkeit schaffen, sie in Gruppen zusammenzufassen, bei denen der maximale Drawdown ebenfalls innerhalb der festgelegten Grenzen lag. Zur Veranschaulichung haben wir mehrere der attraktivsten Kombinationen von Eingaben aus den Optimierungsergebnissen einer einzelnen Strategieinstanz manuell ausgewählt und versucht, sie in einer Gruppe oder sogar in einer Gruppe von drei Gruppen von drei Strategien zu kombinieren. In letzterem Fall haben wir die besten Ergebnisse erzielt.
Wenn wir jedoch die Anzahl der Strategien in Gruppen und die Anzahl der verschiedenen Gruppen, die miteinander kombiniert werden, erhöhen müssen, nimmt der Umfang der manuellen Routinearbeiten stark zu.
Zunächst müssen wir eine einzelne Instanz der Strategie mit unterschiedlichen Optimierungskriterien für jedes Symbol optimieren. Außerdem kann es notwendig sein, für jedes Symbol eine separate Optimierung für verschiedene Zeiträume durchzuführen. Für unsere spezifische Modellstrategie können wir auch eine separate Optimierung nach Art der eröffneten Aufträge (Stop-, Limit- oder Marktpositionen) durchführen.
Zweitens muss aus den resultierenden Parametersätzen, die etwa 20-50 Tausend betragen, eine kleine Anzahl (10-20) der besten ausgewählt werden. Sie sollten jedoch nicht nur alleine, sondern auch in der Gruppe die Besten sein. Auch das Auswählen und Hinzufügen von Strategieinstanzen nacheinander erfordert Zeit und Geduld.
Drittens sollten die erhaltenen Gruppen wiederum zu höheren Gruppen zusammengefasst werden, wobei eine Standardisierung vorgenommen wird. Wenn Sie dies manuell tun, können Sie sich nur zwei oder drei Stufen leisten. Weitere Gruppierungsebenen scheinen zu arbeitsintensiv zu sein.
Daher sollten wir versuchen, diese Phase der EA-Entwicklung zu automatisieren.
Der Weg ist vorgezeichnet
Leider ist es unwahrscheinlich, dass wir in der Lage sein werden, alles auf einmal zu erledigen. Im Gegenteil, die Komplexität der Aufgabe kann dazu führen, dass man sich nicht traut, sie zu lösen. Versuchen wir also, uns dem Thema zumindest von einer Seite zu nähern. Die Hauptschwierigkeit, die uns daran hindert, mit der Umsetzung zu beginnen, ist die Frage, die sich daraus ergibt: „Wird uns das etwas bringen? Ist es möglich, die manuelle Auswahl durch eine automatische Auswahl zu ersetzen, ohne dass die Qualität beeinträchtigt wird (und vorzugsweise mit einer Steigerung)? Würde dieser Prozess insgesamt nicht noch länger dauern als die manuelle Auswahl?“
Solange wir keine Antworten haben, ist es schwierig, eine Lösung zu finden. Gehen wir also folgendermaßen vor: Unsere derzeitige Priorität besteht darin, die Hypothese zu testen, dass eine automatische Gruppenauswahl nützlich sein kann. Um dies zu testen, nehmen wir eine Reihe von Optimierungsergebnissen einer Instanz für ein Symbol und wählen manuell eine gute normalisierte Gruppe aus. Dies wird unsere Basis für den Vergleich der Ergebnisse sein. Dann schreiben wir mit minimalen Kosten die einfachste Automatisierung, die es uns ermöglicht, eine Gruppe auszuwählen. Danach vergleichen wir das Ergebnis der automatisch ausgewählten Gruppe mit dem Ergebnis der manuell ausgewählten Gruppe. Wenn die Vergleichsergebnisse das Potenzial der Automatisierung zeigen, kann man zu einer weiteren, schöneren und korrekten Umsetzung übergehen.
Aufbereitung der Ausgangsdaten
Laden wir die EA-Optimierungsergebnisse SimpleVolumesExpertSingle.mq5 herunter, die wir bei der Implementierung der vorherigen Teile erhalten haben, und exportieren sie nach XML.
Abb. 1. Export von Optimierungsergebnissen zur Weiterverarbeitung
Um die weitere Verwendung zu vereinfachen, werden wir zusätzliche Spalten hinzufügen, die die Werte der nicht an der Optimierung beteiligten Parameter enthalten. Wir müssen Symbol, Zeitrahmen, maxCountOfOrders und, was noch wichtiger ist, fittedBalance hinzufügen. Wir werden den Wert des letzteren auf der Grundlage des bekannten maximalen relativen Drawdowns durch das Eigenkapital berechnen.
Wenn wir von einem Anfangssaldo von 100.000 USD ausgehen, beträgt der absolute Drawdown etwa 100.000 * (relDDpercent / 100). Dieser Wert sollte 10 % von fittedBalance betragen, also erhalten wir:
fittedBalance = 100000 * (relDDProzent / 100) / 0,1 = relDDProzent * 10000
Der im Code angegebene Zeitrahmen wird durch die Konstante PERIOD_H1 als numerischer Wert von 16385 dargestellt.
Als Ergebnis der Ergänzungen erhalten wir eine Datentabelle, die wir im CSV-Format speichern. In transponierter Form sehen die ersten Zeilen der resultierenden Tabelle wie folgt aus:
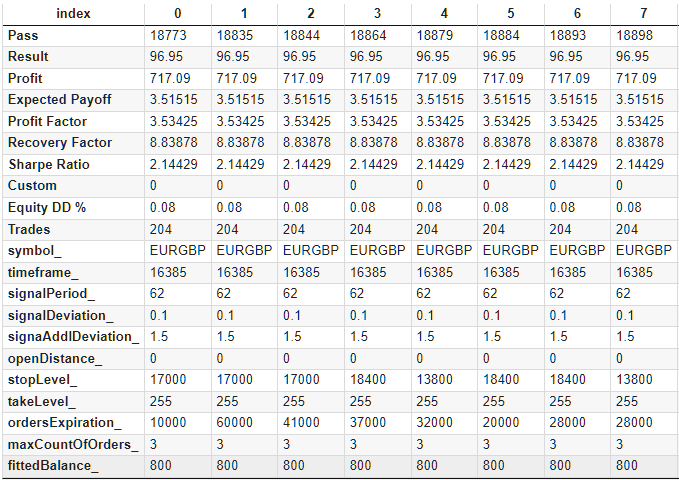
Abb. 2. Ergänzte Tabelle mit Optimierungsergebnissen
Diese Arbeit könnte an einen Computer delegiert werden, z. B. durch die Verwendung der Bibliothek TesterCache oder durch die Implementierung einer anderen Methode zur Speicherung von Daten über jeden Durchlauf während der Optimierung. Aber ich möchte dies mit minimalem Aufwand tun. Daher werde ich diese Arbeit vorerst manuell erledigen.
Diese Tabelle enthält Zeilen mit einem Gewinn von weniger als Null (etwa 1000 Zeilen von 18.000). Wir sind definitiv nicht an diesen Ergebnissen interessiert, also sollten wir sie sofort loswerden.
Danach sind die Ausgangsdaten bereit für die Erstellung einer Basisversion und für die anschließende Auswahl von Gruppen von Strategien, die mit der Basisversion konkurrieren können.
Basislinie
Die Erstellung einer Basisversion ist ein einfacher, aber eintöniger Prozess. Zunächst einmal sollten wir unsere Strategien in der Reihenfolge ihrer abnehmenden „Qualität“ sortieren. Verwenden wir die folgende Methode zur Bewertung der Qualität. Markieren Sie die Spalten, die verschiedene Leistungskennzahlen in dieser Tabelle enthalten: Profit, Expected Payoff, Profit Factor, Recovery Factor, Sharpe Ratio, Equity DD % und Trades. Jede von ihnen ist einer Min-Max-Skalierung unterworfen, die den Bereich [0; 1] ergibt. Wir holen uns zusätzliche Spalten mit dem Suffix „_s“ und verwenden diese, um die Summe für jede Zeile wie folgt zu berechnen:
0.5 * Profit_s + ExpectedPayoff_s + ProfitFactor_s + RecoveryFactor_s + SharpeRatio_s + (1 - EquityDD_s) + 0.3 * Trades_s,
und fügen sie als neue Tabellenspalte hinzu. Wir sortieren sie in absteigender Reihenfolge.
Dann fangen wir an, die Liste durchzugehen, fügen der Gruppe Kandidaten hinzu, die uns gefallen, und prüfen sofort, wie sie zusammenarbeiten. Wir werden versuchen, Parametersätze hinzuzufügen, die sich sowohl in den Parametern als auch in den Ergebnissen so weit wie möglich voneinander unterscheiden.
Zum Beispiel gibt es unter den Parametersätzen solche, die sich nur in der SL-Ebene unterscheiden. Wenn diese Stufe jedoch während des Testzeitraums nie ausgelöst wurde, sind die Ergebnisse bei verschiedenen Stufen gleich. Daher können solche Kombinationen nicht kombiniert werden, da ihre Eröffnungs- und Schließzeiten zusammenfallen und somit auch die Zeitpunkte der maximalen Drawdowns übereinstimmen. Wir wollen die Modelle auswählen, deren Drawdowns zu unterschiedlichen Zeitpunkten auftreten. Dadurch kann die Rentabilität gesteigert werden, da das Volumen der Positionen nicht proportional zur Anzahl der Strategien, sondern durch eine geringere Anzahl von Malen reduziert werden kann.
Wählen wir auf diese Weise 16 standardisierte Strategiefälle aus.
Wir werden auch mit einem festen Saldo für den Handel handeln. Dazu setzen wir FixedBalance = 10000. Bei dieser Wahl ergeben die normalisierten Strategien einzeln einen maximalen Drawdown von 1000. Schauen wir uns die Testergebnisse an:
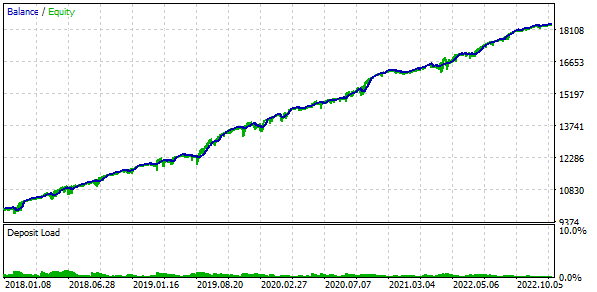
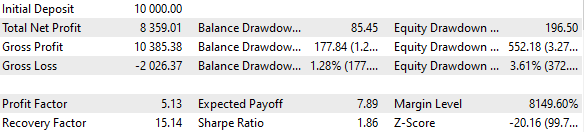
Abb. 3. Ergebnisse des Basisfalls
Es stellt sich heraus, dass, wenn wir 16 Kopien von Strategien kombinieren und die Größe der von jeder Kopie eröffneten Positionen um das 16-fache reduzieren, der maximale Drawdown nur 552 USD statt 1000 USD beträgt. Um diese Gruppe von Strategien in eine normalisierte Gruppe zu verwandeln, führen wir Berechnungen durch, sodass der Skalierungsfaktor Scale gleich 1000 / 552 = 1,81 angewendet werden kann, um den Drawdown von 10 % beizubehalten.

Abb. 4. Die Ergebnisse des Basisfalls mit der normalisierten Gruppe (Skala=1,81)
Um sich daran zu erinnern, dass FixedBalance = 10.000 und Scale = 1.81 verwendet werden müssen, setzen wir diese Zahlen als Standardwerte für die entsprechenden Eingaben. Wir erhalten den folgenden Code:
//+------------------------------------------------------------------+ //| Inputs | //+------------------------------------------------------------------+ input group "::: Money management" input double expectedDrawdown_ = 10; // - Maximum risk (%) input double fixedBalance_ = 10000; // - Used deposit (0 - use all) in the account currency input double scale_ = 1.81; // - Group scaling multiplier input group "::: Other parameters" input ulong magic_ = 27183; // - Magic CVirtualAdvisor *expert; // EA object //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor(magic_, "SimpleVolumes_Baseline"); // Create and fill the array of all selected strategy instances CVirtualStrategy *strategies[] = { new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 48, 1.6, 0.1, 0, 11200, 1160, 51000, 3, 3000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 0.4, 0.7, 0, 15800, 905, 18000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 156, 1, 0.8, 0, 19000, 680, 41000, 3, 900), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 14, 0.3, 0.8, 0, 19200, 495, 27000, 3, 1100), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 38, 1.4, 0.1, 0, 19600, 690, 60000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 98, 0.9, 1, 0, 15600, 1850, 7000, 3, 1300), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 1.8, 1.9, 0, 13000, 675, 45000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 86, 1, 1.7, 0, 17600, 1940, 56000, 3, 1000), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 230, 0.7, 1.2, 0, 8800, 1850, 2000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 44, 0.1, 0.6, 0, 10800, 230, 8000, 3, 1200), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 108, 0.6, 0.9, 0, 12000, 1080, 46000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 182, 1.8, 1.9, 0, 13000, 675, 33000, 3, 600), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 62, 0.1, 1.5, 0, 16800, 255, 2000, 3, 800), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 12, 1.4, 1.7, 0, 9600, 440, 59000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 24, 1.7, 2, 0, 11600, 1930, 23000, 3, 700), new CSimpleVolumesStrategy("EURGBP", PERIOD_H1, 30, 1.1, 0.1, 0, 18400, 1295, 27000, 3, 1500), }; // Add a group of selected strategies to the strategies expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Wir speichern ihn in der Datei BaselineExpert.mq5 im aktuellen Ordner.
Die Basisversion für den Vergleich ist fertig, jetzt geht es an die Implementierung der Automatisierung der Auswahl von Strategieinstanzen in einer Gruppe.
Verfeinerung der Strategie
Die Kombinationen von Eingaben, die wir als Parameter des Strategiekonstruktors ersetzen müssen, sind derzeit in der CSV-Datei gespeichert. Das bedeutet, dass wir sie als Werte vom Typ string erhalten, wenn wir sie von dort lesen. Es wäre praktisch, wenn die Strategie einen Konstruktor hätte, der eine einzige Zeichenkette annimmt, aus der er alle erforderlichen Parameter extrahiert. Ich plane, diese Methode der Übergabe von Parametern an den Konstruktor zu implementieren, zum Beispiel mit der Input_Struct-Bibliothek. Aber der Einfachheit halber fügen wir jetzt den zweiten Konstruktor dieses Typs hinzu:
//+------------------------------------------------------------------+ //| Trading strategy using tick volumes | //+------------------------------------------------------------------+ class CSimpleVolumesStrategy : public CVirtualStrategy { ... public: CSimpleVolumesStrategy(const string &p_params); ... }; //+------------------------------------------------------------------+ //| Constructor | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(const string &p_params) { string param[]; int total = StringSplit(p_params, ',', param); if(total == 11) { m_symbol = param[0]; m_timeframe = (ENUM_TIMEFRAMES) StringToInteger(param[1]); m_signalPeriod = (int) StringToInteger(param[2]); m_signalDeviation = StringToDouble(param[3]); m_signaAddlDeviation = StringToDouble(param[4]); m_openDistance = (int) StringToInteger(param[5]); m_stopLevel = StringToDouble(param[6]); m_takeLevel = StringToDouble(param[7]); m_ordersExpiration = (int) StringToInteger(param[8]); m_maxCountOfOrders = (int) StringToInteger(param[9]); m_fittedBalance = StringToDouble(param[10]); CVirtualReceiver::Get(GetPointer(this), m_orders, m_maxCountOfOrders); // Load the indicator to get tick volumes m_iVolumesHandle = iVolumes(m_symbol, m_timeframe, VOLUME_TICK); // Set the size of the tick volume receiving array and the required addressing ArrayResize(m_volumes, m_signalPeriod); ArraySetAsSeries(m_volumes, true); } }
Dieser Konstruktor geht davon aus, dass die Werte aller Parameter in der richtigen Reihenfolge und durch ein Komma getrennt in eine Zeichenkette gepackt sind. Eine solche Zeichenkette wird als einziger Parameter des Konstruktors übergeben, durch Kommata in Teile geteilt, und jeder Teil wird nach Umwandlung in den entsprechenden Datentyp der gewünschten Klasseneigenschaft zugewiesen.
Speichern wir die Änderungen in der Datei SimpleVolumesStrategy.mqh im aktuellen Ordner.
Verfeinerung des EA
Nehmen wir den EA SimpleVolumesExpert.mq5 als Beispiel. Wir werden einen neuen EA erstellen, der sich mit der Optimierung der Auswahl mehrerer Strategieinstanzen aus derselben CSV-Datei beschäftigt, die wir zuvor für die manuelle Auswahl verwendet haben.
Zunächst fügen wir eine Gruppe von Eingängen hinzu, die es ermöglichen, die Liste der Parameter der Strategieinstanz zu laden und sie in der Gruppe auszuwählen. Der Einfachheit halber beschränken wir die Anzahl der Strategien, die gleichzeitig in einer Gruppe enthalten sind, auf acht und bieten die Möglichkeit, eine kleinere Anzahl als 8 festzulegen.
input group "::: Selection for the group" sinput string fileName_ = "Params_SV_EURGBP_H1.csv"; // File with strategy parameters (*.csv) sinput int count_ = 8; // Number of strategies in the group (1 .. 8) input int i0_ = 0; // Strategy index #1 input int i1_ = 1; // Strategy index #2 input int i2_ = 2; // Strategy index #3 input int i3_ = 3; // Strategy index #4 input int i4_ = 4; // Strategy index #5 input int i5_ = 5; // Strategy index #6 input int i6_ = 6; // Strategy index #7 input int i7_ = 7; // Strategy index #8
Wenn count_ kleiner als 8 ist, wird nur die Anzahl der darin angegebenen Parameter, die die Strategieindizes definieren, für die Enumeration verwendet.
Als Nächstes stoßen wir auf ein Problem. Wenn wir eine Datei mit den Strategieparametern Params_SV_EURGBP_H1.csv im Datenverzeichnis des Terminals ablegen, dann wird sie nur von dort gelesen, wenn dieser EA auf dem Terminal-Chart gestartet wird. Wenn wir es im Tester ausführen, wird diese Datei nicht erkannt, da der Tester mit seinem eigenen Datenverzeichnis arbeitet. Wir können natürlich den Speicherort des Verzeichnisses der Testerdaten finden und die Datei dorthin kopieren, aber das ist umständlich und löst nicht das nächste Problem.
Das nächste Problem ist, dass bei der Optimierung (und genau dafür entwickeln wir diesen EA) die Datendatei dem Agentencluster im lokalen Netzwerk nicht zur Verfügung steht, ganz zu schweigen von den Agenten des MQL5 Cloud Network.
Eine vorübergehende Lösung für die oben genannten Probleme könnte darin bestehen, den Inhalt der Datendatei in den EA-Quellcode aufzunehmen. Wir werden aber weiterhin versuchen, die Möglichkeit zu schaffen, eine externe CSV-Datei zu verwenden. Dazu müssen wir in der Sprache MQL5 Werkzeuge wie die Präprozessordirektive tester_file und die Ereignisbehandlung von OnTesterInit() verwenden. Wir werden auch das Vorhandensein eines gemeinsamen Datenordners für alle Terminals und Prüfmittel auf dem lokalen Computer nutzen.
Wie in der MQL5-Referenz angegeben, kann mit der Direktive tester_file der Dateiname für den Tester angegeben werden. Das bedeutet, dass diese Datei auch dann, wenn das Testgerät auf einem entfernten Server läuft, an diesen gesendet und in das Datenverzeichnis des Testagenten abgelegt wird. Das scheint genau das zu sein, was wir brauchen. Das ist aber nicht der Fall! Dieser Dateiname sollte eine Konstante sein und während der Kompilierung definiert werden. Daher ist es nicht möglich, einen beliebigen Dateinamen, der in den EA-Eingaben nur beim Start der Optimierung übergeben wird, durch diesen zu ersetzen.
Wir müssen die folgende Umgehung anwenden. Wir werden einen festen Dateinamen wählen und ihn im EA festlegen. Sie kann zum Beispiel aus dem Namen des EA selbst gebildet werden. Dieser konstante Name wird in der Richtlinie tester_file angegeben:
#define PARAMS_FILE __FILE__".params.csv" #property tester_file PARAMS_FILE
Als Nächstes fügen wir eine globale Variable für das Array der Strategieparametersätze als Zeichenketten hinzu. In dieses Array werden wir die Daten aus der Datei lesen.
string params[]; // Array of strategy parameter sets as strings
Schreiben wir eine Funktion zum Laden von Daten aus einer Datei, die wie folgt funktionieren wird. Zunächst wird geprüft, ob eine Datei mit dem angegebenen Namen im gemeinsamen Datenordner des Terminals oder im Datenordner vorhanden ist. Wenn sie vorhanden ist, wird sie in die Datei mit dem ausgewählten festen Namen im Datenordner kopiert. Wir öffnen dann die Datei mit dem festgelegten Namen zum Lesen und lesen die Daten aus dieser Datei.
//+------------------------------------------------------------------+ //| Load strategy parameter sets from a CSV file | //+------------------------------------------------------------------+ int LoadParams(const string fileName, string &p_params[]) { bool res = false; // Check if the file exists in the shared folder and in the data folder if(FileIsExist(fileName, FILE_COMMON)) { // If it is in the shared folder, then copy it to the data folder with a fixed name res = FileCopy(fileName, FILE_COMMON, PARAMS_FILE, FILE_REWRITE); } else if(FileIsExist(fileName)) { // If it is in the data folder, then copy it here, but with a fixed name res = FileCopy(fileName, 0, PARAMS_FILE, FILE_REWRITE); } // If there is a file with a fixed name, that is good as well if(FileIsExist(PARAMS_FILE)) { res = true; } // If the file is found, then if(res) { // Open it int f = FileOpen(PARAMS_FILE, FILE_READ | FILE_TXT | FILE_ANSI); // If opened successfully if(f != INVALID_HANDLE) { FileReadString(f); // Ignore data column headers // For all further file strings while(!FileIsEnding(f)) { // Read the string and extract the part containing the strategy inputs string s = CSVStringGet(FileReadString(f), 10, 21); // Add this part to the array of strategy parameter sets APPEND(p_params, s); } FileClose(f); return ArraySize(p_params); } } return 0; }
Wenn dieser Code also auf einem entfernten Testagenten ausgeführt wird, wird die Datei mit dem festen Namen aus der EA-Hauptinstanz, die die Optimierung gestartet hat, bereits an dessen Datenordner übergeben. Um dies zu erreichen, müssen wir den Aufruf dieser Funktion zum Laden der Ereignishandlung von OnTesterInit() hinzufügen.
Hier werden wir die Werte für die Bereiche des Parametersatzes Index-Iteration festlegen, damit wir sie nicht manuell im Fenster für die Optimierungsparameter einstellen müssen. Wenn wir eine Gruppe aus einer Anzahl von Gruppen auswählen müssen, die kleiner als 8 ist, dann werden wir auch hier automatisch die Enumeration unnötiger Indizes deaktivieren.
//+------------------------------------------------------------------+ //| Initialization before optimization | //+------------------------------------------------------------------+ int OnTesterInit(void) { // Load strategy parameter sets int totalParams = LoadParams(fileName_, params); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_FAILED); } // Set scale_ to 1 ParameterSetRange("scale_", false, 1, 1, 1, 2); // Set the ranges of change for the parameters of the set index iteration for(int i = 0; i < 8; i++) { if(i < count_) { ParameterSetRange("i" + (string) i + "_", true, 0, 0, 1, totalParams - 1); } else { // Disable the enumeration for extra indices ParameterSetRange("i" + (string) i + "_", false, 0, 0, 1, totalParams - 1); } } return(INIT_SUCCEEDED); }
Wir wählen als Optimierungskriterium den maximalen Gewinn, der mit einem maximalen Drawdown von 10 % des festen Anfangssaldos erzielt werden kann. Wir fügen OnTester() dem EA hinzu, wo wir den Parameterwert berechnen:
//+------------------------------------------------------------------+ //| Test results | //+------------------------------------------------------------------+ double OnTester(void) { // Maximum absolute drawdown double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Profit double profit = TesterStatistics(STAT_PROFIT); // The ratio of possible increase in position sizes for the drawdown of 10% of fixedBalance_ double coeff = fixedBalance_ * 0.1 / balanceDrawdown; // Recalculate the profit double fittedProfit = profit * coeff; return fittedProfit; }
Durch die Berechnung dieses Parameters erhalten wir in einem Durchgang sofort Informationen darüber, welcher Gewinn erzielt werden kann, wenn wir den in diesem Durchgang erreichten maximalen Drawdown berücksichtigen und den Skalierungsmultiplikator so einstellen, dass der Drawdown 10% erreichen kann.
In der Initialisierung des EAs in OnInit() müssen wir die Strategieparametersätze zuerst laden. Dann nehmen wir die Indizes aus den Eingaben und überprüfen, dass es keine Duplikate unter ihnen gibt. Ist dies nicht der Fall, so wird der Durchlauf mit solchen Eingaben nicht gestartet. Wenn alles in Ordnung ist, extrahieren wir die Sätze mit den angegebenen Indizes aus dem Array der Strategieparametersätze und fügen sie dem EA hinzu.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Load strategy parameter sets int totalParams = LoadParams(fileName_, params); // If nothing is loaded, report an error if(totalParams == 0) { PrintFormat(__FUNCTION__" | ERROR: Can't load data from file %s.\n" "Check that it exists in data folder or in common data folder.", fileName_); return(INIT_PARAMETERS_INCORRECT); } // Form the string from the parameter set indices separated by commas string strIndexes = (string) i0_ + "," + (string) i1_ + "," + (string) i2_ + "," + (string) i3_ + "," + (string) i4_ + "," + (string) i5_ + "," + (string) i6_ + "," + (string) i7_; // Turn the string into the array string indexes[]; StringSplit(strIndexes, ',', indexes); // Leave only the specified number of instances in it ArrayResize(indexes, count_); // Multiplicity for parameter set indices CHashSet<string> setIndexes; // Add all indices to the multiplicity FOREACH(indexes, setIndexes.Add(indexes[i])); // Report an error if if(count_ < 1 || count_ > 8 // number of instances not in the range 1 .. 8 || setIndexes.Count() != count_ // not all indexes are unique ) { return INIT_PARAMETERS_INCORRECT; } // Set parameters in the money management class CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); // Create an EA handling virtual positions expert = new CVirtualAdvisor(magic_, "SimpleVolumes_OptGroup"); // Create and fill the array of all strategy instances CVirtualStrategy *strategies[]; FOREACH(indexes, APPEND(strategies, new CSimpleVolumesStrategy(params[StringToInteger(indexes[i])]))); // Create and add selected groups of strategies to the EA expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Außerdem müssen wir dem EA zumindest das leere OnTesterDeinit() hinzufügen. Dies ist eine Compileranforderung für EAs, die OnTesterInit() verwenden.
Wir werden den erhaltenen Code in der Datei OptGroupExpert.mq5 im aktuellen Ordner speichern.
Einfache Zusammensetzung
Wir starten die Optimierung des implementierten EAs, indem wir den Pfad zu der erstellten CSV-Datei mit den Parametern der Handelsstrategie angeben. Wir werden einen genetischen Algorithmus verwenden, der ein Nutzerkriterium maximiert, nämlich den auf den 10%igen Drawdown normalisierten Gewinn. Wir verwenden für die Optimierung denselben Testzeitraum - von 2018 bis einschließlich 2022.
Ein standardmäßiger genetischer Optimierungsblock mit mehr als 10.000 Durchläufen benötigte etwa 9 Stunden, um mit 13 Testagenten in einem lokalen Netzwerk abgeschlossen zu werden. Überraschenderweise waren die Ergebnisse sogar besser als die des Basissatzes. So sieht der obere Teil der Tabelle mit den Optimierungsergebnissen aus:
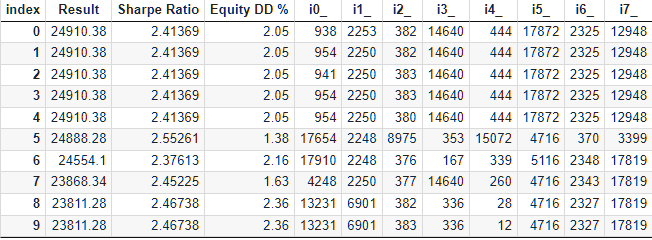
Abb. 6. Ergebnisse der Optimierung der automatischen Auswahl in einer Gruppe
Schauen wir uns das beste Ergebnis genauer an. Um den berechneten Gewinn zu erhalten, müssen wir nicht nur alle Indizes aus der ersten Zeile der Tabelle angeben, sondern auch den Parameter scale_ gleich dem Verhältnis zwischen dem angegebenen Drawdown von 10 % (1.000 USD von 10.000 USD) und dem erreichten maximalen Drawdown nach Eigenkapital setzen. In der Tabelle wird dies als Prozentsatz angegeben. Für eine genauere Berechnung ist es jedoch besser, den absoluten Wert und nicht den relativen Wert zu nehmen.
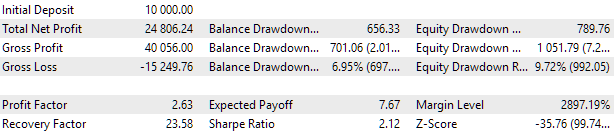
Abb. 7. Testergebnisse der besten Gruppe
Die Gewinnergebnisse weichen geringfügig von den berechneten Ergebnissen ab, aber dieser Unterschied ist sehr unbedeutend und kann vernachlässigt werden. Aber es ist klar, dass die automatisierte Auswahl eine bessere Gruppe finden konnte als die manuell ausgewählte: Der Gewinn betrug 24.800 USD statt 15.200 USD - mehr als eineinhalb Mal besser. Dieser Prozess erforderte kein menschliches Eingreifen. Dies ist bereits ein sehr ermutigendes Ergebnis. Wir können aufatmen und mit größerem Enthusiasmus in dieser Richtung weiterarbeiten.
Wir werden sehen, ob es etwas gibt, was wir im Auswahlverfahren ohne großen Aufwand verbessern können. In der Tabelle, die die Ergebnisse der Auswahl der Strategien in Gruppen enthält, ist deutlich zu erkennen, dass die ersten fünf Gruppen die gleichen Ergebnisse aufweisen und sich nur in einem oder zwei Indizes der Parametersätze unterscheiden. Dies liegt daran, dass in unserer ursprünglichen Datei mit den Strategieparametern einige enthalten waren, die zwar das gleiche Ergebnis erbrachten, sich aber in einigen weniger wichtigen Parametern voneinander unterschieden. Wenn also zwei verschiedene Datensätze, die die gleichen Ergebnisse liefern, in zwei Gruppen fallen, können diese beiden Gruppen die gleichen Ergebnisse liefern.
Das bedeutet auch, dass bei der Optimierung mehrere „identische“ Sätze von Strategieparametern in eine Gruppe aufgenommen werden können. Dies führt zu einer Verringerung der Gruppenvielfalt, die wir anstreben, um den Drawdown zu reduzieren. Versuchen wir, die Optimierungsläufe, bei denen solche „identischen“ Sets in einer Gruppe landen, zu vermeiden.
Zusammensetzung mit Clustering
Um solche Gruppen loszuwerden, werden wir alle Sätze von Strategieparametern aus der ursprünglichen CSV-Datei in mehrere Cluster unterteilen. Jeder Cluster enthält Parametersätze, die entweder völlig identische oder ähnliche Ergebnisse liefern. Für das Clustering wird der vorgefertigter Algorithmus k-means Clustering verwendet. Wir werden die folgenden Spalten als Eingabedaten für das Clustering verwenden: signalPeriod_, signalDeviation_, signaAddlDeviation_, openDistance_, stopLevel_ und takeLevel_. Versuchen wir, alle unsere Parametersätze mit folgendem Python-Code in 64 Cluster aufzuteilen:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df.to_csv('Params_SV_EURGBP_H1-with_cluster.csv', index=False)
Jetzt hat unsere Parametersatzdatei eine weitere Spalte mit der Clusternummer. Um diese Datei zu verwenden, erstellen wir einen neuen EA auf der Grundlage von OptGroupExpert.mq5 und nehmen einige kleine Ergänzungen vor.
Fügen wir einen weiteren Satz hinzu und füllen ihn mit den Nummern der Cluster, die die bei der Initialisierung ausgewählten Parametersätze enthalten. Wir werden einen solchen Lauf nur dann starten, wenn sich die Anzahl aller Cluster in dieser Gruppe von Parametersätzen unterscheidet. Da die aus der Datei gelesenen Zeichenketten nun eine Clusternummer am Ende enthalten, die nicht mit den Strategieparametern zusammenhängt, müssen wir sie aus der Parameterzeichenkette entfernen, bevor wir sie an den Strategiekonstruktor übergeben.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { ... // Multiplicities for parameter and cluster set indices CHashSet<string> setIndexes; CHashSet<string> setClusters; // Add all indices and clusters to the multiplicities FOREACH(indexes, { setIndexes.Add(indexes[i]); string cluster = CSVStringGet(params[StringToInteger(indexes[i])], 11, 12); setClusters.Add(cluster); }); // Report an error if if(count_ < 1 || count_ > 8 // number of instances not in the range 1 .. 8 || setIndexes.Count() != count_ // not all indexes are unique || setClusters.Count() != count_ // not all clusters are unique ) { return INIT_PARAMETERS_INCORRECT; } ... FOREACH(indexes, { // Remove the cluster number from the parameter set string string param = CSVStringGet(params[StringToInteger(indexes[i])], 0, 11); // Add a strategy with a set of parameters with a given index APPEND(strategies, new CSimpleVolumesStrategy(param)) }); // Form and add a group of strategies to the EA expert.Add(CVirtualStrategyGroup(strategies, scale_)); return(INIT_SUCCEEDED); }
Speichern wir diesen Code in der Datei OptGroupClusterExpert.mq5 im aktuellen Ordner.
Diese Art der Optimierung hat aber auch ihre Schwächen gezeigt. Wenn zu viele Individuen mit mindestens zwei identischen Parametersatzindizes in der Anfangspopulation eines genetischen Algorithmus landen, führt dies zu einer schnellen Degeneration der Population und zu einem vorzeitigen Abbruch des Optimierungsalgorithmus. Aber bei einem weiteren Start haben wir vielleicht mehr Glück, und dann erreicht die Optimierung das Ende und findet recht gute Ergebnisse.
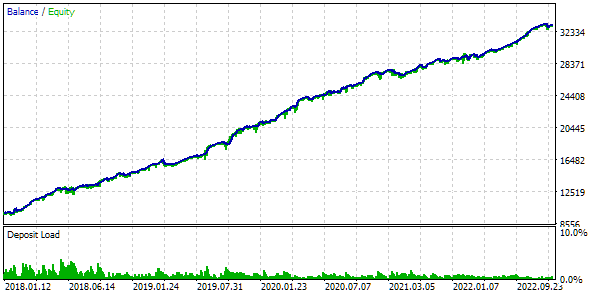
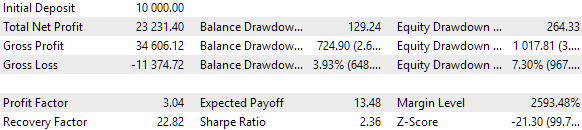
Abb. 8. Testergebnisse der besten Gruppe mit Clustering
Die Wahrscheinlichkeit, eine Degeneration der Population zu verhindern, kann entweder durch eine Mischung der Inputs oder durch eine Verringerung der Anzahl der in der Gruppe enthaltenen Strategien erhöht werden. In jedem Fall verringert sich der Zeitaufwand für die Optimierung um das Anderthalb- bis Zweifache im Vergleich zur Optimierung ohne Clustering.
Eine Instanz des Clusters
Es gibt noch eine andere Möglichkeit, die Degeneration der Population zu verhindern: Lassen wir nur einen Satz, der zu einem bestimmten Cluster gehört, in der Datei. Wir können die Datei mit solchen Daten mit dem folgenden Python-Code erzeugen:
import pandas as pd
from sklearn.cluster import KMeans
df = pd.read_csv('Params_SV_EURGBP_H1.csv')
kmeans = KMeans(n_clusters=64, n_init='auto',
random_state=42).fit(df.iloc[:, [12,13,14,15,17]])
df['cluster'] = kmeans.labels_
df = df.sort_values(['cluster', 'Sharpe Ratio']).groupby('cluster').agg('last').reset_index()
clusters = df.cluster
df = df.iloc[:, 1:]
df['cluster'] = clusters
df.to_csv('Params_SV_EURGBP_H1-one_cluster.csv', index=False
Für diese CSV-Datei mit Daten können wir einen der beiden in diesem Artikel beschriebenen EAs zur Optimierung verwenden.
Wenn sich herausstellt, dass wir zu wenige Sets übrig haben, können wir entweder die Anzahl der Cluster erhöhen oder mehrere Sets aus einem Cluster nehmen.
Werfen wir einen Blick auf die Optimierungsergebnisse dieses EA:
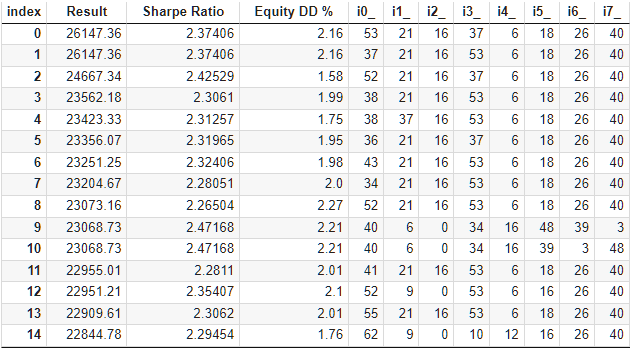
Abb. 9. Ergebnisse der Optimierung der automatischen Auswahl in einer Gruppe von 64 Clustern
Sie sind in etwa dieselben wie bei den beiden vorherigen Ansätzen. Es wurde eine Gruppe gefunden, die alle zuvor gefundenen Gruppen übertraf. Dies ist allerdings mehr eine Frage des Glücks als der Überlegenheit der festgelegten Grenze. Hier sind die Ergebnisse des einzigen Durchgangs der besten Gruppe:
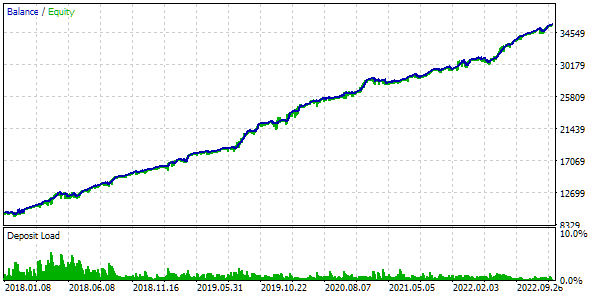
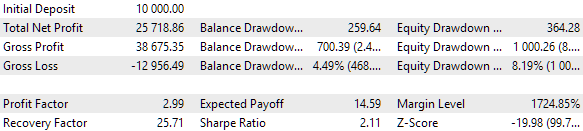
Abb. 10. Testergebnisse der besten Gruppe mit einem Satz im Cluster
In der Ergebnistabelle ist eine Wiederholung der Gruppen zu erkennen, die sich nur durch die Reihenfolge der Indizes der Strategieparametersätze unterscheiden.
Dies kann vermieden werden, indem man den EAs eine Bedingung hinzufügt, die besagt, dass die Kombination der Indizes in den Eingabeparametern eine aufsteigende Folge bilden muss. Dies führt aber wiederum zu Problemen bei der Anwendung der genetischen Optimierung, da die Population sehr schnell degeneriert. Für eine vollständige Aufzählung ergibt selbst die Auswahl einer Gruppe von 8 Sätzen aus 64 Sätzen zu viele Durchgänge. Es ist notwendig, die Methode zur Umwandlung der iterierten Eingaben des EA in Indizes der Strategieparametersätze irgendwie zu ändern. Aber das sind bereits Pläne für die Zukunft.
Es ist erwähnenswert, dass Ergebnisse, die mit denen der manuellen Auswahl vergleichbar sind (Gewinn ~ 15.000 USD), bei Verwendung eines Sets aus dem Cluster buchstäblich in den ersten Minuten der Optimierung gefunden werden. Um jedoch die besten Ergebnisse zu erzielen, müssen wir fast bis zum Ende der Optimierung warten.
Schlussfolgerung
Schauen wir mal, was wir haben. Wir haben bestätigt, dass die automatische Auswahl von Parametersätzen in einer Gruppe zu besseren Rentabilitätsergebnissen führen kann als die manuelle Auswahl. Der Prozess selbst wird mehr Zeit in Anspruch nehmen, aber dieses Mal ist keine menschliche Beteiligung erforderlich, was sehr gut ist. Darüber hinaus können wir sie bei Bedarf erheblich reduzieren, indem wir sie durch den Einsatz von mehr Prüfmitteln ersetzen.
Jetzt können wir weitermachen. Wenn wir die Möglichkeit haben, Gruppen von Strategieinstanzen auszuwählen, dann können wir darüber nachdenken, die Erstellung von Gruppen aus den erhaltenen guten Gruppen zu automatisieren. In Bezug auf den EA-Code besteht der Unterschied nur darin, wie man die Parameter richtig liest und dem EA nicht nur eine, sondern mehrere Gruppen von Strategien hinzufügt. Hier können wir über ein einheitliches Format für die Speicherung von Sätzen optimierter Parameter für Strategien und Gruppen in einer Datenbank nachdenken, anstatt in separaten Dateien.
Es wäre auch schön, das Verhalten unserer guten Gruppen während des Testzeitraums zu betrachten, der außerhalb des Zeitraums liegt, in dem die Parameteroptimierung durchgeführt wurde. Das werde ich wahrscheinlich im nächsten Artikel versuchen.
Vielen Dank für Ihre Aufmerksamkeit! Bis bald!
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14478
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.