
Neuronale Netze leicht gemacht (Teil 49): Soft Actor-Critic

Einführung
Wir setzen unsere Bekanntschaft mit Algorithmen zum Lösen von Problemen durch Verstärkungslernen in einem kontinuierlichen Aktionsraum fort. In den vorangegangenen Artikeln haben wir die Algorithmen Deep Deterministic Policy Gradient (DDPG) und Twin Delayed Deep Deterministic Policy Gradient (TD3) besprochen. In diesem Artikel werden wir uns auf einen anderen Algorithmus konzentrieren - Soft Actor-Critic (SAC). Sie wurde erstmals in dem Artikel „Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor“ (Januar 2018) vorgestellt. Die Methode wurde fast gleichzeitig mit TD3 vorgestellt. Es gibt einige Ähnlichkeiten, aber auch Unterschiede in den Algorithmen. Das Hauptziel von SAC ist die Maximierung der erwarteten Belohnung bei maximaler Entropie der Strategie, wodurch eine Vielzahl optimaler Lösungen in stochastischen Umgebungen gefunden werden kann.
1. Der Algorithmus Soft Actor-Critic
Bei der Betrachtung des SAC-Algorithmus sollten wir vielleicht gleich anmerken, dass er kein direkter Abkömmling der TD3-Methode ist (und umgekehrt). Aber sie haben einige Ähnlichkeiten. Insbesondere:
- beide sind Off-Policy-Algorithmen
- beide nutzen die DDPG-Methoden
- sie verwenden beide 2 Critics.
Im Gegensatz zu den beiden zuvor erörterten Methoden verwendet die SAC jedoch eine stochastische Politik für den Actor (Akteur). Dies ermöglicht es dem Algorithmus, verschiedene Strategien zu erkunden und optimale Lösungen zu finden, wobei die größtmögliche Vielfalt an Aktionen der Actors berücksichtigt wird.
Wenn wir über die Stochastizität der Umwelt sprechen, verstehen wir, dass wir im Zustand S, wenn wir die Aktion A ausführen, die Belohnung R innerhalb [Rmin, Rmax] mit der Wahrscheinlichkeit Psa erhalten.
Soft Actor-Critic verwendet einen Akteur mit einer stochastischen Politik. Das bedeutet, dass der Akteur im Zustand S die Aktion A' aus dem gesamten Aktionsraum mit einer bestimmten Wahrscheinlichkeit Pa' wählen kann. Mit anderen Worten, die Politik des Akteurs in jedem spezifischen Zustand erlaubt es uns, nicht eine bestimmte optimale Handlung zu wählen, sondern eine beliebige der möglichen Handlungen (jedoch mit einem bestimmten Grad an Wahrscheinlichkeit). Während des Trainings lernt der Akteur diese Wahrscheinlichkeitsverteilung für das Erreichen der maximalen Belohnung.
Diese Eigenschaft einer stochastischen Akteurspolitik ermöglicht es uns, verschiedene Strategien zu erforschen und optimale Lösungen zu entdecken, die bei Verwendung einer deterministischen Politik möglicherweise verborgen bleiben. Darüber hinaus berücksichtigt die stochastische Politik des Akteurs die Unsicherheit in der Umwelt. Im Falle von Rauschen oder zufälligen Faktoren können solche Strategien widerstandsfähiger und anpassungsfähiger sein, da sie eine Vielzahl von Maßnahmen entwickeln können, um effektiv mit der Umwelt zu interagieren.
Das Training der stochastischen Politik des Akteurs führt jedoch auch zu Anpassungen im Training. Klassisches Reinforcement Learning zielt darauf ab, den erwarteten Ertrag zu maximieren. Während des Trainings wählen wir für jede Aktion S die Aktion A*, die uns am ehesten eine höhere Rentabilität beschert. Dieser deterministische Ansatz stellt eine klare Beziehung her: St → At → St+1 ⇒ R und lässt keinen Raum für stochastische Aktionen. Um eine stochastische Politik zu trainieren, führen die Autoren des Soft Actor-Critic-Algorithmus eine Entropie-Regularisierung in die Belohnungsfunktion ein.
![]()
Die Entropie(H) ist in diesem Zusammenhang ein Maß für die politische Unsicherheit oder Vielfalt. Der Parameter ɑ>0 ist ein Temperaturkoeffizient, der es uns ermöglicht, ein Gleichgewicht zwischen der Untersuchung der Umwelt und dem Betrieb des Modells herzustellen.
Wie Sie wissen, ist die Entropie ein Maß für die Unsicherheit einer Zufallsvariablen und wird durch die folgende Gleichung bestimmt
![]()
Man beachte, dass es sich um den Logarithmus der Wahrscheinlichkeit der Wahl einer Aktion über den Intervall [0, 1] handelt. In diesem Intervall akzeptabler Werte ist der Graph der Entropiefunktion abnehmend und liegt im Bereich positiver Werte. Je geringer die Wahrscheinlichkeit der Wahl einer Handlung ist, desto höher ist die Belohnung, und das Modell wird ermutigt, die Umgebung zu erkunden.
Wie Sie sehen, werden in diesem Zusammenhang recht hohe Anforderungen an die Wahl des Hyperparameters ɑ gestellt. Derzeit gibt es verschiedene Möglichkeiten, den SAC-Algorithmus zu implementieren. Der herkömmliche Ansatz mit festen Parametern gehört zu uns. Häufig finden wir Implementierungen mit einer allmählichen Abnahme des Parameters. Es ist leicht zu erkennen, dass wir bei ɑ=0 zu deterministischem Reinforcement Learning kommen. Darüber hinaus gibt es verschiedene Ansätze, den ɑ-Parameter während des Trainings durch das Modell selbst zu optimieren.
Machen wir weiter mit der Ausbildung des Kritikers. Ähnlich wie TD3 trainiert SAC 2 Critic-Modelle parallel und verwendet MSE als Verlustfunktion. Für den vorhergesagten Wert des zukünftigen Zustands wird der kleinere Wert aus den beiden Zielmodellen von Ctritic verwendet. Hier gibt es jedoch 2 wesentliche Unterschiede.
Die erste ist die oben beschriebene Belohnungsfunktion. Wir verwenden die Entropie-Regularisierung sowohl für den aktuellen als auch für die nachfolgenden Zustände unter Berücksichtigung des Diskontierungsfaktors, der auf die Kosten des nächsten Zustands des Systems angewendet wird.
Der zweite Unterschied ist der Akteur. SAC verwendet kein Ziel-Akteur-Modell. Für die Auswahl einer Aktion im aktuellen und den nachfolgenden Zuständen wird ein trainiertes Akteursmodell verwendet. Daher betonen wir, dass das Erreichen zukünftiger Belohnungen durch aktuelle Maßnahmen erreicht wird. Darüber hinaus werden durch die Verwendung eines einzigen Akteursmodells die Kosten für Speicher- und Rechenressourcen gesenkt.
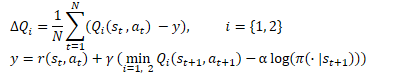
Um die Akteurspolitik zu trainieren, verwenden wir DDPG-Ansätze. Wir erhalten den Fehlergradienten der Handlung, indem wir den Fehlergradienten der vorhergesagten Handlungskosten durch das Critic-Modell zurückverfolgen. Aber im Gegensatz zu TD3 (wo wir nur das Modell Critic 1 verwendet haben), schlagen die Autoren von SAC vor, ein Modell mit niedrigeren geschätzten Handlungskosten zu verwenden.
Es gibt hier noch eine weitere Sache. Während des Trainings ändern wir die Strategie, was zu einer Änderung der Aktionen des Akteurs in einem bestimmten Zustand des Systems führt. Darüber hinaus trägt die Verwendung einer stochastischen Akteurspolitik ebenfalls zur Vielfalt der Akteurshandlungen bei. Gleichzeitig trainieren wir Modelle auf Daten aus dem Erfahrungswiederholungspuffer mit Belohnungen für andere Agentenaktionen. In diesem Fall lassen wir uns von der theoretischen Annahme leiten, dass wir uns beim Training des Akteurs in Richtung der Maximierung der vorhergesagten Belohnung bewegen. Das bedeutet, dass in jedem S-Zustand die Handlungskosten mit der Politik πnew nicht geringer sind als die Handlungskosten der Politik πold.
![]()
Das ist eine ziemlich subjektive Annahme, aber sie entspricht voll und ganz unserem Paradigma der Modellbildung. Um mögliche Fehler nicht zu akkumulieren, kann ich empfehlen, den Erfahrungswiedergabepuffer während des Trainings unter Berücksichtigung von Aktualisierungen der Akteurspolitik häufiger zu aktualisieren.
Die Aktualisierung der Zielmodelle wird ähnlich wie bei TD3 mit dem Faktor τ geglättet.
Es gibt noch einen weiteren Unterschied zur TD3-Methode. Der Algorithmus Soft Actor-Critic verwendet keine Verzögerung beim Training und der Aktualisierung von Zielmodellen durch die Akteure. Hier werden alle Modelle bei jedem Trainingsschritt aktualisiert.
Lassen Sie uns den Soft Actor-Critic-Algorithmus zusammenfassen:
- In die Belohnungsfunktion wird eine Entropie-Regularisierung eingeführt.
- Zu Beginn des Trainings werden die Modelle Actor und 2 Critic mit zufälligen Parametern initialisiert.
- Durch die Interaktion mit der Umwelt wird der Erfahrungswiedergabepuffer aufgefüllt. Wir behalten den Zustand der Umgebung, die Aktion, den nachfolgenden Zustand und die Belohnung bei.
- Nach dem Auffüllen des Erfahrungswiedergabepuffers trainieren wir das Modell
- Wir extrahieren nach dem Zufallsprinzip eine Reihe von Daten aus dem Erfahrungswiedergabepuffer.
- Wir bestimmen die Aktion für den zukünftigen Zustand unter Berücksichtigung der aktuellen Politik des Akteurs.
- Wir bestimmen den voraussichtlichen Wert des zukünftigen Zustands unter Verwendung der aktuellen Politik von mindestens 2 Ziel-Kritik-Modellen.
- Die Modelle von Critic werden aktualisiert.
- Das Model der Politik von Actor wird aktualisiert.
- Die Zielmodelle werden aktualisiert.
Der Prozess des Modelltrainings ist iterativ und wird so lange wiederholt, bis das gewünschte Ergebnis erzielt oder der minimale Extremwert im Graphen der Verlustfunktion der Kritiker erreicht ist.
2. Implementierung mit MQL5
Nach einer theoretischen Einführung in den Soft Actor-Critic-Algorithmus gehen wir zu seiner Implementierung mit MQL5 über. Zunächst geht es darum, die Wahrscheinlichkeit einer bestimmten Handlung zu bestimmen. Eigentlich ist dies eine recht einfache Frage für eine tabellarische Umsetzung der Politik des Akteurs. Bei der Verwendung neuronaler Netze bereitet dies jedoch Schwierigkeiten. Schließlich führen wir keine Statistiken über Umweltbedingungen und durchgeführte Maßnahmen. Sie ist in den anpassbaren Parametern unseres Modells „fest verdrahtet“. In diesem Zusammenhang erinnerte ich mich an das verteilte Q-Training. Wie Sie sich vielleicht erinnern, haben wir über die Untersuchung der Wahrscheinlichkeitsverteilung der erwarteten Belohnung gesprochen. Mit Hilfe des distributiven Q-Learnings konnten wir eine Wahrscheinlichkeitsverteilung für eine bestimmte Anzahl von Belohnungswerten in festen Intervallen ermitteln. Das vollständig parametrisierte Q-Funktionsmodell (FQF) ermöglicht es uns, sowohl Intervallwerte als auch deren Wahrscheinlichkeiten zu untersuchen.
2.1 Erstellen einer neuen Klasse einer neuronalen Schicht
Indem wir von der Klasse CNeuronFQF ableiten, werden wir eine neue neuronale Schichtklasse erstellen, um den vorgeschlagenen Algorithmus CNeuronSoftActorCritic zu implementieren. Der Methodensatz der neuen Klasse ist ziemlich standardisiert, hat aber auch seine Eigenheiten.
In unserer Implementierung haben wir uns insbesondere für die Verwendung von nutzerdefinierten Entropie-Regulierungsparametern entschieden. Zu diesem Zweck wurde die neuronale Schicht cAlphas hinzugefügt. Diese Implementierung verwendet die Schicht des Typs CNeuronConcatenate. Um über die Größe der Verhältnisse zu entscheiden, werden wir die Einbettung des aktuellen Zustands und die Quantilverteilung am Ausgang verwenden.
Außerdem haben wir einen separaten Puffer zur Aufzeichnung von Entropiewerten hinzugefügt, die wir später in der Belohnungsfunktion verwenden werden.
Beide hinzugefügten Objekte werden als statisch deklariert, was es uns ermöglicht, den Konstruktor und den Destruktor der Klasse leer zu lassen.
class CNeuronSoftActorCritic : public CNeuronFQF { protected: CNeuronConcatenate cAlphas; CBufferFloat cLogProbs; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSoftActorCritic(void) {}; ~CNeuronSoftActorCritic(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint actions, uint quantiles, uint numInputs, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcAlphaGradients(CNeuronBaseOCL *NeuronOCL); virtual bool GetAlphaLogProbs(vector<float> &log_probs) { return (cLogProbs.GetData(log_probs) > 0); } virtual bool CalcLogProbs(CBufferFloat *buffer); //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronSoftActorCritic; } virtual void SetOpenCL(COpenCLMy *obj); };
Zunächst werden wir uns die Initialisierungsmethode der Klasse Init ansehen. Die Methodenparameter wiederholen vollständig die Parameter einer ähnlichen Methode der Elternklasse. Wir rufen die Methode der übergeordneten Klasse sofort im Methodenrumpf auf. Wir verwenden diese Technik recht häufig, da alle erforderlichen Steuerelemente in der übergeordneten Klasse implementiert sind. Die Initialisierung aller abgeleiteten Objekte wird ebenfalls durchgeführt. Eine Überprüfung der Ergebnisse der übergeordneten Klassenmethode ersetzt die vollständige Kontrolle über die genannten Operationen. Alles, was wir tun müssen, ist die hinzugefügten Objekte zu initialisieren.
Zunächst wird die Schicht zur Berechnung des Verhältnisses initialisiert. Wie bereits erwähnt, werden wir eine Einbettung des aktuellen Zustands an den Eingang dieses Modells senden, deren Größe der Größe der vorherigen neuronalen Schicht entspricht. Außerdem fügen wir der Ausgabe der aktuellen Schicht eine Quantilverteilung hinzu, die in der internen Schicht cQuantile2 enthalten ist (deklariert und initialisiert in der übergeordneten Klasse). Am Ausgang der cAlphas-Schicht erhalten wir Temperaturkoeffizienten für jede einzelne Aktion. Dementsprechend ist die Größe der Ebene gleich der Anzahl der Aktionen.
Die Koeffizienten sollten nicht-negativ sein. Um diese Anforderung zu erfüllen, haben wir Sigmoid als Aktivierungsfunktion für diese Schicht definiert.
Am Ende der Methode wird der Entropiepuffer mit Nullwerten initialisiert. Seine Größe entspricht ebenfalls der Anzahl der Aktionen. Erzeugt den Puffer sofort im aktuellen OpenCL-Kontext.
bool CNeuronSoftActorCritic::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint actions, uint quantiles, uint numInputs, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFQF::Init(numOutputs, myIndex, open_cl, actions, quantiles, numInputs, optimization_type, batch)) return false; //--- if(!cAlphas.Init(0, 0, OpenCL, actions, numInputs, cQuantile2.Neurons(), optimization_type, batch)) return false; cAlphas.SetActivationFunction(SIGMOID); //--- if(!cLogProbs.BufferInit(actions, 0) || !cLogProbs.BufferCreate(OpenCL)) return false; //--- return true; }
Als Nächstes gehen wir zur Umsetzung des Vorwärtsdurchgangs über. Hier leihen wir uns den Prozess des Trainings von Quantilen und Wahrscheinlichkeitsverteilungen aus der Elternklasse ohne Änderungen. Aber wir müssen auch den Prozess der Bestimmung der Temperaturkoeffizienten und der Berechnung der Entropiewerte organisieren. Während für die Berechnung der Temperatur ein direkter Durchgang durch die cAlphas-Schicht erforderlich ist, sollte die Bestimmung der Entropiewerte von „0“ aus erfolgen.
Wir müssen die Entropie für jede Aktion des Akteurs berechnen. Zum jetzigen Zeitpunkt gehen wir davon aus, dass sich hier nicht viel tun wird. Da sich alle Quelldaten im OpenCL-Kontextspeicher befinden, ist es logisch, unsere Operationen in diese Umgebung zu übertragen. Zunächst erstellen wir den OpenCL-Kernel des Programms SAC_AlphaLogProbs, um diese Funktionalität zu implementieren.
In den Kernel-Parametern werden wir 5 Datenpuffer und 2 Konstanten übergeben:
- outputs — Ergebnispuffer enthält wahrscheinlichkeitsgewichtete Summen von Quantilwerten für jede Aktion
- quantiles — durchschnittliche Quantilwerte (cQuantile2 Ergebnispuffer der inneren Schicht)
- probs — Wahrscheinlichkeitstensor (cSoftMax-Ergebnispuffer der inneren Schicht)
- alphas — Vektor der Temperaturkoeffizienten
- log_probs — Vektor der Entropiewerte (in diesem Fall der Puffer für die Aufzeichnung der Ergebnisse)
- count_quants — Anzahl der Quantile für jede Aktion
- activation — Typ der Aktivierungsfunktion.
Die Klasse CNeuronFQF verwendet die Aktivierungsfunktion am Ausgang nicht. Ich würde sogar sagen, dass dies dem eigentlichen Sinn des Kurses widerspricht. Schließlich wird die Verteilung der Durchschnittswerte der Quantile der erwarteten Belohnung durch die tatsächliche Belohnung selbst während des Modelltrainings begrenzt. In unserem Fall erwarten wir einen bestimmten Wert für die Aktion des Akteurs aus einer kontinuierlichen Verteilung am Ausgang der Schicht. Aufgrund verschiedener technischer oder sonstiger Umstände kann der Umfang der zulässigen Handlungen eines Vertreters eingeschränkt sein. Die Aktivierungsfunktion ermöglicht uns dies. Es ist jedoch sehr wichtig für uns, eine echte Wahrscheinlichkeitsschätzung zu erhalten, dass die Aktivierungsfunktion nach der Bestimmung der Wahrscheinlichkeit der tatsächlichen Aktion angewendet wird. Daher haben wir seine Implementierung in diesen Kernel aufgenommen.
__kernel void SAC_AlphaLogProbs(__global float *outputs, __global float *quantiles, __global float *probs, __global float *alphas, __global float *log_probs, const int count_quants, const int activation ) { const int i = get_global_id(0); int shift = i * count_quants; float quant1 = -1e37f; float quant2 = 1e37f; float prob1 = 0; float prob2 = 0; float value = outputs[i];
Wir ermitteln den aktuellen Ablauf der Operationen im Kernelkörper. Sie zeigt uns die Seriennummer der analysierten Aktion an. Anschließend wird die Verschiebung in den Quantil- und Wahrscheinlichkeitspuffern bestimmt.
Als Nächstes werden wir die lokalen Variablen deklarieren. Um die Wahrscheinlichkeit einer bestimmten Aktion zu bestimmen, müssen wir die 2 am nächsten liegenden Quantile finden. In die Variable quant1 wird der Durchschnittswert des untersten Quantils eingetragen. Die Variable quant2 enthält den Durchschnittswert des Quantils, das dem obersten Wert am nächsten liegt. In der Anfangsphase initialisieren wir die angegebenen Variablen mit offensichtlichen Extremwerten. Wir speichern die entsprechenden Wahrscheinlichkeiten in den Variablen prob1 und prob2, die wir mit Nullwerten initialisieren. Nach unserem Verständnis ist die Wahrscheinlichkeit, solche Extremwerte zu erhalten, gleich „0“.
Wir werden den gewünschten Wert aus dem Puffer in die lokale Variable value speichern.
Aufgrund der spezifischen Speicherorganisation des OpenCL-Kontexts ist der Zugriff auf lokale Variablen um ein Vielfaches schneller als der Abruf von Daten aus dem globalen Speicherpuffer. Indem wir mit lokalen Variablen arbeiten, steigern wir die Leistung des gesamten OpenCL-Programms.
Da wir nun den gewünschten Wert in einer lokalen Variablen gespeichert haben, können wir die Aktivierungsfunktion mühelos auf den Puffer der Operationsergebnisse der neuronalen Schicht anwenden.
switch(activation) { case 0: outputs[i] = tanh(value); break; case 1: outputs[i] = 1 / (1 + exp(-value)); break; case 2: if(value < 0) outputs[i] = value * 0.01f; break; default: break; }
Als Nächstes wird der Zyklus der Suche durch alle durchschnittlichen Quantilwerte und die Suche nach den am nächsten liegenden Werten durchgeführt.
Dabei ist zu beachten, dass wir die durchschnittlichen Quantilwerte nicht sortiert haben. Die Ermittlung des gewogenen Durchschnitts ist davon nicht betroffen, und wir haben es bisher vermieden, unnötige Operationen durchzuführen. Daher befinden sich die Quantile, die dem gewünschten Wert am nächsten liegen, mit hoher Wahrscheinlichkeit nicht in benachbarten Elementen des Quantilpuffers. Deshalb wird über alle Werte iteriert.
Um nicht die Werte desselben Quantils in beide Variablen zu schreiben, verwenden wir den logischen Operator „>=“ für die untere Grenze und streng „<“ für die obere Grenze. Wenn ein Quantil näher an dem zuvor gespeicherten liegt, schreiben wir den Wert in den zuvor deklarierten entsprechenden Variablen in den Quantil-Mittelwert und seine Wahrscheinlichkeit um.
for(int q = 0; q < count_quants; q++) { float quant = quantiles[shift + q]; if(value >= quant && quant1 < quant) { quant1 = quant; prob1 = probs[shift + q]; } if(value < quant && quant2 > quant) { quant2 = quant; prob2 = probs[shift + q]; } }
Nach Abschluss aller Iterationen der Schleife enthalten unsere lokalen Variablen die Daten der nächstgelegenen Quantile. Der erforderliche Wert liegt irgendwo in diesem Bereich. Unser Wissen über die Wahrscheinlichkeitsverteilung von Handlungen ist jedoch nur durch die untersuchte Verteilung begrenzt. In diesem Fall gehen wir von einer linearen Abhängigkeit der Wahrscheinlichkeit zwischen den 2 nächstgelegenen Quantilen aus. Bei einer ausreichend großen Anzahl von Quantilen und unter Berücksichtigung des begrenzten Verteilungsbereichs der Werte des tatsächlichen Aktionsbereichs ist unsere Annahme nicht weit von der Wahrheit entfernt.
float prob = fabs(value - quant1) / fabs(quant2 - quant1); prob = clamp((1-prob) * prob1 + prob * prob2, 1.0e-3f, 1.0f); log_probs[i] = -alphas[i] * log(prob); }
Nach der Ermittlung der Aktionswahrscheinlichkeit bestimmen wir die Entropie der Aktion und multiplizieren den resultierenden Wert mit dem Temperaturkoeffizienten. Um zu hohe Entropiewerte zu vermeiden, habe ich die untere Grenze der Wahrscheinlichkeit auf 0,001 begrenzt.
Gehen wir nun zum Hauptprogramm über. Hier erstellen wir eine Vorwärtsdurchgangsmethode für unsere Klasse CNeuronSoftActorCritic::feedForward.
Wie Sie sich erinnern, nutzen wir hier die Möglichkeiten virtueller Methoden in abgeleiteten Objekten weitgehend aus. Daher wiederholen die Methodenparameter ähnliche Methoden aller zuvor besprochenen Klassen vollständig.
Im Methodenkörper rufen wir zunächst die Vorwärtsdurchgangsmethode der übergeordneten Klasse und eine ähnliche Schichtmethode zur Berechnung der Temperaturkoeffizienten auf. Hier müssen wir nur die Ergebnisse der Ausführung dieser Methoden überprüfen.
bool CNeuronSoftActorCritic::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronFQF::feedForward(NeuronOCL)) return false; if(!cAlphas.FeedForward(GetPointer(cQuantile0), cQuantile2.getOutput())) return false;
Als Nächstes müssen wir die Entropiekomponente der Belohnungsfunktion berechnen. Zu diesem Zweck arrangieren wir das oben beschriebene Verfahren zum Starten des Kernels. Wir werden es in einem eindimensionalen Aufgabenraum entsprechend der Anzahl der zu analysierenden Aktionen ausführen.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
Wie immer, bevor wir den Kernel in die Ausführungswarteschlange stellen, übergeben wir die Anfangsdaten an seine Parameter.
if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_alphas, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_probs, cSoftMax.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_quantiles, cQuantile2.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_count_quants, (int)(cSoftMax.Neurons() / global_work_size[0]))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Bitte beachten Sie, dass wir keine Puffer überprüfen. Denn alle verwendeten Puffer wurden bereits beim direkten Durchlauf der Methode der übergeordneten Klasse und der Schicht zur Berechnung der Temperaturverhältnisse überprüft. Lediglich der interne Puffer für die Aufzeichnung der Ergebnisse der Kernel-Operation blieb ungeprüft. Aber das ist ein internes Objekt. Seine Erstellung wurde in der Initialisierungsphase des Klassenobjekts gesteuert. Es gibt keinen Zugriff auf das Objekt von einem externen Programm aus. Die Wahrscheinlichkeit, dass hier ein Fehler auftritt, ist recht gering. Deshalb gehen wir ein solches Risiko ein, um unser Programm zu beschleunigen.
Am Ende der Methode stellen wir den Kernel in die Ausführungswarteschlange und überprüfen das Ergebnis der Operationen.
if(!OpenCL.Execute(def_k_SAC_AlphaLogProbs, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Ich möchte noch einmal darauf hinweisen, dass wir in diesem Fall das Ergebnis der Platzierung des Kernels in der Ausführungswarteschlange prüfen, nicht aber die Ergebnisse der Ausführung von Operationen innerhalb des Kernels. Um die Ergebnisse zu erhalten, müssen wir die cLogProbs-Pufferdaten in den Hauptspeicher laden. Diese Funktion ist in der Methode GetAlphaLogProbs implementiert. Der Methodencode passt in eine Zeichenkette und wird im Klassenstrukturbeschreibungsblock angegeben.
Fahren wir nun mit der Erstellung der Funktion des Rückwärtsdurchgangs fort. Der Hauptteil der Funktionalität ist bereits in der Methode der übergeordneten Klasse implementiert. So seltsam es auch klingen mag, wir werden nicht einmal die Methode zur Verteilung des Fehlergradienten durch die neuronale Schicht neu definieren. Tatsache ist, dass die Verteilung des Fehlergradienten für die Entropie-Regularisierung nicht vollständig in unsere allgemeine Struktur passt. Wir erhalten den Fehlergradienten durch eine Aktion aus der letzten Schicht des Modells von Critic (Kritiker). Wir haben die Entropie-Regularisierung selbst in die Belohnungsfunktion einbezogen. Dementsprechend wird der Fehler auch auf der Ebene der Belohnungsvorhersage liegen, d.h. auf der Ebene der Ergebnisschicht des Kritikers. Hier erhalten wir 2 Fragen:
- Durch die Einführung eines zusätzlichen Gradientenpuffers wird das Virtualisierungsmodell der Methoden für den Rückwärtsdurchgang gestört.
- In der Phase des Rückwärtsdurchgangs des Akteurs haben wir einfach keine Daten über den Fehler des Kritikers. Es ist notwendig, einen neuen Prozess für das gesamte Modell zu entwickeln.
Um die Dinge zu vereinfachen, habe ich einen neuen parallelen Prozess nur für den Gradienten des Entropie-Regularisierungsfehlers erstellt, ohne den Backpropagation-Prozess im Modell komplett zu überarbeiten.
Zunächst wird ein Kernel im OpenCL-Programm erstellt. Der Code ist ziemlich einfach. Wir multiplizieren einfach den resultierenden Fehlergradienten mit der Entropie. Dann passen wir den resultierenden Wert durch die Ableitung der Aktivierungsfunktion der Schicht zur Berechnung der Temperaturverhältnisse an.
__kernel void SAC_AlphaGradients(__global float *outputs, __global float *gradient, __global float *log_probs, __global float *alphas_grad, const int activation ) { const int i = get_global_id(0); float out = outputs[i]; //--- float grad = -gradient[i] * log_probs[i]; switch(activation) { case 0: out = clamp(out, -1.0f, 1.0f); grad = clamp(grad + out, -1.0f, 1.0f) - out; grad = grad * max(1 - pow(out, 2), 1.0e-4f); break; case 1: out = clamp(out, 0.0f, 1.0f); grad = clamp(grad + out, 0.0f, 1.0f) - out; grad = grad * max(out * (1 - out), 1.0e-4f); break; case 2: if(out < 0) grad = grad * 0.01f; break; default: break; } //--- alphas_grad[i] = grad; }
An dieser Stelle sei darauf hingewiesen, dass wir zur Vereinfachung der Berechnungen den Gradienten einfach mit dem Wert aus dem log_probs-Puffer multiplizieren. Wie Sie sich erinnern, haben wir beim Vorwärtsgang den Entropiewert unter Berücksichtigung des Temperaturverhältnisses festgelegt. Aus mathematischer Sicht müssen wir den Wert aus dem Puffer durch diesen Wert teilen. Für die Temperatur verwenden wir jedoch eine Sigmoidfunktion als Aktivierungsfunktion. Sein Wert liegt daher immer im Bereich [0,1]. Die Division durch eine positive Zahl, die kleiner als 1 ist, erhöht nur den Fehlergradienten. In diesem Fall tun wir dies bewusst nicht.
Nachdem wir die Arbeit am SAC_AlphaGradients-Kernel abgeschlossen haben, gehen wir zur Arbeit am Hauptprogramm über und erstellen die Methode CNeuronSoftActorCritic::calcAlphaGradients. In diesem Stadium werden wir den Kernel zunächst in die Ausführungswarteschlange stellen und anschließend die Methoden der internen Objekte aufrufen. Deshalb wird vor Beginn des Prozesses eine Kontrolleinheit eingerichtet.
bool CNeuronSoftActorCritic::calcAlphaGradients(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL || !NeuronOCL.getGradient() || !NeuronOCL.getGradientIndex()<0) return false;
Als Nächstes definieren wir den Aufgabenbereich des Kernels und übergeben die Eingabedaten an seine Parameter.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_outputs, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_alphas_grad, cAlphas.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_gradient, NeuronOCL.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaGradients, def_k_sac_alg_activation, (int)cAlphas.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Danach stellen wir den Kernel in die Ausführungswarteschlange und überwachen die Ausführung der Operationen.
if(!OpenCL.Execute(def_k_SAC_AlphaGradients, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Am Ende der Methode rufen wir die Methode für den Rückwärtsdurchgang unserer inneren Schicht zur Berechnung des Temperaturkoeffizienten auf.
return cAlphas.calcHiddenGradients(GetPointer(cQuantile0), cQuantile2.getOutput(), cQuantile2.getGradient()); }
Außerdem werden wir die Methode zur Aktualisierung der Parameter der neuronalen Schicht CNeuronSoftActorCritic::updateInputWeights überschreiben. Der Algorithmus der Methode ist recht einfach. Sie ruft nur ähnliche Methoden der übergeordneten Klasse und der internen Objekte auf. Den vollständigen Code dieser Methode finden Sie im Anhang. Dort finden Sie auch den vollständigen Code aller im Artikel verwendeten Methoden und Klassen, einschließlich der Methoden für die Arbeit mit Dateien unserer neuen Klasse, auf die ich jetzt nicht näher eingehen werde.
2.2 Änderungen an der Klasse CNet
Nach Fertigstellung der neuen Klasse deklarieren wir Konstanten für die Wartung der erstellten Kernel. Wir sollten auch neue Kernel zum Initialisierungsprozess des Kontextobjekts und des OpenCL-Programms hinzufügen. Ich habe diese Funktionalität bei der Erstellung jedes neuen Kernels mehr als 50 Mal in Betracht gezogen, sodass ich nicht weiter darauf eingehen werde.
Unsere Bibliotheksfunktionalität erlaubt es dem Nutzer nicht, direkt auf eine bestimmte neuronale Schicht zuzugreifen. Der gesamte Interaktionsprozess wird durch die Funktionalität des Modells als Ganzes auf der Ebene der CNet-Klassen aufgebaut. Um die Werte der Entropiekomponente zu erhalten, erstellen wir die Methode CNet::GetLogProbs.
In den Parametern erhält die Methode den Zeiger auf den Vektor zum Setzen von Werten.
Im Methodenkörper ordnen wir einen Block von Kontrollen mit einer schrittweisen Reduzierung der Objektebene an. Zunächst wird geprüft, ob ein dynamisches Array-Objekt aus neuronalen Schichten vorhanden ist. Dann gehen wir eine Ebene tiefer und überprüfen den Zeiger auf das Objekt der letzten neuronalen Schicht. Als Nächstes gehen wir noch tiefer und überprüfen den Typ der letzten neuronalen Schicht. Dies sollte unsere neue Schicht CNeuronSoftActorCritic sein.
bool CNet::GetLogProbs(vectorf &log_probs) { //--- if(!layers) return false; int total = layers.Total(); if(total <= 0 || !layers.At(total - 1)) return false; CLayer *layer = layers.At(total - 1); if(!layer.At(0) || layer.At(0).Type() != defNeuronSoftActorCritic) return false; //--- CNeuronSoftActorCritic *neuron = layer.At(0);
Erst wenn wir alle Kontrollebenen erfolgreich durchlaufen haben, wenden wir uns einer ähnlichen Methode unserer neuronalen Schicht zu.
return neuron.GetAlphaLogProbs(log_probs);
}
Bitte beachten Sie, dass wir uns in diesem Stadium nur auf die letzte Schicht des Modells beschränken können. Dies bedeutet, dass die Ebene nur als letzte Ebene eines Akteurs verwendet werden kann.
Außerdem liest die Methode nur Daten aus dem Puffer und startet nicht deren Berechnung. Daher ist es nur sinnvoll, ihn nach dem direkten Durchgang des Akteurs aufzurufen. Dies ist in der Tat keine Einschränkung. In der Tat wird die Entropie-Regularisierung nur verwendet, um eine Belohnung zu bilden, während Primärdaten gesammelt und Modelle trainiert werden. Bei diesen Prozessen steht der Vorwärtsgang des Akteurs mit der Erzeugung der Handlung bis zur Ausführung im Vordergrund.
Für den Bedarf des umgekehrten Durchgangs wird die Methode CNet::AlphasGradient erstellt. Wie bereits erwähnt, sprengt die Verteilung des Gradienten durch Entropie den Rahmen des von uns entwickelten Verfahrens. Dies spiegelt sich auch im Algorithmus der Methode wider. Wir haben die Methode so konstruiert, dass wir sie für den Kritiker nennen werden. In den Methodenparametern übergeben wir den Zeiger auf das Actor-Objekt.
Der Algorithmus der Steuereinheit dieser Methode ist entsprechend aufgebaut. Zunächst wird geprüft, ob der Zeiger auf das Actor-Objekt aktuell ist und ob es die neueste CNeuronSoftActorCritic-Schicht enthält.
bool CNet::AlphasGradient(CNet *PolicyNet) { if(!PolicyNet || !PolicyNet.layers) return false; int total = PolicyNet.layers.Total(); if(total <= 0) return false; CLayer *layer = PolicyNet.layers.At(total - 1); if(!layer || !layer.At(0)) return false; if(layer.At(0).Type() != defNeuronSoftActorCritic) return true; //--- CNeuronSoftActorCritic *neuron = layer.At(0);
Der zweite Teil des Kontrollblocks führt ähnliche Prüfungen für die letzte Schicht des Kritikers (Critic) durch. Hier gibt es keine Beschränkung für den Typ einer neuronalen Schicht.
if(!layers) return false; total = layers.Total(); if(total <= 0 || !layers.At(total - 1)) return false; layer = layers.At(total - 1);
Nachdem alle Kontrollen erfolgreich durchgeführt wurden, wenden wir uns der Methode zur Verteilung des Gradienten unserer neuen neuronalen Schicht zu.
return neuron.calcAlphaGradients((CNeuronBaseOCL*) layer.At(0)); }
Fairerweise muss man sagen, dass die Verwendung eines vollständig parametrisierten Modells es uns ermöglicht, die Wahrscheinlichkeiten der einzelnen Aktionen zu bestimmen. Allerdings ist es nicht möglich, eine wirklich stochastische Akteurspolitik zu entwickeln. Die Stochastik von Akteuren beinhaltet das Sampling von Aktionen aus einer gelernten Verteilung, was wir auf der OpenCL-Kontextseite nicht tun können. Im Variations-Autocodierer haben wir zur Lösung eines ähnlichen Problems einen Trick mit einer Neuparametrisierung und einem Vektor von Zufallswerten verwendet, der neben dem Hauptprogramm erzeugt wird. In diesem Fall müssen wir jedoch die Wahrscheinlichkeitsverteilung für die Stichprobe laden. Stattdessen werden wir in der Phase des Sammelns einer Datenbank von Beispielen Werte in einer gewissen Umgebung des berechneten Wertes stichprobenartig erfassen (in Analogie zu TD3) und dann das Modell nach der Entropie solcher Aktionen fragen. Für diese Zwecke erstellen wir die Methode CNet::CalcLogProbs. Ihr Algorithmus ähnelt dem Aufbau der Methode GetLogProbs, aber im Gegensatz zu dieser erhalten wir in den Parametern einen Zeiger auf den Datenpuffer mit den abgetasteten Werten. Als Ergebnis der Methodenoperationen in demselben Puffer erhalten wir ihre Wahrscheinlichkeiten.
Der gesamte Code aller Klassen und Methoden befindet sich in der Anlage.
2.3 Erstellen von EAs für das Modelltraining
Nachdem wir die Arbeit an der Erstellung neuer Objekte für unser Modell abgeschlossen haben, gehen wir dazu über, den Prozess seiner Erstellung und Ausbildung zu organisieren. Wie bisher werden 3 EAs verwendet:
- Research — Sammeln von Beispielen Datenbank
- Study — Modelltraining
- Test — Überprüfung der erzielten Ergebnisse.
Um die Länge des Artikels zu verkürzen und Ihre Zeit zu sparen, werde ich mich nur auf die Änderungen konzentrieren, die an den Versionen ähnlicher Berater aus dem vorherigen Artikel vorgenommen wurden, um den fraglichen Algorithmus zu gestalten.
Zunächst einmal die Modellarchitektur. Hier haben wir nur die letzte Akteursschicht geändert und sie durch die neue Klasse CNeuronSoftActorCritic ersetzt. Wir haben die Schichtgröße durch die Anzahl der Aktionen und 32 Quantile für jede Aktion festgelegt (wie von den Autoren der FQF-Methode empfohlen).
Als Aktivierungsfunktion haben wir Sigmoid verwendet, ähnlich wie bei den Experimenten im vorherigen Artikel.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- Actor ......... ......... //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftActorCritic; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- Critic ......... ......... //--- return true; }
Der „...\SoftActorCritic\Research.mq5“ EA-Algorithmus wurde fast unverändert aus dem vorherigen Artikel übernommen. Weder der Block für die Sammlung historischer Daten noch der Block für die Handelsoperationen wurden geändert. Änderungen wurden nur an der Funktion OnTick in Bezug auf die Umweltbelohnungen vorgenommen. Wie bereits erwähnt, fügt der Soft Actor-Critic-Algorithmus der Belohnungsfunktion eine Entropie-Regularisierung hinzu.
Wie bisher verwenden wir die relative Veränderung des Kontostandes als Ausgleich. Wir fügen auch eine Strafe für den Mangel an offenen Positionen hinzu. Als Nächstes müssen wir jedoch eine Entropie-Regularisierung hinzufügen. Dazu habe ich die oben erwähnte CalcLogProbs-Methode erstellt. Es gibt jedoch einen Vorbehalt. Die Quantilsverteilung unserer Klasse speichert die Werte bis zur Aktivierungsfunktion. Im Entscheidungsprozess verwenden wir die aktivierten Ergebnisse des Akteursmodells. Wir verwenden Sigmoid als Aktivierungsfunktion am Ausgang des Actors.
![]()
Durch mathematische Umformungen gelangen wir zu
![]()
Nutzen wir diese Eigenschaft und passen wir die Stichprobenaktionen an die gewünschte Form an. Dann werden wir die Daten aus dem Vektor in den Datenpuffer übertragen und, wenn möglich, die Informationen in den OpenCL-Kontextspeicher übertragen.
Nach Abschluss dieser vorbereitenden Arbeiten fragen wir den Akteur nach der Entropie der durchgeführten Aktionen.
Man beachte, dass wir die Entropie von 6 Aktionen unter Berücksichtigung des Temperaturverhältnisses erhalten haben. Aber unsere Belohnung ist eine Zahl, die die Gesamtheit des aktuellen Zustands und der Aktion bewertet. In dieser Implementierung haben wir den Wert der Gesamtentropie verwendet, der gut in den Kontext von Wahrscheinlichkeiten und Logarithmen passt, da die Wahrscheinlichkeit eines komplexen Ereignisses gleich dem Produkt der Wahrscheinlichkeiten seiner Komponenten ist. Und der Logarithmus des Produkts ist gleich der Summe der Logarithmen der einzelnen Faktoren. Es kann jedoch auch andere Ansätze geben. Ihre Angemessenheit für jeden einzelnen Fall kann während der Ausbildung überprüft werden. Scheuen Sie sich nicht, zu experimentieren.
void OnTick() { //--- ......... ......... //--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; temp.Clip(0.001f, 0.999f); temp = MathLog((temp - 1.0f) * (-1.0f) / temp) * (-1); Result.AssignArray(temp); if(Result.GetIndex() >= 0) Result.BufferWrite(); if(Actor.CalcLogProbs(Result)) { Result.GetData(temp); reward += temp.Sum(); } if(!Base.Add(sState, reward)) ExpertRemove(); }
Die wichtigsten Änderungen wurden am Modelltraining in der EA „...\SoftActorCritic\Study.mq5“ vorgenommen. Schauen wir uns die Train-Funktion des angegebenen EA genauer an. Hier wird der gesamte Prozess der Modellbildung organisiert.
Zu Beginn der Funktion wird wie zuvor ein Satz von Daten aus dem Erfahrungswiedergabepuffer abgerufen.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Als Nächstes bestimmen wir den voraussichtlichen Wert des zukünftigen Zustands. Der Algorithmus wiederholt einen ähnlichen Prozess bei der Umsetzung der TD3-Methode. Der einzige Unterschied besteht darin, dass es kein Akteursmodell gibt. Hier verwenden wir ein trainierbares Akteursmodell, um die Aktion im zukünftigen Zustand zu bestimmen.
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
Wir füllen die Quelldatenpuffer aus und rufen die Methoden für die Vorwärtsdurchgänge des Akteurs und die 2 Zielmodelle des Kritikers auf.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Wie bei der TD3-Methode verwenden wir den kleinsten vorhergesagten Kostenwert des Zustands, um den Critic zu trainieren. Aber in diesem Fall fügen wir eine Entropiekomponente hinzu.
vector<float> log_prob; if(!Actor.GetLogProbs(log_prob)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) + log_prob.Sum() - Buffer[tr].Revards[i + 1]);
Dabei ist zu beachten, dass wir bei der Speicherung der Trajektorie den kumulierten Betrag der Belohnungen bis zum Ende des Durchgangs unter Berücksichtigung des Diskontierungsfaktors gespeichert haben. In diesem Fall beinhaltet die Belohnung für jeden einzelnen Übergang zu einem neuen Zustand eine Entropie-Regulierung. Zum Trainieren von Critic-Modellen passen wir die gespeicherte akkumulative Belohnung an, um die Verwendung der aktualisierten Richtlinie zu berücksichtigen. Dazu nehmen wir die Differenz zwischen den minimalen vorhergesagten Kosten des nachfolgenden Zustands unter Berücksichtigung der Entropiekomponente und der kumulierten Belohnungserfahrung dieses Zustands, die im Wiederholungspuffer gespeichert ist. Der sich daraus ergebende Wert wird um den Abzinsungsfaktor angepasst und zum gespeicherten Wert des aktuellen Zustands addiert. In diesem Fall gehen wir davon aus, dass die Kosten der Maßnahmen im Laufe der Optimierung der Modelle nicht sinken.
Als Nächstes stehen wir vor der Phase der Ausbildung von Ctric-Modellen. Zu diesem Zweck werden Datenpuffer mit dem aktuellen Zustand des Systems gefüllt.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Update(0, (Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Update(1, Buffer[tr].States[i].account[1] / PrevBalance); Account.Update(2, (Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Update(3, Buffer[tr].States[i].account[2]); Account.Update(4, Buffer[tr].States[i].account[3]); Account.Update(5, Buffer[tr].States[i].account[4] / PrevBalance); Account.Update(6, Buffer[tr].States[i].account[5] / PrevBalance); Account.Update(7, Buffer[tr].States[i].account[6] / PrevBalance); //--- Account.BufferWrite();
Bitte beachten Sie, dass wir in diesem Fall nicht mehr auf das Vorhandensein eines Puffers zur Beschreibung des Kontostands im OpenCL-Kontext prüfen. Unmittelbar nach dem Speichern der Daten rufen wir einfach die Methode zur Übertragung der Daten in den Kontext auf. Dies ist möglich, da alle unsere Modelle im gleichen OpenCL-Kontext arbeiten. Über die Vorteile dieses Ansatzes haben wir bereits früher gesprochen. Beim Aufruf von Vorwärtsdurchgangsmethoden auf Zielmodellen wurde im Kontext bereits ein Puffer angelegt. Andernfalls würden wir bei ihrer Ausführung einen Fehler erhalten. Daher verschwenden wir in diesem Stadium keine Zeit und Ressourcen mehr für unnötige Überprüfungen.
Nach dem Laden der Daten rufen wir die Vorwärtsdurchgangsmethode des Actors auf und laden die Entropiekomponente der Belohnung.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Actor.GetLogProbs(log_prob);
In diesem Stadium haben wir alle notwendigen Daten für die Vorwärts- und Rückwärtsdurchgänge der Kritiker. In diesem Stadium haben wir jedoch eine leichte Abweichung vom Algorithmus der Autoren vorgenommen. Die Autoren der Methode schlagen nämlich vor, nach der Aktualisierung der Parameter der Kritiker einen Kritiker mit einer Mindestpunktzahl zu verwenden, um die Politik des Akteurs zu aktualisieren. Unseren Beobachtungen zufolge ist der Gradient des Handlungsfehlers trotz der Abweichungen bei den Schätzungen praktisch unverändert. Deshalb habe ich beschlossen, die Modelle der Kritiker einfach zu wechseln. Bei geraden Iterationen aktualisieren wir das Modell Critic 2 auf der Grundlage von Aktionen aus dem Erfahrungswiedergabepuffer. Wir trainieren die Politik des Schauspielers auf der Grundlage der Bewertungen des ersten Kritikers.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if((iter % 2) == 0) { if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Clear(); Result.Add(reward-log_prob.Sum()); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Critic1.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Update(0,Buffer[tr].Revards[i]); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Bei ungeraden Iterationen ändern wir die Verwendung von Critic-Modellen.
else { if(!Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Clear(); Result.Add(reward); if(!Critic2.backProp(Result, GetPointer(Actor)) || !Critic2.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Update(0,Buffer[tr].Revards[i]); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Achten Sie auf die Reihenfolge, in der die Methoden der Rückwärtsdurchgänge aufgerufen werden. Zunächst führen wir einen umgekehrten Critic-Durchlauf durch. Anschließend wird der Gradient durch die Entropiekomponente geleitet. Als Nächstes führen wir einen Rückwärtsdurchlauf durch den primären Datenverarbeitungsblock des Akteurs durch. So können wir die Faltungsschichten an die Anforderungen von Critic anpassen. Danach führen wir einen vollständigen Rückwärtsdurchlauf des Akteurs durch, um die Strategie seiner Aktionen zu optimieren.
Am Ende der Funktionsoperationen aktualisieren wir die Zielmodelle und zeigen dem Nutzer eine Informationsmeldung an, um den Trainingsprozess visuell zu überwachen.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Den vollständigen Code des Expert Advisors finden Sie im Anhang. Dort finden Sie auch den Test-EA-Code. Die Änderungen, die daran vorgenommen wurden, ähneln den Änderungen in der primären Datenerhebung EA, und wir werden nicht näher darauf eingehen.
3. Test
Das Modell wurde auf historischen Daten von EURUSD H1 im Zeitraum Januar - Mai 2023 trainiert und getestet. Die Indikatorparameter und alle Hyperparameter wurden auf ihre Standardwerte gesetzt.
Zu meinem Bedauern muss ich zugeben, dass es mir während der Arbeit an diesem Artikel nicht gelungen ist, ein Modell zu trainieren, das in der Lage ist, auf der Trainingsmenge Gewinne zu erzielen. Den Testergebnissen zufolge verlor mein Modell während des 5-monatigen Trainingszeitraums 3,8 %.

Positiv zu vermerken ist, dass der maximale Gewinn 3,6 Mal höher ist als der maximale Verlust pro 1 Trade. Die durchschnittliche Gewinnspanne ist nur geringfügig höher als die durchschnittliche Verlustspanne. Der Anteil der gewinnbringenden Geschäfte liegt jedoch bei 49 %. Im Grunde genommen reichten diese 1 % nicht aus, um „0“ zu erreichen.
Bei Daten außerhalb des Trainingssatzes blieb die Situation nahezu unverändert. Auch der Anteil der gewinnbringenden Handelsgeschäfte stieg auf 51 %. Aber der Umfang des durchschnittlich gewinnbringenden Handels ging zurück, sodass erneut ein Verlust entstand.

Die Stabilität des Modells außerhalb des Trainingssets ist ein positiver Faktor. Aber es bleibt die Frage, wie wir die Verluste loswerden können. Vielleicht liegt der Grund in den Änderungen des Algorithmus oder in einem überhöhten Temperaturverhältnis, das zu mehr Marktforschung anregt.
Außerdem kann es daran liegen, dass die Stichprobenwerte für die Maßnahmen zu stark gestreut sind. Wenn eine Aktion mit einer Wahrscheinlichkeit nahe „0“ ausgewählt wird, erhöht eine hohe Entropie die Belohnungen und verzerrt so die Politik des Akteurs. Um die Ursache zu finden, sind weitere Tests erforderlich. Ich werde ihre Ergebnisse mit Ihnen teilen.
Schlussfolgerung
In diesem Artikel stellen wir den Soft Actor-Critic (SAC) Algorithmus vor, der für die Lösung von Problemen in einem kontinuierlichen Handlungsraum entwickelt wurde. Es basiert auf der Idee der Maximierung der Politikentropie, die es dem Agenten ermöglicht, verschiedene Strategien zu erkunden und optimale Lösungen in stochastischen Umgebungen zu finden, wobei die maximale Vielfalt an Aktionen berücksichtigt wird.
Die Autoren der Methode schlugen vor, eine Entropie-Regularisierung zu verwenden, die der Trainingszielfunktion hinzugefügt wird. Dies ermöglicht es dem Algorithmus, die Erkundung neuer Aktionen zu fördern und verhindert, dass er sich zu sehr auf bestimmte Strategien fixiert.
Wir haben diese Methode mit MQL5 implementiert, waren aber leider nicht in der Lage, eine profitable Strategie zu trainieren. Das trainierte Modell zeigt jedoch eine stabile Leistung innerhalb und außerhalb des Trainingssatzes. Dies zeigt die Fähigkeit der Methode, die gewonnenen Erfahrungen zu verallgemeinern und auf unbekannte Umweltbedingungen zu übertragen.
Ich habe mir zum Ziel gesetzt, nach Möglichkeiten zu suchen, eine gewinnbringende Akteurspolitik zu betreiben. Die Ergebnisse werden später vorgestellt.
Liste der Referenzen
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- Soft Actor-Critic Algorithms and Applications
- Neuronale Netze leicht gemacht (Teil 48): Methoden zur Verringerung der Überschätzung von Q-Funktionswerten
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | Study.mq5 | Expert Advisor | Trainings-EA des Agenten |
| 3 | Test.mq5 | Expert Advisor | Test-EA des Modells |
| 4 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 5 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 6 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/12941
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.