
ONNX meistern: Der Game-Changer für MQL5-Händler

„Die Möglichkeit, KI-Modelle im ONNX-Format zu exportieren und zu importieren, rationalisiert den Entwicklungsprozess und spart Zeit und Ressourcen bei der Integration von KI in verschiedene Sprachökosysteme.“
Einführung
Es ist unbestreitbar, dass wir uns im Zeitalter der KI und des maschinellen Lernens befinden. Jeden Tag gibt es eine neue KI-basierte Technologie, die in den Bereichen Finanzen, Kunst und Spiele, Bildung und vielen anderen Lebensbereichen eingesetzt wird.
Wenn wir Händler lernen, die Macht der künstlichen Intelligenz zu nutzen, könnte uns das einen Vorteil gegenüber dem Markt verschaffen, da wir Muster und Beziehungen erkennen können, die wir mit dem menschlichen Auge nicht sehen können.
Auch wenn KI cool und magisch erscheint, stecken hinter den Modellen komplexe mathematische Operationen, die einen enormen Arbeitsaufwand und ein hohes Maß an Genauigkeit und Konzentration erfordern, wenn man diese maschinellen Lernmodelle von Grund auf neu implementieren will, was dank open-source.
Heutzutage muss man nicht einmal mehr ein Mathe- und Programmiergenie sein, um KI-Modelle zu erstellen und zu implementieren. Man braucht nur ein Grundverständnis für eine bestimmte Programmiersprache oder die Tools, die man für sein Projekt verwenden möchte, und einen PC. In einigen Fällen muss man nicht einmal einen PC besitzen, denn dank Diensten wie Google Colab kann man mit Python kostenlos KI-Modelle programmieren, erstellen und ausführen.
So einfach es ist, Modelle des maschinellen Lernens mit Python und anderen beliebten und ausgereiften Programmiersprachen zu implementieren, so einfach ist es nicht, um ehrlich zu sein, dies in MQL5 zu tun. Wenn Sie das Rad nicht neu erfinden wollen, indem Sie Machine-Learning-Modelle in MQL5 von Grund auf neu erstellen, was wir in dieser Artikelserie tun, würde ich dringend empfehlen, ONNX zu verwenden, um in Python erstellte AI-Modelle in MQL5 zu integrieren. ONNX wird jetzt in MQL5 unterstützt. Ich bin so begeistert, ich glaube, das sollten Sie auch sein.

Ein grundlegendes Verständnis von künstlicher Intelligenz und maschinellem Lernen ist erforderlich, um den Inhalt dieses Artikels zu verstehen, bitte lesen Sie diesen Eintrag und diesen Artikel
Was ist ONNX?
ONNX steht für Open Neural Network Exchange und ist ein Open-Source-Format zur Darstellung von Modellen für maschinelles Lernen und Deep Learning. Damit können Sie Modelle, die in einem Deep-Learning-Framework trainiert wurden, in ein gemeinsames Format konvertieren, das in anderen Frameworks verwendet werden kann, was die Arbeit mit Modellen auf verschiedenen Plattformen und mit verschiedenen Tools erleichtert.
Das bedeutet, dass Sie Modelle für maschinelles Lernen mit jeder Sprache, die dies unterstützt, außer MQL5, erstellen und dann das Modell in das ONNX-Format konvertieren können. Dieses ONNX-Modell kann dann in Ihrem MQL5-Programm verwendet werden.
In diesem Beitrag werde ich Python zum Aufbau von Machine Learning verwenden, da ich damit vertraut bin. Mir wurde gesagt, dass man auch andere Sprachen verwenden kann, ich bin mir aber nicht sicher. Übrigens, die gesamte Dokumentation von ONNX scheint auf Python zu basieren. Ich glaube, dass ONNX im Moment für Python gemacht ist.
Grundlegende Konzepte im ONNX:
Bevor Sie sich mit ONNX beschäftigen, sollten Sie mit einigen Schlüsselbegriffen vertraut sein:
- ONNX Modell: Ein ONNX-Modell ist die Umsetzung eines maschinellen Lernmodells. Es besteht aus einem Berechnungsgraphen, in dem Knoten Operationen (z. B. Faltung, Addition) und Kanten den Datenfluss zwischen den Operationen darstellen.
- Nodes: Node (Knoten) in einem ONNX-Diagramm stellen Operationen oder Funktionen dar, die auf Eingabedaten angewendet werden. Diese Knoten können Operationen wie Faltung, Addition oder nutzerdefinierte Operationen sein.
- Tensoren: Tensoren sind mehrdimensionale Arrays, die den Datenfluss zwischen den Knoten im Berechnungsgraphen darstellen. Sie können Eingaben, Ausgaben oder Zwischendaten sein.
- Operatoren: Operatoren sind Funktionen, die in ONNX auf Tensoren angewendet werden. Jeder Operator steht für eine bestimmte Operation, z. B. Matrixmultiplikation oder elementweise Addition.
Erstellung von Modellen in Python und Bereitstellung in MQL5 mit ONNX
Um erfolgreich ein maschinelles Lernmodell in Python zu erstellen, setzen Sie dieses Modell in Ihrem EA, Indikator oder Skript in MQL5 ein; Es erfordert mehr als nur Python-Code für das Modell. Im Folgenden finden Sie die entscheidenden Schritte, die Sie befolgen müssen, damit Sie am Ende nicht nur ein ONNX-Modell haben, sondern ein Modell, das die gewünschten genauen Vorhersagen liefert;
- Datenerhebung
- Normalisierung der Daten auf der MQL5-Seite
- Erstellung der Modelle in Python
- Das erstellte ONNX-Modell in MQL5 erhalten
- Ausführung des Modells in Echtzeit
01: Datenerhebung
Ich glaube, dass es am besten ist, alle Daten innerhalb Ihres MQL5-Programms zu sammeln, um mit der Art und Weise übereinzustimmen, wie wir die Trainingsdaten und die Daten sammeln, die während des Live-Handels oder der Ausführung des Modells in Echtzeit verwendet werden Beachten Sie, dass die Datenerfassung je nach Art des Problems, das Sie zu lösen versuchen, variieren kann. Wir werden die Marktinformationen OHLC(Open, High, Low, Close) als unseren primären Datensatz verwenden, wobei Open, High und Low als unabhängige Variablen und der Close-Preis als Zielvariable verwendet werden.
Innerhalb von ONNX Daten abrufen.mq5
matrixf GetTrainData(uint start, uint total) { matrixf return_matrix(total, 3); ulong last_col; OPEN.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_LOW, start, total); CLOSE.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_CLOSE, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); csv_name_ = Symbol()+"."+EnumToString(Period())+"."+string(total_bars); x_vars = "OPEN,HIGH,LOW"; return_matrix.Resize(total, 4); //if we are collecting the train data collect the target variable also last_col = return_matrix.Cols()-1; //Column located at the last index is the last column return_matrix.Col(CLOSE, last_col); //put the close price information in the last column of a matrix csv_name_ +=".targ=CLOSE"; csv_header = x_vars + ",CLOSE"; if (!WriteCsv("ONNX Datafolder\\"+csv_name_+".csv", return_matrix, csv_header)) Print("Failed to Write to a csv file"); else Print("Data saved to a csv file successfully"); return return_matrix; }
Beim überwachten maschinellen Lernen muss die Zielvariable spezifiziert und dem Modell übergeben werden, damit es daraus lernen und die Muster zwischen der Zielvariable und den übrigen Variablen verstehen kann. In unserem Fall versucht das Modell zu verstehen, wie diese Indikatorwerte zu einer Hausse oder Baisse führen.
Bei der Bereitstellung des Modells müssen wir die Daten auf dieselbe Weise erfassen, nur dass wir diesmal ohne die Zielvariable erfassen, denn das ist etwas, das unser trainiertes Modell herausfinden soll. Sozusagen zur Vorhersage.
Aus diesem Grund gibt es eine andere Funktion namens GetLiveData, mit der neue Daten für kontinuierliche Vorhersagen auf dem Markt geladen werden.
Innerhalb von ONNX mt5.mq5
matrixf GetLiveData(uint start, uint total) { matrixf return_matrix(total, 3); OPEN.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_LOW, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); return return_matrix; }
Erfassen der Trainingsdaten
matrixf dataset = GetTrainData(start_bar, total_bars); Print("Train data\n",dataset);
Ausgaben:
DK 0 23:10:54.837 ONNX get data (EURUSD,H1) Train data PR 0 23:10:54.837 ONNX get data (EURUSD,H1) [[1.4243405,1.4130603,1.4215617,1.11194] HF 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3976599,1.3894916,1.4053394,1.11189] RK 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.402994,1.3919021,1.397626,1.11123] PM 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3848507,1.3761013,1.3718294,1.11022] FF 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3597701,1.3447646,1.3545419,1.1097701] CH 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3461626,1.3522644,1.3433729,1.1106] NL 0 23:10:54.837 ONNX get data (EURUSD,H1) [1.3683074,1.3525325,1.3582669,1.10996]
Abrufen der Live-Daten
Abrufen der aktuellen Bar Informationen OHL.
matrixf live_data = GetLiveData(0,1); Print("Live data\n",live_data);
Ausgaben:
MN 0 23:15:47.167 ONNX mt5 (EURUSD,H1) Live data KS 0 23:15:47.167 ONNX mt5 (EURUSD,H1) [[-0.21183228,-0.23540309,-0.20334835]]
Die Art und Weise, wie Live-Daten geladen werden, kann bei der Aufbereitung der Daten für die Modelle der Zeitreihen wie RNN, GRU und LSTM leicht variieren.
error 2023.09.18 18:03:53.212 ONNX: invalid parameter size, expected 1044480 bytes instead of 32640
02: Daten-Normalisierung auf der MQL5-Seite
Die Normalisierung von Daten gehört zu den wichtigsten Dingen, die für einen Datensatz, der von einem maschinellen Lernmodell verwendet werden soll, richtig gemacht werden müssen.
Beachten Sie, dass die Normalisierungstechnik, die zur Vorbereitung der Trainingsdaten verwendet wird, dieselbe sein muss, die auch zur Vorbereitung der Test- und Live-Daten verwendet wird. Dies bedeutet, dass, wenn die verwendete Technik MinMaxScaler, die Minimal- und Maximalwerte, die die grundlegenden Variablen in der MinMaxScaler-Gleichung sind, die bei der Vorbereitung der Zugdaten verwendet wurden und die dazu verwendet werden, die neuen Daten, die vom Modell an anderer Stelle verarbeitet werden sollen, weiter zu normalisieren. Um diese Konsistenz zu erreichen, müssen wir die Variablen für jedes Normalisierungsverfahren in einer csv-Datei speichern:
Die Datennormalisierung gilt nur für unabhängige Variablen, es spielt keine Rolle, welche Art von Problem Sie zu lösen versuchen, Sie müssen die Zielvariable nicht normalisieren.
Wir werden die Klasse Preprocessing von hier verwenden.
Innerhalb des ONNX-Skripts get data.mq5
//--- Saving the normalization prameters switch(NORM) { case NORM_MEAN_NORM: //--- saving the mean norm_params.Assign(norm_x.mean_norm_scaler.mean); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.mean.csv",norm_params,x_vars); //--- saving the min norm_params.Assign(norm_x.mean_norm_scaler.min); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.mean_norm_scaler.max); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.max.csv",norm_params,x_vars); break; case NORM_MIN_MAX_SCALER: //--- saving the min norm_params.Assign(norm_x.min_max_scaler.min); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.min_max_scaler.max); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.max.csv",norm_params,x_vars); break; case NORM_STANDARDIZATION: //--- saving the mean norm_params.Assign(norm_x.standardization_scaler.mean); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.mean.csv",norm_params,x_vars); //--- saving the std norm_params.Assign(norm_x.standardization_scaler.std); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.std.csv",norm_params,x_vars); break; }
Ausgaben:

Wenn der „Standardization Scaler“ in den csv-Dateien verwendet wurde, sahen die Parameter wie folgt aus;
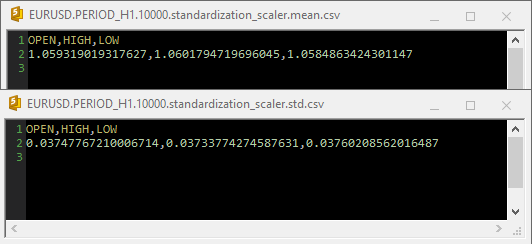
Beachten Sie, dass die Normalisierung auch in die Funktion GetData integriert ist. Da die Normalisierung so wichtig ist, muss jede Datenmatrix, die von den beiden für die Datenerfassung zuständigen Funktionen zurückgegeben wird, eine Matrix mit normalisierten Preiswerten sein.
Innerhalb des ONNX-Skripts get data.mq5
matrixf GetTrainData(uint start, uint total) { matrixf return_matrix(total, 3); ulong last_col; OPEN.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_LOW, start, total); CLOSE.CopyRates(Symbol(), PERIOD_CURRENT, COPY_RATES_CLOSE, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); matrixf norm_params = {}; csv_name_ = Symbol()+"."+EnumToString(Period())+"."+string(total_bars); x_vars = "OPEN,HIGH,LOW"; while (CheckPointer(norm_x) != POINTER_INVALID) delete (norm_x); norm_x = new CPreprocessing<vectorf, matrixf>(return_matrix, NORM); //--- Saving the normalization prameters switch(NORM) { case NORM_MEAN_NORM: //--- saving the mean norm_params.Assign(norm_x.mean_norm_scaler.mean); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.mean.csv",norm_params,x_vars); //--- saving the min norm_params.Assign(norm_x.mean_norm_scaler.min); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.mean_norm_scaler.max); WriteCsv(normparams_folder+csv_name_+".mean_norm_scaler.max.csv",norm_params,x_vars); break; case NORM_MIN_MAX_SCALER: //--- saving the min norm_params.Assign(norm_x.min_max_scaler.min); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.min.csv",norm_params,x_vars); //--- saving the max norm_params.Assign(norm_x.min_max_scaler.max); WriteCsv(normparams_folder+csv_name_+".min_max_scaler.max.csv",norm_params,x_vars); break; case NORM_STANDARDIZATION: //--- saving the mean norm_params.Assign(norm_x.standardization_scaler.mean); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.mean.csv",norm_params,x_vars); //--- saving the std norm_params.Assign(norm_x.standardization_scaler.std); WriteCsv(normparams_folder+csv_name_+".standardization_scaler.std.csv",norm_params,x_vars); break; } return_matrix.Resize(total, 4); //if we are collecting the train data collect the target variable also last_col = return_matrix.Cols()-1; //Column located at the last index is the last column return_matrix.Col(CLOSE, last_col); //put the close price information in the last column of a matrix csv_name_ +=".targ=CLOSE"; csv_header = x_vars + ",CLOSE"; if (!WriteCsv("ONNX Datafolder\\"+csv_name_+".csv", return_matrix, csv_header)) Print("Failed to Write to a csv file"); else Print("Data saved to a csv file successfully"); return return_matrix; }
Schließlich wurden die Daten in einer CSV-Datei gespeichert, sodass sie mit Python-Code gemeinsam genutzt werden konnten.
03: Erstellung der Modelle in Python
Ich werde ein mehrschichtiges Perceptron-Netz aufbauen, aber Sie können auch ein beliebiges Modell Ihrer Wahl erstellen. Das ist nicht auf diese spezielle Art von Modell beschränkt. Beginnen Sie mit der Installation von Python in Ihrem System, falls Sie dies noch nicht getan haben. Danach installieren Sie virtualenv, indem Sie die folgenden Befehle über Windows CMD (nicht zu verwechseln mit Powershell) ausführen!
$ pip3 install virtualenv
Nach diesem Lauf,
$ virtualenv venv
Dadurch wird eine virtuelle Python-Umgebung für Ihren Windows-Rechner erstellt. Ich glaube, die meisten von uns arbeiten mit Windows, für Mac-Nutzer und Linux-Anwender kann der Prozess etwas anders aussehen.
$ venv\Scripts\activate
Danach installieren Sie alle in diesem Tutorial verwendeten Abhängigkeiten durch:
Es ist immer wichtig, das Projekt zu isolieren, indem man eine virtuelle Umgebung erstellt, um Konflikte zwischen den Modulen und Python-Versionen zu vermeiden und die gemeinsame Nutzung des Projekts zu erleichtern.
Importieren und Initialisieren von MT5
import MetaTrader5 as mt5 if not mt5.initialize(): #This will open MT5 app in your pc print("initialize() failed, error code =",mt5.last_error()) quit() # program logic and ML code will be here mt5.shutdown() #This closes the program # Getting the data we stored in the Files path on Metaeditor data_path = terminal_info.data_path dataset_path = data_path + "\\MQL5\\Files\\ONNX Datafolder"
Wir müssen prüfen, ob der Pfad existiert. Wenn er nicht existiert, bedeutet das, dass wir die Daten auf der MT5-Seite nicht gesammelt haben.
import os if not os.path.exists(dataset_path): print("Dataset folder doesn't exist | Be sure you are referring to the correct path and the data is collected from MT5 side of things") quit()
Aufbau eines mehrschichtigen neuronalen Perzeptron-Netzwerks (MLP)
Wir werden einen MLP NN in eine Klasse verpacken, um unseren Code in lesbare Abschnitte zu unterteilen.
01: Initialisierung der Klasse
Die Daten werden gesammelt und in Trainings- und Teststichproben aufgeteilt, wobei wichtige Variablen als für die gesamte Klasse verfügbar erklärt werden,
class NeuralNetworkClass(): def __init__(self, csv_name, target_column, batch_size=32): # Loading the dataset and storing to a variable Array self.data = pd.read_csv(dataset_path+"\\"+csv_name) if self.data.empty: print(f"No such dataset or Empty dataset csv = {csv_name}") quit() # quit the program print(self.data.head()) # Print 5 first rows of a given data self.target_column = target_column # spliting the data into training and testing samples X = self.data.drop(columns=self.target_column).to_numpy() # droping the targeted column, the rest is x variables Y = self.data[self.target_column].to_numpy() # We convert data arrays to numpy arrays compartible with sklearn and tensorflow self.train_x, self.test_x, self.train_y, self.test_y = train_test_split(X, Y, test_size=0.3, random_state=42) # splitting the data into training and testing samples print(f"train x shape {self.train_x.shape}\ntest x shape {self.test_x.shape}") self.input_size = self.train_x.shape[-1] # obtaining the number of columns in x variable as our inputs self.output_size = 1 # We are solving for a regression problem we need to have a single output neuron self.batch_size = batch_size self.model = None # Object to store the model self.plots_directory = "Plots" self.models_directory = "Models"
Ausgaben:

02: Aufbau des neuronalen Netzmodells
Unser einschichtiges neuronales Netz wird mit einer bestimmten Anzahl von Neuronen definiert.
def BuildNeuralNetwork(self, activation_function='relu', neurons = 10): # Create a Feedforward Neural Network model self.model = keras.Sequential([ keras.layers.Input(shape=(self.input_size,)), # Input layer keras.layers.Dense(units=neurons, activation=activation_function, activity_regularizer=l2(0.01), kernel_initializer="he_uniform"), # Hidden layer with an activation function keras.layers.Dense(units=self.output_size, activation='linear', activity_regularizer=l2(0.01), kernel_initializer="he_uniform") ]) # Print a summary of the model's architecture. self.model.summary()
Ausgaben:

03: Training und Test des neuronalen Netzmodells
def train_network(self, epochs=100, learning_rate=0.001, loss='mean_squared_error'): early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) # Early stoppage mechanism | stop training when there is no major change in loss in the last to epochs, defined by the variable patience adam = optimizers.Adam(learning_rate=learning_rate) # Adam optimizer >> https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/ # Compile the model: Specify the loss function, optimizer, and evaluation metrics. self.model.compile(loss=loss, optimizer=adam, metrics=['mae']) # One hot encode the validation and train target variables validation_y = self.test_y y = self.train_y history = self.model.fit(self.train_x, y, epochs=epochs, batch_size=self.batch_size, validation_data=(self.test_x, validation_y), callbacks=[early_stopping], verbose=2) if not os.path.exists(self.plots_directory): #create plots path if it doesn't exist for saving the train-test plots os.makedirs(self.plots_directory) # save the loss and validation loss plot plt.figure(figsize=(12, 6)) plt.plot(history.history['loss'], label='Training Loss') plt.plot(history.history['val_loss'], label='Validation Loss') plt.xlabel('Epochs') plt.ylabel('Loss') plt.legend() title = 'Training and Validation Loss Curves' plt.title(title) plt.savefig(fname=f"{self.plots_directory}\\"+title) # use the trained model to make predictions on the trained data pred = self.model.predict(self.train_x) acc = metrics.r2_score(self.train_y, pred) # Plot actual & pred count = [i*0.1 for i in range(len(self.train_y))] title = f'MLP {self.target_column} - Train' # Saving the plot containing information about predictions and actual values plt.figure(figsize=(7, 5)) plt.plot(count, self.train_y, label = "Actual") plt.plot(count, pred, label = "forecast") plt.xlabel('Actuals') plt.ylabel('Preds') plt.title(title+f" | Train acc={acc}") plt.legend() plt.savefig(fname=f"{self.plots_directory}\\"+title) self.model.save(f"Models\\lstm-pat.{self.target_column}.h5") #saving the model in h5 format, this will help us to easily convert this model to onnx later def test_network(self): # Plot actual & pred count = [i*0.1 for i in range(len(self.test_y))] title = f'MLP {self.target_column} - Test' pred = self.model.predict(self.test_x) acc = metrics.r2_score(self.test_y, pred) # Saving the plot containing information about predictions and actual values plt.figure(figsize=(7, 5)) plt.plot(count, self.test_y, label = "Actual") plt.plot(count, pred, label = "forecast") plt.xlabel('Actuals') plt.ylabel('Preds') plt.title(title+f" | Train acc={acc}") plt.legend() plt.savefig(fname=f"{self.plots_directory}\\"+title) if not os.path.exists(self.plots_directory): #create plots path if it doesn't exist for saving the train-test plots os.makedirs(self.plots_directory) plt.savefig(fname=f"{self.plots_directory}\\"+title) return acc
Ausgaben:
Epoch 1/50 219/219 - 2s - loss: 1.2771 - mae: 0.3826 - val_loss: 0.1153 - val_mae: 0.0309 - 2s/epoch - 8ms/step Epoch 2/50 219/219 - 1s - loss: 0.0836 - mae: 0.0305 - val_loss: 0.0582 - val_mae: 0.0291 - 504ms/epoch - 2ms/step Epoch 3/50 219/219 - 1s - loss: 0.0433 - mae: 0.0283 - val_loss: 0.0323 - val_mae: 0.0284 - 515ms/epoch - 2ms/step Epoch 4/50 219/219 - 0s - loss: 0.0262 - mae: 0.0272 - val_loss: 0.0218 - val_mae: 0.0270 - 482ms/epoch - 2ms/step Epoch 5/50 ... ... Epoch 48/50 219/219 - 0s - loss: 0.0112 - mae: 0.0106 - val_loss: 0.0112 - val_mae: 0.0121 - 490ms/epoch - 2ms/step Epoch 49/50 219/219 - 0s - loss: 0.0112 - mae: 0.0106 - val_loss: 0.0112 - val_mae: 0.0109 - 486ms/epoch - 2ms/step Epoch 50/50 219/219 - 1s - loss: 0.0112 - mae: 0.0106 - val_loss: 0.0112 - val_mae: 0.0097 - 501ms/epoch - 2ms/step 219/219 [==============================] - 0s 2ms/step C:\Users\Omega Joctan\OneDrive\Documents\onnx article\ONNX python\venv\Lib\site-packages\keras\src\engine\training.py:3079: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`. saving_api.save_model( 94/94 [==============================] - 0s 2ms/step Test accuracy = 0.9336617822086006

Das Modell des neuronalen Netzes hatte eine Genauigkeit von 93 % beim Training und etwa 95 % beim Testen. Das könnte „overfitted“ sein, aber wir werden trotzdem damit fortfahren.
04: Speichern des ONNX-Modells.
Es ist im Allgemeinen eine gute Praxis, ein Modell zu speichern, sobald das Training erfolgreich abgeschlossen ist und Sie mit der Leistung des Modells sowohl beim Training als auch bei der Out-of-Sample-Validierung zufrieden sind. Wir müssen ONNX-Laufzeitcode hinzufügen, um das Modell während der Funktion train_network in unserer Klasse zu speichern. Als erstes müssen wir zwei Bibliotheken installieren: onnx und tf2onnx.
def train_network(self, epochs=100, learning_rate=0.001, loss='mean_squared_error'): # at the end of this function # .... self.model.save(f"Models\\MLP.REG.{self.target_column}.{self.data.shape[0]}.h5") #saving the model in h5 format, this will help us to easily convert this model to onnx later self.saveONNXModel() def saveONNXModel(self, folder="ONNX Models"): path = data_path + "\\MQL5\\Files\\" + folder if not os.path.exists(path): # create this path if it doesn't exist os.makedirs(path) onnx_model_name = f"MLP.REG.{self.target_column}.{self.data.shape[0]}.onnx" path += "\\" + onnx_model_name loaded_keras_model = load_model(f"Models\\MLP.REG.{self.target_column}.{self.data.shape[0]}.h5") onnx_model, _ = tf2onnx.convert.from_keras(loaded_keras_model, output_path=path) onnx.save(onnx_model, path ) print(f'Saved model to {path}')
Ausgaben:

Sie haben vielleicht bemerkt, dass ich das ONNX-Modell unter dem übergeordneten Verzeichnis Files gespeichert habe. Warum dieses Verzeichnis? Der Grund dafür ist, dass es einfacher ist, die ONNX-Datei als Ressource in unser MQL5-Programm einzubinden, z. B. in einen Expert Advisor oder einen Indikator.
04: Das erstellte ONNX-Modell in MQL5 erhalten
#resource "\\Files\\ONNX Models\\MLP.REG.CLOSE.10000.onnx" as uchar RNNModel[]
Dies importiert das ONNX-Modell und speichert es im uchar-Array RNNModel.
Als Nächstes müssen wir das ONNX-Handle als globale Variable definieren und das Handle innerhalb der OnInit-Funktion erstellen.
Innerhalb von ONNX mt5.mq5 EA
long mlp_onnxhandle; #include <MALE5\preprocessing.mqh> CPreprocessing<vectorf, matrixf> *norm_x; int inputs[], outputs[]; vectorf OPEN, HIGH, LOW; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!LoadNormParams()) //Load the normalization parameters we saved once { Print("Normalization parameters csv files couldn't be found \nEnsure you are collecting data and Normalizing them using [ONNX get data.ex5] Script \nTrain the Python model again if necessary"); return INIT_FAILED; } //--- ONNX SETTINGS mlp_onnxhandle = OnnxCreateFromBuffer(RNNModel, MQLInfoInteger(MQL_DEBUG) ? ONNX_DEBUG_LOGS : ONNX_DEFAULT); //creating onnx handle buffer | rUN DEGUG MODE during debug mode if (mlp_onnxhandle == INVALID_HANDLE) { Print("OnnxCreateFromBuffer Error = ",GetLastError()); return INIT_FAILED; } //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(mlp_onnxhandle); Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(mlp_onnxhandle,i); Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(mlp_onnxhandle,i,type_info)) { PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(mlp_onnxhandle); Print("model has ",output_count," output(s)"); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(mlp_onnxhandle,i); Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(mlp_onnxhandle,i,type_info)) { PrintTypeInfo(i,"output",type_info); ArrayCopy(outputs, type_info.tensor.dimensions); } } //--- if (MQLInfoInteger(MQL_DEBUG)) { Print("Inputs & Outputs"); ArrayPrint(inputs); ArrayPrint(outputs); } const long input_shape[] = {batch_size, 3}; if (!OnnxSetInputShape(mlp_onnxhandle, 0, input_shape)) //Giving the Onnx handle the input shape { printf("Failed to set the input shape Err=%d",GetLastError()); return INIT_FAILED; } const long output_shape[] = {batch_size, 1}; if (!OnnxSetOutputShape(mlp_onnxhandle, 0, output_shape)) //giving the onnx handle the output shape { printf("Failed to set the input shape Err=%d",GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Ausgaben:
PR 0 18:57:10.265 ONNX mt5 (EURUSD,H1) ONNX: Creating and using per session threadpools since use_per_session_threads_ is true CN 0 18:57:10.265 ONNX mt5 (EURUSD,H1) ONNX: Dynamic block base set to 0 EE 0 18:57:10.266 ONNX mt5 (EURUSD,H1) ONNX: Initializing session. IM 0 18:57:10.266 ONNX mt5 (EURUSD,H1) ONNX: Adding default CPU execution provider. JN 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Use DeviceBasedPartition as default QK 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Saving initialized tensors. GR 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Done saving initialized tensors RI 0 18:57:10.269 ONNX mt5 (EURUSD,H1) ONNX: Session successfully initialized. JF 0 18:57:10.269 ONNX mt5 (EURUSD,H1) model has 1 input(s) QR 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 input name is input_1 NF 0 18:57:10.269 ONNX mt5 (EURUSD,H1) type ONNX_TYPE_TENSOR PM 0 18:57:10.269 ONNX mt5 (EURUSD,H1) data type ONNX_TYPE_TENSOR HI 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape [-1, 3] FS 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 input shape must be defined explicitly before model inference NE 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape of input data can be reduced to [3] if undefined dimension set to 1 GD 0 18:57:10.269 ONNX mt5 (EURUSD,H1) model has 1 output(s) GQ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 output name is dense_1 LJ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) type ONNX_TYPE_TENSOR NQ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) data type ONNX_TYPE_TENSOR LF 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape [-1, 1] KQ 0 18:57:10.269 ONNX mt5 (EURUSD,H1) 0 output shape must be defined explicitly before model inference CO 0 18:57:10.269 ONNX mt5 (EURUSD,H1) shape of output data can be reduced to [1] if undefined dimension set to 1 GR 0 18:57:10.269 ONNX mt5 (EURUSD,H1) Inputs & Outputs IE 0 18:57:10.269 ONNX mt5 (EURUSD,H1) -1 3 CK 0 18:57:10.269 ONNX mt5 (EURUSD,H1) -1 1
Live-Daten abrufen
Wie bereits erwähnt, müssen die Live-Daten vom Markt bezogen und auf dieselbe Weise normalisiert werden, wie dies bei der Erfassung der Daten für die Schulung der Fall war.
Innerhalb von ONNX mt5.mq5 EA
matrixf GetLiveData(uint start, uint total) { matrixf return_matrix(total, 3); OPEN.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_OPEN, start, total); HIGH.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_HIGH, start, total); LOW.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_LOW, start, total); return_matrix.Col(OPEN, 0); return_matrix.Col(HIGH, 1); return_matrix.Col(LOW, 2); if (!norm_x.Normalization(return_matrix)) Print("Failed to Normalize"); return return_matrix; }
Damit die Instanz der Klasse norm_x funktioniert, wurde sie innerhalb der Funktion LoadNormParams() in OnInit deklariert. Diese Funktion lädt die gespeicherten Normalisierungsparameter aus einer entsprechenden CSV-Datei.
Innerhalb von ONNX mt5.mq5 EA
bool LoadNormParams() { vectorf min = {}, max ={}, mean={} , std = {}; csv_name_ = Symbol()+"."+EnumToString(Period())+"."+string(total_bars); switch(NORM) { case NORM_MEAN_NORM: mean = ReadCsvVector(normparams_folder+csv_name_+".mean_norm_scaler.mean.csv"); //--- Loading the mean min = ReadCsvVector(normparams_folder+csv_name_+".mean_norm_scaler.min.csv"); //--- Loading the min max = ReadCsvVector(normparams_folder+csv_name_+".mean_norm_scaler.max.csv"); //--- Loading the max if (MQLInfoInteger(MQL_DEBUG)) Print(EnumToString(NORM),"\nMean ",mean,"\nMin ",min,"\nMax ",max); norm_x = new CPreprocessing<vectorf,matrixf>(max, mean, min); if (mean.Sum()<=0 && min.Sum()<=0 && max.Sum() <=0) return false; break; case NORM_MIN_MAX_SCALER: min = ReadCsvVector(normparams_folder+csv_name_+".min_max_scaler.min.csv"); //--- Loading the min max = ReadCsvVector(normparams_folder+csv_name_+".min_max_scaler.max.csv"); //--- Loading the max if (MQLInfoInteger(MQL_DEBUG)) Print(EnumToString(NORM),"\nMin ",min,"\nMax ",max); norm_x = new CPreprocessing<vectorf,matrixf>(max, min); if (min.Sum()<=0 && max.Sum() <=0) return false; break; case NORM_STANDARDIZATION: mean = ReadCsvVector(normparams_folder+csv_name_+".standardization_scaler.mean.csv"); //--- Loading the mean std = ReadCsvVector(normparams_folder+csv_name_+".standardization_scaler.std.csv"); //--- Loading the std if (MQLInfoInteger(MQL_DEBUG)) Print(EnumToString(NORM),"\nMean ",mean,"\nStd ",std); norm_x = new CPreprocessing<vectorf,matrixf>(mean, std, NORM_STANDARDIZATION); if (mean.Sum()<=0 && std.Sum() <=0) return false; break; } return true; }
05: Ausführen des Modells in Echtzeit
Um das Modell in der Funktion OnTick zu verwenden, müssen wir nur die Funktion OnnxRun aufrufen und ihr das ONNX-Handle, einen Vektor oder eine Matrix von Float-Werten für die Eingaben und Vorhersagen übergeben - das war's.
Innerhalb von ONNX mt5.mq5 EA
void OnTick() { //--- matrixf input_data = GetLiveData(0,1); vectorf output_data(1); //It is very crucial to resize this vector or matrix if (!OnnxRun(mlp_onnxhandle, ONNX_NO_CONVERSION, input_data, output_data)) { Print("Failed to Get the Predictions Err=",GetLastError()); ExpertRemove(); return; } Comment("inputs_data\n",input_data,"\npredictions\n",output_data); }
Der Ausgangsdatenvektor oder die Float-Matrix muss in der Größe angepasst werden, um den Fehlercode 5805 zu vermeiden, der für ERR_ONNX_INVALID_PARAMETER steht. Da ich nur eine Ausgabe im neuronalen Netz habe, habe ich die Größe dieses Vektors auf 1 geändert. Wenn ich eine Matrix verwenden würde, müsste ich die Größe auf 1 Zeile und 1 Spalte ändern,
Ausgaben:

Großartig, alles funktioniert einwandfrei. Wir verwenden jetzt ein neuronales Netzwerkmodell, das mit Python in MetaTrader5 erstellt und trainiert wurde. Das Verfahren ist aber gar nicht so schwierig, Glückwunsch.
Vorteile der Verwendung von ONNX in MQL5
- Interoperabilität: ONNX bietet ein gemeinsames Format für die Darstellung von Deep-Learning-Modellen. Mit diesem Format können Modelle, die in einem Deep-Learning-Framework (wie oder trainiert wurden, in MQL5 verwendet werden, ohne dass eine umfangreiche Neuimplementierung des Modells erforderlich ist. Dadurch können wir viel Zeit sparen, da wir die Modelle nicht mehr von Grund auf neu kodieren müssen, damit sie in MQL5 funktionieren.
- Flexibilität: ONNX unterstützt eine breite Palette von Deep-Learning-Modelltypen, von traditionellen neuronalen Feedforward-Netzwerken bis hin zu komplexeren Modellen wie rekurrenten neuronalen Netzwerken (RNNs) und konvolutionären neuronalen Netzwerken (CNNs). Diese Flexibilität macht es für verschiedene Anwendungen geeignet.
- Effizienz: ONNX-Modelle können für den effizienten Einsatz auf verschiedenen Hardware- und Plattformsystemen optimiert werden. Das bedeutet, dass Sie Modelle auf Edge-Geräten, mobilen Geräten, Cloud-Servern und sogar speziellen Hardware-Beschleunigern einsetzen können.
- Unterstützung der Gemeinschaft: ONNX hat in der Gemeinschaft große Unterstützung gefunden. Die wichtigsten Deep-Learning-Frameworks wie TensorFlow, PyTorch und scikit-learn unterstützen den Export von Modellen im ONNX-Format, und verschiedene Runtime-Engines wie ONNX Runtime erleichtern die Bereitstellung von ONNX-Modellen.
- Breites Ökosystem: ONNX ist in verschiedene Softwarepakete integriert, und es gibt umfangreiche Tools für die Arbeit mit ONNX-Modellen. Mit diesen Werkzeugen können Sie Modelle im ONNX-Format konvertieren, optimieren und ausführen.
- Plattformübergreifende Kompatibilität: ONNX ist plattformübergreifend konzipiert, d. h. Modelle, die im ONNX-Format exportiert werden, können ohne Änderungen auf verschiedenen Betriebssystemen und Hardwarekomponenten ausgeführt werden.
- Modell Evolution: ONNX unterstützt die Versionierung und Weiterentwicklung von Modellen. Sie können Ihre Modelle im Laufe der Zeit verbessern und erweitern, ohne die Kompatibilität mit früheren Versionen zu verlieren.
- Standardisierung: ONNX entwickelt sich zu einem De-facto-Standard für die Interoperabilität zwischen verschiedenen Deep-Learning-Frameworks und erleichtert der Community den Austausch von Modellen und Tools.
Abschließende Überlegungen
ONNX ist besonders wertvoll in Szenarien, in denen Sie Modelle über verschiedene Frameworks hinweg nutzen, Modelle auf einer Vielzahl von Plattformen einsetzen oder mit anderen zusammenarbeiten müssen, die möglicherweise unterschiedliche Deep Learning-Tools verwenden. Es vereinfacht die Arbeit mit Deep-Learning-Modellen, und da das Ökosystem weiter wächst, werden die Vorteile von ONNX noch bedeutender. In diesem Artikel haben wir die 5 wichtigen Schritte gesehen, die man befolgen muss, um mit einem funktionierenden Modell zu beginnen, um es mal so auszudrücken, Sie können diesen Code erweitern, um ihn Ihren Bedürfnissen anzupassen. Damit das Programm auf dem Strategietester funktioniert, müssen die normalisierten CSV-Dateien innerhalb eines Testers gelesen werden, was ich in diesem Artikel nicht behandelt habe.
Mit besten Grüßen
| Datei | Verwendung |
|---|---|
| neuralnet.py | Die Hauptpython-Skriptdatei enthält die gesamte Implementierung des neuronalen Netzes in der Sprache Python |
| ONNX mt5.mq5 | Ein Expert Advisor, der zeigt, wie man das ONNX-Modell in Handelssituationen einsetzt |
| ONNX get data.mq5 | Ein Skript zum Sammeln und Aufbereiten von Daten, die mit dem Python-Skript geteilt werden sollen |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/13394
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.