
Redes neurais de maneira fácil (Parte 88): Codificador denso de séries temporais (TiDE)

Introdução
Para resolver problemas de previsão de séries temporais, foram investigadas quase todas as arquiteturas conhecidas de redes neurais, incluindo modelos recorrentes, convolucionais e gráficos. No entanto, os resultados mais notáveis são demonstrados por modelos baseados na arquitetura Transformer. Nesta série de artigos, também foram apresentados vários desses algoritmos. Contudo, pesquisas recentes mostraram que arquiteturas baseadas em Transformer podem ser menos poderosas do que se esperava. Em alguns benchmarks de previsão de séries temporais, modelos lineares simples podem apresentar resultados comparáveis ou até melhores. Mas, infelizmente, esses modelos lineares possuem limitações, pois não são adequados para modelar dependências não lineares entre a sequência de séries temporais e covariáveis independentes do tempo.
Pesquisas futuras na área de análise e previsão de séries temporais podem ser divididas em duas direções. Alguns veem o potencial ainda não totalmente explorado do Transformer e trabalham para melhorar a eficiência dessas arquiteturas. Outros trabalham para minimizar as desvantagens dos modelos lineares. O artigo "Long-term Forecasting with TiDE: Time-series Dense Encoder" pertence à segunda direção. Este trabalho propõe uma arquitetura simples e eficiente de aprendizado profundo para a previsão de séries temporais, que oferece melhor desempenho em comparação com os modelos de aprendizado profundo existentes em benchmarks populares. O modelo apresentado, baseado em um Perceptron Multicamadas (MLP), é surpreendentemente simples e não possui mecanismos de Self-Attention, camadas recorrentes ou convolucionais. Por isso, ele tem escalabilidade computacional linear em relação ao comprimento do contexto e ao horizonte de previsão, ao contrário de muitas soluções baseadas em Transformer.
O modelo Time-series Dense Encoder (TiDE) usa MLP para codificar a série temporal passada com as covariáveis e decodificar a série temporal prevista junto com as covariáveis futuras.
Os autores do método analisam o modelo linear simplificado TiDE e demonstram que este modelo linear pode atingir quase o erro ótimo em sistemas dinâmicos lineares (LDS), quando a matriz de construção do LDS tem um valor singular máximo diferente de 1. Eles verificam isso empiricamente em dados simulados, onde o modelo linear supera LSTMs e Transformers.
Em benchmarks reais populares de previsão de séries temporais, TiDE alcança resultados melhores ou semelhantes em comparação com os modelos baseados em redes neurais anteriores. Ao mesmo tempo, TiDE é 5 vezes mais rápido em modo de operação e mais de 10 vezes mais rápido no treinamento em comparação com o melhor modelo baseado em Transformer.
1. Algoritmo TiDE
O modelo chamado TiDE (Time-series Dense Encoder) representa uma arquitetura simples e eficiente baseada em MLP para a previsão de séries temporais de longo prazo. Os autores do algoritmo adicionam não-linearidades na forma de MLP, de modo que ele possa processar dados passados e covariáveis.
O modelo é aplicado a canais de dados independentes, ou seja, a entrada do modelo são os dados passados e as covariáveis de uma única série temporal por vez. Ao mesmo tempo, os pesos do modelo são treinados globalmente usando todo o conjunto de dados, ou seja, são os mesmos para todos os canais independentes.
O componente chave do modelo é o bloco MLP com feedback — um MLP com uma camada oculta e ativação ReLU. Ele também possui uma conexão de atalho, que é completamente linear. Os autores do método utilizam Dropout na camada linear, que mapeia a camada oculta para a saída, além de usar a normalização de camada na saída.
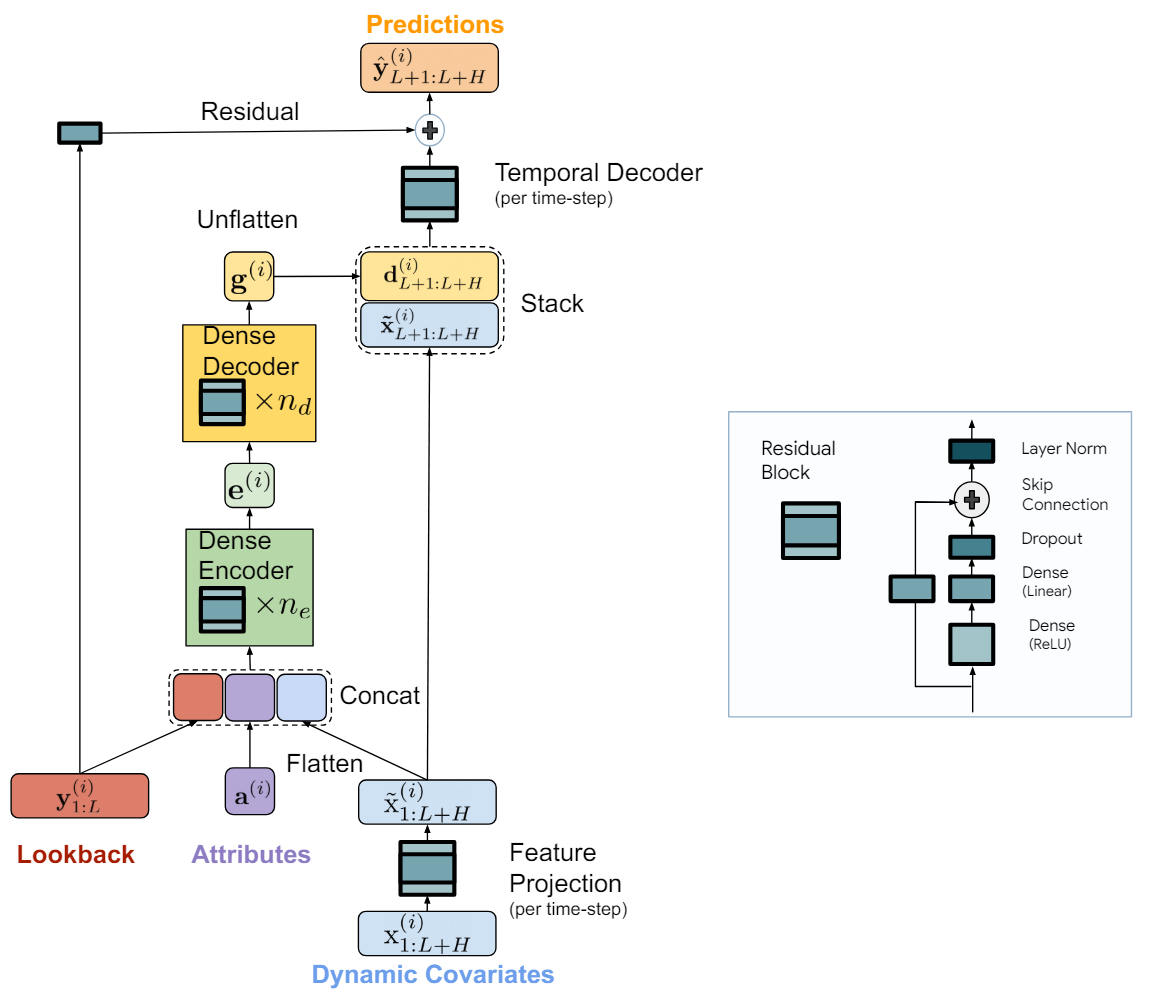
O modelo TiDE é logicamente dividido em seções de codificação e decodificação. A seção de codificação contém a etapa de projeção de características, seguida por um codificador denso MLP. A seção de decodificação consiste em um decodificador denso, seguido por um decodificador temporal.
O codificador denso e o decodificador denso podem ser combinados em um único bloco. No entanto, os autores do método os separam, pois utilizam tamanhos diferentes de camadas ocultas nos dois blocos. Além disso, a última camada do bloco de decodificação é única no sentido de que seu tamanho de saída deve corresponder ao horizonte de planejamento.
A tarefa da etapa de codificação é mapear os dados passados e as covariáveis da série temporal em uma representação densa de características. A codificação no modelo TiDE tem duas etapas principais.
Primeiro, o bloco com feedback é utilizado para mapear as covariáveis em cada passo temporal (tanto no contexto do histórico quanto no horizonte de previsão) para uma projeção de menor dimensão.
Em seguida, combinamos e achatamos todas as covariáveis projetadas passadas e futuras, combinando-as com atributos estáticos e a série temporal passada. Depois, mapeamos isso para uma incorporação usando o codificador denso, que contém vários blocos com feedback.
A decodificação no modelo TiDE mapeia as representações ocultas codificadas para os futuros valores previstos das séries temporais. Ela também envolve duas operações: o decodificador denso e o decodificador temporal.
O decodificador denso é uma pilha de vários blocos com feedback, semelhantes aos blocos do codificador. Ele recebe como entrada os resultados do codificador e os mapeia para um vetor de representação dos estados previstos.
Na saída do modelo, utiliza-se o decodificador temporal para gerar as previsões finais. O decodificador temporal é um bloco com feedback semelhante, que mapeia o vetor decodificado para o t-ésimo passo temporal do horizonte de previsão, combinado com as covariáveis projetadas do período previsto.
Esta operação adiciona uma conexão das covariáveis do período de previsão aos valores previstos da série temporal. Isso pode ser útil se algumas covariáveis tiverem um impacto direto e forte no valor real em um determinado passo temporal. Por exemplo, o ambiente de notícias em certos dias do calendário.
Aos valores do decodificador temporal são adicionados os valores da conexão residual global, que mapeia linearmente o passado da série temporal analisada para o vetor do horizonte de planejamento. Isso garante que o modelo puramente linear seja sempre uma subclasse do modelo TiDE.
A visualização do método proposta pelos autores está apresentada abaixo.
O modelo é treinado usando descida de gradiente por mini-lotes. Os autores do método utilizam o erro quadrático médio (MSE) como função de perda. Cada época inclui todos os pares de passado e horizonte de previsão que podem ser construídos a partir do período de treinamento. Ou seja, dois mini-lotes podem ter pontos temporais sobrepostos.
2. Implementação com MQL5
Após a análise dos aspectos teóricos do algoritmo TiDE, passamos à implementação das abordagens propostas usando MQL5.
Como mencionado acima, o principal "bloco" do método TiDE é o bloco com feedback. Nele, os autores do método utilizam camadas totalmente conectadas. Mas é importante notar que cada bloco desse tipo no modelo é aplicado a um canal independente. Ao mesmo tempo, os parâmetros treináveis do bloco são treinados globalmente e são os mesmos para todos os canais da série temporal multidimensional analisada.
É claro que, em nossa implementação, gostaríamos de realizar o cálculo paralelo para todos os canais independentes da série temporal multidimensional analisada. Em casos semelhantes, já utilizamos camadas convolucionais com vários filtros de convolução. O tamanho da janela de tal camada convolucional é igual ao seu passo e corresponde ao volume de dados de um canal. Acredito que seja óbvio que ele é equivalente à profundidade do histórico da série temporal analisada.
E já que chegamos ao uso de camadas convolucionais, lembro-me do bloco com feedback que criamos ao implementar o método CCMR. O leitor atento notará a diferença na presença de camadas de normalização, que usamos na implementação mencionada. No entanto, no âmbito do trabalho neste artigo, decidi ignorar essa diferença na arquitetura do bloco e utilizar o bloco pronto CResidualConv para construir o novo modelo.
Bem, temos o "bloco" básico do algoritmo proposto TiDE. Agora precisamos montar todo o algoritmo a partir desses blocos.
2.1 Classe do algoritmo TiDE
A implementação das abordagens propostas será encapsulada em uma nova classe CNeuronTiDEOCL, que criaremos como herdeira da classe base de camadas neurais de nosso modelo CNeuronBaseOCL. Para a arquitetura de nossa nova classe, os quatro parâmetros principais são fundamentais, para os quais declararemos variáveis locais:
- iHistory — profundidade do histórico analisado da série temporal;
- iForecast — horizonte de previsão da série temporal.
- iVariables — número de variáveis analisadas (canais);
- iFeatures — número de covariáveis da série temporal.
class CNeuronTiDEOCL : public CNeuronBaseOCL { protected: uint iHistory; uint iForecast; uint iVariables; uint iFeatures; //--- CResidualConv acEncoderDecoder[]; CNeuronConvOCL cGlobalResidual; CResidualConv acFeatureProjection[2]; CResidualConv cTemporalDecoder; //--- CNeuronBaseOCL cHistoryInput; CNeuronBaseOCL cFeatureInput; CNeuronBaseOCL cEncoderInput; CNeuronBaseOCL cTemporalDecoderInput; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); public: CNeuronTiDEOCL(void) {}; ~CNeuronTiDEOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint history, uint forecast, uint variables, uint features, uint &encoder_decoder[], ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronTiDEOCL; } virtual void SetOpenCL(COpenCLMy *obj); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); };
Como pode ser observado, entre as variáveis mencionadas, não há o número de blocos nem no Codificador nem no Decodificador do modelo. Em nossa implementação, combinamos o Codificador e o Decodificador em um único array de blocos acEncoderDecoder[]. O tamanho desse array indicará o número total de blocos com feedback utilizados para codificar os dados históricos e decodificar os valores previstos da série temporal.
Além disso, dividimos a projeção das covariáveis da série temporal em 2 blocos (acFeatureProjection[2]). Em um bloco, geramos a projeção das covariáveis para codificação dos dados históricos, e no outro, para decodificação dos valores previstos.
Também adicionaremos um bloco de decodificação temporal cTemporalDecoder. E para a conexão residual global, utilizaremos uma camada convolucional cGlobalResidual.
Adicionalmente, declararemos 4 camadas totalmente conectadas locais para armazenar valores intermediários. O propósito específico de cada camada será esclarecido durante a implementação.
Todos os objetos em nossa classe foram declarados como estáticos, o que nos permite deixar o construtor e o destrutor da classe "vazios".
Devo dizer que o conjunto de métodos substituíveis é bastante padrão. E, como de costume, começaremos sua análise com o método de inicialização do objeto da classe CNeuronTiDEOCL::Init.
bool CNeuronTiDEOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint history, uint forecast, uint variables, uint features, uint &encoder_decoder[], ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, forecast * variables, optimization_type, batch)) return false;
Nos parâmetros, o método recebe todas as informações necessárias para a implementação da arquitetura exigida. No corpo do método, primeiro chamamos o método de mesmo nome da classe base, onde são realizados o controle mínimo necessário dos parâmetros recebidos e a inicialização dos objetos herdados.
Após a execução bem-sucedida das operações do método de inicialização da classe base, salvamos os valores das constantes-chave.
iHistory = MathMax(history, 1); iForecast = forecast; iVariables = variables; iFeatures = MathMax(features, 1);
Em seguida, passamos para a inicialização dos objetos internos. Primeiro, inicializamos os blocos de projeção das covariáveis.
if(!acFeatureProjection[0].Init(0, 0, OpenCL, iFeatures, iHistory * iVariables, 1, optimization, iBatch)) return false; if(!acFeatureProjection[1].Init(0, 1, OpenCL, iFeatures, iForecast * iVariables, 1, optimization, iBatch)) return false;
Vale mencionar que, em nosso experimento, não utilizamos nenhum conhecimento prévio sobre as covariáveis da série temporal analisada. Em vez disso, projetamos sobre a sequência temporal as harmônicas do carimbo de tempo. Além disso, geraremos projeções próprias para cada canal (variável) do canal temporal multidimensional analisado.
As dimensões das camadas ocultas do codificador e do decodificador são obtidas na forma de um array encoder_decoder[]. O tamanho do array indica o número total de blocos com feedback no codificador e no decodificador. E o valor dos elementos do array indica a dimensionalidade do bloco correspondente. Lembramos que o codificador recebe como entrada o vetor concatenado dos dados históricos da série temporal com a projeção das covariáveis. E na saída do decodificador, precisamos obter um vetor que corresponda ao horizonte de previsão. Para atender a esse requisito, adicionaremos mais um bloco na saída do decodificador, com o tamanho necessário.
int total = ArraySize(encoder_decoder); if(ArrayResize(acEncoderDecoder, total + 1) < total + 1) return false; if(total == 0) { if(!acEncoderDecoder[0].Init(0, 2, OpenCL, 2 * iHistory, iForecast, iVariables, optimization, iBatch)) return false; } else { if(!acEncoderDecoder[0].Init(0, 2, OpenCL, 2 * iHistory, encoder_decoder[0], iVariables, optimization, iBatch)) return false; for(int i = 1; i < total; i++) if(!acEncoderDecoder[i].Init(0, i + 2, OpenCL, encoder_decoder[i - 1], encoder_decoder[i], iVariables, optimization, iBatch)) return false; if(!acEncoderDecoder[total].Init(0, total + 2, OpenCL, encoder_decoder[total - 1], iForecast, iVariables, optimization, iBatch)) return false; }
Em seguida, inicializamos o bloco de decodificação temporal e a camada de feedback global.
if(!cGlobalResidual.Init(0, total + 3, OpenCL, iHistory, iHistory, iForecast, iVariables, optimization, iBatch)) return false; cGlobalResidual.SetActivationFunction(TANH); if(!cTemporalDecoder.Init(0, total + 4, OpenCL, 2 * iForecast, iForecast, iVariables, optimization, iBatch)) return false;
Aqui, é importante destacar dois pontos:
- O decodificador temporal recebe como entrada a matriz concatenada dos valores previstos da série temporal e as projeções das covariáveis previstas. E na saída do bloco, obtemos os valores previstos ajustados da série temporal.
- Na saída de cada bloco CResidualConv, é realizada a normalização dos dados: a média de cada canal é "0", e a variância é "1". Para ajustar os dados globais do bloco de feedback para um formato comparável, utilizamos a tangente hiperbólica (tanh) como função de ativação da camada cGlobalResidual.
A próxima etapa é inicializar os objetos auxiliares para armazenar dados intermediários. Os dados históricos da série temporal multidimensional analisada e as covariáveis recebidas do programa externo serão armazenados em cHistoryInput e cFeatureInput, respectivamente.
if(!cHistoryInput.Init(0, total + 5, OpenCL, iHistory * iVariables, optimization, iBatch)) return false; if(!cFeatureInput.Init(0, total + 6, OpenCL, iFeatures, optimization, iBatch)) return false;
A matriz concatenada dos dados históricos e as projeções das covariáveis serão registradas em cEncoderInput.
if(!cEncoderInput.Init(0, total + 7, OpenCL, 2 * iHistory * iVariables, optimization,iBatch)) return false;
Os resultados do decodificador denso serão concatenados com as covariáveis dos valores previstos e registrados em cTemporalDecoderInput.
if(!cTemporalDecoderInput.Init(0, total + 8, OpenCL, 2 * iForecast * iVariables, optimization, iBatch)) return false;
No final do método de inicialização do objeto da classe, realizaremos a substituição dos buffers de dados para evitar cópias desnecessárias de gradientes de erro entre os buffers de dados dos elementos individuais da nossa classe.
if(cGlobalResidual.getGradient() != Gradient) if(!cGlobalResidual.SetGradient(Gradient)) return false; if(cTemporalDecoder.getGradient() != getGradient()) if(!cTemporalDecoder.SetGradient(Gradient)) return false; //--- return true; }
Após a conclusão da inicialização da instância da classe, passamos para a construção do algoritmo de propagação para frente, descrito no método CNeuronTiDEOCL::feedForward. Nos parâmetros do método, recebemos ponteiros para dois objetos que contêm os dados brutos. Esses são os dados históricos da série temporal multidimensional, na forma de um buffer de resultados da camada neural anterior, e as covariáveis, representadas por buffers de dados separados.
bool CNeuronTiDEOCL::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!NeuronOCL || !SecondInput) return false;
No corpo do método, verificamos imediatamente a validade dos ponteiros recebidos.
Em seguida, precisamos copiar os dados recebidos para os objetos internos. No entanto, em vez de transferir todo o volume de informações, apenas verificaremos os ponteiros para os buffers de dados e, se necessário, os copiaremos.
if(cHistoryInput.getOutputIndex() != NeuronOCL.getOutputIndex()) { CBufferFloat *temp = cHistoryInput.getOutput(); if(!temp.BufferSet(NeuronOCL.getOutputIndex())) return false; } if(cFeatureInput.getOutputIndex() != SecondInput.GetIndex()) { CBufferFloat *temp = cFeatureInput.getOutput(); if(!temp.BufferSet(SecondInput.GetIndex())) return false; }
Depois de realizar o trabalho preparatório, projetamos os dados históricos para a dimensionalidade dos valores previstos. Uma espécie de modelo autorregressivo.
if(!cGlobalResidual.FeedForward(NeuronOCL)) return false;
E geramos as projeções das covariáveis para os valores históricos e previstos.
if(!acFeatureProjection[0].FeedForward(NeuronOCL)) return false; if(!acFeatureProjection[1].FeedForward(cFeatureInput.AsObject())) return false;
Após isso, concatenamos os dados históricos com a matriz de projeção das covariáveis correspondente.
if(!Concat(NeuronOCL.getOutput(), acFeatureProjection[0].getOutput(), cEncoderInput.getOutput(), iHistory, iHistory, iVariables)) return false;
Então, organizamos o ciclo de operações do bloco de codificadores e decodificadores densos.
uint total = acEncoderDecoder.Size(); CNeuronBaseOCL *prev = cEncoderInput.AsObject(); for(uint i = 0; i < total; i++) { if(!acEncoderDecoder[i].FeedForward(prev)) return false; prev = acEncoderDecoder[i].AsObject(); }
Os resultados do decodificador são concatenados com a projeção das covariáveis dos valores previstos.
if(!Concat(prev.getOutput(), acFeatureProjection[1].getOutput(), cTemporalDecoderInput.getOutput(), iForecast, iForecast, iVariables)) return false;
A matriz concatenada serve como dados de entrada para o bloco do decodificador temporal.
if(!cTemporalDecoder.FeedForward(cTemporalDecoderInput.AsObject())) return false;
No final das operações de propagação para frente, somamos os resultados de dois fluxos de dados e normalizamos os resultados obtidos nos canais independentes.
if(!SumAndNormilize(cGlobalResidual.getOutput(), cTemporalDecoder.getOutput(), Output, iForecast, true)) return false; //--- return true; }
Após a propagação para frente, como sempre, segue-se a propagação reversa, que consiste em duas etapas. Primeiro, distribuímos o gradiente de erro entre todos os objetos internos e os dados brutos externos de acordo com sua influência no resultado no método CNeuronTiDEOCL::calcInputGradients. Nos parâmetros, o método recebe ponteiros para objetos para gravar os gradientes de erro dos dados brutos.
bool CNeuronTiDEOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!cTemporalDecoderInput.calcHiddenGradients(cTemporalDecoder.AsObject())) return false;
Lembro que, graças à substituição dos buffers de dados, não há necessidade de copiar os dados dos gradientes de erro da nossa classe para os buffers correspondentes dos objetos internos. Portanto, passamos imediatamente para a chamada dos métodos de distribuição do gradiente de erro dos blocos internos em ordem inversa à da propagação para frente.
Primeiro, passamos o gradiente de erro pelo bloco do decodificador temporal. Distribuímos o resultado das operações entre o decodificador denso e a projeção das covariáveis da série prevista.
int total = (int)acEncoderDecoder.Size(); if(!DeConcat(acEncoderDecoder[total - 1].getGradient(), acFeatureProjection[1].getGradient(), cTemporalDecoderInput.getGradient(), iForecast, iForecast, iVariables)) return false;
Em seguida, distribuímos o gradiente de erro através do bloco de codificadores e decodificadores densos.
for(int i = total - 2; i >= 0; i--) if(!acEncoderDecoder[i].calcHiddenGradients(acEncoderDecoder[i + 1].AsObject())) return false; if(!cEncoderInput.calcHiddenGradients(acEncoderDecoder[0].AsObject())) return false;
O gradiente de erro no nível dos dados brutos do codificador denso é distribuído entre os dados históricos da série temporal multidimensional e suas covariáveis correspondentes.
if(!DeConcat(cHistoryInput.getGradient(), acFeatureProjection[0].getGradient(), cEncoderInput.getGradient(), iHistory, iHistory, iVariables)) return false;
Depois, ajustamos o gradiente de erro da camada de feedback global pela derivada da função de ativação.
if(cGlobalResidual.Activation() != None) { if(!DeActivation(cGlobalResidual.getOutput(), cGlobalResidual.getGradient(), cGlobalResidual.getGradient(), cGlobalResidual.Activation())) return false; }
E passamos o gradiente de erro para o nível dos dados brutos.
if(!NeuronOCL.calcHiddenGradients(cGlobalResidual.AsObject())) return false;
Neste ponto, ajustamos o gradiente de erro do segundo fluxo de dados pela derivada da função de ativação da camada anterior.
if(NeuronOCL.Activation()!=None) if(!DeActivation(cHistoryInput.getOutput(),cHistoryInput.getGradient(), cHistoryInput.getGradient(),SecondActivation)) return false;
Depois, somamos os gradientes de erro de ambos os fluxos de dados.
if(!SumAndNormilize(NeuronOCL.getGradient(), cHistoryInput.getGradient(), NeuronOCL.getGradient(), iHistory, false, 0, 0, 0, 1)) return false;
Neste estágio, o gradiente de erro foi transmitido ao nível dos dados históricos da série temporal multidimensional. Agora só resta passar o gradiente de erro para as covariáveis.
Aqui, vale destacar que, no âmbito do nosso experimento, esse processo é redundante. Afinal, as covariáveis que usamos são harmônicas do carimbo de tempo, definidas por uma fórmula, e essa fórmula não é ajustada durante o treinamento. No entanto, ainda criamos o processo de transmissão do gradiente para o nível das covariáveis como uma "preparação para o futuro". Em experimentos posteriores, pode haver o uso de diferentes modelos de aprendizado para as covariáveis da série temporal.
Primeiro, transmitimos o gradiente de erro das covariáveis dos dados históricos. Os valores obtidos são transferidos para o buffer de gradientes das covariáveis.
if(!cFeatureInput.calcHiddenGradients(acFeatureProjection[0].AsObject())) return false; if(!SumAndNormilize(cFeatureInput.getGradient(), cFeatureInput.getGradient(), SecondGradient, iFeatures, false, 0, 0, 0, 0.5f)) return false;
Em seguida, calculamos os gradientes das covariáveis dos valores previstos e somamos o resultado dos dois fluxos de dados.
if(!cFeatureInput.calcHiddenGradients(acFeatureProjection[1].AsObject())) return false; if(!SumAndNormilize(SecondGradient, cFeatureInput.getGradient(), SecondGradient, iFeatures, false, 0, 0, 0, 1.0f)) return false;
Se necessário, ajustamos o gradiente de erro pela derivada da função de ativação.
if(SecondActivation!=None) if(!DeActivation(SecondInput,SecondGradient,SecondGradient,SecondActivation)) return false; //--- return true; }
A segunda etapa da propagação reversa é o ajuste dos parâmetros treináveis do modelo. Essa funcionalidade é criada no método 1>CNeuronTiDEOCL::updateInputWeights . O algoritmo deste método é bastante simples. Chamamos sequencialmente o método correspondente de todos os objetos internos que possuem parâmetros treináveis.
bool CNeuronTiDEOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { //--- if(!cGlobalResidual.UpdateInputWeights(cHistoryInput.AsObject())) return false; if(!acFeatureProjection[0].UpdateInputWeights(cHistoryInput.AsObject())) return false; if(!acFeatureProjection[1].UpdateInputWeights(cFeatureInput.AsObject())) return false; //--- uint total = acEncoderDecoder.Size(); CNeuronBaseOCL *prev = cEncoderInput.AsObject(); for(uint i = 0; i < total; i++) { if(!acEncoderDecoder[i].UpdateInputWeights(prev)) return false; prev = acEncoderDecoder[i].AsObject(); } //--- if(!cTemporalDecoder.UpdateInputWeights(cTemporalDecoderInput.AsObject())) return false; //--- return true; }
Gostaria de dizer algumas palavras sobre os métodos de manipulação de arquivos. Para economizar espaço em disco, salvamos apenas as constantes-chave e os objetos com parâmetros treináveis.
bool CNeuronTiDEOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; //--- if(FileWriteInteger(file_handle, (int)iHistory, INT_VALUE) < INT_VALUE) return false; if(FileWriteInteger(file_handle, (int)iForecast, INT_VALUE) < INT_VALUE) return false; if(FileWriteInteger(file_handle, (int)iVariables, INT_VALUE) < INT_VALUE) return false; if(FileWriteInteger(file_handle, (int)iFeatures, INT_VALUE) < INT_VALUE) return false; //--- uint total = acEncoderDecoder.Size(); if(FileWriteInteger(file_handle, (int)total, INT_VALUE) < INT_VALUE) return false; for(uint i = 0; i < total; i++) if(!acEncoderDecoder[i].Save(file_handle)) return false; if(!cGlobalResidual.Save(file_handle)) return false; for(int i = 0; i < 2; i++) if(!acFeatureProjection[i].Save(file_handle)) return false; if(!cTemporalDecoder.Save(file_handle)) return false; //--- return true; }
No entanto, isso complica um pouco o algoritmo do método de carregamento de dados CNeuronTiDEOCL::Load. Como antes, nos parâmetros, o método recebe o identificador do arquivo para carregar os dados. Primeiro, carregamos os dados do objeto pai.
bool CNeuronTiDEOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false;
Em seguida, lemos os valores das principais constantes.
if(FileIsEnding(file_handle)) return false; iHistory = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false; iForecast = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false; iVariables = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false; iFeatures = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false;
Depois, precisamos carregar os dados do bloco de codificadores e decodificadores densos. Mas aqui surge o primeiro detalhe. Lemos o tamanho da pilha de blocos do arquivo de dados. Esse tamanho pode ser maior ou menor que o tamanho atual de nosso array acEncoderDecoder. Se necessário, ajustamos o tamanho do array.
int total = FileReadInteger(file_handle); int prev_size = (int)acEncoderDecoder.Size(); if(prev_size != total) if(ArrayResize(acEncoderDecoder, total) < total) return false;
Depois, organizamos um ciclo e lemos os dados dos blocos do arquivo. No entanto, antes de chamar o método de carregamento de dados dos elementos adicionados ao array, precisamos inicializá-los. Isso não se aplica aos objetos criados anteriormente, pois eles foram inicializados nas etapas anteriores.
for(int i = 0; i < total; i++) { if(i >= prev_size) if(!acEncoderDecoder[i].Init(0, i + 2, OpenCL, 1, 1, 1, ADAM, 1)) return false; if(!LoadInsideLayer(file_handle, acEncoderDecoder[i].AsObject())) return false; }
Em seguida, carregamos os objetos de feedback global, projeções das covariáveis e o decodificador temporal. Aqui, não há "armadilhas".
if(!LoadInsideLayer(file_handle, cGlobalResidual.AsObject())) return false; for(int i = 0; i < 2; i++) if(!LoadInsideLayer(file_handle, acFeatureProjection[i].AsObject())) return false; if(!LoadInsideLayer(file_handle, cTemporalDecoder.AsObject())) return false;
Neste ponto, carregamos todos os dados salvos. No entanto, ainda temos objetos auxiliares que inicializamos de forma semelhante ao algoritmo de inicialização da classe.
if(!cHistoryInput.Init(0, total + 5, OpenCL, iHistory * iVariables, optimization, iBatch)) return false; if(!cFeatureInput.Init(0, total + 6, OpenCL, iFeatures, optimization, iBatch)) return false; if(!cEncoderInput.Init(0, total + 7, OpenCL, 2 * iHistory * iVariables, optimization,iBatch)) return false; if(!cTemporalDecoderInput.Init(0, total + 8, OpenCL, 2 * iForecast * iVariables,optimization, iBatch)) return false;
Se necessário, também realizamos a substituição dos buffers de dados.
if(cGlobalResidual.getGradient() != Gradient) if(!cGlobalResidual.SetGradient(Gradient)) return false; if(cTemporalDecoder.getGradient() != getGradient()) if(!cTemporalDecoder.SetGradient(Gradient)) return false; //--- return true; }
Com o código completo de todos os métodos da nossa nova classe, você pode se familiarizar no anexo. Lá, você também encontrará métodos auxiliares da classe que não foram discutidos neste artigo. O algoritmo desses métodos é bastante simples para estudo independente. Agora, passamos a analisar a arquitetura dos modelos treináveis.
2.2 Arquitetura dos modelos treináveis
Acredito que não será difícil deduzir que a nova classe do método TiDE foi inserida na arquitetura do Codificador de estado do ambiente. Foi exatamente isso que fizemos com todos os algoritmos de previsão de estados futuros da série temporal discutidos anteriormente. Como você deve se lembrar, a arquitetura do Codificador é descrita no método CreateEncoderDescriptions. Nos parâmetros desse método, recebemos um ponteiro para o objeto de array dinâmico para registrar a arquitetura do modelo que está sendo criado.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
No corpo do método, verificamos o ponteiro recebido e, se necessário, criamos uma nova instância do objeto de array dinâmico.
Os dados brutos que alimentam o modelo são, como antes, os dados históricos não processados recebidos do terminal.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Esses dados passam por um processamento inicial na camada de normalização em lotes, onde são ajustados para um formato comparável.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Gostaria de lembrar que, no processo de coleta de dados históricos sobre o estado do ambiente, organizamos os dados com base nas velas (candles). O algoritmo do método TiDE prevê a análise de dados com base em canais independentes de características individuais. Para manter a capacidade de usar os buffers de replay de experiência coletados anteriormente para o treinamento do novo modelo, optamos por não refazer o bloco de coleta de dados. Em vez disso, adicionamos uma camada de transposição de dados, que ajusta os dados brutos para o formato necessário.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, vem nossa nova camada de implementação das abordagens do método TiDE.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTiDEOCL;
O número de canais independentes analisados é igual ao tamanho do vetor que descreve uma vela do estado do ambiente.
descr.count = BarDescr;
Ao mesmo tempo, a profundidade dos dados históricos analisados e o horizonte dos valores previstos são determinados por constantes apropriadas.
descr.window = HistoryBars; descr.window_out = NForecast;
A marca temporal é representada por um vetor de 4 harmônicas: ano, mês, semana e dia.
descr.step = 4;
A arquitetura do bloco codificador-decodificador denso é definida como um array de valores, conforme discutido durante a construção da classe.
{
int windows[]={HistoryBars,2*EmbeddingSize,EmbeddingSize,2*EmbeddingSize,NForecast};
if(ArrayCopy(descr.windows,windows)<=0)
return false;
}
Todas as funções de ativação são especificadas nos objetos internos da classe, portanto, não precisamos especificá-las aqui.
descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Lembro que, dentro da camada CNeuronTiDEOCL, a normalização de dados é realizada várias vezes. E para corrigir o deslocamento dos valores previstos, utilizaremos uma camada convolucional sem função de ativação, que executa uma simples função de deslocamento linear dentro dos canais independentes.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = NForecast; descr.step = NForecast; descr.window_out = NForecast; descr.activation=None; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, transponemos os valores previstos para a dimensionalidade da representação original dos dados.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
E retornamos os indicadores estatísticos da distribuição dos dados brutos.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr*NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Com a mudança na arquitetura do Codificador de estado do ambiente, dois pontos precisam de atenção. O primeiro é o ponteiro para a camada que extrai o estado oculto dos valores previstos do ambiente.
#define LatentLayer 4
O segundo é o tamanho desse estado oculto. Se, no artigo anterior, a saída do Codificador de estado incluía a descrição dos dados históricos e dos valores previstos, agora temos apenas os valores previstos. Portanto, precisamos fazer os ajustes apropriados nas arquiteturas dos modelos do Ator e do Crítico.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- ........ ........ //--- Actor ........ ........ //--- layer 2-12 for(int i = 0; i < 10; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } } ........ ........ //--- Critic ........ ........ //--- layer 2-12 for(int i = 0; i < 10; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } } ........ ........ //--- return true; }
Observe que, nesta implementação, continuamos utilizando os algoritmos Transformer nos modelos do Ator e do Crítico. No entanto, realizamos cross-attention nos canais independentes dos valores previstos. Você pode, entretanto, experimentar o uso de cross-attention nos valores previstos organizados em velas. Apenas não se esqueça de alterar o ponteiro para a camada do estado oculto do Codificador, bem como o número de objetos analisados e o tamanho da janela de descrição de um objeto.
2.3 EA de treinamento do Codificador de estado
A próxima etapa do nosso trabalho é o treinamento dos modelos. Aqui, algumas modificações no algoritmo dos EAs de treinamento de modelos foram necessárias. Principalmente no que se refere ao trabalho com o modelo do Codificador de estado do ambiente, pois foi nessa parte que adicionamos a nova classe. Neste artigo, não vamos examinar detalhadamente todos os métodos do EA de treinamento do modelo "...\Experts\TiDE\StudyEncoder.mq5", focando apenas no método de treinamento da função `Train`.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
O início do método mantém o algoritmo discutido nos artigos anteriores. Aqui vemos a já familiar preparação inicial.
Em seguida, temos o ciclo de treinamento do modelo, no qual amostramos uma trajetória do buffer de replay de experiência e seu estado.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
Como antes, carregamos os dados históricos que descrevem o estado do ambiente.
bState.AssignArray(Buffer[tr].States[i].state);
Mas agora, para gerar os valores previstos, também precisamos dos dados das covariáveis. Ao construir o modelo, decidimos usar as harmônicas da data do estado do ambiente. Esperamos que o modelo aprenda sua projeção nos valores históricos e previstos.
Prepararemos o buffer das harmônicas do carimbo de tempo.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Agora, podemos chamar o método de propagação para frente do Codificador de estado do ambiente.
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Depois, como de costume, preparamos os valores-alvo.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
E chamamos o método de propagação reversa do Codificador.
if(!Encoder.backProp(Result, GetPointer(bTime), GetPointer(bTimeGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Aqui, vale notar que, nos parâmetros do método de propagação reversa, além dos valores-alvo, fornecemos ponteiros para os buffers das harmônicas do carimbo de tempo e seus gradientes de erro. À primeira vista, poderíamos não usar os gradientes de erro e, em vez disso, passar o próprio buffer das harmônicas no lugar dos gradientes. Afinal, não utilizamos os gradientes de erro das harmônicas em trabalhos futuros, e as próprias harmônicas serão sobrescritas na próxima iteração. Por que então criar um buffer extra na memória?
No entanto, quero alertá-lo contra essa decisão precipitada. O fato é que, após a propagação do gradiente de erro, realizamos a correção dos parâmetros do modelo. Para ajustar os pesos, cada camada utiliza o gradiente de erro na saída da camada e os dados de entrada. Portanto, se sobrescrevermos as harmônicas da marca temporal com os gradientes de erro, ao atualizar os parâmetros projetando-os nas covariáveis dos dados históricos e nos estados previstos, obteremos gradientes distorcidos dos coeficientes de peso. E, como resultado, uma correção distorcida dos parâmetros do modelo. Acho que não preciso dizer que, nesse caso, o aprendizado da modelo seguirá em uma direção imprevisível.
Após a execução bem-sucedida das operações de propagação para frente e propagação reversa do Codificador, informamos o usuário sobre o andamento do processo de treinamento e passamos para a próxima iteração do ciclo de treinamento.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
O processo de treinamento do modelo se repete até que o número especificado de iterações do ciclo, indicado nos parâmetros externos do ciclo, seja concluído. E, após a conclusão do treinamento, limpamos o campo de comentários no gráfico do instrumento.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Registramos os resultados do treinamento do modelo no diário do terminal e iniciamos o encerramento do trabalho do EA.
No EA de treinamento dos modelos Ator e Crítico "...\\Experts\\TiDE\\Study.mq5" também fazemos ajustes semelhantes no funcionamento do modelo de Codificação do estado do ambiente. Mas não vamos nos aprofundar na descrição desses ajustes agora. Afinal, com a descrição apresentada acima, você facilmente encontrará blocos semelhantes no código do EA por conta própria. O código completo do EA pode ser encontrado no anexo. Lá também estão os EAs de interação com o ambiente e coleta de dados de treinamento, que contêm correções semelhantes.
3. Testes
Acima, conhecemos um novo método de previsão de séries temporais Time-series Dense Encoder (TiDE) e implementamos nossa visão dos métodos propostos usando MQL5.
Como já foi dito anteriormente, mantivemos a estrutura dos dados de entrada das modelos anteriores, o que nos permite utilizar os dados já coletados para o treinamento dos novos modelos.
Lembro que o treinamento de todas as modelos é feito com dados históricos do ativo EURUSD no timeframe H1. É natural que, à medida que os artigos são escritos, o tempo fora da janela também mude. Atualmente, para o treinamento dos meus modelos, utilizo dados históricos reais de 2023. E o teste dos modelos treinados é realizado no testador de estratégias do MetaTrader 5 com os dados de janeiro de 2024. O período de teste segue o período de treinamento, para avaliar o desempenho do modelo com novos dados, que não fazem parte do conjunto de treinamento. Assim, aproximamos ao máximo as condições de quando o modelo trabalha em tempo real com dados novos, que fisicamente não estavam disponíveis no momento do treinamento.
Como em vários artigos anteriores, o modelo de Codificação do estado do ambiente não depende do saldo da conta nem das posições abertas. Portanto, podemos treinar o modelo mesmo em um conjunto de dados de treinamento com uma única passagem de interação com o ambiente, até atingir a precisão desejada na previsão dos estados futuros. Naturalmente, a "precisão desejada da previsão" não pode exceder as capacidades do próprio modelo. Você deve lembrar que "não se pode pular mais alto do que a própria cabeça".
Após o treinamento do modelo de previsão dos estados do ambiente, passamos para a segunda etapa — o treinamento da política de comportamento do Ator. Nesta fase, treinamos iterativamente os modelos do Ator e do Crítico, com a atualização periódica do buffer de reprodução de experiência.
Lembro que, por atualização do buffer de reprodução de experiência, nos referimos ao descarte adicional da experiência de interação com o ambiente, levando em consideração a política de comportamento atualizada do Ator. Afinal, o ambiente financeiro que estamos estudando é bastante multifacetado. E não podemos coletar completamente todas as suas manifestações no buffer de reprodução de experiência. Fazemos apenas um pequeno corte em uma pequena vizinhança das ações da política atual do Ator. Analisando esse corte, damos um pequeno passo no caminho da otimização da política de comportamento do nosso Ator. E, ao nos aproximarmos dos limites desse corte, precisamos coletar dados adicionais, expandindo a área visível nas proximidades da política atualizada do Ator.
Como resultado dessas iterações, consegui treinar uma política de Ator capaz de gerar tanto na amostra de treinamento quanto na amostra de teste.


No gráfico acima, vemos uma operação com prejuízo no início, que é seguida por uma tendência claramente lucrativa. Sim, a proporção de operações lucrativas é inferior a 40%. Praticamente, para cada operação lucrativa, há duas operações com prejuízo. No entanto, observamos que as operações com prejuízo são significativamente menores que as operações lucrativas. A operação lucrativa média é quase duas vezes maior que a operação com prejuízo média. Tudo isso permite que o modelo obtenha lucro no período de teste. Ao final do teste, o fator de lucro foi de 1,23.
Considerações finais
Neste artigo, conhecemos o modelo original TiDE (Time-series Dense Encoder), projetado para previsão de séries temporais de longo prazo. Este modelo difere dos modelos lineares clássicos e dos Transformers, pois utiliza perceptrons multicamadas (MLP) tanto para codificar os dados passados e covariáveis quanto para decodificar as previsões futuras.
Os experimentos realizados pelos autores do método demonstram que a aplicação de modelos MLP tem grande potencial na solução de problemas de análise e previsão de séries temporais. Além disso, o TiDE possui complexidade computacional linear, ao contrário dos Transformers, o que o torna mais eficiente ao lidar com grandes volumes de dados.
Na parte prática deste artigo, implementamos nossa própria visão dos métodos propostos, que difere um pouco da visão dos autores. No entanto, os resultados obtidos indicam a eficácia do método proposto. E sim, o treinamento do modelo é significativamente mais rápido do que o dos Transformers analisados anteriormente.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA de coleta de exemplos pelo método Real-ORL |
| 3 | Study.mq5 | EA | EA de treinamento de Modelos |
| 4 | StudyEncoder.mq5 | EA | EA de treinamento do Codificador |
| 5 | Test.mq5 | EA | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código para programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/14812
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Olá, Dmitriy,
Usar o MLP em vez de outras redes mais complexas é bastante interessante, especialmente porque os resultados são melhores.
Infelizmente, encontrei vários erros ao testar esse algoritmo. Aqui estão algumas das principais linhas do registro:
2024.11.15 00:15:51.269 Core 01 Iterations=100000
2024.11.15 00:15:51.269 Core 01 2024.01.01 00:00:00 TiDEEnc.nnw
2024.11.15 00:15:51.269 Core 01 2024.01.01 00:00:00 Criar novo modelo
2024.11.15 00:15:51.269 Core 01 2024.01.01 00:00:00 OpenCL: Dispositivo de GPU 'GeForce GTX 1060' selecionado
2024.11.15 00:15:51.269 Core 01 2024.01.01 00:00:00 Erro de execução do kernel bool CNeuronBaseOCL::SumAndNormilize(CBufferFloat*,CBufferFloat*,CBufferFloat*,CBufferFloat*,int,bool,int,int,int,float) MatrixSum: erro desconhecido de OpenCL 65536
2024.11.15 00:15:51.269 Core 01 2024.01.01 00:00:00 Train -> 164
2024.11.15 00:15:51.269 Core 01 2024.01.01 00:00:00 Trem -> 179 -> Codificador 1543.0718994
2024.11.15 00:15:51.269 Core 01 2024.01.01 00:00:00:00 Função ExpertRemove() chamada
Você tem alguma ideia do que poderia ser o motivo?
Antes, o OpenCL funcionava muito bem.
Chris.
2024.11.15 00:15:51.269 Core 01 2024.01.01 00:00:00 Train -> 164
2024.11.15 00:15:51.269 Core 01 2024.01.01 00:00:00 Train -> 179 -> Encoder 1543.0718994
2024.11.15 00:15:51.269 Core 01 2024.01.01 00:00:00:00 Função ExpertRemove() chamada
Você tem alguma ideia do que poderia ser o motivo?
Antes, o OpenCL funcionava muito bem.
Chris.
Oi, Chris.
Você fez algumas alterações na arquitetura do modelo ou usou modelos padrão do artigo?
Oi, Chris.
Você fez algumas alterações na arquitetura do modelo ou usou modelos padrão do artigo?
Olá. Não foram feitas alterações. Simplesmente copiei a pasta "Experts" por completo e executei os scripts como estavam, após a compilação, nesta ordem: "Research", "StudyEncoder", "Study" e "Test". Os erros apareceram no estágio "Test". A única diferença foi o instrumento, ou seja, a mudança de EURUSD para EURJPY.
Chris
Dmitriy, tenho uma correção importante. O erro apareceu depois de iniciar o StudyEncoder. Aqui está outro exemplo:
2024.11.18 03:23:51.770 Core 01 Iterations=100000
2024.11.18 03:23:51.770 Core 01 2023.11.01 00:00:00 TiDEEnc.nnw
2024.11.18 03:23:51.770 Core 01 2023.11.01 00:00:00:00 Criar novo modelo
2024.11.18 03:23:51.770 Core 01 opencl.dll successfully loaded
2024.11.18 03:23:51.770 Core 01 device #0: GPU 'GeForce GTX 1060' com OpenCL 1.2 (10 unidades, 1771 MHz, 6144 Mb, versão 457.20, classificação 4444)
2024.11.18 03:23:51.770 Core 01 2023.11.01 00:00:00 OpenCL: dispositivo de GPU 'GeForce GTX 1060' selecionado
2024.11.18 03:23:51.770 Core 01 2023.11.01 00:00:00 Erro de execução do kernel bool CNeuronBaseOCL::SumAndNormilize(CBufferFloat*,CBufferFloat*,CBufferFloat*,CBufferFloat*,int,bool,int,int,int,float) MatrixSum: erro desconhecido de OpenCL 65536
2024.11.18 03:23:51.770 Core 01 2023.11.01 00:00:00 Train -> 164
2024.11.18 03:23:51.770 Core 01 2023.11.01 00:00:00 Train -> 179 -> Encoder 1815.1101074
2024.11.18 03:23:51.770 Core 01 2023.11.01 00:00:00 ExpertRemove() function called
Chris