
MQL5-Assistent-Techniken, die Sie kennen sollten (Teil 31): Auswahl der Verlustfunktion
Einführung
Der MQL5-Assistent kann ein Prüfstand für eine Vielzahl von Ideen sein, wie wir bisher in dieser Serie behandelt haben. Und hin und wieder kommt es vor, dass ein nutzerdefiniertes Signal auf mehr als eine Weise implementiert werden kann. Wir haben uns dieses Szenario in den beiden Artikeln über Lernraten sowie im letzten Artikel über die Stapelnormalisierung angesehen. Jeder dieser Aspekte des maschinellen Lernens bietet mehr als ein potenzielles nutzerdefiniertes Signal, wie erörtert wurde. Die Verlustfunktion befindet sich aufgrund der Tatsache, dass es mehrere Formate gibt, in einer ähnlichen Situation.
Es gibt keine einheitliche Methode, wie das Ergebnis eines Testlaufs mit seinem Ziel verglichen wird. Betrachten wir die Enumerationen von ENUM_LOSS_FUNCTION, es sind 14, und diese Liste ist noch nicht einmal vollständig. Bedeutet dies, dass jede von ihnen einen eigenen Weg zum Training im maschinellen Lernen bietet? Wahrscheinlich nicht, aber der Punkt ist, dass es Unterschiede gibt, einige nuanciert, und diese Unterschiede können oft bedeuten, dass Sie Ihre Verlustfunktion sorgfältig auswählen müssen, abhängig von der Art des Netzes oder des Algorithmus, den Sie trainieren.
Neben der Verlustfunktion könnte man jedoch auch die Verwendung der ENUM_REGRESSION_METRIC in Betracht ziehen, doch wäre diese eher statistische Metrik ungeeignet, da sie besser als Post-Training-Metrik zur Bewertung der Leistung eines Algorithmus für maschinelles Lernen geeignet ist. Insbesondere in Fällen, in denen die endgültige Ausgabe mehr als eine Dimension hat, wäre diese metrische Enumeration sehr hilfreich. Dieser Artikel konzentriert sich jedoch auf die Zielfunktion.
Und die Auswahl der geeigneten Verlustfunktion ist von entscheidender Bedeutung, da neuronale Netze (unser Algorithmus für maschinelles Lernen in diesem Artikel) im Prinzip in die Kategorie Regressoren versus Klassifikatoren oder in die Kategorie überwacht versus unüberwacht fallen können. Darüber hinaus werden Paradigmen wie bestärkendes Lernen einen vielschichtigen Ansatz bei der Verwendung und Anwendung der Verlustfunktion erfordern.
Verlustfunktionen können also auf verschiedene Weise angewendet werden, nicht nur, weil es viele Formate gibt, sondern auch, weil es eine Vielzahl von „Problemen“ (Typen neuronaler Netze) zu lösen gibt. Bei der Lösung dieser Probleme oder beim Training quantifiziert die Verlustfunktion in erster Linie, wie weit die getesteten Parameter von ihrem angestrebten Ziel entfernt sind, ein Prozess, der auch als überwachtes Lernen bezeichnet wird.
Auch wenn die Verlustfunktion immer intuitiv erscheint, dass sie für überwachtes Training gedacht ist, könnte die Frage nach der idealen Verlustfunktion für unüberwachtes Lernen abwegig erscheinen. Nichtsdestotrotz besteht selbst in unüberwachten Umgebungen wie Kohonen-Karten oder Clustering immer die Notwendigkeit, eine standardisierte Metrik zur Messung von Lücken oder Abständen in mehrdimensionalen Daten zu haben, und die Verlustfunktion würde diese Lücke füllen.
Überblick über die Verlustfunktionen
MQL5 bietet also bis zu 14 verschiedene Methoden zur Quantifizierung der Verlustfunktion, und wir werden auf alle eingehen, bevor wir Anwendungsfälle betrachten. Für unseren Zweck wird als Verlust der Verlustgradient verwendet, und die erwarteten Ergebnisse sind Vektoren, keine skalaren Werte. Außerdem wird der MQL5-Code, der diese Formeln implementiert, nicht gemeinsam genutzt, da sie ALLE von eingebauten Vektorfunktionen ausgeführt werden. Im Folgenden wird ein einfaches Skript zum Testen der verschiedenen Verlustfunktionen vorgestellt:
#property script_show_inputs input ENUM_LOSS_FUNCTION __loss = LOSS_HUBER; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector _a = {1.0, 2.0, 4.0}; vector _b = {4.0, 12.0, 36.0 }; vector _loss = _a.LossGradient(_b,__loss); printf(__FUNCSIG__+" for: "+EnumToString(__loss)); Print(" loss gradient is: ",_loss); PrintFormat(" while loss is: %.5f. ",_a.Loss(_b,__loss)); } //+------------------------------------------------------------------+
Der erste Schritt ist die mittlere quadratische Abweichung (MSE). Dies ist eine weit verbreitete Verlustfunktion, deren Ziel es ist, die quadratische Differenz zwischen Vorhersage- und Zielwerten zu messen und so den Fehlerbetrag zu beziffern. Dadurch wird sichergestellt, dass der Fehler immer positiv ist (wobei der Schwerpunkt auf der Größe liegt) und größere Fehler aufgrund der Quadrierung stark bestraft werden. Die Interpretation ist auch natürlicher, da der Fehler immer in den quadrierten Einheiten der Zielvariablen angegeben wird. Die Formel wird ist wie folgt:
![]()
Wobei:
- n ist die Dimensionsgröße der Ziel- und Vergleichsvariablen. Diese Variablen liegen in der Regel im Vektorformat vor
- i ist ein interner Index innerhalb des Vektorraums
- y^ ist ein Ausgabe- oder Vorhersagevektor
- y ist der Zielvektor
Die Vorteile sind die Empfindlichkeit gegenüber großen Fehlern und die Anpassungsfähigkeit an Gradientenabstiegs-Optimierungsmethoden aufgrund des glatten Gradienten. Ein Nachteil wäre die Empfindlichkeit gegenüber Ausreißern.
Als Nächstes steht die Funktion des mittleren absoluten Fehlers (MAE). Dies ist, wie der MSE oben, eine weitere gängige Verlustfunktion, die sich wie der MSE auf den Größenfehler konzentriert, ohne die Richtung zu berücksichtigen. Der Unterschied zum obigen MSE besteht darin, dass große Werte nicht extra gewichtet werden, da keine Quadrierung stattfindet. Da keine Quadrierung verwendet wird, stimmen die Fehlereinheiten mit denen des Zielvektors überein, sodass die Interpretation einfacher ist als beim MSE. Seine Formel, die der oben genannten ähnlich ist, lautet wie folgt:
![]()
Wobei:
- n, i, y und y^ stehen für die gleichen Werte wie in MSE oben
Die Hauptvorteile sind die geringere Empfindlichkeit gegenüber Ausreißern und großen Fehlern, da keine Quadratur durchgeführt wird, sowie die Einfachheit der Beibehaltung der Zieleinheiten, was die Interpretation erleichtert. Sein Gradientenverhalten ist jedoch nicht so glatt wie das von MSE, da der Ausgang bei der Differenzierung entweder +1,0, -1,0 oder Null ist. Der Wechsel zwischen diesen Werten trägt nicht dazu bei, dass der Trainingsprozess so reibungslos konvergiert wie bei MSE, was insbesondere in Regressionsumgebungen ein Problem darstellen kann. Außerdem wirkt sich die Gleichbehandlung aller Fehler in gewissem Maße negativ auf den Konvergenzprozess aus.
Dies führt uns dann zur kategorischen Kreuzentropie (CCE). Diese misst in einem streng multidimensionalen Raum die Differenz zwischen der prognostizierten Wahrscheinlichkeitsverteilung und der tatsächlichen Wahrscheinlichkeitsverteilung. Während wir also MAE und MSE als Vektorausgaben im MQL5-Verlustfunktionsalgorithmus verwenden (da die individuellen Differenzen nicht summiert werden), könnten sie leicht Skalare sein, wie ihre Formeln zeigen. Die kategoriale Kreuzentropie (CCE) hingegen gibt immer ein mehrdimensionales Ergebnis aus. Die Formel hierfür lautet:
![]()
Wobei:
- N ist die Anzahl der Klassen oder die Größe des Datenpunktvektors,
- y ist der Ist- oder Zielwert,
- p ist der vorhergesagte oder Netzausgangswert und,
- log ist der natürliche Logarithmus.
CCE ist von Natur aus ein Klassifikator, kein Regressor, und eignet sich besonders, wenn beim Training mehr als eine Klasse zur Kategorisierung eines Datensatzes verwendet wird. Die Hauptanwendungsbereiche sind die Grafik und die Bildverarbeitung, aber das hält uns natürlich nicht davon ab, nach Möglichkeiten zu suchen, wie dies für Händler angewendet werden kann. Bemerkenswert an CCE ist jedoch, dass es sich besonders gut mit der Soft-Max-Aktivierung kombinieren lässt, die ebenfalls typischerweise einen Vektor von Werten mit dem Zusatz ausgibt, dass sie sich alle zu eins summieren. Dies kommt dem Ziel, Wahrscheinlichkeitsverteilungen der analysierten Klassen für einen bestimmten Datenpunkt zu finden, sehr entgegen. Die logarithmische Komponente bestraft zuversichtliche, aber falsche Vorhersagen stärker als weniger zuversichtliche Vorhersagen, was in erster Linie auf die Praxis der One-Hot-Codierung zurückzuführen ist. Die Soll- bzw. Ist-Werte werden immer so normiert, dass nur die richtige Klasse vollständig gewichtet wird (in der Regel 1,0) und alles andere mit Null bewertet wird. CCE sorgt für glatte Gradienten während der Optimierung und ermutigt die Modelle, sich auf ihre Vorhersagen zu verlassen, da falsche Vorhersagen wie oben beschrieben bestraft werden. Beim Training mit unausgewogenen Populationsgrößen in den verschiedenen Klassen können Gewichtungsanpassungen vorgenommen werden, um das Spielfeld auszugleichen. Es besteht jedoch die Gefahr der Überanpassung, wenn zu viele Klassen vorhanden sind, sodass bei der Festlegung der Anzahl der Klassen, die ein Modell bewerten soll, Vorsicht geboten ist.
Weiters gibt es die binäre Kreuzentropie (BCE), die als Cousin der obigen CCE angesehen werden kann. Sie quantifiziert auch die Lücke zwischen der Vorhersage und dem Ziel in einer 2-Klassen-Umgebung, im Gegensatz zu CCE, das sich besser für mehrere Klassen eignet. Die Ausgabe liegt im Bereich von 0,0 bis 1,0 und wird durch die folgende Formel bestimmt:
Wobei
- N ist wie bei den anderen oben genannten Verlustfunktionen der Stichprobenumfang
- y ist der vorhergesagte Wert
- p ist die Vorhersage
- log ist der natürliche Logarithmus.
Im Fachjargon der BCE werden die beiden betrachteten Klassen oft als Positiv- und Negativklasse bezeichnet. Im Wesentlichen wird die BCE-Ausgabe also immer so verstanden, dass sie eine Wahrscheinlichkeit dafür liefert, inwieweit ein Datenpunkt in der positiven Klasse liegt, und dieser Wert liegt im Bereich von 0,0 bis 1,0, wobei eine geeignete paarweise Aktivierungsfunktion die Hard-Sigmoid-Funktion ist. Die Vektorausgabe der in den Vektordatentyp eingebauten MQL5-Aktivierungsfunktionen gibt einen Vektor aus, der 2 Wahrscheinlichkeiten für die positive und negative Klasse enthalten sollte.
Die ist ein weiterer interessanter Verlustfunktionsalgorithmus, ähnlich wie die Vektorlückenmethoden, die wir oben besprochen haben. Ihre Formel lautet:
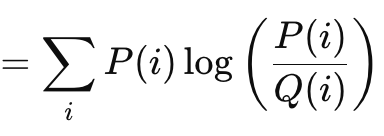
Wobei:
- P ist die Wahrscheinlichkeit, mit der die Vorhersage eintritt
- Q ist die tatsächliche Wahrscheinlichkeit
Seine Ausgaben reichen von 0, was keine Divergenz bedeuten würde, bis zu unendlich. Diese ausschließlich positiven Werte sind ein klarer Indikator dafür, wie weit eine Prognose von der „Wahrheit“ entfernt ist. Wie in der obigen Formel gezeigt, ist die Summierung nur relevant, wenn eine skalare Ausgabe angestrebt wird. Die integrierte Vektor-Implementierung in MQL5 liefert eine Vektorausgabe, die für die Berechnung von Deltas und eventuell Gradienten bei der Durchführung von Rückwärtspropagationen besser geeignet und erforderlich ist. Die Kullback-Liebler-Divergenz ist in der Informationstheorie begründet und hat aufgrund ihrer Geschicklichkeit einige Anwendungen beim Reinforcement Learning sowie bei Variations-Autokodierern gefunden. Nachteilig sind jedoch die Asymmetrie, die Empfindlichkeit gegenüber Nullwerten und die Schwierigkeiten bei der Interpretation angesichts der ungebundenen Natur der Ergebnisse. Die Nullsensitivität ist wichtig, denn wenn eine Klasse eine Wahrscheinlichkeit von Null hat, hat die andere automatisch einen unendlichen Wert, aber die Asymmetrie behindert nicht nur die richtige Interpretation der gegebenen Wahrscheinlichkeit, sondern erschwert auch das Transferlernen. (Die Wahrscheinlichkeit von P bei K ist nicht invers zu der von K bei P). Die Summen der Vorwärts- und Rückwärtswahrscheinlichkeiten sind kein vorgegebener Wert. Manchmal ist es unendlich, manchmal nicht.
Dies führt uns zu Kosinus-Ähnlichkeit die im Gegensatz zu den bisher betrachteten Vektorlückenmaßen die Richtung berücksichtigt. Ihre Formel lautet:
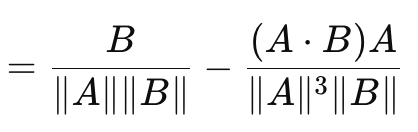
Wobei:
- A.B ist das Punktprodukt von zwei Vektoren
- |A| und |B| sind ihre Größen oder Normen
Die obige Formel gilt für den Verlustgradienten in Bezug auf den Vektor A. Die Formel für den Verlustgradienten in Bezug auf den Vektor B ist eine separate Umkehrformel und ergibt, wenn sie mit dem Kosinus von A zu B summiert wird, keine feste oder beliebige Konstante. In diesem Sinne ist die Kosinusähnlichkeit keine echte Metrik, da sie das Ungleichheitsdreieck nicht erfüllt. (Die Kosinusähnlichkeit von A zu B plus die Kosinusähnlichkeit von B zu C ist nicht immer größer oder gleich der Kosinusähnlichkeit von A zu C). Sein Vorteil ist die Skaleninvarianz, da der von ihm gelieferte Wert unabhängig von der Größe der betreffenden Vektoren ist, was wichtig sein kann, wenn die Richtung und nicht die Größe von Bedeutung ist. Darüber hinaus ist sie weniger rechenintensiv als andere Methoden, was bei sehr tiefen Netzen oder Transformern oder beidem ein wichtiger Aspekt ist! Es hat sich als sehr geeignet für hochdimensionale Daten wie Texteinbettungen großer Sprachmodelle erwiesen, bei denen die abgeleitete Richtung (Bedeutung?) eine relevantere Metrik ist als die einzelnen Größen der einzelnen Vektorwerte. Seine Nachteile sind, dass es nicht für alle Aufgaben geeignet ist, insbesondere in Situationen, in denen die Größe der Vektoren beim Training wichtig ist. Falls einer der Vektoren eine Norm von Null hat (d. h. alle Werte sind Null), wäre die Kosinusähnlichkeit undefiniert. Schließlich wurde bereits erwähnt, dass die Unfähigkeit, eine Metrik zu sein, aus der Nichterfüllung der Ungleichheitsdreiecksregel resultiert. Beispiele dafür, wo dies von entscheidender Bedeutung ist, sind vielleicht etwas hochtrabend, aber sie umfassen: geometrisches Deep Learning, graphenbasierte neuronale Netze und kontrastiver Verlust aus siamesischen Netzen. In jedem dieser Anwendungsfälle ist das Ausmaß wichtiger als die Richtung. Bei der Anwendung der Kosinusähnlichkeit in MQL5 ist es jedoch wichtig zu beachten, dass die Kosinusnähe verwendet und zurückgegeben wird, da diese für das maschinelle Lernen relevanter ist. Er ist das Entfernungsäquivalent des Kosinus des Winkels und wird durch Subtraktion der Kosinusähnlichkeit von eins ermittelt.
Die Poisson-Verlust-Gradient-Funktion eignet sich für die Modellierung abzählbarer oder diskreter Daten. Es ist so, als ob die oben genannten Verlustfunktionen über die eingebauten Funktionen des Datentyps Vektor implementiert werden. Ihre Formel lautet:
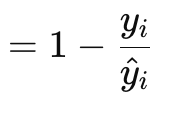
Wobei:
- y ist der Wert des Zielvektors (bei Index i)
- y^ ist der prognostizierte Wert
Die Gradientenwerte werden im Vektorformat zurückgegeben, da dies dem Backpropagation-Prozess viel besser dient. Sie sind auch Ableitungen erster Ordnung der ursprünglichen Formel für die skalare Rückkehr der Poisson-Funktion, die lautet:
![]()
Wobei:
- das die Steigungsformel darstellt
Die Art der diskreten Daten, mit denen Händler ein neuronales Netzwerk in diesem Fall füttern könnten, könnte die Kerzentypen der Preisbalken einschließen, oder ob vorherige Balken auf-, ab- oder seitwärts sind. Seine Anwendungsfälle decken jedoch Szenarien von Zähldaten ab, sodass zum Beispiel ein neuronales Netzwerk, das verschiedene Kerzenpreisbalkenmuster aus der jüngsten Geschichte nimmt, trainiert werden könnte, um die Anzahl eines bestimmten Kerzentyps zurückzugeben, der aus einer Standardstichprobe von sagen wir 10 zukünftigen Preisbalken erwartet werden sollte. Die Koeffizienten sind leicht zu interpretieren, da es sich um logarithmische Verhältnisse handelt, und sie passen gut zur Poisson-Regression, was bedeutet, dass die Analyse nach dem Training leicht mit der Poisson-Regression durchgeführt werden kann. Es stellt auch sicher, dass die Zählprognosen immer positiv (nicht negativ) sind. Das ist nicht der Fall. Zu den guten Eigenschaften gehört die Varianzannahme, bei der immer davon ausgegangen wird, dass der Mittelwert und die Varianz die gleichen oder fast ähnliche Werte haben. Wenn dies eindeutig nicht der Fall ist, dann wird die Verlustfunktion nicht gut funktionieren. Es reagiert empfindlich auf Ausreißer, insbesondere auf solche mit hohen Werten in den Eingabedaten, und die Verwendung des natürlichen Logarithmus birgt die Gefahr, dass NaN oder ungültige Ergebnisse erzielt werden. Außerdem ist seine Anwendung auf positive, zählbare Daten beschränkt, was bedeutet, dass man es in Fällen, in denen kontinuierliche negative Prognosen erforderlich sind, wie z. B. bei der Vorhersage von Preisänderungen, nicht verwenden würde.
Mit der Huber-Gradienten-Verlust-Funktion schließen wir die Auswahl dessen ab, was MQL5 innerhalb des Vektor-Datentyps zu bieten hat. Es gibt noch weitere Klassen, die wir nicht betrachtet haben, wie: Logarithmus des hyperbolischen Kosinus, kategorisches Hinge, quadratisches Hinge, Hinge, mittlerer logarithmischer Fehler im Quadrat und mittlerer absoluter Fehler in Prozent. Diese sind nicht entscheidend dafür, ob ein neuronales Netz ein Regressor oder ein Klassifikator ist, was Teil unseres Schwerpunkts ist, und daher überspringen wir sie. Der Huber-Verlust wird jedoch durch die Formel angegeben:
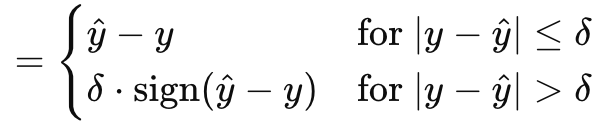
Wobei:
- y^ ist der prognostizierte Wert
- y ist das Ziel
- Delta ist ein Verlust-Eingangswert, bei dem die Beziehung von linear zu quadratisch wechselt
Der Gradient kann, wie der ursprüngliche Huber-Verlust, auf eine von zwei Arten berechnet werden, je nachdem, wie der tatsächliche oder angestrebte Wert mit der Prognose verglichen wird. Es handelt sich um eine teils lineare, teils quadratische Funktion, die eine Abbildung der Differenz zwischen Zielwerten und Prognosewerten bei Anpassung der Eingangsparameter darstellt. Sie ist vorherrschend bei einer robusten Regression da sie das Beste aus MAE und MSE kombiniert und weniger empfindlich auf Ausreißer reagiert, während sie bei kleinen Fehlern stabiler ist als MAE. Da sie vollständig differenzierbar ist, eignet sie sich ideal für den Gradientenabstieg und ist dank des Deltas anpassbar, wobei sie sich bei einem kleineren Delta wie MAE verhält, während sie bei größeren Deltas eher wie MSE wirkt. Dies ermöglicht die Kontrolle über den Kompromiss zwischen Robustheit und Empfindlichkeit. Auf der anderen Seite ist der Huber-Verlust relativ komplex, da nicht nur die Formel stückweise ist, wie oben gezeigt, sondern auch die Berechnung und Bestimmung des idealen Deltas oft eine lästige Übung ist. Zu diesem Zweck gibt die MQL5-Implementierung, die meines Erachtens auf einer Standard-Matrix- und -Vektor-Bibliothek basiert, die ich nicht referenziert habe, nicht an, wie ihr Delta-Wert für die eingebauten Funktionen Huber-Verlust und Huber-Verlust-Gradient berechnet wird. Obwohl sie mit einer Vielzahl von Aktivierungsfunktionen gepaart werden kann, wird die lineare Aktivierung oft als die geeignetere empfohlen.
Verlustfunktionen für Regressionsmodelle
Welcher dieser Verlustalgorithmen würde sich also am besten für Regressionsnetze eignen? Die Antwort: MSE, MAE und Huber-Loss. Hier ist der Grund dafür. Regressionsnetzwerke zeichnen sich dadurch aus, dass sie eher kontinuierliche numerische Werte als kategorische Bezeichnungen oder diskrete Daten prognostizieren. Dies bedeutet, dass die Ausgabeschicht dieser Netze in der Regel reellwertige Zahlen erzeugt, die einen großen Bereich umfassen können. Die Art der Regressionsaufgaben erfordert, dass bei ihrer Optimierung möglichst wenig weitreichende Abweichungen zwischen vorhergesagten und wahren Werten gemessen werden müssen, im Gegensatz zu Klassifizierungsnetzen, bei denen die aufzuzählenden Ergebnisse oft nur wenige sind und in ihrer Anzahl im Voraus bekannt sind.
Dies führt uns also zu MSE. Wie oben festgestellt, hat es große quadratische Strafen für große Fehler, was von vornherein bedeutet, dass es den Gradientenabstieg und die Optimierung in Richtung geringerer Abweichungen lenkt, was für Regressionsnetzwerke wichtig ist, um effizient zu laufen. Auch die Glätte und die einfache Differenzierung machen es zu einer natürlichen Anpassung an die kontinuierlichen Daten, die von Regressionsnetzwerken verarbeitet werden.
Regressionsnetze sind auch sehr anfällig für Ausreißer, sodass eine Verlustfunktion erforderlich ist, die in dieser Hinsicht etwas robuster ist. Auftritt MAE. Im Gegensatz zu MSE, das seinen Fehlern quadratische Strafen auferlegt, erlegt MAE lineare Strafen auf, was es im Vergleich zu MSE weniger empfindlich gegenüber Ausreißern macht. Darüber hinaus ist das Fehlermaß ein robuster Durchschnittsfehler, der bei verrauschten Daten nützlich sein kann.
Schließlich wird argumentiert, dass Regressionsnetze zusätzlich zu den oben genannten Faktoren ein Gleichgewicht oder einen Kompromissmechanismus zwischen Empfindlichkeit gegenüber kleinen Fehlern und Robustheit benötigen. Dies sind zwei Eigenschaften, die die Huber-Verlustfunktion bietet, und darüber hinaus bietet sie Glätte, die bei der Differenzierung während des Optimierungsprozesses hilft.
Wenn alle drei „idealen“ Verlustfunktionen auf Null gesetzt sind, was wäre dann die ideale Palette von Aktivierungsfunktionen, die man bei der Verwendung in einem Regressionsnetz in Betracht ziehen sollte? Offiziell werden eine lineare Aktivierung und eine Identitätsaktivierung empfohlen, wobei letztere bedeutet, dass die Netzausgänge in ihrer Größe erhalten bleiben, um einen möglichst großen Teil der Datenvariabilität zu erfassen. Die Hauptargumente für diese beiden sind die ungebundene Natur ihrer Ausgaben, die sicherstellt, dass keine Daten durch die Netzvorwärtsprozesse und das Training verloren gehen. Ich persönlich glaube an begrenzte Ausgaben, daher würde ich mich eher für Soft-Sign und TANH entscheiden, da diese sowohl negative als auch positive reelle Zahlen erfassen, aber auf -1,0 bis +1,0 begrenzt sind. Ich denke, dass begrenzte Ausgaben wichtig sind, weil sie die Probleme mit explodierenden und verschwindenden Gradienten während der Rückwärtsfortpflanzung vermeiden, die eine große Quelle von Kopfschmerzen sind.
Verlustfunktionen für Klassifizierungsmodelle
Was ist mit neuronalen Netzen zur Klassifizierung? Wie würde die Wahl für Verlust- und Aktivierungsfunktionen ausfallen? Das Verfahren, mit dem wir unsere Auswahl treffen, unterscheidet sich nicht wesentlich, wir schauen uns im Wesentlichen die Hauptmerkmale des Netzes an, die uns bei der Auswahl leiten.
Klassifizierungsnetze dienen der Vorhersage von diskreten Klassenbezeichnungen aus einem Pool von vordefinierten möglichen Kategorien. Diese Netze geben Wahrscheinlichkeiten aus, die die Wahrscheinlichkeit jeder Klasse angeben, wobei das Hauptziel darin besteht, die Genauigkeit dieser Vorhersagen zu maximieren, indem der Verlust minimiert wird. Die Wahl der Verlustfunktion spielt daher eine Schlüsselrolle beim Training des Netzes zur Unterscheidung und Identifizierung der Klassen. Basierend auf diesen Schlüsselmerkmalen besteht ein Konsens darüber, dass die kategoriale Kreuzentropie und die binäre Kreuzentropie die beiden wichtigsten Verlustfunktionen sind, die sich am besten für Klassifizierungsnetzwerke eignen und die über die Enumeration von MQL5 bereitgestellt wird.
BCE klassifiziert aus zwei möglichen Kategorien, allerdings kann die Anzahl der zu treffenden Vorhersagen oft mehr als zwei betragen, und die Größe dieser Gruppe bestimmt die Norm des Gradientenvektors. Der Wert bei jedem Index des Gradientenvektors wäre also eine partielle Ableitung der BCE-Verlustfunktion, wie oben in der gemeinsamen Formel hervorgehoben, und diese Werte würden bei der Back-Propagation verwendet werden. Die Ausgangswerte des Netzes wären jedoch, wie oben erwähnt, Wahrscheinlichkeiten für die positive Klasse, und zwar für jeden projizierten Wert im Ausgangsvektor.
BCE eignet sich für Klassifizierungsnetze, da die Wahrscheinlichkeiten leicht interpretierbar sind, da sie auf die positive Klasse hinweisen. Es reagiert empfindlich auf die verschiedenen Wahrscheinlichkeiten der einzelnen Ausgabewerte, da es sich darauf konzentriert, die logarithmische Wahrscheinlichkeit der richtigen Klassen aus dem Stapel zu maximieren. Da sie nicht als Konstante, sondern als Variable differenziert werden kann, erleichtert dies eine reibungslose und effiziente Gradientenberechnung bei dem Rückwärtsdurchgang erheblich.
CCE erweitert BCE, indem es die Klassifizierung von mehr als 2 Kategorien erlaubt, und die Norm oder Größe des Ausgabevektors ist immer die Anzahl der Klassen, für die jeweils eine Wahrscheinlichkeit angegeben wird. Anders als bei BCE, wo wir Vorhersagen für bis zu 5 Werte machen können und alle Werte für jeden Wert entweder wahr oder falsch sind. Bei CCE wird die Ausgabegröße entsprechend der Klassennummer vorangestellt. Die bereits erwähnte One-Hot-Codierung ist nützlich, um die Zielvektoren zu normalisieren, bevor die Lücken zur Vorhersage gemessen werden.
Die ideale Form der Aktivierung wäre demnach jede Funktion, die im Bereich von 0,0 bis +1,0 liegt. Dazu gehören Soft-Max, Sigmoid und Hard Sigmoid.
Tests
Wir führen daher 2 Testreihen durch, eine für einen regressiven MLP und eine für einen Klassifikator. Der Zweck dieses Tests ist es, die Umsetzung der in diesem Artikel diskutierten Ideen zur Verlustfunktion und Aktivierung in MQL5 und Expert-Advisor-Form zu demonstrieren. Die hier vorgestellten Testergebnisse sind keine Rechtfertigung dafür, den beigefügten Code auf einem Live-Konto einzusetzen und zu verwenden, sondern vielmehr eine Aufforderung an den Leser, seine eigene Sorgfalt walten zu lassen, indem er die Real-Tick-Daten seines Brokers über längere Zeiträume hinweg testet, falls er das/die Handelssystem(e) für geeignet hält. Der Einsatz im Echtbetrieb sollte, wie immer, erst dann ideal sein, wenn eine Kreuzvalidierung oder ein Forward Walk Test durchgeführt wurde, der zufriedenstellende Ergebnisse liefert.
Wir werden also GBPCHF auf dem täglichen Zeitrahmen über das letzte Jahr, 2023, testen. Um ein regressives Netzwerk zu erhalten, beziehen wir uns auf die Klasse „Cmlp“, die wir im letzten Artikel vorgestellt haben. Da unsere Eingabedaten prozentuale Preisänderungen (nicht Punkte) sind, können wir mit der TANH-Aktivierung und der Huber-Verlustfunktion testen, wie handelbar unser System sein könnte. Die nutzerdefinierten Bedingungen für Kauf- und Verkaufs-Signale sind in MQL5 wie folgt implementiert:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalRegr::LongCondition(void) { int result = 0; vector _out; GetOutput(_out); m_close.Refresh(-1); if(_out[0] > 0.0) { result = int(round(100.0*(fabs(_out[0])/(fabs(_out[0])+fabs(m_close.GetData(StartIndex()) - m_close.GetData(StartIndex()+1)))))); } //printf(__FUNCSIG__ + " output is: %.5f, and result is: %i", _out[0], result);return(0); return(result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalRegr::ShortCondition(void) { int result = 0; vector _out; GetOutput(_out); m_close.Refresh(-1); if(_out[0] < 0.0) { result = int(round(100.0*(fabs(_out[0])/(fabs(_out[0])+fabs(m_close.GetData(StartIndex()) - m_close.GetData(StartIndex()+1)))))); } //printf(__FUNCSIG__ + " output is: %.5f, and result is: %i", _out[0], result);return(0); return(result); }
Wir testen den Experten auch gleichzeitig mit dem Training des Netzwerks auf historischen Daten, und zwar auf jedem neuen Kursbalken. Dies ist eine weitere wichtige Entscheidung, die leicht geändert werden kann, wenn das Training einmal alle sechs Monate oder in einem anderen vorher festgelegten längeren Zeitraum durchgeführt wird, um eine Überanpassung des Netzes an kurzfristige Maßnahmen zu vermeiden. Dieses Regressornetz hat eine Größe von 4-7-1 3 Schichten (wobei die Zahlen für die Größe der Schichten stehen), was bedeutet, dass 4 aktuelle Preisänderungen als Eingaben dienen und die einzige Ausgabe die nächste Preisänderung ist.
Die Durchführung von Testläufen auf GBPCHF für das Jahr 2023 auf täglicher Basis liefert uns den folgenden Bericht:


Für das Klassifizierungsnetz verwenden wir weiterhin die Klasse „Cmlp“ als Basis, und unsere Eingabedaten sind die Klassifizierungen der letzten 3 Preispunkte. Dies wird in ein einfaches MLP-Netz mit 3-6-3 Schichten eingespeist, das ebenfalls nur aus drei Schichten besteht. Da wir drei mögliche Klassifizierungen betrachten und unsere Verlustfunktion CCE ist, sollte die letzte Ausgabeschicht ebenfalls eine Größe von drei haben, damit sie als Wahrscheinlichkeitsverteilung dient. Die Erzeugung von Kauf- und Verkaufs-Bedingungen ist in MQL5 wie folgt implementiert:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalClas::LongCondition(void) { int result = 0; vector _out; GetOutput(_out); m_close.Refresh(-1); if(_out[2] > _out[1] && _out[2] > _out[0]) { result = int(round(100.0 * _out[2])); } //printf(__FUNCSIG__ + " output is: %.5f, and result is: %i", _out[2], result);return(0); return(result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalClas::ShortCondition(void) { int result = 0; vector _out; GetOutput(_out); m_close.Refresh(-1); if(_out[0] > _out[1] && _out[0] > _out[2]) { result = int(round(100.0 * _out[0])); } //printf(__FUNCSIG__ + " output is: %.5f, and result is: %i", _out[0], result);return(0); return(result); }
Ähnliche Testläufe für den Klassifikator Expert Advisor liefern uns folgende Ergebnisse:


Der beigefügte Code wird über Wizard Assembly verwendet, um Expert Advisors zu generieren, für die es Anleitungen gibt hier und hier.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass wir die Liste der möglichen Verlustfunktionen, die in MQL5 bei der Entwicklung von Algorithmen für maschinelles Lernen, wie z. B. neuronalen Netzen, zur Verfügung stehen, durchgegangen sind. Es gibt eine sehr lange Liste, die ironischerweise nicht einmal erschöpfend ist. Wir haben jedoch einige wichtige hervorgehoben, die gut mit bestimmten Aktivierungsfunktionen funktionieren, die wir in früheren Artikeln behandelt haben, wobei der Schwerpunkt auf der Vermeidung von explodierenden/verschwindenden Gradienten und Effizienz liegt. Viele der verfügbaren Verlustfunktionen wären für die typischen Regressions- und Klassifizierungsnetze nicht unbedingt geeignet, nicht nur, weil ihre Ausgänge ungebunden sind, sondern auch, weil sie die wichtigsten charakteristischen Anforderungen dieser Netze nicht erfüllen, wie wir hervorgehoben haben, weshalb die in Betracht gezogenen Verlustfunktionen eine kleinere Anzahl der verfügbaren Funktionen darstellen.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/15524
 Die Übertragung der Trading-Signale in einem universalen Expert Advisor.
Die Übertragung der Trading-Signale in einem universalen Expert Advisor.
 Eine alternative Log-datei mit der Verwendung der HTML und CSS
Eine alternative Log-datei mit der Verwendung der HTML und CSS
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.