
Нейросети — это просто (Часть 92): Адаптивное прогнозирование в частотной и временной областях

Введение
Временная и частотная область — это два фундаментальных представления, используемых для анализа данных временных рядов. Во временной области анализ фокусируется на изменениях амплитуды во времени, что позволяет идентифицировать локальные зависимости и переходные процессы внутри сигнала. И наоборот, анализ частотной области направлен на представление временных рядов с точки зрения их частотных компонентов, обеспечивая понимание глобальных зависимостей и спектральных характеристик данных. Объединение преимуществ обеих областей является многообещающим подходом для решения проблемы смешивания различных периодических свойств в реальных временных рядах. И здесь мы сталкиваемся с проблемой эффективного объединения преимуществ временной и частотной областей.
По сравнению с достижениями во временной области, в частотной области все еще остается много неисследованных областей. В последних статьях мы познакомились с некоторыми примерами использования частотной области для лучшей обработки глобальных зависимостей временных рядов. Непосредственное прогнозирование в частотной области позволяет использовать больше спектральной информации для повышения точности прогнозов временных рядов. Однако существуют некоторые проблемы, связанные с прямым прогнозированием спектра в частотной области. Одной из этих проблем является потенциальное несовпадение частотных характеристик между спектром известных анализируемых данных и полным спектром изучаемого временного ряда, возникающее в результате использования дискретного преобразования Фурье (DFT). Это несовпадение затрудняет точное представление информации о конкретных частотах во всем спектре исходных данных, что приводит к неточностям прогнозирования.
Другая проблема заключается в том, как эффективно извлекать информацию о комбинациях частот. Извлечение спектральных характеристик является сложной задачей, поскольку гармонические ряды, возникающие в группах внутри спектра, содержат значительный объем информации.
Для решения упомянутых выше проблем в статье "ATFNet: Adaptive Time-Frequency Ensembled Network for Long-term Time Series Forecasting был предложен метод ATFNet. Он включает модули временной и частотной областей для одновременной обработки локальных и глобальных зависимостей. Кроме того, в статье был представлен новый механизм взвешивания, который динамически распределяет веса между двумя модулями.
Авторы метода предложили энергетическое взвешивание рядов доминантных гармоник, которое способно генерировать соответствующие веса для модулей во временной и частотной областях на основе уровня периодичности, демонстрируемого исходными данными. Это позволяет эффективно использовать преимущества обеих областей при работе с временными рядами с различными периодическими закономерностями.
Кроме того, авторы метода вводят расширенное DFT для выравнивания спектра дискретных частот исходных данных и полного временного ряда, что повышает точность представления конкретных частот.
Авторы метода имплементируют механизм внимания в частотную область и предлагают комплексное спектральное внимание (CSA). Этот подход позволяет собирать информацию из различных комбинаций частотных характеристик, что обеспечивает эффективный способ привлечения внимания к представлениям в частотной области.
В статье представлены результаты экспериментов на восьми реальных наборах данных, согласно которым ATFNet демонстрирует многообещающие результаты и по многим наборам превосходит другие современные методы прогнозирования временных рядов.
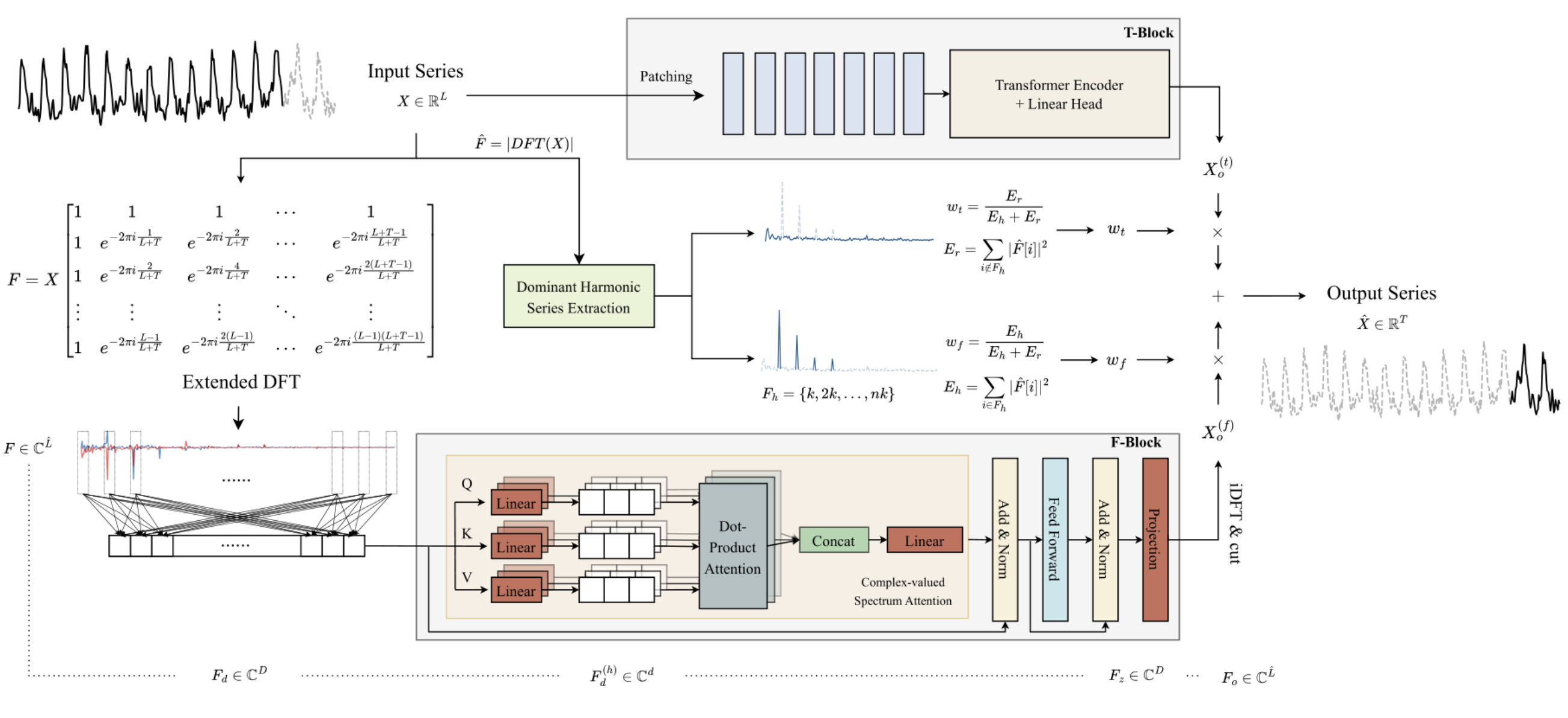
1. Алгоритм ATFNet
Авторы ATFNet эксплуатируют схему независимых каналов, что позволяет предотвратить смешивание спектров разных каналов. Так как каналы могут иметь разные глобальные закономерности, то смешивание их спектров может оказать отрицательное влияние на эффективность работы модели.
Исходные данные унитарного временного ряда T-блок обрабатывает непосредственно во временной области. В результате чего на выходе получается некое прогнозное значение последующих значений анализируемого временного ряда.
Авторы метода используют расширенное дискретное преобразование Фурье (DFT) для преобразования исходных данных унитарного временного ряда в частотную область, генерируя расширенный спектр частот. Затем осуществляется обратное преобразование спектра во временную область с использованием обратного DFT (iDFT). В результате F-блок возвращает прогнозные значения временного рада на основе частотных характеристик.
Результаты прогнозов T-блока и F-блока объединяются с использованием адаптивных весовых коэффициентов для получения окончательного результата прогнозных значений анализируемого временного ряда. Эти веса определяются на основе взвешивания энергии серии доминантных гармоник.
Укрупненно алгоритм можно представить в следующем виде:
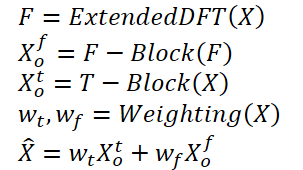
Использование традиционного DFT может привести к несовпадению частот между спектрами исходных данных и всей анализируемой серии. Поэтому модели прогнозирования, построенные на анализе малого блока исходных данных, могут не иметь доступа к полной и точной информации о частотных характеристиках всего анализируемого временного ряда. Это приводит к менее точным прогнозам при построении полного временного ряда.
Для решения этой проблемы авторы метода предлагают расширенное DFT, которое преодолевает ограничение, налагаемое длиной анализируемых исходных данных. Это позволяет получить исходный спектр, который соответствует частотной группе DFT всей серии. В частности, авторы ATFNet заменяют исходный комплексный экспоненциальный базис базисом DFT полного ряда:
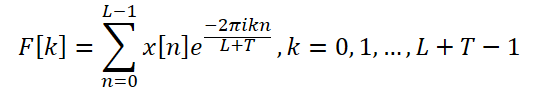
Таким образом, мы получаем спектр частотных характеристик длиной L + T, который совпадает со спектром DFT полной анализируемой серии (исходные + прогнозные данные). Для вещественных временных рядов сопряженная симметрия выходного спектра является важным свойством DFT. Используя это свойство, можно снизить вычислительные затраты, рассматривая только первую половину спектра частотных характеристик исходных данных, поскольку вторая половина предоставляет избыточную информацию.
Архитектура F-Block основана на Энкодере Transformer, все параметры которого имеют комплексные значения. Стоит отметить, что все вычисления в F-блоке выполняются в поле комплексных чисел.
Кроме того, авторы метода используют RevIN для обработки исходного спектра частотных характеристик F. Хотя RevIN изначально был разработан для устранения сдвига распределения во временной области, авторы метода обнаружили его эффективность и при обработке спектров в частотной области. Этот подход позволяет преобразовать спектры рядов с различными глобальными характеристиками в сопоставимое распределение. Перед анализом частотные характеристики F нормализуются. А после обработки данных мы добавляем статистические характеристики частотного распределения обратно.
Поскольку в спектре частотной области мало хронологических зависимостей, авторы метода не используют позиционное кодирование в F-блоке.
Дополнительно авторы метода применили модифицированный механизм внимания с несколькими головами. Для каждой головы h = 1, 2, ..., H, проецируется встроенный спектр Fd по измерению спектра с помощью обучаемых проекций. После чего на каждой голове выполняется комплексное скалярное произведение внимания.
В ATFNet также используются слои LayerNorm и FeedForward с остаточными связями аналогично Transformer, которые расширены до поля комплексных чисел.
После M слоев Энкодера результат работы блока внимания линейно проецируются на горизонт полной серии. Полученные частотные характеристики проецируются во временную область с помощью iDFT. Последние T точек (часть прогнозирования) принимаются в качестве окончательного результата F-блока.
Нужно отметить, что F-блок использует полностью архитектуру нейронной сети с комплексными значениями (CVNN).
T-блок отвечает за фиксацию локальных зависимостей во временных рядах, которые легче обрабатывать во временной области. В данном блоке авторы метода используют уже знакомый нам метод сегментации временных рядов. PatchTST — это интуитивно понятный и эффективный способ фиксации локальных зависимостей во временных рядах. Здесь также используется RevIN для решения проблемы смещения распределения.
Периодические временные ряды постоянно демонстрируют существование по меньшей мере одной гармонической группы в их спектре частотной области, при этом доминирующая гармоническая группа демонстрирует самую высокую концентрацию энергии спектра. И наоборот, эта характеристика редко наблюдается в спектре непериодических временных рядов, где распределение энергии более равномерно. Авторы метода ATFNet показывают, что степень концентрации энергии внутри доминирующего гармонического ряда в частотном спектре может отражать периодичность временного ряда. Отношение энергии доминирующего гармонического ряда к суммарной энергии спектра может служить показателем для количественной оценки концентрации энергии. Интуитивно, когда временной ряд демонстрирует более выраженную периодическую структуру, его можно разложить на компоненты. Следовательно, такой временной ряд обладает более высокой концентрацией энергии внутри доминирующего гармонического ряда.
Основываясь на этом свойстве, авторы ATFNet используют энергетическую долю доминирующего гармонического ряда в качестве показателя для количественной оценки степени периодичности временного ряда. Для идентификации доминирующего гармонического ряда важнейшей задачей является определение основной частоты. Здесь можно использовать различные подходы:
- Наивный метод, который определяет частоту с наибольшим значением амплитуды как основную частоту.
- Алгоритмы определения высоты звука на основе правил.
- Алгоритмы определения высоты звука на основе данных.
Алгоритм ATFNet позволяет использовать любой подход определения основной частоты. Авторы метода рассматривают эту составляющую вместе с ее гармониками и вычисляют полную энергию Eh. Затем определяются веса F-Block, вычисляя отношение энергии доминирующей частоты к полной энергии спектра.
В своей работе авторы метода провели ряд экспериментов по оценке эффективности различных методов определения доминирующей частоты. Они пришли к выводу, что по соотношению точность результатов к затратам на вычисления лидирует наивный метод. Он демонстрирует похвальную точность в большинстве реальных наборов данных временных рядов, при этом сохраняя низкие вычислительные затраты.
Напротив, альтернативным подходам препятствует проблема вычислительной сложности. Кроме того, методы, основанные на данных, требуют маркированных данных о шаге, которые часто сложно получить, что создает серьезное препятствие для их практического использования. Поэтому в своих экспериментах авторы метода ATFNet принимают наивный метод по умолчанию для обнаружения основной частоты.
Авторская визуализация метода ATFNet представлена ниже.
2. Реализация базовых операций с комплексными числами
В предыдущих статьях мы с вами уже немного познакомились с комплексными числами. Их удобно использовать для описания спектра частотных характеристик. Мы используем вещественную часть для представления амплитуды сигнала, а мнимую часть — для записи фазового сдвига. Однако получив из DFT сигнал в комплексном виде, мы отдельно работали с вещественной и мнимой частью. А затем с помощью iDFT преобразовывали полученные таким образом частотные характеристики во временную область.
Несмотря на простоту реализации подхода анализа вещественной и мнимой части как отдельных сущностей, такой подход не оптимален. Авторы метода ATFNet детально рассматривают оба подхода к обработке комплексных чисел и приходят к выводу, что анализ вещественной и мнимой частей как отдельных сущностей ведет к потере информации. А следовательно, для реализации предложенного метода нам предстоит модифицировать блок внимания для работы с комплексными числами.
К нашему сожалению, в OpenCL не реализована поддержка комплексных чисел. Поэтому, нам предстоит самостоятельно реализовать базовые операции комплексной алгебры.
Как уже было сказано выше, комплексное число состоит из вещественной и мнимой частей:
![]()
где a — вещественная часть,
b — мнимая часть,
i — мнимая единица.
И для сохранения комплексного числа на стороне OpenCL удобно использовать вектор из 2 элементов float2.
Сложение и вычитание комплексных чисел практически полностью повторяют реализованные в OpenCL векторные операции. Поэтому мы не будем на них останавливаться.
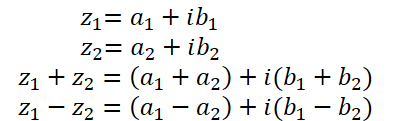
А вот с умножением комплексных чисел немного сложнее.
![]()
Для реализации данной операции создадим функцию ComplexMul в программе OpenCL.
float2 ComplexMul(const float2 a, const float2 b) { float2 result = 0; result.x = a.x * b.x - a.y * b.y; result.y = a.x * b.y + a.y * b.x; return result; }
Обратите внимание, что функция принимает в параметрах 2 вектора float2, возвращает результат в том же формате. Таким образом мы создаем максимально возможное правдоподобие работы с комплексными переменными.
Деление комплексных чисел имеет более сложный вид:
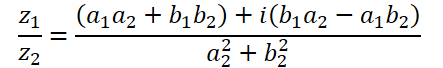
Для выполнения этой операции мы создадим функцию ComplexDiv.
float2 ComplexDiv(const float2 a, const float2 b) { float2 result = 0; float z = pow(b.x, 2) + pow(b.y, 2); if(z > 0) { result.x = (a.x * b.x + a.y * b.y) / z; result.y = (a.y * b.x - a.x * b.y) / z; } return result; }
Абсолютным значением комплексного числа является вещественное число, которое указывает на энергию частотной составляющей:
![]()
Реализуем в функции ComplexAbs.
float ComplexAbs(float2 a) { return sqrt(pow(a.x, 2) + pow(a.y, 2)); }
Формула извлечения квадратного корня из комплексного числа немного сложнее:
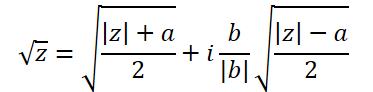
Для её реализации создадим функцию ComplexSqrt.
float2 ComplexSqrt(float2 a)
{
float2 result = 0;
float z = ComplexAbs(a);
result.x = sqrt((z + a.x) / 2);
result.y = sqrt((z - a.x) / 2);
if(a.y < 0)
result.y *= (-1);
//---
return result;
}
Напомню, что в процессе реализации алгоритма Self-Attention, мы нормализуем коэффициенты зависимости с помощью функции SoftMax. И для её реализации в области комплексных чисел нам потребуется экспонента комплекcного числа:
![]()
В коде реализуем функцию следующим образом:
float2 ComplexExp(float2 a)
{
float2 result = exp(clamp(a.x, -20.0f, 20.0f));
result.x *= cos(a.y);
result.y *= sin(a.y);
return result;
}3. Комплексный слой внимания
Выше мы провели подготовительную работу по реализации основных математических операций с комплексными величинами. И теперь мы переходим к следующему этапу, в котором создадим класс нейронного слоя внимания с использованием математики комплексных чисел CNeuronComplexMLMHAttention.
Новый класс мы создадим на базе аналогичного слоя внимания для вещественных величин CNeuronMLMHAttentionOCL. Преимущества такого подхода в том, что мы можем максимально использовать уже имеющийся и настроенный функционал верхнего уровня. Нам необходимо лишь на нижнем уровне переопределить методы для возможности работы с комплексными величинами. Структура нового класса представлена ниже.
class CNeuronComplexMLMHAttention : public CNeuronMLMHAttentionOCL { protected: virtual bool ConvolutionForward(CBufferFloat *weights, CBufferFloat *inputs, CBufferFloat *outputs, uint window, uint window_out, ENUM_ACTIVATION activ, uint step = 0); virtual bool AttentionScore(CBufferFloat *qkv, CBufferFloat *scores, bool mask = false); virtual bool AttentionOut(CBufferFloat *qkv, CBufferFloat *scores, CBufferFloat *out); virtual bool ConvolutuionUpdateWeights(CBufferFloat *weights, CBufferFloat *gradient, CBufferFloat *inputs, CBufferFloat *momentum1, CBufferFloat *momentum2, uint window, uint window_out, uint step = 0); virtual bool ConvolutionInputGradients(CBufferFloat *weights, CBufferFloat *gradient, CBufferFloat *inputs, CBufferFloat *inp_gradient, uint window, uint window_out, uint activ, uint shift_out = 0, uint step = 0); virtual bool AttentionInsideGradients(CBufferFloat *qkv, CBufferFloat *qkv_g, CBufferFloat *scores, CBufferFloat *gradient); virtual bool SumAndNormilize(CBufferFloat *tensor1, CBufferFloat *tensor2, CBufferFloat *out, int dimension, bool normilize = true, int shift_in1 = 0, int shift_in2 = 0, int shift_out = 0, float multiplyer = 0.5f); public: CNeuronComplexMLMHAttention(void) {}; ~CNeuronComplexMLMHAttention(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronComplexMLMHAttentionOCL; } };
Представленная структура нового класса обращает внимание тем, что в ней нет объявления ни одного внутреннего объекта или переменной. В процессе реализации функционала мы полностью будем использовать унаследованные объекты и переменные.
Более того, в структуре класса объявлено лишь переопределение методов в блоке protected. И среди них нет ни одного метода, который бы не был ранее объявлен в родительском классе. И здесь вы не найдете верхнеуровневые методы прямого и обратного проходов feedForward, calcInputGradients и updateInputWeights, в которых мы обычно выстраиваем алгоритм работы класса. Дело в том, что мы полностью сохраняем последовательность действий алгоритма родительского класса. Однако, для работы с комплексными величинами нам необходимо в 2 раза увеличить размеры буферов данных, ведь к каждому вещественному значению добавляется мнимая часть комплексной величины. Кроме того, нам необходимо внедрить в алгоритм математику комплексных чисел. А как вы знаете, практически все математические операции мы выполняем на стороне OpenCL. Поэтому, помимо переопределения методов нижнего уровня, нам предстоит внести изменения и в кернелы программы OpenCL.
3.1 Метод инициализации класса
Работа каждого класса начинается с его инициализации. Как уже было сказано выше, в нашем новом классе мы не объявляем вложенных объектов и переменных. Поэтому конструктор и деструктор класса остаются пустыми. Инициализация унаследованных объектов осуществляется в методе Init. Как обычно, в параметрах данного метода мы получаем от вызывающей программы основные константы, определяющие архитектуру класса. И здесь можно заметить, что структура параметров метода полностью перенесена из аналогичного метода родительского класса. Это и не удивительно. Ведь мы полностью сохраняем базовый алгоритм внимания и структуру родительского класса. А вот сам метод мы перепишем полностью.
bool CNeuronComplexMLMHAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, 2 * window * units_count, optimization_type, batch)) return false;
В теле метода мы, как обычно, вызываем метод инициализации родительского класса. И здесь стоит обратить внимание на 2 момента:
- Мы вызываем метод инициализации не прямого родителя CNeuronMLMHAttentionOCL, а базового класса наших нейронных слоев CNeuronBaseOCL. Дело в том, что инициализация вложенных объектов класса CNeuronMLMHAttentionOCL будет излишней, так как нам необходимо переопределить все буферы с увеличенным размером для возможности хранения комплексных чисел.
- При вызове метода родительского класса, мы в 2 раза увеличиваем размер слоя, что связано с ожидаемым результатом работы слоя в комплексных величинах.
И конечно, мы не забываем проверить логический результат выполнения операций метода родительского класса.
После успешной инициализации объектов, унаследованных от базового класса нейронного слоя, мы сохраним основные параметры архитектуры создаваемого слоя.
iWindow = window; iWindowKey = fmax(window_key, 1); iUnits = units_count; iHeads = fmax(heads, 1); iLayers = fmax(layers, 1);
Следующим шагом мы рассчитаем размеры всех создаваемых буферов. И здесь мы не забываем о хранении комплексных величин. А значит, все буферы увеличиваются в 2 раза по сравнению с родительским классом.
uint num = 2 * 3 * iWindowKey * iHeads * iUnits; //Size of QKV tensor uint qkv_weights = 2 * 3 * (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of QKV tenzor uint scores = 2 * iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = 2 * iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = 2 * iWindow * iUnits; //Size of our tensore uint w0 = 2 * (iWindowKey + 1) * iHeads * iWindow; //Size W0 tensor uint ff_1 = 2 * 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = 2 * (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
Затем организуем цикл по числу создаваемых вложенных слоев внимания, в теле которого мы и будем инициализировать вложенные объекты.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL;
Здесь мы сначала создаем вложенный цикл из 2 итераций, в котором инициализируем объекты для записи данных прямого прохода и соответствующих градиентов ошибки.
for(int d = 0; d < 2; d++) { //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Первым мы создаем конкатенированный буфер сущностей Query, Key и Value. Далее, согласно алгоритму Self-Attention, нам потребуется буфер для записи матрицы коэффициентов зависимости.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
В следующем буфере будут храниться результаты многоголового внимания:
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
Размер которых мы впоследствии уменьшим до уровня буфера исходных данных.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
За блоком Внимания следует блок FeedForward из 2 полносвязных слоев:
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
На этом этапе мы инициализировали буферы для записи результатов прямого прохода и соответствующих градиентов ошибки. Однако для осуществления операций нам потребуются обучаемые параметры весовых коэффициентов. Сначала заполним матрицу обучаемых параметров для генерации сущностей Query, Key и Value:
//--- Initilize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
Затем сгенерируем параметры слоя понижения размерности многоголового внимания:
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
И добавим параметры блока FeedForward:
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
В процессе обучения параметров модели нам потребуются буферы для записи моментов обучения. Количество таких буферов зависит от используемого метода обучения параметров.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } //--- return true; }
Мы в обязательном порядке проверяем результат каждой итерации данного метода, так как в процессе обучения и эксплуатации модели отсутствие даже одного из необходимых буферов приведет к критической ошибке выполнения программы.
После инициализации всех вложенных объектов мы завершаем работу метода и возвращаем логическое значение выполненных операций вызывающей программе.
3.2 Прямой проход
Завершив работу по инициализации класса, мы обычно переходим к работе с методами прямого прохода. Несмотря на то, что верхнеуровневый алгоритм мы наследуем от родительского класса, нам все же предстоит провести некоторую работу с методами прямого прохода на нижнем уровне. И здесь мы построим работу в последовательности алгоритма Self-Attention.
Поступающие на вход слоя исходные данные сначала преобразовываются в сущности Query, Key и Value. Для их генерации в родительском классе мы использовали кернел прямого прохода сверточного слоя. В данной реализации мы будем придерживаться такого же подхода. Только для работы с комплексными переменными нам предстоит создать новый кернел FeedForwardComplexConv на стороне OpenCL программы.
В параметрах кернела мы передаем указатели на 3 буфера данных: матрица обучаемых параметров, исходные данные и буфер для записи результатов.
__kernel void FeedForwardComplexConv(__global float2 *matrix_w, __global float2 *matrix_i, __global float2 *matrix_o, int inputs, int step, int window_in, int activation ) { size_t i = get_global_id(0); size_t out = get_global_id(1); size_t w_out = get_global_size(1);
Обратите внимание, на стороне основной программы мы по-прежнему используем буфера данных типа float, но увеличенного размера. А вот в кернеле на стороне OpenCL программы для буферов данных мы указываем тип float2. Именно такой тип данных мы использовали выше при создании функций комплексных переменных.
В теле метода мы идентифицируем текущий поток в двумерном пространстве задач. Первое измерение указывает на элемент в последовательности результатов, а второе измерение указывает на используемый фильтр. В нашем случае он укажет на позицию в конкатенированном векторе сущностей описания одного элемента анализируемой последовательности.
На основании полученных данных мы определяем смещение в буферах данных:
int w_in = window_in; int shift_out = w_out * i; int shift_in = step * i; int shift = (w_in + 1) * out; int stop = (w_in <= (inputs - shift_in) ? w_in : (inputs - shift_in));
И организовываем цикл вычисления произведения векторов:
float2 sum = matrix_w[shift + w_in]; for(int k = 0; k <= stop; k ++) sum += ComplexMul(matrix_i[shift_in + k], matrix_w[shift + k]);
Обратите внимание, что для вычисления произведения 2 комплексных величин мы используем созданную выше функцию ComplexMul. А суммирование значений осуществляется базовыми векторными операциями.
Кроме того, благодаря объявлению векторного типа float2 для буфера данных, мы обращаемся к ним, как к обычным вещественным буферам данных без корректировки смещения. При этом на каждой операции из буфера извлекается сразу 2 элемента — вещественная и мнимая часть комплексного числа.
Далее мы проверяем вычисленное значение. И в случае переполнения переменной изменяем её значение на "0":
if(isnan(sum.x) || isnan(sum.y) || isinf(sum.x) || isinf(sum.y)) sum = (float2)0;
Теперь нам остается вычислить функцию активации и сохранить значение в буфер результатов.
switch(activation) { case 0: sum = ComplexTanh(sum); break; case 1: sum = ComplexDiv((float2)(1, 0), (float2)(1, 0) + ComplexExp(-sum)); break; case 2: if(sum.x < 0) sum.x *= 0.01f; if(sum.y < 0) sum.y *= 0.01f; break; default: break; } matrix_o[out + shift_out] = sum; }
Для вызова выше созданного кернела на стороне основной программы мы переопределим метод CNeuronComplexMLMHAttention::ConvolutionForward. И обратите внимание, что мы переопределяем метод, а не создаем новый. Поэтому нам очень важно сохранить полную структуру параметров аналогичного метода родительского класса. Только переопределение метода позволит нам осуществить вызов данного метода из верхнеуровневого метода прямого прохода родительского класса без внесения в него каких-либо корректировок.
bool CNeuronComplexMLMHAttention::ConvolutionForward(CBufferFloat *weights, CBufferFloat *inputs, CBufferFloat *outputs, uint window, uint window_out, ENUM_ACTIVATION activ, uint step = 0) { if(CheckPointer(OpenCL) == POINTER_INVALID || CheckPointer(weights) == POINTER_INVALID || CheckPointer(inputs) == POINTER_INVALID || CheckPointer(outputs) == POINTER_INVALID) return false;
В теле метода мы сначала осуществляем проверку актуальности полученных указателей на объекты. А затем проверяем наличие буферов данных на стороне OpenCL контекста.
if(weights.GetIndex() < 0) return false; if(inputs.GetIndex() < 0) return false; if(outputs.GetIndex() < 0) return false; if(step == 0) step = window;
После успешного прохождения блока контролей, мы определяем пространство задач для кернела и смещение в нем:
uint global_work_offset[2] = {0, 0}; uint global_work_size[2]; global_work_size[0] = outputs.Total() / (2 * window_out); global_work_size[1] = window_out;
Затем мы передаем все необходимые параметры кернелу с обязательным контролем выполнения операций:
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardComplexConv, def_k_ffc_matrix_w, weights.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardComplexConv, def_k_ffc_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardComplexConv, def_k_ffc_matrix_o, outputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardComplexConv, def_k_ffc_inputs, (int)(inputs.Total() / 2))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardComplexConv, def_k_ffc_step, (int)step)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardComplexConv, def_k_ffc_window_in, (int)window)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardComplexConv, def_k_ffс_window_out, (int)window_out)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardComplexConv, def_k_ffc_activation - 1, (int)activ)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
После чего осуществляем постановку кернела в очередь выполнения и завершаем работу метода:
if(!OpenCL.Execute(def_k_FeedForwardComplexConv, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel %s: %s", __FUNCSIG__, error); return false; } //--- return true; }
Алгоритм постановки кернелов в очередь выполнения довольно однотипный. Возможны нюансы по размеру пространства задач и вариации с переменными. С целью экономии вашего времени и уменьшения объема статьи, позвольте дальше не останавливаться на методах постановки кернелов в очередь. Их полный код можно найти во вложении. А мы уделим больше внимания алгоритмам построения самих кернелов.
Следуем далее алгоритму Self-Attention. После определения сущностей Query, Key и Value мы переходим к определению коэффициентов зависимости. Для этого нам необходимо умножить матрицу Query на транспонированную матрицу Key. Матрица результатов нормализуется с помощью функции SoftMax.
Описанный функционал выполняется в кернеле ComplexMHAttentionScore, который мы будем вызывать из метода CNeuronComplexMLMHAttention::AttentionScore.
__kernel void ComplexMHAttentionScore(__global float2 *qkv, __global float2 *score, int dimension, int mask ) { int q = get_global_id(0); int h = get_global_id(1); int units = get_global_size(0); int heads = get_global_size(1);
В параметрах кернел получает указатели на 2 буфера данных. Конкатенированный буфер сущностей в качестве исходных данных. И буфер для записи результатов.
Указанный кернел запускается в двумерном пространстве задач. Первое измерение определяет строку матрицы Query, а второе активную голову внимания. Таким образом, каждый отдельный экземпляр запущенного кернела осуществляет операции по вычислению 1 строки матрицы коэффициентов зависимости в рамках 1 головы внимания.
В теле кернела мы идентифицируем текущий поток в обоих измерениях пространства задач и определяем смещения в буферах данных:
int shift_q = dimension * (h + 3 * q * heads); int shift_s = units * (h + q * heads);
Затем мы определим коэффициент нормализации данных:
float2 koef = (float2)(sqrt((float)dimension), 0); if(koef.x < 1) koef.x = 1;
И организуем цикл вычисления коэффициентов зависимости:
float2 sum = 0; for(int k = 0; k < units; k++) { if(mask > 0 && k > q) { score[shift_s + k] = (float2)0; continue; }
Здесь надо сказать, что в представленном алгоритме реализовано маскирование данных, которое позволяет ограничить так называемое "заглядывание вперед", когда модель анализирует коэффициенты зависимости только к предшествующим токенам. Для последующих токенов коэффициенты зависимости приравниваются к 0, чтобы в процессе обучения модель не могла получить информацию "из будущего". Включение данного функционала осуществляется с помощью флага mask, который передается в параметрах кернела.
Далее во вложенном цикле мы осуществляем вычисление очередного элемента вектора зависимостей путем перемножения 2 векторов.
float2 result = (float2)0; int shift_k = dimension * (h + heads * (3 * k + 1)); for(int i = 0; i < dimension; i++) result += ComplexMul(qkv[shift_q + i], qkv[shift_k + i]);
Вычисляем экспоненту для результата произведения:
result = ComplexExp(ComplexDiv(result, koef));
Обязательно определяем переполнение переменной:
if(isnan(result.x) || isnan(result.y) || isinf(result.x) || isinf(result.y)) result = (float2)0;
Результат записываем в буфер результатов и добавляем к общей сумме для последующей нормализации.
score[shift_s + k] = result; sum += result; }
В завершении кернела мы нормализуем вычисленную строку матрицы коэффициентов зависимости:
if(ComplexAbs(sum) > 0) for(int k = 0; k < units; k++) score[shift_s + k] = ComplexDiv(score[shift_s + k], sum); }
Полученная таким образом матрица коэффициентов зависимости Score используется для вычисления результатов блока внимания. Здесь нам необходимо умножить полученную матрицу коэффициентов на матрицу сущностей Value. Эта работа выполняется в кернеле ComplexMHAttentionOut. Аналогично предыдущему, данный кернел работает в том же 2-мерном пространстве задач.
__kernel void ComplexMHAttentionOut(__global float2 *scores, __global float2 *qkv, __global float2 *out, int dimension ) { int u = get_global_id(0); int units = get_global_size(0); int h = get_global_id(1); int heads = get_global_size(1);
В теле кернела мы идентифицируем текущий поток в пространстве задач и определяем смещения в буферах данных:
int shift_s = units * (h + heads * u); int shift_out = dimension * (h + heads * u);
После чего организовываем систему вложенных циклов для проведения математических операций умножения матрицы Value на соответствующую строку коэффициентов зависимости:
for(int d = 0; d < dimension; d++) { float2 result = (float2)0; for(int v = 0; v < units; v++) { int shift_v = dimension * (h + heads * (3 * v + 2)) + d; result += ComplexMul(scores[shift_s + v], qkv[shift_v]); } out[shift_out + d] = result; } }
Полученный таким образом результат многоголового внимания далее консолидируется в единый тензор и понижается в размерности до размера тензора исходных данных. А затем осуществляются операции блока FeedForward. Данные операции осуществляются с помощью описанного выше кернела FeedForwardComplexConv. Таким образом, на этом мы завершаем описание алгоритмов кернелов осуществления операций прямого прохода. А с полным кодом всех кернелов, как и вызывающих их методов, вы можете ознакомиться во вложении.
3.3 Организация обратного прохода
После завершения работы по организации функционала прямого прохода, мы приступаем к реализации алгоритмов обратного прохода. Здесь наша работа аналогична проведенной выше для прямого прохода. Мы эксплуатируем алгоритмы верхнего уровня, унаследованные от родительского класса, и переопределяем методы нижнего уровня.
Как уже было сказано выше, мы не будем останавливаться на описании алгоритмов методов постановки кернелов в очередь выполнения. Все они однотипные. Уделим больше внимания разбору алгоритмов кернелов на стороне OpenCL программы.
Несложно заметить, что наиболее используемым при прямом проходе был кернел FeedForwardComplexConv. Это такой универсальный блок, который используется нами на разных этапах. И вполне естественно, что построение алгоритмов обратного прохода мы начнем именно с кернела распределения градиента ошибки через указанный блок. Данный функционал мы реализуем в кернеле CalcHiddenGradientComplexConv.
__kernel void CalcHiddenGradientComplexConv(__global float2 *matrix_w, __global float2 *matrix_g, __global float2 *matrix_o, __global float2 *matrix_ig, int outputs, int step, int window_in, int window_out, int activation, int shift_out ) { size_t i = get_global_id(0); size_t inputs = get_global_size(0);
Кернел запускается в одномерном пространстве задач по числу элементов в буфере исходных данных. Каждый отдельный поток данного кернела осуществляет сбор градиентов ошибки со всех элементов, на которые оказывает влияние анализируемый элемент исходных данных.
В теле кернела мы идентифицируем текущий поток и определяем смещения в буферах данных. Тут же мы объявляем необходимые локальные переменные:
float2 sum = (float2)0; float2 out = matrix_o[shift_out + i]; int start = i - window_in + step; start = max((start - start % step) / step, 0); int stop = (i + step - 1) / step; if(stop > (outputs / window_out)) stop = outputs / window_out;
После чего мы организовываем систему циклов, в теле которой соберем суммарный градиент ошибки с учетом влияния анализируемого элемента на общий результат:
for(int h = 0; h < window_out; h ++) { for(int k = start; k < stop; k++) { int shift_g = k * window_out + h; int shift_w = (stop - k - 1) * step + i % step + h * (window_in + 1); if(shift_g >= outputs || shift_w >= (window_in + 1) * window_out) break; sum += ComplexMul(matrix_g[shift_out + shift_g], matrix_w[shift_w]); } }
После выхода из цикла мы проверяем переполнение переменной:
if(isnan(sum.x) || isnan(sum.y) || isinf(sum.x) || isinf(sum.y)) sum = (float2)0;
И корректируем полученный градиент ошибки на производную функции активации:
switch(activation) { case 0: sum = ComplexMul(sum, (float2)1.0f - ComplexMul(out, out)); break; case 1: sum = ComplexMul(sum, ComplexMul(out, (float2)1.0f - out)); break; case 2: if(out.x < 0.0f) sum.x *= 0.01f; if(out.y < 0.0f) sum.y *= 0.01f; break; default: break; } matrix_ig[i] = sum; }
Финальный результат мы сохраним в буфере градиентов ошибки предыдущего слоя.
Следующий кернел, который я предлагаю рассмотреть, это кернел распределения градиента ошибки через блок внимания ComplexMHAttentionGradients. В данном кернеле представлен довольно сложный алгоритм, который условно можно разделить на 3 блока по количеству сущностей, для которых выполняется определение значения градиента ошибки.
__kernel void ComplexMHAttentionGradients(__global float2 *qkv, __global float2 *qkv_g, __global float2 *scores, __global float2 *gradient) { size_t u = get_global_id(0); size_t h = get_global_id(1); size_t d = get_global_id(2); size_t units = get_global_size(0); size_t heads = get_global_size(1); size_t dimension = get_global_size(2);
В данном кернеле выполняется довольно много операций. И с целью сокращения общего времени выполнения операций, в процессе обучения модели мы постарались максимально распараллелить операции по вычислению значений отдельных переменных. А чтобы идентификация потока была максимально прозрачной и интуитивно понятной, мы создали 3-мерное пространство задач для данного кернела. Как и в методах прямого прохода блока внимания, здесь мы используем элемент последовательности и голову внимания. Но в третье измерение пространства задач мы выносим позицию элемента в тензоре описания элемента последовательности. Таким образом, несмотря на большое количество операций, каждый отдельный поток запишет только 3 значения в буфер результатов. В данном случае это конкатенированный буфер градиентов ошибки сущностей Query, Key и Value.
В теле кернела сначала мы идентифицируем поток в пространстве задач и определим смещения в буферах данных:
float2 koef = (float2)(sqrt((float)dimension), 0); if(koef.x < 1) koef.x = 1; //--- init const int shift_q = dimension * (heads * 3 * u + h); const int shift_k = dimension * (heads * (3 * u + 1) + h); const int shift_v = dimension * (heads * (3 * u + 2) + h); const int shift_g = dimension * (heads * u + h); int shift_score = h * units; int step_score = units * heads;
Затем мы определим градиент ошибки для анализируемого элемента матрицы Value. Для этого мы умножаем отдельный столбец тензора градиентов ошибки на выходе блока внимания на соответствующий столбец матрицы коэффициентов зависимости:
//--- Calculating Value's gradients float2 sum = (float2)0; for(int i = 0; i < units; i++) sum += ComplexMul(gradient[(h + i * heads) * dimension + d], scores[shift_score + u + i * step_score]); qkv_g[shift_v + d] = sum;
Следующим этапом мы определим градиент ошибки для анализируемого элемента сущности Query. Но тут следует помнить, что данная сущность не оказывает прямого влияния на результат. Есть лишь опосредовательное влияние через матрицу коэффициентов зависимости. Поэтому нам сначала необходимо найти градиент ошибки для соответствующей строки матрицы коэффициентов зависимости. А нормализация данных с помощью функции SoftMax ещё больше усложняет процесс.
//--- Calculating Query's gradients shift_score = h * units + u * step_score; float2 grad = 0; float2 grad_out = gradient[shift_g + d]; for(int k = 0; k < units; k++) { float2 sc_g = (float2)0; float2 sc = scores[shift_score + k]; for(int v = 0; v < units; v++) sc_g += ComplexMul( ComplexMul(scores[shift_score + v], ComplexMul(qkv[dimension * (heads * (3 * v + 2) + h)], grad_out)), ((float2)(k == v, 0) - sc) );
Найденный градиент ошибки для отдельно взятого коэффициента зависимости умножается на соответствующий элемент матрицы сущностей Key. Полученные значения суммируются для накопления общего градиента ошибки:
grad += ComplexMul(ComplexDiv(sc_g, koef), qkv[dimension * (heads * (3 * k + 1) + h) + d]); }
Накопленный градиент ошибки мы записываем в буфер результатов:
qkv_g[shift_q + d] = grad;
Аналогичным образом мы определяем градиент ошибки для элементов сущности Key, которая также оказывает опосредованное влияние на результат через матрицу коэффициентов зависимости. Только на этот раз речь идет о столбце указанной матрицы:
//--- Calculating Key's gradients grad = 0; for(int q = 0; q < units; q++) { shift_score = h * units + q * step_score; float2 sc_g = (float2)0; float2 sc = scores[shift_score + u]; float2 grad_out = gradient[dimension * (heads * q + h) + d]; for(int v = 0; v < units; v++) sc_g += ComplexMul( ComplexMul(scores[shift_score + v], ComplexMul(qkv[dimension * (heads * (3 * v + 2) + h)], grad_out)), ((float2)(u == v, 0) - sc) ); grad += ComplexMul(ComplexDiv(sc_g, koef), qkv[dimension * (heads * 3 * q + h) + d]); } qkv_g[shift_k + d] = grad; }
На этом мы завершаем рассмотрение алгоритмов построения кернелов обратного прохода для организации функционала комплексного слоя внимания. С полным кодом всех методов и кернелов представленного класса можно ознакомиться во вложении.
Заключение
В данной статье мы познакомились с теоретическими особенностями построения метода ATFNet, который совмещает в себе подходы прогнозирования временных рядов как в частотной, так и во временной области.
В практической части данной статьи мы провели огромную работу по построению слоя внимания с использованием комплексных операций. Однако это всего лишь один объект из F-блока предложенного метода. В следующей статье мы продолжим построение алгоритма метода ATFNet и посмотрим на результаты его работы с реальными данными.
Ссылки
- ATFNet: Adaptive Time-Frequency Ensembled Network for Long-term Time Series Forecasting
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Нейросети это просто. Часть 92 😅
Это доступно каждому. А количество статей свидетельствует о многогранности и постоянном развитии.