
Разработка робота на Python и MQL5 (Часть 2): Выбор модели, создание и обучение, кастомный тестер Python

Краткое содержание предыдущей статьи
Итак, в предыдущей статье мы немного рассказали про машинное обучение, провели аугментацию данных, разработали признаки для будущей модели, отобрали лучшие из них. Сейчас пришло время двигаться дальше и создавать уже рабочую модель машинного обучения, которая будет учиться на наших признаках, и торговать (надеемся, успешно). А для оценки модели мы напишем кастомный тестер Python, который поможет нам оценить работоспособность модели и красоту графиков теста. Для более красивых графиков теста и большей устойчивости модели, мы попутно разработаем также ряд классических фишек машинного обучения.
Наша конечная цель — создать рабочую и по максимуму прибыльную модель для прогнозирования цен и торговли. Весь код будет на Python, с включениями библиотеки MQL5.
Версия Python и необходимые модули
Для работы использовался Python версии 3.10.10. Приложенный к статье код содержит несколько функций для предварительной обработки данных, выделения признаков и обучения модели машинного обучения. В частности, он включает в себя:
- Функцию для кластеризации признаков с помощью Gaussian Mixture Model (GMM) от библиотеки sklearn
- Функцию для выделения признаков с помощью Recursive Feature Elimination with Cross-Validation (RFECV) от библиотеки sklearn
- Функцию для обучения классификатора XGBoost
Для запуска этого кода необходимо установить следующие модули Python:
- pandas
- numpy
- sklearn
- xgboost
- matplotlib
- seaborn
- MetaTrader5
- tqdm
Вы можете установить их с помощью pip, утилиты установки пакетов Python. Вот пример команды для установки всех необходимых модулей:
pip install pandas numpy sklearn xgboost matplotlib seaborn tqdm MetaTrader5
Поехали!
Классификация или регрессия?
Один из извечных вопросов в прогнозировании данных. Классификация лучше подходит для бинарных задач, когда нужен четкий ответ "да-нет". Есть еще мультикласс-классификация, эту тему мы также разберем в будущих статьях цикла, она интересна и может существенно усилить модели.
Регрессия подходит для конкретного прогноза конкретного будущего значения непрерывного ряда, в том числе ценового. С одной стороны, это может быть куда удобнее, а с другой, разметка данных для регрессии, как и метки (labels) - задачка для ума, ведь тут мало что можно придумать кроме того, чтобы просто взять будущую цену актива.
Классификация по причине более легкой работы с разметкой данных мне лично нравится больше. Много чего можно загнать в условия "да-нет", а в условия мультикласс-классификации вообще возможно заводить целые сложные ручные торговые системы вроде СмартМани. Впрочем, код разметки данных вы уже видели в предыдущей статье цикла, и она явно подходит для бинарной классификации. Поэтому именно эту схему модели мы и возьмем.
Осталось определиться с самой моделью.
Выбор модели классификации
Необходимо выбрать подходящую модель классификации для наших данных с отобранными фичами. Выбор зависит от количества фич, типов данных, числа классов.
Популярные модели для примера: логистическая регрессия для бинарной классификации, случайный лес для больших размерностей и нелинейностей, нейронные сети для сложных задач. Выбор огромен, и просто глаза разбегаются от многообразия. Перепробовав многое, я пришел к выводу, что в сегодняшних условиях наиболее эффективным является бустинг и модели на его базе.
Я решил использовать передовую модель XGBoost - бустинг над деревьями решений с регуляризацией, параллельностью, множеством настроек. XGBoost часто побеждает на соревнованиях по data science благодаря высокой точности. Это и стало главным критерием выбора модели для работы.
Создание кода модели классификации
Код использует передовую модель XGBoost - градиентный бустинг над деревьями решений. Особенность XGBoost - применение вторых производных для оптимизации, что повышает эффективность и точность по сравнению с другими моделями.
Функция train_xgboost_classifier получает данные и число раундов бустинга. Разделяет данные на фичи X и метки y, создает модель XGBClassifier с настройкой гиперпараметров, обучает ее методом fit().
Данные делятся на трейн/тест, модель обучается на трейне с помощью функции. Тестируется на остатке данных, высчитывается accuracy предсказаний.
Главные преимущества XGBoost: объединение множества моделей в высокоточную, с помощью градиентного бустинга, и оптимизация по вторым производным для эффективности.
Для использования вам потребуется также установить OpenMP runtime библиотеку. Для установки библиотеки XGBoost нужно также поставить OpenMP runtime. Для Windows надо скачать Microsoft Visual C++ Redistributable, соответствующий вашей версии Python.
Переходим к самому коду. В начале кода мы импортируем библиотеку xgboost вот таким образом:
import xgboost as xgb Остальная часть кода:
import xgboost as xgb def train_xgboost_classifier(data, num_boost_rounds=500): # Check if data is not empty if data.empty: raise ValueError("Data should not be empty") # Check if all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check if all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create an XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Test the model on all data train_data = raw_data[raw_data.index <= FORWARD] # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate prediction accuracy accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Обучим модель, и рассмотрим точность Accuracy в 52%.
Итак, наша точность классификации сейчас составляет 53% прибыльных меток. Прошу заметить, что тут речь идет о прогнозировании ситуаций, когда цена изменилась более чем на величину тейка (200 пипсов), и не задела хвостом стоп (100 пипсов). На практике у нас выйдет профит-фактор примерно в троечку, что вполне достаточно для прибыльной торговли. Следующим шагом я вижу написание самописного тестера в Python, для анализа доходности моделей, доходности именно в долларах, а не пунктах. Нужно понять, зарабатывает ли модель с учетом маркапа, или же сливает капитал в трубу.
Написание функции самописного тестера Python
def test_model(model, X_test, y_test, markup, initial_balance=10000.0, point_cost=0.00001): balance = initial_balance trades = 0 profits = [] # Test the model on the test data predicted_labels = model.predict(X_test) for i in range(len(predicted_labels) - 48): if predicted_labels[i] == 1: # Open a long position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price > entry_price + markup: # Close the long position with profit profit = (exit_price - entry_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the long position with loss loss = (entry_price - exit_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) elif predicted_labels[i] == 0: # Open a short position entry_price = X_test.iloc[i]['close'] exit_price = X_test.iloc[i+48]['close'] if exit_price < entry_price - markup: # Close the short position with profit profit = (entry_price - exit_price - markup) / point_cost balance += profit trades += 1 profits.append(profit) else: # Close the short position with loss loss = (exit_price - entry_price + markup) / point_cost balance -= loss trades += 1 profits.append(-loss) # Calculate the cumulative profit or loss total_profit = balance - initial_balance # Plot the balance change over the number of trades plt.plot(range(trades), [balance + sum(profits[:i]) for i in range(trades)]) plt.title('Balance Change') plt.xlabel('Trades') plt.ylabel('Balance ($)') plt.xticks(range(0, len(X_test), int(len(X_test)/10)), X_test.index[::int(len(X_test)/10)].strftime('%Y-%m-%d')) # Add dates to the x-axis plt.axvline(FORWARD, color='r', linestyle='--') # Add a vertical line for the FORWARD date plt.show() # Print the results print(f"Cumulative profit or loss: {total_profit:.2f} $") print(f"Number of trades: {trades}") # Get test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] # Test the model with markup and target labels initial_balance = 10000.0 markup = 0.00001 test_model(xgb_clf, X_test, y_test, markup, initial_balance)
Код создает функцию для тестирования модели машинного обучения на тестовых данных и анализа ее доходности с учетом маркапа (сюда нужно включить потери на спреде и комиссиях разного рода). Свопы не учитываются, все-таки они динамические и зависят от ключевых ставок. Их можно учесть просто добавкой пары пипсов к маркапу.
Функция получает модель, тест-данные, маркап и начальный баланс. Используя предсказания модели, имитируется торговля: лонг при 1, шорт при 0. Если прибыль превысила маркап, позиция закрывается, а прибыль добавляется к балансу.
Ведется учет сделок и прибыли/убытка от каждой. Строится график баланса. Вычисляется накопленный итог прибыли/убытка.
В конце получаются тест-данные, удаляются ненужные столбцы. Обученная модель xgb_clf тестируется с заданным маркапом и начальным балансом. Протестируем же ее!
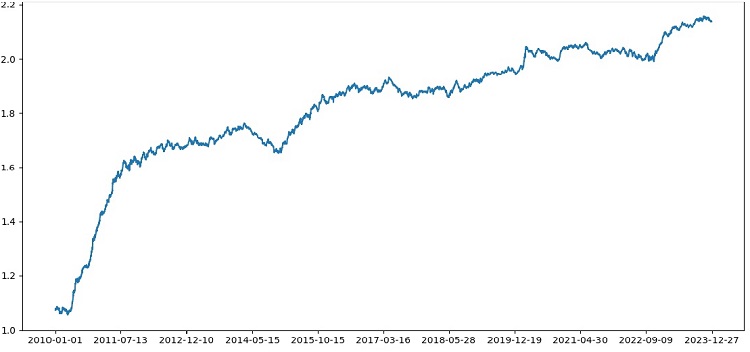
Итак, тестер в целом успешно работает, и мы видим вот такой красивый график доходности. Это самописный тестер для анализа доходности торговой модели машинного обучения с учетом маркапа и меток.
Внедрение кросс-валидации в модель
Для получения более надежной оценки качества модели машинного обучения необходимо использовать кросс-валидацию. Кросс-валидация позволяет оценить модель на нескольких подмножествах данных, что помогает избежать переобучения и получать более объективную оценку.
В нашем случае мы будем использовать 5-кратную кросс-валидацию для оценки модели XGBoost. Для этого воспользуемся функцией cross_val_score из библиотеки sklearn.
Изменим код функции train_xgboost_classifier следующим образом:
def train_xgboost_classifier(data, num_boost_rounds=500): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', max_depth=10, learning_rate=0.3, n_estimators=num_boost_rounds, random_state=1) # Train the model on the data using cross-validation scores = cross_val_score(clf, X, y, cv=5) # Calculate the mean accuracy of the predictions accuracy = scores.mean() print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Train the model on the data without cross-validation clf.fit(X, y) # Return the trained model return clf labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Accuracy: {accuracy:.2f}")
При обучении модели функция train_xgboost_classifier будет выполнять 5-кратную кросс-валидацию и выводить среднюю точность прогноза. В обучении по-прежнему будет участвовать выборка до даты FORWARD.
Кросс-валидация используется только для оценки модели, но не для ее обучения. Обучение выполняется на всех данных до даты FORWARD без кросс-валидации.
Кросс-валидация позволяет получить более надежную и объективную оценку качества модели, что в теории повысит ее устойчивость на новых ценовых данных. Или нет? Давайте проверим и посмотрим на работу тестера.
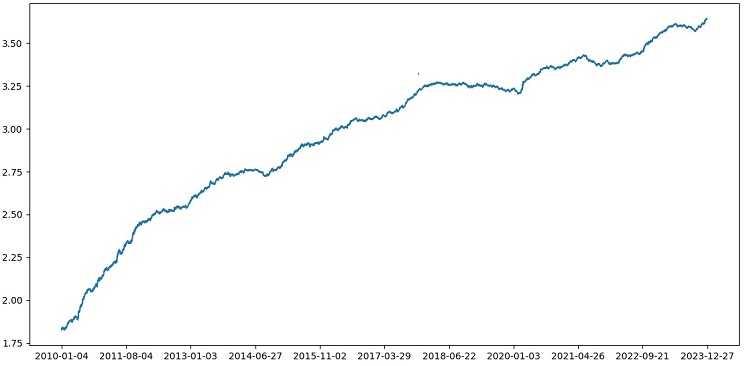
Протестировав XGBoost с кросс-валидацией на данных 1990-2024 гг., получена точность 56% на тесте после 2010 г. Модель показала неплохую робастность на новых данных с первой попытки. Точность также неплохо выросла, это не может не радовать.
Оптимизация гиперпараметров модели по сетке
Оптимизация гиперпараметров - важный этап создания модели машинного обучения для максимизации ее точности и производительности. Она схожа с оптимизацией советников MQL5, просто представьте, что у вас вместо советника - модель МО, и с помощью поиска по сетке вы находите параметры, которые покажут себя лучше всего.
Рассмотрим оптимизацию гиперпараметров XGBoost по сетке с использованием Scikit-learn.
Используем GridSearchCV из Scikit-learn для кросс-валидации модели по всем наборам гиперпараметров из сетки. Выберется набор с максимальной средней точностью на кросс-валидации.
Код для оптимизации:
from sklearn.model_selection import GridSearchCV
# Define the grid of hyperparameters
param_grid = {
'max_depth': [3, 5, 7, 10],
'learning_rate': [0.1, 0.3, 0.5],
'n_estimators': [100, 500, 1000]
}
# Create XGBoost model
clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1)
# Perform grid search to find the best hyperparameters
grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
# Print the best hyperparameters
print("Best hyperparameters:", grid_search.best_params_)
# Print the mean accuracy of the predictions on cross-validation for the best hyperparameters
print("Mean prediction accuracy on cross-validation:", grid_search.best_score_)
Здесь мы определяем сетку гиперпараметров param_grid, создаем модель XGBoost clf и выполняем поиск оптимальных гиперпараметров по сетке с помощью метода GridSearchCV. Затем мы выводим лучшие гиперпараметры grid_search.best_params_ и среднюю точность прогноза на кросс-валидации grid_search.best_score_ .
Обратите внимание, что в этом коде мы используем кросс-валидацию для оптимизации гиперпараметров. Это позволяет нам получить более надежную и объективную оценку качества модели.
После выполнения этого кода мы получим лучшие гиперпараметры для нашей модели XGBoost и среднюю точность прогноза на кросс-валидации. Затем мы можем обучить модель на всех данных с использованием лучших гиперпараметров и протестировать ее на новых данных.
Итак, оптимизация гиперпараметров модели по сетке является важной задачей при создании моделей машинного обучения. Используя метод GridSearchCV из библиотеки Scikit-learn, мы можем автоматизировать этот процесс и найти лучшие гиперпараметры для конкретной модели и данных.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Data is missing required columns: {required_columns}") # Drop the 'label' column since it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 5, 7, 10], 'learning_rate': [0.05, 0.1, 0.2, 0.3, 0.5], 'n_estimators': [50, 100, 600, 1200, 2000] } # Train the model on the data using cross-validation and grid search grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean prediction accuracy on cross-validation: {accuracy:.2f}") # Return the trained model with the best hyperparameters return grid_search.best_estimator_
Ансамблирование моделей
Пришло время сделать нашу модель еще круче и лучше! Ансамблирование моделей - мощный подход в машинном обучении, объединяющий несколько моделей для повышения точности прогнозов. Популярные методы: баггинг (создание моделей на разных подвыборках данных) и бустинг (последовательное обучение моделей для исправления ошибок предыдущих).
В нашей задаче используем ансамблирование XGBoost с баггингом и бустингом. Создаем несколько XGBoost, обученных на разных подвыборках, объединяем их прогнозы. Оптимизируем гиперпараметры каждой модели с GridSearchCV.
Преимущества ансамблирования: более высокая точность, снижение дисперсии, улучшение общего качества модели.
Итоговая функция обучения модели использует кросс-валидацию, ансамблирование, подбор гиперпараметров баггинга по сетке.
def train_xgboost_classifier(data, num_boost_rounds=1000): # Check that data is not empty if data.empty: raise ValueError("Data should not be empty") # Check that all required columns are present in the data required_columns = ['label', 'labels'] if not all(column in data.columns for column in required_columns): raise ValueError(f"Missing required columns in data: {required_columns}") # Remove the 'label' column as it is not a feature X = data.drop(['label', 'labels'], axis=1) y = data['labels'] # Check that all features have numeric data type if not all(pd.api.types.is_numeric_dtype(X[column]) for column in X.columns): raise ValueError("All features should have numeric data type") # Create XGBoostClassifier model clf = xgb.XGBClassifier(objective='binary:logistic', random_state=1) # Define hyperparameters for grid search param_grid = { 'max_depth': [3, 7, 12], 'learning_rate': [0.1, 0.3, 0.5], 'n_estimators': [100, 600, 1200] } # Train the model on the data using cross-validation and hyperparameter tuning grid_search = GridSearchCV(clf, param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # Calculate the mean accuracy of the predictions accuracy = grid_search.best_score_ print(f"Mean accuracy on cross-validation: {accuracy:.2f}") # Return the trained model return grid_search.best_estimator_ labeled_data_engineered = feature_engineering(labeled_data_clustered, n_features_to_select=20) # Get all data raw_data = labeled_data_engineered # Train data train_data = raw_data[raw_data.index <= FORWARD] # Test data test_data = raw_data[raw_data.index <= EXAMWARD] # Train the XGBoost model on the filtered data xgb_clf = train_xgboost_classifier(train_data, num_boost_rounds=100) # Test the model on all data test_data = raw_data[raw_data.index >= FORWARD] X_test = test_data.drop(['label', 'labels'], axis=1) y_test = test_data['labels'] predicted_labels = xgb_clf.predict(X_test) # Calculate the accuracy of the predictions accuracy = (predicted_labels == y_test).mean() print(f"Prediction accuracy: {accuracy:.2f}")
Внедряем ансамблирование моделей через бэггинг, тестируем, получаем следующий результат нашего тестирования:
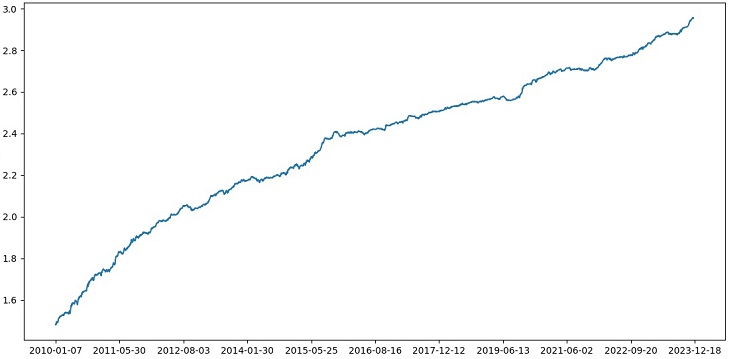
Точность классификации сделок с риском к прибыли в 1:8 выросла до 73%. То есть, ансамблирование и поиск по сетке добавили нам огромный навес точности классификации, нежели в предыдущей версии кода. Считаю это более чем отличным результатом, и по прошлым графикам работы модели на форвардном участке можно явно понять, насколько она усилилась в ходе эволюции кода.
Внедряем экзаменационную выборку и проверяем робастность модели
Теперь я использую для теста данные после EXAMWARD даты. Это позволяет мне проверить работу модели на совершенно новых данных, которые не использовались при обучении и тестировании модели. Так я могу объективно оценить, как модель будет работать в реальных условиях.
Тестирование на экзаменационной выборке - важный этап проверки модели машинного обучения. Это гарантирует, что модель хорошо работает на новых данных, и дает представление о ее реальной эффективности. Тут нужно правильно определить размер выборки и убедиться в ее репрезентативности.
В моем случае я использую данные после EXAMWARD, чтобы протестировать модель на полностью незнакомых данных вне трейна и теста. Так я получаю объективную оценку эффективности и готовности модели к реальному применению.
Провел обучение на данных 2000-2010 гг, тест на 2010-2019 гг, экзамен - с 2019 г. Экзамен имитирует торговлю в неизвестном будущем.
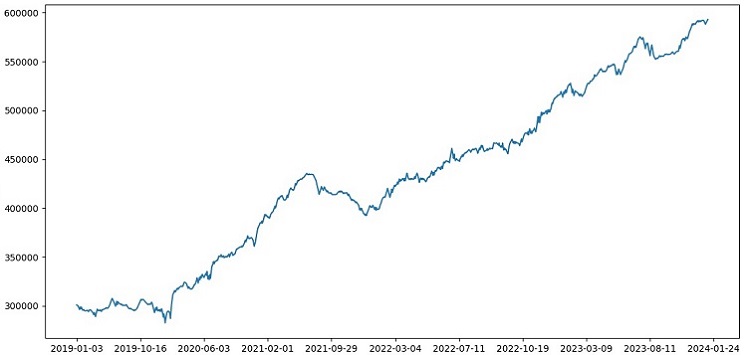
В целом, все выглядит неплохо. Точность на экзамене упала до 60%, но главное - модель прибыльная и довольно робастная, без сильных просадок. Радует, что модель учится понятию риск/прибыль - прогнозирует ситуации с малым риском и большой потенциальной прибылью (используем 1:8 risk-reward).
Заключение
Итак, мы завершаем вторую статью цикла по созданию торгового робота на Python. На данный момент нам удалось решить задачи работы с данными, работы с признаками, задачи отбора и даже генерации признаков, задачу выбора и обучения модели. Написали мы и кастомный тестер, который тестирует модель, и вроде бы, все получается очень даже неплохо. Кстати, я пробовал и другие признаки, в том числе и самые простые, попробовав путь упрощения данных. Мне не удалось достичь результата. Модели с данными признаками успешно сливали счет в нашем же тестере. Это в очередной раз подтверждает то, что признаки и данные не менее важны, чем крутизна самой модели. Можно сделать хорошую модель и применить разного рода улучшения и методы, но если признаки бесполезны, то и она будет безбожно сливать ваш депозит на неизвестных данных. А с хорошими признаками можно даже на не лучшей из моделей получить устойчивый результат.
Планы на будущее
В будущем я планирую создать кастомную версию онлайн-торговли в терминале MetaTrader 5, чтобы торговать прямо через Python. Это удобно. Напомню, что первичным сигналом в мой мозг о том, что нужно делать версию именно для Python, стали проблемы с переносом признаков в MQL5. С признаками, их отбором, с разметкой данных, с аугментацией данных мне все же намного быстрее и удобнее вести работу в Python.
Считаю, что библиотека MQL5 для Python незаслуженно недооценена, видно что ее мало кто использует. Хотя это очень мощная штука, с ее помощью можно создать действительно прекрасные модели, радующие и глаз, и кошелек!
Также хотелось бы реализовать версию, которая будет учиться на исторических данных стакана цен, на реальной бирже, Чикагской или же Московской. Это тоже перспективное направление.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Евгений, с Ваших статей начал изучать ML применительно к торговле, за это большое спасибо.
Не могли бы Вы объяснить следующие моменты.
После обработки данных функцией label_data их объем значительно уменьшается(мы получаем случайный набор баров, которые удовлетворяет условиям функции). Затем данные проходят через несколько функций, и мы делим их на train и test выборки. Модель обучается на train выборке. После этого из тестовой выборки удаляются столбцы ['labels'] , и мы пытаемся предсказать их значения, чтобы оценить модель. Нет ли в тестовых данных подмены понятий? Ведь для тестов мы используем данные, которые прошли функцию label_data(т.е. набор не последовательных баров, выбранных заранее функцией, которая учитывает будущие данные). А далее в тестере есть параметр 10,который, как я понимаю, должен отвечать за то, через сколько баров закрыть сделку, но т.к. у нас не последовательный набор баров, то не понятно, что мы получаем.
Получается следующие вопросы: Где я не прав? Почему для тестов используется не все бары >= FORWARD? И если не использовать все бары >= FORWARD, то как не зная будущего выбирать нужные для предсказания бары?
Спасибо.
Отличная работа, очень интересная, практичная и доступная. Трудно встретить такую хорошую статью с реальными примерами, а не просто теорию без результатов. Большое спасибо за вашу работу и за то, что делитесь с нами, я буду следить за этой серией и ждать ее с нетерпением.
Спасибо большое! Да, впереди еще много реализаций идей, в том числе и расширение этой с переводом на ONNX)
Критические недостатки:
Рекомендации по улучшению: