
Нейросети в трейдинге: Изучение локальной структуры данных

Введение
Задача обнаружения объектов в облаке точек привлекает все больше внимания. Эффективность решения данной задачи сильно зависит от информации о структуре локальных областей. Однако разреженный и нерегулярный характер облаков точек часто делает локальную структуру неполной и зашумленной.
Традиционное обнаружение объектов на основе свертки построено на использовании фиксированных ядер, и все соседние точки обрабатываются одинаково. Поэтому неизбежно учитываются не связанные между собой или зашумленные точки от других объектов.
Transformer показал свою эффективность в решении различных задачах. По сравнению со сверткой, механизм Self-Attention способен адаптивно исключать шумные или неактуальные точки. Тем не менее, ванильный Transformer использует одну функцию для преобразования всех элементов последовательности. Такая изотропная работа игнорирует информацию о локальной структуре в пространственных отношениях и не учитывает направление и расстояние от центральной точки до ее соседей. Если мы поменяем местами позиции точек, то результат работы Transformer останется прежним. Это создает проблемы для распознавания направления объектов, что важно для обнаружения ценовых паттернов.
Авторы статьи "SEFormer: Structure Embedding Transformer for 3D Object Detection" постарались объединить лучшее из двух подходов и разработали новый трансформер кодирования структуры (Structure-Embedding transFormer — SEFormer), который способен кодировать локальную структуру, ориентированную на направление и расстояние. Предложенный SEFormer изучает различные преобразования для Value точек с разных направлений и расстояний. Следовательно, изменение локальной пространственной структуры может быть закодировано в результатах работы модели, что даст ключ к точному распознаванию направлений объектов.
На основе предложенного модуля SEFormer в указанной работе предлагается многомасштабная сеть для обнаружения 3D-объектов.
1. Алгоритм SEFormer
Локальность и пространственная инвариантность свертки хорошо адаптируются к индуктивному смещению на изображениях. Еще одним важным преимуществом свертки является то, что она может кодировать структурную информацию данных. Авторы метода SEFormer декомпозируют свертку как двухшаговый оператор: преобразование и агрегирование. Во время преобразования каждая точка будет умножена на соответствующее ядро wδ. Затем эти баллы будут просто суммироваться с фиксированным коэффициентом агрегации α=1. В свертке ядра по-разному обучаются — в зависимости от их направлений и расстояний до центра ядра. Следовательно, свертка может закодировать локальную пространственную структуру. Однако в свертке все соседние точки в процессе агрегации равны (α=1). Основной оператор свертки использует статическое и жесткое ядро, но облако точек часто бывает нерегулярным и даже неполным. Следовательно, свертка неизбежно включает в себя нерелевантные или зашумленные точки в результирующий признак.
По сравнению со сверткой, механизм Self-Attention в Transformer обеспечивает более эффективный метод сохранения неправильных форм и границ объектов в облаке точек. Для облака точек из N элементов 𝒑=[p1,…, pN], Transformer вычисляет отклик каждой точки следующим образом:
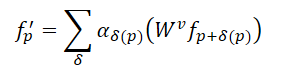
Здесь αδ представляет собой коэффициенты самовнимания между точками в соседней области, в то время как 𝑾v означает преобразование Value. По сравнению со статическим α=1 в свертке, коэффициенты самовнимания позволяют адаптивно выбирать точки для агрегации и исключать влияние не связанных между собой точек. Однако одно и то же преобразование для Value является общим для всех точек в Transformer. Это означает, что возможность кодирования структуры, которой обладает свертка, отсутствует.
Учитывая вышеизложенное, авторы SEFormer обнаружили, что свертка обладает способностью кодировать структуру данных, в то время как Transformer может хорошо сохранять структуру. Следовательно, простая идея состоит в том, чтобы разработать новый оператор, обладающий преимуществами свертки и Transformer. Поэтому они предложили SEFormer, который может быть сформулирован как:
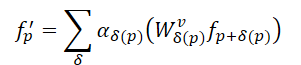
Наибольшее различие между SEFormer и ванильным Transformer заключается в функции преобразования для Value точек, которая обучается на основе взаимного положения между точками.
Учитывая нерегулярность облака точек, авторы метода SEFormer следуют парадигме Point Transformerдля независимой выборки соседних точек вокруг каждой точки Query перед импортом в Transformer. Здесь авторы метода решили использовать интерполяцию сетки для генерации ключевых точек. Вокруг анализируемой точки генерируются несколько виртуальных точек, расположенные по сетке. Расстояние между двумя элементами сетки является предопределенным d.
Затем виртуальные точки интерполируются с их ближайшими соседними элементами анализируемого облака точек. По сравнению с традиционной выборкой, такой как KNN, преимущество сеточной выборки заключается в возможности принудительно отбирать точки из разных направлений. Интерполяция сетки позволяет обеспечить более качественное описание локальной структуры. Однако, для интерполяции по сетке используется фиксированное расстояние d, поэтому авторы метода применяют стратегию с несколькими радиусами для повышения гибкости отбора проб.
SEFormer конструирует пул памяти, содержащий множественные матрицы преобразований для Value (𝑾v). Интерполированные ключевые точки будут искать соответствующие им 𝑾v на основе их относительной координаты к исходной точке. Тогда их признаки преобразятся иначе. Таким образом, SEFormer имеет возможность кодирования структуры, которая отсутствует в ванильном Transformer.
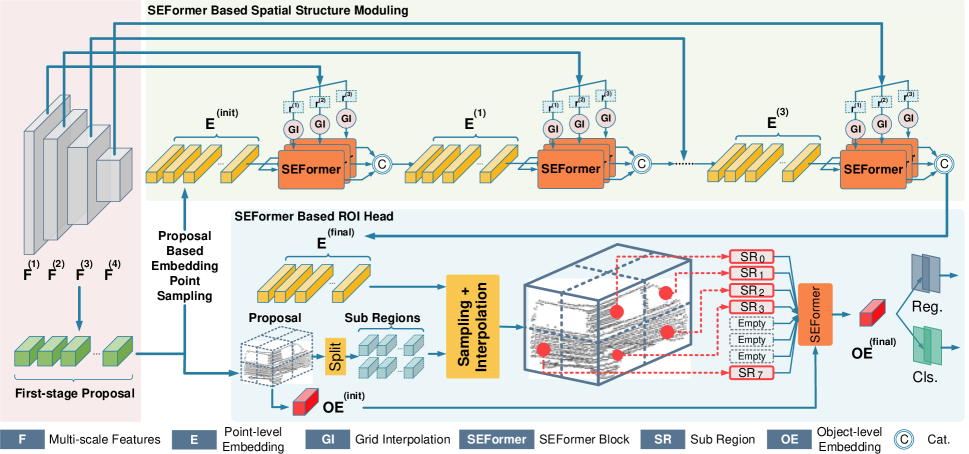
В модели обнаружения объектов, предложенной авторами метода, сначала строится магистраль на основе 3D-свертки, для извлечения многомасштабных воксельных признаков и генерации первичных предложений. Магистраль свертки сначала преобразует исходные данные в ряд воксельных признаков с помощью 1×, 2×, 4× и 8× уменьшений размеров дискретизации. Эти объекты разного размера имеют разные слои глубины. После извлечения признаков, объем 3D-элементов будет сжат по оси Z и преобразованы в 2D карту признаков "с высоты птичьего полета". На основе полученных карт осуществляется первичное прогнозирование объектов-кандидатов.
Затем предложенная пространственная структура модуляции агрегирует многомасштабные объекты [𝑭1, 𝑭2, 𝑭3, 𝑭4] в несколько вложений точечного уровня 𝑬. Начиная с 𝑬init, из функции самого малого масштаба 𝑭1 интерполируются ключевые точки для каждого анализируемого элемента. Авторы метода используют m различных расстояний по сетке d для создания наборов многомасштабных ключевых признаков в виде 𝑭1,1, 𝑭2,1,…, 𝑭m,1. Такая стратегия с несколькими радиусами позволяет лучше справляться с разреженным и нерегулярным распределением облака точек. Применяются m параллельных блоков SEFormer, которые генерируют m обновленных эмбедингов 𝑬1,1, 𝑬2,1,…, 𝑬m,1. Полученные эмбединги конкатенируются и преобразовываются в эмбединг 𝑬1 с помощью ванильного Transformer. После чего 𝑬1 повторяет описанный выше процесс и агрегатирует [𝑭2, 𝑭3, 𝑭4] в итоговый эмбединг 𝑬final. По сравнению с оригинальными функциями вокселей 𝑭, эмбединг 𝑬final содержит более подробное структурное описание локальной области.
На основе полученных эмбедингов, на уровне точек 𝑬final предлагаемая авторами метода голова модели агрегирует их в несколько эмбедингов объектов для создания окончательных предложений. Чтобы быть более точными, сначала каждое предложение первого этапа разделяется на несколько кубических подобластей и интерполирует каждую подобласть с окружающими объектами эмбедингов на уровне точек. Из-за разреженности облака точек, некоторые области часто пусты. Традиционный подход — простое суммирование признаков из непустых областей. В отличие от этого, предлагаемый SEFormer может использовать информацию как заполненных областей, так и пустых. Более широкие возможности встраивания структур в SEFormer могут обеспечить лучшее описание структуры на уровне объекта, а затем генерировать более точные предложения.
Авторская визуализация метода представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов предложенного метода SEFormer, мы переходим к практической части нашей статьи, в которой реализуем свое видение предложенных подходов. И давайте сразу подумаем об архитектуре нашей будущей модели.
Для первичного извлечения признаков авторы метода предлагают использовать воксельную 3D-свертку. В нашем же случае, вектор признаков одного бара может содержать намного больше признаков. И такой подход выглядит не совсем эффективно. Поэтому я предлагаю остановиться на используемом нами ранее подходе агрегирования признаков с использованием блока разреженного внимания с различным уровнем концентрации внимания.
Второй момент, на который хотелось бы обратить внимание, это построение сетки вокруг анализируемой точки. Здесь авторы метода при решении задачи обнаружения 3D-объектов могут себе позволить сжать данные по высоте и анализировать объекты на плоских картах. В нашем же случае многомерного представления данных, каждое измерение в тот или иной момент может оказать ключевое влияние. И мы не можем себе позволить сжать данные по какому-либо измерению. А построение "сетки" в многомерном пространстве может оказаться довольно сложной задачей. При этом количество элементов возрастает в геометрической прогрессии с ростом числа анализируемых признаков. И на мой взгляд, в подобной ситуации более эффективным будет заставить модель выучить наиболее оптимальные точки центроидов в многомерном пространстве.
С учетом вышесказанного я предлагаю построить наш новый объект с наследованием основного функционала от класса CNeuronPointNet2OCL. Общая структура нового класса CNeuronSEFormer представлена ниже.
class CNeuronSEFormer : public CNeuronPointNet2OCL { protected: uint iUnits; uint iPoints; //--- CLayer cQuery; CLayer cKey; CLayer cValue; CLayer cKeyValue; CArrayInt cScores; CLayer cMHAttentionOut; CLayer cAttentionOut; CLayer cResidual; CLayer cFeedForward; CLayer cCenterPoints; CLayer cFinalAttention; CNeuronMLCrossAttentionMLKV SEOut; CBufferFloat cbTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool AttentionOut(CBufferFloat *q, CBufferFloat *kv, int scores, CBufferFloat *out); virtual bool AttentionInsideGradients(CBufferFloat *q, CBufferFloat *q_g, CBufferFloat *kv, CBufferFloat *kv_g, int scores, CBufferFloat *gradient); //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronSEFormer(void) {}; ~CNeuronSEFormer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, uint center_points, uint center_window, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSEFormer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В представленной выше структуре можно заметить уже привычный нам список переопределяемых методов и целый ряд вложенных объектов. Наименование некоторых из них могут напомнить нам об архитектуре Transformer. И это не случайно, ведь авторы метода SEFormer постарались усовершенствовать алгоритм ванильного Transformer. Но обо всем по порядку.
Все внутренние объекты нашего класса мы объявили статично, что позволяет нам оставить "пустыми" конструктор и деструктор класса. Инициализация объявленных и унаследованных объектов осуществляется в методе Init, в параметрах которого, как вы знаете, мы получаем основные константы, определяющие архитектуру создаваемого объекта.
bool CNeuronSEFormer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, uint center_points, uint center_window, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronPointNet2OCL::Init(numOutputs, myIndex, open_cl, window, units_count, output, use_tnets, optimization_type, batch)) return false;
К уже знакомым нам параметрам здесь добавляется количество обучаемых центроидов и размер вектор описания их состояния.
Здесь стоит отметить, что архитектура нашего блока построена таким образом, что размер вектор описания центроида может отличаться от количества признаков описания одного анализируемого бара.
В теле метода мы, как обычно, сразу вызываем одноименный метод родительского класса, в котором уже реализованы механизмы контроля полученных параметров и инициализации унаследованных объектов. Мы лишь проверяем логический результат выполнения операций метода родительского класса.
После чего сохраним некоторые параметры создаваемой архитектуры, которые нам понадобятся при непосредственном выполнении операций выстраиваемого алгоритма.
iUnits = units_count; iPoints = MathMax(center_points, 9);
В качестве массива внутренних объектов я использовал объекты CLayer. Для их корректной работы мы передаём указатель на объект OpenCL-контекста.
cQuery.SetOpenCL(OpenCL); cKey.SetOpenCL(OpenCL); cValue.SetOpenCL(OpenCL); cKeyValue.SetOpenCL(OpenCL); cMHAttentionOut.SetOpenCL(OpenCL); cAttentionOut.SetOpenCL(OpenCL); cResidual.SetOpenCL(OpenCL); cFeedForward.SetOpenCL(OpenCL); cCenterPoints.SetOpenCL(OpenCL); cFinalAttention.SetOpenCL(OpenCL);
Для обучения представления центроидов мы создадим небольшую MLP из 2 последовательных полносвязных слоев.
//--- Init center points CNeuronBaseOCL *base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(iPoints * center_window * 2, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *buf = base.getOutput(); if(!buf || !buf.BufferInit(1, 1) || !buf.BufferWrite()) return false; if(!cCenterPoints.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base.Init(0, 1, OpenCL, iPoints * center_window * 2, optimization, iBatch)) return false; if(!cCenterPoints.Add(base)) return false;
Обратите внимание, что мы создаем центроидов в 2 раза больше заданного количества. Таким образом мы создаем 2 набора центроидов, имитируя построение сетки с разным масштабом.
А далее мы создадим цикл, в котором осуществим инициализацию внутренних объектов в соответствии с количеством слоев масштабирования признаков.
Напомню, что в родительском классе мы агрегируем исходные данные с двумя коэффициентами концентрации внимания. Соответственно, наш цикл будет содержать 2 итерации.
//--- Inside layers for(int i = 0; i < 2; i++) { //--- Interpolation CNeuronMVCrossAttentionMLKV *cross = new CNeuronMVCrossAttentionMLKV(); if(!cross || !cross.Init(0, i * 12 + 2, OpenCL, center_window, 32, 4, 64, 2, iPoints, iUnits, 2, 2, 2, 1, optimization, iBatch)) return false; if(!cCenterPoints.Add(cross)) return false;
Для интерполяции центроидов мы используем блок кросс-внимания, в котором сопоставляем текущее представление центродидов с набором анализируемых исходных данных. Основная идея данного процесса — найти такой набор центроидов, который будет максимально корректно и эффективно разделять исходные данные на локальные области. Тем самым мы изучаем структуру исходных данных.
Далее мы переходим к инициализации объектов предложенного авторами метода блока SEFormter. В данном блоке предполагается обогащение эмбединга анализируемых точек данными о структуре облака. Технически мы будем использовать алгоритм кросс-внимания анализируемых точек к нашим центроидам, обогащенным информацией о структуре облака точек.
Здесь мы используем сверточный слой для генерации сущности Query на основе эмбедингов анализируемых точек.
//--- Query CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 3, OpenCL, 64, 64, 64, iUnits, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false;
Аналогичным образом мы генерируем сущности Key, но уже из представления центроидов.
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 4, OpenCL, center_window, center_window, 32, iPoints, 2, optimization, iBatch)) return false; if(!cKey.Add(conv)) return false;
А вот для генерации сущности Value авторы метода SEFormer предлагают использовать индивидуальную матрицу преобразования каждого элемента последовательности. Поэтому мы используем аналогичный сверточный слой, только элементов в последовательности указываем 1. При этом все количество центроидов переносим в параметр анализируемых переменных. Такой подход позволяет нам получить желаемый результат.
//--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 5, OpenCL, center_window, center_window, 32, 1, iPoints * 2, optimization, iBatch)) return false; if(!cValue.Add(conv)) return false;
Однако стоит напомнить, что все наши кернелы алгоритмом кросс-внимания были созданы для работы с конкатенированным тензором сущностей Key-Value. И чтобы не вносить изменения в OpenCL-программу, мы просто добавим конкатенацию указанных тензоров.
//--- Key-Value base = new CNeuronBaseOCL(); if(!base || !base.Init(0, i * 12 + 6, OpenCL, iPoints * 2 * 32 * 2, optimization, iBatch)) return false; if(!cKeyValue.Add(base)) return false;
Матрица коэффициентов зависимости используется только в OpenCL-контексте и пересчитывается при каждом прямом проходе. Поэтому создание данного буфера в основной памяти не имеет смысла. И мы создаем его только в памяти OpenCL-контекста.
//--- Score int s = int(iUnits * iPoints * 4); s = OpenCL.AddBuffer(sizeof(float) * s, CL_MEM_READ_WRITE); if(s < 0 || !cScores.Add(s)) return false;
Тут же мы создаем слой для записи данных многоголового внимания.
//--- MH Attention Out base = new CNeuronBaseOCL(); if(!base || !base.Init(0, i * 12 + 7, OpenCL, iUnits * 64, optimization, iBatch)) return false; if(!cMHAttentionOut.Add(base)) return false;
И добавим сверточный слой масштабирования полученных результатов.
//--- Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 8, OpenCL, 64, 64, 64, iUnits, 1, optimization, iBatch)) return false; if(!cAttentionOut.Add(conv)) return false;
Согласно алгоритму Transformer, полученные результаты Self-Attention суммируются с исходными данными и нормализуются.
//--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, i * 12 + 9, OpenCL, iUnits * 64, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false;
Далее мы добавим 2 слоя блока FeedForward.
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 10, OpenCL, 64, 64, 256, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(LReLU); if(!cFeedForward.Add(conv)) return false; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, i * 12 + 11, OpenCL, 256, 64, 64, iUnits, 1, optimization, iBatch)) return false; if(!cFeedForward.Add(conv)) return false;
И объект для организации остаточной связи.
//--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, i * 12 + 12, OpenCL, iUnits * 64, optimization, iBatch)) return false; if(!base.SetGradient(conv.getGradient(), true)) return false; if(!cResidual.Add(base)) return false;
Обратите внимание, что в данном случае мы осуществляем подмену буфера градиента ошибки в слое организации остаточной связи. Это позволит нам исключить операцию копирования данных о градиенте ошибки из слоя остаточной связи в последний слой блока прямого прохода.
В завершении модуля SEFormer авторы метода предлагают использовать ванильный Ttransformer. Я же решил воспользоваться более сложной архитектурой и вставил модуль внимания, обусловленный сценой.
//--- Final Attention CNeuronMLMHSceneConditionAttention *att = new CNeuronMLMHSceneConditionAttention(); if(!att || !att.Init(0, i * 12 + 13, OpenCL, 64, 16, 4, 2, iUnits, 2, 1, optimization, iBatch)) return false; if(!cFinalAttention.Add(att)) return false; }
На этом этапе мы инициализировали все объекты одного внутреннего слоя, и переходим к следующей итерации цикла.
После полного выполнения итераций цикла инициализации объектов внутренних слоев следует обратить внимание на тот факт, что мы не используем результаты каждого внутреннего слоя. И наверное, логично было бы конкатенировать их в единый тензор с последующей передачей общего тензора для генерации глобального эмбединга облака точек средствами родительского класса. Конечно, предварительно нам нужно будет масштабировать полученный тензор до требуемого размера. Но в данном случае я решил пойти альтернативным путем. Мы просто воспользуемся блоком кросс-внимания и обогатим данные меньшего масштаба информацией от более крупного.
if(!SEOut.Init(0, 26, OpenCL, 64, 64, 4, 16, 4, iUnits, iUnits, 4, 1, optimization, iBatch)) return false;
И в завершении метода инициализируем вспомогательный буфер временного хранения данных.
if(!cbTemp.BufferInit(buf_size, 0) || !cbTemp.BufferCreate(OpenCL)) return false; //--- return true; }
После чего вернем вызывающей программе логический результат выполнения операций метода.
На данном этапе мы завершили работу над методом инициализации объекта класса. И теперь переходим к построению алгоритма прямого прохода в методе feedForward. Как вы знаете, в параметрах данного метода мы получаем указатель на объект исходных данных.
bool CNeuronSEFormer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- CNeuronBaseOCL *neuron = NULL, *q = NULL, *k = NULL, *v = NULL, *kv = NULL;
В теле метода мы сначала объявили несколько локальных переменных для временного хранения указателей на внутренние объекты. А затем сгенерируем представление центроидов.
//--- Init Points if(bTrain) { neuron = cCenterPoints[1]; if(!neuron || !neuron.FeedForward(cCenterPoints[0])) return false; }
Обратите внимание, что представление центроидов мы генерируем только в процессе обучения модели. В процессе эксплуатации точки центроидов статичны. И нам нет необходимости генерировать их при каждом проходе.
Далее мы организовываем цикл перебора внутренних слоев,
//--- Inside Layers for(int l = 0; l < 2; l++) { //--- Segmentation Inputs if(l > 0 || !cTNetG) { if(!caLocalPointNet[l].FeedForward((l == 0 ? NeuronOCL : GetPointer(caLocalPointNet[l - 1])))) return false; } else { if(!cTurnedG) return false; if(!cTNetG.FeedForward(NeuronOCL)) return false; int window = (int)MathSqrt(cTNetG.Neurons()); if(IsStopped() || !MatMul(NeuronOCL.getOutput(), cTNetG.getOutput(), cTurnedG.getOutput(), NeuronOCL.Neurons() / window, window, window)) return false; if(!caLocalPointNet[0].FeedForward(cTurnedG.AsObject())) return false; }
в теле которого мы сначала сегментируем исходные данные (алгоритм заимствован из родительского класса). А затем обогащаем полученными данными центроиды.
//--- Interpolate center points neuron = cCenterPoints[l + 2]; if(!neuron || !neuron.FeedForward(cCenterPoints[l + 1], caLocalPointNet[l].getOutput())) return false;
Далее мы переходим к модулю внимания с кодированием структуры данных. Вначале мы извлекаем из массивов соответствующие внутренние слои.
//--- Structure-Embedding Attention
q = cQuery[l];
k = cKey[l];
v = cValue[l];
kv = cKeyValue[l];
А затем последовательно генерируем все необходимые сущности.
//--- Query if(!q || !q.FeedForward(GetPointer(caLocalPointNet[l]))) return false; //--- Key if(!k || !k.FeedForward(cCenterPoints[l + 2])) return false; //--- Value if(!v || !v.FeedForward(cCenterPoints[l + 2])) return false;
Результаты генерации Key и Value конкатенируем в единый тензор.
if(!kv || !Concat(k.getOutput(), v.getOutput(), kv.getOutput(), 32 * 2, 32 * 2, iPoints)) return false;
После чего мы можем воспользоваться методами классического Multi-Head Self-Attention.
//--- Multi-Head Attention neuron = cMHAttentionOut[l]; if(!neuron || !AttentionOut(q.getOutput(), kv.getOutput(), cScores[l], neuron.getOutput())) return false;
Полученные данные масштабируем до размера исходных данных.
//--- Scale neuron = cAttentionOut[l]; if(!neuron || !neuron.FeedForward(cMHAttentionOut[l])) return false;
А затем суммируем 2 потока информации и нормализуем полученные данные.
//--- Residual q = cResidual[l * 2]; if(!q || !SumAndNormilize(caLocalPointNet[l].getOutput(), neuron.getOutput(), q.getOutput(), 64, true, 0, 0, 0, 1)) return false;
Аналогично Энкодеру ванильного Transformer, мы используем блок FeedForward с последующей остаточной связью и нормализацией данных.
//--- Feed Forward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.FeedForward(q)) return false; neuron = cFeedForward[l * 2 + 1]; if(!neuron || !neuron.FeedForward(cFeedForward[l * 2])) return false; //--- Residual k = cResidual[l * 2 + 1]; if(!k || !SumAndNormilize(q.getOutput(), neuron.getOutput(), k.getOutput(), 64, true, 0, 0, 0, 1)) return false;
Полученные результаты мы пропускаем через блок внимания с учетом сцены. И переходим к следующей итерации цикла.
//--- Final Attention neuron = cFinalAttention[l]; if(!neuron || !neuron.FeedForward(k)) return false; }
После успешного выполнения операций всех внутренних слоев, мы обогащаем эмбединги точек меньшего масштаба крупномасштабной информацией.
//--- Cross scale attention if(!SEOut.FeedForward(cFinalAttention[0], neuron.getOutput())) return false;
И передаем полученный результат для формирования глобально эмбединга анализируемого облака точек.
//--- Global Point Cloud Embedding if(!CNeuronPointNetOCL::feedForward(SEOut.AsObject())) return false; //--- result return true; }
А в завершении работы метода прямого прохода мы возвращаем логический результат выполненных операций вызывающей программе.
Как можно заметить, в процессе реализации алгоритма прямого прохода мы организовали довольно сложную структуру потока информации, которая далека от линейной. Здесь мы видим остаточные связи. Некоторые объекты используют 2 источника данных. Более того, некоторые потоки информации переплетаются. И разумеется, это отложило отпечаток на алгоритм обратного прохода, который мы реализовали в методе calcInputGradients.
bool CNeuronSEFormer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В параметрах метода мы получаем указатель на объект предшествующего слоя. При прямом проходе он передавал нам исходные данные. А теперь нам предстоит передать в него градиент ошибки, который соответствует влиянию исходных данных на конечный результат работы модели.
В теле метода мы сразу проверяем актуальность полученного указателя, так как в противном случае теряют смысл все дальнейшие операции.
Мы также объявляем ряд локальных переменных для временного хранения указателей на внутренние объекты.
CNeuronBaseOCL *neuron = NULL, *q = NULL, *k = NULL, *v = NULL, *kv = NULL; CBufferFloat *buf = NULL;
После чего, опустим градиент ошибки от глобального эмбединга облака точек до наших внутренних слоев.
//--- Global Point Cloud Embedding if(!CNeuronPointNetOCL::calcInputGradients(SEOut.AsObject())) return false;
Обратите внимание, что при прямом проходе итоговый результат мы получали путем вызова метода родительского класса. Следовательно, и для получения градиента ошибки нам необходимо воспользоваться соответствующим методом родительского класса.
Далее мы распределим градиент ошибки на потоки различного масштаба.
//--- Cross scale attention neuron = cFinalAttention[0]; q = cFinalAttention[1]; if(!neuron.calcHiddenGradients(SEOut.AsObject(), q.getOutput(), q.getGradient(), ( ENUM_ACTIVATION)q.Activation())) return false;
И организуем цикл обратного перебора внутренних слоев.
for(int l = 1; l >= 0; l--) { //--- Final Attention neuron = cResidual[l * 2 + 1]; if(!neuron || !neuron.calcHiddenGradients(cFinalAttention[l])) return false;
Здесь мы сначала опускаем градиент ошибки до уровня слоя остаточной связи.
Напомню, что при инициализации внутренних объектов мы осуществили подмену буфера градиентов ошибки слоя остаточной связи с аналогичным буфером слоя из блока FeedForward. Поэтому сейчас мы можем опустить излишнюю операцию копирования данных и сразу передать градиент ошибки на уровень ниже.
//--- Feed Forward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2 + 1])) return false;
Далее мы опускаем градиент ошибки до слоя остаточной связи блока внимания.
neuron = cResidual[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2])) return false;
А тут мы суммируем градиент ошибки из 2 потоков информации и суммарное значение передаем в блок внимания.
//--- Residual q = cResidual[l * 2 + 1]; k = neuron; neuron = cAttentionOut[l]; if(!neuron || !SumAndNormilize(q.getGradient(), k.getGradient(), neuron.getGradient(), 64, false, 0, 0, 0, 1)) return false;
После чего, распределяем градиент ошибки по головам внимания.
//--- Scale neuron = cMHAttentionOut[l]; if(!neuron || !neuron.calcHiddenGradients(cAttentionOut[l])) return false;
И с помощью алгоритмов ванильного Transformer опустим градиент ошибки до уровня сущностей Query, Key и Value.
//--- MH Attention q = cQuery[l]; kv = cKeyValue[l]; k = cKey[l]; v = cValue[l]; if(!AttentionInsideGradients(q.getOutput(), q.getGradient(), kv.getOutput(), kv.getGradient(), cScores[l], neuron.getGradient())) return false;
В результате выполнения данной операции мы получили 2 тензора градиентов ошибки: на уровне Query и конкатенированного тензора Key-Value. Распределим градиенты ошибки Key и Value по буферам соответствующих внутренних слоев.
if(!DeConcat(k.getGradient(), v.getGradient(), kv.getGradient(), 32 * 2, 32 * 2, iPoints)) return false;
И далее мы можем опустить градиент ошибки от тензора Query до уровня сегментирования исходных данных. Но есть один нюанс. Для последнего слоя эта операция не выделяется особой сложностью. А вот для первого слоя, в буфере градиентов уже будет храниться информация об ошибке с уровня последующего сегментирования. И нам её надо сохранить. Поэтому мы проверяем индекс текущего слоя и, при необходимости, осуществляем подмену указателей на буфера данных.
if(l == 0) { buf = caLocalPointNet[l].getGradient(); if(!caLocalPointNet[l].SetGradient(GetPointer(cbTemp), false)) return false; }
Далее мы спускаем градиент ошибки.
if(!caLocalPointNet[l].calcHiddenGradients(q, NULL)) return false;
И при необходимости, суммируем данные 2 потоков информации с последующим возвращением изъятого указателя на буфер данных.
if(l == 0) { if(!SumAndNormilize(buf, GetPointer(cbTemp), buf, 64, false, 0, 0, 0, 1)) return false; if(!caLocalPointNet[l].SetGradient(buf, false)) return false; }
И тут же мы добавим градиент ошибки остаточных связей блока внимания.
neuron = cAttentionOut[l]; //--- Residual if(!SumAndNormilize(caLocalPointNet[l].getGradient(), neuron.getGradient(), caLocalPointNet[l].getGradient(), 64, false, 0, 0, 0, 1)) return false;
Следующим этапом нам предстоит распределить градиент ошибки до уровня наших центроидов. Здесь нам предстоит распределить градиент ошибки как от сущности Key, так и от сущности Value. Здесь мы также воспользуемся подменой указателей на буфера данных.
//--- Interpolate Center points neuron = cCenterPoints[l + 2]; if(!neuron) return false; buf = neuron.getGradient(); if(!neuron.SetGradient(GetPointer(cbTemp), false)) return false;
После чего опустим первый градиент ошибки от сущности Key.
if(!neuron.calcHiddenGradients(k, NULL)) return false;
Однако первым он будет только для последнего слоя, а вот для первого в нем уже будет содержаться информация о градиенте ошибки от влияния на результат последующего слоя. Поэтому мы проверяем индекс анализируемого внутреннего слоя и, при необходимости, суммируем данные из двух потоков информации.
if(l == 0) { if(!SumAndNormilize(buf, GetPointer(cbTemp), buf, 1, false, 0, 0, 0, 1)) return false; } else { if(!SumAndNormilize(GetPointer(cbTemp), GetPointer(cbTemp), buf, 1, false, 0, 0, 0, 0.5f)) return false; }
Аналогичным образом проведем градиент ошибки от сущности Value и суммируем данные из двух потоков информации.
if(!neuron.calcHiddenGradients(v, NULL)) return false; if(!SumAndNormilize(buf, GetPointer(cbTemp), buf, 1, false, 0, 0, 0, 1)) return false;
После чего возвращаем изъятый ранее указатель на буфер градиентов ошибки.
if(!neuron.SetGradient(buf, false)) return false;
Далее мы распределим градиент ошибки между предыдущим уровнем центроидов и сегментированными данными текущего слоя.
neuron = cCenterPoints[l + 1]; if(!neuron.calcHiddenGradients(cCenterPoints[l + 2], caLocalPointNet[l].getOutput(), GetPointer(cbTemp), (ENUM_ACTIVATION)caLocalPointNet[l].Activation())) return false;
Для сохранения именно этого градиента ошибки мы осуществляли выше подмену буферов в слое центроидов. Более того, стоит заметить, что в буфере градиента ошибки слоя сегментации данных уже сохранена большая часть информации. Поэтому на данном этапе мы запишем градиент ошибки во временный буфер данных. А затем суммируем данные из двух потоков информации.
if(!SumAndNormilize(caLocalPointNet[l].getGradient(), GetPointer(cbTemp), caLocalPointNet[l].getGradient(), 64, false, 0, 0, 0, 1)) return false;
На данном этапе мы распределили градиент ошибки между всеми вновь объявленными внутренними объектами. Но остается распределить градиент ошибки через слои сегментации данных. Данный алгоритм мы полностью заимствуем из метода родительского класса.
//--- Local Net neuron = (l > 0 ? GetPointer(caLocalPointNet[l - 1]) : NeuronOCL); if(l > 0 || !cTNetG) { if(!neuron.calcHiddenGradients(caLocalPointNet[l].AsObject())) return false; } else { if(!cTurnedG) return false; if(!cTurnedG.calcHiddenGradients(caLocalPointNet[l].AsObject())) return false; int window = (int)MathSqrt(cTNetG.Neurons()); if(IsStopped() || !MatMulGrad(neuron.getOutput(), neuron.getGradient(), cTNetG.getOutput(), cTNetG.getGradient(), cTurnedG.getGradient(), neuron.Neurons() / window, window, window)) return false; if(!OrthoganalLoss(cTNetG, true)) return false; //--- CBufferFloat *temp = neuron.getGradient(); neuron.SetGradient(cTurnedG.getGradient(), false); cTurnedG.SetGradient(temp, false); //--- if(!neuron.calcHiddenGradients(cTNetG.AsObject())) return false; if(!SumAndNormilize(neuron.getGradient(), cTurnedG.getGradient(), neuron.getGradient(), 1, false, 0, 0, 0, 1)) return false; } } //--- return true; }
И после выполнения всех итераций нашего цикла перебора внутренних слоев, мы возвращаем вызывающей программе логический результат выполнения операций метода.
Выше мы реализовали алгоритмы прямого прохода и распределения градиента ошибки через внутренние объекты нашего нового класса. Остается реализовать метод обновления обучаемых параметров класса updateInputWeights. В данном случае все обучаемые параметры содержатся во вложенных объектах. Соответственно, для обновления параметров нашего класса достаточно последовательно вызвать одноименные методы внутренних объектов. Данный алгоритм довольно прозаичен, и я предлагаю оставить данный метод для самостоятельного изучения.
Напомню, что полный код нового класса CNeuronSEFormer и всех его методов вы можете найти во вложении. Там же вы найдете код методов, обслуживающих данный класс, которые были объявлены выше для переопределения.
Также следует сказать, что архитектура моделей практически полностью заимствована из предыдущей статьи. Мы лишь заменили 1 слой в Энкодере состояния окружающей среды.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSEFormer; { int temp[] = {BarDescr, 8}; // Variables, Center embedding if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {HistoryBars, 27}; // Units, Centers if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window_out = LatentCount; // Output Dimension descr.step = int(true); // Use input and feature transformation descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Это же касается всех программ взаимодействия с окружающей средой и обучения моделей, которые полностью заимствованы из предыдущей статьи. Поэтому мы не будем на них останавливаться. А полный код всех программ, используемых при подготовке данной статьи, представлен во вложении.
3. Тестирование
И вот, после выполнения довольно большого объема работы, мы подошли к финальной и, наверное, самой волнительной части — обучению моделей и тестированию полученной политики Актера на реальных исторических данных.
Как и ранее, для обучения моделей мы используем реальные исторические данные инструмента EURUSD за полный 2023 год, таймфрейм H1. Параметры всех анализируемых индикаторов используются по умолчанию.
Алгоритм обучения моделей был заимствован из предыдущих статей вместе с программами, используемыми при обучении и тестировании моделей.
Для тестирования обученной политики Актера мы используем реальные исторические данные за Январь 2024 года с сохранением всех прочих параметров. Результаты тестирования представлены ниже.
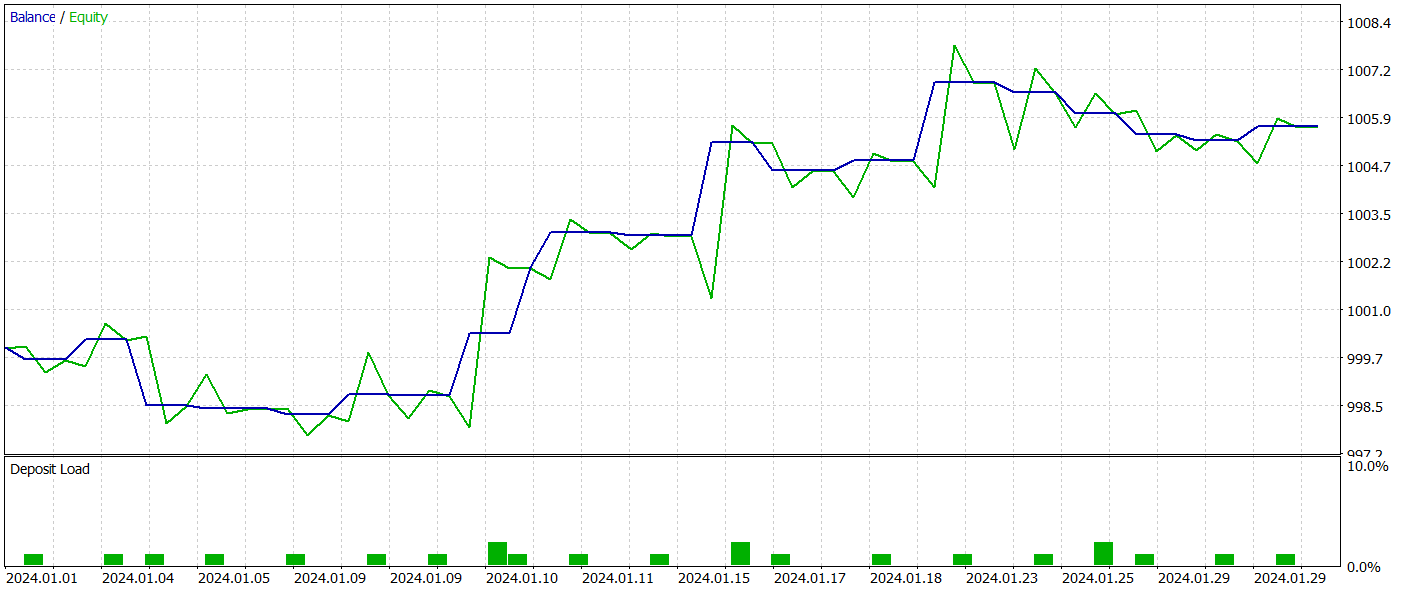
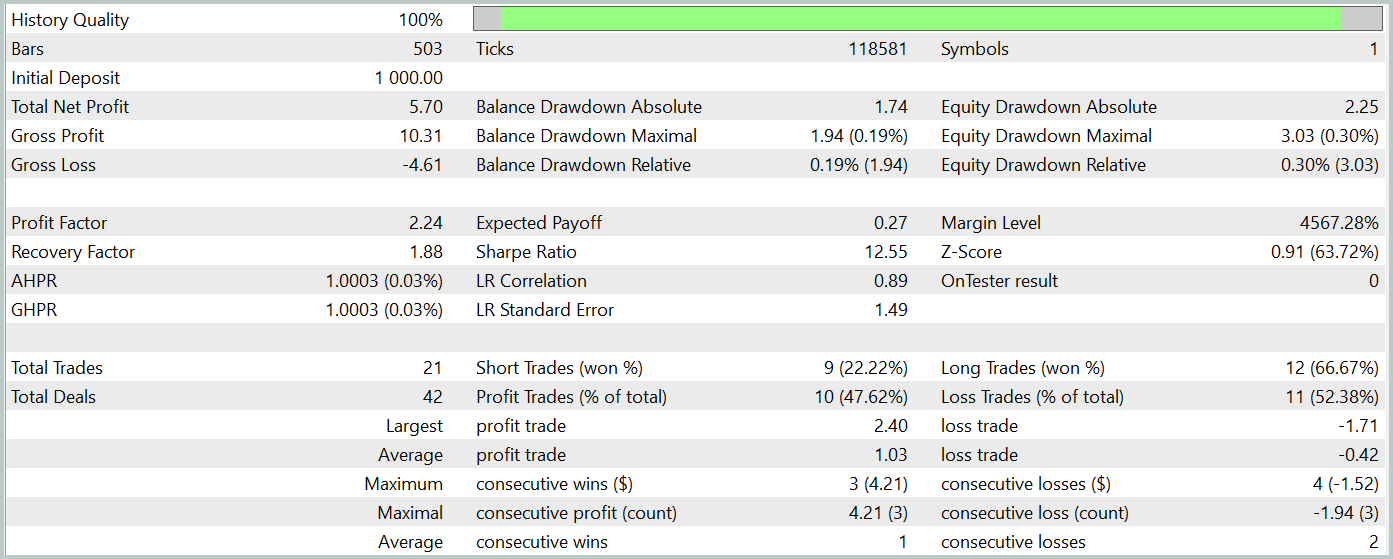
За период тестирования обученная модель совершила 21 сделку, чуть более 47% из них было закрыто с прибылью. Здесь можно отметить, что длинные позиции отличаются значительно большей доходностью (66% против 22%). Очевидно необходимо дополнительное обучение модели. Тем не менее, средняя прибыльная сделка в 2.5 раза превышает аналогичный убыточный показатель, что позволило получить модели общую прибыль по результатам тестирования.
По моему субъективному мнению, модель вышла довольно тяжелой. Наверное в большей степени это связано с использованием алгоритма внимания, обусловленного сценой. Однако, использование подобного подхода в методе HyperDet3D позволило получить лучшие результаты при меньших затратах.
Тем не менее, малое количество сделок и короткий период тестирования в обоих не позволяют судить об эффективности работы методов на более длительном временном отрезке.
Заключение
Метод SEFormer адаптирован для анализа облака точек и позволяет эффективно выявлять локальные зависимости в условиях шума, что является ключевым фактором для точных прогнозов. Это открывает перспективы для более точного прогнозирования рыночных движений и улучшения стратегии принятия решений.
В практической части данной статьи мы реализовали свое видение предложенных подходов средствами MQL5. Обучили и протестировали модель на реальных исторических данных. Полученные результаты демонстрируют потенциал предложенного метода. Однако, перед использованием модели в реальных торговых условиях, необходимо её обучение на более длительном историческом отрезке с последующим всесторонним тестированием обученной политики.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Особенности написания Пользовательских Индикаторов
Особенности написания Пользовательских Индикаторов

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования