Нейросети в трейдинге: Superpoint Transformer (SPFormer)

Введение
Сегментация объектов — это сложная задача для понимания сцены, целью которой является не только обнаружение объектов в разреженном облаке точек, но и предоставление четкой маски для каждого объекта.
Современные методы можно разделить на 2 группы:
- основанные на предположениях;
- основанные на группировке.
Методы, основанные на предположениях, рассматривают сегментацию 3D-объектов как нисходящий конвейер. Сначала они генерируют предположительные области, а затем определяют маски объектов в этих областях. Однако такие методы часто неэффективны из-за разреженности облаков точек. В 3D-полях ограничивающий прямоугольник имеет большую степень свободы, что увеличивает сложность аппроксимации. Более того, точки обычно существуют только на частях поверхности объекта, что приводит к тому, что геометрические центры объекта не обнаруживаются. А предложения по регионам низкого качества влияют на двухдольное сопоставление на основе блоков и еще больше снижают производительность модели.
Напротив, методы, основанные на группировке, используют восходящий конвейер. Они изучают точечные семантические метки и смещение центра экземпляров. Затем они используют смещенные точки и семантические предсказания для агрегирования в экземпляры. Однако и здесь есть свои недостатки. Подобные методы зависят от результатов семантической сегментации, что может привести к неправильным прогнозам. Кроме того, промежуточный шаг агрегации данных увеличивает время обучения и вывода.
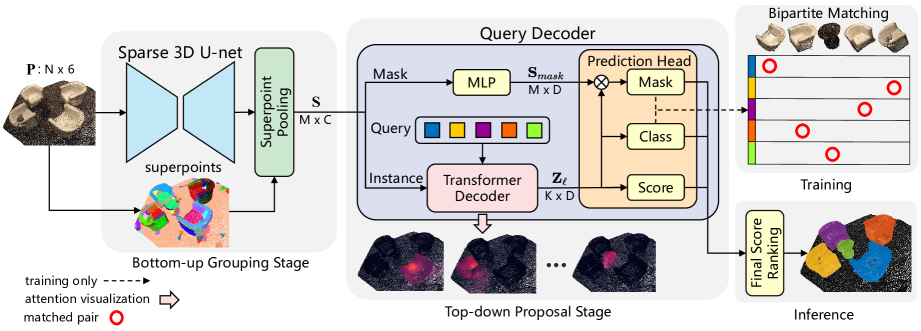
Для минимизации влияния указанных недостатков и извлечения выгоды из обоих подходов авторы работы "Superpoint Transformer for 3D Scene Instance Segmentation" предложили новый сквозной двухступенчатый метод сегментации 3D-объектов на основе Superpoint Transformer (SPFormer). SPFormer группирует восходящие потенциальные объекты из облаков точек в Superpoint и предлагает экземпляры по векторам запросов в виде нисходящего конвейера.
На этапе группировки снизу вверх разреженная 3D U-net используется для извлечения объектов снизу вверх по точкам. Предложен простой слой пула точек для группировки потенциальных точечных объектов в superpoint. Superpoint используют геометрические закономерности для представления однородных соседних точек. Полученные потенциальные объекты позволяют избежать супервизии объектов с помощью непрямых семантических меток и меток центрального расстояния. Авторы метода рассматривают superpoint в качестве потенциального средне уровневого представления 3D-сцены и напрямую используют метки экземпляров для обучения всей модели.
На стадии предположения сверху вниз предлагается новый декодер Transformer c запросами. Авторы метода используют обучаемые векторы запросов, чтобы предложить прогнозирование экземпляров на основе потенциальных функций superpoint в виде нисходящего конвейера. Обучаемый вектор запроса может захватывать информацию об экземпляре с помощью механизма перекрестного внимания к superpoint. С помощью векторов запросов, несущих информацию об экземпляре и функции superpoint, декодер запросов напрямую генерирует прогнозы класса, оценки и маски экземпляра. А с помощью двудольного сопоставления на основе масок superpoint, SPFormer может реализовать сквозное обучение без трудоемкого шага агрегации. Кроме того, SPFormer свободен от постобработки, что еще больше повышает скорость работы модели.
1. Алгоритм SPFormer
Архитектура модели, предложенной авторами метода SPFormer, логично разделена на блоки. Вначале используется разреженная 3D U-net для извлечения восходящих точечных объектов. Предполагая, что исходное облако точек имеет N точек. Каждая точка имеет цвета RGB и координаты XYZ. Авторы метода предлагают вокселизировать облако точек для регуляризации исходных данных и используют магистраль в стиле U-net, состоящую из разреженной свертки для извлечения точечных признаков P′. В отличие от методов, основанных на группировке, предложенный подход не добавляет дополнительную семантическую ветвь.
С целью создания комплексного фреймворка, авторы метода SPFormer напрямую вводят функции точек P' в слой пула superpoint на основе предварительно вычисленных точек. Слой пула Superpoint просто получает объекты S через усреднение по точкам внутри каждой из Superpoint. Примечательно, что слой пула Superpoint надежно понижает дискретизацию исходного облака точек, что значительно снижает вычислительные затраты на последующую обработку и оптимизирует возможности представления всей модели.
Декодер запросов состоит из двух ветвей Instance и Mask. В ветви маскирования простой многослойный персептрон (MLP) направлен на извлечение признаков, поддерживающих маску 𝐒mask. Ветвь Instance состоит из ряда слоев декодера Transformer. Они декодируют обучаемые векторы запросов с помощью перекрестного внимания к Superpoint.
Предположим, что есть K обучаемых векторов запросов. Мы заранее определяем свойства векторов запросов для каждого слоя декодера Transformer как Zl.
Учитывая беспорядок и количественную неопределенность superpoint, авторами метода введена структура Transformer для обработки исходных данных переменной длины. Потенциальная характеристика Superpoint и обучаемых векторов запроса используется в качестве исходных данных декодера Transformer. Детально проработанная архитектура модифицированного слоя декодера Transformer изображена на рисунке ниже.
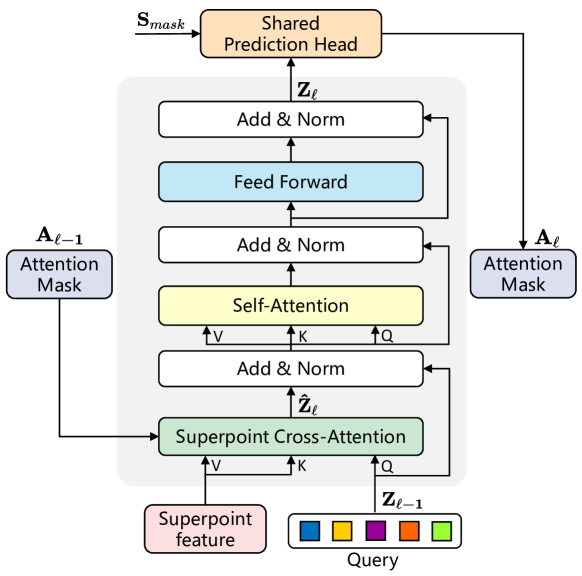
Векторы запросов инициализируются случайным образом перед обучением, а информация об экземпляре каждого облака точек может быть получена только через перекрестное внимание к Superpoint. Поэтому предложенный слой декодера трансформатора меняет местами порядок слоя Self-Attention и слоя Cross-Attention по сравнению со стандартным декодером Transformer. Кроме того, поскольку исходными данными являются потенциальные признаки Superpoint, авторы метода удаляют позиционное кодирование.
Для захвата контекстной информации с помощью механизма перекрестного внимания SuperPoint применяются маски внимания Aij, которые учитывают влияние superpoint j на запрос i. Учитывая прогнозируемые маски Superpoint от ветви Mask Ml, маски внимания Superpoint Al определяются пороговым фильтром τ. Опытным путем авторы метода установили τ равным 0,5.
С наложением слоев декодера Transformer, маски внимания Superpoint Al адаптивно ограничивают перекрестного внимания в экземпляре переднего плана.
С помощью векторов запросов Zl из ветви Instance авторы метода используют две независимых MLP для прогнозирования и классификации каждого вектора запроса и оценки качества предложений. В частности, они добавляют прогноз с вероятностью «без объекта» для того, чтобы присвоить обоснованную достоверность предложениям путем двустороннего сопоставления и рассматривают другие предложения как отрицательные прогнозы.
Более того, ранжирование предложений сильно влияет на результаты сегментации экземпляров, в то время как на практике большинство предложений будут рассматриваться как фоновые из-за стиля соответствия один к одному, что приводит к несогласованности рейтинга качества предложений. Таким образом, авторы метода разрабатывают ветвь оценки, которая оценивает качество прогнозирование масок Superpoint, что позволяет компенсировать смещение.
Учитывая медленную сходимость моделей, основанных на архитектуре Transformer, авторы метода подают каждый выход слоя декодера Transformer в общую головку прогноза для генерации предложений. Во время обучения они присваивают истинную достоверность всем выходным данным из общей головки прогнозирования с разными входными слоями. Это повышает производительность модели и улучшает функцию векторов запросов, которая будет обновляться слой за слоем.
Во время вывода, при наличии облака исходных точек, SPFormer напрямую прогнозирует K объектов с классификацией и соответствующие маски superpoint. Авторы метода дополнительно получают оценку маски путем усреднения вероятности superpoint выше 0,5 в каждой маске. SPFormer не имеет максимального подавления при постобработке, что обеспечивает его высокую скорость вывода.
Авторская визуализация метода SPFormer представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода SPFormer мы, как обычно, переходим к практической части нашей статьи, в которой реализуем свое видение предложенных подходов средствами MQL5. И надо сказать, что сегодня нам предстоит выполнить большой объем работы. Поэтому перейдем к сразу к делу.
2.1 Дополнение OpenCL-программы
Начнем мы работу с модернизации нашей OpenCL-программы. Авторы метода SPFormer предложили новый алгоритм маскирования на основе прогнозных масок объектов. Суть которого заключается в сопоставлении отдельных запросов только с релевантными Superpoint. Это сильно отличается от используемого нами ранее подхода на основе позиции исходных данных, который был предложен в ванильном Transformer. Поэтому нам предстоит построить новые кернелы Cross-Attention и обратного прохода. Вначале мы реализуем кернел прямого прохода MHMaskAttentionOut, алгоритм которого будет во многом заимствован от кернела ванильного метода. Однако мы внесем изменения для реализации нового алгоритма маскирования.
В параметрах кернела мы, как и ранее получаем указатели на глобальные буферы сущностей Query, Key и Value, значение которых сгенерировано ранее. Там же указаны указатели на буферы коэффициентов внимания и результатов. Кроме того мы добавили указатель на глобальный буфер маскирования и пороговое значение маски.
__kernel void MHMaskAttentionOut(__global const float *q, ///<[in] Matrix of Querys __global const float *kv, ///<[in] Matrix of Keys __global float *score, ///<[out] Matrix of Scores __global const float *mask, ///<[in] Mask Matrix __global float *out, ///<[out] Matrix of attention const int dimension, ///< Dimension of Key const int heads_kv, const float mask_level ) { //--- init const int q_id = get_global_id(0); const int k = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_global_size(1); const int heads = get_global_size(2);
Как и ранее, мы планируем вызывать кернел в трех мерном пространстве задач (Query, Key, Heads). При этом мы создадим локальные рабочую группы, что позволит нам обмениваться данными между отдельными потоками выполнения операций в рамках отдельных Query в разрезе голов внимания. В теле метода мы сразу идентифицируем текущий поток операций в пространстве задач и тут же определим параметры пространства задач.
На следующем этапе мы определим смещения в буферах данных и запишем полученные значения в локальные переменные.
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_k = dimension * (2 * heads_kv * k + h_kv); const int shift_v = dimension * (2 * heads_kv * k + heads_kv + h_kv); const int shift_s = kunits * (q_id * heads + h) + k;
После чего вычислим актуальную маску текущего потока и другие вспомогательные константы.
const bool b_mask = (mask[shift_s] < mask_level); const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); float koef = sqrt((float)dimension); if(koef < 1) koef = 1;
Тут же мы создадим массив в локальной памяти для обмена данными между потоками рабочей группы.
__local float temp[LOCAL_ARRAY_SIZE];
Далее мы сначала определим сумму экспоненциальных значений коэффициентов зависимости в рамках одного Query. Для этого мы вначале организуем цикл с последовательным вычислением отдельных сумм и записью их в локальный массив данных.
//--- sum of exp uint count = 0; if(k < ls) { temp[k] = 0; do { if(b_mask || q_id >= (count * ls + k)) if((count * ls) < (kunits - k)) { float sum = 0; int sh_k = 2 * dimension * heads_kv * count * ls; for(int d = 0; d < dimension; d++) sum = q[shift_q + d] * kv[shift_k + d + sh_k]; sum = exp(sum / koef); if(isnan(sum)) sum = 0; temp[k] = temp[k] + sum; } count++; } while((count * ls + k) < kunits); } barrier(CLK_LOCAL_MEM_FENCE);
А затем суммируем все значения локального массива данных.
do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Обратите внимание, что при локальном суммировании значения вычислялись с учетом маски. И теперь мы можем вычислить нормализованные значения коэффициентов внимания с учетом маскирования.
//--- score float sum = temp[0]; float sc = 0; if(b_mask || q_id >= (count * ls + k)) if(sum != 0) { for(int d = 0; d < dimension; d++) sc = q[shift_q + d] * kv[shift_k + d]; sc = exp(sc / koef) / sum; if(isnan(sc)) sc = 0; } score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
В процессе вычисления коэффициентов внимания мы обнулили значения для замаскированных элементов. Следовательно, далее мы модем воспользоваться ванильным алгоритмов для вычисления результатов работы блока Cross-Attention.
for(int d = 0; d < dimension; d++) { uint count = 0; if(k < ls) do { if((count * ls) < (kunits - k)) { float sum = kv[shift_v + d] * (count == 0 ? sc : score[shift_s + count * ls]); if(isnan(sum)) sum = 0; temp[k] = (count > 0 ? temp[k] : 0) + sum; } count++; } while((count * ls + k) < kunits); barrier(CLK_LOCAL_MEM_FENCE); //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : 0); if(k + count < ls) temp[k + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- out[shift_q + d] = temp[0]; } }
Модернизация кернела обратного прохода MHMaskAttentionInsideGradients менее глобальная. Её можно назвать точечной. Дело в том, что обнуление коэффициентов зависимости при прямом проходе позволяет нам использовать ванильный алгоритм для распределения градиента ошибки до сущностей Query, Key и Value. Однако он не позволяет нам передать градиент ошибки до маски. Поэтому к ванильному алгоритму мы добавляем градиент корректировки маски.
__kernel void MHMaskAttentionInsideGradients(__global const float *q, __global float *q_g, __global const float *kv, __global float *kv_g, __global const float *mask, __global float *mask_g, __global const float *scores, __global const float *gradient, const int kunits, const int heads_kv, const float mask_level ) { ........ ........ //--- Mask's gradient for(int k = q_id; k < kunits; k += qunits) { float m = mask[shift_s + k]; if(m < mask_level) mask_g[shift_s + k] = 0; else mask_g[shift_s + k] = 1 - m; } }
Обратите внимание, что актуальные метки маскирования мы стремимся привести к "1". А для неактуальных масок мы обнуляем градиент ошибки, так как они не оказывали влияние на результат работы модели.
На этом мы завершаем работу с OpenCL-программой. А с полным кодом новых кернелов Вы можете ознакомиться во вложении.
2.2 Создание класса метода SPFormer
После завершения модернизации OpenCL-программы мы переходим к работе на стороне основной программы. Здесь мы создадим новый класс CNeuronSPFormer, который унаследует базовый функционал от полносвязного слоя CNeuronBaseOCL. Масштаб корректировок настолько велик, что я не стал наследоваться от ранее созданных блоков кросс-внимания. Структура нового класса представлена ниже.
class CNeuronSPFormer : public CNeuronBaseOCL { protected: uint iWindow; uint iUnits; uint iHeads; uint iSPWindow; uint iSPUnits; uint iSPHeads; uint iWindowKey; uint iLayers; uint iLayersSP; //--- CLayer cSuperPoints; CLayer cQuery; CLayer cSPKeyValue; CLayer cMask; CArrayInt cScores; CLayer cMHCrossAttentionOut; CLayer cCrossAttentionOut; CLayer cResidual; CLayer cQKeyValue; CLayer cMHSelfAttentionOut; CLayer cSelfAttentionOut; CLayer cFeedForward; CBufferFloat cTempSP; CBufferFloat cTempQ; CBufferFloat cTempSelfKV; CBufferFloat cTempCrossKV; //--- virtual bool CreateBuffers(void); virtual bool AttentionOut(CNeuronBaseOCL *q, CNeuronBaseOCL *kv, const int scores, CNeuronBaseOCL *out, CNeuronBaseOCL *mask, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension, const float mask_level = 0.5f); virtual bool AttentionInsideGradients(CNeuronBaseOCL *q, CNeuronBaseOCL *kv, const int scores, CNeuronBaseOCL *out, CNeuronBaseOCL *mask, const int units, const int heads, const int units_kv, const int heads_kv, const int dimension, const float mask_level = 0.5f); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSPFormer(void) {}; ~CNeuronSPFormer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSPFormer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В представленной структуре класса мы видим большое количество переменный и вложенных объектов, наименование которых созвучно с используемыми нами ранее при реализации различных классов внимания. И это не удивительно. А с функционалом всех объектов мы познакомимся в процессе реализации.
Тут же следует отметить, что все внутренние объекты объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор класса. Инициализация всех унаследованных и объявленных объектов осуществляется в методе Init. Как Вы знаете, в параметрах данного метода мы получаем основные константы, однозначно определяющие архитектуру создаваемого объекта.
bool CNeuronSPFormer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В теле метода мы сразу вызываем одноименный метод родительского класса, в котором осуществляется инициализация унаследованных объектов и переменных.
После чего мы сразу сохраняем полученные константы во внутренние переменные класса.
iWindow = window; iUnits = units_count; iHeads = heads; iSPUnits = units_sp; iSPWindow = window_sp; iSPHeads = heads_sp; iWindowKey = window_key; iLayers = MathMax(layers, 1); iLayersSP = MathMax(layers_to_sp, 1);
И следующим этапом инициализируем небольшую MLP генерации вектора обучаемых запросов.
//--- Init Querys CNeuronBaseOCL *base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(iWindow * iUnits, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *buf = base.getOutput(); if(!buf || !buf.BufferInit(1, 1) || !buf.BufferWrite()) return false; if(!cQuery.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base.Init(0, 1, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cQuery.Add(base)) return false;
Затем мы создаем блок извлечения Superpoint. Здесь мы сгенерируем блок из 4 последовательных нейронных слоев, архитектура которых адаптируется к размеру исходной последовательности. Если длина последовательности на входе очередного слоя кратна 2, то мы используем cверточный блок с остаточной связью, который уменьшает размер последовательности в 2 раза.
//--- Init SuperPoints for(int r = 0; r < 4; r++) { if(iSPUnits % 2 == 0) { iSPUnits /= 2; CResidualConv *residual = new CResidualConv(); if(!residual) return false; if(!residual.Init(0, r+2, OpenCL, 2*iSPWindow, iSPWindow, iSPUnits, optimization, iBatch)) return false; if(!cSuperPoints.Add(residual)) return false; }
В противном случае мы используем простой сверточный слой, который анализирует 2 соседних элемента последовательности с шагом в 1 элемент. Таким образом длина последовательности уменьшается на 1.
else { iSPUnits--; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv.Init(0, r+2, OpenCL, 2*iSPWindow, iSPWindow, iSPWindow, iSPUnits, 1, optimization, iBatch)) return false; if(!cSuperPoints.Add(conv)) return false; } }
На этом этапе мы инициализировали объекты предварительной обработки данных. И далее мы приступаем к инициализации внутренних слоев измененного декодера Transformer. Для этого мы создадим локальные переменные временного хранения указателей на объекты и организуем цикл с числом итераций равным заданному количеству внутренних слоев декодера.
CNeuronConvOCL *conv = NULL; CNeuronTransposeOCL *transp = NULL; for(uint l = 0; l < iLayers; l++) { //--- Cross Attention //--- Query conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 6, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; //--- Key-Value if(l % iLayersSP == 0) { conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 7, OpenCL, iSPWindow, iSPWindow, iWindowKey * iSPHeads, iSPUnits, 1, optimization, iBatch)) return false; if(!cSPKeyValue.Add(conv)) return false; }
Здесь мы сначала инициализируем внутренние слои генерации сущностей Query, Key и Value. При этом тензор Key-Value генерируется только при необходимости.
Тут же мы добавим слой генерации масок. Для этого мы воспользуемся сверточным слоем, который сгенерирует коэффициенты маскирования для всех запросов для каждого отдельного элемента последовательности Superpoint. И так как мы используем алгоритм много-голового внимания, то и коэффициенты сгенерируем для каждой головы внимания. Для нормализации значений воспользуемся сигмовидной функцией активации.
//--- Mask conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 8, OpenCL, iSPWindow, iSPWindow, iUnits * iHeads, iSPUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(SIGMOID); if(!cMask.Add(conv)) return false;
Здесь следует обратить внимание, что при проведении кросс-внимания нам понадобятся коэффициенты внимания запросов к Superpoint. Поэтому мы осуществим транспонирование полученного тензора маскирования.
transp = new CNeuronTransposeOCL(); if(!transp) return false; if(!transp.Init(0, l * 14 + 9, OpenCL, iSPUnits, iUnits * iHeads, optimization, iBatch)) return false; if(!cMask.Add(transp)) return false;
И следующим шагом мы подготовим объекты для записи результатов кросс-внимания. Сначала много-голового.
//--- MH Cross Attention out base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 10, OpenCL, iWindow * iUnits * iHeads, optimization, iBatch)) return false; if(!cMHCrossAttentionOut.Add(base)) return false;
А затем сжатых значений.
//--- Cross Attention out conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 11, OpenCL, iWindow * iHeads, iWindow * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cCrossAttentionOut.Add(conv)) return false;
И добавим слой для суммирования с исходными данными.
//--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 12, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false;
Далее идет блок Self-Attention. Здесь мы так же генерируем сущности Query, Key и Value, но уже на результатах кросс-внимания.
//--- Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l*14+13, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQuery.Add(conv)) return false; //--- Key-Value if(l % iLayersSP == 0) { conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l*14+14, OpenCL, iWindow, iWindow, iWindowKey * iSPHeads, iUnits, 1, optimization, iBatch)) return false; if(!cQKeyValue.Add(conv)) return false; }
И добавляем объекты записи результатов много-голового внимания и сжатых значений.
//--- MH Attention out base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 15, OpenCL, iWindow * iUnits * iHeads, optimization, iBatch)) return false; if(!cMHSelfAttentionOut.Add(base)) return false; //--- Attention out conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 16, OpenCL, iWindow * iHeads, iWindow * iHeads, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cSelfAttentionOut.Add(conv)) return false;
Добавим слой суммирования с результатами кросс-внимания.
//--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 17, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false;
И добавим блок FeedForward с остаточной связью.
//--- FeedForward conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 18, OpenCL, iWindow, iWindow, iWindow * 4, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(LReLU); if(!cFeedForward.Add(conv)) return false; conv = new CNeuronConvOCL(); if(!conv) return false; if(!conv.Init(0, l * 14 + 19, OpenCL, iWindow * 4, iWindow * 4, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cFeedForward.Add(conv)) return false; //--- Residual base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, l * 14 + 20, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false; if(!base.SetGradient(conv.getGradient())) return false;
Обратите внимание, что для исключения излишних операций копирования данных мы совмещаем буферы градиентов ошибки последнего слоя блока FeedForward и слоя остаточной связи. Подобную операцию мы выполняем для буфера результатов и градиентов ошибки верхнего уровня на последнем внутреннем слое.
if(l == (iLayers - 1)) { if(!SetGradient(conv.getGradient())) return false; if(!SetOutput(base.getOutput())) return false; } }
Следует отметить, что в процессе инициализации объектов мы не создали буфера данных коэффициентов внимания. Их создание и инициализацию внутренних объектов мы вынесли в отдельный метод.
//--- SetOpenCL(OpenCL); //--- return true; }
После инициализации внутренних объектов мы переходим к построению методов прямого прохода. Алгоритм методов вызова выше созданных кернелов мы оставим для самостоятельного изучения. В них нет особой новизны. Остановимся лишь на алгоритме метода верхнего уровня feedForward, в котором мы выстроим четкую последовательность действий алгоритма SPFormer.
bool CNeuronSPFormer::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *superpoints = NeuronOCL; CNeuronBaseOCL *neuron = NULL, *inputs = NULL, *q = NULL, *kv_cross = NULL, *kv_self = NULL;
В параметрах метода мы получаем указатель на объект исходных данных. А в теле метода мы объявляем ряд локальных переменных для временного хранения указателей на объекты.
Далее мы проводим полученные исходные данные через модель извлечения Superpoint.
//--- Superpoints for(int l = 0; l < cSuperPoints.Total(); l++) { neuron = cSuperPoints[l]; if(!neuron || !neuron.FeedForward(superpoints)) return false; superpoints = neuron; }
И генерируем вектор запросов.
//--- Query neuron = cQuery[1]; if(!neuron || !neuron.FeedForward(cQuery[0])) return false;
На этом завершается подготовительная работа и мы создаем цикл перебора внутренних нейронных слоев нашего декодера.
inputs = neuron; for(uint l = 0; l < iLayers; l++) { //--- Cross Attentionn q = cQuery[l * 2 + 2]; if(!q || !q.FeedForward(inputs)) return false; if((l % iLayersSP) == 0) { kv_cross = cSPKeyValue[l / iLayersSP]; if(!kv_cross || !kv_cross.FeedForward(superpoints)) return false; }
Здесь мы сначала подготавливаем сущности Query, Key и Value.
Сгенерируем маски.
neuron = cMask[l * 2]; if(!neuron || !neuron.FeedForward(superpoints)) return false; neuron = cMask[l * 2 + 1]; if(!neuron || !neuron.FeedForward(cMask[l * 2])) return false;
И выполним алгоритм кросс-внимания с учетом маскирования.
if(!AttentionOut(q, kv_cross, cScores[l * 2], cMHCrossAttentionOut[l], neuron, iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey)) return false;
Результаты много-голового внимания уменьшим до размера тензора запросов.
neuron = cCrossAttentionOut[l]; if(!neuron || !neuron.FeedForward(cMHCrossAttentionOut[l])) return false;
После чего мы проведем суммирование и нормализацию данных из двух потоков информации.
q = inputs; inputs = cResidual[l * 3]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
За блоком Cross-Attention мы выстраиваем алгоритм Self-Attention. Здесь мы снова генерируем сущности Query, Key и Value, но уже на основании результатов кросс-внимания.
//--- Self-Attention q = cQuery[l * 2 + 3]; if(!q || !q.FeedForward(inputs)) return false; if((l % iLayersSP) == 0) { kv_self = cQKeyValue[l / iLayersSP]; if(!kv_self || !kv_self.FeedForward(inputs)) return false; }
На данном этапе мы не используем маскирование. Поэтому при вызове метода внимания мы указываем NULL вместо объекта масок.
if(!AttentionOut(q, kv_self, cScores[l * 2 + 1], cMHSelfAttentionOut[l], NULL, iUnits, iHeads, iUnits, iHeads, iWindowKey)) return false;
Результаты много-голового внимания мы понижаем до уровня размера тензора запросов.
neuron = cSelfAttentionOut[l]; if(!neuron || !neuron.FeedForward(cMHSelfAttentionOut[l])) return false;
А затем суммируем с вектором результатов кросс внимания и нормализуем данные.
q = inputs; inputs = cResidual[l * 3 + 1]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
Далее, аналогично ванильному Transformer, мы осуществляем передачу данных через блок FeedForward. После чего переходим к следующей итерации цикла перебора внутренних слоев.
//--- FeedForward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.FeedForward(inputs)) return false; neuron = cFeedForward[l * 2 + 1]; if(!neuron || !neuron.FeedForward(cFeedForward[l * 2])) return false; q = inputs; inputs = cResidual[l * 3 + 2]; if(!inputs || !SumAndNormilize(q.getOutput(), neuron.getOutput(), inputs.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; } //--- return true; }
Обратите внимание, что перед переходом к следующей итерации цикла мы сохраняем в переменной inputs указатель на последний объект текущего внутреннего слоя.
После успешного выполнения всех итераций цикла перебора внутренних слоев декодера мы возвращаем вызывающей программе логический результат выполнения операций метода.
Следующим этапом мы переходим построению методов обратного прохода. И наибольший интерес для нас представляет метод распределения градиента ошибки до всех элементов нашей модели в соответствии с их влиянием на общий результат работы модели calcInputGradients.
bool CNeuronSPFormer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В параметрах метода мы получаем указатель на объект предшествующего нейронного слоя, который при прямом проходе давал нам исходные данные. И теперь нам предстоит передать в него градиент ошибки в соответствии с влиянием исходных данных на результат работы модели.
В теле метода мы сразу проверяем актуальность полученного указателя, так как в противном случае вся дальнейшая работа метода не имеет смысла.
Затем мы объявляем ряд локальных переменных для временного хранения указателей на объекты.
CNeuronBaseOCL *superpoints = cSuperPoints[cSuperPoints.Total() - 1]; CNeuronBaseOCL *neuron = NULL, *inputs = NULL, *q = NULL, *kv_cross = cSPKeyValue[cSPKeyValue.Total() - 1], *kv_self = cQKeyValue[cQKeyValue.Total() - 1];
Обнулим буферы временного хранения промежуточных данных.
if(!cTempSP.Fill(0) || !cTempSelfKV.Fill(0) || !cTempCrossKV.Fill(0)) return false;
И далее организуем цикл обратного перебора внутренних слоев нашего декодера.
for(int l = int(iLayers - 1); l >= 0; l--) { //--- FeedForward neuron = cFeedForward[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2 + 1])) return false;
Как Вы помните, при инициализации объекта класса мы осуществили подмену указателей на буфера данных градиентов ошибки верхнего уровня и слоя остаточной связи с последним слоем блока FeedForward. Это позволяет нам на данном этапе начать распределение градиента ошибки с блока FeedForward, минуя передачу данных с буфера градиентов ошибки верхнего уровня и от слоя остаточной связи в последний слой блока FeedForward.
Далее мы спускаем градиент ошибки до уровня слоя остаточной связи блока Self-Attention.
neuron = cResidual[l * 3 + 1]; if(!neuron || !neuron.calcHiddenGradients(cFeedForward[l * 2])) return false;
После чего мы суммируем градиент ошибки от двух потоков информации и передадим его на слой результатов Self-Attention.
if(!SumAndNormilize(((CNeuronBaseOCL*)cResidual[l * 3 + 2]).getGradient(), neuron.getGradient(), ((CNeuronBaseOCL*)cSelfAttentionOut[l]).getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
Распределим полученный градиент ошибки по головам внимания.
//--- Self-Attention neuron = cMHSelfAttentionOut[l]; if(!neuron || !neuron.calcHiddenGradients(cSelfAttentionOut[l])) return false;
Получим указатели на буферы сущностей Query, Key и Value блока Self-Attention. И при необходимости обнулим буфер накопления промежуточных значений.
q = cQuery[l * 2 + 3]; if(((l + 1) % iLayersSP) == 0) { kv_self = cQKeyValue[l / iLayersSP]; if(!kv_self || !cTempSelfKV.Fill(0)) return false; }
И передадим на них градиент ошибки в соответствии с влиянием результат работы модели.
if(!AttentionInsideGradients(q, kv_self, cScores[l * 2 + 1], neuron, NULL, iUnits, iHeads, iUnits, iHeads, iWindowKey)) return false;
Здесь стоит напомнить, что мы предусмотрели возможность использования одного тензора Key-Value для нескольких внутренних слоев декодера. Поэтому в зависимости от индекса текущего внутреннего слоя мы суммируем полученное значение с ранее накопленным градиентом ошибки в буфер временного накопления данных или буфер градиентов соответствующего слоя Key-Value.
if(iLayersSP > 1) { if((l % iLayersSP) == 0) { if(!SumAndNormilize(kv_self.getGradient(), GetPointer(cTempSelfKV), kv_self.getGradient(), iWindowKey, false, 0, 0, 0, 1)) return false; } else { if(!SumAndNormilize(kv_self.getGradient(), GetPointer(cTempSelfKV), GetPointer(cTempSelfKV), iWindowKey, false, 0, 0, 0, 1)) return false; } }
И опустим градиент ошибки до уровня слоя остаточной связи блока кросс-внимания. Здесь мы сначала передадим градиент ошибки от сущности Query.
inputs = cResidual[l * 3]; if(!inputs || !inputs.calcHiddenGradients(q, NULL)) return false;
А затем, в случае необходимости добавим градиент ошибки от информационного потока Key-Value.
if((l % iLayersSP) == 0) { CBufferFloat *temp = inputs.getGradient(); if(!inputs.SetGradient(GetPointer(cTempQ), false)) return false; if(!inputs.calcHiddenGradients(kv_self, NULL)) return false; if(!SumAndNormilize(temp, GetPointer(cTempQ), temp, iWindow, false, 0, 0, 0, 1)) return false; if(!inputs.SetGradient(temp, false)) return false; }
Далее мы добавим градиент ошибки от потока остаточной связи блока Self-Attention и передадим полученное значение в блок кросс-внимания.
if(!SumAndNormilize(((CNeuronBaseOCL*)cSelfAttentionOut[l]).getGradient(), inputs.getGradient(), ((CNeuronBaseOCL*)cCrossAttentionOut[l]).getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
И теперь нам предстоит провести градиент ошибки через блок Cross-Attention. Сначала распределим градиент ошибки по головам внимания.
//--- Cross Attention neuron = cMHCrossAttentionOut[l]; if(!neuron || !neuron.calcHiddenGradients(cCrossAttentionOut[l])) return false;
Как и в случае Self-Attention, мы получаем указатели на объекты сущностей Query, Key и Value.
q = cQuery[l * 2 + 2]; if(((l + 1) % iLayersSP) == 0) { kv_cross = cSPKeyValue[l / iLayersSP]; if(!kv_cross || !cTempCrossKV.Fill(0)) return false; }
И проводим градиент ошибки через блок внимания. Однако в данном случае мы добавим указатель на объект маскирования.
if(!AttentionInsideGradients(q, kv_cross, cScores[l * 2], neuron, cMask[l * 2 + 1], iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey)) return false;
Градиент ошибки от сущности Query мы передаем на предыдущий слой декодера или на вектор запросов. Выбор объекта зависит от текущего слоя декодера.
inputs = (l == 0 ? cQuery[1] : cResidual[l * 3 - 1]); if(!inputs.calcHiddenGradients(q, NULL)) return false;
Тут же добавим градиент ошибки по информационному потоку остаточной связи.
if(!SumAndNormilize(inputs.getGradient(), ((CNeuronBaseOCL*)cCrossAttentionOut[l]).getGradient(), inputs.getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
На данном этапе мы завершили передачу данных по магистрали вектора запросов. Однако нам предстоит еще передать градиент ошибки в магистраль Superpoint. Здесь мы сначала проверяем необходимость передачи данных от тензора Key-Value. При необходимости полученные значения добавляем в буфер ранее накопленного градиента ошибки.
if((l % iLayersSP) == 0) { if(!superpoints.calcHiddenGradients(kv_cross, NULL)) return false; if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), GetPointer(cTempSP), iSPWindow, false, 0, 0, 0, 1)) return false; }
А затем распределим градиент ошибки от модели генерации масок.
neuron = cMask[l * 2]; if(!neuron || !neuron.calcHiddenGradients(cMask[l * 2 + 1]) || !DeActivation(neuron.getOutput(), neuron.getGradient(), neuron.getGradient(), neuron.Activation())) return false; if(!superpoints.calcHiddenGradients(neuron, NULL)) return false;
И так же добавим полученное значение к ранее накопленному градиенту ошибки. Но здесь стоит обратить внимание на текущий слой декодера.
if(l == 0) { if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), superpoints.getGradient(), iSPWindow, false, 0, 0, 0, 1)) return false; } else if(!SumAndNormilize(superpoints.getGradient(), GetPointer(cTempSP), GetPointer(cTempSP), iSPWindow, false, 0, 0, 0, 1)) return false; }
В случае анализа первого слоя декодера (в нашем случае последняя итерации цикла), суммарный градиент сохраняем в буфере последнего слоя модели Superpoint. В противном случае мы накапливаем градиент ошибки в буфере временного хранения данных.
И переходим к следующей итерации нашего цикла обратного перебора внутренних слоев декодера.
После успешного проведения градиента ошибки через все внутренние слои декодера Transformer нам остается распределить градиент ошибки через слои модели Supperpoint. Здесь мы имеем линейную структуру модели. Поэтому нам достаточно организовать цикл обратного перебора слоев указанной модели.
for(int l = cSuperPoints.Total() - 2; l >= 0; l--) { superpoints = cSuperPoints[l]; if(!superpoints || !superpoints.calcHiddenGradients(cSuperPoints[l + 1])) return false; }
В завершении операций метода мы передаем градиент ошибки на уровень слоя исходных данных от модели Superpoint и возвращаем логический результат выполнения операций метода вызывающей программе.
if(!NeuronOCL.calcHiddenGradients(superpoints, NULL)) return false; //--- return true; }
На данном этапе мы реализовали процесс распределения градиента ошибки до всех внутренних объектов и исходных данных в соответствии с их влиянием на общий результат работы модели. И далее нам предстоит оптимизировать обучаемые параметры модели с целью минимизации общей ошибки. Данные операции выполняются в методе updateInputWeights.
Здесь стоит сказать, что все обучаемые параметры модели хранятся во внутренних объектах нашего класса. И алгоритм их оптимизации уже реализован в данных объектах. Поэтому в рамках метода обновления параметров нам достаточно поочередно вызывать одноименные методы вложенных объектов. И я предлагаю Вам самостоятельно ознакомиться с алгоритмом данного метода. Напомню, что полный код нашего нового класса и всех его параметров Вы найдете во вложении.
Архитектура обучаемых моделей, а так же все программы их обучения и взаимодействия с окружающей средой полностью заимствованы из предыдущих работ. Были внесены лишь точечные правки в архитектуру модели Энкодера. С ними я предлагаю Вам ознакомиться самостоятельно. Полный код всех классов программ, используемых при подготовке данной статьи, приведены во вложении. А мы переходим к заключительному этапу нашей работы — обучение моделей и тестирование полученных результатов.
3. Тестирование
В рамках данной статьи нами был выполнен большой объем работы по имплементации нашего видения подходов, предложенных авторами метода SPFormer. И теперь подошли к этапу обучения моделей и тестирования полученной политики Актера на реальных исторических данных.
Для обучения моделей мы используем реальные исторические данные инструмента EURUSD за полный 2023 год, таймфрейм H1. Параметры всех анализируемых индикаторов используются по умолчанию.
Алгоритм обучения моделей был заимствован из предыдущих статей вместе с программами, используемыми для их обучения и тестирования.
Тестирования обученной политики Актера осуществляется в тестере стратегий MetaTrader 5 на реальных исторических данных за Январь 2024 года с сохранением всех прочих параметров. Результаты тестирования представлены ниже.
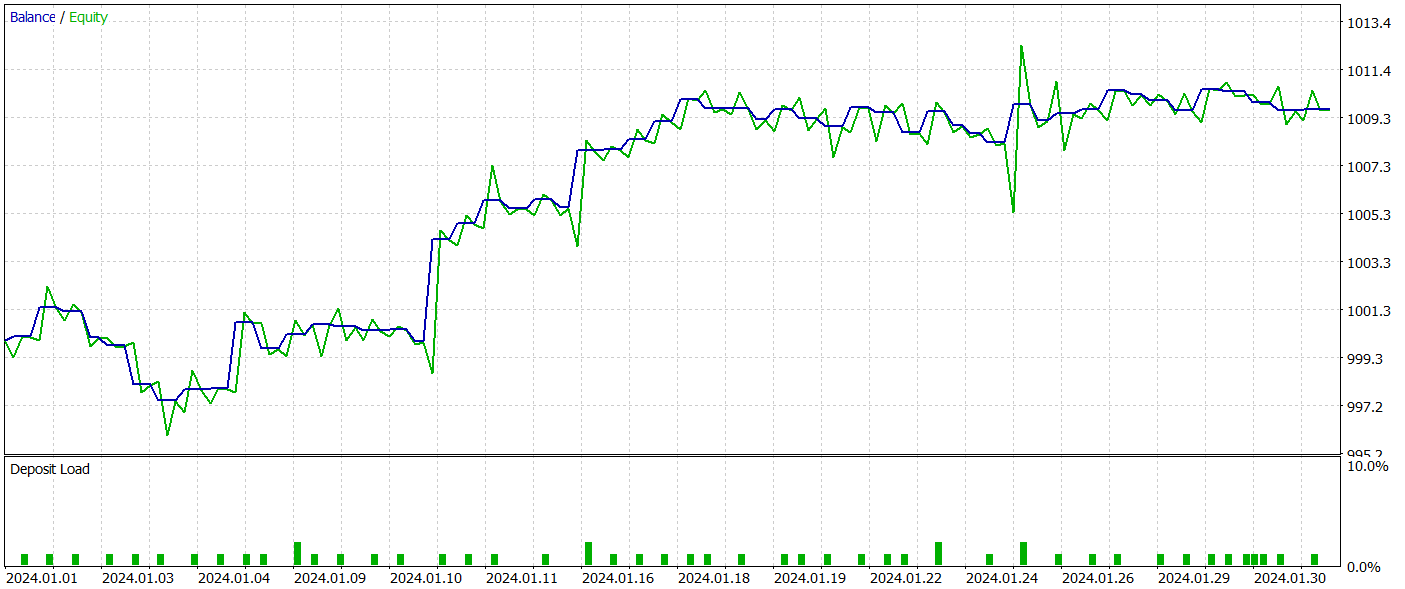
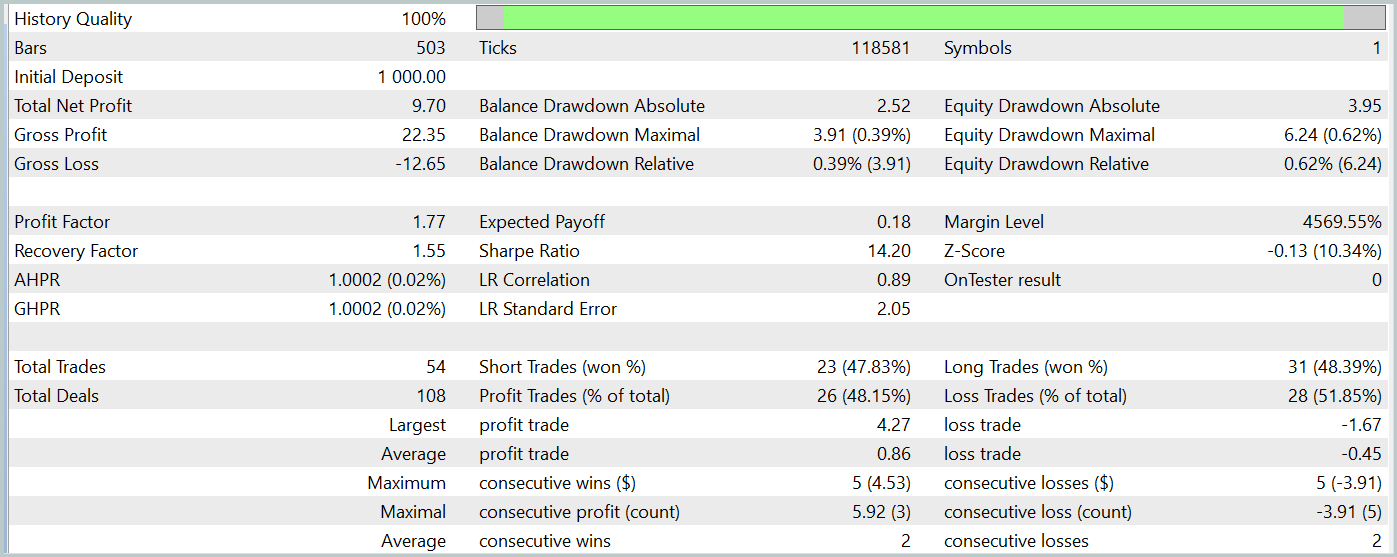
За период тестирования модель совершила 54 сделки, 26 из которых были закрыты с прибылью. Что составило 48% от всех операций. При этом средняя прибыльная сделка в 2 раза превышает аналогичный показатель убыточных сделок. Это позволило модели получить прибыль за период тестирования.
Однако стоит отметить, что малое количество совершенных торговых операций за период тестирования не позволяет нам судить о стабильной работе модели на более длительном временном отрезке.
Заключение
Метод SPFormer может быть адаптирован для применения в трейдинге, особенно для сегментации данных о текущей рыночной ситуации и прогнозирования рыночных сигналов. Вместо традиционных моделей, которые часто зависят от промежуточных шагов и могут терять точность из-за зашумленных данных, данный подход мог бы напрямую работать с Superpoint данных. Использование трансформеров для прогнозирования рыночных паттернов в таком случае позволит избежать необходимости в сложных промежуточных обработках и повысить как точность, так и скорость принятия торговых решений.
В практической части представлено свое видение реализации предложенных подходов средствами MQL5. Мы провели обучение моделей с использованием предложенных подходов и проверили их эффективность на реальных исторических данных. По результатам тестирования модель смогла получить прибыль, что свидетельствует о потенциале использования описанных подходов. Однако в рамках статьи представлены лишь программы для демонстрации технологии. Перед использованием модели на реальных рынках необходимо провести обучение модели на более длительном временном отрезке с тщательным тестированием.
Ссылки Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Дружище, это очень интересно, но очень продвинуто для меня!
Спасибо, что поделились, учусь шаг за шагом.