
Нейросети в трейдинге: Обнаружение объектов с учетом сцены (HyperDet3D)

Введение
В последние годы обнаружение объектов привлекло большое внимание. Основанный на представлениях и объемной свертке, PointNet++ фокусируется на локальной геометрии, элегантно анализируя необработанное облако точек. Что позволило широко использовать его в качестве магистральной сети в различных моделях обнаружения объектов.
Однако атрибуты похожих объектов неоднозначны, что снижает качество работы модели. Как следствие, ограничивается область использования модели или приходится усложнять её архитектуру. Авторы статьи "HyperDet3D: Learning a Scene-conditioned 3D Object Detector" обнаружили, что информация на уровне сцены дает априорные знания для устранения двусмысленности трактования атрибутов объектов. Это позволяет исключить нелогичные результаты обнаружения объектов в аспекте понимания на уровне сцены.
В упомянутой работе был предложен алгоритм HyperDet3D для обнаружения 3D-объектов в облаке точек, который использует структуру на основе гиперсети. HyperDet3D изучает информацию, обусловленную сценой и включает знания на уровне сцены в параметры сети. Это позволяет детектору 3D-объектов динамически настраивается в соответствии с различными исходными данными. В частности, знания, обусловленные сценой, могут быть разложены на два уровня: информация, не зависящая от сцены, и информация, специфичная для сцены.
Для знаний, не зависящих от сцены, авторы метода предлагают изучать эмбединги, которые используется гиперсетью и итеративно обновляются вместе с разбором различных исходных сцен во время обучения модели. Такие знания, не зависящие от сцены, обычно абстрагируются от характеристик обучающих сцен и могут быть использованы детектором во время эксплуатации.
Более того, поскольку обычные детекторы сохраняют один и тот же набор параметров при распознавании объектов в разных сценах, авторы HyperDet3D предлагают включить специфичную для сцены информацию, которая адаптирует детектор к данной сцене во время эксплуатации. Для этого анализируется, насколько текущая сцена соответствует общему представлению (или насколько они отличаются), используя конкретные исходные данные в качестве запроса.
В статье предложена структура нового модуля «Многоголового внимания, обусловленного сценой» (Multi-head Scene-Conditioned Attention — MSA). MSA позволяет агрегировать полученные априорные знания с характеристиками объекта-кандидата, что обеспечивает более эффективное обнаружения объектов.
1. Алгоритм HyperDet3D
Модель HyperDet3D включает 3 основных компонента:
- Магистральный Энкодер;
- Слой Декодера объектов;
- Головка обнаружения.
Исходное облако входных точек сначала обрабатывается магистралью, которая понижает дискретизацию точек до исходных кандидатов в объекты, а так же грубо извлекает их особенности с помощью иерархических архитектур. Авторы метода предлагают использовать PointNet++ в качестве магистральной сети.
Затем слои декодера объектов уточняют потенциальные признаки, включая априорные знания, обусловленные сценой, в представление на уровне объекта. А детектирующая головка регрессирует ограничивающие прямоугольники от местоположения и уточненных признаков этих кандидатов в объекты.
Для обеспечения HyperDet3D осведомленностью о метаинформации на уровне сцены, авторы метода внедряют HyperNetwork, которая представляет собой нейронную сеть, используемую для параметризации обучаемых параметров первичной сети. В отличие от обычных глубоких нейронных сетей, которые сохраняют уровень фиксированным в процессе эксплуатации, гиперсети обеспечивают гибкость изучаемых параметров, изменяя их в зависимости от исходных данных.
HyperDet3D применяет гиперсеть, обусловленную сценой, для интеграции предварительных знаний в параметры слоя декодера Transformer. Это позволяет динамически адаптировать сеть обнаружения к разнообразным исходным сценам. Ключевая концепция заключается в использовании гиперсетей, обусловленных сценой, для обогащения представления объекта 𝒐 из набора кандидатов в объекты, сформированных системообразующим Энкодером, с помощью априорных знаний, параметризованных 𝑾.
Параметры генерируются гиперсетями, обусловленными сценой, которые можно разделить на специфичные для сцены и не зависящие от неё.
Для получения знаний, не зависящих от сцены, авторы метода предлагают обучать набор n векторов эмбедингов, не зависящих от сцены 𝒁a, которые затем поглощаются гиперсетью. На выходе гиперсети получаем матрицу весовых коэффициентов 𝑾a, которая параметризует знания не зависящие от сцены.
Так как свойства объекта итеративно уточняются с помощью ряда слоев декодера, они могут быть последовательно объединены с результатами гиперсети, не зависящей от сцены, которая абстрагирует априорные знания о различных 3D-сценах. Таким образом, HyperDet3D не только поддерживаем общие знания, обусловленные сценой, на всех уровнях декодера, но и экономит вычислительные ресурсы, делясь знаниями с богатыми иерархиями функций.
Для получения знаний о конкретных сценах модель изучает набор эмбедингов 𝒁s аналогичных 𝒁a. Только в данном случае 𝒁s должны содержать информацию, специфичную для отдельных сцен. Этот эффект достигается благодаря использованию блока кросс-внимания, в котором эмбединг анализируемой сцены сопоставляется с выученными эмбедингами 𝒁s. Таким образом с помощью механизма внимания модель измеряет насколько хорошо 𝒁s соответствует анализируемой сцене (или насколько они отличаются) в пространстве встраивания.
Авторская визуализация метода HyperDet3D представлена ниже.
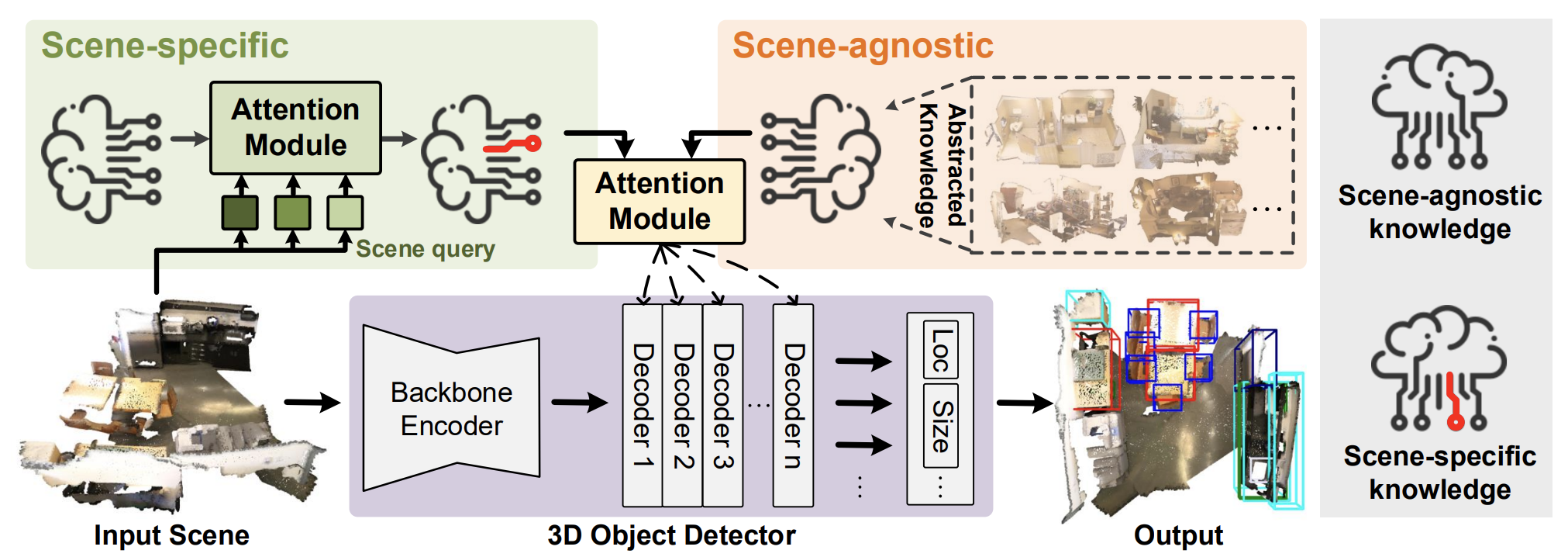
2. Реализация средствами MQL5
После ознакомления с теоретическими аспектами метода HyperDet3D мы переходим к практической части нашей статьи, в которой реализуем свое видение предложенных подходов.
Сразу скажем, что сегодня нам предстоит выполнить довольно большой объем работы. Поэтому мы разделим реализацию на несколько логических блоков. "Засучим рукава" и приступим к работе.
2.1 Модуль специфических знаний
Вначале мы создадим модуль изучения специфических знаний о сцене. Как было сказано в теоретической части статьи, для сопоставления анализируемой сцены и эмбединга специфических знаний о сцене используется алгоритм кросс-внимания. Соответственно, наш новый класс CNeuronSceneSpecific мы создадим наследником от блока кросс-внимания CNeuronMLCrossAttentionMLKV. Структура нового класса представлена ниже.
class CNeuronSceneSpecific : public CNeuronMLCrossAttentionMLKV { protected: CNeuronBaseOCL cOne; CNeuronBaseOCL cSceneSpecificKnowledge; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return feedForward(NeuronOCL); } //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return calcInputGradients(NeuronOCL); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) override { return updateInputWeights(NeuronOCL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSceneSpecific(void) {}; ~CNeuronSceneSpecific(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSceneSpecific; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Здесь следует обратить внимание на одно кардинальное отличие нашего нового класса от его предка. Для корректной работы родительского класса нам необходимо 2 источника данных: анализируемые данные и контекст. В нашем же новом классе в качестве контекста выступают изучаемые специфические данные о сценах из обучающей выборки. А изучать мы их будем в 2 внутренних слоях: cOne и cSceneSpecificKnowledge. По существу, это двухслойная MLP, которая на вход получает "1" и генерирует тензор специфичных знаний о сценах. Не сложно догадаться, что в процессе эксплуатации модели данный тензор будет статичным. Но в процессе обучения мы сможем "записать" в него необходимую информацию.
Следуя указанной логике, мы исключаем из методов нашего нового класса указатели на внешний контекст.
Все внутренние объекты нашего класса объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор класса. Инициализация объекта осуществляется методе Init, в параметрах которого мы получаем основные константы архитектуры создаваемого объекта. Функционал используемых параметров аналогичен одноименному методу родительского класса.
bool CNeuronSceneSpecific::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint units_count_kv, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMLCrossAttentionMLKV::Init(numOutputs, myIndex, open_cl, window, window_key, heads, 16, heads_kv, units_count, units_count_kv, layers, layers_to_one_kv, optimization_type, batch)) return false;
В теле метода мы сразу вызываем метод инициализации родительского класса, в который передаем все полученные параметры. В этом методе осуществляется проверка полученных параметров и инициализация унаследованных объектов.
Далее нам остается лишь инициализировать выше упомянутую MLP специфичных знаний.
Обратите внимание, что первый слой содержит лишь один постоянный элемент. А второй слой нам генерирует набор векторов эмбединга специфичных знаний о состоянии сцены. Для каждого эмбединга мы указали размер вектора в 16 элементов. Количество же таких эмбедингов задается в параметрах метода и зависит от сложности изучаемой среды.
if(!cOne.Init(16 * units_count_kv, 0, OpenCL, 1, optimization, iBatch)) return false; CBufferFloat *out = cOne.getOutput(); if(!out.BufferInit(1, 1) || !out.BufferWrite()) return false; if(!cSceneSpecificKnowledge.Init(0, 1, OpenCL, 16 * units_count_kv, optimization, iBatch)) return false; //--- return true; }
Перед завершением работы метода мы возвращаем логический результат выполнения операций вызывающей программе.
Метод инициализации нашего нового класса получился довольно кратким и лаконичным. И здесь нет ничего удивительного, ведь основной функционал ранее был реализован в методе родительского класса. Впрочем, это относится не только к методу инициализации. Аналогичную картину можно наблюдать и в алгоритме метода прямого прохода feedForward, в параметрах которого мы получаем указатель на объект исходных данных.
bool CNeuronSceneSpecific::feedForward(CNeuronBaseOCL *NeuronOCL) { if(bTrain && !cSceneSpecificKnowledge.FeedForward(cOne.AsObject())) return false;
В теле метода нам предстоит сначала сгенерировать матрицу выученных контекстно-зависимых представлений сцены. Но эту операцию мы выполняем только в процессе обучения модели, когда в процессе корректировки параметров нашего MLP изменяется и результирующий тензор. В процессе эксплуатации модели выученные данные статичны и нам нет необходимости генерировать их повторно. Мы просто используем ранее сохраненную информацию.
Далее нам остается лишь вызвать метод прямого прохода родительского класса, в который мы передадим наши специфические знания о представлениях сцены в качестве контекста.
if(!CNeuronMLCrossAttentionMLKV::feedForward(NeuronOCL, cSceneSpecificKnowledge.getOutput())) return false; //--- return true; }
Аналогичным образом построены и методы обратного прохода. Поэтому я предлагаю их оставить для самостоятельного изучения, чтобы чрезмерно не увеличивать размер статьи. Напомню, что полный код представленного класса и всех его методов Вы можете найти во вложении.
2.2 Построение блока MSA
А мы двигаемся дальше и переходим к построению блока многоголового внимания, обусловленного сценой. И вполне логично, что мы унаследуем основной функционала от одного из ранее реализованных блоков внимания. Структура нового класса CNeuronMLMHSceneConditionAttention представлена ниже.
class CNeuronMLMHSceneConditionAttention : public CNeuronMLMHAttentionMLKV { protected: CLayer cSceneAgnostic; CLayer cSceneSpecific; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMLMHSceneConditionAttention(void) {}; ~CNeuronMLMHSceneConditionAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMLMHSceneConditionAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В представленной выше структуре можно заметить объявление двух новых объектов класса CLayer. Один из них будет содержать контекстно-зависимые представления сцены. А второй — общую информацию об объектах, независимо от сцены.
Однако надо сразу сказать, что наличие 2 объектов не ограничивает создание вложенных нейронных слоев идентификации объектов. В данном случае объекты CLayer используются в качестве динамических массивов. А количество внутренних нейронных слоев определяется пользователем при инициализации нового объекта.
Все внутренние объекты мы объявили статично, что позволяет нам оставить "пустыми" конструктор и деструктор класса. Инициализация всех внутренних и унаследованных объектов, как обычно, осуществляется в методе Init.
bool CNeuronMLMHSceneConditionAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В параметрах метода мы получаем основные константы, определяющие архитектуру создаваемого объекта. И в теле метода мы сразу вызываем одноименный метод предка. Однако в данном случае мы используем метод не прямого родительского класса, а базового полносвязного слоя CNeuronBaseOCL. Это обусловлено значительными различиями в структуре и размере унаследованных объектов.
После успешного выполнения операций метода инициализации предка мы сохраним константы архитектуры нашего нового класса.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(layers, 1); iHeadsKV = fmax(heads_kv, 1); iLayersToOneKV = fmax(layers_to_one_kv, 1);
И вычислим размерности внутренних объектов.
uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeadsKV * iUnits; //Size of KV tensor uint q_weights = (iWindow * iHeads) * iWindowKey; //Size of weights' matrix of Q tenzor uint kv_weights = 2 * (iWindow * iHeadsKV) * iWindowKey; //Size of weights' matrix of KV tenzor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of out tensore uint w0 = (iWindowKey * iHeads + 1) * iWindow; //Size W0 tensor uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
Добавим ещё 2 локальные переменные для временного хранения указателей на объекты нейронных слоев.
CNeuronBaseOCL *base = NULL; CNeuronSceneSpecific *ss = NULL;
И на этом завершается подготовительная работа. Далее мы организуем цикл с числом итераций равным количеству внутренних слоев, указанному в параметрах метода пользователем. На каждой итерации данного цикла мы будем создавать объекты одного внутреннего слоя. Соответственно, после полного завершения заданного количества итераций цикла мы создадим полный набор объектов, необходимый для нормального функционирования требуемого количества внутренних нейронных слоев.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- Initilize Q tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
В теле цикла мы сразу создаем ещё один вложенный цикл из 2 итераций. В теле вложенного цикла мы сохраним буфера данных для записи данных основного потока информации прямого прохода и соответствующих градиентов ошибки при обратном проходе. Именно цикл из 2 итераций позволяет нам создать зеркальную архитектуру для прямого и обратного прохода.
И здесь первым мы создаем буфер для записи сгенерированных сущностей Query. А затем создадим буфер для записи матрицы весовых коэффициентов генерации данной сущности.
//--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
И обратите внимание, если раньше мы всегда заполняли матрицу весовых коэффициентов случайными значения, которые корректировались в процессе обучения модели, то сейчас мы создали буфер с нулевыми значениями. Это связано с внедрением архитектуры гиперсетей, которые и будут генерировать данную матрицу с учетом анализируемой сцены.
Аналогичные операции мы повторим для генерации буферов данных сущностей Key и Value. Только здесь мы добавим возможность использования одного тензора для нескольких внутренних слоев. Поэтому перед созданием буферов данных проверим целесообразность таких операций.
if(i % iLayersToOneKV == 0) { //--- Initilize KV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Tensors.Add(temp)) return false; //--- Initilize KV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!KV_Weights.Add(temp)) return false; }
Далее мы добавим буфер для записи коэффициентов зависимости.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
И результатов многоголового внимания.
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
Как и ранее, результаты многоголового внимания будут масштабироваться до размера исходных данных. Результат данной операции мы запишем в соответствующий буфер данных.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
И добавим буферы работы блока FeedForward.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; //--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Здесь, как и в аналогичном методе родительского класса, для последнего внутреннего слоя на выходе блока FeedForward мы не создаем новые буфера данных, а записываем указатели на соответствующие буфера нашего слоя, унаследованные от базового полносвязного слоя. Именно эти буфера используются для обмена данными между слоями модели. И мы сразу в потоке операций запишем в них данные, исключая излишнюю передачу данных из внутренних слоев на внешние интерфейсы.
После инициализации буферов хранения данных информационных потоков прямого и обратного проходов нам предстоит инициализировать матрицы весовых коэффициентов. Однако для генерации сущностей Query, Key и Value, адаптированных к анализируемому состоянию сцены мы будем использовать 2 гиперсети: априорных знаний об объектах и контекстно-зависимых от состояния сцены. Следовательно, нам предстоит инициализировать эти гиперсети.
И тут есть различные варианты реализации. Как Вы знаете, сущности Key и Value, в отличие от Query, могут генерироваться не на каждом внутреннем слое. Поэтому мы выделили их в отдельный тензор. И мы можем так же создать отдельные гиперсети для генерации соответствующих весовых матриц. Однако это не самый оптимальный подход с точки зрения производительности. Ведь в таком варианте увеличивается количество последовательных операций. И мы приняли решение генерировать их параллельно в рамках одной единых гипермоделей, а затем распределять полученный результат по соответствующим буферам данных.
Но тут надо учесть, что сущности Key и Value генерируются не на каждом внутреннем слое. Следовательно, в случае отсутствия необходимости генерации указанных сущностей мы просто используем модель с тензором результатов меньшего размера.
Звучит логично. Переходим к реализации. Вначале мы разделяем поток операций на 2 направления в зависимости от необходимости генерации тензора Key-Value. Оба потока операций имеют одинаковый алгоритм. Отличие лишь в размере тензора результатов.
if(i % iLayersToOneKV == 0) { //--- Initilize Scene-Specific layers ss = new CNeuronSceneSpecific(); if(!ss) return false; if(!ss.Init((q_weights + kv_weights), cSceneSpecific.Total(), OpenCL, iWindow, iWindowKey, 4, 2, iUnits, 100, 2, 2, optimization, iBatch)) return false; if(!cSceneSpecific.Add(ss)) return false;
Вначале мы работаем с моделью контекстно-зависимого представления. Здесь мы создаем и инициализируем динамический объект модуля специфических знаний, который мы реализовали выше. И указатель на созданный объект в массив контекстно-зависимой модели cSceneSpecific.
Однако здесь стоит обратить внимание на один нюанс. Класс модуля специфических знаний мы построили на базе блока кросс-внимания, который получает в качестве исходных данных анализируемое состояние сцены. И возвращает тензор соответствующего размера, но обогащенный контекстно-зависимыми знаниями модели. Проблема здесь в том, что размер тензора исходных данных, скорее всего, не будет соответствовать размеру необходимой нам матрицы весовых коэффициентов. Поэтому мы добавим полносвязный слой для соответствующего масштабирования данных.
base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneSpecific.Total(), OpenCL, (q_weights + kv_weights), optimization, iBatch)) return false; base.SetActivationFunction(TANH); if(!cSceneSpecific.Add(base)) return false;
Данный слой масштабирования получит гиперболический тангенс в качестве слоя активации, область значений которого находится в диапазоне [-1, 1]. Таким образом, наши контекстно-зависимые знания о состоянии сцены выступаю в роли своеобразного флага, указывающего на возможность присутствия того или иного объекта на анализируемой сцене.
Для модели априорных знаний не зависящих от сцены мы используем двухслойную MLP, аналогичную описанной выше для сохранения контекстно-зависимых эмбедингов.
//--- Initilize Scene-Agnostic layers base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init((q_weights + kv_weights), cSceneAgnostic.Total(), OpenCL, 1, optimization, iBatch)) return false; temp = base.getOutput(); if(!temp.BufferInit(1, 1) || !temp.BufferWrite()) return false; if(!cSceneAgnostic.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneAgnostic.Total(), OpenCL, (q_weights + kv_weights), optimization, iBatch)) return false; if(!cSceneAgnostic.Add(base)) return false; }
В случае отсутствия необходимости генерации тензора Key-Value мы создаем аналогичные объекты, но меньшего размера.
else { //--- Initilize Scene-Specific layers ss = new CNeuronSceneSpecific(); if(!ss) return false; if(!ss.Init(q_weights, cSceneSpecific.Total(), OpenCL, iWindow, iWindowKey, 4, 2, iUnits, 100, 2, 2, optimization, iBatch)) return false; if(!cSceneSpecific.Add(ss)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneSpecific.Total(), OpenCL, q_weights, optimization, iBatch)) return false; base.SetActivationFunction(TANH); if(!cSceneSpecific.Add(base)) return false; //--- Initilize Scene-Agnostic layers base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(q_weights, cSceneAgnostic.Total(), OpenCL, 1, optimization, iBatch)) return false; temp = base.getOutput(); if(!temp.BufferInit(1, 1) || !temp.BufferWrite()) return false; if(!cSceneAgnostic.Add(base)) return false; base = new CNeuronBaseOCL(); if(!base) return false; if(!base.Init(0, cSceneAgnostic.Total(), OpenCL, q_weights, optimization, iBatch)) return false; if(!cSceneAgnostic.Add(base)) return false; }
Для слоя масштабирования данных результатов многоголового внимания и блока FeedForward мы используем обычные матрицы обучаемых параметров, инициализированные случайными параметрами.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < w0; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add(GenerateWeight() * 2 * k - k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
И добавим буферы моментов, которые мы используем в процессе оптимизации созданных матриц обучаемых параметров. Количество буферов моментов определяется указанным методом оптимизации параметров.
//--- for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? w0 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; //--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_1 : 4 * iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit((d == 0 || optimization == ADAM ? ff_2 : iWindow), 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } }
После успешной инициализации всех указанных объектов мы переходим к следующей итерации цикла, в которой мы создадим аналогичные объекты для последующего внутреннего слоя.
В завершении метода инициализации мы инициализируем вспомогательный буфер хранения временных данных и вернем логический результат выполнения операций вызывающей программе.
if(!Temp.BufferInit(MathMax((num_q + num_kv)*iWindow, out), 0)) return false; if(!Temp.BufferCreate(OpenCL)) return false; //--- SetOpenCL(OpenCL); //--- return true; }
Сложная структура и большое количество объектов усложняет понимание выстраиваемого алгоритма. Более того, нам необходимо с особой тщательностью отслеживать поток информации и передачу данных между объектами в процессе реализации методов прямого и обратного проходов. А начнем мы с построения метода прямого прохода feedForward.
bool CNeuronMLMHSceneConditionAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *ss = NULL, *sa = NULL; CBufferFloat *q_weights = NULL, *kv_weights = NULL, *q = NULL, *kv = NULL;
В параметрах метод мы получаем указатель на объект исходных данных. Однако мы не организовываем проверку актуальности полученного указателя. Ведь мы не планируем на данном этапе прямого обращения к объекту исходных данных. Впрочем, мы проведем небольшую подготовительную работу, в ходе которой создадим локальные переменные для временного хранения указателей на различные объекты. И затем создадим цикл перебора внутренних слоев нашего блока.
for(uint i = 0; i < iLayers; i++) { //--- Scene-Specific ss = cSceneSpecific[i * 2]; if(!ss.FeedForward(NeuronOCL)) return false; ss = cSceneSpecific[i * 2 + 1]; if(!ss.FeedForward(cSceneSpecific[i * 2])) return false;
Внутри цикла мы сначала сформируем весовые коэффициенты для создания сущностей Query, Key и Value, используя ранее построенные гиперсети.
Вначале, на основании полученного от вызывающей программы описания состояния сцены мы генерируем матрицу контекстно-зависимых параметров. Как было описано выше, после обогащения контекстно-зависимыми знаниями мы масштабируем тензор описания состояния сцены до размера требуемой матрицы параметров.
Тут же мы генерируем матрицу параметров, независимых от сцены.
//--- Scene-Agnostic sa = cSceneAgnostic[i * 2 + 1]; if(bTrain && !sa.FeedForward(cSceneAgnostic[i * 2])) return false;
Обратите внимание, что операцию генерации матрицы параметров независимых от сцены мы осуществляем только в процессе обучения модели. В процессе эксплуатации матрица остается статичной. И нам нет необходимости повторно её генерировать при каждом проходе.
Далее нам необходимо осуществить поэлементное умножение двух матриц. В результате данной мы получим необходимую нам матрицу весовых параметров, которую мы распределим в ранее созданные буферы данных. Именно распределим, так как мы генерируем одну весовую матрицу, которую делим на 2 части. Одна используется для формирования сущностей Query. Вторая — Key и Value. Но мы же помним, что последние формируются не на каждом проходе. Поэтому в нам предстоит организовать разветвление потока операций в зависимости от необходимости формирования тензора Key-Value.
Однако вначале проведем небольшую подготовительную работу. Мы перенесем в локальную переменную указатель на объект исходных данных текущего внутреннего слоя.
CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(6 * i - 4));
Здесь мы сохраняем указатель на объект исходных данных именно внутреннего слоя. А значит в переменную мы передаем полученный от внешней программы указатель только для первого внутреннего слоя. В остальных случаях мы используем результаты предшествующего внутреннего слоя.
И сохраним в локальные переменные на буферы данных весовых параметров и самого тензора значений сущности Query, которые мы используем в любом из 2 описанных выше вариантов действий.
q_weights = QKV_Weights[i * 2]; q = QKV_Tensors[i * 2];
В случае необходимости формирования тензора Key-Value мы сначала осуществляем поэлементное умножение двух, сформированных выше, матриц весовых коэффициентов. А результат операции запишем в буфер временного хранения данных.
if(i % iLayersToOneKV == 0) { if(IsStopped() || !ElementMult(ss.getOutput(), sa.getOutput(), GetPointer(Temp))) return false;
В локальные переменные сохраним указатели на буферы весовых коэффициентов и значений сущностей Key-Value.
kv_weights = KV_Weights[(i / iLayersToOneKV) * 2]; kv = KV_Tensors[(i / iLayersToOneKV) * 2];
А затем распределим общий тензор весовых параметров по двум буферам данных.
if(IsStopped() || !DeConcat(q_weights, kv_weights, GetPointer(Temp), iHeads, 2 * iHeadsKV, iWindow * iWindowKey)) return false; if(IsStopped() || !MatMul(inputs, kv_weights, kv, iUnits, iWindow, 2 * iHeadsKV * iWindowKey, 1)) return false; }
После чего сформируем тензор сущностей Key-Value путем матричного умножения тензора исходных данных текущего внутреннего слоя на полученную матрицу весовых коэффициентов.
В случае отсутствия необходимости формирования тензора сущностей Key-Value мы только осуществляем операцию поэлементного умножения двух матриц параметров с записью результатов в соответствующий буфер данных. Ведь в данном случае наши гиперсети формируют только матрицу весовых коэффициентов сущности Query.
else { if(IsStopped() || !ElementMult(ss.getOutput(), sa.getOutput(), q_weights)) return false; }
Формирование тензора значений сущности Query осуществляется в любом случае. Поэтому данную операцию мы осуществляем уже в общем потоке.
if(IsStopped() || !MatMul(inputs, q_weights, q, iUnits, iWindow, iHeads * iWindowKey, 1)) return false;
На этом этапе завершается внедрение гиперсетей в алгоритм внимания. И далее следует уже знакомый нам механизм Self-Attention. Вначале мы определяем результаты многоголового внимания.
//--- Score calculation and Multi-heads attention calculation CBufferFloat *temp = S_Tensors[i * 2]; CBufferFloat *out = AO_Tensors[i * 2]; if(IsStopped() || !AttentionOut(q, kv, temp, out)) return false;
Затем понижаем размерность полученного тензора результатов.
//--- Attention out calculation temp = FF_Tensors[i * 6]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9)], out, temp, iWindowKey * iHeads, iWindow, None)) return false;
После чего осуществляем суммирования результатов блока Self-Attention с исходными данными и нормализуем полученный тензор.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow, true)) return false;
Далее данные проходят через блок FeedForward.
//--- Feed Forward inputs = temp; temp = FF_Tensors[i * 6 + 1]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9) + 1], inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors[i * 6 + 2]; if(IsStopped() || !ConvolutionForward(FF_Weights[i * (optimization == SGD ? 6 : 9) + 2], temp, out, 4 * iWindow, iWindow, activation)) return false;
С последующим суммированием и нормализацией данных.
//--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } //--- result return true; }
Операции повторяем для всех внутренних слоев. А после полного перебора всех итераций цикла мы вернем вызывающей программе логический результат выполнения операций метода.
Надеюсь на данном этапе у Вас "сложился пазл" работы алгоритма нашего класса. Но есть ещё нюанс распределения градиента ошибки в процессе обратного прохода, алгоритм которого мы реализовали в методе calcInputGradients.
bool CNeuronMLMHSceneConditionAttention::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
В параметрах метода мы, как обычно, получаем указатель на объект предыдущего слоя, в который нам предстоит передать градиент ошибки в соответствии с влиянием исходных данных на конечный результат. И в теле метода мы сразу осуществляем проверку актуальности полученного указателя. После чего создадим несколько локальных переменных для временного хранения указателей на объекты.
CBufferFloat *out_grad = Gradient; CBufferFloat *kv_g = KV_Tensors[KV_Tensors.Total() - 1]; CNeuronBaseOCL *ss = NULL, *sa = NULL;
И организуем цикл обратного перебора внутренних слоев.
for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) kv_g = KV_Tensors[(i / iLayersToOneKV) * 2 + 1];
Как Вы знаете, алгоритм распределения градиентов ошибки полностью соответствует прямому проходу, но все операции осуществляются в обратном порядке. Поэтому мы и организовали цикл обратного перебора внутренних слоев нашего блока.
Напомню, что вторая половина операций метода прямого прохода полностью повторяла аналогичный блок родительского класса. Следовательно, первую половину нашего метода распределения градиента ошибки мы перенесем из аналогичного метода родительского класса.
Вначале градиент ошибки мы распределяем через блок FeedForward.
//--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9) + 2], out_grad, FF_Tensors[i * 6 + 1], FF_Tensors[i * 6 + 4], 4 * iWindow, iWindow, None)) return false; CBufferFloat *temp = FF_Tensors[i * 6 + 3]; if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9) + 1], FF_Tensors[i * 6 + 4], FF_Tensors[i * 6], temp, iWindow, 4 * iWindow, LReLU)) return false;
После чего суммируем градиент ошибки из двух потоков информации.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
А дальше проведем градиент ошибки через блок Multi-Head Self-Attention.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false; out_grad = temp; //--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights[i * (optimization == SGD ? 6 : 9)], out_grad, AO_Tensors[i * 2], AO_Tensors[i * 2 + 1], iWindowKey * iHeads, iWindow, None)) return false; //--- Passing gradient to query, key and value sa = cSceneAgnostic[i * 2 + 1]; ss = cSceneSpecific[i * 2 + 1]; if(i == int(iLayers - 1) || (i + 1) % iLayersToOneKV == 0) { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors[i * 2], QKV_Tensors[i * 2 + 1], KV_Tensors[(i / iLayersToOneKV) * 2], kv_g, S_Tensors[i * 2], AO_Tensors[i * 2 + 1])) return false; } else { if(IsStopped() || !AttentionInsideGradients(QKV_Tensors[i * 2], QKV_Tensors[i * 2 + 1], KV_Tensors[i / iLayersToOneKV * 2], GetPointer(Temp), S_Tensors[i * 2], AO_Tensors[i * 2 + 1])) return false; if(IsStopped() || !SumAndNormilize(kv_g, GetPointer(Temp), kv_g, iWindowKey, false, 0, 0, 0, 1)) return false; }
Здесь стоит обратить внимание на распределение градиента ошибки до тензора сущностей Key-Value. Нюанс заключается в сборе градиентов ошибки со всех внутренних слоев, на которые оказывает влияние конкретный тензор. Более детально алгоритм описан в статье, посвященной описанию родительского класса.
Далее распределим градиент ошибки на уровень исходных данных по основному потоку информации.
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 6 - 1); inp = FF_Tensors.At(i * 6 - 4); } if(IsStopped() || !MatMulGrad(inp, temp, QKV_Weights[i * 2], QKV_Weights[i * 2 + 1], QKV_Tensors[i * 2 + 1], iUnits, iWindow, iHeads * iWindowKey, 1)) return false; //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false, 0, 0, 0, 1)) return false;
А так же передадим градиент ошибки до гиперсетей в соответствии с их влиянием на общий результат работы модели.
//--- if((i % iLayersToOneKV) == 0) { if(IsStopped() || !MatMulGrad(inp, GetPointer(Temp), KV_Weights[i / iLayersToOneKV * 2], KV_Weights[i / iLayersToOneKV * 2 + 1], KV_Tensors[i / iLayersToOneKV * 2 + 1], iUnits, iWindow, 2 * iHeadsKV * iWindowKey, 1)) return false; if(IsStopped() || !SumAndNormilize(GetPointer(Temp), temp, temp, iWindow, false, 0, 0, 0, 1)) return false; if(!Concat(QKV_Weights[i * 2 + 1], KV_Weights[i / iLayersToOneKV * 2 + 1], ss.getGradient(), iHeads, 2 * iHeadsKV, iWindow * iWindowKey)) return false; if(!ElementMultGrad(ss.getOutput(), ss.getGradient(), sa.getOutput(), sa.getGradient(), ss.getGradient(), ss.Activation(), sa.Activation())) return false; } else { if(!ElementMultGrad(ss.getOutput(), ss.getGradient(), sa.getOutput(), sa.getGradient(), QKV_Weights[i * 2 + 1], ss.Activation(), sa.Activation())) return false; } if(i > 0) out_grad = temp; }
После чего перейдем к следующей итерации нашего цикла перебора внутренних слоев.
Обратите внимание, что в цикле основного потока операций мы только передали градиент ошибки до уровня гиперсетей, но не осуществили его прохождения дальше. И здесь есть несколько нюансов. Во-первых, наша гиперсеть априорных знаний не зависящих от состояния сцены состоит только из двух слоев. Первый статичный и на выходе всегда содержит "1". А второй содержит обучаемые параметры и возвращает результат. В потоке основных операций мы передали градиент ошибки на последний из них. А передача градиента ошибки до уровня первого лишена смысла. Конечно, это частный случай. И при наличии большего количества слоев в гипермодели нам бы пришлось создавать алгоритм передачи градиентов ошибки до всех элементов с обучающимися параметрами.
Второй нюанс относится к построению алгоритма работы контекстно-зависимой от сцены гипермодели. В данной реализации все параметры формируются исходя из исходного описания сцены, передаваемого вызывающей программой. Следовательно, и весь градиент ошибки мы должны передать на указанный уровень. Что бы не нарушать общий поток информации, мы решили вынести распределение градиента данной модели в отдельный цикл. Но это опять же наш частный случай. Если бы мы иной источник описания сцены (к примеру, результат работы предыдущего внутреннего слоя), то и градиент ошибки нам нужно было бы передавать на соответствующий уровень.
Но вернемся к алгоритму нашего метода распределения градиента ошибки. После выполнения итераций цикла обратного перебора внутренних слоев мы записали в буфер градиентов ошибки предыдущего слоя значения влияния исходных данных на результат модели по основному потоку операций. И теперь нам предстоит добавить сюда градиент ошибки от гиперсетей. Для этого мы сначала сохраним указатель на объект буфера градиентов предыдущего слоя в локальную переменную. А в объект слоя временно передадим указатель на наш вспомогательный буфер данных.
CBufferFloat *inp_grad = prevLayer.getGradient(); if(!prevLayer.SetGradient(GetPointer(Temp), false)) return false;
Теперь мы можем передавать градиент ошибки на уровень предыдущего слоя без страха потери ранее сохраненных данных. Организуем цикл перебора объектов нашей контекстно-зависимой гиперсети, в теле которого мы опустим градиент ошибки до уровня слоя исходных данных. И на каждой итерации мы прибавим текущий результат к ранее накопленному градиенту.
for(int i = int(iLayers - 2); (i >= 0 && !IsStopped()); i -= 2) { ss = cSceneSpecific[i]; if(IsStopped() || !ss.calcHiddenGradients(cSceneSpecific[i + 1])) return false; if(IsStopped() || !prevLayer.calcHiddenGradients(ss, NULL)) return false; if(IsStopped() || !SumAndNormilize(prevLayer.getGradient(), inp_grad, inp_grad, iWindow, false, 0, 0, 0, 1)) return false; }
А после успешного выполнения операций цикла мы вернем в объект предыдущего слоя указатель на его буфер с уже накопленным градиентом ошибки от всех потоков информации.
if(!prevLayer.SetGradient(inp_grad, false)) return false; //--- return true; }
Градиент ошибки распределен в полном объеме и возвращаем вызывающей программе логический результат выполнения операций нашего метода распределения градиента ошибки. А с методом обновления параметров модели я предлагаю Вам ознакомиться самостоятельно. Полный код данного класса и всех его методов Вы можете найти во вложении.
2.3 Построение целостного алгоритма HyperDet3D
Выше мы построили отдельные блоки рассмотренного алгоритма HyperDet3D. И теперь пришло объединить все вместе в единую целостную структуру. И надо сказать, что с одной стороны здесь все довольно просто. А с другой — не обошлось и без нюансов.
В рамках данного эксперимента я решил воспользоваться рассмотренным в предыдущей статье алгоритмом Pointformer, в котором заменил блок глобального внимания на модуль MSA. Операция не сложная. Тем более параметры всех методов мы оставили без изменения, включая метод инициализации класса. Да только вот все объекты класса CNeuronPointFormer мы объявили статично. И теперь не можем наследоваться с изменением типа отдельных объектов. Поэтому мы создаем копию класса, в котором изменим тип необходимых нам объектов. Структура нового класса представлена ниже.
class CNeuronHyperDet : public CNeuronPointNet2OCL { protected: CNeuronMLMHSparseAttention caLocalAttention[2]; CNeuronMLCrossAttentionMLKV caLocalGlobalAttention[2]; CNeuronMLMHSceneConditionAttention caGlobalAttention[2]; CNeuronLearnabledPE caLocalPE[2]; CNeuronLearnabledPE caGlobalPE[2]; CNeuronBaseOCL cConcatenate; CNeuronConvOCL cScale; //--- CBufferFloat *cbTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHyperDet(void) {}; ~CNeuronHyperDet(void) { delete cbTemp; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronHyperDet; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
На алгоритмах методов данного класса мы останавливаться не будем, так как все методы созданы путем прямого копирования соответствующих методов класса CNeuronPointFormer.
Архитектура моделей и все программы взаимодействия с окружающей средой и обучения моделей так же заимствованы из предыдущей статьи. Поэтому мы не будем на них останавливаться. Ну а полный код всех программ, используемых при подготовке данной статьи представлен во вложении.
3. Тестирование
Мы провели обширную работу по имплементации своего видения подходов, предложенных авторами метода HyperDet3D. И пришло время перейти к финальной части нашей статьи. Здесь мы осуществим обучение и тестирование моделей, в которых использованы предложенные подходы.
Как и ранее, для обучения моделей мы используем реальные исторические данные инструмента EURUSD за весь 2023 год, таймфрейм H1. Параметры всех анализируемых индикаторов используются по умолчанию. Процесс обучения так же полностью соответствует алгоритму, описанному в предыдущей статье. Поэтому мы остановимся только на результатах тестирования обученной политики Актера, которые представлены ниже.
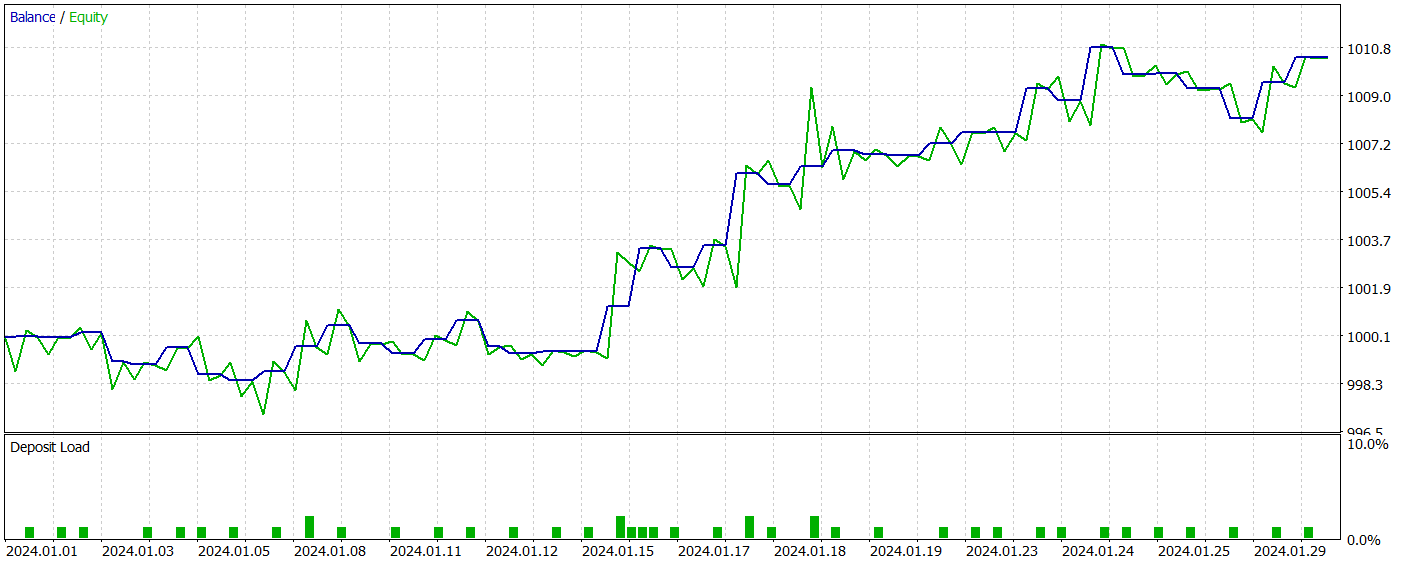
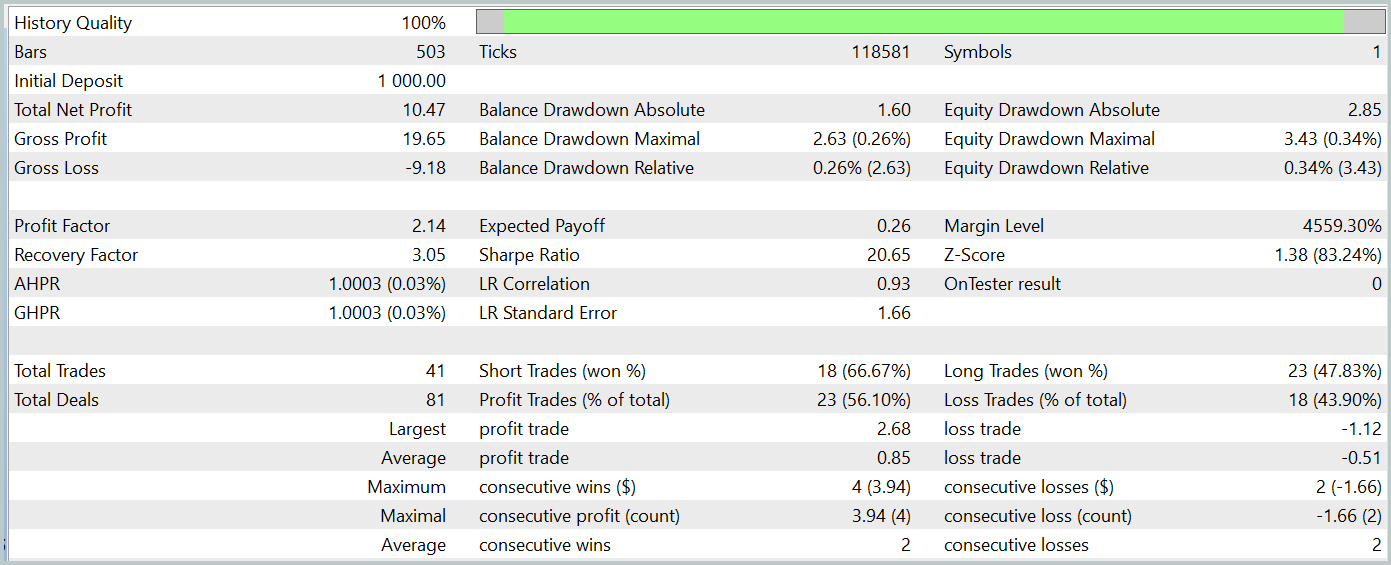
Тестирование обученной модели осуществлялось на исторических данных Января 2024 года, которые не входили в обучающую выборку. И за период тестирования модель совершила 41 сделку, 56% из которых были закрыты с прибылью. При этом максимальная прибыльная сделка в 2.4 раза превышает максимальный убыток, а средняя прибыльная сделка на 67% превышает аналогичный показатель убыточных операций. Все это позволило зафиксировать профит фактор на уровне 2.14, а коэффициент Шарпа достиг отметки 20.65.
В целом за период тестирования модель получила 1% прибыли, при этом максимальная просадка по Эквити не превысила 0.34%. А просадка по балансу была ещё ниже. На графике мы наблюдаем довольно ровный рост баланса, а нагрузка на депозит не превышает 1-2%.
Общее впечатление от полученных результатов хорошее. Модель имеет потенциал. Но короткий период тестирования и малое количество совершенных сделок не позволяют говорить о стабильности работы модели на длительном временном отрезке. Перед использованием модели в реальной работе нам ещё предстоит обучить её на более длительном отрезке исторических данных с преследующим всесторонним тестирование.
Заключение
В данной статье мы познакомились с методом HyperDet3D, который использует гиперсети, обусловленные сценой, для интеграции априорных знаний в архитектуру Transformer. Это позволяет эффективно адаптировать модель под различные сцены для задачи обнаружения объектов, что улучшает качество распознавания за счет динамической настройки параметров детектора на основе информации о сцене, делает систему более универсальной и мощной.
В практической части нашей мы реализовали свое видение предложенных подходов средствами MQL5 и имплементировали их в структуру своей модели. Проведенные результаты тестов демонстрируют потенциал модели. Однако до практического её применения на финансовых рынках нам ещё предстоит выполнить определенный объем работы.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования