
Нейросети в трейдинге: Сегментация данных на основе уточняющих выражений

Введение
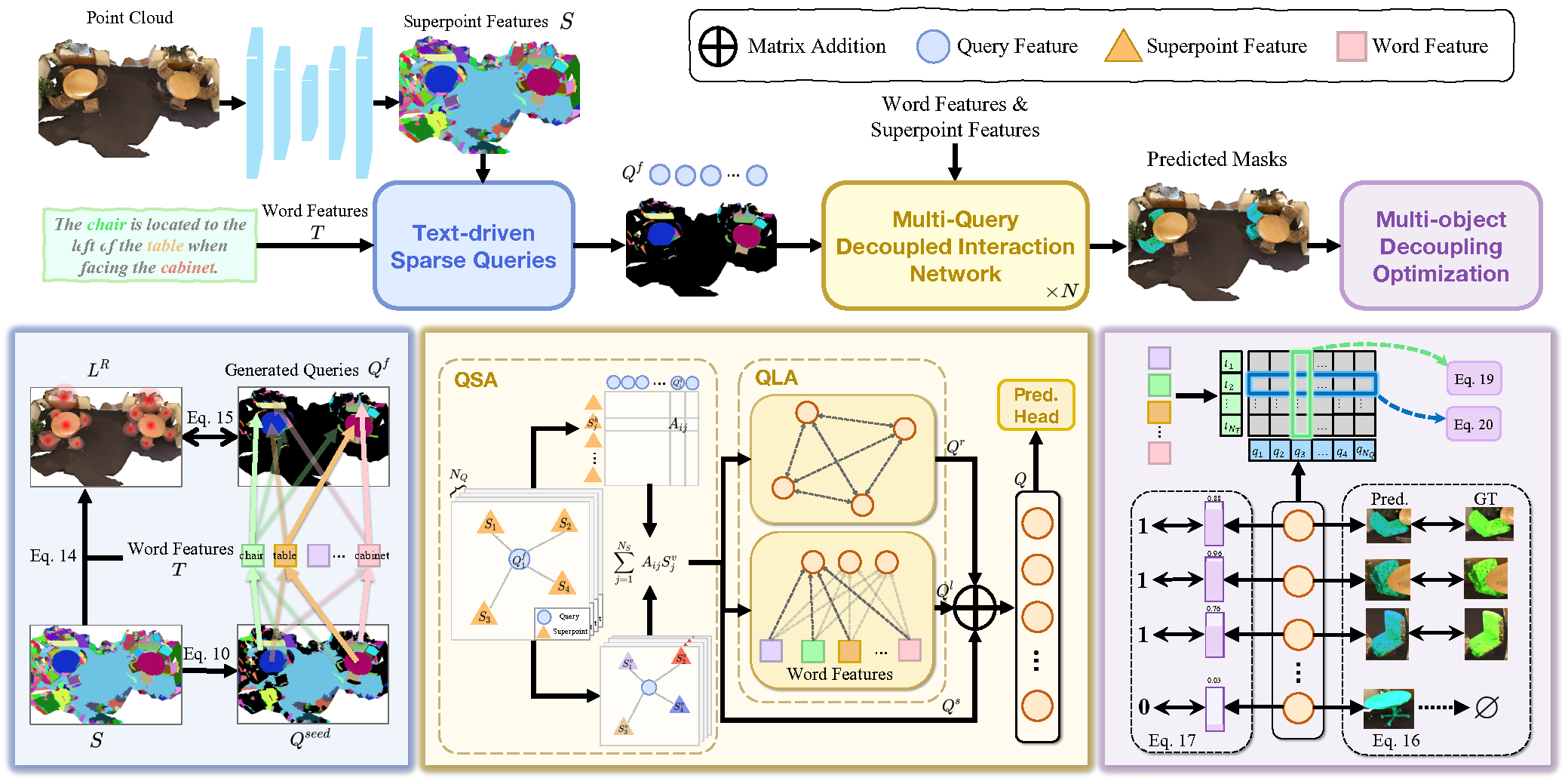
3D Referring Expression Segmentation (3D-RES) — это растущее направление в мультимодальной области, вызывающее широкий интерес со стороны исследователей. Данная задача направлена на сегментацию целевых экземпляров на основе заданных выражений естественного языка. Однако, традиционные методы 3D-RES ограничены рассмотрением случаев с одной целью, что существенно сужает их практическое применение. В реальных сценариях инструкции часто приводят к ситуациям, когда цель не найдена, или необходимо определить несколько целей одновременно. Эта реальность представляет собой проблему, с которой существующие модели 3D-RES не могут справиться. Чтобы восполнить этот пробел, авторы работы "3D-GRES: Generalized 3D Referring Expression Segmentation" предложили новый метод Generalized 3D Referring Expression Segmentation (3D-GRES), предназначенный для интерпретации инструкций, указывающих произвольное количество целей.
Основная задача 3D-GRES заключается в точной идентификации нескольких целей из группы похожих объектов. Ключ к решению таких проблем заключается в разделении задачи, что позволит нескольким запросам одновременно обрабатывать локализацию многообъектной языковой инструкции. При этом каждый запрос отвечает за отдельный экземпляр в многообъектной сцене. Авторы метода 3D-GRES предложили модуль Multi-Query Decoupled Interaction Network (MDIN), который отвечает за облегчение взаимодействия между запросами, суперточками и текстом. Для эффективной обработки произвольного количества целей добавлен механизм, который позволяет нескольким запросам разделяться и совместно генерировать результаты с несколькими объектами. При этом каждый запрос отвечает за одну цель в экземпляре с несколькими объектами.
Для равномерного охвата ключевых целей в облаке точек обучаемыми запросами, авторы метода представили новый модуль разреженных запросов (TSQ) на основе текста уточняющих выражений. Кроме того, для одновременного достижения различительной способности между запросами и поддержания общей семантической согласованности, была разработана стратегия оптимизации с разделением нескольких объектов (MDO). Эта стратегия разделяет многообъектную маску на отдельные однообъектные супервизии, сохраняя различительную способность каждого запроса. Связывание функции запросов и характеристики суперточек в сцене облака точек с текстовой семантикой обеспечивает семантическую согласованность для нескольких целей.
1. Алгоритм 3D-GRES
Классическая задача 3D-RES сфокусирован на создании 3D-маски для одного целевого объекта в сцене облака точек, управляемой ссылочным выражением. Эта традиционная задача имеет существенные ограничения. Во-первых, она не подходит для сценариев, в которых ни один объект в сцене облака точек не соответствует заданному выражению. Во-вторых, она не учитывает случаи, когда несколько объектов соответствуют описанным критериям. Такой значительный разрыв между возможностями модели и применимостью в реальном мире ограничивает практическое применение технологий 3D-RES.
Для преодоления существующих ограничений был предложен метод Generalized 3D Referring Expression Segmentation (3D-GRES), предназначенный для идентификации произвольного количества объектов из текстовых описаний. 3D-GRES анализирует 3D-сцену облака точек P и уточняющее текстовое выражение E. В результате генерируются соответствующие 3D-маски M, которые могут быть пустыми, а могут содержать один или несколько объектов. Представленный метод позволяет находить несколько объектов с помощью многоцелевых выражений и проверять существование конкретных объектов в сцене с помощью выражений «nothing», тем самым обеспечивая повышенную гибкость и надежность при извлечении объектов и взаимодействии.
3D-GRES сначала обрабатывает исходные ссылочные выражения, кодируя их в текстовые токены 𝒯, используя предварительно обученную модель RoBERTa. Чтобы облегчить мультимодальное выравнивание, закодированные объекты затем проецируются в мультимодальное пространство размерности D. К полученным токенам добавляется позиционное кодирование.
Для исходного облака точек с позициями P и признаками F через разреженную 3D U-Net извлекаются Superpoints, которые проецируются в D-мерное мультимодальное пространство.
Multi-Query Decoupled Interaction Network (MDIN) использует несколько запросов для обработки отдельных экземпляров в сценах с несколькими целями, объединяя их в конечный результат. Для сцен без определенных целевых объектов прогнозы делаются на основе оценок достоверности каждого запроса, при этом нулевые целевые показатели прогнозируются, если все запросы имеют низкую оценку.
MDIN состоит из нескольких идентичных модулей, каждый из которых состоит из модулей агрегирования Query-Superpoint (QSA) и агрегирования языковых выражений с Query (QLA), облегчающих взаимодействие между Query, Superpoint и текстом. В отличие от рассмотренных нами ранее моделей, которые используют случайную инициализацию Query, MDIN использует модуль разреженных запросов (TSQ), управляемый текстом, для генерации разреженных Query, обеспечивая эффективный охват сцены. А для поддержки нескольких запросов реализуется стратегия оптимизации с разделением нескольких объектов (MDO).
Query может рассматриваться как якорь в сцене облака точек. В процессе взаимодействия Query с Superpoint, они захватывают глобальную информацию сцены облака точек. Примечательно, что отдельно выбранные суперточки служат запросами в процессе взаимодействия, что обеспечивает более сильную локальную агрегацию. Такая локальная направленность создает благоприятные условия для разъединения запросов.
Первоначально вычисляется распределение сходства между признаком суперточки S и эмбединга запросов Qf. Впоследствии запросы будут агрегировать соответствующие связанные суперточки с использованием распределений сходства. А затем обновленная сцена с учетом Qs подается в модуль QLA для моделирования взаимодействия Query-Query и Query-Language. QLA состоит из блока Self-Attention для функций запроса Qs и мультимодального перекрестного внимания, которое моделируют зависимости между каждым словом и каждым запросом.
Затем функция запросов с учетом отношений Qr, функции запросов с учетом языка Ql и функциями запросов, учитывающими сцену Qs складываются вместе и объединяются с помощью MLP.
Для того, чтобы добиться разреженного распределения инициализированных запросов в пределах облачной сцены точек, при сохранении в большей степени геометрической и семантической информации, авторы 3D-GRES применяют технику выборки самых дальних точек непосредственно для Superpoint.
Для улучшения разделения запросов и делегирования их отдельным объектам, авторы метода используют внутренние атрибуты запросов, генерируемых TSQ. Каждый запрос исходит из суперточки в облаке точек, что по своей сути связывает его с конкретным объектом. Запросы для целевых экземпляров отвечают за сегментацию соответствующих экземпляров, в то время как несвязанные экземпляры назначаются ближайшему запросу. Этот метод использует предварительные визуальные ограничения для распутывания запросов и назначения их отдельным объектам.
Авторская визуализация метода 3D-GRES представлена ниже.
2. Реализация средствами MQL5
После ознакомления с теоретическими аспектами метода 3D-GRES, мы переходим к практической части нашей статьи, в которой реализуем свое видение предложенных подходов средствами MQL5. И прежде всего давайте подумаем, что отличает предложенный алгоритм от рассмотренных нами ранее методов. И что у них общего.
Конечно, в первую очередь это мультимодальность метода 3D-GRES. Мы впервые встречаем уточняющие текстовые выражения, которые должны сделать наш анализ более направленным. И несомненно, мы воспользуемся этим предложением. Только мы не будем использовать языковую модель, а для постановки задачи мы подадим в модель информацию о состоянии счета и открытых позициях. Таким образом, мы предложим модели в зависимости от эмбединга состояния счета искать точки входа или выхода.
Ещё один момент, на который стоит обратить внимание. 3D-GRES, как и рассмотренные нами ранее модели, использует набор обучаемых запросов. Только есть отличие в принципе их формирования. SPFormer и MAFT использовали статичные запросы, которые оптимизировались в процессе обучения, а в момент эксплуатации модели оставались неизменными. Таким образом, модель заучивала некоторые паттерны и затем действовала по "заготовленной схеме". Авторы 3D-GRES предлагают формировать запросы на основе исходных данных, что делает их более локальными и динамичными. А для максимального покрытия пространства анализируемой сцены применяются различные эвристики. Мы так же возьмем на вооружение эту идею.
Кроме того, в методе 3D-GRES используется позиционное кодирование токенов. И это объединяет его с методом MAFT, что послужило отправной точкой для выбора родительского класса в нашей реализации. Ну а начнем мы работу с дополнения OpenCL-программы.
2.1 Диверсификация запросов
Для максимального покрытия пространства сцены обучаемыми запросами мы вводим ошибку диверсификации, которая призвана "отталкивать" запросы от соседних:
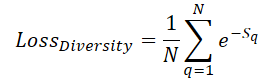
Здесь Sq указывает расстояние до запроса q. Очевидно, что при S=0 ошибка равна 1. А при увеличении среднего расстояния между запросами ошибка стремится к "0". Таким образом, в процессе обучения модель будет равномерно разводить.
Однако нас интересует не столько значение ошибки, сколько направление корректировки параметров запросов в сторону максимального удаления от остальных запросов. Поэтому в своей реализации мы сразу вычисляем градиент ошибки и прибавляем его к основному потоку распределения ошибки работы модели с последующей оптимизацией параметров. Описанный алгоритм мы реализуем в кернеле DiversityLoss.
В параметрах данного кернела мы будем передавать указатели на 2 глобальных буфера данных и 2 переменные. Первый буфер данных содержит текущие признаки запросов, а во второй — мы запишем градиент ошибки диверсификации.
__kernel void DiversityLoss(__global const float *data, __global float *grad, const int activation, const int add ) { const size_t main = get_global_id(0); const size_t slave = get_local_id(1); const size_t dim = get_local_id(2); const size_t total = get_local_size(1); const size_t dimension = get_local_size(2);
Работать наш кернел будет в трехмерном пространстве задач. Первые два равны количеству анализируемых запросов, а третье измерение определяет размерность вектора признаков одного запроса. При этом, для минимизации обращений к медленной глобальной памяти, мы объединим потоки в рабочие группы по последним двум измерениям пространства задач.
В теле кернела мы, как обычно, сначала идентифицируем рабочий поток в пространстве задач по всем измерениям. Затем объявим массив в локальной памяти для обмена данными между отдельными потоками рабочей группы.
__local float Temp[LOCAL_ARRAY_SIZE];
И определим смещение в глобальных буферах данных до анализируемых значений.
const int shift_main = main * dimension + dim; const int shift_slave = slave * dimension + dim;
После чего загрузим из глобальных буферов данных значения и определим отклонение между ними.
const int value_main = data[shift_main]; const int value_slave = data[shift_slave]; float delt = value_main - value_slave;
Обратите внимание, что пространство задач и рабочие группы организованы таким образом, что каждый поток считывает только 2 значения из глобальной памяти. И далее нам предстоит собрать сумму расстояний от всех потоков. Для этого мы сначала организуем цикл со сбором суммы отдельных значений в элементах локального массива.
for(int d = 0; d < dimension; d++) { for(int i = 0; i < total; i += LOCAL_ARRAY_SIZE) { if(d == dim) { if(i <= slave && (i + LOCAL_ARRAY_SIZE) > slave) { int k = i % LOCAL_ARRAY_SIZE; float val = pow(delt, 2.0f) / total; if(isinf(val) || isnan(val)) val = 0; Temp[k] = ((d == 0 && i == 0) ? 0 : Temp[k]) + val; } } barrier(CLK_LOCAL_MEM_FENCE); } }
И здесь, наверное, стоит указать на тот момент, что мы сначала сохранили простую разницу между двумя значениями в переменной delt. И только перед добавлением расстояния в локальный массив возвели его в квадрат. Это связано с тем, что в производной нашей функции потерь участвует именно разница. И мы сохраняем её, чтобы исключить повторное вычисление.
На следующем этапе мы соберем сумму всех значений нашего локального массива.
const int ls = min((int)total, (int)LOCAL_ARRAY_SIZE); int count = ls; do { count = (count + 1) / 2; if(slave < count) { Temp[slave] += ((slave + count) < ls ? Temp[slave + count] : 0); if(slave + count < ls) Temp[slave + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
И лишь потом мы вычисляем значение ошибки диверсификации анализируемого запроса и градиент ошибки соответствующего элемента.
float loss = exp(-Temp[0]); float gr = 2 * pow(loss, 2.0f) * delt / total; if(isnan(gr) || isinf(gr)) gr = 0;
После чего нам предстоит увлекательный путь сбора градиентов ошибки в разрезе отдельных признаков анализируемого запроса. Алгоритм суммирования градиентов ошибки аналогичен описанному выше для суммирования расстояний.
for(int d = 0; d < dimension; d++) { for(int i = 0; i < total; i += LOCAL_ARRAY_SIZE) { if(d == dim) { if(i <= slave && (i + LOCAL_ARRAY_SIZE) > slave) { int k = i % LOCAL_ARRAY_SIZE; Temp[k] = ((d == 0 && i == 0) ? 0 : Temp[k]) + gr; } } barrier(CLK_LOCAL_MEM_FENCE); } //--- int count = ls; do { count = (count + 1) / 2; if(slave < count && d == dim) { Temp[slave] += ((slave + count) < ls ? Temp[slave + count] : 0); if(slave + count < ls) Temp[slave + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); if(slave == 0 && d == dim) { if(isnan(Temp[0]) || isinf(Temp[0])) Temp[0] = 0; if(add > 0) grad[shift_main] += Deactivation(Temp[0],value_main,activation); else grad[shift_main] = Deactivation(Temp[0],value_main,activation); } barrier(CLK_LOCAL_MEM_FENCE); } }
Обратите внимание, что описанный выше алгоритм объединяет итерации прямого и обратного проходов. Это позволяет нам использовать его только при обучении модели и исключить данные операции в процессе эксплуатации, что в свою очередь повлияет на время принятия решения.
На этом мы завершаем работу с OpenCL-программой и переходим к построению нашего класса реализации подходов метода 3D-GRES.
2.2 Класс метода 3D-GRES
Для реализации подходов, предложенных авторами метода 3D-GRES, на стороне основной программы мы создадим новый объект CNeuronGRES. Как было сказано ранее, базовый функционал будет унаследован от класса CNeuronMAFT. Структура нового класса представлена ниже.
class CNeuronGRES : public CNeuronMAFT { protected: CLayer cReference; CLayer cRefKey; CLayer cRefValue; CLayer cMHRefAttentionOut; CLayer cRefAttentionOut; //--- virtual bool CreateBuffers(void); virtual bool DiversityLoss(CNeuronBaseOCL *neuron, const int units, const int dimension, const bool add = false); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronGRES(void) {}; ~CNeuronGRES(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint ref_size, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronGRES; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Вместе с базовым функционалом мы унаследуем от родительского класса и широкий спектр внутренних объектов, которые покроют большую часть наших потребностей. Большую, но не все. И мы добавим объекты для работы с уточняющими выражениями. Все объекты мы объявляем статическими, что позволяет нам оставить "пустыми" конструктор и деструктор класса. Инициализация всех объявленных и унаследованных объектов осуществляется в методе Init, в параметрах которого мы получаем основные константы, позволяющие однозначно определить архитектуру создаваемого объекта.
bool CNeuronGRES::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_sp, uint units_sp, uint heads_sp, uint ref_size, uint layers, uint layers_to_sp, ENUM_OPTIMIZATION optimization_type, uint batch ) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
К сожалению, структура создаваемого нами класса сильно отличается от родительского, что не позволяет нам полноценно использовать все методы родительского. Это отражается и в алгоритме метода инициализации. Здесь нам предстоит провести инициализацию не только добавленных, но и унаследованных объектов.
В теле метода инициализации мы сначала вызываем одноименный метод базового полносвязного слоя, в котором осуществляется первичная проверка полученных параметров и активация интерфейсов обмена данными между нейронными слоями в рамках функционирования модели.
И затем мы сохраним полученные параметры во внутренних переменных нашего класса.
iWindow = window; iUnits = units_count; iHeads = heads; iSPUnits = units_sp; iSPWindow = window_sp; iSPHeads = heads_sp; iWindowKey = window_key; iLayers = MathMax(layers, 1); iLayersSP = MathMax(layers_to_sp, 1);
Тут же мы объявим несколько переменных для временного хранения указателей на объекты различных нейронных слоев, которые мы будем инициализировать в рамках нашего метода.
CNeuronBaseOCL *base = NULL; CNeuronTransposeOCL *transp = NULL; CNeuronConvOCL *conv = NULL; CNeuronLearnabledPE *pe = NULL;
Далее мы переходим к созданию объектов генерации обучаемых запросов. Здесь стоит напомнить, что авторы метода 3D-GRES предложили использовать динамические запросы на основе исходного облака точек. Однако анализируемое облако точек может отличаться от обучаемых запросов как по количеству элементов, так и по размеру вектора признаков описания одного элемента. Данную задачу мы решаем в 2 этапа. Сначала мы транспонируем тензор исходных данных и с помощью сверточного слоя изменяем количество элементов в последовательности. Использование сверточного слоя позволяет нам осуществить указанную операцию в рамках независимых унитарных последовательностей.
//--- Init Querys cQuery.Clear(); transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, 0, OpenCL, iSPUnits, iSPWindow, optimization, iBatch) || !cQuery.Add(transp)) return false; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 1, OpenCL, iSPUnits, iSPUnits, iUnits, 1, iSPWindow, optimization, iBatch) || !cQuery.Add(conv)) return false; conv.SetActivationFunction(SIGMOID);
На втором этапе мы осуществляем обратное транспонирование тензора и делаем его проекцию в мультимодальное пространство.
transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, 2, OpenCL, iSPWindow, iUnits, optimization, iBatch) || !cQuery.Add(transp)) return false; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, 3, OpenCL, iSPWindow, iSPWindow, iWindow, iUnits, 1, optimization, iBatch) || !cQuery.Add(conv)) return false; conv.SetActivationFunction(SIGMOID);
Теперь нам остается лишь добавить полностью обучаемое позиционное кодирование.
pe = new CNeuronLearnabledPE(); if(!pe || !pe.Init(0, 4, OpenCL, iWindow * iUnits, optimization, iBatch) || !cQuery.Add(pe)) return false;
Аналогично алгоритму родительского класса, мы вынесем в отдельный информационный поток данные позиционного кодирования запросов.
base = new CNeuronBaseOCL(); if(!base || !base.Init(0, 5, OpenCL, pe.Neurons(), optimization, iBatch) || !base.SetOutput(pe.GetPE()) || !cQPosition.Add(base)) return false;
Алгоритм генерации архитектуры модели Superpoints мы полностью перенесли из родительского класса без изменений.
//--- Init SuperPoints int layer_id = 6; cSuperPoints.Clear(); for(int r = 0; r < 4; r++) { if(iSPUnits % 2 == 0) { iSPUnits /= 2; CResidualConv *residual = new CResidualConv(); if(!residual || !residual.Init(0, layer_id, OpenCL, 2 * iSPWindow, iSPWindow, iSPUnits, optimization, iBatch) || !cSuperPoints.Add(residual)) return false; } else { iSPUnits--; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, 2 * iSPWindow, iSPWindow, iSPWindow, iSPUnits, 1, optimization, iBatch) || !cSuperPoints.Add(conv)) return false; conv.SetActivationFunction(SIGMOID); } layer_id++; } conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iSPWindow, iSPWindow, iWindow, iSPUnits, 1, optimization, iBatch) || !cSuperPoints.Add(conv)) return false; conv.SetActivationFunction(SIGMOID); layer_id++; pe = new CNeuronLearnabledPE(); if(!pe || !pe.Init(0, layer_id, OpenCL, conv.Neurons(), optimization, iBatch) || !cSuperPoints.Add(pe)) return false; layer_id++;
А для генерации эмбединга уточняющего выражения мы используем полносвязное MLP с добавлением слоя позиционного кодирования.
//--- Reference cReference.Clear(); base = new CNeuronBaseOCL(); if(!base || !base.Init(iWindow * iUnits, layer_id, OpenCL, ref_size, optimization, iBatch) || !cReference.Add(base)) return false; layer_id++; base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindow * iUnits, optimization, iBatch) || !cReference.Add(base)) return false; base.SetActivationFunction(SIGMOID); layer_id++; pe = new CNeuronLearnabledPE(); if(!pe || !pe.Init(0, layer_id, OpenCL, base.Neurons(), optimization, iBatch) || !cReference.Add(pe)) return false; layer_id++;
Здесь стоит обратить внимание, что на выходе MLP мы получаем тензор, соизмеримый с тензором обучаемых запросов. Это сделано для возможности разложения уточняющего выражения на несколько семантических компонент, что позволяет сделать более комплексный анализ текущей рыночной ситуации.
На данном этапе мы завершили работу по инициализации объектов первичной обработки исходных данных. И далее мы создаем цикл инициализации объектов внутренних нейронных слоев. Но предварительно очистим массивы коллекций внутренних объектов.
//--- Inside layers cQKey.Clear(); cQValue.Clear(); cSPKey.Clear(); cSPValue.Clear(); cSelfAttentionOut.Clear(); cCrossAttentionOut.Clear(); cMHCrossAttentionOut.Clear(); cMHSelfAttentionOut.Clear(); cMHRefAttentionOut.Clear(); cRefAttentionOut.Clear(); cRefKey.Clear(); cRefValue.Clear(); cResidual.Clear(); for(uint l = 0; l < iLayers; l++) { //--- Cross-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0,layer_id, OpenCL, iWindow, iWindow, iWindowKey*iHeads, iUnits, 1,optimization, iBatch) || !cQuery.Add(conv)) return false; layer_id++;
В теле цикла мы сначала осуществляем инициализацию объектов кросс-внимания Query-Superpoint. Здесь мы создаем объект генерации сущностей Query для блока внимания. А затем, в случае необходимости, добавляем объекты генерации сущностей Key и Value.
if(l % iLayersSP == 0) { //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iSPHeads, iSPUnits, 1, optimization, iBatch) || !cSPKey.Add(conv)) return false; layer_id++; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindowKey * iSPHeads, iSPUnits, 1, optimization, iBatch) || !cSPValue.Add(conv)) return false; layer_id++; }
Добавим слой записи результатов многоголового внимания.
//--- Multy-Heads Attention Out base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cMHCrossAttentionOut.Add(base)) return false; layer_id++;
И слой масштабирования результатов.
//--- Cross-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch) || !cCrossAttentionOut.Add(conv)) return false; layer_id++;
Блок кросс-внимания завершается слоем остаточных связей.
//--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindow * iUnits, optimization, iBatch) || !cResidual.Add(base)) return false; layer_id++;
Следующим этапом мы инициализируем блок Self-Attention анализа зависимостей Query-Query. Здесь мы генерируем все сущности на основании результатов предыдущего блока кросс-внимания.
//--- Self-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0,layer_id, OpenCL, iWindow, iWindow, iWindowKey*iHeads, iUnits, 1, optimization, iBatch) || !cQuery.Add(conv)) return false; layer_id++; //--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0,layer_id, OpenCL, iWindow, iWindow, iWindowKey*iHeads, iUnits, 1, optimization, iBatch) || !cQKey.Add(conv)) return false; layer_id++; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0,layer_id, OpenCL, iWindow, iWindow, iWindowKey*iHeads, iUnits, 1, optimization, iBatch) || !cQValue.Add(conv)) return false; layer_id++;
При этом, для каждого внутреннего слоя мы генерируем все сущности с одинаковым количеством голов внимания.
Добавляем слой записи результатов многоголового внимания.
//--- Multy-Heads Attention Out base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cMHSelfAttentionOut.Add(base)) return false; layer_id++;
И слой масштабирования результатов.
//--- Self-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindowKey * iHeads, iWindowKey * iHeads, iWindow, iUnits, 1, optimization, iBatch) || !cSelfAttentionOut.Add(conv)) return false; layer_id++;
Параллельно с блоком Self-Attention функционирует блок кросс-внимания Query к семантическим уточняющим выражениям. Здесь сущность Query генерируется по результатам предшествующего блока кросс-внимания.
//--- Reference Cross-Attention //--- Query conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0,layer_id, OpenCL, iWindow, iWindow, iWindowKey*iHeads, iUnits, 1, optimization, iBatch) || !cQuery.Add(conv)) return false; layer_id++;
А тензор Key-Value формируется из ранее подготовленных семантических эмбедингов.
//--- Key conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0,layer_id, OpenCL, iWindow, iWindow, iWindowKey*iHeads, iUnits, 1, optimization, iBatch) || !cRefKey.Add(conv)) return false; layer_id++; //--- Value conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0,layer_id, OpenCL, iWindow, iWindow, iWindowKey*iHeads, iUnits, 1, optimization, iBatch) || !cRefValue.Add(conv)) return false; layer_id++;
Аналогично блоку Self-Attention, все сущности мы генерируем на каждом новом слое с равным количеством голов внимания.
Далее мы добавим слои результатов многоголового внимания и масштабирования результатов.
//--- Multy-Heads Attention Out base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cMHRefAttentionOut.Add(base)) return false; layer_id++; //--- Cross-Attention Out conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0,layer_id, OpenCL, iWindowKey*iHeads, iWindowKey*iHeads, iWindow, iUnits, 1, optimization, iBatch) || !cRefAttentionOut.Add(conv)) return false; layer_id++; if(!conv.SetGradient(((CNeuronBaseOCL*)cSelfAttentionOut[cSelfAttentionOut.Total() - 1]).getGradient(), true)) return false;
И завершает данный блок слой остаточных связей, который объединяет результаты всех трех блоков внимания.
//--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!cResidual.Add(base)) return false; layer_id++;
А окончательная обработка обогащенных запросов осуществляется в блоке FeedForward с остаточной связью, структура которого аналогична ванильному Transformer.
//--- Feed Forward conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, 4*iWindow, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(LReLU); if(!cFeedForward.Add(conv)) return false; layer_id++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, 1, optimization, iBatch)) return false; if(!cFeedForward.Add(conv)) return false; layer_id++; //--- Residual base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, iWindow * iUnits, optimization, iBatch)) return false; if(!base.SetGradient(conv.getGradient())) return false; if(!cResidual.Add(base)) return false; layer_id++;
Кроме того, мы перенесем из родительского класса алгоритм корректировки центров объектов, который не был предусмотрен авторами метода 3D-GRES.
//--- Delta position conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, layer_id, OpenCL, iWindow, iWindow, iWindow, iUnits, 1, optimization, iBatch)) return false; conv.SetActivationFunction(SIGMOID); if(!cQPosition.Add(conv)) return false; layer_id++; base = new CNeuronBaseOCL(); if(!base || !base.Init(0, layer_id, OpenCL, conv.Neurons(), optimization, iBatch)) return false; if(!base.SetGradient(conv.getGradient())) return false; if(!cQPosition.Add(base)) return false; layer_id++; }
И переходим к следующей итерации цикла создания объектов внутреннего слоя. А после успешного выполнения всех итераций цикла мы подменим указатели на буфера данных, что позволит нам сократить количество операций копирования данных и ускорит процесс обучения.
base = cResidual[iLayers * 3 - 1]; if(!SetGradient(base.getGradient())) return false; //--- SetOpenCL(OpenCL); //--- return true; }
А в завершении операций метода мы вернем логический результат выполненных операций вызывающей программе.
Здесь стоит обратить внимание, что, как и в прошлой статье, мы вынесли создание вспомогательных буферов данных в отдельный метод CreateBuffers. Я предлагаю вам самостоятельно ознакомиться с данным методом. Его полный код можно найти во вложении.
После инициализации объекта нашего нового класса, мы переходим к построению алгоритма прямого прохода, который реализован в методе feedForward. На этот раз, в параметрах метода мы получаем уже 2 указателя на объекты исходных данных. Один содержит анализируемое облако точек, а во втором представлено уточняющее выражение.
bool CNeuronGRES::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { //--- Superpoints CNeuronBaseOCL *superpoints = NeuronOCL; int total_sp = cSuperPoints.Total(); for(int i = 0; i < total_sp; i++) { if(!cSuperPoints[i] || !((CNeuronBaseOCL*)cSuperPoints[i]).FeedForward(superpoints)) return false; superpoints = cSuperPoints[i]; }
И в теле метода мы сразу организовываем цикл прямого прохода нашей маленькой модели генерации Superpoints. Затем аналогичным образом генерируем запросы.
//--- Query CNeuronBaseOCL *query = NeuronOCL; for(int i = 0; i < 5; i++) { if(!cQuery[i] || !((CNeuronBaseOCL*)cQuery[i]).FeedForward(query)) return false; query = cQuery[i]; }
А вот с созданием тензора семантических эмбедингов уточняющего выражения нам придётся поработать чуточку больше. Дело в том, что уточняющее выражение мы получаем в виде буфера данных. А метод прямого прохода внутренних объектов требует на вход нейронный слой. Поэтому первый слой внутренней модели генерации семантических эмбедингов уточняющего выражения мы используем для записи исходных данных, аналогично основной модели. Только в данном случае мы не осуществляем полного копирования содержания буфера, а лишь делаем подмену указателей на объекты.
//--- Reference CNeuronBaseOCL *reference = cReference[0]; if(!SecondInput) return false; if(reference.getOutput() != SecondInput) if(!reference.SetOutput(SecondInput, true)) return false;
И далее организуем цикл прямого прохода внутренней модели.
for(int i = 1; i < cReference.Total(); i++) { if(!cReference[i] || !((CNeuronBaseOCL*)cReference[i]).FeedForward(reference)) return false; reference = cReference[i]; }
На этом мы завершаем предварительную обработку исходных данных и переходим к основному алгоритму декодирования данных. Для этого мы организуем цикл перебора внутренних слоев нашего Декодера.
CNeuronBaseOCL *inputs = query, *key = NULL, *value = NULL, *base = NULL, *cross = NULL, *self = NULL; //--- Inside layers for(uint l = 0; l < iLayers; l++) { //--- Calc Position bias cross = cQPosition[l * 2]; if(!cross || !CalcPositionBias(cross.getOutput(), ((CNeuronLearnabledPE*)superpoints).GetPE(), cPositionBias[l], iUnits, iSPUnits, iWindow)) return false;
Здесь мы сначала определим коэффициенты позиционного смещения, аналогично методу MAFT. Это наше отступление от авторского алгоритма 3D-GRES. В своей работе авторы метода использовали MLP для генерации маски внимания.
Далее у нас блок кросс-внимания QSA, в котором осуществляется анализ зависимостей Query-Superpoint. Здесь мы сначала генерируем тензоры сущностей Query, Key и Value. Две последние генерируются только в случае необходимости.
//--- Cross-Attention query = cQuery[l * 3 + 5]; if(!query || !query.FeedForward(inputs)) return false; key = cSPKey[l / iLayersSP]; value = cSPValue[l / iLayersSP]; if(l % iLayersSP == 0) { if(!key || !key.FeedForward(superpoints)) return false; if(!value || !value.FeedForward(cSuperPoints[total_sp - 2])) return false; }
И осуществляем анализ зависимостей с учетом коэффициентов позиционного смещения.
if(!AttentionOut(query, key, value, cScores[l * 3], cMHCrossAttentionOut[l], cPositionBias[l], iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey, true)) return false;
Результаты многоголового внимания мы масштабируем и добавляем значения остаточной связи с последующей нормализацией данных.
base = cCrossAttentionOut[l]; if(!base || !base.FeedForward(cMHCrossAttentionOut[l])) return false; value = cResidual[l * 3]; if(!value || !SumAndNormilize(inputs.getOutput(), base.getOutput(), value.getOutput(), iWindow, false, 0, 0, 0, 1)|| !SumAndNormilize(cross.getOutput(), value.getOutput(), value.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; inputs = value;
Следующим шагом мы организовываем работу модуля QLA. Здесь нам предстоит организовать прямой проход двух блоков внимания:
- Self-Attention → Query-Query;
- Cross-Attention → Query-Reference.
Вначале мы организуем работу блока Self-Attention. Здесь мы в полном объеме генерируем тензоры сущностей Query, Key и Value на основании данных, полученных из предыдущего блока Декодера.
//--- Self-Atention query = cQuery[l * 3 + 6]; if(!query || !query.FeedForward(inputs)) return false; key = cQKey[l]; if(!key || !key.FeedForward(inputs)) return false; value = cQValue[l]; if(!value || !value.FeedForward(inputs)) return false;
Анализируем зависимости в ванильном модуле многоголового внимания.
if(!AttentionOut(query, key, value, cScores[l * 3 + 1], cMHSelfAttentionOut[l], -1, iUnits, iHeads, iUnits, iHeads, iWindowKey, false)) return false; self = cSelfAttentionOut[l]; if(!self || !self.FeedForward(cMHSelfAttentionOut[l])) return false;
После чего масштабируем полученные результаты.
Блок кросс-внимания построен аналогичным образом. Только сущности Key и Value генерируются из семантических эмбедингов референсного выражения.
//--- Reference Cross-Attention query = cQuery[l * 3 + 7]; if(!query || !query.FeedForward(inputs)) return false; key = cRefKey[l]; if(!key || !key.FeedForward(reference)) return false; value = cRefValue[l]; if(!value || !value.FeedForward(reference)) return false; if(!AttentionOut(query, key, value, cScores[l * 3 + 2], cMHRefAttentionOut[l], -1, iUnits, iHeads, iUnits, iHeads, iWindowKey, false)) return false; cross = cRefAttentionOut[l]; if(!cross || !cross.FeedForward(cMHRefAttentionOut[l])) return false;
Далее мы осуществляем суммирование результатов всех трех блоков внимания и нормализуем полученные данные.
value = cResidual[l * 3 + 1]; if(!value || !SumAndNormilize(cross.getOutput(), self.getOutput(), value.getOutput(), iWindow, false, 0, 0, 0, 1) || !SumAndNormilize(inputs.getOutput(), value.getOutput(), value.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; inputs = value;
После чего следует блок FeedForward ванильного Transformer с остаточной связью и нормализацией данных.
//--- Feed Forward base = cFeedForward[l * 2]; if(!base || !base.FeedForward(inputs)) return false; base = cFeedForward[l * 2 + 1]; if(!base || !base.FeedForward(cFeedForward[l * 2])) return false; value = cResidual[l * 3 + 2]; if(!value || !SumAndNormilize(inputs.getOutput(), base.getOutput(), value.getOutput(), iWindow, true, 0, 0, 0, 1)) return false; inputs = value;
Думаю вы заметили, что построенный алгоритм прямого прохода является неким симбиозом методов 3D-GRES и MAFT. И нам остается добавить последний штрих от метода MAFT — корректировку позиций запросов.
//--- Delta Query position base = cQPosition[l * 2 + 1]; if(!base || !base.FeedForward(inputs)) return false; value = cQPosition[(l + 1) * 2]; query = cQPosition[l * 2]; if(!value || !SumAndNormilize(query.getOutput(), base.getOutput(), value.getOutput(), iWindow, false, 0, 0, 0,0.5f)) return false; }
После чего переходим к следующему слою Декодера. А по завершению перебора всех внутренних слоев Декодера, мы суммируем обогащенные значения запросов с их позиционным кодированием. Результаты передаем в следующий слой нашей модели посредством базовых интерфейсов.
value = cQPosition[iLayers * 2]; if(!value || !SumAndNormilize(inputs.getOutput(), value.getOutput(), Output, iWindow, true, 0, 0, 0, 1)) return false; //--- return true; }
А здесь нам остается лишь вернуть вызывающей программе логический результат выполнения операций.
На этом мы завершаем работу по построению методов прямого прохода и переходим к реализации алгоритмов обратного прохода. Здесь, как обычно, весь процесс мы разделим на 2 этапа:
- Распределение градиентов ошибки (calcInputGradients);
- Оптимизация параметров модели (updateInputWeights).
В первом случае мы двигаемся по потоку операций прямого прохода, только в обратном порядке. Во втором — мы лишь вызываем одноименные методы внутренних слоев, содержащих обучаемые параметры. На первый взгляд все, как обычно, но есть один нюанс с диверсификацией запросов. Поэтому мы более подробно остановимся на рассмотрении алгоритма метода calcInputGradients, в котором осуществляется распределение градиента ошибки.
В параметрах метода мы получаем указатели уже на 3 объекта и константу функции активации, применяемой для второго источника исходных данных.
bool CNeuronGRES::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient) return false;
В теле метода мы проверяем актуальность только двух указателей. Напомню, что при прямом проходе мы сохранили указатель на второй источник исходных данных. Поэтому отсутствие актуального указателя в параметрах на данном этапе для нас не критично. Однако этого нельзя сказать о буфере для записи градиентов ошибки. Поэтому мы проверяем его актуальность перед началом работы.
Тут же мы объявим ряд переменных для временного хранения указателей на объекты. И на этом завершен наш этап подготовительной работы.
CNeuronBaseOCL *residual = GetPointer(this), *query = NULL, *key = NULL, *value = NULL, *key_sp = NULL, *value_sp = NULL, *base = NULL;
Далее мы организовываем цикл обратного перебора внутренних слоев Декодера.
//--- Inside layers for(int l = (int)iLayers - 1; l >= 0; l--) { //--- Feed Forward base = cFeedForward[l * 2]; if(!base || !base.calcHiddenGradients(cFeedForward[l * 2 + 1])) return false; base = cResidual[l * 3 + 1]; if(!base || !base.calcHiddenGradients(cFeedForward[l * 2])) return false;
Здесь, благодаря корректно спланированной подмене указателей на буфера данных во внутренних объектах, мы пропускаем излишние операции копирования данных и начинаем работу с проведения градиента ошибки через блок FeedForward.
Градиент ошибки, полученный на уровне исходных данных блока FeedForward мы суммируем с аналогичными значениями на уровне результатов нашего класса, что соответствует потоку данных остаточных связей данного блока. Результат операций мы передаем в буфер результатов блока Self-Attention.
//--- Residual value = cSelfAttentionOut[l]; if(!value || !SumAndNormilize(base.getGradient(), residual.getGradient(), value.getGradient(), iWindow, false, 0, 0, 0, 1)) return false; residual = value;
Здесь следует обратить внимание, что на вход блока FeedForward мы подавали сумму результатов трех блоков внимания. И соответственно, нам необходимо передать полученный градиент ошибки от всех источников. Напомню, что при суммировании данных мы передаем градиент ошибки в полном объеме всем слагаемым. Результаты блока QSA мы использовали в качестве источников и для других модулей нашего Декодера. Поэтому его градиент ошибки мы соберем позже, аналогично потокам остаточных связей. А вот для исключения излишнего копирования градиентов ошибки в блок кросс-внимания Query-Reference, мы предусмотрительно организовали подмену указателей при инициализации объектов. Таким образом, при передаче данных в блок Self-Attention мы одновременно передаем те же данные в блок кросс-внимания Query-Reference. Маленькая хитрость позволяет сократить потребление памяти и время обучения модели за счет исключения избыточных операций.
Далее мы пропускаем градиент ошибки через блок кросс-внимания Query-Reference.
//--- Reference Cross-Attention base = cMHRefAttentionOut[l]; if(!base || !base.calcHiddenGradients(cRefAttentionOut[l], NULL)) return false; query = cQuery[l * 3 + 7]; key = cRefKey[l]; value = cRefValue[l]; if(!AttentionInsideGradients(query, key, value, cScores[l * 3 + 2], base, iUnits, iHeads, iUnits, iHeads, iWindowKey)) return false;
И передаем градиент ошибки от сущности Query в модуль QSA, предварительно добавив к нему градиент ошибки, полученный от блока FeedForward (поток остаточных связей).
base = cResidual[l * 3]; if(!base || !base.calcHiddenGradients(query, NULL)) return false; value = cCrossAttentionOut[l]; if(!SumAndNormilize(base.getGradient(), residual.getGradient(),value.getGradient(), iWindow, false, 0, 0, 0, 1)) return false; residual = value;
Аналогичным образом проводим градиент ошибки через блок Self-Attention.
//--- Self-Attention base = cMHSelfAttentionOut[l]; if(!base || !base.calcHiddenGradients(cSelfAttentionOut[l], NULL)) return false; query = cQuery[l * 3 + 6]; key = cQKey[l]; value = cQValue[l]; if(!AttentionInsideGradients(query, key, value, cScores[l * 2 + 1], base, iUnits, iHeads, iUnits, iHeads, iWindowKey)) return false;
Только теперь нам предстоит добавить в модуль QSA градиент ошибки от всех трех сущностей. Для этого мы последовательно передаем градиент ошибки до уровня слоя остаточных связей и прибавляем полученные значения к ранее накопленной сумме градиентов модуля QSA.
base = cResidual[l * 3 + 1]; if(!base.calcHiddenGradients(query, NULL)) return false; if(!SumAndNormilize(base.getGradient(), residual.getGradient(), residual.getGradient(), iWindow, false, 0, 0, 0, 1)) return false; if(!base.calcHiddenGradients(key, NULL)) return false; if(!SumAndNormilize(base.getGradient(), residual.getGradient(), residual.getGradient(), iWindow, false, 0, 0, 0, 1)) return false; if(!base.calcHiddenGradients(value, NULL)) return false; if(!SumAndNormilize(base.getGradient(), residual.getGradient(), residual.getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
Сумму накопленных значений градиента мы так же передадим в параллельный поток информации от позиционного кодирования запросов, сложив его с градиентами из другого информационного потока.
//--- Qeury position base = cQPosition[l * 2]; value = cQPosition[(l + 1) * 2]; if(!base || !SumAndNormilize(value.getGradient(), residual.getGradient(), base.getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
И теперь нам остается провести градиент ошибки через модуль QSA. Здесь мы используем тот же алгоритм распространения градиента ошибки через блок внимания, но делаем поправку на сбор градиентов ошибки сущностей Key и Value с нескольких слоев Декодера. Мы сначала собираем градиенты ошибки во временные буфера данных, а итоговые значения сохраняем в буферах соответствующих объектов.
//--- Cross-Attention base = cMHCrossAttentionOut[l]; if(!base || !base.calcHiddenGradients(residual, NULL)) return false; query = cQuery[l * 3 + 5]; if(((l + 1) % iLayersSP) == 0 || (l + 1) == iLayers) { key_sp = cSPKey[l / iLayersSP]; value_sp = cSPValue[l / iLayersSP]; if(!key_sp || !value_sp || !cTempCrossK.Fill(0) || !cTempCrossV.Fill(0)) return false; } if(!AttentionInsideGradients(query, key_sp, value_sp, cScores[l * 2], base, iUnits, iHeads, iSPUnits, iSPHeads, iWindowKey)) return false; if(iLayersSP > 1) { if((l % iLayersSP) == 0) { if(!SumAndNormilize(key_sp.getGradient(), GetPointer(cTempCrossK), key_sp.getGradient(), iWindowKey, false, 0, 0, 0, 1)) return false; if(!SumAndNormilize(value_sp.getGradient(), GetPointer(cTempCrossV), value_sp.getGradient(), iWindowKey, false, 0, 0, 0, 1)) return false; } else { if(!SumAndNormilize(key_sp.getGradient(), GetPointer(cTempCrossK), GetPointer(cTempCrossK), iWindowKey, false, 0, 0, 0, 1)) return false; if(!SumAndNormilize(value_sp.getGradient(), GetPointer(cTempCrossV), GetPointer(cTempCrossV), iWindowKey, false, 0, 0, 0, 1)) return false; } }
Градиент ошибки от сущности Query мы передаем на уровень исходных данных и добавляем данные по информационному потоку остаточных связей. После чего переходим к следующей итерации цикла обратного перебора слоев Декодера.
if(l == 0) base = cQuery[4]; else base = cResidual[l * 3 - 1]; if(!base || !base.calcHiddenGradients(query, NULL)) return false; //--- Residual if(!SumAndNormilize(base.getGradient(), residual.getGradient(), base.getGradient(), iWindow, false, 0, 0, 0, 1)) return false; residual = base; }
После успешного проведения градиента ошибки через все слои Декодера, нам осталось передать его до уровня исходных данных через операции модуля предварительной обработки данных. Вначале мы спустим градиент ошибки от наших обучаемых запросов. Для этого мы проводим градиент ошибки через слой позиционного кодирования.
//--- Qeury query = cQuery[3]; if(!query || !query.calcHiddenGradients(cQuery[4])) return false;
И на этом этапе мы сделаем инъекцию градиента ошибки позиционного кодирования из соответствующего потока информации.
base = cQPosition[0]; if(!DeActivation(base.getOutput(), base.getGradient(), base.getGradient(), SIGMOID) || !(((CNeuronLearnabledPE*)cQuery[4]).AddPEGradient(base.getGradient()))) return false;
А затем добавим градиент ошибки диверсификации запросов, но здесь мы уже работаем без информации о позиционном кодировании. Такой шаг сделан намеренно, чтобы ошибка диверсификации не повлияла на позиционное кодирование.
if(!DiversityLoss(query, iUnits, iWindow, true)) return false;
И далее следует простой цикл обратного перебора слоев нашей модели генерации запросов с передачей градиента ошибки на уровень исходных данных.
for(int i = 2; i >= 0; i--) { query = cQuery[i]; if(!query || !query.calcHiddenGradients(cQuery[i + 1])) return false; } if(!NeuronOCL.calcHiddenGradients(query, NULL)) return false;
Здесь следует обратить внимание, что на уровень исходных данных нам предстоит передать градиент ошибки и от внутренней модели генерации Superpoints. Чтобы предотвратить потерю данных, мы сохраним указатель на буфер градиентов объекта исходных данных в локальную переменную. И подменим его в объекте исходных данных на соответствующий буфер слоя транспонирования из модели генерации запросов.
Напомню, что слой транспонирования не содержит обучающих параметров, и потеря градиентов ошибки нам не несет рисков.
CBufferFloat *inputs_gr = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(query.getGradient(), false)) return false;
Следующим этапом мы распределим градиент ошибки через модель генерации Superpoints. Однако здесь следует обратить внимание, что в процессе обратного перебора слоев Декодера мы не передали на нее градиент ошибки. Следовательно, нам сначала необходимо собрать градиент ошибки с соответствующих сущностей Key и Value. При этом мы понимаем, что у нас есть как минимум по одному тензору каждой сущности. Но есть еще один момент: сущность Key мы генерировали из результатов последнего слоя модели Superpoints (с учетом позиционного кодирования), а Value — предпоследнего слоя без учета позиционного кодирования. И градиент ошибки нам предстоит распределить именно такими информационными потоками данных.
Для этого мы сначала вычислим градиент ошибки от первого слоя сущности Key и передадим его в последний слой внутренней модели.
//--- Superpoints //--- From Key int total_sp = cSuperPoints.Total(); CNeuronBaseOCL *superpoints = cSuperPoints[total_sp - 1]; if(!superpoints || !superpoints.calcHiddenGradients(cSPKey[0])) return false;
А затем проверим количество слоев сущности Key и, при необходимости, с целью предотвращения потери ранее полученного градиента ошибки, осуществим подмену буферов данных.
if(cSPKey.Total() > 1) { CBufferFloat *grad = superpoints.getGradient(); if(!superpoints.SetGradient(GetPointer(cTempSP), false)) return false;
И организуем цикл перебора оставшихся слоев данной сущности с вычислением градиента ошибки и последующим суммированием с ранее накопленными значениями.
for(int i = 1; i < cSPKey.Total(); i++) { if(!superpoints.calcHiddenGradients(cSPKey[i]) || !SumAndNormilize(superpoints.getGradient(), grad, grad, iWindow, false, 0, 0, 0, 1)) return false; }
После успешного выполнения всех итераций цикла, мы возвращаем указатель на буфер с суммой накопленного градиента ошибки.
if(!superpoints.SetGradient(grad, false)) return false; }
Таким образом, на последнем слое модели Superpoint мы собрали градиент ошибки со всех слоев сущности Key и теперь можем передать его на один уровень ниже указанной модели.
superpoints = cSuperPoints[total_sp - 2]; if(!superpoints || !superpoints.calcHiddenGradients(cSuperPoints[total_sp - 1])) return false;
И теперь на этот же уровень нам необходимо собрать градиент ошибки от сущности Value. Здесь мы воспользуемся тем же алгоритмом. Только в данном случае в буфере градиентов ошибки у нас уже есть данные, полученные от последующего слоя. Поэтому мы сразу организовываем подмену буферов данных, а затем в цикле собираем информацию с параллельных потоков данных.
//--- From Value CBufferFloat *grad = superpoints.getGradient(); if(!superpoints.SetGradient(GetPointer(cTempSP), false)) return false; for(int i = 0; i < cSPValue.Total(); i++) { if(!superpoints.calcHiddenGradients(cSPValue[i]) || !SumAndNormilize(superpoints.getGradient(), grad, grad, iWindow, false, 0, 0, 0, 1)) return false; } if(!superpoints.SetGradient(grad, false)) return false;
Тут же мы добавим ошибки диверсификации, что позволит нам максимально разнообразить Superpoints.
if(!DiversityLoss(superpoints, iSPUnits, iSPWindow, true)) return false;
И далее, в цикле обратного перебора слоев модели Superpoints, мы опустим градиент ошибки до уровня исходных данных.
for(int i = total_sp - 3; i >= 0; i--) { superpoints = cSuperPoints[i]; if(!superpoints || !superpoints.calcHiddenGradients(cSuperPoints[i + 1])) return false; } //--- Inputs if(!NeuronOCL.calcHiddenGradients(cSuperPoints[0])) return false;
Здесь следует напомнить, что часть градиента ошибки на уровне исходных данных мы сохранили после обработки информационного потока запросов. Тогда же мы сделали подмену буферов данных. И сейчас мы суммируем градиент ошибки обоих информационных потоков. А затем вернем указатель на буфер данных.
if(!SumAndNormilize(NeuronOCL.getGradient(), inputs_gr, inputs_gr, 1, false, 0, 0, 0, 1)) return false; if(!NeuronOCL.SetGradient(inputs_gr, false)) return false;
Таким образом мы собрали градиент ошибки от двух информационных потоков для первого источника исходных данных. Но нам еще осталось передать градиент ошибки на второй объект исходных данных. Для этого мы сначала синхронизируем указатели на буфера градиентов ошибки второго объекта исходных данных и первого слоя модели Reference.
base = cReference[0]; if(base.getGradient() != SecondGradient) { if(!base.SetGradient(SecondGradient)) return false; base.SetActivationFunction(SecondActivation); }
Затем на последнем слое указанной модели соберем градиент ошибки от всех тензоров соответствующих сущностей Key и Value. Алгоритм аналогичен рассмотренному выше.
base = cReference[2]; if(!base || !base.calcHiddenGradients(cRefKey[0])) return false; inputs_gr = base.getGradient(); if(!base.SetGradient(GetPointer(cTempQ), false)) return false; if(!base.calcHiddenGradients(cRefValue[0])) return false; if(!SumAndNormilize(base.getGradient(), inputs_gr, inputs_gr, 1, false, 0, 0, 0, 1)) return false; for(uint i = 1; i < iLayers; i++) { if(!base.calcHiddenGradients(cRefKey[i])) return false; if(!SumAndNormilize(base.getGradient(), inputs_gr, inputs_gr, 1, false, 0, 0, 0, 1)) return false; if(!base.calcHiddenGradients(cRefValue[i])) return false; if(!SumAndNormilize(base.getGradient(), inputs_gr, inputs_gr, 1, false, 0, 0, 0, 1)) return false; } if(!base.SetGradient(inputs_gr, false)) return false;
Пропустим градиент ошибки через слой позиционного кодирования.
base = cReference[1]; if(!base.calcHiddenGradients(cReference[2])) return false;
И добавим ошибку диверсификации векторов, чтобы обеспечить максимальное разнообразие семантических компонент.
if(!DiversityLoss(base, iUnits, iWindow, true)) return false;
После чего передаём градиент ошибки на уровень исходных данных.
base = cReference[0]; if(!base.calcHiddenGradients(cReference[1])) return false; //--- return true; }
В завершении работы метода нам остается лишь передать логический результат выполнения операций вызывающей программе.
На этом мы завершаем рассмотрение алгоритмов методов нашего нового класса. А с полным кодом данного класса и всех его методов вы можете самостоятельно ознакомиться во вложении. Там же вы найдете описание архитектуры обучаемых моделей и все программы, используемые при подготовке данной статьи.
Архитектура обучаемых моделей практически полностью перенесена из предыдущих работ. Мы лишь изменили один слой Энкодера описания состояния окружающей среды.
Кроме того, были внесены точечные правки в программы обучения моделей и взаимодействия с окружающей средой, что было вызвано необходимостью передачи второго источника данных в модель Энкодера состояния окружающей среды. Но эти правки являются точечными. Как уже было сказано выше, в качестве уточняющего выражения мы использовали вектор описания состояния счета. Подготовка данного вектора осуществлялась и ранее, так как он использовался нашим Актером.
3. Тестирование
Мы хорошо потрудились и построили с помощью MQL5 некий симбиоз из подходов, предложенных авторами методов 3D-GRES и MAFT. И пришло время оценки проделанной работы. Нам предстоит на реальных исторических данных обучить модель с применением предложенной технологии и протестировать обученную политику Актера.
Для обучения модели мы используем реальные исторические данные инструмента EURUSD за весь 2023 год на таймфрейме H1. Параметры анализируемых индикаторов используются по умолчанию.
В процессе обучения моделей мы используем алгоритм, проверенный в наших предыдущих работах.
Тестирование обученной политики Актера проводится в тестере стратегий MetaTrader 5 на исторических данных Января 2024 года, при этом остальные параметры сохраняются неизменными. Результаты тестирования приведены ниже.
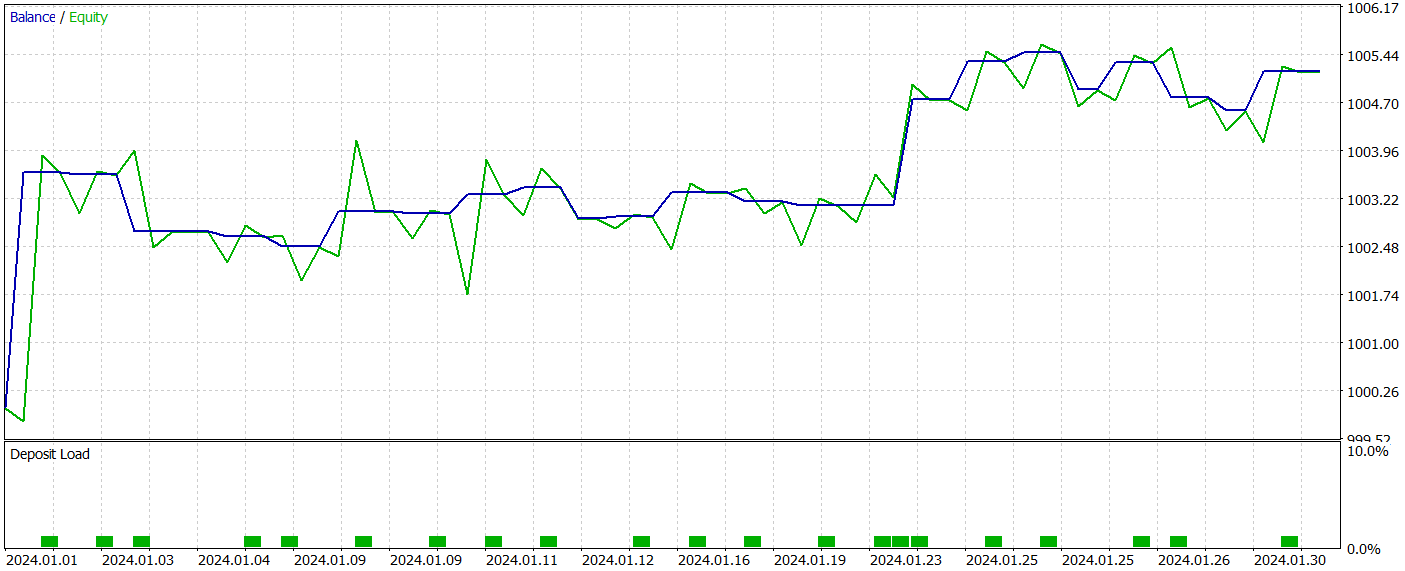
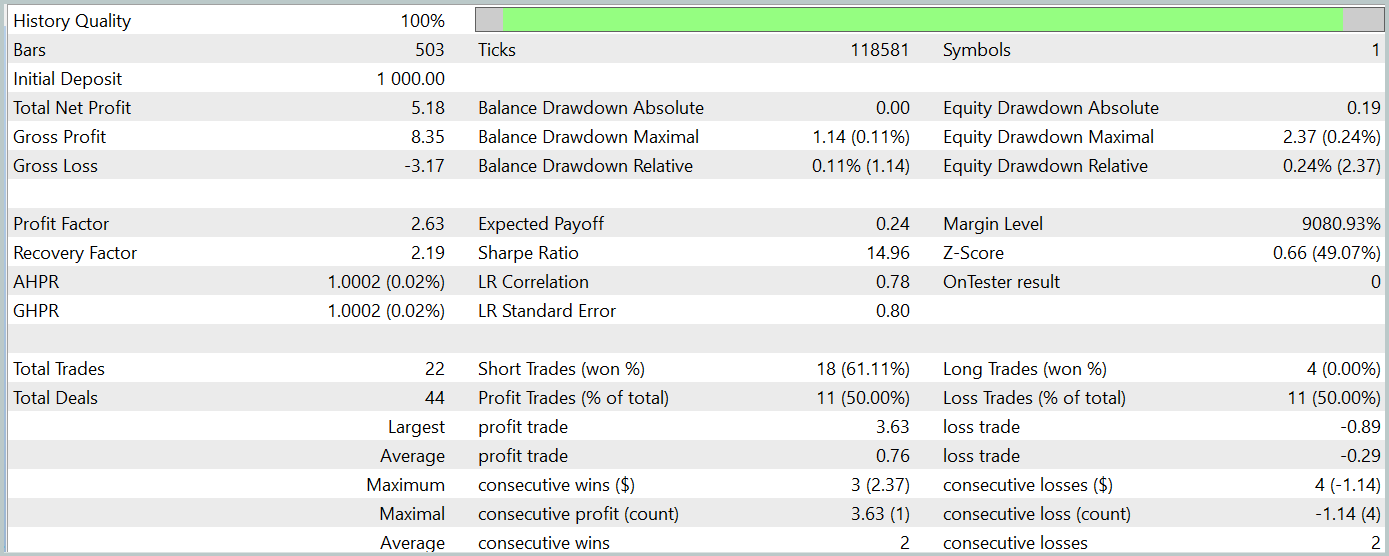
За период тестирования модель совершила 22 сделки, и ровно половина из них была закрыта с прибылью. Примечателен тот факт, что средняя прибыльная сделка более чем в 2 раза превышает среднюю убыточную. А по максимальной прибыльной сделке мы видим четырехкратное превышение. Это позволило модели зафиксировать показатель профит-фактор на уровне 2.63. Однако столь малое количество сделок и короткий период тестирования не позволяют судить об эффективности работы модели на длительном временном отрезке. Перед использованием модели в реальных условиях необходимо её обучение на более длительном временном отрезке исторических данных с последующим всесторонним тестированием.
Заключение
Подходы, предложенные авторами метода Generalized 3D Referring Expression Segmentation (3D-GRES), могут найти свое применение в трейдинге, обеспечивая более глубокий анализ рыночных данных. Предложенный метод может быть адаптирован для сегментации и анализа нескольких рыночных сигналов, что позволит более точно интерпретировать сложные рыночные ситуации, улучшая качество прогнозов и торговых решений.
В практической части данной статьи был приведен один из вариантов реализации предложенных подходов средствами MQL5 и их использования. Проведенные эксперименты демонстрируют потенциал предложенных решений для использования в реальных кейсах.
Ссылки
Программы, используемые в статье| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Особенности написания Пользовательских Индикаторов
Особенности написания Пользовательских Индикаторов

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования