
Нейросети в трейдинге: Иерархическое обучение признаков облака точек

Введение
Геометрическое множество точек представляет собой наборы точек в евклидовом пространстве. Как множество, такие данные должны быть инвариантными к перестановкам его членов. Кроме того, метрика расстояния определяет локальные окрестности, которые могут проявлять различные свойства. Например, плотность и другие атрибуты точек могут быть неоднородными в разных областях.
В предыдущей статье мы познакомились с методом PointNet, основная идея которого заключается в изучении пространственного кодирования каждой точки с последующим агрегированием всех отдельных объектов в глобальную сигнатуру облака точек. PointNet не фиксирует локальную структуру. Однако использование локальной структуры оказалось важным для успеха сверточных архитектур. Сверточные модели принимают исходные данные, определенные в обычных сетках, и способны постепенно захватывать объекты во все более крупных масштабах вдоль иерархии с несколькими разрешениями. На более низких уровнях нейроны имеют меньшие рецептивные поля, тогда как на более высоких уровнях они имеют более крупные рецептивные поля. Возможность абстрагирования локальных шаблонов вдоль иерархии обеспечивает лучшую обобщаемость.
Аналогичный подход был применен в модели PointNet++, которая была представлена в статье "PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space". Общая идея PointNet++ заключается в разделении набора точек на перекрывающиеся локальные области по метрике расстояния в нижележащем пространстве. Подобно сверточным сетям, PointNet++ извлекает локальные особенности, захватывая мелкие геометрические структуры из небольших районов. Такие локальные объекты затем группируются в более крупные элементы и обрабатываются для получения объектов более высокого уровня. Этот процесс повторяется до получения признаков всего набора точек.
При проектировании PointNet++ авторы метода решают две проблемы: разбиение набора точек и абстрагирование наборов точек или локальных признаков с помощью локального изучения функций. Эти две проблемы взаимосвязаны, потому что при разбиении набора точек необходимо создавать общие структуры между разделами для совместного использовать весов обучаемых локальных признаков подобно сверточным моделям. Авторы метода выбрали в качестве локального обучающего устройства PointNet, который является эффективной архитектурой для обработки неупорядоченного набора точек и извлечения семантических признаков. Кроме того, эта архитектура устойчива к повреждению исходных данных. В качестве основного строительного блока PointNet абстрагирует наборы локальных точек или объектов в представления более высокого уровня. В этом представлении PointNet++ применяет PointNet рекурсивно к вложенному секционированию исходных данных.
Одна из проблем, которая все еще остается, заключается в методе создания перекрывающихся разбиений облака точек. Каждая область определяется как шар окрестности в евклидовом пространстве, параметры которого включают местоположение центроида и масштаб. Чтобы равномерно охватить весь набор, центроиды выбираются среди исходных точек, заданных по алгоритму выборки самых дальних из них. По сравнению с объемными сверточными моделями, которые сканируют пространство фиксированными шагами, локальные рецептивные поля PointNet++ зависят как от исходных данных, так и от метрики. Что повышает их эффективность.
1. Алгоритм PointNet++
В архитектуре PointNet используется только одна операция MaxPooling для агрегирования всего набора точек. Авторы PointNet++ выстраивают иерархическую архитектуру группировки точек с постепенным абстрагированием локальных областей вдоль иерархии.
Предложенная иерархическая структура состоит из ряда заданных уровней абстракции. На каждом уровне облако точек обрабатывается и абстрагируется для создания нового набора данных с меньшим количеством элементов. Заданный уровень абстракции состоит из трех ключевых слоев: слой Выборки, слой Группировки и слой PointNet. Слой Выборки выбирает набор точек из исходного облака точек, который определяет центроиды локальных областей. Затем Группирующий слой создает локальные наборы точек, находя «соседние» объекты вокруг центроидов. Слой PointNet использует мини-PointNet для кодирования шаблонов локальных регионов в векторы признаков.
Уровень абстракции принимает матрицу N×(d+C) в качестве исходных данных, которые содержат N точек с d размерностью координат и C размерностью признаков. И возвращает матрицу N′×(d+C′), где N′ субдискретизированные точки с C′ размерностью нового вектора признаков, обобщающего локальный контекст.
Авторы PointNet++ предлагают использовать итерационную выборку самых дальних точек для выбора подмножества точек центроидов. По сравнению со случайной выборкой, такой подход имеет лучший охват всего набора точек при одинаковом количестве центроидов. В отличие от сверточных сетей, которые сканируют векторное пространство, не зависящее от распределения данных, предложенная стратегия выборки генерирует рецептивные поля в зависимости от исходных данных.
Исходными данными для слоя Группировки является облако точек размера N×(d+C) и координаты множества центроидов размера N′×d. На выходе получаются группы наборов точек по размеру N′×K×(d+C), где каждая группа соответствует локальной области и K — количество точек в окрестности центроида.
Обратите внимание, что K варьируется от группы к группе, но последующий слой PointNet способен преобразовывать гибкое количество точек в вектор объектов локального региона фиксированной длины.
В сверточных нейронных сетях локальная область пикселя состоит из пикселей с индексами массива в пределах определенного Манхеттенского расстояния (размера ядра) от пикселя. В облаке точек, выбранном из метрического пространства, окрестности точки определяются метрическим расстоянием.
В процессе группировки модель находит все точки, которые находятся в радиусе от запрашиваемой точки (верхний предел K задается в гиперпараметрах).
В слое PointNet исходными данными являются N′ локальных областей точек с размером данных N′×K×(d+C). Каждая локальная область на выходе абстрагируется своим центроидом и локальным объектом, который кодирует окрестности центроида. Размер тензора результатов равен N′×(d+C).
Координаты точек в локальной области сначала переводятся в локальную систему координат относительно точки центроида:
![]()
для i = 1, 2,…, K и j = 1, 2,…, d, где ![]() — координата центроида.
— координата центроида.
Авторы метода используем PointNet в качестве основного строительного блока для локального обучения шаблонам. Использование относительных координат вместе с точечными объектами позволяет зафиксировать отношения между точками в локальном регионе.
Часто бывает так, что набор точек имеет неравномерную плотность в разных областях. Такая неоднородность создает значительную проблему для изучения признаков точечного набора. Признаки, изученные в плотных данных, могут не распространяться на регионы с разреженной выборкой. Следовательно, модели, обученные для разреженного облака точек, могут не распознавать мелкозернистые локальные структуры.
В идеале необходимо как можно точнее изучить облако точек, чтобы зафиксировать мельчайшие детали в областях с плотной выборкой. Однако такой тщательный осмотр не эффективен в областях с низкой плотностью точек, поскольку локальные закономерности могут быть искажены недостатком значений. В этом случае нужно искать более масштабные модели в большей окрестности. Для достижения поставленной цели авторы PointNet++ предлагают адаптивные по плотности слои PointNet, которые обучаются объединять объекты из регионов разных масштабов при изменении плотности исходной выборки.
В PointNet++ каждый уровень абстракции извлекает несколько масштабов локальных шаблонов и интеллектуально комбинирует их в соответствии с плотностью локальных точек. В авторской статье представлено два типа слоев, адаптивных к плотности.
Простым, но эффективным способом захвата многомасштабных шаблонов является применение группирующих слоев с различными масштабами с последующим присвоением соответствующих PointNets для извлечения особенностей каждого масштаба. Объекты в разных масштабах объединяются в многомасштабный объект.
При этом обучаем сеть для изучения оптимизированной стратегии объединения многомасштабных функций. Это делается путем случайного отбрасывания исходных точек со случайной вероятностью для каждого экземпляра.
Описанный выше подход требует больших вычислительных ресурсов, поскольку он запускает локальную PointNet в крупномасштабных окрестностях для каждой точки центроида. Альтернативный подход, который позволяет избежать столь дорогостоящих вычислений, но при этом сохраняет возможность адаптивной агрегации информации в соответствии с распределительными свойствами точек, представляет собой конкатенацию двух векторов. Один вектор получается путем суммирования объектов в каждой подобласти с нижнего уровня Li-1 с использованием заданного уровня абстракции. Другой вектор — это признак, который получается путем прямой обработки всех исходных точек в локальном регионе с помощью одного PointNet.
При низкой плотности локальной области первый вектор может быть менее надежным, чем второй, так как подобласть при вычислении первого вектора содержит еще более разреженные точки и больше страдает от недостатка выборки. В таком случае второй вектор должен иметь больший вес. С другой стороны, когда плотность локальной области высока, первый вектор предоставляет информацию с более мелкими деталями, поскольку он обладает способностью рекурсивно проверять с более высоким разрешением на более низких уровнях.
Такой метод более эффективен с точки зрения вычислений, поскольку избегает извлечения признаков в крупномасштабных окрестностях на самых низких уровнях.
В слое абстракции исходный набор точек подвергается субдискретизации. Однако в задаче сегментации, такой как семантическая маркировка точек, желательно получить точечные признаки для всех исходных точек. Одним из решений является постоянная выборка всех точек в виде центроидов на всех заданных уровнях абстракции, что, однако, приводит к высокой стоимости вычислений. Другой способ заключается в распространении объектов из субдискретизированных точек в исходные.
Авторская визуализация метода PointNet++ представлена ниже.
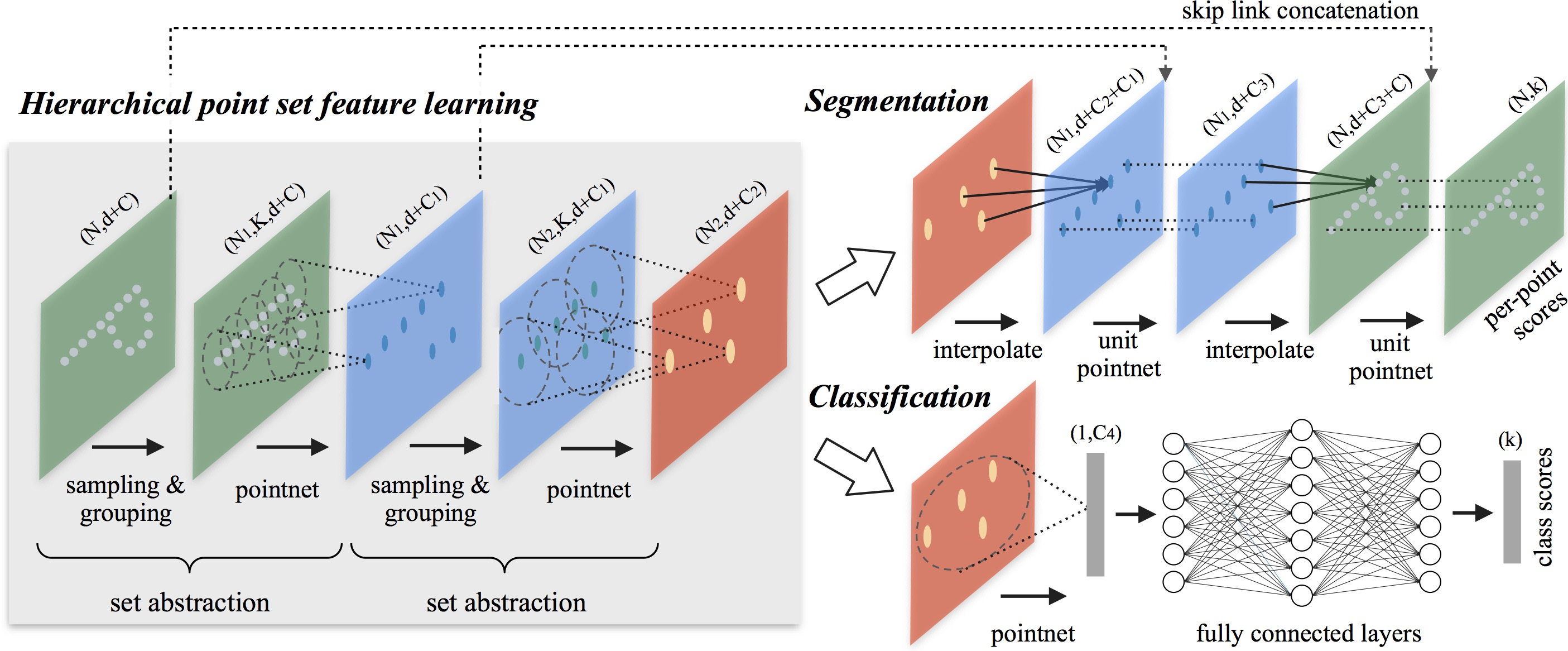
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода PointNet++ мы переходим к практической части нашей статьи, в которой реализуем свое видение предложенных подходов средствами MQL5. И надо сказать, что наша реализация имеет некоторые отличия от описанной выше авторской версии. Но обо всем по порядку.
Свою работу мы разделим на 2 блока. Вначале создадим слой локальной субдискретизации данных, который объединит описанные выше слои Выборки и Группировки. А затем построим класс верхнего уровня, который соберет отдельные блоки в единый алгоритм PointNet++.
2.1 Дополнение OpenCL-программы
Алгоритм локальной субдискретизации мы реализуем в классе CNeuronPointNet2Local. Но прежде чем начать над ним работу, нам ещё предстоит дополнить функционал нашей OpenCL программы.
Для начала мы создадим кернел CalcDistance, в котором определим расстояние между точками анализируемого облака.
Здесь стоит отметить, что расстояние мы будем определять в многомерном пространстве признаков описания точки. И результатом работы кернела будет матрица N×N с нулевыми значениями по диагонали.
В параметрах кернела мы получаем указатели на 2 буфера данных (исходных данных и для записи результатов) и 1 константу, которая укажет размерность вектора признаков точки.
__kernel void CalcDistance(__global const float *data, __global float *distance, const int dimension ) { const size_t main = get_global_id(0); const size_t slave = get_local_id(1); const int total = (int)get_local_size(1);
А в теле кернела мы идентифицируем поток в пространстве задач.
На выходе мы ожидаем получить квадратную матрицу. Поэтому создадим двухмерное пространство задач соответствующего размера. Таким образом, в каждом отдельном потоке мы вычислим значение одного элемента матрицы результатов.
Надо сказать, что здесь будет первое отступление от авторского алгоритма. Мы не будем итерационно определять центроиды локальных областей. В нашей реализации каждая точка облака выступит в качестве центроида локальной области. А для реализации адаптивности размеров областей, мы нормализуем расстояния до каждой точки облака. Для выполнения нормализации расстояний нам потребуется обмен данными между отдельными потоками. И с этой целью мы создадим локальные рабочие группы в разрезе строк матрицы результатов работы кернела.
Для обмена данными в рамках рабочей группы мы создадим локальный массив.
__local float Temp[LOCAL_ARRAY_SIZE]; int ls = min((int)total, (int)LOCAL_ARRAY_SIZE);
И определим константы смещения до необходимых элементов в буферах данных.
const int shift_main = main * dimension; const int shift_slave = slave * dimension; const int shift_dist = main * total + slave;
После чего создадим цикл вычисления расстояния между двумя объектами в многомерном пространстве.
//--- calc distance float dist = 0; if(main != slave) { for(int d = 0; d < dimension; d++) dist += pow(data[shift_main + d] - data[shift_slave + d], 2.0f); }
Обратите внимание, что вычисления осуществляется только для недиагональных элементов. Ведь расстояние от точки до самой себя равно "0". И мы не расходуем ресурсы на излишние вычисления.
Следующим этапом мы определим максимальное расстояние в рамках рабочей группы. Вначале соберем максимальные значения отдельных блоков в локальный массив.
//--- Look Max for(int i = 0; i < total; i += ls) { if(!isinf(dist) && !isnan(dist)) { if(i <= slave && (i + ls) > slave) Temp[slave - i] = max((i == 0 ? 0 : Temp[slave - i]), dist); } else if(i == 0) Temp[slave] = 0; barrier(CLK_LOCAL_MEM_FENCE); }
А затем найдем максимальное значение в массиве.
int count = ls; do { count = (count + 1) / 2; if(slave < count && (slave + count) < ls) { if(Temp[slave] < Temp[slave + count]) Temp[slave] = Temp[slave + count]; Temp[slave + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
После нахождения максимального значения до анализируемой точки мы разделим вычисленные выше расстояния на него. В результате все расстояния между точками будут нормализованы в диапазоне [0, 1].
//--- Normalize if(Temp[0] > 0) dist /= Temp[0]; if(isinf(dist) || isnan(dist)) dist = 1; //--- result distance[shift_dist] = dist; }
И сохраним полученное значение в соответствующий элемент глобального буфера результатов.
Конечно мы понимаем, что максимальное расстояние в рамках анализа 2 отдельных точек, скорее всего, будет разное. А нормализуя значения в рамках отдельных масштабов мы теряем эту разницу. Но в этом и заключается элемент адаптации рецептивных полей.
Если анализируемая точка находится внутри облака значений, то вполне очевидно, что максимально удаленная от нее точка находится на одном из краев облака. С другой стороны, если анализируемая точка находится на краю облака, то максимально удаленная от нее точка находится на противоположном краю облака. И во втором случае расстояние между точками будет больше. Следовательно, и рецептивное поле во втором случае будет больше.
Но мы так же ожидаем, что внутри облака плотность точек будет выше, чем на краях. И в таком случае становится вполне оправданным увеличение рецептивных полей на окраинах анализируемого облака точек.
Далее авторы метода PointNet++ предлагают вычислять локальные смещения точек от соответствующего центроида и затем приметь мини-PointNet к таким локальным подвыборкам данных. Но за видимой простотой действий кроется довольно серьезная проблема реализации.
Как было отмечено выше, количество элементов в каждой локальной области разное и заранее не известно. Здесь возникает вопрос с размерами выделяемых буферов данных. Конечно, мы можем ограничить максимальное количество точек в рецептивном поле и объявить размер буфера "с запасом". Но это ведет к увеличению потребления памяти и повышению вычислительной сложности всей модели. Как следствие — сложность обучения и низкая производительность модели.
Вместо этого мы применили более простой и универсальный подход. Мы отказались от вычисления локальных смещений. А для обучения признаков точек используем одну матрицу весовых параметров для всех элементов, аналогично ванильному PointNet. А вот операцию MaxPooling осуществим в рамках рецептивных полей. Для этого мы создадим новый кернел FeedForwardLocalMax, в параметрах которого передадим указатели на 3 буфера данных: признаков точек, нормализованной дистанции между точками и буфер результатов. Так же мы добавим константу радиуса рецептивного поля.
__kernel void FeedForwardLocalMax(__global const float *matrix_i, __global const float *distance, __global float *matrix_o, const float radius ) { const size_t i = get_global_id(0); const size_t total = get_global_size(0); const size_t d = get_global_id(1); const size_t dimension = get_global_size(1);
Запуск данного кернела мы планируем в двухмерном пространстве задач. По первому измерению мы укажем количество элементов в облаке точек, а во втором — размерность признаков одного элемента. В теле кернела мы сразу идентифицируем текущий поток в обоих измерениях пространства задач. В данном случае каждый поток работает независимо от остальных и нам нет необходимости создавать рабочие группы и обмениваться данными между потоками.
Далее мы определим константы смещения в буферах данных.
const int shift_dist = i * total; const int shift_out = i * dimension + d;
А затем организуем цикл определения максимального значения.
float result = -3.402823466e+38; for(int k = 0; k < total; k++) { if(distance[shift_dist + k] > radius) continue; int shift = k * dimension + d; result = max(result, matrix_i[shift]); } matrix_o[shift_out] = result; }
Обратите внимание, что перед проверкой значения следующего элемента мы в обязательном порядке сначала проверяем его попадание в рецептивное поле соответствующего элемента облака точек.
После завершения итераций цикла мы сохраняем полученное значение в буфере результатов.
Аналогичным образом мы создаем кернел обратного прохода CalcInputGradientLocalMax для распределения градиента ошибки на соответствующие элементы. Алгоритмы кернелов прямого и обратного проходов имеют много общего. И я предлагаю Вам ознакомиться с ним самостоятельно. Полный код всех кернелов Вы можете найти во вложении. А мы переходим к работе над основной программой.
2.2 Класс локальной субдискретизации
Мы провели подготовительную работу на стороне OpenCL-программы и теперь переходим к работе над классом локальной субдискретизации. В ходе реализации кернелов OpenCL-программы мы уже частично начали обсуждение принципов построения алгоритмов. А в процессе реализации методов класса CNeuronPointNet2Local мы познакомимся с ними более детально и посмотрим на их реализацию в коде. Структура нового класса представлена ниже.
class CNeuronPointNet2Local : public CNeuronConvOCL { protected: float fRadius; uint iUnits; //--- CBufferFloat cDistance; CNeuronConvOCL cFeatureNet[3]; CNeuronBatchNormOCL cFeatureNetNorm[3]; CNeuronBaseOCL cLocalMaxPool; CNeuronConvOCL cFinalMLP; //--- virtual bool CalcDistance(CNeuronBaseOCL *NeuronOCL); virtual bool LocalMaxPool(void); virtual bool LocalMaxPoolGrad(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPointNet2Local(void) {}; ~CNeuronPointNet2Local(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint window_out, float radius, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronPointNet2LocalOCL; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В выше представленной структуре можно заметить несколько объектов внутренних нейронных слоев и 2 переменные, с назначением которых мы познакомимся в процессе реализации методов класса.
Здесь мы также видим уже знакомый нам набор переопределяемых методов. Кроме того есть 3 метода, созвучные с созданными выше кернелами:
- CalcDistance(CNeuronBaseOCL *NeuronOCL);
- LocalMaxPool(void);
- LocalMaxPoolGrad(void).
Как Вы уже догадались, это методы постановки кернелов в очередь выполнения. Алгоритм нами уже изученный и мы не будем на нем детально останавливаться в рамках данной статьи.
Так же хочется обратить внимание, что наследуемся мы от класса сверточного слоя CNeuronConvOCL. Ситуация в нашей практике не частая и связана с независимой обработкой признаков локальных групп.
Все внутренние объекты класса объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор класса. Инициализация нового экземпляра объекта осуществляется в методе Init.
bool CNeuronPointNet2Local::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint window_out, float radius, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, 128, 128, window_out, units_count, 1, optimization_type, batch)) return false;
В параметрах метода мы получаем основные константы, определяющие архитектуру объекта. Все они созвучны с аналогичными параметрами сверточного слоя. Добавляется лишь один параметр — radius, который определяет радиус рецептивного окна элемента.
В теле метода мы сразу вызываем одноименный метод родительского класса, в котором уже реализован необходимый контроль полученных данных и инициализация унаследованных объектов. И здесь стоит обратить внимание, что передаваемые значения в метод родительского класса немного отличаются от полученных нами из внешней программы. Это связано с особенностями использования объектов родительского класса, о чем мы еще поговорим в процессе реализации метода прямого прохода feedForward.
После успешного выполнения операций метода родительского класса мы сохраним часть полученных констант, другие были сохранены в рамках выполнения операций родительского класса.
fRadius = MathMax(0.1f, radius); iUnits = units_count;
Далее мы переходим к инициализации внутренних объектов. Первым мы создаем буфер записи дистанций между объектами анализируемого облака точек. Как было сказано выше, это квадратная матрица.
cDistance.BufferFree(); if(!cDistance.BufferInit(iUnits * iUnits, 0) || !cDistance.BufferCreate(OpenCL)) return false;
Для извлечения признаков точек мы создадим блок из 3 сверточных слоев и 3 слоев пакетной нормализации, по аналогии с блоком извлечения признаков алгоритма PointNet. Мы не создаем блок проекции исходных данных, так как предполагаем её наличие в классе верхнего уровня.
if(!cFeatureNet[0].Init(0, 0, OpenCL, window, window, 64, iUnits, 1, optimization, iBatch)) return false; if(!cFeatureNetNorm[0].Init(0, 1, OpenCL, 64 * iUnits, iBatch, optimization)) return false; cFeatureNetNorm[0].SetActivationFunction(LReLU); if(!cFeatureNet[1].Init(0, 2, OpenCL, 64, 64, 128, iUnits, 1, optimization, iBatch)) return false; if(!cFeatureNetNorm[1].Init(0, 3, OpenCL, 128 * iUnits, iBatch, optimization)) return false; cFeatureNetNorm[1].SetActivationFunction(LReLU); if(!cFeatureNet[2].Init(0, 4, OpenCL, 128, 128, 256, iUnits, 1, optimization, iBatch)) return false; if(!cFeatureNetNorm[2].Init(0, 5, OpenCL, 256 * iUnits, iBatch, optimization)) cFeatureNetNorm[2].SetActivationFunction(None);
Тут же мы создадим слой для записи результатов локального MaxPooling.
if(!cLocalMaxPool.Init(0, 6, OpenCL, cFeatureNetNorm[2].Neurons(), optimization, iBatch)) return false;
И добавим один слой результирующего MLP.
if(!cFinalMLP.Init(0, 7, OpenCL, 256, 256, 128, iUnits, 1, optimization, iBatch)) return false; cFinalMLP.SetActivationFunction(LReLU);
В качестве второго слоя мы планируем использовать унаследованный функционал.
Обратите внимание, что, в отличие от ванильного PointNet, на выходе мы так же используем сверточные слои. Это связано с независимой обработкой дескрипторов локальных областей.
В завершении операций метода инициализации мы явно укажем отсутствие функции активации нашего класса и вернем вызывающей программе логический результат выполнения операций.
SetActivationFunction(None); return true; }
После завершения работы по инициализации нового объекта мы переходим к построению алгоритмов прямого прохода в методе feedForward. В параметрах данного метода мы получаем указатель на объект исходных данных.
bool CNeuronPointNet2Local::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CalcDistance(NeuronOCL)) return false;
Как уже было сказано выше, в рамках данного класса мы не планируем осуществлять проекцию данных в каноническое пространство. Предполагается, что в случае необходимости данная операция будет выполнена на верхнем уровне. Поэтому мы сразу осуществляем вычисления расстояния между элементами исходных данных.
Далее мы организуем цикл вычисления признаков анализируемых элементов.
CNeuronBaseOCL *temp = NeuronOCL; uint total = cFeatureNet.Size(); for(uint i = 0; i < total; i++) { if(!cFeatureNet[i].FeedForward(temp)) return false; if(!cFeatureNetNorm[i].FeedForward(cFeatureNet[i].AsObject())) return false; temp = cFeatureNetNorm[i].AsObject(); }
И проведем операции MaxPooling для локальных областей точек.
if(!LocalMaxPool()) return false;
В завершении операций метода мы применим независимый двухслойный MLP к дескрипторам всех локальных областей.
if(!cFinalMLP.FeedForward(cLocalMaxPool.AsObject())) return false; if(!CNeuronConvOCL::feedForward(cFinalMLP.AsObject())) return false; //--- return true; }
В качестве первого слоя MLP мы используем внутренний слой cFinalMLP. А операции второго слоя выполняются за счет унаследованного от родительского класса функционала.
Не забываем на каждом этапе контролировать процесс выполнения операций. И после успешного завершения всех операций вернем логический результат их выполнения вызывающей программе.
Алгоритмы обратного прохода реализованы в методах calcInputGradients и updateInputWeights. В рамках первого метода осуществляется распределение градиента ошибки до всех элементов в соответствии с их влиянием на конечный результат. Его алгоритм построен в полном соответствии с рассмотренным методом прямого прохода, но поток операций осуществляется в обратном порядке. Во втором методе осуществляется обновление обучаемых параметров модели. Здесь мы лишь вызываем одноименный методы внутренних объектов, содержащих обучаемые параметры. Алгоритмы обоих методов просты для понимания. И я предлагаю оставить их для самостоятельного изучения. Напомню, что полный код данного класса и всех его методов Вы найдете во вложении.
2.3 Собираем алгоритм PointNet++
Мы уже выполнили много работы. И теперь выходим на "финишную прямую" нашей реализации. На данном этапе мы соберем разрозненные "кирпичики" в единый алгоритм PointNet++. И осуществим мы эту работу в рамках класса CNeuronPointNet2OCL, структура которого представлена ниже.
class CNeuronPointNet2OCL : public CNeuronPointNetOCL { protected: CNeuronPointNetOCL *cTNetG; CNeuronBaseOCL *cTurnedG; //--- CNeuronPointNet2Local caLocalPointNet[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPointNet2OCL(void) {}; ~CNeuronPointNet2OCL(void) ; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronPointNet2OCL; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Как это не покажется странным, но в данном классе мы объявляем лишь 2 статических объекта локальной дискретизации данных и 2 динамических объекта, которые будут инициализированные в случае необходимости проекции данных в каноническое пространство. Такая внешняя простота достигается благодаря наследованию от класса ванильного PointNet, в рамках которого уже реализована большая часть функционала.
Как уже было сказано выше, динамические объекты инициализируются только в случае необходимости. Поэтому конструктор класса мы оставим пустым, а вот в деструкторе проверим наличие актуальных указателей на динамические объекты и удалим их при необходимости.
CNeuronPointNet2OCL::~CNeuronPointNet2OCL(void) { if(!!cTNetG) delete cTNetG; if(!!cTurnedG) delete cTurnedG; }
Инициализация объекта класса, как обычно, осуществляется в методе Init. В параметрах метода мы получаем основные константы, определяющие архитектуры класса. И здесь мы их полностью сохранили от родительского класса.
bool CNeuronPointNet2OCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronPointNetOCL::Init(numOutputs, myIndex, open_cl, 64, units_count, output, use_tnets, optimization_type, batch)) return false;
В теле метода мы сразу вызываем аналогичный метод родительского класса. После чего проверяем необходимость создания объектов проекции исходных данных в каноническое пространство.
//--- Init T-Nets if(use_tnets) { if(!cTNetG) { cTNetG = new CNeuronPointNetOCL(); if(!cTNetG) return false; } if(!cTNetG.Init(0, 0, OpenCL, window, units_count, window * window, false, optimization, iBatch)) return false;
Здесь, при необходимости, мы сначала создаем необходимые объекты, а потом их инициализируем.
if(!cTurnedG) { cTurnedG = new CNeuronBaseOCL(); if(!cTurned1) return false; } if(!cTurnedG.Init(0, 1, OpenCL, window * units_count, optimization, iBatch)) return false; }
Если пользователь не указал необходимость создания объектов проекции, то мы проверяем наличие актуальных указателей на объекты. И в случае их наличия, удаляем излишние объекты.
else { if(!!cTNetG) delete cTNetG; if(!!cTurnedG) delete cTurnedG; }
Затем мы инициализируем 2 объекта локальной дискретизации данных с различными радиусами рецептивного окна. И завершаем работу метода.
if(!caLocalPointNet[0].Init(0, 0, OpenCL, window, units_count, 64, 0.2f, optimization, iBatch)) return false; if(!caLocalPointNet[1].Init(0, 0, OpenCL, 64, units_count, 64, 0.4f, optimization, iBatch)) return false; //--- return true; }
Обратите внимание, что мы начинаем с малого рецептивного окна с последующим увеличением. При этом мы не увеличиваем рецептивное окно до полного охвата, так как это выполняется функционалом, унаследованным от класса ванильного PointNet.
После завершения работы с методом инициализации объекта класса мы переходим к построению алгоритма прямого прохода в методе feedForward.
bool CNeuronPointNet2OCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- LocalNet if(!cTNetG) { if(!caLocalPointNet[0].FeedForward(NeuronOCL)) return false; }
В параметрах метода мы получаем указатель на объект исходных данных. А в теле метода мы первым делом проверяем необходимость проекции исходных данных в каноническое пространство. Алгоритм действий здесь аналогичен построенному нами при реализации метода класса ванильного PointNet. Если проекция данных не требуется, то мы сразу передаем полученный указатель в метод прямого прохода первого слоя локальной дискретизации данных.
В противном случае мы сначала генерируем матрицу проекции данных.
else { if(!cTurnedG) return false; if(!cTNetG.FeedForward(NeuronOCL)) return false;
После чего выполняется проекция исходных данных путем их умножения на матрицу проекции.
int window = (int)MathSqrt(cTNetG.Neurons()); if(IsStopped() || !MatMul(NeuronOCL.getOutput(), cTNetG.getOutput(), cTurnedG.getOutput(), NeuronOCL.Neurons() / window, window, window)) return false;
И лишь затем передаем полученные значения в метод прямого прохода слоя дискредитации данных.
if(!caLocalPointNet[0].FeedForward(cTurnedG.AsObject())) return false; }
Далее мы осуществляем дискредитацию с большим размером рецептивного окна.
if(!caLocalPointNet[1].FeedForward(caLocalPointNet[0].AsObject())) return false;
И на последнем этапе передаем обогащенные данные в метод прямого прохода родительского класса, где определяется дескриптор анализируемого облака точек в целом.
if(!CNeuronPointNetOCL::feedForward(caLocalPointNet[1].AsObject())) return false; //--- return true; }
Как можно заметить, благодаря довольно сложной структуре наследований нам удалось построить лаконичный метод прямого прохода нашего нового класса. Такие же краткие алгоритмы и у методов обратного прохода, с которыми я предлагаю Вам ознакомиться самостоятельно во вложении. Напомню, что полный код вех классов и их модулей, используемых при подготовке данной статьи Вы можете найти во вложении. Там приведен и полный код программ обучения моделей и взаимодействия с окружающей средой. Тут стоит сказать, что последние перенесены полностью из предыдущей статьи без каких-либо корректировок. Более того, мы практически сохранили архитектуру моделей. На самом деле, в архитектуре Энкодера состояния окружающей среды мы лишь изменили тип одного слоя с полным сохранением прочих параметров.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPointNet2OCL; descr.window = BarDescr; // Variables descr.count = HistoryBars; // Units descr.window_out = LatentCount; // Output Dimension descr.step = int(true); // Use input and feature transformation descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И тем интереснее посмотреть на результаты обучения новой политики Актера.
3. Тестирование
Вот мы и завершили реализация своего видения подходов, предложенных авторами метода PointNet++. И теперь пришло время оценить эффективность нашей реализации на реальных исторических данных. Как и ранее, обучать модели мы будем на исторических данных инструмента EURUSD за весь 2023 год. Таймфрейм H1, параметры всех индикаторов используются по умолчанию. Тестирование обученной модели осуществляется в тестере стратегий MetaTrader 5.
Как уже было сказано выше наша новая модель отличается от предыдущей лишь 1 слоем. Более того, наш новый слой является лишь усовершенствованным вариантом предыдущей работы. И тем интереснее сравнить результаты работы двух моделей. А чтобы сравнение было как можно более честным, обучение моделей мы проведем с полным сохранением обучающей выборки из прошлой работы.
Да, я всегда говорю, что для лучших результатов обучения моделей необходимо периодически обновлять обучающую выборку. Только тогда обучающая выборка будет соответствовать актуальной политики Актера, что позволит получить более точную оценку его действий и скорректировать политику. Но в данном случае, я не могу отказаться от соблазна сравнить 2 похожих метода и оценить эффективность иерархического подхода. В прошлой статье нам удалось на этой обучающей выборке обучить политику Актера, способную генерировать прибыль. И мы ожидаем для новой модели получить результат не хуже.
В результате обучения новая модель смогла выучить политику, способную генерировать прибыль как на обучающей, так и на тестовой выборках. Результаты тестирования новой модели представлены ниже.
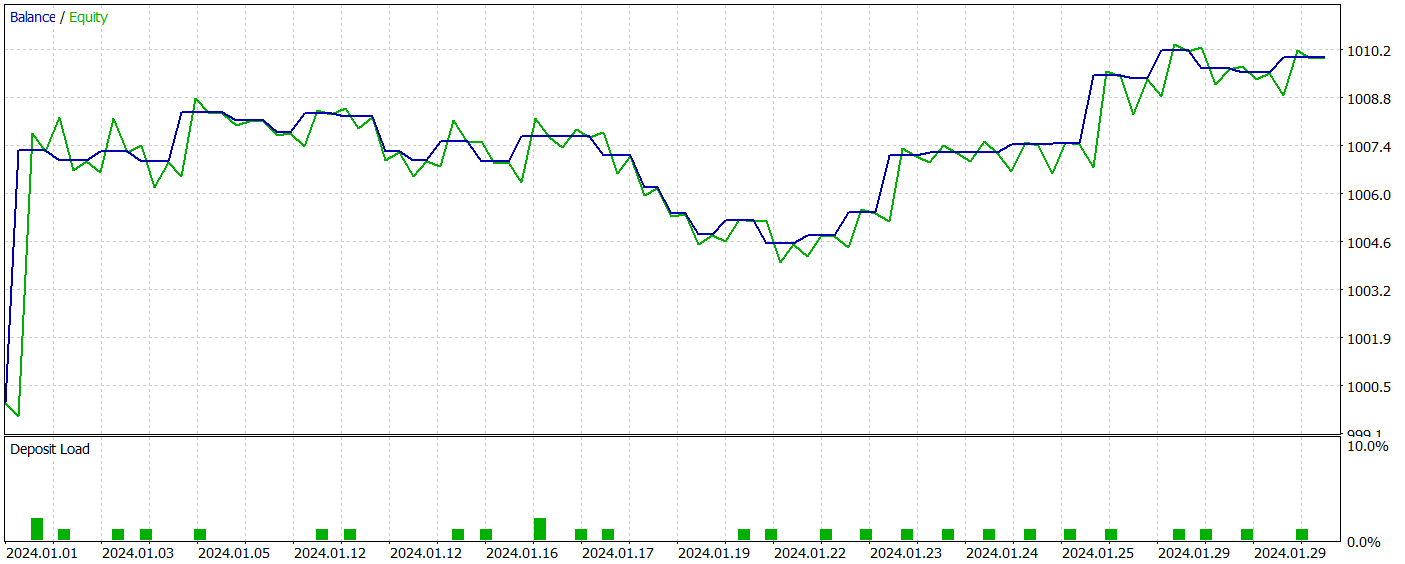
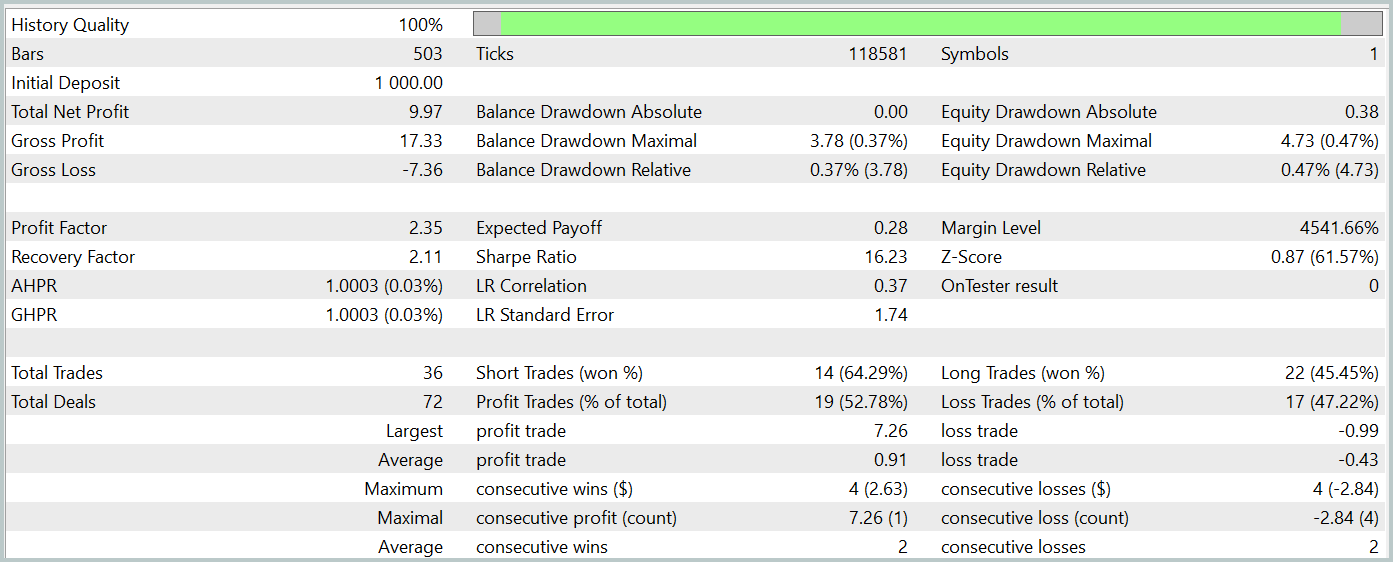
Должен сказать, что довольно сложно сравнивать результаты работы двух моделей. За период тестирования обе модели сгенерировали примерно одинаковую прибыль. Отклонения в просадке как по балансу, так и по эквити на уровне погрешности. Правда новая модель совершила меньше сделок и подросло значение профит-фактора.
Однако малое количество сделок, которые совершили обе модели, не позволяет сделать выводы об эффективности работы моделей на более длительном временном отрезке.
Заключение
Использование метода PointNet++ позволяет эффективно анализировать локальные и глобальные паттерны в сложных финансовых данных, учитывая их многомерную структуру. Усовершенствованный подход к обработке точечных данных повышает точность прогнозирования и стабильность торговых стратегий, что может привести к более информированным и успешным решениям на динамичных рынках.
В практической части статьи мы реализовали свое видение подходов, предложенных авторами метода PointNet++. И надо сказать, что в ходе тестирования модель смогла сгенерировать прибыль на тестовой выборке. Однако представленные программы носят исключительно демонстрационный характер и предназначены для иллюстрации работы метода.
СсылкиПрограммы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Особенности написания Пользовательских Индикаторов
Особенности написания Пользовательских Индикаторов

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования