Нейросети в трейдинге: Transformer для облака точек (Pointformer)

Введение
Обнаружение объектов в облаках точек имеет важное значение для многих реальных приложений. По сравнению с изображениями, облака точек могут обеспечить детализированную геометрию и захватить структуру сцены. С другой стороны, облака точек нерегулярны, что создает большую проблему для эффективного изучения признаков.
Модели на основе архитектуры Transformer добились больших успехов в области обработки естественного языка. Они весьма эффективны при изучении контекстно-зависимых представлений и захвате дальних зависимостей в исходной последовательности. Transformer и ассоциированный с ним механизм Self-Attention не только удовлетворяют требованию инвариантности перестановок, но и доказали свою высокую выразительность. Тем не менее прямое применение Transformer к облакам точек является непомерно дорогим, поскольку стоимость вычислений растет квадратично с размером исходных данных.
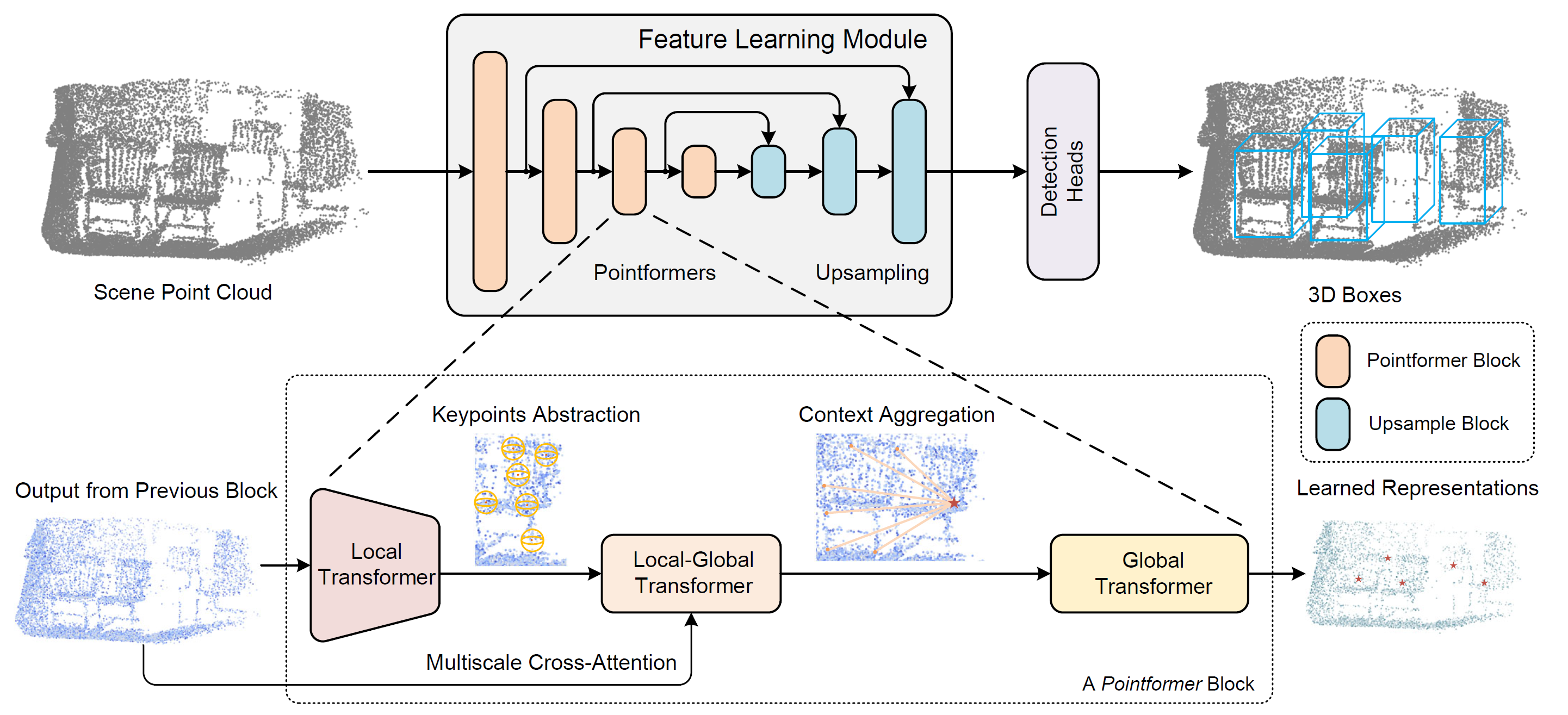
Данную проблему постарались решить авторы метода Pointformer, который был представлен в работе "3D Object Detection with Pointformer". Данный метод позволяет эффективно изучать признаки за счет использования превосходства моделей Transformer на данных, структурированных по множествам. Pointformer представляет собой структуру U-Net с многомасштабными блоками Pointformer. Блок Pointformer состоит из модулей на основе Transformer, которые являются одновременно выразительными и дружественными к задаче обнаружения объектов.
В своем архитектурном решении авторы метода используют 3 модуля Transfotmer:
- Local Trasformer (LT) используется для моделирования взаимодействий между точками в локальном регионе. Он изучает контекстно-зависимые особенности региона на уровне объекта.
- Local-Global Transformer (LGT) позволяет интегрировать локальные и глобальные функции с более высоким разрешением.
- Global Transformer (GT) предназначен для изучения контекстно-зависимых представлений на уровне сцены.
В результате, Pointformer может захватывать как локальные, так и глобальные зависимости, тем самым повышая производительность обучения функций для сцен с несколькими загроможденными объектами.
1. Алгоритм Pointformer
При изучении облаков точек необходимо учитывать их нерегулярный и неупорядоченный характер, а также изменяющийся размер. Авторами метода Pointformer были разработаны модули на основе Transformer для операций с наборами точек. Предложенные модули не только увеличивают выразительность извлечения локальных признаков, но и включают глобальную информацию в представления точек.
Блок Pointformer состоит из трех модулей: Local Transformer (LT), Local-Global Transformer (LGT) и Global Transformer (GT). Для каждого блока LT сначала получает исходные данные из предыдущего блока (высокое разрешение) и извлекает признаки для нового набора с меньшим количеством элементов (низкое разрешение). Затем LGT использует многоуровневый механизм перекрестного внимания для интеграции функций из обоих разрешений. Наконец, GT используется для захвата контекстно-зависимых представлений. Что касается блока повышающей дискретизации, авторы метода используют модуль распространения функций PointNet++.
Чтобы построить иерархическое представление для сцены облака точек, авторы Pointformer используют высокоуровневую методологию построения блоков изучения признаков с различными разрешениями. Вначале для выбора подмножества точек используется выборка самых дальних точек (FPS) в виде набора центроидов. Для каждого центроида выбираются точки локального региона в пределах заданного радиуса. Затем эти объекты группируются вокруг центроидов и передаются в виде последовательности точек в слой Transformer. Общий блок Transformer применяется ко всем локальным областям. А по мере накладывания большего количества слоев Transformer в блок Pointformer, выразительность модуля увеличивается и позволяет извлекать лучшие представления.
Кроме того, учитываются корреляции признаков между соседними точками. При некоторых обстоятельствах соседние точки могут быть даже более информативными, чем точка центроида. Таким образом, используя передачу информации между всеми точками, объекты в локальном регионе учитываются в равной степени, что делает модуль извлечения локальных признаков более эффективным.
Выборка самых дальних точек (FPS) широко используется во многих системах облака точек, поскольку она может генерировать практически однородные точки выборки, сохраняя при этом исходную форму. Это гарантирует, что большая часть точек может быть покрыта ограниченным количеством центроидов. Тем не менее в FPS есть две основные проблемы:
- Чувствителен к выбросам, что приводит к высокой нестабильности, особенно при работе с реальными облаками точек.
- Точки выборки FPS являются подмножеством исходного облака точек, что затрудняет вывод исходной геометрической информации в случаях, когда объекты частично перекрыты или захвачено недостаточное количество точек объекта.
Учитывая, что точки в основном фиксируются на поверхности объектов, второй вопрос может стать более важным, поскольку предложения генерируются на основе выборки точек, что приводит к естественному разрыву между предложением и достоверностью.
Для преодоления указанных недостатков авторы метода Pointformer предлагают модуль уточнения координат точек с помощью карт Self-Attention. Вначале извлекаются карты Self-Attention последнего слоя блока Transformer для каждой головы внимания. А затем вычисляется среднее значение карт внимания. После чего уточненные координаты центроидов вычисляются путем взвешивания значений всех точек в локальном регионе по соответствующим средним коэффициентам карт Self-Attention. С помощью предложенного модуля уточнения координат центроидов адаптивно смещаются ближе к центрам объектов.
Глобальная информация, представляющая контексты сцены и корреляцию границ между различными объектами, так же ценна для задач обнаружения. Pointformer использует возможности модулей Transformer для моделирования нелокальных отношений. В частности, модуль Global Transformer предназначен для передачи информации через все облако точек. Все точки собираются в одну группу и служат исходными данными для модуля GT.
Использование Transformer на уровне сцены, позволяет захватывать контекстно-зависимые представления и способствует передаче информации между различными объектами. Более того, глобальные представления могут быть особенно полезны для обнаружения объектов с очень небольшим количеством точек.
Local-Global Transformer также является ключевым модулем для объединения локальных и глобальных функций, извлеченных модулями LT и GT. LGT использует многомасштабный модуль перекрестного внимания и генерирует отношения между центроидами с низким разрешением и точками с высоким разрешением. Формально здесь используется механизм перекрестного внимания Transformer. Результаты работы LT служат в качестве Query, а данные GT с более высоким разрешением (предыдущего уровня) используются для Key и Value.
Позиционное кодирование является неотъемлемой частью моделей Transformer. Это единственный механизм, который кодирует информацию о положении для каждого токена в исходной последовательности. При адаптации Transformers к данным облаков точек позиционное кодирование играет более важную роль, поскольку координаты облаков точек являются ценными признаками, указывающими на локальные структуры.
Авторская визуализация метода Pointformer представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода Pointformer, мы переходим к практической части данной статьи, в которой реализуем свое видение предложенных подходов средствами MQL5.
При детальном рассмотрении предложенных подходов, можно заметить их некоторое сходство с методом PointNet++. Оба алгоритма используют выборку самых дальних точек для формирования центроидов. И основные операции обоих методов построены на группировке точек вокруг центроидов. Именно поэтому было принято решение использовать объект CNeuronPointNet2OCL в качестве родительского для построения нового класса CNeuronPointFormer, структура которого представлена ниже.
class CNeuronPointFormer : public CNeuronPointNet2OCL { protected: CNeuronMLMHSparseAttention caLocalAttention[2]; CNeuronMLCrossAttentionMLKV caLocalGlobalAttention[2]; CNeuronMLMHAttentionMLKV caGlobalAttention[2]; CNeuronLearnabledPE caLocalPE[2]; CNeuronLearnabledPE caGlobalPE[2]; CNeuronBaseOCL cConcatenate; CNeuronConvOCL cScale; //--- CBufferFloat *cbTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPointFormer(void) {}; ~CNeuronPointFormer(void) { delete cbTemp; } //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronPointFormer; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
В CNeuronPointNet2OCL мы использовали 2 уровня масштабов для извлечения локальных признаков. И в новом классе мы сохраним аналогичный уровень масштабирования, но качество извлечения признаков выведем на новый уровень, благодаря предложенным модулям внимания. Именно об этом свидетельствуют массивы внутренних нейронных слоев, с назначением которых мы познакомимся в процессе реализации методов нашего нового класса CNeuronPointFormer.
В числе внутренних объектов существует лишь один динамически объявленный буфер, который мы удалим в деструкторе класса. При этом, конструктор класса мы оставим пустым. А инициализация всех внутренних объектов осуществляется в методе Init, параметры которого перенесены без изменений из родительского класса.
bool CNeuronPointFormer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint output, bool use_tnets, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronPointNet2OCL::Init(numOutputs, myIndex, open_cl, window, units_count, output, use_tnets, optimization_type, batch)) return false;
В теле метода мы, как обычно, вначале вызываем одноименный метод родительского класса, в котором осуществляется контроль полученных параметров и инициализация унаследованных объектов.
Здесь стоит напомнить, что в родительском классе мы создаем 2 внутренних слоя локальной субдискретизации. На выходе которых получаем вектор из 64 элементов для каждой точки, анализируемого облака.
После каждого слоя локальной дискретизации мы добавим предложенные авторами метода Pointformer модули внимания. Архитектура модулей двух слоев будет идентична. Поэтому инициализацию объектов мы организуем в цикле.
for(int i = 0; i < 2; i++) { if(!caLocalAttention[i].Init(0, i*5, OpenCL, 64, 16, 4, units_count, 2, optimization, iBatch)) return false;
Первым мы инициализируем модуль локального внимания, роль которого выполняет блок разреженного внимания CNeuronMLMHSparseAttention.
Надо сказать, что здесь мы немного отошли от алгоритма, предложенного авторами метода Pointformer. Но сохраняем, как нам кажется, логику действия. В модуле локального внимания авторы метода обогащали точки локальной области общими признаками, что позволяет акцентировать внимание на объекте обобщения. Очевидно, что точки, относящиеся к одному объекту будут обладать большими зависимостями. Использование блока разреженного внимания позволяет не ограничиваться отдельной локальной областью, но акцентировать внимание на элементах с сильной зависимостью. Что можно сопоставить с определением уровней поддержки и сопротивления, о которые цена несколько раз ударялась на различных участках анализируемого исторического интервала.
Далее мы инициализируем блок локально-глобального внимания, в котором мы дополним информацию локальных объектов полутонами от исходных данных.
if(!caLocalGlobalAttention[i].Init(0, i*5+1, OpenCL, 64, 16, 4, 64, 2, units_count, units_count, 2, 2, optimization, iBatch)) return false;
А блок глобального внимания призван выявлять контекстно-зависимые представления на уровне сцены.
if(!caGlobalAttention[i].Init(0, i*5+2, OpenCL, 64, 16, 4, 2, units_count, 2, 2, optimization, iBatch)) return false;
И конечно мы добавим внутренние слои обучаемого позиционного кодирования. Здесь мы используем отдельное позиционное кодирование для локального и глобального представления.
if(!caLocalPE[i].Init(0, i*5+3, OpenCL, 64*units_count, optimization, iBatch)) return false; if(!caGlobalPE[i].Init(0, i*5+4, OpenCL, 64*units_count, optimization, iBatch)) return false; }
Стоит сказать, что мы не используем, предложенный авторами метода Pointformer, блок уточнения координат центроидов. Во-первых, при реализации алгоритма PointNet++ мы определили каждую точку облака в качестве центроида локальной области. Следовательно, изменение координат точек может исказить общую сцену. С другой стороны, функцию уточнения позиций центроидов частично выполняют слои обучаемого позиционного кодирования.
И пару слов о масштабировании извлечения признаков. Инициализированные выше объекты никак не указывают на различие масштабов извлечения признаков. Но есть 2 момента. В родительском классе мы использовали различные радиусы локальной дискретизации. А здесь мы добавим различные уровни разреженности локального внимания.
caLocalAttention[0].Sparse(0.1f); caLocalAttention[1].Sparse(0.3f);
Результаты двух уровней глобального внимания мы конкатенируем в единый тензор.
if(!cConcatenate.Init(0, 10, OpenCL, 128 * units_count, optimization, iBatch)) return false;
А затем понизим его размерность до уровня исходных данных блока извлечения глобального дескриптора облака точек, который был инициализирован в методе родительского класса.
if(!cScale.Init(0, 11, OpenCL, 128, 128, 64, units_count, 1, optimization, iBatch)) return false;
В завершении метода инициализации мы добавим создание буфера хранения промежуточных данных.
if(!!cbTemp) delete cbTemp; cbTemp = new CBufferFloat(); if(!cbTemp || !cbTemp.BufferInit(caGlobalAttention[0].Neurons(), 0) || !cbTemp.BufferCreate(OpenCL)) return false; //--- return true; }
После чего вернем вызывающей программе логический результат выполнения операций и завершим работу метода.
Следующим этапом нашей работы является построение алгоритма прямого прохода в методе feedForward. И здесь, в отличие от метода инициализации, мы не можем в полной мере использовать аналогичный метод родительского класса. В новом методе нам предстоит объединить операции с унаследованными и добавленными объектами.
В параметрах метода прямого прохода мы, как и ранее, получаем указатель на объект исходных данных. И в теле метода мы сразу сохраним полученный указатель в локальную переменную.
bool CNeuronPointFormer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- LocalNet CNeuronBaseOCL *inputs = NeuronOCL;
В большинстве случаев, мы не сохраняем полученный указатель в локальную переменную, так как это не имеет смысла. Но в данном методе нам предстоит реализовать алгоритм последовательной работы 2 вложенных блоков извлечения признаков различного масштаба. А в теле цикла нам удобнее работать с локальной переменной, которой мы можем присваивать указатели на различные объекты.
И далее мы сразу создаем вышеупомянутый цикл.
for(int i = 0; i < 2; i++) { if(!cTNetG || i > 0) { if(!caLocalPointNet[i].FeedForward(inputs)) return false; }
В теле цикла мы сначала осуществляем операции локальной дискретизации, объекты которой были объявлены и инициализированы в родительском классе.
Напомню, что алгоритмом родительского класса предусмотрена возможность проекции исходных данных в каноническое пространство. И эта операция предусмотрена только перед первым слоем локальной дискретизации. Поэтому мы сначала проверяем необходимость осуществления проекции исходных данных и, в случае отсутствия таковой, сразу осуществляем операцию локальной дискретизации.
В противном же случае, мы сначала генерируем матрицу проекции.
else { if(!cTurnedG) return false; if(!cTNetG.FeedForward(inputs)) return false;
Осуществляем операцию проекции исходных данных.
int window = (int)MathSqrt(cTNetG.Neurons()); if(IsStopped() || !MatMul(NeuronOCL.getOutput(), cTNetG.getOutput(), cTurnedG.getOutput(), NeuronOCL.Neurons() / window, window, window)) return false;
И только после этого осуществляем дискретизацию локальных данных.
if(!caLocalPointNet[i].FeedForward(cTurnedG.AsObject())) return false; }
Из слоя дискретизации локальных данных информация передается в модуль локального внимания.
//--- Local Attention if(!caLocalAttention[i].FeedForward(caLocalPointNet[i].AsObject())) return false;
Обратите внимание, что в модуль локального внимания мы передаем данные без позиционного кодирования. При этом хочу напомнить, что алгоритм Self-Attention инвариантен к последовательности анализируемых объектов. Таким образом, в блоке локального внимания мы определяем объекты с высокой степенью взаимного влияния вне зависимости от их координат.
Немного алогично звучит "анализ в блоке локального внимания без привязки к координатам". Казалось бы, локальное внимание подразумевает некую ограниченность анализируемых координат. Но давайте посмотрим на это иначе. Существует ценовой график. Разделим информацию о цене на 2 категории: координаты и признаки. Координатой у нам является время, а уровень цены — это признак. Если мы уберем координаты (данные о времени), то получим некое облако точек в пространстве признаков. И на том уровне, где стоимость инструмента была чаще, количество точек будет больше. При этом данные точки могут быть значительно разделены во времени. Но именно такие области чаще всего выступают уровнями поддержки и сопротивления. Следовательно, наш модуль локального внимания работает в локальном пространстве признаков.
А вот далее мы добавим позиционное кодирование как к результату модуля локального внимания, так и к результату слоя локальной дискретизации данных.
//--- Position Encoder if(!caLocalPE[i].FeedForward(caLocalAttention[i].AsObject())) return false; if(!caGlobalPE[i].FeedForward(caLocalPointNet[i].AsObject())) return false;
И на следующем шаге в модуле локально-глобального внимания мы обогащаем данные локального внимания информацией из глобального контекста с учетом координат объектов.
//--- Local to Global Attention if(!caLocalGlobalAttention[i].FeedForward(caLocalPE[i].AsObject(), caGlobalPE[i].getOutput())) return false;
И завершает операции нашего цикла модуль глобального внимания, в котором обогащается информация объектов общим контекстом сцены.
//--- Global Attention if(!caGlobalAttention[i].FeedForward(caLocalGlobalAttention[i].AsObject())) return false; inputs = caGlobalAttention[i].AsObject(); }
А перед переходом к следующей итерации цикла, не забываем изменить указатель на объект исходных данных в локальной переменной.
После успешного выполнения всех итераций нашего цикла последовательного перебора внутренних слоев, мы конкатенируем результаты всех модулей глобального внимания в единый тензор, что позволяет нам далее учитывать признаки объектов различного масштаба.
if(!Concat(caGlobalAttention[0].getOutput(), caGlobalAttention[1].getOutput(), cConcatenate.getOutput(), 64, 64, cConcatenate.Neurons() / 128)) return false;
Немного уменьшим размер конкатенированного тензора с помощью слоя масштабирования.
if(!cScale.FeedForward(cConcatenate.AsObject())) return false;
И передадим полученные данные в метод прямого прохода класса CNeuronPointNetOCL, который является предком нашего родительского класса. В нем реализован механизм генерации глобального дескриптора облака точек.
if(!CNeuronPointNetOCL::feedForward(cScale.AsObject())) return false; //--- return true; }
Не забываем на каждом шаге контролировать процесс выполнения операций. А после успешного выполнения всех операций метода мы возвращаем их логический результат вызывающей программе.
Далее мы переходим к построению алгоритмов обратного прохода. И здесь, как вы знаете, нам предстоит реализовать 2 метода:
- calcInputGradients — распределение градиента ошибки до всех объектов в соответствии с их влиянием на общий результат;
- updateInputWeights — обновление обучаемых параметров модели.
Для построения алгоритма второго метода мы можем просто взять выше представленный метод прямого прохода. Оставить в нем только иерархию вызова методов объектов с обучаемыми параметрами. И затем заменить вызов метода прямого прохода на метод обновления параметров. С полученным результатом вы можете самостоятельно ознакомиться во вложении.
А вот с алгоритмом метода распределения градиентов ошибки calcInputGradients нам предстоит поработать. Как и ранее, алгоритм метода полностью соответствует потоку операций прямого прохода, но в обратном порядке. Однако есть нюансы, связанные с параллельностью потоков информации.
В параметрах метода мы получаем указатель на объект предыдущего слоя, в который нам предстоит передать градиент ошибки в соответствии с влиянием исходных данных на результат работы модели.
bool CNeuronPointFormer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
И в теле метода мы сразу проверяем актуальность полученного указателя. Ведь при его недействительности теряется всякий смысл проведения дальнейших операций.
Надо сказать, что градиент ошибки на уровне результатов нашего слоя на момент вызова данного метода уже содержится в соответствующем буфере данных. И мы спускаем его до уровня внутреннего слоя масштабирования путем вызова соответствующего метода класса-предка.
if(!CNeuronPointNetOCL::calcInputGradients(cScale.AsObject())) return false;
Далее мы проводим градиент ошибки до уровня слоя конкатенированных данных.
if(!cConcatenate.calcHiddenGradients(cScale.AsObject())) return false;
И распределяем его по соответствующим модулям глобального внимания.
if(!DeConcat(caGlobalAttention[0].getGradient(), caGlobalAttention[1].getGradient(), cConcatenate.getGradient(), 64, 64, cConcatenate.Neurons() / 128)) return false;
И тут нам предстоит последовательно провести градиент ошибки через модули всех внутренних слоев. Для этого мы организуем цикл обратного перебора.
CNeuronBaseOCL *inputs = caGlobalAttention[0].AsObject(); for(int i = 1; i >= 0; i--) { //--- Global Attention if(!caLocalGlobalAttention[i].calcHiddenGradients(caGlobalAttention[i].AsObject())) return false;
В нем мы сначала определим градиент ошибки на уровне модуля локально-глобального внимания. А затем распределим его по слоям обучаемого позиционного кодирования.
if(!caLocalPE[i].calcHiddenGradients(caLocalGlobalAttention[i].AsObject(), caGlobalPE[i].getOutput(), caGlobalPE[i].getGradient(), (ENUM_ACTIVATION)caGlobalPE[i].Activation())) return false;
После чего, от соответствующих слоев позиционного кодирования передадим градиент ошибки до модуля локального внимания и слоя локальной дискретизации.
if(!caLocalAttention[i].calcHiddenGradients(caLocalPE[i].AsObject())) return false; if(!caLocalPointNet[i].calcHiddenGradients(caGlobalPE[i].AsObject())) return false;
Далее следует обратить внимание, что модуль локального внимания также использует в качестве исходных данных результаты работы слоя локальной дискретизации. Следовательно, он должен передать свою часть градиента ошибки на данный объект. Однако в соответствующем буфере данных уже содержится градиент ошибки от слоя позиционного кодирования, который мы не хотели бы потерять. Поэтому перед передачей градиента ошибки от модуля локального внимания, нам необходимо сохранить существующую информацию в буфере временного хранения данных.
И здесь важно отметить, что мы осознанно создали динамический указатель на объект буфера хранения данных. Более того, мы создали его размер равным буферу градиентов ошибки слоя локальной дискретизации. А это позволяет нам вместо копирования данных осуществить простой обмен указателями на объекты.
CBufferFloat *temp = caLocalPointNet[i].getGradient();
caLocalPointNet[i].SetGradient(cbTemp, false);
cbTemp = temp;
И теперь можно спокойно осуществить передачу градиента ошибки от модуля локального внимания без страха потери сохраненных ранее данных.
if(!caLocalPointNet[i].calcHiddenGradients(caLocalAttention[i].AsObject())) return false; if(!SumAndNormilize(caLocalPointNet[i].getGradient(), cbTemp, caLocalPointNet[i].getGradient(), 64, false, 0, 0, 0, 1)) return false;
А затем суммируем градиент ошибки от двух потоков информации.
Следующим шагом нам предстоит передать градиент ошибки на уровень исходных данных. Но тут опять нюанс. В зависимости от итерации цикла мы передаем градиент ошибки на уровень модуля глобального внимания предыдущего внутреннего слоя, или на объект исходных данных, полученный в параметрах метода. В последнем случае алгоритм аналогичен методу родительского класса. А вот в первом следует вспомнить, что выше мы уже сохранили градиент ошибки при деконкатенации данных от модуля генерации глобального дескриптора анализируемого облака данных. И в этом случае мы так же осуществляем подмену указателей на буферы данных. Ведь недаром они были созданы одинакового размера.
if(i > 0) { temp = inputs.getGradient(); inputs.SetGradient(cbTemp, false); cbTemp = temp; }
Далее мы проверяем необходимость корректировки градиента ошибки на проекцию канонического пространства. Если таковой необходимости нет, то сразу передаем градиент соответствующему объекту.
if(!cTNetG || i > 0) { if(!inputs.calcHiddenGradients(caLocalPointNet[i].AsObject())) return false; }
Если же при прямом проходе проекция в каноническое пространство осуществлялась, то мы сначала передадим градиент ошибки до уровня модуля слоя проекции.
else { if(!cTurnedG) return false; if(!cTurnedG.calcHiddenGradients(caLocalPointNet[i].AsObject())) return false;
Затем распределим градиент ошибки между исходными данными и матрицей проекции.
int window = (int)MathSqrt(cTNetG.Neurons()); if(IsStopped() || !MatMulGrad(inputs.getOutput(), inputs.getGradient(), cTNetG.getOutput(), cTNetG.getGradient(), cTurnedG.getGradient(), inputs.Neurons() / window, window, window)) return false;
Скорректируем градиент матрицы проекции на ошибку отклонения от ортогональной матрицы.
if(!OrthoganalLoss(cTNetG, true)) return false;
Здесь мы также организуем операции подмены буферов данных для сохранения градиентов ошибки от 2 потоков информации.
CBufferFloat *temp = inputs.getGradient(); inputs.SetGradient(cTurnedG.getGradient(), false); cTurnedG.SetGradient(temp, false);
Передадим градиент ошибки от модуля генерации матрицы проекции в каноническое пространство на уровень исходных данных.
if(!inputs.calcHiddenGradients(cTNetG.AsObject())) return false;
И суммируем градиент ошибки на уровне исходных данных от 2 потоков информации.
if(!SumAndNormilize(inputs.getGradient(), cTurnedG.getGradient(), inputs.getGradient(), 1, false, 0, 0, 0, 1)) return false; }
Далее мы ещё раз определяем необходимость суммирования градиента ошибки уже из других потоков информации и изменяем указатель в локальной переменной на объект исходных данных. А затем переходим к следующей итерации цикла.
if(i > 0) { if(!SumAndNormilize(inputs.getGradient(), cbTemp, inputs.getGradient(), 64, false, 0, 0, 0, 1)) return false; inputs = caGlobalAttention[i - 1].AsObject(); } else inputs = NeuronOCL; } //--- return true; }
После завершения всех итераций нашего цикла обратного перебора внутренних слоев, мы возвращаем вызывающей программе логическое значение результата операций нашего метода распределения градиента ошибки и завершаем его работу.
На этом мы завершаем рассмотрение алгоритмов построения методов нашего нового класса реализации подходов, предложенных авторами метода Pointformer, CNeuronPointFormer. С полным кодом данного класса и всех его методов Вы можете ознакомиться во вложении.
А далее мы обычно переходим к описанию архитектуры модели, в которую внедряем новый класс. На это раз здесь все довольно просто. Как и ранее, новый класс мы внедряем в модель Энкодера состояния окружающей среды. В качестве базовой архитектуры мы используем модель из предыдущей статьи. При этом, архитектура модели остается практически неизменной. Мы лишь заменяем в ней тип слоя родительского класса на новый с сохранением всех прочих параметров. Подобные корректировки не требуют изменений ни в архитектуре моделей Актера и Критика, ни в алгоритмах программ обучения моделей и взаимодействия с окружающей средой. Которые так же были перенесены без изменений. Поэтому в данной статье мы не будем останавливаться на этих моментах. А с полной архитектурой всех моделей Вы можете ознакомиться во вложении. Там же представлен полный код всех программ, используемых при подготовке статьи.
3. Тестирование
Мы провели большую работу по имплементации своего видения подходов, предложенных авторами метода Pointformer, средствами MQL5.
Я акцентирую внимание, что представленная в статье реализация имеет некоторые отличия от алгоритма, представленного в авторской работе. Поэтому полученные нами результаты могут в той или иной степени отличаться от работы авторского алгоритма.
И теперь пришло время посмотреть на результаты нашей работы. Как и ранее, для обучения моделей мы используем реальные исторические данные за 2023 год финансового инструмента EURUSD, таймфрейм H1. Параметры всех анализируемых индикаторов используются по умолчанию.
Вначале мы осуществляем итерационное офлайн обучение моделей путем запуска советника "...\PointFormer\Study.mq5" в режиме реального времени. Данный советник не осуществляет торговых операций. В его алгоритме заложено лишь обучение моделей.
Первые итерации обучения осуществляются на данных проходов, собранных при обучении моделей из прошлых статей. Структура и параметры анализируемых данных у нас остались без изменений.
Затем мы актуализируем данные обучающей выборки, чтобы они были как можно ближе к текущей политике действий Актера. Это позволяет более качественно осуществлять оценку его действий в процессе обучения и правильно корректировать направление оптимизации политики. Для этого в тестере стратегий мы запускаем режим медленной оптимизации для советника взаимодействия с окружающей средой "...\PointFormer\Research.mq5".
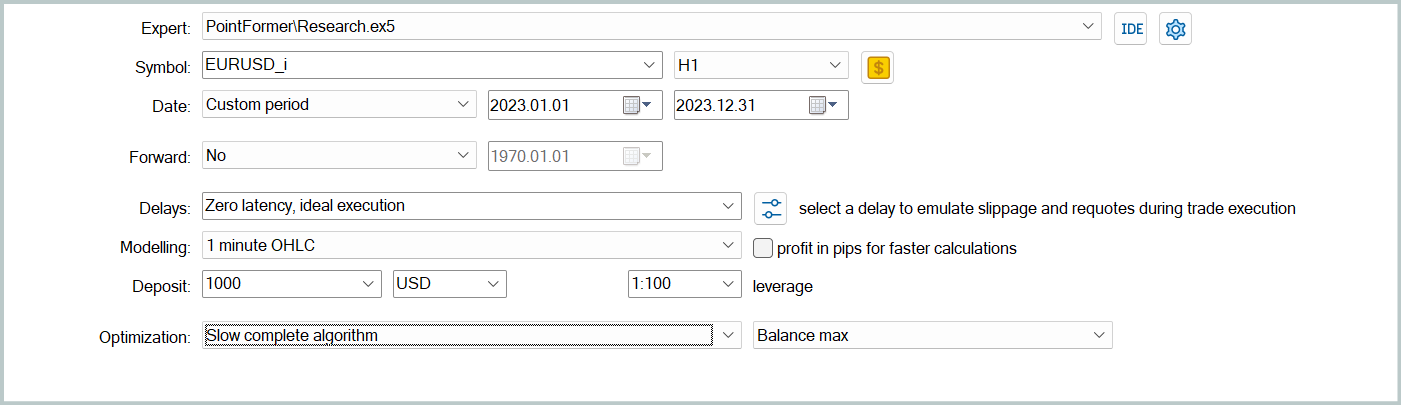
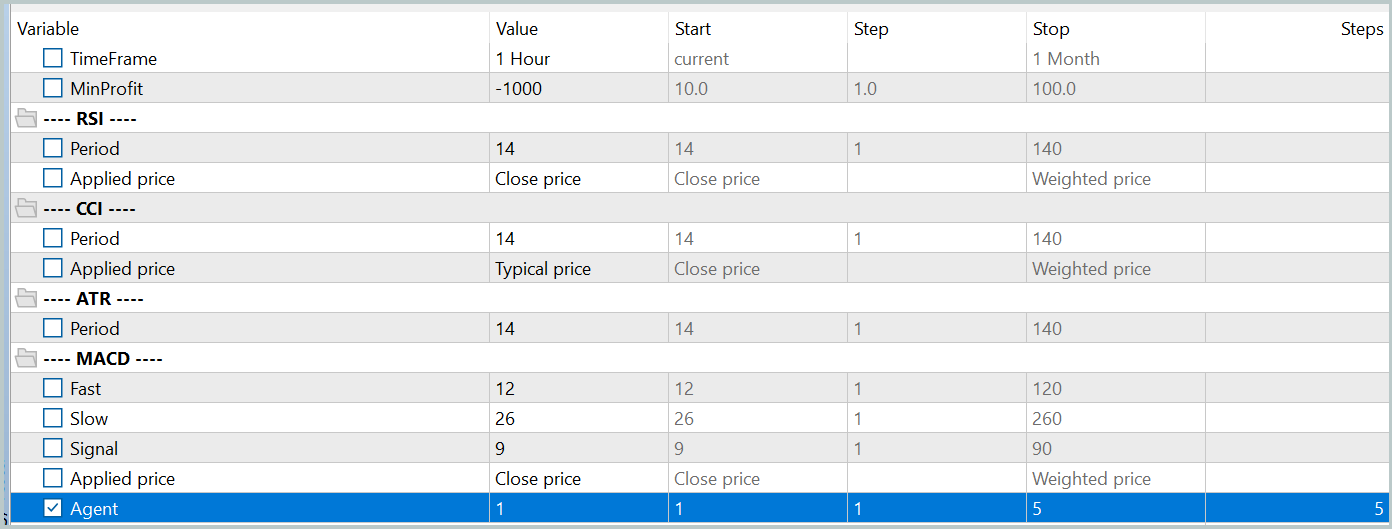
После чего мы повторяем процесс обучения моделей.
Обучение моделей и актуализация обучающей выборки осуществляются итерационно несколько раз. Хорошим сигналом к завершению процесса обучения может служить получения приемлемых результатов при всех проходах последней итерации обновления обучающей выборки.
При этом стоит отметить, что незначительные различия в результатах отдельных проходов допустимы. Это обусловлено использованием стохастической политики Актера, которая подразумевает некоторую стохастичность действий в рамках выученного диапазона. По мере обучения моделей стохастичность действий снижается. Однако некоторый разброс действий допустим, конечно если он кардинально не изменяет доходность политики.
После нескольких итераций обучения моделей и актуализации обучающей выборки, нам удалось получить политику, способную генерировать прибыль как на обучающей, так и на тестовой выборках.
Тестирование обученной модели мы осуществляем в тестере стратегий MetaTrader 5 на исторических данных января 2024 года с сохранением всех прочих параметров. Результаты тестирования представлены ниже.
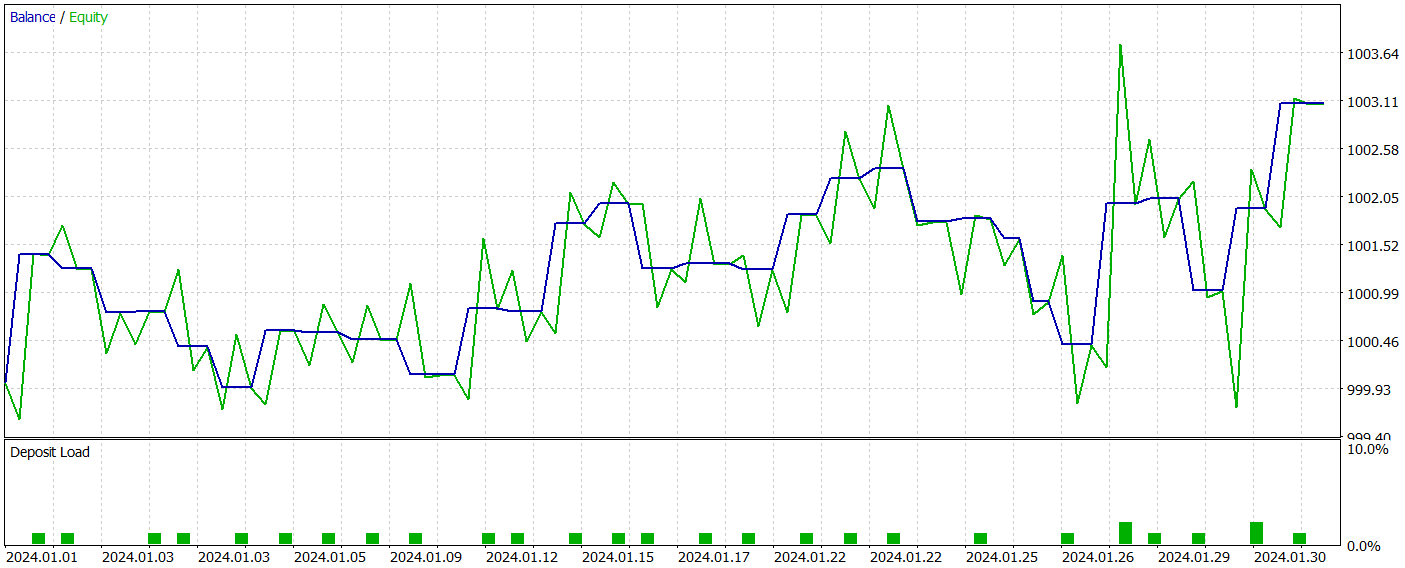

За период тестирования обученная модель совершила всего 31 торговую операцию, половина из которых была закрыта с прибылью. При этом практически 50% превышение максимальной и средней прибыльной сделок над аналогичными показателями убыточных операций позволило зафиксировать значение показателя профит-фактор на уровне 1.53. Но несмотря на то, что график баланса имеет тенденцию к росту, низкое количество совершенных торговых операций не позволяет нам сделать вывод об эффективности работы модели на длинном временном отрезке.
Заключение
В данной статье мы познакомились с методом Pointformer, который предлагает новую архитектуру для работы с облаками точек. Предложенный алгоритм сочетает в себе локальные и глобальные Transformer, что позволяет эффективно извлекать как локальные, так и глобальные пространственные паттерны из многомерных данных. Pointformer использует механизмы внимания для обработки информации с учетом пространственного контекста, а также поддерживает обучение с учетом важности каждой точки.
В практической части статьи мы реализовали свое видение предложенных подходов средствами MQL5. Провели обучение и тестирование модели с использованием предложенных алгоритмов. И полученные результаты демонстрируют потенциал метода для использования в анализе сложных структур данных.
Тем не менее стоит отметить, что для более полного понимания возможностей Pointformer в контексте финансовых данных, требуется дальнейшее исследование и оптимизация.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Особенности написания Пользовательских Индикаторов
Особенности написания Пользовательских Индикаторов

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
на исторических данных января 2024 года
Почему только января, сейчас же уже сентябрь? Или подразумевается, что каждый месяц надо переобучаться?