
ニューラルネットワークが簡単に(第82回):常微分方程式モデル(NeuralODE)

はじめに
新しいモデルファミリー「常微分方程式」について学びましょう。隠れ層の離散的なシーケンスを指定する代わりに、ニューラルネットワークを使用して隠れ状態の導関数をパラメータ化します。このモデルの結果はブラックボックス、つまり微分方程式ソルバーを使用して計算されます。これらの連続深度モデルは、一定量のメモリを使用し、入力信号に応じて推定戦略を適応させます。このようなモデルは、論文「Ordinary Differential Equations」で初めて紹介されました。この論文では、著者は内部操作にアクセスせずに、任意の常微分方程式(ODE)ソルバーを使用してバックプロパゲーションをスケーリングできることを示しています。これにより、より大きなモデルの中でODEをエンドツーエンドで訓練することが可能になります。
1. アルゴリズム
常微分方程式モデルの訓練における主な技術的課題は、ODEソルバーを使って誤差伝播の逆モード微分をおこなうことです。フィードフォワード演算を使った微分は単純ですが、大量のメモリを必要とし、さらに数値誤差が生じます。
この手法の著者は、ODEソルバーをブラックボックスとして扱い、共役感度法を用いて勾配を計算することを提案しています。このアプローチでは、2つ目の拡張ODEを時間的に遡って解くことで勾配を計算することができます。これはすべてのODEソルバーに当てはまります。タスクの大きさに応じてリニアにスケールし、メモリ消費量も少なくなります。さらに、数値的な誤差を明確に抑制しています。
ODEソルバーの結果を入力データとするスカラー損失関数L()の最適化を考えてみましょう。
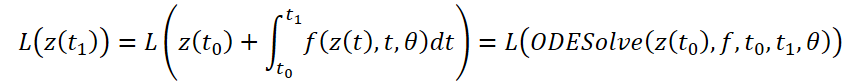
L誤差を最適化するには、θに沿った勾配が必要です。この手法の著者が提案したアルゴリズムの最初のステップは、誤差勾配が各瞬間a(t)=∂L/∂z(t)における隠れた状態z(t)にどのように依存するかを決定することです。そのダイナミクスは別のODEによって与えられ、これはルールのアナログと考えることができます。
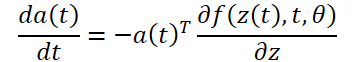
∂L/∂z(t)を計算するには、ODEソルバーをもう1回呼び出します。このソルバーは、初期値∂L/∂z(t1)から逆算する必要があります。難しいのは、このODEを解くには、軌道全体に沿ったz(t)の値を知る必要があることです。しかし、単純にz(t)を最終値z(t1)から過去にさかのぼってリストアップすることができます。
θパラメータによる勾配を計算するには、z(t)とa(t)の両方に依存する3番目の積分を決定する必要があります。
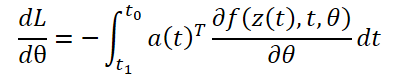
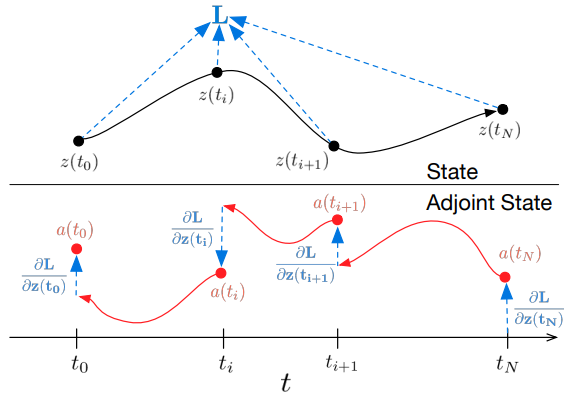
𝐳、𝐚、∂L/∂θを解くためのすべての積分は、元の状態、共役、およびその他の偏導関数を1つのベクトルに結合するODEソルバーを1回呼び出すだけで計算できます。以下は、必要なダイナミクスを構築し、ODEソルバーを呼び出してすべての勾配を同時に計算するアルゴリズムです。

ほとんどのODEソルバーには、z(t)の状態を繰り返し計算する機能があります。損失がこれらの中間状態に依存する場合、逆モード導関数は、連続する出力値の各対の間に1つずつ、一連の個別の解に分解されなければなりません。各観測について、対応する偏微分∂L/∂z(t)の方向に共役を調整しなければなりません。
ODEソルバーは、得られた結果が真の解の所定の許容範囲内にあることをおおよそ保証することができます。トレランスを変更すると、モデルの挙動が変わります。直接呼び出しにかかる時間は関数の評価回数に比例するため、許容誤差を調整することで精度と計算コストのトレードオフが可能になります。高精度で訓練しても、運用中に低精度に切り替えることができます。
2. MQL5での実装
提案するアプローチを実装するために、新しいクラスCNeuronNODEOCLを作成します。このクラスは、全結合層のCNeuronBaseOCLから基本的な機能を継承します。以下は新しいクラスの構成です。基本的なメソッド群に加えて、この構造体にはいくつかの特殊なメソッドとオブジェクトがあります。その機能性については、導入プロセスで検討します。
class CNeuronNODEOCL : public CNeuronBaseOCL { protected: uint iDimension; uint iVariables; uint iLenth; int iBuffersK[]; int iInputsK[]; int iMeadl[]; CBufferFloat cAlpha; CBufferFloat cTemp; CCollection cBeta; CBufferFloat cSolution; CCollection cWeights; //--- virtual bool CalculateKBuffer(int k); virtual bool CalculateInputK(CBufferFloat* inputs, int k); virtual bool CalculateOutput(CBufferFloat* inputs); virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool CalculateOutputGradient(CBufferFloat* inputs); virtual bool CalculateInputKGradient(CBufferFloat* inputs, int k); virtual bool CalculateKBufferGradient(int k); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronNODEOCL(void) {}; ~CNeuronNODEOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint variables, uint lenth, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronNODEOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); };
いくつかの特徴量の埋め込みによって記述された、いくつかの環境状態のシーケンスを扱うことができるようにするために、3次元で提示された初期データを扱うことができるオブジェクトを作成することに注意してください。
- iDimension:個別の環境状態における1つの特徴量の埋め込みベクトルのサイズ
- iVariables:環境の1つの状態を記述する特徴の数
- iLenth:分析されたシステム状態の数
この場合のODE関数は、ReLU活性化関数を挟んだ2つの全結合層で表現されます。しかし、個々の特徴のダイナミクスが異なる可能性があることは認めます。そのため、各属性ごとに独自の重み行列を用意します。このアプローチでは、以前のように畳み込み層を内部層として使うことはできません。したがって、新しいクラスでは、ODE関数の内部層を分解します。内部データ層を構成するデータバッファを宣言します。そして、プロセスを実装するためのカーネルとメソッドを作成します。
2.1 フィードフォワードカーネル
ODE関数のフィードフォワードカーネルを構築する際には、以下の制約から進めます。
- 環境の各状態は、同じ固定数の特徴によって記述されます。
- すべての特徴量は、同じ固定の埋め込みサイズを持っています。
これらの制約を考慮し、OpenCLプログラム側でFeedForwardNODEFカーネルを作成します。カーネルのパラメータには、3つのデータバッファと3つの変数へのポインタを渡します。カーネルは3次元のタスク空間で起動します。
__kernel void FeedForwardNODEF(__global float *matrix_w, ///<[in] Weights matrix __global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_o, ///<[out] Output tensor int dimension, ///< input dimension float step, ///< h int activation ///< Activation type (#ENUM_ACTIVATION) ) { int d = get_global_id(0); int dimension_out = get_global_size(0); int v = get_global_id(1); int variables = get_global_size(1); int i = get_global_id(2); int lenth = get_global_size(2);
カーネル本体では、まずタスク空間の3次元すべてにわたって現在のスレッドを特定します。そして、分析されたデータに対するデータバッファのシフトを決定します。
int shift = variables * i + v; int input_shift = shift * dimension; int output_shift = shift * dimension_out + d; int weight_shift = (v * dimension_out + d) * (dimension + 2);
準備作業の後、ループの中で、初期データのベクトルに対応する重みのベクトルを掛け合わせることによって、現在の結果の値を計算します。
float sum = matrix_w[dimension + 1 + weight_shift] + matrix_w[dimension + weight_shift] * step; for(int w = 0; w < dimension; w++) sum += matrix_w[w + weight_shift] * matrix_i[input_shift + w];
ここで注意しなければならないのは、ODE関数は環境の状態だけでなく、タイムスタンプにも依存するということです。この場合、環境状態全体のタイムスタンプは1つです。特徴量と配列長の重複をなくすため、元データテンソルにタイムスタンプを追加せず、単純にステップパラメータとしてカーネルに渡しました。
次に、得られた値を活性化関数を通して伝播させ、結果を対応するバッファ要素に保存すればよいのです。
if(isnan(sum)) sum = 0; switch(activation) { case 0: sum = tanh(sum); break; case 1: sum = 1 / (1 + exp(-clamp(sum, -20.0f, 20.0f))); break; case 2: if(sum < 0) sum *= 0.01f; break; default: break; } matrix_o[output_shift] = sum; }
2.2 バックプロパゲーションカーネル
フィードフォワードカーネルを実装した後、OpenCL側で逆の機能である誤差勾配分布カーネルHiddenGradientNODEFを作成します。
__kernel void HiddenGradientNODEF(__global float *matrix_w, ///<[in] Weights matrix __global float *matrix_g, ///<[in] Gradient tensor __global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_ig, ///<[out] Inputs Gradient tensor int dimension_out, ///< output dimension int activation ///< Input Activation type (#ENUM_ACTIVATION) ) { int d = get_global_id(0); int dimension = get_global_size(0); int v = get_global_id(1); int variables = get_global_size(1); int i = get_global_id(2); int lenth = get_global_size(2);
このカーネルも3次元タスク空間で起動され、カーネル本体でスレッドを識別します。また、分析された要素に対するデータバッファのシフトも決定します。
int shift = variables * i + v; int input_shift = shift * dimension + d; int output_shift = shift * dimension_out; int weight_step = (dimension + 2); int weight_shift = (v * dimension_out) * weight_step + d;
次に、分析されたソースデータ要素の誤差勾配を合計します。
float sum = 0; for(int k = 0; k < dimension_out; k ++) sum += matrix_g[output_shift + k] * matrix_w[weight_shift + k * weight_step]; if(isnan(sum)) sum = 0;
タイムスタンプは基本的に、個別の状態を表す定数であることに注意してください。そのため、誤差勾配は伝搬しません。
得られた量を活性化関数の微分によって調整し、得られた値をデータバッファの対応する要素に保存します。
float out = matrix_i[input_shift]; switch(activation) { case 0: out = clamp(out, -1.0f, 1.0f); sum = clamp(sum + out, -1.0f, 1.0f) - out; sum = sum * max(1 - pow(out, 2), 1.0e-4f); break; case 1: out = clamp(out, 0.0f, 1.0f); sum = clamp(sum + out, 0.0f, 1.0f) - out; sum = sum * max(out * (1 - out), 1.0e-4f); break; case 2: if(out < 0) sum *= 0.01f; break; default: break; } //--- matrix_ig[input_shift] = sum; }
2.3 ODEソルバー
第一段階の作業は完了しました。では、ODEソルバー側を見てみましょう。実装では、5次のDorman-Prince法を選びました。
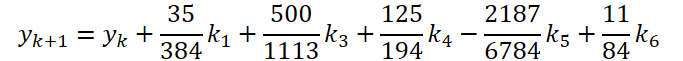
ここで
![]()
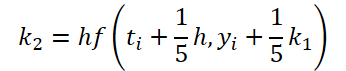
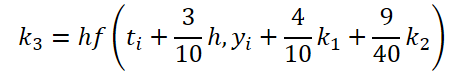
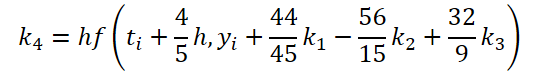
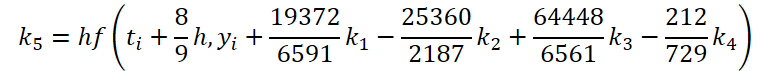
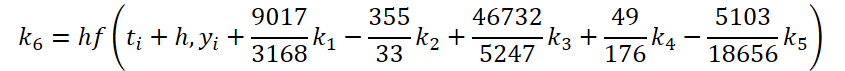
このように、係数k1.k6を計算するための初期データを解く機能と調整する機能は、数値係数が異なるだけです。不足する係数kiに0を乗じて足すことができますが、これは結果に影響しません。そのため、プロセスを統一するために、OpenCL側に1つのFeedForwardNODEInpKカーネルを作成します。カーネルパラメータには、ソースデータとすべての係数kiのバッファへのポインタを渡します。必要な乗数をmatrix_betaバッファに示します。
__kernel void FeedForwardNODEInpK(__global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_k1, ///<[in] K1 tensor __global float *matrix_k2, ///<[in] K2 tensor __global float *matrix_k3, ///<[in] K3 tensor __global float *matrix_k4, ///<[in] K4 tensor __global float *matrix_k5, ///<[in] K5 tensor __global float *matrix_k6, ///<[in] K6 tenтor __global float *matrix_beta, ///<[in] beta tensor __global float *matrix_o ///<[out] Output tensor ) { int i = get_global_id(0);
1次元のタスク空間でカーネルを実行し、結果バッファの各個別の値に対して値を計算します。
フローを特定した後、ループの中で積の合計を集めます。
float sum = matrix_i[i]; for(int b = 0; b < 6; b++) { float beta = matrix_beta[b]; if(beta == 0.0f || isnan(beta)) continue; //--- float val = 0.0f; switch(b) { case 0: val = matrix_k1[i]; break; case 1: val = matrix_k2[i]; break; case 2: val = matrix_k3[i]; break; case 3: val = matrix_k4[i]; break; case 4: val = matrix_k5[i]; break; case 5: val = matrix_k6[i]; break; } if(val == 0.0f || isnan(val)) continue; //--- sum += val * beta; }
結果の値は、結果バッファの対応する要素に保存されます。
matrix_o[i] = sum; }
バックプロパゲーション法では、HiddenGradientNODEInpKカーネルを作成し、同じBeta係数を考慮して、対応するデータバッファに誤差勾配を伝播させます。
__kernel void HiddenGradientNODEInpK(__global float *matrix_ig, ///<[in] Inputs tensor __global float *matrix_k1g, ///<[in] K1 tensor __global float *matrix_k2g, ///<[in] K2 tensor __global float *matrix_k3g, ///<[in] K3 tensor __global float *matrix_k4g, ///<[in] K4 tensor __global float *matrix_k5g, ///<[in] K5 tensor __global float *matrix_k6g, ///<[in] K6 tensor __global float *matrix_beta, ///<[in] beta tensor __global float *matrix_og ///<[out] Output tensor ) { int i = get_global_id(0); //--- float grad = matrix_og[i]; matrix_ig[i] = grad; for(int b = 0; b < 6; b++) { float beta = matrix_beta[b]; if(isnan(beta)) beta = 0.0f; //--- float val = beta * grad; if(isnan(val)) val = 0.0f; switch(b) { case 0: matrix_k1g[i] = val; break; case 1: matrix_k2g[i] = val; break; case 2: matrix_k3g[i] = val; break; case 3: matrix_k4g[i] = val; break; case 4: matrix_k5g[i] = val; break; case 5: matrix_k6g[i] = val; break; } } }
なお、データバッファにはゼロ値も書き込みます。これは、以前に保存した値の二重カウントを避けるために必要です。
2.4 重み更新カーネル
OpenCLプログラム側を完成させるために、ODE関数の重みを更新するためのカーネルを作成します。上に示した式からわかるように、ODE関数はすべてのki係数を決定するために使用されます。したがって、重みを調整する際には、すべての操作から誤差勾配を収集しなければなりません。以前に作った重み更新カーネルは、どれもこれほど多くの勾配バッファを扱うことができなかったので、新しいカーネルを作らなければなりません。実験を単純化するため、NODEF_UpdateWeightsAdamカーネルだけを作り、私が最もよく使うアダムメソッドを使ってパラメータを更新することにします。
__kernel void NODEF_UpdateWeightsAdam(__global float *matrix_w, ///<[in,out] Weights matrix __global const float *matrix_gk1, ///<[in] Tensor of gradients at k1 __global const float *matrix_gk2, ///<[in] Tensor of gradients at k2 __global const float *matrix_gk3, ///<[in] Tensor of gradients at k3 __global const float *matrix_gk4, ///<[in] Tensor of gradients at k4 __global const float *matrix_gk5, ///<[in] Tensor of gradients at k5 __global const float *matrix_gk6, ///<[in] Tensor of gradients at k6 __global const float *matrix_ik1, ///<[in] Inputs tensor __global const float *matrix_ik2, ///<[in] Inputs tensor __global const float *matrix_ik3, ///<[in] Inputs tensor __global const float *matrix_ik4, ///<[in] Inputs tensor __global const float *matrix_ik5, ///<[in] Inputs tensor __global const float *matrix_ik6, ///<[in] Inputs tensor __global float *matrix_m, ///<[in,out] Matrix of first momentum __global float *matrix_v, ///<[in,out] Matrix of seconfd momentum __global const float *alpha, ///< h const int lenth, ///< Number of inputs const float l, ///< Learning rates const float b1, ///< First momentum multiplier const float b2 ///< Second momentum multiplier ) { const int d_in = get_global_id(0); const int dimension_in = get_global_size(0); const int d_out = get_global_id(1); const int dimension_out = get_global_size(1); const int v = get_global_id(2); const int variables = get_global_id(2);
上述したように、カーネルパラメータは多数のグローバルデータバッファへのポインタを渡します。選択された最適化手法の標準的なパラメータは、それらに追加されます。
カーネルを3次元のタスク空間で実行します。このタスク空間では、ソースデータと結果の埋め込みベクトルの次元と、分析された特徴の数を考慮します。カーネル本体では、3次元すべてに沿ったタスク空間の流れを特定します。次に、データバッファのオフセットを決定します。
const int weight_shift = (v * dimension_out + d_out) * dimension_in; const int input_step = variables * (dimension_in - 2); const int input_shift = v * (dimension_in - 2) + d_in; const int output_step = variables * dimension_out; const int output_shift = v * dimension_out + d_out;
次に、ループの中で、すべての環境状態にわたって誤差勾配を収集します。
float weight = matrix_w[weight_shift]; float g = 0; for(int i = 0; i < lenth; i++) { int shift_g = i * output_step + output_shift; int shift_i = i * input_step + input_shift; switch(dimension_in - d_in) { case 1: g += matrix_gk1[shift_g] + matrix_gk2[shift_g] + matrix_gk3[shift_g] + matrix_gk4[shift_g] + matrix_gk5[shift_g] + matrix_gk6[shift_g]; break; case 2: g += matrix_gk1[shift_g] * alpha[0] + matrix_gk2[shift_g] * alpha[1] + matrix_gk3[shift_g] * alpha[2] + matrix_gk4[shift_g] * alpha[3] + matrix_gk5[shift_g] * alpha[4] + matrix_gk6[shift_g] * alpha[5]; break; default: g += matrix_gk1[shift_g] * matrix_ik1[shift_i] + matrix_gk2[shift_g] * matrix_ik2[shift_i] + matrix_gk3[shift_g] * matrix_ik3[shift_i] + matrix_gk4[shift_g] * matrix_ik4[shift_i] + matrix_gk5[shift_g] * matrix_ik5[shift_i] + matrix_gk6[shift_g] * matrix_ik6[shift_i]; break; } }
そして、おなじみのアルゴリズムに従って重みを調整します。
float mt = b1 * matrix_m[weight_shift] + (1 - b1) * g; float vt = b2 * matrix_v[weight_shift] + (1 - b2) * pow(g, 2); float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight));
カーネルの最後に、結果と補助値をデータバッファの対応する要素に保存します。
if(delta * g > 0) matrix_w[weight_shift] = clamp(matrix_w[weight_shift] + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[weight_shift] = mt; matrix_v[weight_shift] = vt; }
これでOpenCLプログラム側は完了です。CNeuronNODEOCLクラスの実装に戻りましょう。
2.5 CNeuronNODEOCLクラス初期化メソッド
クラスオブジェクトの初期化はCNeuronNODEOCL::Initメソッドでおこないます。メソッドのパラメータには、いつものように、オブジェクトのアーキテクチャーの主要なパラメータを渡します。
bool CNeuronNODEOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint variables, uint lenth, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, dimension * variables * lenth, optimization_type, batch)) return false;
メソッド本体では、まず親クラスの関連メソッドを呼び出し、受け取ったパラメータを制御し、継承したオブジェクトを初期化します。親クラスのボディの中で演算を実行した一般化された結果は、返される論理値によって知ることができます。
次に、得られたオブジェクトアーキテクチャのパラメータをローカルクラス変数に保存します。
iDimension = dimension; iVariables = variables; iLenth = lenth;
補助変数を宣言し、必要な値を代入します。
uint mult = 2; uint weights = (iDimension + 2) * iDimension * iVariables;
次に、ki係数のバッファと、その計算のために調整された初期データを見てみましょう。推測できるように、これらのデータバッファの値は、フィードフォワードパスからバックプロパゲーションパスに保存されます。次のフィードフォワードパスの間に、その値は上書きされます。そのため、リソースを節約するために、メインプログラムメモリにはこれらのバッファを作成しません。コンテキストのOpenCL側だけに作成します。このクラスでは、ポインタを格納するために配列を作るだけです。各配列には、k係数の3倍の要素を作成します。これは、誤差勾配を収集するために必要です。
if(ArrayResize(iBuffersK, 18) < 18) return false; if(ArrayResize(iInputsK, 18) < 18) return false;
中間的な計算値についても同様です。しかし、配列のサイズは小さくなります。
if(ArrayResize(iMeadl, 12) < 12) return false;
コードの可読性を高めるため、ループの中でバッファを作成します。
for(uint i = 0; i < 18; i++) { iBuffersK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; iInputsK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iInputsK[i] < 0) return false; if(i > 11) continue; //--- Initilize Meadl Output and Gradient buffers iMeadl[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iMeadl[i] < 0) return false; }
次のステップは、ODE関数モデルの重み係数の行列と、それに対するモーメントを作成することです。前述の通り、2つの層を使用します。
//--- Initilize Weights for(int i = 0; i < 2; i++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(weights)) return false; float k = (float)(1 / sqrt(iDimension + 2)); for(uint w = 0; w < weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cWeights.Add(temp)) return false;
for(uint d = 0; d < 2; d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cWeights.Add(temp)) return false; } }
次に、定数倍バッファを作成します。
- アルファ時間ステップ
{
float temp_ar[] = {0, 0.2f, 0.3f, 0.8f, 8.0f / 9, 1, 1};
if(!cAlpha.AssignArray(temp_ar))
return false;
if(!cAlpha.BufferCreate(OpenCL))
return false;
}
- ソースデータの調整
//--- Beta K1 { float temp_ar[] = {0, 0, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K2 { float temp_ar[] = {0.2f, 0, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K3 { float temp_ar[] = {3.0f / 40, 9.0f / 40, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K4 { float temp_ar[] = {44.0f / 44, -56.0f / 15, 32.0f / 9, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K5 { float temp_ar[] = {19372.0f / 6561, -25360 / 2187.0f, 64448 / 6561.0f, -212.0f / 729, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K6 { float temp_ar[] = {9017 / 3168.0f, -355 / 33.0f, 46732 / 5247.0f, 49.0f / 176, -5103.0f / 18656, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
- ODE解法
{
float temp_ar[] = {35.0f / 384, 0, 500.0f / 1113, 125.0f / 192, -2187.0f / 6784, 11.0f / 84};
if(!cSolution.AssignArray(temp_ar))
return false;
if(!cSolution.BufferCreate(OpenCL))
return false;
}
初期化メソッドの最後に、中間値を記録するためのローカルバッファを追加します。
if(!cTemp.BufferInit(Output.Total(), 0) || !cTemp.BufferCreate(OpenCL)) return false; //--- return true; }
2.6 フィードフォワードパスの構成
クラスオブジェクトを初期化した後、フィードフォワードアルゴリズムの構成に移ります。上記では、OpenCLプログラム側で2つのカーネルを作成し、フィードフォワードパスを整理しました。したがって、それらを呼び出すメソッドを作らなければなりません。まずは、k係数を計算するための初期データを準備する、かなり単純なメソッドCalculateInputKから始めましょう。
bool CNeuronNODEOCL::CalculateInputK(CBufferFloat* inputs, int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
メソッドのパラメータには、前の層から取得したソースデータのバッファへのポインタと、計算する係数のインデックスを受け取ります。メソッドの本体では、指定された係数インデックスが私たちのアーキテクチャに対応しているかどうかを確認します。
コントロールブロックの通過に成功した後、k1の特別なケースを考えます。
![]()
この場合、カーネル実行を呼び出さず、単にソースデータバッファへのポインタをコピーします。
if(k == 0) { if(iInputsK[k] != inputs.GetIndex()) { OpenCL.BufferFree(iInputsK[k]); iInputsK[k] = inputs.GetIndex(); } return true; }
一般的なケースでは、FeedForwardNODEInpKカーネルを呼び出し、調整されたソースデータを適切なバッファに書き込みます。そのために、まずタスク空間を定義します。この場合は一次元空間です。
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
カーネルパラメータにバッファポインタを渡しましょう。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_beta, ((CBufferFloat *)cBeta.At(k)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_o, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルを実行キューに入れます。
if(!OpenCL.Execute(def_k_FeedForwardNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
ソースデータを調整した後、係数の値を計算します。この処理は、CalculateKBufferメソッドの中で整理されます。このメソッドは内部オブジェクトにのみ作用するので、メソッドパラメータに必要な係数のインデックスを指定するだけで、操作を実行できます。
bool CNeuronNODEOCL::CalculateKBuffer(int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
メソッド本体では、結果のインデックスがクラスアーキテクチャにマッチするかどうかを確認します。
次に、3次元の問題空間を定義します。
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iVariables, iLenth};
次に、カーネルにパラメータを渡して第1層を渡します。ここではLReLUを使って非線形性を作り出します。
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_i, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_o, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_dimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_step, float(cAlpha.At(k)))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_activation, int(LReLU))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルを実行キューに入れます。
if(!OpenCL.Execute(def_k_FeedForwardNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
次のステップは、第2層のフィードフォワードパスを実行することです。タスクスペースは変わりません。したがって、対応する配列は変更しません。カーネルにパラメータを渡し直す必要があります。今回は、ソースデータ、重み、結果バッファを変更します。
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_i, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_o, iBuffersK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
また、活性化関数も使いません。
if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_activation, int(None))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
その他のパラメータに変更はありません。
if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_dimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_step, cAlpha.At(k))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルを実行キューに送ります。
if(!OpenCL.Execute(def_k_FeedForwardNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
すべてのk係数を計算した後、ODEを解いた結果を求めることができます。実際には、FeedForwardNODEInpKカーネルを使用します。この呼び出しはすでにCalculateInputKメソッドに実装されています。しかしこの場合、使用するデータバッファを変更しなければなりません。そこで、CalculateOutputメソッドのアルゴリズムを書き換えます。
bool CNeuronNODEOCL::CalculateOutput(CBufferFloat* inputs) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
このメソッドのパラメータには、ソースデータバッファへのポインタだけを受け取ります。メソッド本体では、すぐに1次元の問題空間を定義します。次に、ソースデータバッファへのポインタをカーネルパラメータに渡します。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
乗数については、ODEを解く係数のバッファを示します。
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_beta, cSolution.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
その結果をクラスの結果バッファに書き込みます。
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_o, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルを実行キューに入れます。
if(!OpenCL.Execute(def_k_FeedForwardNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
得られた値をソースデータと組み合わせ、正規化します。
if(!SumAndNormilize(Output, inputs, Output, iDimension, true, 0, 0, 0, 1)) return false; //--- return true; }
フィードフォワードパス処理を整理するために、カーネルを呼び出すメソッドを用意しました。後は、トップレベルのメソッドCNeuronNODEOCL::feedForwardでアルゴリズムを定式化するだけです。
bool CNeuronNODEOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { for(int k = 0; k < 6; k++) { if(!CalculateInputK(NeuronOCL.getOutput(), k)) return false; if(!CalculateKBuffer(k)) return false; } //--- return CalculateOutput(NeuronOCL.getOutput()); }
このメソッドはパラメータで、前の層のオブジェクトへのポインタを受け取ります。メソッドの本体では、ソースデータを順次調整し、すべてのk係数を計算するループを構成します。各反復で、操作を実行するプロセスを制御します。必要な係数の計算に成功したら、ODE解法メソッドを呼びます。多くの準備作業をおこなったため、トップレベルメソッドのアルゴリズムは非常に簡潔なものになりました。
2.7 バックプロパゲーションパスの構成
フィードフォワードアルゴリズムは、モデルを操作するプロセスを提供します。しかし、モデルの訓練はバックプロパゲーションのプロセスと切り離せません。この過程で、モデルの誤差を最小化するために訓練されたパラメータが調整されます。
フィードフォワードカーネルと同様に、OpenCLプログラム側で2つのバックプロパゲーションカーネルを作成しました。さて、メインプログラムの側では、バックプロパゲーションカーネルを呼び出すメソッドを作らなければなりません。後方プロセスを実装しているので、バックプロパゲーションパスの順序でメソッドを扱います。
次の層から誤差勾配を受け取った後、得られた勾配をソースデータ層とk係数の間に分配します。この処理は、HiddenGradientNODEInpKカーネルを呼び出すCalculateOutputGradientメソッドに実装されています。
bool CNeuronNODEOCL::CalculateOutputGradient(CBufferFloat *inputs) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
メソッドのパラメータには、前の層の誤差勾配バッファへのポインタを受け取ります。メソッド本体では、OpenCLプログラムカーネルを呼び出すプロセスを整理します。まず、1次元のタスク空間を定義します。次に、データバッファとカーネルパラメータへのポインタを渡します。
HiddenGradientNODEInpKカーネルパラメータは、FeedForwardNODEInpKカーネルパラメータを完全に再現していることに注意してください。唯一の違いは、フィードフォワードパスがソースデータとk係数のバッファを使用することです。バックプロパゲーションパスは、対応する勾配のバッファを使用します。このため、カーネルバッファの定数は再定義せず、フィードフォワードパスの定数を使用しました。
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_beta, cSolution.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_o, Gradient.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
また、次のことにも注意してください。k係数を記録するために、対応するインデックスが[0, 5]の範囲にあるバッファを使用しました。この場合、[6, 11]の範囲のインデックスを持つバッファを使用し、誤差勾配を記録します。
すべてのパラメータをカーネルに渡すことに成功したら、それを実行キューに入れます。
if(!OpenCL.Execute(def_k_HiddenGradientNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
次に、同じカーネルを呼び出すCalculateInputKGradientメソッドを考えてみましょう。アルゴリズムの構築には、特に注意すべきニュアンスがあります。
1つ目はもちろん、メソッドのパラメータです。ここにはk係数のインデックスが追加されます。
bool CNeuronNODEOCL::CalculateInputKGradient(CBufferFloat *inputs, int k) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
メソッドの本体では、同じ1次元のタスク空間を定義します。そして、パラメータをカーネルに渡します。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
しかし今回は、k係数の誤差勾配を書き込むために、[12, 17]の範囲のインデックスを持つバッファを使用します。これは、各係数の誤差勾配を累積する必要があるためです。
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[13])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[14])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[15])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[16])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[17])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
さらに、cBeta配列の乗数を使用します。
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_beta, ((CBufferFloat *)cBeta.At(k)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_o, iInputsK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルに必要なパラメータをすべて渡すことに成功したら、実行キューに入れます。
if(!OpenCL.Execute(def_k_HiddenGradientNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
次に、現在の誤差勾配と、対応するk係数について以前に蓄積された誤差勾配を合計する必要があります。そのために、解析されたk係数から順に誤差勾配を最小値まで加える後方ループを構成します。
for(int i = k - 1; i >= 0; i--) { float mult = 1.0f / (i == (k - 1) ? 6 - k : 1); uint global_work_offset[1] = {0}; uint global_work_size[1] = {iLenth * iVariables}; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix1, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix2, iBuffersK[k + 12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix_out, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_dimension, iDimension)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_in1, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_in2, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_out, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_multiplyer, mult)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MatrixSum, 1, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
現在の係数より小さい係数を持つk係数の誤差勾配だけを合計することに注意してください。これは、指数が大きい係数のß乗数が明らかに0に等しいことによります。なぜなら、そのような係数は現在の係数の後に計算され、その決定には関与しないからです。したがって、その誤差勾配はゼロとなります。さらに、より安定した訓練のために、累積誤差勾配を平均化します。
誤差勾配伝搬に参加する最後のカーネルは、ODE関数HiddenGradientNODEFの内層を通して誤差勾配を伝搬するカーネルです。CalculateKBufferGradientメソッドで呼び出されます。パラメータでは、この方法は勾配が分布しているk係数のインデックスだけを受け取ります。
bool CNeuronNODEOCL::CalculateKBufferGradient(int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
メソッド本体では、結果のインデックスがオブジェクトのアーキテクチャに準拠しているかどうかを確認します。そして、3次元の問題空間を定義しますが、
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iVariables, iLenth};
カーネルへのパラメータ転送を実装します。誤差勾配をバックプロパゲーションパスの中で分散させるので、まず関数の層2のバッファを指定します。
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_i, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_ig, iMeadl[k * 2 + 1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_g, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_dimension_out, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_activation, int(LReLU))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルを実行キューに入れます。
if(!OpenCL.Execute(def_k_HiddenGradientNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
次のステップで、タスク空間を定義する配列に変更がなければ、関数の第1層のデータをカーネルパラメータに移します。
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_i, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_ig, iInputsK[k + 12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_g, iMeadl[k * 2 + 1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_dimension_out, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_activation, int(None))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルの実行を呼び出します。
if(!OpenCL.Execute(def_k_HiddenGradientNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
誤差勾配を層オブジェクト間で分配するためのカーネルを呼び出すメソッドを作成しました。しかし、この状態では、これらはプログラムの断片が散らばっているだけで、1つのアルゴリズムを形成していません。それらを1つにまとめなければなりません。calcInputGradientsメソッドを用いて、誤差勾配を分配するための一般的なアルゴリズムをクラス内で整理します。
bool CNeuronNODEOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!CalculateOutputGradient(prevLayer.getGradient())) return false; for(int k = 5; k >= 0; k--) { if(!CalculateKBufferGradient(k)) return false; if(!CalculateInputKGradient(GetPointer(cTemp), k)) return false; if(!SumAndNormilize(prevLayer.getGradient(), GetPointer(cTemp), prevLayer.getOutput(), iDimension, false, 0, 0, 0, 1.0f / (k == 0 ? 6 : 1))) return false; } //--- return true; }
パラメータに、このメソッドは前の層のオブジェクトへのポインタを受け取り、そこに誤差勾配を渡す必要があります。最初の段階では、ODE解の係数に従って、後続の層から得られる誤差勾配を前の層とk係数の間に分配します。覚えているように、この処理はCalculateOutputGradientメソッドで実装しました。
そして、対応する係数を計算する際に、ODE関数を通して勾配を伝播させるために後方ループを実行します。ここではまず、CalculateKBufferGradientメソッドで2つの層を通して誤差勾配を伝播させます。次に、CalculateInputKGradientメソッドで、その結果の誤差勾配を対応するk係数と初期データの間に分配します。しかし、前の層からの誤差勾配のバッファの代わりに、一時的なバッファにデータを受け取ります。次に、SumAndNormilizeメソッドを使用して、結果の勾配を前の層の勾配バッファに蓄積された勾配に追加します。最後の反復では、累積誤差勾配を平均します。
この段階で、結果に影響を与えるすべてのオブジェクトの間で、その貢献度に応じて誤差勾配を完全に分配しました。あとはモデルのパラメータを更新するだけです。以前は、このかん数を実行するために、NODEF_UpdateWeightsAdamカーネルを作成しました。さて、メインプログラムの側で、指定されたカーネルへの呼び出しを整理しなければなりません。この機能はupdateInputWeightsメソッドで実行されます。
bool CNeuronNODEOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension + 2, iDimension, iVariables};
パラメータの中で、メソッドは前のニューラル層のオブジェクトへのポインタを受け取ります。この場合、これは名目上のものであり、メソッド仮想化手順にのみ必要です。
実際、フィードフォワードとバックワードパスでは、前の層のデータを使用しました。そこで、ODE関数の第1層のパラメータを更新するために、これらのパラメータが必要になります。フィードフォワードパスの間、前の層の結果バッファへのポインタをインデックス0のiInputsK配列に保存しました。では、実装で使ってみましょう。
手法の本体では、まず3次元の問題空間を定義します。そして、必要なパラメータをカーネルに渡します。まず、層1のパラメータを更新します。
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik1, iInputsK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk1, iMeadl[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik2, iInputsK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk2, iMeadl[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik3, iInputsK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk3, iMeadl[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik4, iInputsK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk4, iMeadl[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik5, iInputsK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk5, iMeadl[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik6, iInputsK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk6, iMeadl[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_m, ((CBufferFloat*)cWeights.At(1)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_v, ((CBufferFloat*)cWeights.At(2)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_alpha, cAlpha.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_lenth, int(iLenth))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
カーネルを実行キューに入れます。
if(!OpenCL.Execute(def_k_NODEF_UpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
そして、この操作を繰り返し、層2のパラメータの更新プロセスを整理します。
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik1, iMeadl[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk1, iBuffersK[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik2, iMeadl[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk2, iBuffersK[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik3, iMeadl[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk3, iBuffersK[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik4, iMeadl[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk4, iBuffersK[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik5, iMeadl[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk5, iBuffersK[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik6, iMeadl[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk6, iBuffersK[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_m, ((CBufferFloat*)cWeights.At(4)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_v, ((CBufferFloat*)cWeights.At(5)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_alpha, cAlpha.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_lenth, int(iLenth))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_NODEF_UpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
2.8 ファイル操作
ここまで、メインクラスのプロセスを整理する方法について見てきました。しかし、ファイルを扱う方法について少し述べておきたいと思います。クラスの内部オブジェクトの構造を注意深く見れば、調整の瞬間の重みを含むcWeightsコレクションだけを選択して保存することができます。また、クラスのアーキテクチャを決定する3つのパラメータを保存することができます。Saveメソッドで保存しましょう。
bool CNeuronNODEOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; if(!cWeights.Save(file_handle)) return false; if(FileWriteInteger(file_handle, int(iDimension), INT_VALUE) < INT_VALUE || FileWriteInteger(file_handle, int(iVariables), INT_VALUE) < INT_VALUE || FileWriteInteger(file_handle, int(iLenth), INT_VALUE) < INT_VALUE) return false; //--- return true; }
パラメータに、このメソッドはデータを保存するためのファイルハンドルを受け取ります。すぐに、メソッド本体の中で、同じ名前の親クラスのメソッドを呼び出します。そして、コレクションと定数を保存します。
クラスの保存方法は非常に簡潔で、ディスク容量を最大限に節約できます。しかし、この節約はデータロード方法に代償を伴います。
bool CNeuronNODEOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; if(!cWeights.Load(file_handle)) return false; cWeights.SetOpenCL(OpenCL); //--- iDimension = (int)FileReadInteger(file_handle); iVariables = (int)FileReadInteger(file_handle); iLenth = (int)FileReadInteger(file_handle);
ここではまず、保存されたデータを読み込みます。そして、読み込まれたオブジェクトアーキテクチャのパラメータに従って、欠落しているオブジェクトを作成するプロセスを整理します。
//--- CBufferFloat *temp = NULL; for(uint i = 0; i < 18; i++) { OpenCL.BufferFree(iBuffersK[i]); OpenCL.BufferFree(iInputsK[i]); //--- iBuffersK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; iInputsK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; if(i > 11) continue; //--- Initilize Output and Gradient buffers OpenCL.BufferFree(iMeadl[i]); iMeadl[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iMeadl[i] < 0) return false; } //--- cTemp.BufferFree(); if(!cTemp.BufferInit(Output.Total(), 0) || !cTemp.BufferCreate(OpenCL)) return false; //--- return true; }
これで、新しいCNeuronNODEOCLクラスのメソッドについての説明を終わります。また、ここで使用されているすべてのメソッドとプログラムの完全なコードは添付ファイルにあります。
2.9 訓練用モデルアーキテクチャ
ODEソルバーCNeuronNODEOCLに基づいて新しいニューラル層クラスを作成しました。前回の記事で作成したエンコーダーのアーキテクチャに、このクラスのオブジェクトを追加してみましょう。
いつものように、モデルのアーキテクチャはCreateDescriptionsメソッドで指定されます。このメソッドのパラメータには、作成されるモデルのアーキテクチャを示す3つの動的配列へのポインタが渡されます。
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
メソッド本体では、受け取ったポインタを確認し、必要であれば新しい配列オブジェクトを作成します。
エンコーダーモデルに、環境の状態を表す生データを送り込みます。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
受信したデータはバッチ正規化層で前処理されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
次に、埋め込み層とそれに続く畳み込み層を使って、得られた状態の埋め込みを生成します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
生成された埋め込みは位置符号化で補完されます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
そして、複雑な文脈に沿ったデータ分析層を使用します。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCCMROCL; descr.count = prev_count; descr.window = prev_wout; descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
ここまでは、これまでの記事のモデルを完全に繰り返してきました。しかし次に、新しいクラスを2層追加してみましょう。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronNODEOCL; descr.count = prev_count; descr.window = EmbeddingSize/4; descr.step = 4; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronNODEOCL; descr.count = prev_count; descr.window = EmbeddingSize/4; descr.step = 4; if(!encoder.Add(descr)) { delete descr; return false; }
ActorとCriticのモデルは、前回の記事をそのままコピーしました。したがって、ここではこれらのモデルについては考慮しません。
新しい層を追加しても、環境との相互作用やモデルの訓練のプロセスには影響しません。従って、これまでのEAもすべてそのまま使用します。全プログラムの完全なコードは添付ファイルにあります。私たちは次の段階に進み、その成果をテストします。
3. テスト
私たちは、常微分方程式の新しいモデル群について考察しました。提案されたアプローチを考慮し、私たちはMQL5を使用して新しいCNeuronNODEOCLクラスを実装し、モデルのニューラル層を構成しました。次に、作業の第3段階である、MetaTrader5のストラテジーテスターで実際のデータを使ってモデルの訓練とテストをおこないます。
前回と同様、モデルはEURUSD H1の履歴データを使用して訓練およびテストされます。モデルの訓練はオフラインでおこないました。この目的のために、2023年の最初の7ヶ月間の過去データに基づく様々な500の軌道から訓練サンプルを収集しました。軌跡のほとんどはランダムパスによって収集されました。採算の取れるパスの割合はかなり低いです。訓練過程におけるパスの平均的な収益性を均等にするため、その結果に優先順位をつけた軌跡サンプリングを使用します。これにより、収益性の高いパスに高い重みを割り当てることができます。これにより、そのようなパスを選択する確率が高まります。
訓練したモデルは、同じ銘柄と時間枠で、2023年8月からの履歴データを使い、ストラテジーテスターでテストされました。このアプローチでは、訓練データセットとテストデータセットの統計量を保持したまま、(訓練サンプルに含まれていない)新しいデータに対する訓練済みモデルの性能を評価することができます。
テスト結果は、訓練期間とテスト期間の両方で利益を生み出す戦略を訓練することが可能であることを示唆しています。テストの画面ショットを以下に示します。


2023年8月のテスト結果に基づくと、訓練済みモデルは160回の取引をおこない、うち84回は利益で決済されました。これは52.5%に相当します。トレードパリティはやや利益の方に傾いていると結論づけることができます。平均利益率は平均損失率より4%高いです。儲かった取引の平均は、負けた取引の平均と同じです。取引回数による最大利益シリーズは、このパラメータによる最大損失シリーズに等しくなります。しかし、最大利益トレードと最大利益シリーズの金額は、負けトレードの同様の変数を上回っています。その結果、テスト期間中、モデルは利益率1.15、シャープレシオ2.14を示しました。
結論
この記事では、新しいクラスの常微分方程式(ODE)モデルを考察しました。機械学習モデルの構成要素としてODEを使用することには、多くの利点と可能性があり、特に動的なプロセスやデータの変化をモデル化する際に非常に有用です。これは、時系列データ、システムダイナミクス、および予測に関連する問題において特に重要な役割を果たします。ニューラルODEは、ディープモデルや再帰型モデルなど、さまざまなニューラルネットワークアーキテクチャにスムーズに統合でき、これによりこれらの手法の応用範囲がさらに広がります。
本稿の実用的な部分では、提案されたアプローチをMQL5で実装し、MetaTrader 5のストラテジーテスターで実際のデータを用いてモデルの訓練とテストをおこないました。テスト結果は前述の通りであり、これらの結果は提案されたアプローチが問題解決に有効であることを示しています。
しかし、この記事で紹介されているすべてのプログラムは、あくまでも参考のためのものであり、提案されているアプローチを実証するためのものであることをお断りしておきます。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルをテストするEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コード基本 | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14569
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索