
ニューラルネットワークが簡単に(第67回):過去の経験を活かした新しい課題の解決

はじめに
強化学習は、環境との相互作用の中で環境から受け取る報酬を最大化することで成り立っています。明らかに、学習プロセスには環境との絶え間ない相互作用が必要です。しかし、状況は異なります。ある課題を解決するとき、環境との相互作用にさまざまな制約が生じることがあります。このような状況に対する可能な解決策は、オフラインの強化学習アルゴリズムを使用することです。これにより、環境との予備的な相互作用の間に収集された軌跡の限られたアーカイブを、それが利用可能な間にモデルを訓練することができます。
もちろん、オフライン強化学習には欠点もあります。特に、限られた訓練サンプルを扱うため、環境の多様性をすべて受け入れることができず、環境を研究する問題はさらに深刻になります。これは特に複雑な確率的環境において当てはまります。前回の記事では、この問題を解決するための選択肢のひとつ(ExORLメソッド)について説明しました。
しかし、時には環境との相互作用の制限が致命的になることもあります。環境探索のプロセスには、ポジティブな報酬とネガティブな報酬が伴うことがあります。ネガティブな報酬は非常に望ましくないものであり、金銭的な損失やその他の受け入れがたい損失を伴うこともあります。しかし、タスクが突然現れることはめったにありません。多くの場合、既存のプロセスを最適化します。そして、この情報技術が発達した現代では、前述のような課題を解決する過程で、探検している環境と相互作用する経験を常に見出すことができます。環境との実際の相互作用から得られるデータを使用することが可能であり、それはある程度、あるいは別の形で、必要とされる行動と状態の空間をカバーすることができます。実際のロボットを制御する際に、このような経験を利用して新しいタスクを解決する実験は、「Real World Offline Reinforcement Learning with Realistic Data Source」稿で紹介されています。この論文の著者は、モデルを訓練するための新しいフレームワーク「Real-ORL」を提案しています。
1.Real-ORLフレームワーク
オフライン強化学習(ORL)はマルコフ決定環境をモデル化します。これは、行動方策の1つまたは混合を使用して収集された軌跡の形で事前に生成されたデータセットへのアクセスを前提としています。ORLの目的は、オフラインのデータセットを使用してほぼ最適な方策πを訓練することです。一般に、探索が不十分で訓練データセットが限られているため、最適な方策π*を学習できる可能性はありません。この場合、利用可能なデータセットに基づいて訓練可能な最良の方策を見つけることを目指します。
ほとんどのオフライン強化学習アルゴリズムには、何らかの正則化や保守性が含まれています。以下のような形態がありますが、これらに限定されるものではありません。
- 方策勾配の正則化
- 近似動的計画法
- 環境モデルを用いた学習
Real-ORLフレームワークの著者は、新しいモデル学習アルゴリズムを提供していません。彼らの研究では、これまで代表的なORLアルゴリズムを探求し、現実的な使用ケースにおける物理的ロボット上での性能を評価しています。このフレームワークの著者は、この論文で分析された学習アルゴリズムは、理想的なデータセット、独立したデータセット、同時データセットを用いたシミュレーションに主眼が置かれていることを指摘しています。しかし、現実の確率的世界では、このアプローチは間違っています。行動に操作上の遅延が伴うからです。このため、訓練された方策の物理的ロボットへの使用は制限されます。シミュレートされたベンチマークや限定された商品評価の結果が、現実のプロセスに一般化できるかどうかは不明です。論文「Real World Offline Reinforcement Learning with Realistic Data Source」は、このギャップを埋めることを目的としています。この論文では、実世界の学習課題に適用されたいくつかのオフライン強化学習アルゴリズムの実証的研究を、訓練セットの領域を超えた汎化に重点を置いて紹介しています。
模倣学習は、ロボット工学における制御方策を学習するための代替的なアプローチです。報酬を最適化することで方策を学習するRLとは異なり、模倣学習は専門家の実演を再現することを目的としています。ほとんどの場合、教師あり学習アプローチを使用し、学習プロセスから報酬関数を除外します。また、強化学習と模倣学習の組み合わせも興味深いです。
Real-ORLフレームワークの著者は、その論文で、ヒューリスティックな手動方策の軌跡からなるオフラインデータセットを使用しています。軌跡は専門家の監督下で収集され、質の高いデータセットとなっています。この手法の著者は、オフライン模倣学習(特に行動クローニング)を実証研究の基本アルゴリズムとしています。
学習法の評価における客観性を最大化するため、本稿では、一般的な操作課題を代表する4つの古典的な操作課題を検証します。各タスクは、固有の報酬関数を持つMDPとしてモデル化されます。分析された各学習方法は、4つのタスクすべてを解くために使用され、すべてのアルゴリズムが全く同じ条件に置かれます。
前述したように、訓練データは専門家の監修のもとで開発された方策を使用して収集されます。基本的に、4つのタスクすべてにおいて成功した軌跡が収集されました。このフレームワークの著者は、最適でない軌道を収集したり、専門家の軌道をさまざまなノイズで歪めたりすることは、ロボット工学では容認されないと考えています。なぜなら、歪んだり無作為な挙動は安全でなく、機器の技術的状態に悪影響を及ぼすからです。同時に、様々なタスクから収集されたデータを使用することで、3つの理由から、オフライン強化学習を実際のロボットに適用するための、より現実的な環境を提供します。
- 実際のロボットで「無作為/探索的」データを自律的に収集するには、広範な安全制限、監督、専門家の指導が必要です。
- このような無作為なデータを大量に記録するためにEAを使用することには、実世界のタスクに意味のある軌跡を収集するためにEAを使用することによりも意味がありません。
- タスクに特化した戦略を開発し、このような強力なデータセットに対してORL能力をストレステストすることは、危ういデータセットを使用するよりも実行可能です。
Real-ORLフレームワークの著者は、タスク(またはアルゴリズム)に有利なバイアスを避けるために、データセットを前もって凍結しています。
Real-ORLの著者は、すべてのタスクでエージェントの方策を訓練するために、各タスクをサブゴールによってマークされた、より単純なステージに分割しています。エージェントは、タスク固有の基準が満たされるまで、サブゴールに向かって小さなステップを踏む。この方法で訓練された方策は、コントローラのノイズとトラッキングエラーにより、理論的に可能な最大限の結果を得ることはできませんでした。しかし、それらは高い成功率でタスクを完了し、人間のデモンストレーションに匹敵するパフォーマンスを持っています。
Real-ORLの著者は、3000以上の訓練軌道、3500以上の評価軌道、そして270時間以上の人手による実験をおこないました。広範な研究を通じて、彼らは次のことを発見しました。
- ドメイン内タスクの場合、強化学習アルゴリズムは、データの乏しい問題ドメインや動的問題にも一般化できる
- 異種データ使用後のORL性能の変化は、エージェント、タスクデザイン、データ特性によって異なる傾向がある
- タスクに依存しないある種の異種軌跡は、重複するデータサポートを提供し、より優れた学習を可能にするため、ORLエージェントはそのパフォーマンスを向上させることができる
- 各タスクに最適なエージェントは、ORLアルゴリズムか、ORLとBCのパリティのどちらかであり、この論文で示された評価は、実世界により現実的な領域外データモードにおいても、オフライン強化学習が効果的なアプローチであることを示している
以下は、著者が提供しているReal-ORLフレームワークを視覚化したものです。
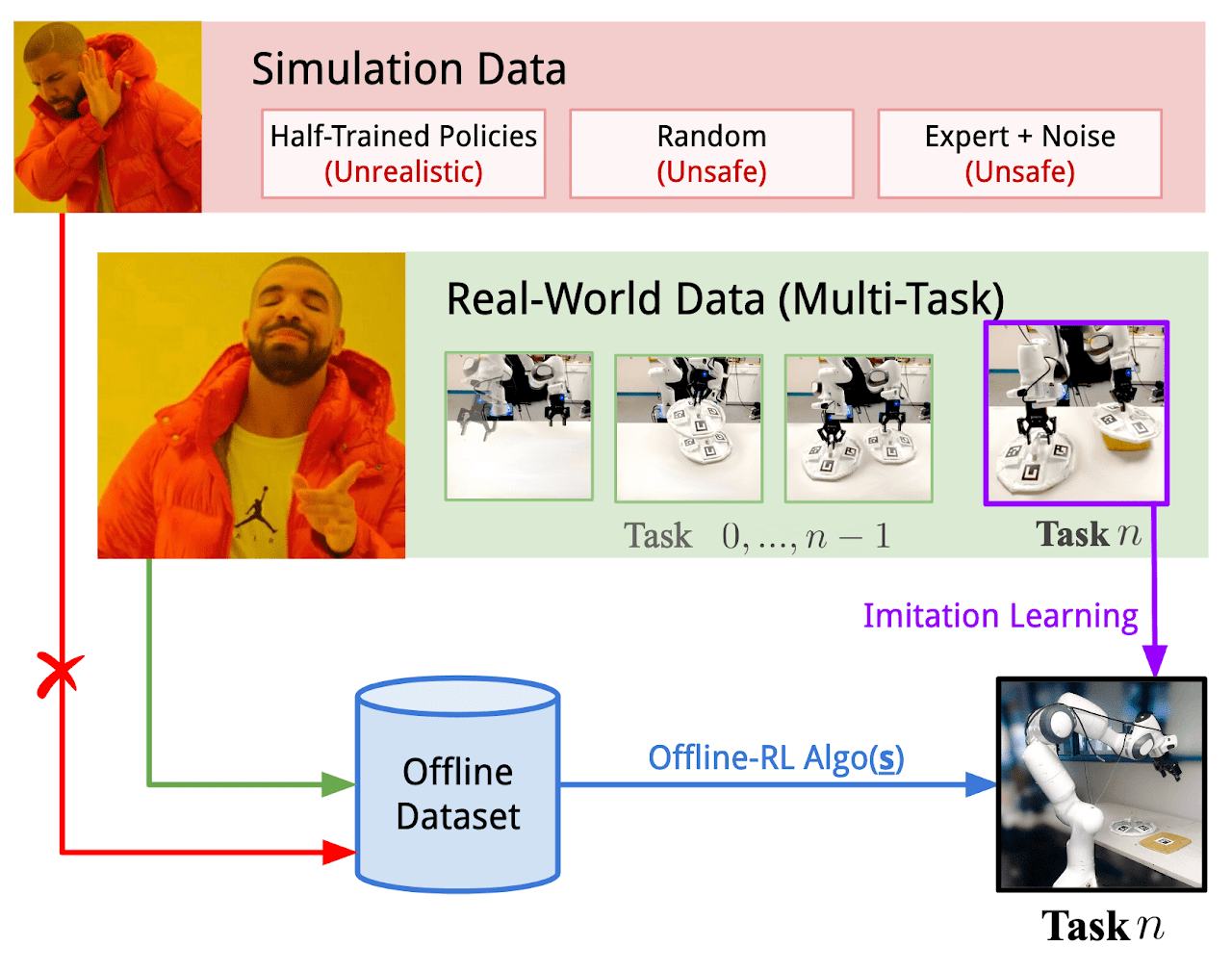
2.MQL5を使用した実装
論文「Real World Offline Reinforcement Learning with Realistic Data Source」は、実世界の課題を解決するためのオフライン強化学習手法の有効性を実証的に確認しています。ただし、私が注目したのは、エージェントの方策を構築するために、似たようなタスクを解決したデータを使用したことです。ここでのデータの基準は環境だけです。つまり、分析対象の環境との相互作用の結果として収集されたデータセットでなければなりません。
どうすればこれから恩恵を受けることができるでしょうか。少なくとも、私たちは環境(私たちの場合は金融市場)の探査に関する広範な情報を受け取っています。強化学習の主要な課題のひとつである環境探索については、これまで何度も話してきました。同時に、私たちは常に、使用しない膨大な量の情報を持っていました。シグナルのことです。下のスクリーンショットでは、意図的に著者とシグナル名を削除しています。私たちの実験では、シグナルの唯一の基準は、選択した金融商品について、訓練期間中の履歴期間に取引が存在することです。

EURUSD商品の2023年の最初の7ヶ月の期間でモデルを訓練します。これらの基準は、シグナルの選択に使用されます。有料シグナルと無料シグナルの両方があります。有料シグナルでは、履歴の一部が非表示になります。通常、最新の情報は隠されていますが、私たちが興味があるのはオープン履歴です。
[口座]タブで、対象期間中の操作を確認します。
[統計]タブで、金融商品の運用状況を確認します。ただし、私たちが探しているのは、対象となる商品だけに有効なシグナルではありません。不要な取引は後で除外します。
これがかなり近似的で間接的な分析であることには同意します。これは、分析対象金融商品について、希望する過去の期間に取引があったことを保証するものではありませんが、取引がある可能性はかなり高いです。この分析は非常にシンプルで簡単です。
適当なシグナルが見つかったら、そのシグナルの[取引履歴]タブにアクセスし、取引履歴のcsvファイルをダウンロードします。

ダウンロードしたファイルは、MetaTrader 5共通フォルダ「...\AppData\Roaming\MetaQuotes\Terminal\Common\Files」に保存する必要があります。使いやすいように、サブディレクトリ「Signals」を作り、すべてのシグナルのファイル名を「SignalX.csv」とします。ここで、Xは保存したシグナル履歴の通し番号です。
ここで注意しなければならないのは、Real-ORLのフレームワークでは、環境との相互作用の経験として、選択された軌跡を使用するということです。決して軌道の完全なクローンを約束するものではありません。したがって、軌跡を選択する際には、使用する指標と取引の相関関係(またはその他の統計分析)を確認することはありません。同じ理由で、訓練されたモデルが、最も収益性の高いシグナルの行動を完全に繰り返すことを期待すべきではありません。
この方法で20のシグナルを選択しました。ただし、出来上がったcsvファイルをそのままモデルの訓練に使用することはできません。取引を過去の値動きデータと取引時の指標の読みに対応させ、使用した各シグナルの軌跡を収集する必要があります。この機能をEA「...\RealORL\ResearchRealORL.mq5」で実行しますが、その前に少し準備作業をします。
シグナルの取引履歴から各取引を記録するために、CDealクラスを作成します。このクラスは内部使用のみを目的としています。無駄な操作を省くため、クラス変数にアクセスするためのラッパーは省略します。すべての変数は公開宣言されます。
class CDeal : public CObject { public: datetime OpenTime; datetime CloseTime; ENUM_POSITION_TYPE Type; double Volume; double OpenPrice; double StopLos; double TakeProfit; double point; //--- CDeal(void); ~CDeal(void) {}; //--- vector<float> Action(datetime current, double ask, double bid, int period_seconds); };
クラス変数はMetaTrader 5のDEALフィールドに相当します。1つの金融銘柄を扱うことになっているので、銘柄名の変数だけを省略しました。ただし、複数通貨モデルを構築する場合は、銘柄名を追加する必要があります。
また、取引では、損切りと利食いを価格の形で指定しますが、モデルはエージェントの行動を相対単位で生成することに注意してください。データを変換できるようにするため、1銘柄ポイントのサイズをpoint変数に格納します。
クラスのコンストラクタでは、変数に初期値を入れます。クラスのデストラクタは空のままです。
void CDeal::CDeal(void) : OpenTime(0), CloseTime(0), Type(POSITION_TYPE_BUY), Volume(0), OpenPrice(0), StopLos(0), TakeProfit(0), point(1e-5) { }
取引をエージェント行動のベクトルに変換するために、Actionメソッドを作成します。パラメータには、現在のバーの開始日時、Bid価格、Ask価格、分析時間枠の間隔(秒)を渡します。常に、各バーの開始時に市場分析とすべての取引操作をおこないます。
収集したシグナルの履歴における取引操作時刻は、使用する時間枠におけるバーの開始時刻と異なる場合があることにご留意ください。バーの内側で損切りや利食いを使用してポジションを閉じられるのであれば、バーが開いたときのみポジションを建てることができます。従って、ここでは、ポジションを建てる価格と時間を仮定し、少し調整します。シグナル履歴で、ポジションが閉じる前に開いていれば、バーが開いたときにポジションを建てるのです。
このロジックに従い、メソッドコードにおいて、現在時刻が、調整を考慮したポジション開始時刻より小さいか、ポジション終了時刻より大きい場合、メソッドはエージェント行動のゼロベクトルを返します。
vector<float> CDeal::Action(datetime current, double ask, double bid, int period_seconds) { vector<float> result = vector<float>::Zeros(NActions); if((OpenTime - period_seconds) > current || CloseTime <= current) return result;
まず結果のNULLベクトルを作成し、それから時間制御を実装して結果を返します。このアプローチによって、生成された結果のゼロベクトルをさらに操作することができます。したがって、行動ベクトルを埋める必要がある場合は、非ゼロ要素のみを埋めます。
行動ベクトルは、ポジションのタイプに応じて、switch選択文の本体に入力されます。ロングポジションの場合、0をインデックスとする要素に取引量を記録します。次に、利食いと損切りが0と異なるかどうかを確認し、必要であれば価格を相対値に変換します。得られた値を、それぞれインデックス1と2の要素に書き込みます。
switch(Type) { case POSITION_TYPE_BUY: result[0] = float(Volume); if(TakeProfit > 0) result[1] = float((TakeProfit - ask) / (MaxTP * point)); if(StopLos > 0) result[2] = float((ask - StopLos) / (MaxSL * point)); break;
ショートポジションに対しても同様の操作をおこないますが、ベクトル要素のインデックスは3つシフトされます。
case POSITION_TYPE_SELL: result[3] = float(Volume); if(TakeProfit > 0) result[4] = float((bid - TakeProfit) / (MaxTP * point)); if(StopLos > 0) result[5] = float((StopLos - bid) / (MaxSL * point)); break; }
生成されたベクトルは呼び出し元に返されます。
//--- return result; }
CDealsクラスでは、1つのシグナルのすべての取引を組み合わせます。このクラスにはオブジェクトの動的配列が格納され、そこに上記で作成したCDealクラスのインスタンスと2つのメソッドが追加されます。
- csv履歴ファイルから取引を読み込むLoadDeals
- エージェントの行動ベクトルを生成するAction
class CDeals { protected: CArrayObj Deals; public: CDeals(void) { Deals.Clear(); } ~CDeals(void) { Deals.Clear(); } //--- bool LoadDeals(string file_name, string symbol, double point); vector<float> Action(datetime current, double ask, double bid, int period_seconds); };
クラスのコンストラクタとデストラクタで、取引の動的配列をクリアします。
csvファイルLoadDealsから取引履歴を読み込むことから、クラスのメソッドを検討し始めることをご提案します。メソッドのパラメータには、ファイル名、分析対象商品名、ポイントサイズを渡します。証券会社によって金融商品の名前に違いがあることが多いので、意図的に銘柄名をパラメータに含めました。そのため、EAが分析対象商品のチャート上で動作している場合でも、履歴ファイルで統一されたシグナルと名前が異なる場合があります。
bool CDeals::LoadDeals(string file_name, string symbol, double point) { if(file_name == NULL || !FileIsExist(file_name, FILE_COMMON)) { PrintFormat("File %s not exist", file_name); return false; }
メソッド本体では、まずファイル名と共通端末フォルダ内の存在を確認します。必要なファイルが見つからない場合は、ユーザーに通知し、false結果でメソッドを完了します。
bool CDeals::LoadDeals(string file_name, string symbol, double point) { if(file_name == NULL || !FileIsExist(file_name, FILE_COMMON)) { PrintFormat("File %s not exist", file_name); return false; }
次のステップは、指定された金融銘柄の名前を確認することです。名前が見つからない場合は、EAが稼働しているチャートの銘柄名を入力します。
if(symbol == NULL) { symbol = _Symbol; point = _Point; }
コントロールブロックの受け渡しに成功したら、メソッドパラメータで指定されたファイルを開き、受け取ったハンドル値を使用して直ちに操作の結果を確認します。何らかの理由でファイルを開けなかった場合は、発生したエラーをユーザーに知らせ、否定的な結果でメソッドを終了します。
ResetLastError(); int handle = FileOpen(file_name, FILE_READ | FILE_ANSI | FILE_CSV | FILE_COMMON, short(';'), CP_ACP); if(handle == INVALID_HANDLE) { PrintFormat("Error of open file %s: %d", file_name, GetLastError()); return false; }
この時点で準備作業の段階は終了し、データ読み取りサイクルの整理に移ります。ループの各反復の前に、ファイルの最後に達したかどうかを確認します。
FileSeek(handle, 0, SEEK_SET); while(!FileIsEnding(handle)) { string s = FileReadString(handle); datetime open_time = StringToTime(s); string type = FileReadString(handle); double volume = StringToDouble(FileReadString(handle)); string deal_symbol = FileReadString(handle); double open_price = StringToDouble(FileReadString(handle)); volume = MathMin(volume, StringToDouble(FileReadString(handle))); datetime close_time = StringToTime(FileReadString(handle)); double close_price = StringToDouble(FileReadString(handle)); s = FileReadString(handle); s = FileReadString(handle); s = FileReadString(handle);
ループの本体では、まず1つのトランザクションのすべての情報を読み込み、ローカル変数に書き込みます。ファイル構造によると、最後の3つの要素には、取引の手数料、スワップ、利益が含まれます。開いた時刻や価格が履歴に示されたものと異なる可能性があるため、このデータは軌跡には使用しません。したがって、利益額も異なる可能性があります。また、手数料やスワップは証券会社の設定によります。
次に、取引操作の金融商品と、パラメータで渡された分析対象の金融商品の対応を確認します。記号が一致しない場合は、ループの次の反復に移ります。
if(StringFind(deal_symbol, symbol, 0) < 0) continue;
目的の金融商品で取引がおこなわれた場合、取引説明オブジェクトのインスタンスを作成します。
ResetLastError(); CDeal *deal = new CDeal(); if(!deal) { PrintFormat("Error of create new deal object: %d", GetLastError()); return false; }
そして、それを埋めます。ただし、以下の点にご注意ください。以下は簡単に保存できます。
- ポジションタイプ
- 開閉時刻
- 始値
- 取引量
- 1点の大きさ
しかし、損切りと利食いの価格は取引履歴に表示されていません。その代わり、ポジションの実際の決済価格のみが表示されます。ここではごく単純なロジックを使用します。
- ポジションが損切りまたは利食いによって決済されたという仮定を導入する
- この場合、ポジションが利益で決済されていれば、利食いで決済され、それ以外は損切りで決済されたことになるので、該当する欄に終値を記入する
- 反対側のフィールドは空のままになる
deal.OpenTime = open_time; deal.CloseTime = close_time; deal.OpenPrice = open_price; deal.Volume = volume; deal.point = point; if(type == "Sell") { deal.Type = POSITION_TYPE_SELL; if(close_price < open_price) { deal.TakeProfit = close_price; deal.StopLos = 0; } else { deal.TakeProfit = 0; deal.StopLos = close_price; } } else { deal.Type = POSITION_TYPE_BUY; if(close_price > open_price) { deal.TakeProfit = close_price; deal.StopLos = 0; } else { deal.TakeProfit = 0; deal.StopLos = close_price; } }
損切りなしで取引することのリスクは十分に理解していますが、同時に、モデルの下流での訓練中に、このリスクが最小化されることを期待しています。
作成された取引の説明を動的配列に追加し、ループの次の反復に移ります。
ResetLastError(); if(!Deals.Add(deal)) { PrintFormat("Error of add new deal: %d", GetLastError()); return false; } }
ファイルの最後に到達したら、ファイルを閉じ、結果をtrueにしてメソッドを終了します。
FileClose(handle); //--- return true; }
エージェントの行動ベクトルを生成するアルゴリズムは非常に単純です。取引の配列全体を調べ、各取引に適したメソッドを呼び出します。
vector<float> CDeals::Action(datetime current, double ask, double bid, int period_seconds) { vector<float> result = vector<float>::Zeros(NActions); for(int i = 0; i < Deals.Total(); i++) { CDeal *deal = Deals.At(i); if(!deal) continue; vector<float> action = deal.Action(current, ask, bid, period_seconds);
ただし、いくつかのニュアンスがあります。シグナルの履歴の中で、異なる方向のものも含めて、複数のポジションが同時に開かれる可能性があると仮定します。したがって、アーカイブの全案件から得られたベクトルを合計する必要がありますが、できるのは量を増やすことだけです。損切りや利食いのレベルを単純に追加するだけでは正しくありません。エージェントの行動ベクトルでは、損切りと利食いは現在価格からの相対単位のシフトとして指定されることを覚えておいてください。従って、損切りと利食いのレベルのベクトルを足すときは、最大偏差を取ります。時間内に決済されなかった数量は、新しいローソク足の開始時にEAによって決済されます。この場合、総ポジションの総数量の減少が予想されるからです。
result[0] += action[0]; result[3] += action[3]; result[1] = MathMax(result[1], action[1]); result[2] = MathMax(result[2], action[2]); result[4] = MathMax(result[4], action[4]); result[5] = MathMax(result[5], action[5]); } //--- return result; }
エージェント行動の最終ベクトルを呼び出しプログラムに渡し、メソッドを終了します。
以上で準備作業は完了です。EA「...\RealORL\ResearchRealORL.mq5」の作成に移ります。このEAは、以前取り上げたEA「...\...\Research.mq5」を基に作成したため、その構築テンプレートを継承しています。また、外部パラメータもすべて継承しています。
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = -10000; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price //--- input int Agent = 1;
同時に、このEAは、取引操作の決定がすでにおこなわれており、シグナル取引の履歴を使用するため、いかなるモデルも使用しません。そのため、すべてのモデルオブジェクトを削除し、CDealsシグナル契約配列オブジェクトを1つ追加します。
SState sState; STrajectory Base; STrajectory Buffer[]; STrajectory Frame[1]; CDeals Deals; //--- float dError; datetime dtStudied; //--- CSymbolInfo Symb; CTrade Trade; //--- MqlRates Rates[]; CiRSI RSI; CiCCI CCI; CiATR ATR; CiMACD MACD; //--- double PrevBalance = 0; double PrevEquity = 0;
同様に、EAの初期化方法では、事前に訓練されたモデルを読み込む代わりに、取引操作の履歴を読み込みます。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- load history if(!Deals.LoadDeals(SignalFile(Agent), "EURUSD", SymbolInfoDouble(_Symbol, SYMBOL_POINT))) return INIT_FAILED; //--- PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
なお、シグナル情報データをダウンロードする際には、ファイル名の代わりにSignalFile(Agent)と表記します。ここではマクロ置換を使用します。このため、以前は統一されたシグナルファイル名「SignalX.csv」というファイル名に統一していました。マクロ置換は、外部Agentパラメータの値を識別子として示すシグナル履歴ファイルの統一名を返します。
#define SignalFile(agent) StringFormat("Signals\\Signal%d.csv",agent)
これにより、その後MetaTrader 5のストラテジーテスターで最適化モードで「...\RealORL\ResearchRealORL.mq5」を実行することができます。Agentパラメータによる最適化により、各パスは独自のシグナル履歴ファイルで動作します。こうすることで、複数のシグナルファイルを並行して処理し、そこから環境との相互作用の軌跡を収集することができます。
環境とのインタラクションはOnTickメソッドで実装されています。ここでは、いつものように、まず新しいバー開始イベントの発生を確認します。
void OnTick() { //--- if(!IsNewBar()) return;
必要に応じて、過去の値動きデータをダウンロードします。また、指標を操作するためのオブジェクトのバッファも更新します。
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
意思決定のためのモデルがないということは、データバッファを埋める必要がないということです。しかし、環境との相互作用の軌跡の情報を保存するためには、状態構造を必要なデータで満たす必要があります。まず、値動きと指標のパフォーマンスに関するデータを収集します。
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; }
次に、口座状況と未決済ポジションに関する情報を入力します。また、現在のバーの開始時間も表示します。この段階では、タイムスタンプのハーモニクスを作成することなく、1つの時間値のみを保存することに注意してください。これにより、情報を失うことなく保存データ量を減らすことができます。
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
報酬ベクトルには、残高とエクイティの変化による影響の要素を即座に記入します。
sState.rewards[0] = float((sState.account[0] - PrevBalance) / PrevBalance); sState.rewards[1] = float(1.0 - sState.account[1] / PrevBalance);
そして、次のバーで報酬を計算するために必要となる残高とエクイティの値を保存します。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
エージェントのフィードフォワードパスの代わりに、シグナル取引の履歴から行動のベクトルを要求します。
vector<float> temp = Deals.Action(TimeCurrent(), SymbolInfoDouble(_Symbol, SYMBOL_ASK), SymbolInfoDouble(_Symbol, SYMBOL_BID), PeriodSeconds(TimeFrame) );
行動ベクトルの処理とデコードは、先に用意したアルゴリズムに従って実行されます。まず、多方向のボリュームを除外します。
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
そしてロングポジションを調整します。ただし、以前は損切りや利食いを指定せずにポジションを建てることはできませんでした。これは今、必要な措置となります。そのため、以前に建てたポジションの決済を確認し、損切り/利食い価格を表示するなどの調整をおこないます。
//--- buy control if(temp[0] < min_lot || (temp[1] > 0 && (temp[1] * MaxTP * Symb.Point()) <= stops) || (temp[2] > 0 && (temp[2] * MaxSL * Symb.Point()) <= stops)) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = (temp[1] > 0 ? NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()) : 0); double buy_sl = (temp[2] > 0 ? NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()) : 0); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
ショートポジション調整ブロックでも同様の調整をおこないます。
//--- sell control if(temp[3] < min_lot || (temp[4] > 0 && (temp[4] * MaxTP * Symb.Point()) <= stops) || (temp[5] > 0 && (temp[5] * MaxSL * Symb.Point()) <= stops)) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = (temp[4] > 0 ? NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()) : 0); double sell_sl = (temp[5] > 0 ? NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()) : 0); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
メソッドの最後に、報酬ベクトルにデータを追加し、行動ベクトルをコピーし、軌跡に追加する構造を渡します。
if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove(); }
残りのメソッドはそのまま使用するので、これでEA「....\RealORL\ResearchRealORL.mq5」のメソッドのレビューは終わりです。EAのすべてのコードと記事で使用したすべてのプログラムは、添付ファイルにあります。
Real-ORL法の著者は、Actor方策を学習するための新しい方法を提案していません。今回の実験では、方策学習アルゴリズムにもモデルアーキテクチャにも変更は加えていません。このステップを意識的に踏むのは、前回のモデルを訓練するのと同等の条件にするためです。最終的には、Real-ORLのフレームワーク自体が方策学習の結果に与える影響を評価することができます。
3.テスト
上記では、様々なシグナルの取引操作に関する情報を収集し、収集した情報を環境との相互作用の軌跡に変換するEAを用意しました。次に、おこなった作業をテストし、選択した軌道がモデルの訓練結果に与える影響を評価します。この研究では、無作為なパラメータで初期化された全く新しいモデルを訓練します。前回の記事では、以前に訓練したモデルを最適化しました。
まず、シグナルの履歴を軌跡に変換するEA「...\RealORLResearchRealORL.mq5」を実行します。EAは完全最適化モードで実行します。
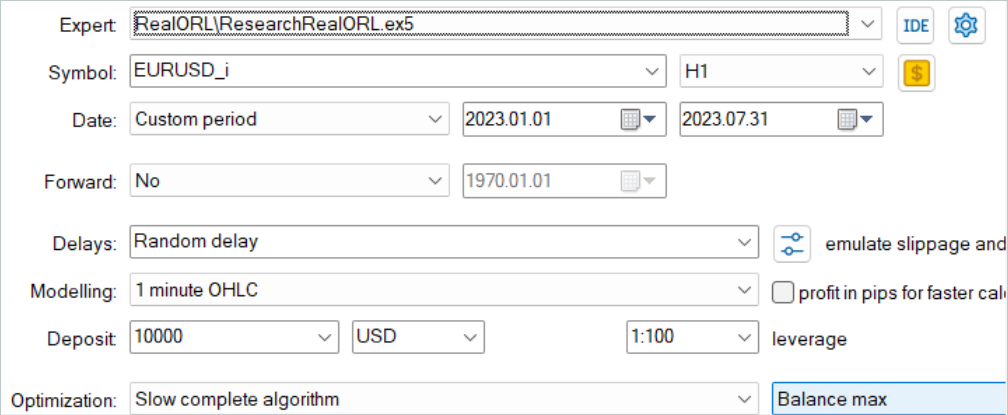
エージェントの1つのパラメータに対してのみ最適化します。パラメータ範囲には、シグナルファイルの最初と最後のIDを1刻みで示します。
その結果、かなり興味深い軌跡が生まれました。
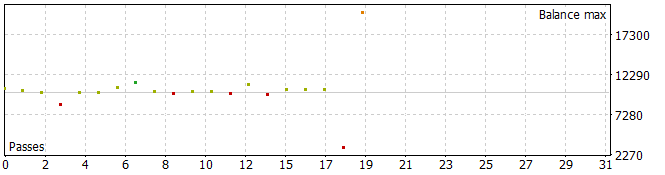
分析期間中のパスのうち5つが損失で終了し、1つでは残高が倍増しました。
2023年7月2日と2023年7月25日に、最も収益性の高い軌跡を一度だけ実行したところ、かなり深いドローダウンが見られました。シグナルの作者が使った戦略については、詳しくないので触れません。加えて、ドローダウンは、ポジションの開始ポイントが分析された時間枠のバーの開始ポイントにシフトすることによって引き起こされた、ポジションの早期開始によって引き起こされる可能性があります。そしてもちろん、意図的にゼロにリセットする損切りの使用は、そのような状況で損失を固定することにつながります。
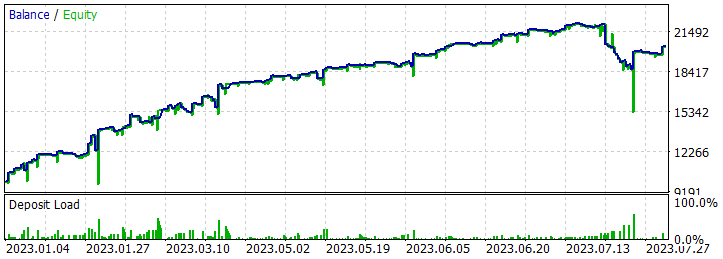
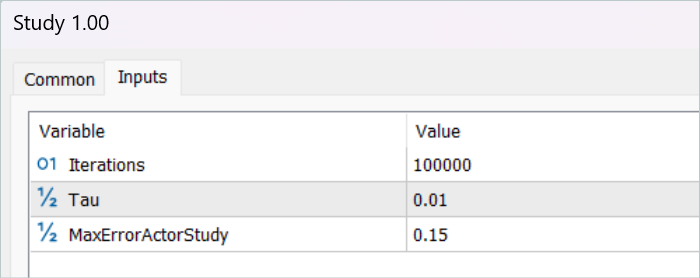
軌跡を保存した後、モデルの訓練に移ります。そのために、EA「...\RealORL\Study.mq5」を実行します。
一次訓練は、シグナル操作の結果から収集された軌道データに対してのみおこなわれました。奇跡は起こらなかったと認めなければなりません。初期訓練後のモデル結果は、望ましいものとはほど遠いものでした。訓練された方策は、2023年の最初の7ヶ月間の訓練期間と、2023年8月のテスト履歴区間の両方で損失を発生させました。しかし、提案されたReal-ORLフレームワークの非効率性については語りません。選択された20の軌道は、フレームワークの著者が使用した3000の軌道とはかけ離れています。この20の軌跡は、エージェントがとりうるさまざまな行動のほんの一部もカバーしていません。
訓練を続ける前に、EA「...\RealORL\Research.mq5」を使用して、訓練軌跡のバッファにデータを追加しました。このEAは、エージェントが事前に訓練した方策に基づいて意思決定をおこない、パスを実行します。環境の探索は、エージェントの潜在的な状態と方策の確率性のおかげで実行されます。この2つの確率によって、エージェントの行動はかなり多様になり、環境を探索することが可能になります。エージェントの方策が学習するにつれて、各パラメータの分散が減少するため、両方の確率が減少します。これにより、エージェントの行動はより予測しやすくなり、意識的になります。
バッファに新しい軌跡を200個追加し、モデルの訓練プロセスを繰り返します。
今回のエージェント方策の訓練プロセスはかなり長いものでした。「....\RealORL\Research.mq5」を使用して何度も再生バッファを更新しました。経験再生バッファが完全に満たされた後に更新する過程で、最も損失の大きい(最も利益の小さい)軌道を、より利益の大きい軌道に置き換えます。その結果、「...\RealORL\Research.mq5」EAで収集した軌跡のみを置き換えました。シグナルの軌跡は、その一般的な収益性により、常に経験再生バッファに残っていました。
前述したように、長時間の訓練の結果、訓練セットで利益を生み出すことができる方策を得ることができました。さらに、その結果得られた方策は、得られた経験を新しいデータに一般化することができました。これは、訓練期間を超えた過去のデータに対する利益によって証明されています。


テストサンプルの履歴データに基づき、エージェントは131件の取引をおこない、その48.85%は利益で決済されました。最大利益の取引は最大損失よりほぼ10%低いです(それぞれ379.89対398.49)。同時に、平均利益率は平均損失率を40%上回っています。その結果、テスト期間のプロフィットファクターは1.34、リカバリーファクターは0.94となりました。
また、ロング(70)とショート(61)の取引がほぼ同じであることにも注目すべきです。これは、大域的なトレンドに追随するだけでなく、局所的トレンドにも目を向けるエージェントの能力を示しています。
結論
この記事では、ロボット工学から生まれたReal-ORLフレームワークについて説明しました。このフレームワークの著者は、実際のロボットを使用してかなり広範な実証研究をおこなっており、それによって以下のような結論を導き出しています。
- ドメイン内タスクの場合、強化学習アルゴリズムは、データの乏しい問題ドメインや動的問題にも一般化できる
- 異種データ使用後のORL性能の変化は、エージェント、タスクデザイン、データ特性によって異なる傾向がある
- タスクに依存しないある種の異種軌跡は、重複するデータサポートを提供し、より優れた学習を可能にするため、ORLエージェントはそのパフォーマンスを向上させることができる
- 各タスクに最適なエージェントは、ORLアルゴリズムか、ORLとBCのパリティのどちらかであり、この論文で示された評価は、実世界により現実的な領域外データモードにおいても、オフライン強化学習が効果的なアプローチであることを示している
私たちの研究では、提案したフレームワークを金融市場の分野で使用する可能性を検討しました。特に、Real-ORLフレームワークの著者が提案したアプローチでは、市場に存在するさまざまなシグナルの履歴を利用してモデルを学習することができます。しかし、環境の多様性を最大化するためには、多数の軌道が必要です。そのため、できるだけ多くの異なる軌道を収集する作業が必要となります。この作業で20の軌道しか使わなかったのは、おそらく間違いだったと考えられます。Real-ORLの著者は3000以上の軌跡を使用しました。
私の個人的な意見は、この手法はモデルの初期訓練に使用でき、使用する必要があり、無作為な軌跡を収集するよりも利点があるということです。ただし、「凍結された」軌道データだけでは、最適なエージェント方策を構築するには不十分です。私が選択した少数の軌道から重大な結果を期待するのは難しいです。しかし、この手法の著者も、理論的に可能な最大限の結果を得ることはできませんでした。さらに、シグナルに関する情報は限られており、すべてのリスクを考慮することはできません。例えば、シグナルには損切りや利食いに関する情報は含まれていません。このようなデータがないことが、リスクの包括的な評価と管理を妨げています。したがって、シグナルの軌跡で訓練されたモデルは、事前に訓練された方策を考慮して得られた追加の軌跡でさらに微調整する必要があります。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | ResearchExORL.mq5 | EA | ExORL法による事例収集のためのEA |
| 4 | Study.mq5 | EA | エージェント訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13854
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索